
1. 概要
このラボでは、最新の畳み込みアーキテクチャについて学習し、その知識を使用して「squeezenet」と呼ばれるシンプルで効果的な convnet を実装します。
このラボには、畳み込みニューラル ネットワークに関する必要な理論的説明が含まれており、ディープ ラーニングを学習するデベロッパーにとって良い出発点となります。
このラボは、「Keras on TPU」シリーズのパート 4 です。これらの手順は、次の順序で実行することも、個別に行うこともできます。
- TPU スピードのデータ パイプライン: tf.data.Dataset と TFRecords
- 転移学習を使用した最初の Keras モデル
- Keras と TPU を使用した畳み込みニューラル ネットワーク
- [このラボ] Keras と TPU を使用した最新の convnets、squeezenet、Xception

学習内容
- Keras の関数型スタイルを習得する
- squeezenet アーキテクチャを使用してモデルを構築するには
- TPU を使用して高速にトレーニングし、アーキテクチャを反復処理する
- tf.data.dataset を使用してデータ拡張を実装する
- TPU で事前トレーニング済みの大規模モデル(Xception)をファインチューニングする
フィードバック
この Codelab で何か問題が見つかった場合は、お知らせください。フィードバックは GitHub の問題 [フィードバック リンク] から送信できます。
2. Google Colaboratory クイック スタート
このラボでは Google Collaboratory を使用するため、ユーザー側での設定は不要です。Colaboratory は、教育目的のオンライン ノートブック プラットフォームです。CPU、GPU、TPU のトレーニングを無料で提供しています。

このサンプル ノートブックを開いて、いくつかのセルを実行すると、Colaboratory の使い方を理解できます。
TPU バックエンドを選択する

Colab のメニューで、[ランタイム] > [ランタイムのタイプを変更] を選択し、[TPU] を選択します。このコードラボでは、ハードウェア アクセラレータによるトレーニングをサポートする強力な TPU(Tensor Processing Unit)を使用します。ランタイムへの接続は、初回実行時に自動的に行われます。右上にある [接続] ボタンを使用することもできます。
ノートブックの実行

セルを 1 つずつ実行するには、セルをクリックして Shift+Enter キーを押します。[ランタイム] > [すべて実行] を選択して、ノートブック全体を実行することもできます。
目次

すべてのノートブックに目次があります。左側の黒い矢印を使用して開くことができます。
非表示のセル

一部のセルにはタイトルのみが表示されます。これは Colab 固有のノートブック機能です。ダブルクリックすると内部のコードを確認できますが、通常はあまり興味深いものではありません。通常はサポート関数またはビジュアリゼーション関数。内部の関数を定義するには、これらのセルを実行する必要があります。
認証

承認済みアカウントで認証すれば、Colab からプライベート Google Cloud Storage バケットにアクセスできます。上記のコード スニペットは、認証プロセスをトリガーします。
3. [INFO] Tensor Processing Unit(TPU)とは
概要

Keras で TPU 上でモデルをトレーニングするコード(TPU が使用できない場合は GPU または CPU にフォールバックします)。
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
今日は、TPU を使用して、インタラクティブな速度(トレーニング実行あたり数分)で花の分類子を構築して最適化します。
TPU を使用する理由
最新の GPU は、プログラマブルな「コア」を中心に構成されています。これは、3D レンダリング、ディープ ラーニング、物理シミュレーションなど、さまざまなタスクを処理できる非常に柔軟なアーキテクチャです。一方、TPU は、従来のベクトル プロセッサと専用の行列乗算ユニットを組み合わせたもので、ニューラル ネットワークなど、大規模な行列乗算が支配的なタスクに優れています。

図: 密ニューラル ネットワーク レイヤを行列乗算として表した図。8 枚の画像のバッチがニューラル ネットワークで一度に処理されます。1 行 x 列の乗算を実行して、画像内のすべてのピクセル値の加重和が実際に計算されていることを確認してください。畳み込みレイヤも行列乗算として表現できますが、少し複雑になります( 説明はこちらのセクション 1 をご覧ください)。
ハードウェア
MXU と VPU
TPU v2 コアは、行列乗算を実行する Matrix Multiply Unit(MXU)と、活性化やソフトマックスなどの他のすべてのタスク用の Vector Processing Unit(VPU)で構成されています。VPU は float32 と int32 の計算を処理します。一方、MXU は混合精度 16 ~ 32 ビットの浮動小数点形式で動作します。

混合精度浮動小数点と bfloat16
MXU は、bfloat16 入力と float32 出力を使用して行列乗算を計算します。中間累積は float32 精度で実行されます。

