
程式碼研究室簡介
1. 簡介
工作流程是資料分析的常見用途,內含擷取、轉換與分析資料,藉此找出有參考價值的資訊。在 Google Cloud Platform 中,您可以使用 Cloud Composer 自動化調度管理工作流程。Cloud Composer 是熱門開放原始碼工作流程工具 Apache Airflow 的託管版本。在本研究室中,您將使用 Cloud Composer 建立簡單的工作流程,藉此建立 Cloud Dataproc 叢集,並使用 Cloud Dataproc 和 Apache Hadoop 加以分析,並在之後刪除 Cloud Dataproc 叢集。
什麼是 Cloud Composer?
Cloud Composer 是一項全代管工作流程自動化調度管理服務,能讓您建立、排程和監控散布於不同雲端和內部部署資料中心的管道。Cloud Composer 以熱門的 Apache Airflow 開放原始碼專案為基礎,執行時使用的是 Python 程式設計語言,不僅相當容易使用,也能讓您免受單一架構限制。
使用 Cloud Composer 而非 Apache Airflow 本機執行個體,使用者無須安裝或管理負擔,就能充分運用 Airflow 的優勢。
什麼是 Apache Airflow?
Apache Airflow 是一項開放原始碼工具,可透過程式編寫、排程及監控工作流程。您會在本研究室中看到一些與 Airflow 相關的重要詞彙:
- DAG - DAG (有向非循環圖) 是一組經過規劃並執行的已整理工作。DAG (又稱為工作流程) 是在標準 Python 檔案中定義
- 運算子:運算子:描述工作流程中的單一工作
什麼是 Cloud Dataproc?
Cloud Dataproc 是 Google Cloud Platform 的全代管 Apache Spark 和 Apache Hadoop 服務。Cloud Dataproc 可輕鬆與其他 GCP 服務整合,透過功能強大且完善的平台,協助您處理資料處理、數據分析和機器學習工作。
處理方式
本程式碼研究室說明如何在 Cloud Composer 中建立及執行 Apache Airflow 工作流程,以完成下列工作:
- 建立 Cloud Dataproc 叢集
- 在叢集上執行 Apache Hadoop 字數工作,並將結果輸出至 Cloud Storage
- 刪除叢集
課程內容
- 如何在 Cloud Composer 中建立及執行 Apache Airflow 工作流程
- 如何使用 Cloud Composer 和 Cloud Dataproc 對資料集執行分析
