
1. Introduction
Dans cet atelier de programmation, vous allez déployer l'application Hackathon Judge sur Google Kubernetes Engine (GKE) et utiliser Kubernetes-sigs Agent Sandbox pour exécuter des charges de travail agentiques de manière sûre et sécurisée.
La plate-forme est conçue pour automatiser le processus d'examen, de test et de notation des projets de hackathon à l'aide d'agents LLM. Étant donné que l'évaluation nécessite d'analyser les codes envoyés par les participants non approuvés, un bac à sable d'exécution sécurisé est essentiel pour éviter l'injection de code, l'élévation des privilèges ou l'utilisation abusive des ressources.
Objectifs de l'atelier
- Provisionnez les services Google Cloud cibles et établissez les API cibles.
- Initialisez GKE Autopilot et installez les CRD Agent Sandbox, les configurations de cluster et le routeur Sandbox.
- Déployez la passerelle Sandbox, le modèle de revendication Sandbox et un WarmPool Sandbox.
- Déployez l'API REST du backend, l'agent worker de l'ADK et l'UI frontend React.
- Configurez le routage externe à équilibrage de charge et accédez à la plate-forme pour exécuter des workflows de notation sécurisés et en bac à sable.
Prérequis
- Un navigateur Web tel que Chrome.
- Un projet Google Cloud avec facturation activée.
Les ressources créées dans cet atelier de programmation devraient coûter moins de 5 $ en frais d'exécution totaux.
2. Le problème : évaluer de manière sécurisée du code non approuvé
Les hackathons sont des événements d'innovation rapides où les participants créent et envoient des projets (souvent avec le code source) pour évaluation. L'évaluation manuelle de ces contenus envoyés est chronophage et nécessite de nombreuses ressources. L'utilisation d'agents d'IA pour automatiser la notation est une solution prometteuse, mais elle pose un défi de sécurité important : comment exécuter en toute sécurité le code fourni par les participants, qui peut être bogué, malveillant ou gourmand en ressources ?
L'exécution de code non approuvé directement sur votre infrastructure vous expose à des risques tels que :
- Injection de code : des scripts malveillants peuvent tenter d'accéder à des données sensibles ou de les modifier.
- Élévation des privilèges : le code peut tenter d'obtenir un accès non autorisé à d'autres systèmes ou ressources réseau.
- Utilisation abusive des ressources : un code mal écrit ou des attaques par déni de service peuvent consommer une quantité excessive de processeur, de mémoire ou de bande passante réseau, ce qui a un impact sur les autres opérations.
Pour automatiser l'évaluation des hackathons avec l'IA, nous avons besoin d'un moyen d'exécuter le code envoyé dans un environnement complètement isolé du reste de notre système et des autres envois.
3. La solution : le bac à sable de l'agent GKE
GKE Agent Sandbox est une fonctionnalité conçue précisément pour relever ce défi. Il permet de gérer les charges de travail isolées, avec état et à réplique unique sur GKE. Il est optimisé pour les cas d'utilisation tels que les runtimes d'agents d'IA, où le code non fiable doit être exécuté de manière sécurisée et efficace.
Voici les principaux avantages de l'Agent Sandbox :
- Isolation au niveau du noyau : fournit une isolation forte au niveau du noyau pour le code non fiable à l'aide de technologies telles que gVisor, empêchant le code d'accéder au système hôte ou à d'autres conteneurs.
- Provisionnement en moins d'une seconde : offre un provisionnement rapide des environnements de bac à sable (généralement en moins d'une seconde), ce qui est essentiel pour l'évaluation du code à la demande.
- Extensibilité cloud native : exploite la puissance de Kubernetes et l'infrastructure gérée de GKE.
En utilisant Agent Sandbox, nous pouvons créer des environnements isolés à la demande pour chaque envoi de hackathon. L'agent de jugement de l'IA peut alors demander à l'Agent Sandbox d'exécuter des tests, de compiler du code ou d'effectuer d'autres étapes d'évaluation dans ce bac à sable sécurisé, sans risquer l'intégrité de la plate-forme globale. Cela permet d'automatiser la notation des hackathons de manière évolutive, sécurisée et efficace.
