
1. परिचय
खास जानकारी
इस लैब में, आपको सामान्य चैटबॉट से आगे बढ़कर, डिस्ट्रिब्यूटेड मल्टी-एजेंट सिस्टम बनाना होगा.
एक एलएलएम सवालों के जवाब दे सकता है. हालांकि, असल ज़िंदगी में कई बार खास भूमिकाओं की ज़रूरत होती है. बैकएंड इंजीनियर से यूज़र इंटरफ़ेस (यूआई) डिज़ाइन करने के लिए नहीं कहा जाता. साथ ही, डिज़ाइनर से डेटाबेस क्वेरी को ऑप्टिमाइज़ करने के लिए नहीं कहा जाता. इसी तरह, हम खास एआई एजेंट बना सकते हैं. ये एजेंट, एक काम पर फ़ोकस करते हैं और मुश्किल समस्याओं को हल करने के लिए एक-दूसरे के साथ मिलकर काम करते हैं.
आपको कोर्स बनाने का सिस्टम बनाना होगा. इसमें ये शामिल होंगे:
- रिसर्चर एजेंट: ताज़ा जानकारी ढूंढने के लिए,
google_searchका इस्तेमाल करता है. - जज एजेंट: रिसर्च की क्वालिटी और पूरी जानकारी के लिए उसकी आलोचना करना.
- कॉन्टेंट बिल्डर एजेंट: रिसर्च को व्यवस्थित कोर्स में बदलना.
- ऑर्केस्ट्रेटर एजेंट: यह एजेंट, वर्कफ़्लो और इन विशेषज्ञों के बीच बातचीत को मैनेज करता है.
ज़रूरी शर्तें
- Python की बुनियादी जानकारी.
- Google Cloud Console के बारे में जानकारी होना.
आपको क्या करना होगा
- टूल का इस्तेमाल करने वाले एजेंट (
researcher) को परिभाषित करें, जो वेब पर खोज कर सकता है. judgeके लिए, Pydantic की मदद से स्ट्रक्चर्ड आउटपुट लागू करो.- Agent-to-Agent (A2A) प्रोटोकॉल का इस्तेमाल करके, रिमोट एजेंट से कनेक्ट करें.
- रिसर्चर और जज के बीच फ़ीडबैक लूप बनाने के लिए,
LoopAgentबनाएं. - ADK का इस्तेमाल करके, डिस्ट्रिब्यूट किए गए सिस्टम को स्थानीय तौर पर चलाएं.
- मल्टी-एजेंट सिस्टम को Google Cloud Run पर डिप्लॉय करें.
आर्किटेक्चर और ऑर्केस्ट्रेशन के सिद्धांत
कोड लिखने से पहले, आइए समझते हैं कि ये एजेंट एक साथ कैसे काम करते हैं. हम कोर्स बनाने की पाइपलाइन तैयार कर रहे हैं.
सिस्टम डिज़ाइन
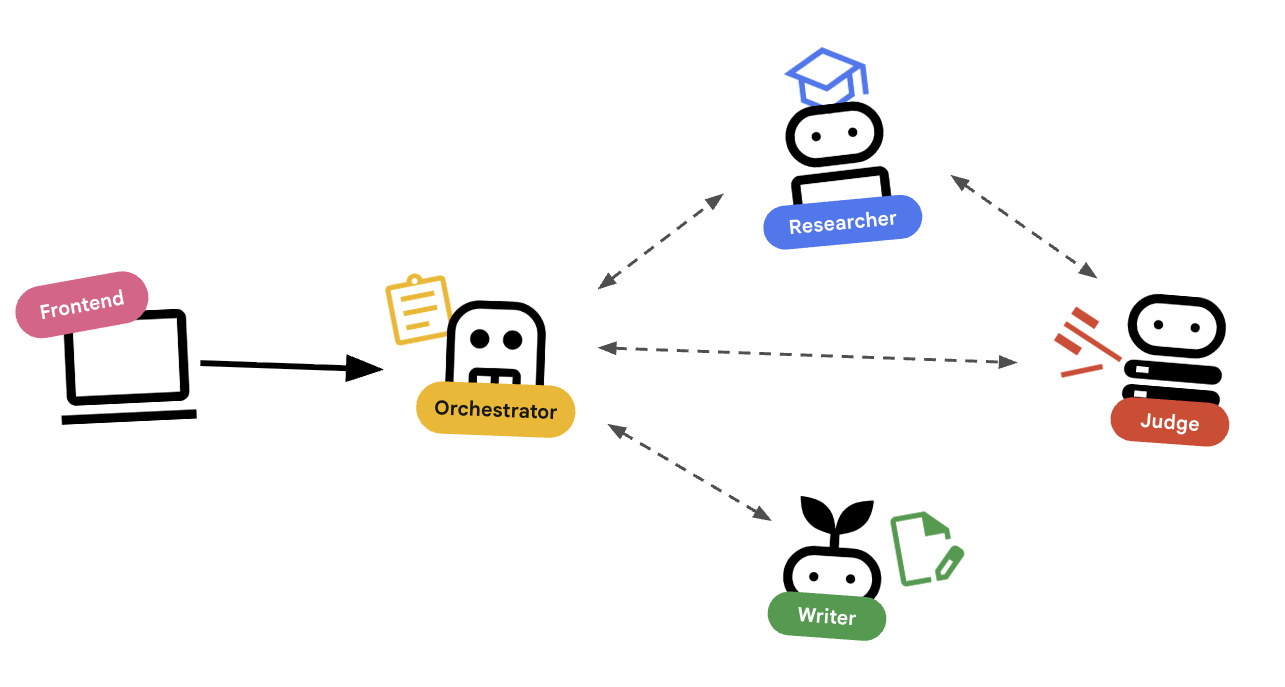
एजेंट की मदद से ऑर्केस्ट्रेशन करना
स्टैंडर्ड एजेंट (जैसे, रिसर्चर) काम करते हैं. ऑर्केस्ट्रेटर एजेंट (जैसे, LoopAgent या SequentialAgent) अन्य एजेंट मैनेज करते हैं. उनके पास अपने टूल नहीं होते; उनका "टूल" काम सौंपना होता है.
