
1. Обзор
В этой лабораторной работе вы научитесь создавать классификатор Keras. Вместо того чтобы пытаться подобрать идеальную комбинацию слоев нейронной сети для распознавания цветов, мы сначала воспользуемся методом, называемым трансферным обучением, чтобы адаптировать мощную предварительно обученную модель к нашему набору данных.
Данная лабораторная работа включает необходимые теоретические объяснения нейронных сетей и является хорошей отправной точкой для разработчиков, изучающих глубокое обучение.
Эта лабораторная работа — вторая часть серии "Keras на TPU". Вы можете выполнять их в указанном порядке или по отдельности.
- Конвейеры обработки данных со скоростью TPU: tf.data.Dataset и TFRecords
- [ЭТА ЛАБОРАТОРИЯ] Ваша первая модель Keras с использованием трансферного обучения.
- Сверточные нейронные сети с использованием Keras и TPU.
- Современные сверточные сети, SqueezeNet, Xception, Keras и TPU.

Что вы узнаете
- Чтобы создать собственный классификатор изображений Keras с слоем softmax и функцией потерь кросс-энтропии,
- Чтобы схитрить 😈, можно использовать трансферное обучение вместо создания собственных моделей.
Обратная связь
Если вы заметите какие-либо ошибки в этом примере кода, пожалуйста, сообщите нам. Обратная связь может быть предоставлена через систему отслеживания проблем GitHub [ ссылка для обратной связи ].
2. Быстрый старт в Google Colaboratory
В этой лабораторной работе используется Google Collaboratory, и вам не потребуется ничего настраивать. Collaboratory — это онлайн-платформа для создания блокнотов в образовательных целях. Она предлагает бесплатное обучение работе с процессорами CPU, GPU и TPU.

Вы можете открыть этот пример блокнота и просмотреть несколько ячеек, чтобы ознакомиться с Colaboratory.
Выберите бэкэнд TPU.
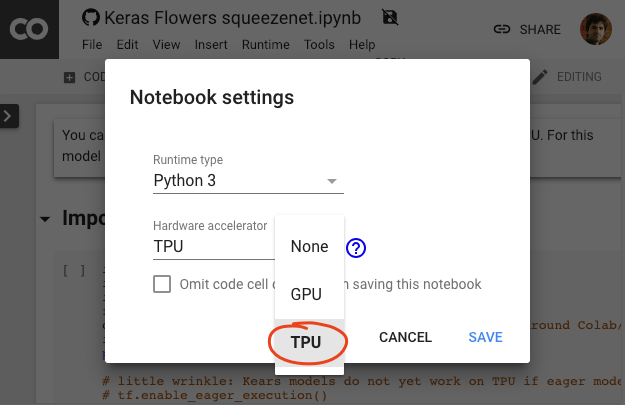
В меню Colab выберите Runtime > Change runtime type , а затем выберите TPU. В этой лабораторной работе вы будете использовать мощный TPU (Tensor Processing Unit), поддерживающий аппаратное ускорение обучения. Подключение к среде выполнения произойдет автоматически при первом запуске, или вы можете использовать кнопку «Подключиться» в правом верхнем углу.
Выполнение блокнота
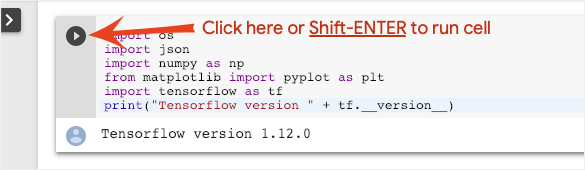
Выполняйте ячейки по одной, щелкая по ячейке и используя сочетание клавиш Shift-ENTER. Вы также можете запустить весь блокнот, выбрав Runtime > Run all.
Оглавление

Во всех блокнотах есть оглавление. Открыть его можно с помощью черной стрелки слева.
Скрытые клетки

В некоторых ячейках отображается только заголовок. Это особенность блокнотов Colab. Вы можете дважды щелкнуть по ним, чтобы увидеть код внутри, но обычно он не очень интересен. Как правило, это вспомогательные или визуализационные функции. Вам все равно нужно запустить эти ячейки, чтобы функции внутри них были определены.
Аутентификация

Colab может получить доступ к вашим частным хранилищам Google Cloud Storage при условии аутентификации с помощью авторизованной учетной записи. Приведенный выше фрагмент кода запустит процесс аутентификации.
3. [ИНФО] Нейронная сеть-классификатор 101
В двух словах
Если все выделенные жирным шрифтом термины в следующем абзаце вам уже знакомы, можете перейти к следующему упражнению. Если вы только начинаете изучать глубокое обучение, добро пожаловать, и, пожалуйста, читайте дальше.
Для моделей, построенных в виде последовательности слоев, Keras предлагает API Sequential. Например, классификатор изображений, использующий три полносвязных слоя, можно записать в Keras следующим образом:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
Плотная нейронная сеть
Это простейшая нейронная сеть для классификации изображений. Она состоит из «нейронов», расположенных слоями. Первый слой обрабатывает входные данные и передает их выходные данные в другие слои. Он называется «плотным», потому что каждый нейрон соединен со всеми нейронами предыдущего слоя.

