
1. Witamy
Dziękujemy za udział w ćwiczeniu „Istio Multi Cloud Burst” od Google.To ćwiczenie wymaga praktycznego doświadczenia na poziomie początkującym w zakresie Kubernetes, Node i Go. Co będzie potrzebne
|
|

Czego się nauczysz
- Jak utworzyć klaster Kubernetes w GKE
- Instalowanie Istio w klastrze Kubernetes za pomocą narzędzia Helm
- Instalowanie Istio Multicluster za pomocą narzędzia Helm
- Wdrażanie aplikacji internetowej ze źródła w Kubernetes
- Tworzenie i stosowanie reguł routingu ruchu w Istio
- Wskaźniki Prometheus
- Tworzenie i przekazywanie obrazów kontenerów w klastrze Kubernetes
2. Przygotowania
Te ćwiczenia możesz wykonać na:
- Google Cloud Shell (zalecane): powłoka w przeglądarce z zainstalowanymi narzędziami.
- laptopa (postępuj zgodnie z instrukcjami poniżej);
Pierwsze kroki z Google Cloud Platform
- Jeśli nie masz konta GCP, odbierz bezpłatną kartę konta użytkownika od instruktora.
- Otwórz konsolę Google Cloud i kliknij „Wybierz projekt”:
- Zanotuj gdzieś „Identyfikator” projektu, a potem kliknij projekt, aby go wybrać:

Opcja 1. Użyj Google Cloud Shell (zalecane)
Cloud Shell udostępnia wiersz poleceń w przeglądarce z zainstalowanymi narzędziami, które są automatycznie uwierzytelniane na Twoim koncie Google Cloud Platform. (Jeśli nie chcesz wykonywać tego ćwiczenia w Cloud Shell, przejdź do następnej sekcji).
Otwórz konsolę Cloud i na pasku narzędzi w prawym górnym rogu kliknij „Aktywuj Cloud Shell”:
Dodawanie narzędzi do Cloud Shell
- Zainstaluj
kubectx****: pobierz skrypty bash z tej strony do lokalizacji w $PATH. - Zainstaluj
helm****, postępując zgodnie z tymi instrukcjami.
Możesz też uruchomić te polecenia, aby zainstalować oba narzędzia w katalogu ~/.bin i dodać je do zmiennej $PATH:
mkdir -p ~/.bin && \
cd ~/.bin && \
curl -LO https://raw.githubusercontent.com/ahmetb/kubectx/master/kubectx && \
chmod +x kubectx && \
curl -LO https://raw.githubusercontent.com/ahmetb/kubectx/master/kubens && \
chmod +x kubens && \
curl -LO https://storage.googleapis.com/kubernetes-helm/helm-v2.12.0-linux-amd64.tar.gz && \
tar xzf helm-v2.12.0-linux-amd64.tar.gz && \
rm helm-v2.12.0-linux-amd64.tar.gz && \
mv linux-amd64/helm ./helm && \
rm -r linux-amd64 && \
export PATH=${HOME}/.bin:${PATH}
Oto kilka szybkich wskazówek, które ułatwią korzystanie z Cloud Shell:
1. Odłącz powłokę do nowego okna: |
|
2. Korzystanie z edytora plików: w prawym górnym rogu kliknij ikonę ołówka, aby uruchomić edytor plików w przeglądarce. Będzie to przydatne, ponieważ będziemy kopiować fragmenty kodu do plików. |
|
3. Otwieranie nowych kart: jeśli potrzebujesz więcej niż jednego wiersza poleceń terminala. |
|
4. Powiększ tekst: domyślny rozmiar czcionki w Cloud Shell może być zbyt mały, aby można go było odczytać. | Ctrl-+ w systemie Linux/Windows, ⌘-+ w systemie macOS. |
Opcja 2. Skonfiguruj laptopa (niezalecane)
Jeśli wolisz korzystać z własnej stacji roboczej zamiast Cloud Shell, skonfiguruj te narzędzia:
- Zainstaluj
gcloud:(wstępnie zainstalowany w Cloud Shell). Postępuj zgodnie z instrukcjami, aby zainstalowaćgcloudna swojej platformie. Użyjemy go do utworzenia klastra Kubernetes. - Zainstaluj
kubectl:(wstępnie zainstalowany w Cloud Shell). Aby zainstalować, uruchom to polecenie:
gcloud components install kubectl
Aby uwierzytelnić gcloud, uruchom to polecenie. Poprosimy Cię o zalogowanie się na konto Google. Następnie wybierz utworzony wcześniej projekt (widoczny powyżej) jako projekt domyślny. (Możesz pominąć konfigurowanie strefy obliczeniowej):
gcloud init
- Zainstaluj
curl:Jest wstępnie zainstalowany na większości systemów Linux/macOS. Prawdopodobnie masz już taką aplikację. W przeciwnym razie poszukaj w internecie informacji o tym, jak ją zainstalować. - Zainstaluj
kubectx****: pobierz skrypty bash z tej strony do lokalizacji w $PATH. - Zainstaluj
helm****, postępując zgodnie z tymi instrukcjami.
3. Konfigurowanie projektu GCP
Włącz w projekcie interfejsy API GKE (Google Kubernetes Engine), GCR (Google Container Registry) i GCB (Google Cloud Build):
gcloud services enable \ cloudapis.googleapis.com \ container.googleapis.com \ containerregistry.googleapis.com \ cloudbuild.googleapis.com
Konfigurowanie zmiennych środowiskowych
Podczas konfiguracji będziemy intensywnie korzystać z projektu Google Cloud. Ustawmy zmienną środowiskową, aby mieć do niego szybki dostęp.
export GCLOUD_PROJECT=$(gcloud config get-value project)
Podczas tych warsztatów utworzymy kilka plików z kodem i plików konfiguracyjnych, więc utwórzmy katalog projektu i przejdźmy do niego.
mkdir -p src/istio-burst && \ cd src/istio-burst && \ export proj=$(pwd)
4. Tworzenie klastra Kubernetes „primary”
Możesz łatwo utworzyć zarządzany klaster Kubernetes za pomocą Google Kubernetes Engine (GKE).
To polecenie utworzy klaster Kubernetes:
- o nazwie „primary”,
- w strefie us-west1-a,
- najnowsza dostępna wersja Kubernetes,
- z 4 węzłami początkowymi.
export cluster=primary
export zone=us-west1-a
gcloud container clusters create $cluster --zone $zone --username "admin" \
--cluster-version latest --machine-type "n1-standard-2" \
--image-type "COS" --disk-size "100" \
--scopes "https://www.googleapis.com/auth/compute",\
"https://www.googleapis.com/auth/devstorage.read_only",\
"https://www.googleapis.com/auth/logging.write",\
"https://www.googleapis.com/auth/monitoring",\
"https://www.googleapis.com/auth/servicecontrol",\
"https://www.googleapis.com/auth/service.management.readonly",\
"https://www.googleapis.com/auth/trace.append" \
--num-nodes "4" --network "default" \
--enable-cloud-logging --enable-cloud-monitoring --enable-ip-alias
(Może to potrwać około 5 minut. Możesz obserwować tworzenie klastra w konsoli Google Cloud).
Po utworzeniu klastra Kubernetes gcloud konfiguruje kubectl za pomocą danych logowania wskazujących klaster.
gcloud container clusters get-credentials $cluster --zone=$zone
Teraz możesz używać kubectl z nowym klastrem.
Uruchom to polecenie, aby wyświetlić listę węzłów Kubernetes w klastrze (powinny mieć stan „Gotowy”):
kubectl get nodes
Modyfikowanie nazw plików Kubeconfig w celu ułatwienia korzystania z nich
Będziemy często przełączać się między kontekstami, więc krótki alias dla naszych klastrów będzie przydatny.
To polecenie zmieni nazwę utworzonego przed chwilą wpisu kubeconfig na primary.
kubectx ${cluster}=gke_${GCLOUD_PROJECT}_${zone}_${cluster}
Ustaw uprawnienia:
Wdrożenie Istio wymaga roli administratora klastra. To polecenie ustawi adres e-mail powiązany z Twoim kontem Google Cloud jako administratora klastra.
kubectl create clusterrolebinding cluster-admin-binding \
--clusterrole=cluster-admin \
--user=$(gcloud config get-value core/account)
5. Tworzenie klastra „burst”
To polecenie utworzy klaster Kubernetes:
- o nazwie „burst”,
- w strefie us-west1-a,
- najnowsza dostępna wersja Kubernetes,
- Z 1 węzłem początkowym
- Włączone autoskalowanie do 5 węzłów
export cluster=burst
export zone=us-west1-a
gcloud container clusters create $cluster --zone $zone --username "admin" \
--cluster-version latest --machine-type "n1-standard-2" \
--image-type "COS" --disk-size "100" \
--scopes "https://www.googleapis.com/auth/compute",\
"https://www.googleapis.com/auth/devstorage.read_only",\
"https://www.googleapis.com/auth/logging.write",\
"https://www.googleapis.com/auth/monitoring",\
"https://www.googleapis.com/auth/servicecontrol",\
"https://www.googleapis.com/auth/service.management.readonly",\
"https://www.googleapis.com/auth/trace.append" \
--num-nodes "1" --enable-autoscaling --min-nodes=1 --max-nodes=5 \
--network "default" \
--enable-cloud-logging --enable-cloud-monitoring --enable-ip-alias
(Może to potrwać około 5 minut. Możesz obserwować tworzenie klastra w konsoli Google Cloud).
Po utworzeniu klastra Kubernetes gcloud konfiguruje kubectl za pomocą danych logowania wskazujących klaster.
gcloud container clusters get-credentials $cluster --zone=$zone
Teraz możesz używać kubectl z nowym klastrem.
Uruchom to polecenie, aby wyświetlić listę węzłów Kubernetes w klastrze (powinny mieć stan „Gotowy”):
kubectl get nodes
Modyfikowanie nazw plików Kubeconfig w celu ułatwienia korzystania z nich
To polecenie zmodyfikuje właśnie utworzony wpis kubeconfig na burst
kubectx ${cluster}=gke_${GCLOUD_PROJECT}_${zone}_${cluster}
Ustaw uprawnienia:
Wdrożenie Istio Remote wymaga uprawnień administratora klastra. To polecenie ustawi adres e-mail powiązany z Twoim kontem Google Cloud jako administratora klastra.
kubectl create clusterrolebinding cluster-admin-binding \
--clusterrole=cluster-admin \
--user=$(gcloud config get-value core/account)
6. Stosowanie reguł zapory sieciowej
Aby oba klastry mogły się ze sobą komunikować, musimy utworzyć regułę zapory sieciowej.