- 如何透過 Google Cloud Platform 主控台、Cloud SDK 和 Airflow 網頁介面存取 Cloud Composer 環境
軟硬體需求
- GCP 帳戶
- 具備 CLI 基本知識
- 對 Python 有基本瞭解
2. 設定 GCP
建立專案
選取或建立 Google Cloud Platform 專案。
記下專案 ID,後續步驟將會用到。
建立新專案時,專案 ID 會顯示在建立頁面的「專案名稱」下方 |
|
如果您已建立專案,即可在「專案資訊卡」的控制台首頁中找到專案 ID |
|


啟用 API
啟用 Cloud Composer、Cloud Dataproc 和 Cloud Storage API。啟用這些 API 後,即可忽略「前往憑證」按鈕並繼續進行教學課程的下一個步驟 |
|


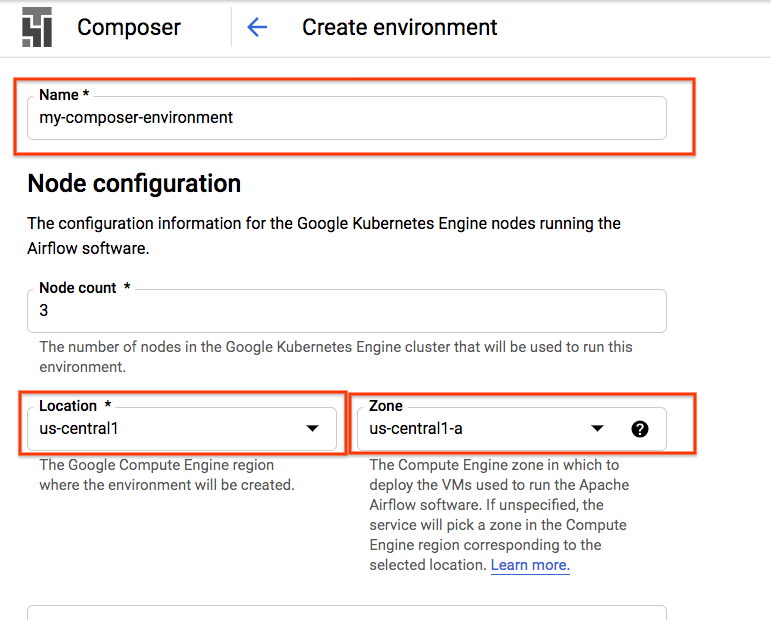
建立 Composer 環境
使用下列設定建立 Cloud Composer 環境:
所有其他設定均可保留預設設定。按一下「建立」。 |
|

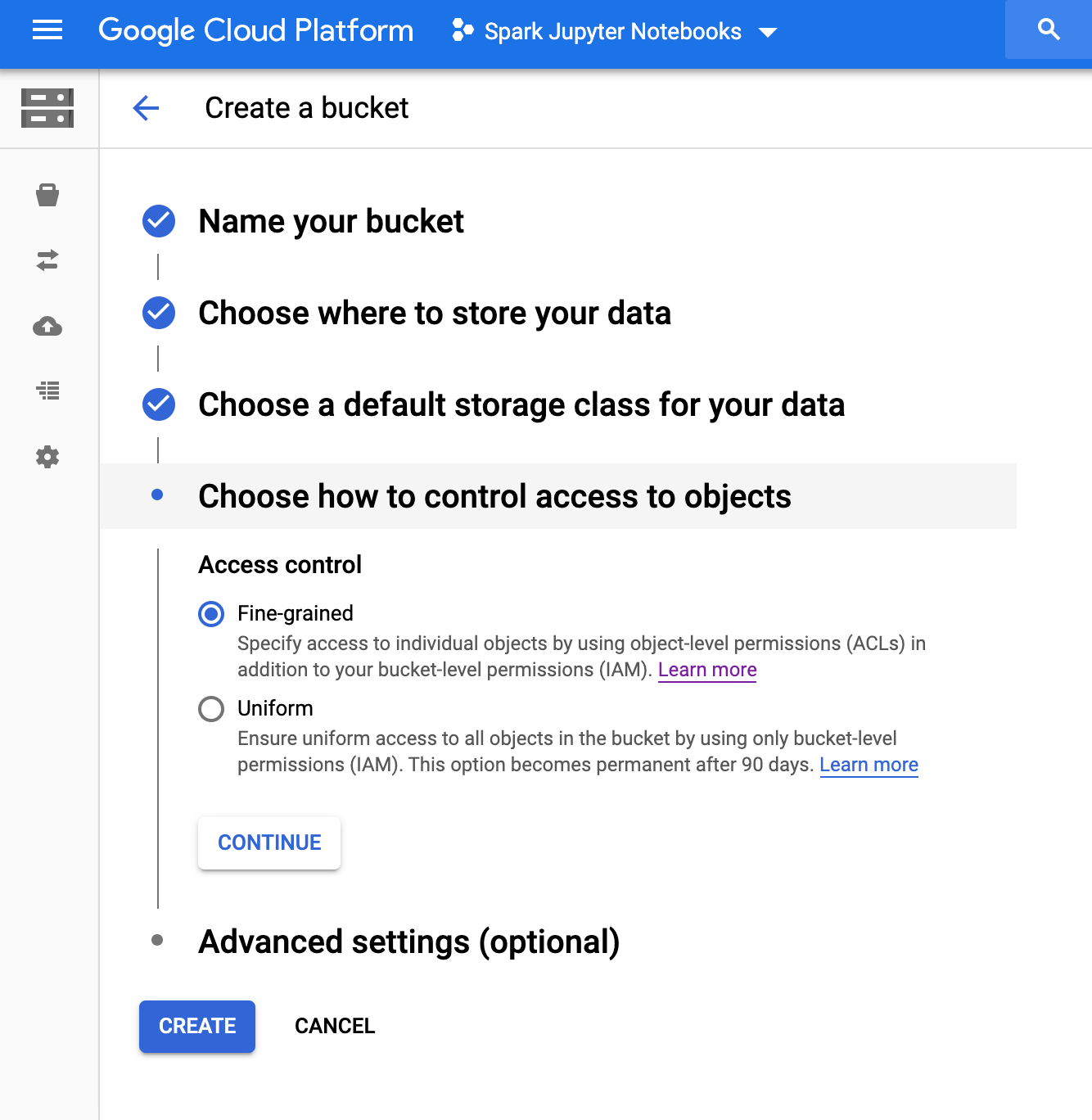
建立 Cloud Storage 值區
在專案中,使用下列設定建立 Cloud Storage 值區:
按下「建立」準備好的時候 |
|
3. 設定 Apache Airflow
檢視 Composer 環境資訊
在 GCP Console 中,開啟「Environments」(環境) 頁面
按一下環境名稱即可查看詳細資料。
「環境詳細資料」頁面提供了一些資訊,例如 Airflow 網頁介面網址、Google Kubernetes Engine 叢集 ID、Cloud Storage 值區名稱,以及 /dags 資料夾的路徑。
Airflow 中的 DAG (有向非循環圖) 是一組經過規劃並執行的工作。DAG 也稱為工作流程,是在標準 Python 檔案中定義。Cloud Composer 只會排定 /dags 資料夾中的 DAG。/dags 資料夾位於 Cloud Composer 在您建立環境時自動建立的 Cloud Storage 值區中。
設定 Apache Airflow 環境變數
Apache Airflow 變數是 Airflow 特有的概念,與環境變數不同。在這個步驟中,您會設定下列三個 Airflow 變數:gcp_project、gcs_bucket 和 gce_zone。
使用 gcloud 設定變數
首先,請開啟 Cloud Shell,已輕鬆安裝 Cloud SDK。
將環境變數 COMPOSER_INSTANCE 設為 Composer 環境名稱
