
1. 소개
최종 업데이트: 2022년 9월 22일
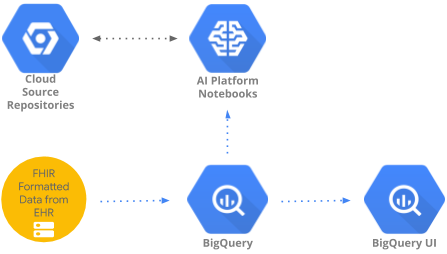
이 Codelab에서는 BigQueryUI 및 AI Platform Notebooks를 사용해 BigQuery에서 집계된 의료 데이터에 액세스하고 분석하는 패턴을 구현합니다. HIPPA 호환 AI Platform Notebooks에서 Pandas, Matplotlib 등 익숙한 도구를 사용하여 대규모 의료 데이터 세트의 데이터 탐색을 보여줍니다. 비결 BigQuery에서 집계의 첫 번째 부분을 수행하고 Pandas 데이터 세트를 다시 가져온 다음 로컬에서 더 작은 Pandas 데이터 세트를 사용하는 것입니다. AI Platform Notebooks는 관리형 Jupyter 환경을 제공하므로 직접 노트북 서버를 실행할 필요가 없습니다. AI Platform Notebooks는 BigQuery 및 Cloud Storage와 같은 다른 GCP 서비스와 원활하게 통합되어 Google Cloud Platform에서 데이터 분석 및 ML 여정을 쉽고 빠르게 시작할 수 있습니다.
이 Codelab에서 학습할 내용은 다음과 같습니다.
- BigQuery UI를 사용하여 SQL 쿼리를 개발하고 테스트합니다.
- GCP에서 AI Platform Notebooks 인스턴스를 만들고 실행합니다.
- 노트북에서 SQL 쿼리를 실행하고 쿼리 결과를 Pandas DataFrame에 저장합니다.
- Matplotlib.
- 노트북을 커밋하고 GCP의 Cloud Source Repository에 푸시합니다.
이 Codelab을 실행하려면 무엇이 필요한가요?
- GCP 프로젝트에 액세스해야 합니다.
- GCP 프로젝트의 소유자 역할을 할당받아야 합니다.
- BigQuery에 의료 데이터 세트가 필요합니다.
GCP 프로젝트가 없으면 이 단계에 따라 새 GCP 프로젝트를 만듭니다.
2. 프로젝트 설정
이 Codelab에서는 BigQuery의 기존 데이터 세트 (hcls-testing-data.fhir_20k_patients_analytics)를 사용합니다. 이 데이터 세트는 합성 의료 데이터로 자동 입력됩니다.
합성 데이터 세트 액세스 권한 얻기
- Cloud 콘솔에 로그인할 때 사용하는 이메일 주소에서 hcls-solutions-external+subscribe@google.com으로 가입을 요청하는 이메일을 전송합니다.
- 작업을 확인하는 방법에 대한 지침이 포함된 이메일이 전송됩니다.
- 옵션을 사용하여 이메일에 답장하고 그룹에 참여하세요.
 버튼을 클릭하지 마세요.
버튼을 클릭하지 마세요. - 확인 이메일을 받으면 Codelab의 다음 단계로 진행할 수 있습니다.
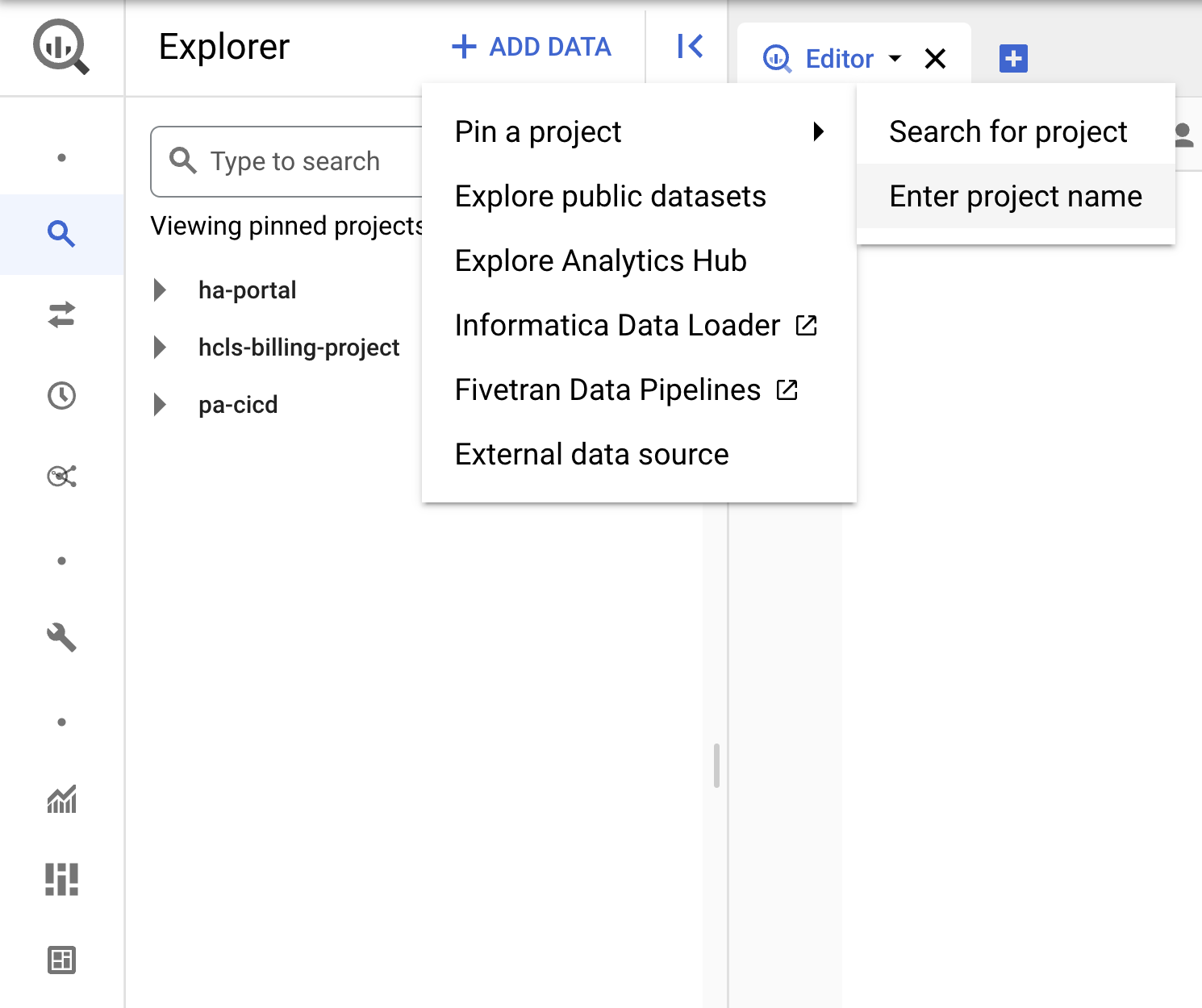
프로젝트 고정
- GCP 콘솔에서 프로젝트를 선택한 다음 BigQuery로 이동합니다.
- +데이터 추가 드롭다운을 클릭하고 '프로젝트 고정'을 선택합니다. > "프로젝트 이름 입력" 에서 자세한 내용을 확인하실 수 있습니다.
