
1. Introduction
Présentation
Dans cet atelier, vous allez aller au-delà des chatbots simples et créer un système multi-agents distribué.
Bien qu'un seul LLM puisse répondre à des questions, la complexité du monde réel nécessite souvent des rôles spécialisés. Vous ne demandez pas à votre ingénieur backend de concevoir l'UI, ni à votre concepteur d'optimiser les requêtes de base de données. De même, nous pouvons créer des agents IA spécialisés qui se concentrent sur une tâche et se coordonnent entre eux pour résoudre des problèmes complexes.
Vous allez créer un système de création de cours composé des éléments suivants :
- Agent de recherche : utilise
google_searchpour trouver des informations à jour. - Agent évaluateur : évalue la qualité et l'exhaustivité de la recherche.
- Agent Content Builder : transformer les recherches en cours structuré.
- Agent d'orchestration : il gère le workflow et la communication entre ces spécialistes.
Prérequis
- Connaissances de base en Python
- Connaissances de base de la console Google Cloud.
Objectifs de l'atelier
- Définissez un agent utilisant des outils (
researcher) capable d'effectuer des recherches sur le Web. - Implémentez une sortie structurée avec Pydantic pour
judge. - Connectez-vous à des agents distants à l'aide du protocole Agent-to-Agent (A2A).
- Construisez un
LoopAgentpour créer une boucle de rétroaction entre le chercheur et le juge. - Exécutez le système distribué en local à l'aide de l'ADK.
- Déployez le système multi-agent sur Google Cloud Run.
Principes d'architecture et d'orchestration
Avant d'écrire du code, comprenons comment ces agents fonctionnent ensemble. Nous allons créer un pipeline de création de cours.
Conception du système
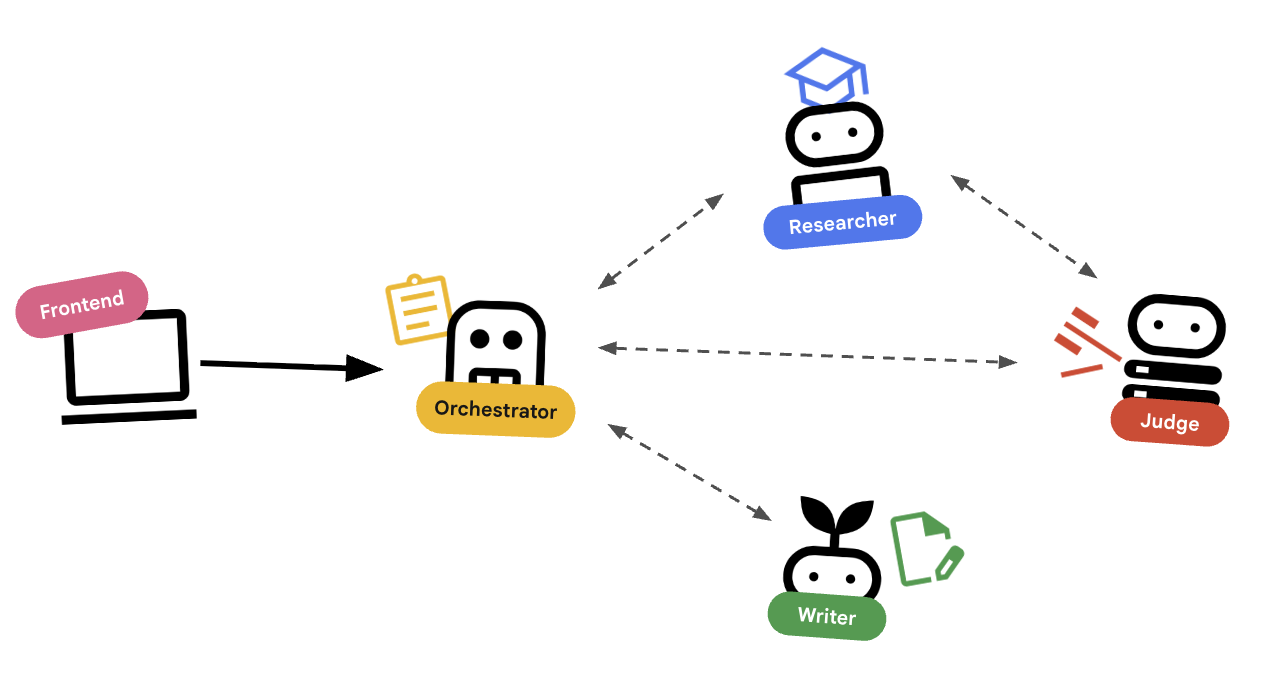
Orchestration avec des agents
Les agents standards (comme le chercheur) fonctionnent. Les agents d'orchestration (comme LoopAgent ou SequentialAgent) gèrent d'autres agents. Elles ne disposent pas de leurs propres outils. Leur "outil" est la délégation.
