
1. Übersicht
In diesem Lab erfahren Sie, wie Sie mit Keras und TensorFlow 2 Ihre eigenen Convolutional Neural Networks erstellen, trainieren und optimieren. Mit TPUs dauert das nur noch wenige Minuten. Sie werden auch verschiedene Ansätze kennenlernen, vom einfachen Transfer Learning bis hin zu modernen Convolutional-Architekturen wie SqueezeNet. Dieses Lab enthält theoretische Erklärungen zu neuronalen Netzwerken und ist ein guter Ausgangspunkt für Entwickler, die mehr über Deep Learning erfahren möchten.
Das Lesen von Deep-Learning-Dokumenten kann schwierig und verwirrend sein. Sehen wir uns moderne Convolutional Neural Network-Architekturen an.

Lerninhalte
- Keras und Tensor Processing Units (TPUs) verwenden, um benutzerdefinierte Modelle schneller zu erstellen.
- Die tf.data.Dataset API und das TFRecord-Format verwenden, um Trainingsdaten effizient zu laden.
- Um zu schummeln 😈, können Sie Transfer Learning verwenden, anstatt eigene Modelle zu erstellen.
- Um sequentielle und funktionale Keras-Modellstile zu verwenden.
- Einen eigenen Keras-Klassifikator mit einer Softmax-Schicht und Cross-Entropy-Verlust erstellen.
- Das Modell mit einer guten Auswahl an Faltungsebenen feinabzustimmen.
- Moderne Ideen für ConvNet-Architekturen wie Module und Global Average Pooling ausprobieren
- Ein einfaches modernes ConvNet mit der SqueezeNet-Architektur erstellen.
Feedback
Wenn Sie in diesem Codelab etwas Ungewöhnliches sehen, teilen Sie uns dies bitte mit. Feedback kann über GitHub-Probleme [ Feedback-Link] gegeben werden.
2. Google Colaboratory – Kurzanleitung
In diesem Lab wird Google Colaboratory verwendet. Sie müssen nichts einrichten. Sie können es auf einem Chromebook ausführen. Öffnen Sie die Datei unten und führen Sie die Zellen aus, um sich mit Colab-Notebooks vertraut zu machen.
TPU-Backend auswählen

Wählen Sie im Colab-Menü Laufzeit > Laufzeittyp ändern und dann „TPU“ aus. In diesem Codelab verwenden Sie eine leistungsstarke TPU (Tensor Processing Unit) für hardwarebeschleunigtes Training. Die Verbindung zur Laufzeit erfolgt bei der ersten Ausführung automatisch. Sie können aber auch die Schaltfläche „Verbinden“ rechts oben verwenden.
Notebook-Ausführung

Führen Sie die Zellen einzeln aus, indem Sie auf eine Zelle klicken und UMSCHALTTASTE + EINGABETASTE drücken. Sie können das gesamte Notebook auch mit Laufzeit > Alle ausführen ausführen.
Inhaltsverzeichnis

Alle Notebooks haben ein Inhaltsverzeichnis. Sie können sie über den schwarzen Pfeil auf der linken Seite öffnen.
Ausgeblendete Zellen

Bei einigen Zellen wird nur der Titel angezeigt. Dies ist eine Colab-spezifische Notebook-Funktion. Sie können doppelt darauf klicken, um den Code zu sehen, aber das ist in der Regel nicht sehr interessant. Sie unterstützen in der Regel Support- oder Visualisierungsfunktionen. Sie müssen diese Zellen weiterhin ausführen, damit die Funktionen darin definiert werden.
Authentifizierung

Colab kann auf Ihre privaten Google Cloud Storage-Buckets zugreifen, sofern Sie sich mit einem autorisierten Konto authentifizieren. Das obige Code-Snippet löst einen Authentifizierungsprozess aus.
3. [INFO] Was sind Tensor Processing Units (TPUs)?
Kurz zusammengefasst

Der Code zum Trainieren eines Modells auf einer TPU in Keras (mit Fallback auf GPU oder CPU, wenn keine TPU verfügbar ist):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Wir verwenden heute TPUs, um einen Blumenklassifikator in interaktiver Geschwindigkeit (Minuten pro Trainingslauf) zu erstellen und zu optimieren.

Warum TPUs?
Moderne GPUs sind um programmierbare „Cores“ herum organisiert. Diese sehr flexible Architektur ermöglicht es ihnen, eine Vielzahl von Aufgaben wie 3D-Rendering, Deep Learning und physikalische Simulationen zu bewältigen. TPUs hingegen kombinieren einen klassischen Vektorprozessor mit einer dedizierten Matrixmultiplikationseinheit und eignen sich hervorragend für alle Aufgaben, bei denen große Matrixmultiplikationen dominieren, z. B. neuronale Netze.

Abbildung: Eine dichte Ebene eines neuronalen Netzwerks als Matrixmultiplikation, bei der ein Batch von acht Bildern gleichzeitig durch das neuronale Netzwerk verarbeitet wird. Führen Sie eine Zeile-mal-Spalte-Multiplikation durch, um zu prüfen, ob tatsächlich eine gewichtete Summe aller Pixelwerte eines Bildes berechnet wird. Auch Faltungsebenen können als Matrixmultiplikationen dargestellt werden, obwohl das etwas komplizierter ist ( weitere Informationen finden Sie hier im Abschnitt 1).
Die Hardware
MXU und VPU
Ein TPU v2-Kern besteht aus einer Matrix Multiply Unit (MXU), die Matrixmultiplikationen ausführt, und einer Vector Processing Unit (VPU) für alle anderen Aufgaben wie Aktivierungen, Softmax usw. Die VPU verarbeitet float32- und int32-Berechnungen. Die MXU hingegen arbeitet in einem gemischten 16-32-Bit-Gleitkommaformat.
Gleitkommawerte mit gemischter Precision und bfloat16
Die MXU berechnet Matrixmultiplikationen mit bfloat16-Eingaben und float32-Ausgaben. Zwischensummen werden mit float32-Genauigkeit berechnet.

Das Training neuronaler Netzwerke ist in der Regel resistent gegenüber dem Rauschen, das durch eine reduzierte Gleitkommazahlgenauigkeit entsteht. In einigen Fällen kann Rauschen sogar dazu beitragen, dass der Optimierer konvergiert. Die 16‑Bit-Gleitkommazahl-Genauigkeit wurde traditionell verwendet, um Berechnungen zu beschleunigen. Die float16- und float32-Formate haben jedoch sehr unterschiedliche Bereiche. Wenn Sie die Genauigkeit von float32 auf float16 reduzieren, kommt es in der Regel zu Über- und Unterläufen. Es gibt Lösungen, aber in der Regel ist zusätzlicher Aufwand erforderlich, um float16 zu verwenden.
Aus diesem Grund hat Google das bfloat16-Format in TPUs eingeführt. bfloat16 ist ein abgeschnittenes float32 mit genau denselben Exponentenbits und demselben Bereich wie float32. Da TPUs Matrixmultiplikationen in gemischter Präzision mit bfloat16-Eingaben, aber float32-Ausgaben berechnen, sind in der Regel keine Codeänderungen erforderlich, um von den Leistungssteigerungen durch die reduzierte Präzision zu profitieren.
Systolic array (Systolisches Array)
Die MXU implementiert Matrixmultiplikationen in Hardware mithilfe einer sogenannten „systolischen Array“-Architektur, in der Daten durch ein Array von Hardware-Recheneinheiten fließen. In der Medizin bezieht sich „systolisch“ auf Herzkontraktionen und den Blutfluss, hier auf den Datenfluss.
Das grundlegende Element einer Matrixmultiplikation ist ein Skalarprodukt zwischen einer Zeile aus einer Matrix und einer Spalte aus der anderen Matrix (siehe Abbildung oben in diesem Abschnitt). Bei einer Matrixmultiplikation Y=X*W wäre ein Element des Ergebnisses:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
Auf einer GPU würde man dieses Skalarprodukt in einen GPU-„Kern“ programmieren und es dann auf so vielen „Kernen“ wie möglich parallel ausführen, um jeden Wert der resultierenden Matrix gleichzeitig zu berechnen. Wenn die resultierende Matrix 128 × 128 groß ist, wären 128 × 128=16.000 „Kerne“ erforderlich, was in der Regel nicht möglich ist. Die größten GPUs haben etwa 4.000 Kerne. Eine TPU hingegen verwendet das absolute Minimum an Hardware für die Recheneinheiten in der MXU: nur bfloat16 x bfloat16 => float32 Multiply-Accumulators, nichts anderes. Sie sind so klein, dass eine TPU 16.000 davon in einer 128 × 128 MXU implementieren und diese Matrixmultiplikation in einem Durchgang verarbeiten kann.