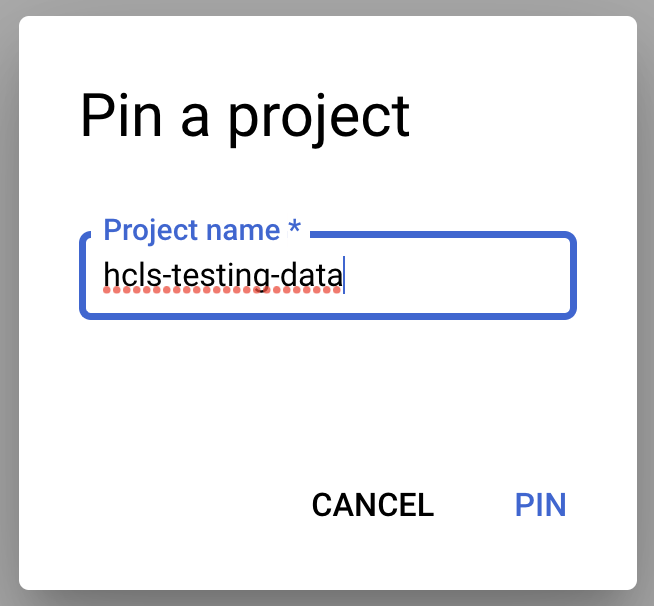
- 프로젝트 이름('hcls-testing-data')을 입력한 후 PIN을 클릭합니다. BigQuery 테스트 데이터 세트 'fhir_20k_patients_analytics' 사용할 수 있습니다
3. BigQuery UI를 사용하여 쿼리 개발
BigQuery UI 설정
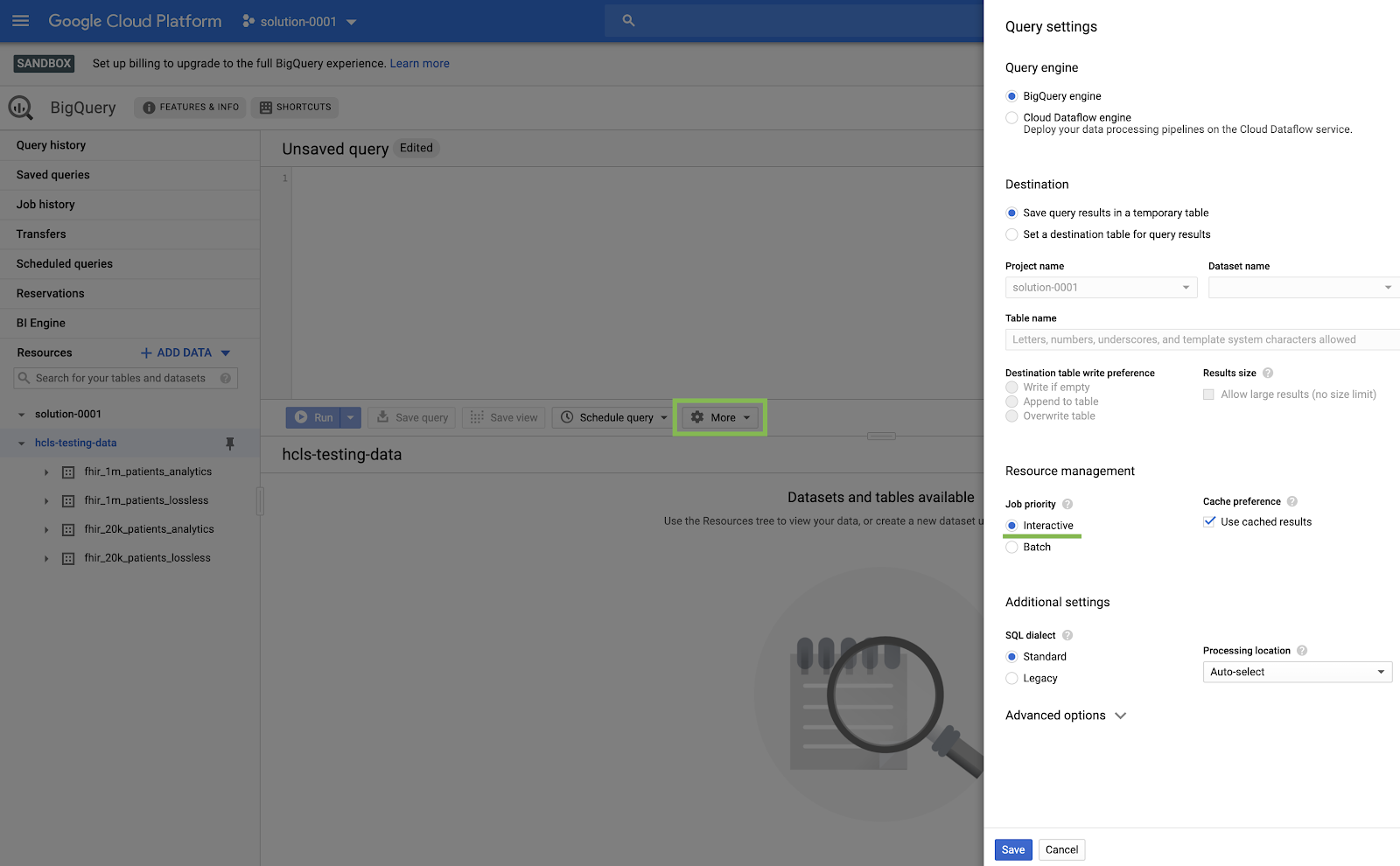
- 왼쪽 상단('햄버거') GCP 메뉴에서 BigQuery를 선택하여 BigQuery 콘솔로 이동합니다.
- BigQuery 콘솔에서 더보기 → 쿼리 설정을 클릭하고 Legacy SQL 메뉴가 선택되지 않았음 (표준 SQL을 사용함) 확인합니다.
쿼리 빌드
쿼리 편집기 창에 다음 쿼리를 입력하고 '실행'을 클릭하여 실행합니다. 그런 다음 '쿼리 결과' 창에서 결과를 확인합니다.
환자 쿼리
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
'쿼리 편집기'의 쿼리 및 결과:
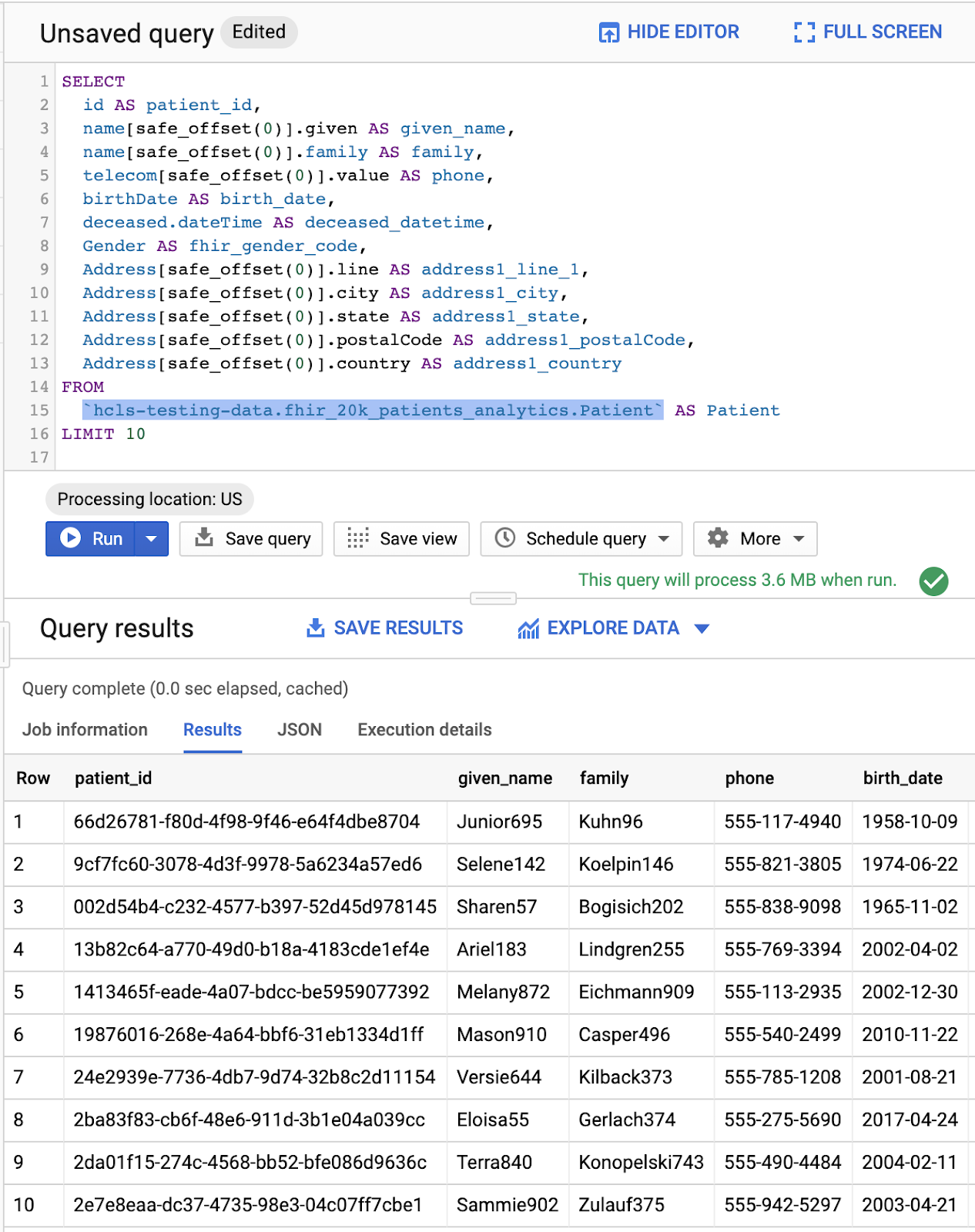
쿼리 실무자
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
쿼리 결과:
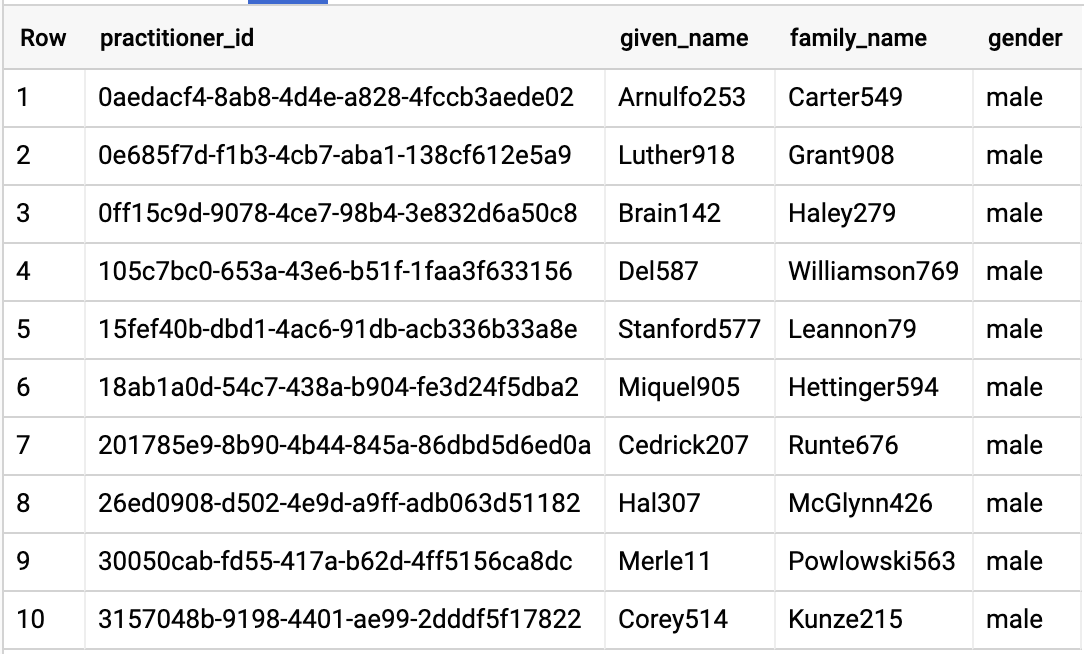
쿼리 조직
데이터 세트와 일치하도록 조직 ID를 변경하세요.