LoopAgent: se comporte comme une bouclewhiledans le code. Il exécute une séquence d'agents de manière répétée jusqu'à ce qu'une condition soit remplie (ou que le nombre maximal d'itérations soit atteint). Nous l'utilisons pour la boucle de recherche :- Un chercheur trouve des informations.
- Un juge le critique.
- Si Judge indique "Échec", EscalationChecker permet à la boucle de se poursuivre.
- Si Judge indique "Pass", EscalationChecker interrompt la boucle.
SequentialAgent: se comporte comme une exécution de script standard. Il exécute les agents les uns après les autres. Nous l'utilisons pour le pipeline de haut niveau :- Tout d'abord, exécutez la boucle de recherche (jusqu'à ce qu'elle se termine avec des données de qualité).
- Exécutez ensuite Content Builder (pour rédiger le cours).
En combinant ces éléments, nous créons un système robuste capable de s'autocorriger avant de générer le résultat final.
2. Configuration
Configuration de l'environnement
- Ouvrez Cloud Shell : cliquez sur l'icône Activer Cloud Shell en haut à droite de la console Google Cloud.
Obtenir le code de démarrage
- Clonez le dépôt de démarrage dans votre répertoire d'accueil :
cd ~ git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter && cd .. && mv temp-repo/agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter . && rm -rf temp-repo cd prai-roadshow-lab-1-starter - Activez les API : exécutez la commande suivante pour activer les services Google Cloud nécessaires :
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - Ouvrez ce dossier dans votre éditeur.
Installer des dépendances
Nous utilisons uv pour une gestion rapide des dépendances.
- Installez les dépendances du projet :
# Ensure you have uv installed: pip install uv uv sync - Configurez des variables d'environnement.
- Conseil : Vous trouverez l'ID de votre projet dans le tableau de bord Cloud Console ou en exécutant
gcloud config get-value project.
.envpour stocker ces variables. Vous pourrez ainsi les recharger facilement si votre session est déconnectée.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true EOF - Conseil : Vous trouverez l'ID de votre projet dans le tableau de bord Cloud Console ou en exécutant
- Définissez les variables d'environnement :
source .envsource .envpour les restaurer.
3. 🕵️ L'agent Researcher
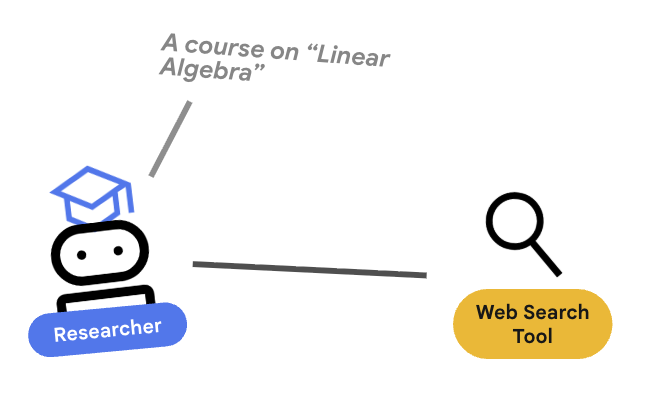
L'assistant de recherche est un spécialiste. Son seul rôle est de trouver des informations. Pour ce faire, elle a besoin d'accéder à un outil : la recherche Google.
Pourquoi séparer le rôle de chercheur ?
En savoir plus : pourquoi ne pas avoir un seul agent pour tout faire ?
Les petits agents ciblés sont plus faciles à évaluer et à déboguer. Si la recherche est mauvaise, itérez sur la requête du chercheur. Si la mise en forme du cours est incorrecte, vous devez itérer sur le générateur de contenu. Dans une requête monolithique "tout-en-un", corriger un élément en casse souvent un autre.
