
1. Introducción
Última actualización: 22/9/2022
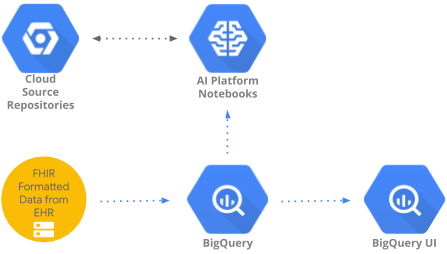
En este codelab, se implementa un patrón para acceder a datos de atención médica agregados en BigQuery y analizarlos con BigQueryUI y AI Platform Notebooks. Se ilustra la exploración de grandes conjuntos de datos de atención médica mediante herramientas conocidas como Pandas, Matplotlib, etc., en AI Platform Notebooks que cumplen con la HIPAA. El "truco" es hacer la primera parte de su agregación en BigQuery, utilizar Pandas para obtener un conjunto de datos reducido y luego trabajar con este de forma local. AI Platform Notebooks proporciona una experiencia administrada de Jupyter, por lo que no tienes que ejecutar servidores de notebook por tu cuenta. AI Platform Notebooks está bien integrado en otros servicios de GCP, como BigQuery y Cloud Storage, lo que facilita y agiliza el inicio de tu recorrido de análisis de datos y AA en Google Cloud Platform.
En este codelab, aprenderás a hacer lo siguiente:
- Desarrollar y probar consultas en SQL con la IU de BigQuery
- Crea y, luego, inicia una instancia de AI Platform Notebooks en GCP.
- Ejecutar consultas en SQL desde el notebook y almacenar los resultados de las consultas en DataFrame de Pandas
- Crear tablas y gráficos con Matplotlib.
- Confirma y envía el notebook a un Cloud Source Repository en GCP.
¿Qué necesitas para ejecutar este codelab?
- Necesitas acceso a un proyecto de GCP.
- Debes tener asignada una función de Propietario para el proyecto de GCP.
- Necesitas un conjunto de datos de atención médica en BigQuery.
Si no tienes un proyecto de GCP, sigue estos pasos para crear uno nuevo.
2. Configura el proyecto
En este codelab, usaremos un conjunto de datos existente en BigQuery (hcls-testing-data.fhir_20k_patients_analytics). Este conjunto de datos se prepropaga con datos sintéticos de atención médica.
Obtén acceso al conjunto de datos sintético
- Desde la dirección de correo electrónico que usas para acceder a la consola de Cloud, envía un correo electrónico a hcls-solutions-external+subscribe@google.com para solicitar unirte.
- Recibirás un correo electrónico con instrucciones para confirmar la acción.
- Usa la opción de responder el correo electrónico para unirte al grupo. NO hagas clic en el botón
 .
. - Una vez que recibas el correo electrónico de confirmación, puedes continuar con el siguiente paso del codelab.
Fija el proyecto
- En la consola de GCP, selecciona tu proyecto y, luego, navega hasta BigQuery.
- Haz clic en el menú desplegable + AGREGAR DATOS y selecciona “Fijar un proyecto”. > "Ingresa el nombre del proyecto" de Google Cloud.
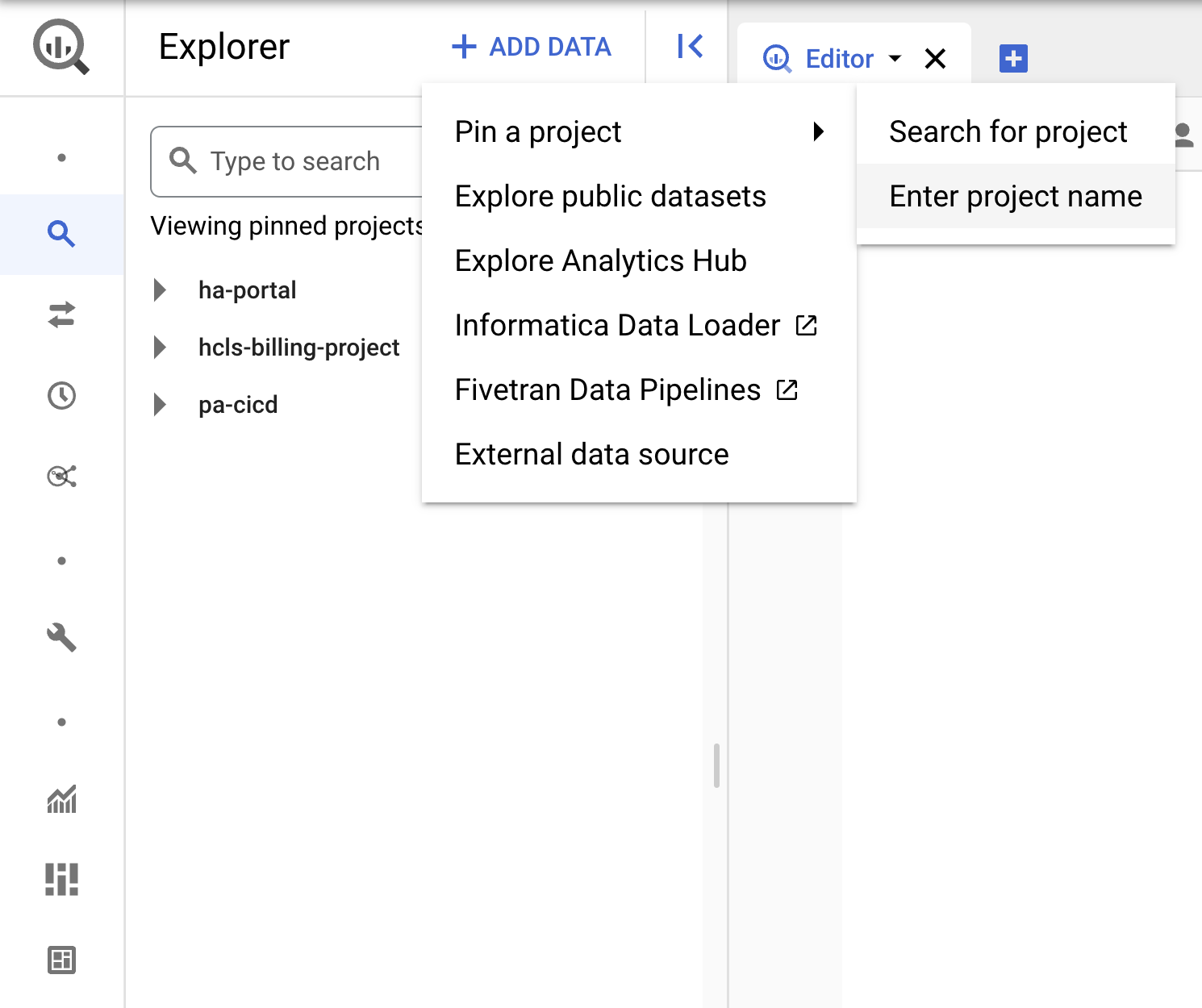
- Ingresa el nombre del proyecto, "hcls-testing-data", y haz clic en PIN. El conjunto de datos de prueba de BigQuery "fhir_20k_patients_analytics" está disponible para su uso.
3. Desarrolla consultas con la IU de BigQuery
Configuración de la IU de BigQuery
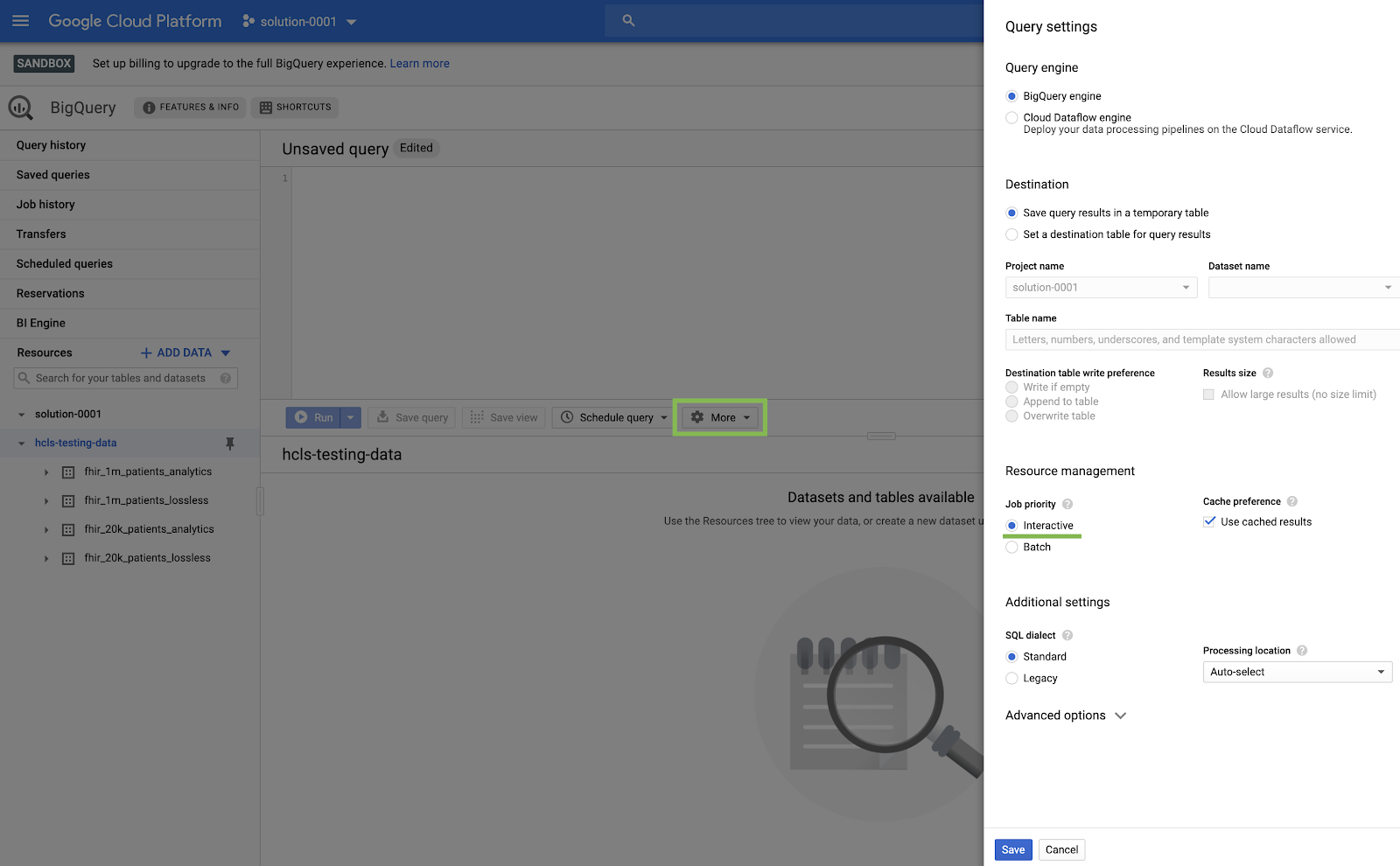
- Navega a la consola de BigQuery. Para ello, selecciona BigQuery en el menú de GCP, en la esquina superior izquierda (“hamburguesa”).