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
쿼리 결과:

환자별 쿼리 반응자
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
쿼리 결과:
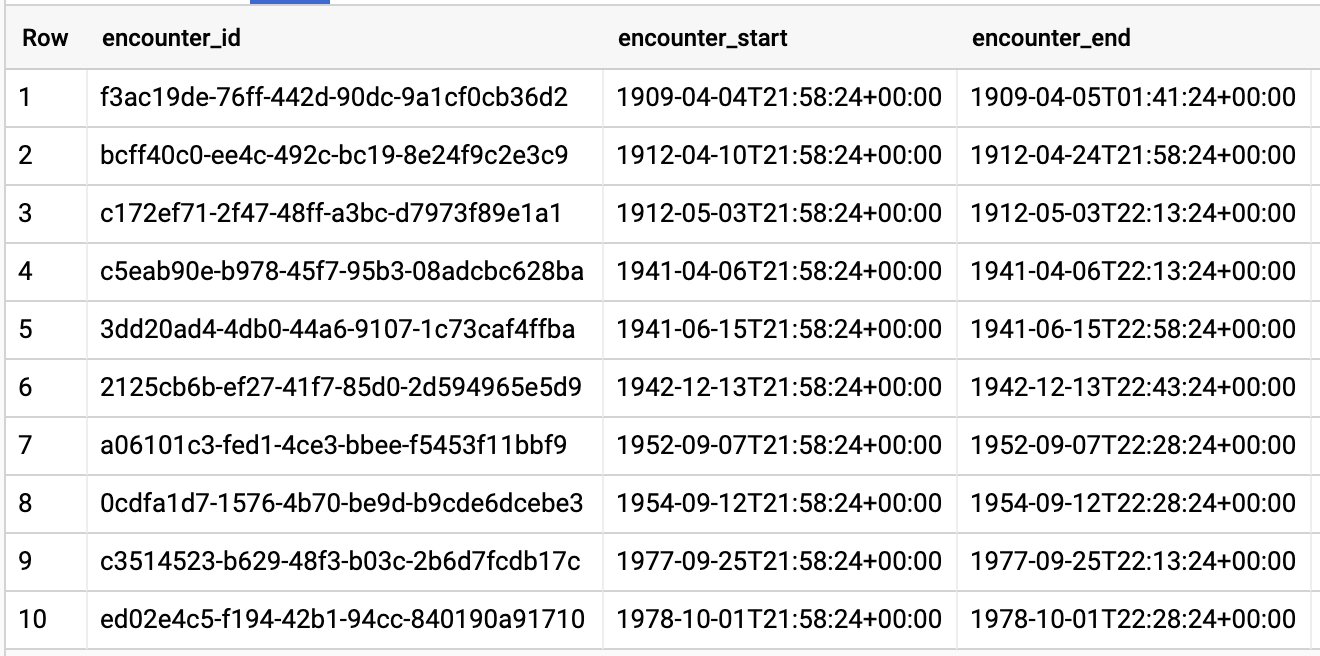
EnCOUNTer Type의 평균 길이 구하기
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
쿼리 결과:
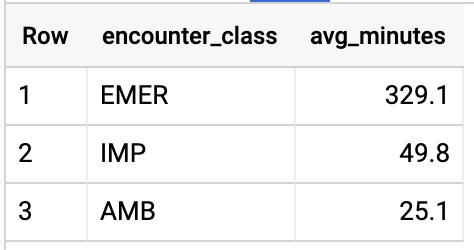
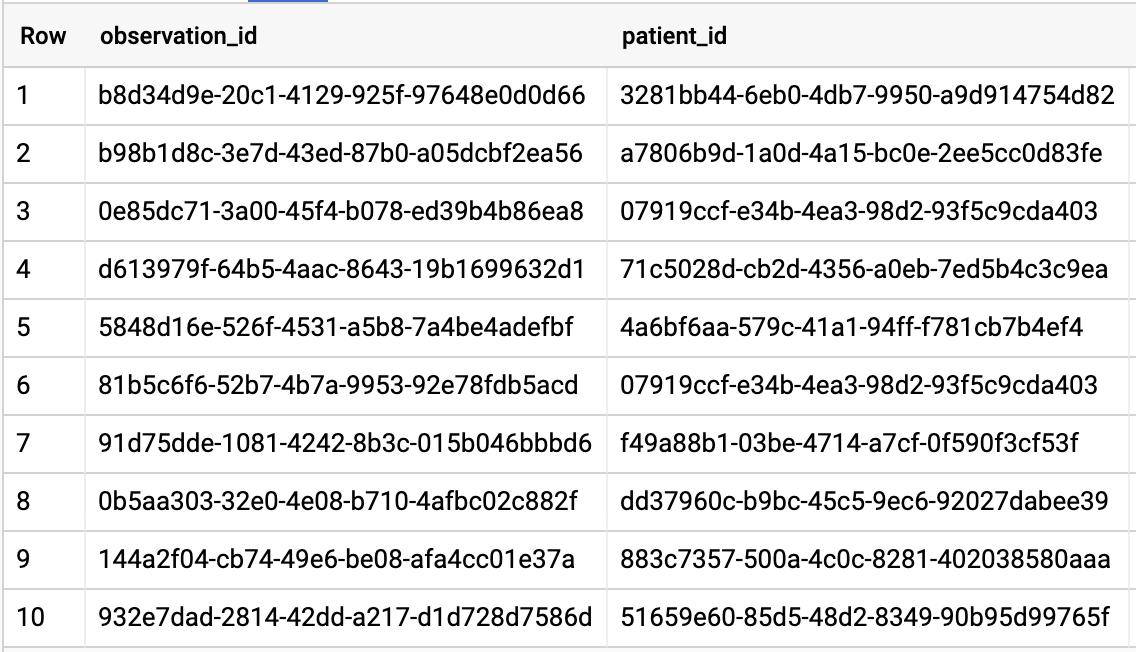
A1C 비율이 6.5 이상인 모든 환자 확인
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
쿼리 결과:
4. AI Platform Notebooks 인스턴스 만들기
이 링크의 안내에 따라 새 AI Platform Notebooks (JupyterLab) 인스턴스를 만듭니다.
Compute Engine API를 사용 설정해야 합니다.
' 기본 옵션으로 새 노트북 만들기" 또는 " 새 노트북을 만들고 옵션을 지정하세요."
5. 데이터 애널리틱스 노트북 빌드하기
AI Platform Notebooks 인스턴스 열기
이 섹션에서는 새 Jupyter 노트북을 처음부터 작성하고 코딩합니다.
- Google Cloud Platform Console의 AI Platform Notebooks 페이지로 이동하여 노트북 인스턴스를 엽니다. AI Platform Notebooks 페이지로 이동
- 열려는 인스턴스의 JupyterLab 열기를 선택합니다.
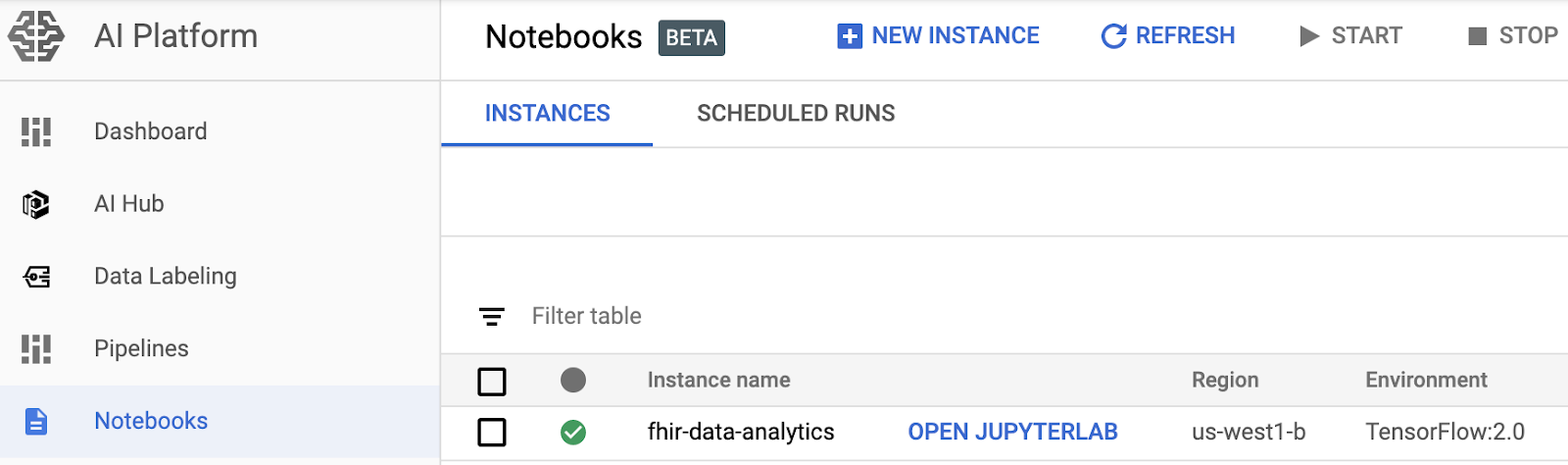
- AI Platform Notebooks가 메모장 인스턴스의 URL로 안내합니다.
