
1. Introduction
Présentation
Dans cet atelier, vous allez créer et déployer une application de chat full stack optimisée par l'IA sur Google Kubernetes Engine (GKE). Cette application "hybride" illustre un modèle architectural puissant : la possibilité de basculer facilement entre un modèle ouvert auto-hébergé (Gemma 3 12B) s'exécutant directement dans votre cluster et un service d'IA géré (Gemini 2.5 Flash via Vertex AI).
+----------------------+
| User (Web Browser) |
+-----------+----------+
|
v
+----------------------------------------------+---------------------------------------------+
| Google Cloud Platform | |
| | +-------+-------+ |
| | | Load Balancer | |
| | +-------+-------+ |
| | v |
| +------------------------------------------+-----------------------------------------+ |
| | Google Kubernetes Engine (GKE) | | |
| | v | |
| | +-----------+-----------+ | |
| | | Gradio Chat App | | |
| | +--+-----------------+--+ | |
| | | | | |
| | (Self-hosted) | | (Managed via SDK) | |
| | v | | |
| | +--------------+---+ | | |
| | | Gemma 3 Model | | | |
| | | (GPU Node) | | | |
| | +------------------+ | | |
| +---------------------------------------------------|--------------------------------+ |
| | |
| v |
| +----------+-----------+ |
| | Vertex AI (Gemini) | |
| +----------------------+ |
| | (Save History) |
| v |
| +----------+-----------+ |
| | Firestore Database | |
| +----------------------+ |
+--------------------------------------------------------------------------------------------+
Vous utiliserez Terraform pour provisionner l'infrastructure, y compris un cluster GKE Autopilot et une base de données Firestore pour conserver l'historique des sessions de chat. Vous allez ensuite compléter le code de l'application Python pour gérer les conversations multitours, interagir avec les deux modèles d'IA et déployer l'application finale à l'aide de Cloud Build et Skaffold.
Points abordés
- Provisionnez l'infrastructure GKE et Firestore à l'aide de Terraform.
- Déployez un grand modèle de langage (Gemma) sur GKE Autopilot à l'aide de manifestes Kubernetes.
- Implémenter une interface de chat Gradio en Python qui peut basculer entre différents backends d'IA.
- Utilisez Firestore pour stocker et récupérer l'historique des sessions de chat.
- Configurer Workload Identity pour accorder un accès sécurisé à vos charges de travail GKE aux services Google Cloud (Vertex AI, Firestore)
Prérequis
- Un projet Google Cloud avec facturation activée.
- Connaissances de base de Python, de Kubernetes et des outils de ligne de commande standards.
- Un jeton Hugging Face avec accès aux modèles Gemma.
2. Configuration du projet
- Si vous ne possédez pas encore de compte Google, vous devez en créer un.
- Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire. Il est possible que des restrictions s'appliquent aux comptes professionnels et scolaires, ce qui vous empêche d'activer les API nécessaires pour cet atelier.
- Connectez-vous à la console Google Cloud.
- Activez la facturation dans la console Cloud.
- Cet atelier devrait vous coûter moins de 1 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour bénéficier d'un crédit de 300$.
- Créez un projet ou réutilisez-en un existant.
Ouvrir l'éditeur Cloud Shell
- Cliquez sur ce lien pour accéder directement à l'éditeur Cloud Shell.
- Si vous êtes invité à autoriser l'accès à un moment donné aujourd'hui, cliquez sur Autoriser pour continuer.
- Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
 .
.
