
1. 개요
이 실습에서는 Keras와 TensorFlow 2를 사용하여 처음부터 자신만의 컨볼루셔널 신경망을 빌드, 학습, 조정하는 방법을 알아봅니다. 이제 TPU의 성능을 사용하여 몇 분 만에 이 작업을 수행할 수 있습니다. 또한 매우 간단한 전이 학습부터 Squeezenet과 같은 최신 컨볼루션 아키텍처까지 다양한 접근 방식을 살펴봅니다. 이 실습에는 신경망에 관한 이론적 설명이 포함되어 있으며 딥 러닝을 배우는 개발자에게 좋은 시작점이 됩니다.
딥 러닝 논문을 읽는 것은 어렵고 혼란스러울 수 있습니다. 최신 컨볼루셔널 신경망 아키텍처를 직접 살펴보겠습니다.

학습할 내용
- Keras 및 텐서 처리 장치 (TPU)를 사용하여 맞춤 모델을 더 빠르게 빌드합니다.
- tf.data.Dataset API와 TFRecord 형식을 사용하여 학습 데이터를 효율적으로 로드합니다.
- 자체 모델을 빌드하는 대신 전이 학습을 사용하여 속임수를 씁니다 😈.
- Keras 순차 및 함수형 모델 스타일을 사용합니다.
- 소프트맥스 레이어와 교차 엔트로피 손실을 사용하여 자체 Keras 분류기를 빌드합니다.
- 컨볼루션 레이어를 적절하게 선택하여 모델을 미세 조정합니다.
- 모듈, 전역 평균 풀링과 같은 최신 컨브넷 아키텍처 아이디어를 살펴봅니다.
- Squeezenet 아키텍처를 사용하여 간단한 최신 컨브넷을 빌드합니다.
의견
이 Codelab에서 잘못된 점이 있으면 알려주세요. GitHub 문제[의견 링크]를 통해 의견을 제공할 수 있습니다.
2. Google Colaboratory 빠른 시작
이 실습에서는 Google Collaboratory를 사용하며 사용자가 설정할 필요가 없습니다. Chromebook에서 실행할 수 있습니다. 아래 파일을 열고 셀을 실행하여 Colab 노트북을 숙지하세요.
TPU 백엔드 선택

Colab 메뉴에서 런타임 > 런타임 유형 변경을 선택한 다음 TPU를 선택합니다. 이 코드 실습에서는 하드웨어 가속 학습을 지원하는 강력한 TPU (Tensor Processing Unit)를 사용합니다. 런타임에 대한 연결은 첫 번째 실행 시 자동으로 이루어지며, 오른쪽 상단의 '연결' 버튼을 사용할 수도 있습니다.
노트북 실행

셀을 클릭하고 Shift-Enter를 사용하여 셀을 한 번에 하나씩 실행합니다. 런타임 > 모두 실행을 사용하여 전체 노트북을 실행할 수도 있습니다.
목차

모든 노트북에는 목차가 있습니다. 왼쪽의 검은색 화살표를 사용하여 열 수 있습니다.
숨겨진 셀

일부 셀에는 제목만 표시됩니다. 이는 Colab 전용 노트북 기능입니다. 더블클릭하면 내부 코드를 볼 수 있지만 일반적으로 그다지 흥미롭지는 않습니다. 일반적으로 지원 또는 시각화 함수입니다. 내부의 함수를 정의하려면 이러한 셀을 실행해야 합니다.
인증

승인된 계정으로 인증하면 Colab에서 비공개 Google Cloud Storage 버킷에 액세스할 수 있습니다. 위의 코드 스니펫은 인증 프로세스를 트리거합니다.
3. [정보] Tensor Processing Unit (TPU)이란 무엇인가요?
요약

Keras에서 TPU로 모델을 학습시키는 코드 (TPU를 사용할 수 없는 경우 GPU 또는 CPU로 대체)는 다음과 같습니다.
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
오늘은 TPU를 사용하여 대화형 속도 (학습 실행당 분)로 꽃 분류기를 빌드하고 최적화합니다.

TPU를 사용해야 하는 이유
최신 GPU는 프로그래밍 가능한 '코어'를 중심으로 구성되어 있으며, 3D 렌더링, 딥 러닝, 물리 시뮬레이션 등 다양한 작업을 처리할 수 있는 매우 유연한 아키텍처를 갖추고 있습니다. 반면 TPU는 기존 벡터 프로세서를 전용 행렬 곱셈 단위와 결합하여 신경망과 같이 대규모 행렬 곱셈이 지배적인 모든 작업에서 뛰어난 성능을 발휘합니다.

그림: 밀집 신경망 레이어가 행렬 곱셈으로 표시되며, 8개의 이미지 배치가 신경망을 통해 한 번에 처리됩니다. 한 줄 x 열 곱셈을 실행하여 이미지의 모든 픽셀 값의 가중 합계를 실제로 계산하는지 확인하세요. 컨볼루션 레이어는 행렬 곱셈으로도 표현할 수 있지만 약간 더 복잡합니다 ( 여기 섹션 1에 설명).
하드웨어
MXU 및 VPU
TPU v2 코어는 행렬 곱셈을 실행하는 행렬 곱셈 단위 (MXU)와 활성화, 소프트맥스 등 기타 모든 작업을 위한 벡터 처리 단위 (VPU)로 구성됩니다. VPU는 float32 및 int32 계산을 처리합니다. 반면 MXU는 혼합 정밀도 16~32비트 부동 소수점 형식으로 작동합니다.

혼합 정밀도 부동 소수점 및 bfloat16
MXU는 bfloat16 입력과 float32 출력을 사용하여 행렬 곱셈을 계산합니다. 중간 누적은 float32 정밀도로 실행됩니다.

신경망 학습은 일반적으로 부동 소수점 정밀도 감소로 인해 발생하는 노이즈에 강합니다. 노이즈가 옵티마이저가 수렴하는 데 도움이 되는 경우도 있습니다. 16비트 부동 소수점 정밀도는 일반적으로 계산을 가속화하는 데 사용되지만 float16 및 float32 형식의 범위는 매우 다릅니다. 정밀도를 float32에서 float16으로 줄이면 일반적으로 오버플로와 언더플로가 발생합니다. 솔루션이 있지만 float16이 작동하려면 일반적으로 추가 작업이 필요합니다.
이러한 이유로 Google에서는 TPU에 bfloat16 형식을 도입했습니다. bfloat16은 float32와 정확히 동일한 지수 비트와 범위를 갖는 잘린 float32입니다. 여기에 TPU가 bfloat16 입력과 float32 출력으로 혼합 정밀도로 행렬 곱셈을 계산한다는 사실을 더하면 일반적으로 정밀도 감소로 인한 성능 향상을 활용하기 위해 코드를 변경할 필요가 없습니다.
시스톨릭 어레이
MXU는 데이터 요소가 하드웨어 계산 단위 배열을 통해 흐르는 소위 '시스톨릭 배열' 아키텍처를 사용하여 하드웨어에서 행렬 곱셈을 구현합니다. (의학에서 '수축기'는 심장 수축과 혈류를 의미하며, 여기서는 데이터 흐름을 의미합니다.)
행렬 곱셈의 기본 요소는 한 행렬의 행과 다른 행렬의 열 사이의 점곱입니다 (이 섹션 상단의 그림 참고). 행렬 곱셈 Y=X*W의 경우 결과의 한 요소는 다음과 같습니다.
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
GPU에서는 이 점곱을 GPU '코어'에 프로그래밍한 다음, 결과 행렬의 모든 값을 한 번에 계산하기 위해 병렬로 사용 가능한 만큼의 '코어'에서 실행합니다. 결과 행렬이 128x128 크기인 경우 128x128=16K '코어'를 사용할 수 있어야 하지만 이는 일반적으로 불가능합니다. 가장 큰 GPU에는 약 4,000개의 코어가 있습니다. 반면 TPU는 MXU의 컴퓨팅 단위를 위해 최소한의 하드웨어만 사용합니다. bfloat16 x bfloat16 => float32 곱셈-누적기만 있고 다른 것은 없습니다. 이러한 연산은 매우 작아서 TPU가 128x128 MXU에서 16,000개를 구현하고 이 행렬 곱셈을 한 번에 처리할 수 있습니다.