노트북 만들기
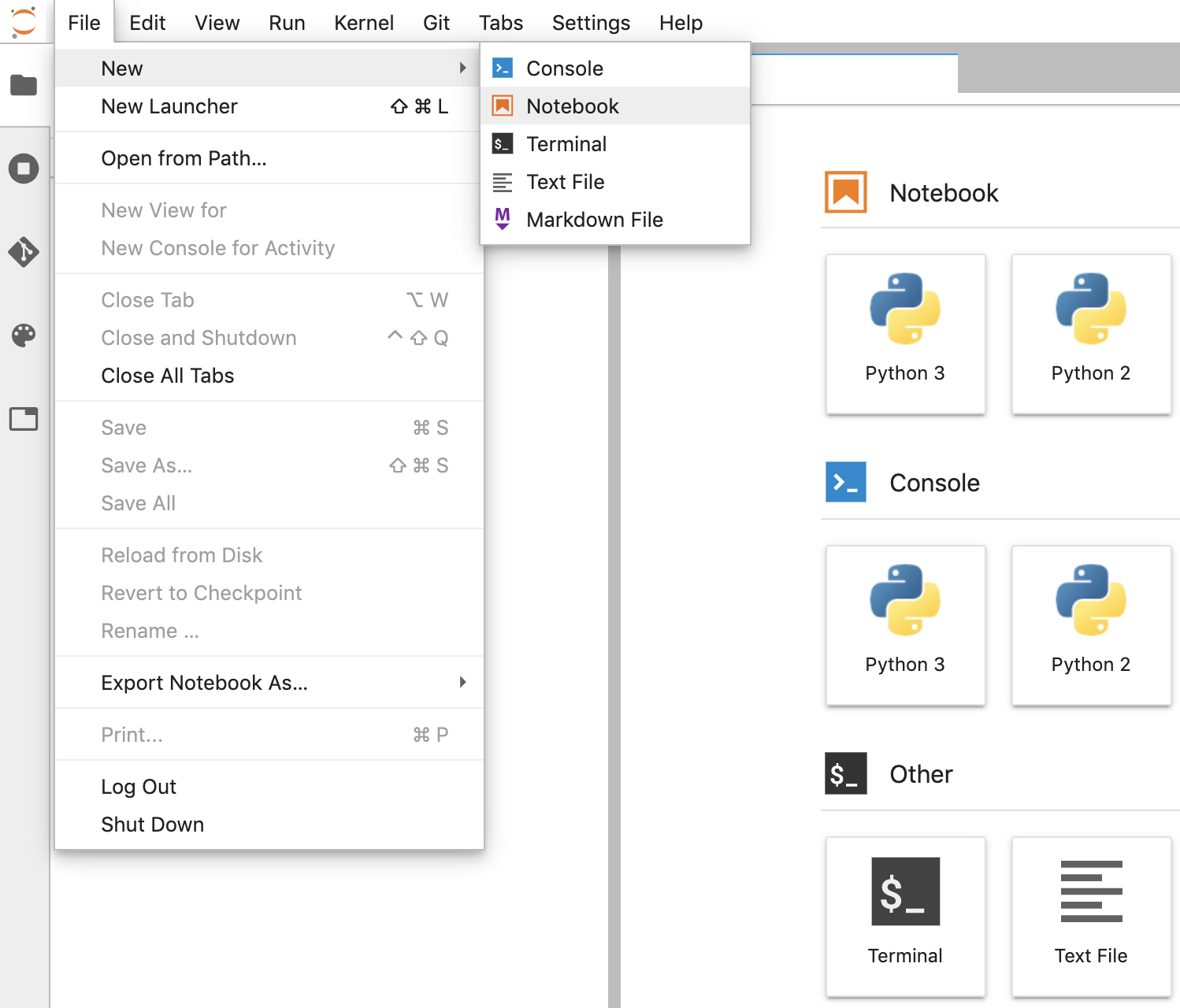
- JupyterLab에서 파일 -> 신규 -> 노트북을 클릭하고 커널 'Python 3'을 선택합니다. 'Python 3'을 선택하거나 런처 창의 노트북 섹션 아래에서 'Untitled.ipynbnotebook'을 만듭니다.
- Untitled.ipynb를 마우스 오른쪽 버튼으로 클릭하고 노트북 이름을 'fhir_data_from_bigquery.ipynb'로 변경합니다. 더블클릭하여 열고 쿼리를 빌드한 후 노트북을 저장합니다.
- *.ipynb 파일을 마우스 오른쪽 버튼으로 클릭하고 메뉴에서 다운로드를 선택하여 노트북을 다운로드할 수 있습니다.
- '위쪽 화살표'를 클릭하여 기존 노트북을 업로드할 수도 있습니다. 버튼을 클릭합니다.
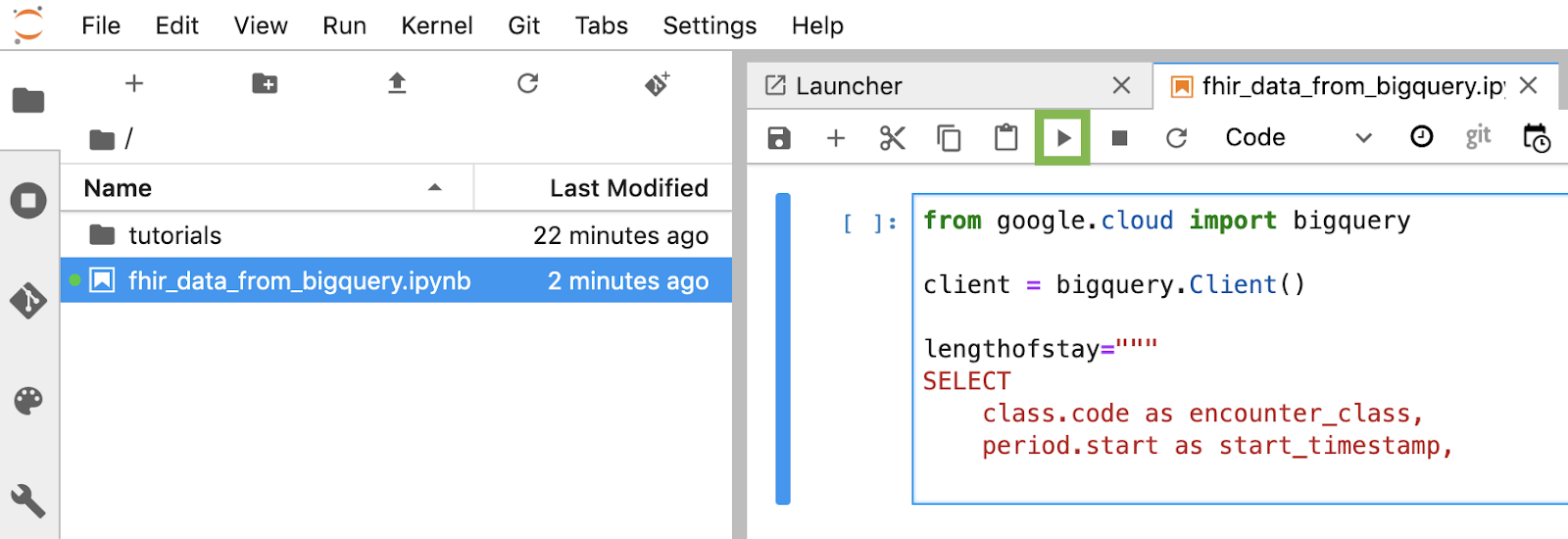
노트북의 각 코드 블록 빌드 및 실행
이 섹션에 제공된 각 코드 블록을 하나씩 복사하여 실행합니다. 코드를 실행하려면 'Run'을 클릭합니다. (삼각형).
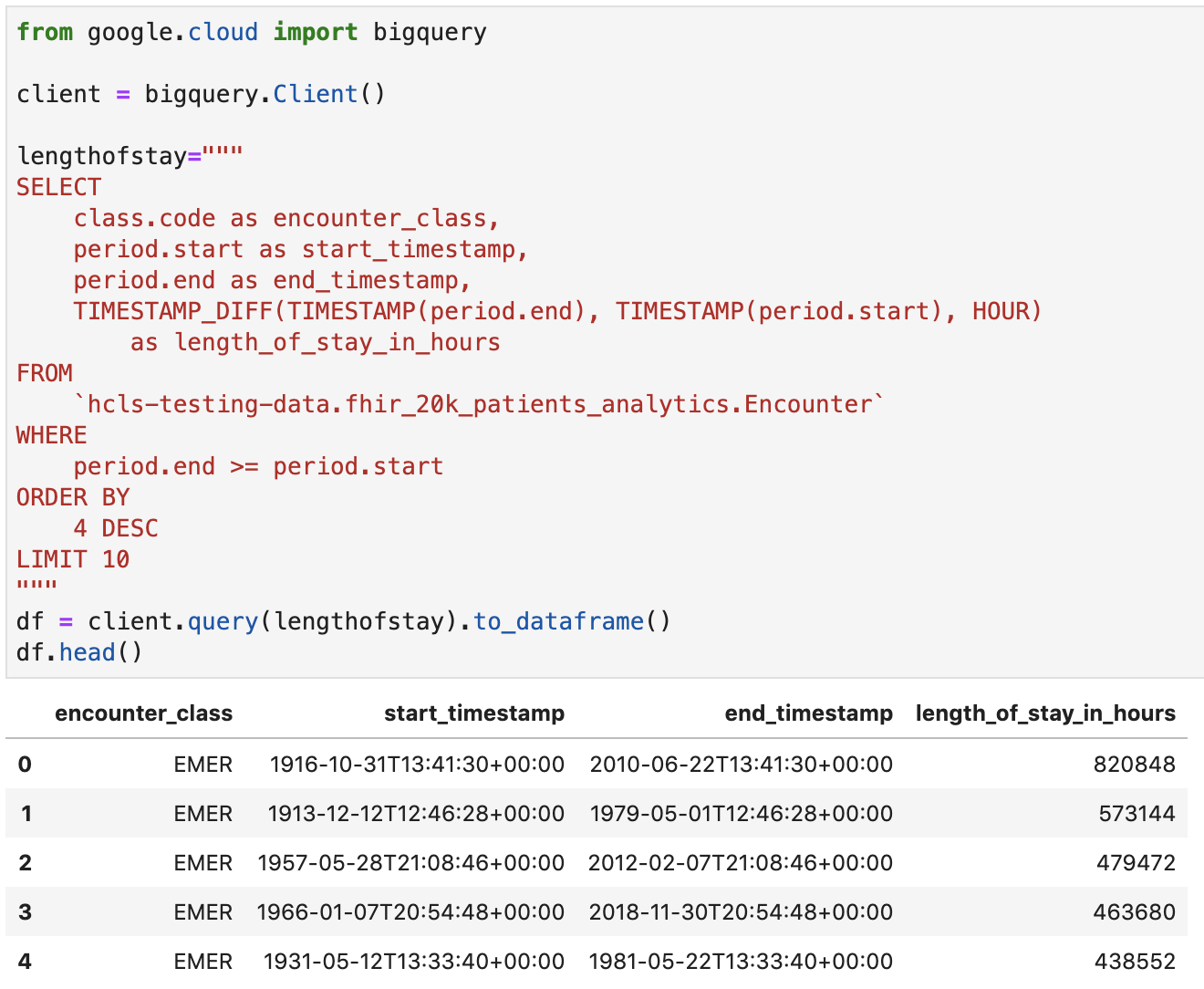
체류 기간 확인(단위: 시간)
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
코드 및 실행 출력:
관찰 결과 가져오기 - 콜레스테롤 값