- Si vous travaillez dans Cloud Shell, exécutez la commande suivante pour ouvrir l'éditeur Cloud Shell :
cloudshell workspace . - Ouvrez
agents/researcher/agent.py. - Vous verrez un squelette avec un TODO.
- Ajoutez le code suivant pour définir l'agent
researcher:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. DO NOT output any function calls. Provide your research directly as text. """, ) root_agent = researcher
Concept clé : Utilisation des outils
Lorsque vous utilisez Gemini 3, l'outil Recherche Google est automatiquement disponible. Si vous utilisiez un autre modèle, par exemple Gemini 2.5, vous devriez transmettre tools=[google_search] en tant que paramètre supplémentaire au constructeur Agent(). L'ADK gère la complexité de la description de cet outil au LLM. Lorsque le modèle décide qu'il a besoin d'informations, il génère un appel d'outil structuré. L'ADK exécute la fonction Python google_search et renvoie le résultat au modèle.
4. ⚖️ L'agent Judge
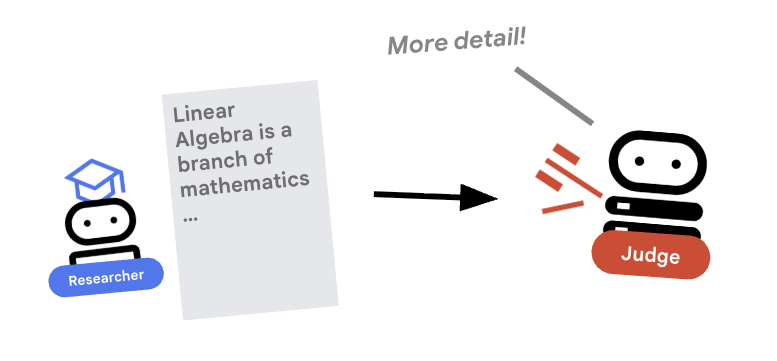
Le chercheur travaille dur, mais les LLM peuvent être paresseux. Nous avons besoin d'un juge pour examiner le travail. Le juge accepte la recherche et renvoie une évaluation structurée (réussite/échec).
Sortie structurée
En savoir plus : Pour automatiser les workflows, nous avons besoin de résultats prévisibles. Il est difficile d'analyser un avis textuel décousu de manière programmatique. En appliquant un schéma JSON (à l'aide de Pydantic), nous nous assurons que le Judge renvoie une valeur booléenne pass ou fail sur laquelle notre code peut s'appuyer de manière fiable.
- Ouvrez
agents/judge/agent.py. - Définissez le schéma
JudgeFeedbacket l'agentjudge.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
Concept clé : restreindre le comportement de l'agent
Nous avons défini disallow_transfer_to_parent=True et disallow_transfer_to_peers=True. Cela oblige le Juge à renvoyer uniquement le JudgeFeedback structuré. Il ne peut pas décider de "discuter" avec l'utilisateur ni déléguer à un autre agent. Il s'agit donc d'un composant déterministe dans notre flux logique.
5. 🧪 Effectuer des tests isolés
Avant de les connecter, nous pouvons vérifier que chaque agent fonctionne. L'ADK vous permet d'exécuter des agents individuellement.
Concept clé : l'environnement d'exécution interactif
adk run crée un environnement léger dans lequel vous êtes l'"utilisateur". Cela vous permet de tester les instructions de l'agent et l'utilisation des outils de manière isolée. Si l'agent échoue ici (par exemple, s'il ne peut pas utiliser la recherche Google), il échouera certainement dans l'orchestration.
- Exécutez le chercheur de manière interactive. Notez que nous pointons vers le répertoire d'agent spécifique :
# This runs the researcher agent in interactive mode uv run adk run agents/researcher - Dans le prompt de chat, saisissez :
Find the population of Tokyo in 2020export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true - Quittez le chat (Ctrl+C).
- Exécutez Judge de manière interactive :
uv run adk run agents/judge - Dans le prompt de chat, simulez l'entrée :
Topic: Tokyo. Findings: Tokyo is a city.status='fail', car les résultats sont trop brefs.
