
1. Введение

Последнее обновление : 22.09.2022
В этом практическом занятии реализован шаблон для доступа и анализа данных здравоохранения, агрегированных в BigQuery, с использованием BigQueryUI и AI Platform Notebooks. Он демонстрирует исследование больших наборов данных здравоохранения с помощью таких привычных инструментов, как Pandas, Matplotlib и др., в AI Platform Notebooks, соответствующих требованиям HIPPA. «Хитрость» заключается в том, чтобы выполнить первую часть агрегации в BigQuery, получить набор данных Pandas, а затем работать с меньшим набором данных Pandas локально. AI Platform Notebooks предоставляет управляемый интерфейс Jupyter, поэтому вам не нужно запускать серверы блокнотов самостоятельно. AI Platform Notebooks хорошо интегрирован с другими сервисами GCP, такими как Big Query и Cloud Storage, что делает быстрым и простым начало вашего пути в области анализа данных и машинного обучения на платформе Google Cloud Platform.
В этой практической работе по программированию вы научитесь:
- Разрабатывайте и тестируйте SQL-запросы с использованием пользовательского интерфейса BigQuery.
- Создайте и запустите экземпляр AI Platform Notebooks в GCP.
- Выполняйте SQL-запросы из блокнота и сохраняйте результаты запросов в DataFrame Pandas.
- Создавайте диаграммы и графики с помощью Matplotlib.
- Зафиксируйте изменения и отправьте ноутбук в облачный репозиторий исходного кода в GCP.
Что вам понадобится для проведения этого практического занятия?
- Вам необходим доступ к проекту GCP .
- Вам необходимо присвоить роль «Владелец» для проекта GCP.
- Вам потребуется набор данных по здравоохранению для работы в BigQuery.
Если у вас нет проекта GCP, выполните следующие шаги для создания нового проекта GCP.
2. Настройка проекта
Для этого практического занятия мы будем использовать существующий набор данных в BigQuery ( hcls-testing-data.fhir_20k_patients_analytics ). Этот набор данных предварительно заполнен синтетическими данными из сферы здравоохранения.
Получите доступ к синтетическому набору данных.
- Отправьте письмо на адрес hcls-solutions-external+subscribe@google.com с того адреса электронной почты, который вы используете для входа в Cloud Console, с просьбой о присоединении.
- Вы получите электронное письмо с инструкциями по подтверждению действия.
- Воспользуйтесь возможностью ответить на электронное письмо, чтобы присоединиться к группе. НЕ нажимайте на кнопку.
 кнопка.
кнопка. - После получения подтверждающего письма вы можете перейти к следующему шагу в практическом задании.
Закрепить проект
- В консоли GCP выберите свой проект, затем перейдите в раздел BigQuery.
- Нажмите на выпадающее меню +ДОБАВИТЬ ДАННЫЕ и выберите "Закрепить проект" > "Введите название проекта".

- Введите название проекта " hcls-testing-data ", затем нажмите PIN-код . Тестовый набор данных BigQuery " fhir_20k_patients_analytics " доступен для использования.

3. Создавайте запросы с помощью пользовательского интерфейса BigQuery.
Настройки пользовательского интерфейса BigQuery
- Чтобы открыть консоль BigQuery, выберите BigQuery в меню GCP в левом верхнем углу (значок «гамбургера»).
- В консоли BigQuery нажмите «Дополнительно» → «Настройки запроса» и убедитесь, что пункт «Устаревший SQL» НЕ отмечен ( мы будем использовать стандартный SQL ).

