
1. Overview
Welcome to the Google Codelab for running a Slurm cluster on Google Cloud Platform! By the end of this codelab you should have a solid understanding of the ease of provisioning and operating an auto-scaling Slurm cluster.

Google Cloud teamed up with SchedMD to release a set of tools that make it easier to launch the Slurm workload manager on Compute Engine, and to expand your existing cluster dynamically when you need extra resources. This integration was built by the experts at SchedMD in accordance with Slurm best practices.
If you're planning on using the Slurm on Google Cloud Platform integrations, or if you have any questions, please consider joining our Google Cloud & Slurm Community Discussion Group!
About Slurm
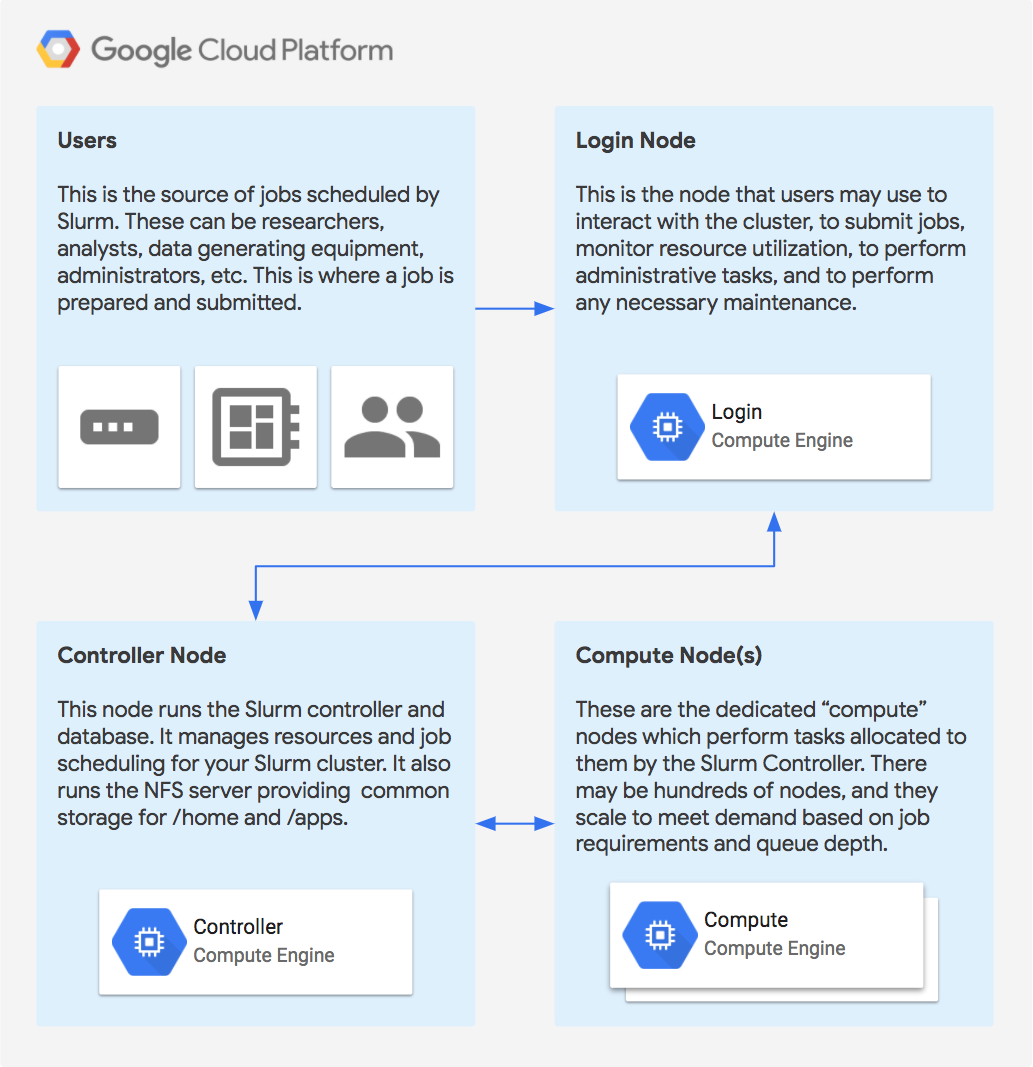
Basic architectural diagram of a stand-alone Slurm Cluster in Google Cloud Platform.
Slurm is one of the leading workload managers for HPC clusters around the world. Slurm provides an open-source, fault-tolerant, and highly-scalable workload management and job scheduling system for small and large Linux clusters. Slurm requires no kernel modifications for its operation and is relatively self-contained. As a cluster workload manager, Slurm has three key functions:
- It allocates exclusive or non-exclusive access to resources (compute nodes) to users for some duration of time so they can perform work.