그림: MXU 시스톨릭 배열. 컴퓨팅 요소는 곱셈 누산기입니다. 한 행렬의 값이 배열 (빨간색 점)에 로드됩니다. 다른 행렬의 값은 배열을 통해 흐릅니다 (회색 점). 세로선은 값을 위로 전파합니다. 가로선은 부분 합계를 전파합니다. 데이터가 배열을 통과할 때 오른쪽에서 행렬 곱셈 결과가 나오는지 확인하는 것은 사용자의 몫입니다.
또한 MXU에서 내적이 계산되는 동안 중간 합계는 인접한 컴퓨팅 단위 사이에서 간단히 흐릅니다. 메모리나 레지스터 파일에 저장하고 검색할 필요가 없습니다. 그 결과 TPU 시스톨릭 어레이 아키텍처는 행렬 곱셈을 계산할 때 GPU에 비해 밀도와 전력 면에서 상당한 이점이 있으며 속도 면에서도 무시할 수 없는 이점이 있습니다.
Cloud TPU
Google Cloud Platform에서 'Cloud TPU v2'를 요청하면 PCI 연결 TPU 보드가 있는 가상 머신 (VM)이 제공됩니다. TPU 보드에는 듀얼 코어 TPU 칩이 4개 있습니다. 각 TPU 코어에는 VPU (벡터 처리 단위)와 128x128 MXU (행렬 곱셈 단위)가 있습니다. 이 'Cloud TPU'는 일반적으로 네트워크를 통해 이를 요청한 VM에 연결됩니다. 따라서 전체 그림은 다음과 같습니다.

그림: 네트워크에 연결된 'Cloud TPU' 액셀러레이터가 있는 VM 'Cloud TPU' 자체는 4개의 듀얼 코어 TPU 칩이 있는 PCI 연결 TPU 보드가 있는 VM으로 구성됩니다.
TPU 포드
Google의 데이터 센터에서 TPU는 고성능 컴퓨팅 (HPC) 상호 연결에 연결되어 매우 큰 가속기 하나로 표시될 수 있습니다. Google에서는 이를 포드라고 하며 최대 512개의 TPU v2 코어 또는 2,048개의 TPU v3 코어를 포함할 수 있습니다.

그림: TPU v3 pod HPC 상호 연결을 통해 연결된 TPU 보드와 랙
학습 중에 그라데이션은 all-reduce 알고리즘을 사용하여 TPU 코어 간에 교환됩니다 ( all-reduce에 대한 좋은 설명은 여기를 참고하세요). 학습 중인 모델은 큰 배치 크기로 학습하여 하드웨어를 활용할 수 있습니다.

그림: Google TPU의 2D 토로이드 메시 HPC 네트워크에서 all-reduce 알고리즘을 사용하여 학습 중에 그라데이션을 동기화합니다.
소프트웨어
대규모 배치 크기 학습
TPU의 이상적인 배치 크기는 TPU 코어당 데이터 항목 128개이지만 하드웨어는 TPU 코어당 데이터 항목 8개부터 이미 좋은 사용률을 보여줄 수 있습니다. 하나의 Cloud TPU에는 8개의 코어가 있습니다.
이 Codelab에서는 Keras API를 사용합니다. Keras에서 지정하는 배치는 전체 TPU의 전역 배치 크기입니다. 배치가 자동으로 8개로 분할되어 TPU의 8개 코어에서 실행됩니다.