Uruchom te polecenia, aby utworzyć w Google Cloud Platform regułę zapory sieciowej, która umożliwi komunikację między klastrami:
function join_by { local IFS="$1"; shift; echo "$*"; }
ALL_CLUSTER_CIDRS=$(gcloud container clusters list \
--filter="(name=burst OR name=primary) AND zone=$zone" \
--format='value(clusterIpv4Cidr)' | sort | uniq)
ALL_CLUSTER_CIDRS=$(join_by , $(echo "${ALL_CLUSTER_CIDRS}"))
ALL_CLUSTER_NETTAGS=$(gcloud compute instances list \
--filter="(metadata.cluster-name=burst OR metadata.cluster-name=primary) AND metadata.cluster-location=us-west1-a" \
--format='value(tags.items.[0])' | sort | uniq)
ALL_CLUSTER_NETTAGS=$(join_by , $(echo "${ALL_CLUSTER_NETTAGS}"))
gcloud compute firewall-rules create istio-multicluster-test-pods \
--allow=tcp,udp,icmp,esp,ah,sctp \
--direction=INGRESS \
--priority=900 \
--source-ranges="${ALL_CLUSTER_CIDRS}" \
--target-tags="${ALL_CLUSTER_NETTAGS}" --quiet
Oba klastry są skonfigurowane i gotowe do wdrożenia w nich aplikacji i Istio.
7. Wprowadzenie do Istio
Co to jest Istio?
Istio to platforma sterująca siatki usług, która ma na celu „łączenie, zabezpieczanie, kontrolowanie i obserwowanie usług”. Odbywa się to na różne sposoby, ale przede wszystkim przez dodanie kontenera proxy ( Envoy) do każdego wdrożonego poda Kubernetes. Kontener proxy kontroluje całą komunikację sieciową między mikroserwisami w połączeniu z uniwersalnym centrum zasad i telemetrii ( Mixer).
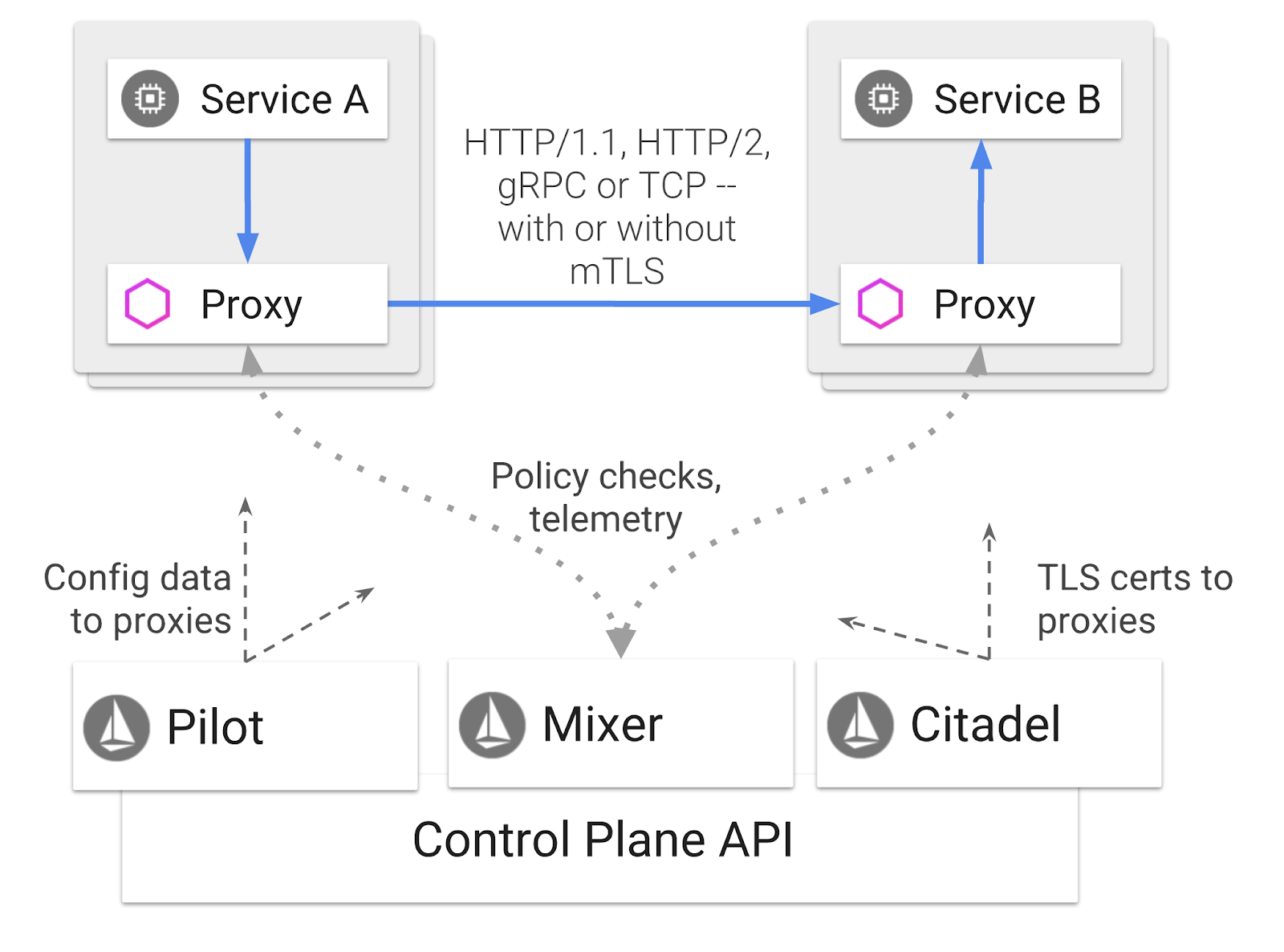
Te zasady można stosować niezależnie od wdrożeń i usług Kubernetes, co oznacza, że operator sieci może obserwować aktywność sieciową, ograniczać, przekierowywać lub przepisywać zasady sieciowe bez ponownego wdrażania powiązanych aplikacji.
Istio obsługuje m.in. te funkcje zarządzania ruchem:
- Wyłączniki obwodu
- Dzielenie ruchu na podstawie procentowego udziału
- Przepisywanie adresów URL
- zakończenie TLS
- Kontrole stanu
- Równoważenie obciążenia
Na potrzeby tego warsztatu skupimy się na podziale ruchu na podstawie procentów.
Terminy związane z Istio, których będziemy używać
VirtualService
VirtualService definiuje zestaw reguł routingu ruchu, które mają być stosowane, gdy host jest adresowany.
Brama
Brama to system równoważenia obciążenia działający na krawędzi siatki, który odbiera przychodzące i wychodzące połączenia HTTP/TCP. Bramy mogą określać porty, konfiguracje SNI itp.
DestinationRule
DestinationRule określa zasady, które mają zastosowanie do ruchu przeznaczonego dla usługi po routingu. Określają one konfigurację równoważenia obciążenia, rozmiar puli połączeń z usługi dodatkowej i ustawienia wykrywania wartości odstających.
Istio Multicluster
Podczas tworzenia 2 klastrów mogliście zauważyć, że klaster primary miał 4 węzły bez autoskalowania, a klaster burst miał 1 węzeł z autoskalowaniem do 5 węzłów.
Ta konfiguracja ma 2 przyczyny.
Najpierw chcemy zasymulować scenariusz „lokalnie” – chmura. W środowisku lokalnym nie masz dostępu do klastrów autoskalowania, ponieważ masz stałą infrastrukturę.
Po drugie, konfiguracja 4 węzłów (zgodnie z definicją powyżej) to minimalne wymagania do uruchomienia Istio. Rodzi to pytanie: jeśli Istio wymaga co najmniej 4 węzłów, jak nasz klaster burst może uruchamiać Istio z 1 węzłem? Odpowiedź jest taka, że Istio Multicluster instaluje znacznie mniejszy zestaw usług Istio i komunikuje się z instalacją Istio w klastrze podstawowym, aby pobierać reguły zasad i publikować informacje telemetryczne.
8. Omówienie architektury aplikacji
Omówienie komponentów
Wdrożymy trzypoziomową aplikację korzystającą z NodeJS i Redis.
Worker
Aplikacja robocza jest napisana w języku NodeJS i będzie nasłuchiwać przychodzących żądań HTTP POST, wykonywać na nich operację mieszania i jeśli zdefiniowana jest zmienna środowiskowa o nazwie PREFIX, będzie dodawać do skrótu tę wartość. Po obliczeniu skrótu aplikacja wysyła wynik na kanale „calculation” na określonym serwerze Redis.
Zmiennej środowiskowej PREFIX użyjemy później, aby zademonstrować funkcję wielu klastrów.
Informacje: to pakiety używane przez aplikację.
body-parser:Umożliwia nam parsowanie żądań HTTP.cors:Zezwala na korzystanie ze współdzielenia zasobów pomiędzy serwerami z różnych domen.dotenv:Łatwe analizowanie zmiennych środowiskowychexpress:Łatwy hosting witryn internetowychioredis:Biblioteka klienta do komunikacji z bazami danych Redismorgan:Udostępnia dobrze uporządkowany dziennik
Frontend
Nasz frontend to również aplikacja NodeJS, która hostuje stronę internetową za pomocą express. Pobiera częstotliwość podaną przez użytkownika i wysyła żądania do naszej aplikacji worker z tą częstotliwością. Ta aplikacja subskrybuje też wiadomości na kanale Redis o nazwie „calculation” i wyświetla wyniki na stronie internetowej.
Aplikacja korzysta z tych zależności:
body-parser:Umożliwia nam parsowanie żądań HTTP.dotenv:Łatwe analizowanie zmiennych środowiskowychexpress:Łatwy hosting witryn internetowychioredis:Biblioteka klienta do komunikacji z bazami danych Redismorgan:Zapewnia dobrze uporządkowane logirequest:Umożliwia wysyłanie żądań HTTP.socket.io:Umożliwia dwukierunkową komunikację między stroną internetową a serwerem.
