
1. Wprowadzenie
Przegląd
W tym module utworzysz i wdrożysz w Google Kubernetes Engine (GKE) pełną aplikację do czatu opartą na AI. Ta „hybrydowa” aplikacja demonstruje zaawansowany wzorzec architektury: możliwość płynnego przełączania się między hostowanym samodzielnie modelem otwartym (Gemma 3 12B) działającym bezpośrednio w Twoim klastrze a zarządzaną usługą AI (Gemini 2.5 Flash w Vertex AI).
+----------------------+
| User (Web Browser) |
+-----------+----------+
|
v
+----------------------------------------------+---------------------------------------------+
| Google Cloud Platform | |
| | +-------+-------+ |
| | | Load Balancer | |
| | +-------+-------+ |
| | v |
| +------------------------------------------+-----------------------------------------+ |
| | Google Kubernetes Engine (GKE) | | |
| | v | |
| | +-----------+-----------+ | |
| | | Gradio Chat App | | |
| | +--+-----------------+--+ | |
| | | | | |
| | (Self-hosted) | | (Managed via SDK) | |
| | v | | |
| | +--------------+---+ | | |
| | | Gemma 3 Model | | | |
| | | (GPU Node) | | | |
| | +------------------+ | | |
| +---------------------------------------------------|--------------------------------+ |
| | |
| v |
| +----------+-----------+ |
| | Vertex AI (Gemini) | |
| +----------------------+ |
| | (Save History) |
| v |
| +----------+-----------+ |
| | Firestore Database | |
| +----------------------+ |
+--------------------------------------------------------------------------------------------+
Do udostępnienia infrastruktury użyjesz Terraform. Obejmuje to klaster GKE z Autopilotem i bazę danych Firestore do przechowywania historii sesji czatu. Następnie uzupełnisz kod aplikacji w Pythonie, aby obsługiwać wieloetapowe rozmowy, korzystać z obu modeli AI i wdrażać aplikację końcową za pomocą Cloud Build i Skaffold.
Czego się nauczysz
- Aprowizuj infrastrukturę GKE i Firestore za pomocą Terraform.
- Wdróż duży model językowy (Gemma) w Autopilocie GKE za pomocą plików manifestu Kubernetes.
- Zaimplementuj w Pythonie interfejs czatu Gradio, który może przełączać się między różnymi backendami AI.
- Używaj Firestore do przechowywania i pobierania historii sesji czatu.
- Skonfiguruj Workload Identity, aby bezpiecznie przyznawać zadaniom GKE dostęp do usług Google Cloud (Vertex AI, Firestore).
Wymagania wstępne
- Projekt Google Cloud z włączonymi płatnościami.
- podstawowa znajomość Pythona, Kubernetes i standardowych narzędzi wiersza poleceń;
- Token Hugging Face z dostępem do modeli Gemma.
2. Konfiguracja projektu
- Jeśli nie masz jeszcze konta Google, musisz je utworzyć.
- Używaj konta osobistego zamiast konta służbowego lub szkolnego. Konta służbowe i szkolne mogą mieć ograniczenia, które uniemożliwiają włączenie interfejsów API potrzebnych do tego ćwiczenia.
- Zaloguj się w konsoli Google Cloud.