В такую нейронную сеть можно подать изображение, преобразовав значения RGB всех его пикселей в длинный вектор и используя его в качестве входных данных. Это не самый лучший метод распознавания изображений, но мы усовершенствуем его позже.
Нейроны, активации, RELU
Нейрон вычисляет взвешенную сумму всех своих входных сигналов, добавляет значение, называемое «смещением», и пропускает результат через так называемую «функцию активации». Веса и смещение изначально неизвестны. Они инициализируются случайным образом и «обучаются» путем тренировки нейронной сети на большом количестве известных данных.

Наиболее популярной функцией активации является RELU (Rectified Linear Unit — выпрямленный линейный блок). Это очень простая функция, как видно на графике выше.
Активация Softmax
Представленная выше нейронная сеть заканчивается слоем из 5 нейронов, поскольку мы классифицируем цветы по 5 категориям (роза, тюльпан, одуванчик, маргаритка, подсолнух). Нейроны в промежуточных слоях активируются с помощью классической функции активации RELU. Однако в последнем слое мы хотим вычислить числа от 0 до 1, представляющие вероятность того, что этот цветок является розой, тюльпаном и так далее. Для этого мы будем использовать функцию активации под названием "softmax".
Применение функции softmax к вектору осуществляется путем экспоненциального вычисления каждого элемента и последующей нормализации вектора, обычно с использованием L1-нормы (суммы абсолютных значений), так что сумма значений равна 1 и может быть интерпретирована как вероятность.

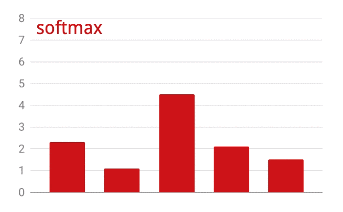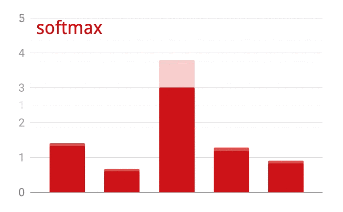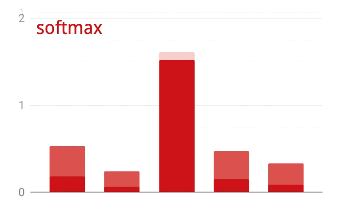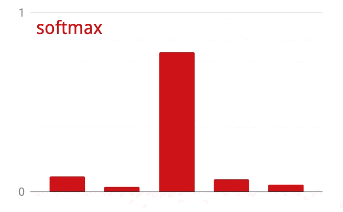
Потери перекрестной энтропии
Теперь, когда наша нейронная сеть выдает предсказания на основе входных изображений, нам нужно измерить, насколько они точны, то есть расстояние между тем, что говорит нам сеть, и правильными ответами, часто называемыми «метками». Помните, что у нас есть правильные метки для всех изображений в наборе данных.
Подойдет любое расстояние, но для задач классификации наиболее эффективным является так называемое «расстояние кросс-энтропии». Мы назовем это нашей функцией ошибки или «функцией потерь»:

Градиентный спуск
«Обучение» нейронной сети на самом деле означает использование обучающих изображений и меток для корректировки весов и смещений с целью минимизации функции потерь кросс-энтропии. Вот как это работает.
Кросс-энтропия — это функция весов, смещений, пикселей обучающего изображения и его известного класса.
Если мы вычислим частные производные кросс-энтропии относительно всех весов и всех смещений, мы получим «градиент», вычисленный для заданного изображения, метки и текущего значения весов и смещений. Следует помнить, что у нас могут быть миллионы весов и смещений, поэтому вычисление градиента кажется очень трудоемким процессом. К счастью, TensorFlow делает это за нас. Математическое свойство градиента заключается в том, что он направлен «вверх». Поскольку мы хотим двигаться туда, где кросс-энтропия низка, мы движемся в противоположном направлении. Мы обновляем веса и смещения на долю градиента. Затем мы повторяем то же самое снова и снова, используя следующие пакеты обучающих изображений и меток, в цикле обучения. Надеемся, что это сойдется к точке, где кросс-энтропия минимальна, хотя ничто не гарантирует, что этот минимум является единственным.

