
۱. مقدمه

آخرین بهروزرسانی : 2022-9-22
این آزمایشگاه کد، الگویی را برای دسترسی و تجزیه و تحلیل دادههای مراقبتهای بهداشتی جمعآوریشده در BigQuery با استفاده از BigQueryUI و AI Platform Notebooks پیادهسازی میکند. این الگو، کاوش دادهها در مجموعه دادههای بزرگ مراقبتهای بهداشتی را با استفاده از ابزارهای آشنایی مانند Pandas، Matplotlib و غیره در یک AI Platform Notebooks سازگار با HIPPA نشان میدهد. "ترفند" این است که بخش اول تجمیع خود را در BigQuery انجام دهید، یک مجموعه داده Pandas را بازیابی کنید و سپس با مجموعه داده کوچکتر Pandas به صورت محلی کار کنید. AI Platform Notebooks یک تجربه Jupyter مدیریتشده را ارائه میدهد و بنابراین نیازی نیست خودتان سرورهای Notebook را اجرا کنید. AI Platform Notebooks به خوبی با سایر سرویسهای GCP مانند Big Query و Cloud Storage یکپارچه شده است که شروع تجزیه و تحلیل دادهها و سفر یادگیری ماشینی شما را در Google Cloud Platform سریع و ساده میکند.
در این آزمایشگاه کد شما یاد خواهید گرفت که:
- با استفاده از BigQuery UI، کوئریهای SQL را توسعه داده و آزمایش کنید.
- یک نمونه از نوتبوکهای پلتفرم هوش مصنوعی را در GCP ایجاد و راهاندازی کنید.
- اجرای کوئریهای SQL از نوتبوک و ذخیره نتایج کوئری در قاب داده Pandas.
- ایجاد نمودارها و گرافها با استفاده از Matplotlib
- نوتبوک را کامیت کرده و به یک مخزن منبع ابری در GCP ارسال کنید.
برای اجرای این codelab به چه چیزهایی نیاز دارید؟
