
1. Introduzione
Panoramica
In questo lab, andrai oltre i semplici chatbot e creerai un sistema multi-agente distribuito.
Anche se un singolo LLM può rispondere alle domande, la complessità del mondo reale spesso richiede ruoli specializzati. Non chiedi al tuo ingegnere backend di progettare la UI e non chiedi al tuo designer di ottimizzare le query del database. Allo stesso modo, possiamo creare agenti AI specializzati che si concentrano su un'attività e si coordinano tra loro per risolvere problemi complessi.
Creerai un sistema di creazione di corsi composto da:
- Agente ricercatore: utilizza
google_searchper trovare informazioni aggiornate. - Giudice: valuta la qualità e la completezza della ricerca.
- Agente Content Builder: trasforma la ricerca in un corso strutturato.
- Agente orchestratore: gestione del flusso di lavoro e della comunicazione tra questi specialisti.
Prerequisiti
- Conoscenza di base di Python.
- Familiarità con la console Google Cloud.
In questo lab proverai a:
- Definisci un agente che utilizza strumenti (
researcher) in grado di effettuare ricerche sul web. - Implementa l'output strutturato con Pydantic per
judge. - Connettiti agli agenti remoti utilizzando il protocollo Agent-to-Agent (A2A).
- Crea un
LoopAgentper creare un ciclo di feedback tra il ricercatore e il giudice. - Esegui il sistema distribuito localmente utilizzando l'ADK.
- Esegui il deployment del sistema multi-agente in Google Cloud Run.
Principi di architettura e orchestrazione
Prima di scrivere il codice, vediamo come funzionano insieme questi agenti. Stiamo creando una pipeline di creazione dei corsi.
Progettazione del sistema
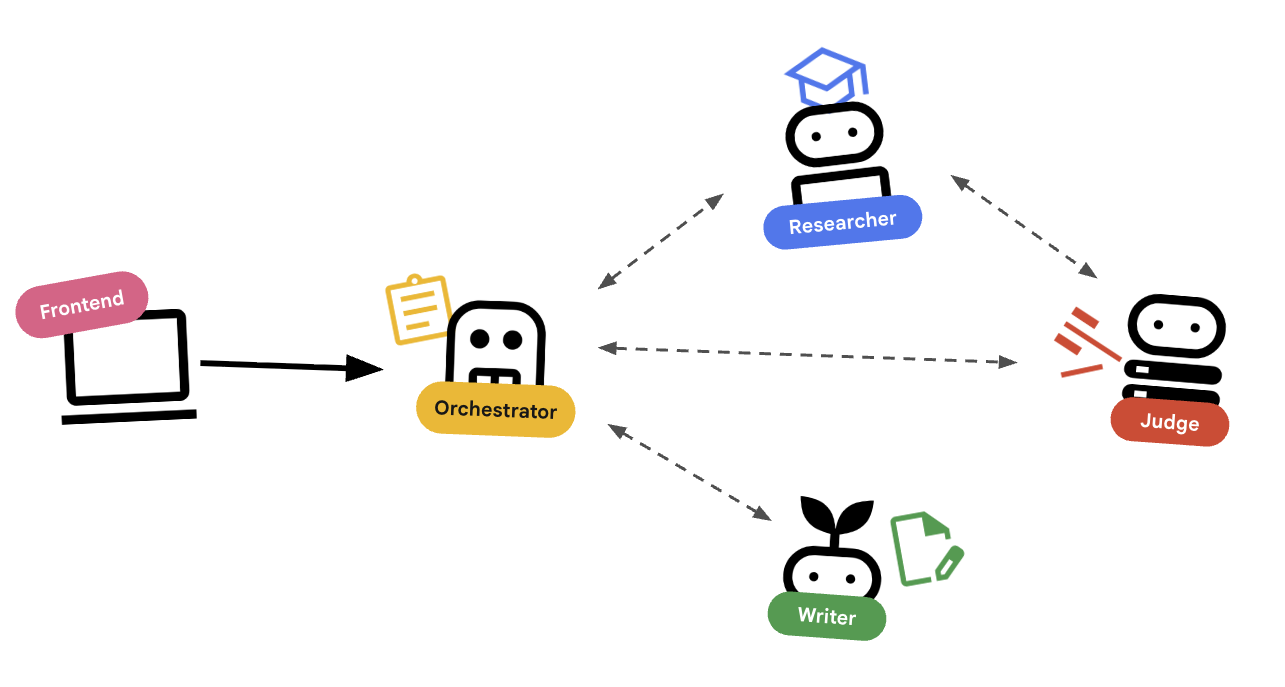
Orchestrazione con gli agenti
Gli agenti standard (come il ricercatore) funzionano. Gli agenti orchestratori (come LoopAgent o SequentialAgent) gestiscono altri agenti. Non hanno strumenti propri, il loro "strumento" è la delega.
