
1. บทนำ
ภาพรวม
ในแล็บนี้ คุณจะได้สร้างระบบแบบหลาย Agent แบบกระจายที่ซับซ้อนกว่าแชทบอททั่วไป
แม้ว่า LLM เดียวจะตอบคำถามได้ แต่ความซับซ้อนในโลกแห่งความเป็นจริงมักต้องมีบทบาทเฉพาะทาง คุณจะไม่ขอให้วิศวกรแบ็กเอนด์ออกแบบ UI และจะไม่ขอให้นักออกแบบเพิ่มประสิทธิภาพการค้นหาฐานข้อมูล ในทำนองเดียวกัน เราสามารถสร้างเอเจนต์ AI เฉพาะทางที่มุ่งเน้นงานเดียวและประสานงานกันเพื่อแก้ปัญหาที่ซับซ้อนได้
คุณจะสร้างระบบการสร้างหลักสูตรซึ่งประกอบด้วย
- Agent นักวิจัย: ใช้
google_searchเพื่อค้นหาข้อมูลล่าสุด - ผู้ตัดสิน Agent: วิจารณ์งานวิจัยเพื่อดูคุณภาพและความสมบูรณ์
- เอเจนต์ตัวสร้างเนื้อหา: เปลี่ยนงานวิจัยให้เป็นหลักสูตรที่มีโครงสร้าง
- Orchestrator Agent: จัดการเวิร์กโฟลว์และการสื่อสารระหว่างผู้เชี่ยวชาญเหล่านี้
ข้อกำหนดเบื้องต้น
- มีความรู้พื้นฐานเกี่ยวกับ Python
- คุ้นเคยกับคอนโซล Google Cloud
สิ่งที่คุณต้องดำเนินการ
- กำหนดเอเจนต์ที่ใช้เครื่องมือ (
researcher) ซึ่งค้นหาในเว็บได้ - ใช้เอาต์พุตที่มีโครงสร้างด้วย Pydantic สำหรับ
judge - เชื่อมต่อกับเอเจนต์ระยะไกลโดยใช้โปรโตคอลAgent-to-Agent (A2A)
- สร้าง
LoopAgentเพื่อสร้างวงจรความคิดเห็นระหว่างนักวิจัยกับผู้ตัดสิน - เรียกใช้ระบบแบบกระจายในเครื่องโดยใช้ ADK
- ติดตั้งใช้งานระบบแบบหลาย Agent ใน Google Cloud Run
หลักการด้านสถาปัตยกรรมและการจัดการเป็นกลุ่ม
ก่อนที่จะเขียนโค้ด เรามาทำความเข้าใจวิธีการทำงานร่วมกันของเอเจนต์เหล่านี้กันก่อน เรากำลังสร้างไปป์ไลน์การสร้างหลักสูตร
การออกแบบระบบ
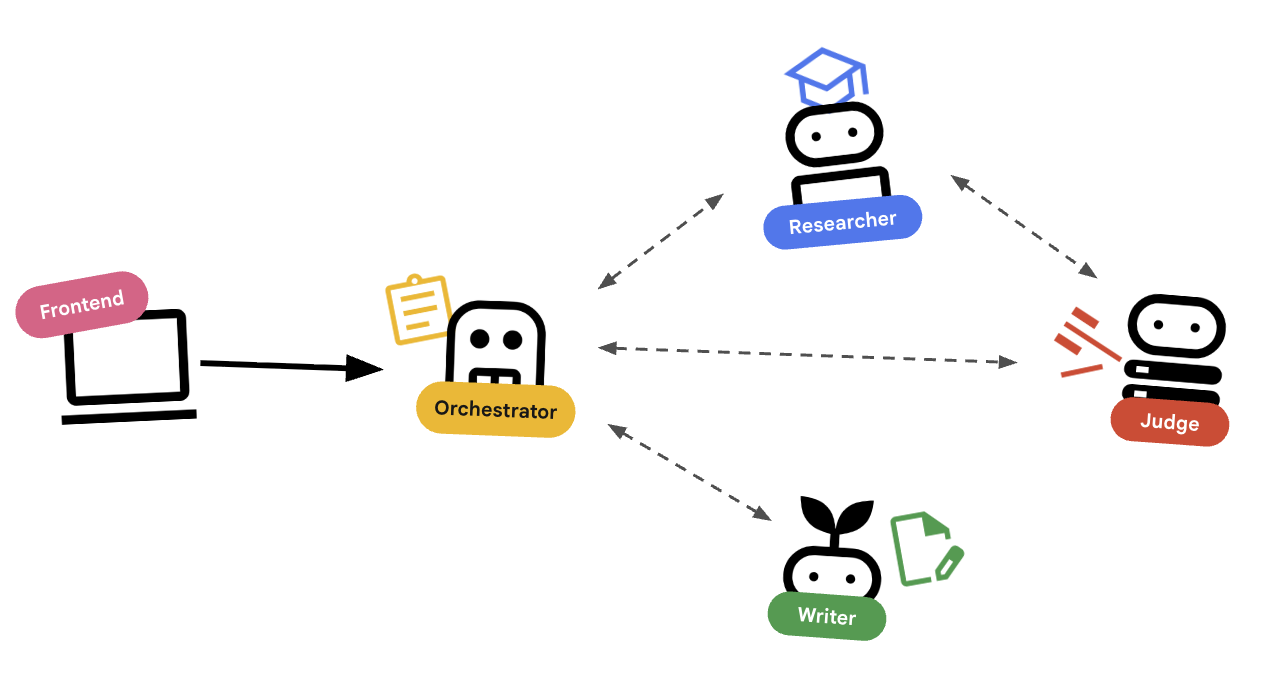
การประสานงานด้วย Agent
เอเจนต์มาตรฐาน (เช่น นักวิจัย) จะทำงาน เอเจนต์ Orchestrator (เช่น LoopAgent หรือ SequentialAgent) จะจัดการเอเจนต์อื่นๆ โดยที่ผู้จัดการไม่ได้มีเครื่องมือของตัวเอง แต่ "เครื่องมือ" ของผู้จัดการคือการมอบหมายงาน
