
1. Tổng quan
Trong phòng thí nghiệm này, bạn sẽ tìm hiểu cách xây dựng, huấn luyện và điều chỉnh mạng nơ-ron tích chập của riêng mình từ đầu bằng Keras và Tensorflow 2. Giờ đây, bạn có thể thực hiện việc này trong vài phút nhờ sức mạnh của TPU. Bạn cũng sẽ khám phá nhiều phương pháp từ học chuyển giao rất đơn giản đến các cấu trúc tích chập hiện đại như Squeezenet. Phòng thí nghiệm này bao gồm các giải thích lý thuyết về mạng nơ-ron và là điểm xuất phát phù hợp cho những nhà phát triển tìm hiểu về học sâu.
Việc đọc các bài viết về học sâu có thể khó khăn và dễ gây nhầm lẫn. Hãy xem xét kỹ lưỡng các cấu trúc mạng nơ-ron tích chập hiện đại.

Kiến thức bạn sẽ học được
- Sử dụng Keras và Tensor Processing Units (TPU) để xây dựng các mô hình tuỳ chỉnh nhanh hơn.
- Sử dụng tf.data.Dataset API và định dạng TFRecord để tải dữ liệu huấn luyện một cách hiệu quả.
- Để gian lận 😈, hãy sử dụng phương pháp học chuyển giao thay vì xây dựng mô hình của riêng bạn.
- Để sử dụng các kiểu mô hình tuần tự và mô hình chức năng của Keras.
- Để tạo trình phân loại Keras của riêng bạn bằng lớp softmax và tổn thất entropy chéo.
- Để tinh chỉnh mô hình bằng cách chọn các lớp tích chập phù hợp.
- Khám phá các ý tưởng về cấu trúc mạng nơ-ron tích chập hiện đại như các mô-đun, tính năng gộp trung bình toàn cục, v.v.
- Để tạo một mạng nơ-ron tích chập hiện đại đơn giản bằng cách sử dụng cấu trúc Squeezenet.
Phản hồi
Nếu bạn thấy có vấn đề trong lớp học lập trình này, vui lòng cho chúng tôi biết. Bạn có thể gửi ý kiến phản hồi thông qua các vấn đề trên GitHub [ đường liên kết phản hồi].
2. Hướng dẫn bắt đầu nhanh về Google Colaboratory
Phòng thí nghiệm này sử dụng Google Colaboratory và bạn không cần thiết lập gì. Bạn có thể chạy ứng dụng này trên Chromebook. Vui lòng mở tệp bên dưới và thực thi các ô để làm quen với sổ tay Colab.
Chọn một phần phụ trợ TPU

Trong trình đơn Colab, hãy chọn Thời gian chạy > Thay đổi loại thời gian chạy rồi chọn TPU. Trong lớp học lập trình này, bạn sẽ sử dụng một TPU (Tensor Processing Unit) mạnh mẽ được hỗ trợ để huấn luyện có tăng tốc phần cứng. Quá trình kết nối với thời gian chạy sẽ diễn ra tự động trong lần thực thi đầu tiên hoặc bạn có thể sử dụng nút "Kết nối" ở góc trên bên phải.
Thực thi sổ tay

Thực thi từng ô bằng cách nhấp vào một ô và sử dụng tổ hợp phím Shift-ENTER. Bạn cũng có thể chạy toàn bộ sổ tay bằng cách chọn Thời gian chạy > Chạy tất cả
Mục lục

Tất cả sổ tay đều có mục lục. Bạn có thể mở trình đơn này bằng cách nhấn vào mũi tên màu đen ở bên trái.
Các ô bị ẩn

Một số ô sẽ chỉ hiển thị tiêu đề. Đây là một tính năng sổ tay dành riêng cho Colab. Bạn có thể nhấp đúp vào các tệp này để xem mã bên trong, nhưng thường thì mã này không có gì thú vị. Thường là các hàm hỗ trợ hoặc trực quan hoá. Bạn vẫn cần chạy các ô này để xác định các hàm bên trong.
Xác thực

Colab có thể truy cập vào các bộ chứa riêng tư của bạn trên Google Cloud Storage, miễn là bạn xác thực bằng một tài khoản được uỷ quyền. Đoạn mã ở trên sẽ kích hoạt một quy trình xác thực.
3. [THÔNG TIN] Tensor Processing Unit (TPU) là gì?
Tóm lại

Mã để huấn luyện một mô hình trên TPU trong Keras (và quay lại GPU hoặc CPU nếu không có TPU):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Hôm nay, chúng ta sẽ sử dụng TPU để xây dựng và tối ưu hoá một trình phân loại hoa ở tốc độ tương tác (vài phút cho mỗi lần chạy huấn luyện).

Tại sao nên dùng TPU?
GPU hiện đại được sắp xếp xung quanh các "lõi" có thể lập trình, một kiến trúc rất linh hoạt cho phép chúng xử lý nhiều tác vụ như kết xuất 3D, học sâu, mô phỏng vật lý, v.v. Mặt khác, TPU kết hợp bộ xử lý vectơ cổ điển với một đơn vị nhân ma trận chuyên dụng và vượt trội ở mọi tác vụ mà phép nhân ma trận lớn chiếm ưu thế, chẳng hạn như mạng nơ-ron.

Minh hoạ: một lớp mạng nơron dày đặc dưới dạng phép nhân ma trận, với một lô gồm 8 hình ảnh được xử lý cùng lúc thông qua mạng nơron. Vui lòng chạy phép nhân một hàng x một cột để xác minh rằng phép nhân này thực sự đang tính tổng có trọng số của tất cả các giá trị pixel của một hình ảnh. Các lớp tích chập cũng có thể được biểu diễn dưới dạng phép nhân ma trận mặc dù phức tạp hơn một chút ( giải thích tại đây, trong phần 1).
Phần cứng
MXU và VPU
Một lõi TPU phiên bản 2 được tạo thành từ Đơn vị nhân ma trận (MXU) chạy các phép nhân ma trận và Đơn vị xử lý vectơ (VPU) cho tất cả các tác vụ khác, chẳng hạn như kích hoạt, softmax, v.v. VPU xử lý các phép tính float32 và int32. Mặt khác, MXU hoạt động ở định dạng dấu phẩy động 16-32 bit có độ chính xác hỗn hợp.

Dấu phẩy động có độ chính xác hỗn hợp và bfloat16
MXU tính toán phép nhân ma trận bằng cách sử dụng đầu vào bfloat16 và đầu ra float32. Các phép tích luỹ trung gian được thực hiện với độ chính xác float32.

Quá trình huấn luyện mạng nơ-ron thường không bị ảnh hưởng bởi nhiễu do độ chính xác của số có dấu phẩy động giảm. Có những trường hợp nhiễu thậm chí còn giúp trình tối ưu hoá hội tụ. Độ chính xác của dấu phẩy động 16 bit thường được dùng để tăng tốc các phép tính, nhưng định dạng float16 và float32 có phạm vi rất khác nhau. Việc giảm độ chính xác từ float32 xuống float16 thường dẫn đến tình trạng tràn số và thiếu số. Các giải pháp hiện có nhưng thường cần thêm công việc để float16 hoạt động.
Đó là lý do Google giới thiệu định dạng bfloat16 trong TPU. bfloat16 là một float32 bị cắt bớt với chính xác các bit số mũ và dải giá trị như float32. Điều này, cộng với việc TPU tính toán các phép nhân ma trận với độ chính xác hỗn hợp bằng đầu vào bfloat16 nhưng đầu ra float32, có nghĩa là thông thường, bạn không cần thay đổi mã để hưởng lợi từ hiệu suất tăng lên do độ chính xác giảm.
Mảng tâm thu
MXU triển khai các phép nhân ma trận trong phần cứng bằng cách sử dụng cái gọi là cấu trúc "mảng tâm thu", trong đó các phần tử dữ liệu truyền qua một mảng các đơn vị tính toán phần cứng. (Trong y học, "tâm thu" đề cập đến sự co bóp của tim và lưu lượng máu, ở đây là lưu lượng dữ liệu.)
Phần tử cơ bản của phép nhân ma trận là tích vô hướng giữa một hàng của ma trận này và một cột của ma trận kia (xem hình minh hoạ ở đầu phần này). Đối với phép nhân ma trận Y=X*W, một phần tử của kết quả sẽ là:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
Trên GPU, người ta sẽ lập trình tích vô hướng này vào một "lõi" GPU, sau đó thực thi tích vô hướng này trên nhiều "lõi" nhất có thể song song để cố gắng tính toán mọi giá trị của ma trận kết quả cùng một lúc. Nếu ma trận kết quả có kích thước 128x128, thì cần có 128x128=16.000 "lõi" và điều này thường không thể thực hiện được. Các GPU lớn nhất có khoảng 4.000 lõi. Mặt khác, TPU sử dụng phần cứng tối thiểu cho các đơn vị tính toán trong MXU: chỉ có bfloat16 x bfloat16 => float32 bộ nhân tích luỹ, không có gì khác. Các đơn vị này nhỏ đến mức một TPU có thể triển khai 16.000 đơn vị trong một MXU 128x128 và xử lý phép nhân ma trận này trong một lần.

