
1. סקירה כללית
בשיעור ה-Lab הזה תלמדו איך לבנות, לאמן ולכוונן רשתות נוירונים קונבולוציוניות משלכם מאפס באמצעות Keras ו-Tensorflow 2. עכשיו אפשר לעשות את זה תוך דקות באמצעות יחידות TPU. בנוסף, תכירו כמה גישות, החל מגישות פשוטות מאוד של למידת העברה ועד לארכיטקטורות מודרניות של רשתות קונבולוציה כמו Squeezenet. ה-Lab הזה כולל הסברים תיאורטיים על רשתות נוירונים, והוא נקודת התחלה טובה למפתחים שרוצים ללמוד על למידה עמוקה.
יכול להיות קשה ומבלבל לקרוא מאמרים על למידה עמוקה. בואו נבחן מקרוב ארכיטקטורות מודרניות של רשתות נוירונים מתקפלות.

מה תלמדו
- כדי להשתמש ב-Keras וב-Tensor Processing Units (TPUs) כדי ליצור מודלים מותאמים אישית מהר יותר.
- להשתמש ב-tf.data.Dataset API ובפורמט TFRecord כדי לטעון נתוני אימון בצורה יעילה.
- כדי לרמות 😈, אפשר להשתמש בלמידת העברה במקום לבנות מודלים משלכם.
- כדי להשתמש בסגנונות של מודלים רציפים ופונקציונליים של Keras.
- כדי לבנות מסווג Keras משלכם עם שכבת softmax ופונקציית הפסד של אנטרופיה צולבת.
- כדי לכוונן את המודל באמצעות בחירה טובה של שכבות קונבולוציה.
- כדי לבחון רעיונות מודרניים לארכיטקטורת רשתות קונבולוציה, כמו מודולים, איגום ממוצע גלובלי וכו'.
- כדי ליצור רשת עצבית קונבולוציונית מודרנית פשוטה באמצעות ארכיטקטורת Squeezenet.
משוב
אם נתקלתם בבעיה כלשהי בשיעור ה-Lab הזה, נשמח לדעת. אפשר לשלוח משוב באמצעות בעיות ב-GitHub [ קישור למשוב].
2. מדריך למתחילים ב-Google Colaboratory
ב-Lab הזה נעשה שימוש ב-Google Collaboratory, ולא נדרשת הגדרה מצדכם. אפשר להריץ אותו מ-Chromebook. כדאי לפתוח את הקובץ שלמטה ולהריץ את התאים כדי להכיר את מחברות Colab.
בחירת TPU backend

בתפריט Colab, בוחרים באפשרות Runtime > Change runtime type (זמן ריצה > שינוי הסוג של זמן הריצה) ואז בוחרים באפשרות TPU. בשיעור ה-Lab הזה תשתמשו ב-TPU (Tensor Processing Unit) עוצמתי שמגובה באימון מואץ באמצעות חומרה. החיבור לסביבת זמן הריצה יתבצע אוטומטית בהרצה הראשונה, או שתוכלו להשתמש בלחצן 'חיבור' בפינה השמאלית העליונה.
הרצת Notebook

מריצים כל תא בנפרד על ידי לחיצה על תא והקשה על Shift-ENTER. אפשר גם להריץ את כל ה-notebook באמצעות סביבת זמן הריצה > הפעלת הכול.
תוכן העניינים

לכל המחברות יש תוכן עניינים. אפשר לפתוח אותו באמצעות החץ השחור שמימין.
תאים מוסתרים

בחלק מהתאים יוצג רק השם שלהם. זו תכונה ספציפית של מחברות Colab. אפשר ללחוץ עליהם לחיצה כפולה כדי לראות את הקוד שבתוכם, אבל בדרך כלל זה לא מעניין במיוחד. בדרך כלל תומכות בפונקציות של תמיכה או ויזואליזציה. עדיין צריך להריץ את התאים האלה כדי שהפונקציות שבתוכם יוגדרו.
אימות

אם תבצעו אימות באמצעות חשבון מורשה, תוכלו לגשת ב-Colab לקטגוריות הפרטיות שלכם ב-Google Cloud Storage. קטע הקוד שלמעלה יפעיל תהליך אימות.
3. [INFO] מהם Tensor Processing Units (TPUs)?
על קצה המזלג

הקוד לאימון מודל ב-TPU ב-Keras (עם חזרה ל-GPU או ל-CPU אם TPU לא זמין):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
אנחנו נשתמש היום ב-TPU כדי לבנות ולבצע אופטימיזציה של מסווג פרחים במהירויות אינטראקטיביות (דקות לכל הרצת אימון).

למה כדאי להשתמש במעבדי TPU?
מעבדי GPU מודרניים מאורגנים סביב 'ליבות' שניתנות לתכנות, ארכיטקטורה גמישה מאוד שמאפשרת להם לטפל במגוון משימות כמו עיבוד תלת-ממד, למידה עמוקה, סימולציות פיזיות וכו'. לעומת זאת, יחידות TPU משלבות מעבד וקטורי קלאסי עם יחידת כפל מטריצות ייעודית, והן מצטיינות בכל משימה שבה כפל מטריצות גדול הוא הדומיננטי, כמו רשתות נוירונים.

איור: שכבת רשת נוירונים צפופה כהכפלה של מטריצה, עם אצווה של שמונה תמונות שעוברות עיבוד ברשת הנוירונים בו-זמנית. כדאי לבצע כפל של שורה אחת בעמודה אחת כדי לוודא שהפעולה היא אכן חישוב של סכום משוקלל של כל ערכי הפיקסלים של התמונה. אפשר לייצג שכבות קונבולוציה גם כמכפלות מטריצות, אבל זה קצת יותר מסובך ( הסבר כאן, בקטע 1).
החומרה
MXU ו-VPU
ליבת TPU v2 מורכבת מיחידת כפל מטריצות (MXU) שמבצעת כפל מטריצות, ומיחידת עיבוד וקטורי (VPU) לכל שאר המשימות, כמו הפעלות, softmax וכו'. יחידת ה-VPU מטפלת בחישובים של float32 ו-int32. לעומת זאת, ה-MXU פועל בפורמט נקודה צפה (floating point) של 16-32 ביט עם דיוק מעורב.

נקודה צפה עם דיוק מעורב ו-bfloat16
ה-MXU מחשב מכפלות מטריצות באמצעות קלט bfloat16 ופלט float32. הצבירות של ערכי הביניים מתבצעות בדיוק float32.

בדרך כלל, אימון של רשת נוירונים עמיד לרעשי רקע שנוצרים כתוצאה מדיוק מופחת של נקודה צפה. יש מקרים שבהם רעשי רקע אפילו עוזרים לכלי האופטימיזציה להגיע לפתרון. באופן מסורתי, נעשה שימוש בדיוק של נקודה צפה של 16 ביט כדי להאיץ חישובים, אבל לפורמטים float16 ו-float32 יש טווחים שונים מאוד. הפחתת הדיוק מ-float32 ל-float16 בדרך כלל מובילה לערכי הצפה (overflow) וערכי חוסר (underflow). יש פתרונות, אבל בדרך כלל נדרשת עבודה נוספת כדי להשתמש ב-float16.
לכן Google הציגה את הפורמט bfloat16 ב-TPU. bfloat16 הוא float32 קטום עם אותם ביטים של מעריך ואותו טווח כמו float32. בנוסף, יחידות ה-TPU מחשבות מכפלות מטריצות בדיוק מעורב עם נתוני קלט מסוג bfloat16 ונתוני פלט מסוג float32. לכן, בדרך כלל לא צריך לשנות את הקוד כדי ליהנות משיפורי הביצועים של דיוק מופחת.
מערך סיסטולי
ה-MXU מבצע כפל מטריצות בחומרה באמצעות ארכיטקטורה שנקראת 'מערך סיסטולי', שבה רכיבי נתונים זורמים דרך מערך של יחידות חישוב בחומרה. (במונחים רפואיים, 'סיסטולי' מתייחס להתכווצויות של הלב ולזרימת הדם, ובמקרה הזה לזרימת הנתונים).
הפעולה הבסיסית במכפלת מטריצות היא מכפלה סקלרית בין שורה ממטריצה אחת לבין עמודה מהמטריצה השנייה (ראו את האיור בראש הקטע הזה). עבור הכפלת מטריצות Y=X*W, רכיב אחד של התוצאה יהיה:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
ב-GPU, מתכנתים את המכפלה הסקלרית הזו ב'ליבה' של ה-GPU, ואז מריצים אותה על כמה שיותר 'ליבות' במקביל כדי לנסות לחשב את כל הערכים של המטריצה שמתקבלת בבת אחת. אם המטריצה שמתקבלת היא בגודל 128x128, יידרשו 128x128=16K ליבות זמינות, וזה בדרך כלל לא אפשרי. במעבדי ה-GPU הגדולים ביותר יש כ-4,000 ליבות. לעומת זאת, TPU משתמש במינימום הנדרש של חומרה ליחידות החישוב ב-MXU: רק bfloat16 x bfloat16 => float32 יחידות של מכפלה-צבירה, שום דבר אחר. הן כל כך קטנות, עד שאפשר להטמיע 16K מהן ב-MXU בגודל 128x128 ולעבד את הכפלת המטריצות הזו בבת אחת.

