
1. Introduction

Dernière mise à jour: 22/09/2022
Cet atelier de programmation implémente un modèle d'accès et d'analyse des données de santé agrégées dans BigQuery à l'aide de BigQueryUI et d'AI Platform Notebooks. Il illustre l'exploration de grands ensembles de données de santé à l'aide d'outils familiers tels que Pandas, Matplotlib, etc. dans un notebook AI Platform conforme à la norme HIPPA. Le plus simple est de réaliser la première partie de l'agrégation dans BigQuery, d'en extraire un ensemble de données Pandas, puis d'utiliser localement cet ensemble de données Pandas plus petit. AI Platform Notebooks offre une expérience Jupyter gérée. Vous n'avez donc pas besoin d'exécuter les serveurs de notebooks vous-même. AI Platform Notebooks est parfaitement intégré à d'autres services GCP tels que BigQuery et Cloud Storage, ce qui vous permet de vous lancer rapidement et facilement dans l'analyse de données et le ML sur Google Cloud Platform.
Dans cet atelier de programmation, vous allez apprendre à:
- Développez et testez des requêtes SQL à l'aide de l'interface utilisateur de BigQuery.
- Créer et lancer une instance AI Platform Notebooks dans GCP
- Exécuter des requêtes SQL à partir du notebook et stocker les résultats des requêtes dans le DataFrame Pandas
- Créer des diagrammes et des graphiques à l'aide de Matplotlib.
- Validez le notebook et transférez-le vers un dépôt Cloud Source Repositories dans GCP.
De quoi avez-vous besoin pour suivre cet atelier de programmation ?
- Vous devez avoir accès à un projet GCP.
- Vous devez disposer d'un rôle de propriétaire pour le projet GCP.
- Vous avez besoin d'un ensemble de données Healthcare dans BigQuery.
Si vous n'avez pas de projet GCP, suivez ces étapes pour en créer un.
2. Configuration du projet
Pour cet atelier de programmation, nous allons utiliser un ensemble de données existant dans BigQuery (hcls-testing-data.fhir_20k_patients_analytics). Cet ensemble de données est prérempli avec des données synthétiques de santé.
Accéder à l'ensemble de données synthétique
- Depuis l'adresse e-mail que vous utilisez pour vous connecter à la console Cloud, envoyez un e-mail à l'adresse hcls-solutions-external+subscribe@google.com pour demander à rejoindre la communauté.
- Vous recevrez un e-mail contenant des instructions pour confirmer l'action.
- Utilisez l'option permettant de répondre à l'e-mail pour rejoindre le groupe. NE cliquez PAS sur le bouton
 .
. - Une fois que vous avez reçu l'e-mail de confirmation, vous pouvez passer à l'étape suivante de l'atelier de programmation.
Épingler le projet
- Dans la console GCP, sélectionnez votre projet, puis accédez à BigQuery.
- Cliquez sur le menu déroulant + AJOUTER DES DONNÉES, puis sélectionnez "Épingler un projet". > "Saisissez le nom du projet" pour en savoir plus.
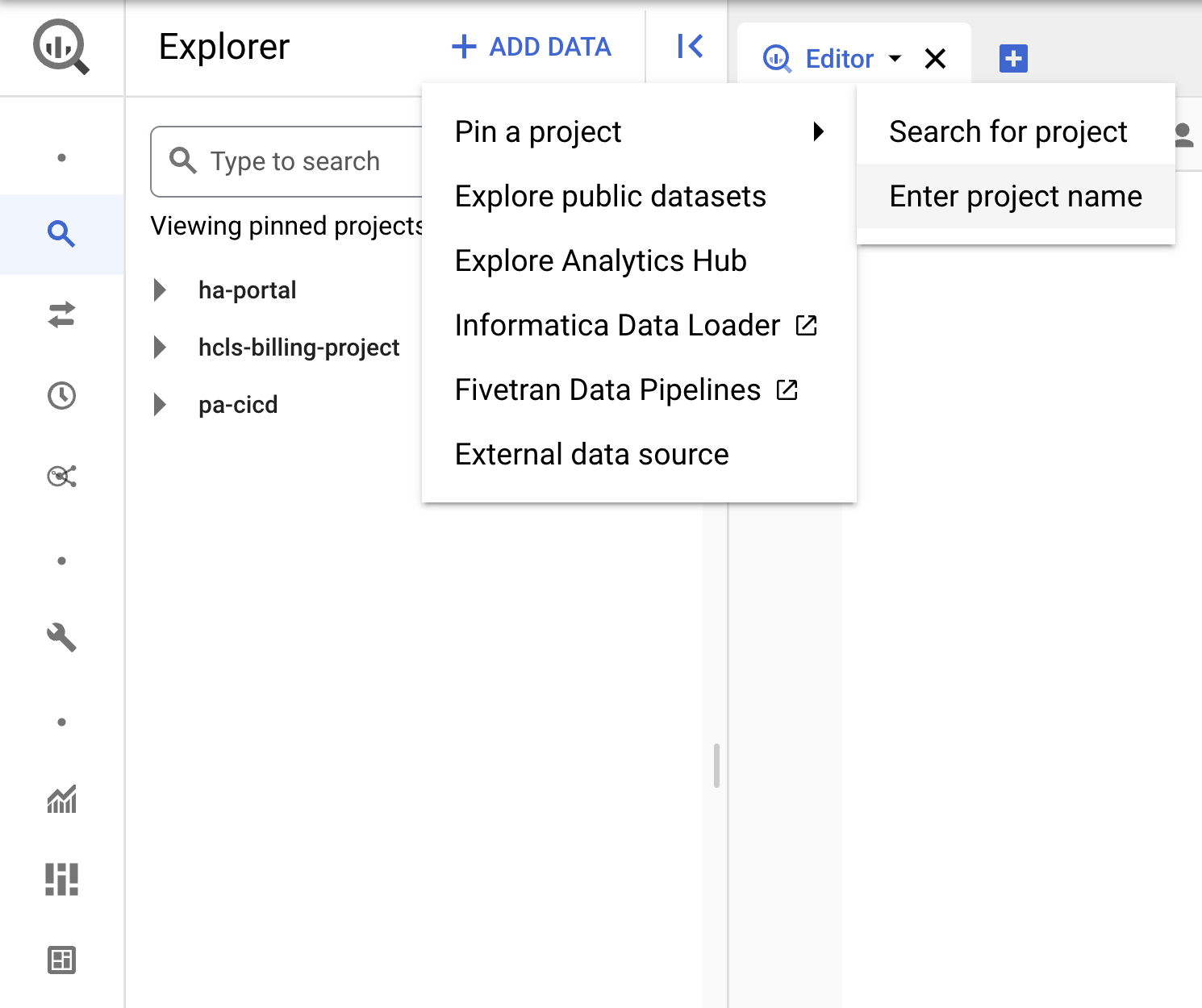
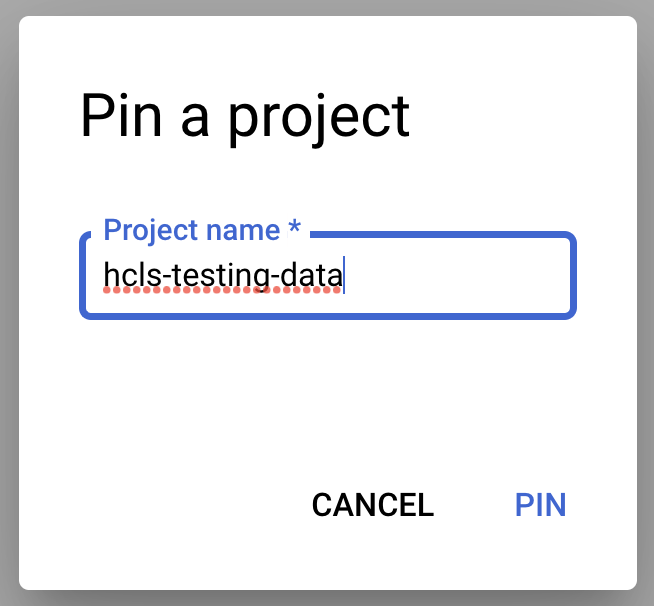
- Saisissez le nom du projet (hcls-testing-data), puis cliquez sur Code. Ensemble de données de test BigQuery "fhir_20k_patients_analytics" est disponible.
3. Développer des requêtes à l'aide de l'UI BigQuery
Paramètre de l'UI BigQuery
- Accédez à la console BigQuery en sélectionnant BigQuery dans le menu GCP en haut à gauche ("hamburger").
- Dans la console BigQuery, cliquez sur Plus > Paramètres de requête et assurez-vous que le menu de l'ancien SQL n'est PAS coché (nous utiliserons le langage SQL standard).
