
1. Panoramica
In questo lab imparerai a creare, addestrare e ottimizzare le tue reti neurali convoluzionali da zero con Keras e TensorFlow 2. Ora è possibile farlo in pochi minuti utilizzando la potenza delle TPU. Esplorerai anche diversi approcci, dal transfer learning molto semplice alle moderne architetture convoluzionali come SqueezeNet. Questo lab include spiegazioni teoriche sulle reti neurali ed è un buon punto di partenza per gli sviluppatori che vogliono imparare a usare il deep learning.
Leggere articoli sul deep learning può essere difficile e confuso. Diamo un'occhiata pratica alle moderne architetture di reti neurali convoluzionali.

Obiettivi didattici
- Per utilizzare Keras e le Tensor Processing Unit (TPU) per creare più rapidamente i tuoi modelli personalizzati.
- Utilizzare l'API tf.data.Dataset e il formato TFRecord per caricare in modo efficiente i dati di addestramento.
- Per barare 😈, utilizzando il transfer learning anziché creare modelli personalizzati.
- Per utilizzare gli stili di modello sequenziale e funzionale di Keras.
- Per creare il tuo classificatore Keras con un livello softmax e una perdita di cross-entropia.
- Per ottimizzare il modello con una buona scelta di livelli convoluzionali.
- Per esplorare idee di architettura convnet moderne come moduli, pooling medio globale e così via.
- Per creare una semplice rete convnet moderna utilizzando l'architettura SqueezeNet.
Feedback
Se noti qualcosa di strano in questo codelab, comunicacelo. Il feedback può essere fornito tramite i problemi di GitHub [link al feedback].
2. Guida rapida di Google Colaboratory
Questo lab utilizza Google Collaboratory e non richiede alcuna configurazione da parte tua. Puoi eseguirlo da un Chromebook. Apri il file riportato di seguito ed esegui le celle per acquisire familiarità con i blocchi note Colab.
Seleziona un backend TPU

Nel menu di Colab, seleziona Runtime > Cambia tipo di runtime e poi TPU. In questo codelab utilizzerai una potente TPU (Tensor Processing Unit) supportata per l'addestramento con accelerazione hardware. La connessione al runtime avverrà automaticamente alla prima esecuzione oppure puoi utilizzare il pulsante "Connetti" nell'angolo in alto a destra.
Esecuzione del notebook

Esegui le celle una alla volta facendo clic su una cella e utilizzando Maiusc+Invio. Puoi anche eseguire l'intero notebook con Runtime > Esegui tutto.
Sommario

Tutti i notebook hanno un sommario. Puoi aprirlo utilizzando la freccia nera a sinistra.
Celle nascoste

Alcune celle mostreranno solo il titolo. Questa è una funzionalità specifica dei notebook di Colab. Puoi fare doppio clic per visualizzare il codice all'interno, ma di solito non è molto interessante. In genere, funzioni di supporto o visualizzazione. Devi comunque eseguire queste celle per definire le funzioni al loro interno.
Autenticazione
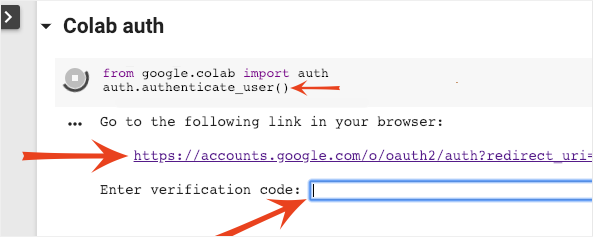
Colab può accedere ai tuoi bucket Google Cloud Storage privati se esegui l'autenticazione con un account autorizzato. Lo snippet di codice riportato sopra attiverà una procedura di autenticazione.
3. [INFO] Che cosa sono le Tensor Processing Unit (TPU)?
In breve

Il codice per l'addestramento di un modello su TPU in Keras (e il fallback su GPU o CPU se una TPU non è disponibile):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Oggi utilizzeremo le TPU per creare e ottimizzare un classificatore di fiori a velocità interattive (minuti per sessione di addestramento).

Perché le TPU?
Le GPU moderne sono organizzate intorno a "core" programmabili, un'architettura molto flessibile che consente loro di gestire una serie di attività come il rendering 3D, il deep learning, le simulazioni fisiche e così via. Le TPU, invece, accoppiano un processore vettoriale classico a un'unità di moltiplicazione della matrice dedicata e sono eccellenti in qualsiasi attività in cui dominano le moltiplicazioni di matrici di grandi dimensioni, come le reti neurali.

Illustrazione: uno strato di rete neurale densa come moltiplicazione di matrici, con un batch di otto immagini elaborate contemporaneamente dalla rete neurale. Esegui una moltiplicazione di una riga per una colonna per verificare che venga effettivamente eseguita una somma ponderata di tutti i valori dei pixel di un'immagine. Anche i livelli convoluzionali possono essere rappresentati come moltiplicazioni di matrici, anche se in modo un po' più complicato ( spiegazione qui, nella sezione 1).
L'hardware
MXU e VPU
Un core TPU v2 è costituito da un'unità di moltiplicazione a matrice (MXU) che esegue moltiplicazioni di matrici e da un'unità di elaborazione vettoriale (VPU) per tutte le altre attività, come attivazioni, softmax e così via. La VPU gestisce i calcoli float32 e int32. L'MXU, invece, opera in un formato a virgola mobile a precisione mista a 16-32 bit.

Virgola mobile a precisione mista e bfloat16
L'MXU calcola le moltiplicazioni di matrici utilizzando input bfloat16 e output float32. Gli accumuli intermedi vengono eseguiti con precisione float32.

