
1. はじめに
最終更新日: 2022 年 9 月 22 日
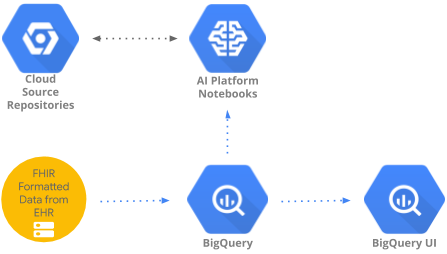
この Codelab では、BigQueryUI と AI Platform Notebooks を使用して、BigQuery に集約された医療データにアクセスして分析するパターンを実装します。HIPPA 準拠の AI Platform Notebooks で、Pandas、Matplotlib などの使い慣れたツールを使用して、大規模な医療データセットのデータ探索について説明します。ポイントは、集計処理の最初の部分を BigQuery で実行して Pandas データセットを取得し、より小規模の Pandas データセットをローカルで処理する点です。AI Platform Notebooks にはマネージド Jupyter 環境が用意されているため、ノートブック サーバーをご自分で実行する必要はありません。AI Platform Notebooks は、Big Query や Cloud Storage などの他の GCP サービスと緊密に統合されているため、Google Cloud Platform でデータ分析や ML の利用を迅速かつ簡単に開始できます。
この Codelab では、以下について学びます。
- BigQuery UI を使用して SQL クエリを開発およびテストする。
- GCP で AI Platform Notebooks インスタンスを作成して起動します。
- ノートブックから SQL クエリを実行し、クエリ結果を Pandas DataFrame に保存します。
- Matplotlib を使用してチャートやグラフを作成します。
- ノートブックを commit して GCP の Cloud Source Repositories に push します。
この Codelab を実行するには何が必要ですか?
- GCP プロジェクトへのアクセス権が必要です。
- GCP プロジェクトのオーナーのロールが割り当てられている必要があります。
- BigQuery の医療データセットが必要です。