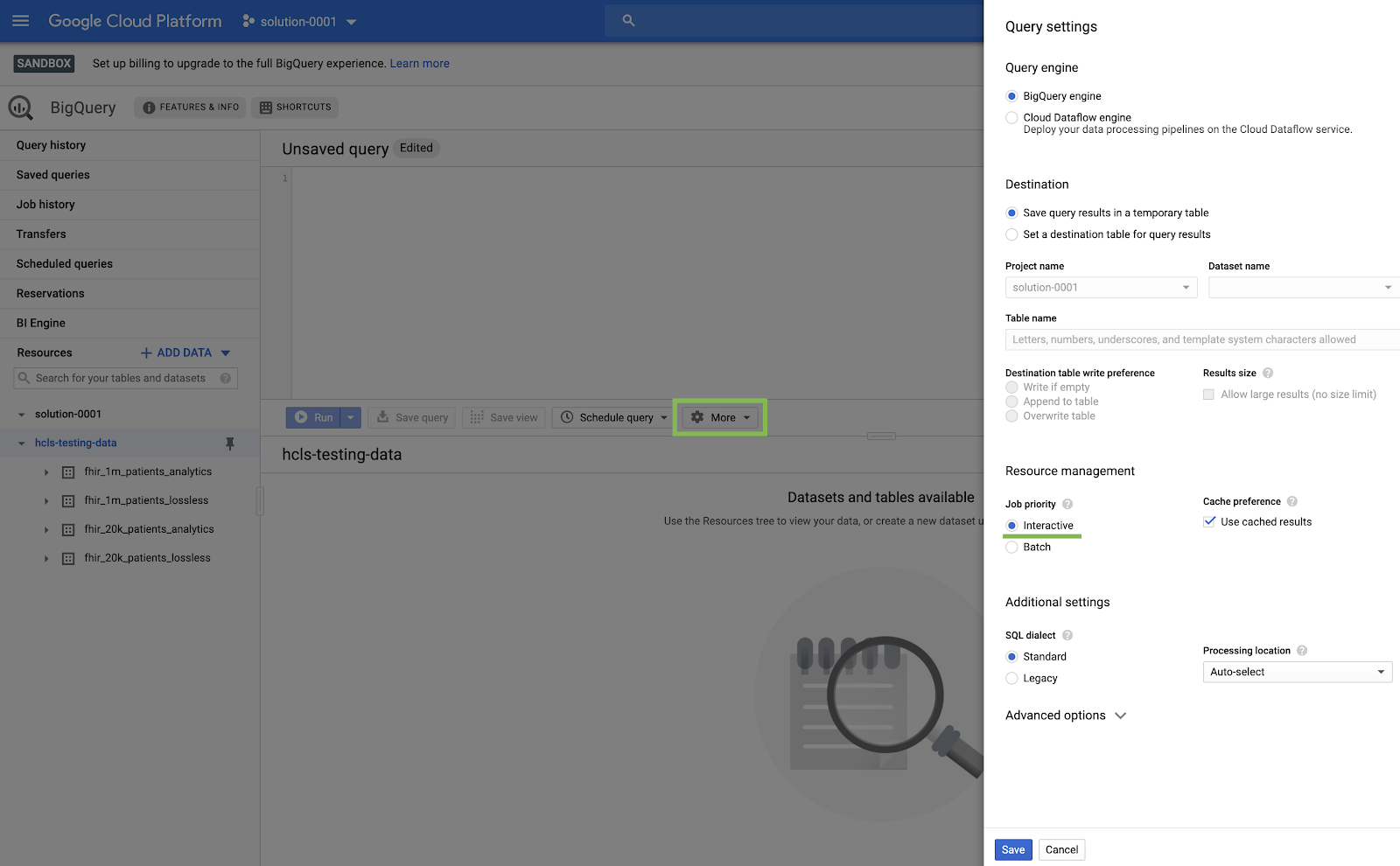
Créer des requêtes
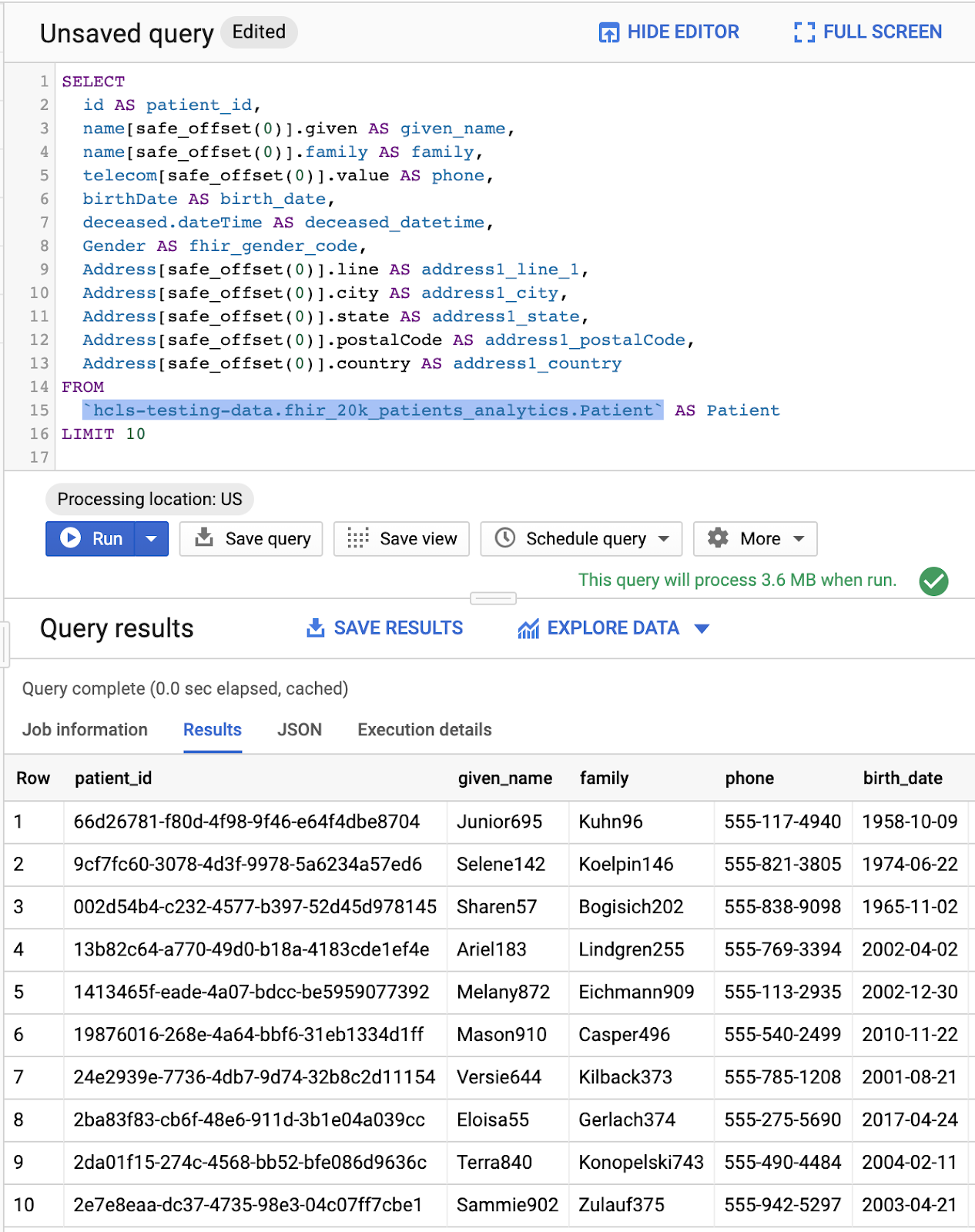
Dans la fenêtre de l'éditeur de requête, saisissez la requête suivante, puis cliquez sur Exécuter pour l'exécuter. Affichez ensuite les résultats dans la fenêtre Résultats de la requête.
PATIENTS DES REQUÊTES
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
Requête dans "Éditeur de requête" et résultats:
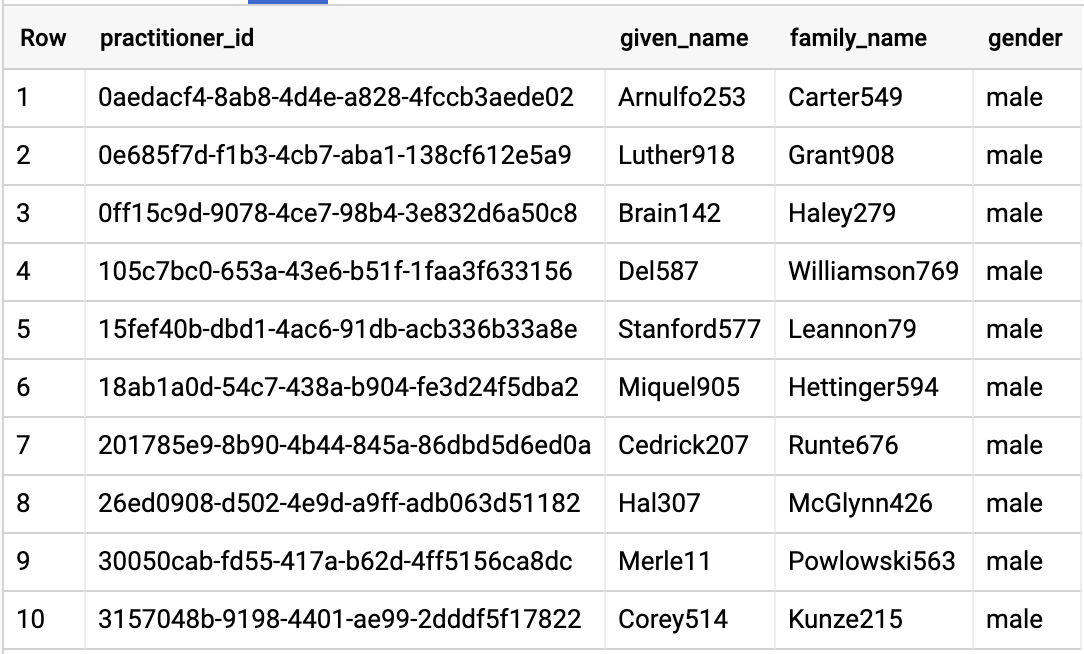
RÉACTEURS DES REQUÊTES
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
Résultats de la requête :
ORGANISATION DES REQUÊTES
Modifiez l'ID de l'organisation pour qu'il corresponde à votre ensemble de données.