Ta strona internetowa używa Bootstrapa do stylizacji i po uruchomieniu wygląda tak:
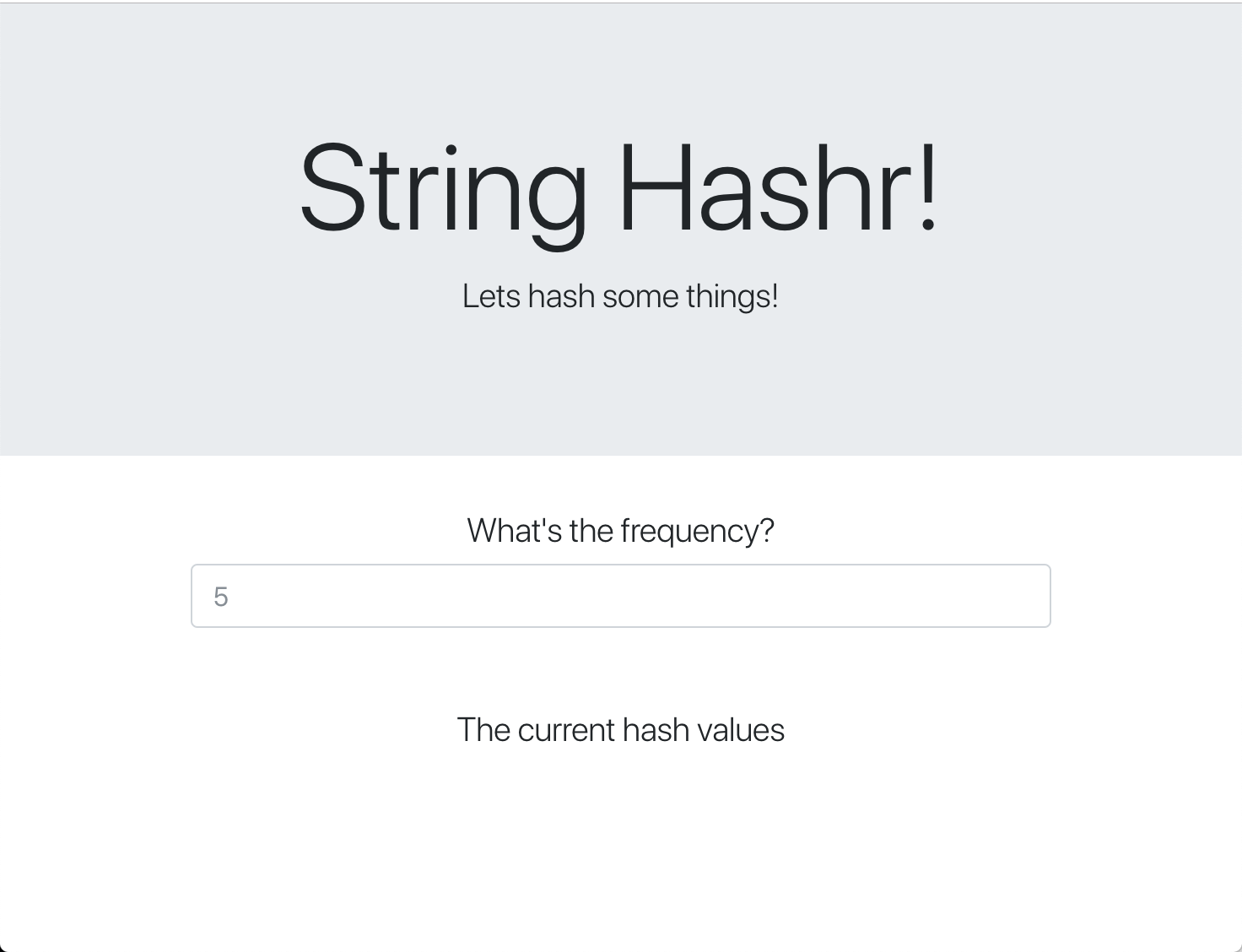
Diagram architektury
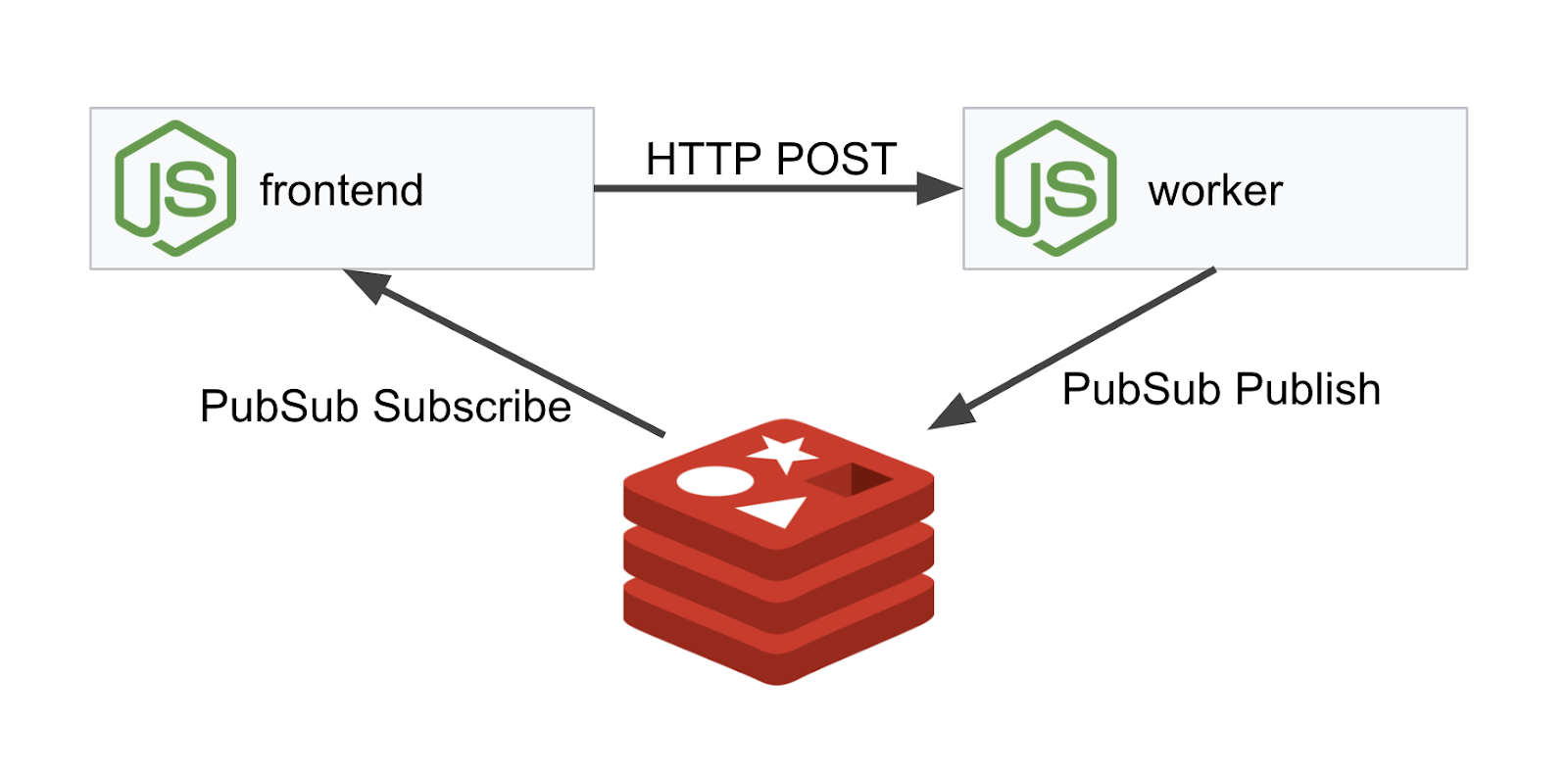
Diagram wdrożenia
Wdrożymy naszą aplikację w 2 utworzonych przez nas klastrach. Klaster primary będzie zawierać wszystkie komponenty (frontend, worker i Redis), ale w klastrze burst będzie wdrożona tylko aplikacja worker.
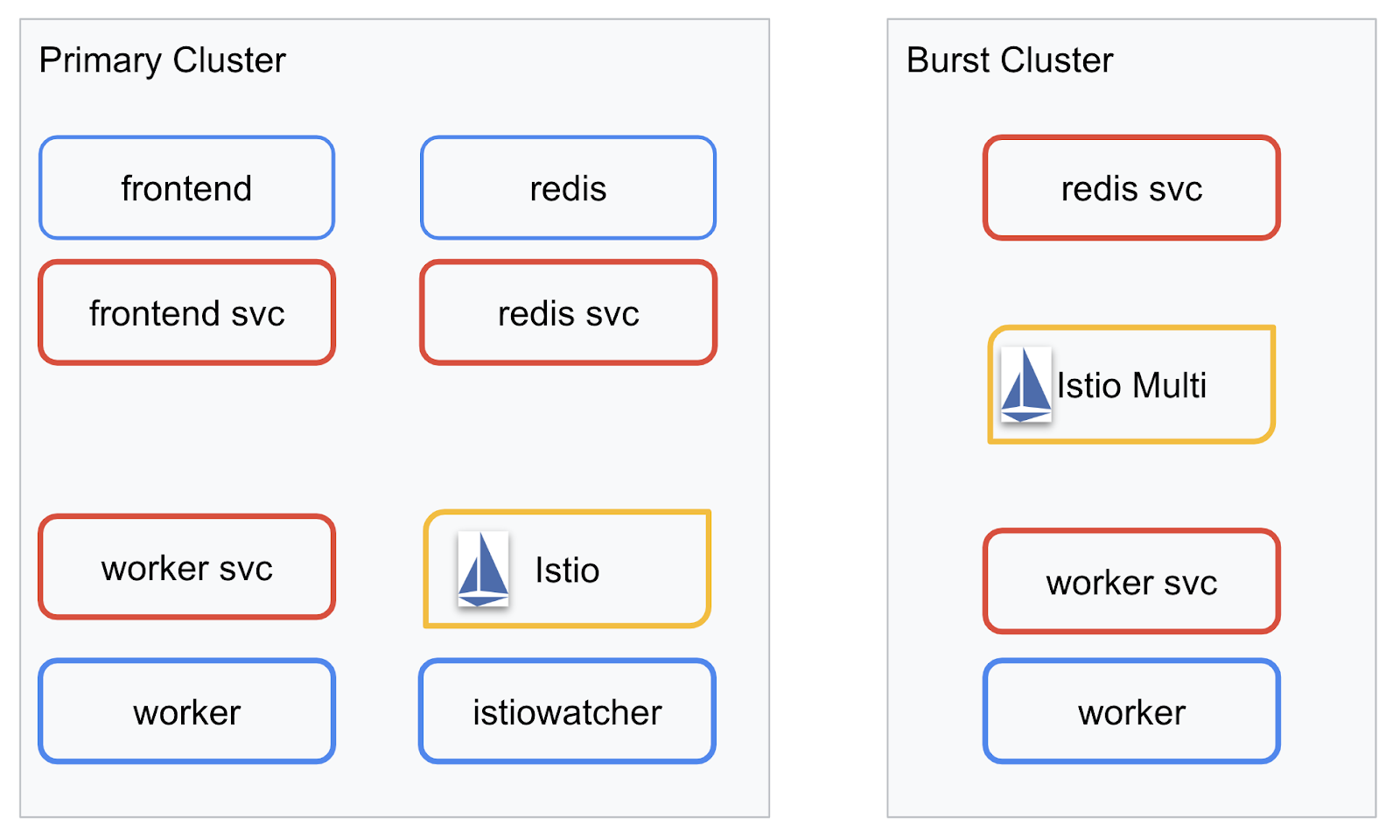
Oto diagram przedstawiający 2 klastry. Czerwone ramki oznaczają usługi Kubernetes, a niebieskie – wdrożenia Kubernetes. Żółte pola oznaczają naszą instalację Istio.