LoopAgent: यह कोड मेंwhileलूप की तरह काम करता है. यह किसी शर्त के पूरा होने या ज़्यादा से ज़्यादा इटरेशन तक पहुंचने तक, एजेंट के क्रम को बार-बार चलाता है. हम इसका इस्तेमाल रिसर्च लूप के लिए करते हैं:- रिसर्चर को जानकारी मिलती है.
- जज इसकी समीक्षा करता है.
- अगर Judge "Fail" कहता है, तो EscalationChecker लूप को जारी रखने देता है.
- अगर जज "पास" कहता है, तो EscalationChecker लूप को तोड़ देता है.
SequentialAgent: यह स्टैंडर्ड स्क्रिप्ट के तौर पर काम करता है. यह एक के बाद एक एजेंट चलाता है. हम इसका इस्तेमाल हाई-लेवल पाइपलाइन के लिए करते हैं:- सबसे पहले, रिसर्च लूप को तब तक चलाएं, जब तक कि यह अच्छे डेटा के साथ पूरा न हो जाए.
- इसके बाद, कोर्स लिखने के लिए Content Builder का इस्तेमाल करें.
इन दोनों को मिलाकर, हम एक ऐसा मज़बूत सिस्टम बनाते हैं जो फ़ाइनल आउटपुट जनरेट करने से पहले, खुद ही गड़बड़ियों को ठीक कर सकता है.
2. सेटअप
एनवायरमेंट सेटअप करना
- Cloud Shell खोलें: Google Cloud Console में सबसे ऊपर दाईं ओर मौजूद, Cloud Shell चालू करें आइकॉन पर क्लिक करें.
स्टार्टर कोड पाना
- स्टार्टर रिपॉज़िटरी को अपनी होम डायरेक्ट्री में क्लोन करें:
cd ~ git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter && cd .. && mv temp-repo/agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter . && rm -rf temp-repo cd prai-roadshow-lab-1-starter - एपीआई चालू करें: ज़रूरी Google Cloud सेवाएं चालू करने के लिए, यह कमांड चलाएं:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - इस फ़ोल्डर को अपने एडिटर में खोलें.
डिपेंडेंसी इंस्टॉल करना
हम uv का इस्तेमाल, डिपेंडेंसी को तेज़ी से मैनेज करने के लिए करते हैं.
- प्रोजेक्ट की डिपेंडेंसी इंस्टॉल करें:
# Ensure you have uv installed: pip install uv uv sync - एनवायरमेंट वैरिएबल सेट अप करें.
- अहम जानकारी: Cloud Console के डैशबोर्ड में जाकर या
gcloud config get-value projectचलाकर, अपना प्रोजेक्ट आईडी देखा जा सकता है.
.envफ़ाइल बनाएंगे. इससे सेशन बंद होने पर, इन्हें आसानी से फिर से लोड किया जा सकेगा.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true EOF - अहम जानकारी: Cloud Console के डैशबोर्ड में जाकर या
- एनवायरमेंट वैरिएबल सोर्स करें:
source .envsource .envचलाएं.
3. 🕵️ रिसर्चर एजेंट
रिसर्चर एक विशेषज्ञ होता है. इसका काम सिर्फ़ जानकारी ढूंढना है. इसके लिए, इसे एक टूल का ऐक्सेस चाहिए: Google Search.
रिसर्चर को अलग क्यों किया गया है?
ज़्यादा जानकारी: एक ही एजेंट को सभी काम क्यों नहीं सौंपे जाते?
छोटे और फ़ोकस किए गए एजेंटों का आकलन और डीबग करना आसान होता है. अगर रिसर्च सही नहीं है, तो रिसर्चर के प्रॉम्प्ट में बदलाव करो. अगर कोर्स का फ़ॉर्मैट सही नहीं है, तो Content Builder का इस्तेमाल करके उसे ठीक करें. एक ही प्रॉम्प्ट में कई तरह के निर्देश देने पर, किसी एक समस्या को ठीक करने से दूसरी समस्या पैदा हो सकती है.