6. ✍️ L'agent Content Builder
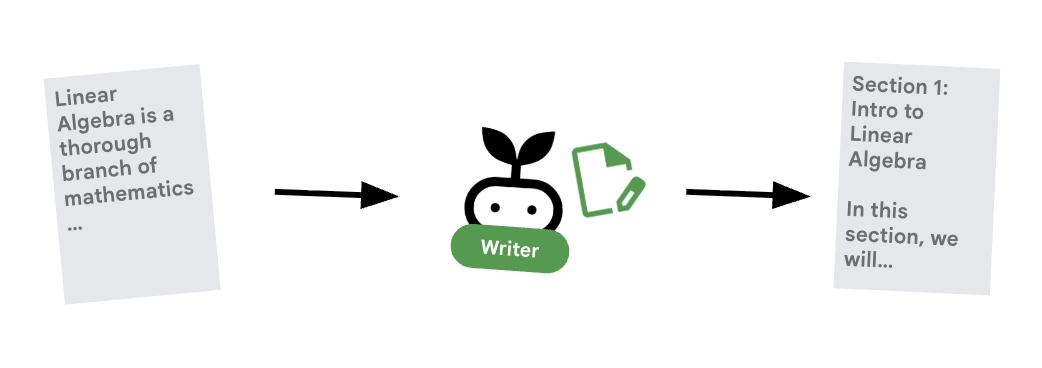
Le Générateur de contenu est le rédacteur créatif. Il transforme les recherches approuvées en cours.
- Ouvrez
agents/content_builder/agent.py. - Définissez l'agent
content_builder.content_builder = Agent( name="content_builder", model=MODEL, description="Transforms research findings into a structured course.", instruction=""" You are an expert course creator. Take the approved 'research_findings' and transform them into a well-structured, engaging course module. **Formatting Rules:** 1. Start with a main title using a single `#` (H1). 2. Use `##` (H2) for main section headings. 3. Use bullet points and clear paragraphs. 4. Maintain a professional but engaging tone. Ensure the content directly addresses the user's original request. """, ) root_agent = content_builder
Concept clé : propagation du contexte
Vous vous demandez peut-être : "Comment le générateur de contenu sait-il ce que le chercheur a trouvé ?" Dans l'ADK, les agents d'un pipeline partagent un session.state. Plus tard, dans l'orchestrateur, nous configurerons le chercheur et le juge pour qu'ils enregistrent leurs résultats dans cet état partagé. Le prompt du générateur de contenu a effectivement accès à cet historique.
7. 🎻 L'outil d'orchestration
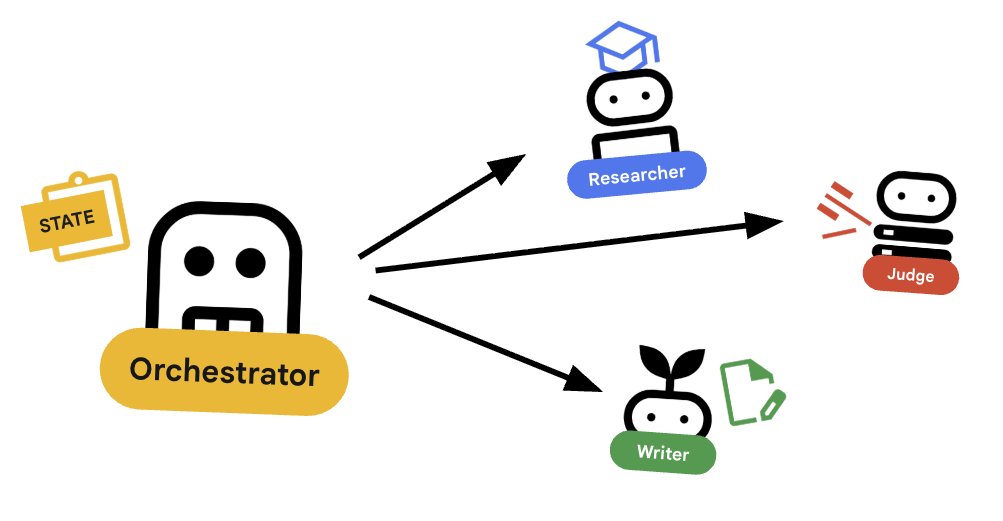
L'orchestrateur est le gestionnaire de notre équipe multi-agents. Contrairement aux agents spécialisés (Chercheur, Juge, Créateur de contenu) qui effectuent des tâches spécifiques, le rôle de l'Orchestrateur est de coordonner le workflow et de s'assurer que les informations circulent correctement entre eux.
