
1. Introdução
Última atualização: 22/09/2022
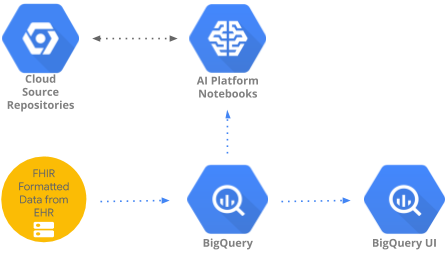
Este codelab implementa um padrão para acessar e analisar dados de saúde agregados no BigQuery usando o BigQueryUI e os Notebooks do AI Platform. Ele ilustra a exploração de grandes conjuntos de dados de saúde usando ferramentas conhecidas, como Pandas, Matplotlib etc. em um AI Platform Notebooks compatível com HIPPA. O segredo é fazer a primeira parte da agregação no BigQuery, recuperar um conjunto de dados do Pandas e trabalhar localmente com o conjunto de dados menor do Pandas. O AI Platform Notebooks fornece uma experiência gerenciada do Jupyter, para que você não precise executar servidores de notebook por conta própria. O AI Platform Notebooks é bem integrado a outros serviços do GCP, como o Big Query e o Cloud Storage, o que torna mais rápido e simples iniciar sua jornada de análise de dados e ML no Google Cloud Platform.
Neste codelab, você vai aprender a:
- Desenvolver e testar consultas SQL usando a interface do BigQuery.
- Crie e inicie uma instância do AI Platform Notebooks no GCP.
- Executar consultas SQL no notebook e armazenar os resultados delas no Pandas DataFrame.
- Criar gráficos usando o Matplotlib.
- Confirme e envie o notebook para um Cloud Source Repository no GCP.
O que é necessário para executar este codelab?
- Você precisa ter acesso a um projeto do GCP.
- Você precisa ter um papel de proprietário no projeto do GCP.
- Você precisa de um conjunto de dados de saúde no BigQuery.
Se você não tiver um projeto do GCP, siga estas etapas para criar um.
2. Configurar o projeto
Neste codelab, usaremos um conjunto de dados existente no BigQuery (hcls-testing-data.fhir_20k_patients_analytics). Esse conjunto de dados é pré-preenchido com dados sintéticos de saúde.
Receber acesso ao conjunto de dados sintético
- No endereço de e-mail que você está usando para fazer login no console do Cloud, envie um e-mail para hcls-solutions-external+subscribe@google.com pedindo para participar.
- Você vai receber um e-mail com instruções para confirmar a ação.
- Use a opção de responder ao e-mail para participar do grupo. NÃO clique no botão
 .
. - Depois de receber o e-mail de confirmação, prossiga para a próxima etapa do codelab.
Fixar o projeto
- No Console do GCP, selecione o projeto e navegue até o BigQuery.
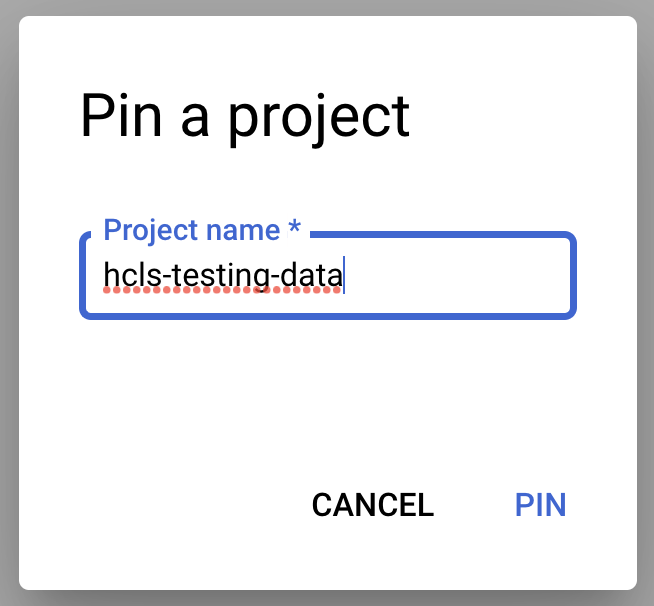
- Clique no menu suspenso +ADICIONAR DADOS e selecione "Fixar um projeto". > "Digite o nome do projeto" ,

