
1. Введение
Обзор
В этой лабораторной работе вы создадите и развернете полнофункциональное чат-приложение на базе искусственного интеллекта на платформе Google Kubernetes Engine (GKE). Это «гибридное» приложение демонстрирует мощную архитектурную модель: возможность беспрепятственного переключения между самостоятельно размещаемой открытой моделью (Gemma 3 12B), работающей непосредственно в вашем кластере, и управляемым сервисом ИИ (Gemini 2.5 Flash от Vertex AI).
+----------------------+
| User (Web Browser) |
+-----------+----------+
|
v
+----------------------------------------------+---------------------------------------------+
| Google Cloud Platform | |
| | +-------+-------+ |
| | | Load Balancer | |
| | +-------+-------+ |
| | v |
| +------------------------------------------+-----------------------------------------+ |
| | Google Kubernetes Engine (GKE) | | |
| | v | |
| | +-----------+-----------+ | |
| | | Gradio Chat App | | |
| | +--+-----------------+--+ | |
| | | | | |
| | (Self-hosted) | | (Managed via SDK) | |
| | v | | |
| | +--------------+---+ | | |
| | | Gemma 3 Model | | | |
| | | (GPU Node) | | | |
| | +------------------+ | | |
| +---------------------------------------------------|--------------------------------+ |
| | |
| v |
| +----------+-----------+ |
| | Vertex AI (Gemini) | |
| +----------------------+ |
| | (Save History) |
| v |
| +----------+-----------+ |
| | Firestore Database | |
| +----------------------+ |
+--------------------------------------------------------------------------------------------+
Для развертывания инфраструктуры, включая кластер GKE Autopilot и базу данных Firestore для сохранения истории чат-сессий, вы будете использовать Terraform. Затем вы завершите написание кода приложения на Python для обработки многоэтапных диалогов, взаимодействия с обеими моделями ИИ и развертывания готового приложения с помощью Cloud Build и Skaffold.
Что вы узнаете
- Разверните инфраструктуру GKE и Firestore с помощью Terraform.
- Разверните крупную языковую модель (Gemma) в GKE Autopilot, используя манифесты Kubernetes.
- Реализуйте на Python интерфейс чата Gradio, который может переключаться между различными бэкэндами ИИ.
- Используйте Firestore для хранения и извлечения истории сеансов чата.
- Настройте идентификацию рабочих нагрузок, чтобы безопасно предоставить вашим рабочим нагрузкам GKE доступ к сервисам Google Cloud (Vertex AI, Firestore).
Предварительные требования
- Проект Google Cloud с включенной функцией выставления счетов.
- Базовые знания Python, Kubernetes и стандартных инструментов командной строки.
- Токен "Обнимающее лицо" , предоставляющий доступ к моделям Джеммы.
2. Настройка проекта
- Если у вас еще нет учетной записи Google, вам необходимо ее создать .
- Используйте личный аккаунт вместо рабочего или учебного. Рабочие и учебные аккаунты могут иметь ограничения, которые не позволят вам включить API, необходимые для этой лабораторной работы.
- Войдите в консоль Google Cloud .
- Включите выставление счетов в облачной консоли.
- Выполнение этой лабораторной работы должно обойтись менее чем в 1 доллар США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
- Создайте новый проект или выберите вариант повторного использования существующего проекта.
Open Cloud Shell Editor
- Нажмите на эту ссылку, чтобы перейти непосредственно в редактор Cloud Shell.
- Если сегодня вам будет предложено авторизоваться, нажмите «Авторизовать» , чтобы продолжить.