Hình minh hoạ: mảng tâm thu MXU. Các phần tử điện toán là bộ tích luỹ nhân. Các giá trị của một ma trận được tải vào mảng (các dấu chấm màu đỏ). Các giá trị của ma trận khác sẽ chảy qua mảng (các dấu chấm màu xám). Các đường thẳng đứng truyền các giá trị lên trên. Các đường kẻ ngang truyền tổng số cộng từng phần. Người dùng cần tự xác minh rằng khi luồng dữ liệu truyền qua mảng, bạn sẽ nhận được kết quả của phép nhân ma trận ở phía bên phải.
Ngoài ra, trong khi các tích vô hướng đang được tính toán trong một MXU, các tổng trung gian chỉ đơn giản là chảy giữa các đơn vị tính toán liền kề. Chúng không cần được lưu trữ và truy xuất đến/từ bộ nhớ hoặc thậm chí là một tệp đăng ký. Kết quả cuối cùng là kiến trúc mảng tâm thu TPU có mật độ và công suất vượt trội đáng kể, cũng như tốc độ vượt trội không thể bỏ qua so với GPU khi tính toán phép nhân ma trận.
Cloud TPU
Khi yêu cầu một " Cloud TPU phiên bản 2" trên Google Cloud Platform, bạn sẽ nhận được một máy ảo (VM) có một bảng TPU được gắn PCI. Bảng TPU có 4 chip TPU lõi kép. Mỗi lõi TPU có một VPU (Vector Processing Unit) và một MXU (MatriX multiply Unit) 128x128. Sau đó, "Cloud TPU" này thường được kết nối qua mạng với VM đã yêu cầu. Vậy bức tranh toàn cảnh sẽ có dạng như sau:

Hình minh hoạ: máy ảo của bạn có một trình tăng tốc "Cloud TPU" được gắn vào mạng. "Cloud TPU" được tạo thành từ một máy ảo có bảng TPU được gắn PCI với 4 chip TPU lõi kép trên đó.
Nhóm TPU
Trong các trung tâm dữ liệu của Google, TPU được kết nối với một hệ thống kết nối điện toán hiệu năng cao (HPC) có thể khiến chúng xuất hiện dưới dạng một bộ tăng tốc rất lớn. Google gọi chúng là các nhóm và chúng có thể bao gồm tối đa 512 lõi TPU phiên bản 2 hoặc 2048 lõi TPU phiên bản 3.

Hình minh hoạ: một nhóm TPU phiên bản 3. Các bảng và giá đỡ TPU được kết nối thông qua HPC interconnect.
Trong quá trình huấn luyện, các độ dốc được trao đổi giữa các lõi TPU bằng cách sử dụng thuật toán giảm tất cả ( giải thích rõ ràng về thuật toán giảm tất cả tại đây). Mô hình đang được huấn luyện có thể tận dụng phần cứng bằng cách huấn luyện trên các kích thước lô lớn.

Hình minh hoạ: quá trình đồng bộ hoá các độ dốc trong quá trình huấn luyện bằng thuật toán giảm tất cả trên mạng HPC dạng lưới hình xuyến 2 chiều của TPU của Google.
Phần mềm
Huấn luyện kích thước lô lớn
Kích thước lô lý tưởng cho TPU là 128 mục dữ liệu trên mỗi lõi TPU, nhưng phần cứng đã có thể cho thấy mức sử dụng tốt từ 8 mục dữ liệu trên mỗi lõi TPU. Hãy nhớ rằng một Cloud TPU có 8 lõi.
Trong lớp học lập trình này, chúng ta sẽ sử dụng API Keras. Trong Keras, lô mà bạn chỉ định là kích thước lô chung cho toàn bộ TPU. Các lô của bạn sẽ tự động được chia thành 8 và chạy trên 8 lõi của TPU.

Để biết thêm các mẹo về hiệu suất, hãy xem Hướng dẫn về hiệu suất TPU. Đối với các kích thước lô rất lớn, bạn có thể cần phải đặc biệt chú ý đến một số mô hình, hãy xem LARSOptimizer để biết thêm thông tin chi tiết.
Tìm hiểu sâu: XLA
Các chương trình Tensorflow xác định đồ thị tính toán. TPU không chạy trực tiếp mã Python mà chạy biểu đồ tính toán do chương trình Tensorflow của bạn xác định. Về cơ bản, một trình biên dịch có tên là XLA (trình biên dịch Đại số tuyến tính được tăng tốc) sẽ chuyển đổi biểu đồ Tensorflow của các nút tính toán thành mã máy TPU. Trình biên dịch này cũng thực hiện nhiều hoạt động tối ưu hoá nâng cao trên mã và bố cục bộ nhớ của bạn. Quá trình biên dịch sẽ diễn ra tự động khi công việc được gửi đến TPU. Bạn không cần phải đưa XLA vào chuỗi bản dựng một cách rõ ràng.

Hình minh hoạ: để chạy trên TPU, biểu đồ tính toán do chương trình Tensorflow của bạn xác định trước tiên sẽ được dịch sang biểu diễn XLA (trình biên dịch Đại số tuyến tính tăng tốc), sau đó được XLA biên dịch thành mã máy TPU.
Sử dụng TPU trong Keras
TPU được hỗ trợ thông qua API Keras kể từ Tensorflow 2.1. Hỗ trợ Keras trên TPU và nhóm TPU. Sau đây là một ví dụ hoạt động trên TPU, (các) GPU và CPU:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Trong đoạn mã này:
TPUClusterResolver().connect()tìm thấy TPU trên mạng. Công cụ này hoạt động mà không cần tham số trên hầu hết các hệ thống của Google Cloud (các công việc trên Nền tảng Trí tuệ nhân tạo, Colaboratory, Kubeflow, VM học sâu được tạo thông qua tiện ích "ctpu up"). Các hệ thống này biết vị trí của TPU nhờ biến môi trường TPU_NAME. Nếu bạn tạo TPU theo cách thủ công, hãy đặt biến môi trường TPU_NAME trên VM mà bạn đang sử dụng hoặc gọiTPUClusterResolverbằng các tham số rõ ràng:TPUClusterResolver(tp_uname, zone, project)TPUStrategylà phần triển khai thuật toán đồng bộ hoá độ dốc "giảm tất cả" và phân phối.- Chiến lược này được áp dụng thông qua một phạm vi. Mô hình phải được xác định trong phạm vi chiến lược().
- Hàm
tpu_model.fitdự kiến sẽ có một đối tượng tf.data.Dataset để làm dữ liệu đầu vào cho quá trình huấn luyện TPU.
Các thao tác di chuyển TPU thường gặp
- Mặc dù có nhiều cách để tải dữ liệu trong mô hình Tensorflow, nhưng đối với TPU, bạn phải sử dụng API
tf.data.Dataset. - TPU có tốc độ rất cao và việc nhập dữ liệu thường trở thành điểm tắc nghẽn khi chạy trên các TPU này. Bạn có thể sử dụng các công cụ để phát hiện điểm tắc nghẽn dữ liệu và các mẹo khác về hiệu suất trong Hướng dẫn về hiệu suất TPU.
- Các số int8 hoặc int16 được coi là int32. TPU không có phần cứng số nguyên hoạt động trên dưới 32 bit.
- Một số thao tác Tensorflow không được hỗ trợ. Danh sách có tại đây. Tin vui là hạn chế này chỉ áp dụng cho mã huấn luyện, tức là lượt truyền xuôi và truyền ngược qua mô hình của bạn. Bạn vẫn có thể sử dụng tất cả các thao tác Tensorflow trong quy trình nhập dữ liệu vì thao tác này sẽ được thực thi trên CPU.
tf.py_funckhông được hỗ trợ trên TPU.
4. Đang tải dữ liệu






Chúng ta sẽ làm việc với một tập dữ liệu gồm các bức ảnh về hoa. Mục tiêu là học cách phân loại chúng thành 5 loại hoa. Quá trình tải dữ liệu được thực hiện bằng API tf.data.Dataset. Trước tiên, hãy tìm hiểu về API này.
Thực hành
Vui lòng mở sổ tay sau, thực thi các ô (Shift-ENTER) và làm theo hướng dẫn bất cứ khi nào bạn thấy nhãn "CẦN THỰC HIỆN".

