
1. Einführung

Zuletzt aktualisiert: 22.09.2022
In diesem Codelab wird ein Muster zum Zugreifen auf und Analysieren von in BigQuery aggregierten Gesundheitsdaten mit BigQueryUI und AI Platform Notebooks implementiert. Darin wird die Datenexploration großer Gesundheitsdatensätze mit gängigen Tools wie Pandas und Matplotlib in einem HIPAA-konformen AI Platform Notebooks veranschaulicht. Dazu führen Sie den ersten Teil der Aggregation in BigQuery durch. Anschließend verarbeiten Sie das resultierende, kleinere Pandas-Dataset lokal weiter. AI Platform Notebooks bietet eine verwaltete Jupyter-Umgebung, sodass Sie selbst keine Notebookserver ausführen müssen. AI Platform Notebooks ist gut in andere GCP-Dienste wie BigQuery und Cloud Storage eingebunden. So können Sie schnell und einfach mit Datenanalysen und ML auf der Google Cloud Platform beginnen.
In diesem Codelab lernen Sie Folgendes:
- SQL-Abfragen mit der BigQuery-Benutzeroberfläche entwickeln und testen.
- Erstellen und starten Sie eine AI Platform Notebooks-Instanz in der GCP.
- SQL-Abfragen aus dem Notebook ausführen und Abfrageergebnisse in einem Pandas DataFrame speichern.
- Diagramme und Grafiken mit Matplotlib erstellen
- Übertragen Sie das Notebook per Commit und Push in ein Cloud Source Repository in der GCP.
Was benötige ich, um dieses Codelab durchzuarbeiten?
- Sie benötigen Zugriff auf ein GCP-Projekt.
