
۱. مرور کلی
در این آزمایشگاه، شما یاد خواهید گرفت که چگونه شبکههای عصبی کانولوشن خود را از ابتدا با Keras و Tensorflow 2 بسازید، آموزش دهید و تنظیم کنید. اکنون این کار را میتوان در عرض چند دقیقه با استفاده از قدرت TPU انجام داد. همچنین رویکردهای متعددی را از یادگیری انتقالی بسیار ساده گرفته تا معماریهای کانولوشنی مدرن مانند Squeezenet بررسی خواهید کرد. این آزمایشگاه شامل توضیحات نظری در مورد شبکههای عصبی است و نقطه شروع خوبی برای توسعهدهندگانی است که در مورد یادگیری عمیق یاد میگیرند.
خواندن مقالات یادگیری عمیق میتواند سخت و گیجکننده باشد. بیایید نگاهی عملی به معماریهای مدرن شبکههای عصبی کانولوشن داشته باشیم.

آنچه یاد خواهید گرفت
- برای استفاده از Keras و Tensor Processing Units (TPUs) برای ساخت سریعتر مدلهای سفارشی شما.
- برای استفاده از API مربوط به tf.data.Dataset و فرمت TFRecord جهت بارگذاری کارآمد دادههای آموزشی.
- برای تقلب 😈، به جای ساختن مدلهای خودتان، از یادگیری انتقالی استفاده کنید.
- برای استفاده از سبکهای مدل ترتیبی و تابعی Keras.
- برای ساخت طبقهبندیکنندهی Keras خودتان با یک لایهی softmax و تلفات آنتروپی متقاطع.
- برای تنظیم دقیق مدل خود با انتخاب خوبی از لایههای کانولوشن.
- برای بررسی ایدههای معماری مدرن کانوِنت مانند ماژولها، میانگین جهانی ادغام و غیره.
- برای ساخت یک شبکه کانوِنت (convnet) مدرن و ساده با استفاده از معماری Squeezenet.
بازخورد
اگر در این آزمایشگاه کد، نکتهی نادرستی میبینید، لطفاً به ما بگویید. میتوانید از طریق GitHub issues [ لینک بازخورد ] بازخورد خود را ارائه دهید.
۲. شروع سریع Google Colaboratory
این آزمایشگاه از Google Collaboratory استفاده میکند و نیازی به هیچ تنظیماتی از طرف شما ندارد. میتوانید آن را از طریق یک Chromebook اجرا کنید. لطفاً فایل زیر را باز کنید و سلولها را اجرا کنید تا با دفترچههای Colab آشنا شوید.
یک پس زمینه TPU انتخاب کنید

در منوی Colab، Runtime > Change runtime type را انتخاب کنید و سپس TPU را انتخاب کنید. در این آزمایشگاه کد، از یک TPU (واحد پردازش تنسور) قدرتمند که برای آموزش شتابدهی سختافزاری پشتیبانی میشود، استفاده خواهید کرد. اتصال به محیط اجرا به طور خودکار در اولین اجرا اتفاق میافتد، یا میتوانید از دکمه "اتصال" در گوشه بالا سمت راست استفاده کنید.
اجرای نوت بوک

با کلیک روی یک سلول و استفاده از Shift-ENTER، سلولها را یکییکی اجرا کنید. همچنین میتوانید کل نوتبوک را با Runtime > Run all اجرا کنید.
فهرست مطالب

همه دفترچهها فهرست مطالب دارند. میتوانید آن را با استفاده از فلش سیاه سمت چپ باز کنید.
سلولهای پنهان

بعضی از سلولها فقط عنوان خود را نشان میدهند. این یک ویژگی مخصوص دفترچه یادداشت Colab است. میتوانید روی آنها دوبار کلیک کنید تا کد داخلشان را ببینید، اما معمولاً خیلی جالب نیست. معمولاً از توابع پشتیبانی یا تجسمسازی میکنند. برای تعریف توابع داخلشان، هنوز باید این سلولها را اجرا کنید.
احراز هویت
دسترسی به مخازن ذخیرهسازی ابری گوگل خصوصی شما برای Colab امکانپذیر است، مشروط بر اینکه با یک حساب کاربری مجاز احراز هویت شوید. قطعه کد بالا فرآیند احراز هویت را آغاز میکند.
۳. [اطلاعات] واحدهای پردازش تنسور (TPU) چیستند؟
به طور خلاصه

کد آموزش یک مدل روی TPU در Keras (و در صورت عدم دسترسی به TPU، استفاده از GPU یا CPU):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
ما امروز از TPUها برای ساخت و بهینهسازی یک طبقهبندیکننده گل با سرعتهای تعاملی (دقیقه در هر اجرای آموزشی) استفاده خواهیم کرد.

چرا TPU ها؟
پردازندههای گرافیکی مدرن حول «هستههای» قابل برنامهریزی سازماندهی شدهاند، معماری بسیار انعطافپذیری که به آنها امکان میدهد وظایف متنوعی مانند رندر سهبعدی، یادگیری عمیق، شبیهسازیهای فیزیکی و غیره را انجام دهند. از سوی دیگر، TPUها یک پردازنده برداری کلاسیک را با یک واحد ضرب ماتریسی اختصاصی جفت میکنند و در هر کاری که در آن ضربهای ماتریسی بزرگ غالب هستند، مانند شبکههای عصبی، عالی عمل میکنند.

تصویر: یک لایه شبکه عصبی متراکم به عنوان یک ضرب ماتریسی، با دستهای از هشت تصویر که به طور همزمان از طریق شبکه عصبی پردازش میشوند. لطفاً ضرب یک خط در ستون را اجرا کنید تا تأیید کنید که واقعاً مجموع وزنی تمام مقادیر پیکسلهای یک تصویر را انجام میدهد. لایههای کانولوشن را میتوان به عنوان ضرب ماتریسی نیز نمایش داد، اگرچه کمی پیچیدهتر است ( توضیح در اینجا، در بخش 1 ).
سختافزار
MXU و VPU
یک هسته TPU نسخه ۲ از یک واحد ضرب ماتریس (MXU) که ضربهای ماتریسی را اجرا میکند و یک واحد پردازش برداری (VPU) برای سایر وظایف مانند فعالسازیها، softmax و غیره ساخته شده است. VPU محاسبات float32 و int32 را مدیریت میکند. از سوی دیگر، MXU با فرمت ممیز شناور با دقت ترکیبی ۱۶ تا ۳۲ بیتی عمل میکند.

ممیز شناور با دقت ترکیبی و bfloat16
MXU ضرب ماتریسها را با استفاده از ورودیهای bfloat16 و خروجیهای float32 محاسبه میکند. جمعهای میانی با دقت float32 انجام میشوند.

آموزش شبکه عصبی معمولاً در برابر نویز ناشی از کاهش دقت ممیز شناور مقاوم است. مواردی وجود دارد که نویز حتی به همگرایی بهینهساز کمک میکند. دقت ممیز شناور ۱۶ بیتی به طور سنتی برای تسریع محاسبات استفاده شده است، اما فرمتهای float16 و float32 محدودههای بسیار متفاوتی دارند. کاهش دقت از float32 به float16 معمولاً منجر به سرریز و سرریز میشود. راهحلهایی وجود دارد، اما معمولاً برای کار کردن float16 به کار اضافی نیاز است.
به همین دلیل است که گوگل فرمت bfloat16 را در TPUها معرفی کرد. bfloat16 یک float32 کوتاه شده با دقیقاً همان بیتهای توان و محدوده float32 است. این، علاوه بر این واقعیت که TPUها ضرب ماتریسها را با دقت مختلط با ورودیهای bfloat16 اما خروجیهای float32 محاسبه میکنند، به این معنی است که معمولاً هیچ تغییر کدی برای بهرهمندی از افزایش عملکرد دقت کاهش یافته لازم نیست.
آرایه سیستولیک
MXU ضرب ماتریسها را در سختافزار با استفاده از معماری به اصطلاح «آرایه سیستولیک» پیادهسازی میکند که در آن عناصر داده از طریق آرایهای از واحدهای محاسباتی سختافزاری جریان مییابند. (در پزشکی، «سیستولیک» به انقباضات قلب و جریان خون اشاره دارد، در اینجا به جریان دادهها اشاره دارد.)
عنصر اساسی ضرب ماتریسی، حاصلضرب نقطهای بین یک خط از یک ماتریس و یک ستون از ماتریس دیگر است (به تصویر بالای این بخش مراجعه کنید). برای ضرب ماتریسی Y=X*W، یکی از عناصر حاصل به صورت زیر خواهد بود:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
در یک پردازنده گرافیکی (GPU)، میتوان این ضرب نقطهای را در یک "هسته" پردازنده گرافیکی (GPU) برنامهریزی کرد و سپس آن را روی هر تعداد "هسته" که به صورت موازی در دسترس هستند اجرا کرد تا سعی شود هر مقدار ماتریس حاصل را به طور همزمان محاسبه کرد. اگر ماتریس حاصل 128x128 بزرگ باشد، برای محاسبه همزمان هر مقدار ماتریس حاصل، به 128x128 = 16K "هسته" نیاز است که معمولاً امکانپذیر نیست. بزرگترین پردازندههای گرافیکی (GPU) حدود 4000 هسته دارند. از سوی دیگر، یک TPU از حداقل سختافزار برای واحدهای محاسباتی در MXU استفاده میکند: فقط bfloat16 x bfloat16 => float32 multibulators، نه چیز دیگری. اینها آنقدر کوچک هستند که یک TPU میتواند 16K از آنها را در یک MXU 128x128 پیادهسازی کند و این ضرب ماتریس را به صورت یکجا پردازش کند.