איור: מערך סיסטולי של MXU. רכיבי החישוב הם יחידות של מכפלה וצבירה. הערכים של מטריצה אחת נטענים למערך (הנקודות האדומות). הערכים של המטריצה האחרת עוברים דרך המערך (הנקודות האפורות). הקווים האנכיים מעבירים את הערכים למעלה. הקווים האופקיים מעבירים את הסכומים החלקיים. המשתמש צריך לוודא שכשהנתונים זורמים דרך המערך, התוצאה של הכפלת המטריצה יוצאת מהצד הימני.
בנוסף, בזמן החישוב של המכפלות הסקלריות ב-MXU, סכומי הביניים פשוט עוברים בין יחידות מחשוב סמוכות. אין צורך לאחסן אותם ולאחזר אותם מהזיכרון או מקובץ רישום. התוצאה הסופית היא שלארכיטקטורת המערך הסיסטולי של TPU יש יתרון משמעותי בצפיפות ובצריכת החשמל, וגם יתרון במהירות שלא ניתן להתעלם ממנו בהשוואה ל-GPU, כשמחשבים מכפלות מטריצות.
Cloud TPU
כשמבקשים Cloud TPU v2 אחד ב-Google Cloud Platform, מקבלים מכונה וירטואלית (VM) עם לוח TPU שמחובר ל-PCI. לוח ה-TPU כולל ארבעה שבבי TPU עם ליבה כפולה. כל ליבת TPU כוללת VPU (יחידת עיבוד וקטורי) ו-MXU (יחידת כפל מטריצות) בגודל 128x128. לאחר מכן, ה-Cloud TPU הזה בדרך כלל מחובר דרך הרשת ל-VM שביקש אותו. כך נראה התמונה המלאה:
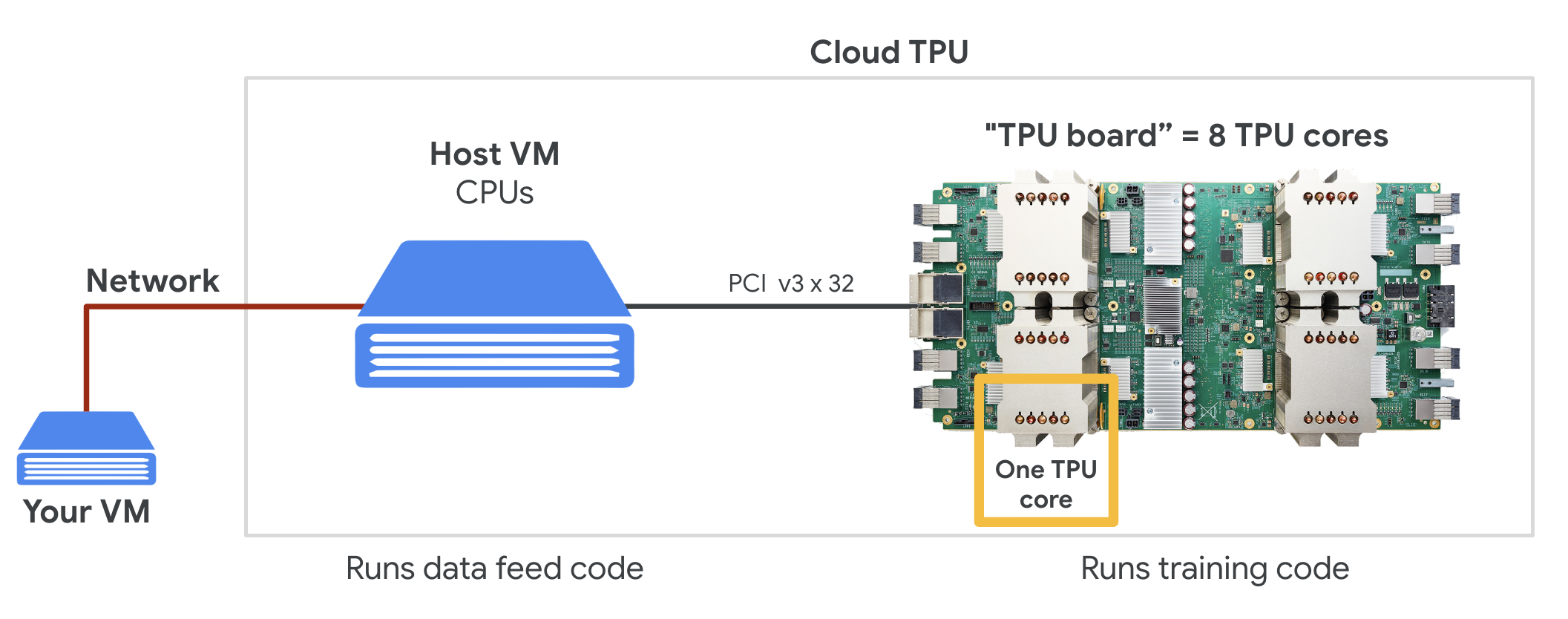
איור: המכונה הווירטואלית עם מאיץ Cloud TPU שמחובר לרשת. "Cloud TPU" עצמו מורכב ממכונה וירטואלית עם לוח TPU שמחובר ל-PCI, עם ארבעה שבבי TPU בעלי ליבה כפולה.
TPU pods
במרכזי הנתונים של Google, יחידות ה-TPU מחוברות לחיבור הדדי (interconnect) של מחשוב עתיר ביצועים (HPC), שיכול לגרום להן להיראות כמאיץ גדול מאוד. Google קוראת להם pods, והם יכולים לכלול עד 512 ליבות TPU v2 או 2,048 ליבות TPU v3.

איור: TPU v3 Pod. לוחות ומתלים של TPU שמחוברים באמצעות HPC interconnect.
במהלך האימון, הגרדיאנטים מועברים בין ליבות ה-TPU באמצעות אלגוריתם all-reduce ( הסבר טוב על all-reduce זמין כאן). המודל שעובר אימון יכול לנצל את היתרונות של החומרה על ידי אימון על גדלים גדולים של אצווה.

איור: סנכרון של גרדיאנטים במהלך אימון באמצעות אלגוריתם all-reduce ברשת HPC של רשת טורואידית דו-ממדית של Google TPU.
התוכנה
אימון עם גודל אצווה גדול
גודל האצווה האידיאלי ל-TPU הוא 128 פריטי נתונים לכל ליבת TPU, אבל החומרה יכולה להציג ניצול טוב כבר מ-8 פריטי נתונים לכל ליבת TPU. חשוב לזכור שלכל Cloud TPU יש 8 ליבות.
בשיעור ה-Lab הזה נשתמש ב-Keras API. ב-Keras, גודל הקבוצה שאתם מציינים הוא גודל הקבוצה הגלובלי לכל ה-TPU. הקבוצות יפוצלו אוטומטית ל-8 ויפעלו על 8 ליבות ה-TPU.