- Ihnen muss die Rolle Inhaber für das GCP-Projekt zugewiesen sein.
- Sie benötigen ein Gesundheitsdataset in BigQuery.
Wenn Sie kein GCP-Projekt haben, erstellen Sie ein neues.
2. Projekt einrichten
In diesem Codelab verwenden wir ein vorhandenes Dataset in BigQuery (hcls-testing-data.fhir_20k_patients_analytics). Dieses Dataset ist bereits mit synthetischen Gesundheitsdaten gefüllt.
Zugriff auf das synthetische Dataset erhalten
- Senden Sie von der E-Mail-Adresse, mit der Sie sich in der Cloud Console anmelden, eine E-Mail an hcls-solutions-external+subscribe@google.com, um eine Beitrittsanfrage zu senden.
- Sie erhalten eine E‑Mail mit einer Anleitung, wie Sie die Aktion bestätigen können.
- Verwenden Sie die Option, um auf die E‑Mail zu antworten und der Gruppe beizutreten. Klicken Sie NICHT auf die Schaltfläche
 .
. - Sobald Sie die Bestätigungs-E-Mail erhalten haben, können Sie mit dem nächsten Schritt im Codelab fortfahren.
Projekt anpinnen
- Wählen Sie in der GCP Console Ihr Projekt aus und rufen Sie BigQuery auf.
- Klicken Sie auf das Drop-down-Menü + DATEN HINZUFÜGEN und wählen Sie „Projekt anpinnen“ > „Projektnamen eingeben“ aus.
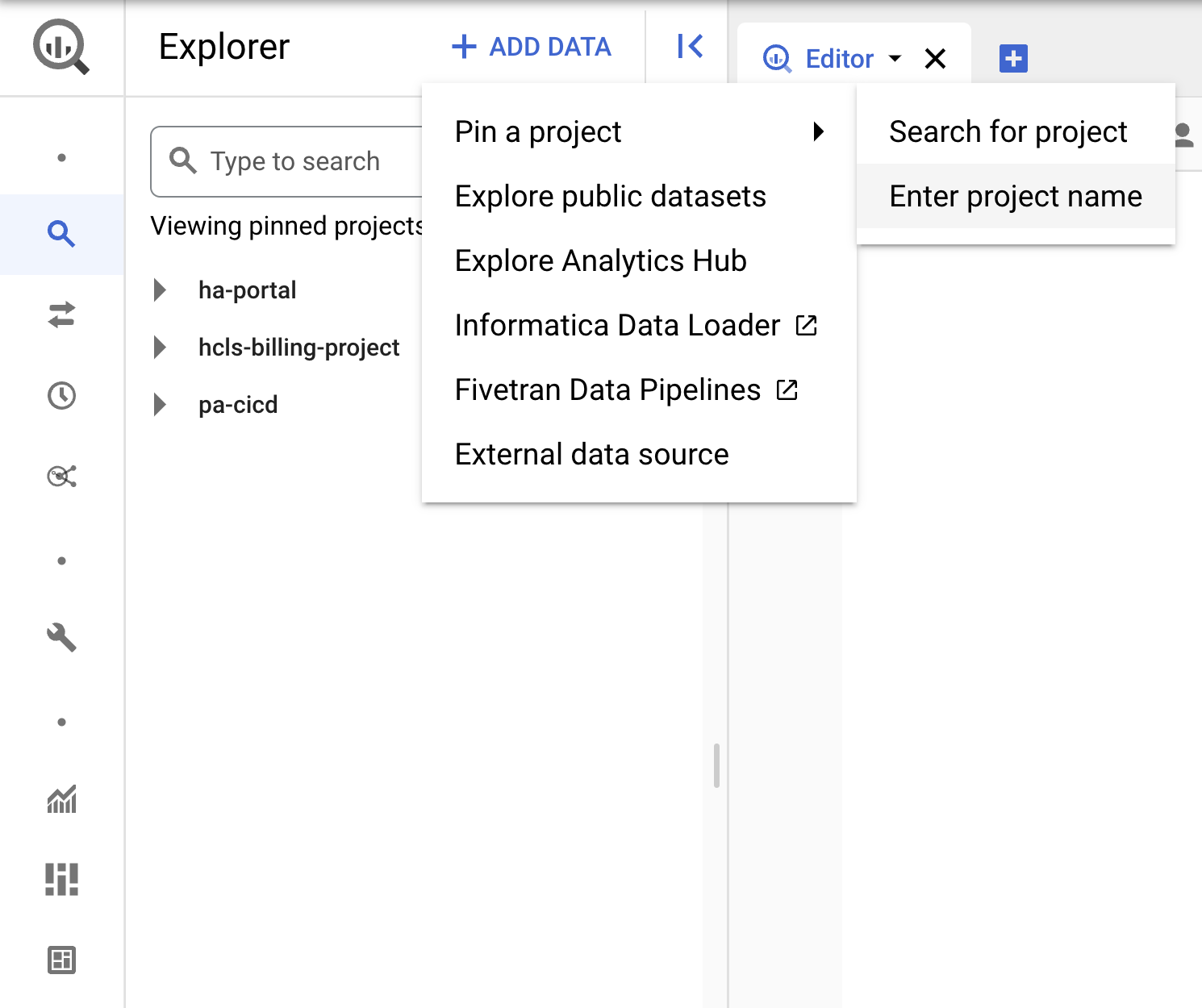
- Geben Sie den Projektnamen hcls-testing-data ein und klicken Sie auf ANPINNEN. Das BigQuery-Testdataset fhir_20k_patients_analytics kann verwendet werden.