通常、ニューラル ネットワークのトレーニングは、浮動小数点精度の低下によって生じるノイズの影響を受けません。ノイズがオプティマイザーの収束に役立つ場合もあります。16 ビット浮動小数点精度は、従来、計算の高速化に使用されてきましたが、float16 形式と float32 形式では範囲が大きく異なります。精度を float32 から float16 に下げると、通常はオーバーフローとアンダーフローが発生します。ソリューションは存在しますが、通常は float16 を機能させるために追加の作業が必要です。
そのため、Google は TPU に bfloat16 形式を導入しました。bfloat16 は、float32 とまったく同じ指数ビットと範囲を持つ切り捨てられた float32 です。また、TPU は bfloat16 入力と float32 出力を使用して混合精度で行列乗算を計算するため、通常は、精度を下げてパフォーマンスを向上させるためにコードを変更する必要はありません。
シストリック アレイ
MXU は、データ要素がハードウェア コンピューティング ユニットの配列を流れる「シストリック アレイ」アーキテクチャを使用して、ハードウェアで行列乗算を実装します。(医学では、収縮期とは心臓の収縮と血流を指しますが、ここではデータの流れを指します)。
行列乗算の基本要素は、一方の行列の行と他方の行列の列の内積です(このセクションの上部の図を参照)。行列乗算 Y=X*W の場合、結果の 1 つの要素は次のようになります。
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
GPU では、このドット積を GPU の「コア」にプログラムし、利用可能なすべての「コア」で並列実行して、結果の行列のすべての値を一度に計算しようとします。結果の行列が 128x128 の大きさの場合、128x128=16K 個の「コア」が必要になりますが、これは通常不可能です。最大の GPU には約 4,000 個のコアがあります。一方、TPU は MXU のコンピューティング ユニットに最小限のハードウェア(bfloat16 x bfloat16 => float32 乗算累算器のみ)を使用します。これらは非常に小さいため、TPU は 128x128 MXU に 16 K 個を実装し、この行列乗算を一度に処理できます。

図: MXU シストリック アレイ。コンピューティング要素は乗算アキュムレータです。1 つの行列の値が配列に読み込まれます(赤い点)。もう一方の行列の値は配列を通過します(灰色の点)。縦線は値を上に伝播します。水平線は部分和を伝播します。配列をデータが流れるときに、右側から行列乗算の結果が得られることを確認するのは、ユーザーの演習として残されています。
また、MXU でドット積が計算されている間、中間合計は隣接するコンピューティング単位間を流れるだけです。メモリやレジスタ ファイルに保存して取得する必要はありません。その結果、TPU シストリック アレイ アーキテクチャは、行列乗算の計算において、GPU よりも密度と電力の面で大きな利点があり、速度の面でも無視できない利点があります。
Cloud TPU
Google Cloud Platform で「Cloud TPU v2」をリクエストすると、PCI 接続の TPU ボードを備えた仮想マシン(VM)が取得されます。TPU ボードには、4 つのデュアルコア TPU チップがあります。各 TPU コアには、VPU(ベクトル処理ユニット)と 128x128 MXU(マトリックス乗算ユニット)があります。この「Cloud TPU」は通常、ネットワークを介してリクエストした VM に接続されます。全体像は次のようになります。

図: ネットワーク接続された「Cloud TPU」アクセラレータを備えた VM。「Cloud TPU」自体は、PCI 接続の TPU ボードと、そのボードに搭載された 4 つのデュアルコア TPU チップを備えた VM で構成されています。
TPU Pod
Google のデータセンターでは、TPU はハイ パフォーマンス コンピューティング(HPC)相互接続に接続されており、1 つの非常に大きなアクセラレータとして認識されることがあります。Google はこれらを Pod と呼び、最大 512 個の TPU v2 コアまたは 2,048 個の TPU v3 コアを包含できます。

図: TPU v3 Pod。HPC 相互接続を介して接続された TPU ボードとラック。
トレーニング中、勾配は all-reduce アルゴリズム(all-reduce の詳細はこちら)を使用して TPU コア間で交換されます。トレーニング対象のモデルは、大きなバッチサイズでトレーニングすることでハードウェアを活用できます。

図: Google TPU の 2 次元トーラス メッシュ HPC ネットワークで all-reduce アルゴリズムを使用してトレーニング中に勾配を同期する。
ソフトウェア
大規模なバッチサイズのトレーニング
TPU の理想的なバッチサイズは TPU コアあたり 128 個のデータ項目ですが、ハードウェアは TPU コアあたり 8 個のデータ項目から高い使用率を示します。1 つの Cloud TPU には 8 個のコアがあります。
この Codelab では、Keras API を使用します。Keras で指定するバッチは、TPU 全体のグローバル バッチサイズです。バッチは自動的に 8 つに分割され、TPU の 8 個のコアで実行されます。