GCP プロジェクトが存在しない場合は、こちらの手順に沿って新しい GCP プロジェクトを作成します。
2. プロジェクトのセットアップ
この Codelab では、BigQuery の既存のデータセット(hcls-testing-data.fhir_20k_patients_analytics)を使用します。このデータセットには、合成医療データが事前入力されます。
合成データセットへのアクセス権を取得する
- Cloud コンソールへのログインに使用しているメールアドレスから、hcls-solutions-external+subscribe@google.com 宛てにメールを送信し、参加をリクエストします。
- 操作の確認方法が記載されたメールが届きます。
- メールに返信するオプションを使用してグループに参加します。
 ボタンはクリックしないでください。
ボタンはクリックしないでください。 - 確認メールが届いたら、Codelab の次のステップに進むことができます。
プロジェクトを固定する
- Google Cloud コンソールでプロジェクトを選択し、BigQuery に移動します。
- [+ データを追加] プルダウンをクリックし、[プロジェクトを固定] を選択します。>「プロジェクト名を入力してください」をタップします。
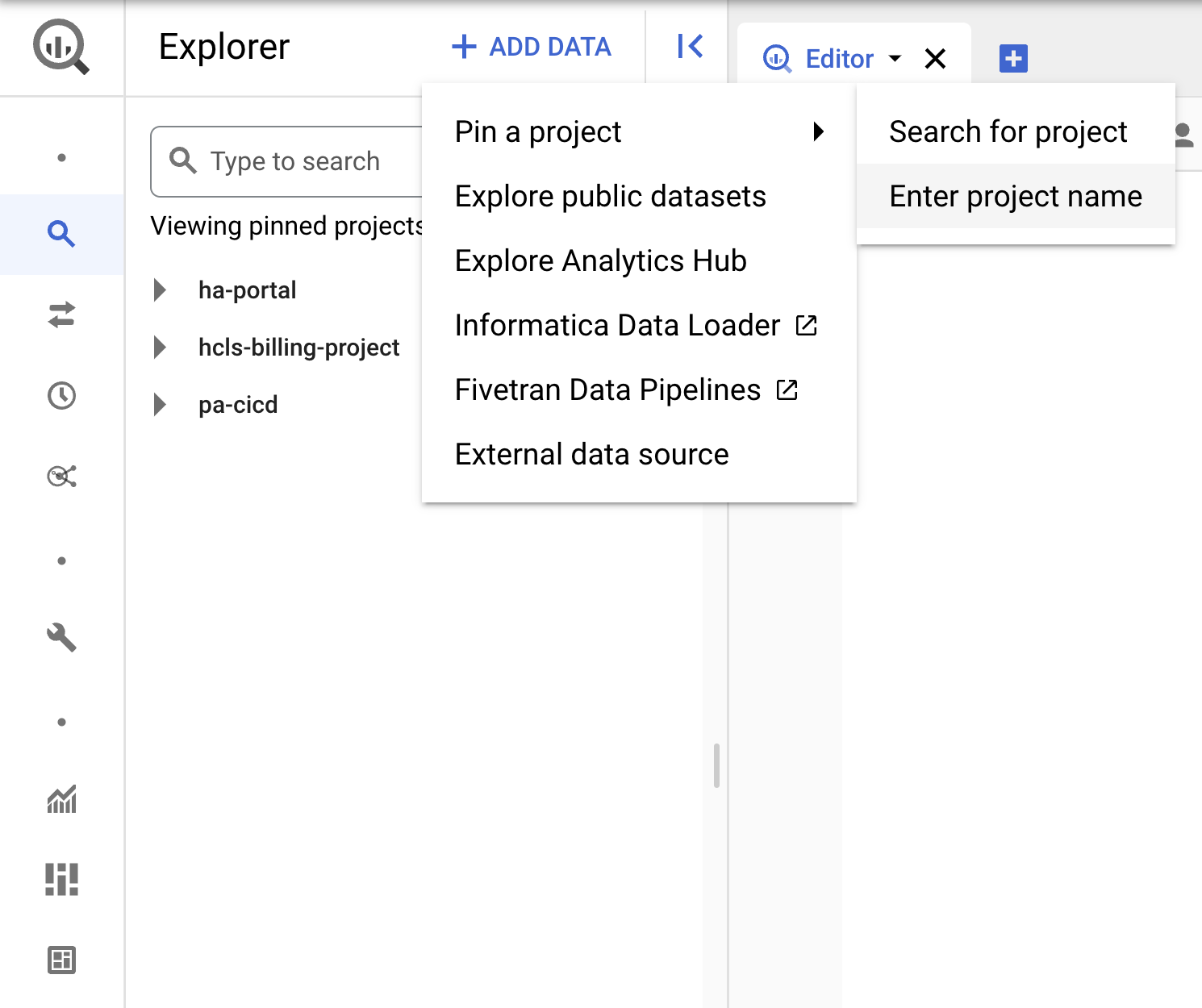
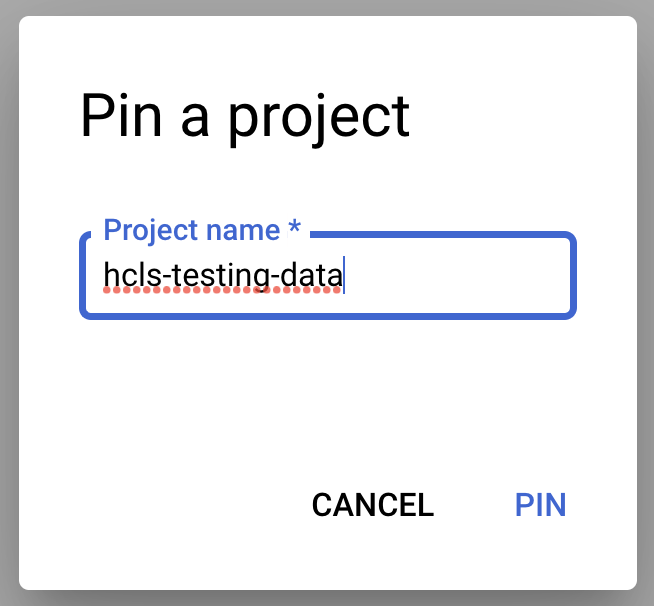
- プロジェクト名「hcls-testing-data」を入力し、[固定] をクリックします。BigQuery テスト データセット「fhir_20k_patients_analytics」使用できます。
3. BigQuery UI を使用してクエリを開発する
BigQuery UI の設定
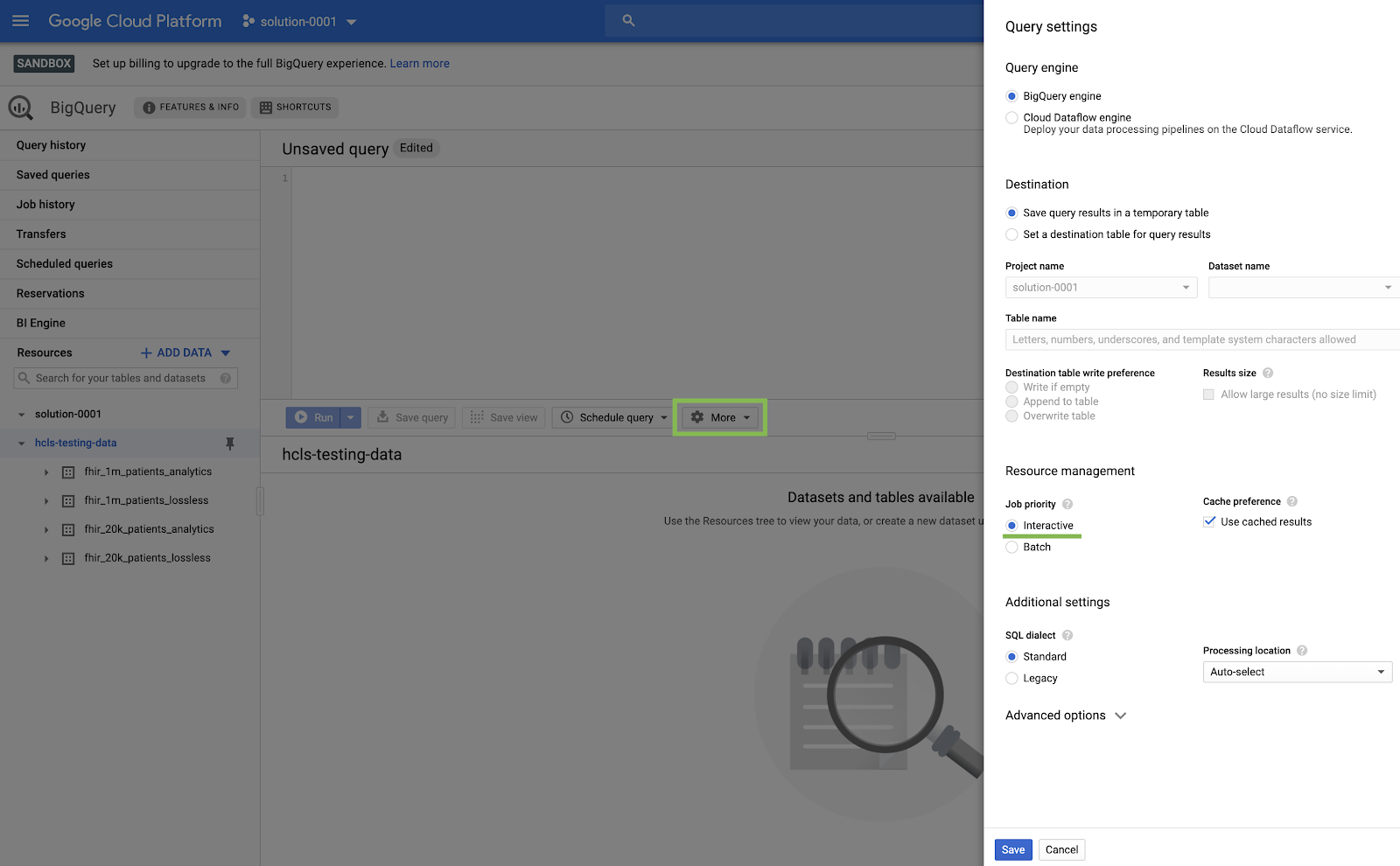
- GCP の左上隅(「ハンバーガー」)メニューから [BigQuery] を選択して、BigQuery コンソールに移動します。