- अगर Cloud Shell में काम किया जा रहा है, तो Cloud Shell एडिटर खोलने के लिए, यह कमांड चलाएं:
cloudshell workspace . agents/researcher/agent.pyखोलें.- आपको एक TODO के साथ स्केलेटन दिखेगा.
researcherएजेंट को तय करने के लिए, यह कोड जोड़ें:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. DO NOT output any function calls. Provide your research directly as text. """, ) root_agent = researcher
मुख्य सिद्धांत: टूल का इस्तेमाल
Gemini 3 का इस्तेमाल करते समय, Google Search टूल अपने-आप उपलब्ध हो जाता है. अगर आपने किसी दूसरे मॉडल, जैसे कि Gemini 2.5 का इस्तेमाल किया था, तो आपको Agent() कंस्ट्रक्टर में tools=[google_search] को एक अतिरिक्त पैरामीटर के तौर पर पास करना होगा. ADK, एलएलएम को इस टूल के बारे में बताने की जटिलता को मैनेज करता है. जब मॉडल को लगता है कि उसे जानकारी की ज़रूरत है, तब वह स्ट्रक्चर्ड टूल कॉल जनरेट करता है. इसके बाद, एडीके Python फ़ंक्शन google_search को लागू करता है और नतीजे को वापस मॉडल को भेजता है.
4. ⚖️ जज एजेंट
रिसर्चर कड़ी मेहनत करता है, लेकिन एलएलएम सुस्त हो सकते हैं. काम की समीक्षा करने के लिए, हमें जज की ज़रूरत है. जज, रिसर्च को स्वीकार करता है और पास/फ़ेल का आकलन करके जवाब देता है.
स्ट्रक्चर्ड आउटपुट
ज़्यादा जानकारी: वर्कफ़्लो को ऑटोमेट करने के लिए, हमें अनुमानित आउटपुट की ज़रूरत होती है. टेक्स्ट की लंबी-चौड़ी समीक्षा को प्रोग्राम के हिसाब से पार्स करना मुश्किल होता है. Pydantic का इस्तेमाल करके, JSON स्कीमा लागू करने से यह पक्का किया जाता है कि Judge, बूलियन pass या fail वैल्यू देता है. इस वैल्यू के आधार पर हमारा कोड भरोसेमंद तरीके से काम कर सकता है.
agents/judge/agent.pyखोलें.JudgeFeedbackस्कीमा औरjudgeएजेंट तय करें.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
मुख्य सिद्धांत: एजेंट के व्यवहार को सीमित करना
हम disallow_transfer_to_parent=True और disallow_transfer_to_peers=True सेट करते हैं. इससे जज को सिर्फ़ स्ट्रक्चर्ड JudgeFeedback वापस करने के लिए मजबूर किया जाता है. यह उपयोगकर्ता के साथ "चैट" करने या किसी दूसरे एजेंट को काम सौंपने का फ़ैसला नहीं कर सकता. इससे यह हमारे लॉजिक फ़्लो में एक डिटरमिनिस्टिक कॉम्पोनेंट बन जाता है.
5. 🧪 आइसोलेशन में टेस्टिंग
इन्हें कनेक्ट करने से पहले, हम यह पुष्टि कर सकते हैं कि हर एजेंट काम करता है. ADK की मदद से, एजेंट को अलग-अलग चलाया जा सकता है.
मुख्य कॉन्सेप्ट: इंटरैक्टिव रनटाइम
adk run एक लाइटवेट एनवायरमेंट बनाता है, जिसमें आप "उपयोगकर्ता" होते हैं. इससे एजेंट के निर्देशों और टूल के इस्तेमाल की अलग से जांच की जा सकती है. अगर एजेंट यहां काम नहीं करता है (जैसे, Google Search का इस्तेमाल नहीं कर पाता), तो वह ऑर्केस्ट्रेशन में भी काम नहीं करेगा.
- रिसर्चर को इंटरैक्टिव तरीके से चलाएं. ध्यान दें कि हम एजेंट की खास डायरेक्ट्री की ओर इशारा करते हैं:
# This runs the researcher agent in interactive mode uv run adk run agents/researcher - चैट प्रॉम्प्ट में, यह टाइप करें:
Find the population of Tokyo in 2020export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true - चैट से बाहर निकलें (Ctrl+C).
- Judge को इंटरैक्टिव तरीके से चलाएं:
uv run adk run agents/judge - चैट प्रॉम्प्ट में, इनपुट को सिम्युलेट करें:
Topic: Tokyo. Findings: Tokyo is a city.status='fail'because the findings are too brief.