- Если терминал не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
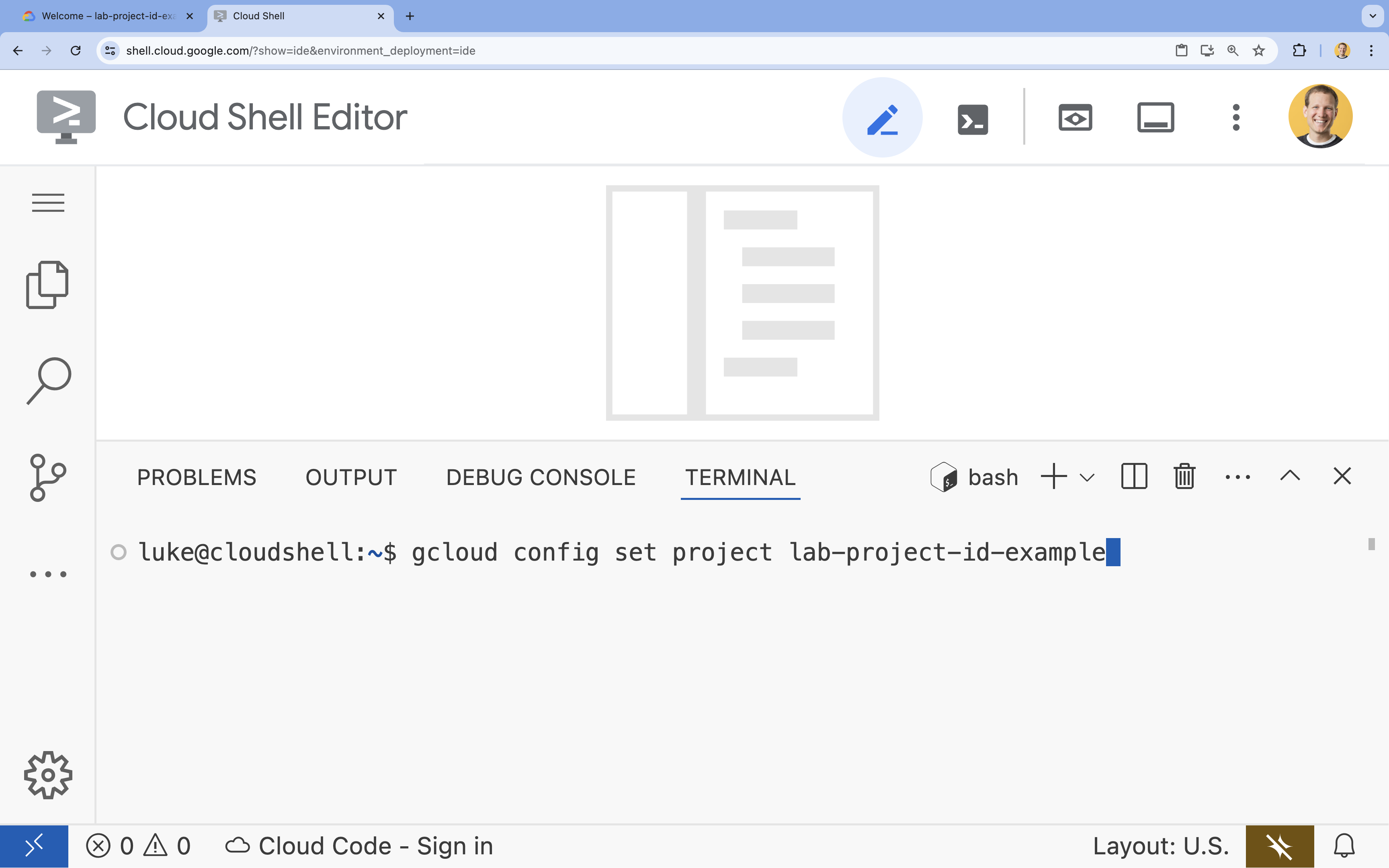
- В терминале настройте свой проект с помощью этой команды:
- Формат:
gcloud config set project [PROJECT_ID] - Пример:
gcloud config set project lab-project-id-example - Если вы не помните идентификатор своего проекта:
- Вы можете вывести список всех идентификаторов ваших проектов с помощью:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Вы можете вывести список всех идентификаторов ваших проектов с помощью:
- Формат:
- Вы должны увидеть следующее сообщение:
Updated property [core/project].
WARNINGи вас спрашиваютDo you want to continue (Y/n)?, то, скорее всего, вы неправильно ввели идентификатор проекта. Нажмитеn, затемEnterи попробуйте снова выполнить командуgcloud config set project.
Клонируйте репозиторий
В терминале Cloud Shell клонируйте репозиторий проекта и перейдите в каталог проекта:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos/containers/gradio-chat-gke
Уделите немного времени изучению структуры проекта:
gradio-chat-gke/
├── app/
│ ├── app.py # Main application logic (you will edit this)
│ ├── requirements.txt # Python dependencies
│ └── themes.py # UI theming
├── deploy/
│ ├── chat-deploy.yaml # Kubernetes deployment for the chat app
│ ├── Dockerfile # Container definition for the chat app
│ └── gemma3-12b-deploy.yaml# Kubernetes deployment for Gemma model
├── infra/
│ └── main.tf # Terraform infrastructure definition
└── skaffold.yaml # Skaffold configuration for building/deploying
Установка переменных среды
Настройте переменные среды для идентификатора и номера вашего проекта. Они будут использоваться Terraform и последующими командами.