Fun with tf.data.Dataset (playground).ipynb
Thông tin khác
Giới thiệu về tập dữ liệu "flowers"
Tập dữ liệu được sắp xếp thành 5 thư mục. Mỗi thư mục chứa một loại hoa. Các thư mục có tên là hoa hướng dương, hoa cúc, hoa bồ công anh, hoa tulip và hoa hồng. Dữ liệu được lưu trữ trong một bộ chứa công khai trên Google Cloud Storage. Đoạn trích:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
Tại sao nên dùng tf.data.Dataset?
Keras và TensorFlow chấp nhận các Tập dữ liệu trong tất cả các hàm huấn luyện và đánh giá. Sau khi bạn tải dữ liệu vào một Tập dữ liệu, API sẽ cung cấp tất cả các chức năng phổ biến hữu ích cho dữ liệu huấn luyện mạng nơ-ron:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
Bạn có thể xem các mẹo về hiệu suất và các phương pháp hay nhất về Tập dữ liệu trong bài viết này. Tài liệu tham khảo có tại đây.
Kiến thức cơ bản về tf.data.Dataset
Dữ liệu thường có trong nhiều tệp, ở đây là hình ảnh. Bạn có thể tạo một tập dữ liệu gồm các tên tệp bằng cách gọi:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
Sau đó, bạn "ánh xạ" một hàm đến từng tên tệp. Hàm này thường sẽ tải và giải mã tệp thành dữ liệu thực tế trong bộ nhớ:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
Cách lặp lại trên một Tập dữ liệu:
for data in my_dataset:
print(data)
Tập dữ liệu của các bộ dữ liệu
Trong học có giám sát, tập dữ liệu huấn luyện thường được tạo thành từ các cặp dữ liệu huấn luyện và câu trả lời chính xác. Để cho phép điều này, hàm giải mã có thể trả về các bộ giá trị. Sau đó, bạn sẽ có một tập dữ liệu gồm các bộ và các bộ sẽ được trả về khi bạn lặp lại trên tập dữ liệu đó. Các giá trị được trả về là các tensor Tensorflow đã sẵn sàng được mô hình của bạn sử dụng. Bạn có thể gọi .numpy() trên các giá trị này để xem giá trị thô:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
Kết luận:tải từng hình ảnh một rất chậm!
Khi lặp lại trên tập dữ liệu này, bạn sẽ thấy rằng bạn có thể tải khoảng 1-2 hình ảnh mỗi giây. Tốc độ đó quá chậm! Các bộ tăng tốc phần cứng mà chúng ta sẽ sử dụng để huấn luyện có thể duy trì tốc độ này nhiều lần. Hãy chuyển đến phần tiếp theo để xem cách chúng ta sẽ đạt được mục tiêu này.
Giải pháp
Sau đây là sổ tay giải pháp. Bạn có thể sử dụng mã này nếu gặp khó khăn.
Fun with tf.data.Dataset (solution).ipynb
Nội dung đã đề cập
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 Tập dữ liệu của các bộ
- 😀 lặp lại qua Tập dữ liệu
Vui lòng dành chút thời gian để xem qua danh sách kiểm tra này.
5. Tải dữ liệu nhanh
Các bộ tăng tốc phần cứng Tensor Processing Unit (TPU) mà chúng ta sẽ sử dụng trong phòng thí nghiệm này có tốc độ rất cao. Thách thức thường gặp là cung cấp cho chúng dữ liệu đủ nhanh để chúng luôn bận rộn. Google Cloud Storage (GCS) có khả năng duy trì thông lượng rất cao, nhưng giống như mọi hệ thống lưu trữ đám mây, việc bắt đầu kết nối sẽ tốn một số thời gian qua lại trên mạng. Do đó, việc lưu trữ dữ liệu dưới dạng hàng nghìn tệp riêng lẻ không phải là cách lý tưởng. Chúng ta sẽ nhóm các tệp này thành một số lượng nhỏ hơn và sử dụng sức mạnh của tf.data.Dataset để đọc song song từ nhiều tệp.
Đọc qua
Mã tải tệp hình ảnh, đổi kích thước thành kích thước chung rồi lưu trữ trên 16 tệp TFRecord nằm trong sổ tay sau. Vui lòng đọc nhanh qua nội dung này. Bạn không cần thực thi thao tác này vì dữ liệu được định dạng TFRecord đúng cách sẽ được cung cấp cho phần còn lại của lớp học lập trình.
Flower pictures to TFRecords.ipynb
Bố cục dữ liệu lý tưởng để có được thông lượng GCS tối ưu
Định dạng tệp TFRecord
Định dạng tệp mà Tensorflow ưu tiên để lưu trữ dữ liệu là định dạng TFRecord dựa trên protobuf. Các định dạng chuyển đổi tuần tự khác cũng sẽ hoạt động, nhưng bạn có thể tải trực tiếp một tập dữ liệu từ các tệp TFRecord bằng cách viết:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Để có hiệu suất tối ưu, bạn nên sử dụng đoạn mã phức tạp hơn sau đây để đọc từ nhiều tệp TFRecord cùng một lúc. Mã này sẽ đọc từ N tệp song song và bỏ qua thứ tự dữ liệu để tăng tốc độ đọc.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Bản tóm tắt về TFRecord
Có 3 loại dữ liệu có thể được lưu trữ trong TFRecords: chuỗi byte (danh sách byte), số nguyên 64 bit và số thực 32 bit. Chúng luôn được lưu trữ dưới dạng danh sách, một phần tử dữ liệu duy nhất sẽ là danh sách có kích thước 1. Bạn có thể sử dụng các hàm trợ giúp sau để lưu trữ dữ liệu vào TFRecord.
writing byte strings
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
viết số nguyên
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
viết nổi
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
viết một TFRecord, sử dụng các trợ giúp ở trên
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
Để đọc dữ liệu từ TFRecord, trước tiên, bạn phải khai báo bố cục của các bản ghi mà bạn đã lưu trữ. Trong khai báo, bạn có thể truy cập vào bất kỳ trường nào được đặt tên dưới dạng danh sách có độ dài cố định hoặc danh sách có độ dài thay đổi:
đọc từ TFRecord
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
Các đoạn mã hữu ích:
đọc các phần tử dữ liệu riêng lẻ
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
đọc danh sách các phần tử có kích thước cố định
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
đọc một số lượng biến của các mục dữ liệu
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
VarLenFeature trả về một vectơ thưa và bạn cần thực hiện thêm một bước sau khi giải mã TFRecord:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
Bạn cũng có thể có các trường không bắt buộc trong TFRecord. Nếu bạn chỉ định một giá trị mặc định khi đọc một trường, thì giá trị mặc định sẽ được trả về thay vì lỗi nếu trường đó bị thiếu.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
Nội dung đã đề cập
- 🤔 phân chia tệp dữ liệu để truy cập nhanh từ GCS
- 😓 cách viết TFRecord. (Bạn đã quên cú pháp rồi ư? Không sao cả, hãy đánh dấu trang này làm tài liệu tham khảo)
- 🤔 tải một Tập dữ liệu từ TFRecords bằng TFRecordDataset
Vui lòng dành chút thời gian để xem qua danh sách kiểm tra này.
6. [THÔNG TIN] Phân loại mạng nơron 101
Tóm lại
Nếu đã biết tất cả các thuật ngữ được in đậm trong đoạn văn tiếp theo, bạn có thể chuyển sang bài tập tiếp theo. Nếu bạn chỉ mới bắt đầu tìm hiểu về học sâu, thì xin chào mừng bạn và vui lòng đọc tiếp.
Đối với các mô hình được tạo dưới dạng một chuỗi các lớp, Keras cung cấp API tuần tự. Ví dụ: bạn có thể viết một trình phân loại hình ảnh sử dụng 3 lớp dày đặc trong Keras như sau:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
Mạng nơ-ron dày đặc
Đây là mạng nơ-ron đơn giản nhất để phân loại hình ảnh. Mạng này được tạo thành từ các "nơ-ron" được sắp xếp theo các lớp. Lớp đầu tiên xử lý dữ liệu đầu vào và chuyển đầu ra của lớp đó vào các lớp khác. Lớp này được gọi là "dày đặc" vì mỗi nơ-ron đều được kết nối với tất cả các nơ-ron trong lớp trước đó.