パフォーマンスに関するその他のヒントについては、TPU パフォーマンス ガイドをご覧ください。バッチサイズが非常に大きい場合は、一部のモデルで特別な注意が必要になることがあります。詳しくは、LARSOptimizer をご覧ください。
仕組み: XLA
Tensorflow プログラムは計算グラフを定義します。TPU は Python コードを直接実行するのではなく、TensorFlow プログラムで定義された計算グラフを実行します。内部では、XLA(高速線形代数コンパイラ)と呼ばれるコンパイラが、計算ノードの Tensorflow グラフを TPU マシンコードに変換します。このコンパイラは、コードとメモリ レイアウトに対して多くの高度な最適化も実行します。コンパイルは、作業が TPU に送信されると自動的に行われます。ビルドチェーンに XLA を明示的に含める必要はありません。
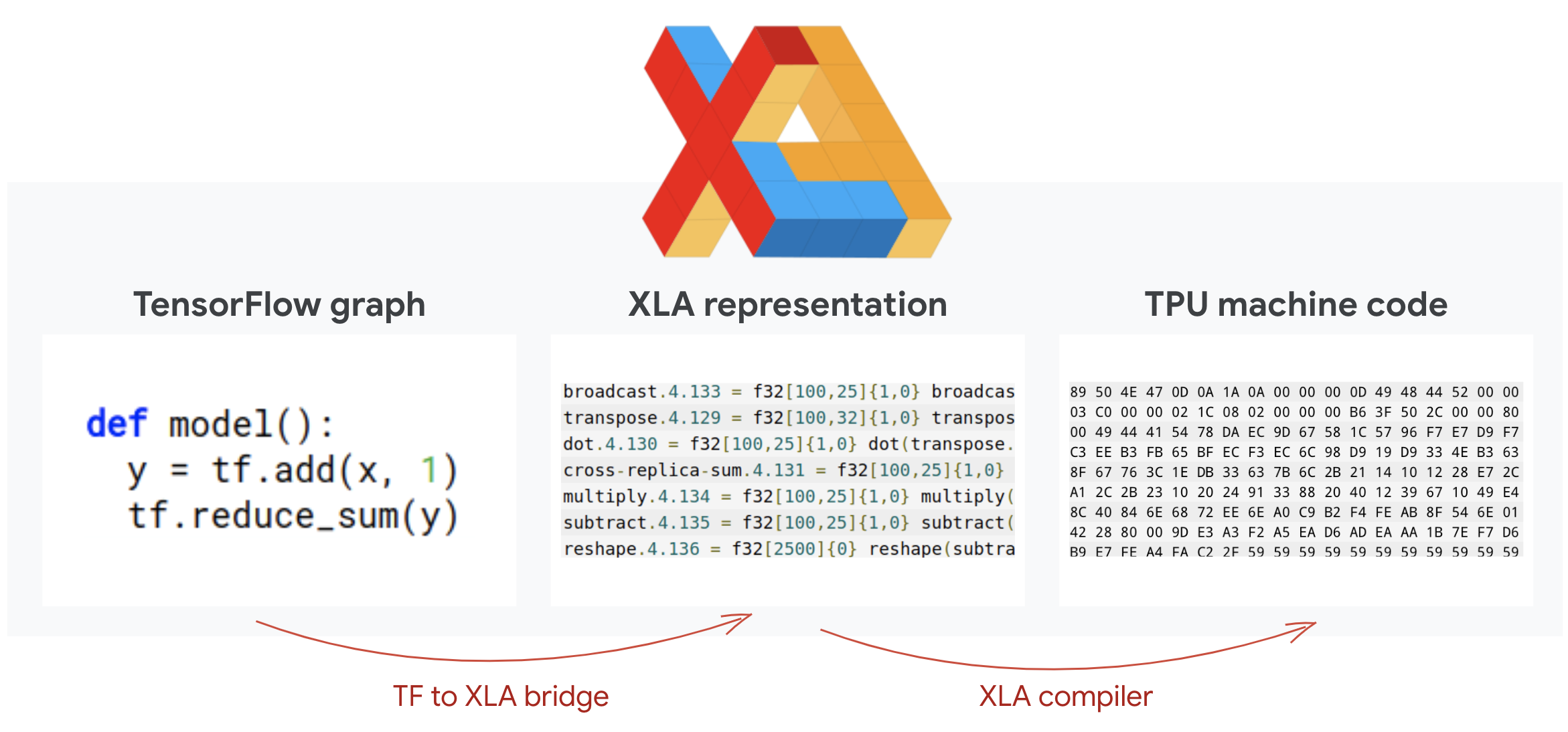
図: TPU で実行するには、TensorFlow プログラムで定義された計算グラフをまず XLA(アクセラレータ線形代数コンパイラ)表現に変換し、次に XLA によって TPU マシンコードにコンパイルします。
Keras で TPU を使用する
Tensorflow 2.1 以降、Keras API を介して TPU がサポートされています。Keras のサポートは、TPU と TPU Pod で機能します。TPU、GPU、CPU で動作する例を次に示します。
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
このコード スニペットでは:
TPUClusterResolver().connect()は、ネットワーク上の TPU を検出します。ほとんどの Google Cloud システム(AI Platform ジョブ、Colaboratory、Kubeflow、ctpu up ユーティリティで作成された Deep Learning VM)でパラメータなしで動作します。これらのシステムは、TPU_NAME 環境変数のおかげで TPU の場所を認識しています。TPU を手動で作成する場合は、使用する VM で TPU_NAME 環境変数を設定するか、明示的なパラメータを指定してTPUClusterResolverを呼び出します。TPUClusterResolver(tp_uname, zone, project)TPUStrategyは、分布と「all-reduce」勾配同期アルゴリズムを実装する部分です。- この戦略はスコープを通じて適用されます。モデルは strategy scope() 内で定義する必要があります。
tpu_model.fit関数は、TPU トレーニングの入力として tf.data.Dataset オブジェクトを想定しています。