Abbildung: Das systolische MXU-Array. Die Recheneinheiten sind Multiplikationsakkumulatoren. Die Werte einer Matrix werden in das Array geladen (rote Punkte). Die Werte der anderen Matrix fließen durch das Array (graue Punkte). Vertikale Linien übertragen die Werte nach oben. Horizontale Linien übertragen Teilergebnisse. Es bleibt dem Nutzer überlassen, zu überprüfen, ob das Ergebnis der Matrixmultiplikation auf der rechten Seite ausgegeben wird, wenn die Daten durch das Array fließen.
Außerdem werden die Zwischensummen, während die Punktprodukte in einer MXU berechnet werden, einfach zwischen benachbarten Recheneinheiten übertragen. Sie müssen nicht im Arbeitsspeicher oder in einer Registerdatei gespeichert und abgerufen werden. Das Ergebnis ist, dass die TPU-Architektur mit systolischen Arrays bei der Berechnung von Matrixmultiplikationen einen erheblichen Vorteil in Bezug auf Dichte und Stromverbrauch sowie einen nicht unerheblichen Geschwindigkeitsvorteil gegenüber einer GPU bietet.
Cloud TPU
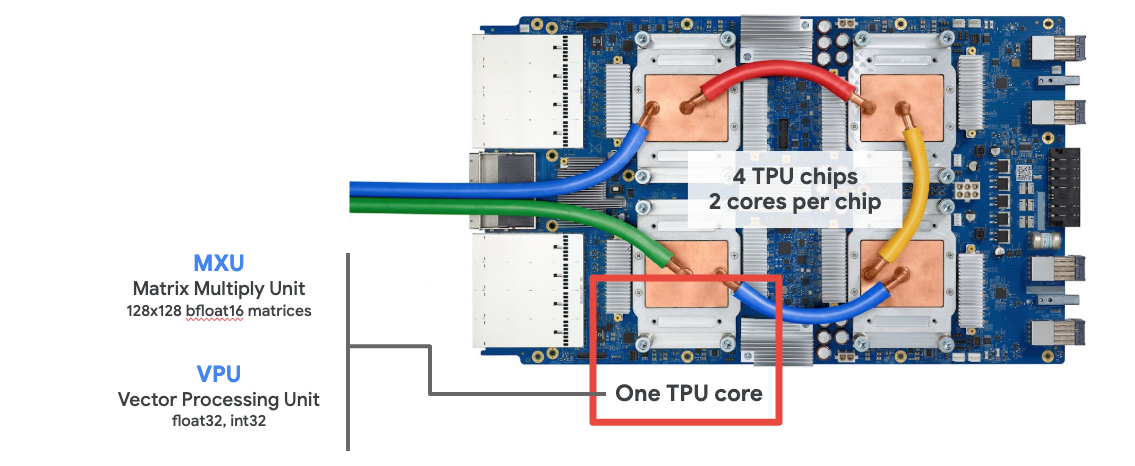
Wenn Sie eine Cloud TPU v2 auf Google Cloud Platform anfordern, erhalten Sie eine virtuelle Maschine (VM) mit einer über PCI angeschlossenen TPU-Karte. Das TPU-Board hat vier Dual-Core-TPU-Chips. Jeder TPU-Kern hat eine VPU (Vector Processing Unit) und eine 128 × 128 MXU (MatriX Multiply Unit). Diese „Cloud TPU“ wird dann in der Regel über das Netzwerk mit der VM verbunden, die sie angefordert hat. Das vollständige Bild sieht so aus:

Abbildung: Ihre VM mit einem netzwerkgebundenen „Cloud TPU“-Beschleuniger. Die Cloud TPU selbst besteht aus einer VM mit einem PCI-angebundenen TPU-Board mit vier Dual-Core-TPU-Chips.
TPU-Pods
In den Rechenzentren von Google sind TPUs mit einem HPC-Interconnect (High Performance Computing, Hochleistungs-Computing) verbunden, wodurch sie als ein sehr großer Beschleuniger erscheinen können. Google bezeichnet sie als Pods. Sie können bis zu 512 TPU v2-Kerne oder 2.048 TPU v3-Kerne umfassen.

Abbildung: TPU v3-Pod. TPU-Boards und ‑Racks, die über HPC-Interconnect-Verbindungen verbunden sind.
Während des Trainings werden Gradienten zwischen TPU-Kernen mit dem All-Reduce-Algorithmus ausgetauscht ( gute Erklärung von All-Reduce). Das trainierte Modell kann die Hardware nutzen, indem es mit großen Batchgrößen trainiert wird.

Abbildung: Synchronisierung von Gradienten während des Trainings mit dem All-Reduce-Algorithmus im zweidimensionalen toroidförmigen Mesh-HPC-Netzwerk von Google TPU.
Die Software
Training mit großer Batchgröße
Die ideale Batchgröße für TPUs beträgt 128 Datenelemente pro TPU-Kern. Die Hardware kann jedoch bereits ab 8 Datenelementen pro TPU-Kern gut genutzt werden. Eine Cloud TPU hat 8 Kerne.
In diesem Codelab verwenden wir die Keras API. In Keras ist der von Ihnen angegebene Batch die globale Batchgröße für die gesamte TPU. Ihre Batches werden automatisch in 8 Teile aufgeteilt und auf den 8 Kernen der TPU ausgeführt.

Weitere Tipps zur Leistung finden Sie im Leistungsleitfaden für Cloud TPU. Bei sehr großen Batchgrößen ist bei einigen Modellen besondere Vorsicht geboten. Weitere Informationen finden Sie unter LARSOptimizer.
Im Detail: XLA
In TensorFlow-Programmen werden Berechnungsgraphen definiert. Die TPU führt keinen Python-Code direkt aus, sondern den Berechnungsgraphen, der von Ihrem TensorFlow-Programm definiert wird. Im Hintergrund wird ein Compiler namens XLA (Accelerated Linear Algebra Compiler) verwendet, um den TensorFlow-Graphen mit Berechnungs-Nodes in TPU-Maschinencode zu transformieren. Dieser Compiler führt auch viele erweiterte Optimierungen an Ihrem Code und Ihrem Speicherlayout durch. Die Kompilierung erfolgt automatisch, wenn Arbeit an die TPU gesendet wird. Sie müssen XLA nicht explizit in Ihre Build-Kette aufnehmen.

Abbildung: Damit der von Ihrem TensorFlow-Programm definierte Berechnungsgraph auf einer TPU ausgeführt werden kann, wird er zuerst in eine XLA-Darstellung (Accelerated Linear Algebra Compiler) übersetzt und dann von XLA in TPU-Maschinencode kompiliert.
TPUs in Keras verwenden
TPUs werden ab Tensorflow 2.1 über die Keras API unterstützt. Die Keras-Unterstützung funktioniert auf TPUs und TPU-Pods. Hier ist ein Beispiel, das auf TPU, GPU(s) und CPU funktioniert:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
In diesem Code-Snippet gilt:
- Mit
TPUClusterResolver().connect()wird die TPU im Netzwerk gefunden. Es funktioniert ohne Parameter auf den meisten Google Cloud-Systemen (AI Platform-Jobs, Colaboratory, Kubeflow, Deep Learning-VMs, die mit dem Tool „ctpu up“ erstellt wurden). Diese Systeme wissen, wo sich ihre TPU befindet, da sie eine Umgebungsvariable namens TPU_NAME haben. Wenn Sie eine TPU manuell erstellen, legen Sie entweder die Umgebungsvariable TPU_NAME auf der VM fest, von der aus Sie sie verwenden, oder rufen SieTPUClusterResolvermit expliziten Parametern auf:TPUClusterResolver(tp_uname, zone, project) TPUStrategyist der Teil, der die Verteilung und den „All-Reduce“-Algorithmus zur Gradientensynchronisierung implementiert.- Die Strategie wird über einen Bereich angewendet. Das Modell muss im Bereich der Strategie definiert werden.
- Die Funktion
tpu_model.fiterwartet für das TPU-Training ein tf.data.Dataset-Objekt als Eingabe.
Häufige Aufgaben beim Portieren auf TPUs
- Es gibt viele Möglichkeiten, Daten in ein TensorFlow-Modell zu laden. Für TPUs ist jedoch die Verwendung der
tf.data.DatasetAPI erforderlich. - TPUs sind sehr schnell und die Aufnahme von Daten wird oft zum Engpass, wenn sie verwendet werden. Im Leistungsleitfaden für Cloud TPU finden Sie Tools, mit denen Sie Datenengpässe erkennen können, sowie weitere Leistungstipps.
- int8- oder int16-Zahlen werden als int32 behandelt. Die TPU hat keine Hardware für Ganzzahlen, die mit weniger als 32 Bit arbeitet.
- Einige TensorFlow-Vorgänge werden nicht unterstützt. Die Liste finden Sie hier. Diese Einschränkung gilt nur für den Trainingscode, d.h. für den Vorwärts- und Rückwärtsdurchlauf durch Ihr Modell. Sie können weiterhin alle TensorFlow-Operationen in Ihrer Dateneingabe-Pipeline verwenden, da sie auf der CPU ausgeführt werden.
tf.py_funcwird auf TPUs nicht unterstützt.
4. Daten werden geladen






Wir arbeiten mit einem Dataset von Blumenbildern. Das Ziel ist, sie in fünf Blumentypen zu kategorisieren. Das Laden von Daten erfolgt über die tf.data.Dataset API. Sehen wir uns zuerst die API an.
Praxisorientiert
Öffnen Sie das folgende Notebook, führen Sie die Zellen aus (Umschalt + EINGABETASTE) und folgen Sie der Anleitung, wenn Sie das Label „WORK REQUIRED“ sehen.