- Włącz płatności w konsoli Google Cloud.
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
- Utwórz nowy projekt lub użyj już istniejącego.
Otwórz edytor Cloud Shell
- Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
- Jeśli terminal nie pojawi się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
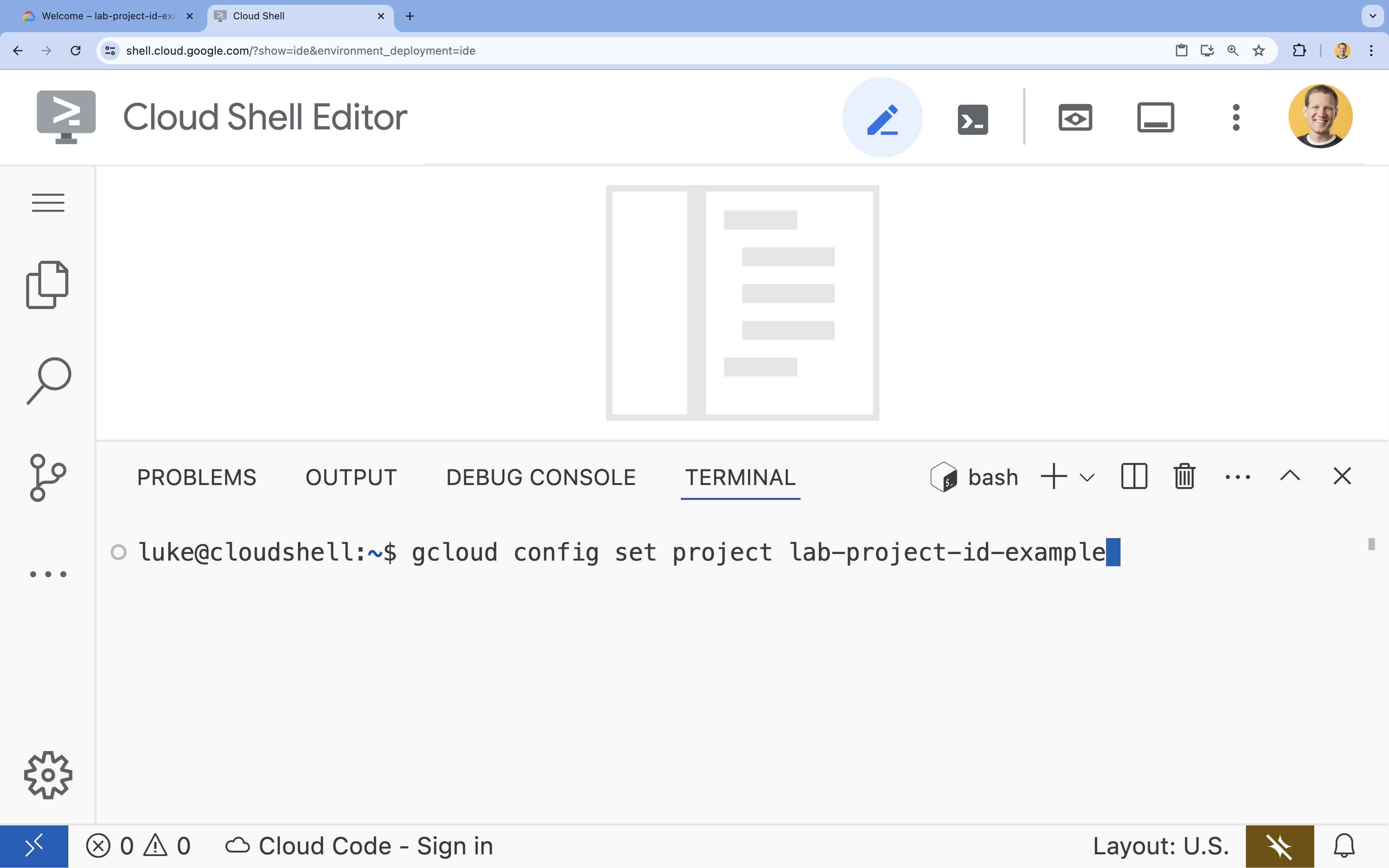
- W terminalu ustaw projekt za pomocą tego polecenia:
- Format:
gcloud config set project [PROJECT_ID] - Przykład:
gcloud config set project lab-project-id-example - Jeśli nie pamiętasz identyfikatora projektu:
- Aby wyświetlić listę wszystkich identyfikatorów projektów, użyj tego polecenia:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Aby wyświetlić listę wszystkich identyfikatorów projektów, użyj tego polecenia:
- Format:
- Powinien wyświetlić się ten komunikat:
Updated property [core/project].
WARNINGi pojawia się pytanieDo you want to continue (Y/n)?, prawdopodobnie identyfikator projektu został wpisany nieprawidłowo. Naciśnijn, a następnieEnteri spróbuj ponownie uruchomić poleceniegcloud config set project.
Klonowanie repozytorium
W terminalu Cloud Shell sklonuj repozytorium projektu i przejdź do katalogu projektu:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/containers/gradio-chat-gke
Poświęć chwilę na zapoznanie się ze strukturą projektu:
gradio-chat-gke/
├── app/
│ ├── app.py # Main application logic (you will edit this)
│ ├── requirements.txt # Python dependencies
│ └── themes.py # UI theming
├── deploy/
│ ├── chat-deploy.yaml # Kubernetes deployment for the chat app
│ ├── Dockerfile # Container definition for the chat app
│ └── gemma3-12b-deploy.yaml# Kubernetes deployment for Gemma model
├── infra/
│ └── main.tf # Terraform infrastructure definition
└── skaffold.yaml # Skaffold configuration for building/deploying
Ustawianie zmiennych środowiskowych
Skonfiguruj zmienne środowiskowe dla identyfikatora projektu i numeru projektu. Będą one używane przez Terraform i kolejne polecenia.
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT --format="value(projectNumber)")
export REGION=us-central1
Włączanie interfejsu Cloud Resource Manager API
Aby zarządzać zasobami projektu, Terraform wymaga włączenia interfejsu Cloud Resource Manager API, więc musimy go najpierw włączyć. Później wdrożymy naszą aplikację do czatu za pomocą Skaffold, która używa Cloud Build do utworzenia obrazu kontenera. Teraz włączymy interfejs Storage API i utworzymy zasobnik potrzebny do Cloud Build. Do włączenia pozostałych interfejsów API wymaganych w tym projekcie użyjemy samego Terraforma.
gcloud services enable cloudresourcemanager.googleapis.com storage-api.googleapis.com
Tworzenie zasobnika tymczasowego Cloud Build
Skaffold korzysta z Google Cloud Build, które wymaga zasobnika Cloud Storage do przechowywania kodu źródłowego.