추가 성능 팁은 TPU 성능 가이드를 참고하세요. 매우 큰 배치 크기의 경우 일부 모델에서 특별한 주의가 필요할 수 있습니다. 자세한 내용은 LARSOptimizer를 참고하세요.
작동 방식: XLA
Tensorflow 프로그램은 계산 그래프를 정의합니다. TPU는 Python 코드를 직접 실행하지 않고 TensorFlow 프로그램에 의해 정의된 연산 그래프를 실행합니다. 내부적으로 XLA (가속 선형 대수 컴파일러)라는 컴파일러가 계산 노드의 TensorFlow 그래프를 TPU 기계어 코드로 변환합니다. 이 컴파일러는 코드와 메모리 레이아웃에 대해 많은 고급 최적화도 실행합니다. 컴파일은 작업을 TPU로 전송할 때 자동으로 이루어집니다. 빌드 체인에 XLA를 명시적으로 포함할 필요는 없습니다.
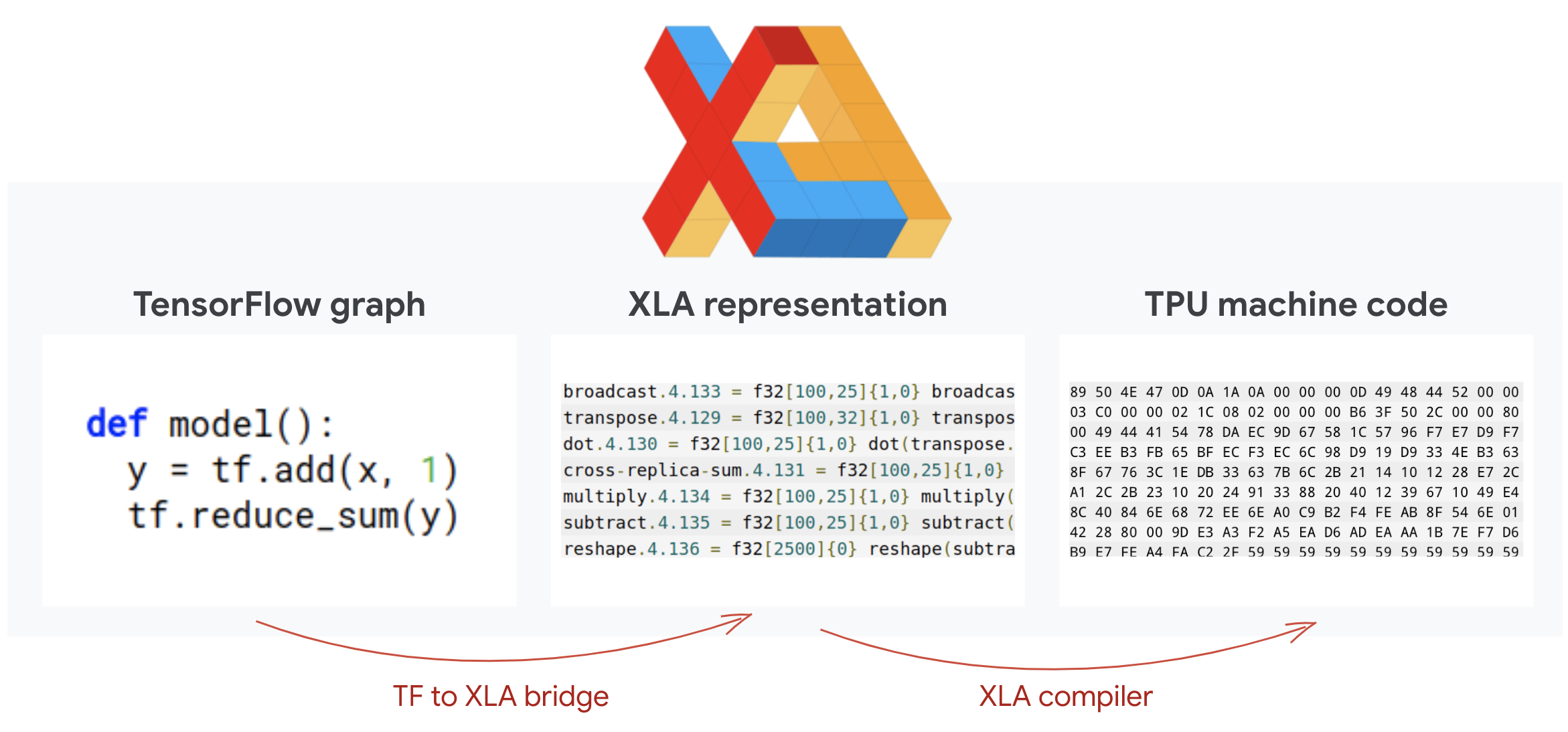
설명: TPU에서 실행하려면 TensorFlow 프로그램에서 정의한 계산 그래프를 먼저 XLA (가속 선형 대수 컴파일러) 표현으로 변환한 다음 XLA에서 TPU 기계어 코드로 컴파일해야 합니다.
Keras에서 TPU 사용하기
TPU는 Tensorflow 2.1부터 Keras API를 통해 지원됩니다. Keras 지원은 TPU 및 TPU 포드에서 작동합니다. 다음은 TPU, GPU, CPU에서 작동하는 예시입니다.
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
이 코드 스니펫에서는 다음 사항이 적용됩니다.
TPUClusterResolver().connect()는 네트워크에서 TPU를 찾습니다. 대부분의 Google Cloud 시스템 (AI Platform 작업, Colaboratory, Kubeflow, 'ctpu up' 유틸리티를 통해 생성된 딥 러닝 VM)에서 매개변수 없이 작동합니다. 이러한 시스템은 TPU_NAME 환경 변수 덕분에 TPU가 어디에 있는지 알고 있습니다. 직접 TPU를 만드는 경우 사용하는 VM에서 TPU_NAME 환경 변수를 설정하거나 명시적 매개변수를 사용하여TPUClusterResolver를 호출합니다.TPUClusterResolver(tp_uname, zone, project)TPUStrategy는 분산 및 'all-reduce' 그라데이션 동기화 알고리즘을 구현하는 부분입니다.- 전략은 범위를 통해 적용됩니다. 모델은 전략 범위 내에 정의되어야 합니다.
tpu_model.fit함수는 TPU 학습을 위한 입력으로 tf.data.Dataset 객체를 예상합니다.
일반적인 TPU 포팅 작업
- Tensorflow 모델에서 데이터를 로드하는 방법은 다양하지만 TPU의 경우
tf.data.DatasetAPI를 사용해야 합니다. - TPU는 매우 빠르며 TPU에서 실행할 때는 데이터 수집이 병목 현상이 되는 경우가 많습니다. TPU 성능 가이드에서 데이터 병목 현상을 감지하는 데 사용할 수 있는 도구와 기타 성능 팁을 확인할 수 있습니다.
- int8 또는 int16 숫자는 int32로 처리됩니다. TPU에는 32비트 미만에서 작동하는 정수 하드웨어가 없습니다.
- 일부 TensorFlow 작업은 지원되지 않습니다. 여기에서 목록을 확인하세요. 다행히 이 제한사항은 학습 코드, 즉 모델을 통한 순방향 및 역방향 패스에만 적용됩니다. CPU에서 실행되므로 데이터 입력 파이프라인에서 모든 TensorFlow 작업을 계속 사용할 수 있습니다.
- TPU에서는
tf.py_func가 지원되지 않습니다.
4. 데이터 로드






꽃 사진 데이터 세트로 작업할 것입니다. 목표는 5가지 꽃 유형으로 분류하는 방법을 배우는 것입니다. 데이터 로드는 tf.data.Dataset API를 사용하여 실행됩니다. 먼저 API를 알아보겠습니다.
실무
다음 노트북을 열고 셀을 실행 (Shift-ENTER)한 다음 '작업 필요' 라벨이 표시되는 곳의 안내를 따르세요.