- En la consola de BigQuery, haz clic en Más → Configuración de consulta y asegúrate de que el menú de SQL heredado NO esté marcado (usaremos SQL estándar).
Consultas de compilación
En la ventana del Editor de consultas, escribe la siguiente consulta y haz clic en “Ejecutar” para ejecutarla. Luego, observa los resultados en la ventana “Resultados de la consulta”.
CONSULTAS DE PACIENTES
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
Consulta en el “Editor de consultas” y resultados:
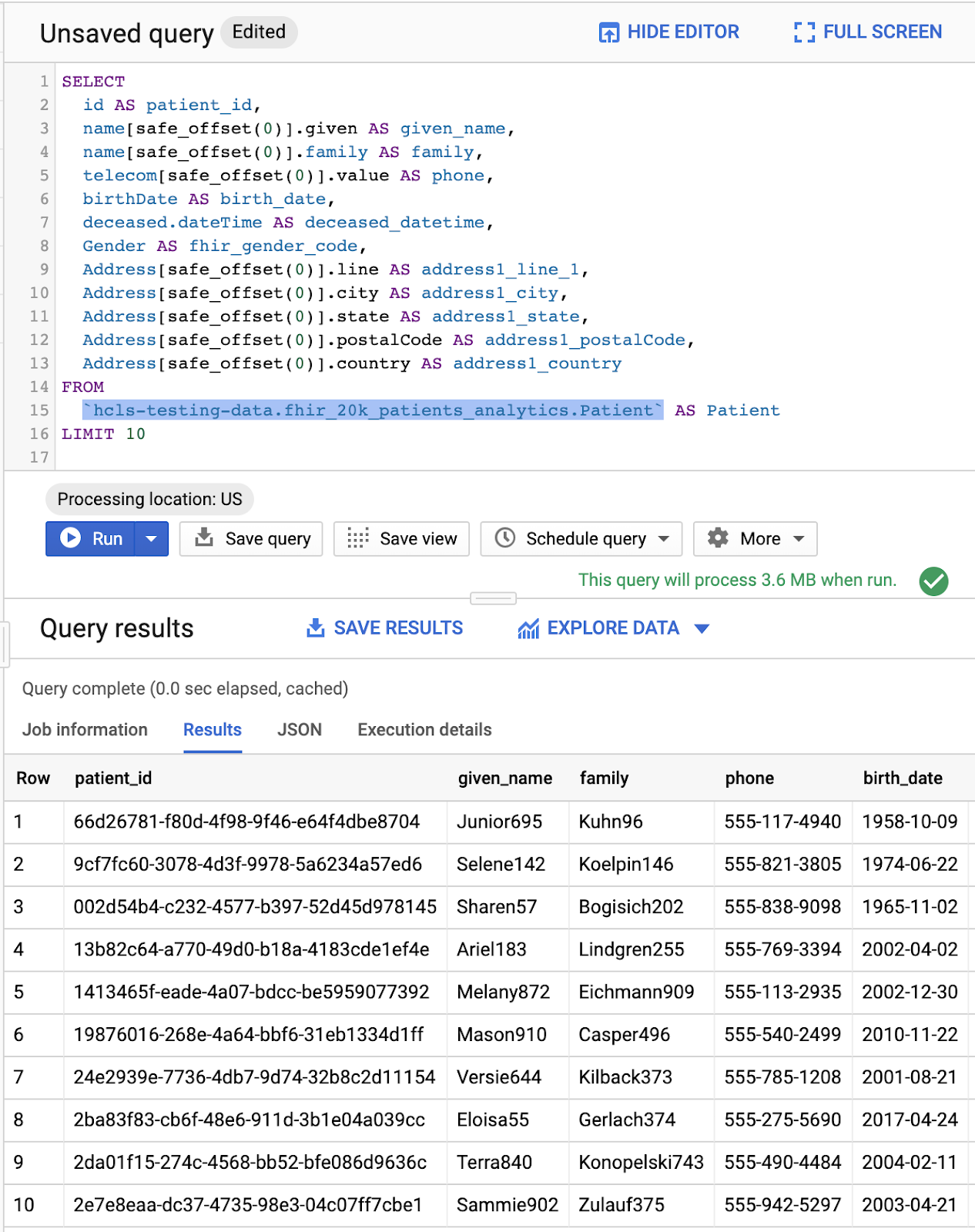
PROFESIONALES DE CONSULTAS
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
Resultados de la consulta:
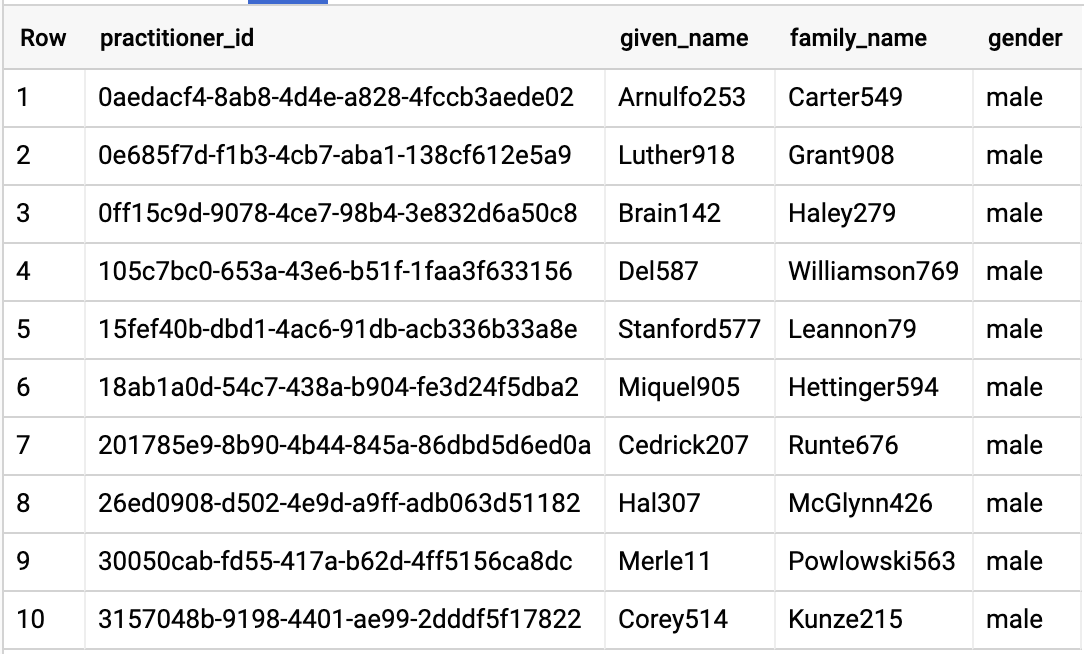
CONSULTAS SOBRE ORGANIZACIÓN
Cambia el ID de la organización para que coincida con tu conjunto de datos.