LoopAgent: si comporta come un ciclowhilenel codice. Esegue ripetutamente una sequenza di agenti finché non viene soddisfatta una condizione (o non viene raggiunto il numero massimo di iterazioni). Utilizziamo questa funzionalità per il ciclo di ricerca:- L'autore della ricerca trova le informazioni.
- Judge lo critica.
- Se Judge indica "Fail", EscalationChecker consente al ciclo di continuare.
- Se Judge dice "Pass", EscalationChecker interrompe il ciclo.
SequentialAgent: si comporta come una normale esecuzione di script. Esegue gli agenti uno dopo l'altro. Lo utilizziamo per la pipeline di alto livello:- Innanzitutto, esegui il ciclo di ricerca (finché non termina con dati validi).
- Quindi, esegui Content Builder (per scrivere il corso).
Combinando questi elementi, creiamo un sistema solido in grado di autocorreggersi prima di generare l'output finale.
2. Configurazione
Configurazione dell'ambiente
- Apri Cloud Shell: fai clic sull'icona Attiva Cloud Shell in alto a destra nella console Google Cloud.
Recuperare il codice iniziale
- Clona il repository iniziale nella tua home directory:
cd ~ git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter && cd .. && mv temp-repo/agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter . && rm -rf temp-repo cd prai-roadshow-lab-1-starter - Abilita le API: esegui il seguente comando per abilitare i servizi Google Cloud necessari:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - Apri questa cartella nell'editor.
Installa le dipendenze
Utilizziamo uv per una gestione rapida delle dipendenze.
- Installa le dipendenze del progetto:
# Ensure you have uv installed: pip install uv uv sync - Configura le variabili di ambiente.
- Suggerimento: puoi trovare l'ID progetto nella dashboard di Cloud Console o eseguendo
gcloud config get-value project.
.envper archiviare queste variabili, in modo che tu possa ricaricarle facilmente in caso di disconnessione della sessione.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true EOF - Suggerimento: puoi trovare l'ID progetto nella dashboard di Cloud Console o eseguendo
- Recupera le variabili di ambiente:
source .envsource .envper ripristinarli.
3. 🕵️ L'agente di ricerca
Il Ricercatore è uno specialista. Il suo unico compito è trovare informazioni. Per farlo, deve accedere a uno strumento: la Ricerca Google.
Perché separare il ruolo di Ricercatore?
Approfondimento:perché non avere un solo agente che faccia tutto?
Gli agenti piccoli e mirati sono più facili da valutare e debuggare. Se la ricerca non è buona, devi modificare il prompt del ricercatore. Se la formattazione del corso non è corretta, devi apportare modifiche al Content Builder. In un prompt monolitico "fai tutto", la correzione di un elemento spesso ne compromette un altro.
- Se lavori in Cloud Shell, esegui questo comando per aprire l'editor di Cloud Shell:
cloudshell workspace . - Apri
agents/researcher/agent.py. - Vedrai uno scheletro con un TO DO.
