
1. Présentation
Dans cet atelier, vous apprendrez à créer, entraîner et paramétrer vos propres réseaux de neurones convolutifs de A à Z avec Keras et TensorFlow 2. Grâce à la puissance des TPU, vous pouvez désormais le faire en quelques minutes. Vous explorerez également plusieurs approches, de l'apprentissage par transfert très simple aux architectures convolutionnelles modernes telles que Squeezenet. Cet atelier inclut des explications théoriques sur les réseaux de neurones et constitue un bon point de départ pour les développeurs qui souhaitent en savoir plus sur le deep learning.
La lecture d'articles sur le deep learning peut être difficile et déroutante. Examinons de plus près les architectures de réseaux de neurones convolutifs modernes.

Points abordés
- Utiliser Keras et les TPU (Tensor Processing Units) pour créer plus rapidement vos modèles personnalisés.
- utiliser l'API tf.data.Dataset et le format TFRecord pour charger efficacement les données d'entraînement ;
- Pour tricher 😈, utilisez l'apprentissage par transfert au lieu de créer vos propres modèles.
- Pour utiliser les styles de modèle Keras Sequential et Functional.
- Pour créer votre propre classificateur Keras avec une couche softmax et une perte d'entropie croisée.
- Pour affiner votre modèle avec un bon choix de couches convolutives.
- Explorer les idées d'architecture de réseau de neurones convolutifs modernes, comme les modules, le pooling moyen global, etc.
- Pour créer un réseau de neurones convolutifs moderne et simple à l'aide de l'architecture SqueezeNet.
Commentaires
Si vous remarquez quelque chose d'inhabituel dans cet atelier de programmation, veuillez nous en informer. Vous pouvez envoyer vos commentaires via les problèmes GitHub [lien vers les commentaires].
2. Démarrage rapide de Google Colaboratory
Cet atelier utilise Google Collaboratory et ne nécessite aucune configuration de votre part. Vous pouvez l'exécuter depuis un Chromebook. Veuillez ouvrir le fichier ci-dessous et exécuter les cellules pour vous familiariser avec les notebooks Colab.
Sélectionner un backend TPU

Dans le menu Colab, sélectionnez Exécution > Modifier le type d'exécution, puis sélectionnez TPU. Dans cet atelier de programmation, vous allez utiliser un puissant TPU (Tensor Processing Unit) pour l'entraînement accéléré par le matériel. La connexion au runtime se fait automatiquement lors de la première exécution. Vous pouvez également utiliser le bouton "Connect" (Se connecter) en haut à droite.
Exécution de notebooks

Exécutez les cellules une par une en cliquant sur une cellule et en utilisant Maj+ENTRÉE. Vous pouvez également exécuter l'intégralité du notebook avec Exécuter > Exécuter tout.
Sommaire

Tous les notebooks contiennent une table des matières. Vous pouvez l'ouvrir à l'aide de la flèche noire sur la gauche.
Cellules masquées

Certaines cellules n'affichent que leur titre. Il s'agit d'une fonctionnalité de notebook spécifique à Colab. Vous pouvez double-cliquer dessus pour afficher le code qu'ils contiennent, mais ce n'est généralement pas très intéressant. Fonctions de support ou de visualisation, généralement. Vous devez toujours exécuter ces cellules pour que les fonctions à l'intérieur soient définies.
Authentification

Colab peut accéder à vos buckets Google Cloud Storage privés à condition que vous vous authentifiiez avec un compte autorisé. L'extrait de code ci-dessus déclenche un processus d'authentification.
3. [INFO] Que sont les Tensor Processing Units (TPU) ?
En bref

Code permettant d'entraîner un modèle sur un TPU dans Keras (et de revenir à un GPU ou un CPU si un TPU n'est pas disponible) :
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Aujourd'hui, nous allons utiliser des TPU pour créer et optimiser un classificateur de fleurs à des vitesses interactives (minutes par exécution d'entraînement).

Pourquoi utiliser des TPU ?
Les GPU modernes sont organisés autour de "cœurs" programmables, une architecture très flexible qui leur permet de gérer diverses tâches telles que le rendu 3D, le deep learning, les simulations physiques, etc. Les TPU, quant à eux, associent un processeur vectoriel classique à une unité de multiplication matricielle dédiée. Ils excellent dans toutes les tâches où les multiplications matricielles de grande taille sont prédominantes, comme les réseaux de neurones.

Illustration : couche de réseau de neurones dense sous forme de multiplication matricielle, avec un lot de huit images traitées simultanément par le réseau de neurones. Veuillez effectuer une multiplication ligne x colonne pour vérifier qu'il s'agit bien d'une somme pondérée de toutes les valeurs de pixels d'une image. Les couches de convolution peuvent également être représentées sous forme de multiplications matricielles, bien que ce soit un peu plus compliqué ( explication ici, dans la section 1).
Le matériel
MXU et VPU
Un cœur de TPU v2 est composé d'une unité de multiplication matricielle (MXU) qui exécute les multiplications matricielles et d'une unité de traitement vectoriel (VPU) pour toutes les autres tâches telles que les activations, softmax, etc. La VPU gère les calculs float32 et int32. L'unité matricielle, quant à elle, fonctionne dans un format à virgule flottante de précision mixte (16-32 bits).

Virgule flottante et bfloat16 à précision mixte
L'unité matricielle calcule les multiplications matricielles à l'aide d'entrées bfloat16 et de sorties float32. Les accumulations intermédiaires sont effectuées avec une précision float32.

L'entraînement des réseaux de neurones est généralement résistant au bruit introduit par une précision à virgule flottante réduite. Dans certains cas, le bruit aide même l'optimiseur à converger. La précision en virgule flottante 16 bits est traditionnellement utilisée pour accélérer les calculs, mais les formats float16 et float32 ont des plages très différentes. La réduction de la précision de float32 à float16 entraîne généralement des dépassements de capacité et des sous-dépassements. Des solutions existent, mais un travail supplémentaire est généralement nécessaire pour que float16 fonctionne.
C'est pourquoi Google a introduit le format bfloat16 dans les TPU. bfloat16 est un float32 tronqué avec exactement les mêmes bits d'exposant et la même plage que float32. De plus, les TPU calculent les multiplications matricielles en précision mixte avec des entrées bfloat16, mais des sorties float32. Cela signifie qu'en général, aucune modification de code n'est nécessaire pour bénéficier des gains de performances liés à la précision réduite.
Tableau systolique
L'unité MXU implémente les multiplications de matrices dans le matériel à l'aide d'une architecture dite "de tableau systolique" dans laquelle les éléments de données circulent dans un tableau d'unités de calcul matérielles. (En médecine, le terme "systolique" fait référence aux contractions cardiaques et au flux sanguin, ici au flux de données.)
L'élément de base d'une multiplication matricielle est un produit scalaire entre une ligne d'une matrice et une colonne de l'autre matrice (voir l'illustration en haut de cette section). Pour une multiplication matricielle Y=X*W, un élément du résultat serait :
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
Sur un GPU, ce produit scalaire serait programmé dans un "cœur" de GPU, puis exécuté sur autant de "cœurs" que possible en parallèle pour essayer de calculer toutes les valeurs de la matrice résultante à la fois. Si la matrice résultante est de 128 x 128, cela nécessiterait 128 x 128=16 000 "cœurs" disponibles, ce qui n'est généralement pas possible. Les plus grands GPU comptent environ 4 000 cœurs. Un TPU, en revanche, utilise le strict minimum de matériel pour les unités de calcul du MXU : uniquement bfloat16 x bfloat16 => float32 accumulateurs-multiplicateurs. Elles sont si petites qu'un TPU peut en implémenter 16 000 dans une MXU 128x128 et traiter cette multiplication matricielle en une seule fois.