טיפים נוספים לשיפור הביצועים מפורטים במדריך לשיפור הביצועים של TPU. במקרים של גודל אצווה גדול מאוד, יכול להיות שיהיה צורך בטיפול מיוחד בחלק מהמודלים. פרטים נוספים זמינים במאמר בנושא LARSOptimizer.
הפרטים הטכניים: XLA
תוכניות Tensorflow מגדירות גרפים של חישובים. ה-TPU לא מריץ קוד Python ישירות, אלא מריץ את גרף החישוב שמוגדר בתוכנית Tensorflow. מתחת לפני השטח, קומפיילר בשם XLA (קומפיילר מואץ של אלגברה לינארית) הופך את גרף Tensorflow של צמתי החישוב לשפת מכונה של TPU. הקומפיילר הזה גם מבצע אופטימיזציות מתקדמות רבות בקוד ובפריסת הזיכרון. הקומפילציה מתבצעת אוטומטית כשהעבודה נשלחת ל-TPU. אין צורך לכלול את XLA בשרשרת הבנייה באופן מפורש.

איור: כדי להריץ ב-TPU, תרשים החישוב שמוגדר בתוכנית Tensorflow מתורגם קודם לייצוג XLA (מהדר אלגברה לינארית מואצת), ואז עובר קומפילציה על ידי XLA לשפת מכונה של TPU.
שימוש ביחידות TPU ב-Keras
החל מ-Tensorflow 2.1, יש תמיכה ב-TPU דרך Keras API. התמיכה ב-Keras פועלת ביחידות TPU וב-TPU pods. דוגמה שפועלת ב-TPU, במעבד גרפי ובמעבד:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
בקטע הקוד הזה:
-
TPUClusterResolver().connect()מאתר את ה-TPU ברשת. הוא פועל ללא פרמטרים ברוב המערכות של Google Cloud (משימות של AI Platform, Colaboratory, Kubeflow, מכונות וירטואליות של למידה עמוקה שנוצרו באמצעות כלי השירות ctpu up). המערכות האלה יודעות איפה נמצא ה-TPU שלהן בזכות משתנה הסביבה TPU_NAME. אם יוצרים TPU באופן ידני, צריך להגדיר את משתנה הסביבה TPU_NAME במכונה הווירטואלית שמשתמשים בה, או להתקשר אלTPUClusterResolverעם פרמטרים מפורשים:TPUClusterResolver(tp_uname, zone, project) -
TPUStrategyהוא החלק שמיישם את ההפצה ואת אלגוריתם הסנכרון של הגרדיאנט 'all-reduce'. - האסטרטגיה מוחלת באמצעות היקף. צריך להגדיר את המודל בתוך היקף האסטרטגיה scope().
- הפונקציה
tpu_model.fitמצפה לקבל אובייקט tf.data.Dataset כקלט לאימון TPU.
משימות נפוצות להעברת קוד ל-TPU
- יש הרבה דרכים לטעון נתונים במודל Tensorflow, אבל כשמשתמשים ב-TPU, חובה להשתמש ב-
tf.data.DatasetAPI. - יחידות TPU הן מהירות מאוד, ולכן כשמריצים עליהן נתונים, צוואר הבקבוק הוא לרוב קליטת הנתונים. במדריך הביצועים של TPU יש כלים שיעזרו לכם לזהות צווארי בקבוק בנתונים וטיפים נוספים לשיפור הביצועים.
- מספרים מסוג int8 או int16 נחשבים למספרים מסוג int32. ל-TPU אין חומרה של מספרים שלמים שפועלת על פחות מ-32 ביט.
- חלק מהפעולות של TensorFlow לא נתמכות. הרשימה זמינה כאן. החדשות הטובות הן שהמגבלה הזו חלה רק על קוד האימון, כלומר על המעבר קדימה ואחורה דרך המודל. עדיין אפשר להשתמש בכל הפעולות של TensorFlow בצינור להזנת נתונים, כי הן יבוצעו במעבד (CPU).
- אין תמיכה ב-
tf.py_funcב-TPU.
4. טעינת נתונים






נשתמש במערך נתונים של תמונות פרחים. המטרה היא ללמוד איך לסווג אותם ל-5 סוגי פרחים. טעינת הנתונים מתבצעת באמצעות tf.data.Dataset API. קודם כל, נכיר את ה-API.
קורס מעשי
צריך לפתוח את ה-notebook הבא, להריץ את התאים (Shift-ENTER) ולפעול לפי ההוראות בכל מקום שמופיעה התווית WORK REQUIRED.