Bạn có thể đưa một hình ảnh vào mạng như vậy bằng cách làm phẳng các giá trị RGB của tất cả các pixel trong hình ảnh đó thành một vectơ dài và sử dụng vectơ đó làm dữ liệu đầu vào. Đây không phải là kỹ thuật tốt nhất để nhận dạng hình ảnh nhưng chúng tôi sẽ cải thiện kỹ thuật này sau.
Nơron, lượt kích hoạt, RELU
Một "nơ-ron" tính tổng có trọng số của tất cả các đầu vào, thêm một giá trị gọi là "độ lệch" và truyền kết quả thông qua một "hàm kích hoạt". Ban đầu, bạn không biết trọng số và độ lệch. Chúng sẽ được khởi tạo ngẫu nhiên và "học" bằng cách huấn luyện mạng nơ-ron trên nhiều dữ liệu đã biết.

Hàm kích hoạt phổ biến nhất được gọi là RELU cho Rectified Linear Unit. Đây là một hàm rất đơn giản như bạn có thể thấy trên biểu đồ ở trên.
Hàm kích hoạt Softmax
Mạng lưới trên kết thúc bằng một lớp 5 nơ-ron vì chúng ta đang phân loại hoa thành 5 danh mục (hoa hồng, hoa tulip, hoa bồ công anh, hoa cúc, hoa hướng dương). Các nơ-ron ở các lớp trung gian được kích hoạt bằng hàm kích hoạt RELU cổ điển. Tuy nhiên, ở lớp cuối cùng, chúng ta muốn tính toán các số từ 0 đến 1, biểu thị xác suất của bông hoa này là hoa hồng, hoa tulip, v.v. Để làm được điều này, chúng ta sẽ sử dụng một hàm kích hoạt có tên là "softmax".
Việc áp dụng softmax trên một vectơ được thực hiện bằng cách lấy hàm mũ của từng phần tử rồi chuẩn hoá vectơ, thường là sử dụng chuẩn L1 (tổng giá trị tuyệt đối) để các giá trị cộng lại thành 1 và có thể được diễn giải là xác suất.


Hàm mất mát cross-entropy
Giờ đây, khi mạng nơ-ron tạo ra các dự đoán từ hình ảnh đầu vào, chúng ta cần đo lường mức độ chính xác của các dự đoán đó, tức là khoảng cách giữa những gì mạng nơ-ron cho chúng ta biết và câu trả lời chính xác (thường được gọi là "nhãn"). Hãy nhớ rằng chúng tôi có nhãn chính xác cho tất cả hình ảnh trong tập dữ liệu.
Bất kỳ khoảng cách nào cũng có thể dùng được, nhưng đối với các vấn đề về phân loại, "khoảng cách cross-entropy" là hiệu quả nhất. Chúng ta sẽ gọi đây là hàm lỗi hoặc "tổn thất":

Phương pháp giảm độ dốc
"Huấn luyện" mạng nơ-ron thực sự có nghĩa là sử dụng hình ảnh và nhãn huấn luyện để điều chỉnh trọng số và độ chệch nhằm giảm thiểu hàm mất mát cross-entropy. Sau đây là cách hoạt động của tính năng này.
Cross-entropy là một hàm của trọng số, độ lệch, pixel của hình ảnh huấn luyện và lớp đã biết của hình ảnh đó.
Nếu tính đạo hàm riêng của cross-entropy tương đối với tất cả các trọng số và tất cả các độ lệch, chúng ta sẽ thu được một "độ dốc", được tính cho một hình ảnh, nhãn và giá trị hiện tại của trọng số và độ lệch nhất định. Hãy nhớ rằng chúng ta có thể có hàng triệu trọng số và độ lệch, vì vậy việc tính toán độ dốc có vẻ như là một việc tốn nhiều công sức. Rất may là Tensorflow đã làm việc này cho chúng ta. Thuộc tính toán học của một độ dốc là nó hướng "lên". Vì chúng ta muốn đi đến nơi có cross-entropy thấp, nên chúng ta sẽ đi theo hướng ngược lại. Chúng ta cập nhật các trọng số và độ lệch theo một phần của độ dốc. Sau đó, chúng ta sẽ lặp lại quy trình này nhiều lần bằng cách sử dụng các lô hình ảnh và nhãn huấn luyện tiếp theo trong một vòng lặp huấn luyện. Hy vọng rằng điều này sẽ hội tụ đến một nơi có cross-entropy tối thiểu, mặc dù không có gì đảm bảo rằng mức tối thiểu này là duy nhất.

Phân lô nhỏ và động lực
Bạn có thể tính toán độ dốc chỉ trên một hình ảnh mẫu và cập nhật ngay các trọng số và độ lệch, nhưng khi thực hiện trên một lô gồm 128 hình ảnh (ví dụ), bạn sẽ nhận được độ dốc thể hiện tốt hơn các ràng buộc do nhiều hình ảnh mẫu áp đặt và do đó, có khả năng hội tụ về giải pháp nhanh hơn. Kích thước của lô nhỏ là một tham số có thể điều chỉnh.
Kỹ thuật này, đôi khi được gọi là "giảm độ dốc ngẫu nhiên", có một lợi ích thực tế khác: làm việc với các lô cũng có nghĩa là làm việc với các ma trận lớn hơn và những ma trận này thường dễ dàng tối ưu hoá trên GPU và TPU hơn.
Tuy nhiên, quá trình hội tụ vẫn có thể hơi hỗn loạn và thậm chí có thể dừng lại nếu vectơ độ dốc bằng 0. Điều đó có nghĩa là chúng ta đã tìm thấy một giá trị tối thiểu? Không phải lúc nào cũng vậy. Một thành phần gradient có thể bằng 0 ở mức tối thiểu hoặc tối đa. Với một vectơ gradient có hàng triệu phần tử, nếu tất cả đều bằng 0, thì xác suất để mọi số 0 tương ứng với một điểm tối thiểu và không có số 0 nào tương ứng với một điểm tối đa là khá nhỏ. Trong không gian nhiều chiều, điểm yên ngựa khá phổ biến và chúng ta không muốn dừng lại ở đó.