Создание запросов
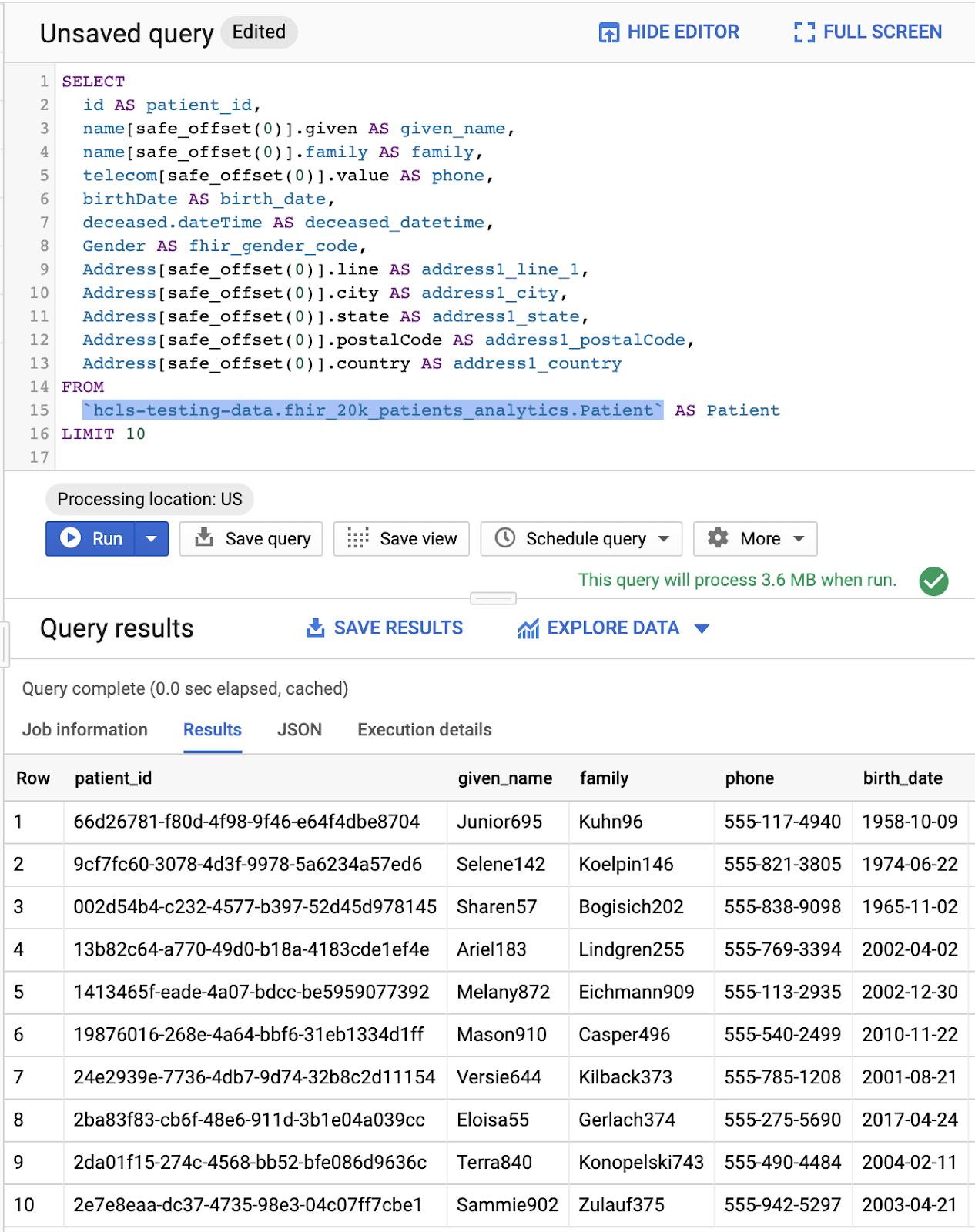
В окне редактора запросов введите следующий запрос и нажмите кнопку «Выполнить» , чтобы его выполнить. Затем просмотрите результаты в окне «Результаты запроса» .
ПАЦИЕНТЫ, ЗАДАЮЩИЕ ЗАПРОСЫ
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
Запрос в «Редакторе запросов» и результаты:
СПЕЦИАЛИСТЫ ПО ЗАПРОСУ
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
Результаты запроса:

Организация запросов
Измените идентификатор организации в соответствии с вашим набором данных.
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
Результаты запроса:

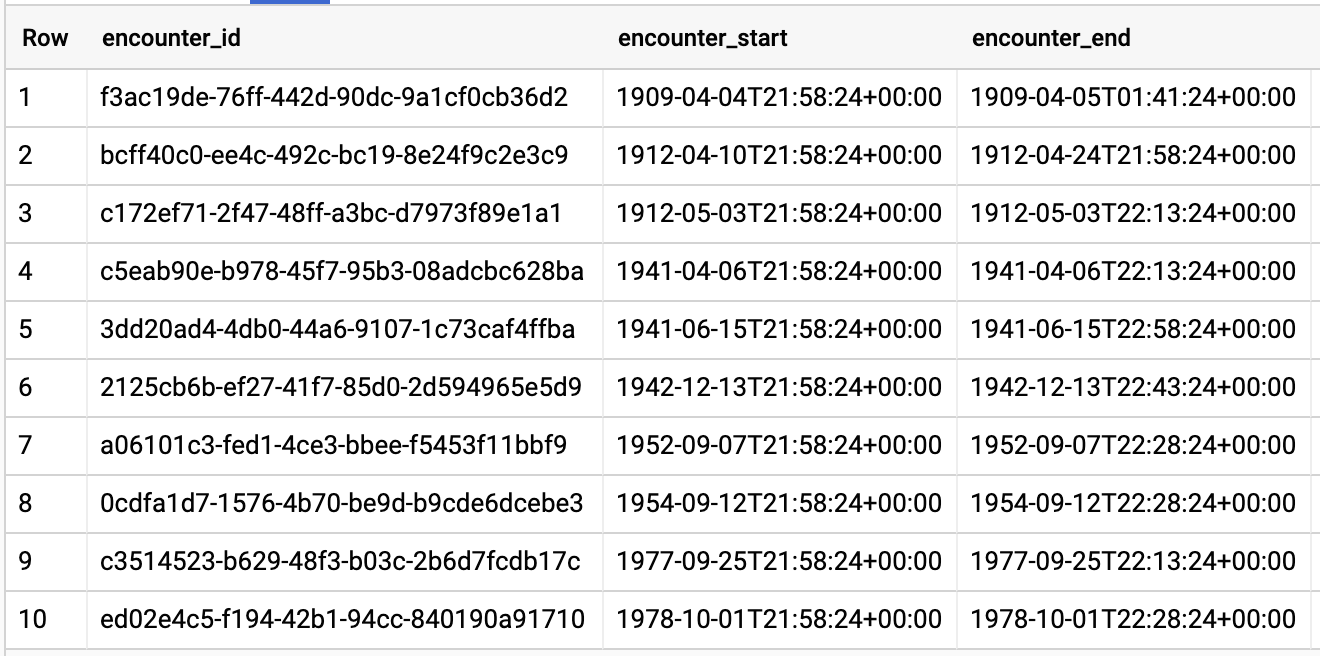
ВОПРОСЫ, КОТОРЫЕ ЗАДАЮТ ПАЦИЕНТЫ
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
Результаты запроса:
Узнайте среднюю продолжительность столкновений по типу столкновения.
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
Результаты запроса:

Необходимо выявить всех пациентов с уровнем HbA1c >= 6,5.
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
Результаты запроса:

4. Создайте экземпляр блокнотов платформы ИИ.
Чтобы создать новый экземпляр AI Platform Notebooks (JupyterLab), следуйте инструкциям по этой ссылке.
Пожалуйста, убедитесь, что API Compute Engine включен .
Вы можете выбрать « Создать новый блокнот с параметрами по умолчанию » или « Создать новый блокнот и указать свои параметры ».
5. Создайте блокнот для анализа данных.
Экземпляр Open AI Platform Notebooks
В этом разделе мы создадим и напишем новый блокнот Jupyter с нуля.
- Откройте экземпляр блокнота, перейдя на страницу « Блокноты платформы ИИ» в консоли Google Cloud Platform. ПЕРЕЙДИТЕ НА СТРАНИЦУ «БЛОКНОТЫ ПЛАТФОРМЫ ИИ»
- Выберите «Открыть JupyterLab» для того экземпляра, который вы хотите открыть.
- AI Platform Notebooks перенаправит вас на URL-адрес вашего экземпляра блокнота.

Создайте блокнот
- В JupyterLab перейдите в меню Файл -> Создать -> Блокнот и выберите ядро "Python 3" во всплывающем окне или выберите "Python 3" в разделе Блокнот в окне запуска, чтобы создать Блокнот Untitled.ipynb.
- Щелкните правой кнопкой мыши по файлу Untitled.ipynb и переименуйте блокнот в "fhir_data_from_bigquery.ipynb". Дважды щелкните, чтобы открыть его, создайте запросы и сохраните блокнот.
- Скачать блокнот можно, щелкнув правой кнопкой мыши по файлу *.ipynb и выбрав в меню пункт «Скачать».

- Вы также можете загрузить уже существующий блокнот, нажав кнопку «Стрелка вверх».

Скомпилируйте и выполните каждый блок кода в блокноте.
Скопируйте и выполните каждый блок кода, представленный в этом разделе, по очереди. Для выполнения кода нажмите кнопку « Выполнить » (треугольник).