6. ✍️ कॉन्टेंट बिल्डर एजेंट
कॉन्टेंट बिल्डर, क्रिएटिव राइटर है. यह मंज़ूरी पा चुकी रिसर्च को कोर्स में बदल देता है.
agents/content_builder/agent.pyखोलें.content_builderएजेंट तय करें.content_builder = Agent( name="content_builder", model=MODEL, description="Transforms research findings into a structured course.", instruction=""" You are an expert course creator. Take the approved 'research_findings' and transform them into a well-structured, engaging course module. **Formatting Rules:** 1. Start with a main title using a single `#` (H1). 2. Use `##` (H2) for main section headings. 3. Use bullet points and clear paragraphs. 4. Maintain a professional but engaging tone. Ensure the content directly addresses the user's original request. """, ) root_agent = content_builder
मुख्य सिद्धांत: कॉन्टेक्स्ट प्रोपगेशन
आपके मन में यह सवाल आ सकता है कि "कॉन्टेंट बिल्डर को यह कैसे पता चलता है कि रिसर्चर ने क्या खोजा है?" ADK में, पाइपलाइन में मौजूद एजेंट session.state शेयर करते हैं. बाद में, Orchestrator में हम Researcher और Judge को कॉन्फ़िगर करेंगे, ताकि वे अपने आउटपुट को इस शेयर किए गए स्टेट में सेव कर सकें. Content Builder के प्रॉम्प्ट के पास इस इतिहास का ऐक्सेस होता है.
7. 🎻 ऑर्केस्ट्रेटर
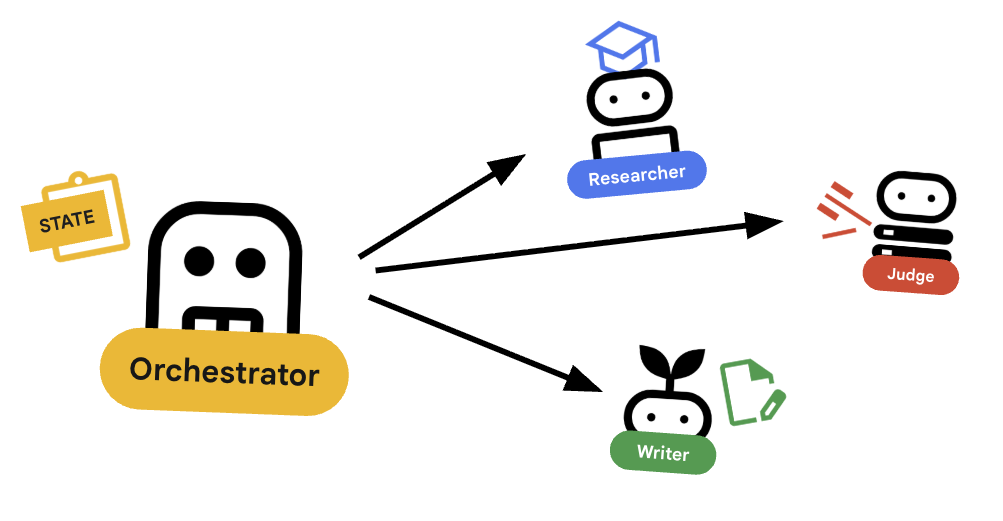
ऑर्केस्ट्रेटर, हमारी मल्टी-एजेंट टीम का मैनेजर होता है. विशेषज्ञ एजेंट (रिसर्चर, जज, कॉन्टेंट बिल्डर) खास टास्क पूरे करते हैं. हालांकि, ऑर्केस्ट्रेटर का काम वर्कफ़्लो को मैनेज करना और यह पक्का करना है कि उनके बीच जानकारी सही तरीके से शेयर हो.
🌐 आर्किटेक्चर: एजेंट-टू-एजेंट (A2A)
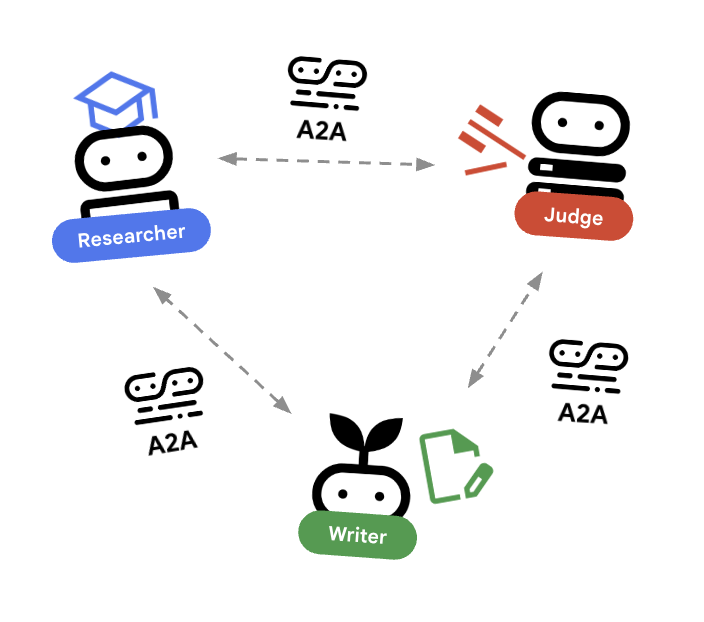
इस लैब में, हम डिस्ट्रिब्यूटेड सिस्टम बना रहे हैं. हम सभी एजेंट को एक ही Python प्रोसेस में चलाने के बजाय, उन्हें स्वतंत्र माइक्रोसेवाओं के तौर पर डिप्लॉय करते हैं. इससे हर एजेंट को अलग-अलग स्केल करने और पूरे सिस्टम को क्रैश किए बिना काम न करने की अनुमति मिलती है.