LoopAgent: การดำเนินการนี้จะทำงานเหมือนลูปwhileในโค้ด โดยจะเรียกใช้ลำดับของเอเจนต์ซ้ำๆ จนกว่าจะเป็นไปตามเงื่อนไข (หรือถึงการวนซ้ำสูงสุด) เราใช้ข้อมูลนี้สำหรับวงจรการวิจัย ดังนี้- นักวิจัยค้นหาข้อมูล
- ผู้พิพากษาวิจารณ์
- หาก Judge ระบุว่า "ไม่สำเร็จ" EscalationChecker จะทำให้ลูปดำเนินการต่อไป
- หากผู้ตรวจสอบพูดว่า "ผ่าน" EscalationChecker จะหยุดการวนซ้ำ
SequentialAgent: การดำเนินการนี้จะเหมือนกับการเรียกใช้สคริปต์มาตรฐาน โดยจะเรียกใช้ Agent ทีละตัว เราใช้ข้อมูลนี้สำหรับไปป์ไลน์ระดับสูง- ก่อนอื่น ให้เรียกใช้วงจรการวิจัย (จนกว่าจะเสร็จสิ้นด้วยข้อมูลที่ดี)
- จากนั้นเรียกใช้เครื่องมือสร้างเนื้อหา (เพื่อเขียนหลักสูตร)
การรวมทั้ง 2 อย่างนี้เข้าด้วยกันทำให้เราสร้างระบบที่มีประสิทธิภาพซึ่งสามารถแก้ไขตัวเองได้ก่อนที่จะสร้างเอาต์พุตสุดท้าย
2. ตั้งค่า
การตั้งค่าสภาพแวดล้อม
- เปิด Cloud Shell: คลิกไอคอนเปิดใช้งาน Cloud Shell ที่ด้านขวาบนของคอนโซล Google Cloud
รับโค้ดเริ่มต้น
- โคลนที่เก็บเริ่มต้นลงในไดเรกทอรีหลัก
cd ~ git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter && cd .. && mv temp-repo/agents/build-with-ai/production-ready-ai/prai-roadshow-lab-1-starter . && rm -rf temp-repo cd prai-roadshow-lab-1-starter - เปิดใช้ API: เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดใช้บริการ Google Cloud ที่จำเป็น
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - เปิดโฟลเดอร์นี้ในโปรแกรมแก้ไข
ติดตั้งการอ้างอิง
เราใช้ uv เพื่อการจัดการทรัพยากร Dependency ที่รวดเร็ว
- ติดตั้งการอ้างอิงของโปรเจ็กต์ด้วยคำสั่งต่อไปนี้