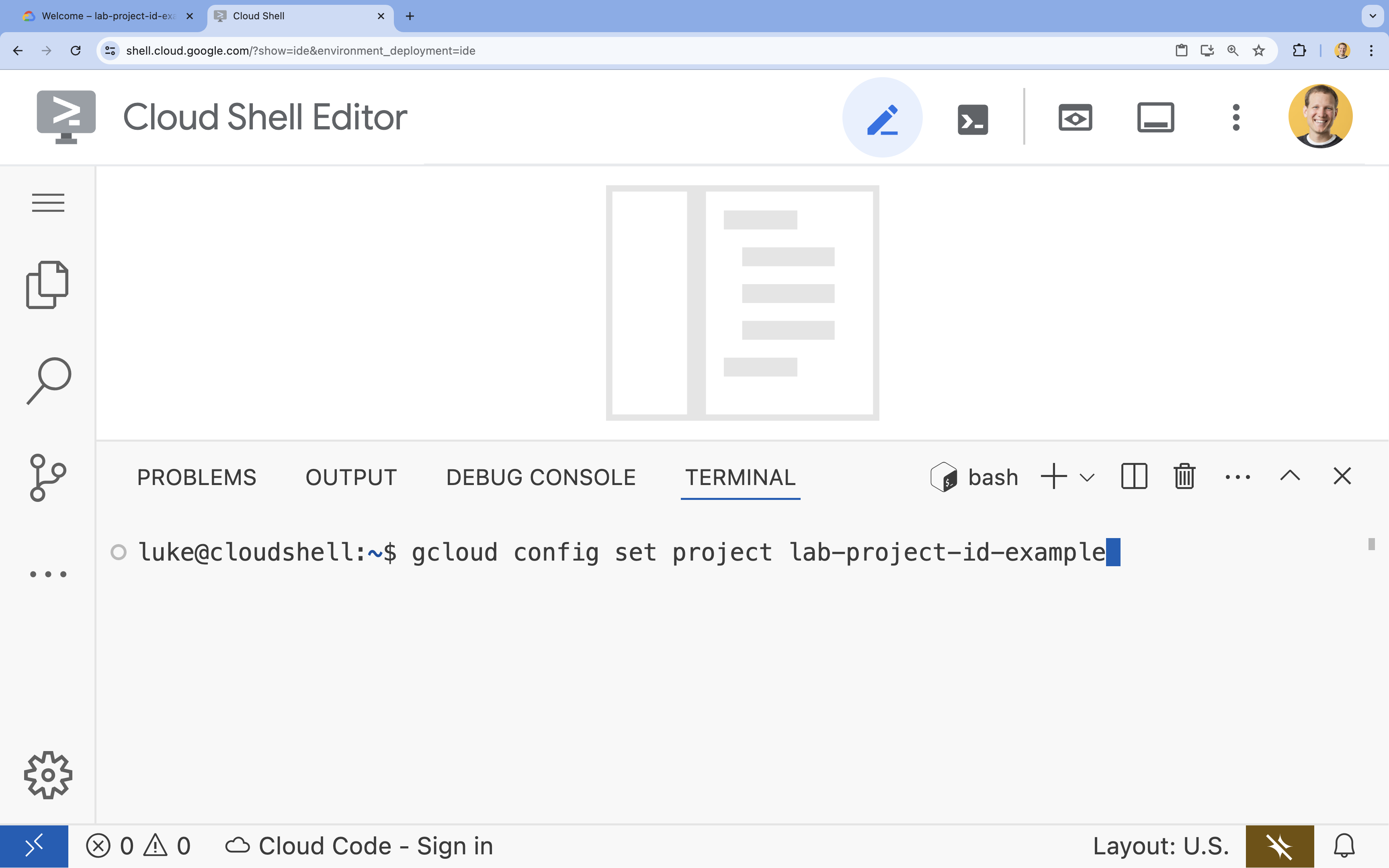
- Dans le terminal, définissez votre projet à l'aide de la commande suivante :
- Format :
gcloud config set project [PROJECT_ID] - Exemple :
gcloud config set project lab-project-id-example - Si vous ne vous souvenez pas de l'ID de votre projet :
- Vous pouvez lister tous vos ID de projet avec la commande suivante :
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Vous pouvez lister tous vos ID de projet avec la commande suivante :
- Format :
- Le message suivant doit s'afficher :
Updated property [core/project].
WARNINGs'affiche et que vous êtes invité àDo you want to continue (Y/n)?, cela signifie probablement que vous avez saisi l'ID de projet de manière incorrecte. Appuyez surn, puis surEnter, et réessayez d'exécuter la commandegcloud config set project.
Cloner le dépôt
Dans votre terminal Cloud Shell, clonez le dépôt du projet et accédez au répertoire du projet :
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/containers/gradio-chat-gke
Prenez quelques instants pour explorer la structure du projet :
gradio-chat-gke/
├── app/
│ ├── app.py # Main application logic (you will edit this)
│ ├── requirements.txt # Python dependencies
│ └── themes.py # UI theming
├── deploy/
│ ├── chat-deploy.yaml # Kubernetes deployment for the chat app
│ ├── Dockerfile # Container definition for the chat app
│ └── gemma3-12b-deploy.yaml# Kubernetes deployment for Gemma model
├── infra/
│ └── main.tf # Terraform infrastructure definition
└── skaffold.yaml # Skaffold configuration for building/deploying
Définir des variables d'environnement
Configurez des variables d'environnement pour l'ID et le numéro de votre projet. Elles seront utilisées par Terraform et les commandes suivantes.
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT --format="value(projectNumber)")
export REGION=us-central1
Activer l'API Cloud Resource Manager
Terraform nécessite l'activation de l'API Cloud Resource Manager pour gérer les ressources de votre projet. Nous devons donc l'activer en premier. Nous déploierons ensuite notre application de chat avec Skaffold, qui utilise Cloud Build pour créer notre image de conteneur. Nous allons maintenant activer l'API Storage et créer le bucket nécessaire pour Cloud Build. Nous utiliserons Terraform lui-même pour activer le reste des API requises pour ce projet.
gcloud services enable cloudresourcemanager.googleapis.com storage-api.googleapis.com
Créer un bucket de préproduction Cloud Build
Skaffold utilise Google Cloud Build, qui nécessite un bucket Cloud Storage pour organiser votre code source.