इसके लिए, हम Agent-to-Agent (A2A) प्रोटोकॉल का इस्तेमाल करते हैं.
A2A प्रोटोकॉल
ज़्यादा जानकारी: प्रोडक्शन सिस्टम में, एजेंट अलग-अलग सर्वर (या अलग-अलग क्लाउड) पर काम करते हैं. A2A प्रोटोकॉल, उन्हें एचटीटीपी पर एक-दूसरे को खोजने और उनसे बातचीत करने का एक स्टैंडर्ड तरीका उपलब्ध कराता है. RemoteA2aAgent, इस प्रोटोकॉल के लिए एडीके क्लाइंट है.
agents/orchestrator/agent.pyखोलें.- टिप्पणी
# TODO: Define connections to remote agentsया रिमोट एजेंट की परिभाषाओं वाला सेक्शन ढूंढें. - कनेक्शन तय करने के लिए, यह कोड जोड़ें. पक्का करें कि आपने इसे इंपोर्ट किए गए एजेंट के बाद और किसी अन्य एजेंट की परिभाषाओं से पहले रखा हो.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 एस्केलेशन चेकर
लूप को रोकने का कोई तरीका होना चाहिए. अगर जज "पास" कहता है, तो हमें लूप से तुरंत बाहर निकलना है और कॉन्टेंट बिल्डर पर जाना है.
BaseAgent के साथ कस्टम लॉजिक
ज़्यादा जानकारी: सभी एजेंट, एलएलएम का इस्तेमाल नहीं करते. कभी-कभी आपको Python के सामान्य लॉजिक की ज़रूरत होती है. BaseAgent की मदद से, सिर्फ़ कोड चलाने वाला एजेंट तय किया जा सकता है. इस मामले में, हम सेशन की स्थिति की जांच करते हैं और EventActions(escalate=True) को रोकने के लिए, EventActions(escalate=True) का इस्तेमाल करते हैं.LoopAgent
- अब भी
agents/orchestrator/agent.pyमें है. EscalationCheckerTODO प्लेसहोल्डर ढूंढें.- इसे इस तरीके से बदलें:
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
मुख्य कॉन्सेप्ट: इवेंट के ज़रिए कंट्रोल फ़्लो
एजेंट, सिर्फ़ टेक्स्ट से नहीं, बल्कि इवेंट से भी कम्यूनिकेट करते हैं. escalate=True के साथ इवेंट को यिल्ड करके, यह एजेंट अपने पैरंट (LoopAgent) को एक सिग्नल भेजता है. LoopAgent को इस सिग्नल को पकड़ने और लूप को खत्म करने के लिए प्रोग्राम किया गया है.
9. 🔁 रिसर्च लूप
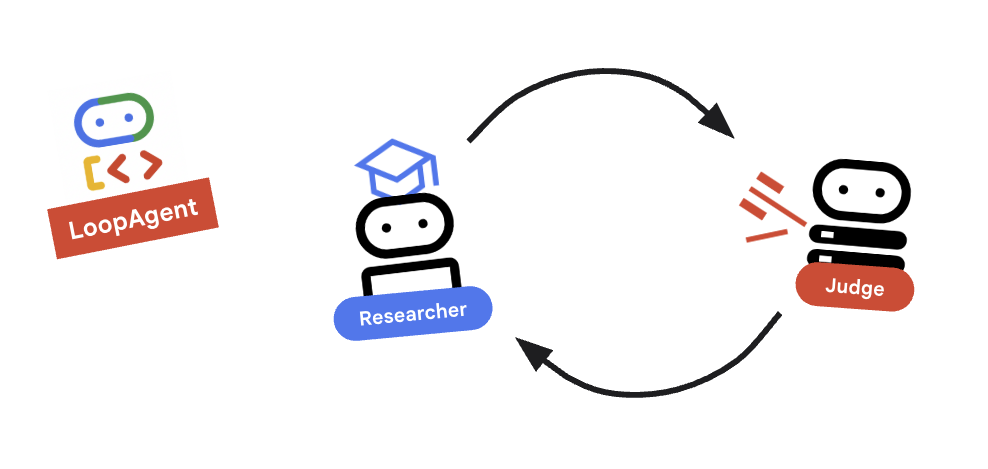
हमें एक फ़ीडबैक लूप की ज़रूरत है: रिसर्च -> जज -> (फ़ेल) -> रिसर्च -> ...
- अब भी
agents/orchestrator/agent.pyमें है. research_loopकी परिभाषा जोड़ें. इसेEscalationCheckerक्लास औरescalation_checkerइंस्टेंस के बाद रखें.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
मुख्य सिद्धांत: LoopAgent
LoopAgent, अपने sub_agents को क्रम से दिखाता है.
researcher: डेटा ढूंढता है.judge: डेटा का आकलन करता है.escalation_checker: यह तय करता है किyield Event(escalate=True)है या नहीं. अगरescalate=Trueहोता है, तो लूप जल्दी खत्म हो जाता है. अगर ऐसा नहीं होता है, तो रिसर्चर (max_iterationsतक) के लिए यह सुविधा फिर से शुरू हो जाती है.