# Ensure you have uv installed: pip install uv uv sync - ตั้งค่าตัวแปรสภาพแวดล้อม
- เคล็ดลับ: คุณดูรหัสโปรเจ็กต์ได้ในแดชบอร์ด Cloud Console หรือโดยการเรียกใช้
gcloud config get-value project
.envเพื่อจัดเก็บตัวแปรเหล่านี้เพื่อให้คุณโหลดซ้ำได้ง่ายๆ หากเซสชันขาดการเชื่อมต่อcat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true EOF - เคล็ดลับ: คุณดูรหัสโปรเจ็กต์ได้ในแดชบอร์ด Cloud Console หรือโดยการเรียกใช้
- ส่งออกตัวแปรสภาพแวดล้อม
source .envsource .envเพื่อกู้คืน
3. 🕵️ Agent ผู้ช่วยค้นคว้าวิจัย
นักวิจัยคือผู้เชี่ยวชาญ หน้าที่ของเครื่องมือนี้มีเพียงการค้นหาข้อมูล โดยต้องมีสิทธิ์เข้าถึงเครื่องมือ Google Search
เหตุใดจึงแยก Researcher
เจาะลึก: ทำไมไม่ใช้ตัวแทนคนเดียวทำทุกอย่าง
เอเจนต์ขนาดเล็กที่มุ่งเน้นเฉพาะทางจะประเมินและแก้ไขข้อบกพร่องได้ง่ายกว่า หากการค้นหาไม่ดี ให้ทำซ้ำพรอมต์ของ Researcher หากการจัดรูปแบบหลักสูตรไม่ดี คุณจะทำซ้ำในเครื่องมือสร้างเนื้อหา ในพรอมต์แบบโมโนลิธที่ "ทำทุกอย่าง" การแก้ไขสิ่งหนึ่งมักจะทำให้สิ่งอื่นเสีย
- หากคุณทำงานใน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้เพื่อเปิด Cloud Shell Editor
cloudshell workspace . - เปิด
agents/researcher/agent.py - คุณจะเห็นโครงสร้างที่มี TODO
- เพิ่มโค้ดต่อไปนี้เพื่อกำหนด
researcherเอเจนต์# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. DO NOT output any function calls. Provide your research directly as text. """, ) root_agent = researcher
แนวคิดหลัก: การใช้เครื่องมือ