🌐 Architecture : Agent-to-Agent (A2A)
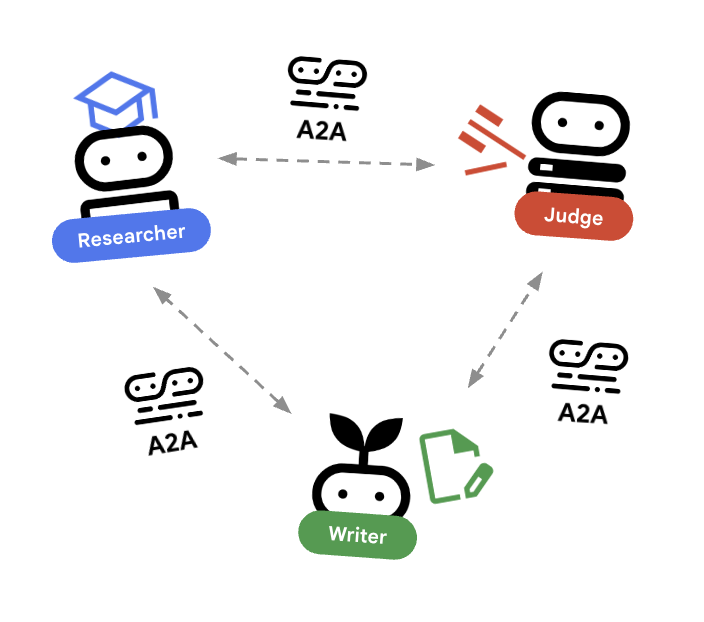
Dans cet atelier, nous allons créer un système distribué. Au lieu d'exécuter tous les agents dans un seul processus Python, nous les déployons en tant que microservices indépendants. Chaque agent peut ainsi évoluer indépendamment et échouer sans faire planter l'ensemble du système.
Pour ce faire, nous utilisons le protocole Agent-to-Agent (A2A).
Protocole A2A
En savoir plus : dans un système de production, les agents s'exécutent sur différents serveurs (voire différents clouds). Le protocole A2A leur permet de se découvrir et de communiquer entre eux via HTTP de manière standardisée. RemoteA2aAgent est le client ADK pour ce protocole.
- Ouvrez
agents/orchestrator/agent.py. - Recherchez le commentaire
# TODO: Define connections to remote agentsou la section des définitions d'agent distant. - Ajoutez le code suivant pour définir les connexions. Veillez à placer cette ligne après les importations et avant toute autre définition d'agent.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 Vérificateur d'escalade
Une boucle doit pouvoir s'arrêter. Si le juge dit "Pass", nous voulons sortir immédiatement de la boucle et passer au Content Builder.
Logique personnalisée avec BaseAgent
En savoir plus : Tous les agents n'utilisent pas de LLM. Parfois, vous avez besoin d'une logique Python simple. BaseAgent vous permet de définir un agent qui exécute uniquement du code. Dans ce cas, nous vérifions l'état de la session et utilisons EventActions(escalate=True) pour signaler l'arrêt de LoopAgent.
- Toujours dans
agents/orchestrator/agent.py. - Recherchez l'espace réservé TODO
- Remplacez-le par l'implémentation suivante :
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
Concept clé : flux de contrôle via les événements
Les agents communiquent non seulement par texte, mais aussi par le biais d'événements. En générant un événement avec escalate=True, cet agent envoie un signal à son parent (le LoopAgent). Le LoopAgent est programmé pour intercepter ce signal et mettre fin à la boucle.