10. 🔗 फ़ाइनल पाइपलाइन
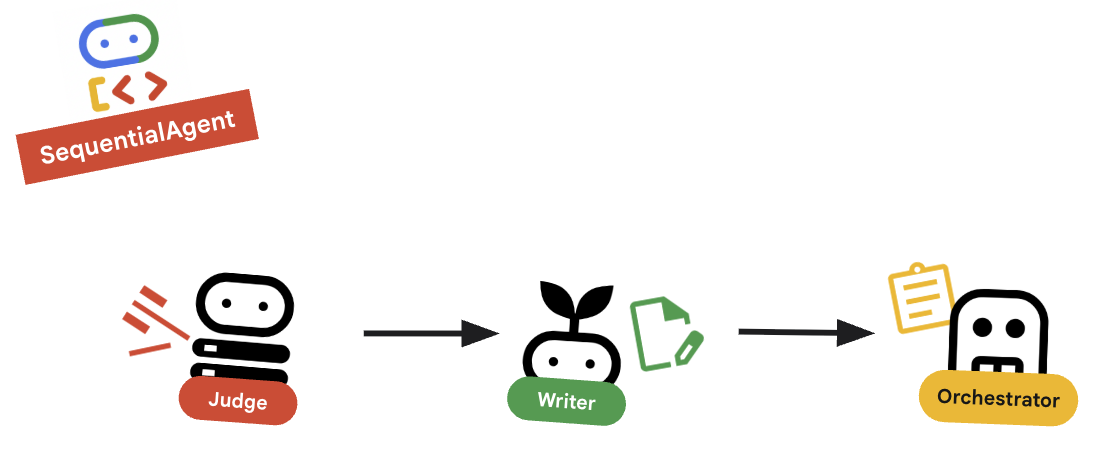
आखिर में, सभी इमेज को एक साथ स्टिच करें.
- अब भी
agents/orchestrator/agent.pyमें है. - फ़ाइल में सबसे नीचे मौजूद
root_agentको तय करें. पक्का करें कि यह मौजूदाroot_agent = Noneप्लेसहोल्डर की जगह ले ले.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
मुख्य सिद्धांत: हैरारकी के हिसाब से कंपोज़िशन
ध्यान दें कि research_loop खुद एक एजेंट (LoopAgent) है. हम इसे SequentialAgent में मौजूद किसी अन्य सब-एजेंट की तरह ही मानते हैं. इस कंपोज़ेबिलिटी की मदद से, सामान्य पैटर्न (सीक्वेंस के अंदर लूप, राउटर के अंदर सीक्वेंस वगैरह) को नेस्ट करके, जटिल लॉजिक बनाया जा सकता है.
11. 💻 स्थानीय तौर पर चलाना
सब कुछ चलाने से पहले, आइए देखते हैं कि ADK, डिस्ट्रिब्यूट किए गए एनवायरमेंट को स्थानीय तौर पर कैसे सिम्युलेट करता है.
ज़्यादा जानकारी: लोकल डेवलपमेंट कैसे काम करता है
माइक्रोसर्विसेज़ आर्किटेक्चर में, हर एजेंट अपने सर्वर के तौर पर काम करता है. डिप्लॉय करने पर, आपके पास चार अलग-अलग Cloud Run सेवाएं होंगी. अगर आपको चार टर्मिनल टैब खोलने हैं और चार कमांड चलाने हैं, तो स्थानीय तौर पर इसका सिम्युलेशन करना मुश्किल हो सकता है.
यह स्क्रिप्ट, रिसर्चर (पोर्ट 8001), जज (8002), और कॉन्टेंट बिल्डर (8003) के लिए uvicorn प्रोसेस शुरू करती है. यह RESEARCHER_AGENT_CARD_URL जैसे एनवायरमेंट वैरिएबल सेट करता है और उन्हें ऑर्केस्ट्रेटर (पोर्ट 8004) को पास करता है. हम इसे बाद में क्लाउड में इसी तरह कॉन्फ़िगर करेंगे!
- ऑर्केस्ट्रेशन स्क्रिप्ट चलाएं:
perl -pi -e 's/us-central1/global/g' run_local.sh ./run_local.sh - इसे आज़माएं:
- Cloud Shell का इस्तेमाल करने पर: वेब झलक बटन (टर्मिनल में सबसे ऊपर दाईं ओर) -> पोर्ट 8080 पर झलक देखें -> पोर्ट बदलें पर क्लिक करके
8000पर सेट करें. - अगर स्थानीय तौर पर चल रहा है: अपने ब्राउज़र में
http://localhost:8000खोलें. - प्रॉम्प्ट: "कॉफ़ी के इतिहास के बारे में एक कोर्स बनाओ."
- देखें: Orchestrator, रिसर्चर को कॉल करेगा. आउटपुट, जज को भेजा जाता है. अगर जज इसे स्वीकार नहीं करता है, तो लूप जारी रहता है!