- شما نیاز به دسترسی به یک پروژه GCP دارید.
- شما باید نقش مالک (Owner) را برای پروژه GCP داشته باشید.
- شما به یک مجموعه داده مراقبتهای بهداشتی در BigQuery نیاز دارید.
اگر پروژه GCP ندارید، برای ایجاد یک پروژه GCP جدید، این مراحل را دنبال کنید.
۲. راهاندازی پروژه
برای این آزمایشگاه کد، از یک مجموعه داده موجود در BigQuery ( hcls-testing-data.fhir_20k_patients_analytics ) استفاده خواهیم کرد. این مجموعه داده از قبل با دادههای مصنوعی مراقبتهای بهداشتی پر شده است.
دسترسی به مجموعه دادههای مصنوعی
- از آدرس ایمیلی که برای ورود به Cloud Console استفاده میکنید، یک ایمیل به hcls-solutions-external+subscribe@google.com ارسال کنید و درخواست عضویت دهید.
- شما یک ایمیل با دستورالعملهایی در مورد نحوه تأیید اقدام دریافت خواهید کرد.
- برای پیوستن به گروه، از گزینه پاسخ به ایمیل استفاده کنید. روی دکمه کلیک نکنید.
 دکمه
دکمه - پس از دریافت ایمیل تأیید، میتوانید به مرحله بعدی در codelab بروید.
پروژه را پین کنید
- در کنسول GCP، پروژه خود را انتخاب کنید، سپس به BigQuery بروید.
- روی منوی کشویی +ADD DATA کلیک کنید و «پین کردن یک پروژه» > «نام پروژه را وارد کنید» را انتخاب کنید.
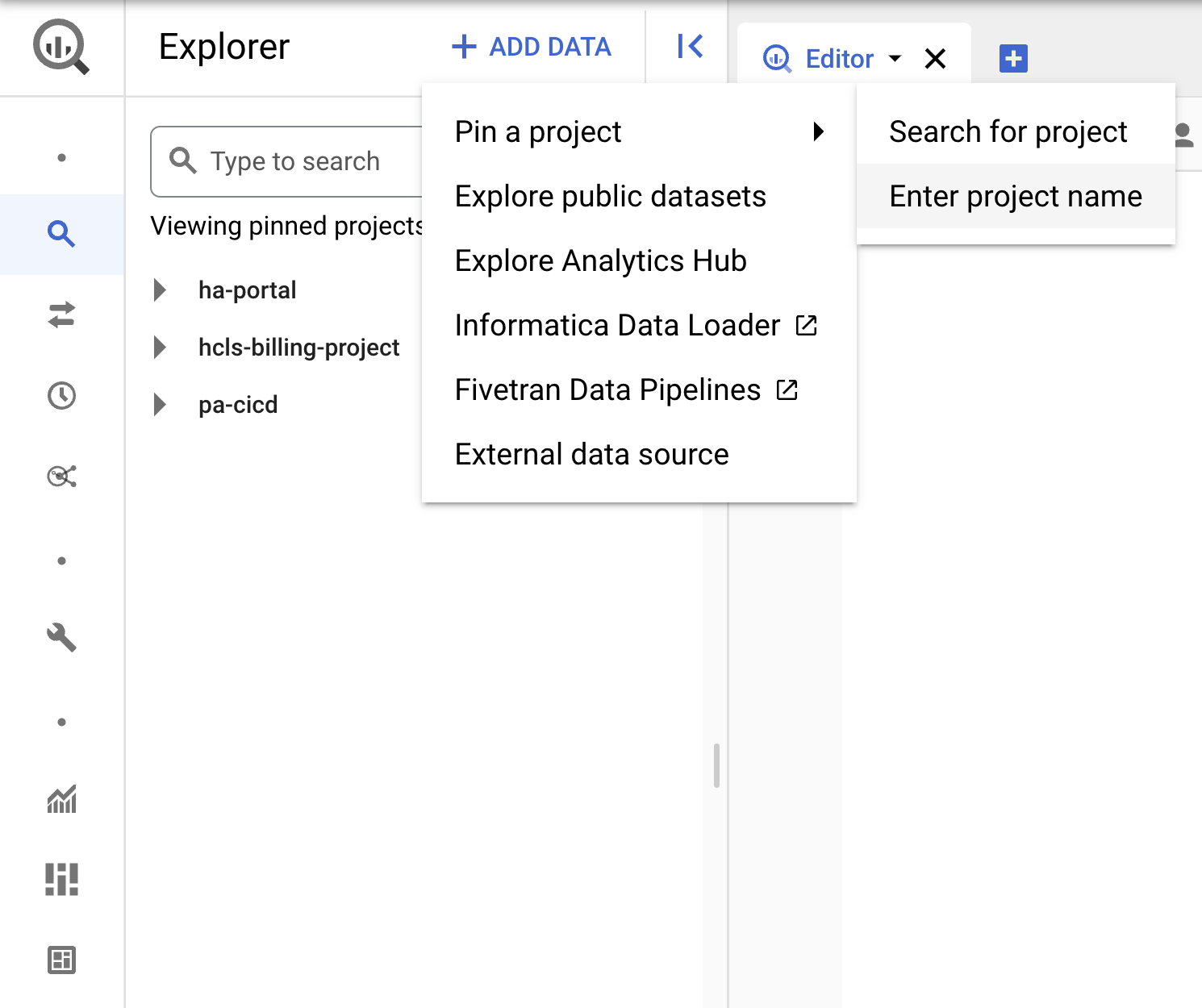
- نام پروژه، « hcls-testing-data » را وارد کنید، سپس روی PIN کلیک کنید. مجموعه دادههای آزمایشی BigQuery با نام « fhir_20k_patients_analytics » برای استفاده در دسترس است.