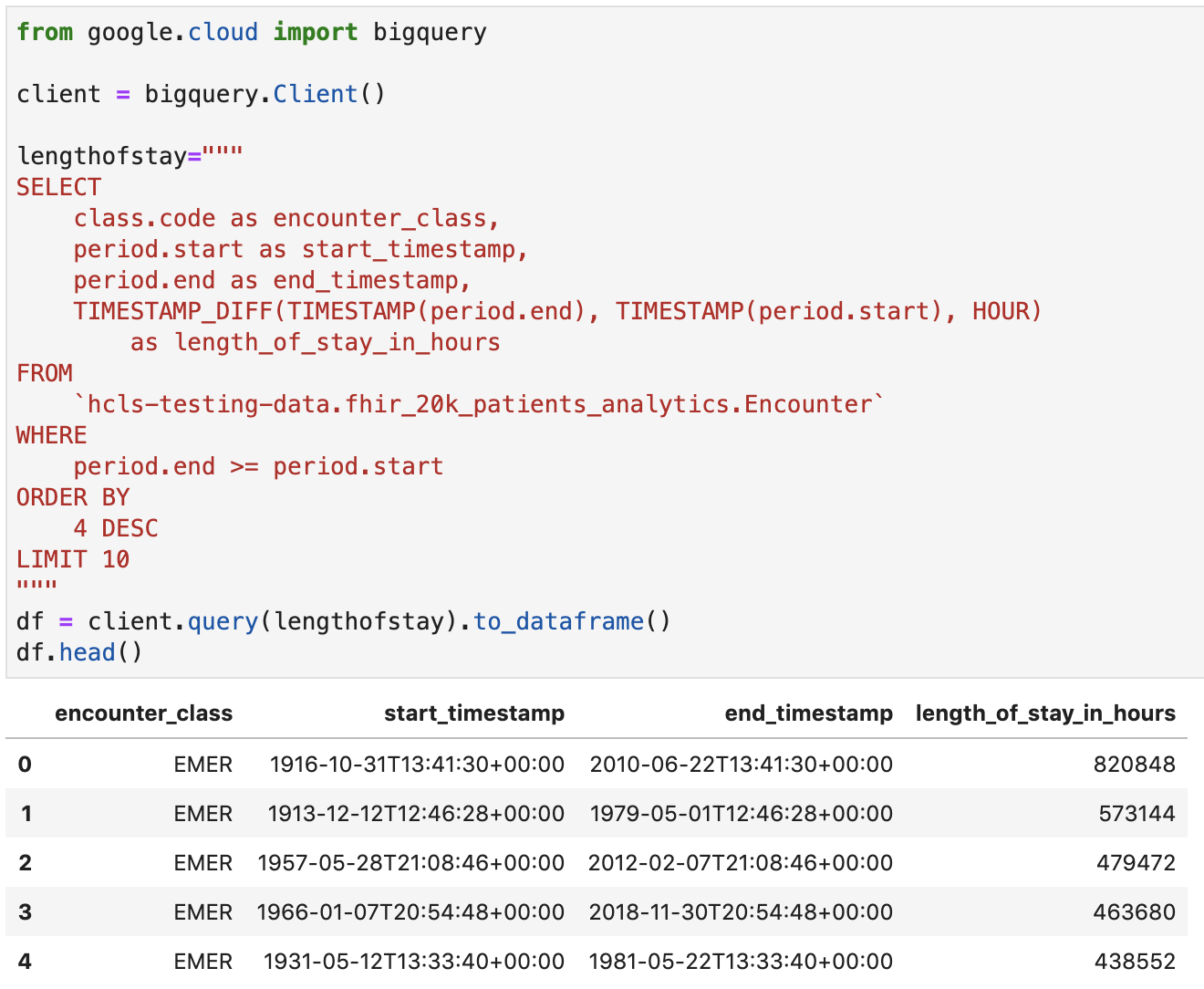
Узнайте продолжительность пребывания для встреч в часах.
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
Код и результаты выполнения:
Получить данные - Значения холестерина
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
Результат выполнения:

Получить приблизительные квантили встреч
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
Результат выполнения:

Узнайте среднюю продолжительность встреч в минутах.
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
Результат выполнения:

Получить количество посещений на одного пациента
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
Результат выполнения:

Получить организации
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
Результат выполнения:

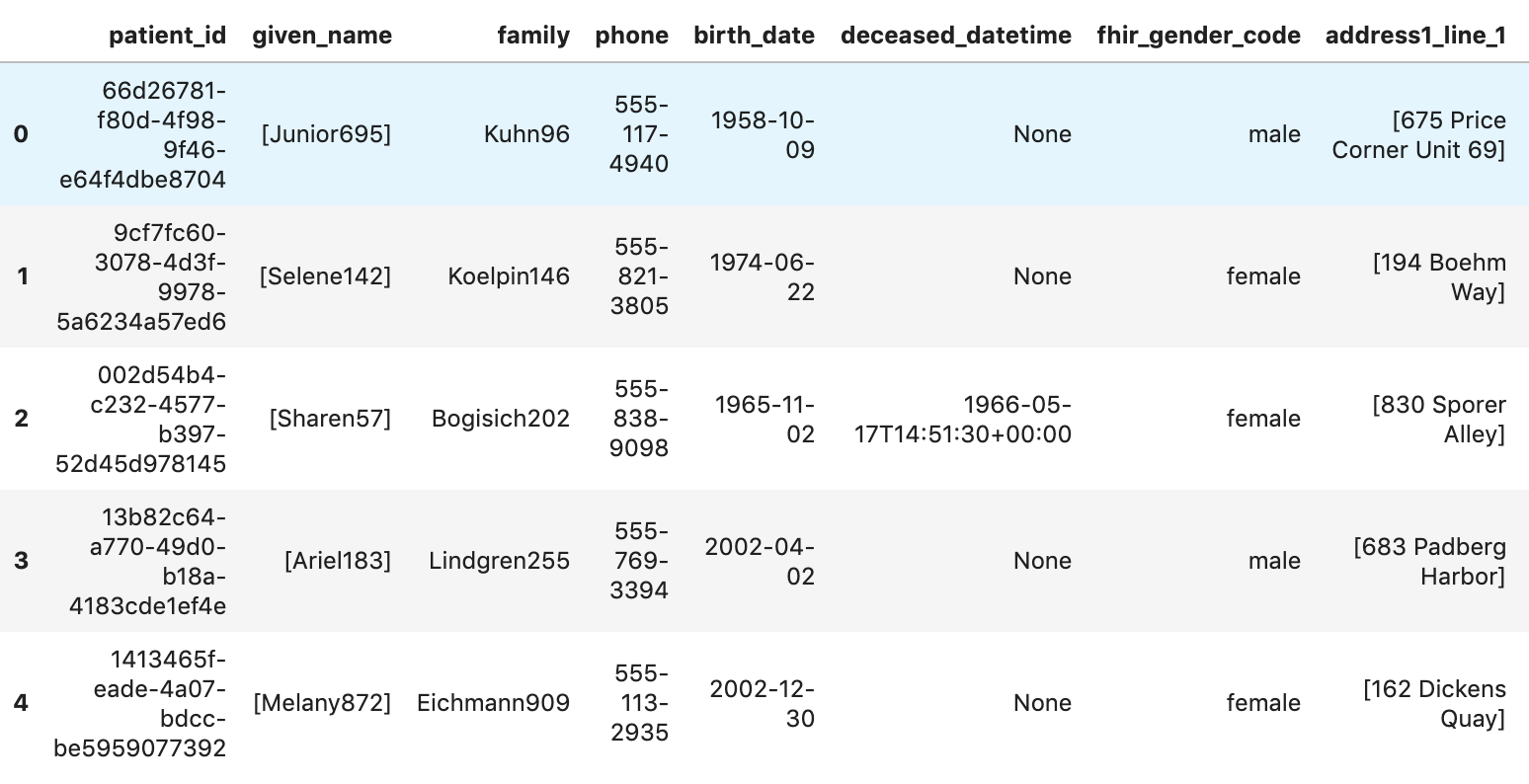
Привлекайте пациентов
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
Результаты выполнения:
6. Создавайте диаграммы и графики в блокнотах платформы ИИ.
Выполните код в ячейках блокнота "fhir_data_from_bigquery.ipynb", чтобы построить столбчатую диаграмму.
Например, получите среднюю продолжительность столкновений в минутах.
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
Код и результаты выполнения:

7. Зафиксируйте изменения в блокноте в облачном репозитории исходного кода.
- В консоли GCP перейдите в раздел «Репозитории исходного кода». Если вы используете его впервые, нажмите «Начать», а затем «Создать репозиторий».

- В дальнейшем перейдите в GCP -> Cloud Source Repositories и нажмите +Add repository, чтобы создать новый репозиторий.

