
1. Introdução
Visão geral
Neste laboratório, você vai além dos chatbots simples e cria um sistema multiagente distribuído.
Embora um único LLM possa responder a perguntas, a complexidade do mundo real geralmente exige funções especializadas. Você não pede para o engenheiro de back-end projetar a interface nem para o designer otimizar as consultas de banco de dados. Da mesma forma, podemos criar agentes de IA especializados que se concentram em uma tarefa e se coordenam para resolver problemas complexos.
Você vai criar um sistema de criação de cursos que consiste em:
- Agente de pesquisa: usa o
google_searchpara encontrar informações atualizadas. - Agente de avaliação: critica a pesquisa em relação à qualidade e integridade.
- Agente do Content Builder: transformar a pesquisa em um curso estruturado.
- Agente de orquestração: gerencia o fluxo de trabalho e a comunicação entre esses especialistas.
Pré-requisitos
- Conhecimento básico de Python.
- Familiaridade com o console do Google Cloud.
Atividades deste laboratório
- Defina um agente de uso de ferramentas (
researcher) que possa pesquisar na Web. - Implemente a saída estruturada com Pydantic para
judge. - Conecte-se a agentes remotos usando o protocolo Agent-to-Agent (A2A).
- Construa um
LoopAgentpara criar um ciclo de feedback entre o pesquisador e o avaliador. - Execute o sistema distribuído localmente usando o ADK.
- Implante o sistema multiagente no Google Cloud Run.
Princípios de arquitetura e orquestração
Antes de escrever o código, vamos entender como esses agentes trabalham juntos. Estamos criando um pipeline de criação de cursos.
O design do sistema
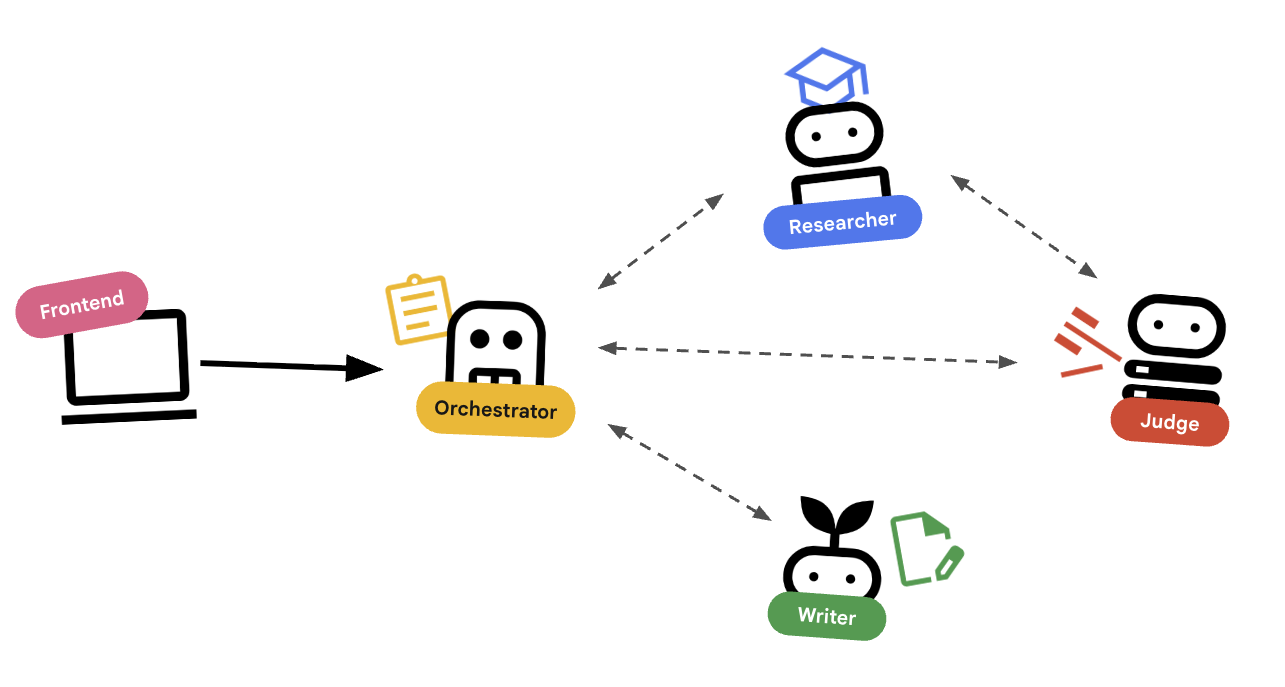
Orquestração com agentes
Os agentes padrão (como o Pesquisador) fazem o trabalho. Os agentes orquestradores (como LoopAgent ou SequentialAgent) gerenciam outros agentes. Elas não têm ferramentas próprias. A "ferramenta" delas é a delegação.