۳. توسعه کوئریها با استفاده از رابط کاربری BigQuery
تنظیمات رابط کاربری BigQuery
- با انتخاب BigQuery از منوی GCP در گوشه بالا سمت چپ ("همبرگر") به کنسول BigQuery بروید.
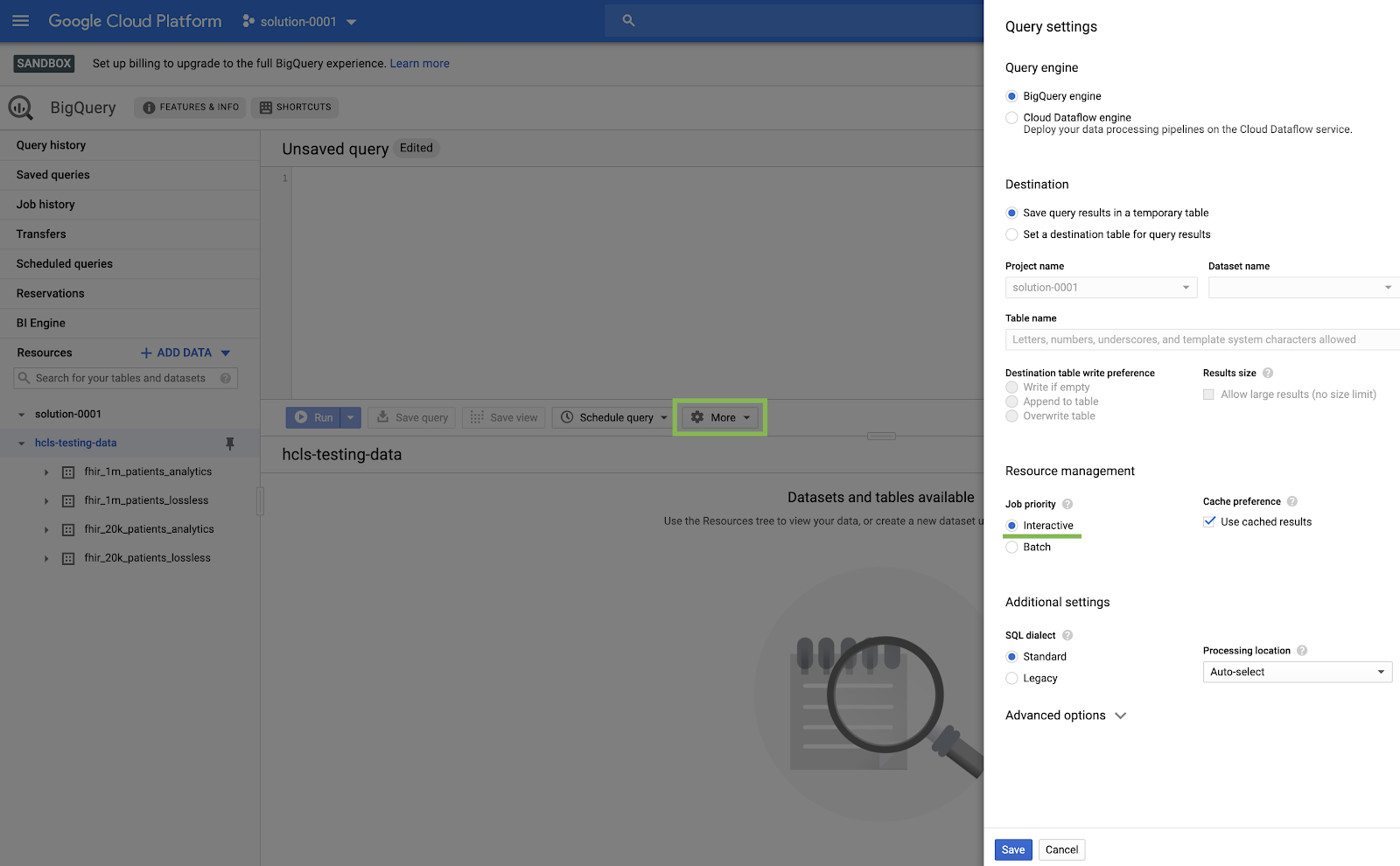
- در کنسول BigQuery، روی More → Query settings کلیک کنید و مطمئن شوید که منوی Legacy SQL تیک نخورده باشد ( ما از Standard SQL استفاده خواهیم کرد ).
ساخت کوئریها
در پنجره ویرایشگر کوئری، کوئری زیر را تایپ کنید و برای اجرای آن روی «اجرا» کلیک کنید. سپس، نتایج را در پنجره «نتایج کوئری» مشاهده کنید.
از بیماران سوال کنید
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
پرس و جو در "ویرایشگر پرس و جو" و نتایج:

متخصصان پرس و جو
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
نتایج پرس و جو:

سازماندهی پرس و جو
شناسه سازمان را تغییر دهید تا با مجموعه دادههای شما مطابقت داشته باشد.
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
نتایج پرس و جو:

تماسهای بیمار را بررسی کنید
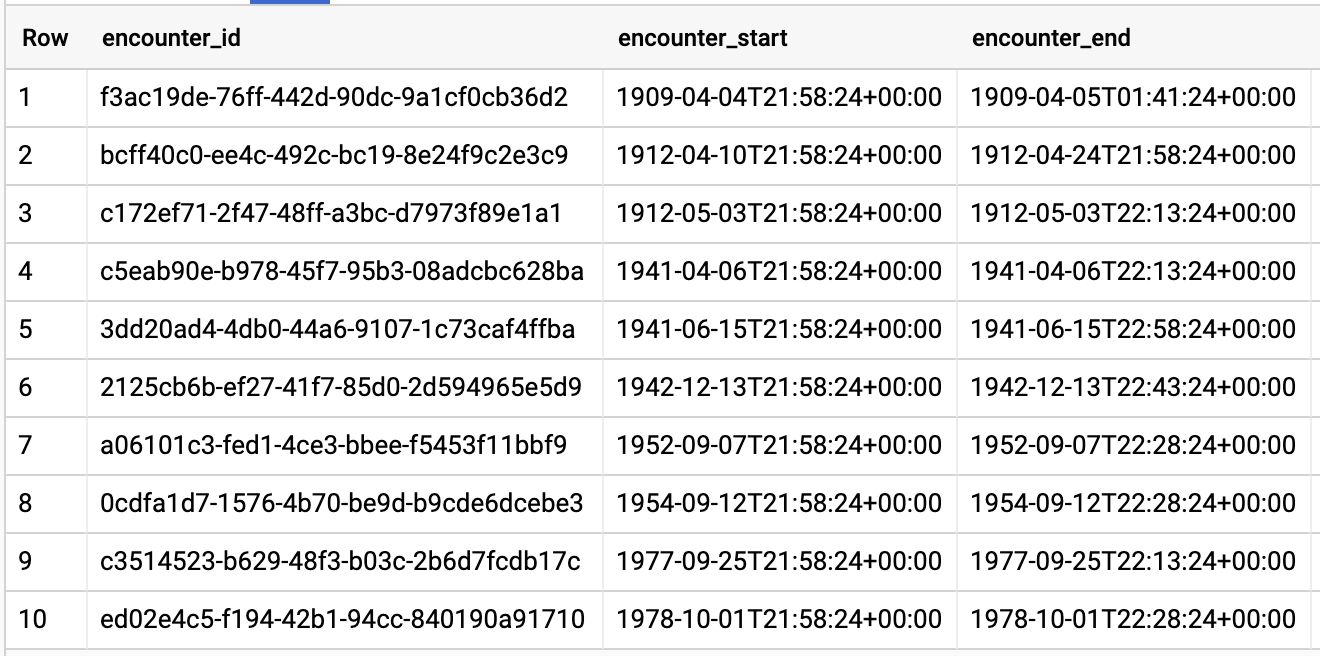
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
نتایج پرس و جو:
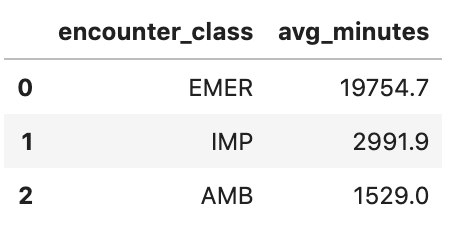
میانگین طول رویاروییها را بر اساس نوع رویارویی بدست آورید
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
نتایج پرس و جو:

تمام بیمارانی که میزان A1C آنها >= 6.5 است را دریافت کنید
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
نتایج پرس و جو:

۴. نمونهای از نوتبوکهای پلتفرم هوش مصنوعی ایجاد کنید
برای ایجاد یک نمونه جدید از AI Platform Notebooks (JupyterLab)، دستورالعملهای موجود در این لینک را دنبال کنید.
لطفاً مطمئن شوید که Compute Engine API را فعال کردهاید .
میتوانید « ایجاد یک دفترچه یادداشت جدید با گزینههای پیشفرض » یا « ایجاد یک دفترچه یادداشت جدید و مشخص کردن گزینههای خود » را انتخاب کنید.
۵. یک دفترچه یادداشت تحلیل داده بسازید
نمونه نوتبوکهای پلتفرم هوش مصنوعی باز
در این بخش، یک نوتبوک ژوپیتر جدید را از ابتدا نوشته و کدنویسی خواهیم کرد.
- با رفتن به صفحه «دفترچههای هوش مصنوعی» در کنسول پلتفرم گوگل کلود، یک نمونه دفترچه یادداشت باز کنید. به صفحه «دفترچههای هوش مصنوعی» بروید
- برای نمونهای که میخواهید باز کنید، گزینهی «باز کردن JupyterLab» را انتخاب کنید.

- نوتبوکهای پلتفرم هوش مصنوعی شما را به یک URL برای نمونه نوتبوکتان هدایت میکنند.

یک دفترچه یادداشت ایجاد کنید
- در JupyterLab، به File -> New -> Notebook بروید و Kernel "Python 3" را در پنجره بازشو انتخاب کنید، یا "Python 3" را در قسمت Notebook در پنجره لانچر انتخاب کنید تا یک Untitled.ipynbnotebook ایجاد کنید.