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
실행 출력:

근사적인 만남 분위수 가져오기
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
실행 출력:
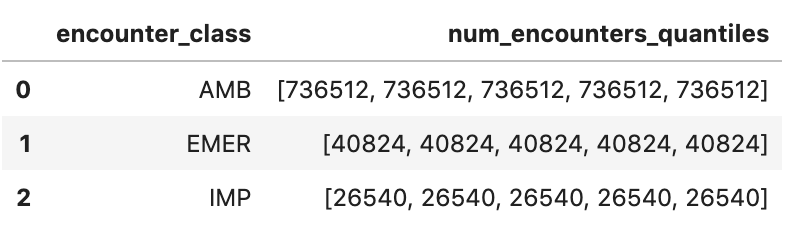
평균 만남 시간(분) 가져오기
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
실행 출력:
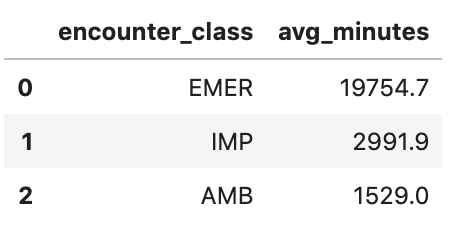
환자당 발생 횟수 확인
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
실행 출력:
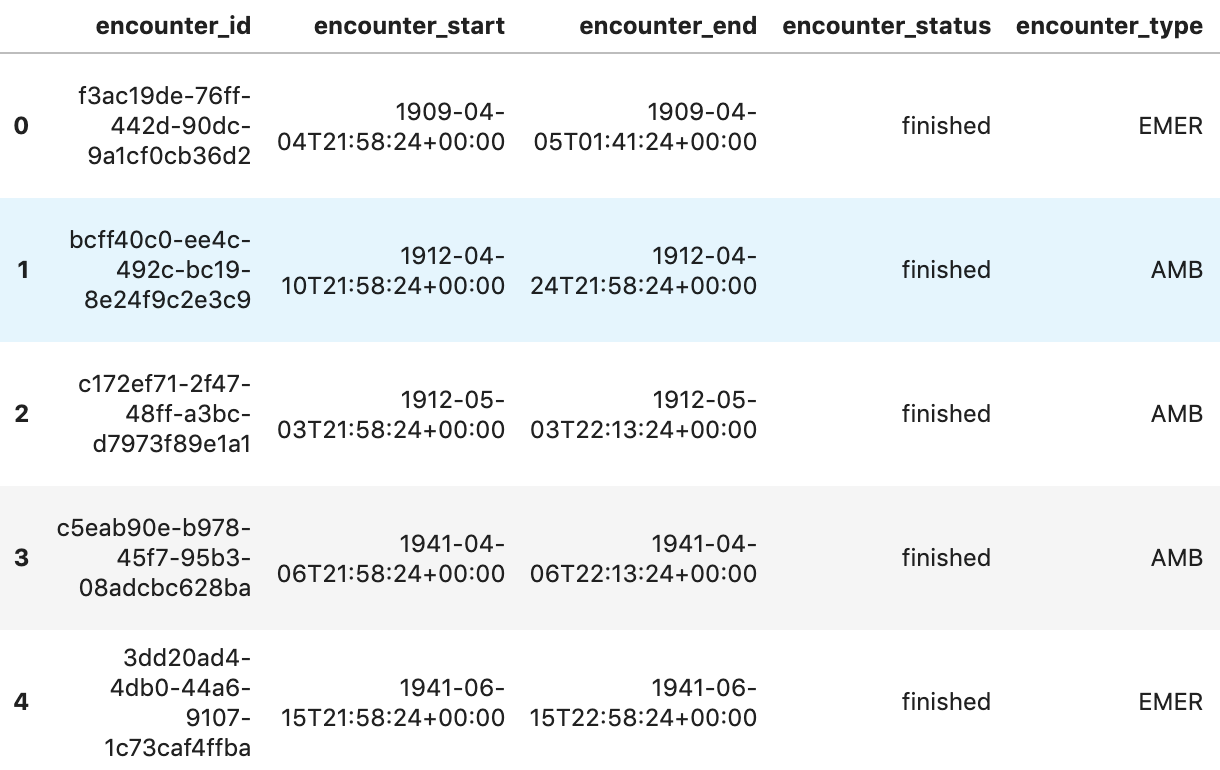
조직 가져오기
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
실행 결과:

환자 가져오기
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
실행 결과:
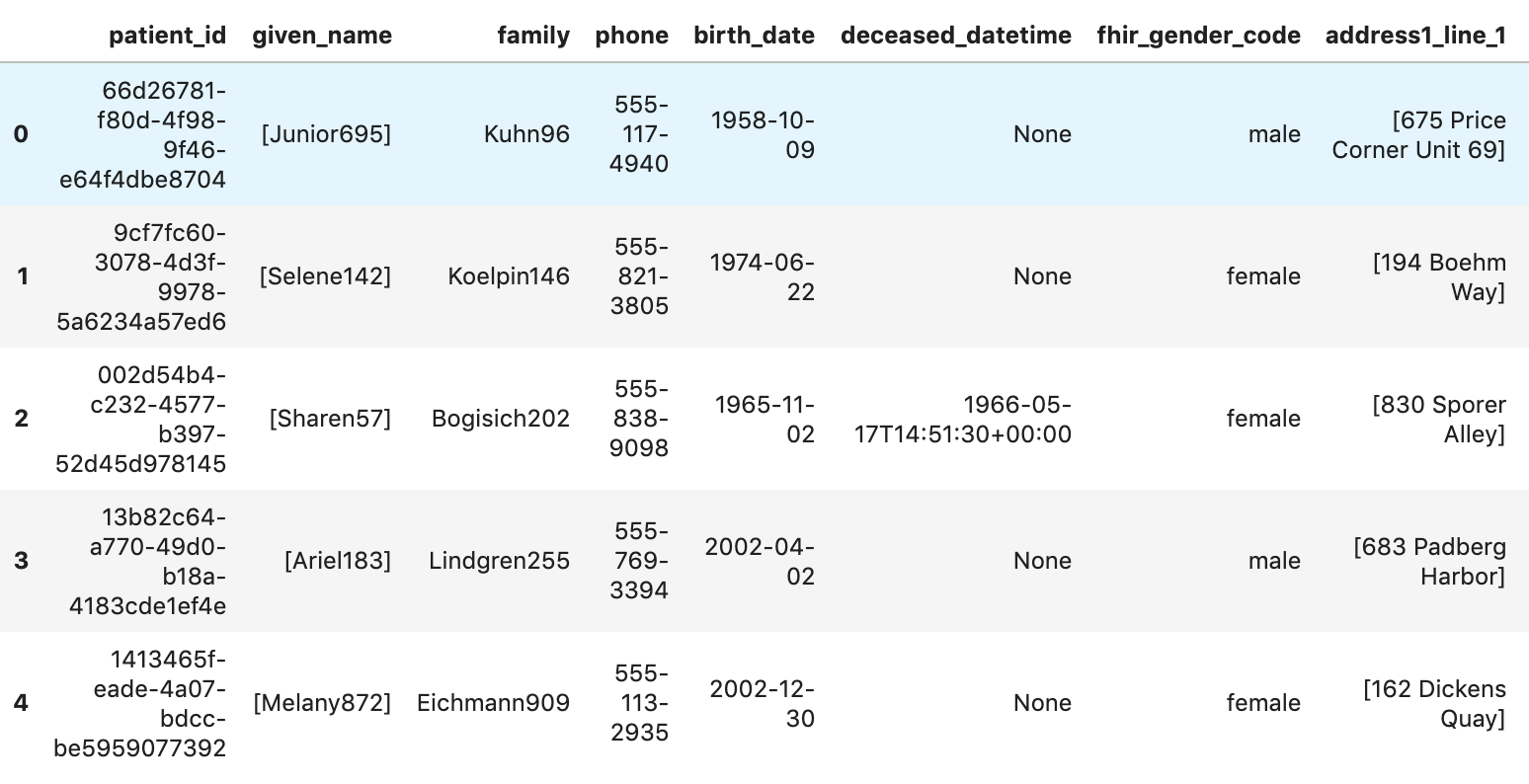
6. AI Platform Notebooks에서 차트 및 그래프 만들기
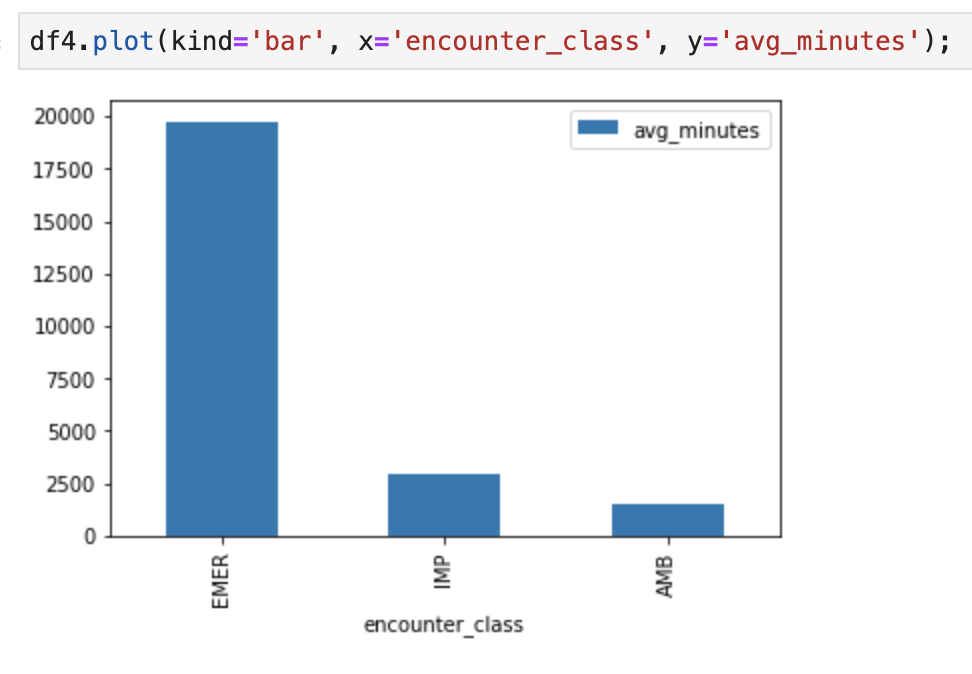
'fhir_data_from_bigquery.ipynb' 노트북에서 코드 셀 실행 막대 그래프를 그립니다.