3. Abfragen mit der BigQuery-Benutzeroberfläche entwickeln
BigQuery-UI-Einstellung
- Wechseln Sie zur BigQuery-Konsole. Klicken Sie dazu links oben im GCP-Menü (Dreistrich-Menü) auf „BigQuery“.
- Klicken Sie in der BigQuery-Konsole auf Mehr → Abfrageeinstellungen und prüfen Sie, ob das Menü „Legacy-SQL“ NICHT ausgewählt ist. Sie verwenden Standard-SQL.

Abfragen erstellen
Geben Sie im Fenster „Abfrageeditor“ die folgende Abfrage ein und klicken Sie auf Ausführen, um sie auszuführen. Sehen Sie sich dann die Ergebnisse im Fenster Abfrageergebnisse an.
PATIENTEN BEFRAGEN
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
Abfrage im „Abfrageeditor“ und Ergebnisse:

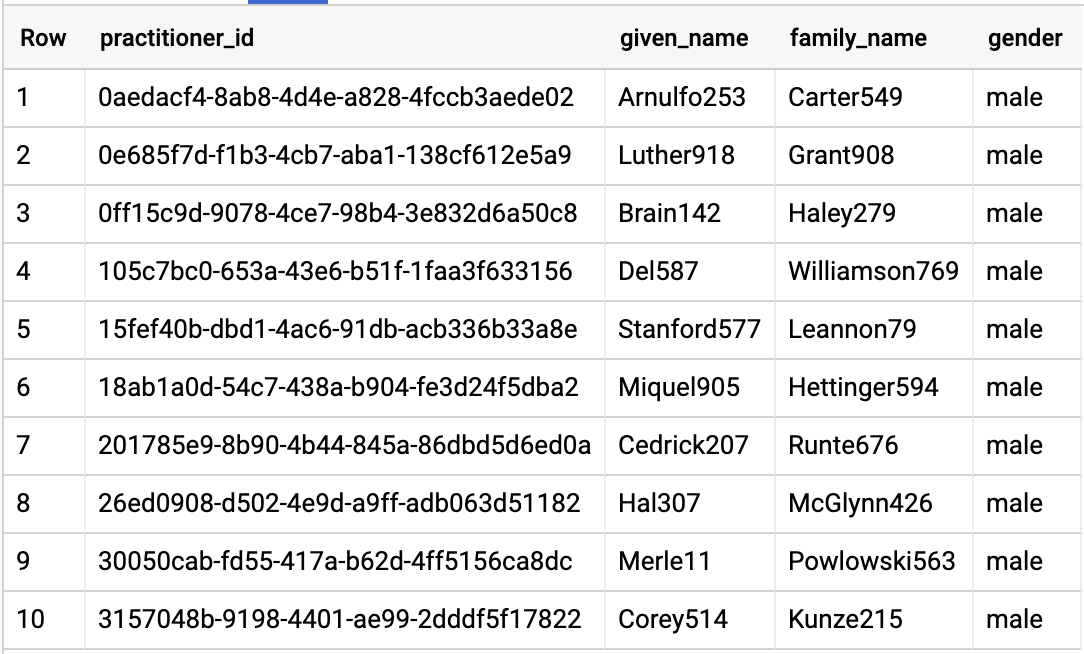
ABFRAGESPEZIALISTEN
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
Abfrageergebnisse:
ORGANISATION ABFRAGEN
Ändern Sie die Organisations-ID so, dass sie Ihrem Dataset entspricht.
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
Abfrageergebnisse:

BEGEGNUNGEN NACH PATIENT ABFRAGEN
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
Abfrageergebnisse:

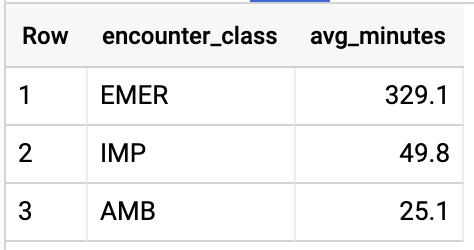
DURCHSCHNITTLICHE LÄNGE VON BEGEGNUNGEN NACH BEGEGNUNGSTYP ABFRAGEN
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
Abfrageergebnisse:
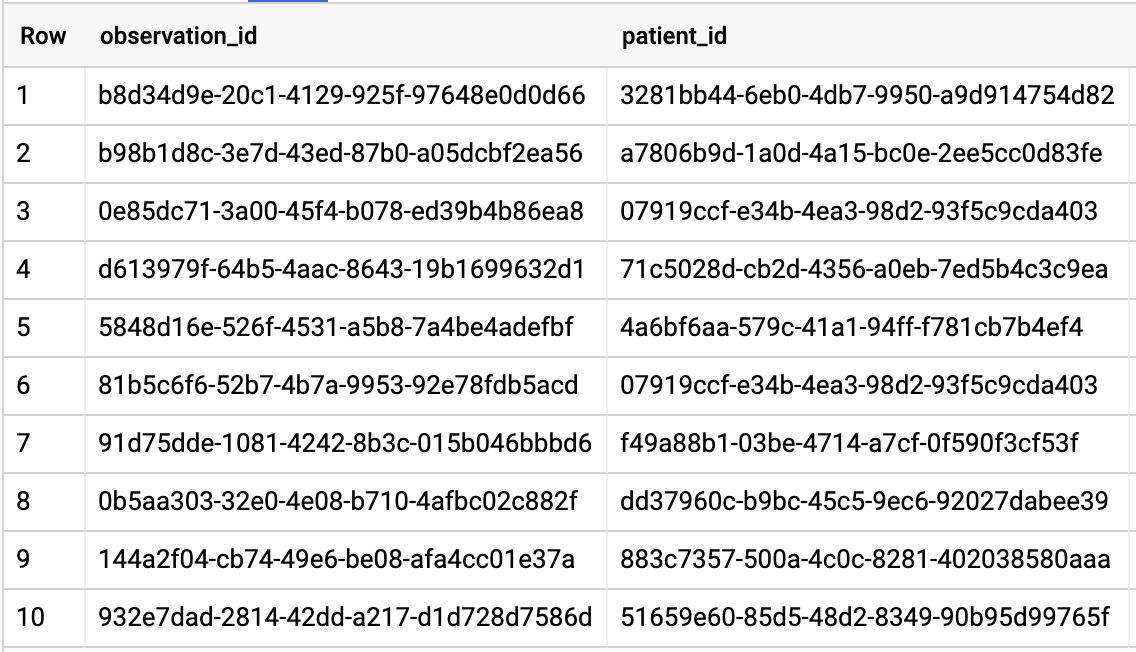
GET ALL PATIENTS WHO HAVE A1C RATE >= 6.5
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
Abfrageergebnisse:
4. AI Platform Notebooks-Instanz erstellen
Folgen Sie der Anleitung unter diesem Link, um eine neue AI Platform Notebooks-Instanz (JupyterLab) zu erstellen.
Aktivieren Sie die Compute Engine API.
Sie können Neues Notebook mit Standardoptionen erstellen oder Neues Notebook erstellen und Optionen festlegen auswählen.
5. Data Analytics-Notebook erstellen
AI Platform Notebooks-Instanz öffnen
In diesem Abschnitt erstellen wir ein neues Jupyter-Notebook von Grund auf.
- Öffnen Sie eine Notebook-Instanz, indem Sie in der Google Cloud Console zur Seite AI Platform Notebooks wechseln. ZUR SEITE „AI PLATFORM NOTEBOOKS“
- Wählen Sie JupyterLab öffnen für das Notebook aus, das Sie öffnen möchten.

- AI Platform Notebooks leitet Sie zu einer URL für Ihre Notebookinstanz weiter.