4. Avant de commencer
Démarrer Cloud Shell
Cliquez sur le bouton ci-dessous pour démarrer Google Cloud Shell, qui est préconfiguré avec les utilitaires de ligne de commande pour les développeurs et le cloud requis.
Activer les API
Exécutez la commande suivante dans Cloud Shell pour activer toutes les API Google Cloud cibles requises pour exécuter la plate-forme :
gcloud services enable \
container.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
iam.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com
Pourquoi nous activons ces API : les services Google Cloud sont désactivés par défaut pour éviter les accès et les frais non autorisés. Nous activons ces API spécifiques pour activer l'orchestration de conteneurs (GKE), le stockage sécurisé de conteneurs (Artifact Registry), l'assemblage de packages sans serveur (Cloud Build), les files d'attente de messages fiables (Pub/Sub), les services de modèles d'IA (Vertex AI), la configuration de projets (Cloud Resource Manager et IAM), l'analyse de données sans serveur (BigQuery) et les liaisons d'IA au niveau de la base de données (BigQuery Connection).
5. Configurer l'infrastructure
Au cours de cette étape, vous allez cloner le dépôt de code et exécuter le script de configuration automatisé pour déployer l'architecture cloud cible et les composants de base du cluster.
Cloner le dépôt
Clonez le dépôt contenant tous les services d'application, les scripts de configuration et les déclarations de fichier manifeste Kubernetes :
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set codelabs/ai-toolkit-lab-2/hackathon-judge
cd codelabs/ai-toolkit-lab-2/hackathon-judge
Exécuter le script de déploiement
La configuration de base de vos ressources cloud, de vos modèles de base de données et de vos règles de référence pour les clusters Kubernetes est automatisée par le script deploy.sh.
Exécutez le script :
./deploy.sh
Suivez les invites du shell interactif pour fournir des configurations telles que votre ID de projet actif et votre région cible. Le script génère automatiquement une configuration .env locale, lie les ressources, compile les images de conteneur et enregistre l'infrastructure de référence GKE.
Voici les opérations cibles effectuées par le script :
1. Configurer la configuration de l'environnement
Le script crée un fichier de configuration .env pour stocker les paramètres des variables GKE, Pub/Sub, BigQuery et du projet. L'approvisionnement de ce fichier remplit de manière dynamique toutes les définitions de fichier manifeste Kubernetes suivantes.
Pourquoi configurer ce fichier d'environnement ? Le fichier .env centralise les paramètres de configuration, ce qui garantit que les manifestes GKE que nous appliquons manuellement lors des étapes suivantes utilisent des paramètres régionaux, des noms de projets et des ressources identiques, en dissociant strictement la configuration de l'environnement du code source.
2. Configuration de Google Cloud CLI et du projet cible
Le script vérifie que les utilitaires gcloud, bq, kubectl et envsubst sont installés, vérifie l'état de l'authentification et verrouille les cibles de configuration actives sur votre projet Google Cloud actif.
Pourquoi cibler le projet actif : définir le projet cible actif empêche les commandes CLI d'affecter d'autres projets de votre compte et effectue des vérifications d'authentification avant le vol, ce qui garantit que les commandes de configuration n'échouent pas en cours de déploiement en raison d'identifiants non valides.
3. Activer les API Google Cloud cibles
Le script effectue une vérification idempotente pour valider et activer les API des services Google Cloud cibles (GKE, Artifact Registry, Cloud Build, Pub/Sub, Vertex AI, BigQuery et IAM).
Pourquoi nous activons les API Google Cloud : les services cloud gérés doivent être activés avant que leurs points de terminaison ne soient accessibles ou que des ressources puissent être créées. En les activant au début, vous préparez la passerelle API GCP régionale à gérer les commandes de provisionnement de ressources ultérieures.
4. Provisionner le dépôt Docker Artifact Registry
Le script provisionne un dépôt de conteneurs Docker nommé hackathon-judge-repo à l'emplacement cible sélectionné.
Pourquoi créer un dépôt Artifact Registry ? Les clusters GKE nécessitent un accès sécurisé aux registres de conteneurs privés du même réseau régional pour extraire rapidement les images d'application. Artifact Registry fournit un hôte sécurisé et privé pour cataloguer, analyser et stocker les images de conteneurs Docker.