L'addestramento della rete neurale è in genere resistente al rumore introdotto da una precisione in virgola mobile ridotta. Esistono casi in cui il rumore aiuta persino lo strumento di ottimizzazione a convergere. La precisione in virgola mobile a 16 bit è stata tradizionalmente utilizzata per accelerare i calcoli, ma i formati float16 e float32 hanno intervalli molto diversi. La riduzione della precisione da float32 a float16 di solito comporta overflow e underflow. Esistono soluzioni, ma in genere è necessario un lavoro aggiuntivo per far funzionare float16.
Per questo motivo, Google ha introdotto il formato bfloat16 nelle TPU. bfloat16 è un float32 troncato con esattamente gli stessi bit di esponente e lo stesso intervallo di float32. Questo, unito al fatto che le TPU calcolano le moltiplicazioni di matrici in precisione mista con input bfloat16 ma output float32, significa che, in genere, non sono necessarie modifiche al codice per trarre vantaggio dai miglioramenti delle prestazioni dovuti alla precisione ridotta.
Array sistolico
L'MXU implementa le moltiplicazioni di matrici nell'hardware utilizzando una cosiddetta architettura "array sistolico" in cui gli elementi di dati scorrono attraverso un array di unità di calcolo hardware. In medicina, "sistolico" si riferisce alle contrazioni cardiache e alla circolazione sanguigna, qui al flusso di dati.
L'elemento di base di una moltiplicazione di matrici è un prodotto scalare tra una riga di una matrice e una colonna dell'altra matrice (vedi l'illustrazione nella parte superiore di questa sezione). Per una moltiplicazione di matrici Y=X*W, un elemento del risultato sarebbe:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
Su una GPU, questo prodotto scalare viene programmato in un "core" della GPU e poi eseguito su tutti i "core" disponibili in parallelo per cercare di calcolare contemporaneamente ogni valore della matrice risultante. Se la matrice risultante è di 128 x 128, sarebbero necessari 128 x 128=16.000 "core" disponibili, il che in genere non è possibile. Le GPU più grandi hanno circa 4000 core. Una TPU, invece, utilizza l'hardware minimo indispensabile per le unità di calcolo nell'MXU: solo bfloat16 x bfloat16 => float32 moltiplicatori-accumulatori, nient'altro. Sono così piccole che una TPU può implementarne 16.000 in una MXU 128x128 ed elaborare questa moltiplicazione di matrici in una sola volta.

Illustrazione: l'array sistolico MXU. Gli elementi di calcolo sono accumulatori di moltiplicazione. I valori di una matrice vengono caricati nell'array (punti rossi). I valori dell'altra matrice scorrono attraverso l'array (punti grigi). Le linee verticali propagano i valori verso l'alto. Le linee orizzontali propagano le somme parziali. L'utente deve verificare che, man mano che il flusso di dati scorre nell'array, il risultato della moltiplicazione delle matrici esca dal lato destro.
Inoltre, mentre i prodotti scalari vengono calcolati in un'MXU, le somme intermedie scorrono semplicemente tra le unità di calcolo adiacenti. Non devono essere archiviati e recuperati dalla memoria o da un file di registro. Il risultato finale è che l'architettura dell'array sistolico della TPU offre un vantaggio significativo in termini di densità e potenza, nonché un vantaggio di velocità non trascurabile rispetto a una GPU, quando si calcolano le moltiplicazioni di matrici.
Cloud TPU
Quando richiedi una "Cloud TPU v2" su Google Cloud, ottieni una macchina virtuale (VM) con una scheda TPU collegata a PCI. La scheda TPU ha quattro chip TPU dual-core. Ogni core TPU è dotato di una VPU (Vector Processing Unit) e di un'unità MXU (MatriX multiply Unit) 128x128. Questa "Cloud TPU" viene quindi solitamente connessa tramite la rete alla VM che l'ha richiesta. Quindi il quadro completo è il seguente:

Illustrazione: la tua VM con un acceleratore "Cloud TPU" collegato alla rete. "La Cloud TPU" stessa è costituita da una VM con una scheda TPU collegata a PCI con quattro chip TPU dual-core.
TPU pod
Nei data center di Google, le TPU sono connesse a un'interconnessione di computing ad alte prestazioni (HPC), che può farle apparire come un unico acceleratore molto grande. Google li chiama pod e possono comprendere fino a 512 core TPU v2 o 2048 core TPU v3.

Illustrazione: un pod TPU v3. Schede e rack TPU connessi tramite l'interconnessione HPC.
Durante l'addestramento, i gradienti vengono scambiati tra i core TPU utilizzando l'algoritmo all-reduce ( qui una buona spiegazione di all-reduce). Il modello in fase di addestramento può sfruttare l'hardware eseguendo l'addestramento su dimensioni batch di grandi dimensioni.

Illustrazione: sincronizzazione dei gradienti durante l'addestramento utilizzando l'algoritmo all-reduce sulla rete HPC a mesh toroidale bidimensionale della TPU di Google.
Il software
Addestramento con dimensioni del batch elevate
La dimensione del batch ideale per le TPU è di 128 elementi di dati per core TPU, ma l'hardware può già mostrare un buon utilizzo a partire da 8 elementi di dati per core TPU. Ricorda che una Cloud TPU ha 8 core.
In questo codelab utilizzeremo l'API Keras. In Keras, il batch che specifichi è la dimensione del batch globale per l'intera TPU. I batch verranno suddivisi automaticamente in 8 e verranno eseguiti sugli 8 core della TPU.

Per ulteriori suggerimenti sul rendimento, consulta la Guida al rendimento delle TPU. Per batch di dimensioni molto grandi, in alcuni modelli potrebbe essere necessario prestare particolare attenzione. Per ulteriori dettagli, consulta LARSOptimizer.
Dietro le quinte: XLA
I programmi TensorFlow definiscono i grafi di calcolo. La TPU non esegue direttamente il codice Python, ma il grafico di calcolo definito dal programma TensorFlow. Sotto il cofano, un compilatore chiamato XLA (accelerated Linear Algebra compiler) trasforma il grafico di nodi di calcolo di TensorFlow in codice macchina TPU. Questo compilatore esegue anche molte ottimizzazioni avanzate sul codice e sul layout della memoria. La compilazione avviene automaticamente quando il lavoro viene inviato alla TPU. Non devi includere XLA nella catena di build in modo esplicito.