LoopAgent: funciona como um loopwhileno código. Ele executa uma sequência de agentes repetidamente até que uma condição seja atendida (ou o número máximo de iterações seja alcançado). Usamos isso para o ciclo de pesquisa:- O Pesquisador encontra informações.
- Judge faz uma crítica.
- Se o Judge disser "Fail", o EscalationChecker vai permitir que o loop continue.
- Se Judge disser "Pass", o EscalationChecker vai interromper o loop.
SequentialAgent: funciona como uma execução de script padrão. Ele executa agentes um após o outro. Usamos isso para o pipeline de alto nível:- Primeiro, execute o Ciclo de pesquisa até que ele termine com bons dados.
- Em seguida, execute o Criador de conteúdo (para escrever o curso).
Ao combinar esses elementos, criamos um sistema robusto que pode se autocorrigir antes de gerar a saída final.
2. Configuração
Configuração do ambiente
- Abra o Cloud Shell: clique no ícone Ativar o Cloud Shell no canto superior direito do console do Google Cloud.
Acessar o código inicial
- Clone o repositório inicial no seu diretório principal:
cd ~ git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter && cd .. && mv temp-repo/agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter . && rm -rf temp-repo cd prai-roadshow-lab-1-starter - Ativar APIs: execute o seguinte comando para ativar os serviços do Google Cloud necessários:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - Abra essa pasta no editor.
Instalar dependências
Usamos o uv para gerenciamento rápido de dependências.
- Instale as dependências do projeto:
# Ensure you have uv installed: pip install uv uv sync - Configure as variáveis de ambiente.
- Dica: é possível encontrar o ID do projeto no painel do console do Cloud ou executando
gcloud config get-value project.
.envpara armazenar essas variáveis. Assim, você pode recarregá-las facilmente se a sessão for desconectada.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true EOF - Dica: é possível encontrar o ID do projeto no painel do console do Cloud ou executando
- Extraia as variáveis de ambiente:
source .envsource .envpara restaurá-las.
3. 🕵️ O agente de pesquisa
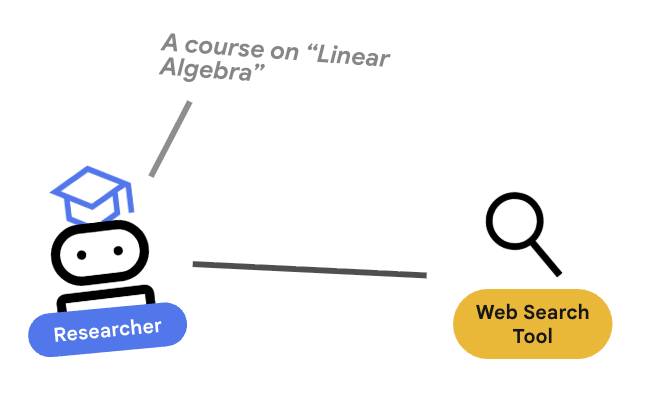
O Pesquisador é um especialista. A única função dele é encontrar informações. Para isso, ele precisa de acesso a uma ferramenta: a Pesquisa Google.
Por que separar o pesquisador?
Análise detalhada:por que não ter apenas um agente para fazer tudo?
Agentes pequenos e focados são mais fáceis de avaliar e depurar. Se a pesquisa for ruim, itere no comando do pesquisador. Se a formatação do curso estiver ruim, faça iterações no Content Builder. Em um comando monolítico "faça tudo", corrigir uma coisa geralmente quebra outra.
- Se você estiver trabalhando no Cloud Shell, execute o seguinte comando para abrir o editor do Cloud Shell:
cloudshell workspace . - Abra
agents/researcher/agent.py. - Você vai ver um esqueleto com um TODO.