- Aggiungi il seguente codice per definire l'agente
researcher:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. DO NOT output any function calls. Provide your research directly as text. """, ) root_agent = researcher
Concetto chiave: utilizzo dello strumento
Quando utilizzi Gemini 3, lo strumento Ricerca Google è disponibile automaticamente. Se utilizzassi un modello diverso, ad esempio Gemini 2.5, dovresti passare tools=[google_search] come parametro aggiuntivo al costruttore Agent(). ADK gestisce la complessità della descrizione di questo strumento per il modello LLM. Quando il modello decide di aver bisogno di informazioni, genera una chiamata di strumento strutturata, l'ADK esegue la funzione Python google_search e restituisce il risultato al modello.
4. ⚖️ L'agente giudice
Il ricercatore lavora sodo, ma gli LLM possono essere pigri. Abbiamo bisogno di un Giudice per esaminare il lavoro. Il giudice accetta la ricerca e restituisce una valutazione strutturata di approvazione/bocciatura.
Output strutturato
Approfondimento:per automatizzare i flussi di lavoro, abbiamo bisogno di output prevedibili. Una recensione testuale prolissa è difficile da analizzare a livello di programmazione. Applicando uno schema JSON (utilizzando Pydantic), ci assicuriamo che Judge restituisca un valore booleano pass o fail su cui il nostro codice può agire in modo affidabile.
- Apri
agents/judge/agent.py. - Definisci lo schema
JudgeFeedbacke l'agentejudge.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
Concetto chiave: limitare il comportamento dell'agente
Abbiamo impostato disallow_transfer_to_parent=True e disallow_transfer_to_peers=True. In questo modo, il giudice è obbligato a restituire solo il JudgeFeedback strutturato. Non può decidere di "chattare" con l'utente o delegare un altro agente. Ciò lo rende un componente deterministico nel nostro flusso logico.
5. 🧪 Test in isolamento
Prima di collegarli, possiamo verificare che ogni agente funzioni. L'ADK ti consente di eseguire gli agenti singolarmente.
Concetto chiave: il runtime interattivo
adk run crea un ambiente leggero in cui tu sei l'"utente". In questo modo puoi testare le istruzioni dell'agente e l'utilizzo degli strumenti in isolamento. Se l'agente non riesce a eseguire l'operazione (ad es. non riesce a utilizzare la Ricerca Google), sicuramente non riuscirà a eseguire l'orchestrazione.
- Esegui Researcher in modo interattivo. Tieni presente che facciamo riferimento alla directory dell'agente specifica:
# This runs the researcher agent in interactive mode uv run adk run agents/researcher - Nel prompt della chat, digita:
Find the population of Tokyo in 2020export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true - Esci dalla chat (Ctrl+C).
- Esegui Judge in modo interattivo:
uv run adk run agents/judge - Nel prompt della chat, simula l'input:
Topic: Tokyo. Findings: Tokyo is a city.status='fail'perché i risultati sono troppo brevi.
6. ✍️ L'agente Content Builder
Content Builder è lo strumento di scrittura creativa. Prende la ricerca approvata e la trasforma in un corso.
- Apri
agents/content_builder/agent.py. - Definisci l'agente
content_builder.content_builder = Agent( name="content_builder", model=MODEL, description="Transforms research findings into a structured course.", instruction=""" You are an expert course creator. Take the approved 'research_findings' and transform them into a well-structured, engaging course module. **Formatting Rules:** 1. Start with a main title using a single `#` (H1). 2. Use `##` (H2) for main section headings. 3. Use bullet points and clear paragraphs. 4. Maintain a professional but engaging tone. Ensure the content directly addresses the user's original request. """, ) root_agent = content_builder
Concetto chiave: propagazione del contesto
Ti starai chiedendo: "Come fa Content Builder a sapere cosa ha trovato il ricercatore?" Nell'ADK, gli agenti in una pipeline condividono un session.state. In un secondo momento, in Orchestrator configureremo Researcher e Judge in modo che salvino i loro output in questo stato condiviso. Il prompt di Content Builder ha effettivamente accesso a questa cronologia.