5. Provisionner le cluster GKE Autopilot
Le script provisionne un cluster Google Kubernetes Engine (GKE) Autopilot nommé hackathon-judge-cluster.
Pourquoi déployer un cluster GKE Autopilot ? GKE Autopilot gère automatiquement le provisionnement, le scaling, la surveillance de l'état et les mises à niveau de sécurité de l'OS hôte des nœuds. Elle fournit une plate-forme de conteneurs de niveau production pour orchestrer nos services persistants et planifie de manière dynamique des bacs à sable sécurisés pour les workers à la demande.
6. Configurer les sujets et les abonnements Pub/Sub
Le script provisionne les sujets de message (judging-tasks et judging-results) ainsi que leurs abonnements de nœud de calcul et d'API correspondants.
Pourquoi déployons-nous des sujets et des abonnements Pub/Sub ? L'évaluation des codes envoyés est lente et nécessite beaucoup de ressources. L'utilisation d'une architecture de file d'attente de messages découple l'API synchrone destinée aux utilisateurs des nœuds de calcul. Le backend de l'API envoie les jobs au thème judging-tasks, et les agents de nœud de calcul extraient les tâches dès qu'elles sont disponibles, ce qui empêche le blocage de l'API et offre des capacités de réessai automatique.
7. Configurer les ensembles de données, les tables et les connexions d'IA BigQuery
Le script crée l'ensemble de données hackathon_judge, applique des schémas de base de données SQL structurés, charge les enregistrements initiaux et accorde les rôles d'IA et de stockage requis au compte de service de connexion BigQuery ML.
8. Déclencher des compilations de conteneurs à l'aide de Cloud Build
Le script déclenche la définition cloudbuild.yaml pour compiler notre UI React, notre serveur REST Go, notre worker ADK Python et notre bac à sable FastAPI, en les empaquetant dans des images de conteneur isolées taguées avec le SHA de commit Git du dépôt actif et en les enregistrant dans Artifact Registry.
9. Enregistrement des définitions de ressources personnalisées (CRD) de l'agent Sandbox
Le script télécharge et enregistre les dernières définitions de ressources personnalisées (CRD) Kubernetes-sigs Agent Sandbox (manifest.yaml et extensions.yaml) pour étendre les fonctionnalités de base de GKE.
Pourquoi installons-nous l'infrastructure Agent Sandbox ? Les clusters Kubernetes standards ne permettent pas d'allouer des bacs à sable protégés à la demande. L'enregistrement des CRD de l'agent Sandbox étend le plan de contrôle de GKE, ce qui permet à Kubernetes d'orchestrer de manière native des micro-conteneurs sécurisés en bac à sable à l'aide de ressources personnalisées (comme SandboxTemplates et SandboxClaims).
10. Configurer les espaces de noms, les comptes de service et Workload Identity
Le script provisionne l'espace de noms hackathon-judge, enregistre les comptes de service Kubernetes (KSA) et établit des mappages Workload Identity pour accorder aux pods GKE les autorisations Google Cloud cibles.
11. Déployer le routeur de bac à sable
Le script applique le fichier manifeste k8s/sandbox_router.yaml, ce qui lance le déploiement et le service Sandbox Router, puis attend qu'ils atteignent un état opérationnel.
Pourquoi déployons-nous le routeur Sandbox ? Le routeur Sandbox est la passerelle centrale du plan de contrôle interne. Il expose une API simple que l'agent de nœud de calcul ADK appelle pour revendiquer, accéder ou libérer des bacs à sable sécurisés, en gérant les mappages de routage et en abstrayant l'allocation de pods au niveau du cluster de la logique d'application.
6. Configurer la passerelle, les revendications et le pool de préchauffage de l'agent Sandbox
Dans cette étape, vous allez configurer manuellement la passerelle réseau Sandbox spécialisée, enregistrer le modèle de revendication Sandbox et déployer le pool de préchauffage Sandbox pour activer le bac à sable à latence ultra-faible.