- روی Untitled.ipynb کلیک راست کنید و نام دفترچه یادداشت را به "fhir_data_from_bigquery.ipynb" تغییر دهید. برای باز کردن آن، ساخت کوئریها و ذخیره دفترچه یادداشت، دوبار کلیک کنید.
- میتوانید با کلیک راست روی فایل *.ipynb و انتخاب گزینه دانلود از منو، یک دفترچه یادداشت دانلود کنید.

- همچنین میتوانید با کلیک روی دکمه «فلش رو به بالا»، یک دفترچه یادداشت موجود را آپلود کنید.

هر بلوک کد را در نوتبوک بسازید و اجرا کنید
هر بلوک کد ارائه شده در این بخش را یک به یک کپی و اجرا کنید. برای اجرای کد، روی « اجرا » (مثلث) کلیک کنید.

مدت زمان اقامت برای برخوردها را بر حسب ساعت دریافت کنید
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
خروجی کد و اجرا:

مشاهدات را دریافت کنید - مقادیر کلسترول
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
خروجی اجرا:

دریافت مقادیر تقریبی برخورد
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
خروجی اجرا:

میانگین مدت زمان برخوردها را بر حسب دقیقه دریافت کنید
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
خروجی اجرا:
دریافت تعداد ملاقاتها به ازای هر بیمار
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
خروجی اجرا:

سازمانها را دریافت کنید
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
نتیجه اجرا:

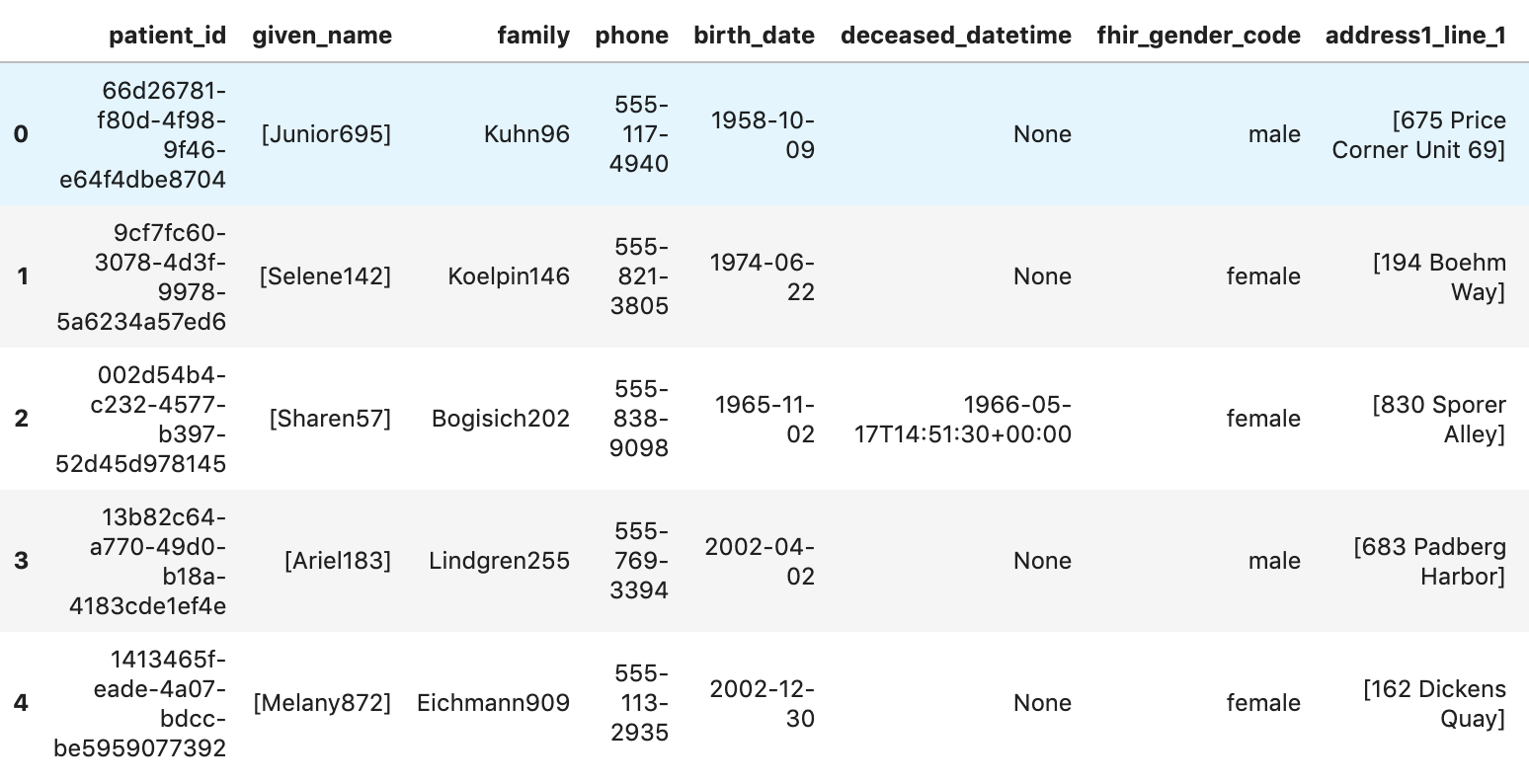
بیماران را دریافت کنید
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
نتایج اجرا:
۶. ایجاد نمودارها و گرافها در نوتبوکهای پلتفرم هوش مصنوعی
سلولهای کد را در دفترچه یادداشت "fhir_data_from_bigquery.ipynb" اجرا کنید تا نمودار میلهای رسم شود.
برای مثال، میانگین مدت زمان رویاروییها را بر حسب دقیقه بدست آورید.
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
نتایج کد و اجرا:

۷. ثبت نوتبوک در مخزن منبع ابری
- در کنسول GCP، به بخش مخازن منبع (Source Repositories) بروید. اگر اولین بار است که از آن استفاده میکنید، روی شروع (Get started) و سپس ایجاد مخزن (Create repository) کلیک کنید.
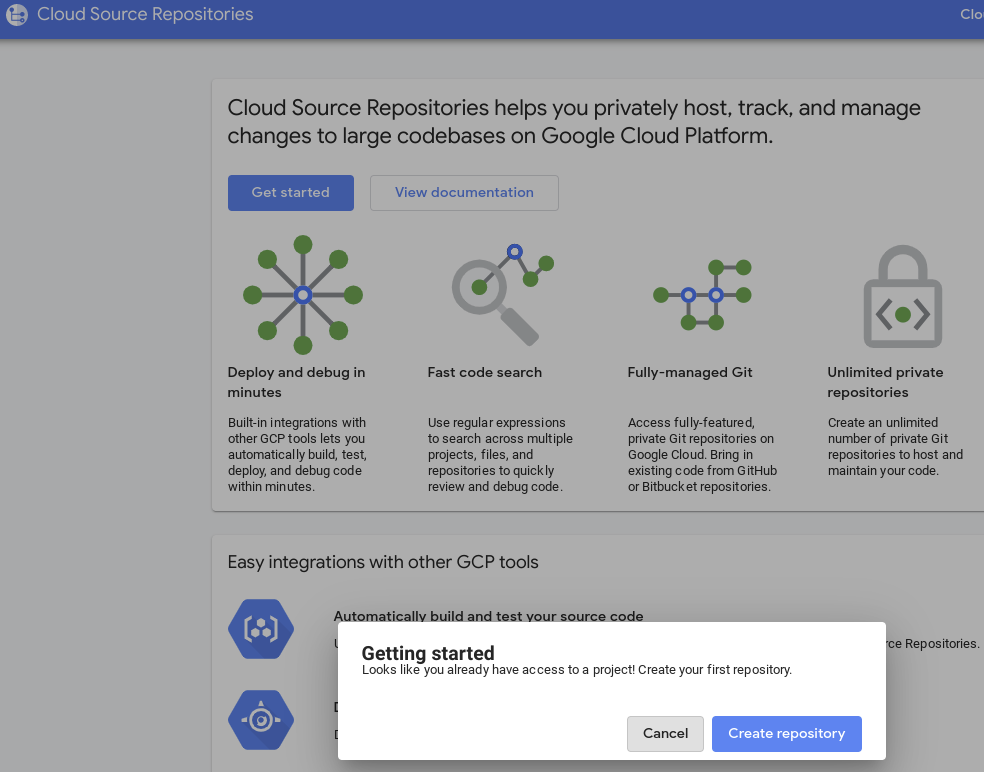
- برای دفعات بعدی، به GCP -> Cloud Source Repositories بروید و برای ایجاد یک مخزن جدید، روی +Add repository کلیک کنید.

- گزینه «ایجاد یک مخزن جدید» را انتخاب کنید، سپس روی ادامه کلیک کنید.
- نام مخزن (Repository name) و نام پروژه (Project name) را وارد کنید، سپس روی ایجاد (Create) کلیک کنید.