Fun with tf.data.Dataset (playground).ipynb
Weitere Informationen
Dataset „Blumen“
Der Datensatz ist in 5 Ordner unterteilt. Jeder Ordner enthält Blumen einer Art. Die Ordner heißen „sunflowers“, „daisy“, „dandelion“, „tulips“ und „roses“. Die Daten werden in einem öffentlichen Bucket in Google Cloud Storage gehostet. Auszug:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
Warum tf.data.Dataset?
Keras und TensorFlow akzeptieren Datasets in allen ihren Trainings- und Bewertungsfunktionen. Sobald Sie Daten in ein Dataset geladen haben, bietet die API alle gängigen Funktionen, die für Trainingsdaten für neuronale Netze nützlich sind:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
In diesem Artikel finden Sie Tipps zur Leistung und Best Practices für Datasets. Die Referenzdokumentation finden Sie hier.
Grundlagen von tf.data.Dataset
Daten werden in der Regel in mehreren Dateien bereitgestellt, hier in Bildern. Sie können ein Dataset mit Dateinamen erstellen, indem Sie Folgendes aufrufen:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
Anschließend „ordnen“ Sie jedem Dateinamen eine Funktion zu, mit der die Datei in der Regel geladen und in tatsächliche Daten im Arbeitsspeicher decodiert wird:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
So iterieren Sie ein Dataset:
for data in my_dataset:
print(data)
Datasets mit Tupeln
Beim überwachten Lernen besteht ein Trainings-Dataset in der Regel aus Paaren von Trainingsdaten und richtigen Antworten. Dazu kann die Decodierungsfunktion Tupel zurückgeben. Sie haben dann ein Dataset mit Tupeln, die zurückgegeben werden, wenn Sie es durchlaufen. Die zurückgegebenen Werte sind TensorFlow-Tensoren, die von Ihrem Modell verwendet werden können. Sie können .numpy() für sie aufrufen, um Rohwerte zu sehen:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
Fazit:Das Laden von Bildern einzeln ist langsam.
Wenn Sie dieses Dataset durchlaufen, werden Sie feststellen, dass Sie etwa 1–2 Bilder pro Sekunde laden können. Das ist zu langsam. Die Hardwarebeschleuniger, die wir für das Training verwenden, können ein Vielfaches dieser Rate bewältigen. Im nächsten Abschnitt erfahren Sie, wie wir das erreichen.
Lösung
Hier finden Sie das Notebook mit der Lösung. Sie können es verwenden, wenn Sie nicht weiterkommen.
Fun with tf.data.Dataset (solution).ipynb
Behandelte Themen
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 Datasets mit Tupeln
- 😀 Datasets durchlaufen
Bitte gehen Sie diese Checkliste kurz durch.
5. Daten schnell laden
Die Hardwarebeschleuniger vom Typ Tensor Processing Unit (TPU), die wir in diesem Lab verwenden, sind sehr schnell. Die Herausforderung besteht oft darin, sie schnell genug mit Daten zu versorgen, damit sie beschäftigt bleiben. Google Cloud Storage (GCS) kann einen sehr hohen Durchsatz aufrechterhalten. Wie bei allen Cloud-Speichersystemen kostet das Herstellen einer Verbindung jedoch etwas Netzwerkverkehr. Daher ist es nicht ideal, wenn unsere Daten als Tausende von einzelnen Dateien gespeichert werden. Wir fassen sie in einer kleineren Anzahl von Dateien zusammen und nutzen die Leistungsfähigkeit von tf.data.Dataset, um parallel aus mehreren Dateien zu lesen.
Durchlesen
Der Code, mit dem Bilddateien geladen, auf eine gemeinsame Größe angepasst und dann in 16 TFRecord-Dateien gespeichert werden, befindet sich im folgenden Notebook. Bitte lesen Sie sie kurz durch. Die Ausführung ist nicht erforderlich, da für den Rest des Codelabs korrekt im TFRecord-Format formatierte Daten bereitgestellt werden.
Flower pictures to TFRecords.ipynb
Ideales Datenlayout für optimalen GCS-Durchsatz
Das TFRecord-Dateiformat
Das bevorzugte Dateiformat von TensorFlow zum Speichern von Daten ist das protobuf-basierte TFRecord-Format. Andere Serialisierungsformate sind ebenfalls möglich. Sie können ein Dataset jedoch direkt aus TFRecord-Dateien laden, indem Sie Folgendes schreiben:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Für eine optimale Leistung wird empfohlen, den folgenden komplexeren Code zu verwenden, um gleichzeitig aus mehreren TFRecord-Dateien zu lesen. Mit diesem Code wird parallel aus N Dateien gelesen. Die Datenreihenfolge wird zugunsten der Lesegeschwindigkeit ignoriert.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
TFRecord-Übersicht
In TFRecords können drei Arten von Daten gespeichert werden: Byte-Strings (Liste von Bytes), 64-Bit-Ganzzahlen und 32-Bit-Gleitkommazahlen. Sie werden immer als Listen gespeichert. Ein einzelnes Datenelement ist eine Liste mit der Größe 1. Mit den folgenden Hilfsfunktionen können Sie Daten in TFRecords speichern.
Bytestrings schreiben
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
Ganzzahlen schreiben
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
Gleitkommazahlen schreiben
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
TFRecord schreiben – mit den oben genannten Hilfsfunktionen
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
Wenn Sie Daten aus TFRecords lesen möchten, müssen Sie zuerst das Layout der gespeicherten Datensätze deklarieren. In der Deklaration können Sie auf jedes benannte Feld als Liste mit fester oder variabler Länge zugreifen:
Aus TFRecords lesen
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
Nützliche Code-Snippets:
einzelne Datenelemente lesen
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
Lesen von Listen mit fester Größe
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
Lesen einer variablen Anzahl von Datenelementen
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
Eine VarLenFeature gibt einen spärlichen Vektor zurück. Nach dem Decodieren des TFRecord ist ein zusätzlicher Schritt erforderlich:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
TFRecords können auch optionale Felder enthalten. Wenn Sie beim Lesen eines Felds einen Standardwert angeben, wird dieser zurückgegeben, wenn das Feld fehlt, anstatt ein Fehler.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
Behandelte Themen
- 🤔 Daten in Dateien aufteilen, um schnell über GCS darauf zuzugreifen
- 😓 TFRecords schreiben. Sie haben die Syntax bereits vergessen? Kein Problem. Setzen Sie ein Lesezeichen für diese Seite, damit Sie sie als Spickzettel verwenden können.
- 🤔 Dataset aus TFRecords mit TFRecordDataset laden
Bitte gehen Sie diese Checkliste kurz durch.
6. [INFO] Klassifikator mit neuronalem Netzwerk – Einführung
Kurz zusammengefasst
Wenn Sie alle fett gedruckten Begriffe im nächsten Absatz bereits kennen, können Sie mit der nächsten Übung fortfahren. Wenn Sie gerade erst mit Deep Learning beginnen, sind Sie hier genau richtig.
Für Modelle, die als Folge von Layern erstellt wurden, bietet Keras die Sequential API. Ein Bildklassifikator mit drei dichten Layern kann in Keras so geschrieben werden:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
Dichtes neuronales Netzwerk
Dies ist das einfachste neuronale Netzwerk für die Klassifizierung von Bildern. Es besteht aus „Neuronen“, die in Schichten angeordnet sind. Die erste Ebene verarbeitet Eingabedaten und leitet die Ausgaben an andere Ebenen weiter. Sie wird als „dicht“ bezeichnet, weil jedes Neuron mit allen Neuronen in der vorherigen Schicht verbunden ist.