Utwórz go teraz, aby mieć pewność, że istnieje:
gcloud storage buckets create gs://${GOOGLE_CLOUD_PROJECT}_cloudbuild
(Jeśli pojawi się błąd informujący, że zasobnik już istnieje, możesz go zignorować).
3. Provision Infrastructure with Terraform
Do skonfigurowania niezbędnych zasobów Google Cloud użyjemy Terraform. Zapewnia to powtarzalne i spójne środowisko.
- Przejdź do katalogu infrastruktury:
cd infra
Ten plik określa dodatkowe interfejsy API, których będziemy potrzebować w tym projekcie: cloudbuild, artifactregistry, container (gke), firestore i aiplatform (vertexai). Sprawdź w pliku lub poniżej, jak włączyć interfejsy API za pomocą Terraform:
resource "google_project_service" "cloudbuild" {
service = "cloudbuild.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "artifactregistry" {
service = "artifactregistry.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "container" {
service = "container.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "firestore" {
service = "firestore.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "vertexai" {
service = "aiplatform.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
Określanie klastra GKE
Otwórz plik infra/main.tf w edytorze. Zobaczysz kilka # TODO komentarzy. Możesz go otworzyć ręcznie lub użyć tego polecenia, aby otworzyć plik w edytorze:
cloudshell edit main.tf
Najpierw musimy zdefiniować klaster Kubernetes. Użyjemy GKE Autopilota, który idealnie nadaje się do zbiorów zadań AI, ponieważ automatycznie zarządza węzłami.
Znajdź # TODO: Create a GKE Autopilot Cluster i dodaj poniżej ten blok:
# Create a GKE Autopilot Cluster
resource "google_container_cluster" "primary" {
name = var.cluster_name
location = var.region
project = var.project_id
# Enable Autopilot mode
enable_autopilot = true
deletion_protection = false
# Networking
network = "default"
subnetwork = "projects/${var.project_id}/regions/${var.region}/subnetworks/default"
# Timeout for cluster creation
timeouts {
create = "30m"
update = "30m"
}
depends_on = [google_project_service.container]
}
Powiadomienie enable_autopilot = true. Ten jeden wiersz kodu zwalnia nas z konieczności zarządzania pulami węzłów, autoskalowaniem i pakowaniem zadań GPU.
Określanie bazy danych Firestore
Następnie potrzebujemy miejsca do przechowywania historii czatu. Firestore to bezserwerowa baza danych NoSQL, która idealnie spełnia te wymagania.
Znajdź # TODO: Create a Firestore Database i dodaj:
resource "google_firestore_database" "database" {
project = var.project_id
name = "chat-app-db"
location_id = "nam5"
type = "FIRESTORE_NATIVE"
depends_on = [google_project_service.firestore]
}
Po dodaniu zasobu bazy danych znajdź # TODO: Create an initial Firestore Document i dodaj ten blok: Ten zasób tworzy w naszej kolekcji początkowy dokument zastępczy, który jest przydatny do inicjowania struktury bazy danych.
resource "google_firestore_document" "initial_document" {
project = var.project_id
collection = "chat_sessions"
document_id = "initialize"
fields = <<EOF
EOF
depends_on = [google_firestore_database.database]
}
Określanie Workload Identity
Na koniec musimy skonfigurować zabezpieczenia. Chcemy, aby nasze pody Kubernetes miały dostęp do Vertex AI i Firestore bez konieczności zarządzania żadnymi tajnymi danymi ani kluczami interfejsu API. Robimy to za pomocą Workload Identity.
Przypiszemy niezbędne role uprawnień do konta usługi Kubernetes (KSA), z którego będzie korzystać nasza aplikacja.
Uwaga: konto usługi Kubernetes (gradio-chat-ksa) wymienione w tych powiązaniach jeszcze nie istnieje. Zostanie on utworzony później, gdy wdrożymy aplikację w klastrze. Wstępne udostępnianie tych powiązań IAM jest w porządku (i jest powszechną praktyką).
Znajdź # TODO: Configure Workload Identity IAM bindings i dodaj:
locals {
ksa_principal = "principal://iam.googleapis.com/projects/${var.project_number}/locations/global/workloadIdentityPools/${var.project_id}.svc.id.goog/subject/ns/default/sa/gradio-chat-ksa"
}
resource "google_project_iam_member" "ksa_token_creator" {
project = var.project_id
role = "roles/iam.serviceAccountTokenCreator"
member = local.ksa_principal
}
resource "google_project_iam_member" "ksa_vertex_user" {
project = var.project_id
role = "roles/aiplatform.user"
member = local.ksa_principal
}
resource "google_project_iam_member" "ksa_datastore_user" {
project = var.project_id
role = "roles/datastore.user"
member = local.ksa_principal
}
Zastosuj konfigurację
Infrastruktura jest już zdefiniowana, więc możemy ją teraz udostępnić.