- BigQuery コンソールで [展開] → [クエリの設定] をクリックし、[レガシー SQL] メニューがオフになっていることを確認します(ここでは標準 SQL を使用します)。
クエリの作成
クエリエディタ ウィンドウで次のクエリを入力し、[実行] をクリックして実行します。その結果を [クエリ結果] ウィンドウで確認できます。
患者をクエリ
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
[クエリエディタ] でのクエリ結果:
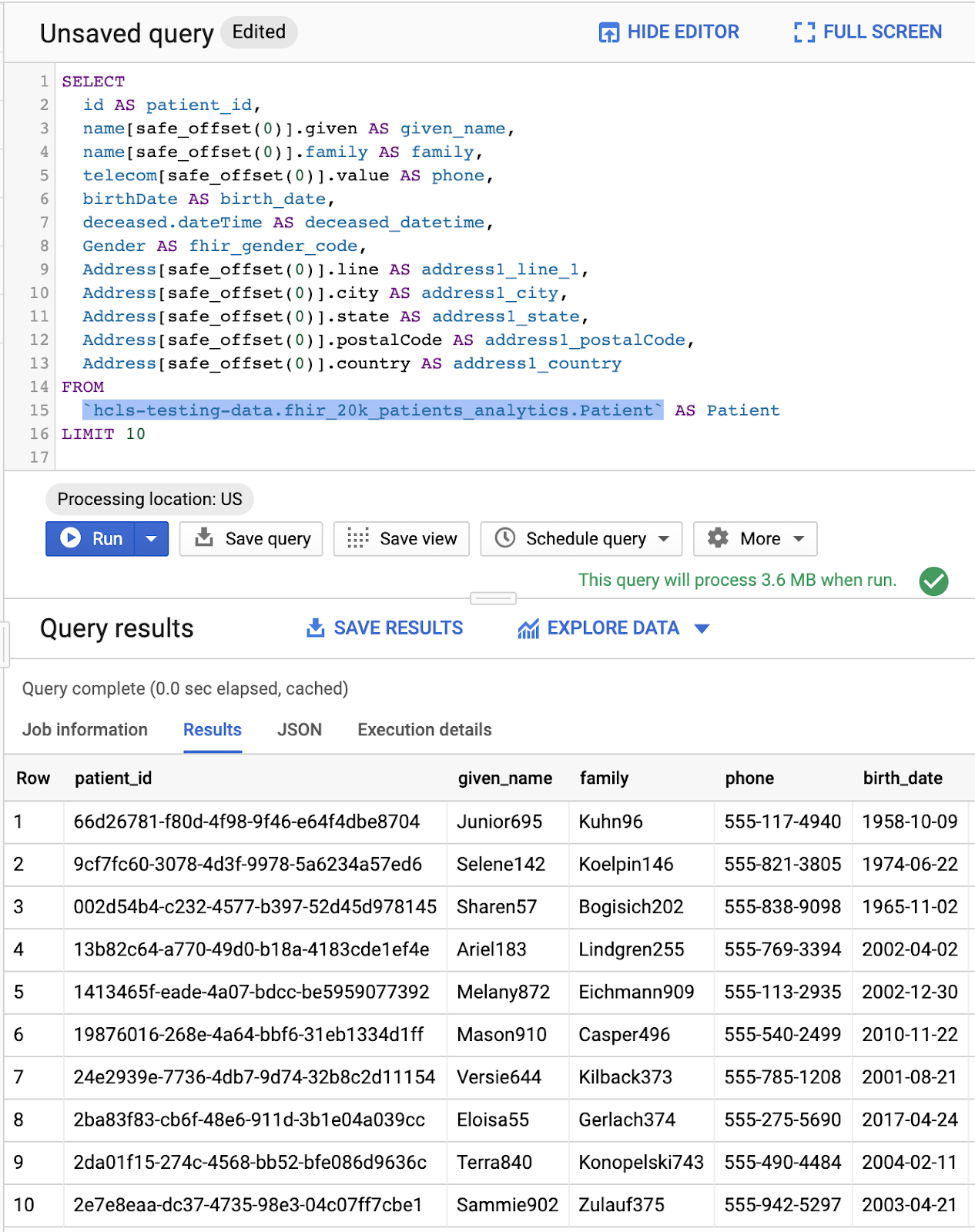
クエリ 実践者
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
クエリ結果:
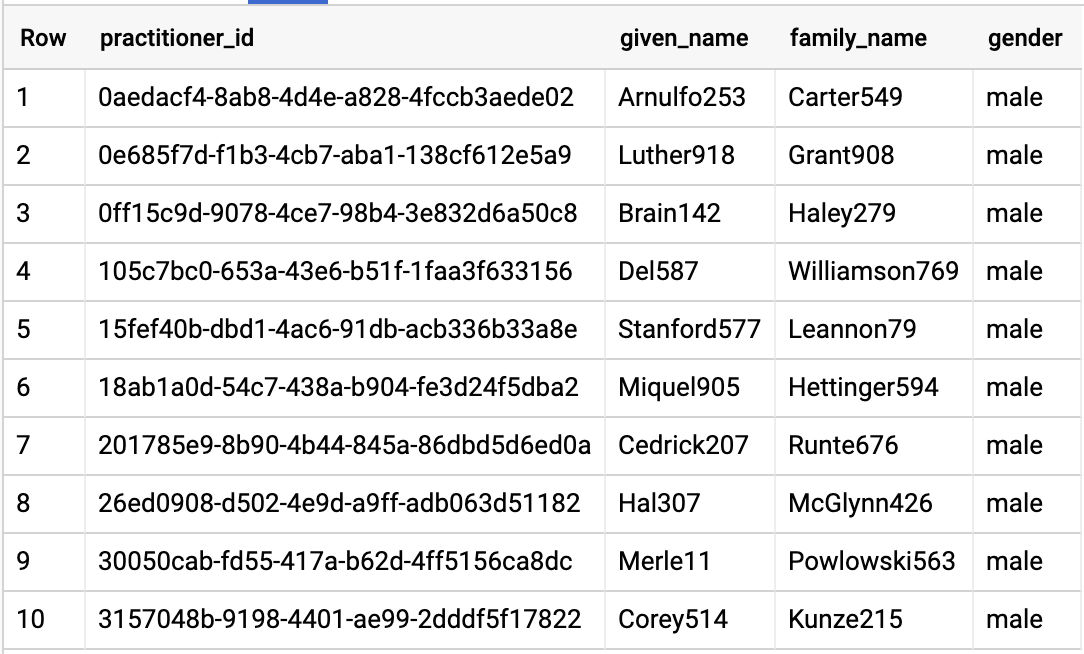
クエリの構成
データセットと一致するように組織 ID を変更します。
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
クエリ結果:

患者別のクエリ件数
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
クエリ結果:
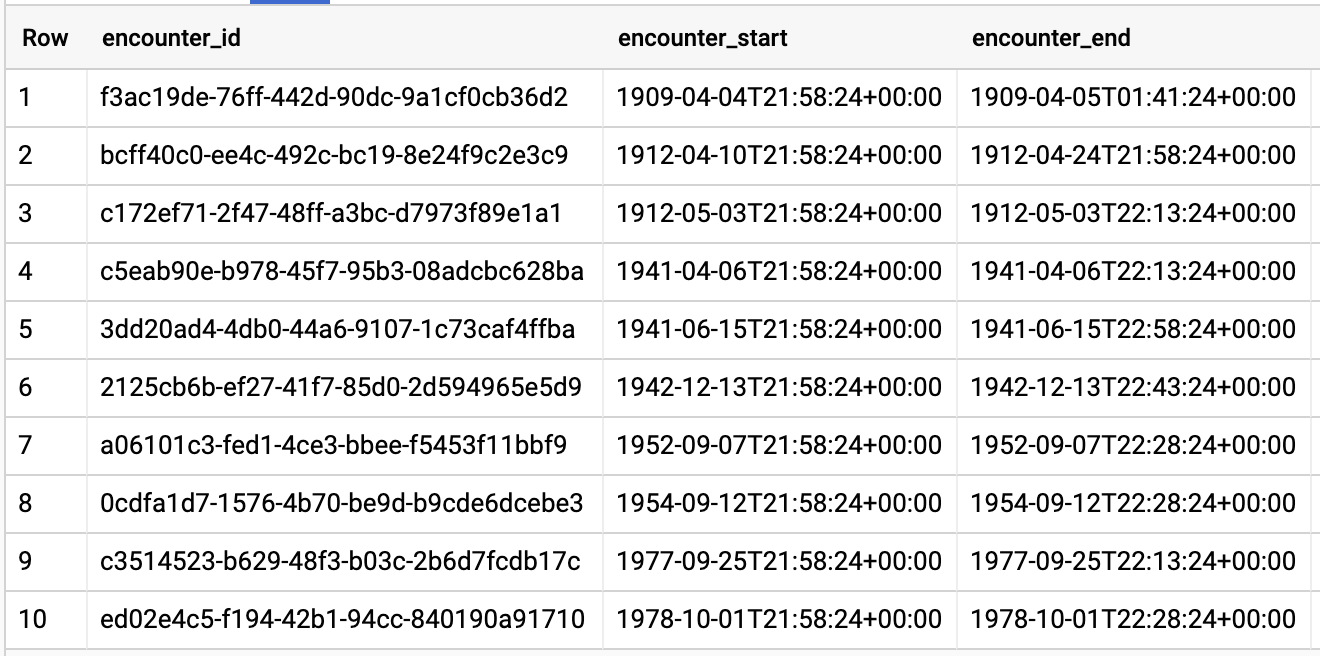
検出数のタイプ別の平均検出数を取得
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
クエリ結果:
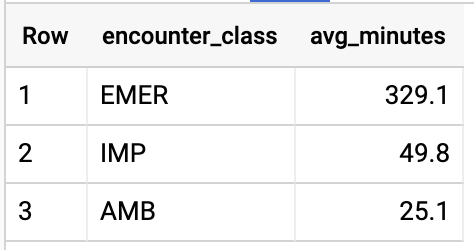
A1C 率が 6.5 以上の患者をすべて対象
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
クエリ結果:

4. AI Platform Notebooks インスタンスを作成する
こちらのリンクの手順に沿って、新しい AI Platform Notebooks(JupyterLab)インスタンスを作成します。
必ず Compute Engine API を有効にしてください。