Variables d'environnement source
Avant d'appliquer des modèles qui nécessitent des variables d'environnement, exécutez le script setup-env.sh pour analyser et exporter toutes les variables nécessaires vers votre shell :
source ./setup-env.sh
Appliquer la passerelle Sandbox
Déployez la passerelle spécifiquement configurée pour le routage du trafic du bac à sable :
kubectl apply -f k8s/sandbox-gateway.yaml
Pourquoi déployer la passerelle Sandbox ? La passerelle Sandbox sert de contrôleur d'entrée sécurisé et hautes performances dédié uniquement au routage du bac à sable. Il isole le réseau du bac à sable, fournissant une cible locale sécurisée qui permet aux agents de nœud de calcul de communiquer avec les bacs à sable revendiqués sans exposer les points de terminaison en externe.
Appliquer le modèle de revendication Sandbox
Utilisez envsubst pour remplir la définition du modèle de bac à sable avec vos variables d'environnement actives, puis appliquez-la :
source ./setup-env.sh
envsubst < k8s/sandbox-claim-template.yaml | kubectl apply -f -
Pourquoi déployons-nous le modèle de revendication du bac à sable ? Le modèle de revendication du bac à sable sert de plan de configuration pour définir l'environnement. Il spécifie l'image de conteneur à exécuter (pré-empaquetée avec des outils pour les développeurs), les paramètres d'environnement (ID du projet GCP), les ports et les limites de ressources (cibles de processeur/mémoire). Il configure GKE pour exécuter ces instances de conteneur à l'aide de gVisor (environnement d'exécution gvisor), ce qui garantit que le code des participants non approuvés s'exécute sous une couche supplémentaire d'isolation de la virtualisation du noyau.
Appliquer le WarmPool du bac à sable
Appliquez le WarmPool du bac à sable pour pré-initialiser les bacs à sable en cours d'exécution :
kubectl apply -f k8s/sandbox-warmpool.yaml
Vérifiez que les instances de secours du pool de préchauffage ont démarré correctement :
kubectl get pods -n hackathon-judge -l app=sandbox
Pourquoi déployons-nous le WarmPool du bac à sable ? Le provisionnement, la planification, l'extraction d'images et le démarrage de pods de conteneurs neufs à la demande entraînent des frais généraux de démarrage importants (temps de démarrage à froid de plus de 30 secondes). Le Sandbox WarmPool gère un pool de secours de pods sandbox actifs et préchauffés (cinq répliques par défaut). Lorsque l'agent de nœud de calcul demande un environnement d'évaluation, le routeur Sandbox alloue immédiatement un pod préchauffé en cours d'exécution, ce qui réduit les délais de démarrage à moins d'une seconde.
7. Déployer les composants de l'application
L'infrastructure de bac à sable sécurisée étant entièrement active, vous allez maintenant déployer l'API de backend central, l'agent de nœud de calcul, l'interface Web React et le mappage de passerelle d'entrée.
Déployer le backend
Déployez le backend de l'API REST de l'orchestrateur :
source ./setup-env.sh
envsubst < k8s/backend.yaml | kubectl apply -f -
Déployer l'agent
Déployez l'agent de nœud de calcul de l'ADK :
source ./setup-env.sh
envsubst < k8s/agent.yaml | kubectl apply -f -
Déployer l'interface
Déployez l'interface utilisateur Web interactive :
source ./setup-env.sh
envsubst < k8s/frontend.yaml | kubectl apply -f -
Configurer une passerelle et un routage externes
Déployez la passerelle principale et les routes HTTP d'entrée qui mappent le trafic client externe :
kubectl apply -f k8s/gateway.yaml
Pourquoi déployer la passerelle d'entrée externe ? La passerelle externe expose nos services à l'aide de l'API Kubernetes Gateway. Il provisionne une adresse IP publique à équilibrage de charge et mappe les routes en fonction des règles de chemin d'accès. Il dirige les requêtes d'API sous /api/* vers le backend Go et mappe tout le trafic Web client (/) vers le frontend React, sécurisant ainsi l'accès public au cluster.