- It provides a framework for starting, executing, and monitoring work (normally a parallel job) on the set of allocated nodes.
- It arbitrates contention for resources by managing a queue of pending work.
What you'll learn
- How to setup up a Slurm cluster using Terraform
- How to run a job using SLURM
- How to query cluster information and monitor running jobs in SLURM
- How to autoscale nodes to accommodate specific job parameters and requirements
- Where to find help with Slurm
Prerequisites
- Google Cloud Platform Account and a Project with Billing
- Basic Linux Experience
2. Setup
Self-paced environment setup
Create a Project
If you don't already have a Google Account (Gmail or G Suite), you must create one. Sign-in to Google Cloud Platform console ( console.cloud.google.com) and open the Manage resources page:
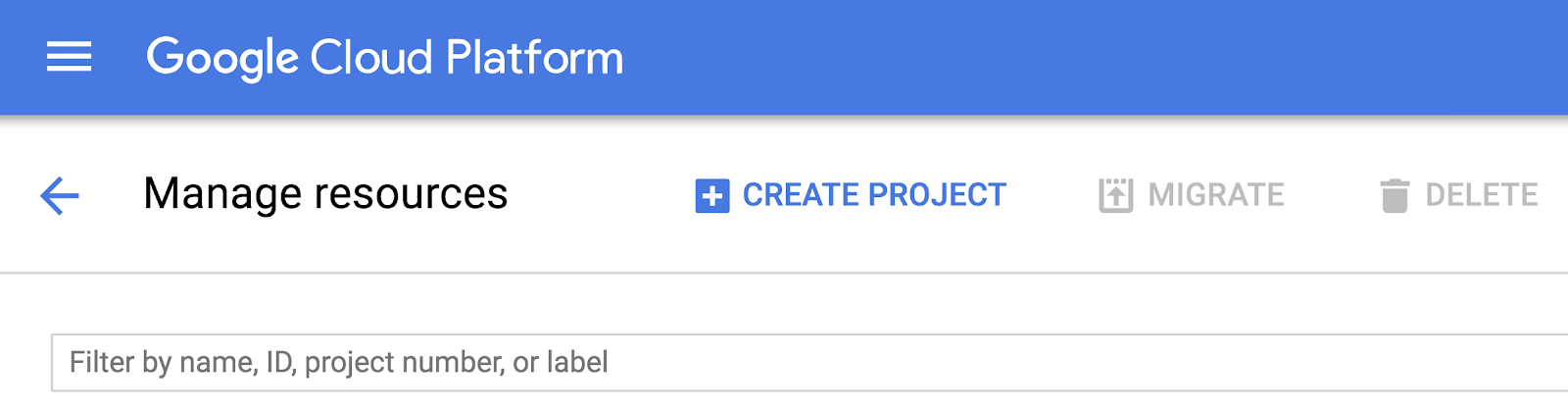
Click Create Project.
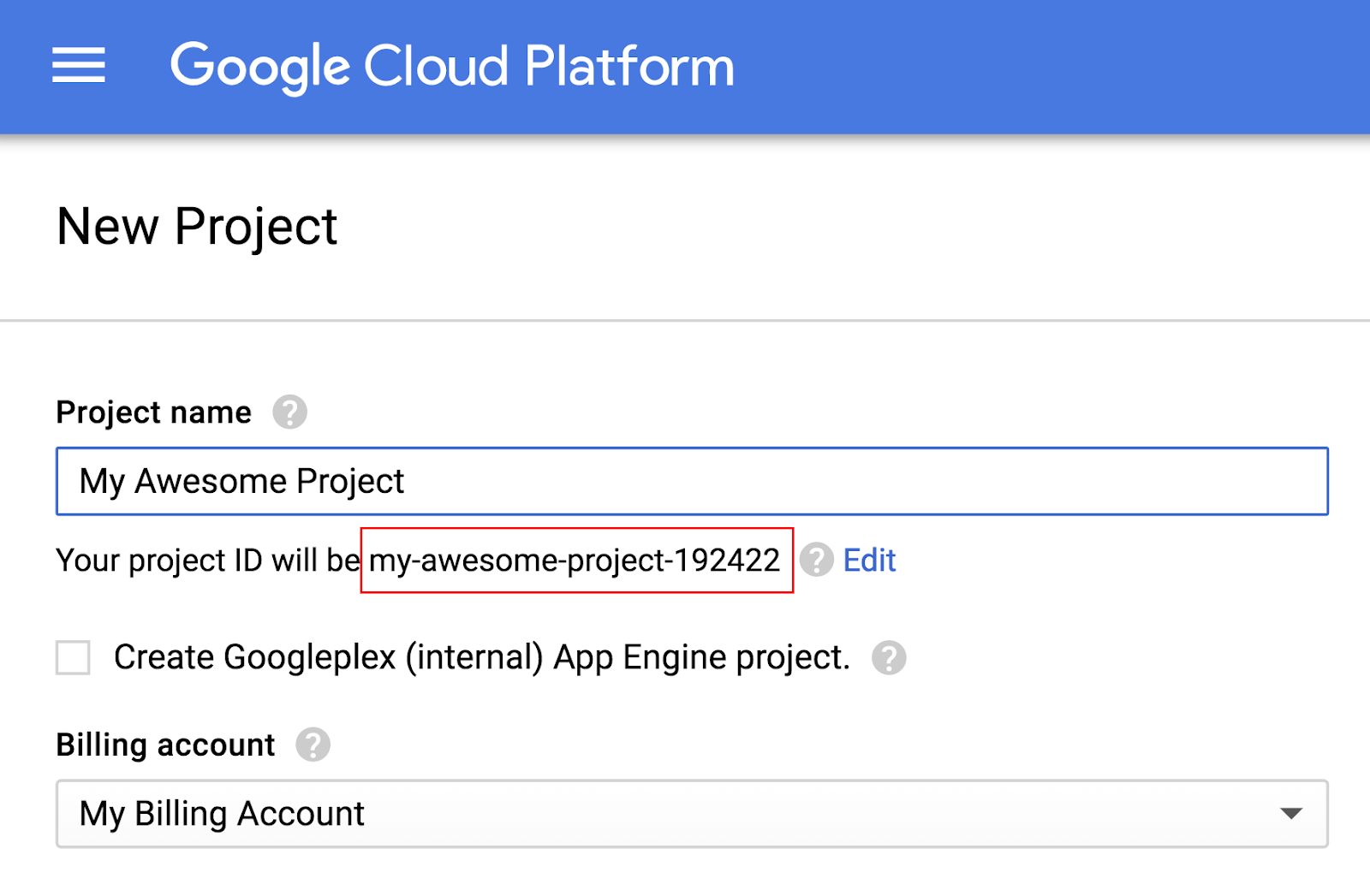
Enter a project name. Remember the project ID (highlighted in red in the screenshot above). The project ID must be a unique name across all Google Cloud projects. If your project name is not unique Google Cloud will generate a random project ID based on the project name.
Next, you'll need to enable billing in the Developers Console in order to use Google Cloud resources.
Running through this codelab shouldn't cost you more than a few dollars, but it could be more if you decide to use more resources or if you leave them running (see "Conclusion" section at the end of this document). The Google Cloud Platform pricing calculator is available here.
New users of Google Cloud Platform are eligible for a $300 free trial.
Google Cloud Shell
While Google Cloud can be operated remotely from your laptop, in this codelab we will be using Google Cloud Shell, a command line environment running in the Cloud.
Launch Google Cloud Shell