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $GOOGLE_CLOUD_PROJECT --format="value(projectNumber)")
export REGION=us-central1
Включить API Cloud Resource Manager
Для управления ресурсами проекта Terraform требует включения API Cloud Resource Manager, поэтому сначала нам нужно его включить. Позже мы развернем наше приложение чата с помощью Skaffold, который использует Cloud Build для создания образа контейнера. Теперь мы включим API хранилища и создадим корзину, необходимую для Cloud Build. Для включения остальных API, необходимых для этого проекта, мы будем использовать сам Terraform.
gcloud services enable cloudresourcemanager.googleapis.com storage-api.googleapis.com
Создать промежуточный сегмент Cloud Build
Skaffold использует Google Cloud Build, для которого требуется хранилище Cloud Storage для размещения исходного кода.
Создайте его прямо сейчас, чтобы гарантировать его существование:
gcloud storage buckets create gs://${GOOGLE_CLOUD_PROJECT}_cloudbuild
(Если вы получите сообщение об ошибке, указывающее на то, что корзина уже существует, можете смело его проигнорировать).
3. Создание инфраструктуры с помощью Terraform
Для настройки необходимых ресурсов Google Cloud мы будем использовать Terraform. Это обеспечит воспроизводимость и согласованность среды.
- Перейдите в каталог инфраструктуры:
cd infra
В этом файле определены дополнительные API, необходимые для этого проекта: cloudbuild, artifactregistry, container (gke), firestore и aiplatform (vertexai). Посмотрите в файле или ниже, как включить эти API с помощью Terraform:
resource "google_project_service" "cloudbuild" {
service = "cloudbuild.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "artifactregistry" {
service = "artifactregistry.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "container" {
service = "container.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "firestore" {
service = "firestore.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
resource "google_project_service" "vertexai" {
service = "aiplatform.googleapis.com"
disable_on_destroy = false
project = var.project_id
}
Определите кластер GKE
Откройте infra/main.tf в редакторе. Вы увидите несколько комментариев # TODO . Вы можете открыть его вручную или использовать эту команду для открытия файла в редакторе:
cloudshell edit main.tf
Для начала нам нужно определить наш кластер Kubernetes. Мы будем использовать GKE Autopilot, который идеально подходит для рабочих нагрузок ИИ, поскольку он автоматически управляет узлами.
Найдите # TODO: Create a GKE Autopilot Cluster и добавьте под ним следующий блок:
# Create a GKE Autopilot Cluster
resource "google_container_cluster" "primary" {
name = var.cluster_name
location = var.region
project = var.project_id
# Enable Autopilot mode
enable_autopilot = true
deletion_protection = false
# Networking
network = "default"
subnetwork = "projects/${var.project_id}/regions/${var.region}/subnetworks/default"
# Timeout for cluster creation
timeouts {
create = "30m"
update = "30m"
}
depends_on = [google_project_service.container]
}
Обратите внимание на enable_autopilot = true . Эта единственная строка избавляет нас от необходимости управлять пулами узлов, автомасштабированием и упаковкой рабочих нагрузок GPU в отдельные блоки.
Определение базы данных Firestore
Далее нам нужно место для хранения истории чатов. Firestore — это бессерверная база данных NoSQL, которая идеально подходит для этой цели.
Найдите # TODO: Create a Firestore Database и добавьте:
resource "google_firestore_database" "database" {
project = var.project_id
name = "chat-app-db"
location_id = "nam5"
type = "FIRESTORE_NATIVE"
depends_on = [google_project_service.firestore]
}
После добавления ресурса базы данных найдите # TODO: Create an initial Firestore Document и добавьте следующий блок. Этот ресурс создает начальный документ-заполнитель в нашей коллекции, что полезно для инициализации структуры базы данных.
resource "google_firestore_document" "initial_document" {
project = var.project_id
collection = "chat_sessions"
document_id = "initialize"
fields = <<EOF
EOF
depends_on = [google_firestore_database.database]
}
Определение идентификатора рабочей нагрузки
Наконец, нам нужно настроить безопасность. Мы хотим, чтобы наши поды Kubernetes могли получать доступ к Vertex AI и Firestore без необходимости управлять какими-либо секретами или ключами API. Мы делаем это с помощью Workload Identity .
Мы предоставим необходимые роли IAM учетной записи службы Kubernetes (KSA), которую будет использовать наше приложение.
Примечание: Учетная запись службы Kubernetes ( gradio-chat-ksa ), указанная в этих привязках, еще не существует! Она будет создана позже при развертывании нашего приложения в кластере. Предварительная настройка этих привязок IAM вполне допустима (и является распространенной практикой).