- Digite o nome do projeto, "hcls-testing-data", e clique em PIN. O conjunto de dados de teste do BigQuery "fhir_20k_patients_analytics" está disponível para uso.
3. Desenvolver consultas usando a interface do BigQuery
Configuração da interface do BigQuery
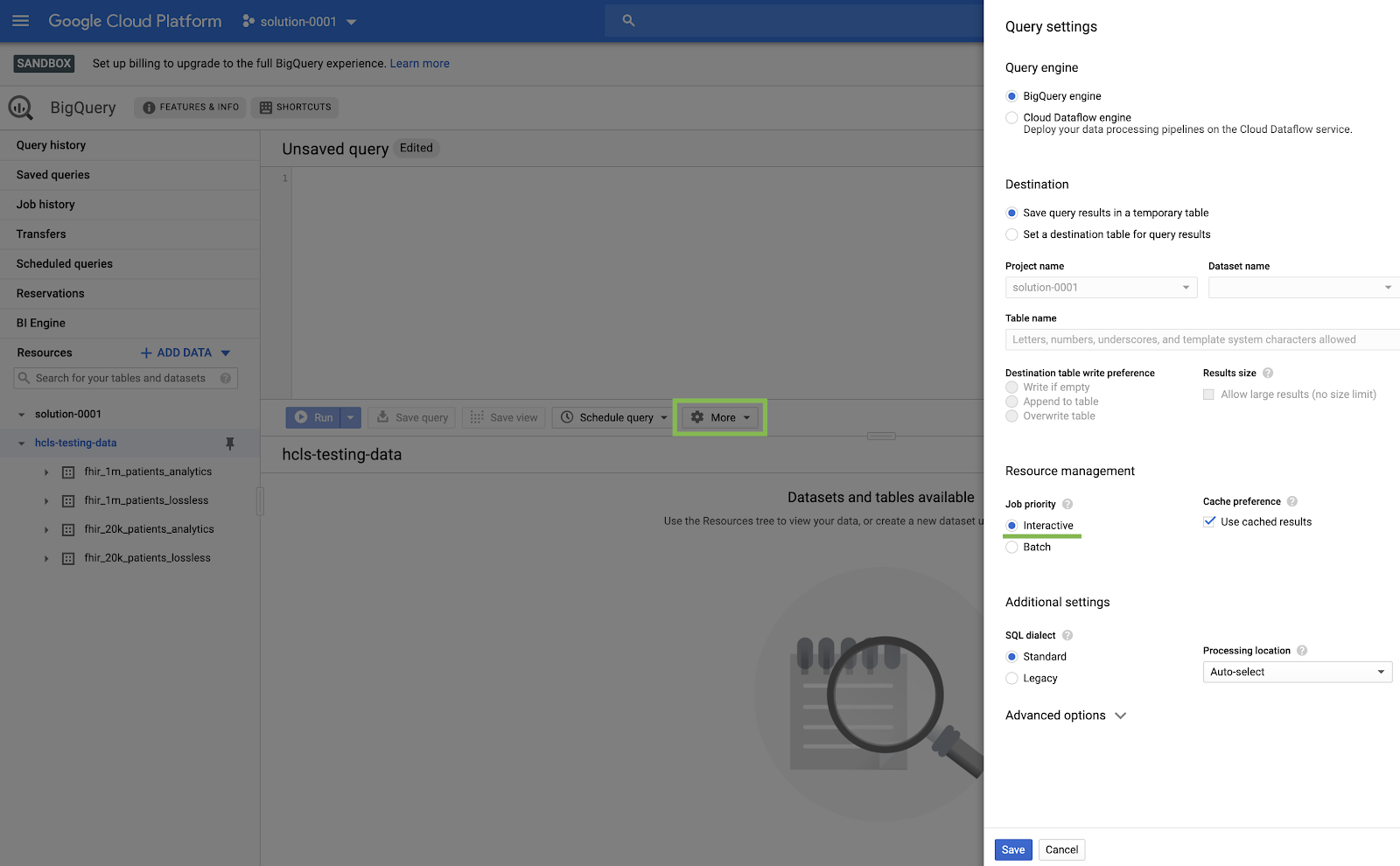
- Navegue até o console do BigQuery selecionando BigQuery no canto superior esquerdo do menu do GCP ("hambúrguer").
- No console do BigQuery, clique em Mais → Configurações de consulta e verifique se o menu SQL legado NÃO está marcado (usaremos SQL padrão).
Criar consultas
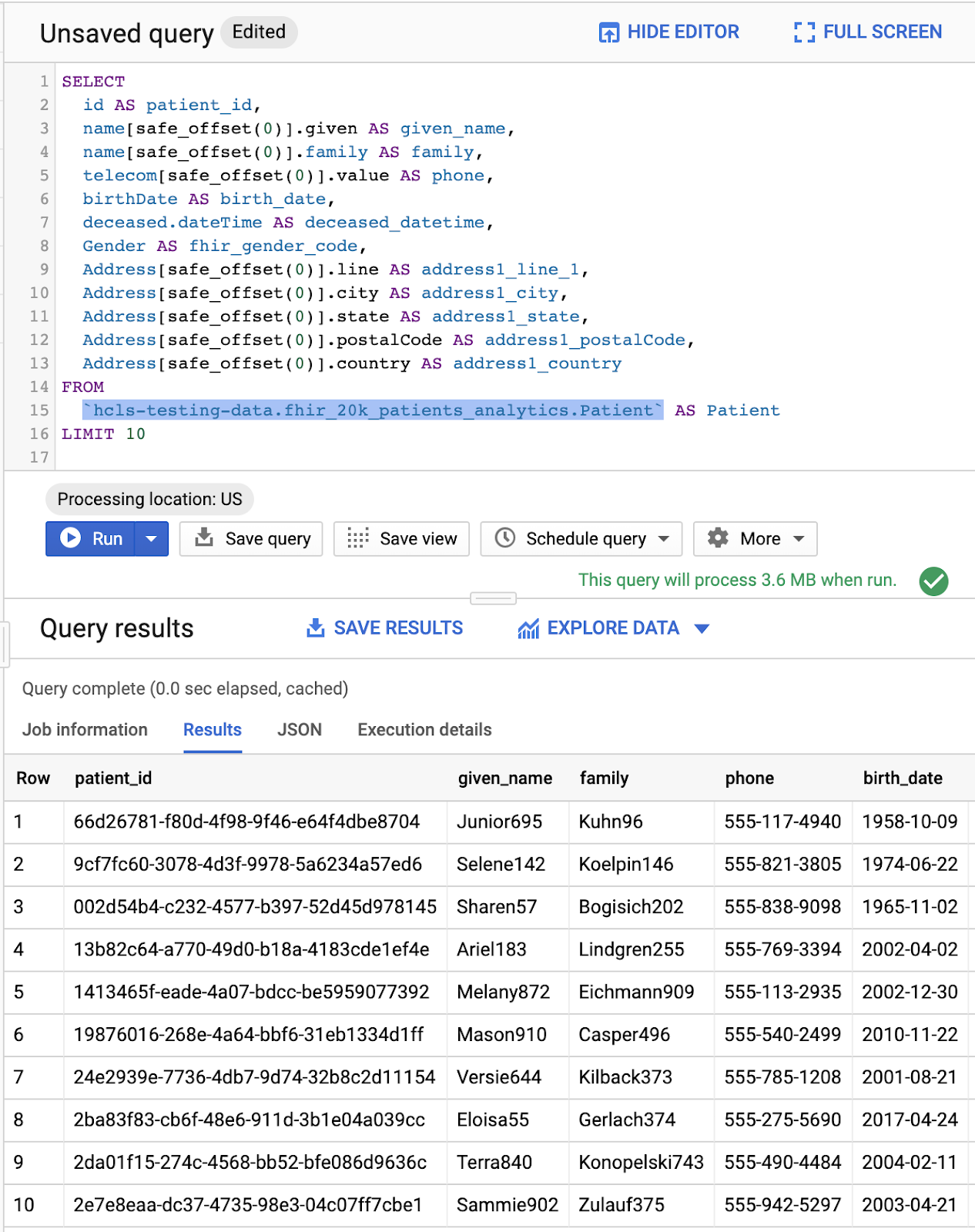
Na janela "Editor de consultas", digite a consulta abaixo e clique em Executar. Em seguida, visualize os resultados na janela "Query results".
CONSULTA PACIENTES
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
Consulta no "Editor de consultas" e resultados:
PRÁTICAS DE CONSULTA
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
Resultados da consulta:

ORGANIZAÇÃO DA CONSULTA
Altere o ID da organização para corresponder ao seu conjunto de dados.
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
Resultados da consulta:

ENCONTRADORES DE CONSULTAS POR PACIENTE
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
Resultados da consulta:

RECEBER A DURAÇÃO MÉDIA DOS CONTAS POR TIPO DE ENCONTAR
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
Resultados da consulta:

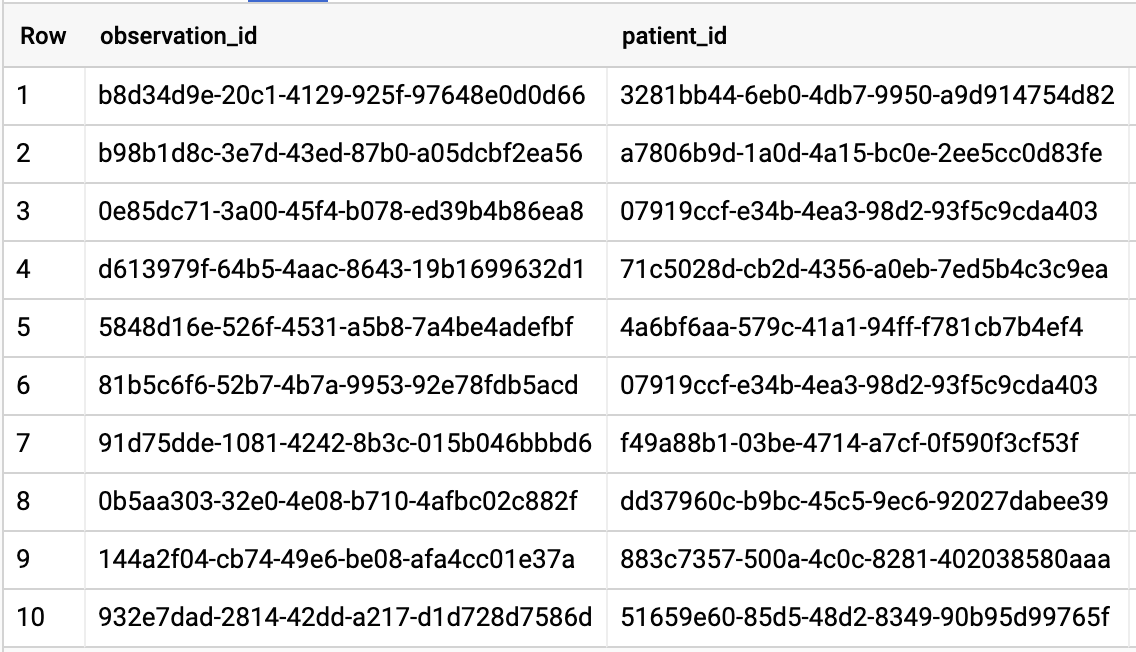
CONFIRA TODOS OS PACIENTES QUE TÊM UMA TAXA DE A1C >= 6,5
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
Resultados da consulta:
4. Criar instância do AI Platform Notebooks
Siga as instruções do link para criar uma nova instância do AI Platform Notebooks (JupyterLab).
Não se esqueça de ativar a API Compute Engine.