Créez-le maintenant pour vous assurer qu'il existe :
gcloud storage buckets create gs://${GOOGLE_CLOUD_PROJECT}_cloudbuild
(Si un message d'erreur indique que le bucket existe déjà, vous pouvez l'ignorer sans problème.)
3. Provisionner une infrastructure avec Terraform
Nous allons utiliser Terraform pour configurer les ressources Google Cloud nécessaires. Cela garantit un environnement reproductible et cohérent.
- Accédez au répertoire de l'infrastructure :
cd infra
Ce fichier définit les API supplémentaires dont nous aurons besoin pour ce projet : cloudbuild, artifactregistry, container (gke), firestore et aiplatform (vertexai). Consultez le fichier ou la section ci-dessous pour découvrir comment les API sont activées via Terraform :
resource "google_project_service" "cloudbuild" {
service = "cloudbuild.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "artifactregistry" {
service = "artifactregistry.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "container" {
service = "container.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "firestore" {
service = "firestore.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "vertexai" {
service = "aiplatform.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
Définir le cluster GKE
Ouvrez infra/main.tf dans votre éditeur. Vous verrez plusieurs commentaires # TODO. Vous pouvez l'ouvrir manuellement ou utiliser cette commande pour ouvrir le fichier dans l'éditeur :
cloudshell edit main.tf
Nous devons d'abord définir notre cluster Kubernetes. Nous allons utiliser GKE Autopilot, qui est idéal pour les charges de travail d'IA, car il gère automatiquement les nœuds.
Recherchez # TODO: Create a GKE Autopilot Cluster et ajoutez le bloc suivant en dessous :
# Create a GKE Autopilot Cluster
resource "google_container_cluster" "primary" {
name = var.cluster_name
location = var.region
project = var.project_id
# Enable Autopilot mode
enable_autopilot = true
deletion_protection = false
# Networking
network = "default"
subnetwork = "projects/${var.project_id}/regions/${var.region}/subnetworks/default"
# Timeout for cluster creation
timeouts {
create = "30m"
update = "30m"
}
depends_on = [google_project_service.container]
}
Avis enable_autopilot = true. Cette ligne unique nous évite de gérer les pools de nœuds, l'autoscaling et le bin-packing de nos charges de travail GPU.
Définir la base de données Firestore
Ensuite, nous avons besoin d'un endroit pour stocker notre historique des discussions. Firestore est une base de données NoSQL sans serveur qui répond parfaitement à ce besoin.
Recherchez # TODO: Create a Firestore Database et ajoutez :
resource "google_firestore_database" "database" {
project = var.project_id
name = "chat-app-db"
location_id = "nam5"
type = "FIRESTORE_NATIVE"
depends_on = [google_project_service.firestore]
}
Après avoir ajouté la ressource de base de données, recherchez # TODO: Create an initial Firestore Document et ajoutez le bloc suivant. Cette ressource crée un document espace réservé initial dans notre collection, ce qui est utile pour initialiser la structure de la base de données.
resource "google_firestore_document" "initial_document" {
project = var.project_id
collection = "chat_sessions"
document_id = "initialize"
fields = <<EOF
EOF
depends_on = [google_firestore_database.database]
}
Définir Workload Identity
Enfin, nous devons configurer la sécurité. Nous souhaitons que nos pods Kubernetes puissent accéder à Vertex AI et Firestore sans que nous ayons à gérer de secrets ni de clés API. Pour ce faire, nous utilisons Workload Identity.
Nous attribuerons les rôles IAM nécessaires au compte de service Kubernetes (KSA) que notre application utilisera.
Remarque : Le compte de service Kubernetes (gradio-chat-ksa) référencé dans ces liaisons n'existe pas encore. Il sera créé ultérieurement lorsque nous déploierons notre application sur le cluster. Il est tout à fait possible (et courant) de provisionner ces liaisons IAM à l'avance.
Recherchez # TODO: Configure Workload Identity IAM bindings et ajoutez :
locals {
ksa_principal = "principal://iam.googleapis.com/projects/${var.project_number}/locations/global/workloadIdentityPools/${var.project_id}.svc.id.goog/subject/ns/default/sa/gradio-chat-ksa"
}
resource "google_project_iam_member" "ksa_token_creator" {
project = var.project_id
role = "roles/iam.serviceAccountTokenCreator"
member = local.ksa_principal
}
resource "google_project_iam_member" "ksa_vertex_user" {
project = var.project_id
role = "roles/aiplatform.user"
member = local.ksa_principal
}
resource "google_project_iam_member" "ksa_datastore_user" {
project = var.project_id
role = "roles/datastore.user"
member = local.ksa_principal
}
Appliquer la configuration
Maintenant que notre infrastructure est définie, provisionnons-la.