COMPOSER_INSTANCE=my-composer-environment
如要透過 gcloud 指令列工具設定 Airflow 變數,請搭配 variables 子指令使用 gcloud composer environments run 指令。這個 gcloud composer 指令會執行 Airflow CLI 子指令 variables。子指令會將引數傳遞至 gcloud 指令列工具。
您將執行這個指令三次,將變數替換為與專案相關的變數。
使用下列指令設定 gcp_project,取代 <your-project-id>並附上您在步驟 2 記下的專案 ID。
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcp_project <your-project-id>
輸出內容應如下所示
kubeconfig entry generated for us-central1-my-composer-env-123abc-gke.
Executing within the following Kubernetes cluster namespace: composer-1-10-0-airflow-1-10-2-123abc
[2020-04-17 20:42:49,713] {settings.py:176} INFO - settings.configure_orm(): Using pool settings. pool_size=5, pool_recycle=1800, pid=449
[2020-04-17 20:42:50,123] {default_celery.py:90} WARNING - You have configured a result_backend of redis://airflow-redis-service.default.svc.cluste
r.local:6379/0, it is highly recommended to use an alternative result_backend (i.e. a database).
[2020-04-17 20:42:50,127] {__init__.py:51} INFO - Using executor CeleryExecutor
[2020-04-17 20:42:50,433] {app.py:52} WARNING - Using default Composer Environment Variables. Overrides have not been applied.