Sie können ein Bild in ein solches Netzwerk einfügen, indem Sie die RGB-Werte aller Pixel in einen langen Vektor umwandeln und als Eingaben verwenden. Es ist nicht die beste Technik für die Bilderkennung, aber wir werden sie später verbessern.
Neuronen, Aktivierungen, RELU
Ein „Neuron“ berechnet eine gewichtete Summe aller seiner Eingaben, addiert einen Wert namens „Bias“ und leitet das Ergebnis durch eine sogenannte „Aktivierungsfunktion“. Die Gewichte und der Bias sind anfangs unbekannt. Sie werden zufällig initialisiert und durch das Trainieren des neuronalen Netzwerks mit vielen bekannten Daten „gelernt“.

Die beliebteste Aktivierungsfunktion ist RELU (Rectified Linear Unit). Wie Sie im Diagramm oben sehen, ist es eine sehr einfache Funktion.
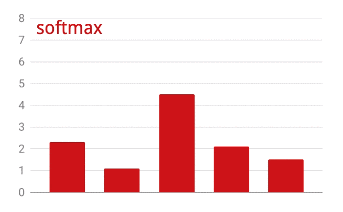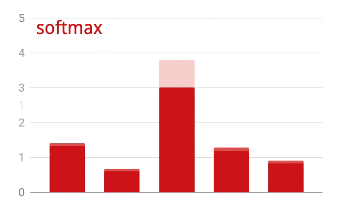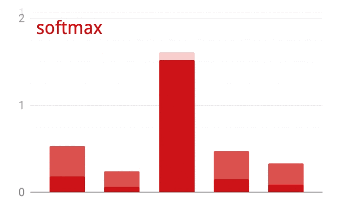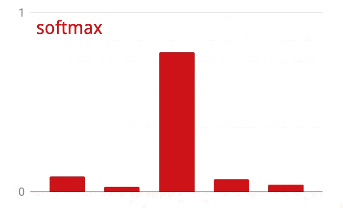
Softmax-Aktivierung
Das oben gezeigte Netzwerk endet mit einer Schicht mit 5 Neuronen, da wir Blumen in 5 Kategorien klassifizieren (Rose, Tulpe, Löwenzahn, Gänseblümchen, Sonnenblume). Neuronen in Zwischenschichten werden mit der klassischen ReLU-Aktivierungsfunktion aktiviert. In der letzten Schicht möchten wir jedoch Zahlen zwischen 0 und 1 berechnen, die die Wahrscheinlichkeit darstellen, dass es sich bei dieser Blume um eine Rose, eine Tulpe usw. handelt. Dazu verwenden wir eine Aktivierungsfunktion namens „Softmax“.
Um Softmax auf einen Vektor anzuwenden, wird von jedem Element die Exponentialfunktion gebildet und der Vektor dann normalisiert, in der Regel mit der L1-Norm (Summe der Absolutwerte), sodass die Werte sich zu 1 addieren und als Wahrscheinlichkeiten interpretiert werden können.

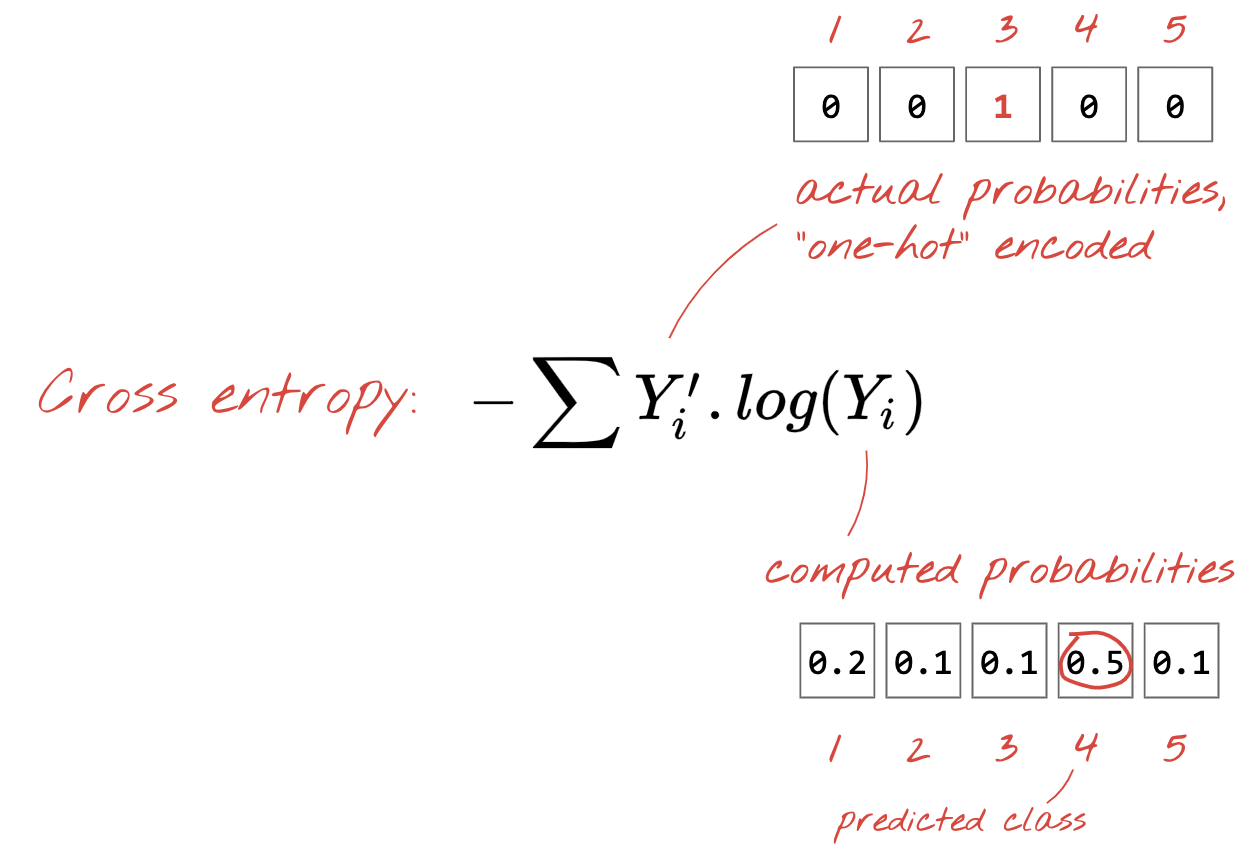
Cross-Entropy Loss
Nachdem unser neuronales Netzwerk Vorhersagen aus Eingabebildern generiert, müssen wir messen, wie gut diese sind. Das heißt, wir müssen den Abstand zwischen dem, was das Netzwerk uns sagt, und den richtigen Antworten, oft als „Labels“ bezeichnet, ermitteln. Wir haben die richtigen Labels für alle Bilder im Dataset.
Jede Distanz würde funktionieren, aber für Klassifizierungsprobleme ist die sogenannte „Kreuzentropie-Distanz“ am effektivsten. Wir nennen dies unsere Fehler- oder Verlustfunktion:
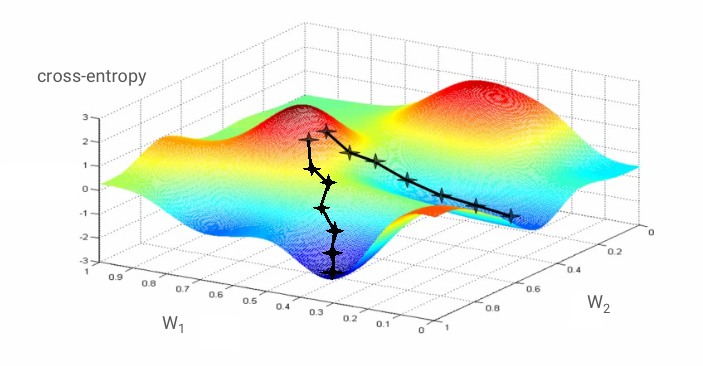
Gradientenabstieg
Das „Trainieren“ des neuronalen Netzwerks bedeutet, dass Trainingsbilder und ‑labels verwendet werden, um Gewichte und Bias so anzupassen, dass die Cross-Entropy-Verlustfunktion minimiert wird. So funktioniert es:
Die Kreuzentropie ist eine Funktion von Gewichten, Bias, Pixeln des Trainingsbilds und seiner bekannten Klasse.
Wenn wir die partiellen Ableitungen der Kreuzentropie in Bezug auf alle Gewichte und alle Bias berechnen, erhalten wir einen „Gradienten“, der für ein bestimmtes Bild, Label und den aktuellen Wert der Gewichte und Bias berechnet wird. Da wir Millionen von Gewichten und Bias haben können, klingt die Berechnung des Gradienten nach viel Arbeit. Glücklicherweise übernimmt Tensorflow diese Aufgabe für uns. Die mathematische Eigenschaft eines Gradienten ist, dass er „nach oben“ zeigt. Da wir dorthin gehen möchten, wo die Kreuzentropie niedrig ist, gehen wir in die entgegengesetzte Richtung. Wir aktualisieren Gewichte und Bias um einen Bruchteil des Gradienten. Das wiederholen wir dann immer wieder mit den nächsten Batches von Trainingsbildern und ‑Labels in einer Trainingsschleife. Im Idealfall wird ein Punkt erreicht, an dem die Kreuzentropie minimal ist. Es gibt jedoch keine Garantie dafür, dass dieses Minimum eindeutig ist.
Mini-Batching und Momentum
Sie können den Gradienten für nur ein Beispielbild berechnen und die Gewichte und Bias sofort aktualisieren. Wenn Sie dies jedoch für einen Batch von z. B. 128 Bildern tun, erhalten Sie einen Gradienten, der die Einschränkungen durch verschiedene Beispielbilder besser repräsentiert und daher wahrscheinlich schneller zur Lösung konvergiert. Die Größe des Mini-Batch ist ein anpassbarer Parameter.
Diese Technik, die manchmal auch als „stochastic gradient descent“ (stochastischer Gradientenabstieg) bezeichnet wird, hat einen weiteren, pragmatischeren Vorteil: Die Arbeit mit Batches bedeutet auch die Arbeit mit größeren Matrizen, die sich in der Regel leichter auf GPUs und TPUs optimieren lassen.
Die Konvergenz kann jedoch immer noch etwas chaotisch sein und sogar stoppen, wenn der Gradientenvektor nur Nullen enthält. Bedeutet das, dass wir ein Minimum gefunden haben? Nimmt immer. Eine Gradientenkomponente kann an einem Minimum oder Maximum null sein. Bei einem Gradientenvektor mit Millionen von Elementen ist die Wahrscheinlichkeit, dass alle Nullen einem Minimum und keine einem Maximum entsprechen, ziemlich gering. In einem Raum mit vielen Dimensionen sind Sattelpunkte ziemlich häufig und wir möchten nicht an ihnen anhalten.