- Nous devons d'abord définir quelques variables que Terraform pourra utiliser. Pour ce faire, nous allons utiliser des variables d'environnement :
export TF_VAR_project_id=$(gcloud config get-value project)
export TF_VAR_project_number=$(gcloud projects describe $TF_VAR_project_id --format="value(projectNumber)")
export TF_VAR_region="us-central1"
- Initialisez Terraform :
terraform init
- Utilisez
terraform planpour prévisualiser les ressources qui seront créées.
terraform plan
- Appliquez la configuration. Lorsque vous y êtes invité, saisissez
yespour confirmer.
terraform apply
Remarque : Le provisionnement d'un cluster GKE peut prendre entre 10 et 15 minutes. En attendant, vous pouvez passer à la section suivante pour examiner le code de l'application.
- Une fois l'opération terminée, configurez
kubectlpour communiquer avec votre nouveau cluster :
gcloud container clusters get-credentials gradio-chat-cluster --region us-central1 --project $TF_VAR_project_id
4. Déployer Gemma auto-hébergé sur GKE
Nous allons ensuite déployer le modèle Gemma 3 12B directement sur votre cluster GKE. Cela permet une inférence à faible latence et un contrôle total sur l'environnement d'exécution du modèle.
Configurer les identifiants Hugging Face
Pour télécharger le modèle Gemma, votre cluster doit s'authentifier auprès de Hugging Face.
- Assurez-vous de disposer d'un jeton Hugging Face.
- Créez un secret Kubernetes avec votre jeton. Remplacez [YOUR_HF_TOKEN] par votre jeton.
kubectl create secret generic hf-secret --from-literal=hf_api_token=[YOUR_HF_TOKEN]
Déployer le modèle
Nous allons utiliser un déploiement Kubernetes standard pour exécuter le modèle. Le fichier manifeste se trouve à l'emplacement deploy/gemma3-12b-deploy.yaml. Vous pouvez l'ouvrir manuellement ou utiliser cette commande pour ouvrir le fichier dans l'éditeur :
cd ../deploy
cloudshell edit gemma3-12b-deploy.yaml
Prenez quelques instants pour examiner ce fichier. Notez la section resources :
resources:
requests:
nvidia.com/gpu: 4
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
Il s'agit d'une infrastructure d'IA déclarative. Nous indiquons à GKE Autopilot que ce pod spécifique nécessite quatre GPU NVIDIA L4. Autopilot trouvera ou provisionnera un nœud qui répond exactement à ces exigences. Si un nœud n'est pas disponible pour le provisionnement, il continuera d'essayer jusqu'à ce qu'un nœud répondant aux exigences soit disponible.
- Appliquez le fichier manifeste de déploiement :
cd .. kubectl apply -f deploy/gemma3-12b-deploy.yamlkubectl get podsgemman'est pas encore opérationnel. L'application de chat se connectera au service Gemma dès qu'il sera disponible. Notez que vous ne pourrez pas interagir avec Gemma via votre application de chat tant que le podgemman'affichera pas l'étatRunninget1/1. En attendant, vous pouvez discuter avec Gemini.
5. Créer l'application Chat
À présent, terminons l'application Python. Ouvrez app/app.py dans l'éditeur Cloud Shell. Vous trouverez plusieurs blocs # TODO à remplir pour que l'application fonctionne.
cloudshell edit app/app.py
Étape 1 : Traiter l'historique des conversations
Les LLM nécessitent que l'historique des conversations soit mis en forme de manière spécifique pour qu'ils comprennent qui a dit quoi.
Le modèle "Universal Translator" : notez que nous allons écrire deux fonctions différentes pour traiter le même historique de chat. Il s'agit d'un modèle clé dans les applications multimodales.
- Source de vérité (Gradio) : notre application conserve l'historique dans un format simple et générique :
[[user_msg1, bot_msg1], ...]. - Cible 1 (Gemma) : doit être convertie en une seule chaîne brute avec des jetons spéciaux spécifiques.
- Cible 2 (Gemini) : doit être converti en liste structurée d'objets API.
En reformatant l'historique générique au format cible à chaque tour, nous pouvons passer d'un modèle à l'autre de manière fluide. Pour ajouter un autre modèle ultérieurement, vous devrez écrire une nouvelle fonction de traitement pour son format spécifique.
Pour Gemma (auto-hébergé)
Comprendre les modèles de chat : lorsque vous hébergez vos propres modèles ouverts, vous devez généralement mettre en forme manuellement l'invite dans une chaîne spécifique que le modèle a été entraîné à reconnaître comme une conversation. C'est ce qu'on appelle un "modèle de chat".