7. 🎻 L'organizzatore
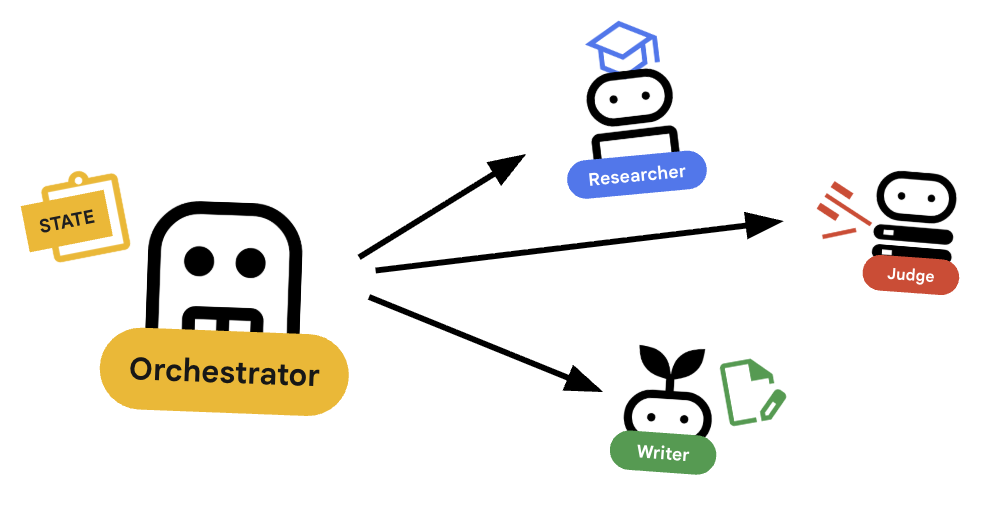
L'Orchestratore è il gestore del nostro team multi-agente. A differenza degli agenti specializzati (Ricercatore, Giudice, Generatore di contenuti) che svolgono attività specifiche, il compito dell'orchestratore è coordinare il workflow e garantire che le informazioni fluiscano correttamente tra loro.
🌐 L'architettura: Agent-to-Agent (A2A)
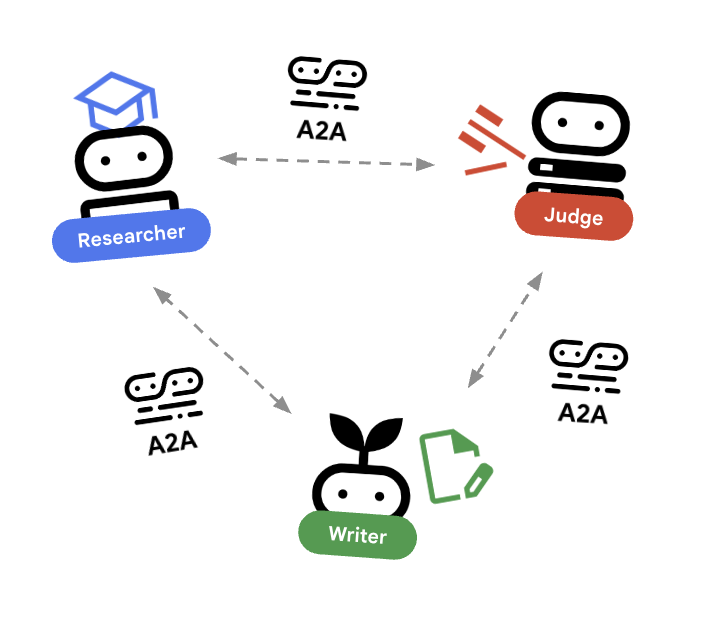
In questo lab, creeremo un sistema distribuito. Anziché eseguire tutti gli agenti in un unico processo Python, li implementiamo come microservizi indipendenti. In questo modo, ogni agente può scalare in modo indipendente e non funzionare senza arrestare in modo anomalo l'intero sistema.
Per rendere possibile questa operazione, utilizziamo il protocollo Agent-to-Agent (A2A).