Illustration du tableau systolique de l'unité matricielle. Les éléments de calcul sont des multiplicateurs-accumulateurs. Les valeurs d'une matrice sont chargées dans le tableau (points rouges). Les valeurs de l'autre matrice sont transmises au tableau (points gris). Les lignes verticales propagent les valeurs vers le haut. Les lignes horizontales propagent les sommes partielles. Il appartient à l'utilisateur de vérifier que, lorsque les données circulent dans le tableau, le résultat de la multiplication matricielle sort du côté droit.
De plus, lorsque les produits scalaires sont calculés dans une MXU, les sommes intermédiaires circulent simplement entre les unités de calcul adjacentes. Il n'est pas nécessaire de les stocker et de les récupérer dans la mémoire ou même dans un fichier de registre. Le résultat final est que l'architecture de réseau systolique TPU présente un avantage significatif en termes de densité et de puissance, ainsi qu'un avantage non négligeable en termes de vitesse par rapport à un GPU, lors du calcul des multiplications matricielles.
Cloud TPU
Lorsque vous demandez un Cloud TPU v2 sur Google Cloud Platform, vous obtenez une machine virtuelle (VM) dotée d'une carte TPU connectée à un port PCI. La carte TPU comporte quatre puces TPU à double cœur. Chaque cœur de TPU comprend une VPU (Vector Processing Unit) et une MXU (MatriX multiply Unit) de 128 x 128. Ce "Cloud TPU" est ensuite généralement connecté via le réseau à la VM qui l'a demandé. Voici à quoi ressemble l'image complète :

Illustration : votre VM avec un accélérateur "Cloud TPU" associé au réseau. Le "Cloud TPU" lui-même est constitué d'une VM avec une carte TPU connectée à un port PCI, qui comporte quatre puces TPU à double cœur.
Pods TPU
Dans les centres de données Google, les TPU sont connectés à une interconnexion de calcul hautes performances (HPC, High Performance Computing), ce qui peut les faire apparaître comme un très grand accélérateur. Google les appelle des pods. Ils peuvent englober jusqu'à 512 cœurs de TPU v2 ou 2 048 cœurs de TPU v3.

Illustration : un pod TPU v3. Cartes et racks TPU connectés via une interconnexion HPC.
Pendant l'entraînement, les gradients sont échangés entre les cœurs de TPU à l'aide de l'algorithme all-reduce ( bonne explication de all-reduce ici). Le modèle en cours d'entraînement peut tirer parti du matériel en s'entraînant sur de grandes tailles de lot.

Illustration : synchronisation des gradients lors de l'entraînement à l'aide de l'algorithme All-Reduce sur le réseau HPC à mailles toriques bidimensionnelles des TPU Google.
Le logiciel
Entraînement avec une grande taille de lot
La taille de lot idéale pour les TPU est de 128 éléments de données par cœur de TPU, mais le matériel peut déjà afficher une bonne utilisation à partir de huit éléments de données par cœur de TPU. N'oubliez pas qu'un Cloud TPU comporte huit cœurs.
Dans cet atelier de programmation, nous utiliserons l'API Keras. Dans Keras, le lot que vous spécifiez correspond à la taille de lot globale pour l'ensemble du TPU. Vos lots seront automatiquement divisés par huit et exécutés sur les huit cœurs du TPU.

Pour obtenir d'autres conseils sur les performances, consultez le Guide sur les performances des TPU. Pour les tailles de batch très importantes, une attention particulière peut être nécessaire dans certains modèles. Pour en savoir plus, consultez LARSOptimizer.
En coulisses : XLA
Les programmes TensorFlow définissent des graphes de calcul. Le TPU n'exécute pas directement le code Python, mais le graphe de calcul défini par votre programme TensorFlow. En coulisses, un compilateur appelé XLA (accelerated Linear Algebra compiler) transforme le graphique TensorFlow des nœuds de calcul en code machine TPU. Ce compilateur effectue également de nombreuses optimisations avancées sur votre code et votre disposition de mémoire. La compilation se produit automatiquement lorsque le travail est envoyé au TPU. Vous n'avez pas besoin d'inclure explicitement XLA dans votre chaîne de compilation.

Illustration : pour s'exécuter sur un TPU, le graphe de calcul défini par votre programme TensorFlow est d'abord traduit en représentation XLA (compilateur d'algèbre linéaire accélérée), puis compilé par XLA en code machine TPU.
Utiliser des TPU dans Keras
Les TPU sont compatibles avec l'API Keras à partir de TensorFlow 2.1. La compatibilité avec Keras fonctionne sur les TPU et les pods TPU. Voici un exemple qui fonctionne sur les TPU, les GPU et les CPU :
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Dans cet extrait de code :
TPUClusterResolver().connect()trouve le TPU sur le réseau. Il fonctionne sans paramètre sur la plupart des systèmes Google Cloud (jobs AI Platform, Colaboratory, Kubeflow, VM de deep learning créées à l'aide de l'utilitaire "ctpu up"). Ces systèmes savent où se trouve leur TPU grâce à une variable d'environnement TPU_NAME. Si vous créez un TPU manuellement, définissez la variable d'environnement TPU_NAME sur la VM à partir de laquelle vous l'utilisez, ou appelezTPUClusterResolveravec des paramètres explicites :TPUClusterResolver(tp_uname, zone, project).TPUStrategyest la partie qui implémente l'algorithme de distribution et de synchronisation des gradients "all-reduce".- La stratégie est appliquée à l'aide d'un champ d'application. Le modèle doit être défini dans la portée de la stratégie (scope()).
- La fonction
tpu_model.fitattend un objet tf.data.Dataset en entrée pour l'entraînement du TPU.
Tâches courantes de portage de TPU
- Bien qu'il existe de nombreuses façons de charger des données dans un modèle TensorFlow, l'utilisation de l'API
tf.data.Datasetest requise pour les TPU. - Les TPU sont très rapides. L'ingestion de données devient souvent un goulot d'étranglement lorsqu'elles sont exécutées sur ces processeurs. Le Guide des performances des TPU contient des outils permettant de détecter les goulots d'étranglement des données et d'autres conseils sur les performances.
- Les nombres int8 ou int16 sont traités comme des nombres int32. Le TPU ne dispose pas de matériel entier fonctionnant sur moins de 32 bits.
- Certaines opérations TensorFlow ne sont pas compatibles. Cliquez ici pour consulter la liste. La bonne nouvelle, c'est que cette limite ne s'applique qu'au code d'entraînement, c'est-à-dire aux passes avant et arrière de votre modèle. Vous pouvez toujours utiliser toutes les opérations TensorFlow dans votre pipeline d'entrée de données, car elles seront exécutées sur le processeur.
tf.py_funcn'est pas compatible avec les TPU.
4. Chargement des données…






Nous allons travailler avec un ensemble de données d'images de fleurs. L'objectif est d'apprendre à les classer en cinq types de fleurs. Le chargement des données s'effectue à l'aide de l'API tf.data.Dataset. Commençons par découvrir l'API.
Pratique
Veuillez ouvrir le notebook suivant, exécuter les cellules (Shift+ENTRÉE) et suivre les instructions chaque fois que vous voyez le libellé "WORK REQUIRED" (ACTION REQUISE).

