
1. 概览
欢迎使用 Google Codelab,了解如何在 Google Cloud Platform 上运行 Lustre 并行文件系统集群!

数据是高性能计算实践的核心,以极高的速度和低延迟访问大量数据一直是运行 HPC 工作负载的关键挑战。这种对高性能存储的要求在云端并没有改变,事实上,快速轻松地利用大量存储的能力变得至关重要。
长期以来,HPC 中心一直在本地使用 Lustre 并行文件系统等技术来满足这一需求。Lustre 是当今最受欢迎的开源高性能存储解决方案之一,自 2005 年 6 月以来,它一直被至少一半的全球十大超级计算机和 100 多台全球最快的超级计算机中的 60 多台使用。Lustre 能够扩容到数百 PB 的容量,并为 HPC 作业提供尽可能高的性能,系统在单个命名空间中提供 TB/s 的吞吐量。
为了满足存储需求,Google Cloud 采取了两种方法。首先,GCP 与 DDN 合作,将其受支持的企业级 DDN EXAScaler Lustre 软件引入 GCP Marketplace。其次,Google Cloud 的工程师开发并开源了一组脚本,以便使用 Google Cloud Deployment Manager 在 Google Compute Engine 上轻松配置和部署 Lustre 存储集群。
Google Cloud Platform 上的 Lustre 同样能够提供其运行的基础架构的最高性能。它在 GCP 上的性能非常出色,以至于在 2019 年与合作伙伴 DDN 一起在 IO-500 存储系统基准测试中排名第 8 位,成为 IO-500 中排名最高的基于云的文件系统。今天,我们将引导您完成 Lustre 的开源 Deployment Manager 脚本的部署。如果您有兴趣获得企业级强化 Lustre 体验,并获得 Lustre 集群的 Lustre 专家支持,以及管理和监控 GUI 或 Lustre 调优等功能,我们建议您了解 DDN EXAScaler Marketplace 产品。
学习内容
- 如何使用 GCP Deployment Manager 服务
- 如何在 GCP 上配置和部署 Lustre 文件系统。
- 如何配置条带化并测试 Lustre 文件系统的简单 I/O。
前提条件
- Google Cloud Platform 账号和已启用结算的项目
- 具备基本的 Linux 经验
2. 设置
自定进度的环境设置
创建项目
如果您还没有 Google 账号(Gmail 或 G Suite),则必须 创建一个。登录 Google Cloud Platform 控制台 ( console.cloud.google.com),然后打开 管理资源页面:

点击 Create project 。

输入 项目名称。记住 项目 ID(在上方的屏幕截图中以红色突出显示)。项目 ID 必须是所有 Google Cloud 项目中的唯一名称。如果您的项目名称不是唯一的,Google Cloud 将根据项目名称生成随机项目 ID。
接下来,您需要在开发者控制台中 启用结算功能 ,才能使用 Google Cloud 资源。
在此 Codelab 中运行仅花费几美元,但是如果您决定使用更多资源或继续让它们运行,费用可能更高(请参阅本文档末尾的“总结”部分)。您可以在 此处 找到 Google Cloud Platform 价格计算器。
Google Cloud Platform 的新用户有资格获享 $300 免费试用。
Google Cloud Shell
虽然 Google Cloud 可以从笔记本电脑远程操作,但在此 Codelab 中,我们将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
启动 Google Cloud Shell
在 GCP 控制台中,点击右上角工具栏上的 Cloud Shell 图标:

然后点击 Start Cloud Shell:

配置和连接到环境应该只需要片刻时间:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能并简化了身份验证。只需使用一个网络浏览器或 Google Chromebook 即可完成本实验中的大部分(甚至全部)工作。
在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的 PROJECT_ID:
$ gcloud auth list
命令输出:
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
$ gcloud config list project
命令输出:
[core]
project = <PROJECT_ID>
如果项目 ID 未正确设置,您可以使用以下命令进行设置:
$ gcloud config set project <PROJECT_ID>
命令输出:
Updated property [core/project].