Найдите # TODO: Configure Workload Identity IAM bindings и добавьте:
locals {
ksa_principal = "principal://iam.googleapis.com/projects/${var.project_number}/locations/global/workloadIdentityPools/${var.project_id}.svc.id.goog/subject/ns/default/sa/gradio-chat-ksa"
}
resource "google_project_iam_member" "ksa_token_creator" {
project = var.project_id
role = "roles/iam.serviceAccountTokenCreator"
member = local.ksa_principal
}
resource "google_project_iam_member" "ksa_vertex_user" {
project = var.project_id
role = "roles/aiplatform.user"
member = local.ksa_principal
}
resource "google_project_iam_member" "ksa_datastore_user" {
project = var.project_id
role = "roles/datastore.user"
member = local.ksa_principal
}
Применить конфигурацию
Теперь, когда наша инфраструктура определена, давайте её настроим.
- Для начала нам нужно задать несколько переменных, которые будет использовать Terraform. Мы сделаем это с помощью переменных окружения:
export TF_VAR_project_id=$(gcloud config get-value project)
export TF_VAR_project_number=$(gcloud projects describe $TF_VAR_project_id --format="value(projectNumber)")
export TF_VAR_region="us-central1"
- Инициализация Terraform:
terraform init
- Используйте
terraform plan, чтобы предварительно просмотреть, какие ресурсы будут созданы.
terraform plan
- Примените настройки. При появлении запроса введите
yesдля подтверждения.
terraform apply
Примечание: Подготовка кластера GKE может занять 10-15 минут. Пока вы ждете, вы можете перейти к изучению кода приложения в следующем разделе.
- После завершения настройте
kubectlдля связи с вашим новым кластером:
gcloud container clusters get-credentials gradio-chat-cluster --region us-central1 --project $TF_VAR_project_id
4. Разверните саморазмещаемую Gemma в GKE.
Далее мы развернем модель Gemma 3 12B непосредственно в вашем кластере GKE. Это обеспечит низкую задержку при выполнении вычислений и полный контроль над средой выполнения модели.
Настройка учетных данных для функции «Объятия по лицу»
Для загрузки модели Gemma вашему кластеру необходима аутентификация через Hugging Face.
- Убедитесь, что у вас есть токен "Обнимающее лицо" .
- Создайте секрет Kubernetes, используя свой токен. Замените [YOUR_HF_TOKEN] на свой фактический токен :
kubectl create secret generic hf-secret --from-literal=hf_api_token=[YOUR_HF_TOKEN]
Разверните модель
Для запуска модели мы будем использовать стандартное развертывание Kubernetes. Манифест находится по адресу deploy/gemma3-12b-deploy.yaml . Вы можете открыть его вручную или использовать эту команду для открытия файла в редакторе:
cd ../deploy
cloudshell edit gemma3-12b-deploy.yaml
Пожалуйста, уделите немного времени изучению этого файла. Обратите внимание на раздел resources :
resources:
requests:
nvidia.com/gpu: 4
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
Это декларативная инфраструктура ИИ. Мы сообщаем GKE Autopilot, что для этого конкретного модуля требуется 4 графических процессора NVIDIA L4. Autopilot найдет или выделит узел, который точно соответствует этим требованиям. Если узел недоступен для выделения, он будет продолжать попытки, пока не появится узел, соответствующий требованиям.
- Примените манифест развертывания:
cd .. kubectl apply -f deploy/gemma3-12b-deploy.yamlkubectl get podsgemmaеще не запущен. Приложение чата подключится к сервису gemma, как только он станет доступен. Имейте в виду, что вы не сможете взаимодействовать с Gemma через приложение чата, пока модульgemmaне покажет статус «Runningи1/1. Но пока вы можете общаться с Gemini!
5. Создайте приложение для чата.
Теперь давайте завершим создание приложения на Python. Откройте app/app.py в редакторе Cloud Shell. Вы найдете несколько блоков # TODO , которые необходимо заполнить, чтобы приложение заработало.
cloudshell edit app/app.py
Шаг 1: Обработка истории разговоров
Для поступления на магистерские программы требуется, чтобы история разговоров была отформатирована таким образом, чтобы было понятно, кто что сказал.
Паттерн «Универсальный переводчик»: Обратите внимание, что мы собираемся написать две разные функции для обработки одной и той же истории чата. Это ключевой паттерн в многомодельных приложениях.
- Источник истины (Gradio): Наше приложение хранит историю в простом, универсальном формате:
[[user_msg1, bot_msg1], ...]. - Цель 1 (Джемма): Необходимо преобразовать это в единую необработанную строку с определенными специальными токенами.
- Цель 2 (Близнецы): Необходимо преобразовать это в структурированный список объектов API.
Переформатируя общую историю в целевой формат на каждом этапе, мы можем плавно переключаться между моделями. Чтобы добавить другую модель позже, потребуется написать новую функцию обработки для ее специфического формата.
Для Джеммы (самостоятельное размещение)
Понимание шаблонов чата: При создании собственных открытых моделей обычно необходимо вручную форматировать запрос в определенную строку, которую модель обучена распознавать как диалог. Это называется «шаблоном чата».