Fun with tf.data.Dataset (playground).ipynb
Informations supplémentaires
À propos de l'ensemble de données "flowers"
L'ensemble de données est organisé en cinq dossiers. Chaque dossier contient des fleurs d'un seul type. Les dossiers sont nommés "sunflowers" (tournesols), "daisy" (marguerites), "dandelion" (pissenlits), "tulips" (tulipes) et "roses" (roses). Les données sont hébergées dans un bucket public sur Google Cloud Storage. Extrait :
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
Pourquoi tf.data.Dataset ?
Keras et TensorFlow acceptent les ensembles de données dans toutes leurs fonctions d'entraînement et d'évaluation. Une fois que vous avez chargé des données dans un ensemble de données, l'API propose toutes les fonctionnalités courantes utiles pour les données d'entraînement des réseaux de neurones :
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
Pour obtenir des conseils sur les performances et les bonnes pratiques concernant les ensembles de données, consultez cet article. Cliquez ici pour accéder à la documentation de référence.
Principes de base de tf.data.Dataset
Les données se présentent généralement sous la forme de plusieurs fichiers (ici, des images). Vous pouvez créer un ensemble de données de noms de fichiers en appelant :
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
Vous "mappez" ensuite une fonction à chaque nom de fichier, ce qui chargera et décodera généralement le fichier en données réelles en mémoire :
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
Pour itérer sur un ensemble de données :
for data in my_dataset:
print(data)
Ensembles de données de tuples
Dans l'apprentissage supervisé, un ensemble de données d'entraînement est généralement constitué de paires de données d'entraînement et de réponses correctes. Pour ce faire, la fonction de décodage peut renvoyer des tuples. Vous disposerez alors d'un ensemble de données de tuples, qui seront renvoyés lorsque vous itérerez dessus. Les valeurs renvoyées sont des Tensors TensorFlow prêts à être utilisés par votre modèle. Vous pouvez appeler .numpy() sur eux pour afficher les valeurs brutes :
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
Conclusion : le chargement des images une par une est lent !
Au fur et à mesure que vous itérez sur cet ensemble de données, vous verrez que vous pouvez charger environ une à deux images par seconde. C'est trop lent ! Les accélérateurs matériels que nous utiliserons pour l'entraînement peuvent supporter plusieurs fois ce taux. Pour savoir comment nous allons y parvenir, consultez la section suivante.
Solution
Voici le notebook de solution. Vous pouvez l'utiliser si vous êtes bloqué.
Fun with tf.data.Dataset (solution).ipynb
Points abordés
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 Ensembles de données de tuples
- 😀 Itérer dans les ensembles de données
Veuillez prendre quelques instants pour passer en revue cette checklist.
5. Charger les données rapidement
Les accélérateurs matériels TPU (Tensor Processing Unit) que nous utiliserons dans cet atelier sont très rapides. Le défi consiste souvent à leur fournir des données assez rapidement pour les occuper. Google Cloud Storage (GCS) est capable de maintenir un débit très élevé, mais comme pour tous les systèmes de stockage cloud, l'établissement d'une connexion entraîne des échanges réseau. Il n'est donc pas idéal que nos données soient stockées sous la forme de milliers de fichiers individuels. Nous allons les regrouper dans un plus petit nombre de fichiers et utiliser la puissance de tf.data.Dataset pour lire plusieurs fichiers en parallèle.
Lecture complète
Le code qui charge les fichiers image, les redimensionne à une taille commune, puis les stocke dans 16 fichiers TFRecord se trouve dans le notebook suivant. Veuillez la lire rapidement. Il n'est pas nécessaire de l'exécuter, car des données au format TFRecord approprié seront fournies pour le reste de l'atelier de programmation.
Flower pictures to TFRecords.ipynb
Disposition idéale des données pour un débit GCS optimal
Format de fichier TFRecord
Le format de fichier préféré de TensorFlow pour stocker des données est le format TFRecord basé sur protobuf. D'autres formats de sérialisation fonctionneraient également, mais vous pouvez charger un ensemble de données à partir de fichiers TFRecord directement en écrivant :
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Pour des performances optimales, il est recommandé d'utiliser le code plus complexe suivant pour lire plusieurs fichiers TFRecord à la fois. Ce code lira N fichiers en parallèle et ignorera l'ordre des données au profit de la vitesse de lecture.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Aide-mémoire TFRecord
Trois types de données peuvent être stockés dans les TFRecords : les chaînes d'octets (liste d'octets), les entiers de 64 bits et les nombres à virgule flottante de 32 bits. Elles sont toujours stockées sous forme de listes. Un élément de données unique sera une liste de taille 1. Vous pouvez utiliser les fonctions d'assistance suivantes pour stocker des données dans des enregistrements TFRecord.
Écrire des chaînes d'octets
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
Écrire des nombres entiers
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
flottants d'écriture
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
Écrire un TFRecord à l'aide des assistants ci-dessus
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
Pour lire les données des TFRecords, vous devez d'abord déclarer la mise en page des enregistrements que vous avez stockés. Dans la déclaration, vous pouvez accéder à n'importe quel champ nommé en tant que liste à longueur fixe ou à longueur variable :
Lecture à partir de TFRecords
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
Extraits de code utiles :
lire des éléments de données individuels ;
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
lire des listes d'éléments de taille fixe
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
lire un nombre variable d'éléments de données
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
Un VarLenFeature renvoie un vecteur creux. Une étape supplémentaire est requise après le décodage du TFRecord :
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
Il est également possible d'avoir des champs facultatifs dans les TFRecords. Si vous spécifiez une valeur par défaut lors de la lecture d'un champ, cette valeur est renvoyée à la place d'une erreur si le champ est manquant.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
Points abordés
- 🤔 Fractionner les fichiers de données pour un accès rapide depuis GCS
- 😓 comment écrire des TFRecords. (Vous avez déjà oublié la syntaxe ? (Pas de panique, vous pouvez ajouter cette page à vos favoris pour vous en servir de pense-bête.)
- 🤔 Charger un ensemble de données à partir de TFRecords à l'aide de TFRecordDataset
Veuillez prendre quelques instants pour passer en revue cette checklist.
6. [INFO] Principes de base du classificateur de réseau de neurones
En bref
Si vous connaissez déjà tous les termes en gras du paragraphe suivant, vous pouvez passer à l'exercice suivant. Si vous débutez dans le deep learning, bienvenue. Veuillez lire la suite.
Pour les modèles créés sous forme de séquence de couches, Keras propose l'API Sequential. Par exemple, un classificateur d'images utilisant trois couches denses peut être écrit dans Keras comme suit :
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
Réseau de neurones dense
Il s'agit du réseau de neurones le plus simple pour classer des images. Il est composé de "neurones" organisés en couches. La première couche traite les données d'entrée et transmet ses sorties à d'autres couches. Elle est appelée "dense" parce que chaque neurone est connecté à tous les neurones de la couche précédente.