Il protocollo A2A
Approfondimento:in un sistema di produzione, gli agenti vengono eseguiti su server diversi (o anche su cloud diversi). Il protocollo A2A crea un modo standard per consentire loro di rilevarsi e comunicare tra loro tramite HTTP. RemoteA2aAgent è il client ADK per questo protocollo.
- Apri
agents/orchestrator/agent.py. - Individua il commento
# TODO: Define connections to remote agentso la sezione per le definizioni degli agenti remoti. - Aggiungi il seguente codice per definire le connessioni. Assicurati di inserire questo codice dopo le importazioni e prima di qualsiasi altra definizione di agente.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 Il controllo dell'escalation
Un ciclo deve avere un modo per fermarsi. Se il giudice dice "Passa", vogliamo uscire immediatamente dal ciclo e passare al Content Builder.
Logica personalizzata con BaseAgent
Approfondimento:non tutti gli agenti utilizzano gli LLM. A volte hai bisogno di una semplice logica Python. BaseAgent ti consente di definire un agente che esegue solo codice. In questo caso, controlliamo lo stato della sessione e utilizziamo EventActions(escalate=True) per segnalare a LoopAgent di interrompersi.
- Ancora in
agents/orchestrator/agent.py. - Trova il segnaposto
EscalationCheckerTODO. - Sostituiscilo con la seguente implementazione:
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
Concetto chiave: controllo del flusso tramite eventi
Gli agenti comunicano non solo con il testo, ma anche con gli eventi. Generando un evento con escalate=True, questo agente invia un segnale al relativo elemento principale (LoopAgent). LoopAgent è programmato per intercettare questo segnale e terminare il loop.
9. 🔁 Il ciclo di ricerca
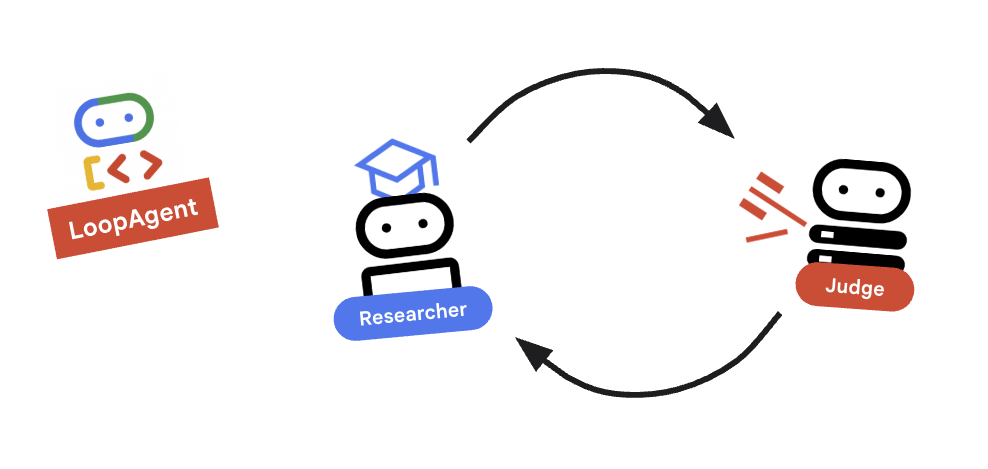
Abbiamo bisogno di un ciclo di feedback: Ricerca -> Giudizio -> (Errore) -> Ricerca -> ...
- Ancora in
agents/orchestrator/agent.py. - Aggiungi la definizione di
research_loop. Posiziona questo dopo la classeEscalationCheckere l'istanzaescalation_checker.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
Concetto chiave: LoopAgent
LoopAgent scorre in ordine le sub_agents.
researcher: trova i dati.judge: valuta i dati.escalation_checker: decide seyield Event(escalate=True). Se si verificaescalate=True, il ciclo si interrompe in anticipo. In caso contrario, riprende dalla ricercatrice (fino amax_iterations).
