
1. Introdução
Visão geral
Neste codelab, você vai criar um job do Cloud Run escrito em Node.js que fornece uma descrição visual de cada cena em um vídeo. Primeiro, seu job vai usar a API Video Intelligence para detectar as marcações de tempo sempre que uma cena mudar. Em seguida, seu trabalho vai usar um binário de terceiros chamado ffmpeg para capturar uma captura de tela de cada carimbo de data/hora de mudança de cena. Por fim, as legendas visuais da Vertex AI são usadas para fornecer uma descrição visual das capturas de tela.
Este codelab também demonstra como usar o ffmpeg em um job do Cloud Run para capturar imagens de um vídeo em um determinado carimbo de data/hora. Como o ffmpeg precisa ser instalado de forma independente, este codelab mostra como criar um Dockerfile para instalar o ffmpeg como parte do seu job do Cloud Run.
Confira uma ilustração de como o job do Cloud Run funciona:
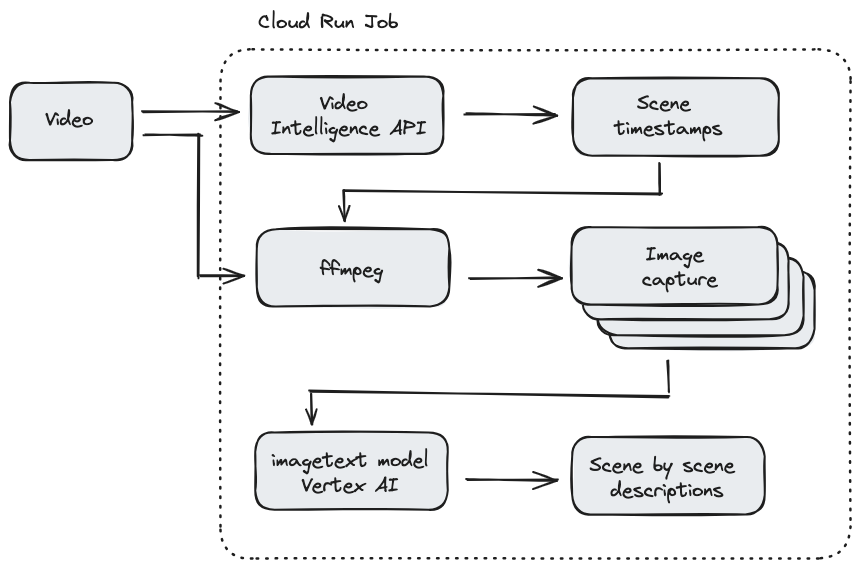
O que você vai aprender
- Como criar uma imagem de contêiner usando um Dockerfile para instalar um binário de terceiros
- Como seguir o princípio de privilégio mínimo criando uma conta de serviço para o job do Cloud Run chamar outros serviços do Google Cloud
- Como usar a biblioteca de cliente da Video Intelligence em um job do Cloud Run
- Como fazer uma chamada para as APIs do Google e receber a descrição visual de cada cena da Vertex AI
2. Configuração e requisitos
Pré-requisitos
- Você fez login no console do Cloud.
- Você já implantou um serviço do Cloud Run. Por exemplo, siga o guia de início rápido para implantar um serviço da Web usando o código-fonte.
Ativar o Cloud Shell
- No Console do Cloud, clique em Ativar o Cloud Shell
 .
.

Se esta for a primeira vez que você inicia o Cloud Shell, uma tela intermediária vai aparecer com a descrição dele. Se isso acontecer, clique em Continuar.

Leva apenas alguns instantes para provisionar e se conectar ao Cloud Shell.

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, quase todo o trabalho pode ser feito com um navegador.
Depois de se conectar ao Cloud Shell, você vai ver que sua conta já está autenticada e que o projeto está configurado com o ID do seu projeto.