เมื่อใช้ Gemini 3 เครื่องมือ Google Search จะพร้อมใช้งานโดยอัตโนมัติ หากคุณใช้โมเดลอื่น เช่น Gemini 2.5 คุณจะต้องส่ง tools=[google_search] เป็นพารามิเตอร์เพิ่มเติมไปยังตัวสร้าง Agent() ADK จะจัดการความซับซ้อนของการอธิบายเครื่องมือนี้ให้ LLM เมื่อโมเดลตัดสินใจว่าต้องการข้อมูล โมเดลจะสร้างการเรียกใช้เครื่องมือที่มีโครงสร้าง ADK จะเรียกใช้ฟังก์ชัน Python google_search และส่งผลลัพธ์กลับไปยังโมเดล
4. ⚖️ ตัวแทนผู้พิพากษา
แม้ว่าโปรแกรมค้นหาจะทำงานอย่างหนัก แต่ LLM อาจทำงานแบบขี้เกียจ เราต้องการผู้พิพากษาเพื่อตรวจสอบผลงาน กรรมการจะยอมรับการวิจัยและส่งผลการประเมินแบบผ่าน/ไม่ผ่านที่มีโครงสร้าง
เอาต์พุตที่มีโครงสร้าง
เจาะลึก: เราต้องมีเอาต์พุตที่คาดการณ์ได้เพื่อทำให้เวิร์กโฟลว์เป็นอัตโนมัติ การรีวิวแบบข้อความที่ยาวเหยียดจะแยกวิเคราะห์โดยอัตโนมัติได้ยาก การบังคับใช้สคีมา JSON (โดยใช้ Pydantic) ช่วยให้มั่นใจได้ว่า Judge จะแสดงผลบูลีน pass หรือ fail ที่โค้ดของเราสามารถดำเนินการได้อย่างน่าเชื่อถือ
- เปิด
agents/judge/agent.py - กำหนดสคีมา
JudgeFeedbackและ Agentjudge# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
แนวคิดหลัก: การจำกัดลักษณะการทำงานของ Agent
เราตั้งค่า disallow_transfer_to_parent=True และ disallow_transfer_to_peers=True ซึ่งจะบังคับให้โมเดล แสดงเฉพาะ JudgeFeedback ที่มีโครงสร้าง โดยไม่สามารถตัดสินใจที่จะ "แชท" กับผู้ใช้หรือมอบหมายให้ตัวแทนรายอื่น ซึ่งทำให้เป็นคอมโพเนนต์ที่กำหนดได้ในโฟลว์ตรรกะของเรา
5. 🧪 การทดสอบแบบแยก
ก่อนเชื่อมต่อ เราสามารถยืนยันได้ว่าเอเจนต์แต่ละรายทำงานได้ ADK ช่วยให้คุณเรียกใช้เอเจนต์แต่ละตัวได้
แนวคิดหลัก: รันไทม์แบบอินเทอร์แอกทีฟ
adk run จะสร้างสภาพแวดล้อมที่มีน้ำหนักเบาซึ่งคุณเป็น "ผู้ใช้" ซึ่งช่วยให้คุณทดสอบวิธีการของเอเจนต์และการใช้เครื่องมือแยกกันได้ หากเอเจนต์ทำงานไม่สำเร็จในขั้นตอนนี้ (เช่น ใช้ Google Search ไม่ได้) ก็จะทำงานไม่สำเร็จในการจัดระเบียบอย่างแน่นอน