Vous pouvez fournir une image à un tel réseau en aplatissant les valeurs RVB de tous ses pixels en un long vecteur et en l'utilisant comme entrée. Ce n'est pas la meilleure technique pour la reconnaissance d'images, mais nous l'améliorerons plus tard.
Neurones, activations, RELU
Un "neurone" calcule une somme pondérée de toutes ses entrées, ajoute une valeur appelée "biais" et transmet le résultat via une "fonction d'activation". Les pondérations et le biais sont inconnus au départ. Ils seront initialisés de manière aléatoire et "appris" en entraînant le réseau de neurones sur de nombreuses données connues.

La fonction d'activation la plus populaire est appelée RELU (Rectified Linear Unit). Comme vous pouvez le voir sur le graphique ci-dessus, il s'agit d'une fonction très simple.
Activation Softmax
Le réseau ci-dessus se termine par une couche de cinq neurones, car nous classons les fleurs dans cinq catégories (rose, tulipe, pissenlit, marguerite et tournesol). Les neurones des couches intermédiaires sont activés à l'aide de la fonction d'activation ReLU classique. Cependant, dans la dernière couche, nous voulons calculer des nombres compris entre 0 et 1 représentant la probabilité que cette fleur soit une rose, une tulipe, etc. Pour ce faire, nous utiliserons une fonction d'activation appelée "softmax".
Pour appliquer softmax à un vecteur, il faut prendre l'exponentielle de chaque élément, puis normaliser le vecteur, généralement à l'aide de la norme L1 (somme des valeurs absolues) afin que les valeurs s'additionnent à 1 et puissent être interprétées comme des probabilités.


Perte d'entropie croisée
Maintenant que notre réseau de neurones produit des prédictions à partir d'images d'entrée, nous devons mesurer leur qualité, c'est-à-dire la distance entre ce que le réseau nous dit et les réponses correctes, souvent appelées "libellés". N'oubliez pas que nous disposons de libellés corrects pour toutes les images de l'ensemble de données.
N'importe quelle distance conviendrait, mais pour les problèmes de classification, la "distance d'entropie croisée" est la plus efficace. Nous appellerons cela notre fonction d'erreur ou de "perte" :

Descente de gradient
"Entraîner" le réseau de neurones signifie en fait utiliser des images et des libellés d'entraînement pour ajuster les pondérations et les biais afin de minimiser la fonction de perte d'entropie croisée. Voici comment cela fonctionne.
L'entropie croisée est une fonction des pondérations, des biais, des pixels de l'image d'entraînement et de sa classe connue.
Si nous calculons les dérivées partielles de l'entropie croisée par rapport à tous les poids et à tous les biais, nous obtenons un "gradient", calculé pour une image, un libellé et une valeur actuelle de poids et de biais donnés. N'oubliez pas que nous pouvons avoir des millions de pondérations et de biais. Le calcul du gradient semble donc être une tâche considérable. Heureusement, TensorFlow le fait pour nous. La propriété mathématique d'un gradient est qu'il pointe vers le haut. Comme nous voulons aller là où l'entropie croisée est faible, nous allons dans la direction opposée. Nous mettons à jour les pondérations et les biais par une fraction du gradient. Nous répétons ensuite la même chose encore et encore en utilisant les lots suivants d'images et d'étiquettes d'entraînement, dans une boucle d'entraînement. Nous espérons que cela convergera vers un endroit où l'entropie croisée est minimale, bien que rien ne garantisse que ce minimum soit unique.

Mini-batching et momentum
Vous pouvez calculer votre gradient sur une seule image d'exemple et mettre à jour immédiatement les pondérations et les biais. Toutefois, si vous le faites sur un lot de, par exemple, 128 images, vous obtiendrez un gradient qui représente mieux les contraintes imposées par différentes images d'exemple et qui est donc susceptible de converger plus rapidement vers la solution. La taille du mini-lot est un paramètre ajustable.
Cette technique, parfois appelée "descente de gradient stochastique", présente un autre avantage plus pragmatique : travailler avec des lots signifie également travailler avec des matrices plus grandes, qui sont généralement plus faciles à optimiser sur les GPU et les TPU.
La convergence peut toutefois rester un peu chaotique et peut même s'arrêter si le vecteur de gradient est entièrement nul. Cela signifie-t-il que nous avons trouvé un minimum ? Non. Un composant de dégradé peut être nul à un minimum ou à un maximum. Avec un vecteur de gradient comportant des millions d'éléments, si tous sont nuls, la probabilité que chaque zéro corresponde à un minimum et qu'aucun ne corresponde à un point maximal est assez faible. Dans un espace à plusieurs dimensions, les points de selle sont assez courants et nous ne voulons pas nous y arrêter.