Illustrazione: per essere eseguito sulla TPU, il grafico di calcolo definito dal programma TensorFlow viene prima tradotto in una rappresentazione XLA (accelerated Linear Algebra compiler), quindi compilato da XLA in codice macchina TPU.
Utilizzo delle TPU in Keras
Le TPU sono supportate tramite l'API Keras a partire da TensorFlow 2.1. Il supporto di Keras funziona su TPU e pod TPU. Ecco un esempio che funziona su TPU, GPU e CPU:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
In questo snippet di codice:
TPUClusterResolver().connect()trova la TPU sulla rete. Funziona senza parametri sulla maggior parte dei sistemi Google Cloud (job AI Platform, Colaboratory, Kubeflow, VM di deep learning create tramite l'utilità "ctpu up"). Questi sistemi sanno dove si trova la TPU grazie a una variabile di ambiente TPU_NAME. Se crei una TPU manualmente, imposta la variabile di ambiente TPU_NAME sulla VM da cui la utilizzi o chiamaTPUClusterResolvercon parametri espliciti:TPUClusterResolver(tp_uname, zone, project)TPUStrategyè la parte che implementa l'algoritmo di sincronizzazione del gradiente di distribuzione e "all-reduce".- La strategia viene applicata tramite un ambito. Il modello deve essere definito nell'ambito della strategia scope().
- La funzione
tpu_model.fitprevede un oggetto tf.data.Dataset come input per l'addestramento della TPU.
Attività comuni di porting della TPU
- Sebbene esistano molti modi per caricare i dati in un modello TensorFlow, per le TPU è necessario utilizzare l'API
tf.data.Dataset. - Le TPU sono molto veloci e l'importazione dei dati spesso diventa il collo di bottiglia quando vengono eseguite. Nella Guida al rendimento delle TPU sono disponibili strumenti che puoi utilizzare per rilevare i colli di bottiglia dei dati e altri suggerimenti sul rendimento.
- I numeri int8 o int16 vengono trattati come int32. La TPU non dispone di hardware per numeri interi che operano su meno di 32 bit.
- Alcune operazioni di TensorFlow non sono supportate. L'elenco è disponibile qui. La buona notizia è che questa limitazione si applica solo al codice di addestramento, ovvero al passaggio in avanti e indietro attraverso il modello. Puoi comunque utilizzare tutte le operazioni TensorFlow nella pipeline di input dei dati, in quanto verranno eseguite sulla CPU.
tf.py_funcnon è supportato sulla TPU.
4. Caricamento dati in corso…






Lavoreremo con un set di dati di immagini di fiori. L'obiettivo è imparare a classificarli in 5 tipi di fiori. Il caricamento dei dati viene eseguito utilizzando l'API tf.data.Dataset. Innanzitutto, scopriamo l'API.
Pratica
Apri il seguente notebook, esegui le celle (Maiusc+Invio) e segui le istruzioni ovunque vedi l'etichetta "LAVORO RICHIESTO".

Fun with tf.data.Dataset (playground).ipynb
Ulteriori informazioni
Informazioni sul set di dati "Fiori"
Il set di dati è organizzato in 5 cartelle. Ogni cartella contiene fiori di un solo tipo. Le cartelle si chiamano girasoli, margherita, tarassaco, tulipani e rose. I dati sono ospitati in un bucket pubblico su Google Cloud Storage. Estratto:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
Perché tf.data.Dataset?
Keras e TensorFlow accettano i set di dati in tutte le loro funzioni di addestramento e valutazione. Una volta caricati i dati in un set di dati, l'API offre tutte le funzionalità comuni utili per i dati di addestramento della rete neurale:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
Puoi trovare suggerimenti sul rendimento e best practice per i set di dati in questo articolo. La documentazione di riferimento è disponibile qui.
Nozioni di base di tf.data.Dataset
I dati di solito sono contenuti in più file, in questo caso immagini. Puoi creare un set di dati di nomi di file chiamando:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
Quindi "mappi" una funzione a ogni nome file, che in genere carica e decodifica il file in dati effettivi in memoria:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
Per eseguire l'iterazione su un set di dati:
for data in my_dataset:
print(data)
Set di dati di tuple
Nell'apprendimento supervisionato, un set di dati di addestramento è in genere costituito da coppie di dati di addestramento e risposte corrette. Per consentirlo, la funzione di decodifica può restituire tuple. Avrai quindi un set di dati di tuple e le tuple verranno restituite quando lo iteri. I valori restituiti sono tensori TensorFlow pronti per essere utilizzati dal modello. Puoi chiamare .numpy() per visualizzare i valori non elaborati:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
Conclusione:caricare le immagini una per volta è lento.
Man mano che esegui l'iterazione su questo set di dati, vedrai che puoi caricare circa 1-2 immagini al secondo. È troppo lento. Gli acceleratori hardware che utilizzeremo per l'addestramento possono sostenere molte volte questa velocità. Vai alla sezione successiva per scoprire come lo faremo.
Soluzione
Ecco il notebook della soluzione. Puoi utilizzarlo se non riesci a risolvere il problema.
Fun with tf.data.Dataset (solution).ipynb
Argomenti trattati
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 Set di dati di tuple
- 😀 Iterazione dei set di dati
Ti invitiamo a esaminare questo elenco di controllo.
5. Caricamento rapido dei dati
Gli acceleratori hardware TPU (Tensor Processing Unit) che utilizzeremo in questo lab sono molto veloci. La sfida spesso consiste nel fornire loro dati abbastanza velocemente da tenerli occupati. Google Cloud Storage (GCS) è in grado di sostenere un throughput elevato, ma come per tutti i sistemi di archiviazione cloud, l'avvio di una connessione comporta un certo traffico di rete. Pertanto, non è ideale che i nostri dati vengano memorizzati come migliaia di file singoli. Li raggrupperemo in batch in un numero inferiore di file e utilizzeremo la potenza di tf.data.Dataset per leggere da più file in parallelo.
Read-through
Il codice che carica i file immagine, li ridimensiona a una dimensione comune e li archivia in 16 file TFRecord si trova nel seguente blocco note. Leggilo rapidamente. L'esecuzione non è necessaria, poiché per il resto del codelab verranno forniti dati formattati correttamente in TFRecord.
Flower pictures to TFRecords.ipynb
Layout dei dati ideale per una velocità effettiva ottimale di GCS
Il formato file TFRecord
Il formato file preferito di TensorFlow per l'archiviazione dei dati è il formato TFRecord basato su protobuf. Anche altri formati di serializzazione funzionerebbero, ma puoi caricare un set di dati dai file TFRecord direttamente scrivendo:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Per prestazioni ottimali, ti consigliamo di utilizzare il seguente codice più complesso per leggere contemporaneamente da più file TFRecord. Questo codice leggerà N file in parallelo e ignorerà l'ordine dei dati a favore della velocità di lettura.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Scheda di riferimento di TFRecord
In TFRecords possono essere archiviati tre tipi di dati: stringhe di byte (elenco di byte), numeri interi a 64 bit e numeri in virgola mobile a 32 bit. Vengono sempre archiviati come elenchi e un singolo elemento di dati sarà un elenco di dimensioni 1. Puoi utilizzare le seguenti funzioni helper per archiviare i dati in TFRecord.
scrittura di stringhe di byte
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
scrittura di numeri interi
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
Scrittura fluttuante
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
Scrivere un TFRecord utilizzando gli helper sopra indicati.
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
Per leggere i dati da TFRecord, devi prima dichiarare il layout dei record che hai archiviato. Nella dichiarazione, puoi accedere a qualsiasi campo denominato come elenco a lunghezza fissa o variabile:
lettura da TFRecord
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
Snippet di codice utili:
lettura di singoli elementi di dati
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
leggere elenchi di elementi a dimensioni fisse
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
leggere un numero variabile di elementi di dati
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
Una VarLenFeature restituisce un vettore sparso ed è necessario un passaggio aggiuntivo dopo la decodifica del TFRecord:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
È anche possibile avere campi facoltativi nei TFRecord. Se specifichi un valore predefinito durante la lettura di un campo, questo valore viene restituito al posto di un errore se il campo non è presente.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
Argomenti trattati
- 🤔 suddivisione dei file di dati per un accesso rapido da GCS
- 😓 come scrivere TFRecord. Hai già dimenticato la sintassi? Non preoccuparti, aggiungi questa pagina ai preferiti come cheat sheet.
- 🤔 caricamento di un set di dati da TFRecords utilizzando TFRecordDataset
Ti invitiamo a esaminare questo elenco di controllo.
6. [INFO] Classificatore di rete neurale 101
In breve
Se conosci già tutti i termini in grassetto nel paragrafo successivo, puoi passare all'esercizio successivo. Se hai appena iniziato a utilizzare il deep learning, benvenuto e continua a leggere.
Per i modelli creati come sequenza di livelli, Keras offre l'API Sequential. Ad esempio, un classificatore di immagini che utilizza tre livelli densi può essere scritto in Keras come segue:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
Rete neurale densa
Si tratta della rete neurale più semplice per classificare le immagini. È composto da "neuroni" disposti in strati. Il primo strato elabora i dati di input e invia gli output ad altri strati. Viene chiamato "denso" perché ogni neurone è collegato a tutti i neuroni dello strato precedente.

