
1. Wprowadzenie
W tym ćwiczeniu wdrożysz aplikację Hackathon Judge w Google Kubernetes Engine (GKE) i użyjesz piaskownicy agentów Kubernetes-sigs do bezpiecznego uruchamiania zadań agentów.
Platforma została zaprojektowana do automatyzacji procesu sprawdzania, testowania i oceniania projektów z hackathonów za pomocą agentów LLM. Ocena wymaga sprawdzenia przesłanych przez uczestników kodów, którym nie można ufać, dlatego bezpieczna piaskownica wykonawcza jest niezbędna, aby zapobiec wstrzykiwaniu kodu, eskalacji uprawnień lub nadużywaniu zasobów.
Jakie zadania wykonasz
- Zainicjuj docelowe usługi Google Cloud i ustal docelowe interfejsy API.
- Zainicjuj GKE Autopilot i zainstaluj definicje CRD piaskownicy agenta, konfiguracje klastra i router piaskownicy.
- Wdróż bramę piaskownicy, szablon roszczenia piaskownicy i pulę wstępnego rozgrzewania piaskownicy.
- Wdróż backend interfejsu API REST, agenta roboczego ADK Judging i interfejs użytkownika frontendu React.
- Połącz zewnętrzne routingi z równoważeniem obciążenia i uzyskaj dostęp do platformy, aby uruchamiać bezpieczne, odizolowane przepływy pracy związane z ocenianiem.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- Projekt Google Cloud z włączonymi płatnościami.
Zasoby utworzone w tym laboratorium powinny kosztować mniej niż 5 USD w przypadku łącznych opłat za czas działania.
2. Problem: bezpieczne ocenianie niezaufanego kodu
Hackathony to szybkie wydarzenia innowacyjne, podczas których uczestnicy tworzą i przesyłają projekty – często zawierające kod źródłowy – do oceny. Ręczne ocenianie tych zgłoszeń jest czasochłonne i wymaga dużych zasobów. Wykorzystanie agentów AI do automatyzacji oceniania to obiecujące rozwiązanie, ale wiąże się z poważnym problemem dotyczącym bezpieczeństwa: jak bezpiecznie uruchamiać kod dostarczony przez uczestników, który może zawierać błędy, być złośliwy lub wymagać dużych zasobów?
Uruchamianie niezaufanego kodu bezpośrednio w infrastrukturze naraża Cię na takie zagrożenia jak:
- Wstrzykiwanie kodu: złośliwe skrypty mogą próbować uzyskać dostęp do danych wrażliwych lub je modyfikować.
- Podniesienie uprawnień: kod może próbować uzyskać nieuprawniony dostęp do innych systemów lub zasobów sieciowych.
- Nadużywanie zasobów: źle napisany kod lub ataki typu „odmowa usługi” mogą zużywać nadmierną ilość procesora, pamięci lub przepustowości sieci, co wpływa na inne operacje.
Aby zautomatyzować ocenianie hackathonu za pomocą AI, potrzebujemy sposobu na uruchamianie przesłanego kodu w środowisku całkowicie odizolowanym od reszty naszego systemu i innych zgłoszeń.
3. Rozwiązanie: piaskownica agenta GKE
Piaskownica agentów GKE to funkcja zaprojektowana z myślą o tym konkretnym wyzwaniu. Pomaga zarządzać izolowanymi, stanowymi i jednoreplikowymi zadaniami w GKE i jest zoptymalizowana pod kątem przypadków użycia, takich jak środowiska wykonawcze agentów AI, w których niezaufany kod musi być wykonywany bezpiecznie i wydajnie.
Najważniejsze zalety piaskownicy agentów:
- Izolacja na poziomie jądra: zapewnia silną izolację na poziomie jądra w przypadku niezaufanego kodu za pomocą technologii takich jak gVisor, co uniemożliwia kodowi dostęp do systemu hosta lub innych kontenerów.
- Udostępnianie w mniej niż sekundę: szybkie udostępnianie środowisk piaskownicy (zwykle <1 s), co jest kluczowe w przypadku oceny kodu na żądanie.
- Rozszerzalność natywna dla chmury: wykorzystuje potencjał Kubernetes i zarządzaną infrastrukturę GKE.
Dzięki Agent Sandbox możemy tworzyć na żądanie odizolowane środowiska dla każdego zgłoszenia na hackathon. Agent oceniający AI może następnie polecić piaskownicy agenta przeprowadzenie testów, skompilowanie kodu lub wykonanie innych kroków oceny w tej bezpiecznej piaskownicy bez ryzyka naruszenia integralności całej platformy. Zapewnia to skalowalny, bezpieczny i wydajny sposób automatyzacji oceniania hackathonów.