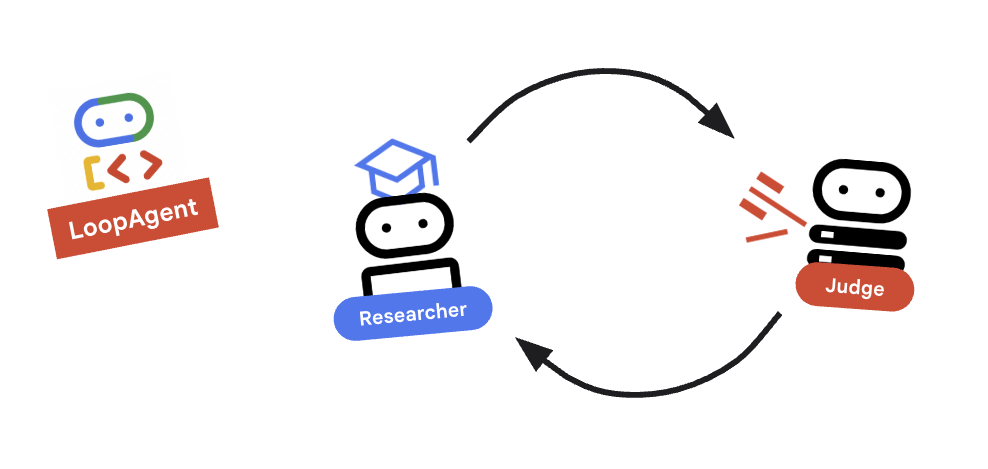
9. 🔁 La boucle de recherche
Nous avons besoin d'une boucle de rétroaction : Recherche -> Évaluation -> (Échec) -> Recherche -> …
- Toujours dans
agents/orchestrator/agent.py. - Ajoutez la définition
research_loop. Placez-le après la classeEscalationCheckeret l'instanceescalation_checker.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
Concept clé : LoopAgent
Le LoopAgent parcourt ses sub_agents dans l'ordre.
researcher: recherche des données.judge: évalue les données.escalation_checker: détermine s'il fautyield Event(escalate=True). Siescalate=Truese produit, la boucle s'arrête prématurément. Sinon, il redémarre au niveau du chercheur (jusqu'àmax_iterations).
10. 🔗 Pipeline final
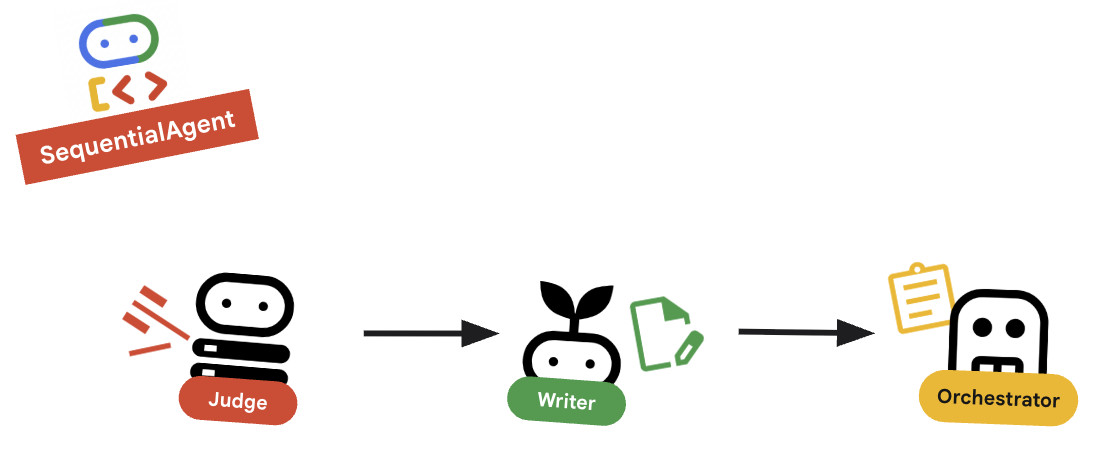
Enfin, assemblez le tout.
- Toujours dans
agents/orchestrator/agent.py. - Définissez le
root_agenten bas du fichier. Assurez-vous que cela remplace tout espace réservéroot_agent = Noneexistant.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
Concept clé : composition hiérarchique
Notez que research_loop est lui-même un agent (un LoopAgent). Nous le traitons comme n'importe quel autre sous-agent dans SequentialAgent. Cette composabilité vous permet de créer une logique complexe en imbriquant des modèles simples (boucles dans des séquences, séquences dans des routeurs, etc.).
11. 💻 Exécuter en local
Avant d'exécuter l'ensemble, examinons comment l'ADK simule l'environnement distribué localement.