From the GCP Console click the Cloud Shell icon on the top right toolbar:

Then click Start Cloud Shell:
It should only take a few moments to provision and connect to the environment:

This virtual machine is loaded with all the development tools you'll need. It offers a persistent 5GB home directory, and runs on the Google Cloud, greatly enhancing network performance and simplifying authentication. Much, if not all, of your work in this lab can be done with simply a web browser or a Google Chromebook.
Once connected to the cloud shell, you should see that you are already authenticated and that the project is already set to your PROJECT_ID:
$ gcloud auth list
Command output:
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
$ gcloud config list project
Command output:
[core]
project = <PROJECT_ID>
If the project ID is not set correctly you can set it with this command:
$ gcloud config set project <PROJECT_ID>
Command output:
Updated property [core/project].
3. Prepare and Review Slurm Terraform Configuration
Download the Slurm Terraform Configuration
In the Cloud Shell session, execute the following command to clone (download) the Git repository that contains the Slurm for Google Cloud Platform Terraform files:
git clone https://github.com/SchedMD/slurm-gcp.git
Switch to the Slurm deployment configuration directory by executing the following command:
cd slurm-gcp
Configure Slurm Terraform tfvars
The basic.tfvars.example file details the configuration of the deployment, including the network, instances, and storage to deploy. Copy it to a new file, which we'll call "the tfvars file", then edit as needed.
cd tf/example/basic cp basic.tfvars.example basic.tfvars
In the Cloud Shell session, open the tfvars file basic.tfvars. You can either use your preferred command line editor (vi, nano, emacs, etc.) or use the Cloud Console Code Editor to view the file contents:

Review the contents of the tfvars file.