- گزینه «کلون کردن مخزن خود در یک مخزن محلی گیت» را انتخاب کنید، سپس اعتبارنامههای تولید شده دستی را انتخاب کنید.
- دستورالعملهای مرحله ۱ «ایجاد و ذخیره اعتبارنامههای گیت» را دنبال کنید (به زیر مراجعه کنید). اسکریپتی را که روی صفحه نمایش شما ظاهر میشود، کپی کنید.

- شروع جلسه ترمینال در ژوپیتر.
- تمام دستورات را از پنجره «پیکربندی گیت» خود در ترمینال ژوپیتر پیست کنید.
- مسیر کلون مخزن را از مخازن منبع GCP Cloud کپی کنید (مرحله 2 در تصویر زیر).
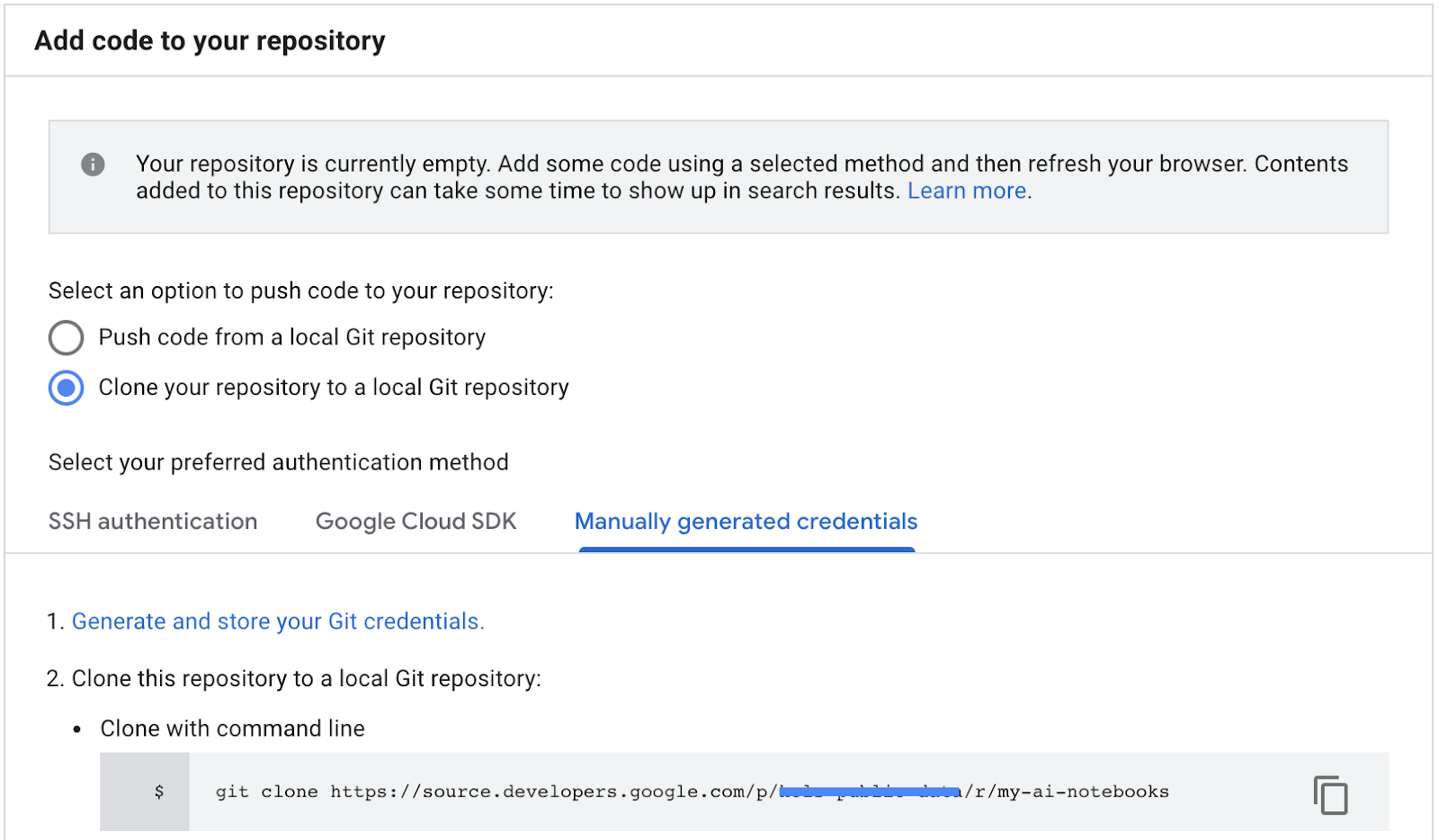
- این دستور را در ترمینال JupiterLab پیست کنید. دستور به شکل زیر خواهد بود:
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- پوشهی «my-ai-notebooks» در Jupyterlab ایجاد شده است.