一般的な TPU の移植タスク
- Tensorflow モデルでデータを読み込む方法は多数ありますが、TPU では
tf.data.DatasetAPI を使用する必要があります。 - TPU は非常に高速であるため、TPU で実行すると、データの取り込みがボトルネックになることがよくあります。TPU パフォーマンス ガイドには、データ ボトルネックを検出するために使用できるツールや、その他のパフォーマンスに関するヒントが記載されています。
- int8 または int16 の数値は int32 として扱われます。TPU には、32 ビット未満で動作する整数ハードウェアはありません。
- 一部の TensorFlow オペレーションはサポートされていません。リストはこちらをご覧ください。この制限はトレーニング コード(モデルのフォワード パスとバックワード パス)にのみ適用されます。データ入力パイプラインでは、すべての TensorFlow オペレーションを CPU で実行できるため、引き続き使用できます。
- TPU では
tf.py_funcはサポートされていません。
4. [INFO] ニューラル ネットワーク分類器 101
概要
次の段落の太字の用語をすべてご存知の場合は、次の演習に進んでください。ディープ ラーニングを始めたばかりの方は、ぜひこのまま読み進めてください。
レイヤのシーケンスとして構築されたモデルの場合、Keras は Sequential API を提供します。たとえば、3 つの密なレイヤを使用する画像分類器は、Keras で次のように記述できます。
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
密結合ニューラル ネットワーク
これは、画像を分類するための最も単純なニューラル ネットワークです。レイヤに配置された「ニューロン」で構成されています。最初のレイヤは入力データを処理し、その出力を他のレイヤに渡します。各ニューロンが前のレイヤのすべてのニューロンに接続されているため、「密」と呼ばれます。
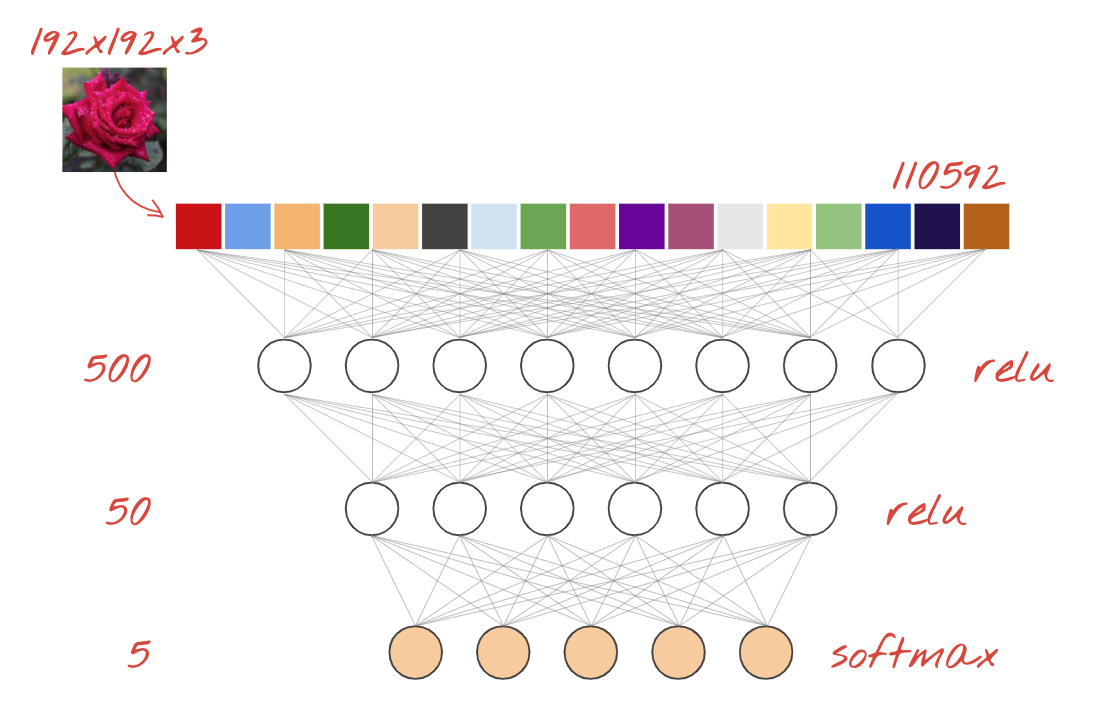
このようなネットワークに画像をフィードするには、すべてのピクセルの RGB 値を長いベクトルに平坦化して入力として使用します。画像認識に最適な手法ではありませんが、後で改善します。
ニューロン、アクティベーション、RELU
「ニューロン」は、すべての入力の加重和を計算し、「バイアス」と呼ばれる値を加算して、結果を「活性化関数」と呼ばれる関数に渡します。重みとバイアスは最初は不明です。これらはランダムに初期化され、既知のデータでニューラル ネットワークをトレーニングすることで「学習」されます。