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
Resultados de la consulta:

ENCUENTROS DE CONSULTAS POR PACIENTE
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
Resultados de la consulta:
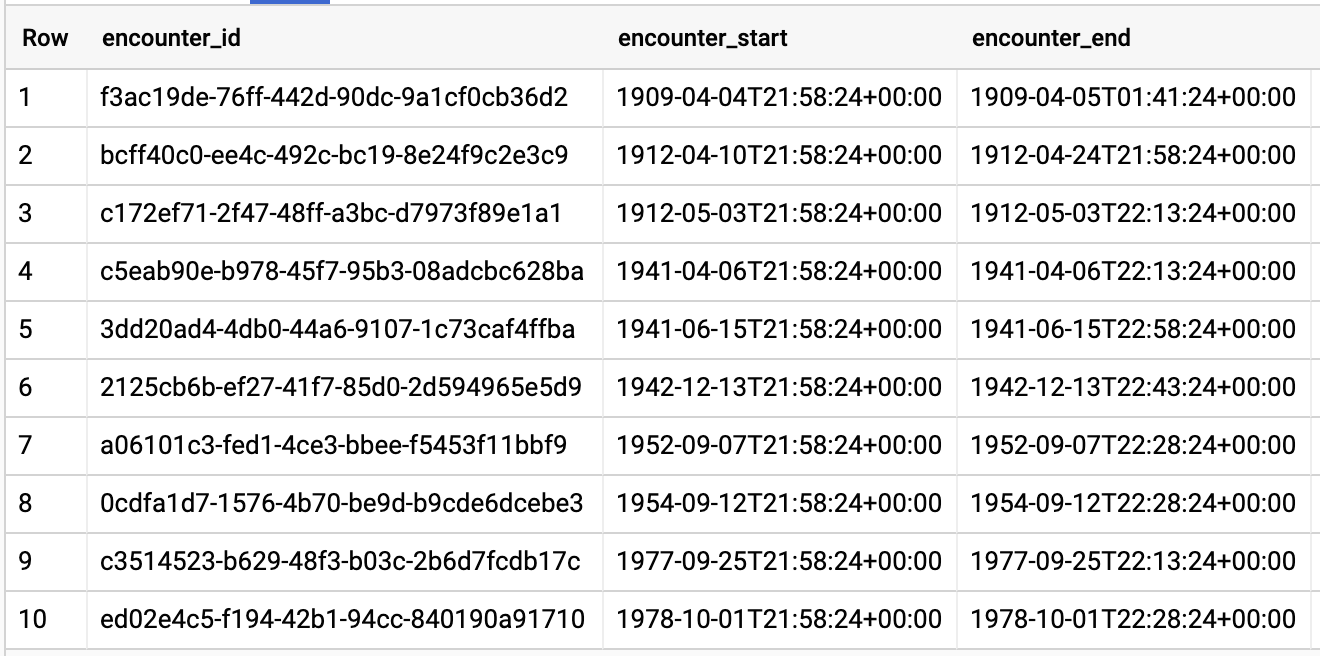
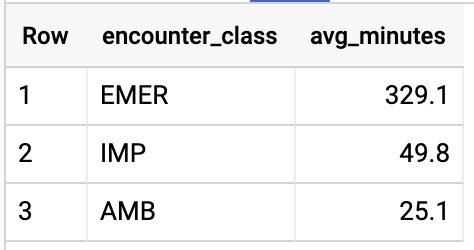
OBTÉN LA DURACIÓN PROMEDIO DE LOS ENCUENTROS POR TIPO DE ENCUENTRO
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
Resultados de la consulta:
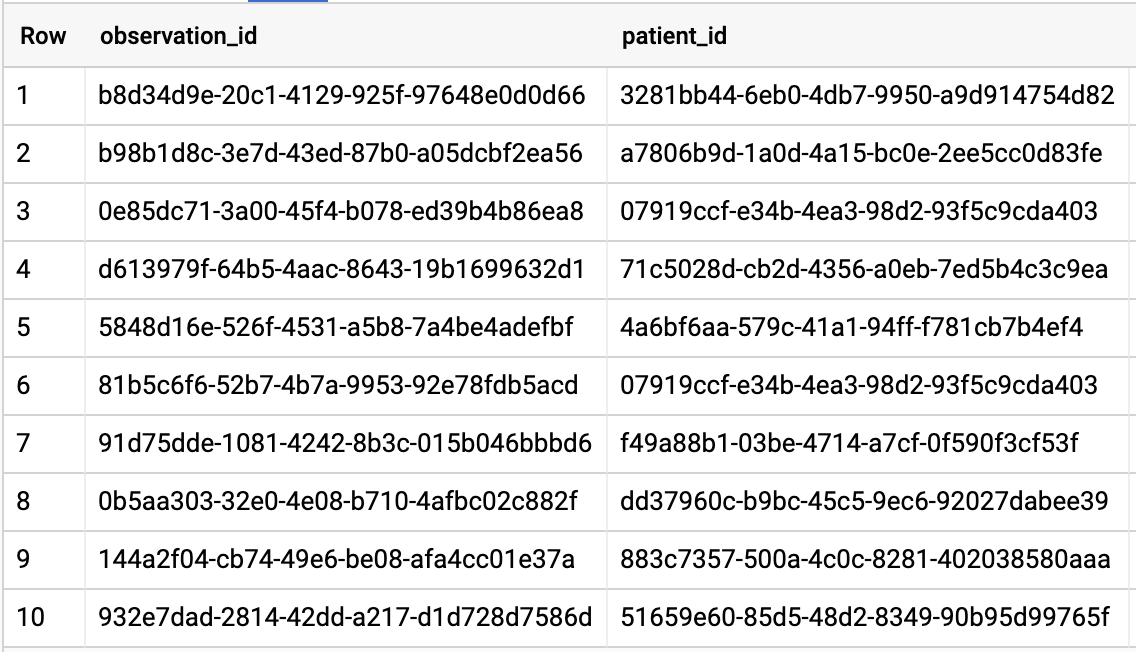
OBTENGA TODOS LOS PACIENTES QUE TIENEN UNA TASA DE A1C >= 6.5
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
Resultados de la consulta:
4. Crea una instancia de AI Platform Notebooks
Sigue las instrucciones de este vínculo para crear una nueva instancia de AI Platform Notebooks (JupyterLab).
Asegúrate de habilitar la API de Compute Engine.
Puedes elegir " Create a new notebook with default options (Crea un notebook nuevo con opciones predeterminadas) o " Crea un notebook nuevo y especifica tus opciones".
5. Crea un notebook de análisis de datos
Abrir la instancia de AI Platform Notebooks
En esta sección, crearemos y programaremos un notebook nuevo de Jupyter desde cero.
- Navega a la página AI Platform Notebooks en Google Cloud Platform Console para abrir una instancia de notebook. IR A LA PÁGINA NOTEBOOKS DE LA PLATAFORMA DE IA
- Selecciona Abrir JupyterLab (Open JupyterLab) para la instancia que deseas abrir.
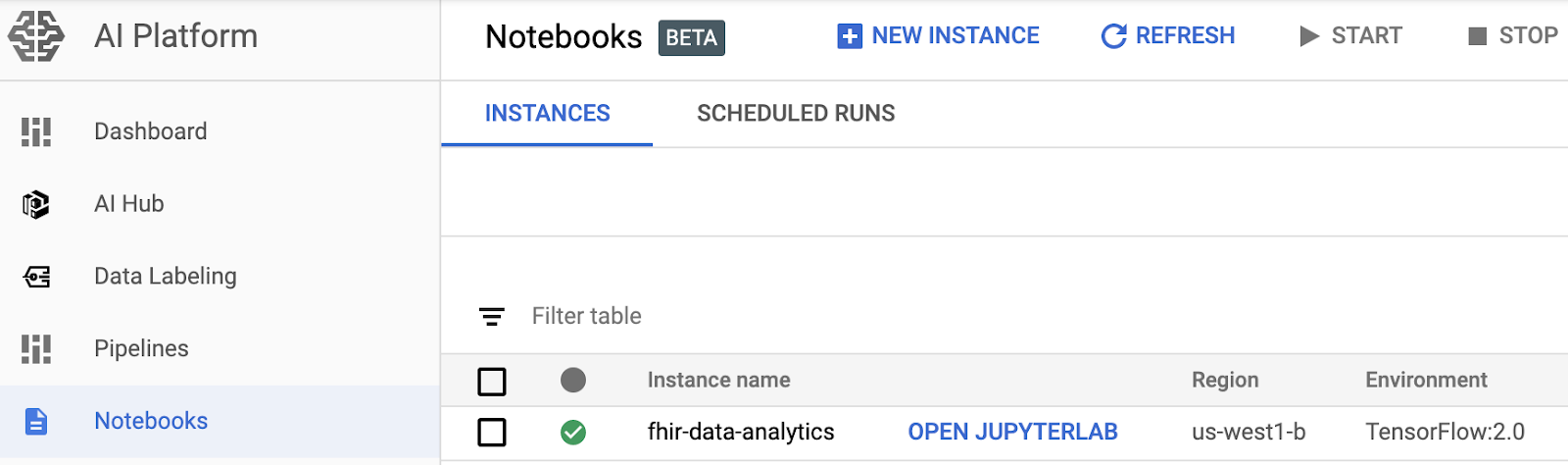
- AI Platform Notebooks te dirige a la URL de tu instancia de notebook.
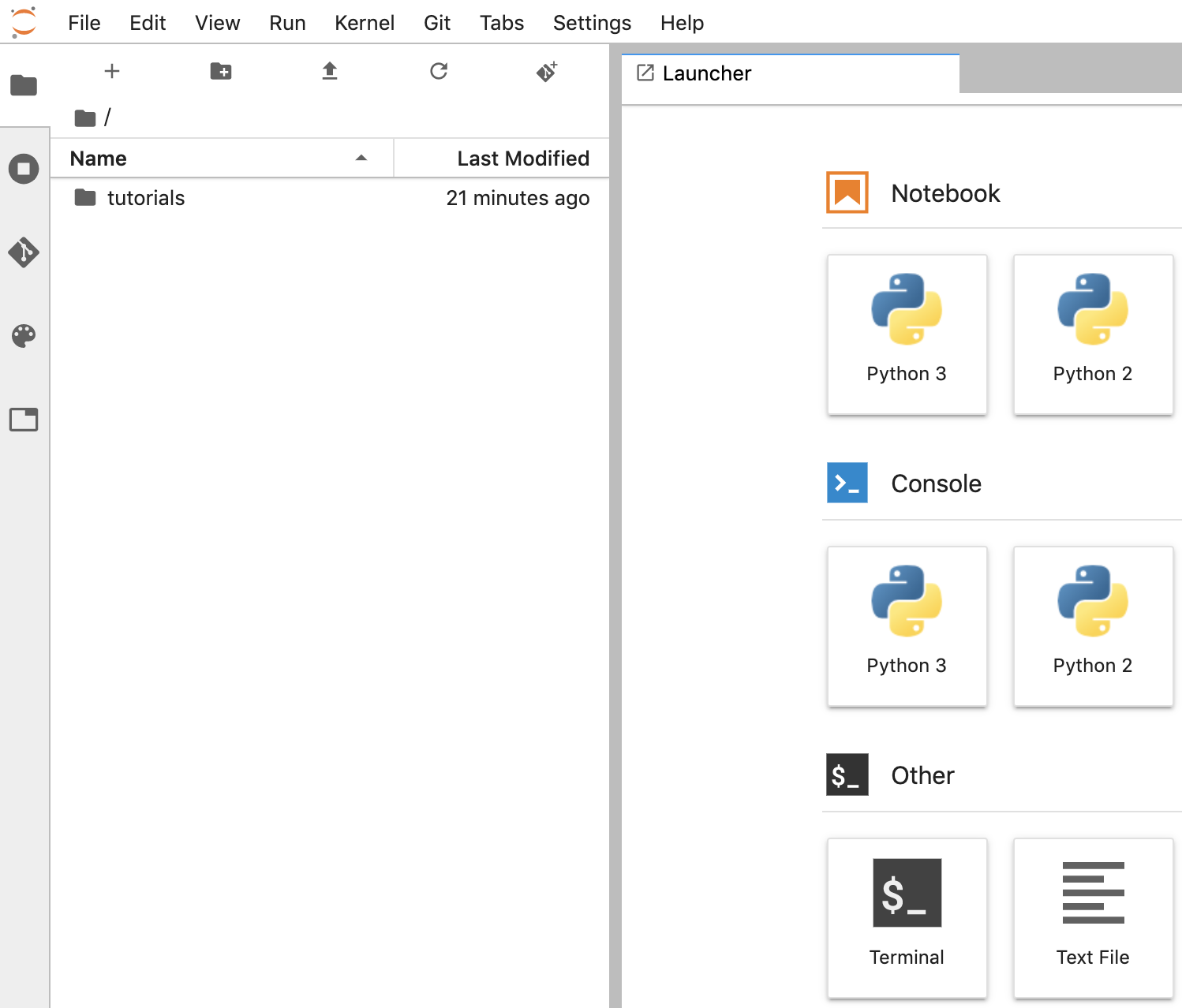
Crea un notebook
- En JupyterLab, ve a File -> Nuevo -> Notebook y selecciona el kernel “Python 3” en la ventana emergente o selecciona "Python 3" en la sección Notebook de la ventana del selector para crear un Untitled.ipynbnotebook.