cluster_name = "g1"
project = "<project>"
zone = "us-west1-b"
# network_name = "<existing network name>"
# subnetwork_name = "<existing subnetwork name>"
# shared_vpc_host_project = "<vpc host project>"
# disable_controller_public_ips = true
# disable_login_public_ips = true
# disable_compute_public_ips = true
# suspend_time = 300
controller_machine_type = "n1-standard-2"
controller_image = "projects/schedmd-slurm-public/global/images/family/schedmd-slurm-20-11-4-hpc-centos-7"
controller_disk_type = "pd-standard"
controller_disk_size_gb = 50
# controller_labels = {
# key1 = "val1"
# key2 = "val2"
# }
# controller_service_account = "default"
# controller_scopes = ["https://www.googleapis.com/auth/cloud-platform"]
# cloudsql = {
# server_ip = "<cloudsql ip>"
# user = "slurm"
# password = "verysecure"
# db_name = "slurm_accounting"
# }
# controller_secondary_disk = false
# controller_secondary_disk_size = 100
# controller_secondary_disk_type = "pd-ssd"
#
# When specifying an instance template, specified controller fields will
# override the template properites.
# controller_instance_template = null
login_machine_type = "n1-standard-2"
login_image = "projects/schedmd-slurm-public/global/images/family/schedmd-slurm-20-11-4-hpc-centos-7"
login_disk_type = "pd-standard"
login_disk_size_gb = 20
# login_labels = {
# key1 = "val1"
# key2 = "val2"
# }
# login_node_count = 1
# login_node_service_account = "default"
# login_node_scopes = [
# "https://www.googleapis.com/auth/monitoring.write",
# "https://www.googleapis.com/auth/logging.write"
# ]
#
# When specifying an instance template, specified login fields will
# override the template properties.
# login_instance_template = null
# Optional network storage fields
# network_storage is mounted on all instances
# login_network_storage is mounted on controller and login instances
# network_storage = [{
# server_ip = "<storage host>"
# remote_mount = "/home"
# local_mount = "/home"
# fs_type = "nfs"
# mount_options = null
# }]
#
# login_network_storage = [{
# server_ip = "<storage host>"
# remote_mount = "/net_storage"
# local_mount = "/shared"
# fs_type = "nfs"
# mount_options = null
# }]
# compute_node_service_account = "default"
# compute_node_scopes = [
# "https://www.googleapis.com/auth/monitoring.write",
# "https://www.googleapis.com/auth/logging.write"
# ]
partitions = [
{ name = "debug"
machine_type = "n1-standard-2"
static_node_count = 0
max_node_count = 10
zone = "us-west1-b"
image ="projects/schedmd-slurm-public/global/images/family/schedmd-slurm-20-11-4-hpc-centos-7"
image_hyperthreads = false
compute_disk_type = "pd-standard"
compute_disk_size_gb = 20
compute_labels = {}
cpu_platform = null
gpu_count = 0
gpu_type = null
network_storage = []
preemptible_bursting = false
vpc_subnet = null
exclusive = false
enable_placement = false
regional_capacity = false
regional_policy = {}
instance_template = null
},
# { name = "partition2"
# machine_type = "n1-standard-16"
# static_node_count = 0
# max_node_count = 20
# zone = "us-west1-b"
# image = "projects/schedmd-slurm-public/global/images/family/schedmd-slurm-20-11-4-hpc-centos-7"
# image_hyperthreads = false
#
# compute_disk_type = "pd-ssd"
# compute_disk_size_gb = 20
# compute_labels = {
# key1 = "val1"
# key2 = "val2"
# }
# cpu_platform = "Intel Skylake"
# gpu_count = 8
# gpu_type = "nvidia-tesla-v100"
# network_storage = [{
# server_ip = "none"
# remote_mount = "<gcs bucket name>"
# local_mount = "/data"
# fs_type = "gcsfuse"
# mount_options = "file_mode=664,dir_mode=775,allow_other"
# }]
# preemptible_bursting = true
# vpc_subnet = null
# exclusive = false
# enable_placement = false
#
# ### NOTE ####
# # regional_capacity is under development. You may see slowness in
# # deleting lots of instances.
# #
# # With regional_capacity : True, the region can be specified in the zone.
# # Otherwise the region will be inferred from the zone.
# zone = "us-west1"
# regional_capacity = True
# # Optional
# regional_policy = {
# locations = {
# "zones/us-west1-a" = {
# preference = "DENY"
# }
# }
# }
#
# When specifying an instance template, specified compute fields will
# override the template properties.
# instance_template = "my-template"
]
Within this tfvars file there are several fields to configure. The only field that must be configured is the project. All other configurations in the example can be used as is, but modify them as required for your situation. For a more detailed description of the configurations options, see here.