最も一般的な活性化関数は、Rectified Linear Unit の略である RELU と呼ばれます。上のグラフでわかるように、非常にシンプルな関数です。
Softmax アクティベーション
上記のネットワークは、花を 5 つのカテゴリ(バラ、チューリップ、タンポポ、デイジー、ヒマワリ)に分類するため、5 つのニューロン レイヤで終わります。中間レイヤのニューロンは、従来の RELU アクティベーション関数を使用してアクティブ化されます。ただし、最後のレイヤでは、この花がバラである確率、チューリップである確率などを表す 0 ~ 1 の数値を計算します。これには、「ソフトマックス」と呼ばれる活性化関数を使用します。
ベクトルに softmax を適用するには、各要素の指数関数を取り、通常は L1 ノルム(絶対値の合計)を使用してベクトルを正規化します。これにより、値の合計が 1 になり、確率として解釈できます。


交差エントロピー損失
ニューラル ネットワークが入力画像から予測を生成するようになったので、その予測の精度を測定する必要があります。つまり、ネットワークが示す内容と正解(ラベルと呼ばれることが多い)との間の距離を測定します。データセット内のすべての画像に正しいラベルが付いていることを思い出してください。
どの距離でも機能しますが、分類問題では「交差エントロピー距離」が最も効果的です。これをエラー関数または損失関数と呼びます。

勾配降下法
ニューラル ネットワークの「トレーニング」とは、実際には、トレーニング画像とラベルを使用して、交差エントロピー損失関数を最小限に抑えるように重みとバイアスを調整することを意味します。仕組みは次のとおりです。
クロスエントロピーは、重み、バイアス、トレーニング画像のピクセル、既知のクラスの関数です。
すべての重みとすべてのバイアスに対してクロスエントロピーの偏導関数を計算すると、特定の画像、ラベル、重みとバイアスの現在の値に対して計算された「勾配」が得られます。重みとバイアスは数百万個になる可能性があるため、勾配の計算は大変な作業になります。幸いなことに、Tensorflow がこの処理を代わりに行ってくれます。グラデーションの数学的特性は、「上」を指すことです。交差エントロピーが低い方向に進みたいので、反対方向に進みます。重みとバイアスは、勾配の分数で更新します。次に、トレーニング ループで、次のバッチのトレーニング画像とラベルを使用して同じ処理を繰り返し行います。この最小値が 1 つである保証はありませんが、この最小値に収束することを期待します。

ミニバッチ処理とモメンタム
1 つのサンプル画像でグラデーションを計算し、重みとバイアスをすぐに更新することもできますが、たとえば 128 枚の画像のバッチでグラデーションを計算すると、さまざまなサンプル画像によって課せられる制約をより適切に表すグラデーションが得られるため、解に収束する可能性が高くなります。ミニバッチのサイズは調整可能なパラメータです。
この手法は「確率的勾配降下法」と呼ばれることもありますが、バッチ処理を行うことで、より大きな行列を扱うことになり、GPU や TPU での最適化が容易になるという実用的なメリットもあります。
ただし、収束はややカオスになる可能性があり、グラデーション ベクトルがすべてゼロの場合には停止することもあります。これは、最小値が見つかったことを意味しますか?必ずしも違反警告を受けるとは限りません。グラデーション コンポーネントは、最小値または最大値でゼロになることがあります。数百万個の要素を持つ勾配ベクトルで、すべての要素がゼロの場合、すべてのゼロが最小値に対応し、最大値に対応するゼロがない確率はかなり小さくなります。多次元空間では鞍点が非常に一般的であり、そこで停止したくありません。