Abbildung: Sattelpunkt. Der Gradient ist 0, aber es handelt sich nicht in allen Richtungen um ein Minimum. (Bildnachweis: Wikimedia: Von Nicoguaro – Eigene Arbeit, CC BY 3.0)
Die Lösung besteht darin, dem Optimierungsalgorithmus etwas Schwung zu verleihen, damit er Sattelpunkte ohne anzuhalten überwinden kann.
Glossar
Batch oder Mini-Batch: Das Training erfolgt immer mit Batches von Trainingsdaten und Labels. Das hilft dem Algorithmus, zu konvergieren. Die Dimension „Batch“ ist in der Regel die erste Dimension von Datentensoren. Ein Tensor mit der Form [100, 192, 192, 3] enthält beispielsweise 100 Bilder mit 192 × 192 Pixeln und drei Werten pro Pixel (RGB).
Kreuzentropie-Verlust: Eine spezielle Verlustfunktion, die häufig in Klassifizierern verwendet wird.
Dense Layer (dichte Schicht): Eine Schicht von Neuronen, in der jedes Neuron mit allen Neuronen in der vorherigen Schicht verbunden ist.
Features: Die Eingaben eines neuronalen Netzwerks werden manchmal als „Features“ bezeichnet. Die Kunst, herauszufinden, welche Teile eines Datasets (oder Kombinationen von Teilen) in ein neuronales Netzwerk eingegeben werden müssen, um gute Vorhersagen zu erhalten, wird als „Feature-Engineering“ bezeichnet.
Labels: ein anderer Name für „Klassen“ oder richtige Antworten in einem überwachten Klassifizierungsproblem
Lernrate: Der Bruchteil des Gradienten, um den Gewichte und Bias bei jeder Iteration der Trainingsschleife aktualisiert werden.
Logits: Die Ausgaben einer Neuronen-Schicht, bevor die Aktivierungsfunktion angewendet wird, werden als „Logits“ bezeichnet. Der Begriff stammt von der „logistischen Funktion“ bzw. „Sigmoid-Funktion“, die früher die beliebteste Aktivierungsfunktion war. „Neuron outputs before logistic function“ (Neuronenausgaben vor logistischer Funktion) wurde zu „Logits“ verkürzt.
loss: Die Fehlerfunktion, mit der die Ausgaben des neuronalen Netzwerks mit den richtigen Antworten verglichen werden.
Neuron: Berechnet die gewichtete Summe seiner Eingaben, fügt einen Bias hinzu und leitet das Ergebnis durch eine Aktivierungsfunktion.
One-Hot-Codierung: Die Klasse 3 von 5 wird als Vektor mit 5 Elementen codiert, die alle null sind, mit Ausnahme des dritten Elements, das 1 ist.
relu: Rektifizierte Lineareinheit. Eine beliebte Aktivierungsfunktion für Neuronen.
sigmoid: Eine weitere Aktivierungsfunktion, die früher beliebt war und in Sonderfällen immer noch nützlich ist.
softmax: Eine spezielle Aktivierungsfunktion, die auf einen Vektor angewendet wird, den Unterschied zwischen der größten Komponente und allen anderen erhöht und den Vektor so normalisiert, dass die Summe 1 ergibt. So kann er als Vektor von Wahrscheinlichkeiten interpretiert werden. Wird als letzter Schritt in Klassifikatoren verwendet.
Tensor: Ein Tensor ist wie eine Matrix, aber mit einer beliebigen Anzahl von Dimensionen. Ein eindimensionaler Tensor ist ein Vektor. Ein 2-dimensionaler Tensor ist eine Matrix. Dann können Sie Tensoren mit 3, 4, 5 oder mehr Dimensionen haben.
7. Lerntransfer
Für ein Bildklassifizierungsproblem reichen dichte Ebenen wahrscheinlich nicht aus. Wir müssen etwas über Convolutional Layers und die vielen Möglichkeiten lernen, sie anzuordnen.
Wir können aber auch eine Abkürzung nehmen. Es sind vollständig trainierte Convolutional Neural Networks zum Herunterladen verfügbar. Es ist möglich, die letzte Ebene, den Softmax-Klassifikationskopf, zu entfernen und durch eine eigene zu ersetzen. Alle trainierten Gewichte und Bias bleiben unverändert. Sie trainieren nur die Softmax-Schicht neu, die Sie hinzufügen. Diese Technik wird als Transfer Learning bezeichnet und funktioniert erstaunlicherweise, solange das Dataset, mit dem das neuronale Netzwerk vortrainiert wird, „nah genug“ an Ihrem Dataset ist.
Praxisorientiert
Öffnen Sie das folgende Notebook, führen Sie die Zellen aus (Umschalt + EINGABETASTE) und folgen Sie der Anleitung, wenn Sie das Label „WORK REQUIRED“ sehen.
Keras Flowers transfer learning (playground).ipynb
Weitere Informationen
Beim Transfer Learning profitieren Sie sowohl von fortschrittlichen Architekturen für Convolutional Neural Networks, die von Spitzenforschern entwickelt wurden, als auch vom Vortraining mit einem riesigen Dataset von Bildern. In unserem Fall werden wir das Transfer Learning von einem Netzwerk ausführen, das auf ImageNet trainiert wurde. ImageNet ist eine Bilddatenbank, die viele Pflanzen und Außenszenen enthält, was für Blumen ausreichend ist.