Recherchez la fonction process_message_gemma dans app.py et remplacez-la par le code suivant :
# This function takes a user's message and the conversation history as input.
# Its job is to format these elements into a single,
# structured prompt that can be understood by the language model (LLM).
# This structured format helps the LLM maintain context and generate more relevant responses.
def process_message_gemma(message, history):
user_prompt_format = "User's Turn:\n>>> {prompt}\n"
assistant_prompt_format = "Assistant's Turn:\n>>> {prompt}\n"
history_message = ""
for user_turn, assistant_turn in history:
history_message += user_prompt_format.format(prompt=user_turn)
history_message += assistant_prompt_format.format(prompt=assistant_turn)
# Format the new user message
new_user_message = user_prompt_format.format(prompt=message)
# Create a new aggregated message to be used as a single flat string in a json object sent to the LLM
aggregated_message = (
history_message + new_user_message + assistant_prompt_format.format(prompt="")
)
return aggregated_message
Pour Gemini (géré)
Les services gérés préfèrent souvent les objets structurés aux chaînes brutes. Nous avons besoin d'une fonction distincte pour mettre en forme l'historique en objets types.Content pour le SDK Gemini.
Recherchez process_message_gemini et remplacez-le par :
def process_message_gemini(message, history):
contents = []
for user_turn, model_turn in history:
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=user_turn)])
)
contents.append(
types.Content(role="model", parts=[types.Part.from_text(text=model_turn)])
)
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=message)])
)
return contents
Étape 2 : Appeler le modèle Gemma auto-hébergé
Nous devons envoyer notre requête formatée au service Gemma exécuté dans notre cluster. Nous utiliserons une requête HTTP POST standard pour le nom DNS interne du service.
Recherchez la fonction call_gemma_model et remplacez-la par :
# Construct the request, send it to Gemma, return the model's response
# aggregated_message = current user message + history
def call_gemma_model(aggregated_message, model_temperature, top_p, max_tokens):
json_message = {
"prompt": aggregated_message,
"temperature": model_temperature,
"top_p": top_p,
"max_tokens": max_tokens,
"stop": ["User's Turn:"],
}
# Log what will be sent to the LLM
print("*** JSON request: " + str(json_message))
# Send the constructed json with the user prompt to the model and put the model's response in the json_data variable
json_data = post_request(json_message)
# The response from the model is a list of predictions. We'll take the first result.
raw_output = json_data["predictions"][0]
# The vLLM server returns the full prompt in the response. We need to extract
# just the newly generated text from the model.
assistant_turn_marker = "Assistant's Turn:\n>>>"
marker_pos = raw_output.rfind(assistant_turn_marker)
if marker_pos != -1:
output = raw_output[marker_pos + len(assistant_turn_marker) :]
else:
output = raw_output
# Clean up potential over-generation
stop_marker = "User's Turn:"
stop_pos = output.lower().find(stop_marker.lower())
if stop_pos != -1:
output = output[:stop_pos]
return output.strip()
Étape 3 : Appelez le modèle Vertex AI Gemini
Pour le modèle géré, nous utiliserons le SDK Google GenAI. C'est beaucoup plus simple, car il gère les appels réseau pour nous.
Recherchez la fonction call_gemini_model et remplacez-la par :
# Send a request to Gemini via the VertexAI API. Return the model's response
# contents = list of types.Content objects
def call_gemini_model(contents, model_temperature, top_p, max_tokens):
gemini_model = "gemini-2.5-flash"
response = client.models.generate_content(
model=gemini_model,
contents=contents,
config={
"temperature": model_temperature,
"max_output_tokens": max_tokens,
"top_p": top_p,
},
)
return response.text
Étape 4 : Implémenter l'interface d'inférence principale
Enfin, nous avons besoin de la fonction d'orchestration principale appelée par Gradio. Cette fonction doit :
- Initialisez l'historique s'il est vide.
- Traitez le message.
- Route la requête vers le modèle sélectionné (Gemma ou Gemini).
- Enregistrez l'interaction dans Firestore.
- Renvoyez la réponse à l'UI.
Gradio et la gestion de l'état : ChatInterface de Gradio gère automatiquement l'état au niveau de la session (affichage des messages dans le navigateur). Toutefois, elle ne prend pas en charge les bases de données externes.
Pour conserver l'historique des discussions à long terme, nous utilisons un modèle standard : nous nous connectons à la fonction inference_interface. En acceptant request: gr.Request comme argument, Gradio nous transmet automatiquement les détails de la session de l'utilisateur actuel. Nous l'utilisons pour créer un document Firestore unique pour chaque utilisateur, ce qui permet de s'assurer que les conversations ne sont pas mélangées dans un environnement multi-utilisateur.