Vérifier les déploiements
Bloquez l'exécution du shell et attendez que les trois déploiements de services principaux aient atteint un état de déploiement sain et prêt :
kubectl rollout status deployment/backend -n hackathon-judge --timeout=300s
kubectl rollout status deployment/agent -n hackathon-judge --timeout=300s
kubectl rollout status deployment/frontend -n hackathon-judge --timeout=300s
8. Valider et utiliser l'application
Accéder à l'UI
Récupérez l'adresse IP publique externe de la passerelle d'équilibreur de charge principal nouvellement provisionnée :
Pour surveiller l'état du provisionnement en temps réel, exécutez la commande avec l'indicateur watch (-w) et attendez qu'une adresse IP publique soit renseignée dans le champ ADDRESS :
kubectl get gateway -n hackathon-judge hackathon-judge-gateway -w
Si le provisionnement a réussi, un résultat semblable à celui-ci s'affiche :
NAME CLASS ADDRESS PROGRAMMED AGE hackathon-judge-gateway gke-l7 34.120.120.120 True 3m
Une fois qu'une adresse IP publique valide apparaît dans la colonne ADDRESS et que l'état PROGRAMMED est défini sur True, appuyez sur Ctrl+C pour arrêter la surveillance.
Pourquoi obtenons-nous l'état de la passerelle ? L'API Gateway gère l'entrée publique. La vérification de l'état de la passerelle renvoie l'adresse IP externe publique et équilibrée en charge allouée par l'équilibreur de charge mondial externe de Google Cloud à notre cluster, qui représente l'adresse publique de notre plate-forme.
Ouvrez l'adresse IP publique attribuée dans votre navigateur pour charger le tableau de bord Hackathon Judge.
Envoyer des tâches
- Utilisez l'interface utilisateur pour accéder au tableau de bord et sélectionner le hackathon.
- Dans n'importe quel projet, vous pouvez cliquer sur
Run Agentpour que l'agent évalue l'ensemble du projet par rapport à la grille d'évaluation.