イラスト: 鞍点。グラデーションは 0 ですが、すべての方向で最小値ではありません。(画像帰属 Wikimedia: By Nicoguaro - Own work, CC BY 3.0)
解決策は、最適化アルゴリズムに運動量を追加して、鞍点を停止せずに通過できるようにすることです。
用語集
バッチまたはミニバッチ: トレーニングは常にトレーニング データとラベルのバッチで実行されます。これにより、アルゴリズムの収束が促進されます。「バッチ」ディメンションは通常、データテンソルの最初のディメンションです。たとえば、シェイプ [100, 192, 192, 3] のテンソルには、192x192 ピクセルの画像が 100 個含まれており、各ピクセルには 3 つの値(RGB)があります。
交差エントロピー損失: 分類子でよく使用される特殊な損失関数。
密結合層: 各ニューロンが前のレイヤのすべてのニューロンに接続されているニューロンのレイヤ。
特徴: ニューラル ネットワークの入力は「特徴」と呼ばれることもあります。優れた予測を得るために、データセットのどの部分(または部分の組み合わせ)をニューラル ネットワークにフィードするかを判断する技術は、「特徴量エンジニアリング」と呼ばれます。
ラベル: 教師あり分類問題における「クラス」または正解の別の名前
学習率: トレーニング ループの各イテレーションで重みとバイアスが更新される勾配の割合。
ロジット: 活性化関数が適用される前のニューロンのレイヤの出力は「ロジット」と呼ばれます。この用語は、かつて最も一般的な活性化関数であった「ロジスティック関数」(「シグモイド関数」とも呼ばれます)に由来します。「Neuron outputs before logistic function」が「logits」に短縮されました。
loss: ニューラル ネットワークの出力と正解を比較する誤差関数
ニューロン: 入力の加重和を計算し、バイアスを追加して、活性化関数を通じて結果をフィードします。
ワンホット エンコード: 5 つのクラスのうちのクラス 3 は、5 つの要素のベクトルとしてエンコードされます。3 番目の要素を除いてすべてゼロです。
relu: 正規化線形ユニット。ニューロンでよく使用される活性化関数。
sigmoid: 以前はよく使用されていた別の活性化関数で、特殊なケースでは今でも有用です。
softmax: ベクトルに作用し、最大成分と他のすべての成分の差を大きくする特別な活性化関数。また、確率のベクトルとして解釈できるように、ベクトルの合計が 1 になるように正規化します。分類子の最後のステップとして使用されます。
tensor: 「テンソル」は行列のようなものですが、任意の数の次元を持つことができます。1 次元テンソルはベクトルです。2 次元テンソルは行列です。3 次元、4 次元、5 次元以上のテンソルを使用することもできます。
5. [INFO] 畳み込みニューラル ネットワーク
概要
次の段落の太字の用語をすべてご存知の場合は、次の演習に進んでください。畳み込みニューラル ネットワークを初めて使用する場合は、このままお読みください。

図: 4x4x3=48 個の学習可能な重みで構成される 2 つの連続したフィルタで画像をフィルタリングする。
Keras での単純な畳み込みニューラル ネットワークは次のようになります。
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
畳み込みニューラル ネットワーク 101
畳み込みネットワークのレイヤでは、1 つの「ニューロン」が、画像の小さな領域のみで、すぐ上のピクセルの加重和を計算します。通常の密結合レイヤのニューロンと同様に、バイアスを追加して、活性化関数を介して合計を渡します。このオペレーションは、同じ重みを使用して画像全体で繰り返されます。密結合レイヤでは、各ニューロンに独自の重みがありました。ここでは、重みの単一の「パッチ」が画像上を双方向にスライドします(「畳み込み」)。出力には、画像内のピクセル数と同じ数の値が含まれます(ただし、エッジでパディングが必要になります)。これは、4×4×3=48 個の重みを持つフィルタを使用するフィルタリング オペレーションです。
ただし、48 個の重みでは不十分です。自由度を高めるために、新しい重みのセットで同じ操作を繰り返します。これにより、新しい一連のフィルタ出力が生成されます。入力画像の R、G、B チャネルとの類似性から、出力の「チャネル」と呼びます。

2 つ以上の重みのセットは、新しいディメンションを追加することで 1 つのテンソルとして合計できます。これにより、畳み込みレイヤの重みテンソルの一般的な形状が得られます。入力チャネルと出力チャネルの数はパラメータであるため、畳み込みレイヤのスタックとチェーンを開始できます。

図: 畳み込みニューラル ネットワークがデータの「キューブ」を別のデータの「キューブ」に変換する。
ストライド畳み込み、最大プーリング
ストライド 2 または 3 で畳み込みを行うことで、結果のデータキューブを水平方向に縮小することもできます。これを行うには、次の 2 つの一般的な方法があります。
- ストライド畳み込み: 上記のスライディング フィルタ。ただし、ストライドが 1 より大きい
- 最大プーリング: MAX オペレーションを適用するスライディング ウィンドウ(通常は 2x2 パッチで、2 ピクセルごとに繰り返されます)

図: コンピューティング ウィンドウを 3 ピクセル スライドさせると、出力値が少なくなります。ストライド畳み込みまたは最大プーリング(ストライド 2 でスライドする 2x2 ウィンドウの最大値)は、水平方向にデータキューブを縮小する方法です。
Convolutional classifier
最後に、最後のデータキューブをフラット化し、密な softmax 活性化レイヤを介してフィードすることで、分類ヘッドを接続します。一般的な畳み込み分類器は次のようになります。

図: 畳み込みレイヤと softmax レイヤを使用する画像分類器。3x3 フィルタと 1x1 フィルタを使用します。maxpool レイヤは、2x2 のデータポイントのグループの最大値を取得します。分類ヘッドは、ソフトマックス活性化関数を持つ密結合レイヤで実装されます。
Keras で
上記の畳み込みスタックは、Keras で次のように記述できます。
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
6. [新情報] 最新の畳み込みアーキテクチャ
概要