- Najpierw musimy ustawić kilka zmiennych, których będzie używać Terraform. Zrobimy to za pomocą zmiennych środowiskowych:
export TF_VAR_project_id=$(gcloud config get-value project)
export TF_VAR_project_number=$(gcloud projects describe $TF_VAR_project_id --format="value(projectNumber)")
export TF_VAR_region="us-central1"
- Zainicjuj Terraform:
terraform init
- Użyj
terraform plan, aby wyświetlić podgląd zasobów, które zostaną utworzone.
terraform plan
- Zastosuj konfigurację. Gdy pojawi się prośba o potwierdzenie, wpisz
yes.
terraform apply
Uwaga: udostępnienie klastra GKE może potrwać 10–15 minut. W tym czasie możesz przejść do sprawdzania kodu aplikacji w następnej sekcji.
- Po zakończeniu skonfiguruj
kubectl, aby komunikować się z nowym klastrem:
gcloud container clusters get-credentials gradio-chat-cluster --region us-central1 --project $TF_VAR_project_id
4. Wdrażanie samodzielnie hostowanej Gemy w GKE
Następnie wdrożymy model Gemma 3 12B bezpośrednio w klastrze GKE. Umożliwia to wnioskowanie z niewielkimi opóźnieniami i pełną kontrolę nad środowiskiem wykonawczym modelu.
Konfigurowanie danych logowania Hugging Face
Aby pobrać model Gemma, klaster musi być uwierzytelniony w Hugging Face.
- Upewnij się, że masz token Hugging Face.
- Utwórz obiekt tajny Kubernetes z tokenem – zastąp ciąg [YOUR_HF_TOKEN] swoim tokenem:
kubectl create secret generic hf-secret --from-literal=hf_api_token=[YOUR_HF_TOKEN]
Wdrażanie modelu
Do uruchomienia modelu użyjemy standardowego wdrożenia Kubernetes. Plik manifestu znajduje się w lokalizacji deploy/gemma3-12b-deploy.yaml. Możesz go otworzyć ręcznie lub użyć tego polecenia, aby otworzyć plik w edytorze:
cd ../deploy
cloudshell edit gemma3-12b-deploy.yaml
Poświęć chwilę na sprawdzenie tego pliku. Zwróć uwagę na sekcję resources:
resources:
requests:
nvidia.com/gpu: 4
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
Jest to deklaratywna infrastruktura AI. Informujemy Autopilota w GKE, że ten konkretny pod wymaga 4 procesorów graficznych NVIDIA L4. Autopilot znajdzie lub udostępni węzeł, który dokładnie spełnia te wymagania. Jeśli węzeł nie jest dostępny do udostępnienia, usługa będzie ponawiać próby, dopóki nie będzie dostępny węzeł spełniający wymagania.
- Zastosuj plik manifestu wdrożenia:
cd .. kubectl apply -f deploy/gemma3-12b-deploy.yamlkubectl get podsgemmapod nie jest jeszcze uruchomiony. Aplikacja do obsługi czatu połączy się z usługą Gemma, gdy tylko będzie ona dostępna. Pamiętaj, że nie będziesz mieć możliwości interakcji z Gemma w komunikatorze, dopóki w przypadkugemmanie pojawi się stanRunningi1/1. W międzyczasie możesz jednak czatować z Gemini.
5. Tworzenie aplikacji do obsługi czatu
Teraz dokończmy aplikację w Pythonie. Otwórz plik app/app.py w edytorze Cloud Shell. Znajdziesz kilka bloków # TODO, które musisz wypełnić, aby aplikacja działała.
cloudshell edit app/app.py
Krok 1. Przetwarzanie historii rozmowy
Modele LLM wymagają specjalnego formatowania historii rozmów, aby wiedzieć, kto co powiedział.
Wzorzec „Uniwersalny tłumacz”: zauważ, że zamierzamy napisać 2 różne funkcje do przetwarzania tej samej historii czatu. Jest to kluczowy wzorzec w aplikacjach wielomodalnych.
- Źródło informacji (Gradio): nasza aplikacja przechowuje historię w prostym, ogólnym formacie:
[[user_msg1, bot_msg1], ...]. - Cel 1 (Gemma): wymaga przekształcenia w jeden ciąg znaków z określonymi tokenami specjalnymi.
- Cel 2 (Gemini): wymaga przekształcenia w listę strukturalną obiektów interfejsu API.
Przekształcając historię ogólną w format docelowy w każdej turze, możemy płynnie przełączać się między modelami. Jeśli później zechcesz dodać inny model, musisz napisać nową funkcję przetwarzania dla jego konkretnego formatu.
Gemma (hostowana samodzielnie)
Szablony czatu: gdy hostujesz własne modele otwarte, zwykle musisz ręcznie sformatować prompt w określony ciąg znaków, który model został wytrenowany do rozpoznawania jako rozmowa. Jest to tzw. „szablon czatu”.