- Execute o seguinte comando no Cloud Shell para confirmar se a conta está autenticada:
gcloud auth list
Resposta ao comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto:
gcloud config list project
Resposta ao comando
[core] project = <PROJECT_ID>
Se o projeto não estiver configurado, configure-o usando este comando:
gcloud config set project <PROJECT_ID>
Resposta ao comando
Updated property [core/project].
3. Ativar APIs e definir variáveis de ambiente
Antes de começar a usar este codelab, você precisa ativar várias APIs. Este codelab exige o uso das seguintes APIs. Para ativar essas APIs, execute o seguinte comando:
gcloud services enable run.googleapis.com \
storage.googleapis.com \
cloudbuild.googleapis.com \
videointelligence.googleapis.com \
aiplatform.googleapis.com
Em seguida, defina as variáveis de ambiente que serão usadas neste codelab.
REGION=<YOUR-REGION> PROJECT_ID=<YOUR-PROJECT-ID> PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)') JOB_NAME=video-describer-job BUCKET_ID=$PROJECT_ID-video-describer SERVICE_ACCOUNT="cloud-run-job-video" SERVICE_ACCOUNT_ADDRESS=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
4. Crie uma conta de serviço
Você vai criar uma conta de serviço para o job do Cloud Run usar no acesso ao Cloud Storage, à Vertex AI e à API Video Intelligence.
Primeiro, crie a conta de serviço.
gcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name="Cloud Run Video Scene Image Describer service account"
Em seguida, conceda à conta de serviço acesso ao bucket do Cloud Storage e às APIs da Vertex AI.
# to view & download storage bucket objects gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$SERVICE_ACCOUNT_ADDRESS \ --role=roles/storage.objectViewer # to call the Vertex AI imagetext model gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$SERVICE_ACCOUNT_ADDRESS \ --role=roles/aiplatform.user
5. Criar um bucket do Cloud Storage
Crie um bucket do Cloud Storage para fazer upload de vídeos para processamento pelo job do Cloud Run com o seguinte comando:
gsutil mb -l us-central1 gs://$BUCKET_ID/
[Opcional] Você pode usar este vídeo de amostra fazendo o download dele localmente.
gsutil cp gs://cloud-samples-data/video/visionapi.mp4 testvideo.mp4
Agora faça upload do arquivo de vídeo para o bucket de armazenamento.
FILENAME=<YOUR-VIDEO-FILENAME> gsutil cp $FILENAME gs://$BUCKET_ID
6. Criar o job do Cloud Run
Primeiro, crie um diretório para o código-fonte e use cd para acessar esse diretório.
mkdir video-describer-job && cd $_
Em seguida, crie um arquivo package.json com o seguinte conteúdo:
{
"name": "video-describer-job",
"version": "1.0.0",
"private": true,
"description": "describes the image in every scene for a given video",
"main": "app.js",
"author": "Google LLC",
"license": "Apache-2.0",
"scripts": {
"start": "node app.js"
},
"dependencies": {
"@google-cloud/storage": "^7.7.0",
"@google-cloud/video-intelligence": "^5.0.1",
"axios": "^1.6.2",
"fluent-ffmpeg": "^2.1.2",
"google-auth-library": "^9.4.1"
}
}
Esse app consiste em vários arquivos de origem para melhorar a legibilidade. Primeiro, crie um arquivo de origem app.js com o conteúdo abaixo. Esse arquivo contém o ponto de entrada do job e a lógica principal do app.