Você pode escolher " Criar um novo notebook com opções padrão" ou " Crie um notebook e especifique suas opções".
5. Criar um notebook de análise de dados
Abrir instância do AI Platform Notebooks
Nesta seção, criaremos e codificaremos um novo notebook do Jupyter do zero.
- Abra uma instância de notebook navegando até a página Notebooks do AI Platform no console do Google Cloud Platform. ACESSAR A PÁGINA "NOTEBOOKS DO AI PLATFORM
- Selecione Abrir JupyterLab para a instância a ser aberta.
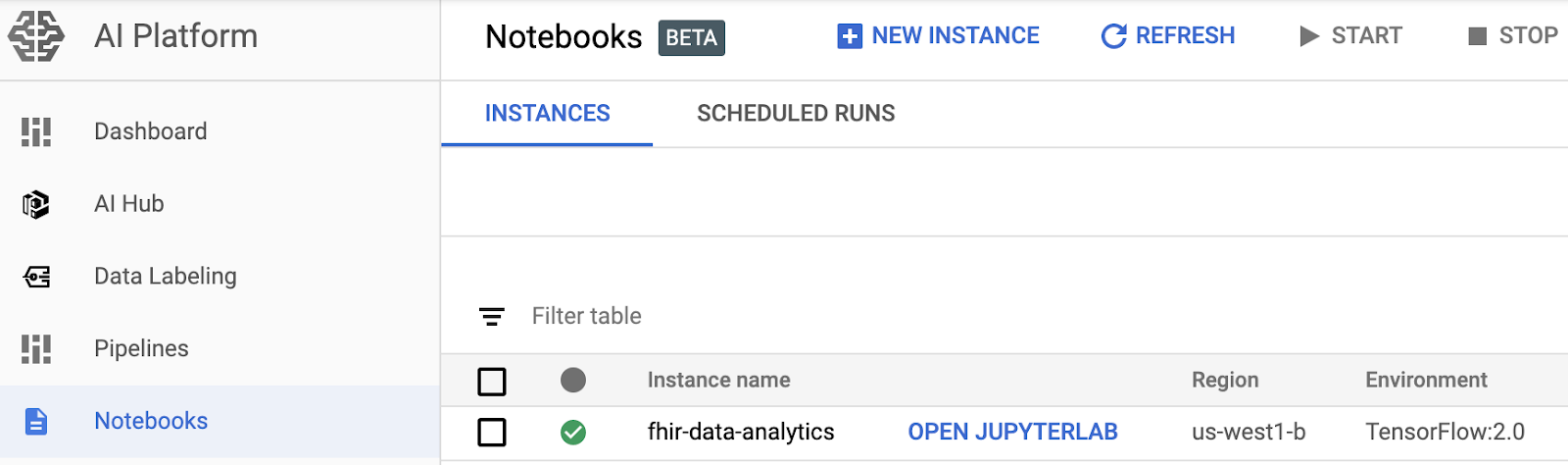
- Os notebooks do AI Platform direcionarão você para um URL da instância de notebook.
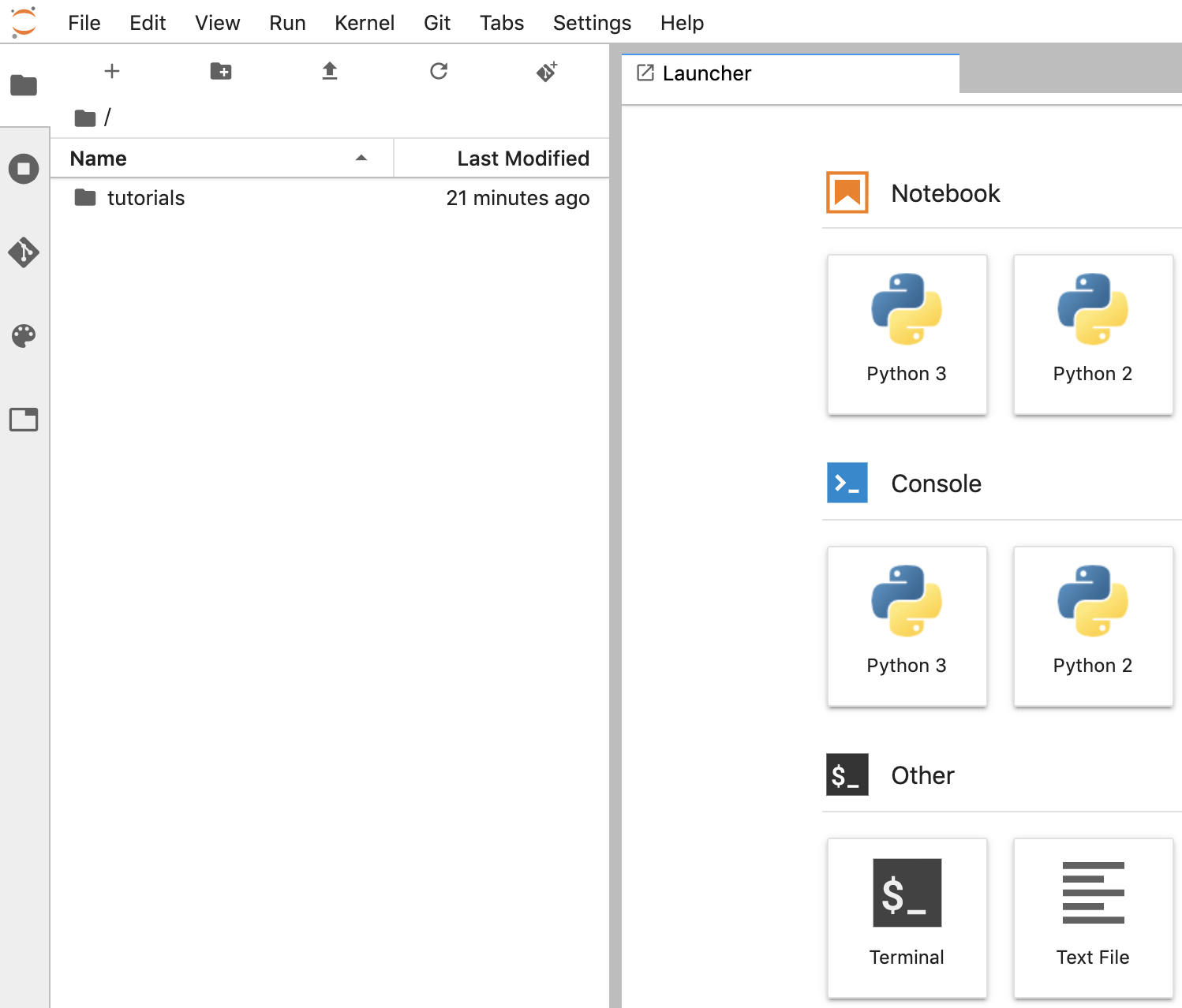
Criar um notebook
- No JupyterLab, acesse File -> Novo -> Notebook e selecione o Kernel "Python 3" no pop-up ou selecione "Python 3" na seção "Notebook" na janela de acesso rápido, para criar um notebook "Untitled.ipynb".