4. Zanim zaczniesz
Uruchamianie Cloud Shell
Kliknij poniższy przycisk, aby uruchomić Google Cloud Shell, które jest wstępnie skonfigurowane z wymaganymi narzędziami wiersza poleceń dla programistów i usług w chmurze.
Włącz interfejsy API
Aby włączyć wszystkie docelowe interfejsy Cloud APIs Google Cloud wymagane do uruchomienia platformy, uruchom w Cloud Shell to polecenie:
gcloud services enable \
container.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
iam.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com
Dlaczego włączamy te interfejsy API: usługi Google Cloud są domyślnie wyłączone, aby zapobiec nieautoryzowanemu dostępowi i obciążeniom. Włączamy te interfejsy API, aby aktywować orkiestrację kontenerów (GKE), bezpieczne przechowywanie kontenerów (Artifact Registry), bezserwerowe pakowanie kompilacji (Cloud Build), niezawodne kolejki wiadomości (Pub/Sub), usługi modeli AI (Vertex AI), konfigurację projektu (Cloud Resource Manager i IAM), bezserwerową analitykę danych (BigQuery) oraz powiązania AI na poziomie bazy danych (BigQuery Connection).
5. Konfigurowanie infrastruktury
W tym kroku sklonujesz repozytorium kodu i wykonasz zautomatyzowany skrypt konfiguracji, aby wdrożyć docelową architekturę chmury i podstawowe komponenty klastra.
Klonowanie repozytorium
Sklonuj repozytorium zawierające wszystkie usługi aplikacji, skrypty konfiguracji i deklaracje manifestu Kubernetes:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set codelabs/ai-toolkit-lab-2/hackathon-judge
cd codelabs/ai-toolkit-lab-2/hackathon-judge
Uruchamianie skryptu wdrażania
Podstawowa konfiguracja zasobów w chmurze, modeli bazy danych i podstawowych zasad klastra Kubernetes jest zautomatyzowana przez skrypt deploy.sh.
Uruchom skrypt:
./deploy.sh
Postępuj zgodnie z instrukcjami wyświetlanymi w interaktywnej powłoce, aby podać konfiguracje, takie jak aktywny identyfikator projektu i region docelowy. Skrypt automatycznie generuje lokalną konfigurację .env, wiąże zasoby, kompiluje obrazy kontenerów i rejestruje infrastrukturę bazową GKE.
Oto operacje docelowe wykonywane przez skrypt:
1. Konfigurowanie środowiska
Skrypt tworzy plik konfiguracyjny .env do przechowywania parametrów zmiennych GKE, Pub/Sub, BigQuery i projektu. Dynamiczne pobieranie tego pliku wypełnia wszystkie kolejne definicje manifestu Kubernetes.
Dlaczego konfigurujemy ten plik środowiska: plik .env centralizuje parametry konfiguracji, dzięki czemu manifesty GKE, które zastosujemy ręcznie w kolejnych krokach, będą używać identycznych ustawień regionalnych, nazw projektów i zasobów, co ściśle oddziela konfigurację środowiska od kodu źródłowego.
2. Google Cloud CLI i konfiguracja projektu docelowego
Skrypt sprawdza, czy zainstalowane są narzędzia gcloud, bq, kubectl i envsubst, weryfikuje stan uwierzytelniania i blokuje aktywne środowiska docelowe konfiguracji w aktywnym projekcie w chmurze Google.
Dlaczego kierujemy reklamy na aktywny projekt: ustawienie aktywnego projektu docelowego zapobiega wpływaniu poleceń interfejsu wiersza poleceń na inne projekty na Twoim koncie i umożliwia przeprowadzenie wstępnych kontroli uwierzytelniania, dzięki czemu polecenia konfiguracji nie kończą się niepowodzeniem w trakcie wdrażania z powodu nieprawidłowych danych logowania.
3. Włączanie docelowych interfejsów API Google Cloud
Skrypt wykonuje idempotentne sprawdzenie, aby zweryfikować i włączyć interfejsy API docelowych usług Google Cloud (GKE, Artifact Registry, Cloud Build, Pub/Sub, Vertex AI, BigQuery i IAM).
Dlaczego włączamy interfejsy Google Cloud API: zarządzane usługi w chmurze muszą zostać aktywowane, zanim ich punkty końcowe staną się dostępne lub będzie można utworzyć zasoby. Włączenie ich na początku przygotowuje regionalną bramę API GCP do obsługi kolejnych poleceń udostępniania zasobów.