「デフォルトのオプションで新しいノートブックを作成する」または新しいノートブックを作成し、オプションを指定する」というメッセージが表示されます。
5. データ分析ノートブックを作成する
AI Platform Notebooks インスタンスを開く
このセクションでは、新しい Jupyter ノートブックをゼロから作成してコーディングします。
- Google Cloud Platform コンソールの [AI Platform Notebooks] ページに移動して、ノートブック インスタンスを開きます。AI Platform の [ノートブック] ページに移動
- 開きたいインスタンスの [JupyterLab を開く] を選択します。
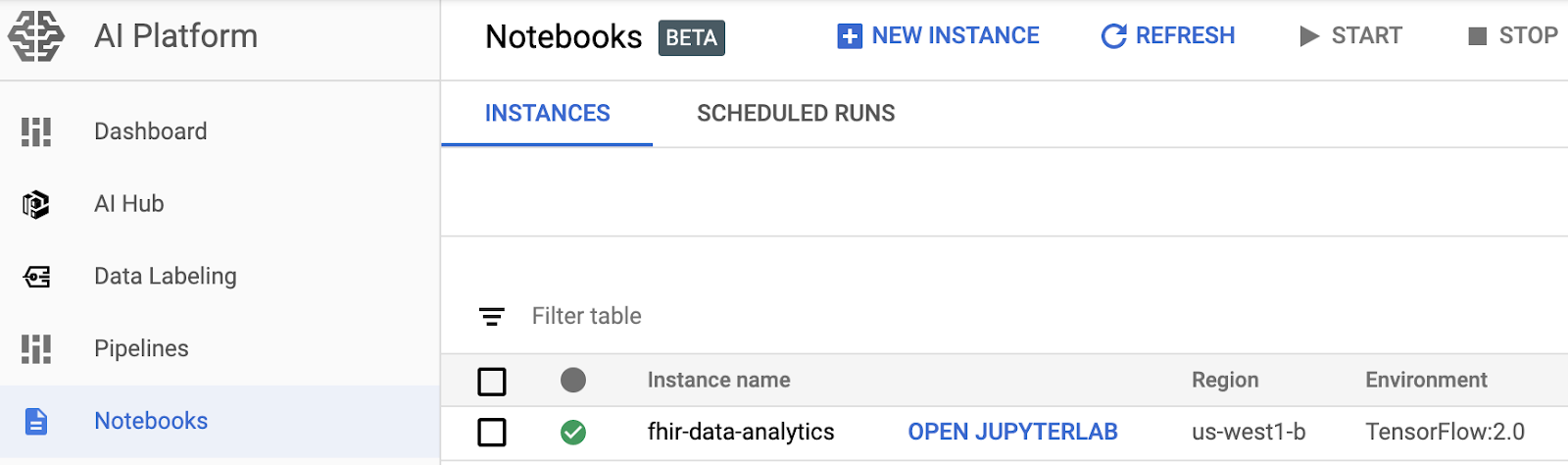
- AI Platform Notebooks により、ノートブック インスタンスの URL に自動的に移動します
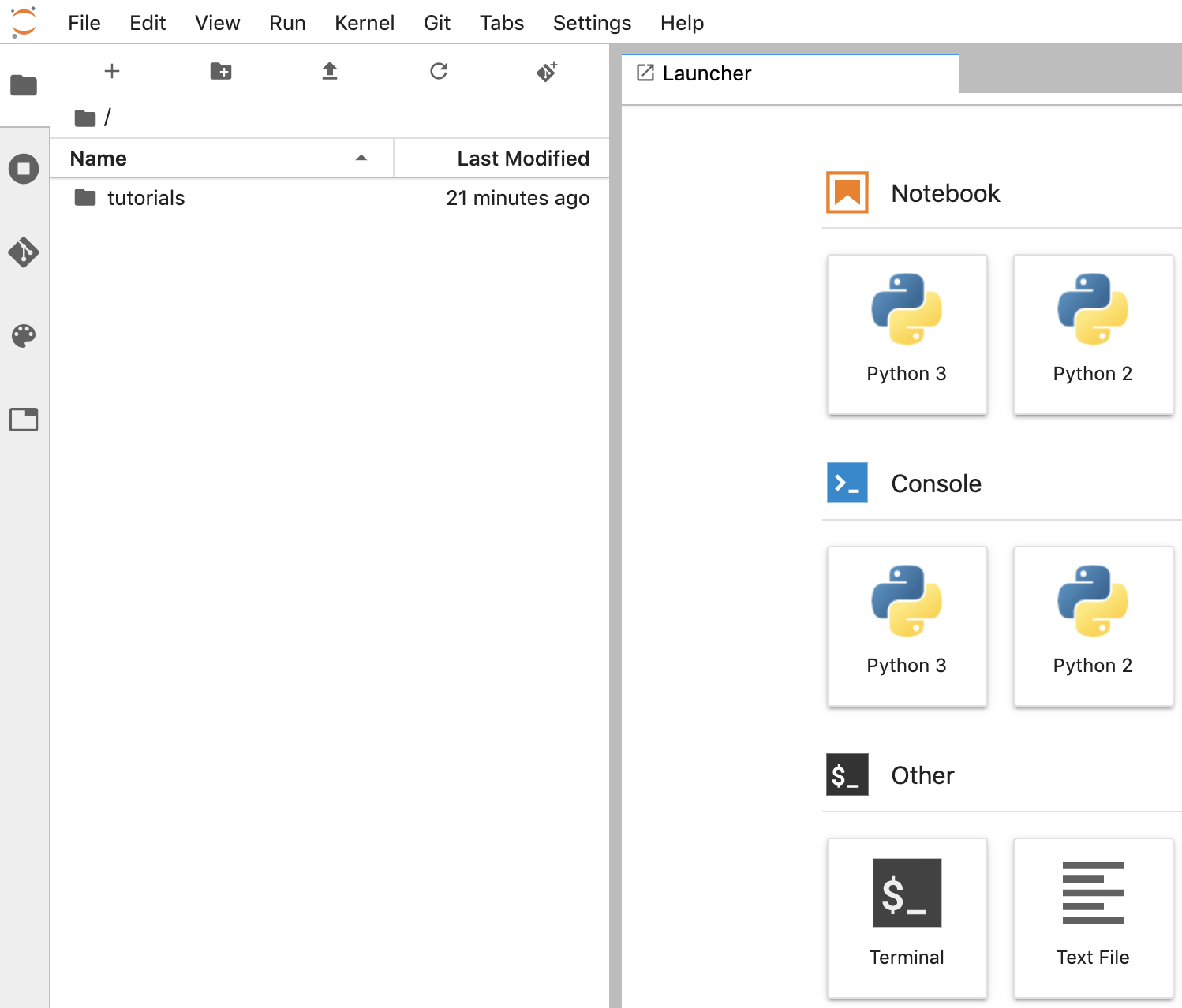
ノートブックを作成する
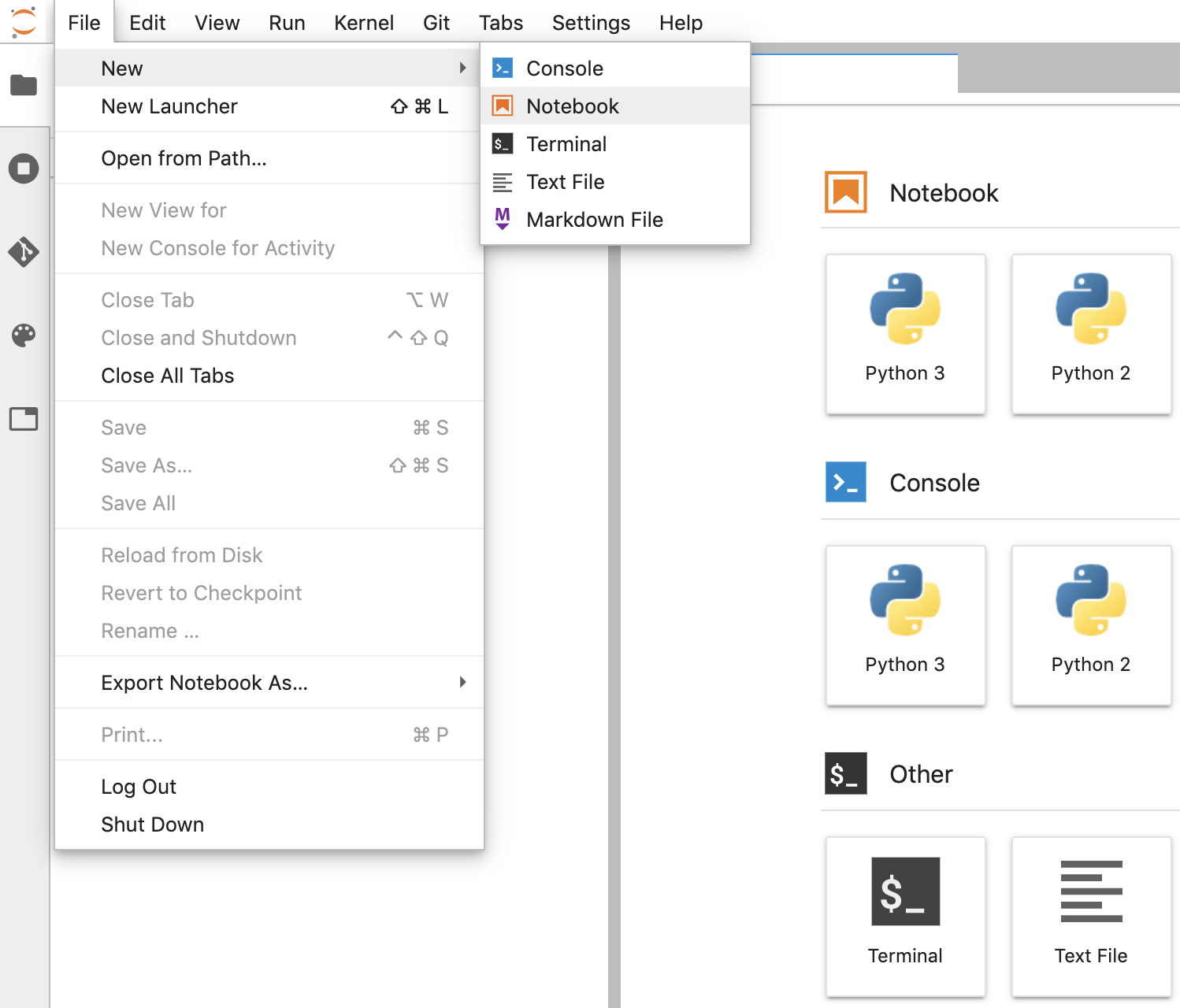
- JupyterLab で、[File] ->新規 ->Notebook」に移動し、カーネルとして [Python 3] を選択します。[Python 3]をクリックして、Untitled.ipynbnotebook を作成します。
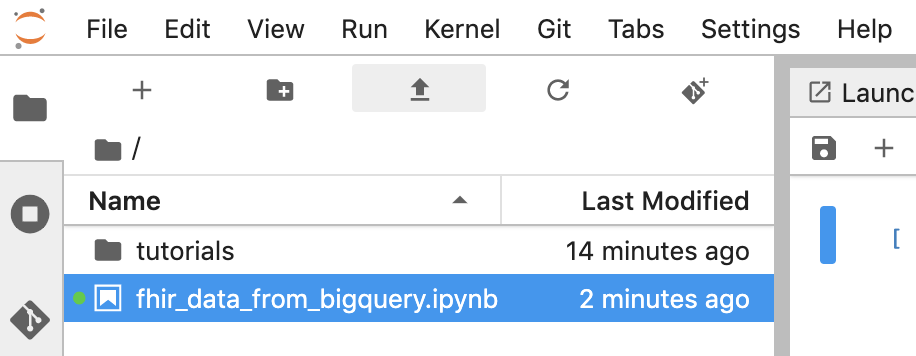
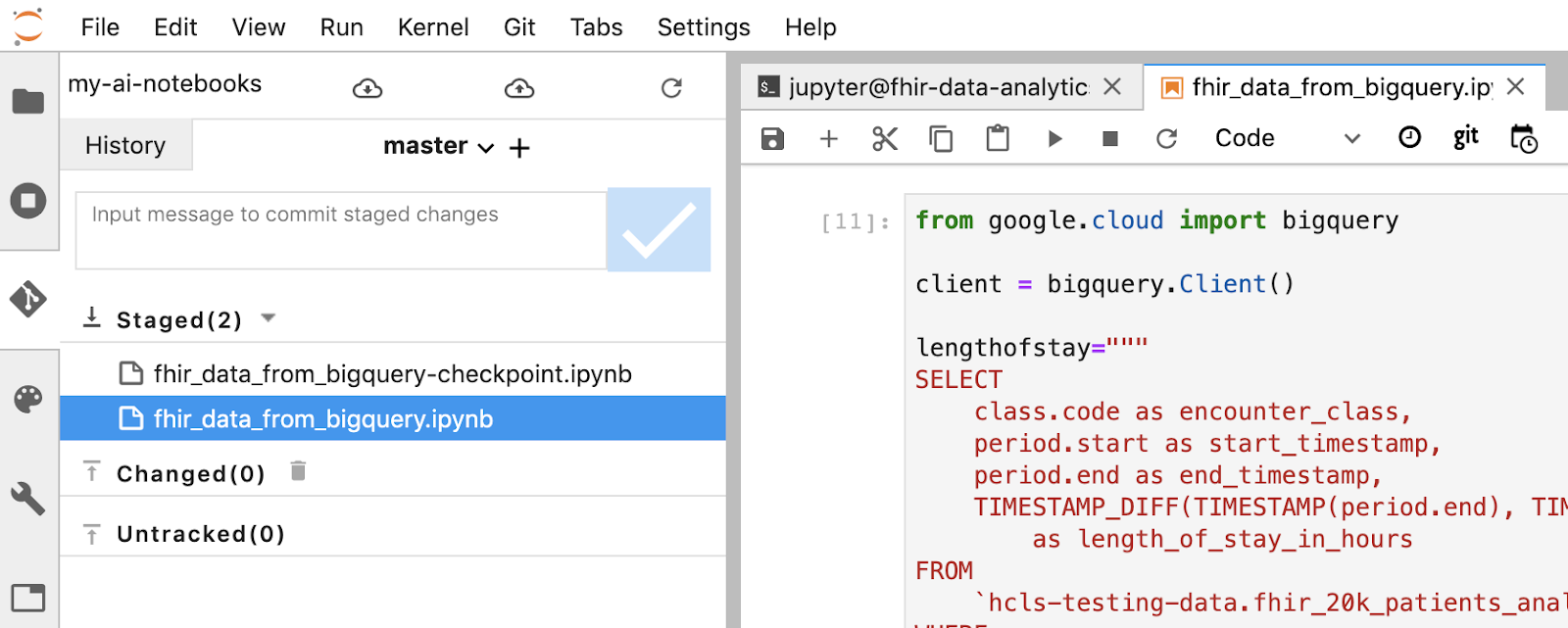
- [Untitled.ipynb] を右クリックし、ノートブックの名前を「fhir_data_from_bigquery.ipynb」に変更します。ダブルクリックして開き、クエリを作成してノートブックを保存します。
- ノートブックをダウンロードするには、*.ipynb ファイルを右クリックし、メニューから [ダウンロード] を選択します。

- [上矢印] をクリックして、既存のノートブックをアップロードすることもできます。] ボタンを離します。
ノートブックで各コードブロックをビルドして実行する