- cluster_name: Name of the Slurm cluster
- project: Google Cloud Project ID for where resources will be deployed
- zone: Google Cloud zone which will contain the controller and login instances of this cluster - More Info
- network_name: Virtual Private Cloud network to deploy the Slurm cluster into
- subnetwork_name: Virtual Private Cloud subnetwork to deploy the Slurm cluster into
- shared_vpc_host_project: Shared VPC network to deploy the Slurm cluster into
- disable_controller_public_ips: Assign external IP to the Slurm controller?
- disable_login_public_ips: Assign external IP to the Slurm login node?
- disable_compute_login_ips: Assign external IP to the Slurm login node?
- suspend_time: Time to wait after a node is idle before suspending the node
- controller_machine_type: Controller node instance type
- controller_image: GCP image used to create the Slurm controller instance
- controller_disk_type: Type of the controller instance boot disk
- controller_disk_size_gb: Size of a controller instance boot disk
- controller_labels: Label(s) to attach to the controller instance
- controller_service_account: Service account to be used on the controller instance
- controller_scopes: Access scope of the controller instance
- cloudsql: Google CloudSQL server to use as the Slurm database instead of hosting a database on the controller instance
- server_ip: CloudSQL server IP
- user: CloudSQL username
- password: CloudSQL password
- db_name: CloudSQL database name
- controller_secondary_disk: Add a secondary disk for NFS server storage?
- controller_secondary_disk_type: Type of the controller secondary disk
- controller_secondary_disk_size_gb: Size of the controller secondary disk
- controller_instance_template: The GCP instance template to use for the controller instance. Any compute fields specified will override the template properties. Eg. if controller_image is specified, it will overwrite the image in the instance template.
- login_machine_type: Login (SSH-accessible) node instance type
- login_image: GCP image used to create the Slurm login instance
- login_disk_type: Type of the login instance boot disk
- login_disk_size_gb: Size of the login instance boot disk
- login_labels: Label(s) to attach to the login instance
- login_node_count: Number of login nodes to create
- login_node_service_account: Service account to be used on the login instance(s)
- login_node_scopes: Access scope of the login instance
- login_instance_template: The GCP instance template to use for the login instance. Any compute fields specified will override the template properties. Eg. if login_image is specified, it will overwrite the image in the instance template.
- network_storage: Network storage to mount on all nodes. Fields will be added directly to fstab. Can be repeated for additional mounts.
- server_ip: Storage server IP
- remote_mount: Storage mount name (filesystem name)
- local_mount: Local mount directory
- fs_type: Filesystem type (NFS, CIFS, Lustre, GCSFuse installed automatically)
- mount_options: Mount options (i.e. defaults,_netdev)
- login_network_storage: Network storage to mount on login and controller nodes. NFS, CIFS, Lustre, and GCSFuse will be installed automatically. Can be repeated for additional mounts.
- server_ip: Storage server IP
- remote_mount: Storage mount name (filesystem name)
- local_mount: Local mount directory
- fs_type: Filesystem type (NFS, CIFS, Lustre, GCSFuse installed automatically)
- mount_options: Mount options (i.e. defaults,_netdev)
- compute_node_service_account: Service account to be used on the compute instance(s)
- compute_node_scopes: Access scope of the compute instances
- partitions: Slurm partition configuration. Can be repeated for additional partitions.
- name: Partition name
- machine_type: Compute node(s) instance type
- static_node_count: Number of always-on compute nodes
- max_node_count: Maximum number of total compute nodes allowed - 64K maximum
- zone: Google Cloud zone which will contain the resources of this partition - More Info
- image: Compute image node machine type
- image_hyperthreads: Turn on or off hyperthreading on the instance
- compute_disk_type: Type of a compute instance boot disk (pd-standard, pd-ssd)
- compute_disk_size_gb: Size of a compute instance boot disk
- compute_labels: Label(s) to attach to the compute instance
- cpu_platform: Minimum CPU platform required for all compute nodes
- gpu_count: Number of GPUs to attach to each instance in the partition
- gpu_type: GPU type to attach to the partition's instances
- network_storage: Network storage to mount on all compute nodes in the partition. Fields will be added directly to fstab. Can be repeated for additional mounts.
- server_ip: Storage server IP
- remote_mount: Storage mount name (filesystem name)
- local_mount: Local mount directory
- fs_type: Filesystem type (NFS, CIFS, Lustre, GCSFuse installed automatically)
- mount_options: Mount option
- preemptible_bursting: Will the instances be preemptible instances?
- vpc_subnet: Virtual Private Cloud subnetwork to deploy the Slurm partition into
- exclusive: Enable Slurm to allocate entire nodes to jobs
- enable_placement: Enable placement policies where instances will be located close to each other for low network latency between the instances.