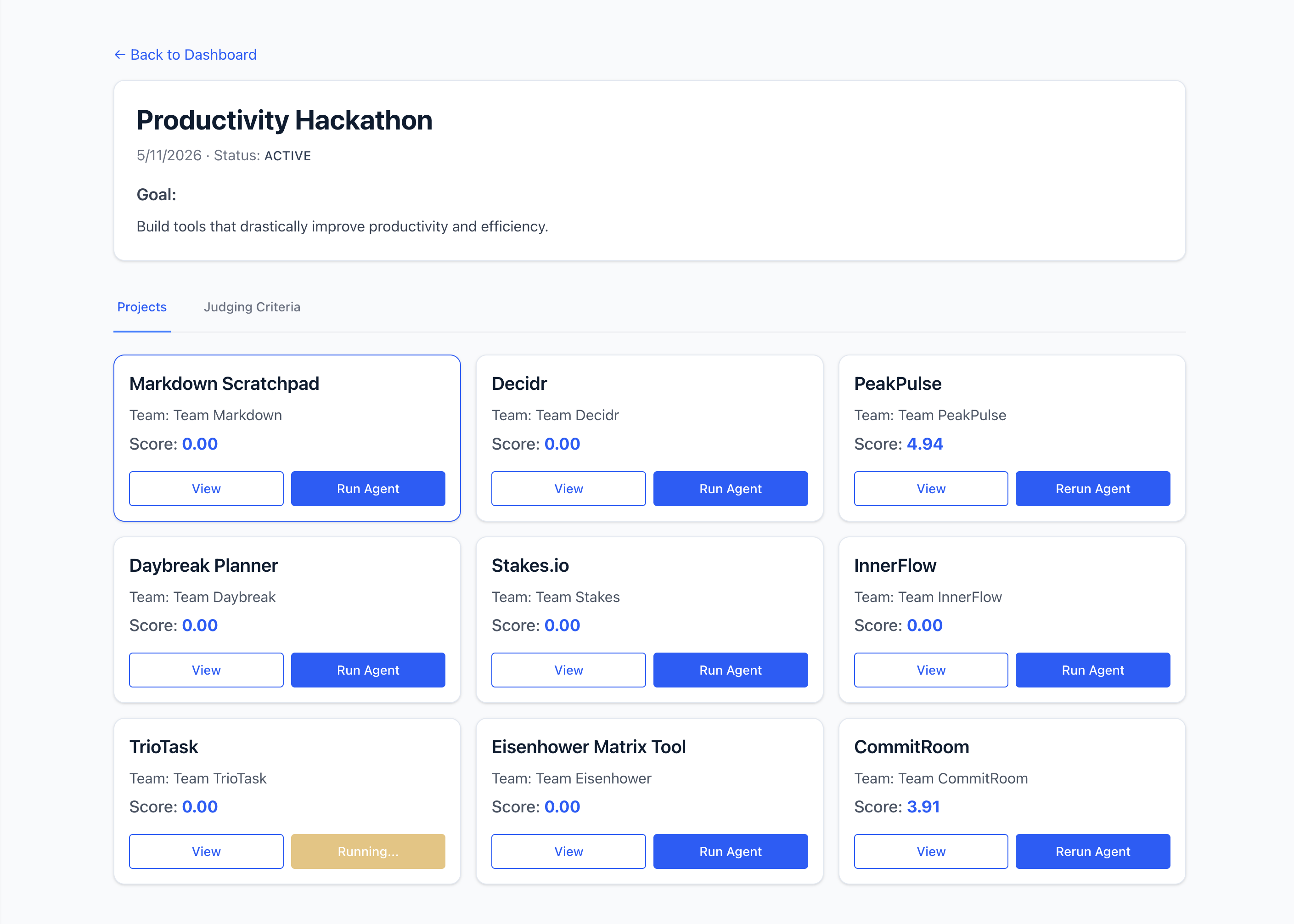
Regarder le lancement du bac à sable Watch
Surveillez les pods actifs dans l'espace de noms hackathon-judge pour voir un pod de bac à sable revendiqué et provisionné de manière dynamique pour l'exécution du jugement :
kubectl get pods -n hackathon-judge -w
Consultez les journaux du pod de l'agent de nœud de calcul pour observer la logique d'évaluation ADK pas à pas :
kubectl logs -l app=agent -n hackathon-judge
Pourquoi inspecter les journaux d'agent ? L'inspection des journaux d'agent de nœud de calcul affiche les étapes internes détaillées du pipeline d'évaluation en temps réel. Vous pouvez suivre l'agent ADK qui récupère la tâche, demande un conteneur sandbox, exécute les cibles de compilation, analyse les rapports avec Gemini et publie les tableaux de données.
9. (Facultatif) Fonctionnement
Architecture de la sandbox d'agent
Bien que les fonctions d'IA de BigQuery soient incroyables pour évaluer les contributions textuelles et les affirmations des fichiers README, l'évaluation d'un projet d'ingénierie nécessite de compiler du code, d'installer des bibliothèques tierces et d'exécuter de véritables suites de tests.
L'exécution de code utilisateur brut présente d'énormes risques de sécurité, y compris la compromission de l'hôte, les échappements de conteneurs et l'accès non autorisé aux ressources. Le framework GKE Agent Sandbox atténue ces risques en orchestrant des charges de travail sandbox isolées à l'aide de la virtualisation gVisor (runsc).
Flux d'interaction avec le système
Le schéma ci-dessous montre comment les différents éléments de notre système événementiel communiquent lors d'une exécution sécurisée de l'évaluation dans le bac à sable :
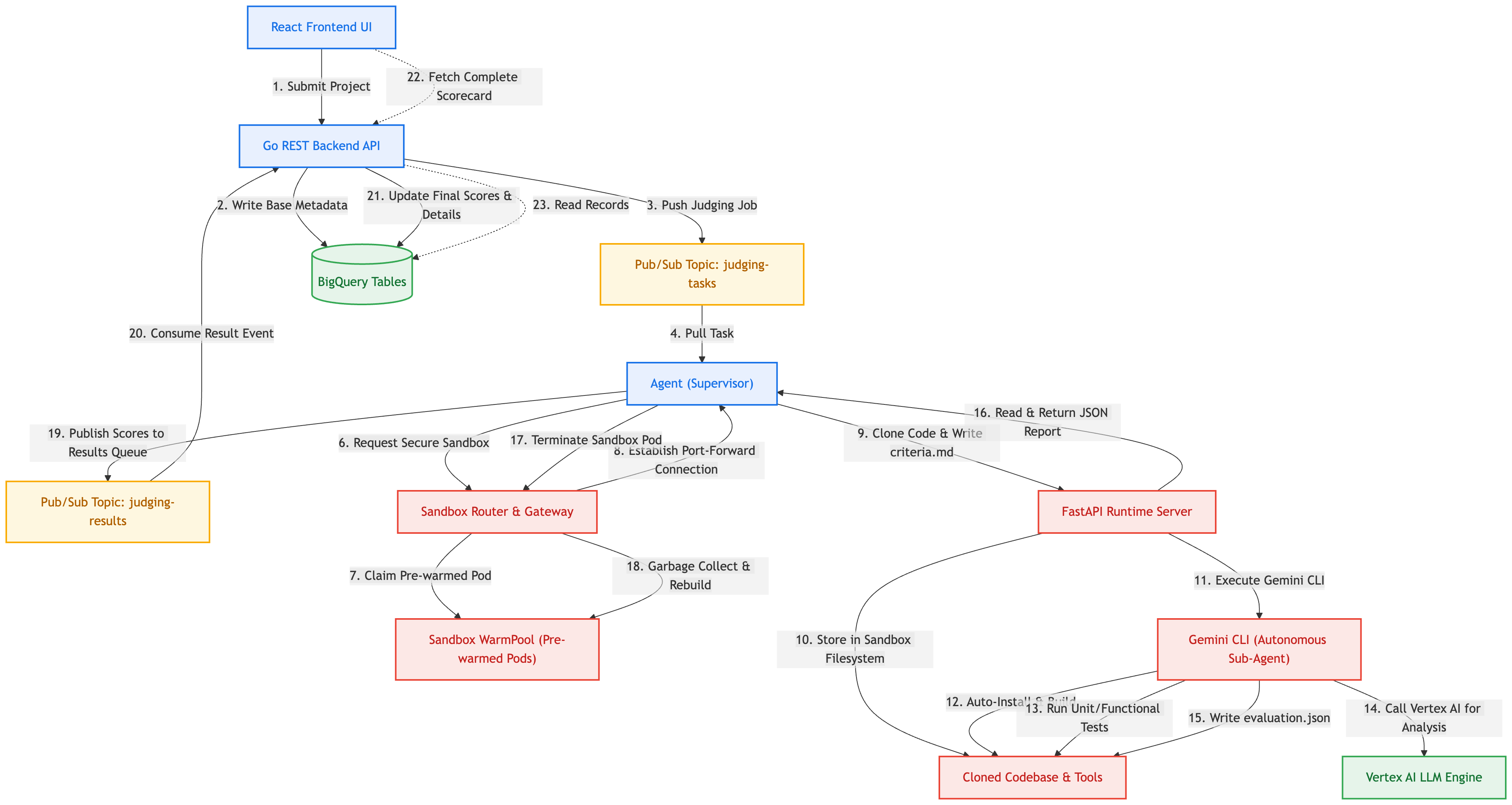