Найдите функцию process_message_gemma в app.py и замените её следующим кодом:
# This function takes a user's message and the conversation history as input.
# Its job is to format these elements into a single,
# structured prompt that can be understood by the language model (LLM).
# This structured format helps the LLM maintain context and generate more relevant responses.
def process_message_gemma(message, history):
user_prompt_format = "User's Turn:\n>>> {prompt}\n"
assistant_prompt_format = "Assistant's Turn:\n>>> {prompt}\n"
history_message = ""
for user_turn, assistant_turn in history:
history_message += user_prompt_format.format(prompt=user_turn)
history_message += assistant_prompt_format.format(prompt=assistant_turn)
# Format the new user message
new_user_message = user_prompt_format.format(prompt=message)
# Create a new aggregated message to be used as a single flat string in a json object sent to the LLM
aggregated_message = (
history_message + new_user_message + assistant_prompt_format.format(prompt="")
)
return aggregated_message
Для Gemini (управляемый)
Управляемые сервисы часто предпочитают структурированные объекты обычным строкам. Нам нужна отдельная функция для форматирования истории в объекты types.Content для SDK Gemini.
Найдите process_message_gemini и замените её на:
def process_message_gemini(message, history):
contents = []
for user_turn, model_turn in history:
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=user_turn)])
)
contents.append(
types.Content(role="model", parts=[types.Part.from_text(text=model_turn)])
)
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=message)])
)
return contents
Шаг 2: Вызовите модель самостоятельного размещения Gemma.
Нам нужно отправить отформатированное приглашение в службу Gemma, работающую в нашем кластере. Мы будем использовать стандартный HTTP POST-запрос к внутреннему DNS-имени службы.
Найдите функцию call_gemma_model и замените её на:
# Construct the request, send it to Gemma, return the model's response
# aggregated_message = current user message + history
def call_gemma_model(aggregated_message, model_temperature, top_p, max_tokens):
json_message = {
"prompt": aggregated_message,
"temperature": model_temperature,
"top_p": top_p,
"max_tokens": max_tokens,
"stop": ["User's Turn:"],
}
# Log what will be sent to the LLM
print("*** JSON request: " + str(json_message))
# Send the constructed json with the user prompt to the model and put the model's response in the json_data variable
json_data = post_request(json_message)
# The response from the model is a list of predictions. We'll take the first result.
raw_output = json_data["predictions"][0]
# The vLLM server returns the full prompt in the response. We need to extract
# just the newly generated text from the model.
assistant_turn_marker = "Assistant's Turn:\n>>>"
marker_pos = raw_output.rfind(assistant_turn_marker)
if marker_pos != -1:
output = raw_output[marker_pos + len(assistant_turn_marker) :]
else:
output = raw_output
# Clean up potential over-generation
stop_marker = "User's Turn:"
stop_pos = output.lower().find(stop_marker.lower())
if stop_pos != -1:
output = output[:stop_pos]
return output.strip()
Шаг 3: Вызовите модель Vertex AI Gemini.
Для управляемой модели мы будем использовать SDK Google GenAI. Это гораздо проще, поскольку он обрабатывает сетевые запросы за нас.
Найдите функцию call_gemini_model и замените её на:
# Send a request to Gemini via the VertexAI API. Return the model's response
# contents = list of types.Content objects
def call_gemini_model(contents, model_temperature, top_p, max_tokens):
gemini_model = "gemini-2.5-flash"
response = client.models.generate_content(
model=gemini_model,
contents=contents,
config={
"temperature": model_temperature,
"max_output_tokens": max_tokens,
"top_p": top_p,
},
)
return response.text
Шаг 4: Реализация основного интерфейса вывода
Наконец, нам нужна основная функция оркестратора, которую вызывает Gradio. Эта функция должна:
- Инициализировать историю, если она пуста.
- Обработайте сообщение.
- Направьте запрос выбранной модели (Gemma или Gemini).
- Сохраните взаимодействие в Firestore.
- Верните ответ в пользовательский интерфейс.
Gradio и управление состоянием: ChatInterface от Gradio автоматически обрабатывает состояние на уровне сессии (отображает сообщения в браузере). Однако он не имеет встроенной поддержки внешних баз данных.
Для долговременного сохранения истории чата мы используем стандартный подход: мы подключаемся к функции inference_interface . Принимая в качестве аргумента request: gr.Request , Gradio автоматически передает нам данные сессии текущего пользователя. Мы используем это для создания уникального документа Firestore для каждого пользователя, гарантируя, что беседы не будут перемешаны в многопользовательской среде.