10. 🔗 La pipeline finale
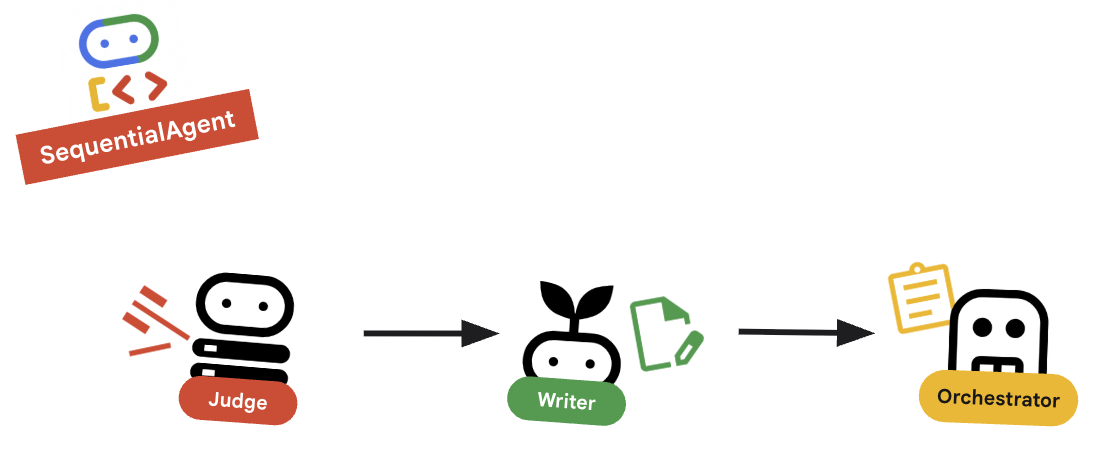
Infine, unisci tutti i pezzi.
- Ancora in
agents/orchestrator/agent.py. - Definisci
root_agentnella parte inferiore del file. Assicurati che questo sostituisca qualsiasi segnapostoroot_agent = Noneesistente.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
Concetto chiave: composizione gerarchica
Tieni presente che research_loop è a sua volta un agente (un LoopAgent). Lo trattiamo come qualsiasi altro sub-agente in SequentialAgent. Questa componibilità ti consente di creare logiche complesse nidificando pattern semplici (cicli all'interno di sequenze, sequenze all'interno di router e così via).
11. 💻 Esegui in locale
Prima di eseguire tutto, vediamo come l'ADK simula l'ambiente distribuito localmente.
Approfondimento: come funziona lo sviluppo locale
In un'architettura di microservizi, ogni agente viene eseguito come server autonomo. Quando esegui il deployment, avrai 4 diversi servizi Cloud Run. Simulare questa situazione in locale può essere difficile se devi aprire quattro schede del terminale ed eseguire quattro comandi.
Questo script avvia uvicorn processi per Researcher (porta 8001), Judge (8002) e Content Builder (8003). Imposta variabili di ambiente come RESEARCHER_AGENT_CARD_URL e le passa all'agente di orchestrazione (porta 8004). È esattamente così che lo configureremo nel cloud in un secondo momento.
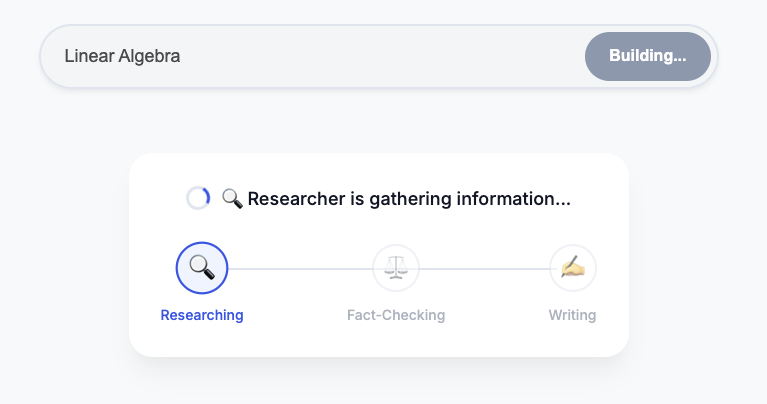
- Esegui lo script di orchestrazione:
perl -pi -e 's/us-central1/global/g' run_local.sh ./run_local.sh - Prova:
- Se utilizzi Cloud Shell:fai clic sul pulsante Anteprima web (in alto a destra nel terminale) -> Anteprima sulla porta 8080 -> Cambia porta in
8000. - Se esegui l'app localmente:apri
http://localhost:8000nel browser. - Prompt: "Crea un corso sulla storia del caffè".