Abbildung: Ein komplexes, bereits trainiertes faltendes neuronales Netzwerk wird als Blackbox verwendet und nur der Klassifikations-Head wird neu trainiert. Das ist Lerntransfer. Wie diese komplizierten Anordnungen von Faltungsebenen funktionieren, sehen wir uns später an. Im Moment ist es das Problem eines anderen.
Lerntransfer in Keras
In Keras können Sie ein vortrainiertes Modell aus der tf.keras.applications.*-Sammlung instanziieren. MobileNet V2 ist beispielsweise eine sehr gute Faltungsarchitektur, die eine angemessene Größe hat. Wenn Sie include_top=False auswählen, erhalten Sie das vortrainierte Modell ohne die letzte Softmax-Schicht, sodass Sie Ihre eigene hinzufügen können:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
Beachten Sie auch die Einstellung pretrained_model.trainable = False. Dabei werden die Gewichte und Bias des vortrainierten Modells eingefroren, sodass nur die Softmax-Schicht trainiert wird. Dazu sind in der Regel relativ wenige Gewichte erforderlich und es kann schnell und ohne sehr großen Datensatz erfolgen. Wenn Sie jedoch viele Daten haben, kann Transfer Learning mit pretrained_model.trainable = True noch besser funktionieren. Die vortrainierten Gewichte bieten dann hervorragende Anfangswerte und können durch das Training noch angepasst werden, um besser zu Ihrem Problem zu passen.
Beachten Sie schließlich die Flatten()-Ebene, die vor der dichten Softmax-Ebene eingefügt wurde. Dichte Ebenen arbeiten mit flachen Datenvektoren, aber wir wissen nicht, ob das vortrainierte Modell diese zurückgibt. Deshalb müssen wir die Hierarchie vereinfachen. Im nächsten Kapitel, in dem wir uns mit faltenden Architekturen befassen, erklären wir das von faltenden Layern zurückgegebene Datenformat.
Mit diesem Ansatz sollten Sie eine Genauigkeit von etwa 75% erreichen.
Lösung
Hier finden Sie das Notebook mit der Lösung. Sie können es verwenden, wenn Sie nicht weiterkommen.
Keras Flowers transfer learning (solution).ipynb
Behandelte Themen
- 🤔 Klassifikator in Keras schreiben
- 🤓 mit einer Softmax-Ausgabeschicht und Cross-Entropy-Verlust konfiguriert
- 😈 Lerntransfer
- 🤔 Erstes Modell trainieren
- 🧐 Verlust und Genauigkeit während des Trainings beobachten
Bitte gehen Sie diese Checkliste kurz durch.
8. [INFO] Convolutional Neural Networks
Kurz zusammengefasst
Wenn Sie alle fett gedruckten Begriffe im nächsten Absatz bereits kennen, können Sie mit der nächsten Übung fortfahren. Wenn Sie gerade erst mit Convolutional Neural Networks beginnen, lesen Sie bitte weiter.

Abbildung: Filtern eines Bildes mit zwei aufeinanderfolgenden Filtern mit jeweils 4 × 4 × 3=48 lernbaren Gewichten.
So sieht ein einfaches Convolutional Neural Network in Keras aus:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
Convolutional Neural Networks 101
In einer Schicht eines faltenden Netzwerks berechnet ein „Neuron“ eine gewichtete Summe der Pixel direkt darüber, und zwar nur in einem kleinen Bereich des Bildes. Es wird ein Bias hinzugefügt und die Summe wird durch eine Aktivierungsfunktion geleitet, genau wie bei einem Neuron in einer regulären dichten Schicht. Dieser Vorgang wird dann mit denselben Gewichten für das gesamte Bild wiederholt. In dichten Schichten hatte jedes Neuron eigene Gewichte. Hier wird ein einzelner „Patch“ von Gewichten in beide Richtungen über das Bild geschoben (eine „Faltung“). Die Ausgabe enthält so viele Werte wie das Bild Pixel hat. An den Rändern ist jedoch etwas Auffüllung erforderlich. Es handelt sich um einen Filtervorgang mit einem Filter von 4 × 4 × 3=48 Gewichten.
48 Gewichte reichen jedoch nicht aus. Um weitere Freiheitsgrade hinzuzufügen, wiederholen wir denselben Vorgang mit einer neuen Gruppe von Gewichten. Dadurch wird eine neue Reihe von Filterausgaben erstellt. Wir nennen sie analog zu den R-, G- und B-Kanälen im Eingabebild einen „Kanal“ von Ausgaben.

Die beiden (oder mehr) Gewichtssätze können als ein Tensor zusammengefasst werden, indem eine neue Dimension hinzugefügt wird. Das ist die allgemeine Form des Gewichtetensors für eine Faltungsschicht. Da die Anzahl der Ein- und Ausgabekanäle Parameter sind, können wir mit dem Stapeln und Verketten von Faltungsschichten beginnen.

Abbildung: Ein Convolutional Neural Network transformiert „Datenwürfel“ in andere „Datenwürfel“.
Strided Convolutions, Max Pooling
Durch die Durchführung der Faltungen mit einem Stride von 2 oder 3 können wir den resultierenden Datenwürfel auch in seinen horizontalen Dimensionen verkleinern. Dafür gibt es zwei gängige Möglichkeiten:
- Strided Convolution: Ein gleitender Filter wie oben, aber mit einem Stride > 1
- Max. Pooling: Ein gleitendes Fenster, das den MAX-Vorgang anwendet (in der Regel auf 2x2-Felder, die alle 2 Pixel wiederholt werden)

Abbildung: Wenn das Berechnungsfenster um 3 Pixel verschoben wird, ergeben sich weniger Ausgabewerte. Strided Convolutions oder Max Pooling (Maximum in einem 2×2-Fenster, das mit einem Schritt von 2 verschoben wird) sind eine Möglichkeit, den Datenwürfel in den horizontalen Dimensionen zu verkleinern.
Konvolutioneller Klassifikator
Schließlich fügen wir einen Klassifikations-Head hinzu, indem wir den letzten Datenwürfel vereinfachen und ihn durch eine dichte, softmax-aktivierte Ebene leiten. Ein typischer faltender Klassifikator kann so aussehen:

Abbildung: Ein Bildklassifizierer mit Faltungs- und Softmax-Ebenen. Es werden 3×3- und 1×1-Filter verwendet. Die Maxpool-Ebenen nehmen das Maximum von Gruppen mit 2 × 2 Datenpunkten. Der Klassifikations-Head wird mit einer dichten Schicht mit Softmax-Aktivierung implementiert.
In Keras
Der oben dargestellte Faltungs-Stack kann in Keras so geschrieben werden:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
9. Ihr benutzerdefiniertes ConvNet
Praxisorientiert
Wir erstellen und trainieren ein Convolutional Neural Network von Grund auf. Mit einer TPU können wir sehr schnell iterieren. Öffnen Sie das folgende Notebook, führen Sie die Zellen aus (Umschalt + EINGABETASTE) und folgen Sie der Anleitung, wenn Sie das Label „WORK REQUIRED“ sehen.
Keras_Flowers_TPU (playground).ipynb
Ziel ist es, die 75% Genauigkeit des Transfer Learning-Modells zu übertreffen. Dieses Modell hatte einen Vorteil, da es mit einem Dataset von Millionen von Bildern vortrainiert wurde, während wir hier nur 3.670 Bilder haben. Kannst du es zumindest anpassen?
Weitere Informationen
Wie viele Schichten und wie groß?
Die Auswahl der Schichtgrößen ist eher eine Kunst als eine Wissenschaft. Sie müssen das richtige Gleichgewicht zwischen zu wenigen und zu vielen Parametern (Gewichtungen und Bias) finden. Bei zu wenigen Gewichten kann das neuronale Netzwerk die Komplexität der Blütenformen nicht darstellen. Bei zu vielen kann es zu einer „Überanpassung“ kommen, d.h. das Modell spezialisiert sich auf die Trainingsbilder und kann nicht verallgemeinern. Bei vielen Parametern dauert das Trainieren des Modells auch länger. In Keras wird mit der Funktion model.summary() die Struktur und die Anzahl der Parameter Ihres Modells angezeigt:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
Ein paar Tipps:
- Die Wirksamkeit von „tiefen“ neuronalen Netzwerken beruht auf der Verwendung mehrerer Schichten. Für dieses einfache Problem der Blumenerkennung sind 5 bis 10 Ebenen sinnvoll.
- Verwenden Sie kleine Filter. In der Regel sind 3 × 3-Filter überall gut geeignet.
- Auch 1×1-Filter können verwendet werden und sind kostengünstig. Sie filtern nicht wirklich etwas, sondern berechnen lineare Kombinationen von Channels. Wechseln Sie zwischen ihnen und echten Filtern. Weitere Informationen zu 1×1-Faltungen finden Sie im nächsten Abschnitt.
- Bei einem solchen Klassifizierungsproblem sollten Sie häufig Downsampling mit Max-Pooling-Layern (oder Faltungen mit Stride > 1) durchführen. Es ist Ihnen egal, wo sich die Blume befindet. Wichtig ist nur, dass es sich um eine Rose oder einen Löwenzahn handelt. Daher ist der Verlust von x- und y-Informationen nicht wichtig und das Filtern kleinerer Bereiche ist kostengünstiger.
- Die Anzahl der Filter ähnelt in der Regel der Anzahl der Klassen am Ende des Netzwerks (warum? siehe den Trick „Global Average Pooling“ unten). Wenn Sie Hunderte von Klassen klassifizieren, erhöhen Sie die Filteranzahl in aufeinanderfolgenden Layern schrittweise. Für den Blumendatensatz mit 5 Klassen reicht das Filtern mit nur 5 Filtern nicht aus. Sie können in den meisten Layern dieselbe Filteranzahl verwenden, z. B. 32, und sie gegen Ende verringern.
- Die letzte(n) Dense-Ebene(n) ist/sind teuer. Sie können mehr Gewichte haben als alle Convolutional-Layer zusammen. Selbst bei einer sehr angemessenen Ausgabe des letzten Datenwürfels mit 24 × 24 × 10 Datenpunkten würde eine dichte Schicht mit 100 Neuronen 24 × 24 × 10 × 100=576.000 Gewichte kosten. Überlegen Sie sich das gut oder verwenden Sie Global Average Pooling (siehe unten).
Global Average Pooling
Anstatt am Ende eines faltenden neuronalen Netzwerks eine rechenintensive dichte Ebene zu verwenden, können Sie den eingehenden Datenwürfel in so viele Teile aufteilen, wie Sie Klassen haben, die Werte mitteln und diese durch eine Softmax-Aktivierungsfunktion leiten. Für diese Art der Erstellung des Klassifikations-Heads sind keine Gewichte erforderlich. In Keras lautet die Syntax tf.keras.layers.GlobalAveragePooling2D().