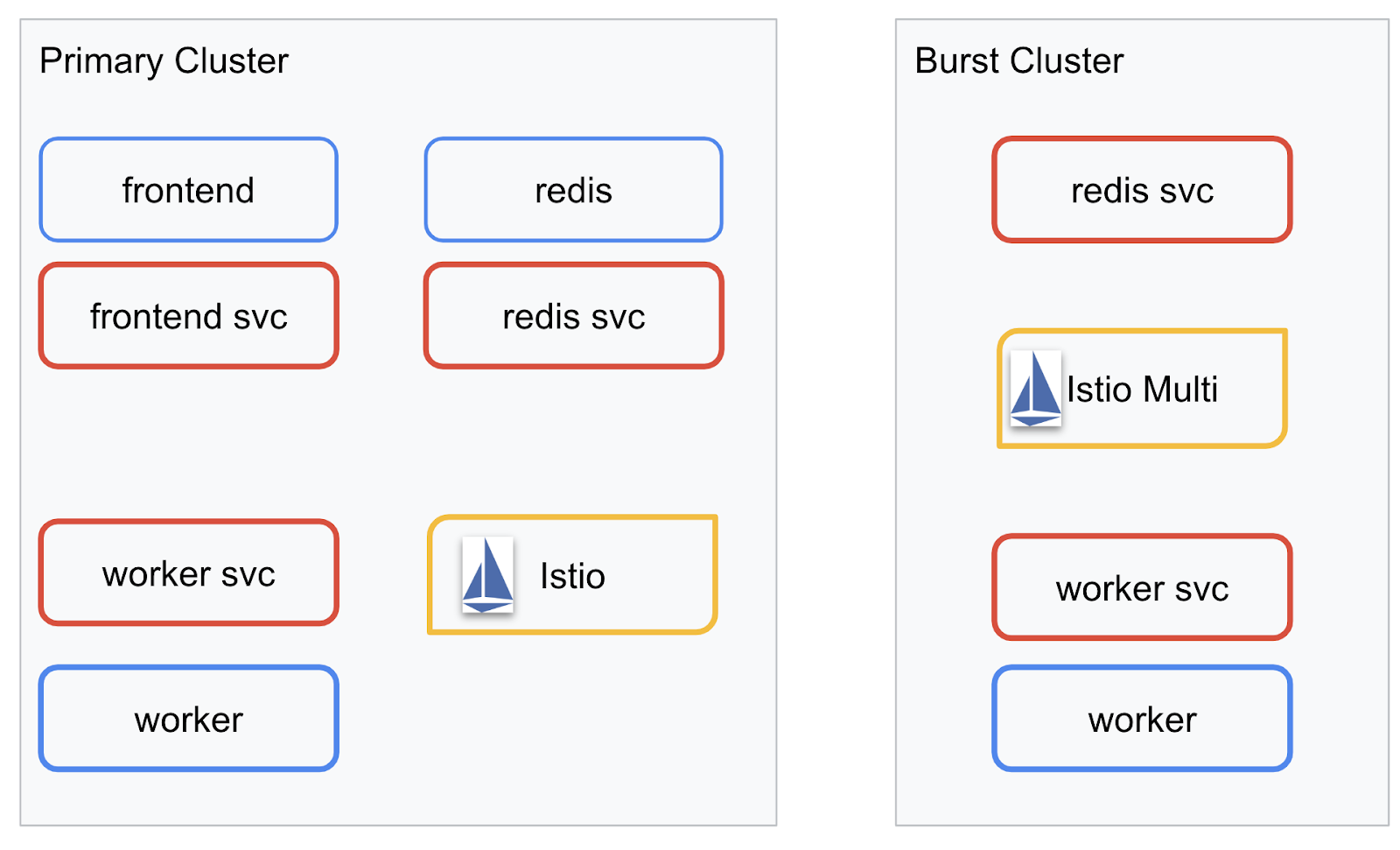
Zwróć uwagę, że klaster burst nadal ma wdrożoną usługę Redis, mimo że w klastrze nie ma wdrożenia Redis. Musimy mieć tę usługę w klastrze, aby DNS Kubernetes mógł rozwiązać żądanie, ale gdy żądanie zostanie faktycznie wysłane, serwer proxy Istio przekieruje je do wdrożenia Redis w klastrze primary.
Ostateczna aplikacja będzie miała dodatkowy Deployment działający w klastrze primary o nazwie istiowatcher.. Umożliwi nam to dynamiczne przekierowywanie ruchu do klastra burst automatycznie, gdy ruch przekroczy określony próg.
9. Tworzenie plików wdrożenia aplikacji
Aby wdrożyć aplikację, musimy utworzyć zestaw plików manifestu Kubernetes.
Przejdź do katalogu głównego projektu i utwórz nowy folder o nazwie kubernetes.
mkdir ${proj}/kubernetes && cd ${proj}/kubernetes
Napisz plik frontend.yaml
Spowoduje to utworzenie zarówno wdrożenia Kubernetes, jak i usługi, która umożliwi dostęp do obrazu frontendu.
Wstaw do pliku frontend.yaml tę treść.
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: frontend-deployment
labels:
app: frontend
spec:
replicas: 1
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend
image: gcr.io/istio-burst-workshop/frontend
ports:
- containerPort: 8080
readinessProbe:
initialDelaySeconds: 10
httpGet:
path: "/_healthz"
port: 8080
httpHeaders:
- name: "Cookie"
value: "istio_session-id=x-readiness-probe"
livenessProbe:
initialDelaySeconds: 10
httpGet:
path: "/"
port: 8080
httpHeaders:
- name: "Cookie"
value: "istio_session-id=x-liveness-probe"
env:
- name: PORT
value: "8080"
- name: PROCESSOR_URL
value: "http://worker-service"
- name: REDIS_URL
value: "redis-cache-service:6379"
---
apiVersion: v1
kind: Service
metadata:
name: frontend-service
spec:
type: ClusterIP
selector:
app: frontend
ports:
- name: http
port: 80
targetPort: 8080
Najważniejsze elementy w Deployment
- Określiliśmy, że aplikacja będzie działać na porcie
8080. - Adres pracownika ustawiliśmy na „
http://worker-service” i użyjemy wbudowanej funkcji DNS Kubernetes do rozpoznania wynikowej usługi. - Adres naszego
REDIS_URLto „redis-cache-service:6379”. Do rozpoznawania wynikowych adresów IP będziemy używać wbudowanej funkcji DNS platformy Kubernetes. - Ustawiliśmy też sondy
livenessireadinessw kontenerze, aby informować Kubernetes, kiedy kontener jest uruchomiony.
Napisz plik worker-service.yaml
Definicję usługi Kubernetes zapisujemy w osobnym pliku niż definicję wdrożenia, ponieważ będziemy używać tej usługi w wielu klastrach, ale dla każdego klastra utworzymy inne wdrożenie.
Wstaw do pliku worker-service.yaml te informacje:
apiVersion: v1
kind: Service
metadata:
name: worker-service
spec:
type: ClusterIP
selector:
app: worker
ports:
- name: http
port: 80
targetPort: 8081
Utwórz plik worker-primary.yaml
Będzie to wdrożenie worker, które zostanie przesłane do klastra głównego.
Wstaw do pliku worker-primary.yaml tę treść.
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: worker-deployment
labels:
app: worker
spec:
replicas: 1
selector:
matchLabels:
app: worker
template:
metadata:
labels:
app: worker
cluster-type: primary-cluster
spec:
containers:
- name: worker
image: gcr.io/istio-burst-workshop/worker
imagePullPolicy: Always
ports:
- containerPort: 8081
readinessProbe:
initialDelaySeconds: 10
httpGet:
path: "/_healthz"
port: 8081
httpHeaders:
- name: "Cookie"
value: "istio_session-id=x-readiness-probe"
livenessProbe:
initialDelaySeconds: 10
httpGet:
path: "/"
port: 8081
httpHeaders:
- name: "Cookie"
value: "istio_session-id=x-liveness-probe"
env:
- name: PORT
value: "8081"
- name: REDIS_URL
value: "redis-cache-service:6379"
Zauważ, że w tym przypadku postępujemy zgodnie z tym samym wzorcem, dostarczając sondy liveness i readiness oraz określając zmienne środowiskowe PORT i REDIS_URL, z których będzie korzystać nasza aplikacja.
Kolejną rzeczą, na którą warto zwrócić uwagę w tym wdrożeniu, jest brak zmiennej środowiskowej PREFIX. Oznacza to, że wyniki obliczeń będą surowymi haszami (bez prefiksu).
Ostatnim kluczowym elementem tego wdrożenia jest etykieta cluster-type: primary-cluster. Wykorzystamy to później, gdy będziemy kierować ruchem w Istio Multicluster.
Zapisz plik redis.yaml
Komunikacja między instancją roboczą a interfejsem odbywa się za pomocą kanału Redis, dlatego musimy wdrożyć w klastrze aplikację Redis.
Wstaw do pliku redis.yaml te informacje:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: redis-cache
spec:
template:
metadata:
labels:
app: redis-cache
spec:
containers:
- name: redis
image: redis:alpine
ports:
- containerPort: 6379
readinessProbe:
periodSeconds: 5
tcpSocket:
port: 6379
livenessProbe:
periodSeconds: 5
tcpSocket:
port: 6379
volumeMounts:
- mountPath: /data
name: redis-data
resources:
limits:
memory: 256Mi
cpu: 125m
requests:
cpu: 70m
memory: 200Mi
volumes:
- name: redis-data
emptyDir: {}
Jest to częściowo standardowe wdrożenie aplikacji Redis. Tworzy kontener na podstawie obrazu redis:alpine, udostępnia odpowiednie porty i ustawia rozsądne limity zasobów.
Utwórz plik redis-service.yaml
Do komunikacji z aplikacją Redis potrzebujemy usługi Kubernetes.
Wstaw do pliku redis-service.yaml te informacje:
apiVersion: v1
kind: Service
metadata:
name: redis-cache-service
spec:
type: ClusterIP
selector:
app: redis-cache
ports:
- port: 6379
targetPort: 6379
Zapewnia to usługę o nazwie redis-cache-service, która umożliwia dostęp do wdrożenia Redis.
10. Wdrażanie aplikacji
Po przesłaniu obrazów do GCR i napisaniu plików manifestu Kubernetes możemy wdrożyć aplikację i sprawdzić, jak działa.
Aby wdrożyć aplikację, uruchom te polecenia:
- Sprawdź, czy jesteśmy w odpowiedniej klastrze
kubectx primary
- Wdrażanie pamięci podręcznej Redis
kubectl apply -f redis.yaml
- Wdrażanie usługi Redis
kubectl apply -f redis-service.yaml
- Wdrażanie frontendu
kubectl apply -f frontend.yaml
- Wdróż instancję roboczą
kubectl apply -f worker-primary.yaml
- Usługa Deploy Worker
kubectl apply -f worker-service.yaml
Wdrożyliśmy naszą aplikację w GKE. Gratulacje!
Test
Poczekaj, aż pody będą online.
kubectl get pods -w
Gdy wszystkie pody będą w stanie „Running”, naciśnij Ctrl + C.
NAME READY STATUS RESTARTS AGE frontend-deployment-695d95fbf7-76sd8 1/1 Running 0 2m redis-cache-7475999bf5-nxj8x 1/1 Running 0 2m worker-deployment-5b9cf9956d-g975p 1/1 Running 0 2m
Zauważysz, że nie udostępniliśmy frontendu za pomocą usługi LoadBalancer. Dzieje się tak, ponieważ później będziemy uzyskiwać dostęp do aplikacji za pomocą Istio. Aby sprawdzić, czy wszystko działa prawidłowo, użyj kubectl port-forward. Uruchom to polecenie, aby przekierować port 8080 na komputerze lokalnym (lub w Cloud Shell) do portu 8080, na którym działa wdrożenie frontend.
kubectl port-forward \
$(kubectl get pods -l app=frontend -o jsonpath='{.items[0].metadata.name}') \
8080:8080
Jeśli korzystasz z lokalnego środowiska wykonawczego: otwórz przeglądarkę i przejdź na stronę http://localhost:8080.
Jeśli korzystasz z Cloud Shell: kliknij przycisk „Podgląd w przeglądarce” i wybierz „Podejrzyj na porcie 8080”.