- regional_capacity: Allow an instance to be placed in any zone in the region based on availability
- regional_policy: If regional_capacity is true, this policy is to determine what region to use and any zones in that region not to use
- Instance_template: The GCP instance template to use for compute instances. Any compute fields specified will override the template properties. Eg. if image is specified, it will overwrite the image in the instance template.
Advanced Configuration
If desired you may choose to install additional packages and software as part of the cluster deployment process. You can install software on your slurm cluster in multiple ways outlined in our "Installing apps in a Slurm cluster on Compute Engine", or by customizing the image deployed by Slurm. Currently Slurm deploys a SchedMD-provided VM Image that's based on the Google Cloud HPC VM Image, with Slurm installed on top of it.
In order to use your own image, build an image with your own configuration based on the public SchedMD VM Image listed in the tfvars file. Next, replace the image URI specified in the tfvars file with your own image, and test the change.
Troubleshooting
Throughout this codelab, please refer to the Troubleshooting section of the Slurm-GCP repository's ReadMe.
The most common issues seen are mistakes made in configuring the tfvars file, and quota restrictions. This codelab is designed to run within a new user's standard quota allotment and within the $300 free credit a new user receives. If an attempt to create VMs fails, check the /var/log/slurm/resume.log file on the controller node to check for API errors.
4. Deploying and verifying the configuration
Deploy the Configuration
In the Cloud Shell session, execute the following command from the slurm-gcp/tf/example folder:
terraform init terraform apply -var-file=basic.tfvars
You will be prompted to accept the actions described, based on the configurations that's been set. Enter "yes" to begin the deployment. You can also view the configuration to be deployed by running "terraform plan".
Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes
The operation can take a few minutes to complete, so please be patient.
Once the deployment has completed you will see output similar to:
Apply complete! Resources: 8 added, 0 changed, 0 destroyed.
Outputs:
controller_network_ips = [
[
"10.0.0.2",
],
]
login_network_ips = [
[
"10.0.0.3",
],
]
Verify VM instance creation
Open the navigation menu and select Compute Engine > VM Instances.
You should see a controller and a login VM instance listed:

Under VM instances review the two virtual machine instances that have been created by Terraform.
The names will be different if you modified the cluster_name field.
- g1-controller
- g1-login0
5. Login to the Slurm Cluster
Access the Slurm Cluster
Return to your Code Editor/Cloud Shell tab. Run the following command to login to your instance, substituting <ZONE> for the g1-login0 node's zone (should be us-central1-b):
gcloud compute ssh g1-login0 --zone=<ZONE>
This command will log you into the g1-login0 virtual machine.
Another method to easily access the login node is by clicking the "SSH" button next to the g1-login0 VM on the VM Instances page to open a new tab with an SSH connection.

If this is the first time you have used cloud shell, you may see a message like the one below asking you to create an SSH key:
WARNING: The public SSH key file for gcloud does not exist. WARNING: The private SSH key file for gcloud does not exist. WARNING: You do not have an SSH key for gcloud. WARNING: SSH keygen will be executed to generate a key. This tool needs to create the directory [/home/user/.ssh] before being able to generate SSH keys. Do you want to continue (Y/n)?
If so, enter Y. If requested to select a passphrase, leave it blank by pressing Enter twice.
If the following message appears upon login:
*** Slurm is currently being configured in the background. *** A terminal broadcast will announce when installation and configuration is complete.
Wait and do not proceed with the lab until you see this message (approx 5 mins):
*** Slurm login setup complete ***
Once you see the above message, you will have to log out and log back in to g1-login0 to continue the lab. To do so, press CTRL + C to end the task.
Then execute the following command logout of your instance:
exit
Now, reconnect to your login VM. Run the following command to login to your instance, substituting <ZONE> for the g1-login0 node's zone:
gcloud compute ssh g1-login0 --zone=<ZONE>
Like above, you may have to wait a minute or two before you are able to connect and all aspects of the setup are complete.
Tour of the Slurm CLI Tools
You're now logged in to your cluster's Slurm login node. This is the node that's dedicated to user/admin interaction, scheduling Slurm jobs, and administrative activity.
Let's run a couple commands to introduce you to the Slurm command line.
Execute the sinfo command to view the status of our cluster's resources:
sinfo
Sample output of sinfo appears below. sinfo reports the nodes available in the cluster, the state of those nodes, and other information like the partition, availability, and any time limitation imposed on those nodes.
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 10 idle~ g1-compute-0-[0-9]
You can see our 10 nodes, dictated by the debug partition's "max_node_count" of 10, are marked as "idle~" (the node is in an idle and non-allocated mode, ready to be spun up).