Fun with tf.data.Dataset (playground).ipynb
추가 정보
'flowers' 데이터 세트 정보
데이터 세트는 5개의 폴더로 구성되어 있습니다. 각 폴더에는 한 종류의 꽃이 들어 있습니다. 폴더 이름은 해바라기, 데이지, 민들레, 튤립, 장미입니다. 데이터는 Google Cloud Storage의 공개 버킷에 호스팅됩니다. 발췌문:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
tf.data.Dataset을 사용하는 이유
Keras와 TensorFlow는 모든 학습 및 평가 함수에서 데이터 세트를 허용합니다. 데이터 세트에 데이터를 로드하면 API는 신경망 학습 데이터에 유용한 모든 일반 기능을 제공합니다.
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
이 도움말에서 성능 팁과 데이터 세트 권장사항을 확인할 수 있습니다. 참조 문서는 여기에서 확인할 수 있습니다.
tf.data.Dataset 기본사항
데이터는 일반적으로 여러 파일(여기서는 이미지)로 제공됩니다. 다음과 같이 호출하여 파일 이름 데이터 세트를 만들 수 있습니다.
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
그런 다음 각 파일 이름에 함수를 '매핑'합니다. 이 함수는 일반적으로 파일을 로드하고 메모리의 실제 데이터로 디코딩합니다.
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
데이터 세트를 반복하려면 다음을 실행하세요.
for data in my_dataset:
print(data)
튜플 데이터 세트
지도 학습에서 학습 데이터 세트는 일반적으로 학습 데이터와 정답의 쌍으로 구성됩니다. 이를 허용하기 위해 디코딩 함수는 튜플을 반환할 수 있습니다. 그러면 튜플 데이터 세트가 생성되고 이를 반복하면 튜플이 반환됩니다. 반환된 값은 모델에서 사용할 수 있는 TensorFlow 텐서입니다. .numpy()를 호출하여 원시 값을 확인할 수 있습니다.
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
결론:이미지를 하나씩 로드하는 것은 느립니다.
이 데이터 세트를 반복하면 초당 1~2개의 이미지를 로드할 수 있습니다. 너무 느립니다. 학습에 사용할 하드웨어 가속기는 이 속도의 몇 배를 유지할 수 있습니다. 다음 섹션으로 이동하여 이를 달성하는 방법을 알아보세요.
해결 방법
솔루션 노트북은 다음과 같습니다. 막히는 부분이 있으면 사용하세요.
Fun with tf.data.Dataset (solution).ipynb
학습한 내용
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 튜플 데이터 세트
- 😀 데이터 세트 반복
잠시 시간을 내어 이 체크리스트를 살펴보세요.
5. 데이터를 빠르게 로드
이 실습에서 사용할 Tensor Processing Unit (TPU) 하드웨어 가속기는 매우 빠릅니다. 문제는 AI를 계속 작동시킬 만큼 충분히 빠른 속도로 데이터를 제공하는 것입니다. Google Cloud Storage (GCS)는 매우 높은 처리량을 유지할 수 있지만 모든 클라우드 스토리지 시스템과 마찬가지로 연결을 시작하는 데 약간의 네트워크 왕복이 필요합니다. 따라서 데이터를 수천 개의 개별 파일로 저장하는 것은 이상적이지 않습니다. 더 적은 수의 파일로 일괄 처리하고 tf.data.Dataset의 기능을 사용하여 여러 파일에서 동시에 읽어옵니다.
읽기 전용
이미지 파일을 로드하고, 공통 크기로 크기를 조정한 후 16개의 TFRecord 파일에 저장하는 코드는 다음 노트북에 있습니다. 빠르게 읽어보세요. 나머지 Codelab에서는 TFRecord 형식의 데이터가 제공되므로 실행하지 않아도 됩니다.
Flower pictures to TFRecords.ipynb
최적의 GCS 처리량을 위한 이상적인 데이터 레이아웃
TFRecord 파일 형식
데이터를 저장하는 데 권장되는 TensorFlow 파일 형식은 protobuf 기반 TFRecord 형식입니다. 다른 직렬화 형식도 작동하지만 다음을 작성하여 TFRecord 파일에서 데이터 세트를 직접 로드할 수 있습니다.
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
최적의 성능을 위해 다음의 더 복잡한 코드를 사용하여 여러 TFRecord 파일에서 한 번에 읽는 것이 좋습니다. 이 코드는 N개의 파일에서 병렬로 읽고 읽기 속도를 위해 데이터 순서를 무시합니다.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
TFRecord 요약본
TFRecord에는 바이트 문자열 (바이트 목록), 64비트 정수, 32비트 부동 소수점 수의 세 가지 유형의 데이터를 저장할 수 있습니다. 항상 목록으로 저장되며 단일 데이터 요소는 크기가 1인 목록이 됩니다. 다음 도우미 함수를 사용하여 데이터를 TFRecord에 저장할 수 있습니다.
바이트 문자열 쓰기
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
정수 쓰기
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
부동 소수점 쓰기
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
위의 도우미를 사용하여 TFRecord 작성
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
TFRecord에서 데이터를 읽으려면 먼저 저장한 레코드의 레이아웃을 선언해야 합니다. 선언에서 이름이 지정된 필드에 고정 길이 목록 또는 가변 길이 목록으로 액세스할 수 있습니다.
TFRecord에서 읽기
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
유용한 코드 스니펫:
단일 데이터 요소 읽기
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
고정 크기 요소 목록 읽기
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
가변 데이터 항목 읽기
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
VarLenFeature는 희소 벡터를 반환하며 TFRecord를 디코딩한 후 추가 단계가 필요합니다.
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
TFRecord에 선택적 필드가 있을 수도 있습니다. 필드를 읽을 때 기본값을 지정하면 필드가 누락된 경우 오류 대신 기본값이 반환됩니다.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
학습한 내용
- 🤔 GCS에서 빠르게 액세스할 수 있도록 데이터 파일 샤딩
- 😓 TFRecord를 작성하는 방법 (벌써 구문을 잊으셨나요? 괜찮습니다. 이 페이지를 치트 시트로 북마크하세요.)
- 🤔 TFRecordDataset을 사용하여 TFRecord에서 데이터 세트 로드
잠시 시간을 내어 이 체크리스트를 살펴보세요.
6. [정보] 신경망 분류기 101
요약
다음 단락의 굵은 글씨로 표시된 모든 용어를 이미 알고 있다면 다음 연습으로 이동하세요. 이제 막 딥 러닝을 시작하셨다면 환영합니다. 계속 읽어 주세요.
레이어 시퀀스로 빌드된 모델의 경우 Keras는 Sequential API를 제공합니다. 예를 들어 밀집층 3개를 사용하는 이미지 분류기는 Keras에서 다음과 같이 작성할 수 있습니다.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
밀집 신경망
이미지를 분류하는 가장 간단한 신경망입니다. 레이어로 배열된 '뉴런'으로 구성됩니다. 첫 번째 레이어는 입력 데이터를 처리하고 출력을 다른 레이어에 제공합니다. 각 뉴런이 이전 레이어의 모든 뉴런에 연결되어 있기 때문에 '밀도'라고 합니다.

모든 픽셀의 RGB 값을 긴 벡터로 평탄화하고 이를 입력으로 사용하여 이러한 네트워크에 이미지를 공급할 수 있습니다. 이미지 인식에 가장 적합한 기술은 아니지만 나중에 개선할 예정입니다.
뉴런, 활성화, ReLU
'뉴런'은 모든 입력의 가중 합을 계산하고 '바이어스'라는 값을 추가한 후 결과를 소위 '활성화 함수'를 통해 전달합니다. 가중치와 편향은 처음에는 알 수 없습니다. 무작위로 초기화되고 알려진 많은 데이터로 신경망을 학습시켜 '학습'됩니다.

가장 인기 있는 활성화 함수는 정류 선형 유닛(Rectified Linear Unit)의 약자인 ReLU입니다. 위 그래프에서 볼 수 있듯이 매우 간단한 함수입니다.
소프트맥스 활성화
위의 네트워크는 꽃을 5가지 카테고리 (장미, 튤립, 민들레, 데이지, 해바라기)로 분류하므로 5개의 뉴런 레이어로 끝납니다. 중간 레이어의 뉴런은 클래식 ReLU 활성화 함수를 사용하여 활성화됩니다. 하지만 마지막 레이어에서는 이 꽃이 장미, 튤립 등일 확률을 나타내는 0과 1 사이의 숫자를 계산해야 합니다. 이를 위해 '소프트맥스'라는 활성화 함수를 사용합니다.
벡터에 소프트맥스를 적용하려면 각 요소의 지수를 취한 다음 일반적으로 L1 norm (절댓값의 합)을 사용하여 벡터를 정규화합니다. 이렇게 하면 값이 합산되어 1이 되고 확률로 해석할 수 있습니다.


교차 엔트로피 손실
이제 신경망이 입력 이미지에서 예측을 생성하므로 예측의 정확도, 즉 신경망이 알려주는 값과 정답(일반적으로 '라벨'이라고 함) 간의 거리를 측정해야 합니다. 데이터 세트의 모든 이미지에 올바른 라벨이 지정되어 있습니다.
어떤 거리든 사용할 수 있지만 분류 문제의 경우 소위 '교차 엔트로피 거리'가 가장 효과적입니다. 이를 오류 또는 '손실' 함수라고 합니다.