Notebook erstellen
- Wählen Sie in JupyterLab File -> New -> Notebook (Datei -> Neu -> Notebook) aus und wählen Sie im Pop-up-Fenster den Kernel „Python 3“ aus. Alternativ können Sie im Launcher-Fenster unter „Notebook“ die Option „Python 3“ auswählen, um ein Notebook mit dem Namen „Untitled.ipynb“ zu erstellen.
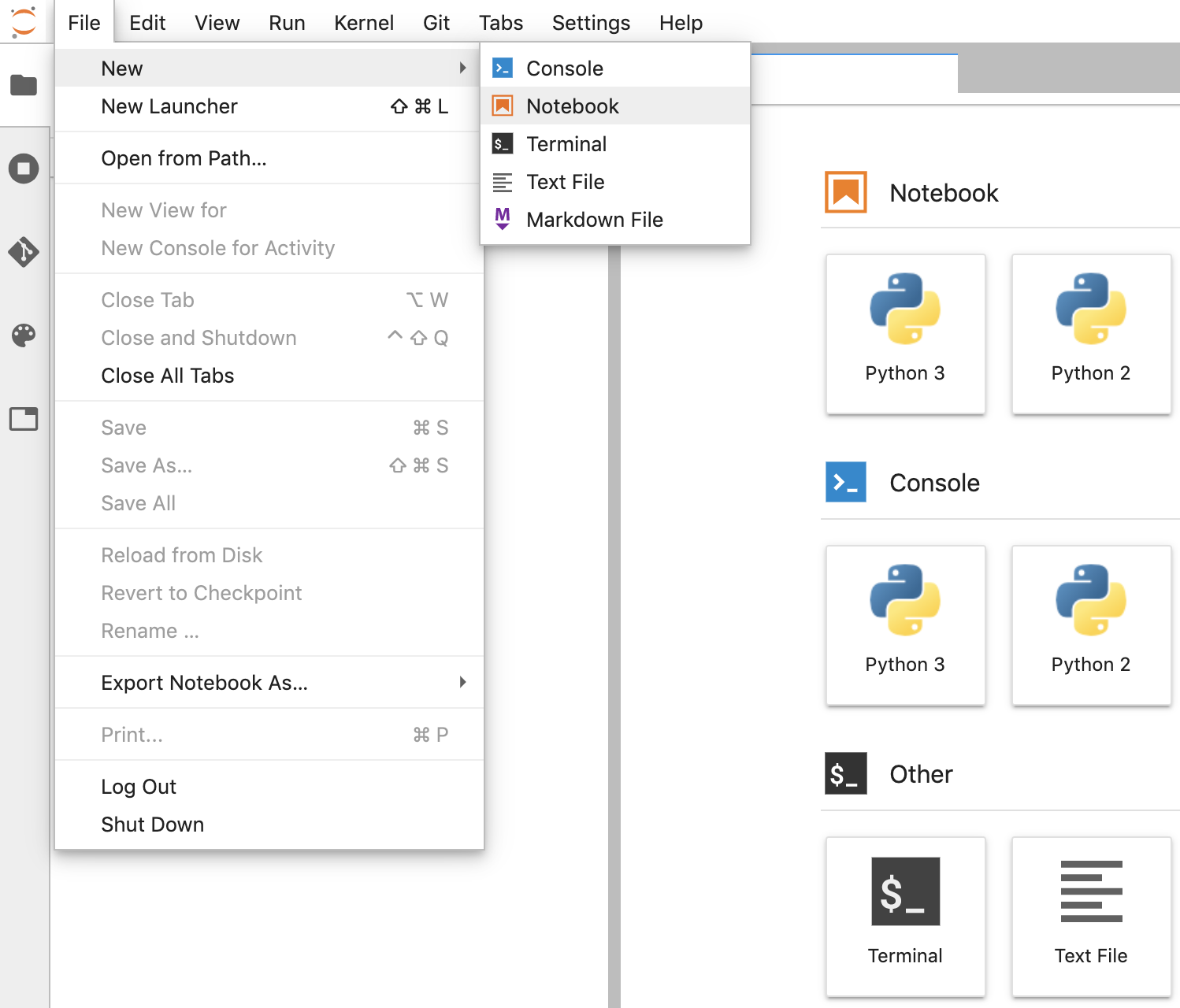
- Klicken Sie mit der rechten Maustaste auf „Untitled.ipynb“ und benennen Sie das Notebook in „fhir_data_from_bigquery.ipynb“ um. Doppelklicken Sie darauf, um es zu öffnen, die Abfragen zu erstellen und das Notebook zu speichern.
- Sie können ein Notebook herunterladen, indem Sie mit der rechten Maustaste auf die Datei „*.ipynb“ klicken und im Menü „Herunterladen“ auswählen.

- Sie können auch ein vorhandenes Notebook hochladen, indem Sie auf die Schaltfläche mit dem Aufwärtspfeil klicken.

Jeden Codeblock im Notebook erstellen und ausführen
Kopieren Sie jeden Codeblock in diesem Abschnitt und führen Sie ihn einzeln aus. Klicken Sie zum Ausführen des Codes auf Ausführen (Dreieck).