Znajdź funkcję process_message_gemma w pliku app.py i zastąp ją tym kodem:
# This function takes a user's message and the conversation history as input.
# Its job is to format these elements into a single,
# structured prompt that can be understood by the language model (LLM).
# This structured format helps the LLM maintain context and generate more relevant responses.
def process_message_gemma(message, history):
user_prompt_format = "User's Turn:\n>>> {prompt}\n"
assistant_prompt_format = "Assistant's Turn:\n>>> {prompt}\n"
history_message = ""
for user_turn, assistant_turn in history:
history_message += user_prompt_format.format(prompt=user_turn)
history_message += assistant_prompt_format.format(prompt=assistant_turn)
# Format the new user message
new_user_message = user_prompt_format.format(prompt=message)
# Create a new aggregated message to be used as a single flat string in a json object sent to the LLM
aggregated_message = (
history_message + new_user_message + assistant_prompt_format.format(prompt="")
)
return aggregated_message
W przypadku Gemini (zarządzanego)
Usługi zarządzane często preferują obiekty strukturalne od surowych ciągów znaków. Potrzebujemy osobnej funkcji, która sformatuje historię w obiekty types.Content dla pakietu Gemini SDK.
Znajdź process_message_gemini i zastąp go:
def process_message_gemini(message, history):
contents = []
for user_turn, model_turn in history:
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=user_turn)])
)
contents.append(
types.Content(role="model", parts=[types.Part.from_text(text=model_turn)])
)
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=message)])
)
return contents
Krok 2. Wywołaj model Gemma hostowany samodzielnie
Musimy wysłać sformatowany prompt do usługi Gemma działającej w naszym klastrze. Użyjemy standardowego żądania HTTP POST do wewnętrznej nazwy DNS usługi.
Znajdź funkcję call_gemma_model i zastąp ją tym kodem:
# Construct the request, send it to Gemma, return the model's response
# aggregated_message = current user message + history
def call_gemma_model(aggregated_message, model_temperature, top_p, max_tokens):
json_message = {
"prompt": aggregated_message,
"temperature": model_temperature,
"top_p": top_p,
"max_tokens": max_tokens,
"stop": ["User's Turn:"],
}
# Log what will be sent to the LLM
print("*** JSON request: " + str(json_message))
# Send the constructed json with the user prompt to the model and put the model's response in the json_data variable
json_data = post_request(json_message)
# The response from the model is a list of predictions. We'll take the first result.
raw_output = json_data["predictions"][0]
# The vLLM server returns the full prompt in the response. We need to extract
# just the newly generated text from the model.
assistant_turn_marker = "Assistant's Turn:\n>>>"
marker_pos = raw_output.rfind(assistant_turn_marker)
if marker_pos != -1:
output = raw_output[marker_pos + len(assistant_turn_marker) :]
else:
output = raw_output
# Clean up potential over-generation
stop_marker = "User's Turn:"
stop_pos = output.lower().find(stop_marker.lower())
if stop_pos != -1:
output = output[:stop_pos]
return output.strip()
Krok 3. Wywołaj model Gemini w Vertex AI
W przypadku modelu zarządzanego użyjemy pakietu Google GenAI SDK. Jest to znacznie prostsze, ponieważ obsługuje wywołania sieciowe.
Znajdź funkcję call_gemini_model i zastąp ją tym kodem:
# Send a request to Gemini via the VertexAI API. Return the model's response
# contents = list of types.Content objects
def call_gemini_model(contents, model_temperature, top_p, max_tokens):
gemini_model = "gemini-2.5-flash"
response = client.models.generate_content(
model=gemini_model,
contents=contents,
config={
"temperature": model_temperature,
"max_output_tokens": max_tokens,
"top_p": top_p,
},
)
return response.text
Krok 4. Wdróż główny interfejs wnioskowania
Na koniec potrzebujemy głównej funkcji orkiestracji, którą wywołuje Gradio. Ta funkcja musi:
- Zainicjuj historię, jeśli jest pusta.
- Przetwarzanie wiadomości
- Przekieruj prośbę do wybranego modelu (Gemma lub Gemini).
- Zapisz interakcję w Firestore.
- Zwróć odpowiedź do interfejsu.
Gradio i zarządzanie stanem: interfejs ChatInterface Gradio automatycznie obsługuje stan na poziomie sesji (wyświetlanie wiadomości w przeglądarce). Nie ma jednak wbudowanej obsługi zewnętrznych baz danych.
Aby zachować historię czatu na dłuższy czas, używamy standardowego wzorca: podłączamy się do funkcji inference_interface. Akceptując request: gr.Request jako argument, Gradio automatycznie przekazuje nam szczegóły sesji bieżącego użytkownika. Używamy go do tworzenia unikalnego dokumentu Firestore dla każdego użytkownika, aby w środowisku wielu użytkowników rozmowy nie były ze sobą mylone.