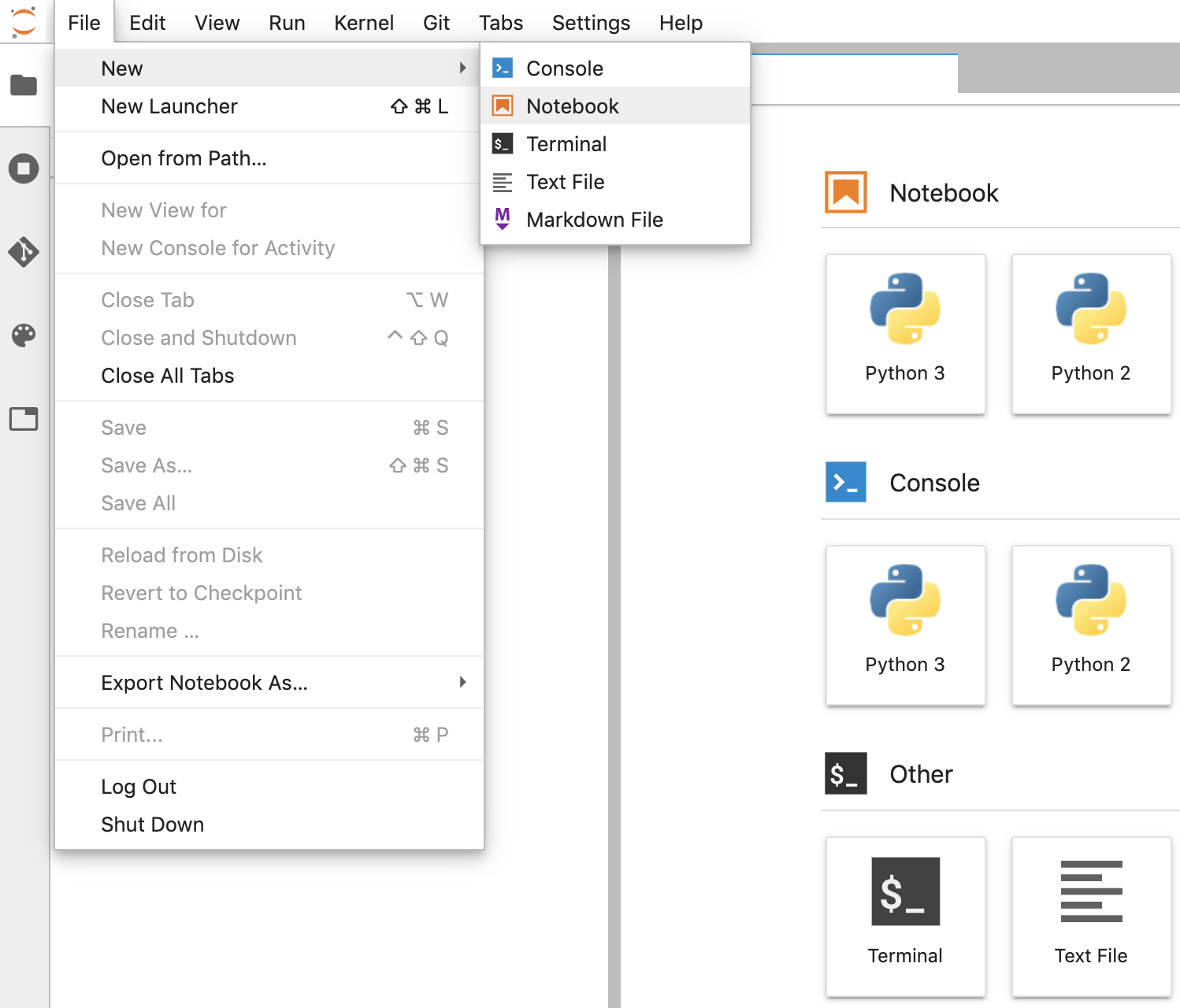
- Haz clic con el botón derecho en Untitled.ipynb y cambia el nombre del notebook a “fhir_data_from_bigquery.ipynb”. Haz doble clic para abrirlo, compilar las consultas y guardar el notebook.
- Para descargar un notebook, haz clic con el botón derecho en el archivo *.ipynb y selecciona Descargar en el menú.
- También puedes cargar un bloc de notas existente haciendo clic en la "flecha hacia arriba" .
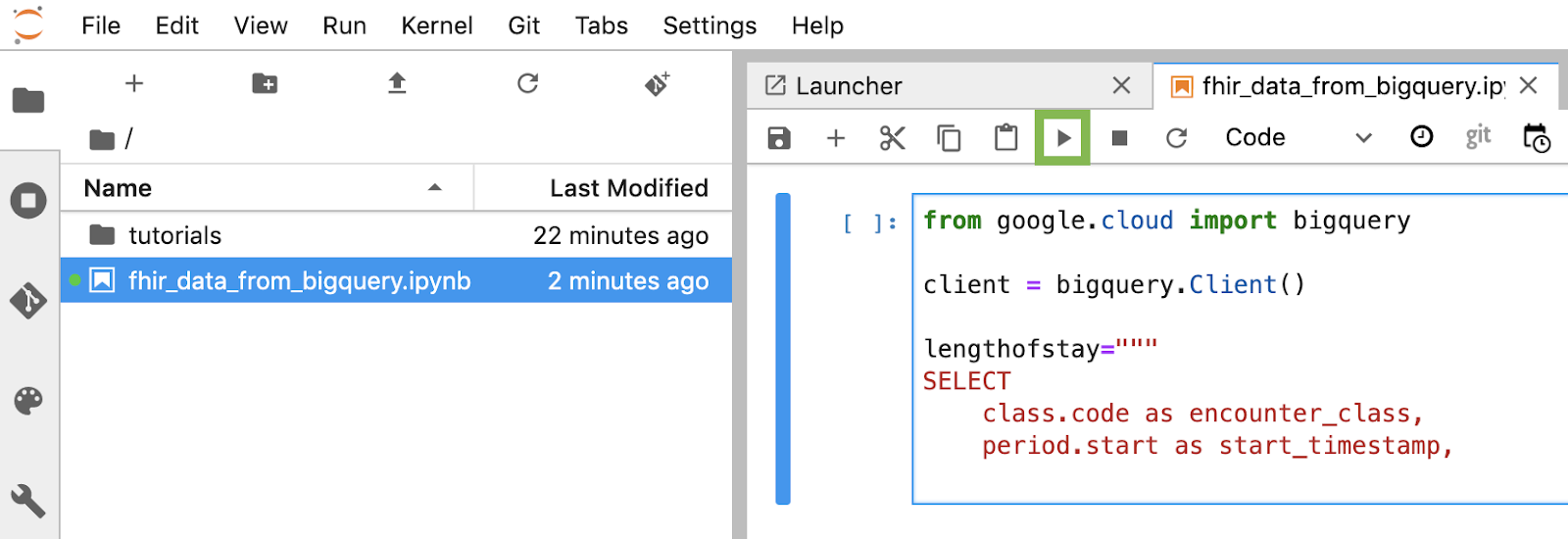
Compila y ejecuta cada bloque de código en el notebook
Copia y ejecuta cada bloque de código proporcionado en esta sección uno por uno. Para ejecutar el código, haz clic en "Run". (triángulo).