- Adicione o seguinte código para definir o agente
researcher:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. DO NOT output any function calls. Provide your research directly as text. """, ) root_agent = researcher
Conceito principal: uso de ferramentas
Ao usar o Gemini 3, a ferramenta Pesquisa Google fica disponível automaticamente. Se você estivesse usando um modelo diferente, como o Gemini 2.5, precisaria transmitir tools=[google_search] como um parâmetro adicional ao construtor Agent(). O ADK lida com a complexidade de descrever essa ferramenta para o LLM. Quando o modelo decide que precisa de informações, ele gera uma chamada de ferramenta estruturada, o ADK executa a função Python google_search e envia o resultado de volta ao modelo.
4. ⚖️ O agente Judge
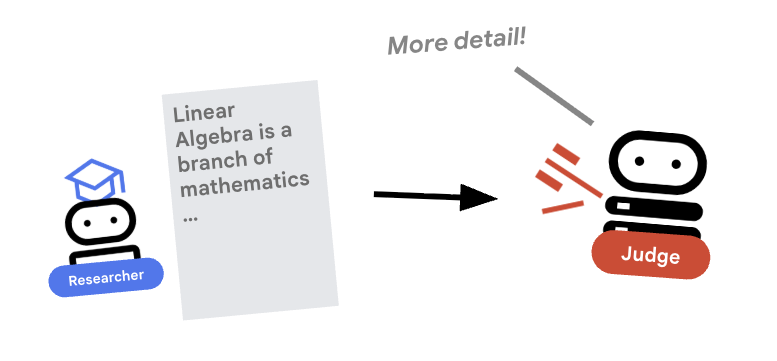
O pesquisador se esforça muito, mas os LLMs podem ser preguiçosos. Precisamos de um juiz para analisar o trabalho. O juiz aceita a pesquisa e retorna uma avaliação estruturada de aprovação/reprovação.
Resposta estruturada
Análise detalhada:para automatizar fluxos de trabalho, precisamos de resultados previsíveis. Uma avaliação de texto confusa é difícil de analisar de forma programática. Ao aplicar um esquema JSON (usando Pydantic), garantimos que o juiz retorne um booleano pass ou fail em que nosso código pode agir de maneira confiável.
- Abra
agents/judge/agent.py. - Defina o esquema
JudgeFeedbacke o agentejudge.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
Conceito principal: restringir o comportamento do agente
Definimos disallow_transfer_to_parent=True e disallow_transfer_to_peers=True. Isso obriga o juiz a apenas retornar o JudgeFeedback estruturado. Ele não pode decidir "conversar" com o usuário ou delegar a outro agente. Isso o torna um componente determinista no nosso fluxo de lógica.
5. 🧪 Teste em isolamento
Antes de conectá-los, podemos verificar se cada agente funciona. O ADK permite executar agentes individualmente.
Conceito principal: o ambiente de execução interativo
O adk run cria um ambiente leve em que você é o "usuário". Isso permite testar as instruções e o uso de ferramentas do agente de maneira isolada. Se o agente falhar aqui (por exemplo, não conseguir usar a Pesquisa Google), ele certamente vai falhar na orquestração.
- Execute o Pesquisador de forma interativa. Observe que apontamos para o diretório específico do agente:
# This runs the researcher agent in interactive mode uv run adk run agents/researcher - No comando de chat, digite:
Find the population of Tokyo in 2020export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true - Saia da conversa (Ctrl+C).
- Execute o Judge de forma interativa:
uv run adk run agents/judge - No comando de chat, simule a entrada:
Topic: Tokyo. Findings: Tokyo is a city.status='fail'porque as descobertas são muito breves.