4. Aprowizacja repozytorium Dockera w Artifact Registry
Skrypt udostępnia repozytorium kontenerów Dockera o nazwie hackathon-judge-repo w wybranej lokalizacji docelowej.
Dlaczego tworzymy repozytorium Artifact Registry: klastry GKE wymagają bezpiecznego dostępu do prywatnych rejestrów kontenerów w tej samej sieci regionalnej, aby szybko pobierać obrazy aplikacji. Artifact Registry udostępnia bezpieczny, prywatny host do katalogowania, skanowania i przechowywania obrazów kontenerów Dockera.
5. Provisioning the GKE Autopilot Cluster
Skrypt obsługuje administracyjnie klaster Autopilot Google Kubernetes Engine (GKE) o nazwie hackathon-judge-cluster.
Dlaczego wdrażamy klaster GKE z Autopilotem: GKE Autopilot automatycznie zarządza udostępnianiem węzłów, skalowaniem, monitorowaniem stanu i uaktualnianiem zabezpieczeń systemu operacyjnego hosta. Zapewnia platformę kontenerową klasy produkcyjnej do orkiestracji naszych trwałych usług i dynamicznego planowania bezpiecznych piaskownic pracowników na żądanie.
6. Konfigurowanie tematów i subskrypcji Pub/Sub
Skrypt udostępnia tematy wiadomości (judging-tasks i judging-results) wraz z odpowiednimi subskrypcjami instancji roboczej i interfejsu API.
Dlaczego wdrażamy tematy i subskrypcje Pub/Sub: ocena przesłanych kodów jest powolna i wymaga dużych zasobów. Architektura kolejki komunikatów oddziela synchroniczny interfejs API dla użytkowników od węzłów roboczych. Backend interfejsu API przesyła zadania do tematu judging-tasks, a agenty robocze pobierają zadania, gdy są dostępne, co zapobiega blokowaniu interfejsu API i zapewnia automatyczne ponawianie.
7. Konfigurowanie zbiorów danych, tabel i połączeń AI w BigQuery
Skrypt tworzy zbiór danych hackathon_judge, stosuje strukturalne schematy bazy danych SQL, wczytuje rekordy początkowe i przyznaje wymagane role AI i pamięci masowej kontu usługi połączenia BigQuery ML.
8. Wywoływanie kompilacji kontenerów za pomocą Cloud Build
Skrypt wywołuje definicję cloudbuild.yaml, aby skompilować interfejs React, serwer REST w Go, proces ADK w Pythonie i piaskownicę FastAPI, spakować je w izolowane obrazy kontenerów oznaczone aktywnym SHA zatwierdzenia Git repozytorium i zapisać je w Artifact Registry.
9. Rejestrowanie definicji zasobów niestandardowych (CRD) piaskownicy agenta
Skrypt pobiera i rejestruje najnowsze definicje zasobów niestandardowych piaskownicy agentów Kubernetes-sigs (manifest.yaml i extensions.yaml), aby rozszerzyć podstawowe możliwości GKE.
Dlaczego instalujemy infrastrukturę Agent Sandbox: standardowe klastry Kubernetes nie obsługują przydzielania chronionych piaskownic na żądanie. Rejestrowanie definicji CRD piaskownicy agentów rozszerza platformę sterującą GKE, umożliwiając Kubernetesowi natywne zarządzanie bezpiecznymi mikrokontenerami w piaskownicy za pomocą zasobów niestandardowych (takich jak SandboxTemplates i SandboxClaims).
10. Konfigurowanie przestrzeni nazw, kont usługi i Workload Identity
Skrypt udostępnia przestrzeń nazw hackathon-judge, rejestruje konta usługi Kubernetes (KSA) i tworzy mapowania Workload Identity, aby przyznać zasobnikom GKE docelowe uprawnienia Google Cloud.
11. Wdrażanie routera piaskownicy
Skrypt stosuje manifest k8s/sandbox_router.yaml, inicjując wdrożenie i usługę Sandbox Router oraz czekając, aż osiągną one stan prawidłowy.
Dlaczego wdrażamy router piaskownicy: router piaskownicy to centralna wewnętrzna brama platformy sterującej. Udostępnia prosty interfejs API, który jest wywoływany przez agenta roboczego ADK w celu przejmowania, uzyskiwania dostępu do bezpiecznych piaskownic i zwalniania ich. Zarządza on mapowaniami routingu i oddziela alokację podów na poziomie klastra od logiki aplikacji.