const bucketName = "<YOUR_BUCKET_ID>";
const videoFilename = "<YOUR-VIDEO-FILENAME>";
const { captureImages } = require("./helpers/imageCapture.js");
const { detectSceneChanges } = require("./helpers/sceneDetector.js");
const { getImageCaption } = require("./helpers/imageCaptioning.js");
const storageHelper = require("./helpers/storage.js");
const authHelper = require("./helpers/auth.js");
const fs = require("fs").promises;
const path = require("path");
const main = async () => {
try {
// download the file to locally to the Cloud Run Job instance
let localFilename = await storageHelper.downloadVideoFile(
bucketName,
videoFilename
);
// PART 1 - Use Video Intelligence API
// detect all the scenes in the video & save timestamps to an array
// EXAMPLE OUTPUT
// Detected scene changes at the following timestamps:
// [1, 7, 11, 12]
let timestamps = await detectSceneChanges(localFilename);
console.log(
"Detected scene changes at the following timestamps: ",
timestamps
);
// PART 2 - Use ffmpeg via dockerfile install
// create an image of each scene change
// and save to a local directory called "output"
// returns the base filename for the generated images
// EXAMPLE OUTPUT
// creating screenshot for scene: 1 at output/video-filename-1.png
// creating screenshot for scene: 7 at output/video-filename-7.png
// creating screenshot for scene: 11 at output/video-filename-11.png
// creating screenshot for scene: 12 at output/video-filename-12.png
// returns the base filename for the generated images
let imageBaseName = await captureImages(localFilename, timestamps);
// PART 3a - get Access Token to call Vertex AI APIs via REST
// needed for the image captioning
// since we're calling the Vertex AI APIs directly
let accessToken = await authHelper.getAccessToken();
console.log("got an access token");
// PART 3b - use Image Captioning to describe each scene per screenshot
// EXAMPLE OUTPUT
/*
[
{
timestamp: 1,
description:
"an aerial view of a city with a bridge in the background"
},
{
timestamp: 7,
description:
"a man in a blue shirt sits in front of shelves of donuts"
},
{
timestamp: 11,
description:
"a black and white photo of people working in a bakery"
},
{
timestamp: 12,
description:
"a black and white photo of a man and woman working in a bakery"
}
]; */
// instantiate the data structure for storing the scene description and timestamp
// e.g. an array of json objects,
// [{ timestamp: 5, description: "..." }, ...]
let scenes = [];
// for each timestamp, send the image to Vertex AI
console.log("getting Vertex AI description for each timestamps");
scenes = await Promise.all(
timestamps.map(async (timestamp) => {
let filepath = path.join(
"./output",
imageBaseName + "-" + timestamp + ".png"
);
// get the base64 encoded image bc sending via REST
const encodedFile = await fs.readFile(filepath, "base64");
// send each screenshot to Vertex AI for description
let description = await getImageCaption(
accessToken,
encodedFile
);
return { timestamp: timestamp, description: description };
})
);
console.log("finished collecting all the scenes");
console.log(scenes);
} catch (error) {
//return an error
console.error("received error: ", error);
}
};
// Start script
main().catch((err) => {
console.error(err);
});
Em seguida, crie o Dockerfile.
# Copyright 2020 Google, LLC. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Use the official lightweight Node.js image. # https://hub.docker.com/_/node FROM node:20.10.0-slim # Create and change to the app directory. WORKDIR /usr/src/app RUN apt-get update && apt-get install -y ffmpeg # Copy application dependency manifests to the container image. # A wildcard is used to ensure both package.json AND package-lock.json are copied. # Copying this separately prevents re-running npm install on every code change. COPY package*.json ./ # Install dependencies. # If you add a package-lock.json speed your build by switching to 'npm ci'. # RUN npm ci --only=production RUN npm install --production # Copy local code to the container image. COPY . . # Run the job on container startup. CMD [ "npm", "start" ]
Crie um arquivo chamado .dockerignore para ignorar a contêinerização de determinados arquivos.
Dockerfile .dockerignore node_modules npm-debug.log
Agora, crie uma pasta chamada helpers. Essa pasta vai conter cinco arquivos auxiliares.
mkdir helpers cd helpers
Em seguida, crie um arquivo sceneDetector.js com o seguinte conteúdo. Esse arquivo usa a API Video Intelligence para detectar quando as cenas mudam no vídeo.