- Clique com o botão direito do mouse em Untitled.ipynb e renomeie o notebook como "fhir_data_from_bigquery.ipynb". Clique duas vezes para abrir, criar as consultas e salvar o notebook.
- É possível fazer o download de um notebook clicando com o botão direito do mouse no arquivo *.ipynb e selecione Download no menu.
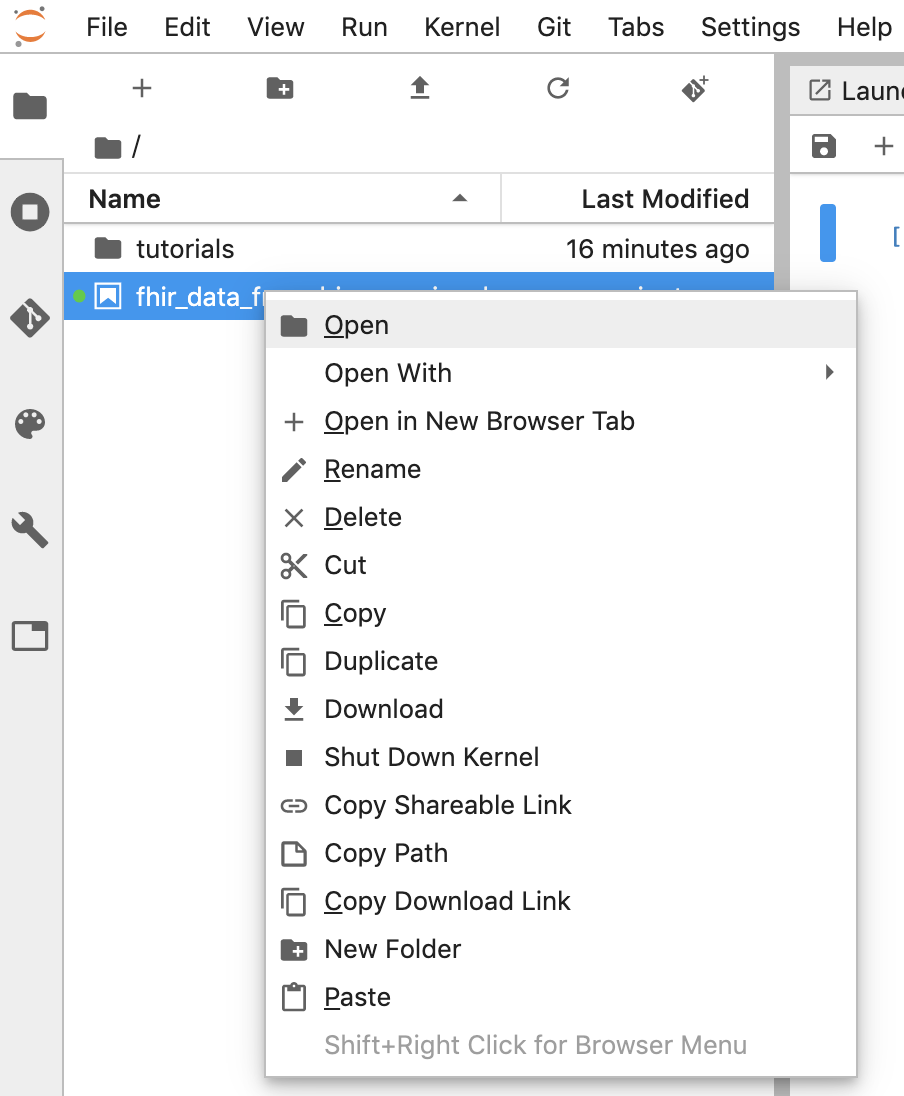
- Também é possível fazer upload de um notebook existente clicando na "seta para cima" .
Crie e execute cada bloco de código no notebook
Copie e execute um bloco de código fornecido nesta seção, um por um. Para executar o código, clique em Executar (triângulo).

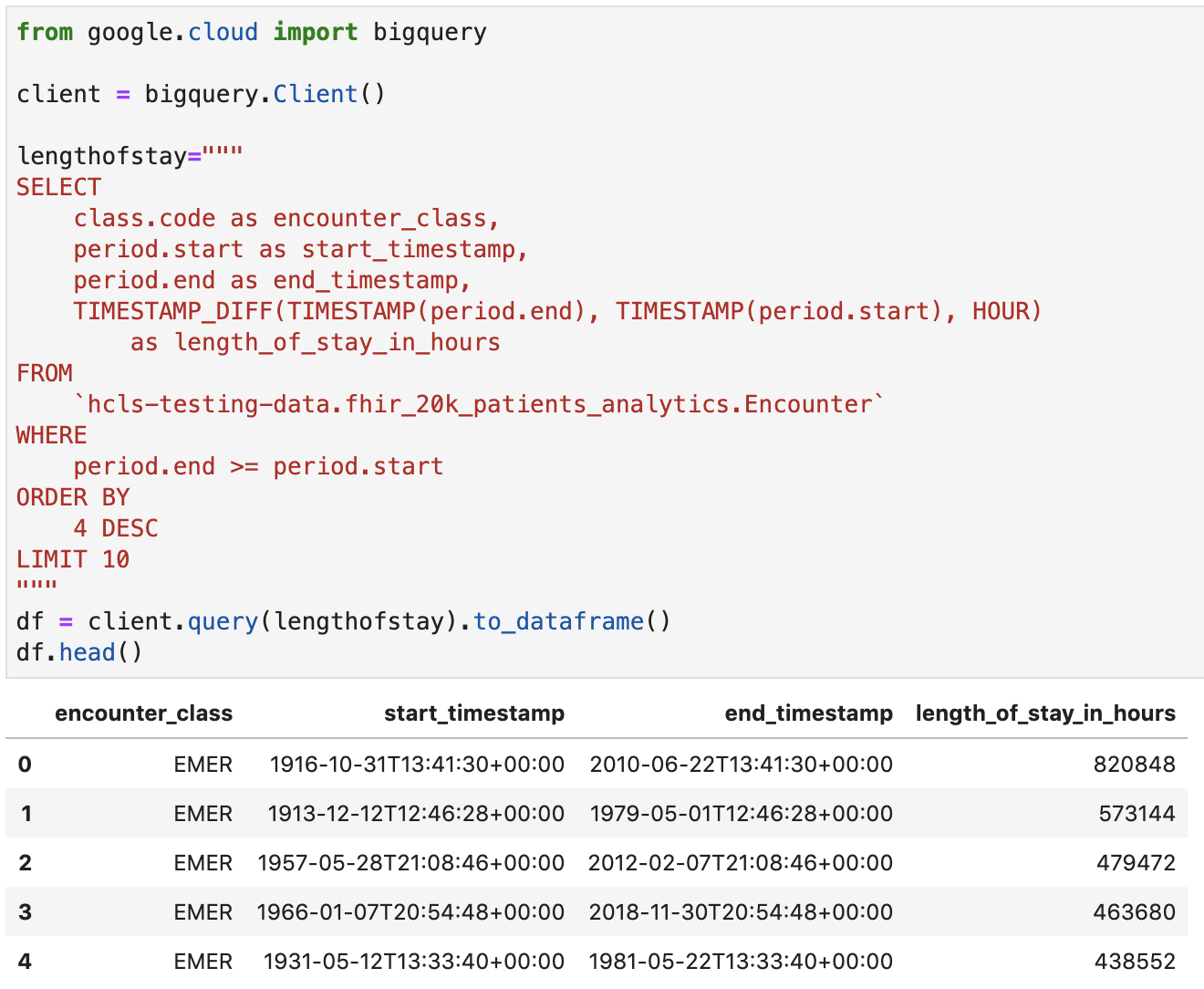
Confira a duração da estadia para encontros em horas
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
Código e saída da execução:
Obter observações: valores de colesterol
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
Saída da execução:

Conseguir quantis de encontro aproximado
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
Saída da execução:

Obter duração média de contatos em minutos
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
Saída da execução:

Acessar encontros por paciente
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
Saída da execução:

Acessar organizações
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
Resultado da execução:

Acessar pacientes
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
Resultados da execução:

6. criar gráficos no AI Platform Notebooks
Executar células de código no notebook "fhir_data_from_bigquery.ipynb" para desenhar um gráfico de barras.
Por exemplo, veja a duração média de encontros em minutos.
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
Resultados de código e execução:

7. Notebook de confirmação para o Cloud Source Repository
- No console do GCP, navegue até Source Repositories. Se você estiver usando o recurso pela primeira vez, clique em "Começar" e depois em "Criar repositório".
- Para um momento posterior, navegue até GCP -> Cloud Source Repositories e clique em "+Adicionar repositório" para criar um novo repositório.

- Selecione "Criar um novo repositório" e clique em "Continuar".
- Forneça o nome do repositório e do projeto e clique em "Criar".
- Selecione "Clonar seu repositório para um repositório Git local" e, em seguida, "Credenciais geradas manualmente".
- Siga a etapa 1 "Gerar e armazenar credenciais do Git" instruções de configuração (confira abaixo). Copie o script que aparece na tela.
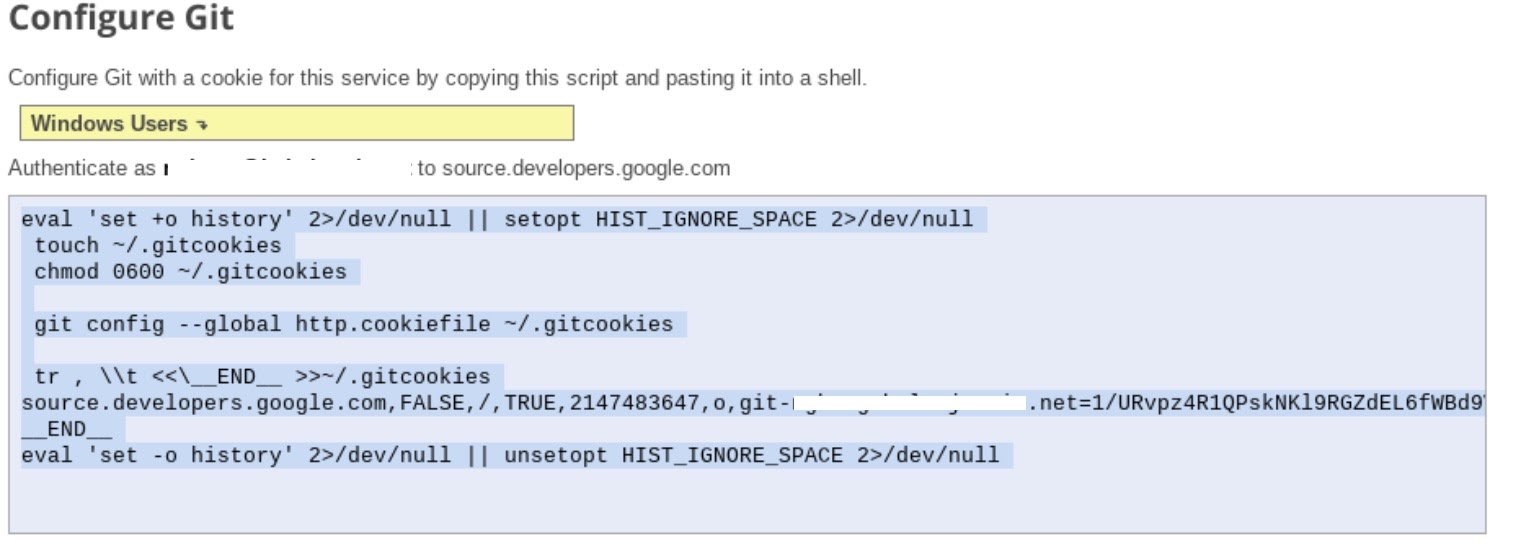
- Inicie a sessão do terminal no Jupyter.
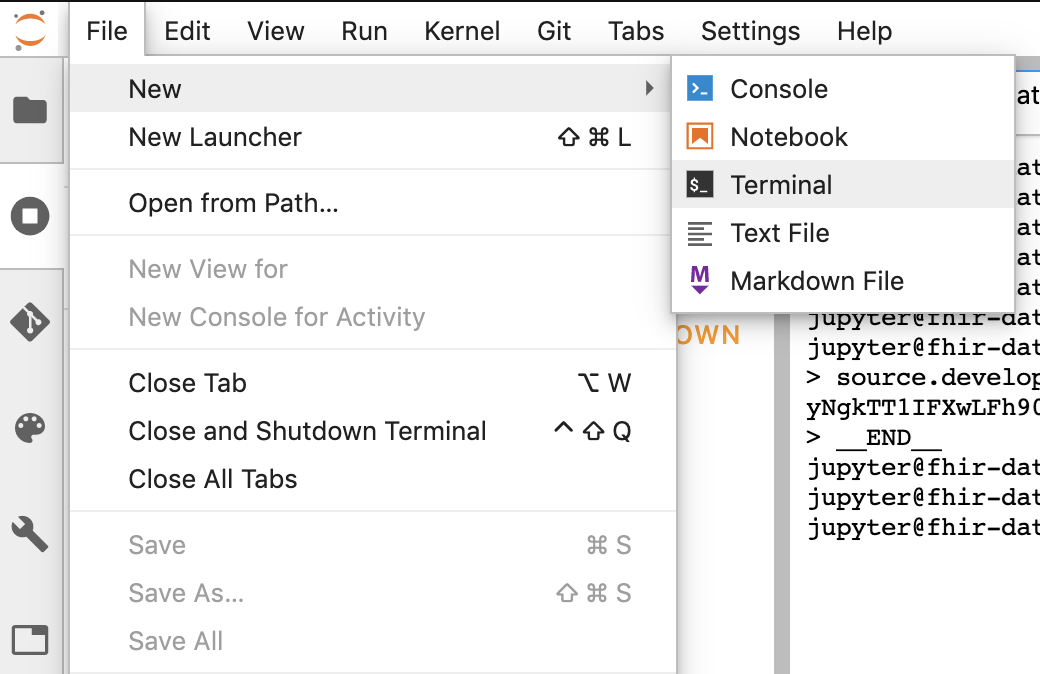
- Cole todos os comandos de "Configure Git" no terminal do Jupyter.
- Copie o caminho do clone do repositório dos repositórios de origem do Cloud do GCP (etapa 2 na captura de tela abaixo).