6. Konfigurowanie bramy piaskownicy agenta, roszczeń i puli WarmPool
Na tym etapie ręcznie skonfigurujesz specjalistyczną bramę sieci piaskownicy, zarejestrujesz szablon deklaracji piaskownicy i wdrożysz pulę wstępną piaskownicy, aby umożliwić piaskownicę o bardzo małym opóźnieniu.
Zmienne środowiskowe źródła
Przed zastosowaniem szablonów wymagających zmiennych środowiskowych uruchom skrypt setup-env.sh, aby przeanalizować i wyeksportować wszystkie niezbędne zmienne do powłoki:
source ./setup-env.sh
Stosowanie bramy piaskownicy
Wdróż bramę skonfigurowaną specjalnie pod kątem kierowania ruchu z piaskownicy:
kubectl apply -f k8s/sandbox-gateway.yaml
Dlaczego wdrażamy bramę piaskownicy: brama piaskownicy działa jako bezpieczny kontroler wejścia o wysokiej wydajności, który jest przeznaczony wyłącznie do routingu w piaskownicy. Izoluje ona sieć piaskownicy, zapewniając bezpieczny, lokalny cel, który umożliwia agentom roboczym komunikowanie się z przejętymi piaskownicami bez udostępniania punktów końcowych na zewnątrz.
Zastosuj szablon roszczenia w piaskownicy
Użyj polecenia envsubst, aby wypełnić definicję szablonu piaskownicy aktywnymi zmiennymi środowiskowymi i zastosować ją:
source ./setup-env.sh
envsubst < k8s/sandbox-claim-template.yaml | kubectl apply -f -
Dlaczego wdrażamy szablon roszczenia dotyczący piaskownicy: szablon roszczenia dotyczący piaskownicy pełni funkcję konfiguracji planu, która określa środowisko. Określa obraz kontenera do uruchomienia (wstępnie spakowany z narzędziami dla programistów), parametry środowiska (identyfikator projektu GCP), porty i limity zasobów (docelowe wartości procesora i pamięci). Konfiguruje GKE do uruchamiania tych instancji kontenerów przy użyciu gVisor (środowiska wykonawczego gvisor), co gwarantuje, że niezaufany kod uczestnika będzie działać pod dodatkową warstwą izolacji wirtualizacji jądra.
Zastosuj pulę wstępną piaskownicy
Zastosuj pulę wstępną piaskownicy, aby wstępnie zainicjować działające piaskownice:
kubectl apply -f k8s/sandbox-warmpool.yaml
Sprawdź, czy instancje gotowości w puli wstępnego rozgrzewania zostały uruchomione:
kubectl get pods -n hackathon-judge -l app=sandbox
Dlaczego wdrażamy pulę Sandbox WarmPool: udostępnianie, planowanie, pobieranie obrazów i uruchamianie nowych podów kontenerów na żądanie wiąże się ze znacznym narzutem na uruchomienie (czas uruchomienia „na zimno” wynosi ponad 30 sekund). Piaskownica WarmPool utrzymuje pulę gotowości aktywnych, wstępnie rozgrzanych zasobników piaskownicy (domyślnie 5 replik). Gdy agent roboczy zażąda środowiska testowego, router piaskownicy natychmiast przydzieli uruchomiony, wstępnie rozgrzany zasobnik, skracając opóźnienia przy uruchamianiu do mniej niż sekundy.
7. Wdrażanie komponentów aplikacji
Po pełnym aktywowaniu bezpiecznej infrastruktury piaskownicy wdrożysz centralny backend interfejsu API, agenta roboczego, interfejs internetowy React i mapowanie bramy wejściowej.
Wdrażanie backendu
Wdróż backend interfejsu API REST aranżera:
source ./setup-env.sh
envsubst < k8s/backend.yaml | kubectl apply -f -
Wdrażanie agenta
Wdróż agenta oceniającego ADK:
source ./setup-env.sh
envsubst < k8s/agent.yaml | kubectl apply -f -
Wdrażanie frontendu
Wdróż interaktywny internetowy interfejs użytkownika:
source ./setup-env.sh
envsubst < k8s/frontend.yaml | kubectl apply -f -
Konfigurowanie zewnętrznej bramy i routingu
Wdróż główną bramę i wejściowe trasy HTTP mapujące ruch klientów zewnętrznych:
kubectl apply -f k8s/gateway.yaml
Dlaczego wdrażamy zewnętrzną bramę Ingress: zewnętrzna brama udostępnia nasze usługi za pomocą interfejsu Kubernetes Gateway API. Zapewnia on publiczny adres IP z równoważeniem obciążenia i mapuje trasy na podstawie reguł ścieżek – kieruje żądania API w /api/* do backendu Go i mapuje cały inny ruch internetowy klienta (/) do frontendu React, zabezpieczając dostęp do klastra publicznego.