Найдите функцию inference_interface и замените её на:
# This is the primary chat function. Every time a user sends a message, gradio calls this function,
# which sends the user's input to the appropriate AI (as indicated on the user interface), updates
# the chat history for future use during this session, and records the chat history in Firestore.
def inference_interface(
message,
history,
model_name,
model_temperature,
top_p,
max_tokens,
request: gr.Request,
):
# set history to empty array
if history is None:
history = []
# Get or create session document
session_hash = request.session_hash
doc_id = f"session-{session_hash}"
doc_ref = db.collection("chat_sessions").document(doc_id)
# Create the session document if it doesn't exist
if not doc_ref.get().exists:
doc_ref.set({"Session start": datetime.datetime.now()})
# Log info
print("Model: " + model_name)
print("LLM Engine: " + llm_engine)
print("* History: " + str(history))
# Pass the message and history to the appropriate model, as indicated by the user via the ui
if model_name == "Gemma3 12b it":
aggregated_message = process_message_gemma(message, history)
output = call_gemma_model(
aggregated_message, model_temperature, top_p, max_tokens
)
elif model_name == "Gemini":
gemini_contents = process_message_gemini(message, history)
output = call_gemini_model(
gemini_contents, model_temperature, top_p, max_tokens
)
else:
# Handle the case where no valid model is selected
output = "Error: Invalid model selected."
interaction = {"user": message, model_name: output}
# Log the updated chat history
print("* History: " + str(history) + " " + str(interaction))
# Save the updated history to Firestore
save_chat_history(interaction, doc_ref)
return output
6. Проверьте файл app.py.
На этом этапе ваше чат-приложение на основе Gradio должно быть готово к развертыванию. Убедитесь, что оно точно соответствует приведенному ниже полному файлу.
Устранение неполадок: Если после развертывания приложения вы получаете ошибку «отказано в подключении» или «Невозможно подключиться к этому сайту», попробуйте повторить действия, описанные выше, начиная с копирования всего этого файла и вставки его в файл app.py.
# Copyright 2024 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import datetime
import google.auth
import google.cloud
import gradio as gr
import requests
import themes
from google import genai
from google.cloud import firestore
from google.genai import types
## Do one-time initialization things
## grab the project id from google auth
_, project = google.auth.default()
print(f"Project: {project}")
# Set initial values for model
llm_engine = "vllm"
host = "http://gemma-service:8000"
context_path = "/generate"
# initialize vertex for interacting with Gemini
client = genai.Client(
vertexai=True,
project=project,
location="global",
)
# Initialize Firestore client
db = firestore.Client(database="chat-app-db")
# This is the primary chat function. Every time a user sends a message, gradio calls this function,
# which sends the user's input to the appropriate AI (as indicated on the user interface), updates
# the chat history for future use during this session, and records the chat history in Firestore.
def inference_interface(
message,
history,
model_name,
model_temperature,
top_p,
max_tokens,
request: gr.Request,
):
# set history to empty array
if history is None:
history = []
# Get or create session document
session_hash = request.session_hash
doc_id = f"session-{session_hash}"
doc_ref = db.collection("chat_sessions").document(doc_id)
# Create the session document if it doesn't exist
if not doc_ref.get().exists:
doc_ref.set({"Session start": datetime.datetime.now()})
# Log info
print("Model: " + model_name)
print("LLM Engine: " + llm_engine)
print("* History: " + str(history))
# Pass the message and history to the appropriate model, as indicated by the user via the ui
if model_name == "Gemma3 12b it":
aggregated_message = process_message_gemma(message, history)
output = call_gemma_model(
aggregated_message, model_temperature, top_p, max_tokens
)
elif model_name == "Gemini":
gemini_contents = process_message_gemini(message, history)
output = call_gemini_model(
gemini_contents, model_temperature, top_p, max_tokens
)
else:
# Handle the case where no valid model is selected
output = "Error: Invalid model selected."
interaction = {"user": message, model_name: output}
# Log the updated chat history
print("* History: " + str(history) + " " + str(interaction))
# Save the updated history to Firestore
save_chat_history(interaction, doc_ref)
return output
# Construct the request, send it to Gemma, return the model's response
# aggregated_message = current user message + history
def call_gemma_model(aggregated_message, model_temperature, top_p, max_tokens):
json_message = {
"prompt": aggregated_message,
"temperature": model_temperature,
"top_p": top_p,
"max_tokens": max_tokens,
"stop": ["User's Turn:"],
}
# Log what will be sent to the LLM
print("*** JSON request: " + str(json_message)) # Log the JSON request
# Send the constructed json with the user prompt to the model and put the model's response in the json_data variable
json_data = post_request(json_message)