- دفترچه یادداشت خود (fhir_data_from_bigquery.ipynb) را به پوشه "my-ai-notebooks" منتقل کنید.
- در ترمینال ژوپیتر، دایرکتوری را به «cd my-ai-notebooks» تغییر دهید.
- تغییرات خود را با استفاده از ترمینال Jupyter مرحلهبندی کنید. همچنین میتوانید از رابط کاربری Jupyter استفاده کنید (روی فایلهای موجود در ناحیه Untracked کلیک راست کنید، Track را انتخاب کنید، سپس فایلها به ناحیه Tracked منتقل میشوند و برعکس. ناحیه Changed حاوی فایلهای اصلاحشده است).
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks

- تغییرات خود را با استفاده از ترمینال Jupyter یا رابط کاربری Jupyter اعمال کنید (پیام را تایپ کنید، سپس روی دکمه «بررسی شد» کلیک کنید).
git commit -m "message goes here"
- تغییرات خود را با استفاده از ترمینال Jupyter یا رابط کاربری Jupyter به مخزن راه دور ارسال کنید (روی نماد "اعمال تغییرات ثبت شده" کلیک کنید).
 ).
).
git push --all
- در کنسول GCP، به مخازن منبع (Source Repositories) بروید. روی my-ai-notebooks کلیک کنید. توجه داشته باشید که "fhir_data_from_bigquery.ipynb" اکنون در مخزن منبع GCP ذخیره شده است.

۸. پاکسازی
برای جلوگیری از تحمیل هزینه به حساب پلتفرم گوگل کلود خود برای منابع استفاده شده در این آزمایشگاه کد، پس از اتمام آموزش، میتوانید منابعی را که در GCP ایجاد کردهاید پاک کنید تا سهمیه شما را اشغال نکنند و در آینده برای آنها هزینهای از شما دریافت نشود. بخشهای زیر نحوه حذف یا غیرفعال کردن این منابع را شرح میدهند.
حذف مجموعه داده BigQuery
برای حذف مجموعه داده BigQuery که به عنوان بخشی از این آموزش ایجاد کردهاید، این دستورالعملها را دنبال کنید. یا اگر از مجموعه داده آزمایشی fhir_20k_patients_analytics استفاده کردهاید ، به کنسول BigQuery و UnPIN project hcls-testing-data بروید.
خاموش کردن نمونهی هوش مصنوعی پلتفرم نوتبوکز
برای خاموش کردن یک نمونه نوتبوک پلتفرم هوش مصنوعی، دستورالعملهای موجود در این لینک را دنبال کنید.
حذف پروژه
سادهترین راه برای حذف هزینهها، حذف پروژهای است که برای آموزش ایجاد کردهاید.
برای حذف پروژه:
- در کنسول GCP، به صفحه پروژهها بروید. به صفحه پروژهها بروید
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید، سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
۹. تبریک
تبریک میگوییم، شما با موفقیت آزمایشگاه کد را برای دسترسی، پرسوجو و تجزیه و تحلیل دادههای مراقبتهای بهداشتی با فرمت FHIR با استفاده از BigQuery و AI Platform Notebooks به پایان رساندید.
شما به یک مجموعه داده عمومی BigQuery در GCP دسترسی پیدا کردید.
شما با استفاده از BigQuery UI کوئریهای SQL را توسعه داده و آزمایش کردید.
شما یک نمونه از نوتبوکهای پلتفرم هوش مصنوعی ایجاد و راهاندازی کردید.
شما کوئریهای SQL را در JupyterLab اجرا کردید و نتایج کوئری را در Pandas DataFrame ذخیره کردید.
شما نمودارها و گرافها را با استفاده از Matplotlib ایجاد کردید.
شما کامیت کردید و نوتبوک خود را به یک مخزن منبع ابری در GCP منتقل کردید.
اکنون مراحل کلیدی مورد نیاز برای شروع سفر تحلیل دادههای مراقبتهای بهداشتی خود با BigQuery و هوش مصنوعی پلتفرم نوتبوکها در پلتفرم گوگل کلود را میدانید.
©شرکت گوگل یا شرکتهای وابسته به آن. تمامی حقوق محفوظ است. توزیع نکنید.