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
Résultats de la requête :

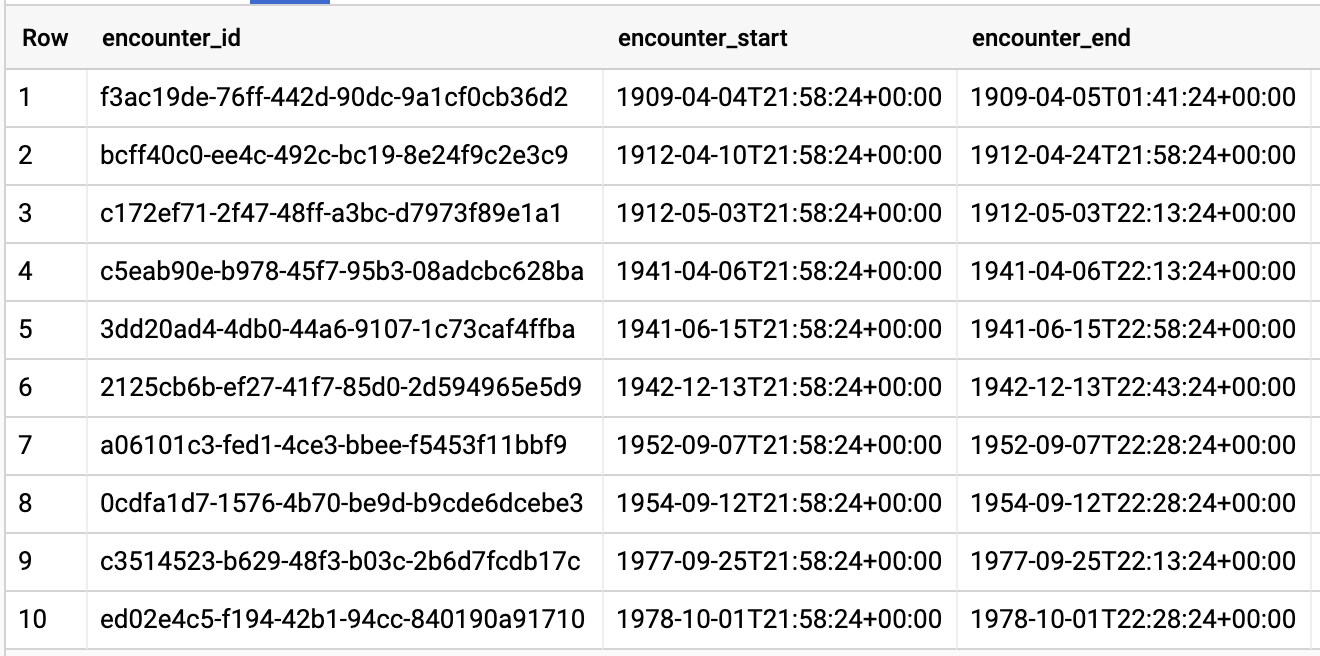
REQUÊTES DE REQUÊTES PAR PATIENT
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
Résultats de la requête :
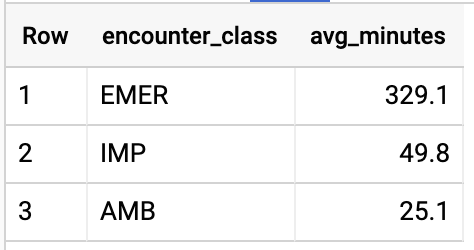
OBTENIR LA DURÉE MOY. DES RENCONTRES PAR TYPE DE RENCONTRE
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
Résultats de la requête :
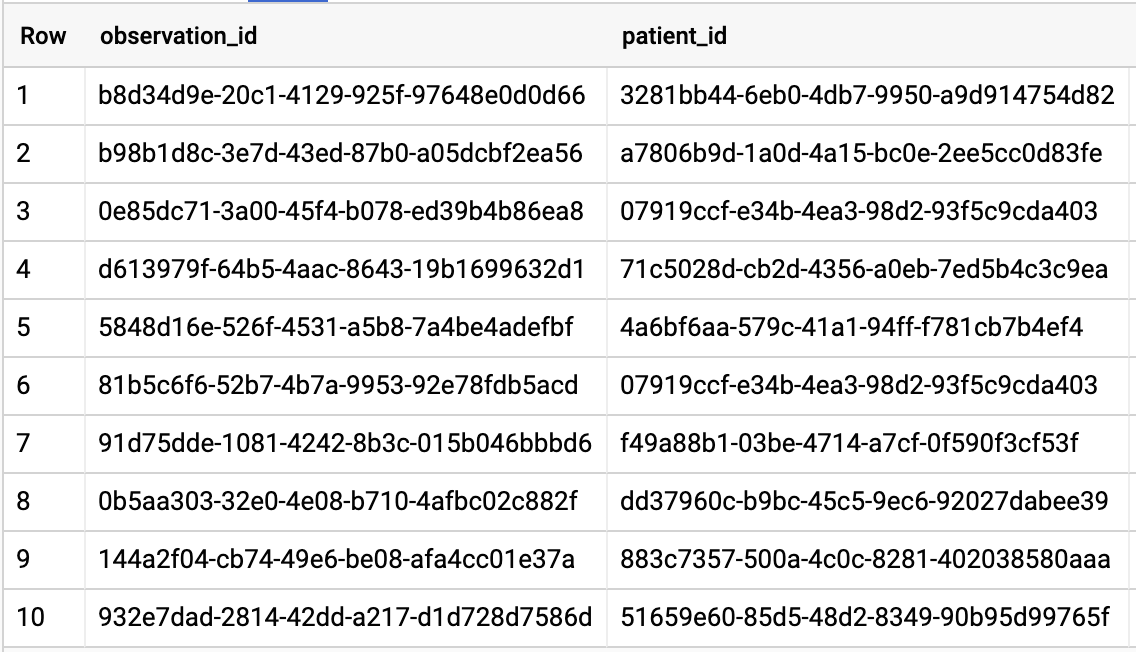
OBTENIR TOUS LES PATIENTS QUI ONT UN TAUX A1C ≥ 6,5
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
Résultats de la requête :
4. Créer une instance AI Platform Notebooks
Suivez les instructions de ce lien pour créer une instance AI Platform Notebooks (JupyterLab).
Veillez à activer l'API Compute Engine.
Vous pouvez choisir " Create a new notebook with default options (Créer un notebook avec les options par défaut) ou " Créez un notebook et spécifiez vos options".
5. Créer un notebook d'analyse de données
Ouvrir une instance AI Platform Notebooks
Dans cette section, nous allons créer et coder un nouveau notebook Jupyter en partant de zéro.
- Ouvrez une instance de notebook en accédant à la page AI Platform Notebooks de la console Google Cloud Platform. ACCÉDER À LA PAGE "NOTEBOOKS" D'AI PLATFORM
- Sélectionnez Ouvrir JupyterLab pour l'instance que vous souhaitez ouvrir.
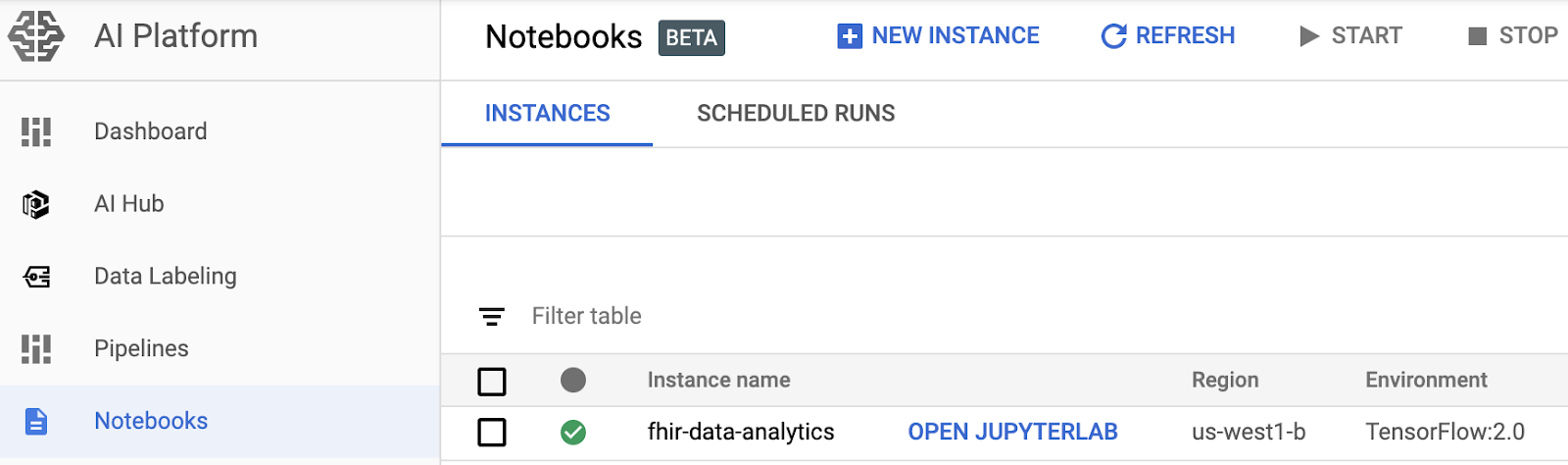
- AI Platform Notebooks vous dirige vers une URL pour l'instance de notebook.