6. ✍️ O agente do Content Builder
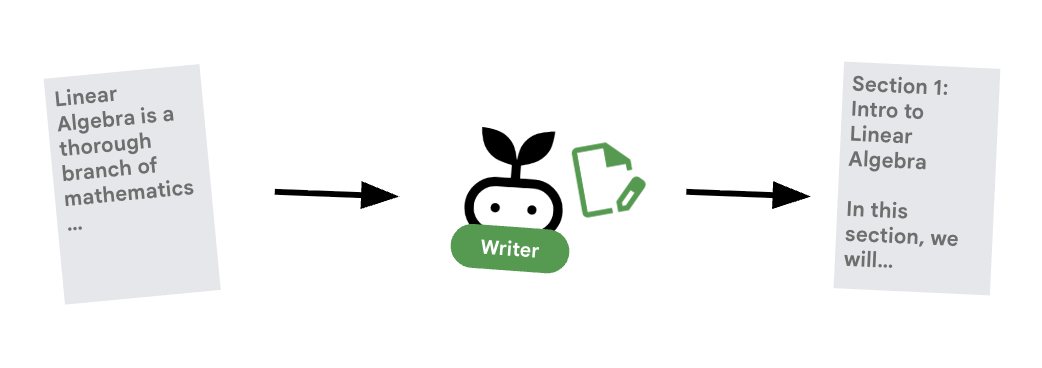
O Criador de conteúdo é o escritor criativo. Ela pega a pesquisa aprovada e a transforma em um curso.
- Abra
agents/content_builder/agent.py. - Defina o agente
content_builder.content_builder = Agent( name="content_builder", model=MODEL, description="Transforms research findings into a structured course.", instruction=""" You are an expert course creator. Take the approved 'research_findings' and transform them into a well-structured, engaging course module. **Formatting Rules:** 1. Start with a main title using a single `#` (H1). 2. Use `##` (H2) for main section headings. 3. Use bullet points and clear paragraphs. 4. Maintain a professional but engaging tone. Ensure the content directly addresses the user's original request. """, ) root_agent = content_builder
Conceito principal: propagação de contexto
Você pode se perguntar: "Como o criador de conteúdo sabe o que o pesquisador encontrou?" No ADK, os agentes em um pipeline compartilham um session.state. Mais tarde, no Orchestrator, vamos configurar o pesquisador e o avaliador para salvar as saídas nesse estado compartilhado. O comando do Content Builder tem acesso a esse histórico.
7. 🎻 O orquestrador
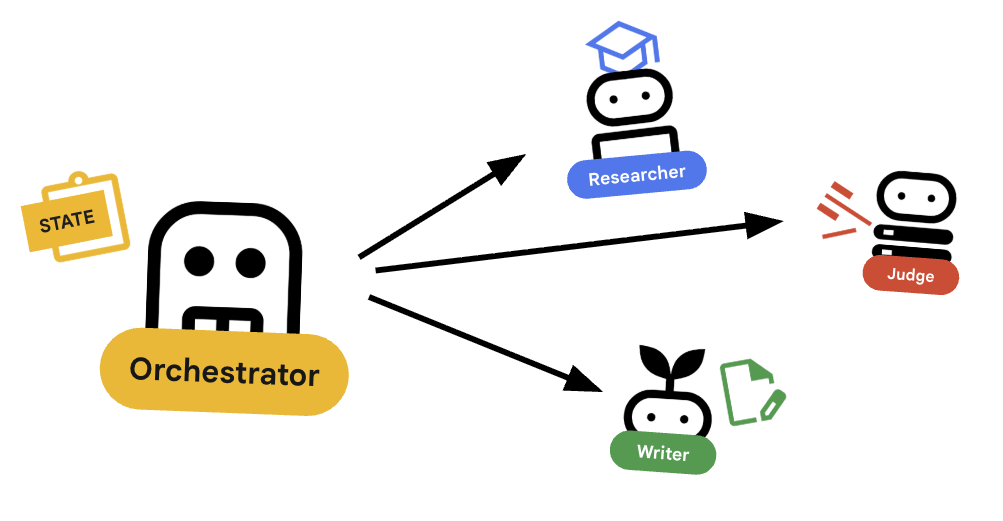
O orquestrador é o gerente da nossa equipe multiagente. Ao contrário dos agentes especializados (Pesquisador, Avaliador, Criador de conteúdo) que realizam tarefas específicas, o trabalho do Orquestrador é coordenar o fluxo de trabalho e garantir que as informações fluam corretamente entre eles.