- เรียกใช้ Researcher แบบอินเทอร์แอกทีฟ โปรดทราบว่าเราชี้ไปยังไดเรกทอรีตัวแทนที่เฉพาะเจาะจง
# This runs the researcher agent in interactive mode uv run adk run agents/researcher - พิมพ์ข้อความต่อไปนี้ในพรอมต์แชท
Find the population of Tokyo in 2020export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=true - ออกจากแชท (Ctrl+C)
- เรียกใช้ Judge แบบอินเทอร์แอกทีฟ
uv run adk run agents/judge - ในพรอมต์แชท ให้จำลองอินพุตดังนี้
Topic: Tokyo. Findings: Tokyo is a city.status='fail'เนื่องจากผลการค้นหาสั้นเกินไป
6. ✍️ เอเจนต์สร้างเนื้อหา
เครื่องมือสร้างเนื้อหาคือผู้เขียนครีเอทีฟโฆษณา โดยจะนำงานวิจัยที่ได้รับอนุมัติมาเปลี่ยนเป็นหลักสูตร
- เปิด
agents/content_builder/agent.py - กำหนด
content_builderเอเจนต์content_builder = Agent( name="content_builder", model=MODEL, description="Transforms research findings into a structured course.", instruction=""" You are an expert course creator. Take the approved 'research_findings' and transform them into a well-structured, engaging course module. **Formatting Rules:** 1. Start with a main title using a single `#` (H1). 2. Use `##` (H2) for main section headings. 3. Use bullet points and clear paragraphs. 4. Maintain a professional but engaging tone. Ensure the content directly addresses the user's original request. """, ) root_agent = content_builder
แนวคิดหลัก: การส่งต่อบริบท
คุณอาจสงสัยว่า "เครื่องมือสร้างเนื้อหารู้ได้อย่างไรว่าเครื่องมือวิจัยค้นพบอะไร" ใน ADK เอเจนต์ในไปป์ไลน์จะแชร์ session.state ต่อมาใน Orchestrator เราจะกำหนดค่า Researcher และ Judge ให้บันทึกเอาต์พุตไปยังสถานะที่แชร์นี้ พรอมต์ของเครื่องมือสร้างเนื้อหาจะเข้าถึงประวัติการสนทนานี้ได้อย่างมีประสิทธิภาพ