図: 畳み込み「モジュール」。この時点で最適な方法はどれですか?最大プーリング レイヤの後に 1x1 畳み込みレイヤが続くのか、それとも別のレイヤの組み合わせなのか?すべてを試して結果を連結し、ネットワークに判断させます。右: このようなモジュールを使用する「 inception」畳み込みアーキテクチャ。
Keras でデータフローが分岐するモデルを作成するには、「関数型」モデル スタイルを使用する必要があります。以下に例を示します。
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
その他の安易な方法
3x3 の小さなフィルタ

この図では、連続する 2 つの 3x3 フィルタの結果を示しています。結果に寄与したデータポイントをトレースバックしてみましょう。これらの 2 つの連続した 3x3 フィルタは、5x5 領域の組み合わせを計算します。5x5 フィルタで計算される組み合わせとまったく同じではありませんが、2 つの連続する 3x3 フィルタは 1 つの 5x5 フィルタよりも安価であるため、試してみる価値はあります。
1x1 畳み込みとは?

数学的には、「1x1」畳み込みは定数による乗算であり、あまり有用な概念ではありません。ただし、畳み込みニューラル ネットワークでは、フィルタは 2D 画像だけでなくデータキューブにも適用されることを覚えておいてください。したがって、「1x1」フィルタは 1x1 のデータ列の加重合計を計算します(図を参照)。このフィルタをデータ上でスライドさせると、入力のチャネルの線形結合が得られます。これは実際に役立ちます。チャネルを個々のフィルタリング オペレーションの結果と考えると、たとえば「尖った耳」のフィルタ、「ひげ」のフィルタ、「縦長の目」のフィルタがあるとします。この場合、「1x1」の畳み込みレイヤは、これらの特徴の複数の可能な線形結合を計算します。これは、「猫」を探す場合に役立ちます。また、1x1 レイヤは重みの使用量が少なくなります。
7. Squeezenet
これらのアイデアを組み合わせる簡単な方法が、「Squeezenet」論文で紹介されています。著者は、1x1 と 3x3 の畳み込みレイヤのみを使用する非常にシンプルな畳み込みモジュール設計を提案しています。

図: 「ファイア モジュール」に基づく SqueezeNet アーキテクチャ。垂直方向に受信データを「圧縮」する 1x1 レイヤと、データの深さを再び「拡張」する 2 つの並列 1x1 および 3x3 畳み込みレイヤを交互に使用します。
ハンズオン
前のノートブックを続行し、SqueezeNet にインスパイアされた畳み込みニューラル ネットワークを構築します。モデルコードを Keras の「関数スタイル」に変更する必要があります。

Keras_Flowers_TPU (playground).ipynb
追加情報
この演習では、squeezenet モジュールのヘルパー関数を定義すると便利です。
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
今回の目標は 80% の精度を達成することです。
お試しください
単一の畳み込みレイヤから始め、MaxPooling2D(pool_size=2) レイヤと交互に fire_modules を続けます。ネットワークで 2 ~ 4 個の最大プーリング レイヤを試すことができます。また、最大プーリング レイヤ間に 1、2、3 個の連続するファイア モジュールを試すこともできます。
火のモジュールでは、通常、「squeeze」パラメータは「expand」パラメータよりも小さくする必要があります。これらのパラメータは、実際にはフィルタの数です。通常、8 ~ 196 の範囲で指定できます。ネットワーク全体でフィルタの数が徐々に増加するアーキテクチャや、すべての fire モジュールでフィルタの数が同じであるシンプルなアーキテクチャを試すことができます。
以下に例を示します。
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
この時点で、テストがうまくいかず、80% の精度目標が遠く感じられるかもしれません。もういくつか簡単なトリックをご紹介します。
バッチ正規化
バッチ正規化は、発生している収束の問題の解決に役立ちます。この手法の詳細については、次のワークショップで説明します。ここでは、ネットワークの各畳み込みレイヤの後に(fire_module 関数内のレイヤを含む)次の行を追加して、ブラック ボックスの「マジック」のヘルパーとして使用してください。
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
データセットが小さいため、モーメンタム パラメータのデフォルト値 0.99 を 0.9 に減らす必要があります。この詳細は今は気にしないでください。
データ拡張
彩度の左右反転などの簡単な変換でデータを拡張すると、数パーセントの精度向上が見込めます。