🌐 A arquitetura: Agent-to-Agent (A2A)
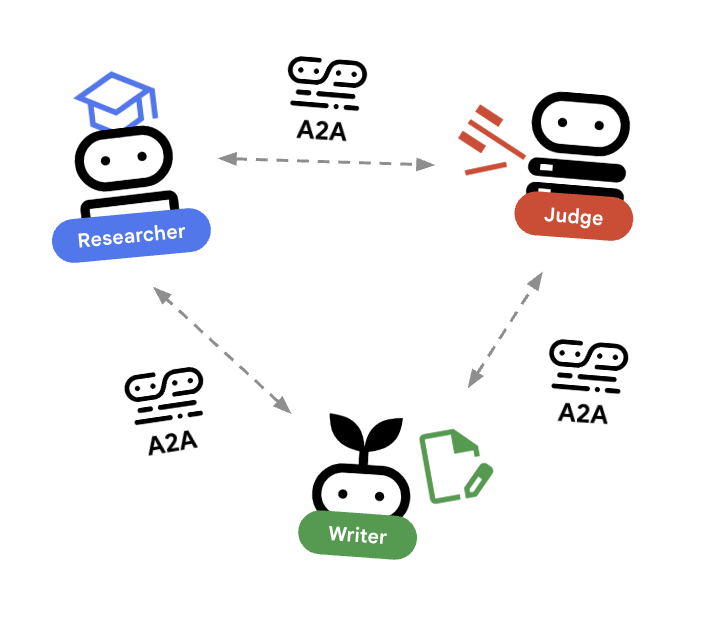
Neste laboratório, vamos criar um sistema distribuído. Em vez de executar todos os agentes em um único processo Python, implantamos como microsserviços independentes. Isso permite que cada agente seja escalonado de forma independente e falhe sem falhar em todo o sistema.
Para isso, usamos o protocolo Agent-to-Agent (A2A).
O protocolo A2A
Análise detalhada:em um sistema de produção, os agentes são executados em servidores diferentes (ou até mesmo em nuvens diferentes). O protocolo A2A cria uma maneira padrão para que eles se descubram e conversem entre si por HTTP. RemoteA2aAgent é o cliente do ADK para esse protocolo.
- Abra
agents/orchestrator/agent.py. - Localize o comentário
# TODO: Define connections to remote agentsou a seção de definições de agente remoto. - Adicione o código a seguir para definir as conexões. Coloque esse depois das importações e antes de qualquer outra definição de agente.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 O verificador de encaminhamento
Um loop precisa de uma maneira de parar. Se o juiz disser "Aprovado", queremos sair do loop imediatamente e passar para o Content Builder.
Lógica personalizada com BaseAgent
Análise detalhada:nem todos os agentes usam LLMs. Às vezes, você precisa de uma lógica simples do Python. BaseAgent permite definir um agente que apenas executa código. Nesse caso, verificamos o estado da sessão e usamos EventActions(escalate=True) para sinalizar a interrupção de LoopAgent.
- Ainda em
agents/orchestrator/agent.py. - Encontre o marcador de posição
EscalationCheckerTODO. - Substitua pela seguinte implementação:
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
Conceito principal: fluxo de controle via eventos
Os agentes se comunicam não apenas com texto, mas também com eventos. Ao gerar um evento com escalate=True, esse agente envia um sinal para o pai dele (o LoopAgent), que é programado para capturar esse sinal e encerrar o loop.LoopAgent
9. 🔁 O ciclo de pesquisa
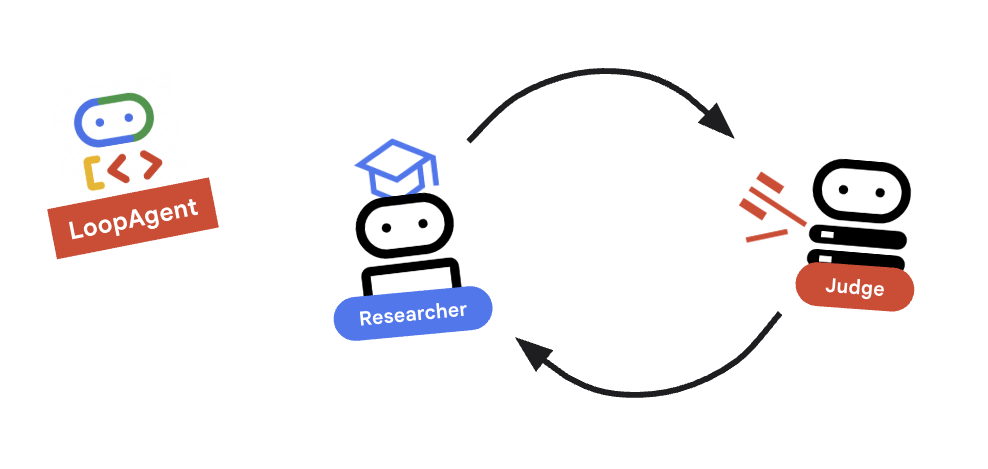
Precisamos de um ciclo de feedback: Pesquisa -> Avaliação -> (Falha) -> Pesquisa -> ...