7. 🎻 The Orchestrator
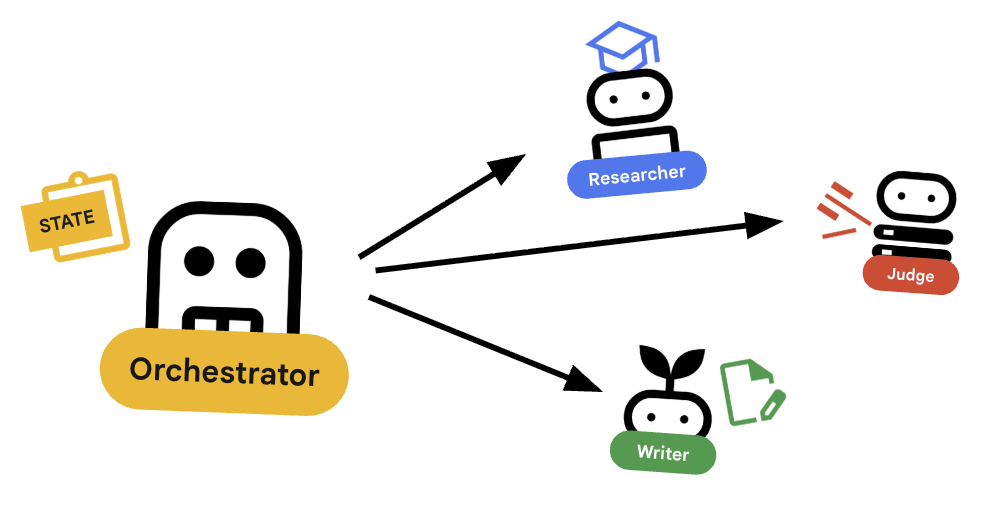
Orchestrator เป็นผู้จัดการทีมแบบหลายเอเจนต์ของเรา ซึ่งแตกต่างจากเอเจนต์ผู้เชี่ยวชาญ (นักวิจัย ผู้ตัดสิน ผู้สร้างเนื้อหา) ที่ทำหน้าที่เฉพาะเจาะจง งานของ Orchestrator คือการประสานงานเวิร์กโฟลว์และตรวจสอบว่าข้อมูลไหลเวียนระหว่างเอเจนต์อย่างถูกต้อง
🌐 สถาปัตยกรรม: ตัวแทนถึงตัวแทน (A2A)
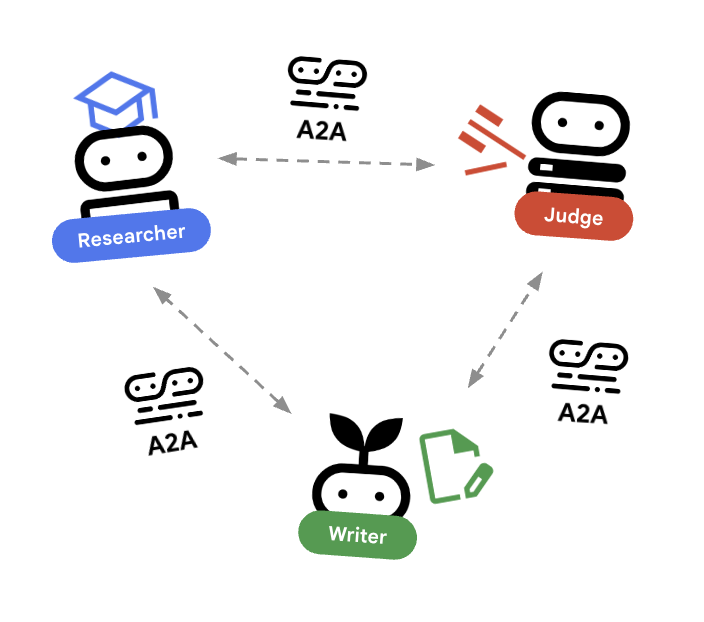
ใน Lab นี้ เราจะสร้างระบบแบบกระจาย เราจะทำให้เอเจนต์ทำงานเป็นไมโครเซอร์วิสอิสระแทนที่จะให้ทำงานทั้งหมดในกระบวนการ Python เดียว ซึ่งช่วยให้แต่ละเอเจนต์ปรับขนาดได้อย่างอิสระและล้มเหลวได้โดยไม่ทำให้ระบบทั้งหมดล่ม
เราใช้โปรโตคอลAgent-to-Agent (A2A) เพื่อให้การดำเนินการนี้เป็นไปได้
โปรโตคอล A2A
เจาะลึก: ในระบบที่ใช้งานจริง เอเจนต์จะทำงานบนเซิร์ฟเวอร์ที่แตกต่างกัน (หรือแม้แต่ในระบบคลาวด์ที่แตกต่างกัน) โปรโตคอล A2A สร้างวิธีมาตรฐานให้ค้นพบและสื่อสารกันผ่าน HTTP RemoteA2aAgent เป็นไคลเอ็นต์ ADK สำหรับโปรโตคอลนี้
- เปิด
agents/orchestrator/agent.py - ค้นหาความคิดเห็น
# TODO: Define connections to remote agentsหรือส่วนคำจำกัดความของ Agent ระยะไกล - เพิ่มโค้ดต่อไปนี้เพื่อกำหนดการเชื่อมต่อ โปรดวางไว้หลังการนำเข้าและก่อนคำจำกัดความของเอเจนต์อื่นๆ
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 เครื่องมือตรวจสอบการยกระดับ
ลูปต้องมีวิธีหยุด หากผู้พิพากษาพูดว่า "ผ่าน" เราต้องการออกจากลูปทันทีและไปที่เครื่องมือสร้างเนื้อหา
ตรรกะที่กำหนดเองด้วย BaseAgent