Powinna się wyświetlić strona front-end. Jeśli w polu „Częstotliwość” wpiszesz liczbę, powinny zacząć się pojawiać hasze.
Gratulujemy. Wszystko działa.
Naciśnij Ctrl+C, aby zatrzymać przekierowywanie portu.
11. Czyszczenie wdrożonej aplikacji
Zastosujemy Istio w naszym klastrze, a następnie ponownie wdrożymy aplikację, więc najpierw zwalniamy miejsce dla naszej obecnej aplikacji.
Aby usunąć wszystkie wdrożenia i usługi, które zostały utworzone, uruchom te polecenia:
- Usuń:
redis-cache-service
kubectl delete -f redis-service.yaml
- Usuń:
redis
kubectl delete -f redis.yaml
- Usuń:
frontend
kubectl delete -f frontend.yaml
- Usuń:
worker
kubectl delete -f worker-primary.yaml
- Usuń:
worker-service
kubectl delete -f worker-service.yaml
12. Instalowanie Istio w klastrze podstawowym
Pobierz Istio
Wersje Istio są hostowane w GitHubie. Poniższe polecenia pobiorą i rozpakują wersję 1.0.0 istio.
- Przejdź do katalogu głównego projektu
cd ${proj}
- Pobieranie archiwum
curl -LO https://github.com/istio/istio/releases/download/1.0.0/istio-1.0.0-linux.tar.gz
- Wyodrębnianie i usuwanie archiwum
tar xzf istio-1.0.0-linux.tar.gz && rm istio-1.0.0-linux.tar.gz
Utwórz szablon Istio
Uruchomienie tego polecenia Helm spowoduje utworzenie szablonu do zainstalowania Istio w klastrze.
helm template istio-1.0.0/install/kubernetes/helm/istio \ --name istio --namespace istio-system \ --set prometheus.enabled=true \ --set servicegraph.enabled=true > istio-primary.yaml
W bieżącym katalogu zostanie utworzony plik o nazwie istio-primary.yaml, który zawiera wszystkie definicje i specyfikacje potrzebne do wdrożenia i uruchomienia Istio.
Zwróć uwagę na 2 parametry --set. Dodają one do systemu Istio obsługę Prometheus i ServiceGraph. Usługi Prometheus użyjemy w dalszej części tego modułu.
Wdrażanie Istio
Aby wdrożyć Istio, musimy najpierw utworzyć przestrzeń nazw o nazwie istio-system, w której będą działać wdrożenia i usługi Istio.
kubectl create namespace istio-system
Na koniec zastosuj utworzony przez nas za pomocą narzędzia Helm plik istio-primary.yaml.
kubectl apply -f istio-primary.yaml
Domyślna przestrzeń nazw etykiety
Istio działa przez wstrzykiwanie pomocniczego proxy do każdego Deploymentu. Odbywa się to na zasadzie dobrowolności, więc musimy oznaczyć naszą przestrzeń nazw default etykietą istio-injection=enabled, aby Istio mogło automatycznie wstrzykiwać dla nas kontener dodatkowy.
kubectl label namespace default istio-injection=enabled
Gratulacje! Mamy już uruchomiony klaster z Istio, który jest gotowy do wdrożenia naszej aplikacji.
13. Wdrażanie aplikacji za pomocą zarządzania ruchem Istio
Tworzenie plików konfiguracyjnych zarządzania ruchem Istio
Istio działa podobnie do Kubernetes, ponieważ do konfiguracji używa plików YAML. W tym celu musimy utworzyć zestaw plików, które poinformują Istio, jak udostępniać i kierować nasz ruch.
Utwórz katalog o nazwie istio-manifests i przejdź do niego.
mkdir ${proj}/istio-manifests && cd ${proj}/istio-manifests
Napisz plik frontend-gateway.yaml
Ten plik udostępni nasz klaster Kubernetes w sposób podobny do usługi LoadBalancer w GKE i będzie kierować cały ruch przychodzący do naszej usługi frontendu.
Utwórz plik o nazwie frontend-gateway.yaml i wstaw do niego ten kod:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: frontend-gateway
spec:
selector:
istio: ingressgateway # use Istio default gateway implementation
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: frontend-ingress-virtual-service
spec:
hosts:
- "*"
gateways:
- frontend-gateway
http:
- route:
- destination:
host: frontend-service
port:
number: 80
Napisz plik redis-virtualservice.yaml
Utwórz plik o nazwie redis-virtualservice.yaml i wstaw do niego ten kod:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: redis-virtual-service
spec:
hosts:
- redis-cache-service
gateways:
- mesh
tcp:
- route:
- destination:
host: redis-cache-service.default.svc.cluster.local
Napisz plik worker-virtualservice.yaml
Utwórz plik o nazwie worker-virtualservice.yaml i wstaw do niego ten kod:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: worker-virtual-service
spec:
hosts:
- worker-service
gateways:
- mesh
http:
- route:
- destination:
host: worker-service.default.svc.cluster.local
port:
number: 80
Wdrażanie zasad zarządzania ruchem Istio
Wdrażanie zasad Istio odbywa się w taki sam sposób jak w przypadku innych zasobów Kubernetes, za pomocą polecenia kubectl apply
- Zastosuj naszą bramę
kubectl apply -f frontend-gateway.yaml
- Stosowanie naszego VirtualService Redis
kubectl apply -f redis-virtualservice.yaml
- Zastosuj usługę wirtualną Worker
kubectl apply -f worker-virtualservice.yaml
Wdrażanie aplikacji
- Wróć do katalogu
kubernetes.
cd ${proj}/kubernetes
- Wdrażanie pamięci podręcznej Redis
kubectl apply -f redis.yaml
- Wdrażanie usługi Redis
kubectl apply -f redis-service.yaml
- Wdrażanie frontendu
kubectl apply -f frontend.yaml
- Wdróż instancję roboczą
kubectl apply -f worker-primary.yaml
- Usługa Deploy Worker
kubectl apply -f worker-service.yaml
Potwierdź
Wdrożyliśmy już naszą aplikację w klastrze z Istio i zasadami zarządzania ruchem.
Poczekajmy, aż wszystkie nasze zadania zostaną uruchomione.
Gdy wszystkie będą online, pobierz skonfigurowaną przez nas bramę IngressGateway w frontend-ingressgateway.yaml
$ kubectl -n istio-system get svc istio-ingressgateway NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE istio-ingressgateway LoadBalancer 10.36.3.112 35.199.158.10 80:31380/TCP,
Przejdź do adresu <EXTERNAL-IP> lub użyj polecenia curl, aby wyświetlić frontend.
$ curl 35.199.158.10
<!doctype html>
<html>
<head>
<title>String Hashr</title>
<!-- Bootstrap -->
...
14. Instalowanie Istio w klastrze „burst”
Poświęciliśmy dużo czasu na konfigurowanie i wdrażanie w naszym klastrze primary, ale mamy jeszcze jeden klaster, w którym musimy wdrożyć aplikację.
W tej sekcji musimy pobrać zmienne konfiguracji z obu klastrów, więc uważnie sprawdzaj, do którego klastra odnosi się każde polecenie.
Utwórz zdalny plik manifestu Istio
Podobnie jak w przypadku wdrażania Istio w klastrze primary, do utworzenia szablonu wdrożenia zdalnego Istio w klastrze burst użyjemy narzędzia Helm. Zanim to zrobimy, musimy uzyskać informacje o naszym klastrze primary.
Zbieranie informacji o klastrze podstawowym
Przełącz na klaster primary
kubectx primary
Poniższe polecenia pobierają adresy IP różnych podów w klastrze podstawowym. Są one używane przez Istio Remote do komunikacji z klastrem głównym.
export PILOT_POD_IP=$(kubectl -n istio-system get pod -l istio=pilot -o jsonpath='{.items[0].status.podIP}')
export POLICY_POD_IP=$(kubectl -n istio-system get pod -l istio-mixer-type=policy -o jsonpath='{.items[0].status.podIP}')
export STATSD_POD_IP=$(kubectl -n istio-system get pod -l istio=statsd-prom-bridge -o jsonpath='{.items[0].status.podIP}')
export TELEMETRY_POD_IP=$(kubectl -n istio-system get pod -l istio-mixer-type=telemetry -o jsonpath='{.items[0].status.podIP}')
export ZIPKIN_POD_IP=$(kubectl -n istio-system get pod -l app=jaeger -o jsonpath='{range .items[*]}{.status.podIP}{end}')
Utwórz szablon zdalny
Teraz użyjemy helm, aby utworzyć plik o nazwie istio-remote-burst.yaml, który możemy następnie wdrożyć w klastrze burst.
Przejdź do katalogu głównego projektu
cd $proj
helm template istio-1.0.0/install/kubernetes/helm/istio-remote --namespace istio-system \
--name istio-remote \
--set global.remotePilotAddress=${PILOT_POD_IP} \
--set global.remotePolicyAddress=${POLICY_POD_IP} \
--set global.remoteTelemetryAddress=${TELEMETRY_POD_IP} \
--set global.proxy.envoyStatsd.enabled=true \
--set global.proxy.envoyStatsd.host=${STATSD_POD_IP} \
--set global.remoteZipkinAddress=${ZIPKIN_POD_IP} > istio-remote-burst.yaml
Instalowanie Istio Remote w klastrze burst
Aby zainstalować Istio w klastrze burst, musimy wykonać te same czynności co w przypadku instalacji w klastrze primary, ale zamiast tego musimy użyć pliku istio-remote-burst.yaml.
Zmień kubecontext na burst
kubectx burst
Utwórz przestrzeń nazw istio-system
kubectl create ns istio-system
Zastosuj plik istio-burst.yaml
kubectl apply -f istio-remote-burst.yaml
Domyślna przestrzeń nazw etykiety
Ponownie musimy oznaczyć przestrzeń nazw default, aby można było automatycznie wstrzyknąć serwer proxy.
kubectl label namespace default istio-injection=enabled
Gratulacje! W tym momencie skonfigurowaliśmy Istio Remote w klastrze burst. W tym momencie klastry nadal nie mogą się komunikować. Musimy wygenerować plik kubeconfig dla klastra burst, który możemy wdrożyć w klastrze primary, aby je połączyć.
Tworzenie pliku kubeconfig dla klastra „burst”
Przejście na klaster serii
kubectx burst
Konfigurowanie środowiska
Aby utworzyć plik kubeconfig dla klastra, musimy zebrać o nim kilka informacji.
- Pobieranie nazwy klastra
CLUSTER_NAME=$(kubectl config view --minify=true -o "jsonpath={.clusters[].name}")
- Pobieranie nazwy serwera klastra
SERVER=$(kubectl config view --minify=true -o "jsonpath={.clusters[].cluster.server}")
- Pobierz nazwę obiektu tajnego dla
istio-multiurzędu certyfikacji konta usługi.
SECRET_NAME=$(kubectl get sa istio-multi -n istio-system -o jsonpath='{.secrets[].name}')
- Pobierz dane urzędu certyfikacji przechowywane w poprzednim sekrecie.
CA_DATA=$(kubectl get secret ${SECRET_NAME} -n istio-system -o "jsonpath={.data['ca\.crt']}")
- Pobierz token zapisany w poprzednim sekrecie.