- Ainda em
agents/orchestrator/agent.py. - Adicione a definição
research_loop. Coloque esse depois da classeEscalationCheckere da instânciaescalation_checker.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
Conceito principal: LoopAgent
O LoopAgent passa pelos sub_agents em ordem.
researcher: encontra dados.judge: avalia dados.escalation_checker: decide se é necessárioyield Event(escalate=True). Seescalate=Trueacontecer, o loop será interrompido antes. Caso contrário, ele será reiniciado no pesquisador (atémax_iterations).
10. 🔗 O pipeline final
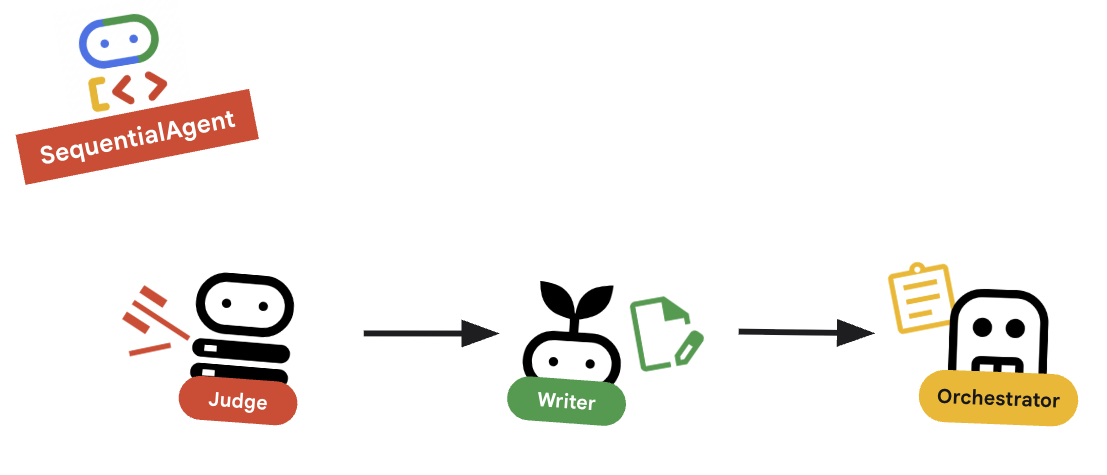
Por fim, junte tudo.
- Ainda em
agents/orchestrator/agent.py. - Defina o
root_agentna parte de baixo do arquivo. Verifique se isso substitui qualquer marcador de posiçãoroot_agent = Noneatual.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
Conceito principal: composição hierárquica
Observe que research_loop é um agente (um LoopAgent). Ele é tratado como qualquer outro subagente no SequentialAgent. Essa capacidade de composição permite criar lógicas complexas aninhando padrões simples (loops dentro de sequências, sequências dentro de roteadores etc.).
11. 💻 Executar localmente
Antes de executar tudo, vamos ver como o ADK simula o ambiente distribuído localmente.
Análise detalhada: como o desenvolvimento local funciona
Em uma arquitetura de microsserviços, cada agente é executado como um servidor independente. Ao implantar, você terá quatro serviços diferentes do Cloud Run. Simular isso localmente pode ser complicado se você tiver que abrir quatro guias de terminal e executar quatro comandos.
Esse script inicia processos uvicorn para o pesquisador (porta 8001), o juiz (8002) e o criador de conteúdo (8003). Ele define variáveis de ambiente, como RESEARCHER_AGENT_CARD_URL, e as transmite ao orquestrador (porta 8004). É exatamente assim que vamos configurar na nuvem mais tarde.