Lösung
Hier finden Sie das Notebook mit der Lösung. Sie können es verwenden, wenn Sie nicht weiterkommen.
Keras_Flowers_TPU (solution).ipynb
Behandelte Themen
- 🤔 Mit Convolutional Layers experimentiert
- 🤓 Sie haben mit Max-Pooling, Strides, Global Average Pooling usw. experimentiert.
- 😀 Ein reales Modell schnell auf einer TPU iterieren
Bitte gehen Sie diese Checkliste kurz durch.
10. [INFO] Moderne Convolutional-Architekturen
Kurz zusammengefasst

Abbildung: Ein faltendes „Modul“. Was ist jetzt am besten? Eine Max-Pooling-Schicht gefolgt von einer 1×1-Faltungsschicht oder einer anderen Kombination von Schichten? Probieren Sie alle aus, verketten Sie die Ergebnisse und lassen Sie das Netzwerk entscheiden. Rechts: die Inception-Faltungsarchitektur mit solchen Modulen.
In Keras müssen Sie den „funktionalen“ Modellstil verwenden, um Modelle zu erstellen, bei denen der Datenfluss verzweigen kann. Hier ein Beispiel:
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
Andere billige Tricks
Kleine 3×3-Filter
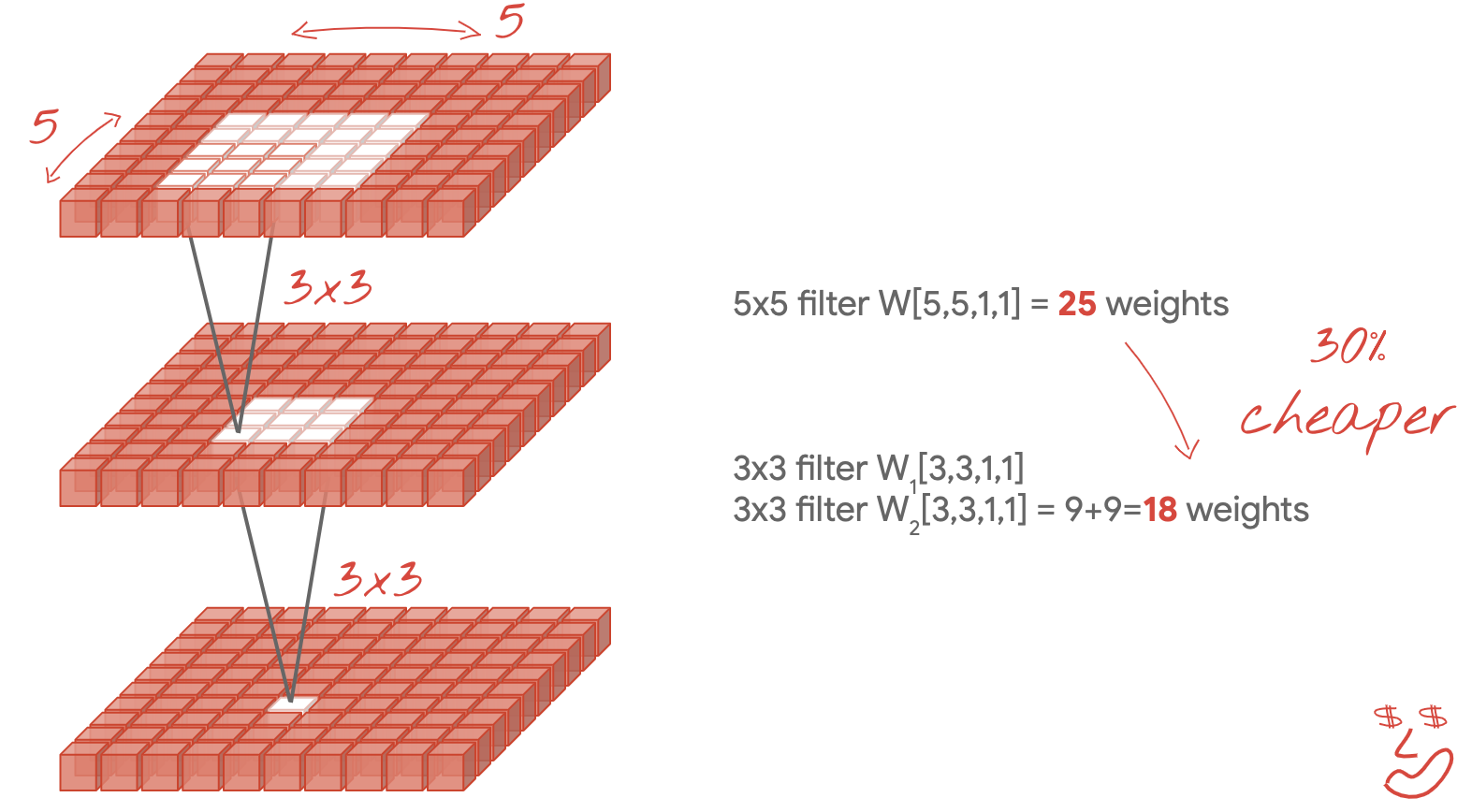
In dieser Abbildung sehen Sie das Ergebnis von zwei aufeinanderfolgenden 3×3-Filtern. Versuchen Sie, nachzuvollziehen, welche Datenpunkte zum Ergebnis beigetragen haben: Diese beiden aufeinanderfolgenden 3×3-Filter berechnen eine Kombination aus einer 5×5-Region. Es ist nicht genau dieselbe Kombination, die ein 5×5-Filter berechnen würde, aber es ist einen Versuch wert, da zwei aufeinanderfolgende 3×3-Filter günstiger sind als ein einzelner 5×5-Filter.
1 × 1-Faltungen

Mathematisch gesehen ist eine „1×1“-Faltung eine Multiplikation mit einer Konstanten, was kein sehr nützliches Konzept ist. Bei faltenden neuronalen Netzen wird der Filter jedoch auf einen Datenwürfel und nicht nur auf ein 2D-Bild angewendet. Bei einem „1x1“-Filter wird also eine gewichtete Summe einer 1x1-Datenspalte berechnet (siehe Abbildung). Wenn Sie den Filter über die Daten schieben, erhalten Sie eine lineare Kombination der Channels der Eingabe. Das ist wirklich nützlich. Wenn Sie sich die Channels als die Ergebnisse einzelner Filtervorgänge vorstellen, z. B. einen Filter für „spitze Ohren“, einen weiteren für „Schnurrhaare“ und einen dritten für „schlitzförmige Augen“, dann berechnet eine „1x1“-Faltungsschicht mehrere mögliche lineare Kombinationen dieser Merkmale, was bei der Suche nach einer „Katze“ hilfreich sein kann. Außerdem werden für 1×1-Ebenen weniger Gewichte verwendet.
11. Squeezenet
Eine einfache Möglichkeit, diese Ideen zu kombinieren, wird im Squeezenet-Paper beschrieben. Die Autoren schlagen ein sehr einfaches Design für das Faltungsmodul vor, das nur 1×1- und 3×3-Faltungsebenen verwendet.