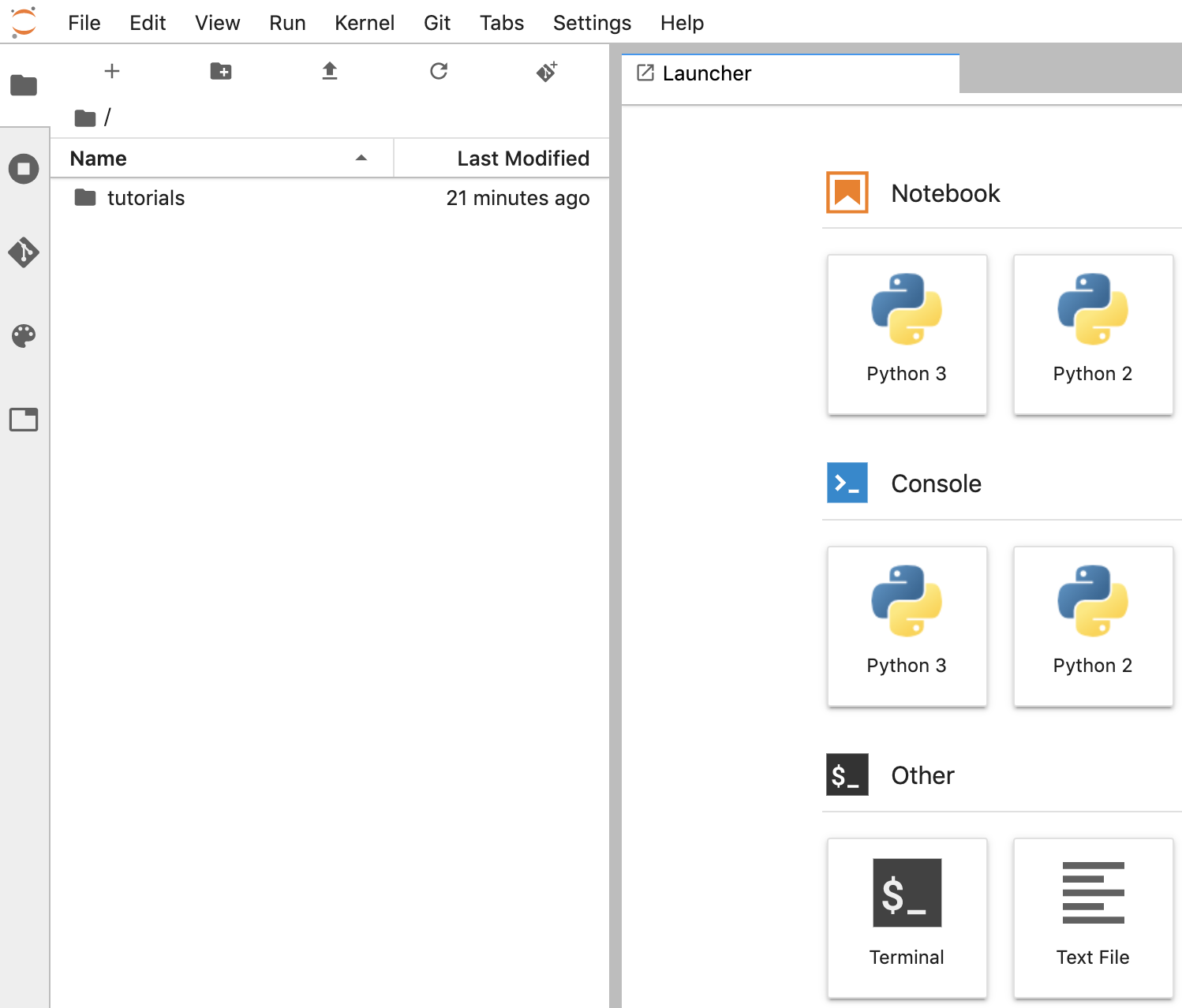
Créer un notebook
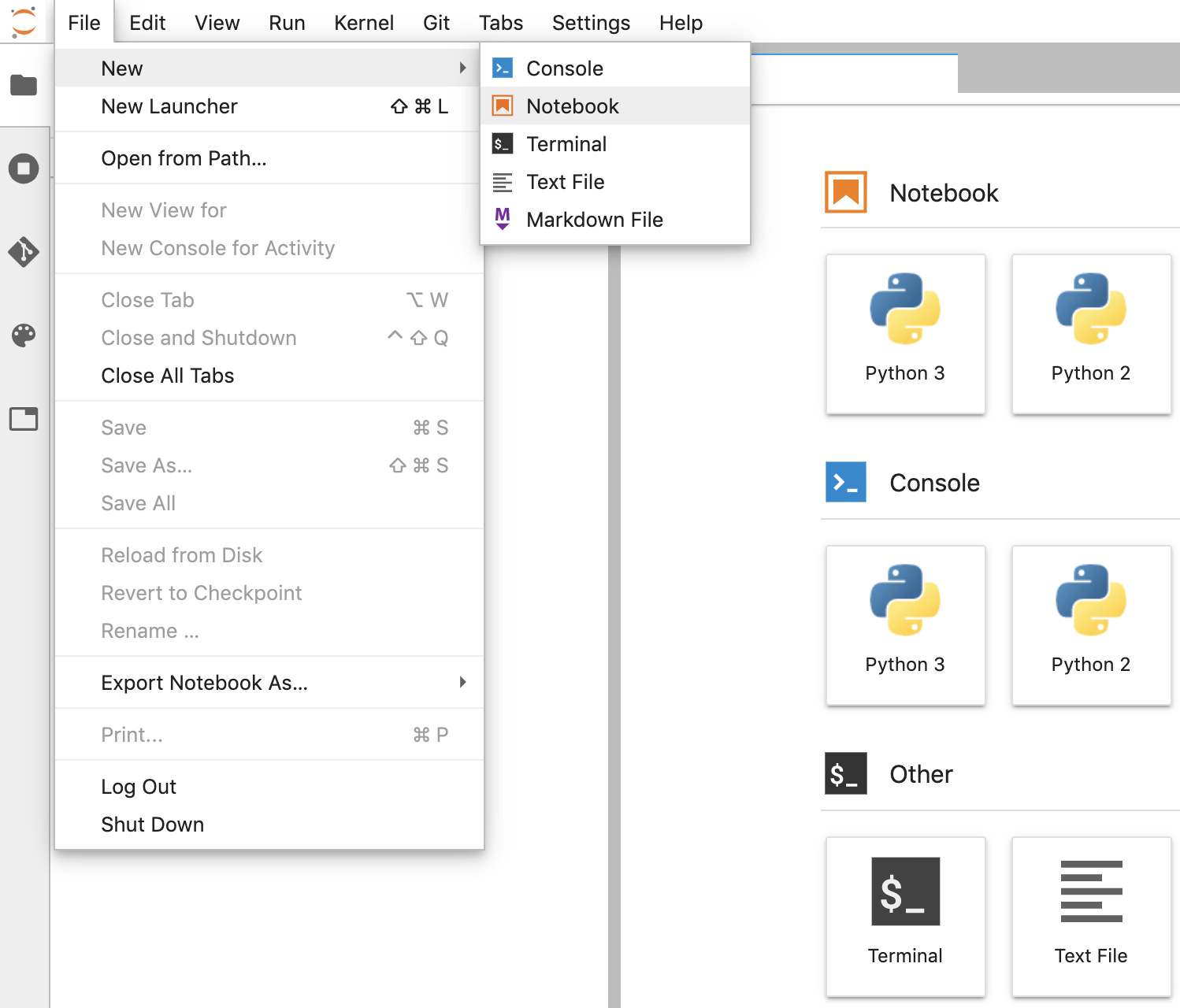
- Dans JupyterLab, accédez à Fichier -> Nouveau -> Notebook et sélectionnez le noyau "Python 3". dans la fenêtre pop-up, ou sélectionnez "Python 3" dans la section "Notebook" de la fenêtre du lanceur d'applications pour créer un notebook Untitled.ipynb.
- Effectuez un clic droit sur Untitled.ipynb et renommez le notebook "fhir_data_from_bigquery.ipynb". Double-cliquez dessus pour l'ouvrir, créez les requêtes et enregistrez le notebook.
- Vous pouvez télécharger un notebook en effectuant un clic droit sur le fichier *.ipynb, puis en sélectionnant "Télécharger" dans le menu.
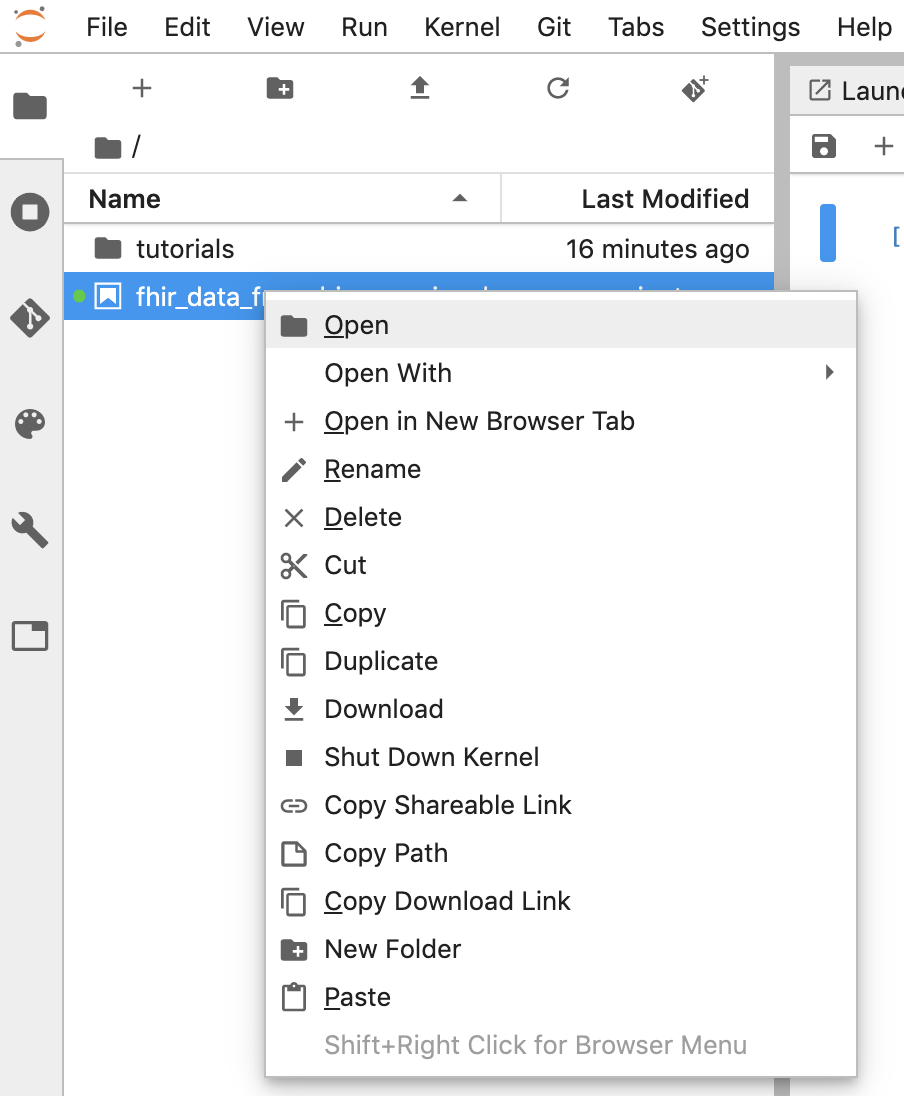
- Vous pouvez également importer un notebook existant en cliquant sur la flèche vers le haut .