TensorFlow では、tf.data.Dataset API を使用してこれを簡単に行うことができます。データの新しい変換関数を定義します。
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
次に、最終的なデータ変換(セル「トレーニング データセットと検証データセット」、関数「get_batched_dataset」)で使用します。
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
データ拡張をオプションにし、トレーニング用データセットのみが拡張されるように必要なコードを追加することを忘れないでください。検証データセットを拡張しても意味がありません。
35 エポックで 80% の精度を達成できるようになりました。
ソリューション
ソリューション ノートブックは次のとおりです。行き詰まった場合は、こちらをご利用ください。
Keras_Flowers_TPU_squeezenet.ipynb
学習した内容
- 🤔 Keras の「関数スタイル」モデル
- 🤓 Squeezenet アーキテクチャ
- 🤓 tf.data.datset を使用したデータ拡張
このチェックリストを頭の中で確認してください。
8. Xception ファインチューニング済み
分離可能な畳み込み
最近、畳み込みレイヤの別の実装方法である深さ方向分離畳み込みが人気を集めています。少し複雑な用語ですが、コンセプトは非常にシンプルです。これらは、Tensorflow と Keras で tf.keras.layers.SeparableConv2D として実装されています。
分離可能な畳み込みも画像に対してフィルタを実行しますが、入力画像の各チャネルに別々の重みセットを使用します。その後に「1x1 畳み込み」が続きます。これは、フィルタされたチャネルの重み付き合計を生成する一連のドット積です。新しい重みを使用して、必要に応じてチャネルの重み付き再結合を計算します。

イラスト: 分離可能な畳み込み。フェーズ 1: チャネルごとに個別のフィルタを使用した畳み込み。フェーズ 2: チャネルの線形再結合。目的の出力チャネル数に達するまで、新しい重みセットで繰り返されます。フェーズ 1 も繰り返すことができます。そのたびに新しい重みが使用されますが、実際にはほとんど行われません。
分離可能な畳み込みは、MobileNetV2、Xception、EfficientNet など、最新の畳み込みネットワーク アーキテクチャで使用されています。ちなみに、MobileNetV2 は以前に転移学習で使用したものです。
通常の畳み込みよりも安価で、実際には同等の効果があることがわかっています。上記の例の重みの数は次のとおりです。
畳み込みレイヤ: 4 × 4 × 3 × 5 = 240
分離可能な畳み込みレイヤ: 4 x 4 x 3 + 3 x 5 = 48 + 15 = 63
各スタイルの畳み込みレイヤ スケールを適用するために必要な乗算の数を計算するのは、読者の練習問題として残されています。分離可能な畳み込みは、サイズが小さく、計算効率が大幅に向上します。
ハンズオン
「転移学習」の Playground ノートブックから再開しますが、今回は事前トレーニング済みモデルとして Xception を選択します。Xception は分離可能な畳み込みのみを使用します。すべての重みをトレーニング可能にします。事前トレーニング済みのレイヤをそのまま使用するのではなく、データで事前トレーニング済みの重みをファインチューニングします。
Keras Flowers transfer learning (playground).ipynb
目標: 精度 95% 超(真面目な話、可能です!)
これが最後の演習なので、コードとデータ サイエンスの作業が少し多くなります。
ファインチューニングに関する追加情報
Xception は、tf.keras.application.* の標準の事前トレーニング済みモデルで使用できます。今回はすべての重みをトレーニング可能にすることを忘れないでください。
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
モデルをファインチューニングして良好な結果を得るには、学習率に注意し、立ち上げ期間のある学習率スケジュールを使用する必要があります。この場合、次のように指定します。

標準の学習率で開始すると、モデルの事前トレーニング済みの重みが中断されます。プログレッシブ スタートでは、モデルがデータにラッチして、それらを適切な方法で変更できるようになるまで、それらが保持されます。ランプアップ後、学習率を一定に保つか、指数関数的に減衰させることができます。
Keras では、各エポックの適切な学習率を計算できるコールバックで学習率を指定します。Keras は、各エポックの正しい学習率をオプティマイザーに渡します。
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
ソリューション
ソリューション ノートブックは次のとおりです。行き詰まった場合は、こちらをご利用ください。
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
学習した内容
- 🤔 深度分離畳み込み
- 🤓 学習率のスケジュール
- 😈 事前トレーニング済みモデルのファインチューニング。
このチェックリストを頭の中で確認してください。
9. 完了
最初の最新の畳み込みニューラル ネットワークを構築し、TPU のおかげで数分で連続するトレーニングを繰り返し、90% 以上の精度でトレーニングしました。これで、4 つの「TPU での Keras Codelab」は終了です。
- TPU スピードのデータ パイプライン: tf.data.Dataset と TFRecords
- 転移学習を使用した最初の Keras モデル
- Keras と TPU を使用した畳み込みニューラル ネットワーク
- [このラボ] Keras と TPU を使用した最新の convnets、squeezenet、Xception
TPU の実践
TPU と GPU は Cloud AI Platform で使用できます。
- Deep Learning VM の場合
- AI Platform Notebooks で
- AI Platform Training ジョブの場合
最後に、皆様のフィードバックをお待ちしています。このラボで不具合が見つかった場合や、改善すべき点があると思われる場合は、お知らせください。フィードバックは GitHub の問題 [フィードバック リンク] から送信できます。

|