Abbildung: SqueezeNet-Architektur basierend auf „Fire-Modulen“. Sie wechseln sich mit einer 1×1-Schicht ab, die die eingehenden Daten in der vertikalen Dimension „zusammendrückt“, gefolgt von zwei parallelen 1×1- und 3×3-Faltungsschichten, die die Tiefe der Daten wieder „erweitern“.
Praxisorientiert
Fahren Sie mit Ihrem vorherigen Notebook fort und erstellen Sie ein Convolutional Neural Network, das von SqueezeNet inspiriert ist. Sie müssen den Modellcode in den „funktionalen Stil“ von Keras ändern.
Keras_Flowers_TPU (playground).ipynb
Weitere Informationen
Für diese Übung ist es hilfreich, eine Hilfsfunktion für ein SqueezeNet-Modul zu definieren:
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
Dieses Mal ist das Ziel, eine Genauigkeit von 80% zu erreichen.
Das können Sie versuchen
Beginnen Sie mit einer einzelnen Faltungsschicht, gefolgt von „fire_modules“, und wechseln Sie sich mit MaxPooling2D(pool_size=2)-Schichten ab. Sie können mit 2 bis 4 Max-Pooling-Layern im Netzwerk und mit 1, 2 oder 3 aufeinanderfolgenden Fire-Modulen zwischen den Max-Pooling-Layern experimentieren.
In Feuermodulen sollte der Parameter „squeeze“ in der Regel kleiner als der Parameter „expand“ sein. Bei diesen Parametern handelt es sich um die Anzahl der Filter. Sie können in der Regel zwischen 8 und 196 liegen. Sie können Architekturen testen, bei denen die Anzahl der Filter im Netzwerk allmählich zunimmt, oder einfache Architekturen, bei denen alle Fire-Module dieselbe Anzahl von Filtern haben.
Hier ein Beispiel:
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
An diesem Punkt stellen Sie möglicherweise fest, dass Ihre Tests nicht so gut laufen und das Ziel von 80% Genauigkeit in weiter Ferne scheint. Zeit für ein paar weitere Tricks.
Batch-Normalisierung
Die Batch-Normalisierung kann bei den Konvergenzproblemen helfen, die Sie haben. Im nächsten Workshop wird diese Technik ausführlich erläutert. Verwenden Sie sie vorerst als „magischen“ Helfer, indem Sie diese Zeile nach jeder Faltungsschicht in Ihrem Netzwerk hinzufügen, einschließlich der Schichten in der Funktion „fire_module“:
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
Der Momentum-Parameter muss von seinem Standardwert von 0,99 auf 0,9 verringert werden, da unser Dataset klein ist. Lass uns dieses Detail erst einmal ignorieren.
Data Augmentation
Durch die Erweiterung der Daten mit einfachen Transformationen wie dem Spiegeln von links nach rechts oder Änderungen der Sättigung lässt sich die Genauigkeit um einige Prozentpunkte steigern:


Mit der tf.data.Dataset API in TensorFlow ist das ganz einfach. Definieren Sie eine neue Transformationsfunktion für Ihre Daten:
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
Verwenden Sie sie dann in der endgültigen Datentransformation (Zelle „training and validation datasets“, Funktion „get_batched_dataset“):
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
Vergessen Sie nicht, die Datenerweiterung optional zu machen und den erforderlichen Code hinzuzufügen, damit nur der Trainingsdatensatz erweitert wird. Es ist nicht sinnvoll, das Validierungs-Dataset zu erweitern.
Eine Genauigkeit von 80% sollte nach 35 Epochen nun erreichbar sein.
Lösung
Hier finden Sie das Notebook mit der Lösung. Sie können es verwenden, wenn Sie nicht weiterkommen.
Keras_Flowers_TPU_squeezenet.ipynb
Behandelte Themen
- 🤔 Keras-Modelle im „funktionalen Stil“
- 🤓 SqueezeNet-Architektur
- 🤓 Data Augmentation mit tf.data.dataset
Bitte gehen Sie diese Checkliste kurz durch.
12. Xception-Modell mit Feinabstimmung
Separable Convolutions
Eine andere Art der Implementierung von Convolutional Layers hat in letzter Zeit an Popularität gewonnen: die tiefenseparable Faltung. Ich weiß, das ist ein Zungenbrecher, aber das Konzept ist ganz einfach. Sie werden in TensorFlow und Keras als tf.keras.layers.SeparableConv2D implementiert.
Bei einer separablen Faltung wird ebenfalls ein Filter auf das Bild angewendet, aber für jeden Kanal des Eingabebilds wird ein separater Satz von Gewichten verwendet. Danach folgt eine „1×1-Faltung“, eine Reihe von Punktprodukten, die zu einer gewichteten Summe der gefilterten Kanäle führen. Mit neuen Gewichten werden so viele gewichtete Rekombinationen der Channels berechnet, wie nötig.

Abbildung: Separable Faltungen. Phase 1: Faltungen mit einem separaten Filter für jeden Kanal. Phase 2: Lineare Rekombinationen von Channels. Wird mit einem neuen Satz von Gewichten wiederholt, bis die gewünschte Anzahl von Ausgabekanälen erreicht ist. Phase 1 kann auch wiederholt werden, wobei jedes Mal neue Gewichte verwendet werden. In der Praxis ist das jedoch selten der Fall.
Separable Faltungen werden in den meisten aktuellen Architekturen von faltenden neuronalen Netzwerken verwendet: MobileNetV2, Xception, EfficientNet. MobileNetV2 haben Sie übrigens bereits für den Lerntransfer verwendet.
Sie sind günstiger als reguläre Faltungen und haben sich in der Praxis als ebenso effektiv erwiesen. Hier ist die Anzahl der Gewichte für das oben gezeigte Beispiel:
Faltungsschicht: 4 × 4 × 3 × 5 = 240
Separable Convolutional Layer: 4 × 4 × 3 + 3 × 5 = 48 + 15 = 63
Es bleibt dem Leser überlassen, die Anzahl der Multiplikationen zu berechnen, die erforderlich sind, um die einzelnen Arten von Faltungsschichtskalen auf ähnliche Weise anzuwenden. Separable Faltungen sind kleiner und viel recheneffizienter.
Praxisorientiert
Starten Sie das Playground-Notebook für den Lerntransfer neu, wählen Sie dieses Mal aber Xception als vortrainiertes Modell aus. Xception verwendet nur separable Faltungen. Lassen Sie alle Gewichte trainierbar. Wir werden die vortrainierten Gewichte anhand unserer Daten optimieren, anstatt die vortrainierten Ebenen als solche zu verwenden.
Keras Flowers transfer learning (playground).ipynb
Ziel: Genauigkeit > 95% (Ja, das ist wirklich möglich!)
Da es sich um die letzte Übung handelt, sind etwas mehr Code und Data-Science-Arbeit erforderlich.
Weitere Informationen zur Feinabstimmung
Xception ist in den standardmäßigen vortrainierten Modellen in tf.keras.application.* verfügbar. Vergessen Sie nicht, alle Gewichte trainierbar zu lassen.
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
Um gute Ergebnisse beim Feinabstimmen eines Modells zu erzielen, müssen Sie auf die Lernrate achten und einen Lernratenplan mit einer Anlaufphase verwenden. Ein Beispiel:

Wenn Sie mit einer Standardlernrate beginnen, werden die vortrainierten Gewichte des Modells gestört. Durch die progressive Anpassung bleiben sie erhalten, bis das Modell Ihre Daten erfasst hat und sie sinnvoll ändern kann. Nach der Steigerung können Sie mit einer konstanten oder exponentiell abnehmenden Lernrate fortfahren.
In Keras wird die Lernrate über einen Callback angegeben, in dem Sie die passende Lernrate für jede Epoche berechnen können. Keras übergibt die richtige Lernrate für jede Epoche an den Optimierer.
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
Lösung
Hier finden Sie das Notebook mit der Lösung. Sie können es verwenden, wenn Sie nicht weiterkommen.
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
Behandelte Themen
- 🤔 Tiefengetrennte Faltung
- 🤓 Zeitpläne für die Lernrate
- 😈 Feinabstimmung eines vortrainierten Modells.
Bitte gehen Sie diese Checkliste kurz durch.
13. Glückwunsch!
Sie haben Ihr erstes modernes Convolutional Neural Network erstellt und mit TPUs in nur wenigen Minuten auf eine Genauigkeit von über 90% trainiert.
TPUs in der Praxis
TPUs und GPUs sind in Vertex AI von Google Cloud verfügbar:
Und schließlich freuen wir uns über Feedback. Bitte teilen Sie uns mit, wenn Sie in diesem Lab etwas Ungewöhnliches feststellen oder wenn Sie der Meinung sind, dass es verbessert werden sollte. Feedback kann über GitHub-Probleme [ Feedback-Link] gegeben werden.

|
|