Recherchez la fonction inference_interface et remplacez-la par :
# This is the primary chat function. Every time a user sends a message, gradio calls this function,
# which sends the user's input to the appropriate AI (as indicated on the user interface), updates
# the chat history for future use during this session, and records the chat history in Firestore.
def inference_interface(
message,
history,
model_name,
model_temperature,
top_p,
max_tokens,
request: gr.Request,
):
# set history to empty array
if history is None:
history = []
# Get or create session document
session_hash = request.session_hash
doc_id = f"session-{session_hash}"
doc_ref = db.collection("chat_sessions").document(doc_id)
# Create the session document if it doesn't exist
if not doc_ref.get().exists:
doc_ref.set({"Session start": datetime.datetime.now()})
# Log info
print("Model: " + model_name)
print("LLM Engine: " + llm_engine)
print("* History: " + str(history))
# Pass the message and history to the appropriate model, as indicated by the user via the ui
if model_name == "Gemma3 12b it":
aggregated_message = process_message_gemma(message, history)
output = call_gemma_model(
aggregated_message, model_temperature, top_p, max_tokens
)
elif model_name == "Gemini":
gemini_contents = process_message_gemini(message, history)
output = call_gemini_model(
gemini_contents, model_temperature, top_p, max_tokens
)
else:
# Handle the case where no valid model is selected
output = "Error: Invalid model selected."
interaction = {"user": message, model_name: output}
# Log the updated chat history
print("* History: " + str(history) + " " + str(interaction))
# Save the updated history to Firestore
save_chat_history(interaction, doc_ref)
return output
6. Vérifier votre fichier app.py
À ce stade, votre application de chat basée sur Gradio devrait être prête à être déployée. Assurez-vous qu'il correspond exactement au fichier complet suivant.
Dépannage : Si vous déployez votre application et que vous obtenez une erreur "refus de connexion" ou "Ce site est inaccessible" lorsque vous essayez de vous y connecter, essayez de répéter les étapes à partir de ce point, en commençant par copier l'intégralité de ce fichier et en le collant dans votre fichier app.py.
# Copyright 2024 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import datetime
import google.auth
import google.cloud
import gradio as gr
import requests
import themes
from google import genai
from google.cloud import firestore
from google.genai import types
## Do one-time initialization things
## grab the project id from google auth
_, project = google.auth.default()
print(f"Project: {project}")
# Set initial values for model
llm_engine = "vllm"
host = "http://gemma-service:8000"
context_path = "/generate"
# initialize vertex for interacting with Gemini
client = genai.Client(
vertexai=True,
project=project,
location="global",
)
# Initialize Firestore client
db = firestore.Client(database="chat-app-db")
# This is the primary chat function. Every time a user sends a message, gradio calls this function,
# which sends the user's input to the appropriate AI (as indicated on the user interface), updates
# the chat history for future use during this session, and records the chat history in Firestore.
def inference_interface(
message,
history,
model_name,
model_temperature,
top_p,
max_tokens,
request: gr.Request,
):
# set history to empty array
if history is None:
history = []
# Get or create session document
session_hash = request.session_hash
doc_id = f"session-{session_hash}"
doc_ref = db.collection("chat_sessions").document(doc_id)
# Create the session document if it doesn't exist
if not doc_ref.get().exists:
doc_ref.set({"Session start": datetime.datetime.now()})
# Log info
print("Model: " + model_name)
print("LLM Engine: " + llm_engine)
print("* History: " + str(history))
# Pass the message and history to the appropriate model, as indicated by the user via the ui
if model_name == "Gemma3 12b it":
aggregated_message = process_message_gemma(message, history)
output = call_gemma_model(
aggregated_message, model_temperature, top_p, max_tokens
)
elif model_name == "Gemini":
gemini_contents = process_message_gemini(message, history)
output = call_gemini_model(
gemini_contents, model_temperature, top_p, max_tokens
)
else:
# Handle the case where no valid model is selected
output = "Error: Invalid model selected."
interaction = {"user": message, model_name: output}
# Log the updated chat history
print("* History: " + str(history) + " " + str(interaction))
# Save the updated history to Firestore
save_chat_history(interaction, doc_ref)
return output
# Construct the request, send it to Gemma, return the model's response
# aggregated_message = current user message + history
def call_gemma_model(aggregated_message, model_temperature, top_p, max_tokens):
json_message = {
"prompt": aggregated_message,
"temperature": model_temperature,
"top_p": top_p,
"max_tokens": max_tokens,
"stop": ["User's Turn:"],
}
# Log what will be sent to the LLM
print("*** JSON request: " + str(json_message)) # Log the JSON request
# Send the constructed json with the user prompt to the model and put the model's response in the json_data variable
json_data = post_request(json_message)