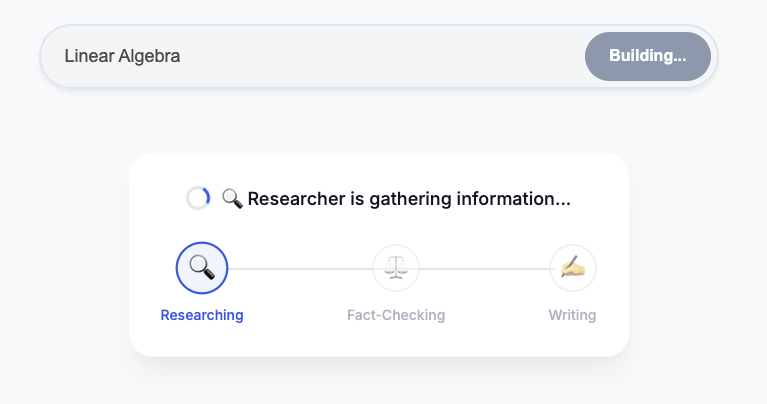
- Execute o script de orquestração:
perl -pi -e 's/us-central1/global/g' run_local.sh ./run_local.sh - Teste:
- Se você estiver usando o Cloud Shell:clique no botão Visualização na Web (canto superior direito do terminal) -> Visualizar na porta 8080 -> Alterar porta para
8000. - Se estiver executando localmente:abra
http://localhost:8000no navegador. - Comando: "Crie um curso sobre a história do café"
- Observação:o Orquestrador vai chamar o pesquisador. A saída vai para o juiz. Se o juiz reprovar, o loop continua.
- "Erro interno do servidor" / Erros de autenticação:se você encontrar erros de autenticação (por exemplo, relacionados a
google-auth), verifique se executougcloud auth application-default loginem uma máquina local. No Cloud Shell, verifique se a variável de ambienteGOOGLE_CLOUD_PROJECTestá definida corretamente. - Erros de terminal:se o comando falhar em uma nova janela de terminal, reexporte as variáveis de ambiente (
GOOGLE_CLOUD_PROJECTetc.).
- Se você estiver usando o Cloud Shell:clique no botão Visualização na Web (canto superior direito do terminal) -> Visualizar na porta 8080 -> Alterar porta para
- Teste de agentes isolados:mesmo quando o sistema completo está em execução, é possível testar agentes específicos segmentando as portas deles diretamente. Isso é útil para depurar um componente específico sem acionar toda a cadeia.Observação:esses são endpoints de API, não páginas da Web. Não é possível acessá-los por um navegador. Em vez disso, use
curlpara verificar se eles estão em execução (por exemplo, buscando o card do agente).- Somente pesquisador (porta 8001):
- Verifique o status (e encontre o endpoint
url):curl http://localhost:8001/a2a/agent/.well-known/agent-card.json - Envie uma consulta (usando o protocolo JSON-RPC A2A):
curl -X POST http://localhost:8001/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-1", "role": "user", "parts": [ { "text": "What is the capital of France?", "kind": "text" } ] } } }'
- Verifique o status (e encontre o endpoint
- Somente juiz (porta 8002):
- Verificar status:
curl http://localhost:8002/a2a/agent/.well-known/agent-card.json - Envie uma consulta:
curl -X POST http://localhost:8002/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-2", "role": "user", "parts": [ { "text": "Topic: Tokyo. Findings: Tokyo is the capital of Japan.", "kind": "text" } ] } } }'
- Verificar status:
- Somente o Content Builder (porta 8003):
curl http://localhost:8003/a2a/agent/.well-known/agent-card.json - Orchestrator (porta 8004):
curl http://localhost:8004/a2a/agent/.well-known/agent-card.json
- Somente pesquisador (porta 8001):
12. 🚀 Implantar no Cloud Run
A validação final é executada na nuvem. Vamos implantar cada agente como um serviço separado.