[2020-04-17 20:42:50,440] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
[2020-04-17 20:42:50,452] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
使用下列指令設定 gcs_bucket,並將 <your-bucket-name> 替換為您在步驟 2 中記下的值區 ID。如果遵循我們的建議,您的值區名稱會與專案 ID 相同。輸出內容會與上一個指令類似,
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gcs_bucket gs://<your-bucket-name>
使用下列指令設定 gce_zone。輸出內容會與先前的指令類似。
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --set gce_zone us-central1-a
(選用) 使用 gcloud 查看變數
如要查看變數的值,請使用 get 引數執行 Airflow CLI 子指令 variables,或使用 Airflow UI。
例如:
gcloud composer environments run ${COMPOSER_INSTANCE} \
--location us-central1 variables -- --get gcs_bucket
您可以使用您剛剛設定的三個變數來測試:gcp_project、gcs_bucket 和 gce_zone。
4. 工作流程範例
接著來看看步驟 5 中要使用的 DAG 程式碼。別擔心,請先按照這裡的步驟操作。
這裡有許多需要解開的地方,讓我們稍微詳細說明。
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
首先介紹一些 Airflow 匯入作業:
airflow.models- 允許我們在 Airflow 資料庫中存取及建立資料。airflow.contrib.operators- 社區業者的居住地。在這個範例中,我們需要dataproc_operator來存取 Cloud Dataproc API。airflow.utils.trigger_rule:用於在運算子中加入觸發條件規則。觸發條件規則可讓您精細地控管運算子是否應根據其父項狀態執行。
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
這會指定輸出檔案的位置。這裡值得注意的線條是 models.Variable.get('gcs_bucket'),這會從 Airflow 資料庫擷取 gcs_bucket 變數值。
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
WORDCOUNT_JAR- 我們最終要在 Cloud Dataproc 叢集上執行的 .jar 檔案位置。並會由 GCP 代管。input_file- 儲存 Hadoop 工作資料的檔案所在位置。我們會在步驟 5 中一起將資料上傳至該位置。wordcount_args- 我們會傳入 jar 檔案的引數。
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
如此一來,我們就能得到相當於前一天午夜的日期時間物件。例如,如果此要求是在 3 月 4 日 11:00 執行,則日期時間物件表示 3 月 3 日的 00:00。這與 Airflow 處理排程的方式有關。詳情請參閱這篇文章。
default_dag_args = {
'start_date': yesterday,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
每次建立新 DAG 時,都必須提供字典形式的 default_dag_args 變數:
'email_on_failure'- 指定工作失敗時是否應傳送電子郵件快訊'email_on_retry'- 指出是否應在重試工作時傳送電子郵件快訊'retries'- 表示在發生 DAG 故障的情況下, Airflow 應執行的重試次數'retry_delay'- 表示 Airflow 在嘗試重試之前應等待多久'project_id'- 告知 DAG 要與哪個 GCP 專案 ID 建立關聯,稍後與 Dataproc 操作者需要使用該 ID
with models.DAG(
'composer_hadoop_tutorial',
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
使用 with models.DAG 會指示指令碼在同一個 DAG 中納入其下的所有內容。我們也看到三個傳入的引數:
- 第一個是字串,也就是為我們要建立的 DAG 提供的名稱。在本例中,我們將使用
composer_hadoop_tutorial。 schedule_interval-datetime.timedelta物件,這裡已設定為一天。也就是說,此 DAG 會在'default_dag_args'中稍早設定的'start_date'之後一天嘗試執行一次default_args:我們先前建立的字典,內含 DAG 的預設引數
建立 Dataproc 叢集
接下來,請建立 dataproc_operator.DataprocClusterCreateOperator 來建立 Cloud Dataproc 叢集。
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
在這個運算子中,雖然我們看到幾個引數,但第一個引數專屬於這個運算子:
task_id- 就像在 BashOperator 中一樣,這是您指派給運算子的名稱,該名稱可透過 Airflow UI 查看cluster_name:我們為 Cloud Dataproc 叢集指派的名稱。並將該名稱命名為composer-hadoop-tutorial-cluster-{{ ds_nodash }}(如需其他資訊,請參閱資訊方塊)num_workers:我們分配給 Cloud Dataproc 叢集的工作站數量zone:希望叢集儲存的地理區域,儲存在 Airflow 資料庫中。這會讀取您在步驟 3 中設定的'gce_zone'變數master_machine_type:要分配給 Cloud Dataproc 主要執行個體的機器類型worker_machine_type:要分配給 Cloud Dataproc 工作站的機器類型
提交 Apache Hadoop 工作
dataproc_operator.DataProcHadoopOperator 可讓我們將工作提交至 Cloud Dataproc 叢集。
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
我們提供數種參數:
task_id- 指派給這個 DAG 的名稱main_jar- 我們要對叢集執行的 .jar 檔案的位置cluster_name- 要用來執行工作的叢集名稱,您會注意到與前一個運算子中找到的相同arguments- 傳遞至 jar 檔案的引數,就像從指令列執行 .jar 檔案一樣
刪除叢集
我們要建立的最後一個運算子是 dataproc_operator.DataprocClusterDeleteOperator。
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
顧名思義,這個運算子將刪除指定的 Cloud Dataproc 叢集。我們在這裡看到三個引數:
task_id- 就像在 BashOperator 中一樣,這是您指派給運算子的名稱,該名稱可透過 Airflow UI 查看cluster_name:我們為 Cloud Dataproc 叢集指派的名稱。我們將該叢集命名為composer-hadoop-tutorial-cluster-{{ ds_nodash }}(如需額外資訊,請參閱「建立 Dataproc 叢集」後方的資訊方塊)trigger_rule- 我們在這個步驟開始時,曾短暫提及觸發條件,但這裡有一些作用中的只是功用。根據預設,除非所有上游運算子均成功完成,否則 Airflow 運算子不會執行。ALL_DONE觸發規則只要求所有上游運算子都已完成,不論是否成功都一樣。這表示即使 Hadoop 工作失敗,我們仍然想要拆解叢集。
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
最後,我們希望這些運算子依特定順序執行,而使用 Python Bitshift 運算子即可表示這點。在此情況下,系統會一律先執行 create_dataproc_cluster,再執行 run_dataproc_hadoop,最後再執行 delete_dataproc_cluster。
將所有程式碼整合在一起,程式碼看起來會像這樣:
# Copyright 2018 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# [START composer_hadoop_tutorial]
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to use for result of Hadoop job.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
input_file = 'gs://pub/shakespeare/rose.txt'
wordcount_args = ['wordcount', input_file, output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
# [START composer_hadoop_schedule]
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# [END composer_hadoop_schedule]
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# [START composer_hadoop_steps]
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
# [END composer_hadoop_steps]
# [END composer_hadoop]
5. 將 Airflow 檔案上傳至 Cloud Storage
將 DAG 複製到 /dags 資料夾
- 首先,請開啟 Cloud Shell,已輕鬆安裝 Cloud SDK。
- 複製 Python 範例存放區,並變更為 Composer/workflows 目錄
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git && cd python-docs-samples/composer/workflows
- 執行下列指令,將 DAG 資料夾名稱設為環境變數
DAGS_FOLDER=$(gcloud composer environments describe ${COMPOSER_INSTANCE} \
--location us-central1 --format="value(config.dagGcsPrefix)")
- 執行下列
gsutil指令,將教學課程程式碼複製到建立 /dags 資料夾的位置
gsutil cp hadoop_tutorial.py $DAGS_FOLDER
輸出內容應如下所示:
Copying file://hadoop_tutorial.py [Content-Type=text/x-python]... / [1 files][ 4.1 KiB/ 4.1 KiB] Operation completed over 1 objects/4.1 KiB.