const fs = require("fs");
const util = require("util");
const readFile = util.promisify(fs.readFile);
const ffmpeg = require("fluent-ffmpeg");
const Video = require("@google-cloud/video-intelligence");
const client = new Video.VideoIntelligenceServiceClient();
module.exports = {
detectSceneChanges: async function (downloadedFile) {
// Reads a local video file and converts it to base64
const file = await readFile(downloadedFile);
const inputContent = file.toString("base64");
// setup request for shot change detection
const videoContext = {
speechTranscriptionConfig: {
languageCode: "en-US",
enableAutomaticPunctuation: true
}
};
const request = {
inputContent: inputContent,
features: ["SHOT_CHANGE_DETECTION"]
};
// Detects camera shot changes
const [operation] = await client.annotateVideo(request);
console.log("Shot (scene) detection in progress...");
const [operationResult] = await operation.promise();
// Gets shot changes
const shotChanges =
operationResult.annotationResults[0].shotAnnotations;
console.log(
"Shot (scene) changes detected: " + shotChanges.length
);
// data structure to be returned
let sceneChanges = [];
// for the initial scene
sceneChanges.push(1);
// if only one scene, keep at 1 second
if (shotChanges.length === 1) {
return sceneChanges;
}
// get length of video
const videoLength = await getVideoLength(downloadedFile);
shotChanges.forEach((shot, shotIndex) => {
if (shot.endTimeOffset === undefined) {
shot.endTimeOffset = {};
}
if (shot.endTimeOffset.seconds === undefined) {
shot.endTimeOffset.seconds = 0;
}
if (shot.endTimeOffset.nanos === undefined) {
shot.endTimeOffset.nanos = 0;
}
// convert to a number
let currentTimestampSecond = Number(
shot.endTimeOffset.seconds
);
let sceneChangeTime = 0;
// double-check no scenes were detected within the last second
if (currentTimestampSecond + 1 > videoLength) {
sceneChangeTime = currentTimestampSecond;
} else {
// otherwise, for simplicity, just round up to the next second
sceneChangeTime = currentTimestampSecond + 1;
}
sceneChanges.push(sceneChangeTime);
});
return sceneChanges;
}
};
async function getVideoLength(localFile) {
let getLength = util.promisify(ffmpeg.ffprobe);
let length = await getLength(localFile);
console.log("video length: ", length.format.duration);
return length.format.duration;
}
Agora crie um arquivo chamado imageCapture.js com o conteúdo a seguir. Esse arquivo usa o pacote do nó fluent-ffmpeg para executar comandos ffmpeg em um app do nó.
const ffmpeg = require("fluent-ffmpeg");
const path = require("path");
const util = require("util");
module.exports = {
captureImages: async function (localFile, scenes) {
let imageBaseName = path.parse(localFile).name;
try {
for (scene of scenes) {
console.log("creating screenshot for scene: ", +scene);
await createScreenshot(localFile, imageBaseName, scene);
}
} catch (error) {
console.log("error gathering screenshots: ", error);
}
console.log("finished gathering the screenshots");
return imageBaseName; // return the base filename for each image
}
};
async function createScreenshot(localFile, imageBaseName, scene) {
return new Promise((resolve, reject) => {
ffmpeg(localFile)
.screenshots({
timestamps: [scene],
filename: `${imageBaseName}-${scene}.png`,
folder: "output",
size: "320x240"
})
.on("error", () => {
console.log(
"Failed to create scene for timestamp: " + scene
);
return reject(
"Failed to create scene for timestamp: " + scene
);
})
.on("end", () => {
return resolve();
});
});
}
Por fim, crie um arquivo chamado imageCaptioning.js com o conteúdo a seguir. Esse arquivo usa a Vertex AI para receber uma descrição visual de cada imagem de cena.