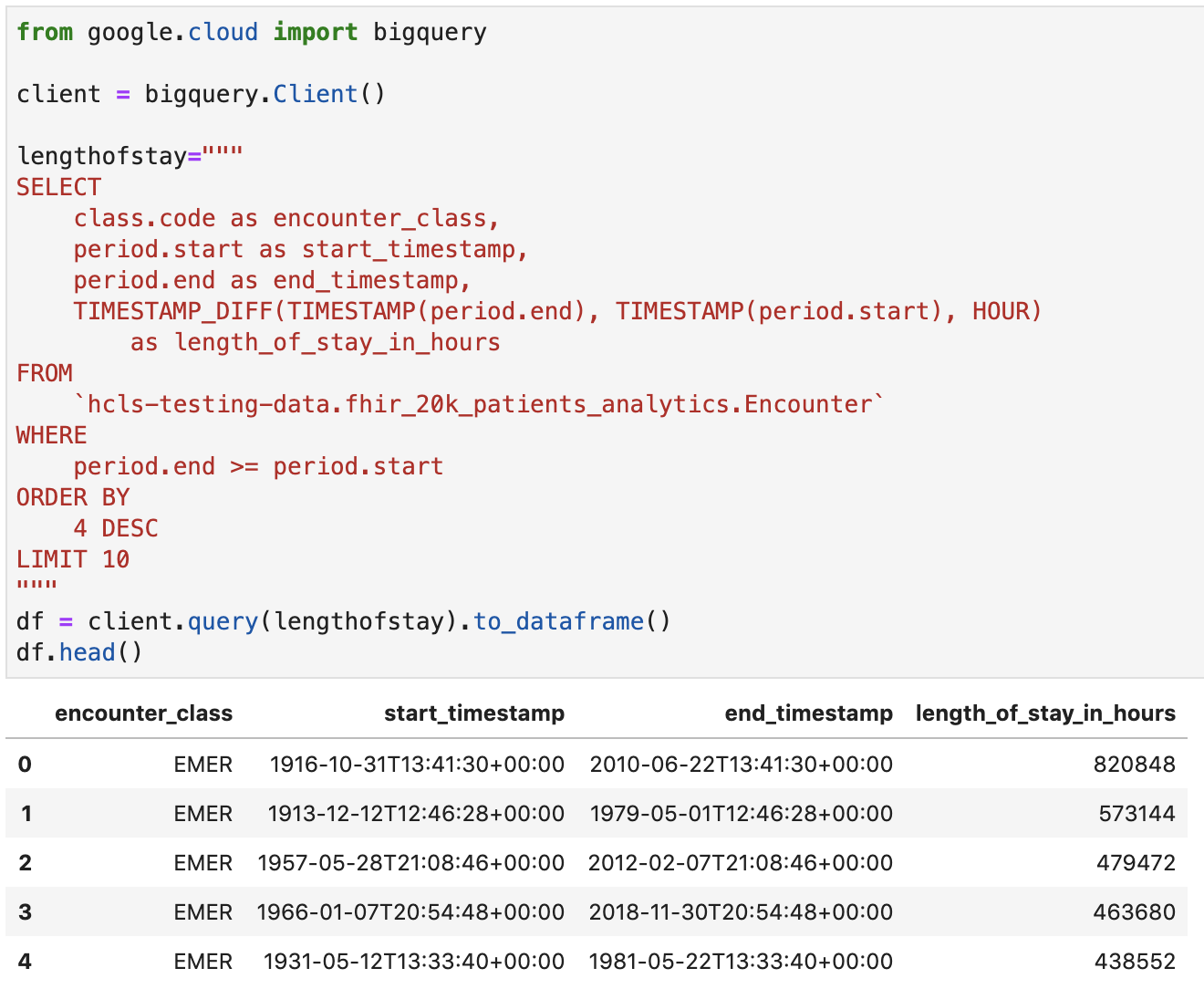
Obtén la duración de la estadía de los encuentros en horas
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
Resultado del código y la ejecución:
Obtener observaciones sobre los valores de colesterol
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
Resultado de la ejecución:

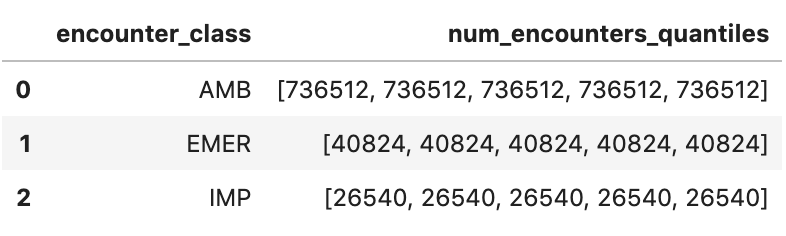
Obtén cuantiles de encuentro aproximados
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
Resultado de la ejecución:
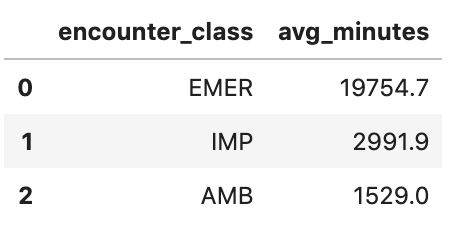
Obtén la duración promedio de los encuentros en minutos
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
Resultado de la ejecución:
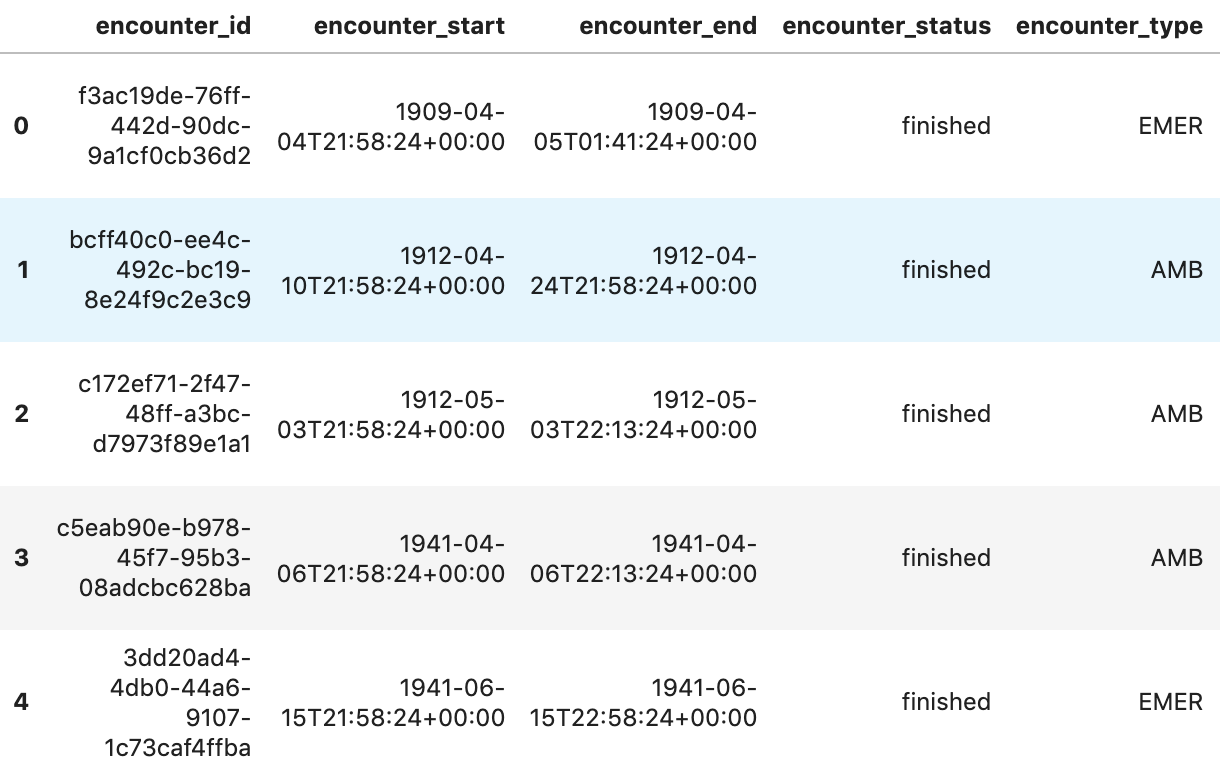
Obtener encuentros por paciente
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
Resultado de la ejecución:
Obtener organizaciones
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
Resultado de la ejecución:

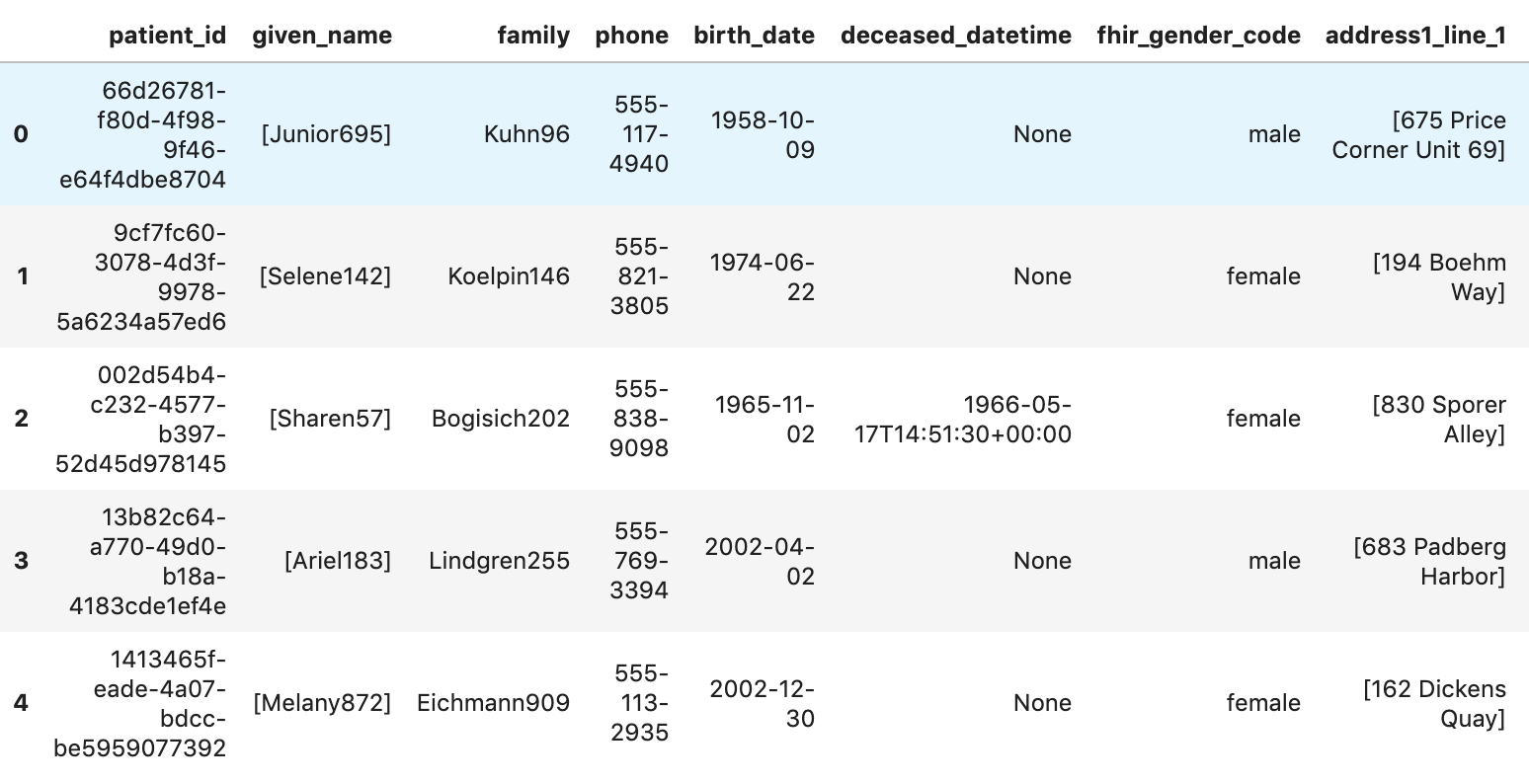
Otorga permiso para obtener pacientes.