Мини-пакетирование и импульс
Вы можете вычислить градиент на одном примере изображения и немедленно обновить веса и смещения, но если сделать это на пакете, например, из 128 изображений, градиент будет лучше отражать ограничения, накладываемые различными примерами изображений, и, следовательно, с большей вероятностью быстрее сойдется к решению. Размер мини-пакета является регулируемым параметром.
Этот метод, иногда называемый «стохастическим градиентным спуском», имеет еще одно, более прагматичное преимущество: работа с пакетами данных также означает работу с большими матрицами, которые обычно проще оптимизировать на графических и тензорных процессорах.
Однако сходимость может быть несколько хаотичной и даже остановиться, если вектор градиента состоит из одних нулей. Означает ли это, что мы нашли минимум? Не всегда. Компонент градиента может быть равен нулю как в точке минимума, так и в точке максимума. В векторе градиента, содержащем миллионы элементов, если все они равны нулю, вероятность того, что каждый ноль соответствует минимуму, а ни один из них — максимуму, довольно мала. В многомерном пространстве седловые точки встречаются довольно часто, и мы не хотим останавливаться на них.

Иллюстрация: седловая точка. Градиент равен 0, но точка не является минимумом во всех направлениях. (Источник изображения: Wikimedia: Nicoguaro - собственная работа, CC BY 3.0 )
Решение состоит в том, чтобы добавить алгоритму оптимизации некоторый импульс, чтобы он мог проходить седловые точки, не останавливаясь.
Глоссарий
Пакетная обработка или мини-пакетная обработка : обучение всегда выполняется на пакетах обучающих данных и меток. Это помогает алгоритму сойтись. Размерность «пакета» обычно представляет собой первую размерность тензоров данных. Например, тензор формы [100, 192, 192, 3] содержит 100 изображений размером 192x192 пикселя с тремя значениями на пиксель (RGB).
Функция потерь кросс-энтропии : специальная функция потерь, часто используемая в классификаторах.
Плотный слой : слой нейронов, в котором каждый нейрон соединен со всеми нейронами предыдущего слоя.
Признаки : входные данные нейронной сети иногда называют «признаками». Искусство определения того, какие части набора данных (или комбинации частей) следует подавать в нейронную сеть для получения хороших прогнозов, называется «инженерией признаков».
метки : другое название для «классов» или правильных ответов в задаче классификации с учителем.
Скорость обучения : доля градиента, на которую обновляются веса и смещения на каждой итерации цикла обучения.
Логиты : выходные сигналы слоя нейронов до применения функции активации называются «логитами». Термин происходит от «логистической функции», также известной как «сигмоидная функция», которая раньше была наиболее популярной функцией активации. Выражение «выходные сигналы нейронов до применения логистической функции» было сокращено до «логиты».
Функция потерь : функция ошибки, сравнивающая выходные данные нейронной сети с правильными ответами.
Нейрон : вычисляет взвешенную сумму своих входных сигналов, добавляет смещение и пропускает результат через функцию активации.
One-hot кодирование : класс 3 из 5 кодируется как вектор из 5 элементов, все из которых равны нулю, кроме третьего, который равен 1.
relu : выпрямленная линейная единица. Популярная функция активации для нейронов.
сигмоидная функция : еще одна функция активации, которая когда-то была популярна и до сих пор полезна в особых случаях.
softmax : специальная функция активации, которая действует на вектор, увеличивая разницу между наибольшей компонентой и всеми остальными, а также нормализует вектор так, чтобы его сумма равнялась 1, что позволяет интерпретировать его как вектор вероятностей. Используется в качестве последнего шага в классификаторах.
Тензор : «Тензор» — это как матрица, но с произвольным числом измерений. Одномерный тензор — это вектор. Двумерный тензор — это матрица. И, наконец, могут существовать тензоры с 3, 4, 5 или более измерениями.
4. Перенос знаний
Для задачи классификации изображений, вероятно, будет недостаточно полносвязных слоев. Нам необходимо изучить сверточные слои и множество способов их расположения.
Но можно и пойти по короткому пути! В продаже имеются полностью обученные сверточные нейронные сети, которые можно скачать. Можно удалить их последний слой, классификационную часть softmax, и заменить его своим собственным. Все обученные веса и смещения остаются неизменными, переобучается только добавленный слой softmax. Этот метод называется трансферным обучением, и, что удивительно, он работает, если набор данных, на котором предварительно обучена нейронная сеть, достаточно «близок» к вашему.
Практический опыт
Пожалуйста, откройте следующий блокнот, выполните действия в ячейках (Shift-ENTER) и следуйте инструкциям везде, где видите пометку "ТРЕБУЕТСЯ РАБОТА".