- "इंटरनल सर्वर एरर" / पुष्टि करने से जुड़ी गड़बड़ियां: अगर आपको पुष्टि करने से जुड़ी गड़बड़ियां दिखती हैं (जैसे,
google-authसे जुड़ी गड़बड़ियां), तो पक्का करें कि आपने लोकल मशीन परgcloud auth application-default loginचलाया हो. Cloud Shell में, पक्का करें कि आपकाGOOGLE_CLOUD_PROJECTएनवायरमेंट वैरिएबल सही तरीके से सेट किया गया हो. - टर्मिनल से जुड़ी गड़बड़ियां: अगर नई टर्मिनल विंडो में कमांड काम नहीं करती है, तो अपने एनवायरमेंट वैरिएबल (
GOOGLE_CLOUD_PROJECTवगैरह) को फिर से एक्सपोर्ट करना न भूलें.
- Cloud Shell का इस्तेमाल करने पर: वेब झलक बटन (टर्मिनल में सबसे ऊपर दाईं ओर) -> पोर्ट 8080 पर झलक देखें -> पोर्ट बदलें पर क्लिक करके
- अलग-अलग एजेंट की टेस्टिंग: पूरा सिस्टम चालू होने पर भी, सीधे तौर पर उनके पोर्ट को टारगेट करके, खास एजेंट की टेस्टिंग की जा सकती है. यह पूरी चेन को ट्रिगर किए बिना, किसी कॉम्पोनेंट को डीबग करने के लिए काम आता है.ध्यान दें: ये एपीआई एंडपॉइंट हैं, वेब पेज नहीं. इन्हें ब्राउज़र से ऐक्सेस नहीं किया जा सकता. इसके बजाय,
curlका इस्तेमाल करके पुष्टि करें कि वे चल रहे हैं. उदाहरण के लिए, उनके एजेंट कार्ड को फ़ेच करके.- सिर्फ़ रिसर्चर के लिए (पोर्ट 8001):
- स्टेटस देखें (और
urlएंडपॉइंट ढूंढें):curl http://localhost:8001/a2a/agent/.well-known/agent-card.json - A2A JSON-RPC प्रोटोकॉल का इस्तेमाल करके क्वेरी भेजें:
curl -X POST http://localhost:8001/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-1", "role": "user", "parts": [ { "text": "What is the capital of France?", "kind": "text" } ] } } }'
- स्टेटस देखें (और
- सिर्फ़ जज करें (पोर्ट 8002):
- स्थिति देखें:
curl http://localhost:8002/a2a/agent/.well-known/agent-card.json - क्वेरी भेजें:
curl -X POST http://localhost:8002/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-2", "role": "user", "parts": [ { "text": "Topic: Tokyo. Findings: Tokyo is the capital of Japan.", "kind": "text" } ] } } }'
- स्थिति देखें:
- सिर्फ़ Content Builder (पोर्ट 8003):
curl http://localhost:8003/a2a/agent/.well-known/agent-card.json - ऑर्केस्ट्रेटर (पोर्ट 8004):
curl http://localhost:8004/a2a/agent/.well-known/agent-card.json
- सिर्फ़ रिसर्चर के लिए (पोर्ट 8001):
12. 🚀 Cloud Run पर डिप्लॉय करना
क्लाउड में पुष्टि की जा रही है. हम हर एजेंट को एक अलग सेवा के तौर पर डिप्लॉय करेंगे.
डिप्लॉयमेंट कॉन्फ़िगरेशन के बारे में जानकारी
Cloud Run पर एजेंट डिप्लॉय करते समय, हम कई एनवायरमेंट वैरिएबल पास करते हैं. इनसे एजेंट के व्यवहार और कनेक्टिविटी को कॉन्फ़िगर किया जाता है:
GOOGLE_CLOUD_PROJECT: इससे यह पक्का किया जाता है कि एजेंट, लॉगिंग और Vertex AI कॉल के लिए सही Google Cloud प्रोजेक्ट का इस्तेमाल करे.GOOGLE_GENAI_USE_VERTEXAI: यह एजेंट फ़्रेमवर्क (ADK) को बताता है कि मॉडल इन्फ़रेंस के लिए, Gemini API को सीधे तौर पर कॉल करने के बजाय Vertex AI का इस्तेमाल करें.GOOGLE_CLOUD_LOCATION: इससे एजेंट फ़्रेमवर्क (एडीके) को यह पता चलता है कि किस एंडपॉइंट का इस्तेमाल करना है.[AGENT]_AGENT_CARD_URL: यह Orchestrator के लिए ज़रूरी है. इससे Orchestrator को यह पता चलता है कि रिमोट एजेंट कहां मिलेंगे. इसे डिप्लॉय किए गए Cloud Run यूआरएल (खास तौर पर एजेंट कार्ड पाथ) पर सेट करके, हम Orchestrator को इंटरनेट पर Researcher, Judge, और Content Builder को खोजने और उनसे कम्यूनिकेट करने की अनुमति देते हैं.