Weryfikowanie wdrożeń
Zablokuj wykonanie powłoki i poczekaj, aż wszystkie 3 wdrożenia usług podstawowych osiągną stan wdrożenia gotowy do użycia:
kubectl rollout status deployment/backend -n hackathon-judge --timeout=300s
kubectl rollout status deployment/agent -n hackathon-judge --timeout=300s
kubectl rollout status deployment/frontend -n hackathon-judge --timeout=300s
8. Weryfikacja i korzystanie z aplikacji
Otwieranie interfejsu
Pobierz zewnętrzny publiczny adres IP nowo utworzonej głównej bramy systemu równoważenia obciążenia:
Aby śledzić stan udostępniania w czasie rzeczywistym, uruchom polecenie z flagą watch (-w) i poczekaj, aż w polu ADDRESS pojawi się publiczny adres IP:
kubectl get gateway -n hackathon-judge hackathon-judge-gateway -w
Po pomyślnym udostępnieniu powinny pojawić się dane wyjściowe podobne do tych:
NAME CLASS ADDRESS PROGRAMMED AGE hackathon-judge-gateway gke-l7 34.120.120.120 True 3m
Gdy w kolumnie ADDRESS zobaczysz prawidłowy publiczny adres IP, a stan PROGRAMMED będzie True, naciśnij Ctrl+C, aby zatrzymać zegarek.
Dlaczego otrzymujemy stan Gateway: interfejs Gateway API obsługuje publiczny ruch przychodzący. Sprawdzenie stanu bramy zwraca publiczny, zrównoważony zewnętrzny adres IP przydzielony do naszego klastra przez zewnętrzny globalny system równoważenia obciążenia Google Cloud, który reprezentuje publiczny adres naszej platformy.
Otwórz przydzielony publiczny adres IP w przeglądarce, aby załadować panel sędziów hackathonu.
Przesyłanie zadań
- W interfejsie użytkownika przejdź do panelu i wybierz hackathon.
- W dowolnym projekcie możesz kliknąć
Run Agent, aby rozpocząć ocenę całego projektu przez agenta na podstawie kryteriów oceny.