3. 准备和查看 Lustre 部署配置
下载 Lustre Deployment Manager 脚本
在 Cloud Shell 会话中,执行以下命令以克隆(下载)包含 Lustre for Google Cloud Platform deployment-manager 文件的 Git 代码库:
git clone https://github.com/GoogleCloudPlatform/deploymentmanager-samples.git
执行以下命令,切换到 Lustre 部署配置目录:
cd deploymentmanager-samples/community/lustre/
配置 Lustre 部署 YAML
Deployment Manager 使用 YAML 文件来提供部署配置。此 YAML 文件详细介绍了部署的配置,例如要部署的 Lustre 版本以及要部署的机器实例类型。默认情况下,该文件配置为在新项目中部署,而无需增加配额,但您可以根据此 Codelab 的需要更改机器类型或容量。此 Codelab 编写为使用这些默认值,因此如果您进行任何更改,则必须在此 Codelab 中进行这些更改,以避免错误。在生产环境中,我们建议 MDS 节点至少使用 32 个 vCPU 的实例,OSS 节点至少使用 8 个或 16 个 vCPU 的实例,具体取决于存储容量和类型。
如需在 Cloud Shell 会话中查看或修改 YAML 文件,请打开 部署配置 YAML 文件 Lustre-cluster.yaml 。您可以使用自己喜欢的命令行编辑器(vi、nano、emacs 等),也可以使用 Cloud 控制台代码编辑器来查看文件内容:

文件的内容如下所示:
# [START cluster_yaml]
imports:
- path: lustre.jinja
resources:
- name: lustre
type: lustre.jinja
properties:
## Cluster Configuration
cluster_name : lustre
zone : us-central1-f
cidr : 10.20.0.0/16
external_ips : True
### Use these fields to deploy Lustre in an existing VPC, Subnet, and/or Shared VPC
#vpc_net : < VPC Network Name >
#vpc_subnet : < VPC Subnet Name >
#shared_vpc_host_proj : < Shared VPC Host Project name >
## Filesystem Configuration
fs_name : lustre
### Review https://downloads.whamcloud.com/public/ to determine version naming
lustre_version : latest-release
e2fs_version : latest
## Lustre MDS/MGS Node Configuration
#mds_node_count : 1
mds_ip_address : 10.20.0.2
mds_machine_type : n1-standard-8
### MDS/MGS Boot disk
mds_boot_disk_type : pd-standard
mds_boot_disk_size_gb : 10
### Lustre MetaData Target disk
mdt_disk_type : pd-ssd
mdt_disk_size_gb : 1000
## Lustre OSS Configuration
oss_node_count : 4
oss_ip_range_start : 10.20.0.5
oss_machine_type : n1-standard-4