Présentation détaillée : fonctionnement du développement local
Dans une architecture de microservices, chaque agent s'exécute en tant que serveur distinct. Lors du déploiement, vous disposerez de quatre services Cloud Run différents. La simulation en local peut être fastidieuse si vous devez ouvrir quatre onglets de terminal et exécuter quatre commandes.
Ce script démarre les processus uvicorn pour le chercheur (port 8001), le juge (8002) et le créateur de contenu (8003). Il définit des variables d'environnement telles que RESEARCHER_AGENT_CARD_URL et les transmet à l'orchestrateur (port 8004). C'est exactement comme ça que nous le configurerons dans le cloud plus tard.
- Exécutez le script d'orchestration :
perl -pi -e 's/us-central1/global/g' run_local.sh ./run_local.sh - Testez-le :
- Si vous utilisez Cloud Shell : cliquez sur le bouton Aperçu sur le Web (en haut à droite du terminal) > Prévisualiser sur le port 8080 > Modifier le port et définissez la valeur sur
8000. - Si vous exécutez le code en local : ouvrez
http://localhost:8000dans votre navigateur. - Requête : "Crée un cours sur l'histoire du café."
- Observation : L'orchestrateur appelle le chercheur. Le résultat est envoyé au Judge. Si le juge échoue, la boucle continue !
- Erreur de serveur interne/Erreurs d'authentification : si des erreurs d'authentification s'affichent (par exemple, liées à
google-auth), assurez-vous d'avoir exécutégcloud auth application-default loginsi vous exécutez l'outil sur une machine locale. Dans Cloud Shell, assurez-vous que votre variable d'environnementGOOGLE_CLOUD_PROJECTest correctement définie. - Erreurs de terminal : si la commande échoue dans une nouvelle fenêtre de terminal, n'oubliez pas de réexporter vos variables d'environnement (
GOOGLE_CLOUD_PROJECT, etc.).
- Si vous utilisez Cloud Shell : cliquez sur le bouton Aperçu sur le Web (en haut à droite du terminal) > Prévisualiser sur le port 8080 > Modifier le port et définissez la valeur sur
- Tester les agents de manière isolée : même lorsque le système complet est en cours d'exécution, vous pouvez tester des agents spécifiques en ciblant directement leurs ports. Cela permet de déboguer un composant spécifique sans déclencher toute la chaîne.Remarque : Il s'agit de points de terminaison d'API, et non de pages Web. Vous ne pouvez pas y accéder via un navigateur. Utilisez plutôt
curlpour vérifier qu'ils sont en cours d'exécution (par exemple, en récupérant leur fiche d'agent).- Chercheur uniquement (port 8001) :
- Vérifiez l'état (et trouvez le point de terminaison
url) :curl http://localhost:8001/a2a/agent/.well-known/agent-card.json - Envoyez une requête (à l'aide du protocole A2A JSON-RPC) :
curl -X POST http://localhost:8001/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-1", "role": "user", "parts": [ { "text": "What is the capital of France?", "kind": "text" } ] } } }'
- Vérifiez l'état (et trouvez le point de terminaison
- Judge Only (port 8002) :
- Vérifiez l'état :
curl http://localhost:8002/a2a/agent/.well-known/agent-card.json - Envoyez une requête :
curl -X POST http://localhost:8002/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-2", "role": "user", "parts": [ { "text": "Topic: Tokyo. Findings: Tokyo is the capital of Japan.", "kind": "text" } ] } } }'
- Vérifiez l'état :
- Content Builder uniquement (port 8003) :
curl http://localhost:8003/a2a/agent/.well-known/agent-card.json - Orchestrator (port 8004) :
curl http://localhost:8004/a2a/agent/.well-known/agent-card.json
- Chercheur uniquement (port 8001) :
12. 🚀 Déployer sur Cloud Run
La validation ultime s'exécute dans le cloud. Nous déploierons chaque agent en tant que service distinct.