Znajdź funkcję inference_interface i zastąp ją tym kodem:
# This is the primary chat function. Every time a user sends a message, gradio calls this function,
# which sends the user's input to the appropriate AI (as indicated on the user interface), updates
# the chat history for future use during this session, and records the chat history in Firestore.
def inference_interface(
message,
history,
model_name,
model_temperature,
top_p,
max_tokens,
request: gr.Request,
):
# set history to empty array
if history is None:
history = []
# Get or create session document
session_hash = request.session_hash
doc_id = f"session-{session_hash}"
doc_ref = db.collection("chat_sessions").document(doc_id)
# Create the session document if it doesn't exist
if not doc_ref.get().exists:
doc_ref.set({"Session start": datetime.datetime.now()})
# Log info
print("Model: " + model_name)
print("LLM Engine: " + llm_engine)
print("* History: " + str(history))
# Pass the message and history to the appropriate model, as indicated by the user via the ui
if model_name == "Gemma3 12b it":
aggregated_message = process_message_gemma(message, history)
output = call_gemma_model(
aggregated_message, model_temperature, top_p, max_tokens
)
elif model_name == "Gemini":
gemini_contents = process_message_gemini(message, history)
output = call_gemini_model(
gemini_contents, model_temperature, top_p, max_tokens
)
else:
# Handle the case where no valid model is selected
output = "Error: Invalid model selected."
interaction = {"user": message, model_name: output}
# Log the updated chat history
print("* History: " + str(history) + " " + str(interaction))
# Save the updated history to Firestore
save_chat_history(interaction, doc_ref)
return output
6. Sprawdź plik app.py
Na tym etapie aplikacja do czatu oparta na Gradio powinna być gotowa do wdrożenia. Upewnij się, że jest on dokładnie taki sam jak ten poniżej.
Rozwiązywanie problemów: jeśli po wdrożeniu aplikacji podczas próby połączenia z nią pojawi się błąd „odmowa połączenia” lub „nie można otworzyć tej witryny”, spróbuj powtórzyć czynności od tego momentu, zaczynając od skopiowania całego pliku i wklejenia go do pliku app.py.
# Copyright 2024 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import datetime
import google.auth
import google.cloud
import gradio as gr
import requests
import themes
from google import genai
from google.cloud import firestore
from google.genai import types
## Do one-time initialization things
## grab the project id from google auth
_, project = google.auth.default()
print(f"Project: {project}")
# Set initial values for model
llm_engine = "vllm"
host = "http://gemma-service:8000"
context_path = "/generate"
# initialize vertex for interacting with Gemini
client = genai.Client(
vertexai=True,
project=project,
location="global",
)
# Initialize Firestore client
db = firestore.Client(database="chat-app-db")
# This is the primary chat function. Every time a user sends a message, gradio calls this function,
# which sends the user's input to the appropriate AI (as indicated on the user interface), updates
# the chat history for future use during this session, and records the chat history in Firestore.
def inference_interface(
message,
history,
model_name,
model_temperature,
top_p,
max_tokens,
request: gr.Request,
):
# set history to empty array
if history is None:
history = []
# Get or create session document
session_hash = request.session_hash
doc_id = f"session-{session_hash}"
doc_ref = db.collection("chat_sessions").document(doc_id)
# Create the session document if it doesn't exist
if not doc_ref.get().exists:
doc_ref.set({"Session start": datetime.datetime.now()})
# Log info
print("Model: " + model_name)
print("LLM Engine: " + llm_engine)
print("* History: " + str(history))
# Pass the message and history to the appropriate model, as indicated by the user via the ui
if model_name == "Gemma3 12b it":
aggregated_message = process_message_gemma(message, history)
output = call_gemma_model(
aggregated_message, model_temperature, top_p, max_tokens
)
elif model_name == "Gemini":
gemini_contents = process_message_gemini(message, history)
output = call_gemini_model(
gemini_contents, model_temperature, top_p, max_tokens
)
else:
# Handle the case where no valid model is selected
output = "Error: Invalid model selected."
interaction = {"user": message, model_name: output}
# Log the updated chat history
print("* History: " + str(history) + " " + str(interaction))
# Save the updated history to Firestore
save_chat_history(interaction, doc_ref)
return output
# Construct the request, send it to Gemma, return the model's response
# aggregated_message = current user message + history
def call_gemma_model(aggregated_message, model_temperature, top_p, max_tokens):
json_message = {
"prompt": aggregated_message,
"temperature": model_temperature,
"top_p": top_p,
"max_tokens": max_tokens,
"stop": ["User's Turn:"],
}
# Log what will be sent to the LLM
print("*** JSON request: " + str(json_message)) # Log the JSON request
# Send the constructed json with the user prompt to the model and put the model's response in the json_data variable
json_data = post_request(json_message)