このセクションに記載されている各コードブロックを 1 つずつコピーして実行します。コードを実行するには、[Run] をクリックします。(三角形)。
面会の滞在日数を時間単位で取得できます
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
コードと実行の出力:
観察結果の取得 - コレステロール値
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
実行出力:

近似エンカウンタ分位数を取得する
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
実行出力:
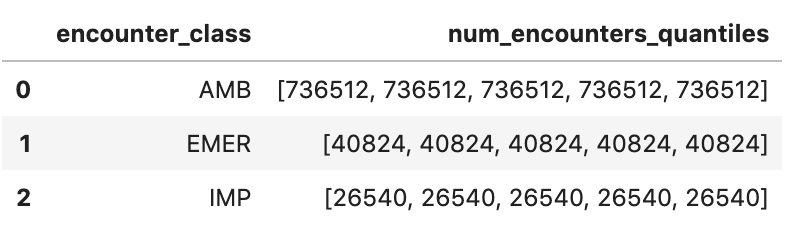
面談の平均時間を分単位で取得
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
実行出力:
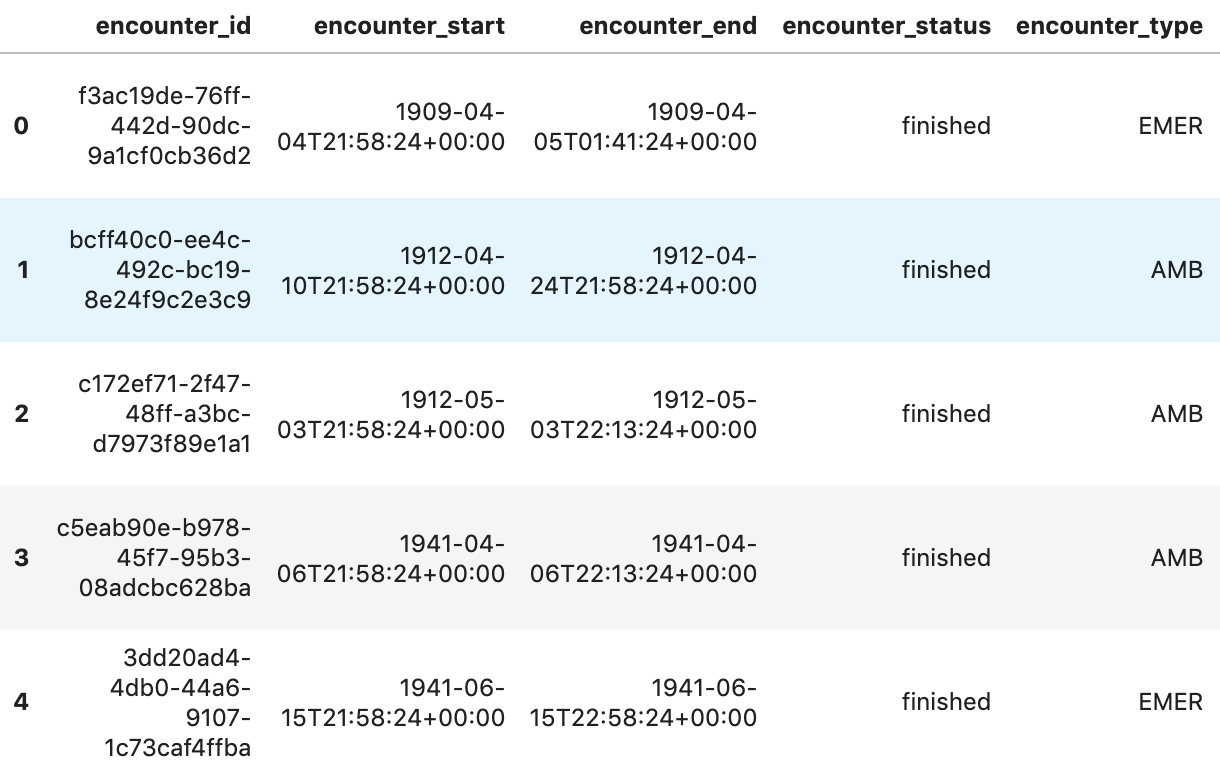
患者あたりの診察数を取得
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
実行出力:
組織を取得する
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
実行結果:

患者の取得
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
実行結果:

6. AI Platform Notebooks でチャートやグラフを作成する
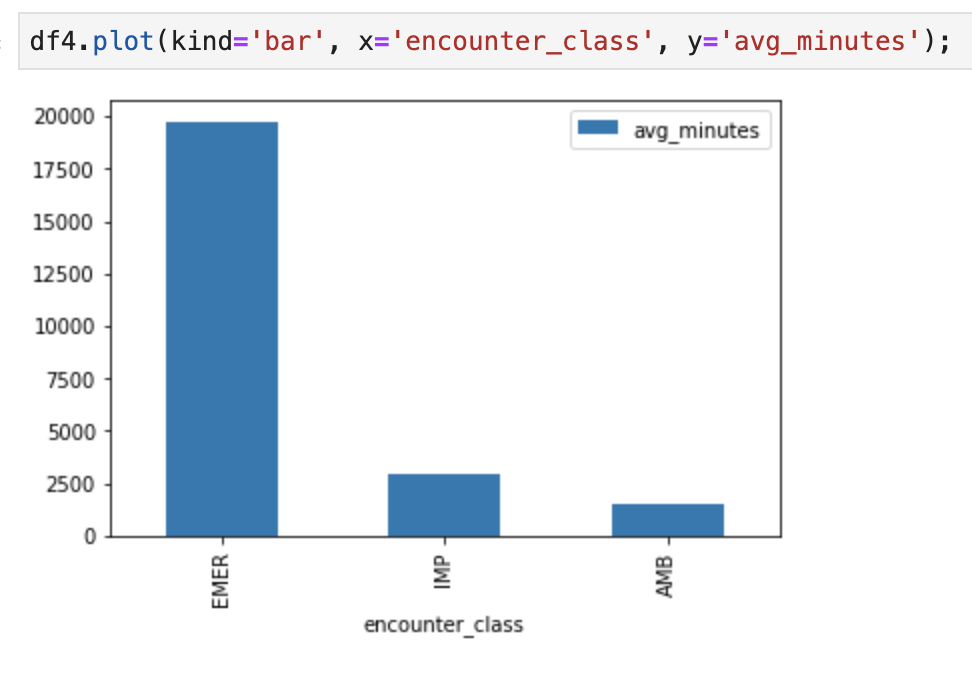
ノートブック「fhir_data_from_bigquery.ipynb」のコードセルを実行する棒グラフを描画します
たとえば、Encounters の平均時間を分単位で取得できます。
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
コードと実行の結果:
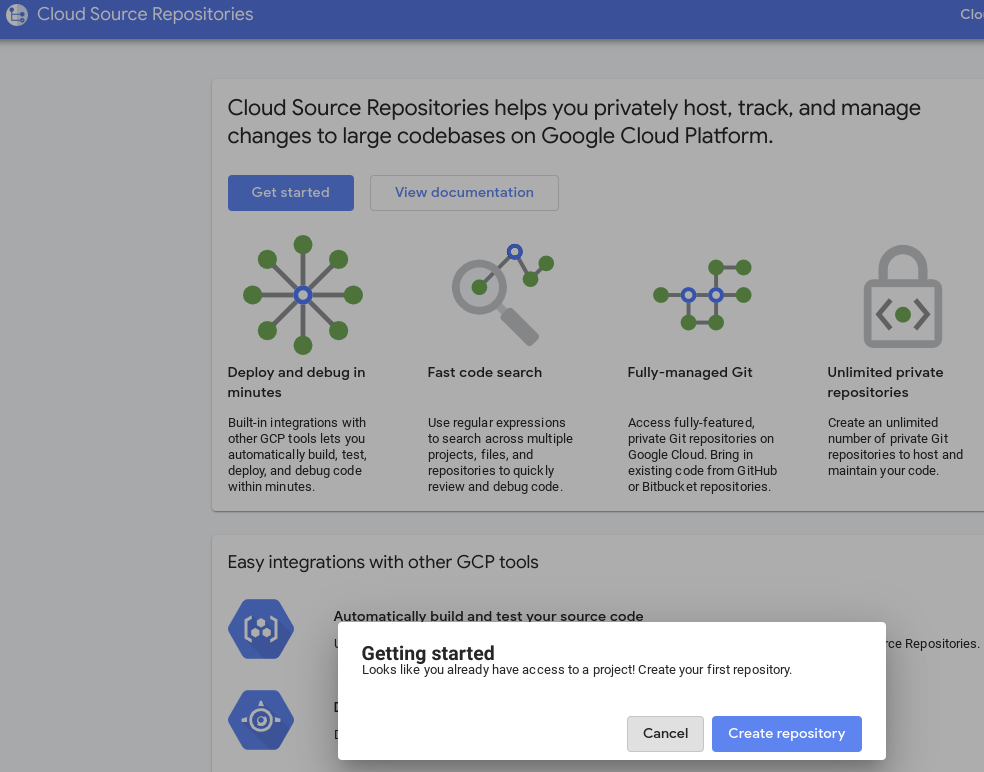