Puoi inserire un'immagine in una rete di questo tipo appiattendo i valori RGB di tutti i suoi pixel in un lungo vettore e utilizzandolo come input. Non è la tecnica migliore per il riconoscimento delle immagini, ma la miglioreremo in futuro.
Neuroni, attivazioni, ReLU
Un "neurone" calcola una somma ponderata di tutti i suoi input, aggiunge un valore chiamato "bias" e inserisce il risultato in una cosiddetta "funzione di attivazione". All'inizio, i pesi e il bias sono sconosciuti. Verranno inizializzati in modo casuale e "appresi" addestrando la rete neurale su molti dati noti.

La funzione di attivazione più popolare è chiamata ReLU, acronimo di Rectified Linear Unit. È una funzione molto semplice, come puoi vedere nel grafico sopra.
Attivazione Softmax
La rete precedente termina con un livello di 5 neuroni perché stiamo classificando i fiori in 5 categorie (rosa, tulipano, tarassaco, margherita, girasole). I neuroni negli strati intermedi vengono attivati utilizzando la classica funzione di attivazione ReLU. Nell'ultimo livello, invece, vogliamo calcolare numeri compresi tra 0 e 1 che rappresentano la probabilità che questo fiore sia una rosa, un tulipano e così via. Per questo, utilizzeremo una funzione di attivazione chiamata "softmax".
L'applicazione di softmax a un vettore viene eseguita prendendo l'esponenziale di ogni elemento e poi normalizzando il vettore, in genere utilizzando la norma L1 (somma dei valori assoluti) in modo che i valori sommati diano 1 e possano essere interpretati come probabilità.


Perdita di entropia incrociata
Ora che la nostra rete neurale produce previsioni dalle immagini di input, dobbiamo misurare la loro qualità, ovvero la distanza tra ciò che ci dice la rete e le risposte corrette, spesso chiamate "etichette". Ricorda che abbiamo le etichette corrette per tutte le immagini del set di dati.
Qualsiasi distanza andrebbe bene, ma per i problemi di classificazione la cosiddetta "distanza di entropia incrociata" è la più efficace. La chiameremo funzione di errore o "perdita":

Discesa del gradiente
"Addestrare" la rete neurale significa utilizzare immagini e etichette di addestramento per regolare pesi e bias in modo da ridurre al minimo la funzione di perdita di entropia incrociata. Ecco come funziona.
L'entropia incrociata è una funzione di pesi, bias, pixel dell'immagine di addestramento e della sua classe nota.
Se calcoliamo le derivate parziali dell'entropia incrociata rispetto a tutti i pesi e a tutti i bias, otteniamo un "gradiente", calcolato per una determinata immagine, etichetta e valore attuale di pesi e bias. Ricorda che possiamo avere milioni di pesi e bias, quindi il calcolo del gradiente sembra un'attività molto impegnativa. Fortunatamente, TensorFlow lo fa per noi. La proprietà matematica di un gradiente è che punta "verso l'alto". Poiché vogliamo andare dove l'entropia incrociata è bassa, andiamo nella direzione opposta. Aggiorniamo pesi e bias di una frazione del gradiente. Quindi, ripetiamo la stessa operazione più e più volte utilizzando i batch successivi di immagini e etichette di addestramento, in un ciclo di addestramento. Si spera che questo converga in un punto in cui l'entropia incrociata sia minima, anche se nulla garantisce che questo minimo sia univoco.