# The response from the model is a list of predictions.
# We'll take the first result.
raw_output = json_data["predictions"][0]
# The vLLM server returns the full prompt in the response. We need to extract
# just the newly generated text from the model. The prompt ends with
# "Assistant's Turn:\n>>>", so we find the last occurrence of that and
# take everything after it.
assistant_turn_marker = "Assistant's Turn:\n>>>"
marker_pos = raw_output.rfind(assistant_turn_marker)
if marker_pos != -1:
# Get the text generated by the assistant
output = raw_output[marker_pos + len(assistant_turn_marker) :]
else:
# Fallback in case the marker isn't found
output = raw_output
# The model sometimes continues the conversation and includes the next user's turn.
# The 'stop' parameter is a good hint, but we parse the output as a safeguard.
stop_marker = "User's Turn:"
stop_pos = output.lower().find(stop_marker.lower())
if stop_pos != -1:
output = output[:stop_pos]
# The model also sometimes prefixes its response with "Output:". We'll remove this.
output = output.lstrip()
prefix_marker = "Output:"
if output.lower().startswith(prefix_marker.lower()):
output = output[len(prefix_marker) :]
return output.strip()
# Send a request to Gemini via the VertexAI API. Return the model's response
# contents = list of types.Content objects
def call_gemini_model(contents, model_temperature, top_p, max_tokens):
gemini_model = "gemini-2.5-flash"
response = client.models.generate_content(
model=gemini_model,
contents=contents,
config={
"temperature": model_temperature,
"max_output_tokens": max_tokens,
"top_p": top_p,
},
)
output = response.text # Extract the generated text
# Consider handling additional response attributes (safety, usage, etc.)
return output
def process_message_gemini(message, history):
contents = []
for user_turn, model_turn in history:
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=user_turn)])
)
contents.append(
types.Content(role="model", parts=[types.Part.from_text(text=model_turn)])
)
contents.append(
types.Content(role="user", parts=[types.Part.from_text(text=message)])
)
return contents
# This function takes a user's message and the conversation history as input.
# Its job is to format these elements into a single,
# structured prompt that can be understood by the language model (LLM).
# This structured format helps the LLM maintain context and generate more relevant responses.
def process_message_gemma(message, history):
user_prompt_format = "User's Turn:\n>>> {prompt}\n"
assistant_prompt_format = "Assistant's Turn:\n>>> {prompt}\n"
history_message = ""
for user_turn, assistant_turn in history:
history_message += user_prompt_format.format(prompt=user_turn)
history_message += assistant_prompt_format.format(prompt=assistant_turn)
# Format the new user message
new_user_message = user_prompt_format.format(prompt=message)
# Create a new aggregated message to be used as a single flat string in a json object sent to the LLM
aggregated_message = (
history_message + new_user_message + assistant_prompt_format.format(prompt="")
)
return aggregated_message
# Function to save chat history to Firestore
def save_chat_history(interaction, doc_ref):
timestamp_str = str(datetime.datetime.now())
# Save the chat history, merging with existing data
doc_ref.update({timestamp_str: interaction})
print("Chat history saved successfully!") # Optional: Log success
# Send the json message to the model and return the model's response. This is used for Gemma but not Gemini. It could also be used for other models.
def post_request(json_message):
print("*** Request" + str(json_message), flush=True)
# Set a timeout and check for HTTP errors. This will raise an exception on a bad status code (4xx or 5xx).
response = requests.post(host + context_path, json=json_message, timeout=60)
response.raise_for_status()
json_data = response.json()
print("*** Output: " + str(json_data), flush=True)
return json_data
# custom css to hide default footer
css = """
footer {display: none !important;} .gradio-container {min-height: 0px !important;}
"""
# Add a dropdown to select the model to chat with
model_dropdown = gr.Dropdown(
["Gemma3 12b it", "Gemini"],
label="Model",
info="Select the model you would like to chat with.",
value="Gemma3 12b it",
)
# Make the model temperature, top_p, and max tokents modifiable via sliders in the GUI
model_temperature = gr.Slider(
minimum=0.1, maximum=1.0, value=0.9, label="Temperature", render=False
)
top_p = gr.Slider(minimum=0.1, maximum=1.0, value=0.95, label="Top_p", render=False)
max_tokens = gr.Slider(
minimum=1, maximum=4096, value=1024, label="Max Tokens", render=False
)
# Call gradio to create the chat interface
app = gr.ChatInterface(
inference_interface,
additional_inputs=[model_dropdown, model_temperature, top_p, max_tokens],
theme=themes.google_theme(),
css=css,
title="Chat with AI",
)
app.launch(server_name="0.0.0.0", allowed_paths=["images"])
7. Разверните приложение чата.