7. ノートブックを Cloud Source Repositories のリポジトリに commit
- GCP コンソールで、Source Repositories に移動します。初めて使用する場合は、[使ってみる] をクリックし、[リポジトリを作成] をクリックします。
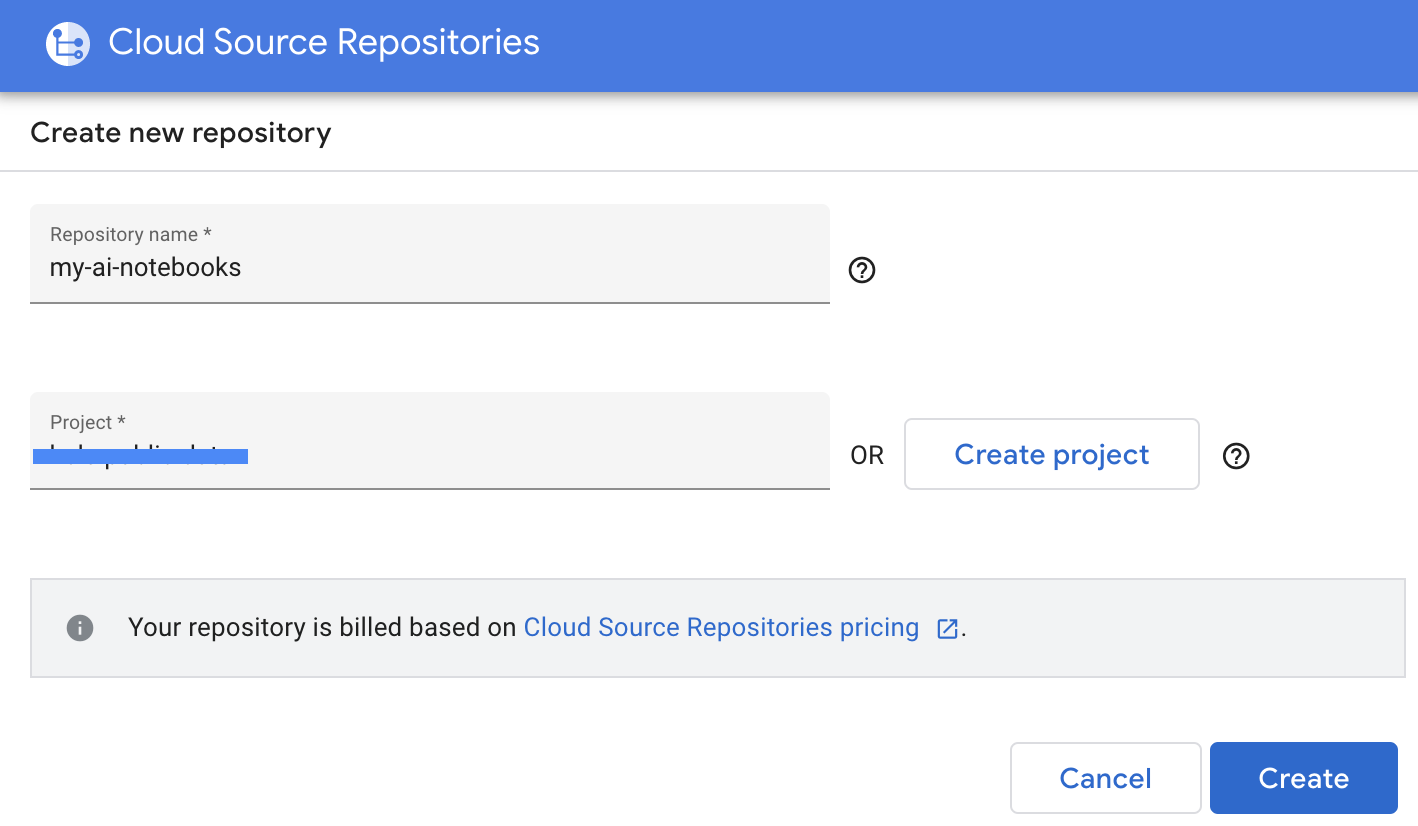
- 後日 GCP ->Cloud Source Repositories に移動し、[+ リポジトリを追加] をクリックして新しいリポジトリを作成します。

- [新しいリポジトリを作成] を選択し、[続行] をクリックします。
- リポジトリ名とプロジェクト名を指定して、[作成] をクリックします。
- [ローカル Git リポジトリにリポジトリのクローンを作成する] を選択し、[手動で生成した認証情報] を選択します。
- ステップ 1「Git 認証情報を生成して保存する」の手順を行います。(下記をご覧ください)。画面に表示されるスクリプトをコピーします。
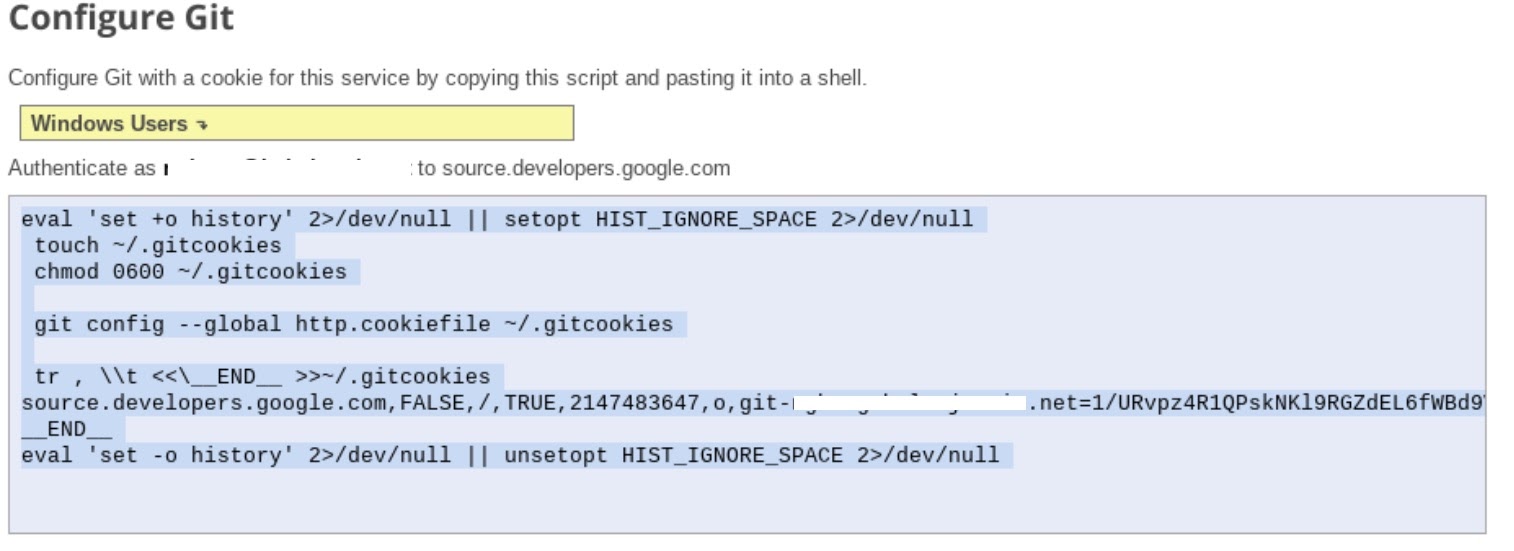
- Jupyter でターミナル セッションを開始します。
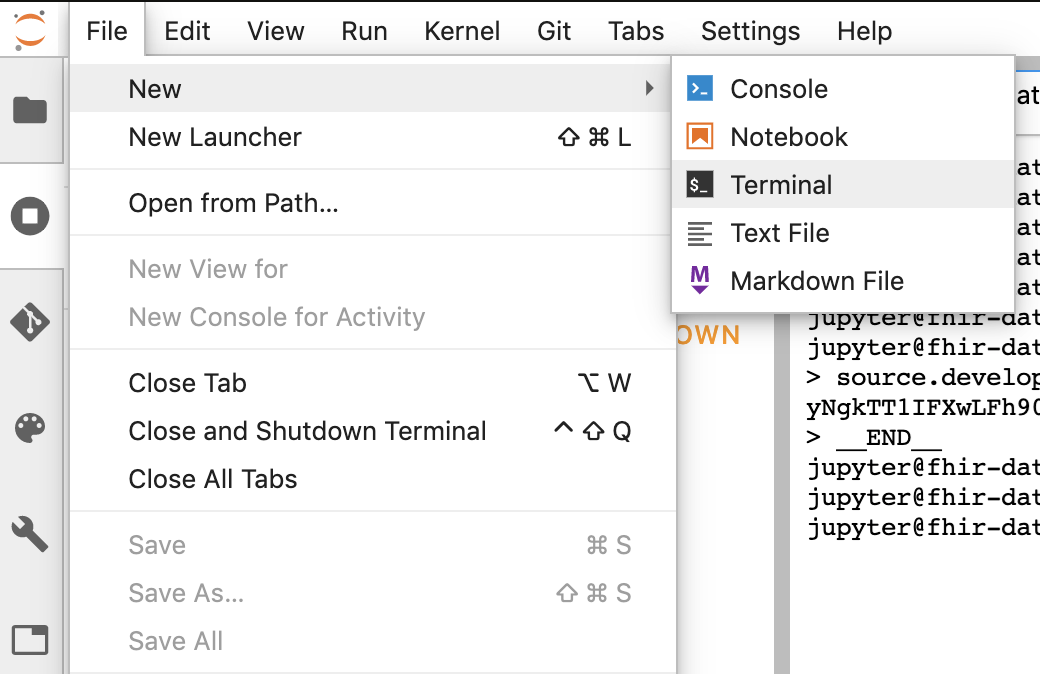
- 「Configure Git」からすべてのコマンドを貼り付けます。Jupyter ターミナルに移動します。
- GCP Cloud ソース リポジトリからリポジトリのクローンパスをコピーします(以下のスクリーンショットの手順 2)。
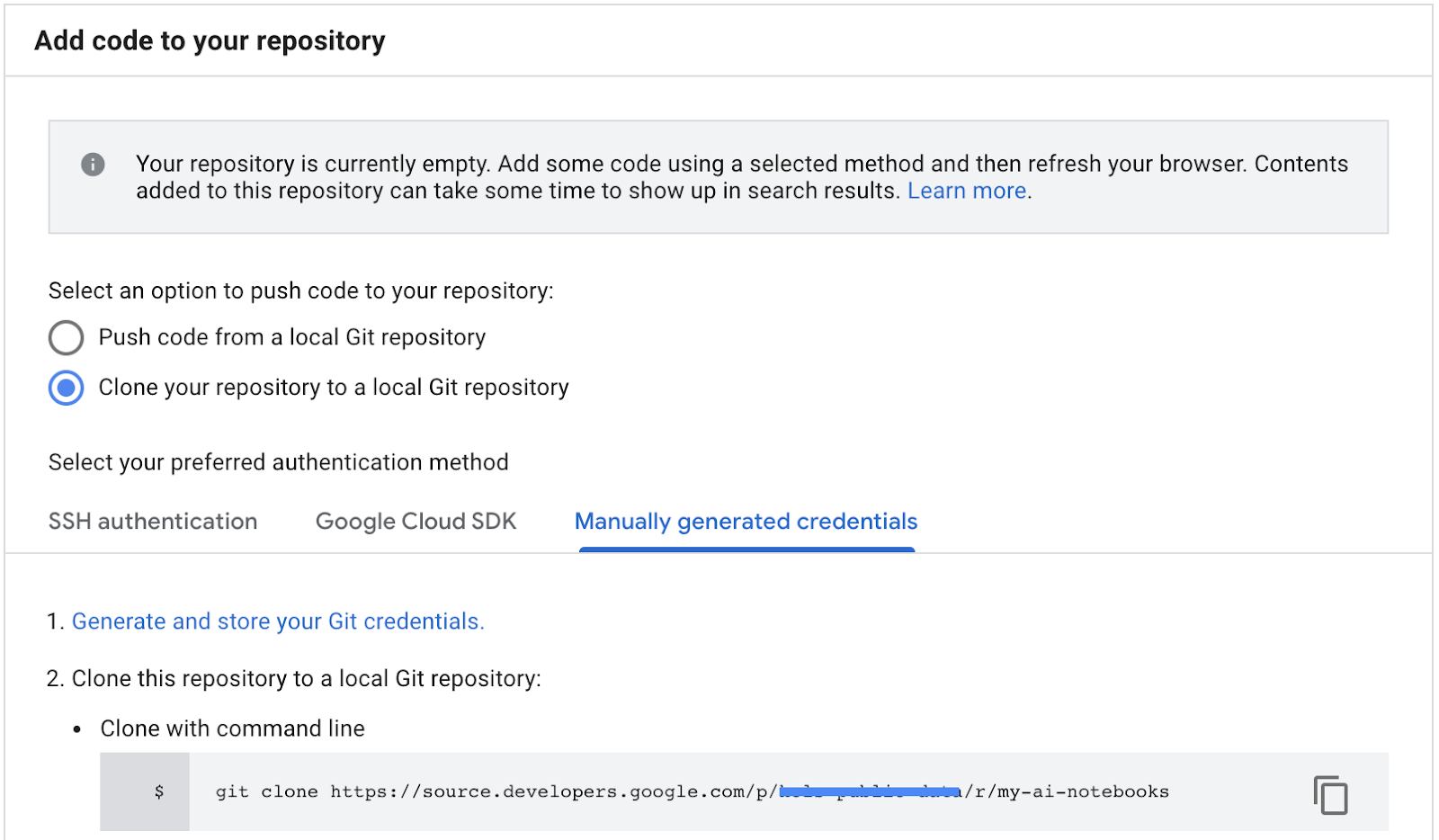
- このコマンドを JupiterLab ターミナルに貼り付けます。コマンドは次のようになります。
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- 「my-ai-notebooks」は、フォルダが作成されます。
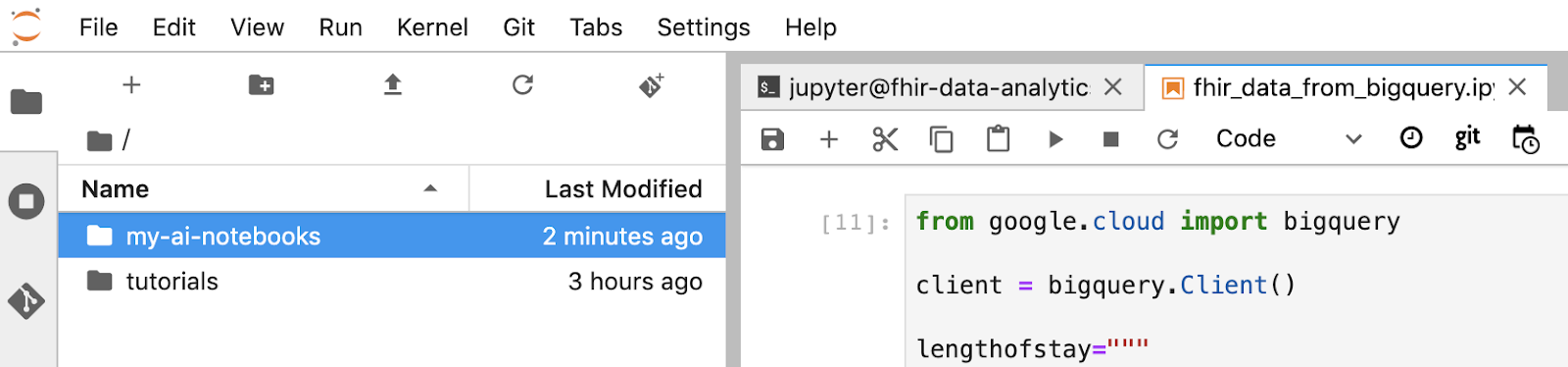