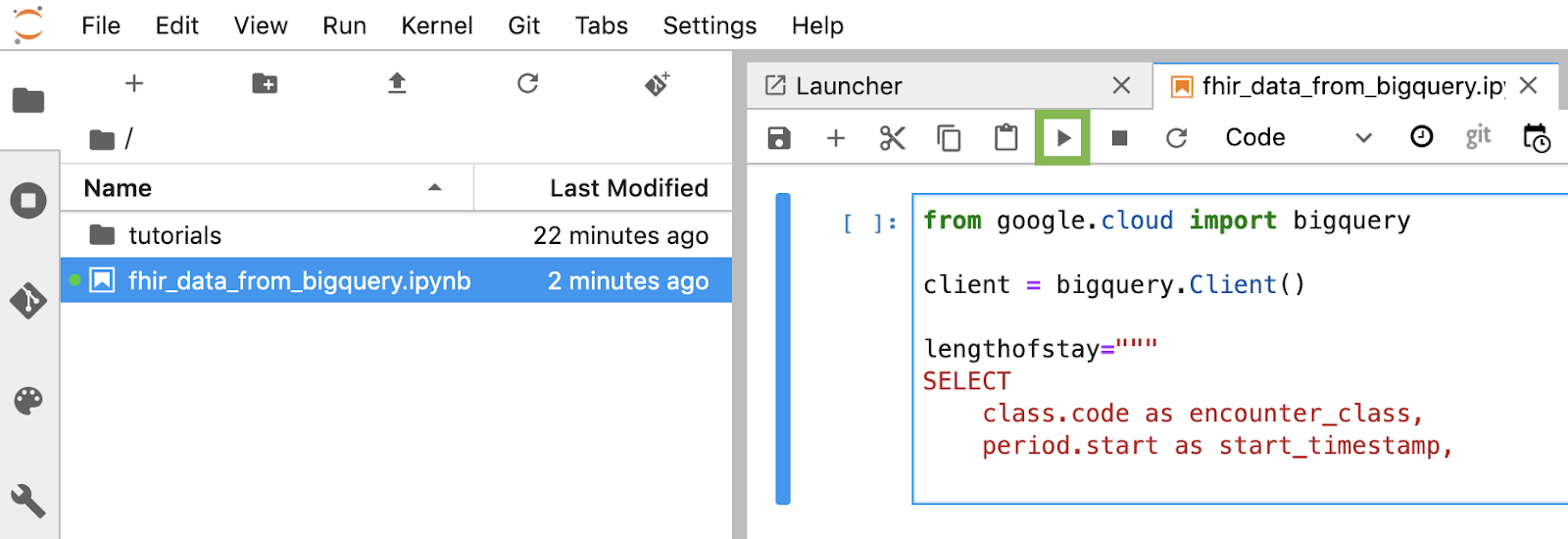
Créer et exécuter chaque bloc de code dans le notebook
Copiez et exécutez un par un chaque bloc de code fourni dans cette section. Pour exécuter le code, cliquez sur Run (Exécuter). (Triangle).
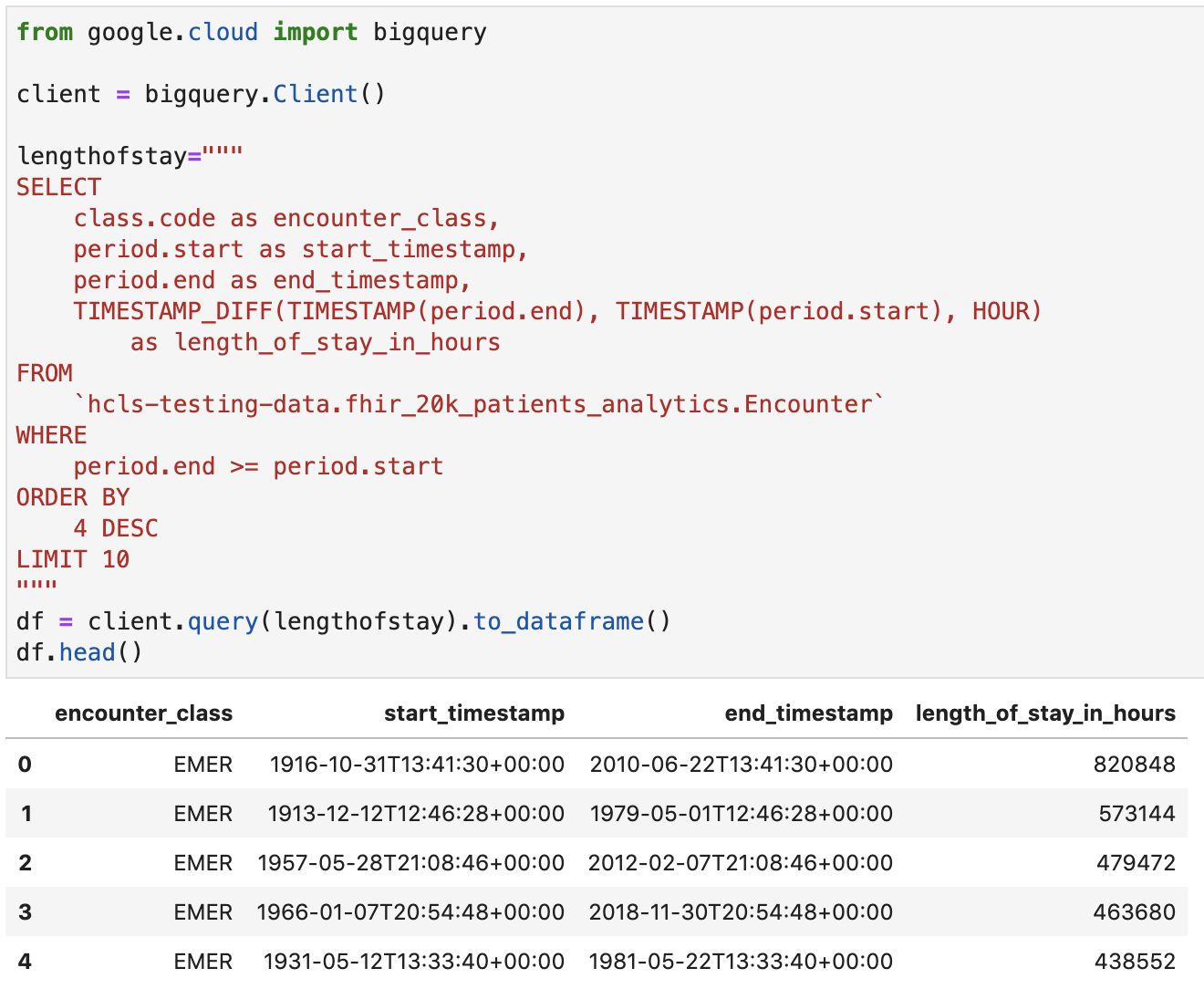
Obtenez la durée du séjour en heures pour les rencontres
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
Code et sortie d'exécution:
Obtenir les observations : valeurs de cholestérol
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
Sortie d'exécution:

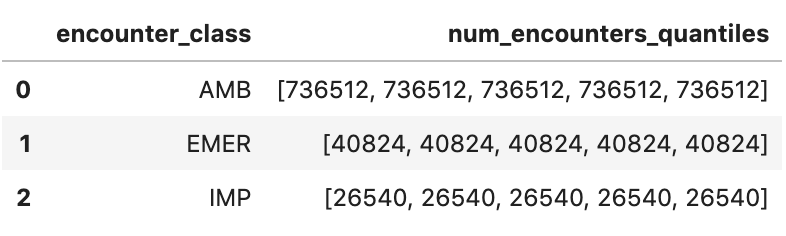
Obtenir les quantiles de rencontre approximatifs
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
Sortie d'exécution:
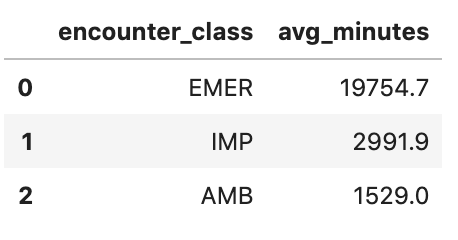
Obtenir la durée moyenne des rencontres en minutes
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
Sortie d'exécution:
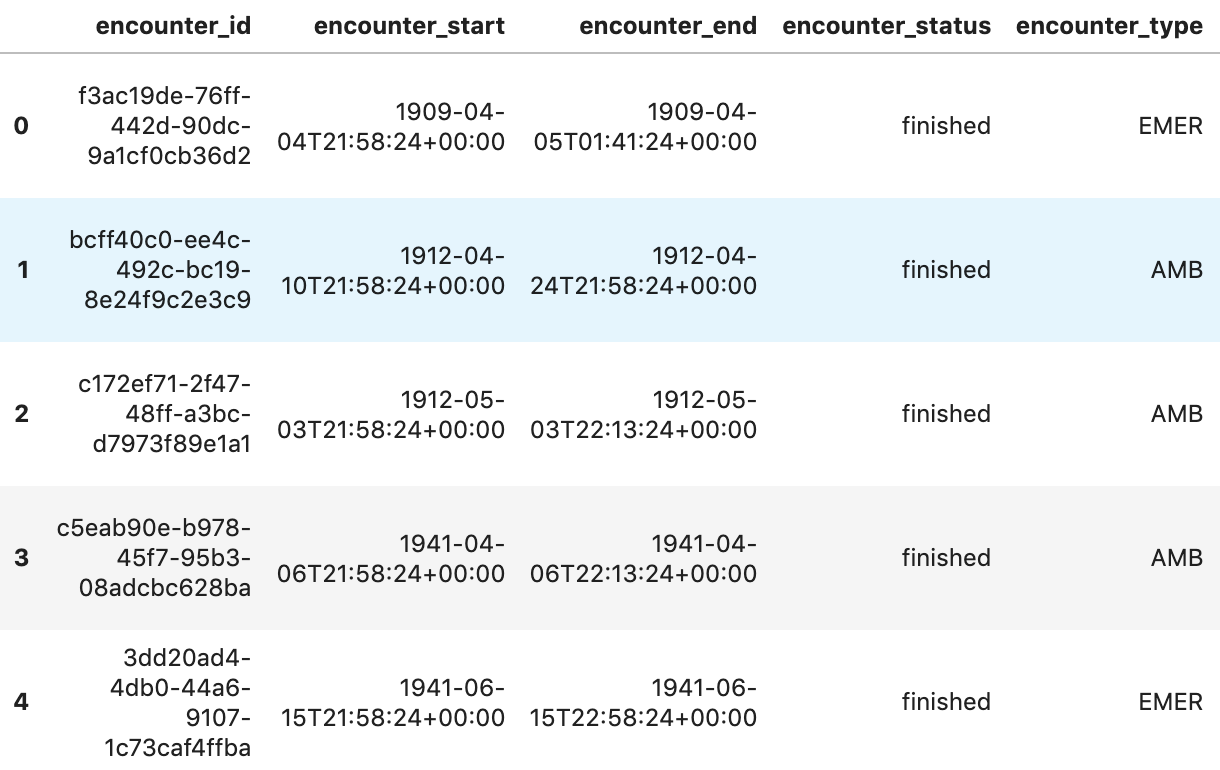
Obtenir le nombre de rencontres par patient
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
Sortie d'exécution:
Obtenir des organisations
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