تصویر: آرایه سیستولیک MXU. عناصر محاسباتی، ضرب-انباشتگر هستند. مقادیر یک ماتریس در آرایه بارگذاری میشوند (نقاط قرمز). مقادیر ماتریس دیگر در آرایه جریان مییابند (نقاط خاکستری). خطوط عمودی مقادیر را به سمت بالا منتشر میکنند. خطوط افقی جمعهای جزئی را منتشر میکنند. به عنوان یک تمرین، به کاربر واگذار میشود تا تأیید کند که با جریان دادهها در آرایه، نتیجه ضرب ماتریس از سمت راست خارج میشود.
علاوه بر این، در حالی که ضربهای نقطهای در یک MXU محاسبه میشوند، جمعهای میانی به سادگی بین واحدهای محاسباتی مجاور جریان مییابند. آنها نیازی به ذخیره و بازیابی به/از حافظه یا حتی یک فایل رجیستر ندارند. نتیجه نهایی این است که معماری آرایه سیستولیک TPU هنگام محاسبه ضربهای ماتریسی، از نظر چگالی و قدرت و همچنین از نظر سرعت نسبت به GPU برتری قابل توجهی دارد که قابل چشمپوشی نیست.
TPU ابری
وقتی شما یک " Cloud TPU نسخه ۲" را در پلتفرم ابری گوگل درخواست میکنید، یک ماشین مجازی (VM) دریافت میکنید که دارای یک برد TPU متصل به PCI است. برد TPU دارای چهار تراشه TPU دو هستهای است. هر هسته TPU دارای یک VPU (واحد پردازش برداری) و یک MXU (واحد ضرب MatriX) با ابعاد ۱۲۸x۱۲۸ است. این "Cloud TPU" معمولاً از طریق شبکه به ماشین مجازی که آن را درخواست کرده است متصل میشود. بنابراین تصویر کامل به این شکل است:

تصویر: ماشین مجازی شما با یک شتابدهنده "Cloud TPU" متصل به شبکه. خود "Cloud TPU" از یک ماشین مجازی با یک برد TPU متصل به PCI با چهار تراشه TPU دو هستهای روی آن ساخته شده است.
غلافهای TPU
در مراکز داده گوگل، TPU ها به یک اتصال داخلی محاسبات با کارایی بالا (HPC) متصل هستند که میتواند آنها را به عنوان یک شتابدهنده بسیار بزرگ نشان دهد. گوگل آنها را پاد مینامد و میتوانند تا ۵۱۲ هسته TPU v2 یا ۲۰۴۸ هسته TPU v3 را در خود جای دهند.

تصویر: یک غلاف TPU نسخه ۳. بردها و رکهای TPU از طریق اتصال HPC به هم متصل شدهاند.
در طول آموزش، گرادیانها با استفاده از الگوریتم all-reduce بین هستههای TPU رد و بدل میشوند ( توضیح خوبی در مورد all-reduce در اینجا آمده است ). مدلی که آموزش داده میشود میتواند با آموزش در اندازههای دستهای بزرگ، از سختافزار بهره ببرد.

تصویر: همگامسازی گرادیانها در طول آموزش با استفاده از الگوریتم all-reduce در شبکه HPC مش چنبره دوبعدی Google TPU.
نرمافزار
آموزش در اندازه دستههای بزرگ
اندازه ایدهآل دسته برای TPUها، ۱۲۸ آیتم داده در هر هسته TPU است، اما سختافزار میتواند از ۸ آیتم داده در هر هسته TPU به خوبی استفاده کند. به یاد داشته باشید که یک TPU ابری دارای ۸ هسته است.
در این آزمایشگاه کد، ما از API کرس استفاده خواهیم کرد. در کرس، دستهای که شما مشخص میکنید، اندازه دسته سراسری برای کل TPU است. دستههای شما به طور خودکار به ۸ قسمت تقسیم شده و روی ۸ هسته TPU اجرا میشوند.

برای نکات بیشتر در مورد عملکرد، به راهنمای عملکرد TPU مراجعه کنید. برای اندازههای دستهای بسیار بزرگ، ممکن است در برخی مدلها نیاز به مراقبت ویژه باشد، برای جزئیات بیشتر به LARSOptimizer مراجعه کنید.
زیر کاپوت: XLA
برنامههای Tensorflow نمودارهای محاسباتی را تعریف میکنند. TPU مستقیماً کد پایتون را اجرا نمیکند، بلکه نمودار محاسباتی تعریف شده توسط برنامه Tensorflow شما را اجرا میکند. در پشت صحنه، کامپایلری به نام XLA (کامپایلر جبر خطی شتابیافته) نمودار گرههای محاسباتی Tensorflow را به کد ماشین TPU تبدیل میکند. این کامپایلر همچنین بهینهسازیهای پیشرفته زیادی را روی کد و طرحبندی حافظه شما انجام میدهد. کامپایل به طور خودکار با ارسال کار به TPU انجام میشود. لازم نیست XLA را به طور صریح در زنجیره ساخت خود بگنجانید.
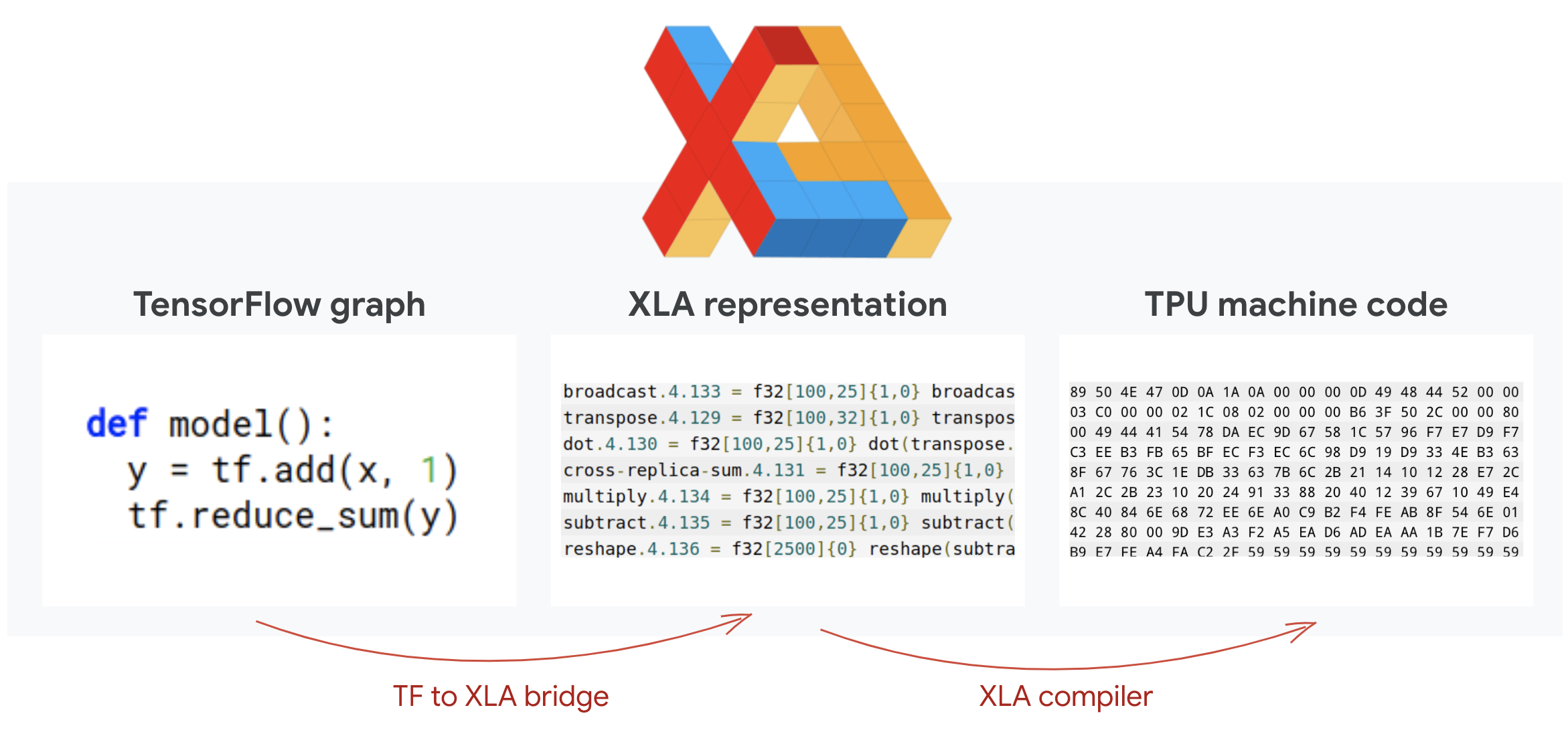
تصویر: برای اجرا روی TPU، نمودار محاسباتی تعریف شده توسط برنامه Tensorflow شما ابتدا به یک نمایش XLA (کامپایلر جبر خطی شتاب یافته) ترجمه میشود، سپس توسط XLA به کد ماشین TPU کامپایل میشود.
استفاده از TPU در Keras
TPUها از طریق رابط برنامهنویسی کاربردی Keras از Tensorflow 2.1 پشتیبانی میشوند. پشتیبانی Keras روی TPUها و TPU podها کار میکند. در اینجا مثالی آورده شده است که روی TPU، GPU(ها) و CPU کار میکند:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
در این قطعه کد:
-
TPUClusterResolver().connect()واحد پردازش مرکزی (TPU) را در شبکه پیدا میکند. این تابع در اکثر سیستمهای ابری گوگل (مشاغل پلتفرم هوش مصنوعی، Colaboratory، Kubeflow، ماشینهای مجازی یادگیری عمیق که از طریق ابزار 'ctpu up' ایجاد شدهاند) بدون پارامتر کار میکند. این سیستمها به لطف متغیر محیطی TPU_NAME میدانند که TPU آنها کجاست. اگر یک TPU را به صورت دستی ایجاد میکنید، یا متغیر محیطی TPU_NAME را روی ماشین مجازی که از آن استفاده میکنید تنظیم کنید، یاTPUClusterResolverرا با پارامترهای صریح فراخوانی کنید:TPUClusterResolver(tp_uname, zone, project) -
TPUStrategyبخشی است که توزیع و الگوریتم همگامسازی گرادیان «تماماً کاهشی» را پیادهسازی میکند. - استراتژی از طریق یک محدوده اعمال میشود. مدل باید در محدوده ()strike تعریف شود.
- تابع
tpu_model.fitبرای آموزش TPU، یک شیء tf.data.Dataset را به عنوان ورودی دریافت میکند.
وظایف رایج پورت کردن TPU
- در حالی که روشهای زیادی برای بارگذاری دادهها در یک مدل Tensorflow وجود دارد، برای TPUها، استفاده از API
tf.data.Datasetالزامی است. - TPUها بسیار سریع هستند و دریافت دادهها اغلب هنگام اجرا روی آنها به یک گلوگاه تبدیل میشود. ابزارهایی وجود دارد که میتوانید برای تشخیص گلوگاههای داده و سایر نکات مربوط به عملکرد در راهنمای عملکرد TPU از آنها استفاده کنید.
- اعداد int8 یا int16 به عنوان int32 در نظر گرفته میشوند. TPU سختافزار عدد صحیحی که روی کمتر از ۳۲ بیت کار کند، ندارد.
- برخی از عملیات Tensorflow پشتیبانی نمیشوند. لیست آنها اینجاست . خبر خوب این است که این محدودیت فقط برای کد آموزشی، یعنی عبور رو به جلو و عقب از مدل شما اعمال میشود. شما همچنان میتوانید از تمام عملیات Tensorflow در خط لوله ورودی داده خود استفاده کنید زیرا روی CPU اجرا خواهد شد.
-
tf.py_funcدر TPU پشتیبانی نمیشود.
۴. بارگذاری دادهها