Fun with tf.data.Dataset (playground).ipynb
מידע נוסף
מידע על מערך הנתונים 'פרחים'
מערך הנתונים מאורגן ב-5 תיקיות. כל תיקייה מכילה פרחים מסוג אחד. שמות התיקיות הם חמניות, חיננית, שן הארי, צבעונים ושושנים. הנתונים מתארחים בקטגוריה ציבורית ב-Google Cloud Storage. קטע:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
למה tf.data.Dataset?
Keras ו-Tensorflow מקבלים מערכי נתונים בכל פונקציות האימון וההערכה שלהם. אחרי שמעלים נתונים למערך נתונים, ה-API מציע את כל הפונקציות הנפוצות ששימושיות לנתוני אימון של רשתות נוירונים:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
במאמר הזה מפורטים טיפים לשיפור הביצועים ושיטות מומלצות לשימוש בקבוצות נתונים. מאמרי העזרה זמינים כאן.
היסודות של tf.data.Dataset
הנתונים מגיעים בדרך כלל בכמה קבצים, כמו תמונות. אפשר ליצור מערך נתונים של שמות קבצים באמצעות הקריאה:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
לאחר מכן, אתם 'ממפים' פונקציה לכל שם קובץ, שבדרך כלל תטען ותפענח את הקובץ לנתונים בפועל בזיכרון:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
כדי לבצע איטרציה על מערך נתונים:
for data in my_dataset:
print(data)
מערכי נתונים של טאפלים
בלמידה מונחית, מערך נתוני אימון מורכב בדרך כלל מזוגות של נתוני אימון ותשובות נכונות. כדי לאפשר זאת, פונקציית הפענוח יכולה להחזיר טאפלים. לאחר מכן תקבלו מערך נתונים של טאפלים, והטאפלים יוחזרו כשמבצעים איטרציה על המערך. הערכים שמוחזרים הם טנסורים של TensorFlow שמוכנים לשימוש במודל. אפשר לקרוא ל-.numpy() כדי לראות את הערכים הגולמיים:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
מסקנה:טעינת תמונות אחת אחרי השנייה היא איטית!
במהלך האיטרציה על מערך הנתונים הזה, תראו שאפשר לטעון בערך תמונה אחת או שתיים בשנייה. הפעולה איטית מדי. מאיצי החומרה שבהם נשתמש לאימון יכולים לתמוך בקצב גבוה פי כמה. בקטע הבא מוסבר איך נשיג את זה.
המוצר
מחברת הפתרון אתם יכולים להשתמש בו אם אתם נתקעים.
Fun with tf.data.Dataset (solution).ipynb
מה נכלל
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 מערכי נתונים של טאפלים
- 😀 iterating through Datasets
כדאי להקדיש רגע כדי לעבור על רשימת המשימות הבאה.
5. טעינת נתונים במהירות
מאיצי החומרה של Tensor Processing Unit (TPU) שבהם נשתמש בשיעור ה-Lab הזה הם מהירים מאוד. האתגר הוא בדרך כלל לספק להם נתונים מספיק מהר כדי שהם יהיו עסוקים. ל-Google Cloud Storage (GCS) יש יכולת לשמור על קצב העברה גבוה מאוד, אבל כמו בכל מערכות אחסון בענן, יצירת חיבור כרוכה בהעברת נתונים הלוך ושוב ברשת. לכן, אחסון הנתונים שלנו באלפי קבצים נפרדים הוא לא אידיאלי. נאגד אותם למספר קטן יותר של קבצים ונשתמש ביכולות של tf.data.Dataset כדי לקרוא מכמה קבצים במקביל.
קריאה ראשונה
הקוד שמעמיס קובצי תמונה, משנה את הגודל שלהם לגודל משותף ואז מאחסן אותם ב-16 קובצי TFRecord מופיע במחברת הבאה. כדאי לקרוא אותו במהירות. אין צורך להריץ אותו כי נספק נתונים בפורמט TFRecord תקין בהמשך ה-codelab.
Flower pictures to TFRecords.ipynb
פריסת נתונים אידיאלית להעברת נתונים אופטימלית ב-GCS
פורמט הקובץ TFRecord
פורמט הקובץ המועדף של TensorFlow לאחסון נתונים הוא פורמט TFRecord שמבוסס על protobuf. פורמטים אחרים של סריאליזציה יעבדו גם כן, אבל אפשר לטעון מערך נתונים מקובצי TFRecord ישירות על ידי כתיבת:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
כדי לשפר את הביצועים, מומלץ להשתמש בקוד המורכב יותר הבא כדי לקרוא מכמה קובצי TFRecord בו-זמנית. הקוד הזה יקרא מ-N קבצים במקביל, ולא יתייחס לסדר הנתונים כדי להגדיל את מהירות הקריאה.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
מדריך מקוצר לשימוש ב-TFRecord
אפשר לאחסן ב-TFRecords שלושה סוגי נתונים: מחרוזות בייטים (רשימה של בייטים), מספרים שלמים של 64 ביט ומספרים עשרוניים של 32 ביט. הם תמיד מאוחסנים כרשימות, ורכיב נתונים יחיד יהיה רשימה בגודל 1. אפשר להשתמש בפונקציות העזר הבאות כדי לאחסן נתונים ב-TFRecords.
כתיבת מחרוזות בייטים
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
כתיבת מספרים שלמים
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
כתיבת צפים
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
כתיבת TFRecord באמצעות כלי העזר שלמעלה
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
כדי לקרוא נתונים מ-TFRecords, צריך קודם להצהיר על הפריסה של הרשומות ששמרתם. בהצהרה, אפשר לגשת לכל שדה עם שם כרשימה באורך קבוע או כרשימה באורך משתנה:
קריאה מ-TFRecords
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
קטעי קוד שימושיים:
קריאת רכיבי נתונים בודדים
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
קריאה של רשימות של רכיבים בגודל קבוע
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
קריאה של מספר משתנה של פריטי נתונים
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
VarLenFeature מחזיר וקטור דליל, ונדרש שלב נוסף אחרי פענוח ה-TFRecord:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
אפשר גם להשתמש בשדות אופציונליים ב-TFRecords. אם מציינים ערך ברירת מחדל כשקוראים שדה, ערך ברירת המחדל מוחזר במקום שגיאה אם השדה חסר.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
מה נכלל
- 🤔 פיצול (sharding) קובצי נתונים כדי לאפשר גישה מהירה מ-GCS
- 😓 איך לכתוב TFRecords. (שכחת את התחביר? זה בסדר, אפשר להוסיף את הדף הזה לסימניות כדף עזר)
- 🤔 טעינת Dataset מ-TFRecords באמצעות TFRecordDataset
כדאי להקדיש רגע כדי לעבור על רשימת המשימות הבאה.
6. [INFO] סיווג רשתות נוירונים למתחילים
על קצה המזלג
אם אתם כבר מכירים את כל המונחים מודגשים בפסקה הבאה, אתם יכולים לעבור לתרגיל הבא. אם אתם רק מתחילים ללמוד על למידה עמוקה, אתם מוזמנים להמשיך לקרוא.
למודלים שנבנו כרצף של שכבות, Keras מציעה את Sequential API. לדוגמה, אפשר לכתוב ב-Keras מסווג תמונות שמשתמש בשלוש שכבות צפופות באופן הבא:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
רשת נוירונים צפופה
זו רשת הנוירונים הפשוטה ביותר לסיווג תמונות. היא מורכבת מ'נוירונים' שמסודרים בשכבות. השכבה הראשונה מעבדת את נתוני הקלט ומעבירה את הפלט שלה לשכבות אחרות. השם 'צפופה' ניתן לה כי כל נוירון מחובר לכל הנוירונים בשכבה הקודמת.

אפשר להזין תמונה לרשת כזו על ידי שיטוח ערכי ה-RGB של כל הפיקסלים שלה לווקטור ארוך, ולהשתמש בו כקלט. זו לא הטכניקה הכי טובה לזיהוי תמונות, אבל נשפר אותה בהמשך.
נוירונים, הפעלות, RELU
'נוירון' מחשב סכום משוקלל של כל הקלטים שלו, מוסיף ערך שנקרא 'הטיה' ומעביר את התוצאה דרך מה שנקרא 'פונקציית הפעלה'. המשקלים וההטיה לא ידועים בהתחלה. הן יאותחלו באופן אקראי וילמדו על ידי אימון רשת הנוירונים על הרבה נתונים ידועים.

פונקציית ההפעלה הפופולרית ביותר נקראת RELU, קיצור של Rectified Linear Unit (יחידה ליניארית מתוקנת). זו פונקציה פשוטה מאוד, כפי שאפשר לראות בגרף שלמעלה.
הפעלת Softmax
הרשת שלמעלה מסתיימת בשכבה של 5 נוירונים כי אנחנו מסווגים פרחים ל-5 קטגוריות (ורד, צבעוני, שן הארי, חרצית וחמנייה). נוירונים בשכבות ביניים מופעלים באמצעות פונקציית ההפעלה הקלאסית RELU. עם זאת, בשכבה האחרונה אנחנו רוצים לחשב מספרים בין 0 ל-1 שמייצגים את ההסתברות לכך שהפרח הזה הוא ורד, צבעוני וכן הלאה. לשם כך, נשתמש בפונקציית הפעלה שנקראת softmax.
כדי להחיל softmax על וקטור, מחשבים את האקספוננט של כל רכיב ואז מבצעים נורמליזציה של הווקטור, בדרך כלל באמצעות נורמת L1 (סכום הערכים המוחלטים) כך שסכום הערכים יהיה 1 ואפשר יהיה לפרש אותם כהסתברויות.
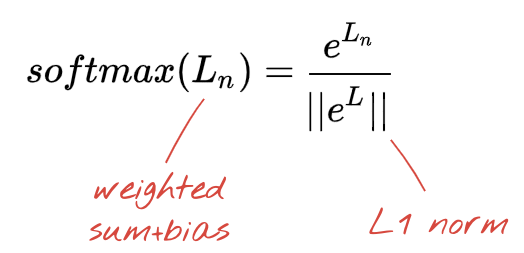

Cross-entropy loss
עכשיו, אחרי שרשת הנוירונים שלנו מייצרת תחזיות מתמונות קלט, אנחנו צריכים למדוד את רמת הדיוק שלהן, כלומר את המרחק בין מה שהרשת אומרת לנו לבין התשובות הנכונות, שלרוב נקראות 'תוויות'. חשוב לזכור שיש לנו תוויות נכונות לכל התמונות במערך הנתונים.
כל מרחק יתאים, אבל לבעיות סיווג, מה שנקרא 'מרחק אנטרופיה צולבת' הוא היעיל ביותר. נקרא לזה פונקציית השגיאה או 'ההפסד':