Mini-batching e momentum
Puoi calcolare il gradiente su una sola immagine di esempio e aggiornare immediatamente i pesi e i bias, ma farlo su un batch di, ad esempio, 128 immagini fornisce un gradiente che rappresenta meglio i vincoli imposti da diverse immagini di esempio e quindi è più probabile che converga più rapidamente verso la soluzione. La dimensione del mini-batch è un parametro regolabile.
Questa tecnica, a volte chiamata "discesa del gradiente stocastico", ha un altro vantaggio più pragmatico: lavorare con i batch significa anche lavorare con matrici più grandi e queste sono generalmente più facili da ottimizzare su GPU e TPU.
La convergenza può comunque essere un po' caotica e può persino interrompersi se il vettore gradiente è tutto zero. Significa che abbiamo trovato un minimo? Non sempre. Un componente gradiente può essere zero su un minimo o un massimo. Con un vettore gradiente con milioni di elementi, se sono tutti zero, la probabilità che ogni zero corrisponda a un minimo e nessuno a un punto massimo è piuttosto bassa. In uno spazio con molte dimensioni, i punti di sella sono piuttosto comuni e non vogliamo fermarci.

Illustrazione: un punto di sella. Il gradiente è 0, ma non è un minimo in tutte le direzioni. (Attribuzione immagine Wikimedia: di Nicoguaro - Own work, CC BY 3.0)
La soluzione consiste nell'aggiungere un po' di slancio all'algoritmo di ottimizzazione in modo che possa superare i punti di sella senza fermarsi.
Glossario
Batch o mini-batch: l'addestramento viene sempre eseguito su batch di dati di addestramento ed etichette. In questo modo, l'algoritmo converge. La dimensione "batch" è in genere la prima dimensione dei tensori di dati. Ad esempio, un tensore di forma [100, 192, 192, 3] contiene 100 immagini di 192 x 192 pixel con tre valori per pixel (RGB).
Perdita di entropia incrociata: una funzione di perdita speciale spesso utilizzata nei classificatori.
Strato denso: uno strato di neuroni in cui ogni neurone è collegato a tutti i neuroni dello strato precedente.
Caratteristiche: gli input di una rete neurale a volte vengono chiamati "caratteristiche". L'arte di capire quali parti di un set di dati (o combinazioni di parti) inserire in una rete neurale per ottenere buone previsioni è chiamata "feature engineering".
Etichette: un altro nome per "classi" o risposte corrette in un problema di classificazione supervisionata
Tasso di apprendimento: frazione del gradiente in base alla quale vengono aggiornati pesi e bias a ogni iterazione del ciclo di addestramento.
Logit: gli output di un livello di neuroni prima dell'applicazione della funzione di attivazione sono chiamati "logit". Il termine deriva dalla "funzione logistica", nota anche come "funzione sigmoide", che in passato era la funzione di attivazione più popolare. "Neuron outputs before logistic function" è stato abbreviato in "logits".
Perdita: la funzione di errore che confronta gli output della rete neurale con le risposte corrette
Neurone: calcola la somma ponderata dei suoi input, aggiunge un bias e trasmette il risultato tramite una funzione di attivazione.
Codifica one-hot: la classe 3 su 5 viene codificata come un vettore di 5 elementi, tutti pari a zero tranne il terzo, che è pari a 1.
relu: unità lineare rettificata. Una funzione di attivazione popolare per i neuroni.
sigmoid: un'altra funzione di attivazione che era popolare e che è ancora utile in casi speciali.
softmax: una funzione di attivazione speciale che agisce su un vettore, aumenta la differenza tra il componente più grande e tutti gli altri e normalizza il vettore in modo che la somma sia pari a 1, in modo che possa essere interpretato come un vettore di probabilità. Utilizzato come ultimo passaggio nei classificatori.
Tensore: un "tensore" è come una matrice, ma con un numero arbitrario di dimensioni. Un tensore unidimensionale è un vettore. Un tensore bidimensionale è una matrice. Poi puoi avere tensori con 3, 4, 5 o più dimensioni.
7. Transfer learning
Per un problema di classificazione delle immagini, i livelli densi probabilmente non saranno sufficienti. Dobbiamo imparare a conoscere i livelli convoluzionali e i molti modi in cui è possibile disporli.
Ma possiamo anche prendere una scorciatoia. Sono disponibili per il download reti neurali convoluzionali completamente addestrate. È possibile eliminare l'ultimo livello, l'intestazione di classificazione softmax, e sostituirlo con il proprio. Tutti i pesi e i bias addestrati rimangono invariati, viene riaddestrato solo il livello softmax che aggiungi. Questa tecnica è chiamata transfer learning e, cosa sorprendente, funziona se il set di dati su cui è pre-addestrata la rete neurale è "abbastanza vicino" al tuo.
Pratico
Apri il seguente notebook, esegui le celle (Maiusc+Invio) e segui le istruzioni ovunque vedi l'etichetta "LAVORO RICHIESTO".
Keras Flowers transfer learning (playground).ipynb
Ulteriori informazioni
Con il transfer learning, puoi usufruire sia di architetture avanzate di reti neurali convoluzionali sviluppate dai migliori ricercatori sia del preaddestramento su un enorme set di dati di immagini. Nel nostro caso, utilizzeremo il transfer learning da una rete addestrata su ImageNet, un database di immagini contenente molte piante e scene all'aperto, che è abbastanza simile ai fiori.