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
Resultados de la ejecución:
6. Crear gráficos en AI Platform Notebooks
Ejecuta celdas de código en el notebook “fhir_data_from_bigquery.ipynb” para dibujar un gráfico de barras.
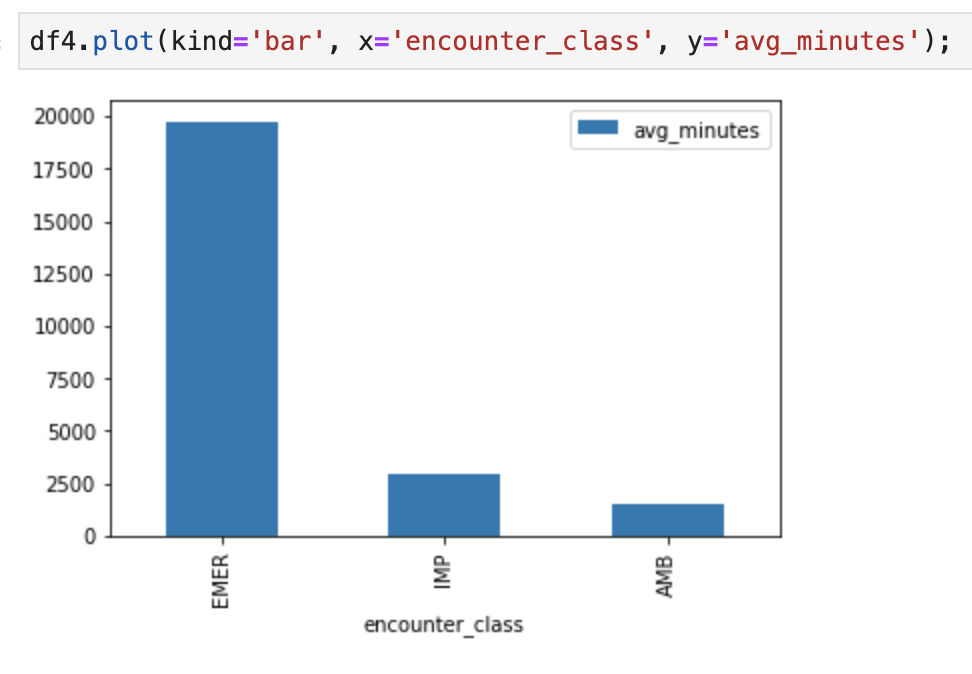
Por ejemplo, obtén la duración promedio de los encuentros en minutos.
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
Resultados del código y la ejecución:
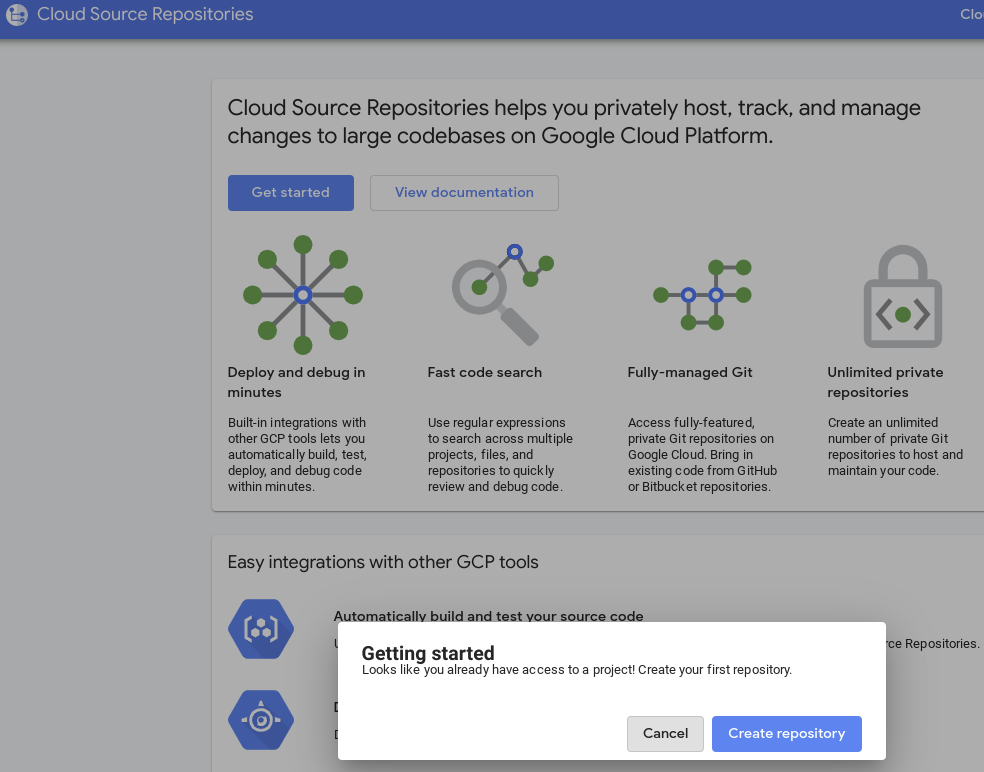
7. Confirmar notebook en Cloud Source Repository
- En GCP Console, navega a Source Repositories. Si es la primera vez que lo usas, haz clic en Comenzar y, luego, en Crear repositorio.
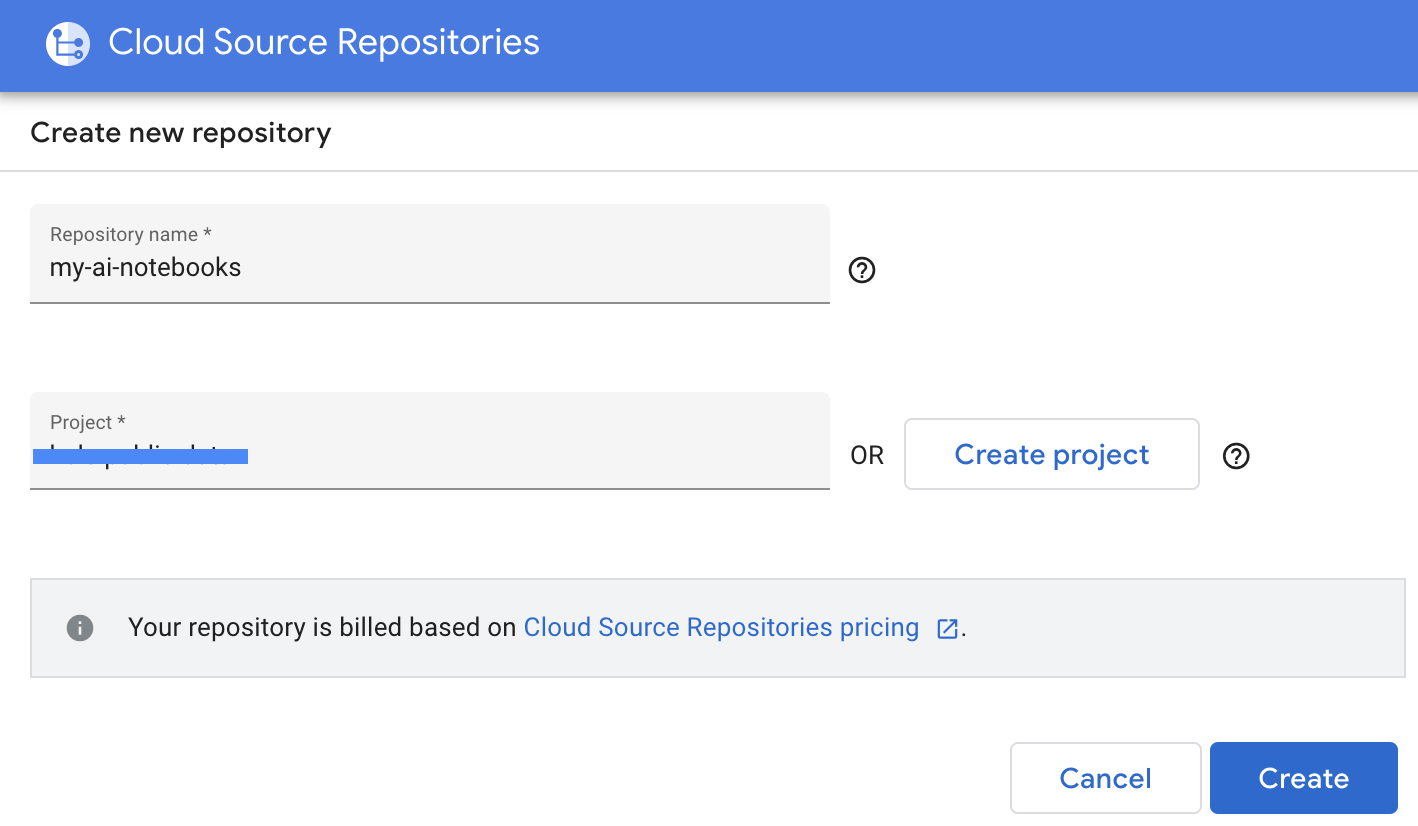
- Para continuar, navega a GCP -> Cloud Source Repositories y haz clic en +Agregar repositorio para crear uno nuevo.

- Selecciona “Crear un repositorio nuevo” y, luego, haz clic en Continuar.
- Proporciona el nombre del repositorio y el nombre del proyecto y, luego, haz clic en Crear.