Gradient descent
'אימון' רשת הנוירונים בעצם אומר שימוש בתמונות ובתוויות של אימון כדי להתאים את המשקלים וההטיות, כך שפונקציית ההפסד של האנטרופיה הצולבת תהיה מינימלית. כך זה עובד:
האנטרופיה הצולבת היא פונקציה של משקלים, הטיה, פיקסלים של תמונת האימון והסיווג הידוע שלה.
אם נחשב את הנגזרות החלקיות של האנטרופיה הצולבת ביחס לכל המשקלים ולכל ההטיות, נקבל 'גרדיאנט' שמחושב עבור תמונה, תווית וערך נוכחי של משקלים והטיות. חשוב לזכור שיכולים להיות מיליוני משקלים והטיות, ולכן חישוב הגרדיאנט נשמע כמו עבודה רבה. למזלנו, Tensorflow עושה את זה בשבילנו. המאפיין המתמטי של גרדיאנט הוא שהוא מצביע "למעלה". מכיוון שאנחנו רוצים להגיע למקום שבו האנטרופיה הצולבת נמוכה, אנחנו הולכים בכיוון ההפוך. אנחנו מעדכנים את המשקלים וההטיות בחלק קטן מהגרדיאנט. לאחר מכן אנחנו חוזרים על הפעולה שוב ושוב באמצעות קבוצות התמונות והתוויות הבאות לאימון, בלולאת אימון. התהליך הזה אמור להוביל למצב שבו האנטרופיה הצולבת היא מינימלית, אבל אין ערובה לכך שהמינימום הזה הוא ייחודי.

חלוקה לקבוצות קטנות ומומנטום
אפשר לחשב את הגרדיאנט רק על תמונה לדוגמה אחת ולעדכן את המשקלים וההטיות באופן מיידי, אבל אם עושים את זה על קבוצה של 128 תמונות לדוגמה, מקבלים גרדיאנט שמייצג טוב יותר את האילוצים שמוטלים על ידי תמונות לדוגמה שונות, ולכן סביר להניח שהפתרון יתקבל מהר יותר. גודל המיני-batch הוא פרמטר שניתן להתאמה.
לטכניקה הזו, שנקראת לפעמים "ירידה סטוכסטית של גרדיאנט", יש יתרון פרגמטי נוסף: עבודה עם אצוות פירושה גם עבודה עם מטריצות גדולות יותר, ובדרך כלל קל יותר לבצע אופטימיזציה שלהן ב-GPU וב-TPU.
עם זאת, יכול להיות שההתכנסות תהיה קצת כאוטית, ואפילו תיפסק אם וקטור הגרדיאנט יהיה אפס. האם זה אומר שמצאנו מינימום? לא תמיד. רכיב של מעבר צבעים יכול להיות אפס במינימום או במקסימום. אם יש וקטור גרדיאנט עם מיליוני אלמנטים, וכולם אפסים, ההסתברות שכל אפס מתאים לנקודת מינימום ואף אחד מהם לא מתאים לנקודת מקסימום היא קטנה למדי. במרחב עם הרבה ממדים, נקודות אוכף הן די נפוצות ואנחנו לא רוצים לעצור בהן.

איור: נקודת אוכף. השיפוע הוא 0, אבל זה לא מינימום בכל הכיוונים. (Attribution של התמונה Wikimedia: By Nicoguaro - Own work, CC BY 3.0)
הפתרון הוא להוסיף לאלגוריתם האופטימיזציה תנופה מסוימת, כדי שהוא יוכל לעבור את נקודות האוכף בלי לעצור.
מילון מונחים
אצווה או אצווה קטנה: האימון מתבצע תמיד על אצוות של נתוני אימון ותוויות. כך האלגוריתם יכול להתכנס. המאפיין 'batch' הוא בדרך כלל המאפיין הראשון של טנסורים של נתונים. לדוגמה, טנסור בצורה [100, 192, 192, 3] מכיל 100 תמונות בגודל 192x192 פיקסלים עם שלושה ערכים לכל פיקסל (RGB).
פונקציית אובדן של אנטרופיה צולבת: פונקציית אובדן מיוחדת שמשמשת לעיתים קרובות בסיווגים.
שכבה צפופה: שכבה של נוירונים שבה כל נוירון מחובר לכל הנוירונים בשכבה הקודמת.
תכונות: הקלטים של רשת נוירונים נקראים לפעמים 'תכונות'. האומנות של בחירת החלקים של מערך נתונים (או שילובים של חלקים) שיוזנו לרשת נוירונים כדי לקבל חיזויים טובים נקראת 'הנדסת פיצ'רים (feature engineering)'.
תוויות: שם נוסף ל'סיווגים' או לתשובות נכונות בבעיית סיווג בפיקוח
קצב למידה: חלק מהשיפוע שלפיו המשקולות וההטיות מתעדכנים בכל איטרציה של לולאת האימון.
לוגיטים: הפלט של שכבת נוירונים לפני שמחילים את פונקציית ההפעלה נקרא 'לוגיטים'. המונח הזה מגיע מהפונקציה הלוגיסטית, שנקראת גם פונקציית סיגמואיד, שהייתה פונקציית ההפעלה הכי פופולרית. השם 'Neuron outputs before logistic function' (פלט של נוירון לפני פונקציה לוגיסטית) קוצר ל-'logits'.
loss: פונקציית השגיאה שמשווה בין התפוקות של רשת נוירונים לבין התשובות הנכונות
נוירון: מחשב את הסכום המשוקלל של הקלט שלו, מוסיף הטיה ומעביר את התוצאה דרך פונקציית הפעלה.
קידוד one-hot: מחלקה 3 מתוך 5 מקודדת כווקטור של 5 אלמנטים, כולם אפסים חוץ מהאלמנט השלישי שהוא 1.
relu: יחידה לינארית מתוקנת. פונקציית הפעלה פופולרית לנוירונים.
sigmoid: פונקציית הפעלה נוספת שהייתה פופולרית בעבר ועדיין שימושית במקרים מיוחדים.
softmax: פונקציית הפעלה מיוחדת שפועלת על וקטור, מגדילה את ההפרש בין הרכיב הגדול ביותר לבין כל שאר הרכיבים, וגם מבצעת נורמליזציה של הווקטור כך שהסכום שלו יהיה 1, כדי שאפשר יהיה לפרש אותו כווקטור של הסתברויות. משמש כשלב האחרון בסיווגים.
tensor: טנזור הוא כמו מטריצה, אבל עם מספר שרירותי של ממדים. טנסור חד-ממדי הוא וקטור. טנסור דו-ממדי הוא מטריצה. אחר כך אפשר ליצור טנסורים עם 3, 4, 5 או יותר מימדים.
7. למידה בהעברה
בבעיה של סיווג תמונות, שכבות צפופות כנראה לא יספיקו. צריך ללמוד על שכבות קונבולוציה ועל הדרכים הרבות שבהן אפשר לסדר אותן.
אבל אפשר גם לקצר את הדרך! אפשר להוריד רשתות נוירונים מתקפלות שאומנו באופן מלא. אפשר להסיר את השכבה האחרונה שלהם, את ראש הסיווג softmax, ולהחליף אותה בשכבה משלכם. כל המשקלים וההטיות שאומנו נשארים כמו שהם, ואתם מאמנים מחדש רק את שכבת ה-softmax שאתם מוסיפים. הטכניקה הזו נקראת 'למידת העברה', והיא פועלת כל עוד קבוצת הנתונים שעליה הרשת העצבית מאומנת מראש דומה מספיק לנתונים שלכם.
מעשי
צריך לפתוח את ה-notebook הבא, להריץ את התאים (Shift-ENTER) ולפעול לפי ההוראות בכל מקום שמופיעה התווית WORK REQUIRED.
Keras Flowers transfer learning (playground).ipynb
מידע נוסף
בעזרת למידת העברה, אתם נהנים גם מארכיטקטורות מתקדמות של רשתות נוירונים מתקפלות שפותחו על ידי חוקרים מובילים, וגם מאימון מוקדם על קבוצת נתונים עצומה של תמונות. במקרה שלנו, נשתמש בשיטת העברת הלמידה מרשת שאומנה על ImageNet, מסד נתונים של תמונות שמכיל הרבה צמחים וסצנות בחוץ, שקרובים מספיק לפרחים.