เจาะลึก: ตัวแทนบางรายไม่ได้ใช้ LLM บางครั้งคุณก็ต้องการตรรกะ Python ที่เรียบง่าย BaseAgent ช่วยให้คุณกำหนด Agent ที่เรียกใช้โค้ดเท่านั้นได้ ในกรณีนี้ เราจะตรวจสอบสถานะเซสชันและใช้ EventActions(escalate=True) เพื่อส่งสัญญาณให้ LoopAgent หยุด
- ยังอยู่ใน
agents/orchestrator/agent.py - ค้นหาตัวยึดตําแหน่ง
EscalationCheckerTODO - แทนที่ด้วยการติดตั้งใช้งานต่อไปนี้
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
แนวคิดหลัก: การควบคุมโฟลว์ผ่านเหตุการณ์
Agent ไม่ได้สื่อสารด้วยข้อความเท่านั้น แต่ยังสื่อสารด้วยเหตุการณ์ด้วย เมื่อส่งเหตุการณ์ด้วย escalate=True เอเจนต์นี้จะส่งสัญญาณไปยังองค์ประกอบระดับบนสุด (LoopAgent) โดย LoopAgent ได้รับการตั้งโปรแกรมให้ตรวจจับสัญญาณนี้และสิ้นสุดลูป
9. 🔁 วงจรการวิจัย
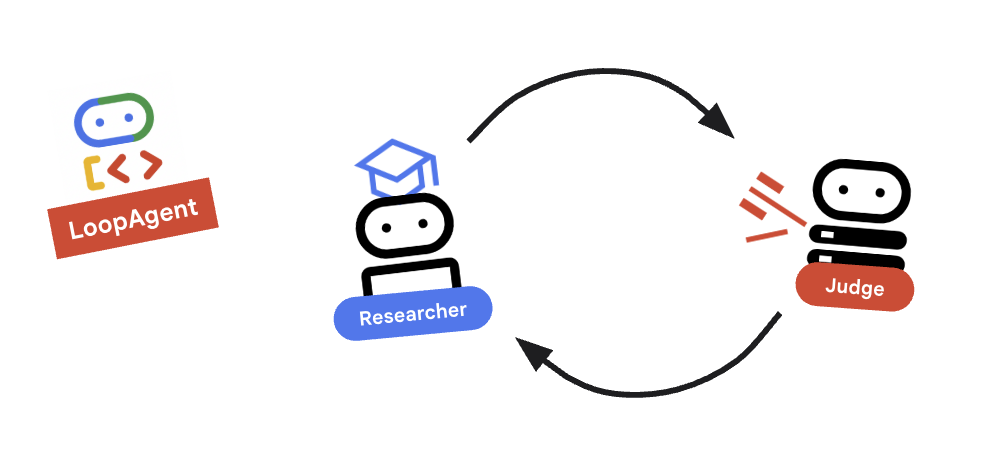
เราต้องการวงจรความคิดเห็น: การวิจัย -> การตัดสิน -> (ล้มเหลว) -> การวิจัย -> ...
- ยังอยู่ใน
agents/orchestrator/agent.py - เพิ่มคำจำกัดความของ
research_loopวางไว้หลังคลาสEscalationCheckerและอินสแตนซ์escalation_checkerresearch_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
แนวคิดหลัก: LoopAgent
LoopAgent จะsub_agentsตามลำดับ
researcher: ค้นหาข้อมูลjudge: ประเมินข้อมูลescalation_checker: ตัดสินใจว่าจะyield Event(escalate=True)หรือไม่ หากescalate=Trueเกิดขึ้น ลูปจะหยุดก่อนกำหนด มิเช่นนั้น ระบบจะรีสตาร์ทที่ผู้เข้าร่วมการวิจัย (สูงสุดmax_iterations)
10. 🔗 ไปป์ไลน์สุดท้าย
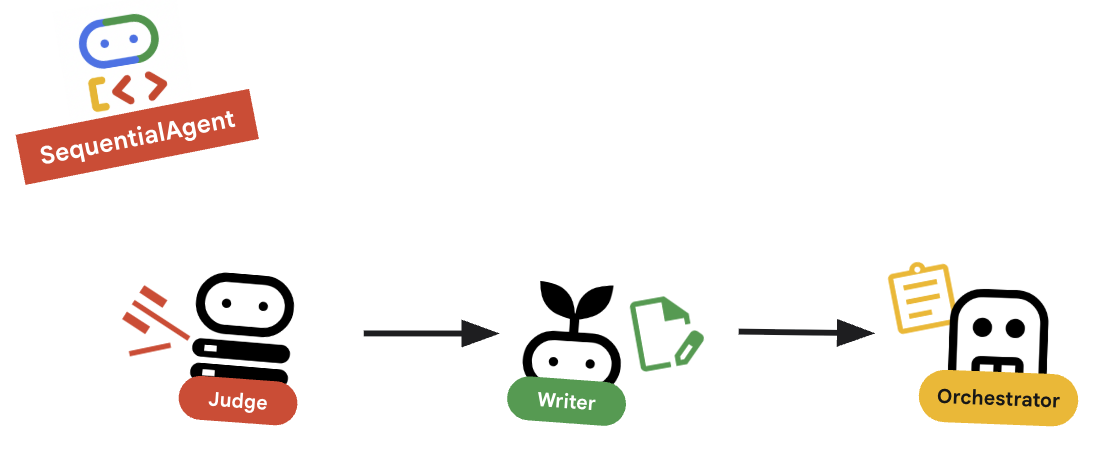
สุดท้ายก็เย็บทุกอย่างเข้าด้วยกัน
- ยังอยู่ใน
agents/orchestrator/agent.py - กำหนด
root_agentที่ด้านล่างของไฟล์ ตรวจสอบว่าข้อความนี้แทนที่ตัวยึดตำแหน่งroot_agent = Noneที่มีอยู่root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