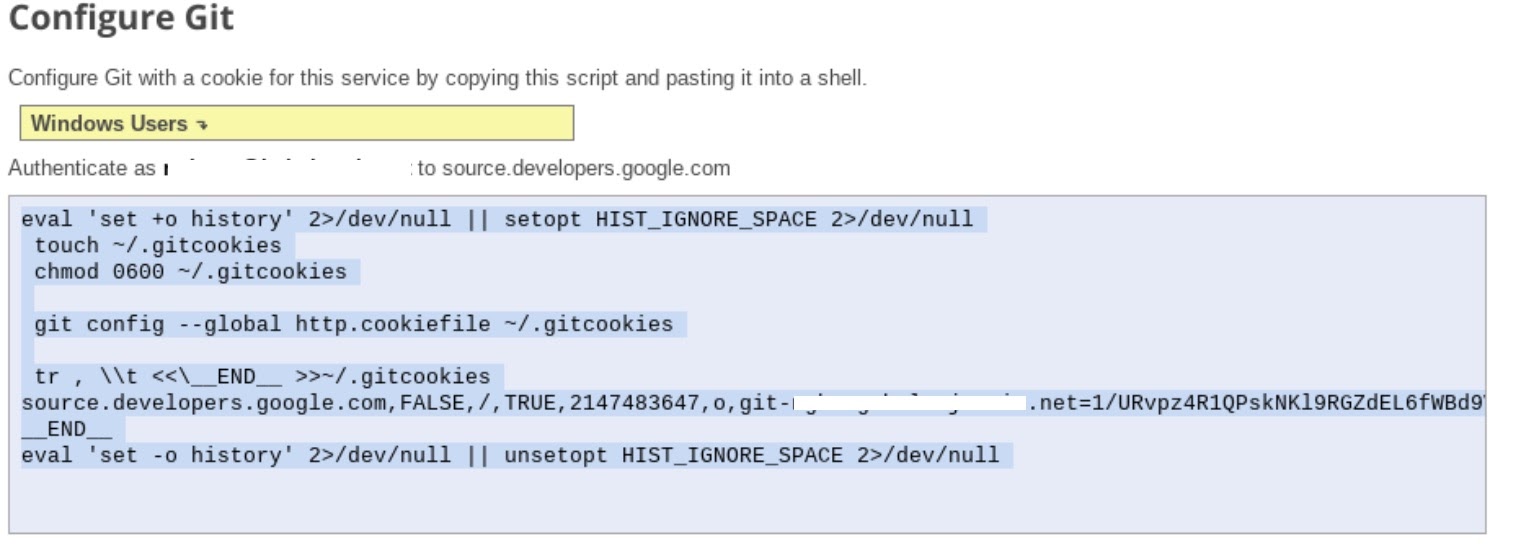
- Selecciona "Clonar tu repositorio a un repositorio de Git local" y, luego, selecciona Credenciales generadas de forma manual.
- Sigue el paso 1, "Genera y almacena credenciales de Git". instrucciones (consulta a continuación). Copia la secuencia de comandos que aparece en la pantalla.
- Inicia la sesión de la terminal en Jupyter.
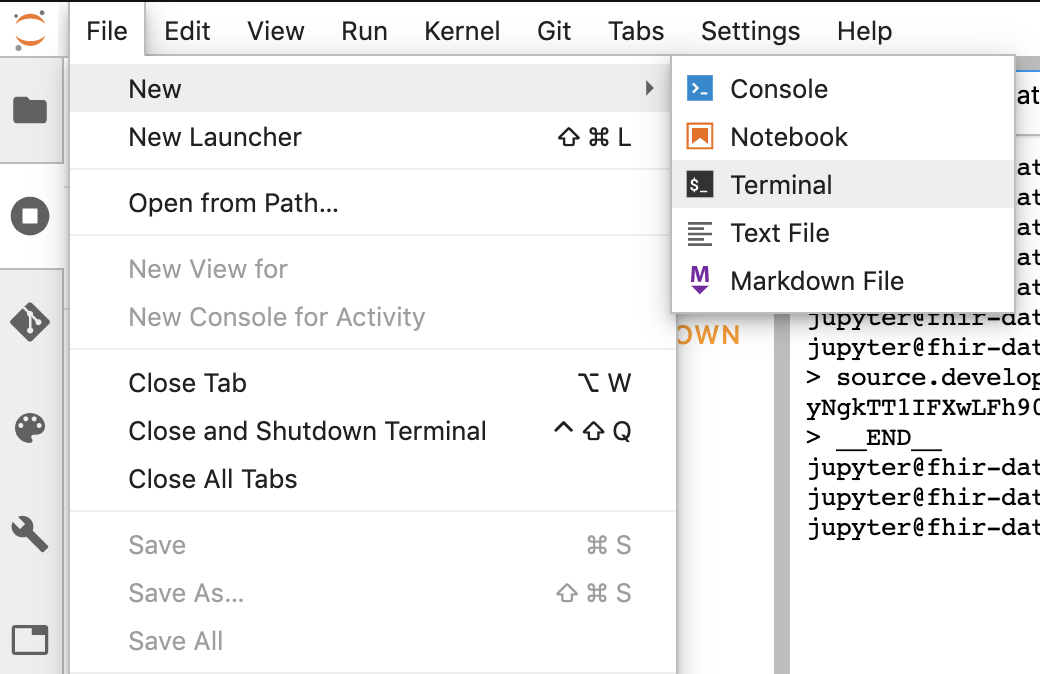
- Pega todos los comandos desde tu “Configurar Git” en la terminal de Jupyter.
- Copia la ruta de acceso de la clonación del repositorio de los repositorios de origen de Cloud para GCP (paso 2 en la captura de pantalla a continuación).
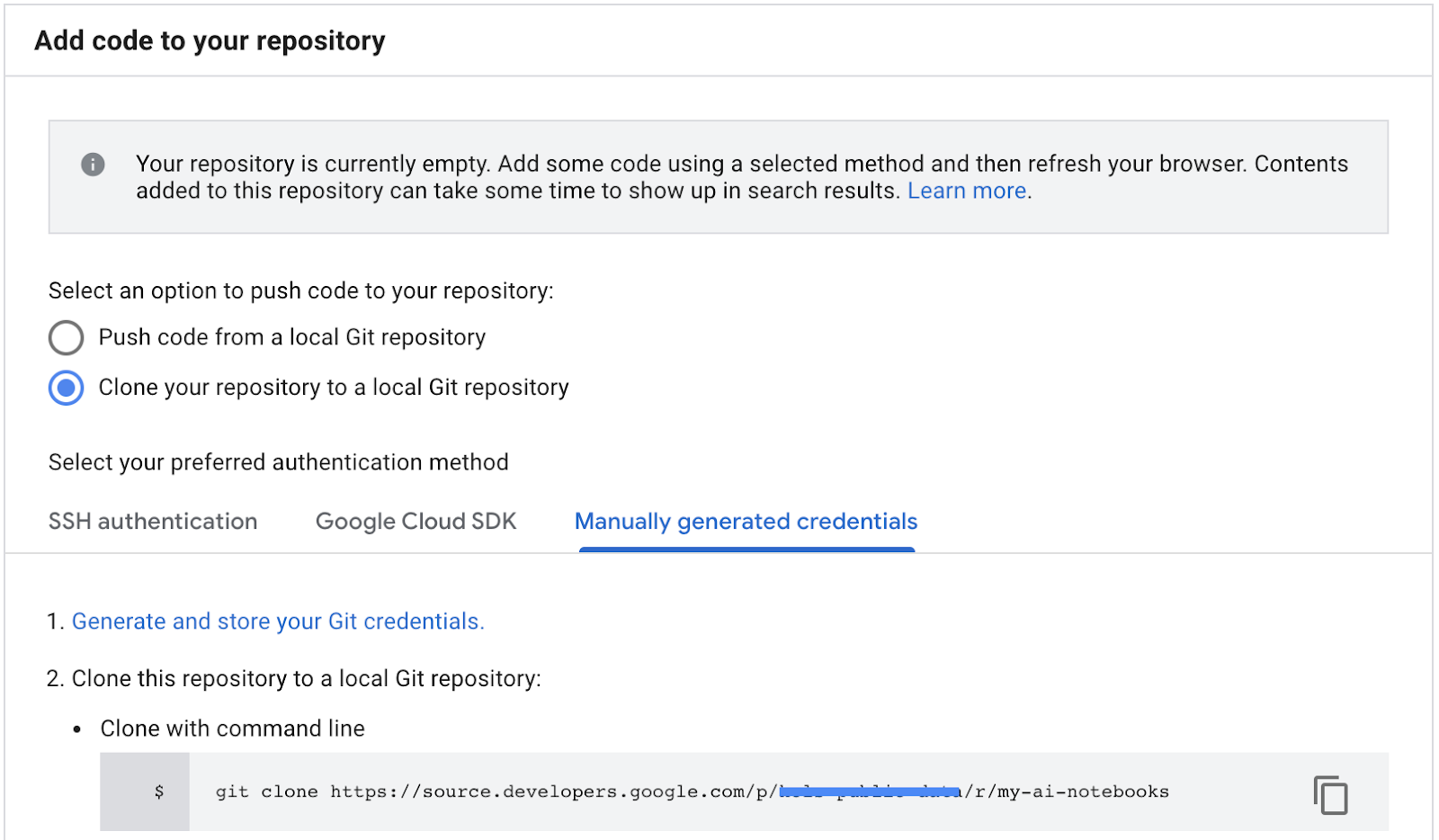
- Pega este comando en la terminal de JupiterLab. El comando se verá como el siguiente:
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- La herramienta “my-ai-notebooks” de Terraform en JupyterLab.