- ノートブック(fhir_data_from_bigquery.ipynb)をフォルダ「my-ai-notebooks」に移動します。
- Jupyter ターミナルでディレクトリを「cd my-ai-notebooks」に変更します。
- Jupyter ターミナルを使用して変更をステージングします。Jupyter UI を使用することもできます。[Untracked] 領域でファイルを右クリックし、[Track] を選択してからファイルが追跡領域に移動されます。逆も同様です。変更された領域に変更されたファイルを含む)。
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- Jupyter ターミナルまたは Jupyter UI を使用して変更を commit します(メッセージを入力し、[オン] ボタンをクリックします)。
git commit -m "message goes here"
- Jupyter ターミナルまたは Jupyter UI を使用して(「commit された変更を push」アイコン
 をクリック)して、リモート リポジトリに変更を push します。
をクリック)して、リモート リポジトリに変更を push します。
git push --all
- GCP コンソールで、Source Repositories に移動します。[my-ai-notebooks] をクリックします。「fhir_data_from_bigquery.ipynb」GCP Source Repository に保存されます

8. クリーンアップ
この Codelab で使用したリソースについて、Google Cloud Platform アカウントに課金されないようにするには、チュートリアルの完了後に GCP で作成したリソースをクリーンアップして、今後料金が発生しないようにします。次のセクションで、このようなリソースを削除または無効にする方法を説明します。
BigQuery データセットの削除