Hình minh hoạ: điểm yên ngựa. Độ dốc bằng 0 nhưng không phải là độ dốc tối thiểu theo mọi hướng. (Thông tin ghi nhận tác giả của hình ảnh Wikimedia: Tác giả Nicoguaro – Tự sáng tạo, CC BY 3.0)
Giải pháp là thêm một số Momentum cho thuật toán tối ưu hoá để thuật toán có thể vượt qua các điểm yên mà không dừng lại.
Bảng thuật ngữ
batch (lô) hoặc mini-batch (lô nhỏ): quá trình huấn luyện luôn được thực hiện trên các lô dữ liệu huấn luyện và nhãn. Việc này giúp thuật toán hội tụ. Phương diện "lô" thường là phương diện đầu tiên của các tensor dữ liệu. Ví dụ: một tensor có hình dạng [100, 192, 192, 3] chứa 100 hình ảnh có kích thước 192x192 pixel với 3 giá trị trên mỗi pixel (RGB).
cross-entropy loss: một hàm mất mát đặc biệt thường được dùng trong các thuật toán phân loại.
lớp dày đặc: một lớp nơ-ron, trong đó mỗi nơ-ron được kết nối với tất cả các nơ-ron trong lớp trước đó.
đặc điểm: đầu vào của một mạng nơ-ron đôi khi được gọi là "đặc điểm". Nghệ thuật tìm ra những phần nào của một tập dữ liệu (hoặc tổ hợp các phần) để đưa vào mạng nơron nhằm nhận được dự đoán chính xác được gọi là "kỹ thuật trích xuất tính chất".
nhãn: một tên gọi khác của "lớp" hoặc câu trả lời chính xác trong một vấn đề phân loại có giám sát
tốc độ học: phần nhỏ của độ dốc mà theo đó các trọng số và độ lệch được cập nhật ở mỗi vòng lặp của vòng lặp huấn luyện.
logits: đầu ra của một lớp nơ-ron trước khi hàm kích hoạt được áp dụng được gọi là "logits". Thuật ngữ này bắt nguồn từ "hàm logistic", còn gọi là "hàm sigmoid", từng là hàm kích hoạt phổ biến nhất. "Đầu ra của nơ-ron trước hàm logistic" được rút ngắn thành "logits".
loss: hàm lỗi so sánh đầu ra của mạng nơ-ron với câu trả lời chính xác
neuron: tính tổng có trọng số của các đầu vào, thêm độ lệch và truyền kết quả thông qua một hàm kích hoạt.
mã one-hot: loại 3 trong số 5 được mã hoá dưới dạng một vectơ gồm 5 phần tử, tất cả đều là 0 ngoại trừ phần tử thứ 3 là 1.
relu: đơn vị tuyến tính được chỉnh sửa. Một hàm kích hoạt phổ biến cho các nơ-ron.
sigmoid: một hàm kích hoạt khác từng phổ biến và vẫn hữu ích trong các trường hợp đặc biệt.
softmax: một hàm kích hoạt đặc biệt hoạt động trên một vectơ, làm tăng sự khác biệt giữa thành phần lớn nhất và tất cả các thành phần khác, đồng thời chuẩn hoá vectơ để có tổng bằng 1, nhờ đó có thể diễn giải vectơ này dưới dạng một vectơ xác suất. Được dùng làm bước cuối cùng trong các trình phân loại.
tensor: "tensor" giống như ma trận nhưng có số lượng chiều tuỳ ý. Tenxơ 1 chiều là một vectơ. Tensor 2 chiều là một ma trận. Sau đó, bạn có thể có các tensor với 3, 4, 5 hoặc nhiều chiều hơn.
7. Học chuyển giao
Đối với vấn đề phân loại hình ảnh, các lớp dày đặc có thể sẽ không đủ. Chúng ta phải tìm hiểu về các lớp tích chập và nhiều cách sắp xếp các lớp này.
Nhưng chúng ta cũng có thể đi đường tắt! Bạn có thể tải các mạng nơ-ron tích chập được huấn luyện đầy đủ xuống. Bạn có thể cắt bỏ lớp cuối cùng của các mô hình này (đầu phân loại softmax) và thay thế bằng lớp của riêng bạn. Tất cả các trọng số và độ lệch đã được huấn luyện vẫn giữ nguyên, bạn chỉ cần huấn luyện lại lớp softmax mà bạn thêm. Kỹ thuật này được gọi là học chuyển giao và điều đáng ngạc nhiên là kỹ thuật này hoạt động miễn là tập dữ liệu mà mạng nơ-ron được huấn luyện trước "đủ gần" với tập dữ liệu của bạn.
Thực hành
Vui lòng mở sổ tay sau, thực thi các ô (Shift-ENTER) và làm theo hướng dẫn bất cứ khi nào bạn thấy nhãn "CẦN THỰC HIỆN".
Keras Flowers transfer learning (playground).ipynb
Thông tin khác
Với phương pháp học chuyển giao, bạn sẽ được hưởng lợi từ cả các cấu trúc mạng nơ-ron tích chập nâng cao do các nhà nghiên cứu hàng đầu phát triển và từ quá trình huấn luyện trước trên một tập dữ liệu khổng lồ gồm các hình ảnh. Trong trường hợp này, chúng ta sẽ học chuyển giao từ một mạng được huấn luyện trên ImageNet, một cơ sở dữ liệu hình ảnh chứa nhiều cảnh thực vật và cảnh ngoài trời, đủ gần với hoa.

Hình minh hoạ: sử dụng một mạng nơ-ron tích chập phức tạp (đã được huấn luyện) dưới dạng một hộp đen, chỉ huấn luyện lại lớp phân loại. Đây là học chuyển giao. Sau này, chúng ta sẽ tìm hiểu cách hoạt động của những cách sắp xếp phức tạp này của các lớp tích chập. Hiện tại, đó là vấn đề của người khác.
Học chuyển giao trong Keras
Trong Keras, bạn có thể tạo thực thể một mô hình được huấn luyện tiền kỳ từ tập hợp tf.keras.applications.*. Ví dụ: MobileNet V2 là một cấu trúc tích chập rất tốt và có kích thước hợp lý. Khi chọn include_top=False, bạn sẽ nhận được mô hình được huấn luyện tiền kỳ mà không có lớp softmax cuối cùng để bạn có thể thêm lớp softmax của riêng mình:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
Ngoài ra, hãy lưu ý chế độ cài đặt pretrained_model.trainable = False. Thao tác này sẽ cố định các trọng số và độ chệch của mô hình được huấn luyện tiền kỳ để bạn chỉ huấn luyện lớp softmax. Việc này thường liên quan đến tương đối ít trọng số và có thể được thực hiện nhanh chóng mà không cần đến một tập dữ liệu rất lớn. Tuy nhiên, nếu có nhiều dữ liệu, thì việc học chuyển giao có thể hoạt động hiệu quả hơn nữa với pretrained_model.trainable = True. Sau đó, các trọng số được huấn luyện trước sẽ cung cấp các giá trị ban đầu tuyệt vời và vẫn có thể được điều chỉnh bằng quá trình huấn luyện để phù hợp hơn với vấn đề của bạn.
Cuối cùng, hãy chú ý đến lớp Flatten() được chèn trước lớp softmax dày đặc. Các lớp dày đặc hoạt động trên các vectơ dữ liệu phẳng nhưng chúng ta không biết liệu đó có phải là những gì mô hình được huấn luyện trước trả về hay không. Đó là lý do chúng ta cần làm phẳng đường cong. Trong chương tiếp theo, khi tìm hiểu sâu về các cấu trúc tích chập, chúng ta sẽ giải thích định dạng dữ liệu do các lớp tích chập trả về.
Bạn sẽ đạt được độ chính xác gần 75% với phương pháp này.
Giải pháp
Sau đây là sổ tay giải pháp. Bạn có thể sử dụng mã này nếu gặp khó khăn.
Keras Flowers transfer learning (solution).ipynb
Nội dung đã đề cập
- 🤔 Cách viết một trình phân loại trong Keras
- 🤓 được định cấu hình bằng lớp cuối cùng softmax và tổn thất entropy chéo
- 😈 Học chuyển giao
- 🤔 Huấn luyện mô hình đầu tiên
- 🧐 Theo dõi tổn thất và độ chính xác trong quá trình huấn luyện
Vui lòng dành chút thời gian để xem qua danh sách kiểm tra này.
8. [THÔNG TIN] Mạng nơron tích chập
Tóm lại
Nếu đã biết tất cả các thuật ngữ được in đậm trong đoạn văn tiếp theo, bạn có thể chuyển sang bài tập tiếp theo. Nếu bạn chỉ mới bắt đầu tìm hiểu về mạng nơ-ron tích chập, vui lòng đọc tiếp.