ما با یک مجموعه داده از تصاویر گل کار خواهیم کرد. هدف این است که یاد بگیریم آنها را به 5 نوع گل دسته بندی کنیم. بارگذاری داده ها با استفاده از API tf.data.Dataset انجام می شود. ابتدا، بیایید با API آشنا شویم.
عملی
لطفاً دفترچه یادداشت زیر را باز کنید، سلولها را اجرا کنید (Shift-ENTER) و هر جا که برچسب «WORK REQUIRED» را دیدید، دستورالعملها را دنبال کنید.

Fun with tf.data.Dataset (playground).ipynb
اطلاعات تکمیلی
درباره مجموعه داده «گلها»
مجموعه دادهها در ۵ پوشه سازماندهی شده است. هر پوشه شامل گلهایی از یک نوع است. پوشهها به نامهای گل آفتابگردان، گل مینا، قاصدک، لاله و رز نامگذاری شدهاند. دادهها در یک مخزن عمومی در فضای ذخیرهسازی ابری گوگل میزبانی میشوند. گزیدهای از:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
چرا tf.data.Dataset؟
Keras و Tensorflow در تمام توابع آموزش و ارزیابی خود، Datasetها را میپذیرند. پس از بارگذاری دادهها در یک Dataset، API تمام قابلیتهای رایجی را که برای دادههای آموزش شبکه عصبی مفید هستند، ارائه میدهد:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
میتوانید نکات مربوط به عملکرد و بهترین شیوههای مجموعه داده را در این مقاله بیابید. مستندات مرجع اینجا است.
اصول اولیه tf.data.Dataset
دادهها معمولاً در چندین فایل، در اینجا تصاویر، قرار میگیرند. میتوانید با فراخوانی دستور زیر، یک مجموعه داده از نام فایلها ایجاد کنید:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
سپس یک تابع را به هر نام فایل "نگاشت" میکنید که معمولاً فایل را بارگذاری و به دادههای واقعی در حافظه رمزگشایی میکند:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
برای تکرار روی یک مجموعه داده:
for data in my_dataset:
print(data)
مجموعه دادههای تاپلها
در یادگیری نظارتشده، یک مجموعه داده آموزشی معمولاً از جفت دادههای آموزشی و پاسخهای صحیح ساخته میشود. برای این کار، تابع رمزگشایی میتواند تاپلها را برگرداند. سپس شما یک مجموعه داده از تاپلها خواهید داشت و تاپلها هنگام تکرار روی آن بازگردانده میشوند. مقادیر برگردانده شده، تانسورهای Tensorflow هستند که آماده مصرف توسط مدل شما میباشند. میتوانید برای مشاهده مقادیر خام .numpy() را روی آنها فراخوانی کنید:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
نتیجهگیری: بارگذاری تصاویر تک تک کند است!
با تکرار این مجموعه داده، خواهید دید که میتوانید چیزی حدود ۱-۲ تصویر در ثانیه بارگذاری کنید. این خیلی کند است! شتابدهندههای سختافزاری که ما برای آموزش استفاده خواهیم کرد میتوانند چندین برابر این سرعت را تحمل کنند. برای دیدن نحوه دستیابی به این هدف، به بخش بعدی بروید.
راه حل
این دفترچهی حل مسئله است. اگر به مشکلی برخوردید، میتوانید از آن استفاده کنید.
Fun with tf.data.Dataset (solution).ipynb
آنچه ما پوشش دادهایم
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 مجموعه دادههای تاپلها
- 😀 تکرار در مجموعه دادهها
لطفا چند لحظه وقت بگذارید و این چک لیست را در ذهن خود مرور کنید.
۵. بارگذاری سریع دادهها
شتابدهندههای سختافزاری واحد پردازش تنسور (TPU) که در این آزمایشگاه استفاده خواهیم کرد، بسیار سریع هستند. چالش اغلب این است که دادهها را به اندازهای سریع به آنها بدهیم که مشغول بمانند. فضای ذخیرهسازی ابری گوگل (GCS) قادر به حفظ توان عملیاتی بسیار بالا است، اما مانند همه سیستمهای ذخیرهسازی ابری، شروع یک اتصال هزینه رفت و برگشت شبکه را دارد. بنابراین، ذخیره دادههای ما به صورت هزاران فایل جداگانه ایدهآل نیست. ما قصد داریم آنها را در تعداد کمتری فایل دستهبندی کنیم و از قدرت tf.data.Dataset برای خواندن از چندین فایل به صورت موازی استفاده کنیم.
خواندنی
کدی که فایلهای تصویر را بارگذاری میکند، اندازه آنها را به یک اندازه معمول تغییر میدهد و سپس آنها را در ۱۶ فایل TFRecord ذخیره میکند، در دفترچه راهنمای زیر آمده است. لطفاً آن را سریع بخوانید. اجرای آن ضروری نیست زیرا دادههای با فرمت TFRecord به درستی برای بقیه کد ارائه خواهند شد.
Flower pictures to TFRecords.ipynb
طرحبندی ایدهآل دادهها برای توان عملیاتی بهینه GCS
فرمت فایل TFRecord
فرمت فایل ترجیحی Tensorflow برای ذخیره دادهها، فرمت TFRecord مبتنی بر protobuf است. سایر فرمتهای سریالسازی نیز کار میکنند، اما میتوانید با نوشتن دستور زیر، یک مجموعه داده را مستقیماً از فایلهای TFRecord بارگذاری کنید:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
برای عملکرد بهینه، توصیه میشود از کد پیچیدهتر زیر برای خواندن همزمان چندین فایل TFRecord استفاده کنید. این کد به صورت موازی از N فایل میخواند و ترتیب دادهها را به نفع سرعت خواندن نادیده میگیرد.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
برگه تقلب TFRecord
سه نوع داده را میتوان در TFRecords ذخیره کرد: رشتههای بایتی (لیستی از بایتها)، اعداد صحیح ۶۴ بیتی و اعداد اعشاری ۳۲ بیتی. آنها همیشه به صورت لیست ذخیره میشوند، یک عنصر داده واحد، لیستی با اندازه ۱ خواهد بود. میتوانید از توابع کمکی زیر برای ذخیره دادهها در TFRecords استفاده کنید.
نوشتن رشتههای بایتی
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
نوشتن اعداد صحیح
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
نوشتن شناورها
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
نوشتن یک TFRecord با استفاده از تابعهای کمکی بالا
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
برای خواندن دادهها از TFRecords، ابتدا باید طرحبندی رکوردهایی را که ذخیره کردهاید، تعریف کنید. در تعریف، میتوانید به هر فیلد نامگذاری شده به عنوان یک لیست با طول ثابت یا یک لیست با طول متغیر دسترسی داشته باشید:
خواندن از TFRecords
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
قطعه کدهای مفید:
خواندن عناصر دادهای منفرد
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
خواندن لیستهای با اندازه ثابت از عناصر
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
خواندن تعداد متغیری از اقلام داده
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
یک VarLenFeature یک بردار پراکنده برمیگرداند و یک مرحله اضافی پس از رمزگشایی TFRecord لازم است:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
همچنین میتوان فیلدهای اختیاری در TFRecords داشت. اگر هنگام خواندن یک فیلد، مقدار پیشفرض را مشخص کنید، در صورت عدم وجود فیلد، مقدار پیشفرض به جای خطا بازگردانده میشود.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
آنچه ما پوشش دادهایم
- 🤔 تقسیمبندی فایلهای داده برای دسترسی سریع از GCS
- 😓 نحوه نوشتن TFRecords. (نحوه نوشتن را فراموش کردهاید؟ اشکالی ندارد، این صفحه را به عنوان یک برگه تقلب نشانهگذاری کنید)
- 🤔 بارگذاری یک مجموعه داده از TFRecords با استفاده از TFRecordDataset
لطفا چند لحظه وقت بگذارید و این چک لیست را در ذهن خود مرور کنید.
۶. [اطلاعات] طبقهبندیکننده شبکه عصبی ۱۰۱
به طور خلاصه
اگر تمام اصطلاحات پررنگشده در پاراگراف بعدی را از قبل میدانید، میتوانید به تمرین بعدی بروید. اگر تازه یادگیری عمیق را شروع کردهاید، خوش آمدید و لطفاً ادامه مطلب را بخوانید.
برای مدلهایی که به صورت دنبالهای از لایهها ساخته شدهاند، Keras رابط برنامهنویسی کاربردی Sequential را ارائه میدهد. برای مثال، یک طبقهبندیکننده تصویر با استفاده از سه لایه متراکم را میتوان در Keras به صورت زیر نوشت:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
شبکه عصبی متراکم
این سادهترین شبکه عصبی برای طبقهبندی تصاویر است. این شبکه از «نورونها»یی ساخته شده که در لایهها مرتب شدهاند. لایه اول دادههای ورودی را پردازش میکند و خروجیهای آن را به لایههای دیگر میدهد. به این شبکه «متراکم» میگویند زیرا هر نورون به تمام نورونهای لایه قبلی متصل است.