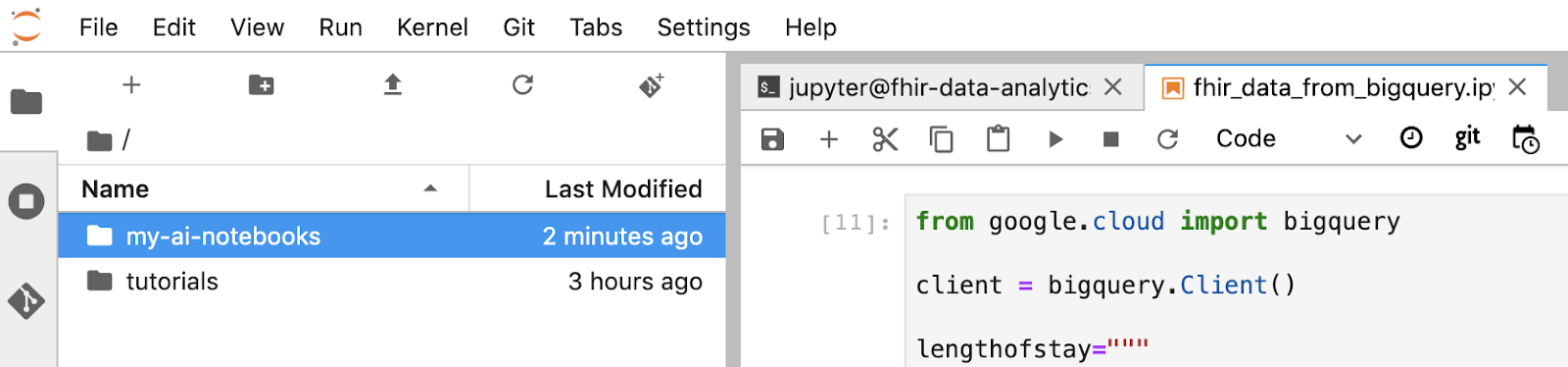
- Mueve tu notebook (fhir_data_from_bigquery.ipynb) a la carpeta “my-ai-notebooks”.
- En la terminal de Jupyter, cambia el directorio a “cd my-ai-notebooks”.
- Almacena los cambios en etapa intermedia con la terminal de Jupyter. También puedes usar la IU de Jupyter (haz clic con el botón derecho en los archivos en el área Sin seguimiento, selecciona Realizar seguimiento y, luego, los archivos se mueven al área Con seguimiento, y viceversa). El área modificada contiene los archivos modificados).
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
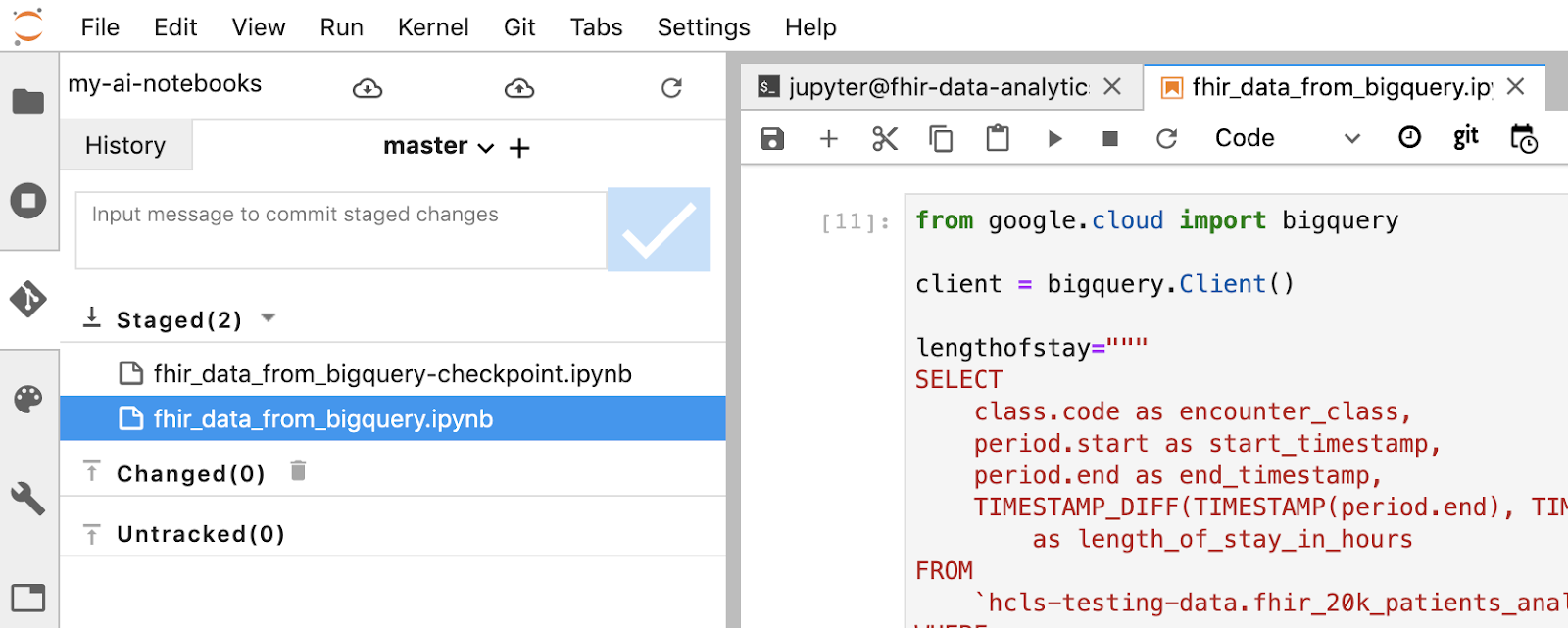
- Confirma los cambios con la terminal o la IU de Jupyter (escribe el mensaje y haz clic en el botón “Checked”).
git commit -m "message goes here"
- Envía los cambios al repositorio remoto con la terminal o la IU de Jupyter (haz clic en el ícono “enviar cambios confirmados”
 ).
).
git push --all
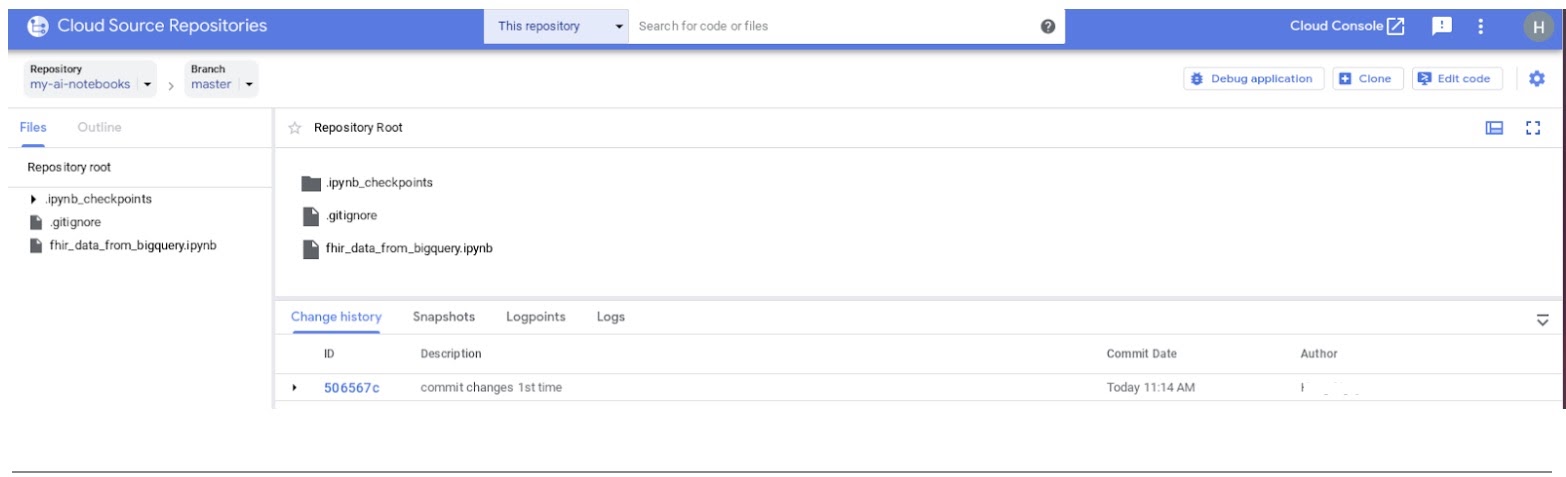
- En GCP Console, navega a Source Repositories. Haz clic en my-ai-notebooks. Ten en cuenta que "fhir_data_from_bigquery.ipynb" ahora se guarda en GCP Source Repository.
8. Limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud Platform por los recursos que usaste en este codelab, una vez que hayas terminado el instructivo, puedes limpiar los recursos que creaste en GCP para que no consuman tu cuota y no se te facture por ellos en el futuro. En las secciones siguientes, se describe cómo borrar o desactivar estos recursos.
Borra el conjunto de datos de BigQuery
Sigue estas instrucciones para borrar el conjunto de datos de BigQuery que creaste como parte de este instructivo. O bien, navega a la consola de BigQuery, en el proyecto UnPIN hcls-testing-data,si usaste el conjunto de datos de prueba fhir_20k_patients_analytics.
Cierra la instancia de AI Platform Notebooks
Sigue las instrucciones de este vínculo Cierra una instancia de notebook | AI Platform Notebooks para cerrar una instancia de AI Platform Notebooks
Borra el proyecto
La manera más fácil de eliminar la facturación es borrar el proyecto que creaste para el instructivo.
Para borrar el proyecto, haz lo siguiente:
- En GCP Console, ve a la página Proyectos. IR A LA PÁGINA PROYECTOS
- En la lista de proyectos, selecciona el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
9. Felicitaciones
Felicitaciones, completaste correctamente el codelab para acceder, consultar y analizar datos de atención médica con formato FHIR con BigQuery y AI Platform Notebooks.
Accediste a un conjunto de datos públicos de BigQuery en GCP.
Desarrollaste y probaste consultas en SQL con la IU de BigQuery.
Creaste y, luego, iniciaste una instancia de AI Platform Notebooks.
Ejecutaste consultas en SQL en JupyterLab y almacenaste los resultados de las consultas en Pandas DataFrame.
Creaste tablas y gráficos con Matplotlib.
Confirmaste y enviaste tu notebook a un Cloud Source Repository en GCP.
Ahora conoces los pasos clave necesarios para comenzar tu recorrido de análisis de datos de atención médica con BigQuery y AI Platform Notebooks de Google Cloud Platform.
©Google, Inc. or its affiliates. All rights reserved. Do not distribute.