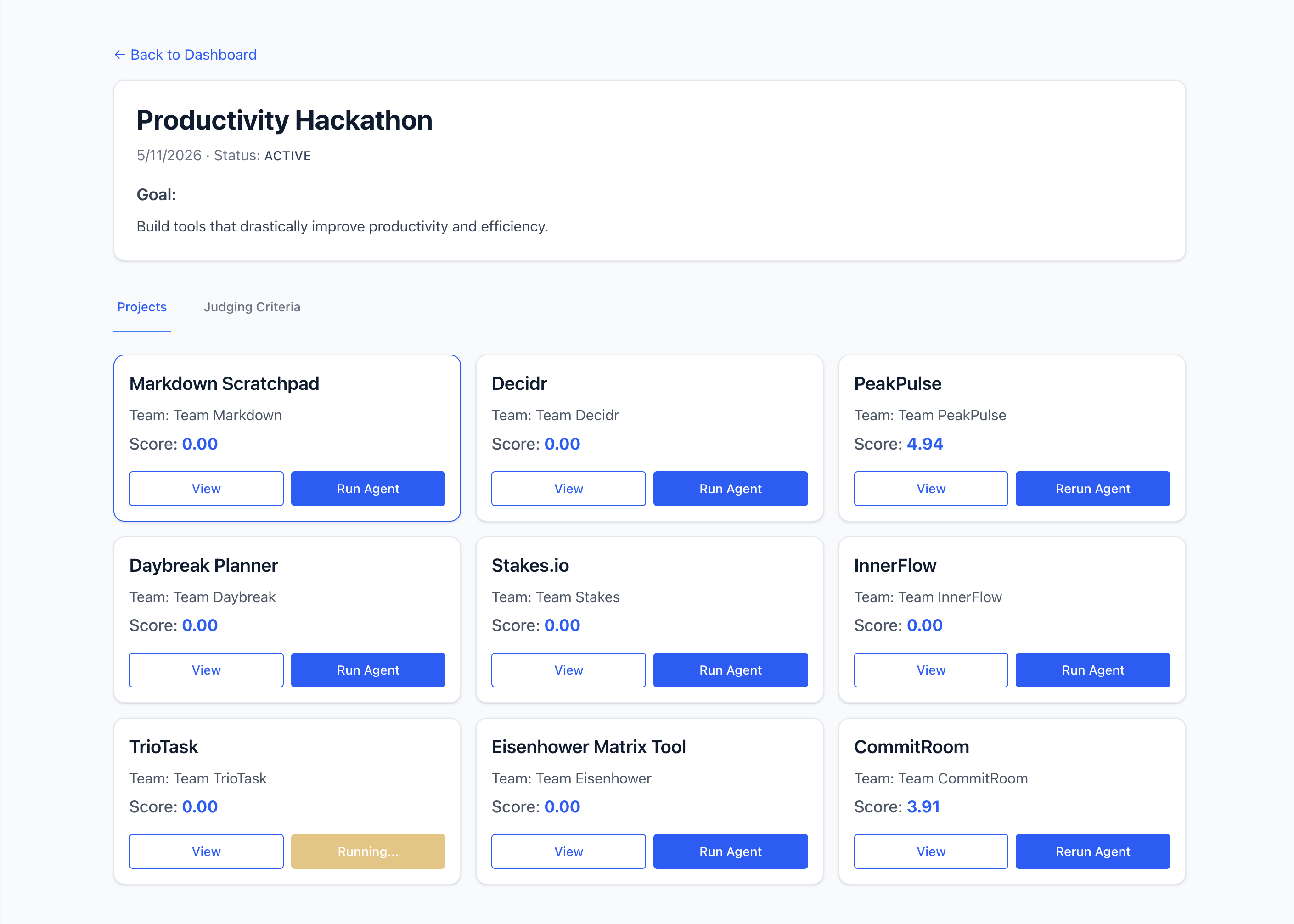
Obejrzyj rozpoczęcie okresu próbnego w piaskownicy
Monitoruj aktywne pody w przestrzeni nazw hackathon-judge, aby zobaczyć, jak pod piaskownicy jest dynamicznie przypisywany i udostępniany na potrzeby oceny wykonania:
kubectl get pods -n hackathon-judge -w
Sprawdź logi poda agenta instancji roboczej, aby zobaczyć krok po kroku logikę oceny ADK:
kubectl logs -l app=agent -n hackathon-judge
Dlaczego sprawdzamy logi agenta: sprawdzanie logów agenta pracownika wyświetla szczegółowe wewnętrzne kroki potoku oceny w czasie rzeczywistym. Możesz śledzić, jak agent ADK pobiera zadanie, wysyła prośbę o kontener piaskownicy, wykonuje cele kompilacji, analizuje raporty za pomocą Gemini i publikuje podsumowania statystyk.
9. (Opcjonalnie) Jak to działa
Architektura piaskownicy agenta
Funkcje AI w BigQuery są świetne do oceny zgłoszeń tekstowych i twierdzeń w plikach README, ale ocena projektu inżynieryjnego wymaga skompilowania kodu, zainstalowania bibliotek innych firm i uruchomienia prawdziwych zestawów testów.
Uruchamianie nieprzetworzonego kodu użytkownika stwarza ogromne zagrożenia dla bezpieczeństwa, w tym naruszenie bezpieczeństwa hosta, wyjście z kontenera i nieautoryzowany dostęp do zasobów. Platforma GKE Agent Sandbox zmniejsza te zagrożenia, organizując izolowane zadania w piaskownicy przy użyciu wirtualizacji gVisor (runsc).
Przebieg interakcji z systemem
Diagram poniżej pokazuje, jak różne elementy naszego systemu opartego na zdarzeniach komunikują się podczas bezpiecznego wykonywania oceny w środowisku piaskownicy:
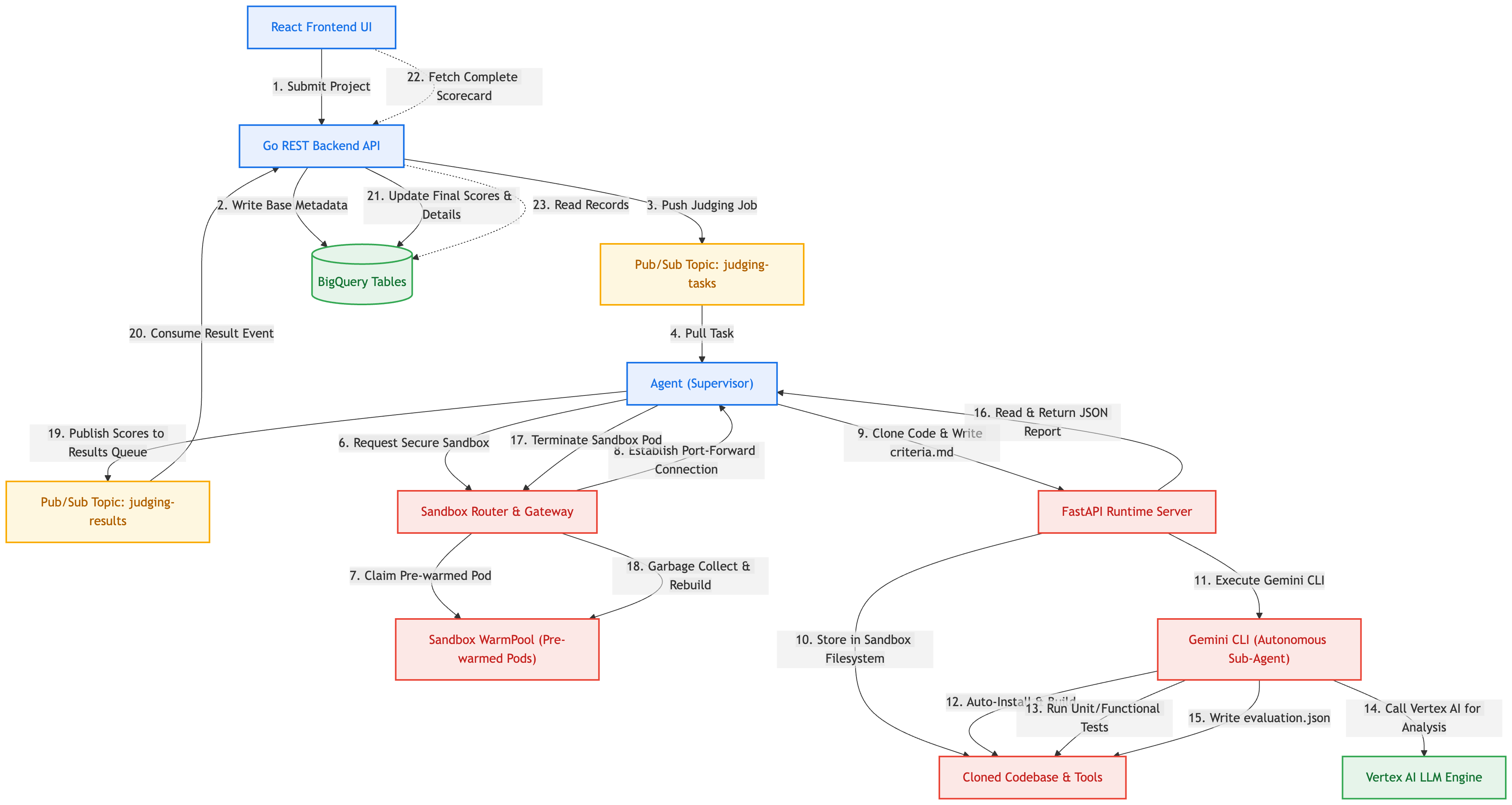
Jak współpracują ze sobą zaangażowane narzędzia i komponenty