شما میتوانید با تبدیل مقادیر RGB تمام پیکسلهای یک تصویر به یک بردار طولانی و استفاده از آن به عنوان ورودی، آن را به چنین شبکهای وارد کنید. این بهترین تکنیک برای تشخیص تصویر نیست، اما بعداً آن را بهبود خواهیم بخشید.
نورونها، فعالسازیها، RELU
یک «نورون» مجموع وزنی تمام ورودیهای خود را محاسبه میکند، مقداری به نام «بایاس» به آن اضافه میکند و نتیجه را از طریق چیزی به نام «تابع فعالسازی» ارسال میکند. وزنها و بایاس در ابتدا ناشناخته هستند. آنها به صورت تصادفی مقداردهی اولیه میشوند و با آموزش شبکه عصبی روی تعداد زیادی از دادههای شناخته شده، «یاد گرفته» میشوند.

محبوبترین تابع فعالسازی، RELU (Rectified Linear Unit) نام دارد. همانطور که در نمودار بالا میبینید، این تابع بسیار ساده است.
فعالسازی سافتمکس
شبکه فوق با یک لایه ۵ نورونی به پایان میرسد زیرا ما گلها را به ۵ دسته (رز، لاله، قاصدک، مینا، آفتابگردان) طبقهبندی میکنیم. نورونهای لایههای میانی با استفاده از تابع فعالسازی کلاسیک RELU فعال میشوند. با این حال، در لایه آخر، میخواهیم اعداد بین ۰ و ۱ را محاسبه کنیم که نشاندهنده احتمال این است که این گل رز، لاله و غیره باشد. برای این کار، از یک تابع فعالسازی به نام "softmax" استفاده خواهیم کرد.
اعمال softmax روی یک بردار با در نظر گرفتن تابع نمایی هر عنصر و سپس نرمالسازی بردار، معمولاً با استفاده از نرم L1 (مجموع قدرمطلقها) انجام میشود، به طوری که مجموع مقادیر برابر با ۱ شود و بتوان آنها را به عنوان احتمال تفسیر کرد.


اتلاف آنتروپی متقاطع
حالا که شبکه عصبی ما پیشبینیهایی از تصاویر ورودی تولید میکند، باید میزان دقت آنها را اندازهگیری کنیم، یعنی فاصله بین آنچه شبکه به ما میگوید و پاسخهای صحیح، که اغلب "برچسب" نامیده میشوند. به یاد داشته باشید که ما برای همه تصاویر موجود در مجموعه دادهها برچسبهای صحیح داریم.
هر فاصلهای جواب میدهد، اما برای مسائل طبقهبندی، فاصلهای که «فاصله آنتروپی متقاطع» نامیده میشود، مؤثرترین است. ما این را تابع خطا یا «زیان» مینامیم:
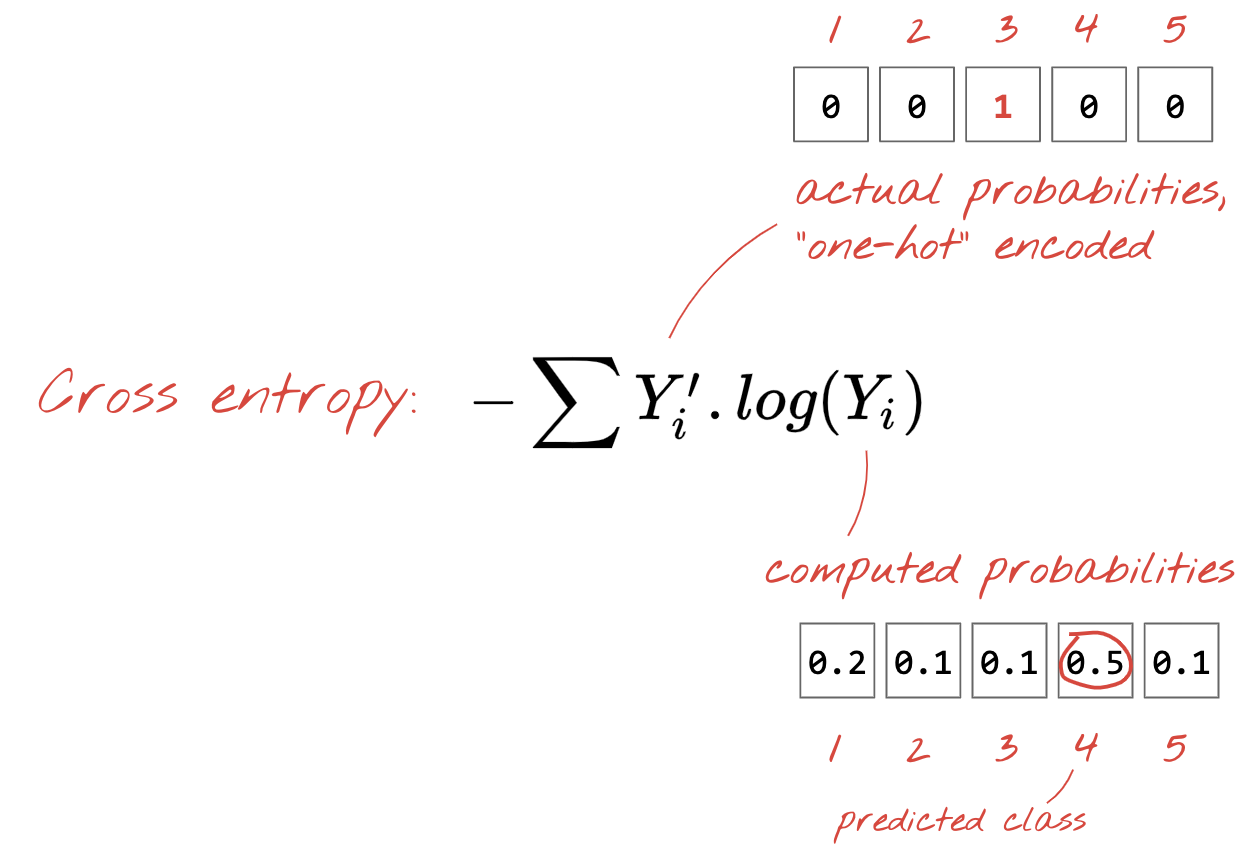
گرادیان نزولی
«آموزش» شبکه عصبی در واقع به معنای استفاده از تصاویر آموزشی و برچسبها برای تنظیم وزنها و بایاسها به منظور به حداقل رساندن تابع زیان آنتروپی متقاطع است. در اینجا نحوه کار آن آمده است.
آنتروپی متقاطع تابعی از وزنها، بایاسها، پیکسلهای تصویر آموزشی و کلاس شناختهشده آن است.
اگر مشتقات جزئی آنتروپی متقاطع را نسبت به تمام وزنها و تمام بایاسها محاسبه کنیم، یک "گرادیان" به دست میآوریم که برای یک تصویر، برچسب و مقدار فعلی وزنها و بایاسهای داده شده محاسبه میشود. به یاد داشته باشید که میتوانیم میلیونها وزن و بایاس داشته باشیم، بنابراین محاسبه گرادیان به نظر کار زیادی میآید. خوشبختانه، Tensorflow این کار را برای ما انجام میدهد. خاصیت ریاضی گرادیان این است که به سمت "بالا" اشاره میکند. از آنجایی که میخواهیم به جایی برویم که آنتروپی متقاطع کم است، در جهت مخالف میرویم. وزنها و بایاسها را با کسری از گرادیان بهروزرسانی میکنیم. سپس همین کار را بارها و بارها با استفاده از دستههای بعدی تصاویر آموزشی و برچسبها، در یک حلقه آموزشی انجام میدهیم. امیدواریم که این به جایی همگرا شود که آنتروپی متقاطع حداقل باشد، اگرچه هیچ چیز تضمین نمیکند که این حداقل منحصر به فرد باشد.