예를 들어 인카운터 평균 시간을 분 단위로 확인할 수 있습니다.
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
코드 및 실행 결과:
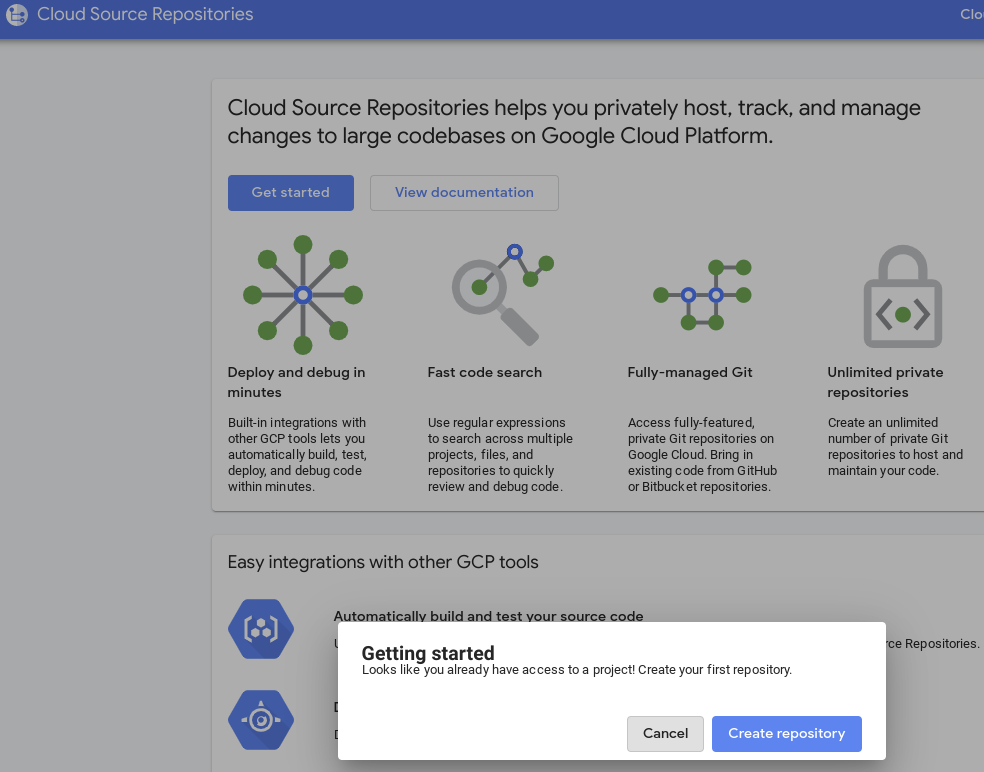
7. Cloud Source Repository에 노트북 커밋
- GCP 콘솔에서 소스 저장소로 이동합니다. 처음 사용하는 경우 '시작하기'를 클릭한 다음 '저장소 만들기'를 클릭합니다.
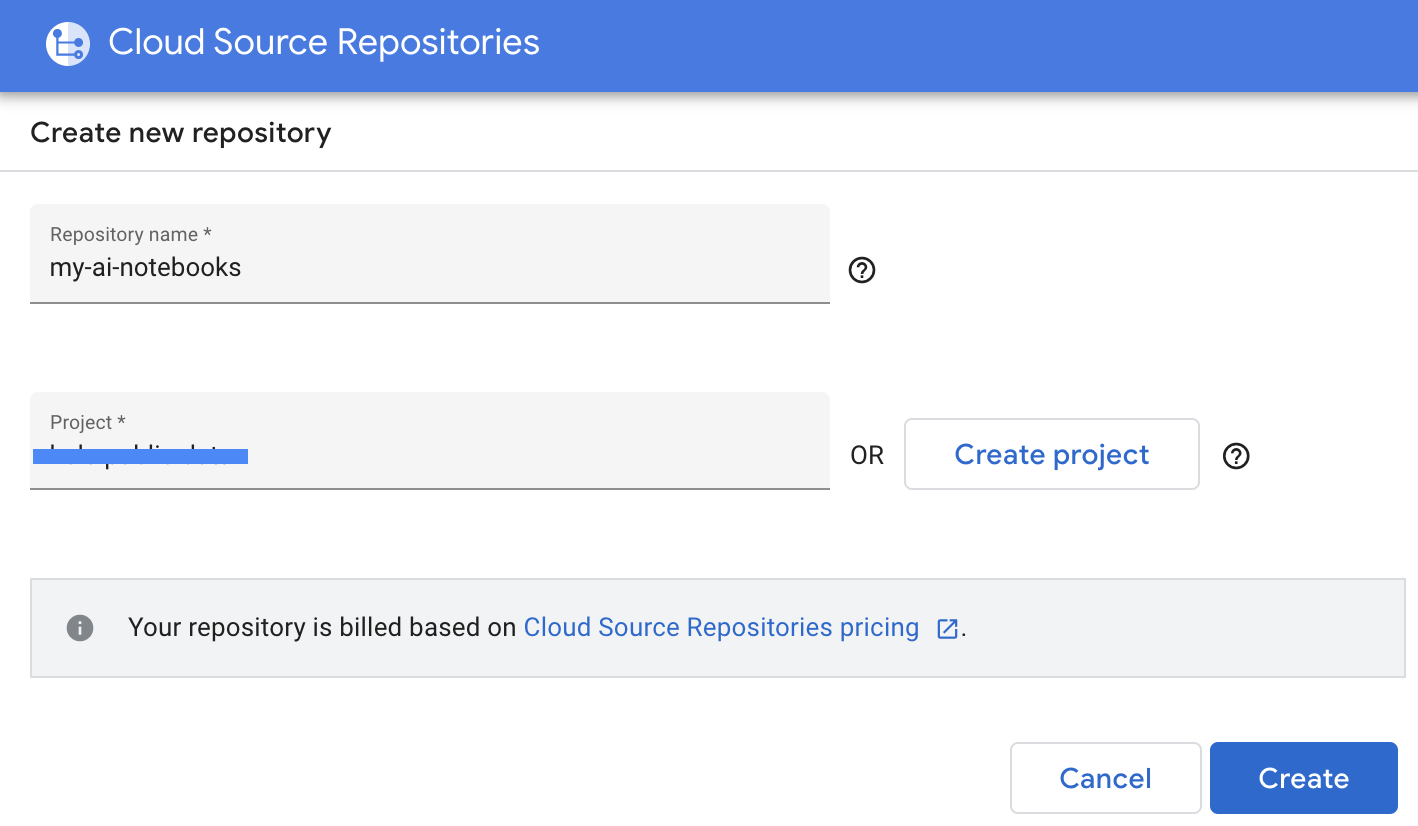
- 나중에 보려면 GCP로 이동합니다. -> Cloud Source Repositories를 선택하고 +저장소 추가를 클릭하여 새 저장소를 만듭니다.

- '새 저장소 만들기'를 선택한 후 계속을 클릭합니다.
- 저장소 이름과 프로젝트 이름을 입력한 후 '만들기'를 클릭합니다.
- '저장소를 로컬 Git 저장소로 클론'을 선택한 후 수동으로 생성된 사용자 인증 정보를 선택합니다.
- 1단계 'Git 사용자 인증 정보 생성 및 저장' 수행 참조하세요 (아래 참고). 화면에 표시되는 스크립트를 복사합니다.