איור: שימוש ברשת נוירונים קונבולוציונית מורכבת, שכבר אומנה, כקופסה שחורה, ואימון מחדש רק של ראש הסיווג. זהו למידת העברה. בהמשך נראה איך הסידורים המורכבים האלה של שכבות קונבולוציה פועלים. בינתיים, זאת בעיה של מישהו אחר.
למידה של העברות ב-Keras
ב-Keras, אפשר ליצור מופע של מודל שעבר אימון מראש מתוך אוסף tf.keras.applications.*. לדוגמה, MobileNet V2 היא ארכיטקטורה טובה מאוד של רשת קונבולוציה, והגודל שלה סביר. אם בוחרים באפשרות include_top=False, מקבלים את המודל שאומן מראש בלי שכבת ה-softmax הסופית שלו, כדי שתוכלו להוסיף משלכם:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
שימו לב גם להגדרה pretrained_model.trainable = False. הוא מקפיא את המשקולות וההטיות של המודל שעבר אימון מראש, כך שאתם מאמנים רק את שכבת ה-softmax. בדרך כלל התהליך הזה כולל מספר קטן יחסית של משקלים, ואפשר לבצע אותו במהירות בלי להשתמש במערך נתונים גדול מאוד. עם זאת, אם יש לכם הרבה נתונים, למידת העברה יכולה לעבוד אפילו טוב יותר עם pretrained_model.trainable = True. המשקלים שאומנו מראש מספקים ערכים ראשוניים מצוינים, ועדיין אפשר להתאים אותם באמצעות האימון כדי שיתאימו יותר לבעיה שלכם.
לבסוף, שימו לב לשכבת Flatten() שנוספה לפני שכבת ה-softmax הצפופה. שכבות צפופות פועלות על וקטורים שטוחים של נתונים, אבל אנחנו לא יודעים אם זה מה שהמודל שאומן מראש מחזיר. לכן אנחנו צריכים לשטח את התמונה. בפרק הבא, כשנעמיק בארכיטקטורות של רשתות קונבולוציה, נסביר את פורמט הנתונים שמוחזר על ידי שכבות קונבולוציה.
הגישה הזו אמורה להניב רמת דיוק של כ-75%.
המוצר
מחברת הפתרון אתם יכולים להשתמש בו אם אתם נתקעים.
Keras Flowers transfer learning (solution).ipynb
מה נכלל
- 🤔 איך כותבים מסווג ב-Keras
- 🤓 מוגדר עם שכבת softmax אחרונה ועם הפסד אנטרופיה צולבת
- 😈 Transfer learning
- 🤔 אימון המודל הראשון
- 🧐 מעקב אחרי ההפסד והדיוק במהלך האימון
כדאי להקדיש רגע כדי לעבור על רשימת המשימות הבאה.
8. [INFO] רשתות נוירונים מלאכותיות
על קצה המזלג
אם אתם כבר מכירים את כל המונחים מודגשים בפסקה הבאה, אתם יכולים לעבור לתרגיל הבא. אם אתם רק מתחילים להשתמש ברשתות עצביות קונבולוציוניות, כדאי שתמשיכו לקרוא.

איור: סינון תמונה באמצעות שני מסננים עוקבים, כל אחד עם 48 משקלים שניתנים ללמידה (4x4x3=48).
כך נראית רשת נוירונים מתקפלת פשוטה ב-Keras:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
רשתות עצביות מתקפלות (CNN) – מדריך למתחילים
בשכבה של רשת קונבולוציונית, 'נוירון' אחד מבצע סכום משוקלל של הפיקסלים שמעליו, רק באזור קטן של התמונה. הוא מוסיף הטיה ומעביר את הסכום דרך פונקציית הפעלה, בדיוק כמו נוירון בשכבה צפופה רגילה. הפעולה הזו חוזרת על עצמה בכל התמונה באמצעות אותם משקלים. חשוב לזכור שבשכבות צפופות, לכל נוירון יש משקלים משלו. כאן, 'תיקון' יחיד של משקלים מחליק על פני התמונה בשני הכיוונים (פעולת 'קונבולוציה'). בפלט יש מספר ערכים כמספר הפיקסלים בתמונה (אבל צריך להוסיף קצת ריפוד בשוליים). זו פעולת סינון, באמצעות מסנן של 4x4x3=48 משקלים.
עם זאת, 48 משקלים לא יספיקו. כדי להוסיף עוד דרגות חופש, חוזרים על אותה פעולה עם קבוצה חדשה של משקלים. כך נוצרת קבוצה חדשה של פלט מסנן. אפשר לקרוא לזה 'ערוץ' של פלטים, בהשוואה לערוצי ה-R,G,B בתמונת הקלט.

אפשר לסכם את שני סטים המשקלים (או יותר) לטנזור אחד על ידי הוספת מימד חדש. כך מקבלים את הצורה הכללית של טנסור המשקלים בשכבת קונבולוציה. מכיוון שמספר ערוצי הקלט והפלט הם פרמטרים, אפשר להתחיל להוסיף שכבות של קונבולוציה.

איור: רשת נוירונים מלאכותית (CNN) מבצעת טרנספורמציה של 'קוביות' נתונים ל'קוביות' נתונים אחרות.
קיפולים (קונבולציות) עם צעדים, יצירת מאגרים מקסימליים
אם מבצעים את הקונבולוציות עם צעד של 2 או 3, אפשר גם להקטין את קוביית הנתונים שמתקבלת בממדים האופקיים שלה. יש שתי דרכים נפוצות לעשות את זה:
- קונבולוציה עם צעדים: מסנן הזזה כמו למעלה, אבל עם צעד >1
- איגום מקסימלי: חלון הזזה שמחיל את פעולת ה-MAX (בדרך כלל על תיקוני 2x2, שחוזרים על עצמם כל 2 פיקסלים)

איור: הזזה של חלון החישוב ב-3 פיקסלים מובילה לפחות ערכי פלט. הפעלת קונבולוציה עם דילוגים או איגום מקסימלי (מקסימום בחלון 2x2 עם דילוג של 2) הן דרך לצמצם את קוביית הנתונים בממדים האופקיים.
סיווג באמצעות רשת קונבולוציה
לבסוף, אנחנו מוסיפים שכבת סיווג על ידי שיטוח של קוביית הנתונים האחרונה והזנתה דרך שכבה צפופה עם הפעלת softmax. מסווג קונבולוציוני טיפוסי יכול להיראות כך:

איור: מסווג תמונות שמשתמש בשכבות קונבולוציה ושכבות softmax. הוא משתמש במסננים בגודל 3x3 ו-1x1. שכבות ה-maxpool לוקחות את המקסימום של קבוצות של נקודות נתונים בגודל 2x2. שכבת הסיווג מיושמת באמצעות שכבה צפופה עם הפעלת softmax.
ב-Keras
אפשר לכתוב את המקבץ של שכבות קונבולוציה שמוצג למעלה ב-Keras כך:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
9. רשת עצבית קונבולוציונית בהתאמה אישית
מעשי
בואו נבנה ונאמן רשת נוירונים קונבולוציונית מאפס. שימוש ב-TPU יאפשר לנו לבצע איטרציות מהר מאוד. צריך לפתוח את ה-notebook הבא, להריץ את התאים (Shift-ENTER) ולפעול לפי ההוראות בכל מקום שמופיעה התווית WORK REQUIRED.
Keras_Flowers_TPU (playground).ipynb
המטרה היא להגיע לרמת דיוק גבוהה יותר מ-75% של מודל למידת ההעברה. למודל הזה היה יתרון, כי הוא עבר אימון מראש על מערך נתונים של מיליוני תמונות, בעוד שיש לנו כאן רק 3,670 תמונות. אפשר לפחות להשוות את המחיר?
מידע נוסף
כמה שכבות, מה הגודל?
בחירת גדלי השכבות היא יותר אומנות מאשר מדע. צריך למצוא את האיזון הנכון בין מעט מדי פרמטרים (משקלים והטיות) לבין יותר מדי פרמטרים. אם יש מעט מדי משקלים, רשת הנוירונים לא יכולה לייצג את המורכבות של צורות הפרחים. אם יש יותר מדי תמונות, יכול להיות שהמודל יתאים את עצמו יותר מדי לנתוני האימון, כלומר יתמחה בתמונות האימון ולא יוכל להכליל. אם יש הרבה פרמטרים, האימון של המודל יהיה איטי. ב-Keras, הפונקציה model.summary() מציגה את המבנה ואת מספר הפרמטרים של המודל:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
כמה טיפים:
- היעילות של רשתות נוירונים 'עמוקות' נובעת מכך שיש להן כמה שכבות. לבעיה הפשוטה הזו של זיהוי פרחים, כדאי להשתמש ב-5 עד 10 שכבות.
- להשתמש במסננים קטנים. בדרך כלל מסננים בגודל 3x3 מתאימים לכל מקום.
- אפשר גם להשתמש במסננים בגודל 1x1, והם זולים. הם לא באמת מסננים שום דבר, אלא מחשבים שילובים לינאריים של ערוצים. אפשר להשתמש בהם לסירוגין עם מסננים אמיתיים. (מידע נוסף על 'קונבולוציות 1x1' מופיע בקטע הבא).
- בבעיית סיווג כזו, מומלץ לבצע דגימת חסר לעיתים קרובות באמצעות שכבות של איגום מקסימלי (או קונבולוציות עם צעד >1). לא משנה לכם איפה הפרח נמצא, רק אם הוא ורד או שן הארי, ולכן לא חשוב לאבד את נתוני x ו-y, וסינון אזורים קטנים יותר הוא זול יותר.
- בדרך כלל מספר המסננים דומה למספר המחלקות בסוף הרשת (למה? ראו את הטריק של 'איגום ממוצע גלובלי' בהמשך). אם אתם מסווגים למאות מחלקות, כדאי להגדיל את מספר המסננים בהדרגה בשכבות עוקבות. במערך הנתונים של הפרחים עם 5 מחלקות, סינון עם 5 מסננים בלבד לא יספיק. אפשר להשתמש באותו מספר מסננים ברוב השכבות, למשל 32, ולהקטין אותו לקראת הסוף.
- השכבה הצפופה הסופית יקרה. יכול להיות שיש להם יותר משקלים מכל השכבות הקונבולוציוניות יחד. לדוגמה, גם אם יש פלט סביר מאוד מקוביית הנתונים האחרונה של 24x24x10 נקודות נתונים, שכבה צפופה של 100 נוירונים תעלה 24x24x10x100=576,000 משקלים!!! כדאי לחשוב על זה, או לנסות איגום ממוצע גלובלי (ראו בהמשך).
Global average pooling
במקום להשתמש בשכבה צפופה יקרה בסוף של רשת נוירונים קונבולוציונית, אפשר לפצל את הנתונים הנכנסים לריבוע לכמה חלקים שרוצים, לחשב את הממוצע של הערכים שלהם ולהזין אותם דרך פונקציית הפעלה של softmax. השיטה הזו לבניית ראש הסיווג לא כרוכה בעלויות משקל. ב-Keras, התחביר הוא tf.keras.layers.GlobalAveragePooling2D().

המוצר
מחברת הפתרון אתם יכולים להשתמש בו אם אתם נתקעים.
Keras_Flowers_TPU (solution).ipynb
מה נכלל
- 🤔 שיחקת עם שכבות קונבולוציה
- 🤓 ניסיתי שיטות שונות של איגום (pooling), כמו איגום מקסימלי, צעדים (strides), איגום ממוצע גלובלי וכו'.
- 😀 ביצע איטרציה מהירה במודל מהעולם האמיתי, ב-TPU
כדאי להקדיש רגע כדי לעבור על רשימת המשימות הבאה.
10. [INFO] ארכיטקטורות מודרניות של רשתות קונבולוציה
על קצה המזלג

איור: 'מודול' של רשת קונבולוציה. מה הכי טוב לעשות בשלב הזה? שכבת איגום מקסימלי ואחריה שכבת קונבולוציה 1x1 או שילוב אחר של שכבות? אפשר לנסות את כולם, לשרשר את התוצאות ולתת לרשת להחליט. משמאל: ארכיטקטורת הקונבולוציה (convolutional) של Inception באמצעות מודולים כאלה.
ב-Keras, כדי ליצור מודלים שבהם זרימת הנתונים יכולה להתפצל פנימה והחוצה, צריך להשתמש בסגנון המודל 'פונקציונלי'. לדוגמה:
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
טריקים זולים אחרים
מסננים קטנים בגודל 3x3

באיור הזה אפשר לראות את התוצאה של שני מסננים עוקבים בגודל 3x3. כדאי לנסות להתחקות אחרי נקודות הנתונים שתרמו לתוצאה: שני המסננים העוקבים בגודל 3x3 מחשבים שילוב כלשהו של אזור בגודל 5x5. זה לא בדיוק אותו שילוב שמסנן 5x5 יחשב, אבל כדאי לנסות כי שני מסנני 3x3 עוקבים זולים יותר ממסנן 5x5 יחיד.
מהן קונבולוציות 1x1?

במונחים מתמטיים, קונבולוציה של 1x1 היא כפל בקבוע, ולא מדובר במושג שימושי במיוחד. עם זאת, ברשתות עצביות קונבולוציוניות, חשוב לזכור שהמסנן מוחל על קוביית נתונים, ולא רק על תמונה דו-ממדית. לכן, מסנן '1x1' מחשב סכום משוקלל של עמודת נתונים בגודל 1x1 (ראו איור), וכשמזיזים אותו לאורך הנתונים, מתקבל שילוב לינארי של הערוצים של הקלט. המידע הזה שימושי. אם חושבים על הערוצים כעל התוצאות של פעולות סינון נפרדות, למשל מסנן ל'אוזניים מחודדות', מסנן אחר ל'שפמים' ומסנן שלישי ל'עיניים מלוכסנות', אז שכבת קונבולוציה של '1x1' תחשב כמה שילובים לינאריים אפשריים של התכונות האלה, שיכולים להיות שימושיים כשמחפשים 'חתול'. בנוסף, שכבות 1x1 משתמשות בפחות משקלים.
11. Squeezenet
דרך פשוטה לשלב בין הרעיונות האלה מוצגת במאמר Squeezenet. המחברים מציעים עיצוב פשוט מאוד של מודול קונבולוציה, שכולל רק שכבות קונבולוציה בגודל 1x1 ו-3x3.