경사하강법
신경망을 '학습'한다는 것은 실제로 교차 엔트로피 손실 함수를 최소화하기 위해 학습 이미지와 라벨을 사용하여 가중치와 편향을 조정한다는 의미입니다. 작동 방식은 다음과 같습니다.
교차 엔트로피는 가중치, 편향, 학습 이미지의 픽셀, 알려진 클래스의 함수입니다.
모든 가중치와 모든 편향에 대한 교차 엔트로피의 편미분을 계산하면 주어진 이미지, 라벨, 현재 가중치 및 편향 값에 대해 계산된 '기울기'가 구해집니다. 가중치와 편향이 수백만 개 있을 수 있으므로 경사를 계산하는 것은 많은 작업이 필요합니다. 다행히 TensorFlow가 이 작업을 대신해 줍니다. 그라데이션의 수학적 속성은 '위'를 가리킨다는 것입니다. 교차 엔트로피가 낮은 곳으로 이동해야 하므로 반대 방향으로 이동합니다. 경사의 일부를 사용하여 가중치와 편향을 업데이트합니다. 그런 다음 학습 루프에서 다음 학습 이미지 및 라벨 배치를 사용하여 동일한 작업을 반복합니다. 이 최소값이 고유하다는 보장은 없지만 크로스 엔트로피가 최소인 지점으로 수렴되기를 바랍니다.

미니 배치 및 모멘텀
하나의 예시 이미지에서만 그라데이션을 계산하고 가중치와 편향을 즉시 업데이트할 수 있지만, 예를 들어 128개의 이미지 배치에서 이렇게 하면 다양한 예시 이미지에서 부과된 제약 조건을 더 잘 나타내는 그라데이션이 제공되므로 솔루션으로 더 빠르게 수렴될 수 있습니다. 미니 배치 크기는 조정 가능한 매개변수입니다.
'확률적 경사 하강법'이라고도 하는 이 기법에는 또 다른 실용적인 이점이 있습니다. 배치로 작업하면 더 큰 행렬로 작업하게 되며, 이러한 행렬은 일반적으로 GPU와 TPU에서 최적화하기가 더 쉽습니다.
하지만 수렴은 여전히 약간 혼란스러울 수 있으며, 경사 벡터가 모두 0이면 중지될 수도 있습니다. 최솟값을 찾았다는 뜻인가요? 항상 그렇지는 않습니다. 그라데이션 구성요소는 최소 또는 최대에서 0일 수 있습니다. 요소가 수백만 개인 그라데이션 벡터에서 모든 요소가 0인 경우 모든 0이 최소값에 해당하고 최대값에 해당하는 요소가 없을 확률은 매우 작습니다. 다차원 공간에서는 안장점이 매우 일반적이며 안장점에서 멈추고 싶지 않습니다.

그림: 안장점 기울기는 0이지만 모든 방향에서 최소값은 아닙니다. (이미지 저작자 표시: Wikimedia: Nicoguaro - Own work, CC BY 3.0)
해결책은 최적화 알고리즘에 모멘텀을 추가하여 안장점을 멈추지 않고 지나갈 수 있도록 하는 것입니다.
용어집
배치 또는 미니 배치: 학습은 항상 학습 데이터와 라벨의 배치에서 실행됩니다. 이렇게 하면 알고리즘이 수렴하는 데 도움이 됩니다. '배치' 측정기준은 일반적으로 데이터 텐서의 첫 번째 측정기준입니다. 예를 들어 모양이 [100, 192, 192, 3] 인 텐서에는 픽셀당 값이 3개 (RGB)인 192x192 픽셀 이미지가 100개 포함되어 있습니다.
교차 엔트로피 손실: 분류기에서 자주 사용되는 특수 손실 함수입니다.
밀집층: 각 뉴런이 이전 레이어의 모든 뉴런에 연결된 뉴런 레이어입니다.
특성: 신경망의 입력을 '특성'이라고도 합니다. 좋은 예측을 얻기 위해 데이터 세트의 어떤 부분 (또는 부분의 조합)을 신경망에 입력해야 하는지 파악하는 기술을 '특성 엔지니어링'이라고 합니다.
라벨: 지도 분류 문제에서 '클래스' 또는 정답의 또 다른 이름
학습률: 학습 루프의 각 반복에서 가중치와 편향이 업데이트되는 기울기의 비율입니다.
로짓: 활성화 함수가 적용되기 전의 뉴런 레이어의 출력을 '로짓'이라고 합니다. 이 용어는 가장 인기 있는 활성화 함수였던 '로지스틱 함수' 즉 '시그모이드 함수'에서 유래했습니다. '로지스틱 함수 전의 뉴런 출력'이 '로짓'으로 단축되었습니다.
손실: 신경망 출력을 정답과 비교하는 오류 함수
뉴런: 입력의 가중 합을 계산하고 편향을 추가하고 활성화 함수를 통해 결과를 제공합니다.
원-핫 인코딩: 5개 클래스 중 3번째 클래스는 3번째 요소를 제외한 모든 요소가 0인 5개 요소 벡터로 인코딩됩니다.
relu: 정류 선형 유닛입니다. 뉴런에 사용되는 인기 있는 활성화 함수입니다.
sigmoid: 한때 인기가 있었으며 특수한 경우에 여전히 유용한 또 다른 활성화 함수입니다.
softmax: 벡터에 작용하고 가장 큰 구성요소와 다른 모든 구성요소 간의 차이를 늘리며 확률 벡터로 해석될 수 있도록 벡터의 합이 1이 되도록 정규화하는 특수 활성화 함수입니다. 분류기의 마지막 단계로 사용됩니다.
텐서: '텐서'는 행렬과 비슷하지만 차원 수가 임의로 지정됩니다. 1차원 텐서는 벡터입니다. 2차원 텐서는 행렬입니다. 그런 다음 3, 4, 5개 이상의 차원이 있는 텐서를 사용할 수 있습니다.
7. 전이 학습
이미지 분류 문제의 경우 밀집 레이어로는 충분하지 않을 수 있습니다. 컨볼루션 레이어와 이를 배열하는 다양한 방법을 알아야 합니다.
하지만 바로가기를 사용할 수도 있습니다. 완전히 학습된 컨볼루셔널 신경망을 다운로드할 수 있습니다. 마지막 레이어인 소프트맥스 분류 헤드를 잘라내고 자체 레이어로 대체할 수 있습니다. 학습된 가중치와 편향은 그대로 유지되며 추가한 소프트맥스 레이어만 재학습됩니다. 이 기법을 전이 학습이라고 하며, 신경망이 사전 학습된 데이터 세트가 내 데이터 세트와 '충분히 유사'한 경우에 작동합니다.
실습
다음 노트북을 열고 셀을 실행 (Shift-ENTER)한 다음 '작업 필요' 라벨이 표시되는 곳의 안내를 따르세요.
Keras Flowers transfer learning (playground).ipynb
추가 정보
전이 학습을 사용하면 최고의 연구자가 개발한 고급 컨볼루션 신경망 아키텍처와 방대한 이미지 데이터 세트에 대한 사전 학습의 이점을 모두 누릴 수 있습니다. 이 경우 꽃과 매우 유사한 많은 식물과 야외 장면이 포함된 이미지 데이터베이스인 ImageNet에서 학습된 네트워크로부터 전이 학습을 수행합니다.