Aufenthaltsdauer für Begegnungen in Stunden abrufen
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
Code und Ausführungsausgabe:

Beobachtungen abrufen – Cholesterinwerte
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
Ausführungsausgabe:

Ungefähre Quantile für Begegnungen abrufen
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
Ausführungsausgabe:

Durchschnittliche Dauer der Begegnungen in Minuten abrufen
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
Ausführungsausgabe:

Behandlungen pro Patient abrufen
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
Ausführungsausgabe:

Organisationen abrufen
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
Ausführungsergebnis:

Patienten abrufen
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
Ausführungsergebnisse:

6. Diagramme in AI Platform Notebooks erstellen
Führen Sie Codezellen im Notebook „fhir_data_from_bigquery.ipynb“ aus, um ein Balkendiagramm zu erstellen.
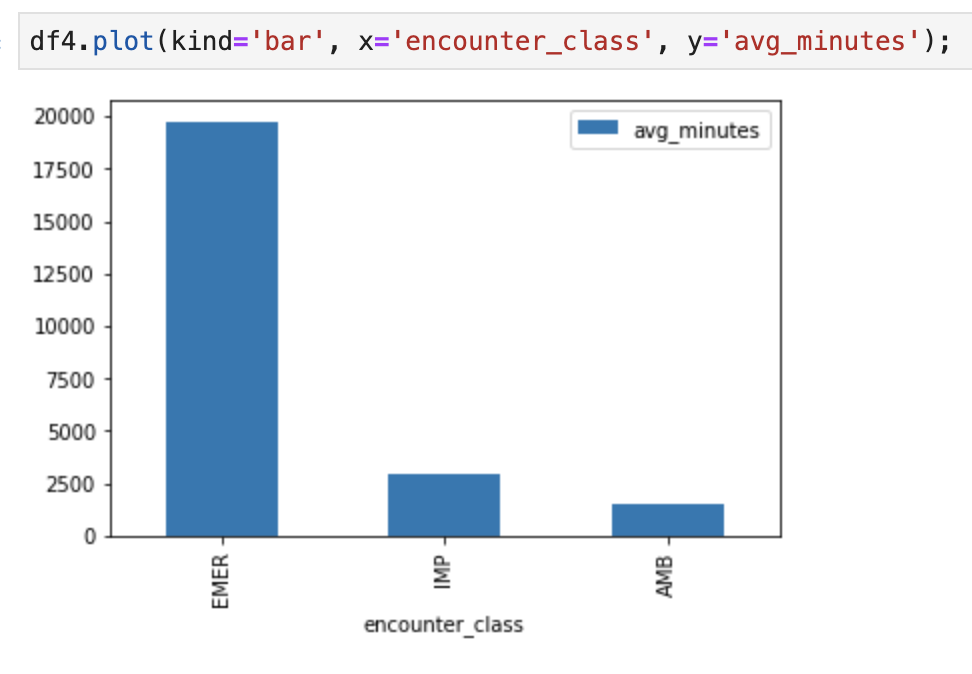
Sie können beispielsweise die durchschnittliche Dauer von Begegnungen in Minuten abrufen.
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
Code und Ausführungsergebnisse:
7. Notebook in Cloud Source Repositories übernehmen
- Rufen Sie in der GCP Console Source Repositories auf. Wenn Sie das Tool zum ersten Mal verwenden, klicken Sie auf „Erste Schritte“ und dann auf „Repository erstellen“.

- Rufen Sie GCP > Cloud Source Repositories auf und klicken Sie auf „+Repository hinzufügen“, um ein neues Repository zu erstellen.