Résultat de l'exécution:

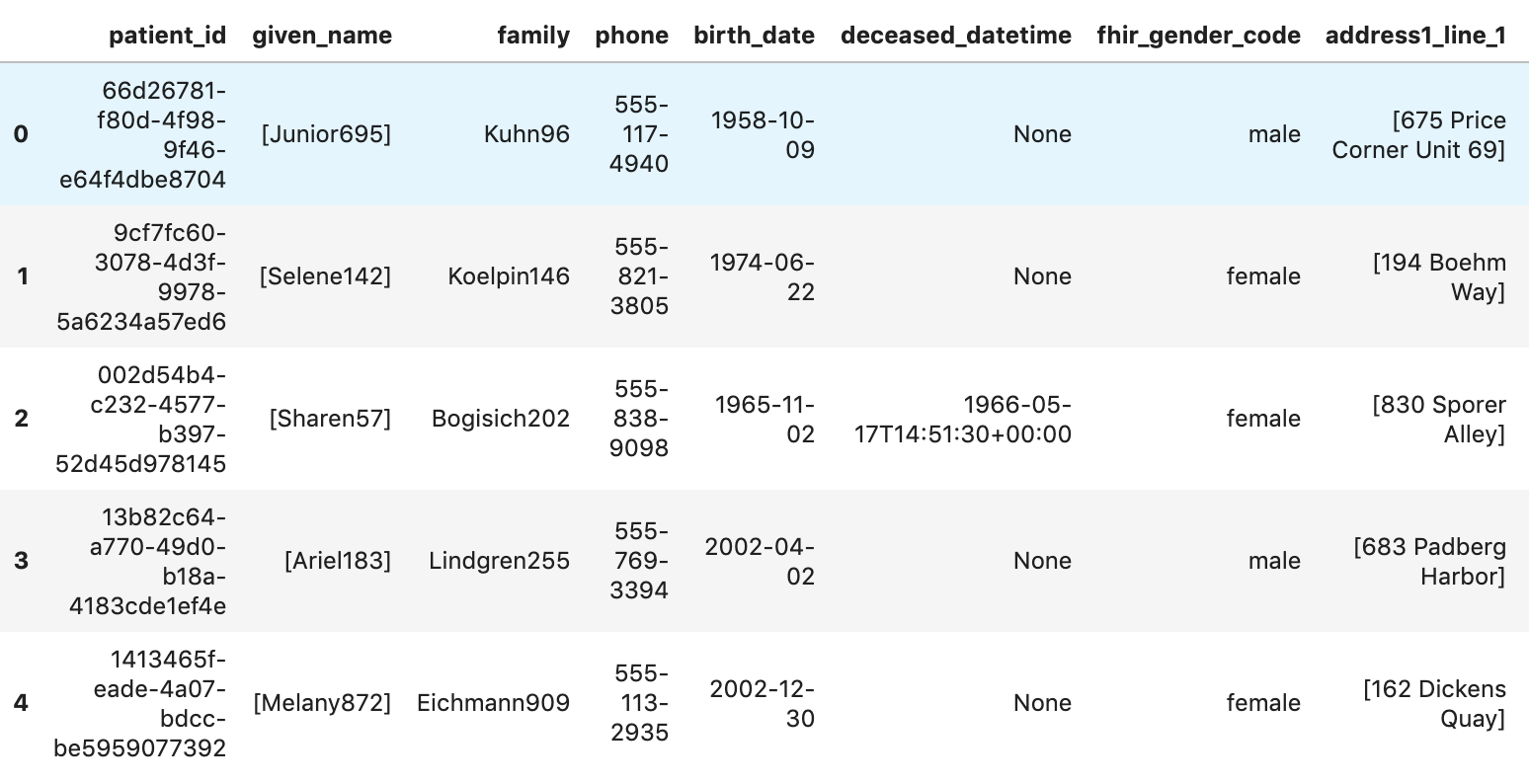
Obtenir des patients
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
Résultats de l'exécution:
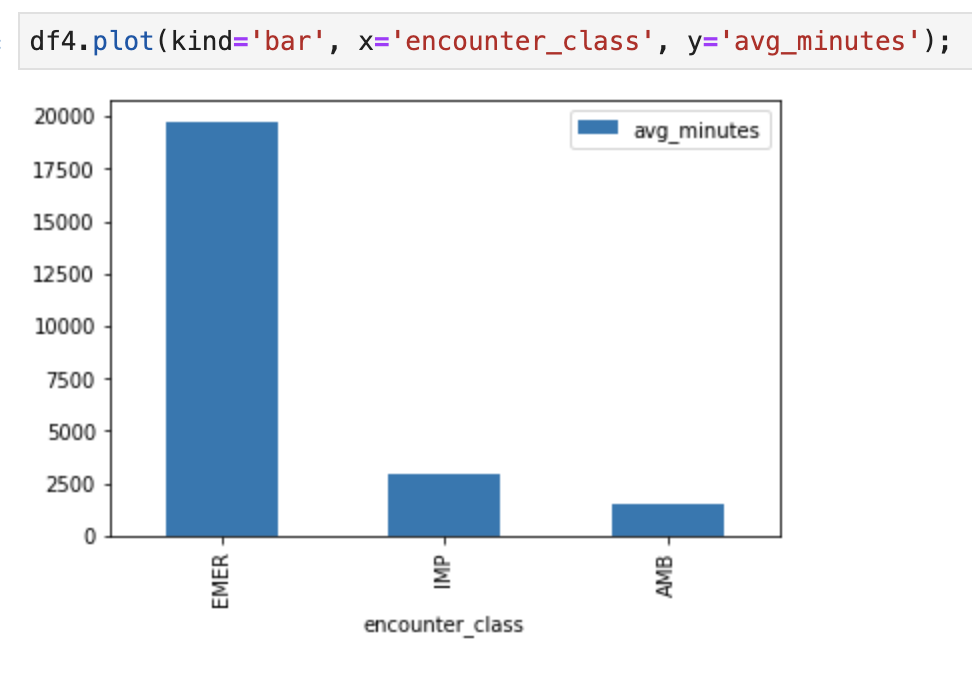
6. Créer des graphiques dans AI Platform Notebooks
Exécuter les cellules de code dans le notebook "fhir_data_from_bigquery.ipynb" pour dessiner un graphique à barres.
Par exemple, obtenez la durée moyenne des rencontres en minutes.
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
Résultats du code et de l'exécution:
7. Valider le notebook dans un dépôt Cloud Source Repositories
- Dans la console GCP, accédez à "Source Repositories". Si vous l'utilisez pour la première fois, cliquez sur "Commencer", puis sur "Créer un dépôt".
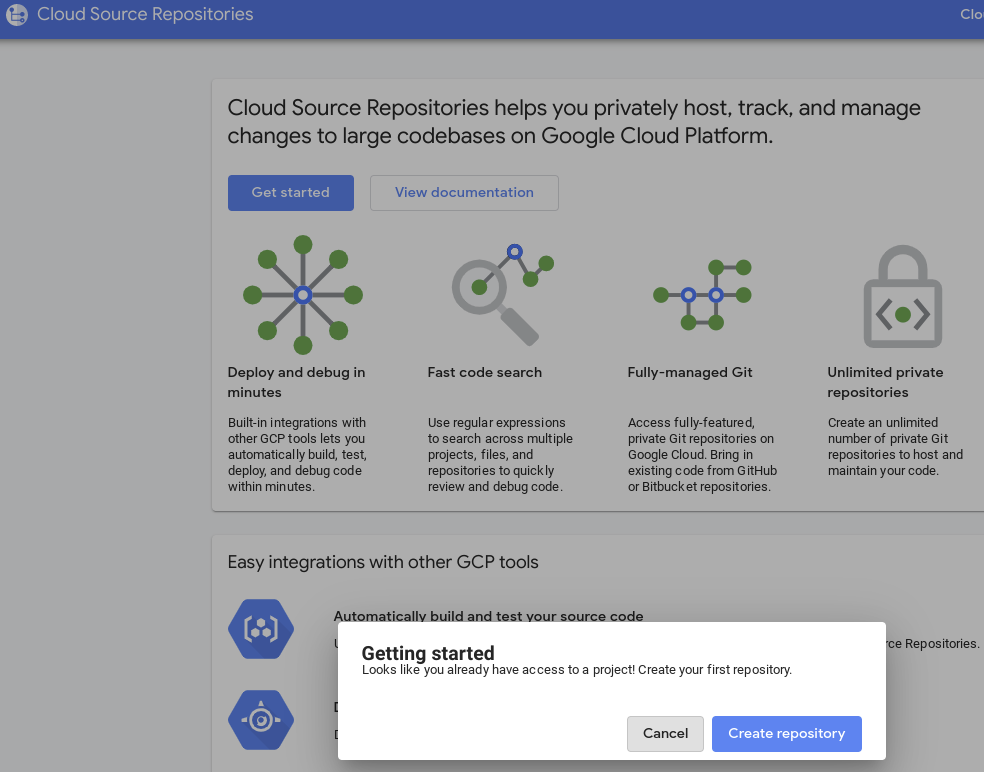
- Par la suite, accédez à GCP -> Cloud Source Repositories, puis cliquez sur "+ Ajouter un dépôt" pour créer un dépôt.

- Sélectionnez "Create a new Repository" (Créer un dépôt), puis cliquez sur "Continue" (Continuer).
- Indiquez le nom du dépôt et le nom du projet, puis cliquez sur "Créer".