# The response from the model is a list of predictions.
# We'll take the first result.
raw_output = json_data["predictions"][0]
# The vLLM server returns the full prompt in the response. We need to extract
# just the newly generated text from the model. The prompt ends with
# "Assistant's Turn:\n>>>", so we find the last occurrence of that and
# take everything after it.
assistant_turn_marker = "Assistant's Turn:\n>>>"
marker_pos = raw_output.rfind(assistant_turn_marker)
if marker_pos != -1:
# Get the text generated by the assistant
output = raw_output[marker_pos + len(assistant_turn_marker) :]
else:
# Fallback in case the marker isn't found
output = raw_output
# The model sometimes continues the conversation and includes the next user's turn.
# The 'stop' parameter is a good hint, but we parse the output as a safeguard.
stop_marker = "User's Turn:"
stop_pos = output.lower().find(stop_marker.lower())
if stop_pos != -1:
output = output[:stop_pos]
# The model also sometimes prefixes its response with "Output:". We'll remove this.
output = output.lstrip()
prefix_marker = "Output:"
if output.lower().startswith(prefix_marker.lower()):
output = output[len(prefix_marker) :]
return output.strip()
# Send a request to Gemini via the VertexAI API. Return the model's response
# contents = list of types.Content objects
def call_gemini_model(contents, model_temperature, top_p, max_tokens):
gemini_model = "gemini-2.5-flash"
response = client.models.generate_content(
model=gemini_model,
contents=contents,
config={
"temperature": model_temperature,
"max_output_tokens": max_tokens,
"top_p": top_p,
},
)
output = response.text # Extract the generated text
# Consider handling additional response attributes (safety, usage, etc.)
return output
def process_message_gemini(message, history):
contents = []
for user_turn, model_turn in history:
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=user_turn)])
)
contents.append(
types.Content(role="model", parts=[types.Part.from_text(text=model_turn)])
)
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=message)])
)
return contents
# This function takes a user's message and the conversation history as input.
# Its job is to format these elements into a single,
# structured prompt that can be understood by the language model (LLM).
# This structured format helps the LLM maintain context and generate more relevant responses.
def process_message_gemma(message, history):
user_prompt_format = "User's Turn:\n>>> {prompt}\n"
assistant_prompt_format = "Assistant's Turn:\n>>> {prompt}\n"
history_message = ""
for user_turn, assistant_turn in history:
history_message += user_prompt_format.format(prompt=user_turn)
history_message += assistant_prompt_format.format(prompt=assistant_turn)
# Format the new user message
new_user_message = user_prompt_format.format(prompt=message)
# Create a new aggregated message to be used as a single flat string in a json object sent to the LLM
aggregated_message = (
history_message + new_user_message + assistant_prompt_format.format(prompt="")
)
return aggregated_message
# Function to save chat history to Firestore
def save_chat_history(interaction, doc_ref):
timestamp_str = str(datetime.datetime.now())
# Save the chat history, merging with existing data
doc_ref.update({timestamp_str: interaction})
print("Chat history saved successfully!") # Optional: Log success
# Send the json message to the model and return the model's response. This is used for Gemma but not Gemini. It could also be used for other models.
def post_request(json_message):
print("*** Request" + str(json_message), flush=True)
# Set a timeout and check for HTTP errors. This will raise an exception on a bad status code (4xx or 5xx).
response = requests.post(host + context_path, json=json_message, timeout=60)
response.raise_for_status()
json_data = response.json()
print("*** Output: " + str(json_data), flush=True)
return json_data
# custom css to hide default footer
css = """
footer {display: none !important;} .gradio-container {min-height: 0px !important;}
"""
# Add a dropdown to select the model to chat with
model_dropdown = gr.Dropdown(
["Gemma3 12b it", "Gemini"],
label="Model",
info="Select the model you would like to chat with.",
value="Gemma3 12b it",
)
# Make the model temperature, top_p, and max tokents modifiable via sliders in the GUI
model_temperature = gr.Slider(
minimum=0.1, maximum=1.0, value=0.9, label="Temperature", render=False
)
top_p = gr.Slider(minimum=0.1, maximum=1.0, value=0.95, label="Top_p", render=False)
max_tokens = gr.Slider(
minimum=1, maximum=4096, value=1024, label="Max Tokens", render=False
)
# Call gradio to create the chat interface
app = gr.ChatInterface(
inference_interface,
additional_inputs=[model_dropdown, model_temperature, top_p, max_tokens],
theme=themes.google_theme(),
css=css,
title="Chat with AI",
)
app.launch(server_name="0.0.0.0", allowed_paths=["images"])
7. Wdrażanie aplikacji Google Chat
Użyjemy Skaffold do utworzenia obrazu kontenera i wdrożenia go w klastrze. Skaffold to narzędzie wiersza poleceń, które koordynuje i automatyzuje proces tworzenia, przesyłania i wdrażania aplikacji w Kubernetes. Upraszcza proces programowania, ponieważ umożliwia wywołanie całego procesu za pomocą jednego polecenia, co jest idealne do iteracyjnego rozwijania aplikacji.