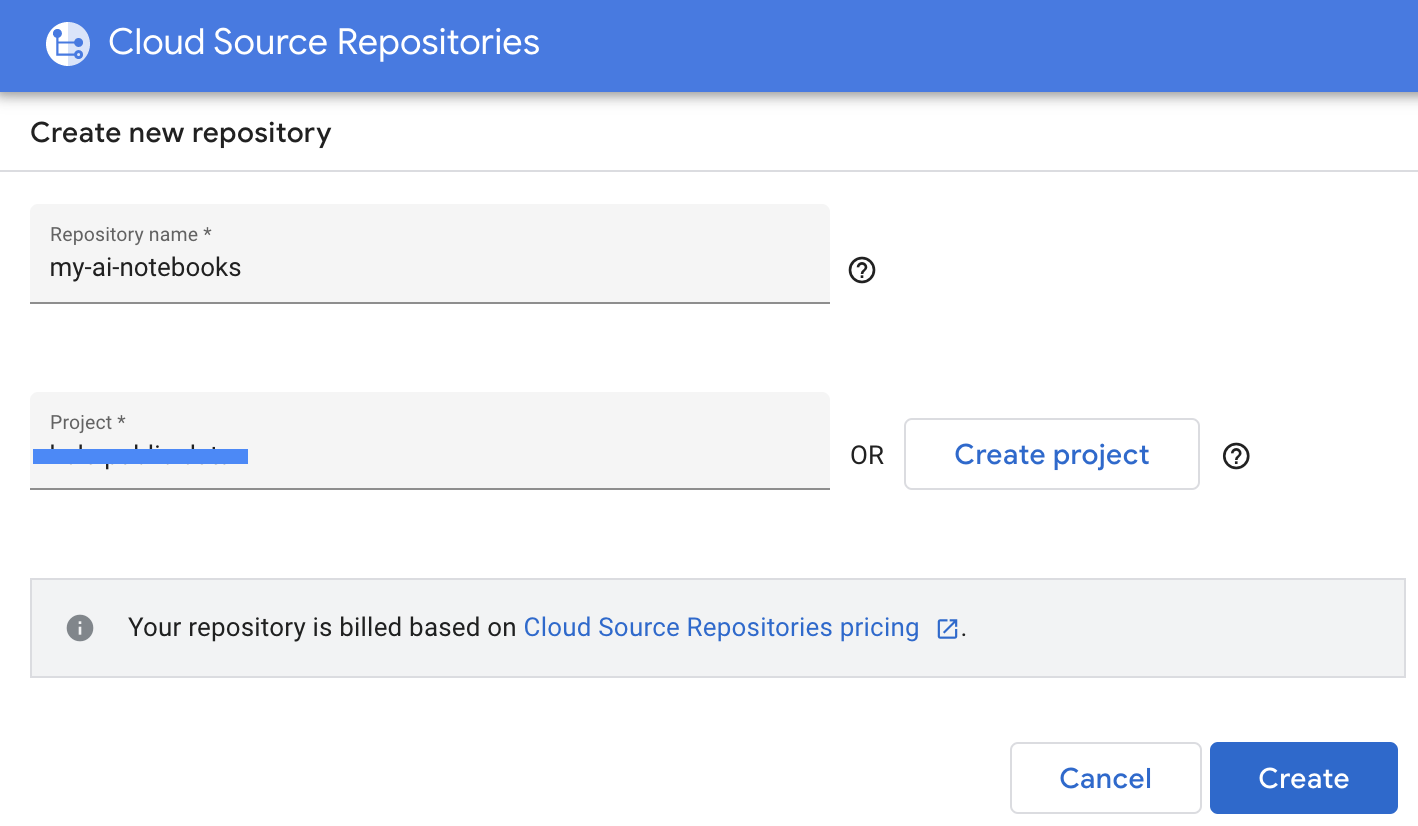
- Wählen Sie „Neues Repository erstellen“ aus und klicken Sie auf „Weiter“.
- Geben Sie einen Repository-Namen und einen Projektnamen ein und klicken Sie auf „Erstellen“.
- Wählen Sie „Ihr Repository in ein lokales Git-Repository klonen“ und dann „Manuell generierte Anmeldedaten“ aus.
- Folgen Sie der Anleitung in Schritt 1 „Git-Anmeldedaten generieren und speichern“ (siehe unten). Kopieren Sie das Skript, das auf dem Bildschirm angezeigt wird.

- Starten Sie eine Terminalsitzung in Jupyter.

- Fügen Sie alle Befehle aus dem Fenster „Git konfigurieren“ in das Jupyter-Terminal ein.
- Kopieren Sie den Repository-Klonpfad aus den GCP Cloud Source Repositories (Schritt 2 im Screenshot unten).