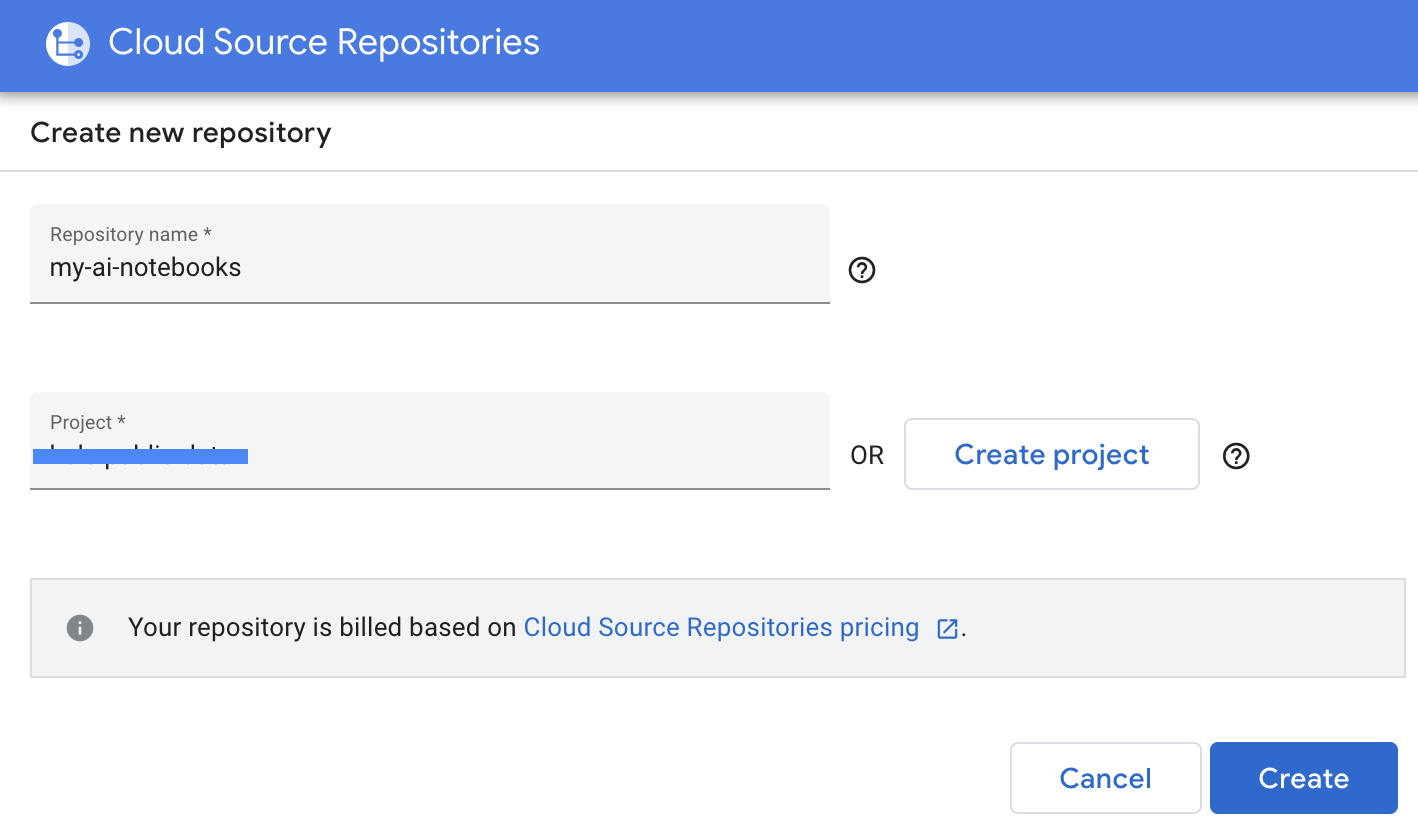
- Sélectionnez "Clone yourrepository to a local Git dépôt" (Cloner votre dépôt vers un dépôt Git local), puis sélectionnez "Identifiants générés manuellement".
- Suivez l'étape 1 "Générer et stocker des identifiants Git". instructions (voir ci-dessous). Copiez le script qui s'affiche à l'écran.
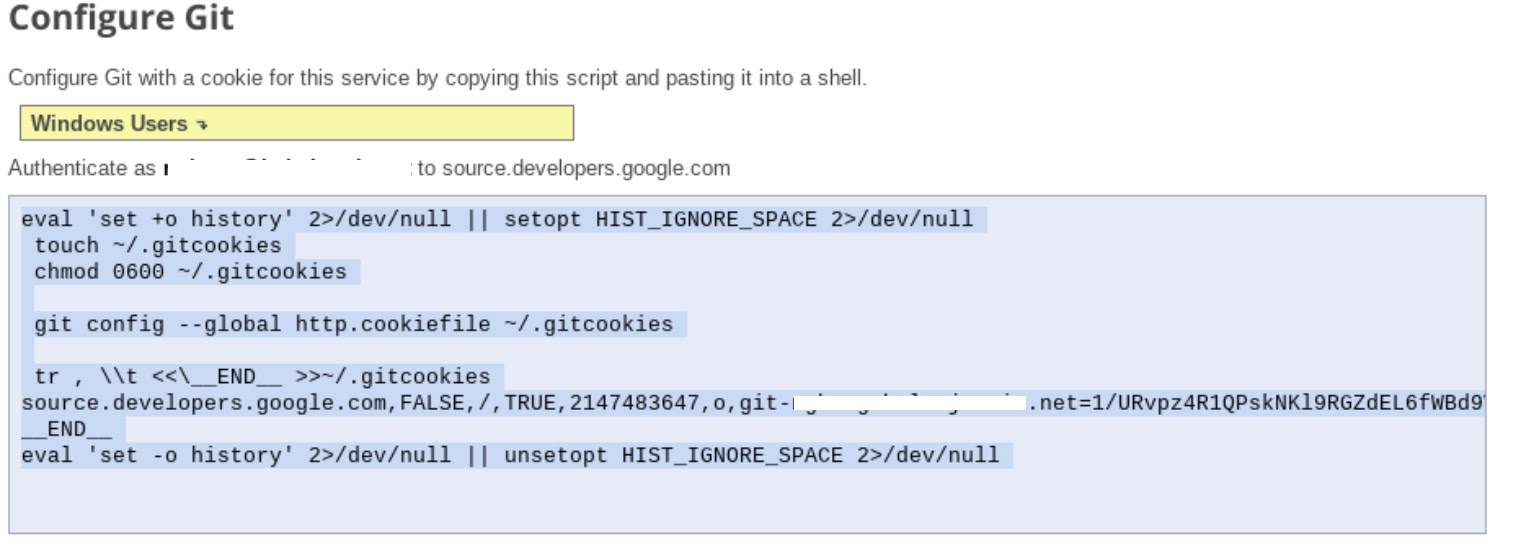
- Démarrez une session de terminal dans Jupyter.
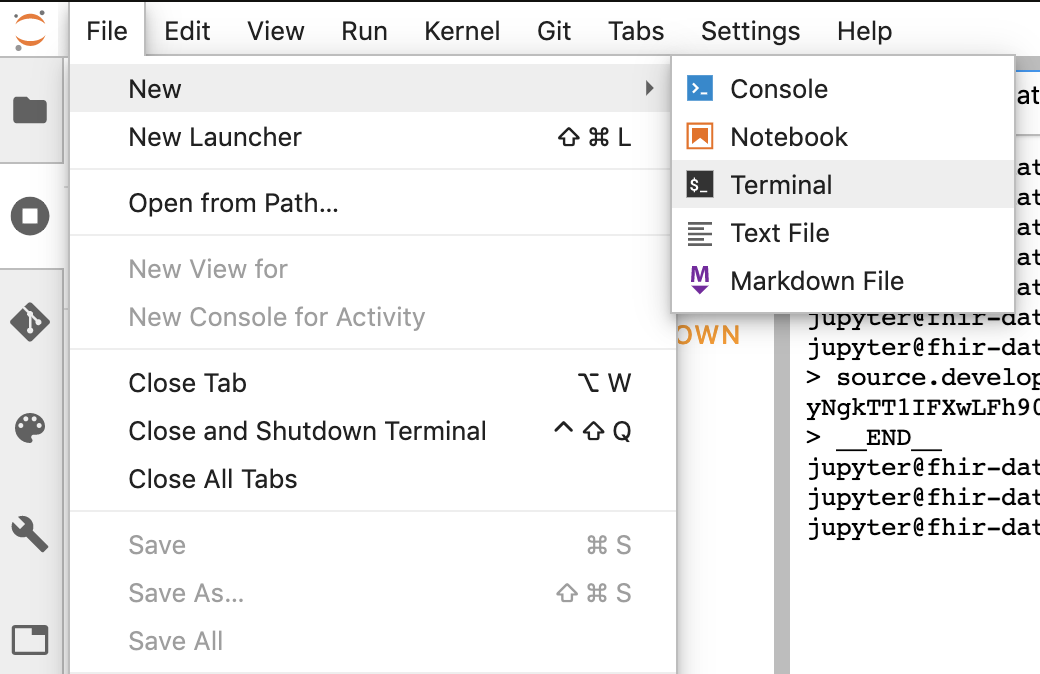
- Collez toutes les commandes de la configuration dans le terminal Jupyter.
- Copiez le chemin d'accès du clone du dépôt depuis les dépôts sources Cloud GCP (étape 2 de la capture d'écran ci-dessous).

- Collez cette commande dans le terminal JupiterLab. La commande se présente comme suit:
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- Les blocs-notes "my-ai-notebooks" est créé dans JupyterLab.