Hình minh hoạ: lọc một hình ảnh bằng 2 bộ lọc liên tiếp, mỗi bộ lọc có 4x4x3=48 trọng số có thể học được.
Đây là giao diện của một mạng nơ-ron tích chập đơn giản trong Keras:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
Hướng dẫn cơ bản về mạng nơron tích chập
Trong một lớp của mạng tích chập, một "nơ-ron" sẽ tính tổng có trọng số của các pixel ngay phía trên nó, chỉ trong một vùng nhỏ của hình ảnh. Nó thêm một độ lệch và truyền tổng qua một hàm kích hoạt, giống như một nơ-ron trong lớp dày đặc thông thường. Sau đó, thao tác này được lặp lại trên toàn bộ hình ảnh bằng cách sử dụng cùng một trọng số. Hãy nhớ rằng trong các lớp dày đặc, mỗi nơ-ron đều có trọng số riêng. Ở đây, một "mảng" trọng số duy nhất sẽ trượt trên hình ảnh theo cả hai hướng (một "tích chập"). Đầu ra có nhiều giá trị như số lượng pixel trong hình ảnh (mặc dù cần có một số khoảng đệm ở các cạnh). Đây là một hoạt động lọc, sử dụng bộ lọc có 4x4x3=48 trọng số.
Tuy nhiên, 48 trọng số sẽ không đủ. Để tăng thêm mức độ tự do, chúng ta lặp lại thao tác tương tự với một nhóm trọng số mới. Thao tác này sẽ tạo ra một nhóm đầu ra bộ lọc mới. Hãy gọi đó là "kênh" đầu ra theo cách tương tự như các kênh R,G,B trong hình ảnh đầu vào.

Bạn có thể cộng hai (hoặc nhiều) nhóm trọng số thành một tensor bằng cách thêm một phương diện mới. Điều này cho chúng ta hình dạng chung của tensor trọng số cho một lớp tích chập. Vì số lượng kênh đầu vào và đầu ra là các tham số, nên chúng ta có thể bắt đầu xếp chồng và liên kết các lớp tích chập.

Hình minh hoạ: một mạng nơ-ron tích chập chuyển đổi "các khối" dữ liệu thành "các khối" dữ liệu khác.
Tích chập có bước sải, gộp tối đa
Bằng cách thực hiện các phép tích chập với bước sải là 2 hoặc 3, chúng ta cũng có thể thu nhỏ khối dữ liệu kết quả theo chiều ngang. Có 2 cách phổ biến để thực hiện việc này:
- Phép tích chập có bước sải: bộ lọc trượt như trên nhưng có bước sải > 1
- Gộp tối đa: một cửa sổ trượt áp dụng thao tác MAX (thường là trên các mảng 2x2, lặp lại sau mỗi 2 pixel)

Minh hoạ: việc trượt cửa sổ tính toán 3 pixel sẽ dẫn đến ít giá trị đầu ra hơn. Các phép tích chập có bước sải hoặc gộp tối đa (tối đa trên cửa sổ 2x2 trượt theo bước sải là 2) là một cách thu nhỏ khối dữ liệu theo chiều ngang.
Bộ phân loại tích chập
Cuối cùng, chúng ta sẽ đính kèm một tiêu đề phân loại bằng cách làm phẳng khối dữ liệu cuối cùng và truyền khối dữ liệu đó qua một lớp dày đặc được kích hoạt bằng softmax. Một bộ phân loại tích chập điển hình có thể có dạng như sau:

Minh hoạ: một trình phân loại hình ảnh sử dụng các lớp tích chập và softmax. Nó sử dụng bộ lọc 3x3 và 1x1. Các lớp maxpool lấy giá trị tối đa của các nhóm gồm 2x2 điểm dữ liệu. Đầu phân loại được triển khai bằng một lớp dày đặc với chế độ kích hoạt softmax.
Trong Keras
Bạn có thể viết ngăn xếp tích chập minh hoạ ở trên trong Keras như sau:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
9. Mạng nơ-ron tích chập tuỳ chỉnh của bạn
Thực hành
Hãy cùng xây dựng và huấn luyện một mạng nơron tích chập từ đầu. Việc sử dụng TPU sẽ giúp chúng tôi lặp lại rất nhanh. Vui lòng mở sổ tay sau, thực thi các ô (Shift-ENTER) và làm theo hướng dẫn bất cứ khi nào bạn thấy nhãn "CẦN THỰC HIỆN".
Keras_Flowers_TPU (playground).ipynb
Mục tiêu là đạt được độ chính xác cao hơn 75% so với mô hình học chuyển giao. Mô hình đó có lợi thế hơn vì đã được huấn luyện trước trên một tập dữ liệu gồm hàng triệu hình ảnh, trong khi chúng ta chỉ có 3670 hình ảnh ở đây. Bạn có thể giảm giá ít nhất bằng mức giá đó không?
Thông tin khác
Có bao nhiêu lớp, kích thước bao nhiêu?
Việc chọn kích thước lớp thiên về nghệ thuật hơn là khoa học. Bạn phải tìm được sự cân bằng phù hợp giữa việc có quá ít và quá nhiều tham số (trọng số và độ lệch). Nếu có quá ít trọng số, mạng nơ-ron sẽ không thể biểu thị độ phức tạp của hình dạng hoa. Nếu có quá nhiều, mô hình có thể dễ bị "quá khớp", tức là chỉ chuyên về hình ảnh huấn luyện và không thể khái quát hoá. Với nhiều tham số, mô hình cũng sẽ huấn luyện chậm. Trong Keras, hàm model.summary() sẽ hiển thị cấu trúc và số lượng tham số của mô hình:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
Một vài mẹo:
- Việc có nhiều lớp là yếu tố giúp mạng nơ-ron "sâu" hoạt động hiệu quả. Đối với vấn đề nhận dạng hoa đơn giản này, 5 đến 10 lớp là hợp lý.
- Sử dụng bộ lọc nhỏ. Thông thường, bộ lọc 3x3 sẽ phù hợp ở mọi nơi.
- Bạn cũng có thể dùng bộ lọc 1x1 và chúng có giá thành rẻ. Chúng không thực sự "lọc" bất cứ thứ gì mà chỉ tính toán các tổ hợp tuyến tính của các kênh. Thay thế các bộ lọc đó bằng bộ lọc thực. ("1x1 convolutions" sẽ được đề cập thêm trong phần tiếp theo.)
- Đối với một vấn đề phân loại như thế này, hãy giảm mẫu thường xuyên bằng các lớp gộp tối đa (hoặc các lớp tích chập có bước sải > 1). Bạn không quan tâm đến vị trí của bông hoa, mà chỉ quan tâm đến việc đó là hoa hồng hay hoa bồ công anh. Vì vậy, việc mất thông tin x và y không quan trọng và việc lọc các khu vực nhỏ hơn sẽ rẻ hơn.
- Số lượng bộ lọc thường tương tự như số lượng lớp ở cuối mạng (tại sao? xem thủ thuật "gộp trung bình toàn cục" bên dưới). Nếu bạn phân loại thành hàng trăm lớp, hãy tăng dần số lượng bộ lọc trong các lớp liên tiếp. Đối với tập dữ liệu hoa có 5 lớp, chỉ lọc bằng 5 bộ lọc sẽ không đủ. Bạn có thể sử dụng cùng một số lượng bộ lọc trong hầu hết các lớp, ví dụ: 32 và giảm số lượng này về cuối.
- (Các) lớp dày đặc cuối cùng khá tốn kém. Nó/chúng có thể có trọng số lớn hơn tổng trọng số của tất cả các lớp tích chập. Ví dụ: ngay cả khi có đầu ra rất hợp lý từ khối dữ liệu cuối cùng gồm 24x24x10 điểm dữ liệu, một lớp dày đặc gồm 100 nơ-ron sẽ tốn 24x24x10x100=576.000 trọng số!!! Hãy cố gắng suy nghĩ thấu đáo hoặc thử tính năng gộp trung bình toàn cục (xem bên dưới).
Gộp trung bình toàn cục
Thay vì sử dụng một lớp dày đặc tốn kém ở cuối mạng nơ-ron tích chập, bạn có thể chia "khối" dữ liệu đến thành nhiều phần như số lượng loại bạn có, tính trung bình các giá trị của chúng và đưa các giá trị này qua một hàm kích hoạt softmax. Cách tạo phần đầu phân loại này không tốn trọng số. Trong Keras, cú pháp là tf.keras.layers.GlobalAveragePooling2D().