### OSS Boot disk
oss_boot_disk_type : pd-standard
oss_boot_disk_size_gb : 10
### Lustre Object Storage Target disk
ost_disk_type : pd-standard
ost_disk_size_gb : 5000
# [END cluster_yaml]
此 YAML 文件中有多个字段。带有星号 (*) 的字段是必需的。这些字段包括:
集群配置
- cluster_name* - Lustre 集群的名称,会添加到所有已部署资源的前面
- zone* - 要将集群部署到的可用区
- cidr* - CIDR 格式的 IP 范围
- external_ips* - True/False,Lustre 节点具有外部 IP 地址。如果为 false,则将 Cloud NAT 设置为 NAT 网关
- vpc_net - 定义此字段和 vpc_subnet 字段,以将 Lustre 集群部署到现有 VPC
- vpc_subnet - 要将 Lustre 集群部署到的现有 VPC 子网
- shared_vpc_host_proj - 定义此字段以及 vpc_net 和 vpc_subnet 字段,以将集群部署到共享 VPC
文件系统配置
- fs_name - Lustre 文件系统名称
- lustre_version - 要部署的 Lustre 版本,使用“latest-release”部署 https://downloads.whamcloud.com/public/lustre/ 中的最新分支,或使用 lustre-X.X.X 部署任何其他版本
- e2fs_version - 要部署的 E2fsprogs 版本,使用“latest”部署 https://downloads.whamcloud.com/public/e2fsprogs/ 中的最新分支,或使用 X.XX.X.wcX 部署任何其他版本
MDS/MGS 配置
- mds_ip_address - 为 MDS/MGS 节点指定的内部 IP 地址
- mds_machine_type - 用于 MDS/MGS 节点的机器类型(请参阅 https://cloud.google.com/compute/docs/machine-types)
- mds_boot_disk_type - 用于 MDS/MGS 启动磁盘的磁盘类型 (pd-standard, pd-ssd)
- mds_boot_disk_size_gb - MDS 启动磁盘的大小(以 GB 为单位)
- mdt_disk_type* - 用于元数据目标 (MDT) 磁盘的磁盘类型 (pd-standard, pd-ssd, local-ssd)
- mdt_disk_size_gb* - MDT 磁盘的大小(以 GB 为单位)
OSS 配置
- oss_node_count* - 要创建的对象存储服务器 (OSS) 节点数
- oss_ip_range_start - OSS 节点的 IP 范围的开头。如果未指定,请使用自动 IP 分配
- oss_machine_type - 用于 OSS 节点的机器类型
- oss_boot_disk_type - 用于 OSS 启动磁盘的磁盘类型 (pd-standard, pd-ssd)
- oss_boot_disk_size_gb - MDS 启动磁盘的大小(以 GB 为单位)
- ost_disk_type* - 用于对象存储目标 (OST) 磁盘的磁盘类型 (pd-standard, pd-ssd, local-ssd)
- ost_disk_size_gb* - OST 磁盘的大小(以 GB 为单位)
4. 部署和验证配置
部署配置
在 Cloud Shell 会话中,从 Lustre-gcp 文件夹执行 以下命令:
gcloud deployment-manager deployments create lustre --config lustre.yaml