그림: 이미 학습된 복잡한 컨볼루션 신경망을 블랙박스로 사용하여 분류 헤드만 재학습합니다. 이것이 전이 학습입니다. 컨볼루션 레이어의 복잡한 배열이 어떻게 작동하는지는 나중에 살펴보겠습니다. 지금은 다른 사람의 문제입니다.
Keras의 전이 학습
Keras에서는 tf.keras.applications.* 컬렉션에서 사전 학습된 모델을 인스턴스화할 수 있습니다. 예를 들어 MobileNet V2는 크기가 적당한 매우 우수한 컨볼루션 아키텍처입니다. include_top=False를 선택하면 최종 소프트맥스 레이어가 없는 사전 학습된 모델이 제공되므로 자체 레이어를 추가할 수 있습니다.
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
pretrained_model.trainable = False 설정도 확인합니다. 소프트맥스 레이어만 학습할 수 있도록 사전 학습된 모델의 가중치와 편향을 고정합니다. 일반적으로 비교적 적은 가중치가 필요하며 매우 큰 데이터 세트가 필요하지 않고도 빠르게 실행할 수 있습니다. 하지만 데이터가 많은 경우 pretrained_model.trainable = True를 사용하면 전이 학습이 훨씬 더 효과적일 수 있습니다. 사전 학습된 가중치는 우수한 초기 값을 제공하며 학습을 통해 문제에 더 적합하도록 조정할 수 있습니다.
마지막으로 밀도 높은 소프트맥스 레이어 앞에 삽입된 Flatten() 레이어를 확인합니다. 밀집층은 평탄한 데이터 벡터에서 작동하지만 사전 학습된 모델이 이를 반환하는지는 알 수 없습니다. 따라서 평탄화가 필요합니다. 다음 장에서 컨볼루션 아키텍처를 자세히 살펴보면서 컨볼루션 레이어에서 반환되는 데이터 형식을 설명하겠습니다.
이 접근 방식을 사용하면 정확도가 75% 에 가까워집니다.
해결 방법
솔루션 노트북은 다음과 같습니다. 막히는 부분이 있으면 사용하세요.
Keras Flowers transfer learning (solution).ipynb
학습한 내용
- 🤔 Keras로 분류기를 작성하는 방법
- 🤓 소프트맥스 마지막 레이어와 교차 엔트로피 손실로 구성됨
- 😈 전이 학습
- 🤔 첫 번째 모델 학습시키기
- 🧐 학습 중 손실 및 정확도 추적
잠시 시간을 내어 이 체크리스트를 살펴보세요.
8. [정보] 컨볼루셔널 신경망
요약
다음 단락의 굵은 글씨로 표시된 모든 용어를 이미 알고 있다면 다음 연습으로 이동하세요. 컨볼루셔널 신경망을 처음 사용하는 경우 계속 읽어 보세요.

설명: 각각 4x4x3=48개의 학습 가능한 가중치로 구성된 두 개의 연속 필터로 이미지를 필터링합니다.
Keras에서 간단한 컨볼루셔널 신경망은 다음과 같습니다.
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
컨볼루셔널 신경망 101
컨볼루션 네트워크의 레이어에서 한 '뉴런'은 이미지의 작은 영역에서만 바로 위에 있는 픽셀의 가중치를 합산합니다. 일반적인 밀집 레이어의 뉴런과 마찬가지로 편향을 추가하고 활성화 함수를 통해 합계를 공급합니다. 그런 다음 동일한 가중치를 사용하여 전체 이미지에 걸쳐 이 작업이 반복됩니다. 밀집층에서는 각 뉴런에 자체 가중치가 있었습니다. 여기서 가중치의 단일 '패치'가 양방향으로 이미지 전체를 슬라이드합니다('컨볼루션'). 출력에는 이미지의 픽셀 수만큼 값이 있습니다 (가장자리에 패딩이 필요함). 4x4x3=48 가중치의 필터를 사용하는 필터링 작업입니다.
하지만 48개의 가중치로는 충분하지 않습니다. 자유도를 더 추가하기 위해 새로운 가중치 집합으로 동일한 작업을 반복합니다. 그러면 새로운 필터 출력이 생성됩니다. 입력 이미지의 R,G,B 채널과 유사하게 출력의 '채널'이라고 부르겠습니다.

두 개 이상의 가중치 집합은 새 차원을 추가하여 하나의 텐서로 합산할 수 있습니다. 이를 통해 컨볼루션 레이어의 가중치 텐서의 일반적인 모양을 알 수 있습니다. 입력 및 출력 채널 수는 매개변수이므로 컨볼루션 레이어를 스태킹하고 연결할 수 있습니다.

그림: 컨볼루셔널 신경망이 데이터 '큐브'를 다른 데이터 '큐브'로 변환합니다.
스트라이드 컨볼루션, 최대 풀링
보폭이 2 또는 3인 컨볼루션을 수행하면 결과 데이터 큐브를 가로 방향으로 축소할 수도 있습니다. 이 작업을 실행하는 두 가지 일반적인 방법은 다음과 같습니다.
- 스트라이드 컨볼루션: 위와 같이 슬라이딩 필터가 있지만 스트라이드가 1보다 큼
- 최대 풀링: 최대 작업을 적용하는 슬라이딩 윈도우 (일반적으로 2x2 패치에서 2픽셀마다 반복됨)

그림: 컴퓨팅 창을 3픽셀씩 슬라이드하면 출력 값이 줄어듭니다. 스트라이드 컨볼루션 또는 최대 풀링 (스트라이드 2로 슬라이딩되는 2x2 창의 최대값)은 가로 방향으로 데이터 큐브를 축소하는 방법입니다.
Convolutional classifier
마지막으로 마지막 데이터 큐브를 평탄화하고 밀도 있는 소프트맥스 활성화 레이어를 통해 공급하여 분류 헤드를 연결합니다. 일반적인 컨볼루션 분류기는 다음과 같습니다.