مینی بچینگ و مومنتوم
شما میتوانید گرادیان خود را فقط روی یک تصویر نمونه محاسبه کنید و وزنها و بایاسها را فوراً بهروزرسانی کنید، اما انجام این کار روی یک دسته، مثلاً ۱۲۸ تصویر، گرادیانی را ارائه میدهد که محدودیتهای اعمال شده توسط تصاویر نمونه مختلف را بهتر نشان میدهد و بنابراین احتمالاً سریعتر به سمت راهحل همگرا میشود. اندازه مینی-دسته یک پارامتر قابل تنظیم است.
این تکنیک که گاهی اوقات «کاهش گرادیان تصادفی» نامیده میشود، یک مزیت عملیتر دیگر نیز دارد: کار با دستهها به معنای کار با ماتریسهای بزرگتر نیز هست و بهینهسازی این ماتریسها روی GPUها و TPUها معمولاً آسانتر است.
با این حال، همگرایی هنوز میتواند کمی آشوبناک باشد و حتی اگر بردار گرادیان همه صفر باشد، میتواند متوقف شود. آیا این بدان معناست که ما یک مینیمم پیدا کردهایم؟ نه همیشه. یک مؤلفه گرادیان میتواند روی یک مینیمم یا یک ماکزیمم صفر باشد. با یک بردار گرادیان با میلیونها عنصر، اگر همه آنها صفر باشند، احتمال اینکه هر صفر مربوط به یک مینیمم باشد و هیچ یک از آنها به یک نقطه ماکزیمم نرسد، بسیار کم است. در فضایی با ابعاد زیاد، نقاط زینی بسیار رایج هستند و ما نمیخواهیم در آنها متوقف شویم.

تصویر: یک نقطه زینی. گرادیان صفر است اما در همه جهات حداقل نیست. (منبع تصویر: ویکیمدیا: نوشته نیکوگوارو - اثر شخصی، CC BY 3.0 )
راه حل این است که مقداری مومنتوم به الگوریتم بهینهسازی اضافه کنیم تا بتواند بدون توقف از نقاط زینی عبور کند.
واژهنامه
دستهای یا مینی-دستهای : آموزش همیشه روی دستههایی از دادههای آموزشی و برچسبها انجام میشود. انجام این کار به همگرایی الگوریتم کمک میکند. بُعد «دستهای» معمولاً اولین بُعد از تانسورهای داده است. به عنوان مثال، یک تانسور شکل [100، 192، 192، 3] شامل 100 تصویر با ابعاد 192x192 پیکسل با سه مقدار در هر پیکسل (RGB) است.
تابع زیان آنتروپی متقاطع : یک تابع زیان ویژه که اغلب در طبقهبندیکنندهها استفاده میشود.
لایه متراکم : لایهای از نورونها که در آن هر نورون به تمام نورونهای لایه قبلی متصل است.
ویژگیها : ورودیهای یک شبکه عصبی گاهی اوقات «ویژگیها» نامیده میشوند. هنر تشخیص اینکه کدام بخشهای یک مجموعه داده (یا ترکیبی از بخشها) باید به یک شبکه عصبی داده شوند تا پیشبینیهای خوبی حاصل شود، «مهندسی ویژگی» نامیده میشود.
برچسبها : نام دیگری برای «کلاسها» یا پاسخهای صحیح در یک مسئله طبقهبندی نظارتشده
نرخ یادگیری : کسری از گرادیان که وزنها و بایاسها در هر تکرار حلقه آموزش بهروزرسانی میشوند.
لوجیتها : خروجیهای یک لایه از نورونها قبل از اعمال تابع فعالسازی، «لوجیت» نامیده میشوند. این اصطلاح از «تابع لجستیک» یا «تابع سیگموئید» گرفته شده است که قبلاً محبوبترین تابع فعالسازی بود. «خروجیهای نورون قبل از تابع لجستیک» به «لوجیتها» خلاصه شد.
تابع خطا (loss) : تابع خطایی که خروجیهای شبکه عصبی را با پاسخهای صحیح مقایسه میکند.
نورون : مجموع وزنی ورودیهایش را محاسبه میکند، یک بایاس اضافه میکند و نتیجه را از طریق یک تابع فعالسازی ارسال میکند.
کدگذاری وان-هات : کلاس ۳ از ۵ به صورت برداری با ۵ عنصر کدگذاری میشود که همه عناصر آن صفر هستند به جز عنصر سوم که ۱ است.
relu : واحد خطی یکسو شده. یک تابع فعالسازی محبوب برای نورونها.
سیگموئید : تابع فعالسازی دیگری که قبلاً محبوب بود و هنوز هم در موارد خاص مفید است.
softmax : یک تابع فعالسازی ویژه که روی یک بردار عمل میکند، تفاوت بین بزرگترین مؤلفه و سایر مؤلفهها را افزایش میدهد، و همچنین بردار را طوری نرمالسازی میکند که مجموع آن ۱ باشد تا بتوان آن را به عنوان برداری از احتمالات تفسیر کرد. به عنوان آخرین مرحله در طبقهبندیکنندهها استفاده میشود.
تانسور : یک "تانسور" مانند یک ماتریس است اما با تعداد دلخواهی از ابعاد. یک تانسور یک بعدی یک بردار است. یک تانسور دو بعدی یک ماتریس است. و سپس میتوانید تانسورهایی با ۳، ۴، ۵ یا بیشتر بعد داشته باشید.
۷. انتقال یادگیری
برای یک مسئله طبقهبندی تصویر، لایههای متراکم احتمالاً کافی نخواهند بود. ما باید در مورد لایههای کانولوشن و روشهای مختلف چیدمان آنها اطلاعات کسب کنیم.
اما میتوانیم از یک راه میانبر هم استفاده کنیم! شبکههای عصبی کانولوشنی کاملاً آموزشدیده برای دانلود موجود هستند. میتوان آخرین لایه آنها، یعنی هد طبقهبندی softmax، را جدا کرد و آن را با لایه خودتان جایگزین کرد. تمام وزنها و بایاسهای آموزشدیده به همان شکل باقی میمانند، شما فقط لایه softmax اضافه شده را دوباره آموزش میدهید. این تکنیک یادگیری انتقالی نام دارد و به طرز شگفتانگیزی، تا زمانی که مجموعه دادهای که شبکه عصبی روی آن از قبل آموزش دیده است، "به اندازه کافی نزدیک" به مجموعه داده شما باشد، کار میکند.
عملی
لطفاً دفترچه یادداشت زیر را باز کنید، سلولها را اجرا کنید (Shift-ENTER) و هر جا که برچسب «WORK REQUIRED» را دیدید، دستورالعملها را دنبال کنید.
Keras Flowers transfer learning (playground).ipynb
اطلاعات تکمیلی
با یادگیری انتقالی، شما از معماریهای پیشرفته شبکه عصبی کانولوشنی توسعهیافته توسط محققان برتر و همچنین پیشآموزش روی مجموعه دادههای عظیمی از تصاویر بهرهمند میشوید. در مورد ما، یادگیری انتقالی از شبکهای آموزشدیده روی ImageNet، پایگاه دادهای از تصاویر حاوی گیاهان و صحنههای بیرونی فراوان، که به اندازه کافی به گلها نزدیک است، انجام خواهد شد.