# The response from the model is a list of predictions.
# We'll take the first result.
raw_output = json_data["predictions"][0]
# The vLLM server returns the full prompt in the response. We need to extract
# just the newly generated text from the model. The prompt ends with
# "Assistant's Turn:\n>>>", so we find the last occurrence of that and
# take everything after it.
assistant_turn_marker = "Assistant's Turn:\n>>>"
marker_pos = raw_output.rfind(assistant_turn_marker)
if marker_pos != -1:
# Get the text generated by the assistant
output = raw_output[marker_pos + len(assistant_turn_marker) :]
else:
# Fallback in case the marker isn't found
output = raw_output
# The model sometimes continues the conversation and includes the next user's turn.
# The 'stop' parameter is a good hint, but we parse the output as a safeguard.
stop_marker = "User's Turn:"
stop_pos = output.lower().find(stop_marker.lower())
if stop_pos != -1:
output = output[:stop_pos]
# The model also sometimes prefixes its response with "Output:". We'll remove this.
output = output.lstrip()
prefix_marker = "Output:"
if output.lower().startswith(prefix_marker.lower()):
output = output[len(prefix_marker) :]
return output.strip()
# Send a request to Gemini via the VertexAI API. Return the model's response
# contents = list of types.Content objects
def call_gemini_model(contents, model_temperature, top_p, max_tokens):
gemini_model = "gemini-2.5-flash"
response = client.models.generate_content(
model=gemini_model,
contents=contents,
config={
"temperature": model_temperature,
"max_output_tokens": max_tokens,
"top_p": top_p,
},
)
output = response.text # Extract the generated text
# Consider handling additional response attributes (safety, usage, etc.)
return output
def process_message_gemini(message, history):
contents = []
for user_turn, model_turn in history:
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=user_turn)])
)
contents.append(
types.Content(role="model", parts=[types.Part.from_text(text=model_turn)])
)
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=message)])
)
return contents
# This function takes a user's message and the conversation history as input.
# Its job is to format these elements into a single,
# structured prompt that can be understood by the language model (LLM).
# This structured format helps the LLM maintain context and generate more relevant responses.
def process_message_gemma(message, history):
user_prompt_format = "User's Turn:\n>>> {prompt}\n"
assistant_prompt_format = "Assistant's Turn:\n>>> {prompt}\n"
history_message = ""
for user_turn, assistant_turn in history:
history_message += user_prompt_format.format(prompt=user_turn)
history_message += assistant_prompt_format.format(prompt=assistant_turn)
# Format the new user message
new_user_message = user_prompt_format.format(prompt=message)
# Create a new aggregated message to be used as a single flat string in a json object sent to the LLM
aggregated_message = (
history_message + new_user_message + assistant_prompt_format.format(prompt="")
)
return aggregated_message
# Function to save chat history to Firestore
def save_chat_history(interaction, doc_ref):
timestamp_str = str(datetime.datetime.now())
# Save the chat history, merging with existing data
doc_ref.update({timestamp_str: interaction})
print("Chat history saved successfully!") # Optional: Log success
# Send the json message to the model and return the model's response. This is used for Gemma but not Gemini. It could also be used for other models.
def post_request(json_message):
print("*** Request" + str(json_message), flush=True)
# Set a timeout and check for HTTP errors. This will raise an exception on a bad status code (4xx or 5xx).
response = requests.post(host + context_path, json=json_message, timeout=60)
response.raise_for_status()
json_data = response.json()
print("*** Output: " + str(json_data), flush=True)
return json_data
# custom css to hide default footer
css = """
footer {display: none !important;} .gradio-container {min-height: 0px !important;}
"""
# Add a dropdown to select the model to chat with
model_dropdown = gr.Dropdown(
["Gemma3 12b it", "Gemini"],
label="Model",
info="Select the model you would like to chat with.",
value="Gemma3 12b it",
)
# Make the model temperature, top_p, and max tokents modifiable via sliders in the GUI
model_temperature = gr.Slider(
minimum=0.1, maximum=1.0, value=0.9, label="Temperature", render=False
)
top_p = gr.Slider(minimum=0.1, maximum=1.0, value=0.95, label="Top_p", render=False)
max_tokens = gr.Slider(
minimum=1, maximum=4096, value=1024, label="Max Tokens", render=False
)
# Call gradio to create the chat interface
app = gr.ChatInterface(
inference_interface,
additional_inputs=[model_dropdown, model_temperature, top_p, max_tokens],
theme=themes.google_theme(),
css=css,
title="Chat with AI",
)
app.launch(server_name="0.0.0.0", allowed_paths=["images"])
7. Déployer l'application Chat
Nous allons utiliser Skaffold pour créer notre image de conteneur et la déployer sur le cluster. Skaffold est un outil de ligne de commande qui orchestre et automatise le processus de compilation, de transfert et de déploiement d'applications sur Kubernetes. Il simplifie le workflow de développement en vous permettant de déclencher l'ensemble du processus avec une seule commande, ce qui est idéal pour itérer sur votre application.