Next, execute the squeue command to view the status of our cluster's queue:
squeue
The expected output of squeue appears below. squeue reports the status of the queue for a cluster. This includes each the job ID of each job scheduled on the cluster, the partition the job is assigned to, the name of the job, the user that launched the job, the state of the job, the wall clock time the job has been running, and the nodes that job is allocated to. We don't have any jobs running, so the contents of this command is empty.
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
The Slurm commands "srun" and "sbatch" are used to run jobs that are put into the queue. "srun" runs parallel jobs, and can be used as a wrapper for mpirun. "sbatch" is used to submit a batch job to slurm, and can call srun once or many times in different configurations. "sbatch" can take batch scripts, or can be used with the –wrap option to run the entire job from the command line.
Let's run a job so we can see Slurm in action and get a job in our queue!
6. Run a Slurm Job and Scale the Cluster
Run a Slurm Job and Scale the Cluster
Now that we have our Slurm cluster running, let's run a job and scale our cluster up.
The "sbatch" command is used to run Slurm batch commands and scripts. Let's run a simple sbatch script that will run "hostname" on our auto-scaled VMs.
While logged in to g1-login0, run the following command:
sbatch -N2 --wrap="srun hostname"
This command runs the Slurm batch command. It specifies that sbatch will run 2 nodes with the "-N" option. It also specifies that each of those nodes will run an "srun hostname" command in the "–wrap" option.
By default, sbatch will write it's output to "slurm-%j.out" in the working directory the command is run from, where %j is substituted for the Job ID according to the Slurm Filename Patterns. In our example sbatch is being run from the user's /home folder, which is a NFS-based shared file system hosted on the controller by default. This allows compute nodes to share input and output data if desired. In a production environment, the working storage should be separate from the /home storage to avoid performance impacts to the cluster operations. Separate storage mounts can be specified in the tfvars file in the "network_storage" options.
After executing the sbatch script using the sbatch command line it will return a Job ID for the scheduled job, for example:
Submitted batch job 2
We can use the Job ID returned by the sbatch command to track and manage the job execution and resources. Execute the following command to view the Slurm job queue:
squeue
You will likely see the job you executed listed like below:
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
2 debug g1-compute-0-[0-1] username R 0:10 2 g1-compute-0-[0-1]
Since we didn't have any compute nodes provisioned, Slurm will automatically create compute instances according to the job requirements. The automatic nature of this process has two benefits. First, it eliminates the work typically required in a HPC cluster of manually provisioning nodes, configuring the software, integrating the node into the cluster, and then deploying the job. Second, it allows users to save money because idle, unused nodes are scaled down until the minimum number of nodes is running.
You can execute the sinfo command to view the Slurm cluster spinning up:
sinfo
This will show the nodes listed in squeue in the "alloc#" state, meaning the nodes are being allocated:
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 8 idle~ g1-compute-0-[2-9] debug* up infinite 2 alloc# g1-compute-0-[0-1]
You can also check the VM instances section in Google Cloud Console to view the newly provisioned nodes. It will take a few minutes to spin up the nodes and get Slurm running before the job is allocated to the newly allocated nodes. Your VM instances list will soon resemble the following:

Once the nodes are running the job the instances will move to an "alloc" state, meaning the jobs are allocated to a job:
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 8 idle~ g1-compute-0-[2-9] debug* up infinite 2 alloc g1-compute-0-[0-1]
Once a job is complete, it will no longer be listed in squeue, and the "alloc" nodes in sinfo will return to the "idle" state. Run "squeue" periodically until the job is completed, after a minute or two.
The output file slurm-%j.out will have been written to your NFS-shared /home folder, and will contain the hostnames. Open or cat the output file (typically slurm-2.out), it contents of the output file will contain:
g1-compute-0-0 g1-compute-0-1
Great work, you've run a job and scaled up your Slurm cluster!
7. Run an MPI Job
Now let's run an MPI job across our nodes. While logged in to g1-login0, use wget to download an MPI program written in the C programming language:
wget https://raw.githubusercontent.com/mpitutorial/mpitutorial/gh-pages/tutorials/mpi-hello-world/code/mpi_hello_world.c
To use OpenMPI tools you need to to load the OpenMPI modules by running this command:
module load openmpi
We'll use the "mpicc" tool to compile the MPI C code. Execute the following command:
mpicc mpi_hello_world.c -o mpi_hello_world
This compiles our C code to machine code so that we can run the code across our cluster through Slurm.
Next, use your preferred text editor to create a sbatch script called "helloworld_batch":
vi helloworld_batch
Type i to enter the vi insert mode.