איור: ארכיטקטורת squeezenet שמבוססת על 'מודולי אש'. הן מחליפות שכבת 1x1 ש'דוחסת' את הנתונים הנכנסים בממד האנכי, ואחריה שתי שכבות קונבולוציה מקבילות של 1x1 ו-3x3 ש'מרחיבות' שוב את עומק הנתונים.
מעשי
ממשיכים במחברת הקודמת ויוצרים רשת נוירונים קונבולוציונית בהשראת SqueezeNet. תצטרכו לשנות את קוד המודל ל'סגנון פונקציונלי' של Keras.
Keras_Flowers_TPU (playground).ipynb
מידע נוסף
כדאי להגדיר פונקציית עזר למודול squeezenet:
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
היעד הפעם הוא להגיע לרמת דיוק של 80%.
דברים שכדאי לנסות
מתחילים בשכבת קונבולוציה אחת, ואז ממשיכים עם fire_modules, לסירוגין עם שכבות MaxPooling2D(pool_size=2). אפשר להתנסות עם 2 עד 4 שכבות של איגום מקסימלי ברשת, וגם עם 1, 2 או 3 מודולים עוקבים של Fire בין השכבות של האיגום המקסימלי.
במודולים של Fire, הפרמטר squeeze בדרך כלל צריך להיות קטן מהפרמטר expand. הפרמטרים האלה הם בעצם מספרים של מסננים. הם יכולים לנוע בין 8 ל-196, בדרך כלל. אתם יכולים להתנסות בארכיטקטורות שבהן מספר המסננים גדל בהדרגה ברשת, או בארכיטקטורות פשוטות שבהן לכל מודולי האש יש את אותו מספר מסננים.
לדוגמה:
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
בשלב הזה, יכול להיות שתשימו לב שהניסויים לא מתנהלים בצורה טובה, ושנראה שהיעד של 80% דיוק רחוק מלהתממש. הגיע הזמן לעוד כמה טריקים זולים.
Batch Normalization
הנרמול באצווה יעזור לכם לפתור את בעיות ההתכנסות שבהן נתקלתם. בסדנה הבאה יהיו הסברים מפורטים על הטכניקה הזו. בינתיים, אפשר להשתמש בה כעוזרת 'קסם' של קופסה שחורה על ידי הוספת השורה הזו אחרי כל שכבת קונבולוציה ברשת, כולל השכבות בתוך הפונקציה fire_module:
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
צריך להקטין את פרמטר המומנטום מערך ברירת המחדל שלו, 0.99, ל-0.9 כי מערך הנתונים שלנו קטן. לא חשוב כרגע.
הגדלת מערך הנתונים
תוכלו לקבל עוד כמה אחוזים אם תעשירו את הנתונים באמצעות טרנספורמציות פשוטות כמו שינויים בהיפוך משמאל לימין של רוויה:


קל מאוד לעשות את זה ב-Tensorflow באמצעות tf.data.Dataset API. מגדירים פונקציית טרנספורמציה חדשה לנתונים:
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
אחר כך משתמשים בו בטרנספורמציה הסופית של הנתונים (התא 'training and validation datasets', הפונקציה 'get_batched_dataset'):
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
חשוב לזכור להגדיר את העשרת הנתונים כאופציונלית ולהוסיף את הקוד הנדרש כדי לוודא שרק מערך הנתונים לאימון יעבור העשרה. אין טעם להגדיל את מערך הנתונים validation.
עכשיו אפשר להגיע לרמת דיוק של 80% ב-35 תקופות.
המוצר
מחברת הפתרון אתם יכולים להשתמש בו אם אתם נתקעים.
Keras_Flowers_TPU_squeezenet.ipynb
מה נכלל
- 🤔 מודלים של Keras בסגנון פונקציונלי
- 🤓 ארכיטקטורת Squeezenet
- 🤓 הגדלת מערך הנתונים באמצעות tf.data.datset
כדאי להקדיש רגע כדי לעבור על רשימת המשימות הבאה.
12. Xception fine-tuned
Separable convolutions
לאחרונה, שיטה אחרת להטמעת שכבות קונבולוציה צוברת פופולריות: קונבולוציות שניתנות להפרדה לפי עומק. אני יודע, זה שם ארוך, אבל הרעיון די פשוט. הם מוטמעים ב-Tensorflow וב-Keras כ- tf.keras.layers.SeparableConv2D.
גם בפעולת קונבולוציה ניתנת להרצה של מסנן על התמונה, אבל נעשה שימוש בקבוצה נפרדת של משקלים לכל ערוץ של תמונת הקלט. אחריו מתבצעת 'קונבולוציה של 1x1', סדרה של מכפלות סקלריות שמובילות לסכום משוקלל של הערוצים המסוננים. בכל פעם מחושבים שילובים משוקללים של הערוצים עם משקלים חדשים, לפי הצורך.

איור: קונבולוציות שאפשר להפריד. שלב 1: קונבולוציות עם מסנן נפרד לכל ערוץ. שלב 2: שילובים לינאריים של ערוצים. הפעולה חוזרת על עצמה עם קבוצה חדשה של משקלים עד שמגיעים למספר הרצוי של ערוצי פלט. אפשר לחזור על שלב 1 גם כן, עם משקלים חדשים בכל פעם, אבל בפועל זה קורה לעיתים רחוקות.
הפעלת קונבולוציה נפרדת נמצאת בשימוש ברוב הארכיטקטורות העדכניות של רשתות קונבולוציה: MobileNetV2, Xception, EfficientNet. אגב, MobileNetV2 הוא המודל שבו השתמשתם בעבר ללמידת העברה.
הן זולות יותר מקונבולוציות רגילות, ונמצא שהן יעילות באותה מידה בפועל. הנה ספירת המשקלים בדוגמה שלמעלה:
שכבת קונבולוציה: 4 x 4 x 3 x 5 = 240
שכבת קונבולוציה ניתנת להפרדה: 4 x 4 x 3 + 3 x 5 = 48 + 15 = 63
הקוראים מוזמנים לחשב את מספר הפעמים שצריך להכפיל כדי להחיל כל סגנון של שכבת קונבולוציה באופן דומה. קונבולוציות ניתנות להפרדה הן קטנות ויעילות הרבה יותר מבחינת חישובים.
מעשי
מפעילים מחדש את מחברת ה-playground של 'למידת העברה', אבל הפעם בוחרים ב-Xception כמודל שעבר אימון מראש. ב-Xception נעשה שימוש רק בקונבולוציות נפרדות. השארת כל המשקלים ניתנים לאימון. אנחנו נבצע כוונון עדין של המשקלים שאומנו מראש על הנתונים שלנו, במקום להשתמש בשכבות שאומנו מראש כמו שהן.
Keras Flowers transfer learning (playground).ipynb
יעד: דיוק של יותר מ-95% (כן, זה אפשרי!)
זה התרגיל האחרון, ולכן הוא דורש קצת יותר עבודה עם קוד ומדעי הנתונים.
מידע נוסף על כוונון עדין
Xception זמין במודלים הרגילים שעברו אימון מראש ב-tf.keras.application.* אל תשכחו להשאיר את כל המשקלים ניתנים לאימון הפעם.
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
כדי לקבל תוצאות טובות כשמבצעים כוונון עדין של מודל, צריך לשים לב לקצב הלמידה ולהשתמש בלוח זמנים של קצב למידה עם תקופת הרצה של קמפיין. כך:

התחלה עם קצב למידה רגיל תשבש את המשקלים שאומנו מראש של המודל. השינויים יתבצעו בהדרגה עד שהמודל יתבסס על הנתונים שלכם ויוכל לשנות אותם בצורה הגיונית. אחרי העלייה ההדרגתית, אפשר להמשיך עם קצב למידה קבוע או עם קצב למידה שפוחת באופן אקספוננציאלי.
ב-Keras, קצב הלמידה מוגדר באמצעות קריאה חוזרת (callback) שבה אפשר לחשב את קצב הלמידה המתאים לכל תקופה. Keras תעביר את קצב הלמידה הנכון לאופטימיזציה של כל תקופה.
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
המוצר
מחברת הפתרון אתם יכולים להשתמש בו אם אתם נתקעים.
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
מה נכלל
- 🤔 Depth-separable convolution
- 🤓 לוחות זמנים של קצב למידה
- 😈 כוונון עדין של מודל שעבר אימון מראש.
כדאי להקדיש רגע כדי לעבור על רשימת המשימות הבאה.
13. מעולה!
בניתם את רשת הנוירונים המתקפלת המודרנית הראשונה שלכם ואימנתם אותה לרמת דיוק של 90% ומעלה, תוך חזרה על הרצות אימון חוזרות תוך דקות ספורות הודות ליחידות ה-TPU.
מעבדי TPU בפועל
מעבדי TPU ו-GPU זמינים ב-Vertex AI של Google Cloud:
- ב-Deep Learning VMs
- ב-Vertex AI Notebooks
- במשימות של Vertex AI Training Jobs
בסופו של דבר, נשמח לקבל משוב. נשמח לדעת אם משהו לא בסדר בשיעור ה-Lab הזה או אם יש לך רעיונות לשיפור. אפשר לשלוח משוב באמצעות בעיות ב-GitHub [ קישור למשוב].

|
|