Uwaga: spowoduje to również wdrożenie konta usługi Kubernetes, które jest potrzebne w przypadku Workload Identity. Jego definicję znajdziesz w pliku deploy/chat-deploy.yaml. Jego definicję znajdziesz tutaj:
apiVersion: v1
kind: ServiceAccount
metadata:
name: gradio-chat-ksa
Uruchom Skaffold, aby utworzyć i wdrożyć aplikację:
skaffold run --default-repo=us-central1-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/chat-app-repo
Skaffold użyje Cloud Build do utworzenia obrazu kontenera, wypchnie go do Artifact Registry utworzonego przez Terraform, a następnie zastosuje manifesty Kubernetes w klastrze.
8. Testowanie aplikacji
- Poczekaj, aż usługa aplikacji do czatu uzyska zewnętrzny adres IP:
kubectl get svc gradio-chat-service --watchEXTERNAL-IPzmieni się zpendingna rzeczywisty adres IP, naciśnijCtrl+C, aby zatrzymać oglądanie. - Otwórz przeglądarkę i wejdź na stronę
http://[EXTERNAL-IP]:7860. - Wypróbuj interakcję z modelem. Aplikacja jest domyślnie skonfigurowana tak, aby umożliwiać czatowanie z modelem Gemma hostowanym lokalnie. Jeśli chcesz porozmawiać z Gemini, zmień model w menu „Dodatkowe dane wejściowe”. Na przykład zapytaj AI: „Opowiedz mi dowcip o Kubernetes”.
Rozwiązywanie problemów:
- Jeśli zobaczysz błąd „Nie można otworzyć tej witryny” lub „[EXTERNAL-IP] odmówił połączenia”, oznacza to, że coś poszło nie tak z plikiem app.py. Wróć do kroku „Sprawdź plik app.py” i powtórz czynności.
- Interfejs domyślnie używa modelu „Gemma3 12b it”. Jeśli od razu pojawi się błąd, prawdopodobnie oznacza to, że pod Gemma nie jest jeszcze gotowy. Wskazówka: możesz przełączyć menu na „Gemini”, aby przetestować interakcję z aplikacją do czatu podczas oczekiwania na zainicjowanie Gemy.
Testowanie Gemmy: w menu wybierz „Gemma3 12b it” i wyślij wiadomość (np. „Opowiedz mi żart o Kubernetes”).
Wypróbuj Gemini: w menu kliknij „Gemini” i zadaj inne pytanie (np. „Jaka jest różnica między podem a węzłem?”).
Sprawdź historię: po zakończeniu rozmowy z modelem (Gemma lub Gemini) w komunikatorze sprawdź bazę danych „chat-app-db” w Firestore, aby zobaczyć logi czatu. Jeśli udało Ci się porozmawiać z obydwoma modelami, zauważ, że historia rozmowy jest zachowywana nawet po przełączeniu modelu.
9. Dalsze informacje
Skoro masz już działającą hybrydową aplikację do czatu, zastanów się nad tymi wyzwaniami, aby lepiej zrozumieć jej działanie:
- Niestandardowy profil: spróbuj zmodyfikować funkcje
process_message_gemmaiprocess_message_gemini, aby na początku dodać „prompt systemowy”. Możesz na przykład powiedzieć modelowi: „Jesteś pomocnym asystentem-piratem” i sprawdzić, jak to wpłynie na jego odpowiedzi. - Trwała tożsamość użytkownika: obecnie aplikacja generuje nowy losowy identyfikator UUID dla każdej sesji. Jak zintegrować prawdziwy system uwierzytelniania (np. logowanie przez Google), aby użytkownik mógł wyświetlać historię poprzednich rozmów na różnych urządzeniach?
- Eksperymentowanie z modelem: spróbuj zmienić położenie suwaka
temperaturew interfejsie. Jak wysoka temperatura (bliska 1,0) wpływa na kreatywność i dokładność odpowiedzi w porównaniu z niską temperaturą (bliską 0,1)?
10. Podsumowanie
Gratulacje! Udało Ci się utworzyć hybrydową aplikację AI. Wiesz już, jak:
- Używaj Terraform do infrastruktury jako kodu w Google Cloud.
- Hostuj własne modele LLM o otwartej architekturze w GKE, aby mieć pełną kontrolę.
- Integracja zarządzanych usług AI, takich jak Vertex AI, w celu zapewnienia elastyczności.
- Utwórz aplikację stanową, która do przechowywania danych używa Firestore.
- Zabezpieczanie zbiorów zadań za pomocą Workload Identity.
Czyszczenie
Aby uniknąć opłat, usuń utworzone zasoby:
cd infra
terraform destroy -var="project_id=$GOOGLE_CLOUD_PROJECT" -var="project_number=$PROJECT_NUMBER" -var="region=$REGION"