تصویر: استفاده از یک شبکه عصبی کانولوشنی پیچیده، که قبلاً آموزش دیده است، به عنوان یک جعبه سیاه، و آموزش مجدد فقط سر طبقهبندی. این یادگیری انتقالی است. بعداً خواهیم دید که این چیدمانهای پیچیده لایههای کانولوشنی چگونه کار میکنند. فعلاً، این مشکل شخص دیگری است.
یادگیری انتقالی در کراس
در Keras، میتوانید یک مدل از پیش آموزشدیده را از مجموعه tf.keras.applications.* نمونهسازی کنید. به عنوان مثال، MobileNet V2 یک معماری کانولوشن بسیار خوب است که از نظر اندازه معقول باقی میماند. با انتخاب include_top=False ، مدل از پیش آموزشدیده را بدون لایه softmax نهایی آن دریافت میکنید تا بتوانید لایه خودتان را اضافه کنید:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
همچنین به تنظیم pretrained_model.trainable = False توجه کنید. این تنظیم، وزنها و بایاسهای مدل از پیش آموزشدیده را ثابت نگه میدارد تا شما فقط لایه softmax خود را آموزش دهید. این کار معمولاً شامل وزنهای نسبتاً کمی است و میتواند به سرعت و بدون نیاز به مجموعه دادههای بسیار بزرگ انجام شود. با این حال، اگر دادههای زیادی دارید، یادگیری انتقالی میتواند با pretrained_model.trainable = True حتی بهتر عمل کند. سپس وزنهای از پیش آموزشدیده، مقادیر اولیه بسیار خوبی ارائه میدهند و همچنان میتوانند توسط آموزش تنظیم شوند تا با مسئله شما مطابقت بیشتری داشته باشند.
در نهایت، به لایه Flatten() که قبل از لایه softmax متراکم شما قرار داده شده است، توجه کنید. لایههای متراکم روی بردارهای مسطح دادهها کار میکنند، اما ما نمیدانیم که آیا این همان چیزی است که مدل از پیش آموزش دیده برمیگرداند یا خیر. به همین دلیل است که باید آن را مسطح کنیم. در فصل بعد، همانطور که به معماریهای کانولوشن میپردازیم، فرمت دادهای که توسط لایههای کانولوشن برگردانده میشود را توضیح خواهیم داد.
با این رویکرد باید به دقتی نزدیک به ۷۵٪ برسید.
راه حل
این دفترچهی حل مسئله است. اگر به مشکلی برخوردید، میتوانید از آن استفاده کنید.
Keras Flowers transfer learning (solution).ipynb
آنچه ما پوشش دادهایم
- 🤔 نحوه نوشتن یک طبقهبندیکننده در Keras
- 🤓 با یک لایه آخر softmax و تلفات آنتروپی متقاطع پیکربندی شده است
- 😈 انتقال یادگیری
- 🤔 آموزش اولین مدل شما
- 🧐 دنبال کردن میزان از دست دادن و دقت آن در طول آموزش
لطفا چند لحظه وقت بگذارید و این چک لیست را در ذهن خود مرور کنید.
۸. [اطلاعات] شبکههای عصبی کانولوشن
به طور خلاصه
اگر تمام اصطلاحات پررنگشده در پاراگراف بعدی را از قبل میدانید، میتوانید به تمرین بعدی بروید. اگر تازه با شبکههای عصبی کانولوشن شروع کردهاید، لطفاً ادامه مطلب را بخوانید.

تصویر: فیلتر کردن یک تصویر با دو فیلتر متوالی که هر کدام از ۴x۴x۳=۴۸ وزن قابل یادگیری ساخته شدهاند.
یک شبکه عصبی کانولوشن ساده در Keras به این شکل است:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
شبکههای عصبی کانولوشنی ۱۰۱
در یک لایه از یک شبکه کانولوشن، یک "نورون" مجموع وزنی پیکسلهای درست بالای خود را، فقط در یک ناحیه کوچک از تصویر، انجام میدهد. این یک بایاس اضافه میکند و مجموع را از طریق یک تابع فعالسازی تغذیه میکند، درست همانطور که یک نورون در یک لایه متراکم معمولی انجام میدهد. سپس این عملیات در کل تصویر با استفاده از همان وزنها تکرار میشود. به یاد داشته باشید که در لایههای متراکم، هر نورون وزنهای خود را داشت. در اینجا، یک "وصله" از وزنها در هر دو جهت در تصویر میلغزد (یک "کانولوشن"). خروجی به تعداد پیکسلهای موجود در تصویر، مقادیر دارد (البته مقداری لایهگذاری در لبهها ضروری است). این یک عملیات فیلترینگ است که از یک فیلتر با وزنهای 4x4x3=48 استفاده میکند.
با این حال، ۴۸ وزن کافی نخواهد بود. برای اضافه کردن درجات آزادی بیشتر، همین عملیات را با مجموعهای جدید از وزنها تکرار میکنیم. این کار مجموعهای جدید از خروجیهای فیلتر را تولید میکند. بیایید آن را «کانال» خروجیها بنامیم، مشابه کانالهای R، G و B در تصویر ورودی.
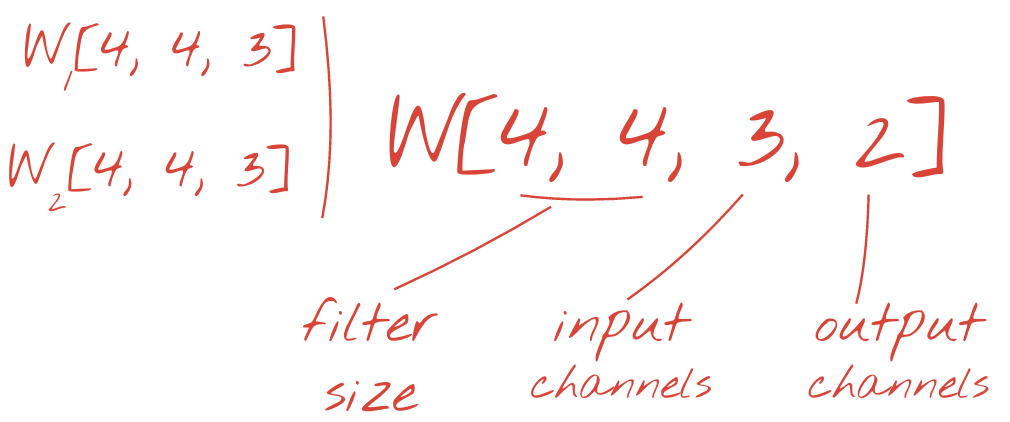
دو (یا چند) مجموعه از وزنها را میتوان با اضافه کردن یک بُعد جدید به عنوان یک تانسور خلاصه کرد. این به ما شکل کلی تانسور وزنها را برای یک لایه کانولوشن میدهد. از آنجایی که تعداد کانالهای ورودی و خروجی پارامترها هستند، میتوانیم شروع به انباشت و زنجیرهسازی لایههای کانولوشن کنیم.

تصویر: یک شبکه عصبی کانولوشنی، «مکعبهای» داده را به «مکعبهای» داده دیگر تبدیل میکند.
کانولوشنهای گامبهگام، حداکثر تجمع
با انجام کانولوشنها با گام ۲ یا ۳، میتوانیم مکعب داده حاصل را در ابعاد افقی نیز کوچک کنیم. دو روش رایج برای انجام این کار وجود دارد:
- کانولوشن گامدار: یک فیلتر لغزشی مانند بالا اما با گام بزرگتر از ۱
- حداکثر ادغام: یک پنجره کشویی که عملیات MAX را اعمال میکند (معمولاً روی تکههای ۲x۲، که هر ۲ پیکسل تکرار میشود)

تصویر: جابجایی پنجره محاسبات به اندازه ۳ پیکسل منجر به مقادیر خروجی کمتری میشود. کانولوشنهای گامدار یا حداکثر تجمع (حداکثر در یک پنجره ۲x۲ که با گام ۲ جابجا میشود) راهی برای کوچک کردن مکعب داده در ابعاد افقی هستند.
طبقهبندیکنندهی تکاملی C
در نهایت، با مسطح کردن آخرین مکعب داده و عبور آن از یک لایه متراکم و فعالشده با softmax، یک هد طبقهبندی متصل میکنیم. یک طبقهبندیکننده کانولوشنی معمولی میتواند به شکل زیر باشد:

تصویر: یک طبقهبندیکننده تصویر با استفاده از لایههای کانولوشن و softmax. این طبقهبندیکننده از فیلترهای ۳x۳ و ۱x۱ استفاده میکند. لایههای maxpool حداکثر گروههای نقاط داده ۲x۲ را میگیرند. سر طبقهبندیکننده با یک لایه متراکم با فعالسازی softmax پیادهسازی شده است.
در کراس
پشته کانولوشنی نشان داده شده در بالا را میتوان در Keras به صورت زیر نوشت:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
۹. کانوِنت سفارشی شما
عملی
بیایید یک شبکه عصبی کانولوشن را از ابتدا بسازیم و آموزش دهیم. استفاده از TPU به ما امکان میدهد خیلی سریع تکرار کنیم. لطفاً دفترچه یادداشت زیر را باز کنید، سلولها را اجرا کنید (Shift-ENTER) و هر جا که برچسب "WORK REQUIRED" را دیدید، دستورالعملها را دنبال کنید.
Keras_Flowers_TPU (playground).ipynb
هدف، غلبه بر دقت ۷۵ درصدی مدل یادگیری انتقالی است. آن مدل یک مزیت داشت، آن هم این بود که روی مجموعه دادهای متشکل از میلیونها تصویر از قبل آموزش دیده بود، در حالی که ما اینجا فقط ۳۶۷۰ تصویر داریم. آیا میتوانید حداقل با آن برابری کنید؟
اطلاعات تکمیلی
چند لایه، چقدر بزرگ؟
انتخاب اندازه لایهها بیشتر یک هنر است تا یک علم. شما باید تعادل مناسبی بین داشتن پارامترهای خیلی کم و خیلی زیاد (وزنها و بایاسها) پیدا کنید. با وزنهای خیلی کم، شبکه عصبی نمیتواند پیچیدگی شکلهای گل را نشان دهد. با وزنهای خیلی زیاد، میتواند مستعد "بیشبرازش" باشد، یعنی در تصاویر آموزشی تخصص پیدا میکند و قادر به تعمیم نیست. با پارامترهای زیاد، مدل نیز در آموزش کند خواهد بود. در Keras، تابع model.summary() ساختار و تعداد پارامترهای مدل شما را نمایش میدهد:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
چند نکته:
- داشتن چندین لایه چیزی است که شبکههای عصبی «عمیق» را مؤثر میکند. برای این مسئله ساده تشخیص گل، ۵ تا ۱۰ لایه منطقی است.
- از فیلترهای کوچک استفاده کنید. معمولاً فیلترهای ۳x۳ در همه جا خوب هستند.
- فیلترهای ۱x۱ هم میتوانند استفاده شوند و ارزان هستند. آنها واقعاً چیزی را «فیلتر» نمیکنند، بلکه ترکیبهای خطی کانالها را محاسبه میکنند. آنها را با فیلترهای واقعی جایگزین کنید. (در بخش بعدی درباره «کانولوشنهای ۱x۱» بیشتر توضیح داده خواهد شد.)
- برای یک مسئله طبقهبندی مانند این، مرتباً با لایههای max-pooling (یا کانولوشنهایی با stride >1) نمونهبرداری کاهشی انجام دهید. برای شما مهم نیست گل کجا باشد، فقط مهم این است که گل رز باشد یا قاصدک، بنابراین از دست دادن اطلاعات x و y مهم نیست و فیلتر کردن نواحی کوچکتر ارزانتر است.
- تعداد فیلترها معمولاً مشابه تعداد کلاسها در انتهای شبکه میشود (چرا؟ به ترفند «میانگین جهانی ادغام» در زیر مراجعه کنید). اگر دادهها را به صدها کلاس طبقهبندی میکنید، تعداد فیلترها را به تدریج در لایههای متوالی افزایش دهید. برای مجموعه داده گل با ۵ کلاس، فیلتر کردن فقط با ۵ فیلتر کافی نخواهد بود. میتوانید در اکثر لایهها از تعداد فیلتر یکسانی استفاده کنید، مثلاً ۳۲ و هر چه به انتها نزدیکتر میشوید، آن را کاهش دهید.
- لایه(های) متراکم نهایی گران/گران هستند. این لایه/لایهها میتوانند وزنهای بیشتری نسبت به مجموع تمام لایههای کانولوشن داشته باشند. برای مثال، حتی با یک خروجی بسیار معقول از آخرین مکعب داده شامل ۲۴x۲۴x۱۰ نقطه داده، یک لایه متراکم ۱۰۰ نورونی هزینهای معادل ۲۴x۲۴x۱۰x۱۰۰=۵۷۶۰۰۰ وزن خواهد داشت!!! سعی کنید با فکر عمل کنید، یا از روش میانگینگیری سراسری (global average pooling) استفاده کنید (به پایین مراجعه کنید).
میانگین جهانی تجمیع
به جای استفاده از یک لایه متراکم و پرهزینه در انتهای یک شبکه عصبی کانولوشن، میتوانید «مکعب» دادههای ورودی را به تعداد کلاسهایی که دارید به بخشهای مختلف تقسیم کنید، مقادیر آنها را میانگین بگیرید و اینها را از طریق یک تابع فعالسازی softmax تغذیه کنید. این روش ساخت رأس طبقهبندی، هیچ وزنی ندارد. در Keras، سینتکس آن tf.keras.layers.GlobalAveragePooling2D().

راه حل
این دفترچهی حل مسئله است. اگر به مشکلی برخوردید، میتوانید از آن استفاده کنید.
Keras_Flowers_TPU (solution).ipynb
آنچه ما پوشش دادهایم
- 🤔 با لایههای کانولوشنی بازی شده است
- 🤓 با حداکثر تجمع، گامها، تجمع میانگین جهانی و ... آزمایش کردم.
- 😀 به سرعت روی یک مدل دنیای واقعی، روی TPU، تکرار شد
لطفا چند لحظه وقت بگذارید و این چک لیست را در ذهن خود مرور کنید.
۱۰. [اطلاعات] معماریهای کانولوشن مدرن
به طور خلاصه

تصویر: یک "ماژول" کانولوشن. در حال حاضر بهترین گزینه چیست؟ یک لایه max-pool و به دنبال آن یک لایه کانولوشن 1x1 یا ترکیبی متفاوت از لایهها؟ همه آنها را امتحان کنید، نتایج را به هم پیوند دهید و بگذارید شبکه تصمیم بگیرد. در سمت راست: معماری کانولوشن " inception " با استفاده از چنین ماژولهایی.
در کِرَس، برای ایجاد مدلهایی که جریان دادهها میتواند به شاخههای مختلف تقسیم شود، باید از سبک مدل «تابعی» استفاده کنید. در اینجا مثالی آورده شده است:
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
ترفندهای ارزان دیگر
فیلترهای کوچک ۳x۳

در این تصویر، نتیجه دو فیلتر متوالی ۳x۳ را مشاهده میکنید. سعی کنید نقاط دادهای که در نتیجه نقش داشتهاند را ردیابی کنید: این دو فیلتر متوالی ۳x۳ ترکیبی از یک ناحیه ۵x۵ را محاسبه میکنند. این دقیقاً همان ترکیبی نیست که یک فیلتر ۵x۵ محاسبه میکند، اما ارزش امتحان کردن را دارد زیرا دو فیلتر متوالی ۳x۳ ارزانتر از یک فیلتر ۵x۵ هستند.
کانولوشنهای ۱x۱؟

از نظر ریاضی، کانولوشن "1x1" ضرب در یک ثابت است، که مفهوم خیلی مفیدی نیست. با این حال، در شبکههای عصبی کانولوشن، به یاد داشته باشید که فیلتر روی یک مکعب داده اعمال میشود، نه فقط یک تصویر دوبعدی. بنابراین، یک فیلتر "1x1" مجموع وزنی یک ستون 1x1 از دادهها را محاسبه میکند (به تصویر مراجعه کنید) و همانطور که آن را روی دادهها میلغزانید، یک ترکیب خطی از کانالهای ورودی به دست خواهید آورد. این در واقع مفید است. اگر کانالها را به عنوان نتایج عملیات فیلترینگ جداگانه در نظر بگیرید، به عنوان مثال یک فیلتر برای "گوشهای نوکتیز"، یکی دیگر برای "سبیلها" و سومی برای "چشمهای شکافدار"، یک لایه کانولوشن "1x1" چندین ترکیب خطی ممکن از این ویژگیها را محاسبه میکند که ممکن است هنگام جستجوی "گربه" مفید باشد. علاوه بر این، لایههای 1x1 از وزنهای کمتری استفاده میکنند.
11. اسکوئیزنت
یک روش ساده برای کنار هم قرار دادن این ایدهها در مقاله "Squeezenet" ارائه شده است. نویسندگان، یک طراحی ماژول کانولوشنی بسیار ساده را پیشنهاد میکنند که تنها از لایههای کانولوشنی 1x1 و 3x3 استفاده میکند.