- Cole esse comando no terminal do JupiterLab. O comando ficará assim:
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- "my-ai-notebooks" é criada no JupyterLab.

- Mova o notebook (fhir_data_from_bigquery.ipynb) para a pasta "my-ai-notebooks".
- No terminal do Jupyter, mude o diretório para "cd my-ai-notebooks".
- Prepare suas mudanças usando o terminal do Jupyter. Como alternativa, é possível usar a interface do Jupyter (clique com o botão direito do mouse nos arquivos na área Não rastreados, selecione Rastrear e os arquivos serão movidos para a área Rastreados e vice-versa. A área alterada contém os arquivos modificados).
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
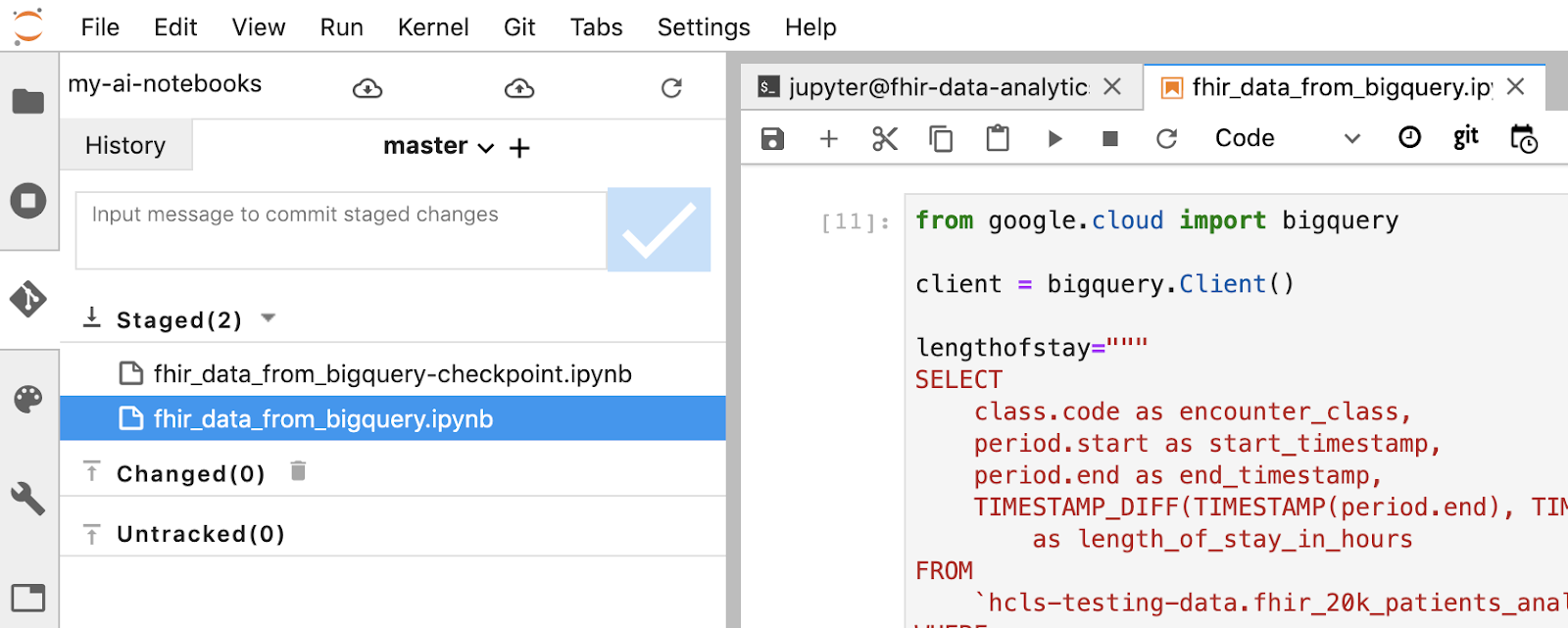
- Confirme suas alterações usando o terminal ou a interface do Jupyter (digite a mensagem e clique no botão "Checked").
git commit -m "message goes here"
- Envie as alterações para o repositório remoto usando o terminal do Jupyter ou a interface do Jupyter. Clique no ícone "Enviar alterações confirmadas"
 .
.
git push --all
- No console do GCP, navegue até Source Repositories. Clique em "my-ai-notebooks". Observe que "fhir_data_from_bigquery.ipynb" será salvo no repositório de origem do GCP.
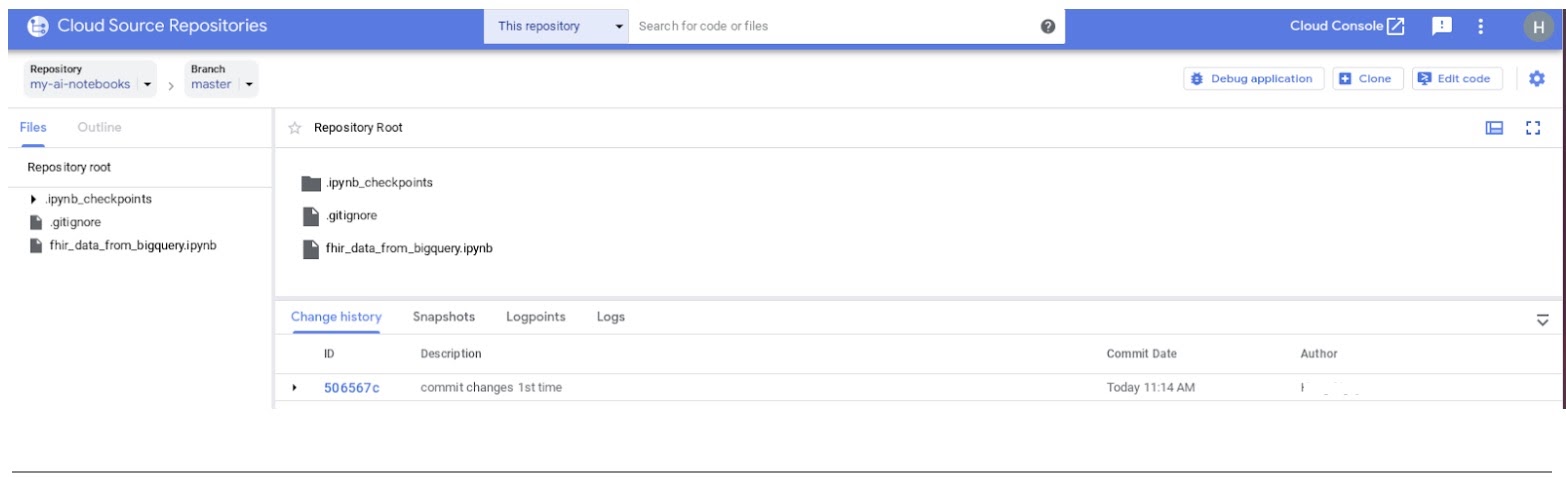
8. Limpeza
Para evitar cobranças na sua conta do Google Cloud Platform pelos recursos usados neste codelab, depois de concluir o tutorial, limpe os recursos criados no GCP para que eles não ocupem sua cota e você não seja cobrado por eles no futuro. As próximas seções descrevem como excluir ou desativar esses recursos.