Giải pháp
Sau đây là sổ tay giải pháp. Bạn có thể sử dụng mã này nếu gặp khó khăn.
Keras_Flowers_TPU (solution).ipynb
Nội dung đã đề cập
- 🤔 Chơi với các lớp tích chập
- 🤓 Thử nghiệm với tính năng gộp tối đa, bước sải, tính năng gộp trung bình toàn cục, ...
- 😀 lặp lại nhanh chóng trên một mô hình thực tế, trên TPU
Vui lòng dành chút thời gian để xem qua danh sách kiểm tra này.
10. [THÔNG TIN] Cấu trúc tích chập hiện đại
Tóm lại

Hình minh hoạ: một "mô-đun" tích chập. Đâu là lựa chọn tốt nhất ở thời điểm này? Một lớp gộp tối đa theo sau là một lớp tích chập 1x1 hoặc một tổ hợp lớp khác? Hãy thử tất cả, nối kết quả và để mạng quyết định. Ở bên phải: cấu trúc tích chập " inception" sử dụng các mô-đun như vậy.
Trong Keras, để tạo các mô hình mà luồng dữ liệu có thể phân nhánh vào và ra, bạn phải sử dụng kiểu mô hình "dựa trên hàm". Dưới đây là ví dụ:
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
Các thủ đoạn khác
Bộ lọc 3x3 nhỏ

Trong hình minh hoạ này, bạn sẽ thấy kết quả của 2 bộ lọc 3x3 liên tiếp. Hãy thử truy tìm những điểm dữ liệu đóng góp vào kết quả: hai bộ lọc 3x3 liên tiếp này tính toán một số tổ hợp của vùng 5x5. Đây không phải là tổ hợp giống hệt như tổ hợp mà bộ lọc 5x5 sẽ tính toán, nhưng bạn nên thử vì hai bộ lọc 3x3 liên tiếp sẽ rẻ hơn một bộ lọc 5x5.
1x1 convolutions ?

Về mặt toán học, phép tích chập "1x1" là phép nhân với một hằng số, không phải là một khái niệm hữu ích. Tuy nhiên, trong mạng nơ-ron tích chập, hãy nhớ rằng bộ lọc được áp dụng cho một khối dữ liệu, chứ không chỉ là hình ảnh 2D. Do đó, bộ lọc "1x1" tính toán tổng có trọng số của cột dữ liệu 1x1 (xem hình minh hoạ) và khi trượt bộ lọc này trên dữ liệu, bạn sẽ nhận được một tổ hợp tuyến tính của các kênh đầu vào. Điều này thực sự hữu ích. Nếu bạn coi các kênh là kết quả của các thao tác lọc riêng lẻ, chẳng hạn như một bộ lọc cho "tai nhọn", một bộ lọc khác cho "râu" và bộ lọc thứ ba cho "mắt hẹp", thì lớp tích chập "1x1" sẽ tính toán nhiều tổ hợp tuyến tính có thể có của các đặc điểm này, điều này có thể hữu ích khi tìm kiếm một "con mèo". Ngoài ra, các lớp 1x1 sử dụng ít trọng số hơn.
11. Squeezenet
Một cách đơn giản để kết hợp những ý tưởng này đã được trình bày trong bài viết"Squeezenet". Các tác giả đề xuất một thiết kế mô-đun tích chập rất đơn giản, chỉ sử dụng các lớp tích chập 1x1 và 3x3.
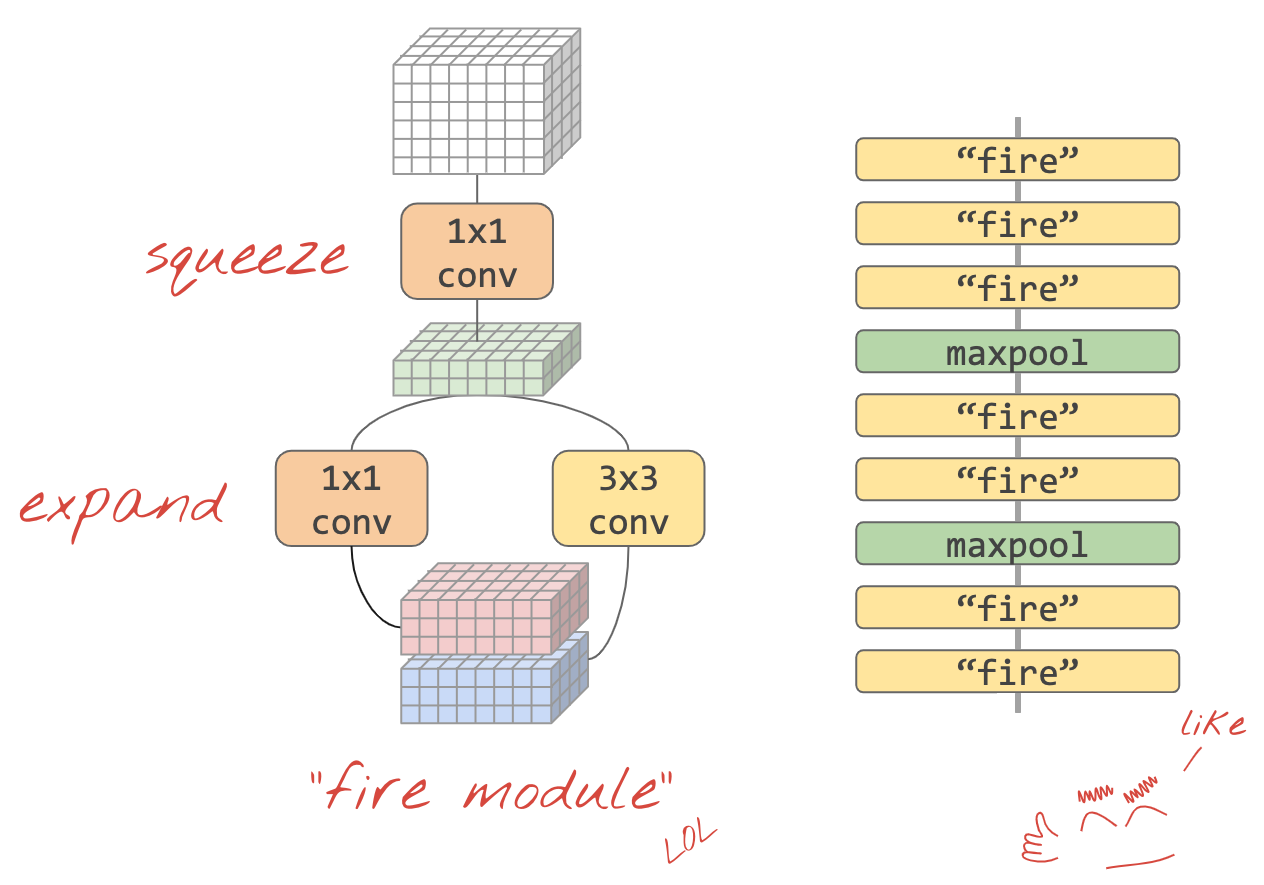
Hình minh hoạ: kiến trúc squeezenet dựa trên "mô-đun lửa". Các lớp này thay thế một lớp 1x1 "nén" dữ liệu đến theo chiều dọc, sau đó là hai lớp tích chập 1x1 và 3x3 song song "mở rộng" độ sâu của dữ liệu một lần nữa.
Thực hành
Tiếp tục trong sổ tay trước đó và xây dựng một mạng nơ-ron tích chập lấy cảm hứng từ SqueezeNet. Bạn sẽ phải thay đổi mã mô hình thành "kiểu chức năng" Keras.
Keras_Flowers_TPU (playground).ipynb
Thông tin bổ sung
Bạn nên xác định một hàm trợ giúp cho mô-đun squeezenet trong bài tập này:
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
Mục tiêu lần này là đạt được độ chính xác 80%.
Những việc nên thử
Bắt đầu bằng một lớp tích chập duy nhất, sau đó theo dõi bằng "fire_modules", xen kẽ với các lớp MaxPooling2D(pool_size=2). Bạn có thể thử nghiệm với 2 đến 4 lớp gộp tối đa trong mạng và cũng có thể thử nghiệm với 1, 2 hoặc 3 mô-đun fire liên tiếp giữa các lớp gộp tối đa.
Trong các mô-đun lửa, thông số "squeeze" (bóp) thường phải nhỏ hơn thông số "expand" (mở rộng). Những tham số này thực ra là số lượng bộ lọc. Thông thường, số lượng này có thể dao động từ 8 đến 196. Bạn có thể thử nghiệm với các cấu trúc mà số lượng bộ lọc tăng dần thông qua mạng hoặc các cấu trúc đơn giản mà tất cả các mô-đun fire đều có cùng số lượng bộ lọc.
Dưới đây là ví dụ:
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
Tại thời điểm này, bạn có thể nhận thấy rằng các thử nghiệm của mình không diễn ra suôn sẻ và mục tiêu đạt độ chính xác 80% có vẻ xa vời. Đã đến lúc xem thêm một vài mẹo hay.
Chuẩn hoá theo lô
Chuẩn hoá theo lô sẽ giúp giải quyết các vấn đề về sự hội tụ mà bạn đang gặp phải. Sẽ có phần giải thích chi tiết về kỹ thuật này trong hội thảo tiếp theo. Hiện tại, vui lòng sử dụng kỹ thuật này như một trợ lý "kỳ diệu" không rõ ràng bằng cách thêm dòng này sau mỗi lớp tích chập trong mạng của bạn, bao gồm cả các lớp bên trong hàm fire_module:
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
Tham số động lượng phải giảm từ giá trị mặc định là 0,99 xuống 0,9 vì tập dữ liệu của chúng ta nhỏ. Hiện tại, bạn không cần quan tâm đến chi tiết này.
Tăng cường dữ liệu
Bạn sẽ nhận được thêm một vài điểm phần trăm bằng cách tăng cường dữ liệu bằng các phép biến đổi đơn giản như lật trái phải của các thay đổi về độ bão hoà:


Bạn có thể dễ dàng thực hiện việc này trong TensorFlow bằng API tf.data.Dataset. Xác định một hàm chuyển đổi mới cho dữ liệu của bạn:
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
Sau đó, hãy sử dụng dữ liệu này trong quá trình biến đổi dữ liệu cuối cùng (ô "training and validation datasets", hàm "get_batched_dataset"):
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
Đừng quên đặt chế độ tăng cường dữ liệu là không bắt buộc và thêm mã cần thiết để đảm bảo chỉ tập dữ liệu huấn luyện được tăng cường. Không có ý nghĩa gì khi tăng cường tập dữ liệu xác thực.
Giờ đây, bạn có thể đạt được độ chính xác 80% trong 35 giai đoạn.
Giải pháp
Sau đây là sổ tay giải pháp. Bạn có thể sử dụng mã này nếu gặp khó khăn.
Keras_Flowers_TPU_squeezenet.ipynb
Nội dung đã đề cập
- 🤔 Mô hình "kiểu chức năng" Keras
- 🤓 Kiến trúc Squeezenet
- 🤓 Tăng cường dữ liệu bằng tf.data.datset
Vui lòng dành chút thời gian để xem qua danh sách kiểm tra này.
12. Xception được tinh chỉnh
Phép tích chập có thể tách rời
Gần đây, một cách triển khai các lớp tích chập khác đã trở nên phổ biến: tích chập có thể tách rời theo chiều sâu. Tôi biết rằng tên này khá dài, nhưng khái niệm này khá đơn giản. Chúng được triển khai trong Tensorflow và Keras dưới dạng tf.keras.layers.SeparableConv2D.
Phép tích chập có thể tách rời cũng chạy một bộ lọc trên hình ảnh nhưng sử dụng một bộ trọng số riêng biệt cho từng kênh của hình ảnh đầu vào. Sau đó là "tích chập 1x1", một chuỗi các tích vô hướng dẫn đến tổng có trọng số của các kênh được lọc. Với trọng số mới mỗi lần, hệ thống sẽ tính toán nhiều tổ hợp có trọng số của các kênh khi cần.

Hình minh hoạ: tích chập có thể tách rời. Giai đoạn 1: tích chập với một bộ lọc riêng cho mỗi kênh. Giai đoạn 2: kết hợp tuyến tính các kênh. Lặp lại với một bộ trọng số mới cho đến khi đạt được số lượng kênh đầu ra mong muốn. Bạn cũng có thể lặp lại giai đoạn 1, mỗi lần với trọng số mới, nhưng trên thực tế thì hiếm khi xảy ra trường hợp này.
Các phép tích chập có thể tách rời được dùng trong hầu hết các cấu trúc mạng tích chập gần đây nhất: MobileNetV2, Xception, EfficientNet. Nhân tiện, MobileNetV2 là mô hình bạn đã dùng để học chuyển giao trước đây.
Chúng rẻ hơn so với các phép tích chập thông thường và đã được chứng minh là có hiệu quả tương đương trong thực tế. Sau đây là số lượng trọng số cho ví dụ minh hoạ ở trên:
Lớp tích chập: 4 x 4 x 3 x 5 = 240
Lớp tích chập có thể tách rời: 4 x 4 x 3 + 3 x 5 = 48 + 15 = 63
Bạn đọc có thể tự tính toán số phép nhân cần thiết để áp dụng từng kiểu tỷ lệ lớp tích chập theo cách tương tự. Các phép tích chập có thể tách rời có kích thước nhỏ hơn và hiệu quả hơn nhiều về mặt tính toán.
Thực hành
Khởi động lại từ sổ tay "học chuyển giao" nhưng lần này hãy chọn Xception làm mô hình được huấn luyện tiền kỳ. Xception chỉ sử dụng các phép tích chập có thể tách rời. Để tất cả các trọng số có thể huấn luyện. Chúng tôi sẽ tinh chỉnh các trọng số được huấn luyện trước trên dữ liệu của mình thay vì sử dụng các lớp được huấn luyện trước như vậy.
Keras Flowers transfer learning (playground).ipynb
Mục tiêu: độ chính xác > 95% (Không, thật sự có thể đạt được!)
Đây là bài tập cuối cùng nên bạn cần thực hiện thêm một số công việc về mã và khoa học dữ liệu.
Thông tin bổ sung về quy trình tinh chỉnh
Xception có trong các mô hình được huấn luyện trước tiêu chuẩn trong tf.keras.application.* Đừng quên để tất cả các trọng số có thể huấn luyện lần này.
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
Để có kết quả tốt khi tinh chỉnh một mô hình, bạn sẽ cần chú ý đến tốc độ học và sử dụng lịch tốc độ học có giai đoạn chạy đà. Chẳng hạn như:

Bắt đầu bằng tốc độ học tập tiêu chuẩn sẽ làm gián đoạn các trọng số được huấn luyện trước của mô hình. Việc bắt đầu một cách từ từ sẽ giúp duy trì các giá trị này cho đến khi mô hình đã được liên kết với dữ liệu của bạn và có thể sửa đổi các giá trị này một cách hợp lý. Sau giai đoạn tăng tốc, bạn có thể tiếp tục với tốc độ học tập không đổi hoặc giảm theo hàm mũ.
Trong Keras, tốc độ học tập được chỉ định thông qua một lệnh gọi lại mà bạn có thể tính toán tốc độ học tập phù hợp cho mỗi giai đoạn. Keras sẽ truyền tốc độ học tập chính xác đến trình tối ưu hoá cho mỗi giai đoạn.
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
Giải pháp
Sau đây là sổ tay giải pháp. Bạn có thể sử dụng mã này nếu gặp khó khăn.
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
Nội dung đã đề cập
- 🤔 Phép tích chập có thể tách theo chiều sâu
- 🤓 Lịch trình tốc độ học
- 😈 Tinh chỉnh một mô hình được huấn luyện tiền kỳ.
Vui lòng dành chút thời gian để xem qua danh sách kiểm tra này.
13. Xin chúc mừng!
Bạn đã xây dựng mạng nơron tích chập hiện đại đầu tiên và huấn luyện mạng này đạt độ chính xác trên 90%, lặp lại các lần huấn luyện liên tiếp chỉ trong vài phút nhờ TPU.
TPU trong thực tế
TPU và GPU có trên Vertex AI của Google Cloud:
- Trên Máy ảo học sâu
- Trong Vertex AI Notebooks
- Trong các tác vụ Vertex AI Training Jobs
Cuối cùng, chúng tôi rất mong nhận được ý kiến phản hồi. Vui lòng cho chúng tôi biết nếu bạn thấy có điều gì sai sót trong phòng thí nghiệm này hoặc nếu bạn nghĩ rằng chúng tôi nên cải thiện. Bạn có thể gửi ý kiến phản hồi thông qua các vấn đề trên GitHub [ đường liên kết phản hồi].

|
|