Comprendre la configuration du déploiement
Lorsque vous déployez des agents sur Cloud Run, nous transmettons plusieurs variables d'environnement pour configurer leur comportement et leur connectivité :
GOOGLE_CLOUD_PROJECT: garantit que l'agent utilise le bon projet Google Cloud pour la journalisation et les appels Vertex AI.GOOGLE_GENAI_USE_VERTEXAI: indique au framework de l'agent (ADK) d'utiliser Vertex AI pour l'inférence du modèle au lieu d'appeler directement les API Gemini.GOOGLE_CLOUD_LOCATION: indique au framework d'agent (ADK) le point de terminaison à utiliser.[AGENT]_AGENT_CARD_URL: cette valeur est essentielle pour l'orchestrateur. Il indique à l'orchestrateur où trouver les agents distants. En définissant cette valeur sur l'URL Cloud Run déployée (plus précisément le chemin d'accès à la fiche de l'agent), nous permettons à l'orchestrateur de découvrir le chercheur, le juge et le créateur de contenu, et de communiquer avec eux sur Internet.
- Déployez les sous-agents (en parallèle) : pour gagner du temps, nous allons déployer les agents Researcher, Judge et Content Builder simultanément.Ouvrez trois nouveaux onglets de terminal. Dans chaque nouvel onglet, exécutez la commande suivante pour configurer votre environnement :
cd ~/prai-roadshow-lab-1-starter source .envgcloud run deploy researcher \ --source agents/researcher/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy judge \ --source agents/judge/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy content-builder \ --source agents/content_builder/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true" - Capturez les URL : une fois les trois déploiements terminés, revenez à votre terminal d'origine (où vous allez déployer l'orchestrateur). Exécutez les commandes suivantes pour capturer les URL de service :
RESEARCHER_URL=$(gcloud run services describe researcher --region us-west1 --format='value(status.url)') JUDGE_URL=$(gcloud run services describe judge --region us-west1 --format='value(status.url)') CONTENT_BUILDER_URL=$(gcloud run services describe content-builder --region us-west1 --format='value(status.url)') echo "Researcher: $RESEARCHER_URL" echo "Judge: $JUDGE_URL" echo "Content Builder: $CONTENT_BUILDER_URL" - Déployez l'orchestrateur : utilisez les variables d'environnement capturées pour configurer l'orchestrateur.
gcloud run deploy orchestrator \ --source agents/orchestrator/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars RESEARCHER_AGENT_CARD_URL=$RESEARCHER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars JUDGE_AGENT_CARD_URL=$JUDGE_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars CONTENT_BUILDER_AGENT_CARD_URL=$CONTENT_BUILDER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"ORCHESTRATOR_URL=$(gcloud run services describe orchestrator --region us-west1 --format='value(status.url)') echo $ORCHESTRATOR_URL - Déployez l'interface :
gcloud run deploy course-creator \ --source app \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars AGENT_SERVER_URL=$ORCHESTRATOR_URL \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT - Testez le déploiement à distance : ouvrez l'URL de votre Orchestrator déployé. Il s'exécute désormais entièrement dans le cloud, en utilisant l'infrastructure sans serveur de Google pour faire évoluer vos agents. Conseil : Vous trouverez tous les microservices et leurs URL dans l'interface Cloud Run.
13. Résumé
Félicitations ! Vous avez réussi à créer et à déployer un système multi-agents distribué prêt pour la production.
Nos réussites
- Décomposition d'une tâche complexe : au lieu d'un seul prompt géant, nous avons réparti le travail en rôles spécialisés (chercheur, juge, créateur de contenu).
- Contrôle qualité mis en place : nous avons utilisé un
LoopAgentet unJudgestructuré pour nous assurer que seules des informations de haute qualité atteignent l'étape finale. - Conçu pour la production : en utilisant le protocole Agent-to-Agent (A2A) et Cloud Run, nous avons créé un système dans lequel chaque agent est un microservice indépendant et évolutif. Cette approche est beaucoup plus robuste que d'exécuter l'ensemble du processus dans un seul script Python.
- Orchestration : nous avons utilisé
SequentialAgentetLoopAgentpour définir des modèles de flux de contrôle clairs.
Étapes suivantes
Maintenant que vous avez les bases, vous pouvez étendre ce système :
- Ajouter d'autres outils : accordez au chercheur l'accès à des documents internes ou à des API.
- Améliorer le juge : ajoutez des critères plus spécifiques ou même une étape "Human in the Loop".
- Échanger des modèles : essayez d'utiliser différents modèles pour différents agents (par exemple, un modèle plus rapide pour le juge et un modèle plus performant pour le rédacteur de contenu).
Vous êtes maintenant prêt à créer des workflows agentiques complexes et fiables sur Google Cloud.