- Interfejs React Frontend UI: udostępnia interaktywny interfejs, w którym użytkownicy mogą konfigurować modele kryteriów, rejestrować zespoły, przesyłać adresy URL projektów i sprawdzać ostateczne karty wyników, w tym pełne rozbieżności w plikach i komentarze inżynierów.
- Go REST Backend API: zarządza globalnymi punktami końcowymi interfejsu API. Przechowuje konfiguracje projektów w BigQuery i przesyła zadania oceny do Pub/Sub, aby oddzielić potoki wykonywania obliczeń o dużej mocy.
- Google Pub/Sub: broker zorientowany na wiadomości, który bezpiecznie przechowuje wiadomości o zadaniach w kolejce, asynchronicznie koordynując komunikację między interfejsem API a aktywnymi instancjami procesów roboczych.
- Proces roboczy ADK w Pythonie (agent nadzorujący): proces działający w tle, który pobiera zadania z Pub/Sub. Wykorzystuje on pakiet Google Agent Development Kit (ADK), aby uruchomić agenta nadzorującego wyższego poziomu, który ma za zadanie koordynować ocenę. Nadzorca wywołuje swoje główne narzędzie
evaluate_repository, aby delegować testowanie poleceń pierwotnych. - Router i brama piaskownicy (płaszczyzna sterowania GKE): wewnętrzna brama sterowania, która rejestruje standardowe definicje zasobów niestandardowych piaskownicy (
SandboxClaims,SandboxTemplates). Koordynuje sieci GKE w celu przydzielania i zabezpieczania podów, zwracając strumienie połączeń do klientów roboczych. - Sandbox WarmPool: aby uniknąć długiego czasu uruchamiania kontenerów GKE („zimne starty” trwające ponad 30 sekund), WarmPool utrzymuje aktywne pody w trybie gotowości. Gdy sandbox zostanie zarezerwowany, router natychmiast mapuje go w czasie poniżej sekundy, a następnie planuje jego ponowne wykorzystanie po zwolnieniu.