Copy and paste the following text into the file to create a simple sbatch script:
#!/bin/bash # #SBATCH --job-name=hello_world #SBATCH --output=hello_world-%j.out # #SBATCH --nodes=2 srun mpi_hello_world
Save and exit the code editor by pressing escape and typing ":wq" without quotes.
This script defines the Slurm batch execution environment and tasks. First, the execution environment is defined as bash. Next, the script defines the Slurm options first with the "#SBATCH" lines. The job name is defined as "hello_world".
The output file is set as "hello_world_%j.out" where %j is substituted for the Job ID according to the Slurm Filename Patterns. This output file is written to the directory the sbatch script is run from. In our example this is the user's /home folder, which is a NFS-based shared file system. This allows compute nodes to share input and output data if desired. In a production environment, the working storage should be separate from the /home storage to avoid performance impacts to the cluster operations.
Finally, the number of nodes this script should run on is defined as 2.
After the options are defined the executable commands are provided. This script will run the mpi_hello_world code in a parallel manner using the srun command, which is a drop-in replacement for the mpirun command.
Then execute the sbatch script using the sbatch command line:
sbatch helloworld_batch
Running sbatch will return a Job ID for the scheduled job, for example:
Submitted batch job 3
This will run the hostname command across 2 nodes, with one task per node, as well as printing the output to the hello_world-3.out file.
Since we had 2 nodes already provisioned this job will run quickly.
Monitor squeue until the job has completed and no longer listed:
squeue
Once completed open or cat the hello_world-3.out file and confirm it ran on g1-compute-0-[0-1]:
Hello world from processor g1-compute-0-0, rank 0 out of 2 processors Hello world from processor g1-compute-0-1, rank 1 out of 2 processors
After being idle for 5 minutes (configurable with the YAML's suspend_time field, or slurm.conf's SuspendTime field) the dynamically provisioned compute nodes will be de-allocated to release resources. You can validate this by running sinfo periodically and observing the cluster size fall back to 0:
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 10 idle~ g1-compute-0-[0-9]
Try spinning up more instances, up to your Quota allowed in the region you deployed the cluster in, and running different MPI applications.
8. Conclusion
Congratulations, you've created a Slurm cluster on Google Cloud Platform and used its latest features to auto-scale your cluster to meet workload demand! You can use this model to run any variety of jobs, and it scales to hundreds of instances in minutes by simply requesting the nodes in Slurm.
If you would like to continue learning to use Slurm on GCP, be sure to continue with the " Building Federated HPC Clusters with Slurm" codelab. This codelab will guide you through setting up two federated Slurm clusters in the cloud, to represent how you might achieve a multi-cluster federation, whether on-premise or in the cloud.
Are you building something cool using Slurm's new GCP-native functionality? Have questions? Have a feature suggestion? Reach out to the Google Cloud team today through Google Cloud's High Performance Computing Solutions website, or chat with us in the Google Cloud & Slurm Discussion Group!
Clean Up the Terraform Deployment
Logout of the slurm node:
exit
Let any auto-scaled nodes scale down before deleting the deployment. You can also delete these nodes manually by running "gcloud compute instances delete <Instance Name>" for each instance, or by using the Console GUI to select multiple nodes and clicking "Delete".
You can easily clean up the Terraform deployment after we're done by executing the following command from your Google Cloud Shell, after logging out of g1-login0:
cd ~/slurm-gcp/tf/examples/basic terraform destroy -var-file=basic.tfvars
When prompted, type yes to continue. This operation can take several minutes, please be patient.
Delete the Project
To cleanup, we simply delete our project.
- In the navigation menu select IAM & Admin
- Then click on settings in the submenu
- Click on the trashcan icon with the text "Delete Project"
- Follow the prompts instructions
What we've covered
- How to use deploy Slurm on GCP using Terraform.
- How to run a job using Slurm on GCP.
- How to query cluster information and monitor running jobs in Slurm.
- How to autoscale nodes with Slurm on GCP to accommodate specific job parameters and requirements.
- How to compile and run MPI applications on Slurm on GCP.
Find Slurm Support
If you need support using these integrations in testing or production environments please contact SchedMD directly using their contact page here: https://www.schedmd.com/contact.php
You may also use the Troubleshooting guides available:
- Slurm on GCP Troubleshooting guide: https://github.com/SchedMD/slurm-gcp#troubleshooting
- SchedMD's Troubleshooting guide: https://slurm.schedmd.com/troubleshoot.html
Finally, you may also post your question to the Google Cloud & Slurm Discussion Group found here: https://groups.google.com/g/google-cloud-slurm-discuss
Learn More
Feedback
Please submit feedback about this codelab using this link. Feedback takes less than 5 minutes to complete. Thank you!