此命令会创建一个名为 Lustre 的部署。此操作可能需要 10-20 分钟才能完成,因此请耐心等待 。
部署完成后,您将看到类似于以下内容的输出:
Create operation operation-1572410719018-5961966591cad-e25384f6-d4c905f8 completed successfully.
NAME TYPE STATE ERRORS INTENT
lustre-all-internal-firewall-rule compute.v1.firewall COMPLETED []
lustre-lustre-network compute.v1.network COMPLETED []
lustre-lustre-subnet compute.v1.subnetwork COMPLETED []
lustre-mds1 compute.v1.instance COMPLETED []
lustre-oss1 compute.v1.instance COMPLETED []
lustre-oss2 compute.v1.instance COMPLETED []
lustre-oss3 compute.v1.instance COMPLETED []
lustre-oss4 compute.v1.instance COMPLETED []
lustre-ssh-firewall-rule compute.v1.firewall COMPLETED []
验证 Deployment

请按照以下步骤在 Google Cloud Platform 控制台中查看部署:
- 在 Cloud Platform 控制台中,打开控制台左上角的产品和服务 菜单(三条横线)。
- 点击 Deployment Manager 。
- 点击 Lustre 以查看部署的详细信息。
- 点击 Overview - Lustre 。Deployment properties 窗格会显示整体部署配置。
- 点击 Config 属性中的“View”。Config 窗格会显示之前修改的部署配置 YAML 文件的内容。请先验证内容是否正确,然后再继续。如果您需要更改部署配置,只需按照“清理部署”中的步骤删除部署,然后按照“配置 Lustre 部署 YAML”中的步骤重新启动部署即可。
- (可选)在 Lustre-cluster 部分下,点击 Lustre.jinja 模板创建的每个资源,然后查看详细信息。
验证部署的配置后,我们来确认集群的实例已启动。在 Cloud Platform 控制台的产品和服务 菜单中,点击 Compute Engine > 虚拟机实例 。
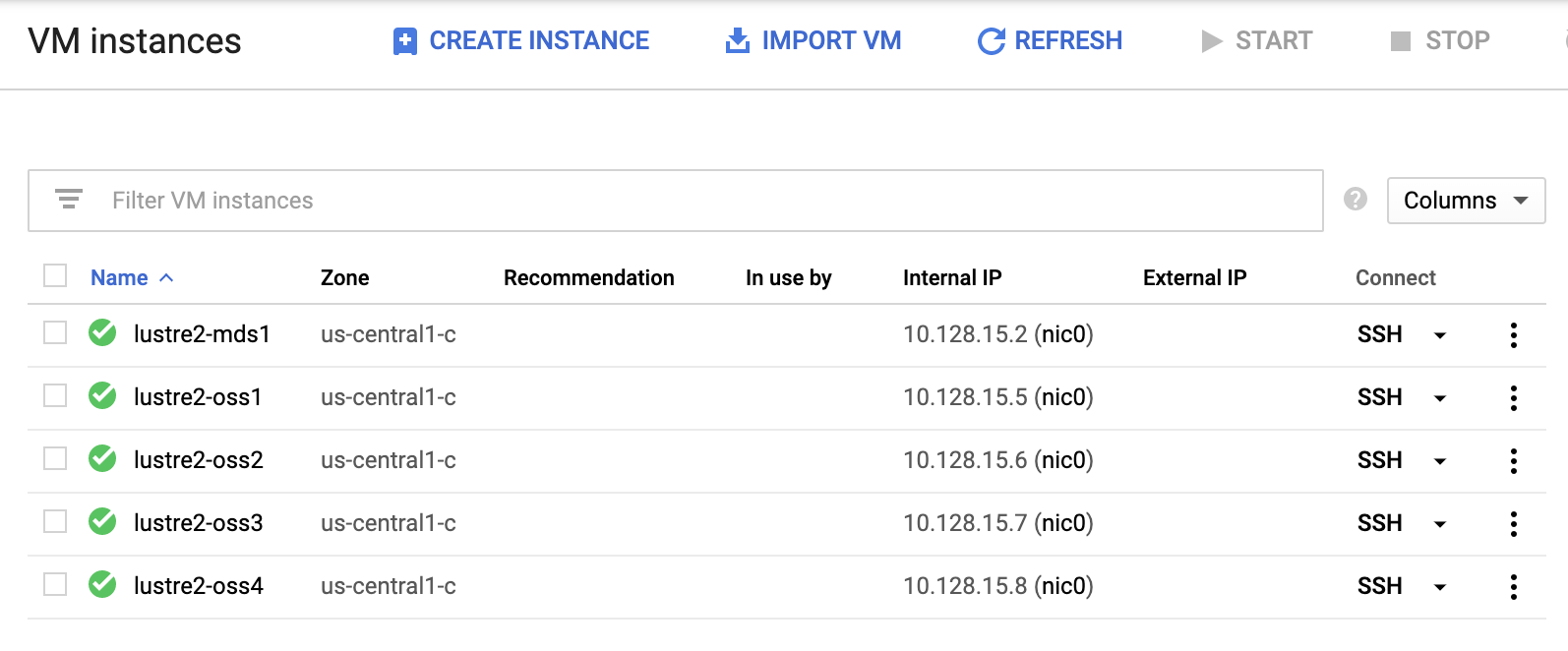
在虚拟机实例 页面上,查看部署管理器创建的五个虚拟机实例。其中包括 lustre-mds1 、lustre-oss1 、lustre-oss2、lustre-oss3 和 lustre-oss4 。
5. 访问 Lustre 集群
监控安装过程
在“虚拟机实例”页面上,点击 lustre-mds1 以打开“实例详情”页面。

点击 Serial port 1 (console) 以打开串行控制台输出页面。我们将使用此串行输出监控 MDS 实例的安装过程,并等待 startup-script 完成。点击页面顶部的“刷新”按钮以更新串行输出。节点将重启一次以启动到 Lustre 内核,并显示类似于以下内容的消息:
Startup finished in 838ms (kernel) + 6.964s (initrd) + 49.302s (userspace) = 57.105s.
Lustre: lustre-MDT0000: Connection restored to 374e2d80-0b31-0cd7-b2bf-de35b8119534 (at 0@lo)
这意味着 Lustre 已安装在 Lustre 集群上,并且文件系统已准备好使用!