Illustration : un point-selle. Le gradient est nul, mais il ne s'agit pas d'un minimum dans toutes les directions. (Attribution de l'image : Wikimedia : par Nicoguaro – Own work, CC BY 3.0)
La solution consiste à ajouter de l'élan à l'algorithme d'optimisation afin qu'il puisse dépasser les points-selles sans s'arrêter.
Glossaire
Lot ou mini-lot : l'entraînement est toujours effectué sur des lots de données et d'étiquettes d'entraînement. Cela permet à l'algorithme de converger. La dimension "batch" est généralement la première dimension des Tensors de données. Par exemple, un Tensor de forme [100, 192, 192, 3] contient 100 images de 192 x 192 pixels avec trois valeurs par pixel (RVB).
Perte d'entropie croisée : fonction de perte spéciale souvent utilisée dans les classificateurs.
Couche dense : couche de neurones où chaque neurone est connecté à tous les neurones de la couche précédente.
Caractéristiques : les entrées d'un réseau de neurones sont parfois appelées "caractéristiques". L'art de déterminer quelles parties d'un ensemble de données (ou combinaisons de parties) transmettre à un réseau de neurones pour obtenir de bonnes prédictions s'appelle l'ingénierie des caractéristiques.
Libellés : autre nom pour les "classes" ou les réponses correctes dans un problème de classification supervisée.
Taux d'apprentissage : fraction du gradient par laquelle les pondérations et les biais sont mis à jour à chaque itération de la boucle d'entraînement.
logits : les sorties d'une couche de neurones avant l'application de la fonction d'activation sont appelées "logits". Le terme provient de la "fonction logistique", également appelée "fonction sigmoïde", qui était la fonction d'activation la plus populaire. "Sorties de neurones avant la fonction logistique" a été raccourci en "logits".
loss : fonction d'erreur comparant les sorties du réseau de neurones aux bonnes réponses
Neurone : calcule la somme pondérée de ses entrées, ajoute un biais et transmet le résultat via une fonction d'activation.
Encodage one-hot : la classe 3 sur 5 est encodée sous forme de vecteur de cinq éléments, tous nuls sauf le troisième qui est égal à 1.
relu : unité de rectification linéaire. Fonction d'activation populaire pour les neurones.
sigmoid : autre fonction d'activation qui était populaire et qui est toujours utile dans des cas particuliers.
softmax : fonction d'activation spéciale qui agit sur un vecteur, augmente la différence entre le plus grand composant et tous les autres, et normalise également le vecteur pour que la somme soit égale à 1, afin qu'il puisse être interprété comme un vecteur de probabilités. Utilisé comme dernière étape dans les classificateurs.
Tenseur : un tenseur est semblable à une matrice, mais avec un nombre arbitraire de dimensions. Un Tensor unidimensionnel est un vecteur. Un Tensor à deux dimensions est une matrice. Vous pouvez ensuite avoir des Tensors avec 3, 4, 5 ou plus de dimensions.
7. Apprentissage par transfert
Pour un problème de classification d'images, les couches denses ne suffiront probablement pas. Nous devons en apprendre davantage sur les couches de convolution et les nombreuses façons de les organiser.
Mais nous pouvons aussi prendre un raccourci ! Des réseaux de neurones convolutifs entièrement entraînés sont disponibles au téléchargement. Il est possible de supprimer leur dernière couche, la tête de classification softmax, et de la remplacer par la vôtre. Tous les poids et biais entraînés restent tels quels. Vous n'avez qu'à réentraîner la couche softmax que vous ajoutez. Cette technique s'appelle l'apprentissage par transfert. Étonnamment, elle fonctionne tant que l'ensemble de données sur lequel le réseau de neurones est pré-entraîné est "suffisamment proche" du vôtre.
Pratique
Veuillez ouvrir le notebook suivant, exécuter les cellules (Shift+ENTRÉE) et suivre les instructions chaque fois que vous voyez le libellé "WORK REQUIRED" (ACTION REQUISE).
Keras Flowers transfer learning (playground).ipynb
Informations supplémentaires
L'apprentissage par transfert vous permet de bénéficier à la fois des architectures avancées de réseaux de neurones convolutifs développées par les meilleurs chercheurs et du pré-entraînement sur un énorme ensemble de données d'images. Dans notre cas, nous allons effectuer un transfert d'apprentissage à partir d'un réseau entraîné sur ImageNet, une base de données d'images contenant de nombreuses plantes et scènes d'extérieur, ce qui est suffisamment proche des fleurs.
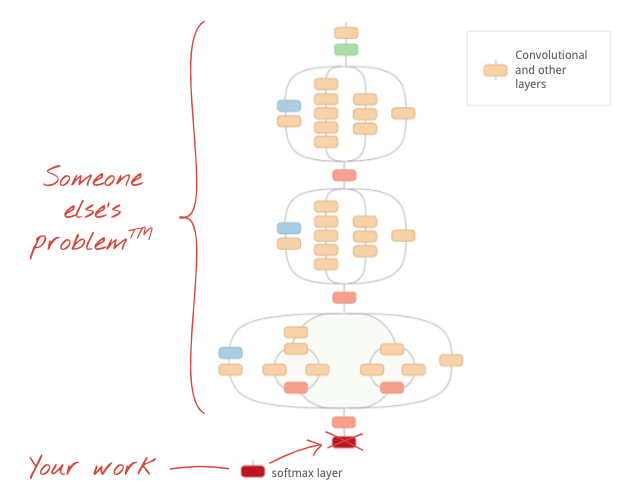
Illustration : utilisation d'un réseau de neurones convolutif complexe, déjà entraîné, comme boîte noire, en réentraînant uniquement la tête de classification. C'est ce qu'on appelle l'apprentissage par transfert. Nous verrons plus tard comment fonctionnent ces arrangements complexes de couches de convolution. Pour l'instant, c'est le problème de quelqu'un d'autre.
Apprentissage par transfert dans Keras
Dans Keras, vous pouvez instancier un modèle pré-entraîné à partir de la collection tf.keras.applications.*. MobileNet V2, par exemple, est une très bonne architecture convolutionnelle qui reste de taille raisonnable. En sélectionnant include_top=False, vous obtenez le modèle pré-entraîné sans sa dernière couche softmax, ce qui vous permet d'ajouter la vôtre :
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
Notez également le paramètre pretrained_model.trainable = False. Il fige les pondérations et les biais du modèle pré-entraîné afin que vous n'entraîniez que votre couche softmax. Cela implique généralement un nombre relativement faible de pondérations et peut être effectué rapidement sans nécessiter un très grand ensemble de données. Toutefois, si vous disposez de nombreuses données, l'apprentissage par transfert peut fonctionner encore mieux avec pretrained_model.trainable = True. Les pondérations pré-entraînées fournissent ensuite d'excellentes valeurs initiales et peuvent toujours être ajustées par l'entraînement pour mieux s'adapter à votre problème.
Enfin, notez que la couche Flatten() est insérée avant votre couche softmax dense. Les couches denses fonctionnent sur des vecteurs de données plats, mais nous ne savons pas si c'est ce que renvoie le modèle préentraîné. C'est pourquoi nous devons l'aplatir. Dans le prochain chapitre, lorsque nous aborderons les architectures convolutionnelles, nous expliquerons le format de données renvoyé par les couches convolutionnelles.
Vous devriez obtenir une précision proche de 75 % avec cette approche.
Solution
Voici le notebook de solution. Vous pouvez l'utiliser si vous êtes bloqué.
Keras Flowers transfer learning (solution).ipynb
Points abordés
- 🤔 Écrire un classificateur dans Keras
- 🤓 configuré avec une dernière couche softmax et une perte d'entropie croisée
- 😈 Apprentissage par transfert
- 🤔 Entraîner votre premier modèle
- 🧐 Suivre sa perte et sa précision pendant l'entraînement
Veuillez prendre quelques instants pour passer en revue cette checklist.
8. [INFO] Réseaux de neurones convolutifs
En bref
Si vous connaissez déjà tous les termes en gras du paragraphe suivant, vous pouvez passer à l'exercice suivant. Si vous débutez avec les réseaux de neurones convolutifs, veuillez lire la suite.

Illustration : filtrage d'une image avec deux filtres successifs composés chacun de 4 x 4 x 3=48 poids pouvant être appris.
Voici à quoi ressemble un réseau de neurones convolutif simple dans Keras :
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
Principes de base des réseaux de neurones convolutifs
Dans une couche d'un réseau convolutif, un "neurone" effectue une somme pondérée des pixels situés juste au-dessus, uniquement sur une petite région de l'image. Il ajoute un biais et transmet la somme via une fonction d'activation, comme le ferait un neurone dans une couche dense régulière. Cette opération est ensuite répétée sur l'ensemble de l'image en utilisant les mêmes pondérations. N'oubliez pas que dans les couches denses, chaque neurone avait ses propres pondérations. Ici, un seul "patch" de pondérations glisse sur l'image dans les deux sens (une "convolution"). La sortie comporte autant de valeurs que de pixels dans l'image (un remplissage est toutefois nécessaire sur les bords). Il s'agit d'une opération de filtrage utilisant un filtre de 4 x 4 x 3=48 pondérations.
Toutefois, 48 pondérations ne suffiront pas. Pour ajouter des degrés de liberté, nous répétons la même opération avec un nouvel ensemble de pondérations. Un nouvel ensemble de résultats de filtrage est alors généré. Appelons-le "canal" de sorties par analogie avec les canaux R, G et B de l'image d'entrée.