- Izolacja gVisor (runsc): wirtualne jądro przestrzeni użytkownika, które działa jako bezpieczna granica piaskownicy. Przechwytuje wywołania systemowe z przestrzeni kontenera do jąder węzłów GKE, zapewniając, że niebezpieczne polecenia pierwotne (takie jak skrypty systemowe lub konfiguracje pakietów) są uruchamiane w warunkach całkowitej izolacji wirtualizacji.
- Środowisko wykonawcze Piaskownicy FastAPI: lekki serwer interfejsu API w Pythonie działający w kontenerze piaskownicy. Udostępnia bezpieczne punkty końcowe (
/execute,/upload,/download), które umożliwiają zewnętrznym narzędziom roboczym manipulowanie plikami i wywoływanie zadań powłoki. - Interfejs wiersza poleceń Gemini
@google/gemini-cli: skrypt autonomicznego agenta zainstalowany w piaskownicy. Gdy jest wywoływany za pomocą flagi środowiska wykonawczego środowiska deweloperskiego (--yolo), korzysta z rygorystycznego arkusza instrukcji oceniania (prompt.md) i definicji kryteriów (criteria.md), aby:- Dynamicznie analizuj hierarchię bazy kodu (za pomocą narzędzi takich jak
treelubripgrep). - automatycznie instalować wymagania (za pomocą poleceń takich jak
npm install,pip install,go build); - Przeprowadzaj prawdziwe testy deweloperskie (np.
npm testlubpytest), aby sprawdzić działanie. - Wywołuj modele Vertex AI (za pomocą danych logowania powiązanych z Workload Identity kontenera), aby oceniać logikę plików, sprawdzać twierdzenia w porównaniu z plikiem README, wykrywać nieistniejące funkcje, rejestrować problemy z jakością i zapisywać w
evaluation.jsonraport z wynikami w formacie strukturalnym.
- Dynamicznie analizuj hierarchię bazy kodu (za pomocą narzędzi takich jak
- Standardowe środowiska deweloperskie: w obrazie kontenera piaskownicy znajdują się węzeł, npm, yarn, pnpm, python, pip, uv, go, gh, git, tree, ripgrep i playwright, co zapewnia autonomicznemu sub-agentowi kompletne środowisko testowe.
10. Czyszczenie
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone podczas tego ćwiczenia.
./destroy.sh
Dlaczego zwalniamy miejsce w zasobach: Google Cloud rozlicza się na podstawie modelu wykorzystania zasobów. Aktywne zasoby, takie jak klastry GKE z Autopilotem, sieciowe systemy równoważenia obciążenia i dyski trwałe, generują bieżące opłaty nawet wtedy, gdy są nieaktywne. Wykonanie tego kroku spowoduje usunięcie przestrzeni nazw klastra w celu wyczyszczenia obiektów Kubernetes oraz usunięcie samego hosta klastra GKE Autopilot, aby natychmiast zakończyć naliczanie opłat.
11. Gratulacje
Gratulacje! Udało Ci się wdrożyć aplikację Hackathon Judge z Agent Sandbox w GKE.
Wdrożono bezpieczną, nowoczesną platformę AI opartą na zdarzeniach, która umożliwia testowanie i ocenianie przesłanych, niezaufanych baz kodu w izolowanych kontenerach z ograniczeniami bezpieczeństwa.
Czego się dowiedziałeś(-aś)
- Infrastruktura GKE: jak udostępniać GKE Autopilot i powiązane usługi Google Cloud, takie jak Pub/Sub i BigQuery.
- Konfiguracja piaskownicy agenta: jak skonfigurować definicje zasobów niestandardowych, szablony piaskownicy, roszczenia piaskownicy i pule wstępnego rozgrzewania piaskownicy o wysokiej wydajności.
- Wdrażanie mikroserwisów: jak skonfigurować powiązania Workload Identity i wdrożyć wieloskładnikową architekturę mikroserwisów (Frontend React, REST Go, Worker ADK Agent i Isolated Sandbox).
- Bezpieczna piaskownica: jak używać zwirtualizowanych kontenerów gVisor do bezpiecznego uruchamiania niezaufanych poleceń innych firm w węzłach GKE.
Dalsze kroki
- Zapoznaj się z dokumentacją piaskownicy agentów.
- Dowiedz się więcej o funkcjach Autopilota w GKE.
- Zapoznaj się z dokumentacją Agent Platform.