- Osserva:l'orchestratore chiamerà il ricercatore. L'output viene inviato al giudice. Se il giudice non lo supera, il ciclo continua.
- "Internal Server Error" (Errore interno del server) / Auth Errors (Errori di autenticazione):se visualizzi errori di autenticazione (ad es. relativi a
google-auth), assicurati di aver eseguitogcloud auth application-default loginse esegui l'operazione su una macchina locale. In Cloud Shell, assicurati che la variabile di ambienteGOOGLE_CLOUD_PROJECTsia impostata correttamente. - Errori del terminale:se il comando non va a buon fine in una nuova finestra del terminale, ricordati di esportare nuovamente le variabili di ambiente (
GOOGLE_CLOUD_PROJECTe così via).
- Se utilizzi Cloud Shell:fai clic sul pulsante Anteprima web (in alto a destra nel terminale) -> Anteprima sulla porta 8080 -> Cambia porta in
- Test degli agenti in isolamento:anche quando l'intero sistema è in esecuzione, puoi testare agenti specifici scegliendo come target le loro porte direttamente. Ciò è utile per eseguire il debug di un componente specifico senza attivare l'intera catena.Nota:questi sono endpoint API, non pagine web. Non puoi accedervi tramite un browser. Utilizza invece
curlper verificare che siano in esecuzione (ad es. recuperando la scheda dell'agente).- Solo ricercatore (porta 8001):
- Controlla lo stato (e trova l'endpoint
url):curl http://localhost:8001/a2a/agent/.well-known/agent-card.json - Invia una query (utilizzando il protocollo JSON-RPC A2A):
curl -X POST http://localhost:8001/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-1", "role": "user", "parts": [ { "text": "What is the capital of France?", "kind": "text" } ] } } }'
- Controlla lo stato (e trova l'endpoint
- Judge Only (Port 8002):
- Controlla lo stato:
curl http://localhost:8002/a2a/agent/.well-known/agent-card.json - Invia una query:
curl -X POST http://localhost:8002/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-2", "role": "user", "parts": [ { "text": "Topic: Tokyo. Findings: Tokyo is the capital of Japan.", "kind": "text" } ] } } }'
- Controlla lo stato:
- Solo Content Builder (porta 8003):
curl http://localhost:8003/a2a/agent/.well-known/agent-card.json - Orchestrator (porta 8004):
curl http://localhost:8004/a2a/agent/.well-known/agent-card.json
- Solo ricercatore (porta 8001):
12. 🚀 Esegui il deployment in Cloud Run
La convalida finale viene eseguita nel cloud. Eseguiremo il deployment di ogni agente come servizio separato.
Informazioni sulla configurazione del deployment
Quando esegui il deployment degli agenti in Cloud Run, passiamo diverse variabili di ambiente per configurarne il comportamento e la connettività:
GOOGLE_CLOUD_PROJECT: garantisce che l'agente utilizzi il progetto Google Cloud corretto per il logging e le chiamate Vertex AI.GOOGLE_GENAI_USE_VERTEXAI: indica al framework dell'agente (ADK) di utilizzare Vertex AI per l'inferenza del modello anziché chiamare direttamente le API Gemini.GOOGLE_CLOUD_LOCATION: indica al framework dell'agente (ADK) quale endpoint utilizzare.[AGENT]_AGENT_CARD_URL: questo è fondamentale per l'orchestratore. Indica all'agente di orchestrazione dove trovare gli agenti remoti. Se imposti questo valore sull'URL di Cloud Run di cui è stato eseguito il deployment (in particolare il percorso della scheda dell'agente), consenti a Orchestrator di rilevare e comunicare con Researcher, Judge e Content Builder su internet.