Les deux ensembles de pondérations (ou plus) peuvent être résumés en un seul Tensor en ajoutant une nouvelle dimension. Cela nous donne la forme générique du Tensor de poids pour une couche de convolution. Étant donné que le nombre de canaux d'entrée et de sortie sont des paramètres, nous pouvons commencer à empiler et à enchaîner des couches de convolution.

Illustration : un réseau de neurones convolutif transforme des "cubes" de données en d'autres "cubes" de données.
Convolutions avec stride, pooling maximal
En effectuant les convolutions avec un pas de 2 ou 3, nous pouvons également réduire le cube de données résultant dans ses dimensions horizontales. Pour ce faire, deux méthodes courantes s'offrent à vous :
- Convolution à pas : filtre coulissant comme ci-dessus, mais avec un pas > 1
- Pooling maximal : fenêtre glissante appliquant l'opération MAX (généralement sur des blocs 2x2, répétés tous les deux pixels)

Illustration : si vous faites glisser la fenêtre de calcul de trois pixels, vous obtiendrez moins de valeurs de sortie. Les convolutions à pas ou le pooling maximal (max sur une fenêtre 2x2 glissant par un pas de 2) permettent de réduire le cube de données dans les dimensions horizontales.
Classificateur à convolution
Enfin, nous ajoutons un en-tête de classification en aplatissant le dernier cube de données et en l'insérant dans une couche dense activée par softmax. Un classificateur convolutif typique peut se présenter comme suit :

Illustration : un classificateur d'images utilisant des couches convolutives et softmax. Il utilise des filtres 3x3 et 1x1. Les couches maxpool prennent le maximum des groupes de points de données 2x2. La tête de classification est implémentée avec une couche dense avec activation softmax.
Dans Keras
La pile de convolution illustrée ci-dessus peut être écrite dans Keras comme suit :
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
9. Votre réseau de neurones convolutifs personnalisé
Pratique
Nous allons créer et entraîner un réseau de neurones convolutif de A à Z. L'utilisation d'un TPU nous permettra d'itérer très rapidement. Veuillez ouvrir le notebook suivant, exécuter les cellules (Shift+ENTRÉE) et suivre les instructions chaque fois que vous voyez le libellé "WORK REQUIRED" (ACTION REQUISE).
Keras_Flowers_TPU (playground).ipynb
L'objectif est de dépasser la précision de 75 % du modèle d'apprentissage par transfert. Ce modèle avait l'avantage d'avoir été pré-entraîné sur un ensemble de données de plusieurs millions d'images, alors que nous n'en avons que 3 670 ici. Pouvez-vous au moins l'égaler ?
Informations supplémentaires
Combien de couches et quelle taille ?
La sélection de la taille des couches est plus un art qu'une science. Vous devez trouver le bon équilibre entre un nombre de paramètres (pondérations et biais) trop faible et un nombre trop élevé. Avec trop peu de poids, le réseau de neurones ne peut pas représenter la complexité des formes de fleurs. Si vous en utilisez trop, le modèle peut être sujet au "surapprentissage", c'est-à-dire qu'il se spécialise dans les images d'entraînement et n'est pas capable de généraliser. Si le modèle comporte de nombreux paramètres, son entraînement sera également lent. Dans Keras, la fonction model.summary() affiche la structure et le nombre de paramètres de votre modèle :
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
Voici quelques conseils :
- L'efficacité des réseaux de neurones "profonds" réside dans le fait qu'ils comportent plusieurs couches. Pour ce problème simple de reconnaissance de fleurs, 5 à 10 couches sont appropriées.
- Utilisez des filtres de petite taille. En général, les filtres 3x3 sont efficaces partout.
- Les filtres 1x1 peuvent également être utilisés et sont peu coûteux. Ils ne "filtrent" rien, mais calculent des combinaisons linéaires de canaux. Alternez-les avec de vrais filtres. (Nous aborderons les convolutions 1x1 plus en détail dans la section suivante.)
- Pour un problème de classification comme celui-ci, sous-échantillonnez fréquemment avec des couches de mise en commun maximale (ou des convolutions avec un pas > 1). Peu importe où se trouve la fleur, il suffit qu'il s'agisse d'une rose ou d'un pissenlit. Il n'est donc pas important de perdre les informations x et y, et il est moins coûteux de filtrer les zones plus petites.
- Le nombre de filtres devient généralement similaire au nombre de classes à la fin du réseau (pourquoi ? Voir l'astuce "pooling moyen global" ci-dessous). Si vous effectuez une classification dans des centaines de classes, augmentez progressivement le nombre de filtres dans les couches consécutives. Pour l'ensemble de données sur les fleurs avec cinq classes, le filtrage avec seulement cinq filtres ne suffirait pas. Vous pouvez utiliser le même nombre de filtres dans la plupart des couches (par exemple, 32) et le diminuer vers la fin.
- La ou les dernières couches denses sont coûteuses. Il/Elle peut avoir plus de pondérations que toutes les couches de convolution combinées. Par exemple, même avec une sortie très raisonnable du dernier cube de données de 24x24x10 points de données, une couche dense de 100 neurones coûterait 24x24x10x100=576 000 poids !!! Essayez d'être réfléchi ou essayez le pooling moyen global (voir ci-dessous).
Pooling moyen global
Au lieu d'utiliser une couche dense coûteuse à la fin d'un réseau neuronal convolutif, vous pouvez diviser le "cube" de données entrantes en autant de parties que vous avez de classes, calculer la moyenne de leurs valeurs et les transmettre via une fonction d'activation softmax. Cette façon de créer l'en-tête de classification ne coûte aucun poids. Dans Keras, la syntaxe est tf.keras.layers.GlobalAveragePooling2D().