- Fügen Sie diesen Befehl in das JupiterLab-Terminal ein. Der Befehl sieht so aus:
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- Der Ordner „my-ai-notebooks“ wird in JupyterLab erstellt.

- Verschieben Sie Ihr Notebook (fhir_data_from_bigquery.ipynb) in den Ordner „my-ai-notebooks“.
- Wechseln Sie im Jupyter-Terminal mit „cd my-ai-notebooks“ in das Verzeichnis.
- Stellen Sie Ihre Änderungen über das Jupyter-Terminal bereit. Alternativ können Sie die Jupyter-Benutzeroberfläche verwenden. Klicken Sie mit der rechten Maustaste auf die Dateien im Bereich „Nicht verfolgt“, wählen Sie „Verfolgen“ aus und die Dateien werden in den Bereich „Verfolgt“ verschoben. Das funktioniert auch umgekehrt. Der geänderte Bereich enthält die geänderten Dateien.
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks

- Übernehmen Sie Ihre Änderungen über das Jupyter-Terminal oder die Jupyter-Benutzeroberfläche (geben Sie die Nachricht ein und klicken Sie dann auf die Schaltfläche „Checked“).
git commit -m "message goes here"
- Übertragen Sie die Änderungen auf das Remote-Repository über das Jupyter-Terminal oder die Jupyter-Benutzeroberfläche (klicken Sie auf das Symbol „Committed changes übertragen“
 ).
).
git push --all
- Rufen Sie in der GCP Console „Source Repositories“ auf. Klicken Sie auf „my-ai-notebooks“. Beachten Sie, dass „fhir_data_from_bigquery.ipynb“ jetzt im GCP-Quell-Repository gespeichert ist.

8. Bereinigen
Um zu vermeiden, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden, können Sie die in der GCP erstellten Ressourcen bereinigen, damit diese kein Kontingent verbrauchen und Ihnen in Zukunft nicht in Rechnung gestellt werden. In den folgenden Abschnitten wird erläutert, wie Sie diese Ressourcen löschen oder deaktivieren.
BigQuery-Dataset löschen
Folgen Sie dieser Anleitung, um das BigQuery-Dataset zu löschen, das Sie im Rahmen dieser Anleitung erstellt haben. Alternativ können Sie in der BigQuery-Konsole das Projekt hcls-testing-data entpinnen, wenn Sie das Test-Dataset fhir_20k_patients_analytics verwendet haben.
AI Platform Notebooks-Instanz herunterfahren
Folgen Sie der Anleitung unter Notebook-Instanz herunterfahren | AI Platform Notebooks, um eine AI Platform Notebooks-Instanz herunterzufahren.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten durch Löschen des für die Anleitung erstellten Projekts.
So löschen Sie das Projekt:
- Rufen Sie in der GCP Console die Seite Projekte auf. ZUR SEITE „PROJEKTE“
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
9. Glückwunsch
Herzlichen Glückwunsch! Sie haben das Codelab zum Zugreifen auf, Abfragen und Analysieren von Gesundheitsdaten im FHIR-Format mit BigQuery und AI Platform Notebooks erfolgreich abgeschlossen.
Sie haben in GCP auf ein öffentliches BigQuery-Dataset zugegriffen.
Sie haben SQL-Abfragen mit der BigQuery-Benutzeroberfläche entwickelt und getestet.
Sie haben eine AI Platform Notebooks-Instanz erstellt und gestartet.
Sie haben SQL-Abfragen in JupyterLab ausgeführt und die Abfrageergebnisse in Pandas DataFrame gespeichert.
Sie haben Diagramme und Grafiken mit Matplotlib erstellt.
Sie haben Ihr Notebook übernommen und per Push in ein Cloud Source-Repository in GCP übertragen.
Sie kennen jetzt die wichtigsten Schritte, die erforderlich sind, um mit BigQuery und AI Platform Notebooks auf der Google Cloud Platform mit der Analyse von Gesundheitsdaten zu beginnen.
© Google LLC oder deren Tochtergesellschaften. Alle Rechte vorbehalten. Nicht weitergeben.