访问 Lustre 集群
在 Cloud Shell 会话中,点击 Google Cloud 控制台中 lustre-mds1 实例旁边的 SSH 按钮。或者,在 Cloud Shell 中执行 以下命令,将 <ZONE> 替换为 lustre-mds1 节点的可用区:
gcloud compute ssh lustre-mds1 --zone=<ZONE>
此命令会登录 lustre-mds1 虚拟机。这是 Lustre 元数据服务器 (MDS) 实例,它也充当 Lustre 管理服务器 (MGS) 实例。此实例处理文件系统的所有身份验证和元数据请求。
让我们在 lustre-mds1 实例上装载文件系统,以便稍后对其进行测试。执行 以下命令:
sudo mkdir /mnt/lustre sudo mount -t lustre lustre-mds1:/lustre /mnt/lustre cd /mnt/lustre
这三个命令会执行三项操作。第一个命令会创建一个本地目录,我们将该目录用作装载点,位于“/mnt/lustre”。第二个命令会运行“mount”命令来装载“lustre”类型的文件系统,该文件系统位于 lustre-mds1 服务器上,文件系统名称为“lustre”,显示为“/lustre”。mount 命令会将 Lustre 文件系统装载到本地“/mnt/lustre”目录。最后,第三个命令会将目录更改为 /mnt/lustre 目录,Lustre 装载在该目录中。
您现在已将 Lustre 文件系统装载到 /mnt/lustre。我们来看看如何使用此文件系统。
6. Lustre CLI 工具简介
如果您不熟悉 Lustre 及其工具,我们将在此处介绍几个重要命令。
Lustre 的低级别集群管理工具是“lctl”。我们可以使用 lctl 配置和管理 Lustre 集群,并查看 Lustre 集群的服务。如需查看新 Lustre 集群中的服务和实例,请执行 :
sudo lctl dl
您将看到类似于以下内容的输出,具体取决于您对 Lustre YAML 配置文件所做的更改:
0 UP osd-ldiskfs lustre-MDT0000-osd lustre-MDT0000-osd_UUID 11
1 UP mgs MGS MGS 12
2 UP mgc MGC10.128.15.2@tcp 374e2d80-0b31-0cd7-b2bf-de35b8119534 4
3 UP mds MDS MDS_uuid 2
4 UP lod lustre-MDT0000-mdtlov lustre-MDT0000-mdtlov_UUID 3
5 UP mdt lustre-MDT0000 lustre-MDT0000_UUID 12
6 UP mdd lustre-MDD0000 lustre-MDD0000_UUID 3
7 UP qmt lustre-QMT0000 lustre-QMT0000_UUID 3
8 UP lwp lustre-MDT0000-lwp-MDT0000 lustre-MDT0000-lwp-MDT0000_UUID 4
9 UP osp lustre-OST0000-osc-MDT0000 lustre-MDT0000-mdtlov_UUID 4
10 UP osp lustre-OST0002-osc-MDT0000 lustre-MDT0000-mdtlov_UUID 4
11 UP osp lustre-OST0001-osc-MDT0000 lustre-MDT0000-mdtlov_UUID 4
12 UP osp lustre-OST0003-osc-MDT0000 lustre-MDT0000-mdtlov_UUID 4
我们可以看到 Lustre 管理服务器 (MGS) 为第 1 项,Lustre 元数据服务器 (MDS) 为第 3 项,Lustre 元数据目标 (MDT) 为第 5 项,以及四个 Lustre 对象存储服务器 (OSS) 为第 8 到 12 项。如需了解其他服务,请查看 Lustre 手册。
Lustre 的文件系统配置工具是“lfs”。我们可以使用 lfs 来管理文件在 Lustre 对象存储服务器 (OSS) 及其各自的对象存储目标 (OST) 之间的条带化,以及运行常见的文件系统操作,例如 find、df 和配额管理。