Solution
Voici le notebook de solution. Vous pouvez l'utiliser si vous êtes bloqué.
Keras_Flowers_TPU (solution).ipynb
Points abordés
- 🤔 J'ai joué avec les couches convolutives
- 🤓 Vous avez expérimenté le pooling maximal, les foulées, le pooling moyen global, etc.
- 😀 a itéré rapidement sur un modèle réel, sur TPU
Veuillez prendre quelques instants pour passer en revue cette checklist.
10. [INFO] Architectures convolutionnelles modernes
En bref
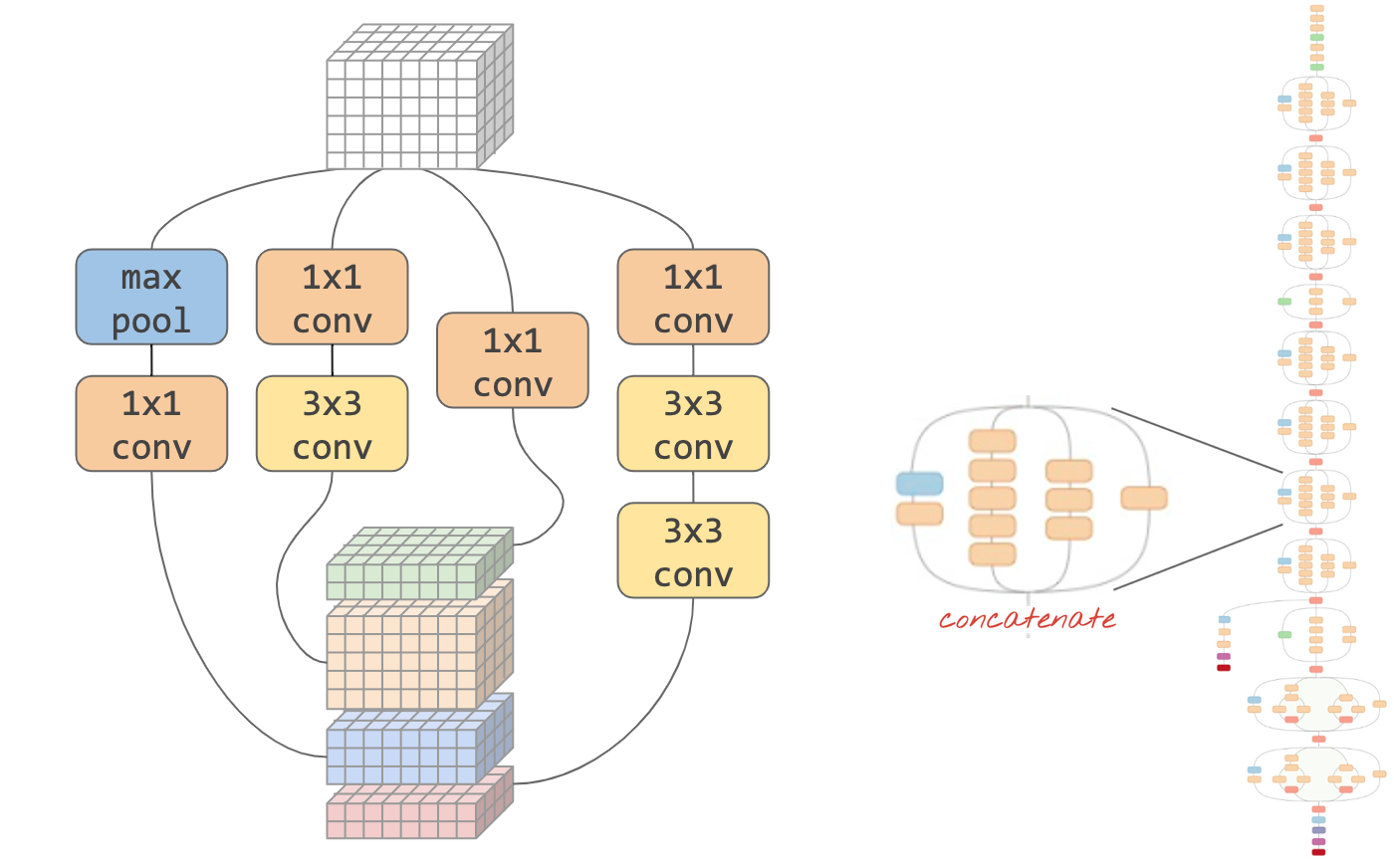
Illustration : un "module" de convolution. Que faire à ce stade ? Une couche de pooling maximal suivie d'une couche convolutive 1x1 ou d'une autre combinaison de couches ? Essayez-les tous, concaténez les résultats et laissez le réseau décider. À droite : architecture convolutionnelle inception utilisant de tels modules.
Dans Keras, pour créer des modèles où le flux de données peut se ramifier, vous devez utiliser le style de modèle "fonctionnel". Voici un exemple :
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
Autres astuces à bas prix
Petits filtres 3x3

Dans cette illustration, vous voyez le résultat de deux filtres 3x3 consécutifs. Essayez de remonter à la source des points de données qui ont contribué au résultat : ces deux filtres 3x3 consécutifs calculent une combinaison d'une région 5x5. Il ne s'agit pas exactement de la même combinaison qu'un filtre 5x5 calculerait, mais cela vaut la peine d'essayer, car deux filtres 3x3 consécutifs sont moins chers qu'un seul filtre 5x5.
Convolutions 1 x 1 ?

En termes mathématiques, une convolution "1x1" est une multiplication par une constante, ce qui n'est pas un concept très utile. Toutefois, dans les réseaux de neurones convolutifs, n'oubliez pas que le filtre est appliqué à un cube de données, et pas seulement à une image 2D. Par conséquent, un filtre "1x1" calcule une somme pondérée d'une colonne de données 1x1 (voir l'illustration). Lorsque vous le faites glisser sur les données, vous obtenez une combinaison linéaire des canaux de l'entrée. C'est vraiment utile. Si vous considérez les canaux comme les résultats d'opérations de filtrage individuelles (par exemple, un filtre pour les "oreilles pointues", un autre pour les "moustaches" et un troisième pour les "yeux en amande"), une couche de convolution "1x1" calculera plusieurs combinaisons linéaires possibles de ces caractéristiques, ce qui peut être utile pour rechercher un "chat". De plus, les couches 1x1 utilisent moins de pondérations.
11. Squeezenet
Une façon simple de combiner ces idées a été présentée dans l'article sur Squeezenet. Les auteurs suggèrent une conception de module de convolution très simple, n'utilisant que des couches de convolution 1x1 et 3x3.

Illustration : architecture SqueezeNet basée sur des "modules Fire". Ils alternent une couche 1x1 qui "compresse" les données entrantes dans la dimension verticale, suivie de deux couches convolutionnelles parallèles 1x1 et 3x3 qui "décompressent" à nouveau la profondeur des données.
Pratique
Poursuivez dans votre notebook précédent et créez un réseau de neurones convolutif inspiré de SqueezeNet. Vous devrez modifier le code du modèle pour le passer au "style fonctionnel" de Keras.
Keras_Flowers_TPU (playground).ipynb
Informations supplémentaires
Il sera utile pour cet exercice de définir une fonction d'assistance pour un module squeezenet :
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
L'objectif est cette fois d'atteindre une précision de 80 %.
À essayer
Commencez par une seule couche de convolution, puis suivez avec "fire_modules", en alternant avec les couches MaxPooling2D(pool_size=2). Vous pouvez tester entre deux et quatre couches de pooling maximal dans le réseau, ainsi qu'un, deux ou trois modules Fire consécutifs entre les couches de pooling maximal.
Dans les modules Fire, le paramètre "squeeze" doit généralement être inférieur au paramètre "expand". Ces paramètres sont en fait des nombres de filtres. Elles peuvent aller de 8 à 196, généralement. Vous pouvez expérimenter des architectures où le nombre de filtres augmente progressivement dans le réseau, ou des architectures simples où tous les modules fire ont le même nombre de filtres.
Voici un exemple :
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
À ce stade, vous constaterez peut-être que vos tests ne se déroulent pas très bien et que l'objectif de précision de 80 % semble lointain. Il est temps de découvrir quelques autres astuces.
Normalisation par lot
La normalisation par lot vous aidera à résoudre les problèmes de convergence que vous rencontrez. Des explications détaillées sur cette technique seront fournies lors du prochain atelier. Pour l'instant, veuillez l'utiliser comme une boîte noire "magique" en ajoutant cette ligne après chaque couche de convolution de votre réseau, y compris les couches à l'intérieur de votre fonction fire_module :
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
Le paramètre d'élan doit être réduit de sa valeur par défaut de 0,99 à 0,9, car notre ensemble de données est petit. Ne vous souciez pas de ce détail pour le moment.
Augmentation des données
Vous obtiendrez quelques points de pourcentage supplémentaires en augmentant les données avec des transformations simples, comme des inversions gauche-droite des changements de saturation :