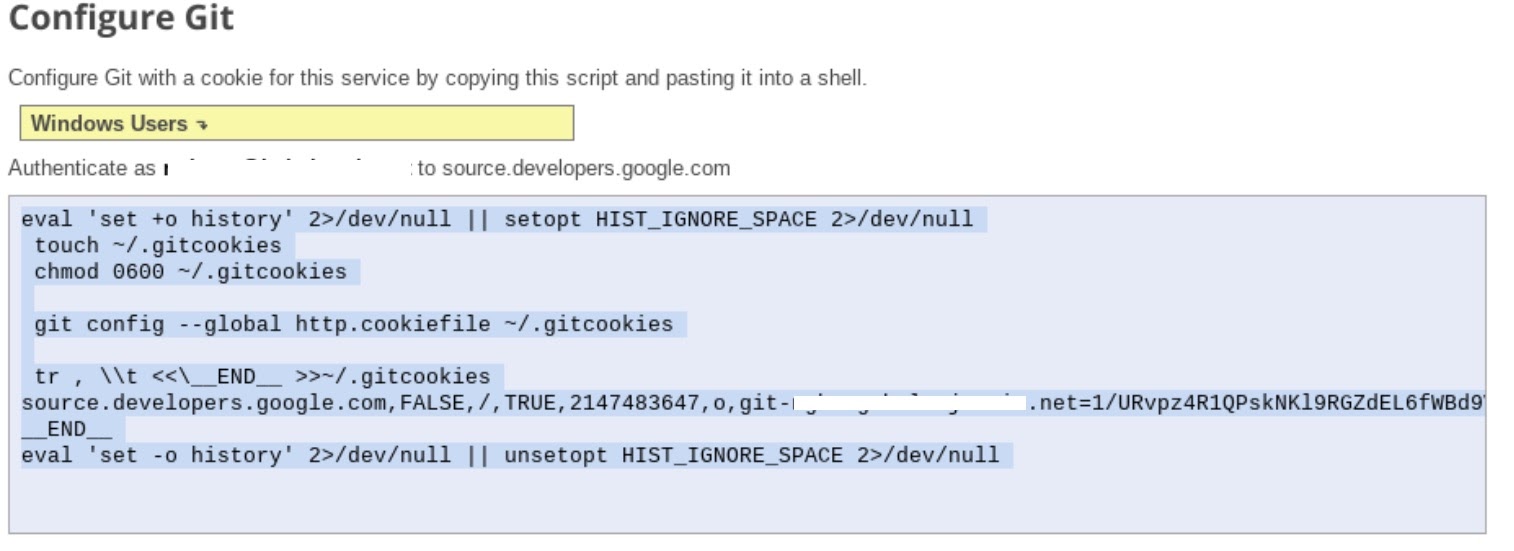
- Jupyter에서 터미널 세션을 시작합니다.
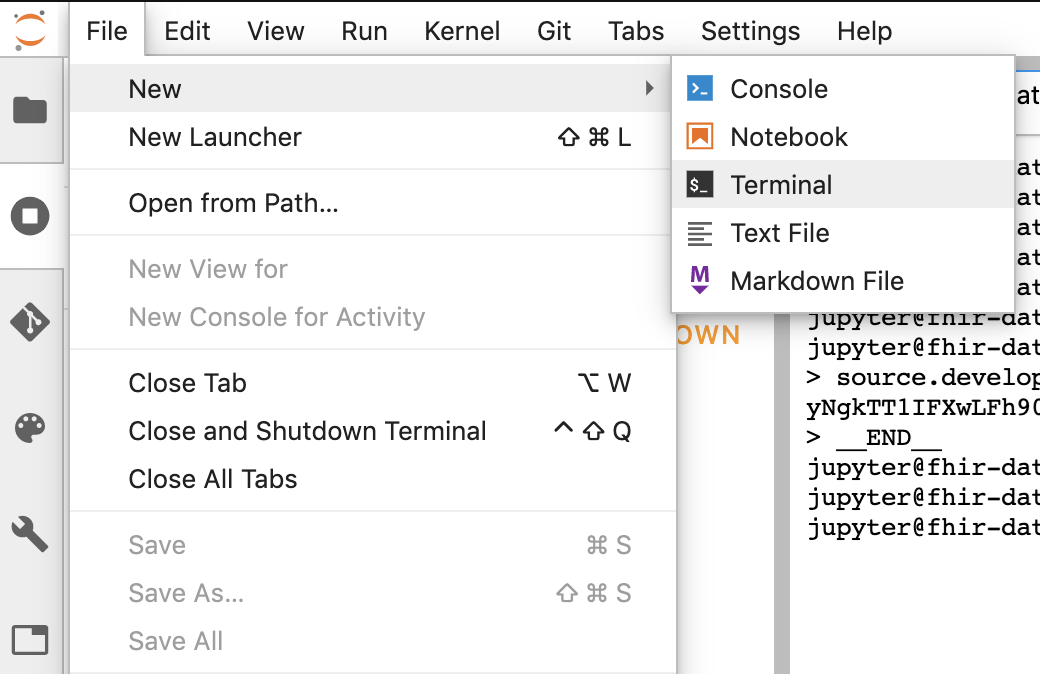
- 'Configure Git'(Git 구성)의 모든 명령어를 붙여넣습니다. Jupyter 터미널에 추가합니다
- GCP Cloud 소스 저장소에서 저장소 클론 경로를 복사합니다 (아래 스크린샷의 2단계).
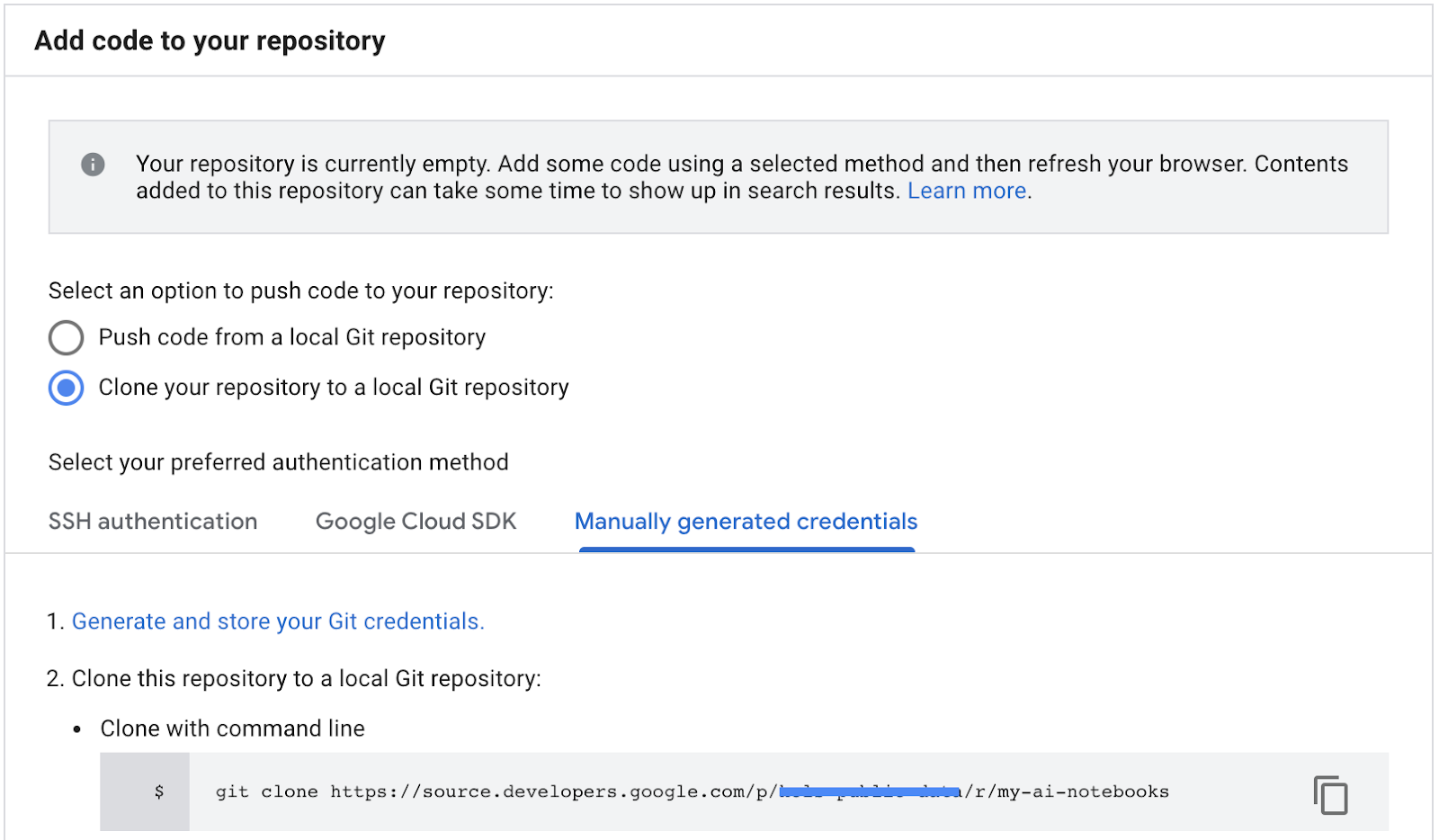
- JupiterLab 터미널에 다음 명령어를 붙여넣습니다. 명령어는 다음과 같습니다.
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- 'my-ai-notebooks' Jupyterlab에서 생성됩니다
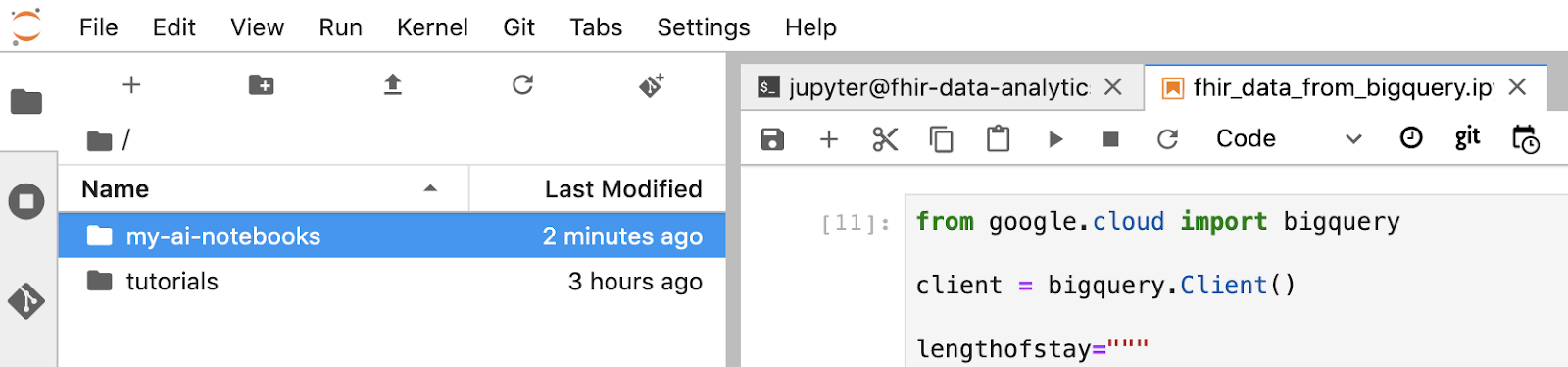
- 노트북 (fhir_data_from_bigquery.ipynb)을 'my-ai-notebooks' 폴더로 이동합니다.