TOKEN=$(kubectl get secret ${SECRET_NAME} -n istio-system -o "jsonpath={.data['token']}" | base64 --decode)
Tworzenie pliku kubeconfig
Po ustawieniu wszystkich zmiennych środowiskowych musimy utworzyć plik kubeconfig.
cat <<EOF > burst-kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: ${CA_DATA}
server: ${SERVER}
name: ${CLUSTER_NAME}
contexts:
- context:
cluster: ${CLUSTER_NAME}
user: ${CLUSTER_NAME}
name: ${CLUSTER_NAME}
current-context: ${CLUSTER_NAME}
kind: Config
preferences: {}
users:
- name: ${CLUSTER_NAME}
user:
token: ${TOKEN}
EOF
W bieżącym katalogu utworzy to nowy plik o nazwie burst-kubeconfig, który może być używany przez klaster primary do uwierzytelniania i zarządzania klastrem burst.
Powrót do klastra podstawowego
kubectx primary
Zastosuj kubeconfig dla „burst”, tworząc obiekt tajny i nadając mu etykietę
kubectl create secret generic burst-kubeconfig --from-file burst-kubeconfig -n istio-system
Oznacz obiekt tajny, aby Istio wiedziało, że ma go używać do uwierzytelniania w wielu klastrach.
kubectl label secret burst-kubeconfig istio/multiCluster=true -n istio-system
Gratulacje! Oba klastry są uwierzytelnione i komunikują się ze sobą za pomocą Istio Multicluster. Wdróżmy aplikację w wielu klastrach.
15. Wdrażanie aplikacji międzyklastrowej
Tworzenie wdrożeń
Przejdź do katalogu kubernetes.
cd ${proj}/kubernetes
Utwórz wdrożenie procesów roboczych dla klastra „burst”: worker-burst.yaml
Utwórz plik o nazwie worker-burst.yaml i wstaw do niego ten kod:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: worker-deployment
labels:
app: worker
spec:
replicas: 1
selector:
matchLabels:
app: worker
template:
metadata:
labels:
app: worker
cluster-type: burst-cluster
spec:
containers:
- name: worker
image: gcr.io/istio-burst-workshop/worker
imagePullPolicy: Always
ports:
- containerPort: 8081
readinessProbe:
initialDelaySeconds: 10
httpGet:
path: "/_healthz"
port: 8081
httpHeaders:
- name: "Cookie"
value: "istio_session-id=x-readiness-probe"
livenessProbe:
initialDelaySeconds: 10
httpGet:
path: "/"
port: 8081
httpHeaders:
- name: "Cookie"
value: "istio_session-id=x-liveness-probe"
env:
- name: PORT
value: "8081"
- name: REDIS_URL
value: "redis-cache-service:6379"
- name: PREFIX
value: "bursty-"
Zwróć uwagę, że jest on niemal identyczny z plikiem worker-primary.yaml utworzonym wcześniej. Są między nimi 2 główne różnice:
Pierwsza kluczowa różnica polega na tym, że dodaliśmy zmienną środowiskową PREFIX o wartości „bursty-”.
env:
- name: PORT
value: "8081"
- name: REDIS_URL
value: "redis-cache-service:6379"
- name: PREFIX
value: "bursty-"
Oznacza to, że instancja robocza w klastrze burst będzie dodawać do wszystkich wysyłanych przez siebie haszy prefiks „bursty-”. Dzięki temu będziemy mieć pewność, że nasza aplikacja działa w wielu klastrach.
Druga kluczowa różnica polega na tym, że w przypadku tego wdrożenia zmieniliśmy etykietę cluster-type z primary-cluster na burst-cluster.
labels:
app: worker
cluster-type: burst-cluster
Użyjemy tej etykiety później, gdy będziemy aktualizować VirtualService.
Modyfikowanie usług Istio
Obecnie nasze usługi Istio nie korzystają z obu wdrożeń. 100% ruchu jest kierowane do klastra „podstawowego”. Zmieńmy to.
Przejdź do katalogu istio-manifests.
cd ${proj}/istio-manifests
Edytuj plik worker-virtualservice.yaml, aby uwzględnić w nim DestinationRules
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: worker-virtual-service
spec:
hosts:
- worker-service
gateways:
- mesh
http:
- route:
- destination:
host: worker-service.default.svc.cluster.local
subset: primary
port:
number: 80
weight: 50
- destination:
host: worker-service.default.svc.cluster.local
subset: burst
port:
number: 80
weight: 50
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: worker-destination-rule
spec:
host: worker-service
trafficPolicy:
loadBalancer:
simple: RANDOM
subsets:
- name: primary
labels:
cluster-type: primary-cluster
- name: burst
labels:
cluster-type: burst-cluster
Jak widać, dodaliśmy drugie miejsce docelowe do naszej usługi VirtualService. Nadal odwołuje się do tego samego hosta (worker-service.default.svc.cluster.local)), ale 50% ruchu jest kierowane do podzbioru primary, a pozostałe 50% – do podzbioru burst.
Zdefiniowaliśmy podzbiór primary jako wdrożenia z etykietą cluster-type: primary-cluster, a podzbiór burst jako wdrożenia z etykietą cluster-type: burst-cluster.
W ten sposób dzielimy ruch między te 2 klastry w proporcjach 50/50.
Wdróż w klastrze
Wdróż plik redis-service.yaml w klastrze burst
Zmień na burst kubeconfig
kubectx burst
Przejdź do katalogu głównego projektu
cd ${proj}
Następnie wdróż
Wdróż plik redis-service.yaml w klastrze burst
kubectl apply -f kubernetes/redis-service.yaml
Wdróż plik worker-burst.yaml w klastrze burst
kubectl apply -f kubernetes/worker-burst.yaml
Wdróż plik worker-service.yaml w klastrze burst
kubectl apply -f kubernetes/worker-service.yaml
Stosowanie usług wirtualnych Istio
Zmień na primary kubeconfig
kubectx primary
Następnie kliknij Wdróż.
kubectl apply -f istio-manifests/worker-virtualservice.yaml
Sprawdź, czy działa
Aby sprawdzić, czy działa, przejdź do punktu wejścia Istio Ingress i zwróć uwagę, że około 50% hashów ma przedrostek „burst-”.
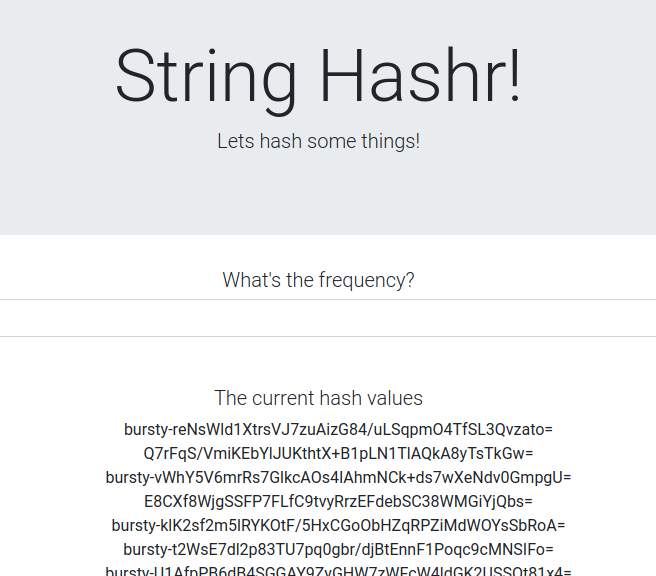
Oznacza to, że komunikacja między klastrami działa. Spróbuj zmienić wagi w różnych usługach i zastosować plik worker-virtualservice.yaml. To świetny sposób na równoważenie ruchu między klastrami, ale co by było, gdybyśmy mogli robić to automatycznie?
16. Korzystanie ze wskaźników Prometheus
Wprowadzenie do pakietu Prometheus
Prometheus to zestaw narzędzi open source do monitorowania systemów i alertowania, który został pierwotnie opracowany w SoundCloud. Utrzymuje wielowymiarowy model danych z danymi szeregów czasowych identyfikowanymi przez nazwę danych i pary klucz/wartość.
Dla porównania przedstawiamy schemat architektury Prometheus:
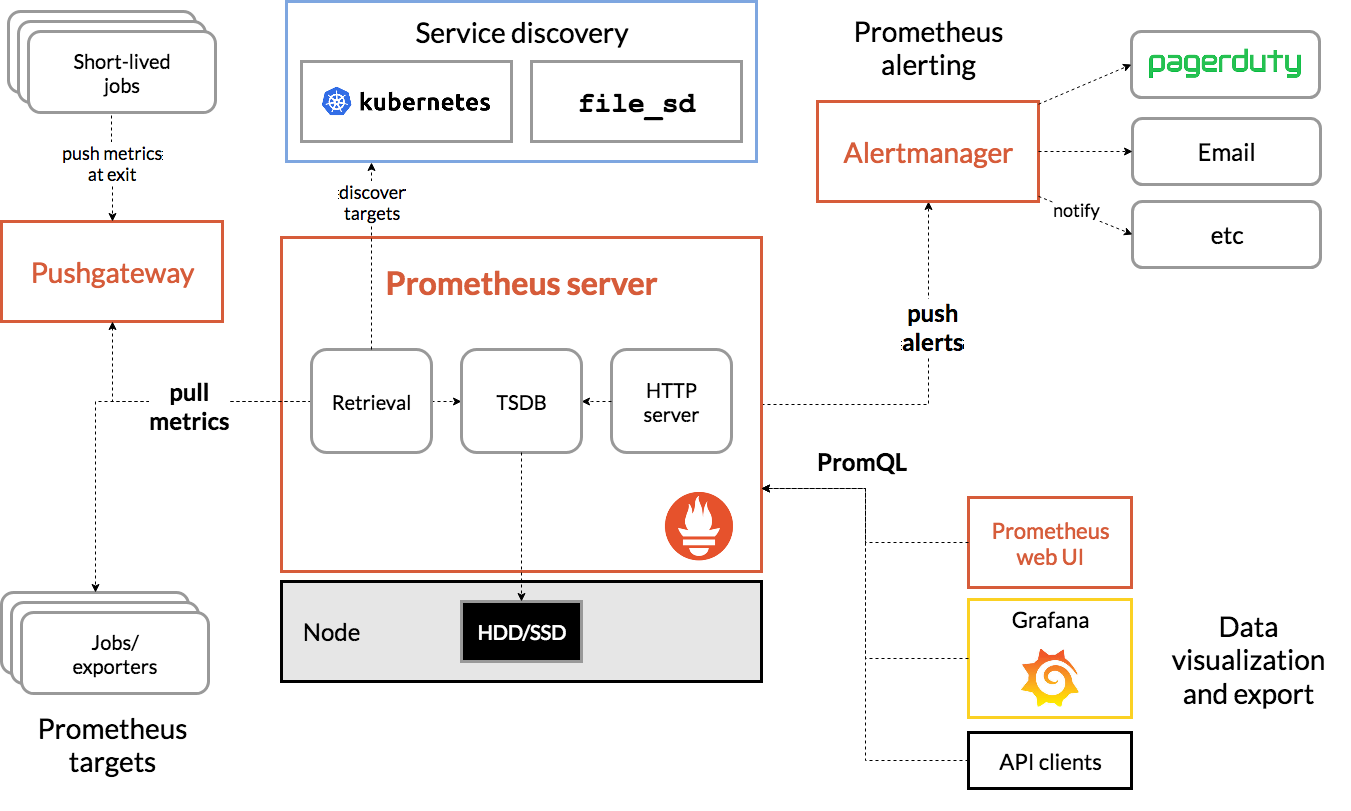
Istio, gdy jest wdrażany z Prometheusem, automatycznie przesyła różne dane do serwera Prometheus. Możemy używać tych danych do zarządzania klastrami w czasie rzeczywistym.