Illustrazione: utilizzo di una rete neurale convoluzionale complessa, già addestrata, come scatola nera, riaddestramento solo dell'intestazione di classificazione. Questo è il transfer learning. Vedremo più avanti come funzionano queste complesse disposizioni di livelli convoluzionali. Per ora, è un problema di qualcun altro.
Transfer learning in Keras
In Keras, puoi creare un'istanza di un modello preaddestrato dalla raccolta tf.keras.applications.*. MobileNet V2, ad esempio, è un'ottima architettura convoluzionale che mantiene dimensioni ragionevoli. Se selezioni include_top=False, ottieni il modello preaddestrato senza il livello softmax finale, in modo da poter aggiungere il tuo:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
Nota anche l'impostazione pretrained_model.trainable = False. Congela i pesi e i bias del modello preaddestrato in modo da addestrare solo lo strato softmax. In genere, ciò comporta un numero relativamente ridotto di pesi e può essere eseguito rapidamente e senza richiedere un set di dati molto grande. Tuttavia, se disponi di molti dati, il transfer learning può funzionare ancora meglio con pretrained_model.trainable = True. I pesi preaddestrati forniscono quindi valori iniziali eccellenti e possono comunque essere modificati dall'addestramento per adattarsi meglio al tuo problema.
Infine, nota il livello Flatten() inserito prima del livello softmax denso. I livelli densi funzionano su vettori di dati piatti, ma non sappiamo se è questo che restituisce il modello preaddestrato. Ecco perché dobbiamo appiattire la curva. Nel capitolo successivo, quando approfondiremo le architetture convoluzionali, spiegheremo il formato dei dati restituito dai layer convoluzionali.
Con questo approccio dovresti raggiungere un'accuratezza del 75%.
Soluzione
Ecco il notebook della soluzione. Puoi utilizzarlo se non riesci a risolvere il problema.
Keras Flowers transfer learning (solution).ipynb
Argomenti trattati
- 🤔 Come scrivere un classificatore in Keras
- 🤓 configurato con un ultimo livello softmax e una perdita di entropia incrociata
- 😈 Transfer learning
- 🤔 Addestramento del primo modello
- 🧐 Monitoraggio della perdita e dell'accuratezza durante l'addestramento
Ti invitiamo a esaminare questo elenco di controllo.
8. [INFO] Reti neurali convoluzionali
In breve
Se conosci già tutti i termini in grassetto nel paragrafo successivo, puoi passare all'esercizio successivo. Se hai appena iniziato a utilizzare le reti neurali convoluzionali, continua a leggere.

Illustrazione: filtro di un'immagine con due filtri successivi composti da 48 pesi apprendibili ciascuno.
Ecco come appare una semplice rete neurale convoluzionale in Keras:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
Reti neurali convoluzionali 101
In un livello di una rete convoluzionale, un "neurone" esegue una somma ponderata dei pixel appena sopra, solo in una piccola regione dell'immagine. Aggiunge un bias e alimenta la somma tramite una funzione di attivazione, proprio come farebbe un neurone in un normale livello denso. Questa operazione viene poi ripetuta sull'intera immagine utilizzando gli stessi pesi. Ricorda che negli strati densi ogni neurone aveva i propri pesi. Qui, una singola "patch" di pesi scorre sull'immagine in entrambe le direzioni (una "convoluzione"). L'output ha tanti valori quanti sono i pixel nell'immagine (anche se è necessario un po' di padding ai bordi). Si tratta di un'operazione di filtraggio che utilizza un filtro di 4x4x3=48 pesi.
Tuttavia, 48 pesi non saranno sufficienti. Per aggiungere altri gradi di libertà, ripetiamo la stessa operazione con un nuovo insieme di pesi. Viene generata una nuova serie di output del filtro. Chiamiamolo "canale " di output per analogia con i canali R, G e B nell'immagine di input.

I due (o più) insiemi di pesi possono essere riassunti in un unico tensore aggiungendo una nuova dimensione. In questo modo otteniamo la forma generica del tensore dei pesi per un livello convoluzionale. Poiché il numero di canali di input e output sono parametri, possiamo iniziare ad accumulare e concatenare i livelli convoluzionali.

Illustrazione: una rete neurale convoluzionale trasforma "cubi" di dati in altri "cubi" di dati.
Convoluzioni con passo, max pooling
Eseguendo le convoluzioni con uno stride di 2 o 3, possiamo anche ridurre il cubo di dati risultante nelle sue dimensioni orizzontali. Esistono due modi comuni per farlo:
- Convoluzione con passo: un filtro scorrevole come sopra, ma con un passo > 1
- Max pooling: una finestra scorrevole che applica l'operazione MAX (in genere su patch 2x2, ripetute ogni 2 pixel)

Illustrazione: se si sposta la finestra di calcolo di 3 pixel, si ottengono meno valori di output. Le convoluzioni con passo o il max pooling (massimo in una finestra 2x2 che scorre con un passo di 2) sono un modo per ridurre il cubo di dati nelle dimensioni orizzontali.
Classificatore convoluzionale
Infine, colleghiamo un'intestazione di classificazione appiattendo l'ultimo cubo di dati e inserendolo in un livello denso attivato da softmax. Un tipico classificatore convoluzionale può avere il seguente aspetto:

Illustrazione: un classificatore di immagini che utilizza strati convoluzionali e softmax. Utilizza filtri 3x3 e 1x1. I livelli maxpool prendono il massimo di gruppi di punti dati 2x2. L'intestazione di classificazione viene implementata con un livello denso con attivazione softmax.
In Keras
Lo stack convoluzionale illustrato sopra può essere scritto in Keras nel seguente modo:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
9. La tua rete neurale convoluzionale personalizzata
Pratico
Creiamo e addestriamo una rete neurale convoluzionale da zero. L'utilizzo di una TPU ci consentirà di eseguire iterazioni molto rapidamente. Apri il seguente notebook, esegui le celle (Maiusc+Invio) e segui le istruzioni ovunque vedi l'etichetta "LAVORO RICHIESTO".
Keras_Flowers_TPU (playground).ipynb
L'obiettivo è superare l'accuratezza del 75% del modello di transfer learning. Questo modello aveva un vantaggio, essendo stato preaddestrato su un set di dati di milioni di immagini, mentre qui ne abbiamo solo 3670. Puoi almeno pareggiare l'offerta?
Ulteriori informazioni
Quanti livelli, quanto è grande?
La selezione delle dimensioni dei livelli è più un'arte che una scienza. Devi trovare il giusto equilibrio tra un numero troppo basso e troppo alto di parametri (pesi e bias). Con un numero troppo ridotto di pesi, la rete neurale non può rappresentare la complessità delle forme dei fiori. Se sono troppe, può verificarsi un "overfitting", ovvero una specializzazione nelle immagini di addestramento e l'incapacità di generalizzare. Con molti parametri, anche l'addestramento del modello sarà lento. In Keras, la funzione model.summary() mostra la struttura e il conteggio dei parametri del modello:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
Ecco un paio di suggerimenti:
- La presenza di più livelli è ciò che rende efficaci le reti neurali "profonde". Per questo semplice problema di riconoscimento dei fiori, sono ragionevoli 5-10 livelli.
- Utilizza filtri piccoli. In genere, i filtri 3x3 vanno bene ovunque.
- Possono essere utilizzati anche filtri 1x1, che sono economici. Non "filtrano" nulla, ma calcolano combinazioni lineari di canali. Alternali con filtri reali. Scopri di più sulle "convoluzioni 1x1" nella sezione successiva.
- Per un problema di classificazione come questo, esegui il sottocampionamento di frequente con livelli di max pooling (o convoluzioni con stride > 1). Non ti interessa dove si trova il fiore, ma solo che sia una rosa o un tarassaco, quindi perdere le informazioni x e y non è importante e filtrare aree più piccole è più economico.
- Il numero di filtri di solito diventa simile al numero di classi alla fine della rete (perché? Vedi il trucco del "pooling medio globale" di seguito). Se classifichi in centinaia di classi, aumenta progressivamente il conteggio dei filtri nei livelli consecutivi. Per il set di dati sui fiori con 5 classi, il filtraggio con soli 5 filtri non sarebbe sufficiente. Puoi utilizzare lo stesso numero di filtri nella maggior parte dei livelli, ad esempio 32, e diminuirlo verso la fine.
- L'ultimo o gli ultimi strati Dense sono costosi. Può avere più pesi di tutti i livelli convoluzionali combinati. Ad esempio, anche con un output molto ragionevole dell'ultimo cubo di dati di 24x24x10 punti dati, un livello denso di 100 neuroni costerebbe 24x24x10x100=576.000 pesi. Cerca di fare attenzione o prova il pooling medio globale (vedi sotto).
Pooling medio globale
Invece di utilizzare un costoso strato denso alla fine di una rete neurale convoluzionale, puoi dividere il "cubo" di dati in entrata in tante parti quante sono le classi, calcolare la media dei valori e inserirli in una funzione di attivazione softmax. Questo modo di creare l'intestazione di classificazione costa 0 pesi. In Keras, la sintassi è tf.keras.layers.GlobalAveragePooling2D().