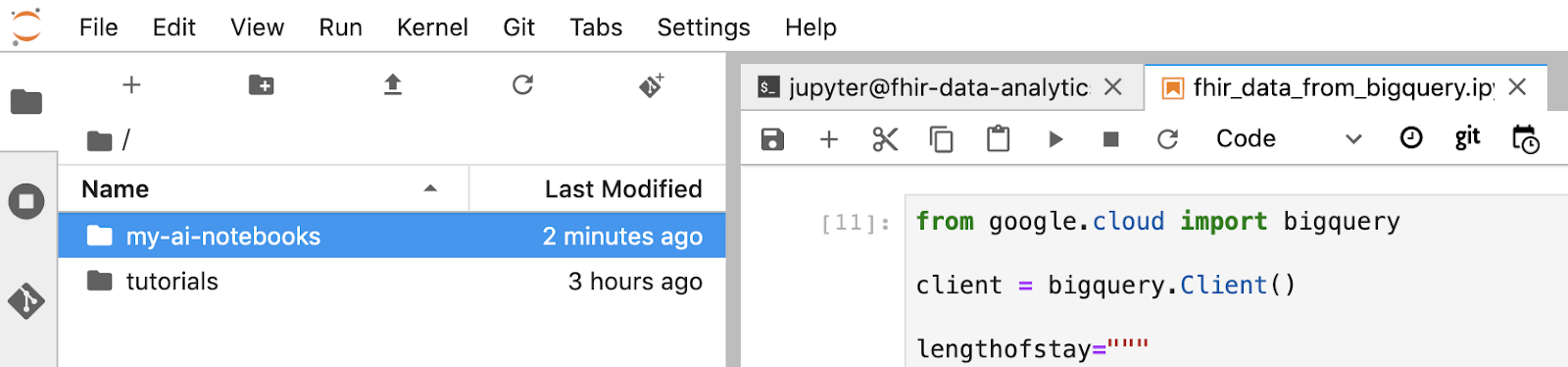
- Déplacez votre notebook (fhir_data_from_bigquery.ipynb) dans le dossier "my-ai-notebooks".
- Dans le terminal Jupyter, remplacez le répertoire par "cd my-ai-notebooks".
- Intégrez vos modifications par étapes à l'aide du terminal Jupyter. Vous pouvez également utiliser l'interface utilisateur Jupyter. Effectuez un clic droit sur les fichiers dans la zone "Non suivis", sélectionnez "Suivre", puis déplacez les fichiers dans la zone "Suivis", et inversement. La zone modifiée contient les fichiers modifiés).
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
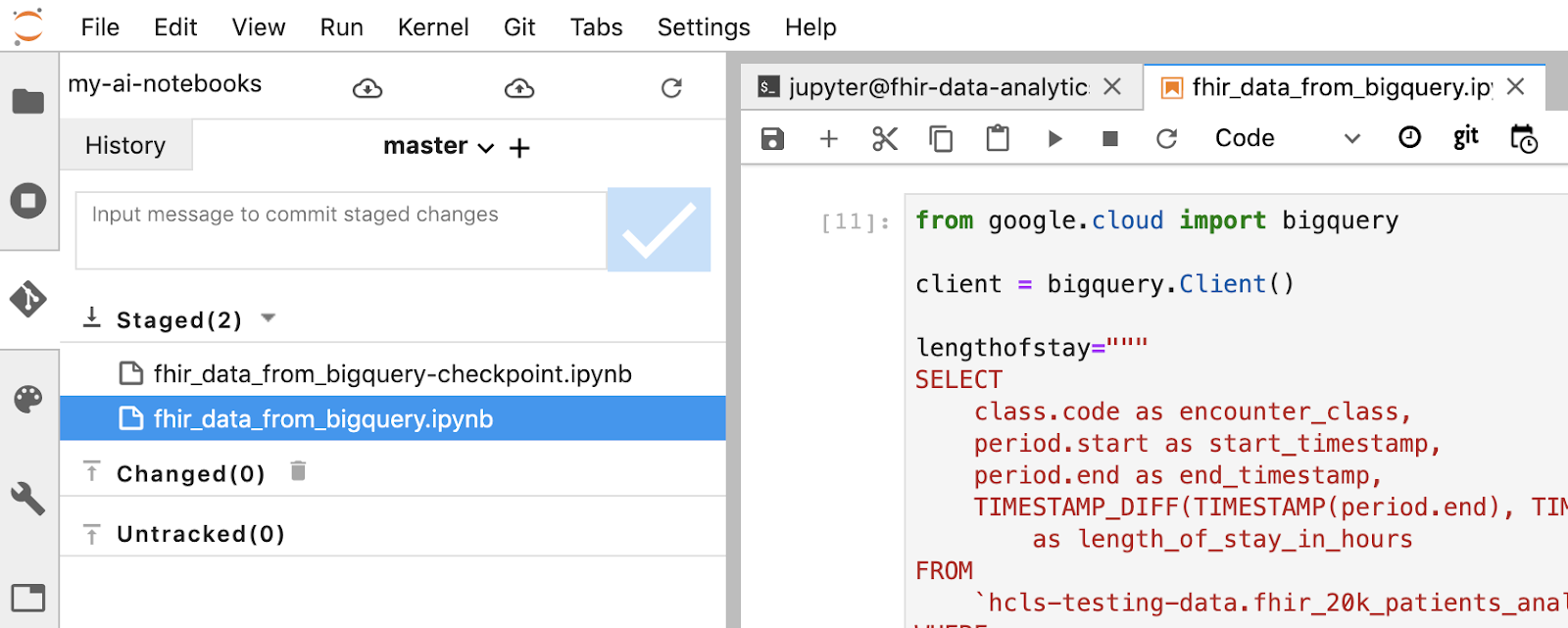
- Validez vos modifications à l'aide du terminal ou de l'interface utilisateur Jupyter (saisissez le message, puis cliquez sur le bouton "Checked" (Coché)).
git commit -m "message goes here"
- Transférez vos modifications dans le dépôt distant à l'aide du terminal ou de l'interface utilisateur Jupyter (cliquez sur l'icône "push changes" (Déployer les modifications validées))
 .
.
git push --all
- Dans la console GCP, accédez à "Source Repositories". Cliquez sur my-ai-notebooks. Notez que "fhir_data_from_bigquery.ipynb" est à présent enregistré dans le dépôt GCP Source Repositories.
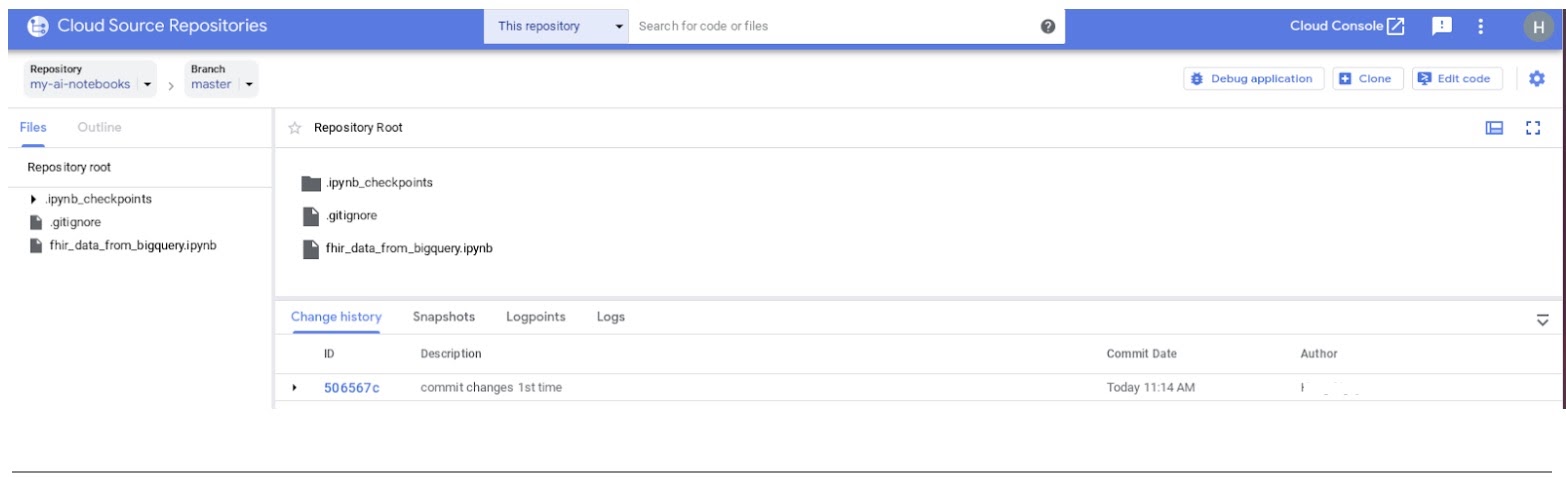
8. Nettoyage
Pour éviter que les ressources utilisées dans cet atelier de programmation ne soient facturées sur votre compte Google Cloud Platform, une fois le tutoriel terminé, vous pouvez nettoyer les ressources que vous avez créées sur GCP afin qu'elles ne soient pas comptabilisées dans votre quota et qu'elles ne vous soient plus facturées. Dans les sections suivantes, nous allons voir comment supprimer ou désactiver ces ressources.
Supprimer l'ensemble de données BigQuery
Suivez ces instructions pour supprimer l'ensemble de données BigQuery que vous avez créé dans le cadre de ce tutoriel. Vous pouvez également accéder à la console BigQuery, annuler le code d'accès du projet hcls-testing-data si vous avez utilisé l'ensemble de données de test fhir_20k_patients_analytics.
Arrêter l'instance AI Platform Notebooks
Suivez les instructions fournies dans le lien Arrêter une instance de notebook | AI Platform Notebooks pour arrêter une instance AI Platform Notebooks.
Supprimer le projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé pour ce tutoriel.
Pour supprimer le projet :
- Dans la console GCP, accédez à la page Projets. ACCÉDER À LA PAGE "PROJETS"
- Dans la liste des projets, sélectionnez celui que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
9. Félicitations
Félicitations ! Vous avez terminé l'atelier de programmation qui vous permettra d'accéder à des données de santé au format FHIR, de les interroger et de les analyser à l'aide de BigQuery et d'AI Platform Notebooks.
Vous avez accédé à un ensemble de données BigQuery public dans GCP.
Vous avez développé et testé des requêtes SQL à l'aide de l'interface utilisateur de BigQuery.
Vous avez créé et lancé une instance AI Platform Notebooks.
Vous avez exécuté des requêtes SQL dans JupyterLab et stocké les résultats de ces requêtes dans le DataFrame pandas.
Vous avez créé des tableaux et des graphiques à l'aide de Matplotlib.
Vous avez validé votre notebook et l'avez transféré vers un dépôt Cloud Source Repositories dans GCP.
Vous connaissez maintenant les principales étapes nécessaires pour commencer votre parcours d'analyse de données de santé avec BigQuery et AI Platform Notebooks sur Google Cloud Platform.
©Google, Inc. or its affiliates. Tous droits réservés. Ne pas diffuser.