Comment les outils et composants engagés fonctionnent ensemble
- Interface utilisateur React Frontend : expose une interface interactive où les utilisateurs peuvent configurer des modèles de critères, enregistrer des équipes, envoyer des URL de projets et examiner les fiches d'évaluation finales, y compris les écarts complets des fichiers et les commentaires techniques.
- API de backend Go REST : gère les points de terminaison d'API mondiaux. Il stocke les configurations de projet dans BigQuery et envoie les tâches de jugement à Pub/Sub pour découpler les pipelines d'exécution de calcul intensif.
- Google Pub/Sub : courtier orienté message qui conserve les messages de tâches en file d'attente de manière sécurisée, en orchestrant la communication de manière asynchrone entre l'API et les instances de worker actives.
- Worker ADK Python (agent superviseur) : worker d'arrière-plan qui extrait les tâches de Pub/Sub. Il s'appuie sur le Google Agent Development Kit (ADK) pour démarrer un agent superviseur de haut niveau, chargé d'orchestrer l'évaluation. Le superviseur appelle son outil principal,
evaluate_repository, pour déléguer les tests de commandes brutes approfondis. - Routeur et passerelle Sandbox (plan de contrôle GKE) : passerelle de contrôle interne qui enregistre les définitions de ressources personnalisées Sandbox standards (
SandboxClaims,SandboxTemplates). Elle coordonne les réseaux GKE pour allouer et sécuriser les pods, en renvoyant les flux de connexion aux clients Worker. - Sandbox WarmPool : pour éviter les longs temps de démarrage des conteneurs GKE ("démarrages à froid" de plus de 30 secondes), WarmPool maintient des pods actifs en veille. Lorsqu'un bac à sable est revendiqué, le routeur le mappe immédiatement en moins d'une seconde, puis planifie le recyclage lors de la libération.