Poznaj wskaźniki Prometheus
Aby rozpocząć, musimy udostępnić wdrożenie Prometheusa.
Otwórz kartę Zadania w GKE i przejdź do zadania „prometheus”.

Po wyświetleniu szczegółów wdrożenia kliknij Działania –> Udostępnij.
Wybierz przekazywanie do portu 9090 i wpisz „System równoważenia obciążenia”.
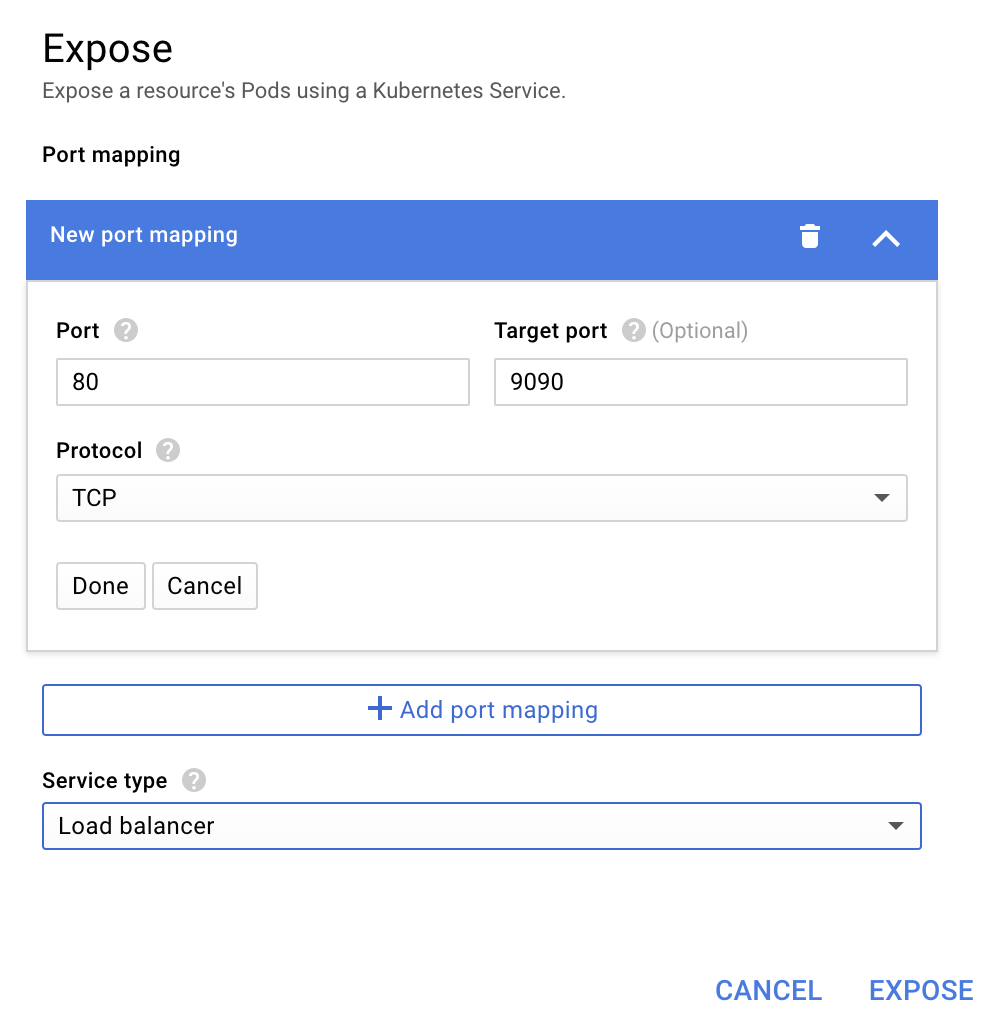
i wybierz „Udostępnij”.
Spowoduje to utworzenie usługi pod publicznie dostępnym adresem IP, którego możemy użyć do eksplorowania wskaźników Prometheus.
Poczekaj, aż punkt końcowy zacznie działać, a następnie kliknij adres IP obok pozycji „Zewnętrzne punkty końcowe” 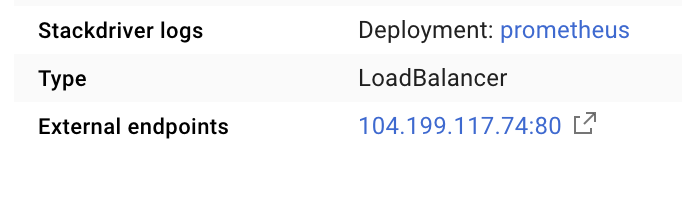 .
.
Powinien być teraz widoczny interfejs Prometheus.
Prometheus udostępnia wystarczającą liczbę danych, aby można było na ich podstawie przeprowadzić warsztaty. Na razie zaczniemy od zbadania wskaźnika istio_requests_total.
Wykonanie tego zapytania zwraca wiele danych. Są to dane dotyczące wszystkich żądań przechodzących przez siatkę usług Istio, a jest ich bardzo dużo. Zmienimy wyrażenie, aby filtrować tylko to, co nas naprawdę interesuje:
Żądania, w których usługa docelowa to worker-service.default.svc.cluster.local, a źródło to frontend-deployment, ograniczone do ostatnich 15 sekund.
Zapytanie wygląda tak:
istio_requests_total{reporter="destination",
destination_service="worker-service.default.svc.cluster.local",
source_workload="frontend-deployment"}[15s]
Dzięki temu mamy do dyspozycji znacznie łatwiejszy w obsłudze zbiór danych.
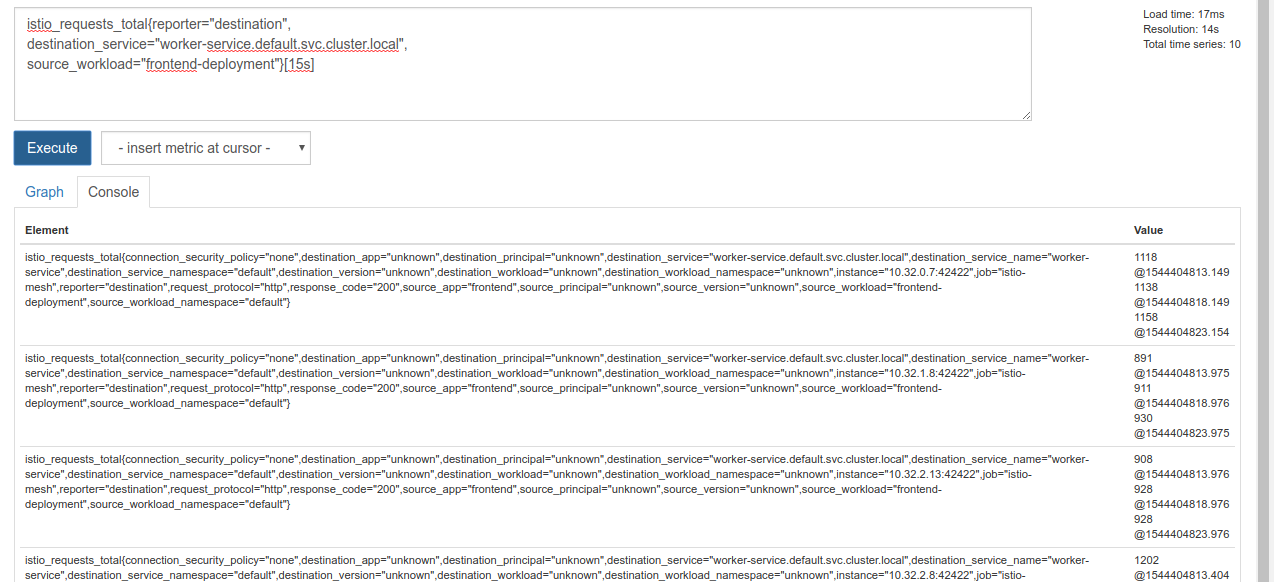
ale jest nadal trochę gęsty. Interesuje nas liczba żądań na sekundę, a nie wszystkie żądania.
Aby to zrobić, możemy użyć wbudowanej funkcji rate.
rate(istio_requests_total{reporter="destination",
destination_service="worker-service.default.svc.cluster.local",
source_workload="frontend-deployment"}[15s])

To nas przybliża do celu, ale musimy jeszcze trochę zmniejszyć liczbę tych danych, aby utworzyć logiczną grupę.
Aby to zrobić, możemy użyć słów kluczowych sum i by do grupowania i sumowania wyników.
sum(rate(istio_requests_total{reporter="destination",
destination_service="worker-service.default.svc.cluster.local",
source_workload="frontend-deployment"}[15s])) by (source_workload,
source_app, destination_service)
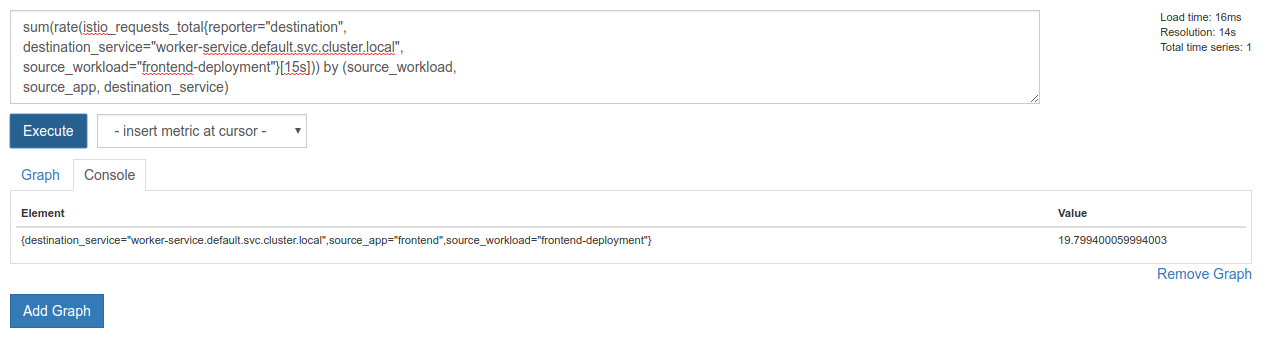
Super! Z Prometheusa możemy uzyskać dokładne potrzebne nam dane.
Ostateczne zapytanie Prometheus
Na podstawie zdobytej wiedzy możemy zadać usłudze Prometheus to zapytanie:
sum(rate(istio_requests_total{reporter="destination",
destination_service="worker-service.default.svc.cluster.local",
source_workload="frontend-deployment"}[15s])) by (source_workload,
source_app, destination_service)
Teraz możemy użyć ich interfejsu HTTP API, aby uzyskać te dane.