6. 使用 Airflow UI
如要使用 GCP 主控台存取 Airflow 網頁介面,請按照下列步驟操作:
|
|

如要瞭解 Airflow UI,請參閱存取網頁介面。
查看變數
您先前設定的變數會保留在您的環境中。如要查看變數,請選取「管理」>「Airflow UI 選單列中的變數。

探索 DAG 執行作業
當您將 DAG 檔案上傳到 Cloud Storage 中的 dags 資料夾時,Cloud Composer 會剖析檔案。如果找不到錯誤,工作流程名稱就會顯示在 DAG 清單內,且工作流程會排入佇列以立即執行。如要查看 DAG,請按一下頁面頂端的「DAG」。
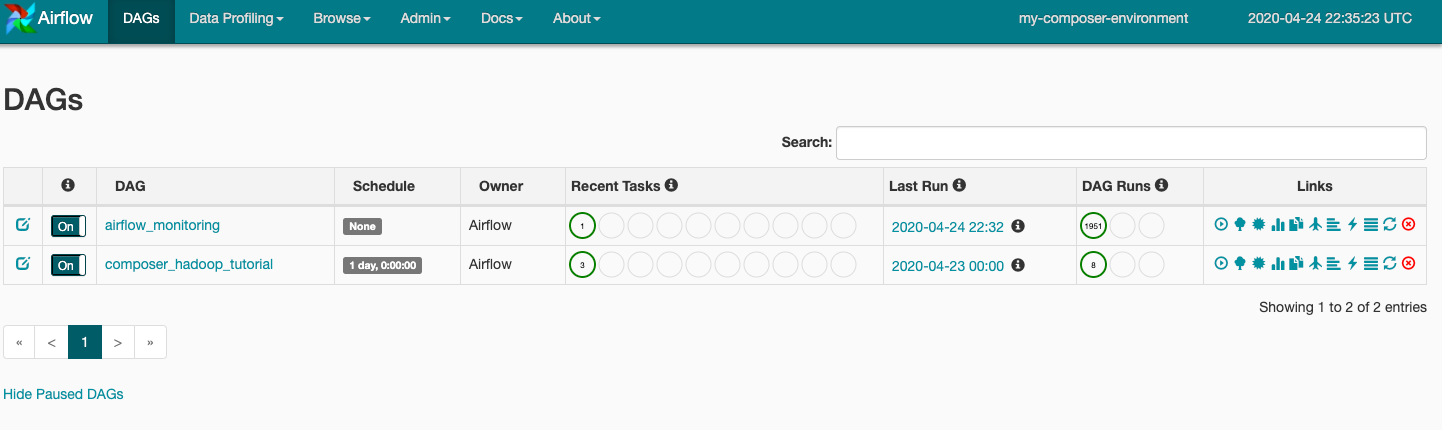
按一下 composer_hadoop_tutorial 開啟 DAG 詳細資料頁面。此頁面會透過圖形呈現工作流程工作和依附元件。

現在,按一下工具列中的「圖表檢視」,然後將滑鼠遊標懸停在各項工作的圖像上,即可查看工作狀態。請注意,每個工作周圍的框線也會指出狀態,例如綠色框線表示執行中,紅色框線表示執行失敗等。
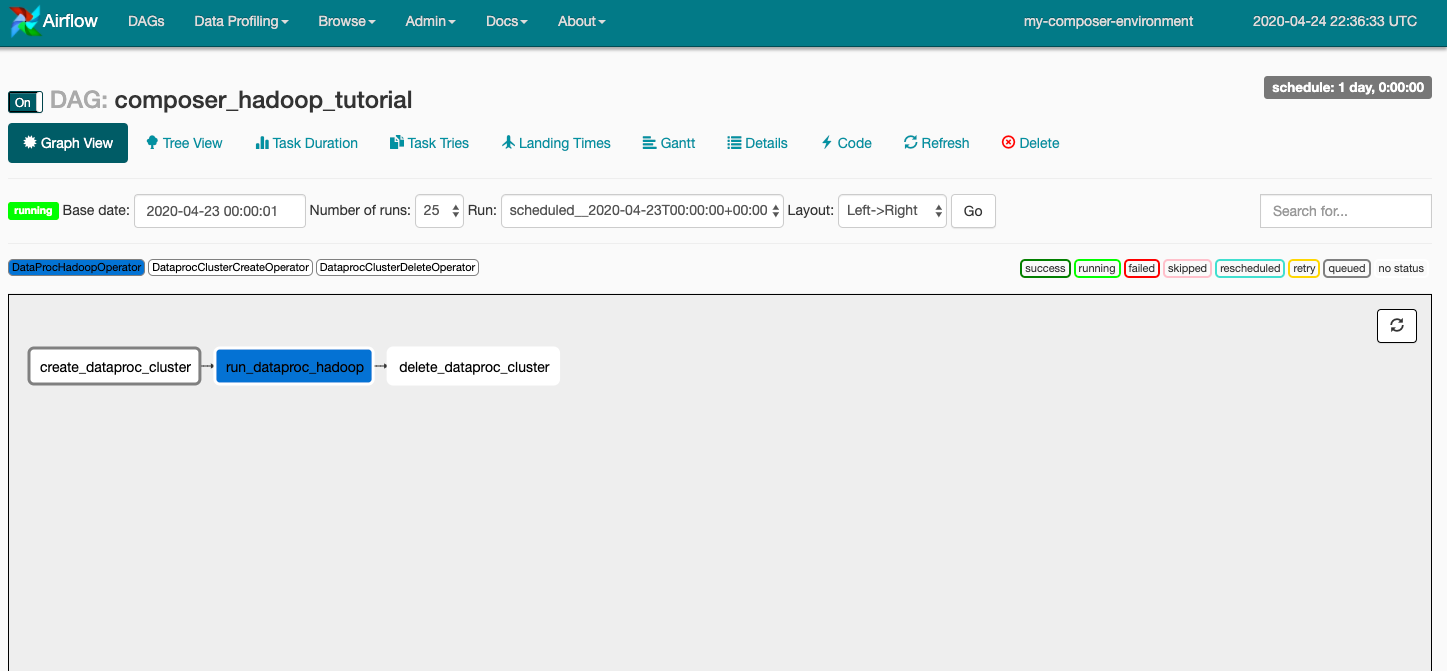
如要從「Graph View」再次執行工作流程:
- 在 Airflow UI 圖表檢視畫面中,按一下
create_dataproc_cluster圖形。 - 按一下「清除」重設這三項工作,然後按一下「確定」確認。