手順に沿って、このチュートリアルで作成した BigQuery データセットを削除します。テスト データセット fhir_20k_patients_analytics を使用した場合は、BigQuery コンソールに移動してプロジェクト hcls-testing-data の固定を解除します。
AI Platform Notebooks インスタンスをシャットダウンする
ノートブック インスタンスをシャットダウンする |AI Platform Notebooks を使用して、AI Platform Notebooks インスタンスをシャットダウンします。
プロジェクトの削除
課金を停止する最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには、次の操作を行います。
- GCP Console でプロジェクト ページに移動します。プロジェクト ページに移動
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
9. 完了
これで、BigQuery と AI Platform Notebooks を使用して FHIR 形式の医療データにアクセスする、クエリ、分析するための Codelab は終了です。
ここでは、GCP で BigQuery の一般公開データセットにアクセスしました。
ここでは、BigQuery UI を使用して SQL クエリを開発し、テストしました。
AI Platform Notebooks インスタンスを作成して起動しました。
JupyterLab で SQL クエリを実行し、クエリ結果を Pandas DataFrame に保存しました。
Matplotlib を使用してチャートやグラフを作成しました。
ノートブックを GCP の Cloud Source Repositories に commit して push しました。
ここでは、Google Cloud Platform で BigQuery と AI Platform Notebooks を使用して医療データ分析を開始するために必要な主な手順を学習しました。
©Google, Inc. or its affiliates. All rights reserved. Do not distribute.