- उप-एजेंट (पैरलल) डिप्लॉय करें: समय बचाने के लिए, हम रिसर्चर, जज, और कॉन्टेंट बिल्डर को एक साथ डिप्लॉय करेंगे.तीन नए टर्मिनल टैब खोलें. हर नए टैब में, अपना एनवायरमेंट सेट अप करने के लिए यह कमांड चलाएं:
cd ~/prai-roadshow-lab-1-starter source .envgcloud run deploy researcher \ --source agents/researcher/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy judge \ --source agents/judge/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy content-builder \ --source agents/content_builder/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true" - यूआरएल कैप्चर करें: तीनों डिप्लॉयमेंट पूरे होने के बाद, अपने ओरिजनल टर्मिनल पर वापस जाएं. यहीं से Orchestrator को डिप्लॉय किया जाएगा. सेवा के यूआरएल कैप्चर करने के लिए, ये कमांड चलाएं:
RESEARCHER_URL=$(gcloud run services describe researcher --region us-west1 --format='value(status.url)') JUDGE_URL=$(gcloud run services describe judge --region us-west1 --format='value(status.url)') CONTENT_BUILDER_URL=$(gcloud run services describe content-builder --region us-west1 --format='value(status.url)') echo "Researcher: $RESEARCHER_URL" echo "Judge: $JUDGE_URL" echo "Content Builder: $CONTENT_BUILDER_URL" - ऑर्केस्ट्रेटर को डिप्लॉय करें: कैप्चर किए गए एनवायरमेंट वैरिएबल का इस्तेमाल करके, Orchestrator को कॉन्फ़िगर करें.
gcloud run deploy orchestrator \ --source agents/orchestrator/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars RESEARCHER_AGENT_CARD_URL=$RESEARCHER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars JUDGE_AGENT_CARD_URL=$JUDGE_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars CONTENT_BUILDER_AGENT_CARD_URL=$CONTENT_BUILDER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"ORCHESTRATOR_URL=$(gcloud run services describe orchestrator --region us-west1 --format='value(status.url)') echo $ORCHESTRATOR_URL - फ़्रंटएंड को डिप्लॉय करना:
gcloud run deploy course-creator \ --source app \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars AGENT_SERVER_URL=$ORCHESTRATOR_URL \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT - रिमोट डिप्लॉयमेंट की जांच करें: डिप्लॉय किए गए Orchestrator का यूआरएल खोलें. अब यह पूरी तरह से क्लाउड में चल रहा है. साथ ही, यह Google के बिना सर्वर वाले इंफ़्रास्ट्रक्चर का इस्तेमाल करके, आपके एजेंट को स्केल कर रहा है!अहम जानकारी: आपको सभी माइक्रो-सेवाएं और उनके यूआरएल, Cloud Run इंटरफ़ेस में मिलेंगे
13. खास जानकारी
बधाई हो! आपने प्रोडक्शन के लिए तैयार, डिस्ट्रिब्यूट किया गया मल्टी-एजेंट सिस्टम बना लिया है और उसे डिप्लॉय कर दिया है.
हमने क्या-क्या हासिल किया
- मुश्किल टास्क को छोटे-छोटे हिस्सों में बांटा गया: हमने एक बड़े प्रॉम्प्ट के बजाय, काम को अलग-अलग भूमिकाओं (रिसर्चर, जज, कॉन्टेंट बिल्डर) में बांटा.
- क्वालिटी कंट्रोल लागू किया गया: हमने
LoopAgentऔर स्ट्रक्चर्डJudgeका इस्तेमाल किया, ताकि यह पक्का किया जा सके कि फ़ाइनल चरण में सिर्फ़ अच्छी क्वालिटी की जानकारी पहुंचे. - प्रोडक्शन के लिए बनाया गया: हमने एजेंट-टू-एजेंट (A2A) प्रोटोकॉल और Cloud Run का इस्तेमाल करके एक ऐसा सिस्टम बनाया है जिसमें हर एजेंट एक स्वतंत्र और स्केल की जा सकने वाली माइक्रोसेवा है. यह एक ही Python स्क्रिप्ट में सब कुछ चलाने से ज़्यादा बेहतर है.
- ऑर्केस्ट्रेशन: हमने कंट्रोल फ़्लो के पैटर्न को साफ़ तौर पर तय करने के लिए,
SequentialAgentऔरLoopAgentका इस्तेमाल किया.
अगले चरण
अब आपके पास बुनियादी जानकारी है. इसलिए, इस सिस्टम को बेहतर बनाया जा सकता है:
- ज़्यादा टूल जोड़ना: रिसर्चर को अपने संगठन के दस्तावेज़ों या एपीआई का ऐक्सेस दें.
- जज को बेहतर बनाएं: ज़्यादा खास मानदंड जोड़ें या "ह्यूमन इन द लूप" चरण जोड़ें.
- मॉडल बदलना: अलग-अलग एजेंट के लिए अलग-अलग मॉडल इस्तेमाल करके देखें. उदाहरण के लिए, जज के लिए तेज़ मॉडल और कॉन्टेंट राइटर के लिए बेहतर मॉडल.
अब आपके पास Google Cloud पर, भरोसेमंद और जटिल एजेंटिक वर्कफ़्लो बनाने का विकल्प है!