Keras Flowers transfer learning (playground).ipynb
Дополнительная информация
При использовании трансферного обучения вы получаете преимущества как от передовых архитектур сверточных нейронных сетей, разработанных ведущими исследователями, так и от предварительного обучения на огромном наборе данных изображений. В нашем случае мы будем использовать трансферное обучение на сети, обученной на ImageNet, базе данных изображений, содержащей множество растений и пейзажей, что достаточно близко к цветам.
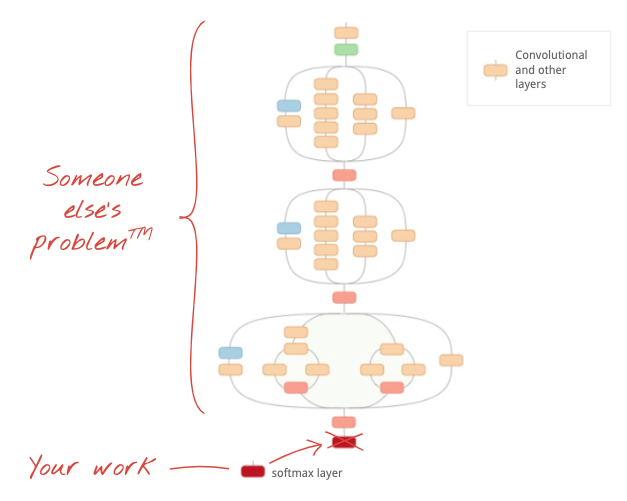
Иллюстрация: использование сложной, уже обученной сверточной нейронной сети в качестве «черного ящика», переобучение только классификационной части. Это трансферное обучение. Мы увидим, как работают такие сложные конфигурации сверточных слоев, позже. А пока это уже задача кого-то другого.
Перенос обучения в Keras
В Keras можно создать экземпляр предварительно обученной модели из коллекции tf.keras.applications.* . Например, MobileNet V2 — это очень хорошая сверточная архитектура, которая остается разумной по размеру. Выбрав include_top=False , вы получите предварительно обученную модель без финального слоя softmax, чтобы добавить свой собственный:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
Обратите внимание также на параметр pretrained_model.trainable = False . Он фиксирует веса и смещения предварительно обученной модели, так что вы обучаете только слой softmax. Обычно это включает относительно небольшое количество весов и может быть выполнено быстро и без необходимости использования очень большого набора данных. Однако, если у вас много данных, трансферное обучение может работать еще лучше с pretrained_model.trainable = True . В этом случае предварительно обученные веса обеспечивают отличные начальные значения и могут быть скорректированы в процессе обучения для лучшего соответствия вашей задаче.
Наконец, обратите внимание на слой Flatten() вставленный перед плотным слоем softmax. Плотные слои работают с плоскими векторами данных, но мы не знаем, возвращает ли их предварительно обученная модель. Вот почему нам нужно использовать Flatten(). В следующей главе, когда мы углубимся в сверточные архитектуры, мы объясним формат данных, возвращаемых сверточными слоями.
При таком подходе вы должны получить точность, близкую к 75%.
Решение
Вот блокнот с решениями. Вы можете использовать его, если у вас возникнут трудности.
Keras Flowers transfer learning (solution).ipynb
Что мы рассмотрели
- 🤔 Как написать классификатор в Keras
- 🤓 сконфигурирован с последним слоем softmax и функцией потерь кросс-энтропии.
- 😈 Перенос знаний
- 🤔 Обучение вашей первой модели
- 🧐 После потери точности во время тренировки
Пожалуйста, уделите немного времени, чтобы мысленно пройтись по этому контрольному списку.
5. Поздравляем!
Теперь вы можете создать модель Keras. Пожалуйста, перейдите к следующей лабораторной работе, чтобы узнать, как собрать сверточные слои.
- Конвейеры обработки данных со скоростью TPU: tf.data.Dataset и TFRecords
- [ЭТА ЛАБОРАТОРИЯ] Ваша первая модель Keras с использованием трансферного обучения.
- Сверточные нейронные сети с использованием Keras и TPU.
- Современные сверточные сети, SqueezeNet, Xception, Keras и TPU.
ТПУ на практике
TPU и GPU доступны на платформе Cloud AI Platform :
- В виртуальных машинах для глубокого обучения
- В блокнотах для платформ искусственного интеллекта
- Вакансии в сфере обучения работе с платформами искусственного интеллекта.
Наконец, мы будем рады вашим отзывам. Пожалуйста, сообщите нам, если вы заметите какие-либо недостатки в этой тестовой версии или если считаете, что её следует улучшить. Отзывы можно оставить через систему отслеживания проблем GitHub [ ссылка для обратной связи ].

|