Możemy wysłać do interfejsu API zapytanie, tworząc żądanie GET w ten sposób. Zastąp <prometheus-ip-here>
curl http://<prometheus-ip-here>/api/v1/query?query=sum\(rate\(istio_requests_total%7Breporter%3D%22destination%22%2C%0Adestination_service%3D%22worker-service.default.svc.cluster.local%22%2C%0Asource_workload%3D%22frontend-deployment%22%7D%5B15s%5D\)\)%20by%20\(source_workload%2C%0Asource_app%2C%20destination_service\)
Oto przykładowa odpowiedź:
{
"status": "success",
"data": {
"resultType": "vector",
"result": [
{
"metric": {
"destination_service": "worker-service.default.svc.cluster.local",
"source_app": "frontend",
"source_workload": "frontend-deployment"
},
"value": [
1544404907.503,
"18.892886390062788"
]
}
]
}
}
Teraz możemy wyodrębnić wartość danych z pliku JSON.
Czyszczenie
Musimy usunąć usługę, której użyliśmy do udostępnienia Prometheus. W konsoli Google Cloud otwórz utworzoną usługę i kliknij „Usuń”.
Dalsze kroki:
Po opracowaniu sposobu wykrywania ruchu w klastrze i jego szybkości kolejnym krokiem jest napisanie małego pliku binarnego, który okresowo wysyła zapytania do Prometheus. Jeśli liczba żądań na sekundę do worker przekroczy określony próg, zastosuje różne wagi docelowe w naszej wirtualnej usłudze roboczej, aby wysyłać cały ruch do klastra burst. Gdy liczba żądań na sekundę spadnie poniżej niższego progu, przekieruj cały ruch z powrotem do primary.
17. Tworzenie rozszerzenia międzyklastrowego
Konfiguracja
Ustawianie całego ruchu w usłudze worker-service na klaster podstawowy
Uważamy, że cały ruch kierowany do worker-service i przekierowywany do klastra primary jest „domyślnym” stanem naszej aplikacji.
Zmień $proj/istio-manifests/worker-virtualservice.yaml tak, aby wyglądało jak poniżej.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: worker-virtual-service
spec:
hosts:
- worker-service
gateways:
- mesh
http:
- route:
- destination:
host: worker-service.default.svc.cluster.local
subset: primary
port:
number: 80
weight: 100
- destination:
host: worker-service.default.svc.cluster.local
subset: burst
port:
number: 80
weight: 0
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: worker-destination-rule
spec:
host: worker-service
trafficPolicy:
loadBalancer:
simple: RANDOM
subsets:
- name: primary
labels:
cluster-type: primary-cluster
- name: burst
labels:
cluster-type: burst-cluster
Sprawdź, czy masz połączenie z klastrem primary.
kubectx primary
Zastosuj plik istio-manifests/worker-virtualservice.yaml
kubectl apply -f istio-manifests/worker-virtualservice.yaml
Napisz demona istiowatcher
Do napisania tej usługi użyjemy języka Go ze względu na jego szybkość i przenośność. Ogólny przepływ aplikacji będzie polegać na uruchamianiu i co sekundę wysyłaniu zapytań do Prometheusa.
Utwórz w katalogu src nowy katalog o nazwie istiowatcher.
mkdir -p ${proj}/src/istiowatcher && cd ${proj}/src/istiowatcher
Będziemy wywoływać istioctl z poziomu kontenera, aby manipulować platformą sterującą Istio w klastrze.
Napisz plik istiowatcher.go
Utwórz w tym katalogu plik o nazwie istiowatcher.go i wstaw do niego ten kod:
package main
import (
"github.com/tidwall/gjson"
"io/ioutil"
"log"
"net/http"
"os/exec"
"time"
)
func main() {
//These are in requests per second
var targetLow float64 = 10
var targetHigh float64 = 15
// This is for the ticker in milliseconds
ticker := time.NewTicker(1000 * time.Millisecond)
isBurst := false
// Our prometheus query
reqQuery := `/api/v1/query?query=sum(rate(istio_requests_total{reporter="destination",destination_service="worker-service.default.svc.cluster.local",source_workload="frontend-deployment"}[15s]))by(source_workload,source_app,destination_service)`
for t := range ticker.C {
log.Printf("Checking Prometheus at %v", t)
// Check prometheus
// Note that b/c we are querying over the past 5 minutes, we are getting a very SLOW ramp of our reqs/second
// If we wanted this to be a little "snappier" we can scale it down to say 30s
resp, err := http.Get("http://prometheus.istio-system.svc.cluster.local:9090" + reqQuery)
if err != nil {
log.Printf("Error: %v", err)
continue
}
defer resp.Body.Close()
body, _ := ioutil.ReadAll(resp.Body)
val := gjson.Get(string(body), "data.result.0.value.1")
log.Printf("Value: %v", val)
currentReqPerSecond := val.Float()
log.Printf("Reqs per second %f", currentReqPerSecond)
if currentReqPerSecond > targetHigh && !isBurst {
applyIstio("burst.yaml")
log.Println("Entering burst mode")
isBurst = true
} else if currentReqPerSecond < targetLow && isBurst {
applyIstio("natural.yaml")
log.Println("Returning to natural state.")
isBurst = false
}
}
}
func applyIstio(filename string) {
cmd := exec.Command("istioctl", "replace", "-f", filename)
if err := cmd.Run(); err != nil {
log.Printf("Error hit applying istio manifests: %v", err)
}
}
Napisz plik Dockerfile
Utwórz nowy plik o nazwie Dockerfile i wstaw do niego ten kod.
FROM golang:1.11.2-stretch as base
FROM base as builder
WORKDIR /workdir
RUN curl -LO https://github.com/istio/istio/releases/download/1.0.0/istio-1.0.0-linux.tar.gz
RUN tar xzf istio-1.0.0-linux.tar.gz
RUN cp istio-1.0.0/bin/istioctl ./istioctl
FROM base
WORKDIR /go/src/istiowatcher
COPY . .
COPY --from=builder /workdir/istioctl /usr/local/bin/istioctl
RUN go get -d -v ./...
RUN go install -v ./...
CMD ["istiowatcher"]
Wielostopniowy plik Dockerfile pobiera i wyodrębnia wersję 1.0.0 Istio w pierwszym etapie. W drugim etapie wszystko z naszego katalogu jest kopiowane do obrazu, a następnie z etapu kompilacji do /usr/local/bin (aby można było wywołać je w naszej aplikacji). Pobierane są zależności, kompilowany jest kod, a wartość CMD jest ustawiana na „istiowatcher”.istioctl
Napisz plik burst.yaml
Jest to plik, który istiowatcher zastosuje, gdy liczba żądań na sekundę wysyłanych do worker z frontend przekroczy 15.
Utwórz nowy plik o nazwie burst.yaml i wstaw do niego ten kod.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: worker-virtual-service
spec:
hosts:
- worker-service
gateways:
- mesh
http:
- route:
- destination:
host: worker-service.default.svc.cluster.local
subset: primary
port:
number: 80
weight: 0
- destination:
host: worker-service.default.svc.cluster.local
subset: burst
port:
number: 80
weight: 100
Utwórz plik natural.yaml
Będziemy to traktować jako „naturalny” stan, do którego wracamy, gdy liczba żądań na sekundę z frontend do worker spadnie poniżej 10. W tym stanie 100% ruchu jest kierowane do klastra primary.
Utwórz nowy plik o nazwie natural.yaml i wstaw do niego ten kod:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: worker-virtual-service
spec:
hosts:
- worker-service
gateways:
- mesh
http:
- route:
- destination:
host: worker-service.default.svc.cluster.local
subset: primary
port:
number: 80
weight: 100
- destination:
host: worker-service.default.svc.cluster.local
subset: burst
port:
number: 80
weight: 0
Kompilowanie i wypychanie narzędzia istiowatcher
Uruchom to polecenie, aby wysłać bieżący katalog do Google Cloud Build (GCB), który utworzy i otaguje obraz w GCR.
gcloud builds submit -t gcr.io/${GCLOUD_PROJECT}/istiowatcher
Wdróż istiowatcher
Przejdź do katalogu kubernetes.
cd ${proj}/kubernetes/
Utwórz plik wdrożenia: istiowatcher.yaml
Utwórz plik o nazwie istiowatcher.yaml i wstaw do niego poniższy kod (zastąp <your-project-id>).
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: istiowatcher-deployment
labels:
app: istiowatcher
spec:
replicas: 1
selector:
matchLabels:
app: istiowatcher
template:
metadata:
labels:
app: istiowatcher
spec:
serviceAccountName: istio-pilot-service-account
automountServiceAccountToken: true
containers:
- name: istiowatcher
image: gcr.io/<your-project-id>/istiowatcher
imagePullPolicy: Always
Wdróż
Sprawdź, czy działamy w klastrze głównym.
kubectx primary
Wdróż istiowatcher.yaml w przestrzeni nazw istio-system.
kubectl apply -n istio-system -f istiowatcher.yaml
Ważne są dyrektywy serviceAccountName i automountServiceAccountToken w pliku YAML. Dzięki temu uzyskujemy dane logowania potrzebne do uruchomienia istioctl w klastrze.
Musimy też wdrożyć to w przestrzeni nazw istio-system, aby mieć dane logowania do istio-pilot-service-account. (nie istnieje w przestrzeni nazw default).
Obserwuj, jak ruch automatycznie się przełącza.
A teraz magiczna chwila. Przejdźmy do interfejsu i zwiększmy liczbę żądań na sekundę do 20.
Zauważ, że zajmuje to kilka sekund, ale wszystkie nasze hasze mają prefiks „bursty-”.
Dzieje się tak, ponieważ próbujemy prometheus w zakresie 15s, co nieco opóźnia czas reakcji. Jeśli chcemy uzyskać znacznie węższy zakres, możemy zmienić zapytanie do Prometeusza na 5s.
18. Co dalej?
Czyszczenie
Jeśli korzystasz z konta tymczasowego udostępnionego na potrzeby tych warsztatów, nie musisz zwalniać miejsca.
Możesz usunąć klastry Kubernetes, regułę zapory sieciowej i obrazy w GCR.
gcloud container clusters delete primary --zone=us-west1-a
gcloud container clusters delete burst --zone=us-west1-a
gcloud compute firewall-rules delete istio-multicluster-test-pods
gcloud container images delete gcr.io/$GCLOUD_PROJECT/istiowatcher
Dalsze działania
- Weź udział w Istio Talks.
- Uzyskaj certyfikat: tworzenie kolejnej aplikacji za pomocą Kubernetes i Istio
- Keynote: Kubernetes, Istio, Knative: The New Open Cloud Stack - Aparna Sinha, Group Product Manager for Kubernetes, Google
- Samouczek: korzystanie z Istio – Lee Calcote i Girish Ranganathan, SolarWinds
- Istio - The Packet's-Eye View - Matt Turner, Tetrate
- Czy Istio to najbardziej zaawansowana zapora sieciowa nowej generacji? – John Morello, Twistlock
- Zapoznaj się z dokumentacją Istio.
- Dołącz do grup roboczych Istio
- Obserwuj @IstioMesh na Twitterze