Remarque : Cela déploiera également le compte de service Kubernetes dont nous avons besoin pour Workload Identity. Vous pouvez consulter sa définition dans le fichier deploy/chat-deploy.yaml. Pour rappel, voici sa définition :
apiVersion: v1
kind: ServiceAccount
metadata:
name: gradio-chat-ksa
Exécutez Skaffold pour créer et déployer :
skaffold run --default-repo=us-central1-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/chat-app-repo
Skaffold utilisera Cloud Build pour créer l'image de conteneur, la transférer vers le dépôt Artifact Registry créé par Terraform, puis appliquer les manifestes Kubernetes à votre cluster.
8. Tester l'application
- Attendez que le service d'application de chat obtienne une adresse IP externe :
kubectl get svc gradio-chat-service --watchEXTERNAL-IPpasse dependingà une adresse IP réelle, appuyez surCtrl+Cpour arrêter de surveiller les nœuds. - Ouvrez un navigateur Web et accédez à
http://[EXTERNAL-IP]:7860. - Essayez d'interagir avec le modèle ! Par défaut, l'application est configurée pour vous permettre de discuter avec votre modèle Gemma hébergé localement. Si vous souhaitez discuter avec Gemini, modifiez le modèle dans le menu déroulant "Inputs supplémentaires". Par exemple, essayez de demander à l'IA : "Raconte-moi une blague sur Kubernetes."
Dépannage :
- Si vous recevez une erreur telle que "Ce site est inaccessible" ou "[EXTERNAL-IP] a refusé la connexion", cela signifie qu'un problème s'est peut-être produit avec votre fichier app.py. Revenez à l'étape intitulée "Vérifier votre fichier app.py" et répétez les étapes à partir de là.
- L'interface utilisateur est définie par défaut sur le modèle "Gemma3 12b it". Si vous recevez immédiatement un message d'erreur, cela signifie probablement que le pod Gemma n'est pas encore prêt. Remarque : Vous pouvez remplacer le menu déroulant par "Gemini" pour tester l'interaction avec l'application de chat en attendant l'initialisation de Gemma.
Tester Gemma : assurez-vous que "Gemma3 12b it" est sélectionné dans le menu déroulant, puis envoyez un message (par exemple, "Raconte-moi une blague sur Kubernetes").
Tester Gemini : définissez le menu déroulant sur "Gemini" et posez une autre question (par exemple, "Quelle est la différence entre un pod et un nœud ?").
Vérifier l'historique : une fois que vous avez discuté avec un modèle (Gemma ou Gemini) dans l'application de chat, consultez la base de données chat-app-db dans Firestore pour voir les journaux de chat. Si vous avez pu discuter avec les deux modèles, vous remarquerez que l'historique des conversations est conservé même lorsque vous changez de modèle.
9. Aller plus loin
Maintenant que vous disposez d'une application de chat hybride opérationnelle, réfléchissez aux défis suivants pour approfondir vos connaissances :
- Personnalité personnalisée : essayez de modifier les fonctions
process_message_gemmaetprocess_message_geminipour inclure une "invite système" au début. Par exemple, dites aux modèles "Vous êtes un assistant pirate serviable" et voyez comment cela modifie leurs réponses. - Identité utilisateur persistante : actuellement, l'application génère un nouvel UUID aléatoire pour chaque session. Comment intégrer un système d'authentification réel (comme Google Sign-In) pour qu'un utilisateur puisse consulter l'historique de ses conversations passées sur différents appareils ?
- Expérimentation du modèle : essayez de modifier le curseur
temperaturedans l'UI. Comment une température élevée (proche de 1,0) affecte-t-elle la créativité et la précision des réponses par rapport à une température basse (proche de 0,1) ?
10. Conclusion
Félicitations ! Vous avez créé une application d'IA hybride. Vous avez appris à effectuer les tâches suivantes :
- Utilisez Terraform pour l'infrastructure en tant que code sur Google Cloud.
- Hébergez vos propres LLM open-weight sur GKE pour un contrôle total.
- Intégrez des services d'IA gérés comme Vertex AI pour plus de flexibilité.
- Créez une application avec état à l'aide de Firestore pour la persistance.
- Sécurisez vos charges de travail à l'aide de Workload Identity.
Effectuer un nettoyage
Pour éviter que des frais ne vous soient facturés, détruisez les ressources que vous avez créées :
cd infra
terraform destroy -var="project_id=$GOOGLE_CLOUD_PROJECT" -var="project_number=$PROJECT_NUMBER" -var="region=$REGION"