تصویر: معماری squeezenet مبتنی بر "ماژولهای آتش". آنها یک لایه ۱x۱ را که دادههای ورودی را در بعد عمودی "فشرده" میکند، به طور متناوب قرار میدهند و به دنبال آن دو لایه کانولوشنی موازی ۱x۱ و ۳x۳ قرار دارند که عمق دادهها را دوباره "گسترش" میدهند.
عملی
در ادامهی دفترچه یادداشت قبلی خود، یک شبکه عصبی کانولوشنی با الهام از squeezenet بسازید. شما باید کد مدل را به «سبک تابعی» Keras تغییر دهید.
Keras_Flowers_TPU (playground).ipynb
اطلاعات تکمیلی
برای این تمرین، تعریف یک تابع کمکی برای ماژول squeezenet مفید خواهد بود:
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
هدف این بار رسیدن به دقت ۸۰ درصدی است.
چیزهایی که باید امتحان کنید
با یک لایه کانولوشنی واحد شروع کنید، سپس با " fire_modules " ادامه دهید و به طور متناوب از لایههای MaxPooling2D(pool_size=2) استفاده کنید. میتوانید با ۲ تا ۴ لایه max pooling در شبکه و همچنین با ۱، ۲ یا ۳ ماژول fire متوالی بین لایههای max pooling آزمایش کنید.
در ماژولهای آتش، پارامتر "فشردهسازی" معمولاً باید کوچکتر از پارامتر "گسترش" باشد. این پارامترها در واقع تعداد فیلترها هستند. معمولاً میتوانند از ۸ تا ۱۹۶ متغیر باشند. میتوانید معماریهایی را آزمایش کنید که در آنها تعداد فیلترها به تدریج در شبکه افزایش مییابد، یا معماریهای سادهای که در آنها همه ماژولهای آتش تعداد فیلتر یکسانی دارند.
در اینجا یک مثال آورده شده است:
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
در این مرحله، ممکن است متوجه شوید که آزمایشهای شما چندان خوب پیش نمیروند و هدف دقت ۸۰٪ دور از دسترس به نظر میرسد. وقت آن است که چند ترفند ارزان دیگر را امتحان کنید.
نرمالسازی دستهای
هنجار دستهای به شما در حل مشکلات همگرایی که با آن مواجه هستید کمک خواهد کرد. توضیحات مفصلی در مورد این تکنیک در کارگاه بعدی ارائه خواهد شد، فعلاً لطفاً با اضافه کردن این خط بعد از هر لایه کانولوشن در شبکه خود، از جمله لایههای داخل تابع fire_module، از آن به عنوان یک دستیار "جادویی" جعبه سیاه استفاده کنید:
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
پارامتر مومنتوم باید از مقدار پیشفرض ۰.۹۹ به ۰.۹ کاهش یابد زیرا مجموعه دادههای ما کوچک است. فعلاً به این جزئیات کاری نداشته باشید.
افزایش داده
با افزایش دادهها با تبدیلهای سادهای مانند تغییر اشباع به چپ و راست، چند درصد امتیاز بیشتری خواهید گرفت:


انجام این کار در Tensorflow با استفاده از API مربوط به tf.data.Dataset بسیار آسان است. یک تابع تبدیل جدید برای دادههای خود تعریف کنید:
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
سپس از آن در تبدیل نهایی دادهها استفاده کنید (سلول "مجموعه دادههای آموزش و اعتبارسنجی"، تابع "get_batched_dataset"):
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
فراموش نکنید که افزایش داده را اختیاری کنید و کد لازم را اضافه کنید تا مطمئن شوید که فقط مجموعه داده آموزشی افزایش داده میشود . افزایش مجموعه داده اعتبارسنجی منطقی نیست.
اکنون باید به دقت ۸۰٪ در ۳۵ دوره زمانی دست یافت.
راه حل
این دفترچهی حل مسئله است. اگر به مشکلی برخوردید، میتوانید از آن استفاده کنید.
Keras_Flowers_TPU_squeezenet.ipynb
آنچه ما پوشش دادهایم
- 🤔 مدلهای «سبک کاربردی» کراس
- 🤓 معماری اسکوئیزنت
- 🤓 افزایش داده با tf.data.datset
لطفا چند لحظه وقت بگذارید و این چک لیست را در ذهن خود مرور کنید.
۱۲. اکسپشن با تنظیمات دقیق
کانولوشنهای جداشدنی
اخیراً روش متفاوتی برای پیادهسازی لایههای کانولوشن محبوبیت پیدا کرده است: کانولوشنهای جداشونده از عمق. میدانم، شاید طولانی به نظر برسد، اما مفهوم آن بسیار ساده است. آنها در Tensorflow و Keras به صورت tf.keras.layers.SeparableConv2D پیادهسازی میشوند.
یک کانولوشن جداشدنی نیز یک فیلتر را روی تصویر اجرا میکند، اما برای هر کانال از تصویر ورودی از مجموعهای مجزا از وزنها استفاده میکند. در ادامه، یک کانولوشن "1x1" اجرا میشود، مجموعهای از ضربهای نقطهای که منجر به مجموع وزندار کانالهای فیلتر شده میشود. با وزنهای جدید در هر بار، به تعداد لازم، بازترکیبهای وزندار کانالها محاسبه میشوند.

تصویر: کانولوشنهای جداشدنی. فاز ۱: کانولوشنهایی با یک فیلتر جداگانه برای هر کانال. فاز ۲: ترکیبهای خطی مجدد کانالها. با مجموعهای جدید از وزنها تکرار میشود تا زمانی که به تعداد دلخواه کانالهای خروجی برسیم. فاز ۱ را میتوان هر بار با وزنهای جدید نیز تکرار کرد، اما در عمل به ندرت این اتفاق میافتد.
کانولوشنهای جداپذیر در اکثر معماریهای شبکههای کانولوشنی جدید استفاده میشوند: MobileNetV2، Xception، EfficientNet. ضمناً، MobileNetV2 همان چیزی است که قبلاً برای یادگیری انتقالی استفاده میکردید.
آنها ارزانتر از کانولوشنهای معمولی هستند و در عمل به همان اندازه مؤثر بودهاند. در اینجا شمارش وزن برای مثال نشان داده شده در بالا آمده است:
لایه کانولوشن: ۴ × ۴ × ۳ × ۵ = ۲۴۰
لایه کانولوشنی جداپذیر: ۴ × ۴ × ۳ + ۳ × ۵ = ۴۸ + ۱۵ = ۶۳
به عنوان یک تمرین، محاسبه تعداد ضربهای مورد نیاز برای اعمال هر سبک از مقیاسهای لایه کانولوشن به روشی مشابه، به خواننده واگذار شده است. کانولوشنهای جداپذیر کوچکتر و از نظر محاسباتی بسیار مؤثرتر هستند.
عملی
از دفترچه یادداشت «یادگیری انتقالی» دوباره شروع کنید، اما این بار Xception را به عنوان مدل از پیش آموزشدیده انتخاب کنید. Xception فقط از کانولوشنهای جداشدنی استفاده میکند. همه وزنها را قابل آموزش بگذارید. ما به جای استفاده از لایههای از پیش آموزشدیده، وزنهای از پیش آموزشدیده را روی دادههای خود تنظیم دقیق خواهیم کرد.
Keras Flowers transfer learning (playground).ipynb
هدف: دقت > ۹۵٪ (نه، جدی میگم، شدنیه!)
از آنجایی که این تمرین نهایی است، به کمی کدنویسی و کار بیشتر در زمینه علوم داده نیاز دارد.
اطلاعات تکمیلی در مورد تنظیم دقیق
استثنا در مدلهای استاندارد از پیش آموزشدیده در tf.keras.application موجود است.* فراموش نکنید که این بار همه وزنها را قابل آموزش بگذارید.
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
برای رسیدن به نتایج خوب هنگام تنظیم دقیق یک مدل، باید به نرخ یادگیری توجه کنید و از یک برنامه نرخ یادگیری با یک دوره افزایش سرعت استفاده کنید. مانند این:

شروع با یک نرخ یادگیری استاندارد، وزنهای از پیش آموزشدیده مدل را مختل میکند. شروع تدریجی، آنها را حفظ میکند تا زمانی که مدل به دادههای شما متصل شود و بتواند آنها را به روشی معقول تغییر دهد. پس از مرحله شیب، میتوانید با یک نرخ یادگیری ثابت یا با نرخ یادگیری نمایی نزولی ادامه دهید.
در کِرَس، نرخ یادگیری از طریق یک فراخوانی برگشتی مشخص میشود که در آن میتوانید نرخ یادگیری مناسب را برای هر دوره محاسبه کنید. کِرَس نرخ یادگیری صحیح را برای هر دوره به بهینهساز ارسال میکند.
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
راه حل
این دفترچهی حل مسئله است. اگر به مشکلی برخوردید، میتوانید از آن استفاده کنید.
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
آنچه ما پوشش دادهایم
- 🤔 کانولوشن تفکیکپذیر از عمق
- 🤓 برنامههای نرخ یادگیری
- 😈 تنظیم دقیق یک مدل از پیش آموزشدیده.
لطفا چند لحظه وقت بگذارید و این چک لیست را در ذهن خود مرور کنید.
۱۳. تبریک میگویم!
شما اولین شبکه عصبی کانولوشن مدرن خود را ساختهاید و آن را با دقت بیش از ۹۰٪ آموزش دادهاید و به لطف TPUها، تکرار آموزشهای متوالی تنها در عرض چند دقیقه انجام میشود.
TPU ها در عمل
TPUها و GPUها در Vertex AI گوگل کلود موجود هستند:
- در مورد ماشینهای مجازی یادگیری عمیق
- در نوتبوکهای هوش مصنوعی ورتکس
- مشاغل آموزش هوش مصنوعی در ورتکس
در نهایت، ما عاشق بازخورد هستیم. لطفاً اگر در این آزمایشگاه نکتهی اشتباهی میبینید یا فکر میکنید باید بهبود یابد، به ما بگویید. بازخورد را میتوانید از طریق GitHub issues [ لینک بازخورد ] ارائه دهید.

|
|