Soluzione
Ecco il notebook della soluzione. Puoi utilizzarlo se non riesci a risolvere il problema.
Keras_Flowers_TPU (solution).ipynb
Argomenti trattati
- 🤔 Ha giocato con i livelli convoluzionali
- 🤓 Ha sperimentato il max pooling, gli stride, il global average pooling e così via.
- 😀 ha eseguito l'iterazione di un modello reale rapidamente su TPU
Ti invitiamo a esaminare questo elenco di controllo.
10. [INFO] Architetture convoluzionali moderne
In breve

Illustrazione: un "modulo" convoluzionale. Qual è la cosa migliore da fare a questo punto? Un livello max-pool seguito da un livello convoluzionale 1x1 o una diversa combinazione di livelli? Provali tutti, concatena i risultati e lascia che sia la rete a decidere. A destra: l'architettura convoluzionale " inception" che utilizza questi moduli.
In Keras, per creare modelli in cui il flusso di dati può ramificarsi in entrata e in uscita, devi utilizzare lo stile di modello "funzionale". Ecco un esempio:
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
Altri trucchi economici
Filtri piccoli 3x3

In questa illustrazione, vedi il risultato di due filtri 3x3 consecutivi. Prova a risalire ai punti dati che hanno contribuito al risultato: questi due filtri 3x3 consecutivi calcolano una combinazione di una regione 5x5. Non è esattamente la stessa combinazione che calcolerebbe un filtro 5x5, ma vale la pena provare perché due filtri 3x3 consecutivi sono più economici di un singolo filtro 5x5.
Convoluzioni 1x1?

In termini matematici, una convoluzione "1x1" è una moltiplicazione per una costante, un concetto non molto utile. Nelle reti neurali convoluzionali, invece, ricorda che il filtro viene applicato a un cubo di dati, non solo a un'immagine 2D. Pertanto, un filtro "1x1" calcola una somma ponderata di una colonna di dati 1x1 (vedi l'illustrazione) e, man mano che lo sposti sui dati, ottieni una combinazione lineare dei canali dell'input. È davvero utile. Se pensi ai canali come ai risultati di singole operazioni di filtraggio, ad esempio un filtro per "orecchie a punta", un altro per "baffi" e un terzo per "occhi a fessura", un livello convoluzionale "1x1" calcolerà più combinazioni lineari possibili di queste caratteristiche, il che potrebbe essere utile quando cerchi un "gatto". Inoltre, i livelli 1x1 utilizzano meno pesi.
11. Squeezenet
Un modo semplice per combinare queste idee è stato illustrato nell'articolo "Squeezenet". Gli autori suggeriscono un design del modulo convoluzionale molto semplice, utilizzando solo livelli convoluzionali 1x1 e 3x3.

Illustrazione: architettura SqueezeNet basata su "moduli fire". Alternano un livello 1x1 che "comprime" i dati in entrata nella dimensione verticale seguito da due livelli convoluzionali paralleli 1x1 e 3x3 che "espandono" nuovamente la profondità dei dati.
Pratico
Continua nel notebook precedente e crea una rete neurale convoluzionale ispirata a SqueezeNet. Dovrai modificare il codice del modello in modo che utilizzi lo "stile funzionale" di Keras.
Keras_Flowers_TPU (playground).ipynb
Altre informazioni
Per questo esercizio, sarà utile definire una funzione helper per un modulo SqueezeNet:
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
L'obiettivo questa volta è raggiungere una precisione dell'80%.
Cose da provare
Inizia con un singolo livello convoluzionale, poi segui con "fire_modules", alternando i livelli MaxPooling2D(pool_size=2). Puoi sperimentare con 2-4 livelli di pooling massimo nella rete e anche con 1, 2 o 3 moduli Fire consecutivi tra i livelli di pooling massimo.
Nei moduli antincendio, il parametro "squeeze" (compressione) in genere deve essere inferiore al parametro "expand" (espansione). Questi parametri sono in realtà numeri di filtri. In genere, possono variare da 8 a 196. Puoi sperimentare architetture in cui il numero di filtri aumenta gradualmente nella rete o architetture semplici in cui tutti i moduli Fire hanno lo stesso numero di filtri.
Ecco un esempio:
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
A questo punto, potresti notare che i tuoi esperimenti non stanno andando molto bene e che l'obiettivo di accuratezza dell'80% sembra lontano. È ora di un altro paio di trucchetti economici.
Normalizzazione batch
La normalizzazione dei batch ti aiuterà a risolvere i problemi di convergenza che stai riscontrando. Nel prossimo workshop verranno fornite spiegazioni dettagliate su questa tecnica. Per ora, utilizzala come helper "magico" a scatola chiusa aggiungendo questa riga dopo ogni livello convoluzionale nella rete, inclusi i livelli all'interno della funzione fire_module:
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
Il parametro momentum deve essere ridotto dal valore predefinito di 0,99 a 0,9 perché il nostro set di dati è piccolo. Per il momento, non preoccuparti di questo dettaglio.
Aumento dei dati
Otterrai un paio di punti percentuali in più aumentando i dati con trasformazioni semplici come l'inversione sinistra-destra delle variazioni di saturazione:


È molto facile da fare in TensorFlow con l'API tf.data.Dataset. Definisci una nuova funzione di trasformazione per i tuoi dati:
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
Quindi, utilizzalo nella trasformazione finale dei dati (cella "training and validation datasets", funzione "get_batched_dataset"):
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
Non dimenticare di rendere facoltativa l'aumento dei dati e di aggiungere il codice necessario per assicurarti che venga aumentato solo il set di dati di addestramento. Non ha senso aumentare il set di dati di convalida.
Ora dovresti riuscire a raggiungere un'accuratezza dell'80% in 35 epoche.
Soluzione
Ecco il notebook della soluzione. Puoi utilizzarlo se non riesci a risolvere il problema.
Keras_Flowers_TPU_squeezenet.ipynb
Argomenti trattati
- 🤔 Modelli "funzionali" di Keras
- 🤓 Architettura Squeezenet
- 🤓 Aumento dei dati con tf.data.datset
Ti invitiamo a esaminare questo elenco di controllo.
12. Xception ottimizzato
Convoluzioni separabili
Un modo diverso di implementare i livelli convoluzionali ha guadagnato popolarità di recente: le convoluzioni separabili in profondità. Lo so, è un po' complicato, ma il concetto è piuttosto semplice. Sono implementati in TensorFlow e Keras come tf.keras.layers.SeparableConv2D.
Una convoluzione separabile esegue anche un filtro sull'immagine, ma utilizza un insieme distinto di pesi per ciascun canale dell'immagine di input. Segue una "convoluzione 1x1", una serie di prodotti scalari che danno come risultato una somma ponderata dei canali filtrati. Con nuovi pesi ogni volta, vengono calcolate tutte le ricombinazioni ponderate dei canali necessarie.

Illustrazione: convoluzioni separabili. Fase 1: convoluzioni con un filtro separato per ogni canale. Fase 2: ricombinazioni lineari dei canali. Ripetuto con un nuovo set di pesi fino a raggiungere il numero desiderato di canali di output. Anche la fase 1 può essere ripetuta, con nuovi pesi ogni volta, ma in pratica è raro.
Le convoluzioni separabili vengono utilizzate nelle architetture di rete convoluzionale più recenti: MobileNetV2, Xception, EfficientNet. A proposito, MobileNetV2 è ciò che hai utilizzato in precedenza per il transfer learning.
Sono più economici delle convoluzioni regolari e si sono dimostrati altrettanto efficaci nella pratica. Ecco il conteggio del peso per l'esempio illustrato sopra:
Livello convoluzionale: 4 x 4 x 3 x 5 = 240
Livello convoluzionale separabile: 4 x 4 x 3 + 3 x 5 = 48 + 15 = 63
Il lettore può calcolare il numero di moltiplicazioni necessarie per applicare ogni stile di strato convoluzionale in modo simile. Le convoluzioni separabili sono più piccole e molto più efficaci dal punto di vista computazionale.
Pratico
Riavvia il notebook del playground "transfer learning", ma questa volta seleziona Xception come modello preaddestrato. Xception utilizza solo convoluzioni separabili. Lascia tutti i pesi addestrabili. Per i nostri dati, eseguiremo il perfezionamento dei pesi pre-addestrati anziché utilizzare i livelli pre-addestrati così come sono.
Keras Flowers transfer learning (playground).ipynb
Obiettivo: accuratezza > 95% (no, non è uno scherzo, è possibile!)
Essendo l'ultimo esercizio, richiede un po' più di codice e lavoro di data science.
Ulteriori informazioni sul perfezionamento
Xception è disponibile nei modelli pre-addestrati standard in tf.keras.application.* Non dimenticare di lasciare tutti i pesi addestrabili questa volta.
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
Per ottenere buoni risultati durante l'ottimizzazione di un modello, devi prestare attenzione al tasso di apprendimento e utilizzare una pianificazione del tasso di apprendimento con un periodo iniziale. Esempio:

Se iniziassi con un tasso di apprendimento standard, i pesi preaddestrati del modello verrebbero interrotti. L'avvio progressivo li conserva finché il modello non si aggancia ai tuoi dati ed è in grado di modificarli in modo sensato. Dopo la rampa, puoi continuare con un tasso di apprendimento costante o con un decadimento esponenziale.
In Keras, il tasso di apprendimento viene specificato tramite un callback in cui puoi calcolare il tasso di apprendimento appropriato per ogni epoca. Keras passerà il tasso di apprendimento corretto all'ottimizzatore per ogni epoca.
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
Soluzione
Ecco il notebook della soluzione. Puoi utilizzarlo se non riesci a risolvere il problema.
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
Argomenti trattati
- 🤔 Convoluzione separabile in profondità
- 🤓 Pianificazioni del tasso di apprendimento
- 😈 Ottimizzazione di un modello preaddestrato.
Ti invitiamo a esaminare questo elenco di controllo.
13. Complimenti!
Hai creato la tua prima rete neurale convoluzionale moderna e l'hai addestrata con un'accuratezza superiore al 90%, eseguendo l'iterazione su successive sessioni di addestramento in pochi minuti grazie alle TPU.
TPU in pratica
TPU e GPU sono disponibili su Vertex AI di Google Cloud:
- Su Deep Learning VM
- In Vertex AI Notebooks
- Nei job Vertex AI Training Jobs
Infine, ci piacerebbe ricevere un tuo feedback. Segnalaci eventuali anomalie in questo lab o se ritieni che debba essere migliorato. Il feedback può essere fornito tramite i problemi di GitHub [link al feedback].

|
|