설명: 컨볼루션 및 소프트맥스 레이어를 사용하는 이미지 분류기 3x3 및 1x1 필터를 사용합니다. maxpool 레이어는 2x2 데이터 포인트 그룹의 최댓값을 취합니다. 분류 헤드는 소프트맥스 활성화가 있는 밀집 레이어로 구현됩니다.
Keras에서
위에서 설명한 컨볼루션 스택은 다음과 같이 Keras로 작성할 수 있습니다.
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
9. 맞춤 컨브넷
실습
컨볼루셔널 신경망을 처음부터 빌드하고 학습시켜 보겠습니다. TPU를 사용하면 매우 빠르게 반복할 수 있습니다. 다음 노트북을 열고 셀을 실행 (Shift-ENTER)한 다음 '작업 필요' 라벨이 표시되는 곳의 안내를 따르세요.
Keras_Flowers_TPU (playground).ipynb
목표는 전이 학습 모델의 정확도인 75% 를 넘는 것입니다. 이 모델은 수백만 개의 이미지 데이터 세트로 사전 학습되었기 때문에 이점이 있었습니다. 반면 여기에는 3, 670개의 이미지만 있습니다. 최소한 일치시켜 줄 수 있나요?
추가 정보
레이어는 몇 개이고 크기는 얼마나 되나요?
레이어 크기를 선택하는 것은 과학보다는 예술에 가깝습니다. 매개변수 (가중치 및 편향)가 너무 적거나 너무 많지 않도록 적절한 균형을 찾아야 합니다. 가중치가 너무 적으면 신경망이 꽃 모양의 복잡성을 나타낼 수 없습니다. 너무 많으면 '과적합'이 발생하기 쉽습니다. 즉, 학습 이미지에 특화되어 일반화할 수 없습니다. 매개변수가 많으면 모델 학습도 느려집니다. Keras에서 model.summary() 함수는 모델의 구조와 매개변수 수를 표시합니다.
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
몇 가지 팁을 알려드립니다.
- 여러 레이어가 있어야 '심층' 신경망이 효과적입니다. 이 간단한 꽃 인식 문제의 경우 5~10개의 레이어가 적합합니다.
- 작은 필터를 사용합니다. 일반적으로 3x3 필터는 어디에서나 적합합니다.
- 1x1 필터를 사용할 수도 있으며 저렴합니다. 실제로 아무것도 '필터링'하지 않고 채널의 선형 조합을 계산합니다. 실제 필터로 대체합니다. ('1x1 컨볼루션'에 대한 자세한 내용은 다음 섹션 참고)
- 이와 같은 분류 문제의 경우 최대 풀링 레이어 (또는 스트라이드가 1보다 큰 컨볼루션)를 사용하여 자주 다운샘플링합니다. 꽃의 위치는 중요하지 않고 장미인지 민들레인지만 중요하므로 x 및 y 정보를 잃는 것은 중요하지 않으며 작은 영역을 필터링하는 것이 더 저렴합니다.
- 필터 수는 일반적으로 네트워크 끝에 있는 클래스 수와 비슷해집니다 (이유는 아래의 '전역 평균 풀링' 트릭 참고). 수백 개의 클래스로 분류하는 경우 연속 레이어에서 필터 수를 점진적으로 늘립니다. 클래스가 5개인 꽃 데이터 세트의 경우 필터 5개만으로는 충분하지 않습니다. 대부분의 레이어에서 동일한 필터 수(예: 32)를 사용하고 끝으로 갈수록 줄일 수 있습니다.
- 마지막 밀도 레이어의 비용이 많이 듭니다. 이러한 레이어는 모든 컨볼루션 레이어를 합친 것보다 더 많은 가중치를 가질 수 있습니다. 예를 들어 24x24x10 데이터 포인트의 마지막 데이터 큐브에서 매우 합리적인 출력이 나오더라도 100개의 뉴런 밀도 레이어에는 24x24x10x100=576,000개의 가중치가 필요합니다. 신중하게 생각하거나 전역 평균 풀링을 사용해 보세요 (아래 참고).
전역 평균 풀링
컨볼루션 신경망의 끝에 비용이 많이 드는 밀집 레이어를 사용하는 대신 들어오는 데이터 '큐브'를 클래스 수만큼 여러 부분으로 분할하고 값을 평균화하여 소프트맥스 활성화 함수를 통해 공급할 수 있습니다. 이러한 방식으로 분류 헤드를 빌드하는 데는 가중치가 0입니다. Keras에서 구문은 tf.keras.layers.GlobalAveragePooling2D().입니다.

해결 방법
솔루션 노트북은 다음과 같습니다. 막히는 부분이 있으면 사용하세요.
Keras_Flowers_TPU (solution).ipynb
학습한 내용
- 🤔 컨볼루션 레이어 사용
- 🤓 최대 풀링, 스트라이드, 전역 평균 풀링 등을 실험했습니다.
- 😀 TPU에서 실제 모델을 빠르게 반복했습니다.
잠시 시간을 내어 이 체크리스트를 살펴보세요.
10. [정보] 최신 컨볼루션 아키텍처
요약

그림: 컨볼루션 '모듈'. 이 시점에서 가장 좋은 방법은 무엇인가요? 최대 풀링 레이어 다음에 1x1 컨볼루션 레이어가 오는 것이 좋을까요 아니면 다른 레이어 조합이 좋을까요? 모두 시도하고 결과를 연결하여 네트워크에서 결정하도록 합니다. 오른쪽: 이러한 모듈을 사용하는 ' 인셉션' 컨볼루션 아키텍처
Keras에서 데이터 흐름이 분기될 수 있는 모델을 만들려면 '함수형' 모델 스타일을 사용해야 합니다. 예를 들면 다음과 같습니다.
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
기타 저렴한 방법
소형 3x3 필터

이 그림에서는 연속된 두 개의 3x3 필터의 결과를 확인할 수 있습니다. 결과에 기여한 데이터 포인트를 추적해 보세요. 연속된 두 개의 3x3 필터는 5x5 영역의 일부 조합을 계산합니다. 5x5 필터가 계산하는 조합과 정확히 동일하지는 않지만 연속된 두 개의 3x3 필터가 단일 5x5 필터보다 저렴하므로 시도해 볼 만합니다.
1x1 컨볼루션?

수학적 용어로 '1x1' 컨볼루션은 상수와의 곱셈이며 그다지 유용한 개념은 아닙니다. 하지만 컨볼루션 신경망에서는 필터가 2D 이미지가 아닌 데이터 큐브에 적용된다는 점을 기억하세요. 따라서 '1x1' 필터는 1x1 데이터 열의 가중치 합계를 계산하며 (그림 참고) 데이터를 가로로 슬라이드하면 입력 채널의 선형 조합이 표시됩니다. 이 기능은 실제로 유용합니다. 채널을 개별 필터링 작업의 결과라고 생각하면 됩니다. 예를 들어 '뾰족한 귀' 필터, '수염' 필터, '가늘게 뜬 눈' 필터가 있다면 '1x1' 컨볼루션 레이어는 이러한 특징의 가능한 여러 선형 조합을 계산하며, 이는 '고양이'를 찾을 때 유용할 수 있습니다. 또한 1x1 레이어는 가중치를 더 적게 사용합니다.
11. Squeezenet
이러한 아이디어를 결합하는 간단한 방법은 'Squeezenet' 논문에 소개되어 있습니다. 저자는 1x1 및 3x3 컨볼루션 레이어만 사용하는 매우 간단한 컨볼루션 모듈 설계를 제안합니다.