C'est très facile à faire dans TensorFlow avec l'API tf.data.Dataset. Définissez une nouvelle fonction de transformation pour vos données :
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
Utilisez-le ensuite dans votre transformation finale des données (cellule "training and validation datasets", fonction "get_batched_dataset") :
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
N'oubliez pas de rendre l'augmentation des données facultative et d'ajouter le code nécessaire pour vous assurer que seul l'ensemble de données d'entraînement est augmenté. Il n'est pas judicieux d'augmenter l'ensemble de données de validation.
Vous devriez maintenant pouvoir atteindre une précision de 80 % en 35 époques.
Solution
Voici le notebook de solution. Vous pouvez l'utiliser si vous êtes bloqué.
Keras_Flowers_TPU_squeezenet.ipynb
Points abordés
- 🤔 Modèles Keras "style fonctionnel"
- 🤓 Architecture Squeezenet
- 🤓 Augmentation des données avec tf.data.datset
Veuillez prendre quelques instants pour passer en revue cette checklist.
12. Xception affiné
Convolutions séparables
Une autre façon d'implémenter les couches de convolution a gagné en popularité récemment : les convolutions séparables en profondeur. Je sais, c'est un peu long, mais le concept est assez simple. Elles sont implémentées dans TensorFlow et Keras sous la forme tf.keras.layers.SeparableConv2D.
Une convolution séparable exécute également un filtre sur l'image, mais elle utilise un ensemble de pondérations distinct pour chaque canal de l'image d'entrée. Elle est suivie d'une "convolution 1x1", une série de produits scalaires qui aboutissent à une somme pondérée des canaux filtrés. De nouveaux poids sont utilisés à chaque fois, et autant de recombinaisons pondérées des canaux que nécessaire sont calculées.

Illustration : convolutions séparables. Phase 1 : convolutions avec un filtre distinct pour chaque canal. Phase 2 : recombinaisons linéaires des canaux. Répété avec un nouvel ensemble de pondérations jusqu'à ce que le nombre de canaux de sortie souhaité soit atteint. La phase 1 peut également être répétée, avec de nouvelles pondérations à chaque fois, mais en pratique, c'est rarement le cas.
Les convolutions séparables sont utilisées dans les architectures de réseaux convolutifs les plus récentes : MobileNetV2, Xception, EfficientNet. Au passage, MobileNetV2 est ce que vous avez utilisé pour l'apprentissage par transfert précédemment.
Elles sont moins chères que les convolutions classiques et se sont avérées tout aussi efficaces en pratique. Voici le nombre de pondérations pour l'exemple illustré ci-dessus :
Couche convolutive : 4 x 4 x 3 x 5 = 240
Couche convolutive séparable : 4 x 4 x 3 + 3 x 5 = 48 + 15 = 63
Le lecteur est invité à calculer le nombre de multiplications nécessaires pour appliquer chaque style de couche de convolution à l'échelle de manière similaire. Les convolutions séparables sont plus petites et beaucoup plus efficaces en termes de calcul.
Pratique
Redémarrez à partir du notebook bac à sable "transfer learning", mais sélectionnez cette fois Xception comme modèle pré-entraîné. Xception n'utilise que des convolutions séparables. Laissez toutes les pondérations entraînables. Nous allons affiner les pondérations pré-entraînées sur nos données au lieu d'utiliser les couches pré-entraînées telles quelles.
Keras Flowers transfer learning (playground).ipynb
Objectif : précision > 95 % (oui, c'est possible !)
Comme il s'agit du dernier exercice, il nécessite un peu plus de code et de travail de data science.
Informations supplémentaires sur le réglage fin
Xception est disponible dans les modèles pré-entraînés standards de tf.keras.application.* N'oubliez pas de laisser tous les poids entraînables cette fois-ci.
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
Pour obtenir de bons résultats lorsque vous ajustez un modèle, vous devez faire attention au taux d'apprentissage et utiliser un programme de taux d'apprentissage avec une période d'augmentation. Exemple :
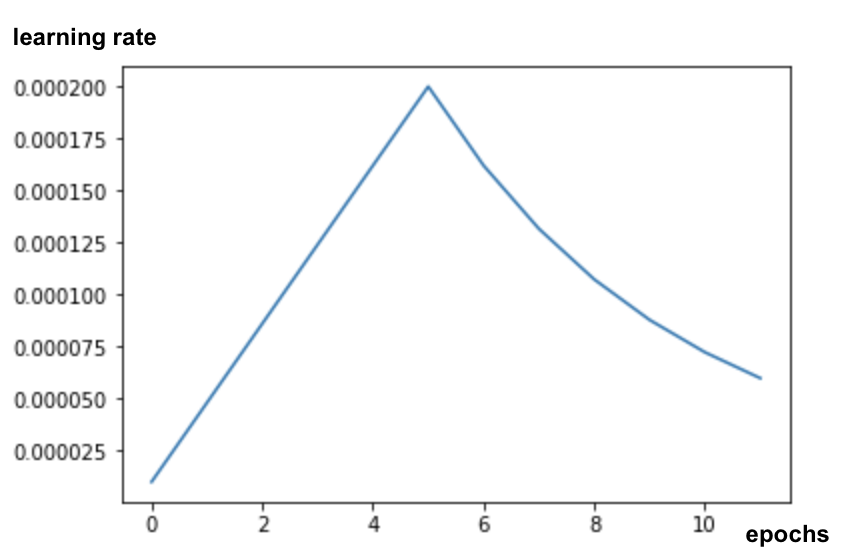
Si vous commencez avec un taux d'apprentissage standard, vous perturberez les pondérations pré-entraînées du modèle. Le démarrage progressif les préserve jusqu'à ce que le modèle soit ancré dans vos données et puisse les modifier de manière judicieuse. Après la phase d'augmentation, vous pouvez continuer avec un taux d'apprentissage constant ou à décroissance exponentielle.
Dans Keras, le taux d'apprentissage est spécifié par le biais d'un rappel dans lequel vous pouvez calculer le taux d'apprentissage approprié pour chaque époque. Keras transmettra le taux d'apprentissage approprié à l'optimiseur pour chaque époque.
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
Solution
Voici le notebook de solution. Vous pouvez l'utiliser si vous êtes bloqué.
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
Points abordés
- 🤔 Convolution séparable en profondeur
- 🤓 Planifications du taux d'apprentissage
- 😈 Affinage d'un modèle pré-entraîné.
Veuillez prendre quelques instants pour passer en revue cette checklist.
13. Félicitations !
Vous avez créé votre premier réseau de neurones convolutif moderne et l'avez entraîné pour atteindre une précision de plus de 90 %. Vous avez pu itérer sur les exécutions d'entraînement successives en quelques minutes seulement grâce aux TPU.
Les TPU en pratique
Les TPU et les GPU sont disponibles sur Vertex AI de Google Cloud :
- Sur les VM Deep Learning
- Dans Vertex AI Notebooks
- Dans les jobs Vertex AI Training
Enfin, vos commentaires nous intéressent. N'hésitez pas à nous contacter si vous remarquez quelque chose d'inhabituel dans cet atelier ou si vous pensez qu'il devrait être amélioré. Vous pouvez envoyer vos commentaires via les problèmes GitHub [lien vers les commentaires].

|
|