- Esegui il deployment dei subagenti (in parallelo): per risparmiare tempo, eseguiremo il deployment di Researcher, Judge e Content Builder contemporaneamente.Apri tre nuove schede del terminale. In ogni nuova scheda, esegui il comando seguente per configurare l'ambiente:
cd ~/prai-roadshow-lab-1-starter source .envgcloud run deploy researcher \ --source agents/researcher/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy judge \ --source agents/judge/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy content-builder \ --source agents/content_builder/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true" - Acquisisci gli URL:una volta completati tutti e tre i deployment, torna al terminale originale (dove eseguirai il deployment di Orchestrator). Esegui questi comandi per acquisire gli URL del servizio:
RESEARCHER_URL=$(gcloud run services describe researcher --region us-west1 --format='value(status.url)') JUDGE_URL=$(gcloud run services describe judge --region us-west1 --format='value(status.url)') CONTENT_BUILDER_URL=$(gcloud run services describe content-builder --region us-west1 --format='value(status.url)') echo "Researcher: $RESEARCHER_URL" echo "Judge: $JUDGE_URL" echo "Content Builder: $CONTENT_BUILDER_URL" - Esegui il deployment di Orchestrator:utilizza le variabili di ambiente acquisite per configurare Orchestrator.
gcloud run deploy orchestrator \ --source agents/orchestrator/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars RESEARCHER_AGENT_CARD_URL=$RESEARCHER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars JUDGE_AGENT_CARD_URL=$JUDGE_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars CONTENT_BUILDER_AGENT_CARD_URL=$CONTENT_BUILDER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"ORCHESTRATOR_URL=$(gcloud run services describe orchestrator --region us-west1 --format='value(status.url)') echo $ORCHESTRATOR_URL - Esegui il deployment del frontend:
gcloud run deploy course-creator \ --source app \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars AGENT_SERVER_URL=$ORCHESTRATOR_URL \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT - Testa l'implementazione remota:apri l'URL di Orchestrator di cui è stato eseguito il deployment. Ora viene eseguito interamente nel cloud, utilizzando l'infrastruttura serverless di Google per scalare gli agenti.Suggerimento: troverai tutti i microservizi e i relativi URL nell'interfaccia di Cloud Run.
13. Riepilogo
Complimenti! Hai creato e implementato correttamente un sistema multi-agente distribuito pronto per la produzione.
Cosa abbiamo realizzato
- Decomposizione di un'attività complessa: invece di un unico prompt gigante, abbiamo suddiviso il lavoro in ruoli specializzati (Ricercatore, Giudice, Generatore di contenuti).
- Implementazione del controllo qualità: abbiamo utilizzato un
LoopAgente unJudgestrutturato per garantire che solo le informazioni di alta qualità raggiungano la fase finale. - Creato per la produzione: utilizzando il protocollo Agent-to-Agent (A2A) e Cloud Run, abbiamo creato un sistema in cui ogni agente è un microservizio indipendente e scalabile. Questo approccio è molto più solido rispetto all'esecuzione di tutto in un unico script Python.
- Orchestrazione: abbiamo utilizzato
SequentialAgenteLoopAgentper definire pattern di flusso di controllo chiari.
Passaggi successivi
Ora che hai le basi, puoi estendere questo sistema:
- Aggiungi altri strumenti: concedi al ricercatore l'accesso a documenti o API interni.
- Migliora il giudice: aggiungi criteri più specifici o anche un passaggio "Human in the Loop".
- Scambia modelli: prova a utilizzare modelli diversi per agenti diversi (ad es. un modello più veloce per il giudice, un modello più potente per il creatore di contenuti).
Ora puoi creare flussi di lavoro agentici complessi e affidabili su Google Cloud.