Como excluir o conjunto de dados do BigQuery
Siga estas instruções para excluir o conjunto de dados do BigQuery que você criou como parte deste tutorial. Também é possível acessar o console do BigQuery, remover o PIN do projeto hcls-testing-data, ,se você usou o conjunto de dados de teste fhir_20k_patients_analytics.
Como encerrar a instância do AI Platform Notebooks
Siga as instruções neste link Encerrar uma instância de notebook | AI Platform Notebooks para encerrar uma instância do AI Platform Notebooks.
Excluir o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para este tutorial.
Para excluir o projeto:
- No Console do GCP, acesse a página Projetos. ACESSAR A PÁGINA "PROJETOS"
- Na lista de projetos, selecione um e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
9. Parabéns
Parabéns, você concluiu o codelab para acessar, consultar e analisar dados de saúde formatados pelo FHIR usando o BigQuery e os Notebooks do AI Platform.
Você acessou um conjunto de dados público do BigQuery no GCP.
Você desenvolveu e testou consultas SQL usando a interface do BigQuery.
Você criou e iniciou uma instância do AI Platform Notebooks.
Você executou consultas SQL no JupyterLab e armazenou os resultados delas no Pandas DataFrame.
Você criou gráficos usando o Matplotlib.
Você confirmou e enviou seu notebook para um Cloud Source Repository no GCP.
Agora você sabe as principais etapas necessárias para iniciar sua jornada de análise de dados de saúde com o BigQuery e os Notebooks do AI Platform no Google Cloud Platform.
©Google, Inc. ou afiliadas. Todos os direitos reservados. Distribuição proibida.