- Jupyter 터미널에서 디렉터리를 'cd my-ai-notebooks'로 변경합니다.
- Jupyter 터미널을 사용하여 변경사항을 스테이징합니다. 또는 Jupyter UI를 사용할 수 있습니다. '추적되지 않음' 영역에서 파일을 마우스 오른쪽 버튼으로 클릭하고 '추적'을 선택하면 파일이 '추적됨' 영역으로 이동하며 반대의 경우도 마찬가지입니다. 변경된 영역에는 수정된 파일이 포함되어 있습니다.
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
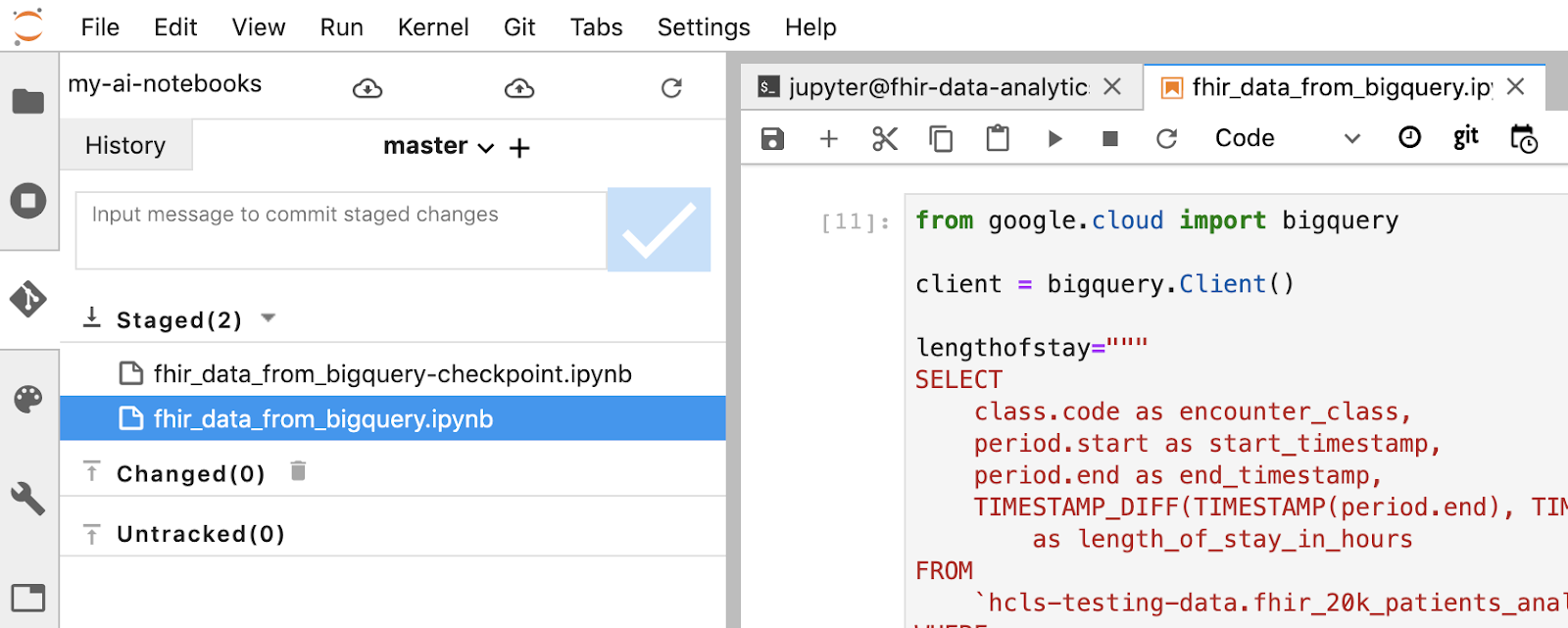
- Jupyter 터미널 또는 Jupyter UI를 사용하여 변경사항을 커밋합니다 (메시지를 입력한 다음 '확인됨' 버튼 클릭).
git commit -m "message goes here"
- Jupyter 터미널 또는 Jupyter UI를 사용하여 변경사항을 원격 저장소로 푸시합니다('커밋된 변경사항 푸시' 아이콘
 클릭).
클릭).
git push --all
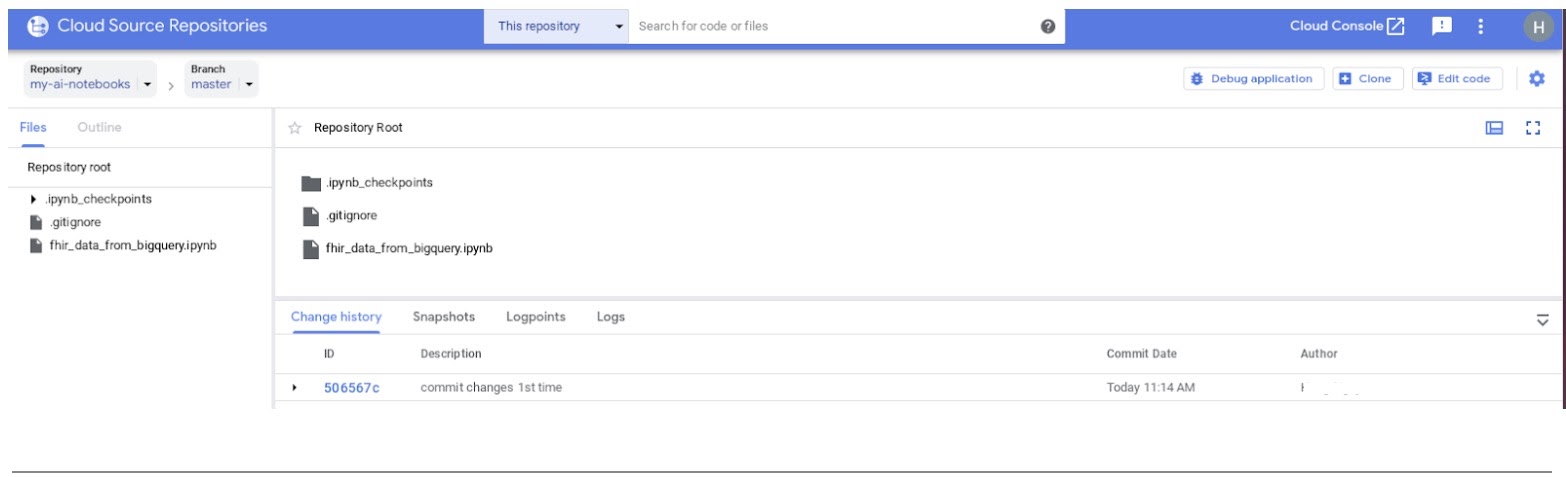
- GCP 콘솔에서 소스 저장소로 이동합니다. my-ai-notebooks를 클릭합니다. 'fhir_data_from_bigquery.ipynb'가 GCP Source Repository에 저장됩니다.
8. 삭제
이 Codelab에서 사용한 리소스 비용이 Google Cloud Platform 계정에 청구되지 않도록 하려면 가이드를 완료한 후 GCP에서 만든 리소스가 할당량을 차지하여 이후에 요금이 청구되지 않도록 이 리소스를 삭제할 수 있습니다. 다음 섹션에서는 이러한 리소스를 삭제 또는 해제하는 방법을 설명합니다.
BigQuery 데이터세트 삭제
다음 안내에 따라 이 튜토리얼의 일부로 만든 BigQuery 데이터 세트를 삭제합니다. 또는 테스트 데이터 세트 fhir_20k_patients_analytics를 사용한 경우 BigQuery 콘솔로 이동하여 프로젝트 hcls-testing-data의 PIN을 해제합니다.
AI Platform Notebooks 인스턴스 종료
다음 링크의 안내를 따릅니다. 노트북 인스턴스 종료 | AI Platform Notebooks - AI Platform Notebooks 인스턴스를 종료합니다.
프로젝트 삭제
비용이 청구되지 않도록 하는 가장 쉬운 방법은 튜토리얼에서 만든 프로젝트를 삭제하는 것입니다.
프로젝트를 삭제하는 방법은 다음과 같습니다.
- GCP 콘솔에서 프로젝트 페이지로 이동합니다. 프로젝트 페이지로 이동
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
9. 축하합니다
수고하셨습니다. BigQuery 및 AI Platform Notebooks를 사용하여 FHIR 형식의 의료 데이터에 액세스하고 쿼리하고 분석하는 Codelab을 성공적으로 완료했습니다.
GCP에서 공개 BigQuery 데이터 세트에 액세스했습니다.
BigQuery UI를 사용하여 SQL 쿼리를 개발하고 테스트했습니다.
AI Platform Notebooks 인스턴스를 만들고 실행했습니다.
JupyterLab에서 SQL 쿼리를 실행하고 쿼리 결과를 Pandas DataFrame에 저장했습니다.
Matplotlib을 사용하여 차트와 그래프를 만들었습니다.
노트북을 커밋하고 GCP의 Cloud Source Repository에 푸시했습니다.
지금까지 Google Cloud Platform에서 BigQuery 및 AI Platform Notebooks를 사용하여 의료 데이터 분석 여정을 시작하는 데 필요한 주요 단계를 알아보았습니다.
©Google, Inc. or its affiliates. All rights reserved. 배포 금지.