const axios = require("axios");
const { GoogleAuth } = require("google-auth-library");
const auth = new GoogleAuth({
scopes: "https://www.googleapis.com/auth/cloud-platform"
});
module.exports = {
getImageCaption: async function (token, encodedFile) {
// this example shows you how to call the Vertex REST APIs directly
// https://cloud.google.com/vertex-ai/generative-ai/docs/image/image-captioning#get-captions-short
// https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/image-captioning
let projectId = await auth.getProjectId();
let config = {
headers: {
"Authorization": "Bearer " + token,
"Content-Type": "application/json; charset=utf-8"
}
};
const json = {
"instances": [
{
"image": {
"bytesBase64Encoded": encodedFile
}
}
],
"parameters": {
"sampleCount": 1,
"language": "en"
}
};
let response = await axios.post(
"https://us-central1-aiplatform.googleapis.com/v1/projects/" +
projectId +
"/locations/us-central1/publishers/google/models/imagetext:predict",
json,
config
);
return response.data.predictions[0];
}
};
Crie um arquivo chamado auth.js. Esse arquivo vai usar a biblioteca de cliente de autenticação do Google para receber um token de acesso necessário para chamar os endpoints da Vertex AI diretamente.
const { GoogleAuth } = require("google-auth-library");
const auth = new GoogleAuth({
scopes: "https://www.googleapis.com/auth/cloud-platform"
});
module.exports = {
getAccessToken: async function () {
return await auth.getAccessToken();
}
};
Por fim, crie um arquivo chamado storage.js. Esse arquivo vai usar as bibliotecas de cliente do Cloud Storage para baixar um vídeo do armazenamento em nuvem.
const { Storage } = require("@google-cloud/storage");
module.exports = {
downloadVideoFile: async function (bucketName, videoFilename) {
// Creates a client
const storage = new Storage();
// keep same name locally
let localFilename = videoFilename;
const options = {
destination: localFilename
};
// Download the file
await storage
.bucket(bucketName)
.file(videoFilename)
.download(options);
console.log(
`gs://${bucketName}/${videoFilename} downloaded locally to ${localFilename}.`
);
return localFilename;
}
};
7. Implantar e executar o job do Cloud Run
Primeiro, verifique se você está no diretório raiz video-describer-job do codelab.
cd .. && pwd
Em seguida, use este comando para implantar o job do Cloud Run.
gcloud run jobs deploy $JOB_NAME --source . --region $REGION
Agora, é possível executar o job do Cloud Run com o seguinte comando:
gcloud run jobs execute $JOB_NAME
Depois que o job terminar de ser executado, execute o comando a seguir para receber um link para o URI do registro. Ou use o console do Cloud e acesse os jobs do Cloud Run diretamente para ver os registros.
gcloud run jobs executions describe <JOB_EXECUTION_ID>
Você vai ver a seguinte saída nos registros:
[{ timestamp: 1, description: 'what is google cloud vision api ? is written on a white background .'},
{ timestamp: 3, description: 'a woman wearing a google cloud vision api shirt sits at a table'},
{ timestamp: 18, description: 'a person holding a cell phone with the words what is cloud vision api on the bottom' }, ...]
8. Parabéns!
Parabéns por concluir o codelab!
Recomendamos que você consulte a documentação sobre a API Video Intelligence, o Cloud Run e a legenda visual da Vertex AI.
O que vimos
- Como criar uma imagem de contêiner usando um Dockerfile para instalar um binário de terceiros
- Como seguir o princípio de privilégio mínimo criando uma conta de serviço para o job do Cloud Run chamar outros serviços do Google Cloud
- Como usar a biblioteca de cliente da Video Intelligence em um job do Cloud Run
- Como fazer uma chamada para as APIs do Google e receber a descrição visual de cada cena da Vertex AI
9. Limpar
Para evitar cobranças acidentais, por exemplo, se esse job do Cloud Run for invocado mais vezes do que sua alocação mensal de invocações do Cloud Run no nível sem custo financeiro, exclua o job do Cloud Run ou o projeto criado na etapa 2.
Para excluir o job do Cloud Run, acesse o console do Cloud Run em https://console.cloud.google.com/run/ e exclua a função video-describer-job (ou $JOB_NAME se você usou um nome diferente).
Se você quiser excluir todo o projeto, acesse https://console.cloud.google.com/cloud-resource-manager, selecione o projeto criado na Etapa 2 e escolha "Excluir". Se você excluir o projeto, vai precisar mudar de projeto no SDK Cloud. Para conferir a lista de todos os projetos disponíveis, execute gcloud projects list.