- Isolation gVisor (runsc) : noyau virtuel d'espace utilisateur qui sert de limite de bac à sable sécurisée. Il intercepte les appels système de l'espace de conteneur vers les kernels de nœud GKE, ce qui garantit que les commandes brutes dangereuses (comme les scripts système ou les configurations de packages) s'exécutent sous une isolation de virtualisation absolue.
- Environnement d'exécution FastAPI Sandbox : serveur d'API Python léger s'exécutant dans le conteneur bac à sable. Il expose des points de terminaison sécurisés (
/execute,/upload,/download) qui permettent aux outils de traitement externes de manipuler des fichiers et de déclencher des tâches shell. - Gemini CLI (
@google/gemini-cli) : script d'agent autonome installé dans le bac à sable. Lorsqu'il est déclenché avec le flag d'environnement de développement (--yolo), il utilise une fiche d'instructions de notation rigoureuse (prompt.md) et une définition des critères (criteria.md) pour :- Analysez dynamiquement la hiérarchie du code de base (à l'aide d'outils tels que
treeouripgrep). - Installer automatiquement les exigences (via des commandes telles que
npm install,pip install,go build). - Exécutez de vrais tests de développement (tels que
npm testoupytest) pour vérifier le bon fonctionnement. - Appelez les modèles Vertex AI (via les identifiants d'association Workload Identity du conteneur) pour évaluer la logique des fichiers, vérifier les revendications par rapport au fichier README, détecter les fonctionnalités fantômes, consigner les problèmes de qualité et rédiger un rapport structuré sur la fiche d'évaluation dans
evaluation.json.
- Analysez dynamiquement la hiérarchie du code de base (à l'aide d'outils tels que
- Environnements de développement standards : regroupe node, npm, yarn, pnpm, python, pip, uv, go, gh, git, tree, ripgrep et playwright dans l'image de conteneur bac à sable, ce qui donne au sous-agent autonome un espace de travail de test complet.
10. Effectuer un nettoyage
Pour éviter que les ressources créées lors de cet atelier de programmation soient facturées en permanence sur votre compte Google Cloud, supprimez-les.
./destroy.sh
Pourquoi nettoyer les ressources : Google Cloud facture selon un modèle d'utilisation des ressources. Les ressources actives telles que les clusters GKE Autopilot, les équilibreurs de charge réseau et les disques persistants entraînent des frais continus, même lorsqu'elles sont inactives. Cette étape supprime l'espace de noms du cluster pour effacer les objets Kubernetes et supprime l'hôte du cluster GKE Autopilot lui-même pour mettre fin immédiatement à tous les frais de facturation sous-jacents.
11. Félicitations
Félicitations ! Vous avez déployé l'application Hackathon Judge avec Agent Sandbox sur GKE.
Vous avez implémenté une plate-forme d'IA moderne et sécurisée basée sur les événements, capable de tester et d'évaluer les soumissions de code non fiables dans des contraintes de sécurité conteneurisées isolées.
Connaissances acquises
- Infrastructure GKE : comment provisionner GKE Autopilot et les services Google Cloud associés, comme Pub/Sub et BigQuery.
- Configuration de la sandbox de l'agent : comment configurer les définitions de ressources personnalisées, les SandboxTemplates, les SandboxClaims et les Sandbox WarmPools hautes performances.
- Déploiement de microservices : découvrez comment configurer les liaisons Workload Identity et déployer une architecture de microservices à plusieurs composants (Frontend React, REST Go, agent ADK Worker et bac à sable isolé).
- Bac à sable sécurisé : découvrez comment utiliser les conteneurs virtualisés gVisor pour exécuter des commandes tierces non approuvées de manière sécurisée sur les nœuds GKE.
Étapes suivantes
- Consultez la documentation sur le bac à sable de l'agent.
- En savoir plus sur les fonctionnalités de GKE Autopilot
- Consultez la documentation Agent Platform.