Noções básicas sobre a configuração da implantação
Ao implantar agentes no Cloud Run, transmitimos várias variáveis de ambiente para configurar o comportamento e a conectividade deles:
GOOGLE_CLOUD_PROJECT: garante que o agente use o projeto correto do Google Cloud para geração de registros e chamadas da Vertex AI.GOOGLE_GENAI_USE_VERTEXAI: informa à estrutura do agente (ADK) para usar a Vertex AI na inferência de modelos em vez de chamar as APIs Gemini diretamente.GOOGLE_CLOUD_LOCATION: informa ao framework do agente (ADK) qual endpoint usar.[AGENT]_AGENT_CARD_URL: é crucial para o Orchestrator. Ele informa ao orquestrador onde encontrar os agentes remotos. Ao definir isso como o URL implantado do Cloud Run (especificamente o caminho do card do agente), permitimos que o orquestrador descubra e se comunique com o pesquisador, o avaliador e o criador de conteúdo pela Internet.
- Implante os subagentes (paralelo): para economizar tempo, vamos implantar o pesquisador, o avaliador e o criador de conteúdo simultaneamente.Abra três novas guias do terminal. Em cada nova guia, execute o seguinte para configurar seu ambiente:
cd ~/prai-roadshow-lab-1-starter source .envgcloud run deploy researcher \ --source agents/researcher/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy judge \ --source agents/judge/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy content-builder \ --source agents/content_builder/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true" - Capture os URLs:depois que todas as três implantações forem concluídas, volte ao terminal original (onde você vai implantar o Orchestrator). Execute os comandos a seguir para capturar os URLs de serviço:
RESEARCHER_URL=$(gcloud run services describe researcher --region us-west1 --format='value(status.url)') JUDGE_URL=$(gcloud run services describe judge --region us-west1 --format='value(status.url)') CONTENT_BUILDER_URL=$(gcloud run services describe content-builder --region us-west1 --format='value(status.url)') echo "Researcher: $RESEARCHER_URL" echo "Judge: $JUDGE_URL" echo "Content Builder: $CONTENT_BUILDER_URL" - Implante o Orchestrator:use as variáveis de ambiente capturadas para configurar o Orchestrator.
gcloud run deploy orchestrator \ --source agents/orchestrator/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars RESEARCHER_AGENT_CARD_URL=$RESEARCHER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars JUDGE_AGENT_CARD_URL=$JUDGE_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars CONTENT_BUILDER_AGENT_CARD_URL=$CONTENT_BUILDER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"ORCHESTRATOR_URL=$(gcloud run services describe orchestrator --region us-west1 --format='value(status.url)') echo $ORCHESTRATOR_URL - Implante o front-end:
gcloud run deploy course-creator \ --source app \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars AGENT_SERVER_URL=$ORCHESTRATOR_URL \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT - Teste a implantação remota:abra o URL do Orchestrator implantado. Agora ele é executado totalmente na nuvem, usando a infraestrutura sem servidor do Google para escalonar seus agentes.Dica: você encontra todos os microsserviços e os URLs deles na interface do Cloud Run.
13. Resumo
Parabéns! Você criou e implantou um sistema multiagente distribuído pronto para produção.
O que já fizemos
- Decomposição de uma tarefa complexa: em vez de um comando gigante, dividimos o trabalho em funções especializadas (pesquisador, avaliador, criador de conteúdo).
- Controle de qualidade implementado: usamos um
LoopAgente umJudgeestruturado para garantir que apenas informações de alta qualidade cheguem à etapa final. - Criado para produção: usando o protocolo Agent-to-Agent (A2A) e o Cloud Run, criamos um sistema em que cada agente é um microsserviço independente e escalonável. Isso é muito mais robusto do que executar tudo em um único script Python.
- Orquestração: usamos
SequentialAgenteLoopAgentpara definir padrões claros de fluxo de controle.
Próximas etapas
Agora que você tem a base, pode estender este sistema:
- Adicionar mais ferramentas: dê ao pesquisador acesso a documentos internos ou APIs.
- Melhore o julgamento: adicione critérios mais específicos ou até mesmo uma etapa de "Human in the Loop".
- Trocar modelos: use modelos diferentes para agentes diferentes (por exemplo, um modelo mais rápido para o juiz e um modelo mais eficiente para o escritor de conteúdo).
Agora você já sabe como criar fluxos de trabalho de agentes complexos e confiáveis no Google Cloud.