您也可以前往以下 GCP 控制台頁面,查看「composer-hadoop-tutorial」工作流程的狀態和結果:
- 監控叢集的建立和刪除作業的 Cloud Dataproc 叢集。請注意,工作流程建立的叢集是暫時性的:叢集僅在工作流程期間存在,且會做為最後一個工作流程任務的一部分刪除。
- Cloud Dataproc 工作,查看或監控 Apache Hadoop 字數工作。按一下工作 ID 即可查看工作記錄輸出。
- Cloud Storage 瀏覽器:前往為這個程式碼研究室建立的 Cloud Storage 值區,查看
wordcount資料夾中的字詞計數結果。
7. 清除所用資源
如要避免系統向您的 GCP 帳戶收取您在本程式碼研究室中所用資源的費用,請按照下列步驟操作:
- (選用) 如要儲存資料,請從 Cloud Composer 環境以及您為本程式碼研究室建立的儲存空間值區下載資料。
- 刪除您為本程式碼研究室建立的 Cloud Storage 值區。
- 刪除環境的 Cloud Storage 值區。
- 刪除 Cloud Composer 環境。請注意,刪除環境並不會刪除環境的儲存空間值區。
您也可以選擇刪除專案:
- 在 GCP 控制台中,前往「專案」頁面。
- 在專案清單中,選取要刪除的專案,然後按一下「Delete」(刪除)。
- 在方塊中輸入專案 ID,然後按一下「Shut down」(關閉) 即可刪除專案。