Мы будем использовать Skaffold для сборки образа контейнера и его развертывания в кластере. Skaffold — это инструмент командной строки, который организует и автоматизирует процесс сборки, отправки и развертывания приложений в Kubernetes. Он упрощает рабочий процесс разработки, позволяя запустить весь этот процесс одной командой, что делает его идеальным для итеративной работы над вашим приложением.
Примечание: это также развернет учетную запись Kubernetes Service, необходимую для Workload Identity. Ее определение можно найти в файле deploy/chat-deploy.yaml. Для справки, ее определение можно посмотреть здесь:
apiVersion: v1
kind: ServiceAccount
metadata:
name: gradio-chat-ksa
Запустите Skaffold для сборки и развертывания:
skaffold run --default-repo=us-central1-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/chat-app-repo
Skaffold будет использовать Cloud Build для создания образа контейнера, загрузит его в реестр артефактов, созданный Terraform, а затем применит манифесты Kubernetes к вашему кластеру.
8. Протестируйте приложение.
- Дождитесь, пока служба чат-приложения получит внешний IP-адрес:
kubectl get svc gradio-chat-service --watchEXTERNAL-IPизменится сpendingна фактический IP-адрес, нажмитеCtrl+Cчтобы остановить просмотр. - Откройте веб-браузер и перейдите по адресу
http://[EXTERNAL-IP]:7860. - Попробуйте пообщаться с моделью! По умолчанию приложение настроено на общение с локально размещенной моделью Gemma. Если вы хотите пообщаться с Gemini, измените модель в выпадающем меню «Дополнительные входные данные». Например, попробуйте спросить ИИ: «Расскажи мне анекдот про Kubernetes».
Поиск неисправностей:
- Если вы получаете ошибку типа «Невозможно связаться с этим сайтом» или «[EXTERNAL-IP] отказано в подключении», возможно, что-то пошло не так с вашим файлом app.py. Вернитесь к шагу «Проверьте файл app.py» и повторите действия, описанные там.
- По умолчанию пользовательский интерфейс использует модель "Gemma3 12b it". Если сразу же возникает ошибка, скорее всего, это связано с тем, что модуль Gemma еще не готов. Совет: вы можете переключиться на "Gemini" в выпадающем списке, чтобы проверить взаимодействие с чатом, пока ждете инициализации Gemma!
Протестируйте Gemma: убедитесь, что в выпадающем списке выбран пункт "Gemma3 12b it", и отправьте сообщение (например, "Расскажите мне анекдот о Kubernetes").
Проверьте Gemini: переключите выпадающее меню на "Gemini" и задайте другой вопрос (например, "В чем разница между подом и узлом?").
Проверка истории: После успешного общения с моделью (Джеммой или Близнецами) в чат-приложении проверьте свою базу данных "chat-app-db" в Firestore, чтобы просмотреть журналы чата. Если вам удалось пообщаться с обеими моделями, обратите внимание, что история переписки сохраняется даже при переключении между моделями.
9. Идем дальше
Теперь, когда у вас есть работающее гибридное приложение для чата, рассмотрите следующие задачи, чтобы углубить свои знания:
- Пользовательская персона: Попробуйте изменить функции
process_message_gemmaиprocess_message_gemini, добавив в начало «системную подсказку». Например, скажите моделям: «Вы — полезный помощник пирата» и посмотрите, как это повлияет на их ответы. - Постоянная идентификация пользователя: В настоящее время приложение генерирует новый случайный UUID для каждой сессии. Как интегрировать реальную систему аутентификации (например, Google Sign-In), чтобы пользователь мог видеть историю своих предыдущих разговоров на разных устройствах?
- Эксперимент с моделью: Попробуйте изменить ползунок
temperatureв пользовательском интерфейсе. Как высокая температура (близкая к 1,0) влияет на креативность и точность ответов по сравнению с низкой температурой (близкой к 0,1)?
10. Заключение
Поздравляем! Вы успешно создали гибридное приложение на основе искусственного интеллекта. Вы научились:
- Используйте Terraform для создания инфраструктуры как кода в Google Cloud.
- Размещайте собственные открытые LLM-курсы на GKE для полного контроля.
- Интегрируйте управляемые сервисы искусственного интеллекта, такие как Vertex AI, для обеспечения гибкости.
- Создайте приложение с сохранением состояния, используя Firestore для обеспечения постоянного хранения данных.
- Защитите свои рабочие нагрузки с помощью системы идентификации рабочих нагрузок.
Уборка
Чтобы избежать дополнительных расходов, уничтожьте созданные вами ресурсы:
cd infra
terraform destroy -var="project_id=$GOOGLE_CLOUD_PROJECT" -var="project_number=$PROJECT_NUMBER" -var="region=$REGION"