그림: 'fire 모듈'을 기반으로 한 SqueezeNet 아키텍처 수직 방향으로 들어오는 데이터를 '압축'하는 1x1 레이어와 데이터의 깊이를 다시 '확장'하는 두 개의 병렬 1x1 및 3x3 컨볼루션 레이어가 번갈아 나타납니다.
실습
이전 노트북에서 계속해서 squeezenet에서 영감을 받은 컨볼루셔널 신경망을 빌드합니다. 모델 코드를 Keras '함수형 스타일'로 변경해야 합니다.
Keras_Flowers_TPU (playground).ipynb
추가 정보
이 연습에서는 SqueezeNet 모듈의 도우미 함수를 정의하는 것이 유용합니다.
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
이번에는 정확도 80% 를 달성하는 것이 목표입니다.
시도해 볼 만한 작업
단일 컨볼루션 레이어로 시작한 다음 MaxPooling2D(pool_size=2) 레이어와 번갈아 가며 'fire_modules'를 따릅니다. 네트워크에서 최대 풀링 레이어를 2~4개로 실험하고 최대 풀링 레이어 사이에 연속된 파이어 모듈을 1, 2 또는 3개로 실험할 수 있습니다.
화재 모듈에서 'squeeze' 매개변수는 일반적으로 'expand' 매개변수보다 작아야 합니다. 이러한 매개변수는 실제로 필터 수입니다. 일반적으로 8~196 범위입니다. 네트워크를 통해 필터 수가 점진적으로 증가하는 아키텍처나 모든 fire 모듈의 필터 수가 동일한 간단한 아키텍처를 실험할 수 있습니다.
예를 들면 다음과 같습니다.
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
이 시점에서 실험이 잘 진행되지 않고 80% 정확도 목표가 멀게 느껴질 수 있습니다. 몇 가지 저렴한 트릭을 더 살펴볼 시간입니다.
배치 정규화
배치 정규화는 발생하고 있는 수렴 문제를 해결하는 데 도움이 됩니다. 이 기법에 대한 자세한 설명은 다음 워크숍에서 제공됩니다. 지금은 fire_module 함수 내부의 레이어를 포함하여 네트워크의 모든 컨볼루션 레이어 뒤에 다음 줄을 추가하여 블랙박스 '마법' 도우미로 사용하세요.
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
데이터 세트가 작기 때문에 모멘텀 매개변수를 기본값인 0.99에서 0.9로 줄여야 합니다. 지금은 이 세부정보를 무시하세요.
데이터 증강
포화도 변경을 좌우로 뒤집는 것과 같은 간단한 변환으로 데이터를 증강하면 몇 퍼센트 포인트 더 얻을 수 있습니다.


Tensorflow에서는 tf.data.Dataset API를 사용하여 이 작업을 매우 쉽게 할 수 있습니다. 데이터의 새 변환 함수를 정의합니다.
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
그런 다음 최종 데이터 변환 (셀 'training and validation datasets', 함수 'get_batched_dataset')에서 사용합니다.
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
데이터 증강을 선택사항으로 만들고 학습 데이터 세트만 증강되도록 필요한 코드를 추가해야 합니다. 검증 데이터 세트를 늘리는 것은 의미가 없습니다.
이제 35세대에서 80% 정확도를 달성할 수 있습니다.
해결 방법
솔루션 노트북은 다음과 같습니다. 막히는 부분이 있으면 사용하세요.
Keras_Flowers_TPU_squeezenet.ipynb
학습한 내용
- 🤔 Keras '함수형 스타일' 모델
- 🤓 Squeezenet 아키텍처
- 🤓 tf.data.datset을 사용한 데이터 증강
잠시 시간을 내어 이 체크리스트를 살펴보세요.
12. Xception 미세 조정
분리형 컨볼루션
컨볼루션 레이어를 구현하는 또 다른 방법인 깊이 분리 컨볼루션이 최근 인기를 얻고 있습니다. 이름이 길지만 개념은 매우 간단합니다. Tensorflow 및 Keras에서 tf.keras.layers.SeparableConv2D로 구현됩니다.
분리 가능한 컨볼루션도 이미지에 필터를 실행하지만 입력 이미지의 각 채널에 대해 별도의 가중치 집합을 사용합니다. '1x1 컨볼루션'이 이어지며, 이는 필터링된 채널의 가중 합계를 생성하는 일련의 내적입니다. 매번 새로운 가중치를 사용하여 필요한 만큼 채널의 가중치 재조합이 계산됩니다.

분리형 컨볼루션 그림. 1단계: 채널별 별도의 필터를 사용한 컨볼루션 2단계: 채널의 선형 재조합 원하는 출력 채널 수에 도달할 때까지 새로운 가중치 세트로 반복됩니다. 1단계도 매번 새로운 가중치를 사용하여 반복할 수 있지만 실제로는 거의 그렇지 않습니다.
분리형 컨볼루션은 최신 컨볼루션 네트워크 아키텍처(MobileNetV2, Xception, EfficientNet)에서 사용됩니다. 참고로 MobileNetV2는 이전에 전이 학습에 사용한 모델입니다.
이러한 컨볼루션은 일반 컨볼루션보다 저렴하며 실제로 효과적인 것으로 확인되었습니다. 위의 예시의 가중치 수는 다음과 같습니다.
컨볼루션 레이어: 4 x 4 x 3 x 5 = 240
분리형 컨볼루셔널 레이어: 4 x 4 x 3 + 3 x 5 = 48 + 15 = 63
각 스타일의 컨볼루션 레이어를 적용하는 데 필요한 곱셈 수는 유사한 방식으로 확장된다는 것을 계산하는 것은 독자의 몫입니다. 분리형 컨볼루션은 더 작고 훨씬 더 효과적으로 계산됩니다.
실습
'전이 학습' Playground 노트북에서 다시 시작하되 이번에는 Xception을 사전 학습된 모델로 선택합니다. Xception은 분리형 컨볼루션만 사용합니다. 모든 가중치를 학습 가능으로 둡니다. 사전 학습된 레이어를 그대로 사용하는 대신 Google의 데이터에 사전 학습된 가중치를 미세 조정합니다.
Keras Flowers transfer learning (playground).ipynb
목표: 정확도 95% 이상(진짜로 가능합니다!)
마지막 연습이므로 코드와 데이터 과학 작업이 조금 더 필요합니다.
세부 조정에 관한 추가 정보
Xception은 tf.keras.application.*의 표준 사전 학습 모델에서 사용할 수 있습니다. 이번에는 모든 가중치를 학습 가능하도록 설정해야 합니다.
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
모델을 미세 조정할 때 좋은 결과를 얻으려면 학습률에 주의하고 램프업 기간이 있는 학습률 일정을 사용해야 합니다. 다음 행을 추가하면 됩니다.

표준 학습률로 시작하면 모델의 사전 학습된 가중치가 중단됩니다. 점진적으로 시작하면 모델이 데이터에 고정될 때까지 보존되며, 모델이 데이터를 적절한 방식으로 수정할 수 있습니다. 램프 후에는 상수 또는 지수함수형 붕괴 학습률을 계속 사용할 수 있습니다.
Keras에서는 각 에포크에 적절한 학습률을 계산할 수 있는 콜백을 통해 학습률을 지정합니다. Keras는 각 에포크의 옵티마이저에 올바른 학습률을 전달합니다.
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
해결 방법
솔루션 노트북은 다음과 같습니다. 막히는 부분이 있으면 사용하세요.
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
학습한 내용
- 🤔 깊이 분리형 컨볼루션
- 🤓 학습률 일정
- 😈 사전 학습된 모델 미세 조정
잠시 시간을 내어 이 체크리스트를 머릿속으로 살펴보세요.
13. 축하합니다.
첫 번째 최신 컨볼루셔널 신경망을 빌드하고 TPU 덕분에 몇 분 만에 연속 학습 실행을 반복하여 90% 이상의 정확도로 학습했습니다.
실제 TPU
TPU 및 GPU는 Google Cloud의 Vertex AI에서 사용할 수 있습니다.
마지막으로 의견을 보내주세요. 이 실습에서 잘못된 점이 있거나 개선해야 할 점이 있다면 알려주세요. GitHub 문제[의견 링크]를 통해 의견을 제공할 수 있습니다.

|
|