借助条带化,我们可以配置文件在 Lustre 集群中的分布方式,以提供尽可能高的性能。虽然在尽可能多的 OSS 中对大型文件进行条带化通常可以通过并行化 IO 来提供最佳性能,但对小型文件进行条带化可能会导致性能比仅将该文件写入单个实例时更差。
为了对此进行测试,我们来设置两个目录,一个条带计数为 1 个 OSS,另一个条带计数为“-1”,表示在该目录中写入的文件应在尽可能多的 OSS 中进行条带化。目录可以保存由其中创建的文件继承的条带化配置,但该目录中的子目录和单个文件随后可以配置为以不同的方式进行条带化(如果需要)。如需创建这两个目录,请在“/mnt/lustre”目录中执行 以下命令:
sudo mkdir stripe_one sudo mkdir stripe_all sudo lfs setstripe -c 1 stripe_one/ sudo lfs setstripe -c -1 stripe_all/
您可以使用 lfs getstripe 查看文件或目录的条带设置:
sudo lfs getstripe stripe_all/
您将看到输出,其中显示条带计数设置为 -1:
stripe_all/
stripe_count: -1 stripe_size: 1048576 pattern: raid0 stripe_offset: -1
现在,我们已准备好测试通过在多个 OSS 中写入大型文件来实现的性能改进。
7. 测试 Lustre I/O
我们将运行两个简单的 Lustre IO 测试,以展示 Lustre 文件系统可能具有的性能优势和扩缩能力。首先,我们将使用“dd”实用程序运行一个简单的测试,将 5GB 文件写入“stripe_one”目录。执行 以下命令:
sudo dd if=/dev/zero of=stripe_one/test bs=1M count=5000
将 5GB 数据写入文件系统的过程平均需要大约 27 秒,写入单个对象存储服务器 (OSS) 上的单个永久性磁盘 (PD)。
如需测试在多个 OSS(因此也是多个 PD)之间的条带化,我们只需更改写入的输出目录即可。执行 以下命令:
sudo dd if=/dev/zero of=stripe_all/test bs=1M count=5000
请注意,我们将“of=stripe_one/test”更改为“of=stripe_all/test”。这样,我们的单流写入就可以将其写入分布到所有对象存储服务器,并在平均 5.5 秒内完成写入,使用四个 OSS 时速度大约快 4 倍。
随着您添加对象存储服务器,此性能会继续提高,并且您可以在文件系统在线时添加 OSS,并开始将数据条带化到这些 OSS,以在线提高容量和性能。在 Google Cloud Platform 上使用 Lustre 的可能性是无限的,我们很高兴看到您能构建什么,以及您能解决什么问题。
8. 总结
恭喜,您已在 Google Cloud Platform 上创建了 Lustre 集群!您可以将这些脚本作为构建自己的 Lustre 集群的起点,并将其与基于云的计算集集群成。
清理部署
退出 Lustre 节点:
exit
退出 Lustre 集群后,您可以从 Google Cloud Shell 执行以下命令,轻松清理部署:
gcloud deployment-manager deployments delete lustre
系统提示时,输入 Y 以继续。此操作可能需要一些时间,请耐心等待。
删除项目
如需清理,我们只需删除项目即可。
- 在导航菜单中,选择“IAM 和管理”
- 然后,点击子菜单中的“设置”
- 点击带有“删除项目”文本的垃圾桶图标
- 按照提示说明操作
所学内容
- 如何使用 GCP Deployment Manager 服务。
- 如何在 GCP 上配置和部署 Lustre 文件系统。
- 如何配置条带化并测试 Lustre 文件系统的简单 I/O。
寻求支持
您是否正在使用 Lustre Deployment Manager 脚本构建一些很酷的东西?有疑问?在 Google Cloud Lustre 讨论组 中与我们聊天。如需请求功能、提供反馈或报告错误,请使用 此表单,或者随意修改代码并提交拉取请求!想与 Google Cloud 专家交流?立即通过 Google Cloud 的高性能计算网站 与 Google Cloud 团队联系。
了解详情
反馈
请使用此链接提交有关此 Codelab 的反馈。填写反馈所需的时间不到 5 分钟。谢谢!