- Выберите «Создать новый репозиторий», затем нажмите «Продолжить».
- Укажите название репозитория и название проекта, затем нажмите «Создать».

- Выберите «Клонировать репозиторий в локальный репозиторий Git», затем выберите «Учетные данные, сгенерированные вручную».
- Следуйте инструкциям шага 1 «Сгенерировать и сохранить учетные данные Git» (см. ниже). Скопируйте скрипт, который появится на экране.

- Запустите терминальную сессию в Jupyter.

- Вставьте все команды из окна "Настройка Git" в терминал Jupyter.
- Скопируйте путь к клону репозитория из исходных репозиториев облака GCP (шаг 2 на скриншоте ниже).

- Вставьте эту команду в терминал JupiterLab. Команда будет выглядеть примерно так:
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- В Jupyterlab создается папка "my-ai-notebooks".
- Переместите свой блокнот (fhir_data_from_bigquery.ipynb) в папку "my-ai-notebooks".
- В терминале Jupyter перейдите в каталог "cd my-ai-notebooks".
- Вносите изменения в папку с помощью терминала Jupyter. В качестве альтернативы можно использовать пользовательский интерфейс Jupyter (щелкните правой кнопкой мыши по файлам в области «Неотслеживаемые», выберите «Отслеживать», после чего файлы будут перемещены в область «Отслеживаемые», и наоборот. Область «Измененные» содержит измененные файлы).
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks

- Подтвердите изменения, используя терминал Jupyter или пользовательский интерфейс Jupyter (введите сообщение, затем нажмите кнопку «Checked»).
git commit -m "message goes here"
- Отправьте изменения в удаленный репозиторий, используя терминал Jupyter или пользовательский интерфейс Jupyter (нажмите значок «Отправить зафиксированные изменения»).
 ).
).
git push --all
- В консоли GCP перейдите в раздел «Репозитории исходного кода». Щелкните my-ai-notebooks. Обратите внимание, что файл "fhir_data_from_bigquery.ipynb" теперь сохранен в репозитории исходного кода GCP.

8. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud Platform за ресурсы, использованные в этом практическом занятии, после завершения обучения вы можете удалить созданные вами ресурсы в GCP, чтобы они не занимали вашу квоту, и вам не выставлялись за них счета в будущем. В следующих разделах описано, как удалить или отключить эти ресурсы.
Удаление набора данных BigQuery
Следуйте этим инструкциям, чтобы удалить набор данных BigQuery, созданный вами в рамках этого руководства. Или перейдите в консоль BigQuery, открепите проект hcls-testing-data, если вы использовали тестовый набор данных fhir_20k_patients_analytics.
Завершение работы экземпляра AI Platform Notebooks
Чтобы остановить работу экземпляра AI Platform Notebooks, следуйте инструкциям по этой ссылке: Выключение экземпляра блокнота | AI Platform Notebooks.
Удаление проекта
Самый простой способ избежать выставления счетов — удалить проект, созданный для этого урока.
Чтобы удалить проект:
- В консоли GCP перейдите на страницу «Проекты» . ПЕРЕЙДИТЕ НА СТРАНИЦУ ПРОЕКТОВ
- В списке проектов выберите проект, который хотите удалить, и нажмите «Удалить» .
- В диалоговом окне введите идентификатор проекта, затем нажмите «Завершить» , чтобы удалить проект.
9. Поздравляем!
Поздравляем, вы успешно завершили лабораторную работу по программированию, посвященную доступу, запросам и анализу медицинских данных в формате FHIR с использованием BigQuery и AI Platform Notebooks.
Вы получили доступ к общедоступному набору данных BigQuery в GCP.
Вы разрабатывали и тестировали SQL-запросы с использованием пользовательского интерфейса BigQuery.
Вы создали и запустили экземпляр AI Platform Notebooks .
Вы выполняли SQL-запросы в JupyterLab и сохраняли результаты запросов в DataFrame Pandas.
Вы создали диаграммы и графики с помощью Matplotlib.
Вы зафиксировали изменения и отправили свой ноутбук в репозиторий Cloud Source Repository в GCP.
Теперь вы знаете ключевые шаги, необходимые для начала работы с анализом данных в сфере здравоохранения с помощью BigQuery и AI Platform Notebooks на платформе Google Cloud.
©Google, Inc. или ее дочерние компании. Все права защищены. Распространение запрещено.