แนวคิดหลัก: การจัดองค์ประกอบแบบลำดับชั้น
โปรดทราบว่า research_loop เป็น Agent (LoopAgent) เราจะถือว่า research_loop เป็นเหมือน Agent ย่อยอื่นๆ ใน SequentialAgent ความสามารถในการประกอบนี้ช่วยให้คุณสร้างตรรกะที่ซับซ้อนได้โดยการซ้อนรูปแบบที่เรียบง่าย (ลูปภายในลำดับ ลำดับภายในเราเตอร์ ฯลฯ)
11. 💻 เรียกใช้ในเครื่อง
ก่อนที่จะเรียกใช้ทุกอย่าง มาดูวิธีที่ ADK จำลองสภาพแวดล้อมแบบกระจายในเครื่องกันก่อน
เจาะลึก: วิธีการทำงานของการพัฒนาในพื้นที่
ในสถาปัตยกรรมแบบไมโครเซอร์วิส เอเจนต์ทุกตัวจะทำงานเป็นเซิร์ฟเวอร์ของตัวเอง เมื่อทำการติดตั้งใช้งาน คุณจะมีบริการ Cloud Run 4 รายการที่แตกต่างกัน การจำลองนี้ในเครื่องอาจเป็นเรื่องยากหากคุณต้องเปิดแท็บเทอร์มินัล 4 แท็บและเรียกใช้คำสั่ง 4 คำสั่ง
สคริปต์นี้จะเริ่มกระบวนการ uvicorn สำหรับ Researcher (พอร์ต 8001), Judge (8002) และ Content Builder (8003) โดยจะตั้งค่าตัวแปรสภาพแวดล้อม เช่น RESEARCHER_AGENT_CARD_URL และส่งไปยัง Orchestrator (พอร์ต 8004) นี่คือวิธีที่เราจะกำหนดค่าในระบบคลาวด์ในภายหลัง
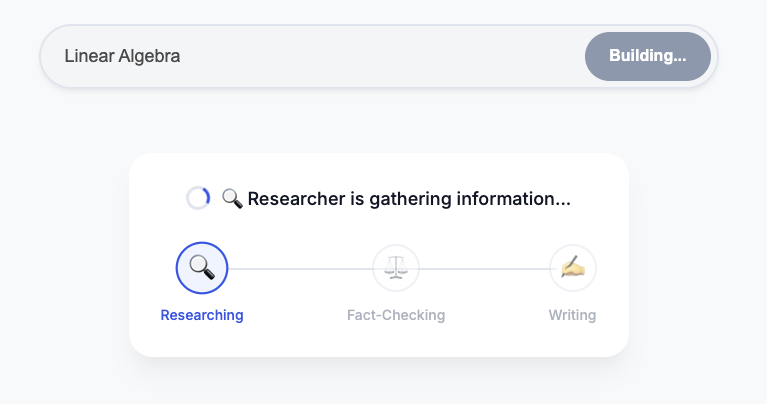
- เรียกใช้สคริปต์การจัดระเบียบ
perl -pi -e 's/us-central1/global/g' run_local.sh ./run_local.sh - ทดสอบ
- หากใช้ Cloud Shell: คลิกปุ่มตัวอย่างเว็บ (ด้านขวาบนของเทอร์มินัล) -> แสดงตัวอย่างบนพอร์ต 8080 -> เปลี่ยนพอร์ตเป็น
8000 - หากเรียกใช้ในเครื่อง: เปิด
http://localhost:8000ในเบราว์เซอร์ - พรอมต์: "สร้างหลักสูตรเกี่ยวกับประวัติศาสตร์ของกาแฟ"
- สังเกต: Orchestrator จะโทรหานักวิจัย โดยเอาต์พุตจะส่งไปยังผู้พิพากษา หากกรรมการไม่เห็นด้วย วงจรก็จะดำเนินต่อไป
- "ข้อผิดพลาดเกี่ยวกับเซิร์ฟเวอร์ภายใน" / ข้อผิดพลาดในการตรวจสอบสิทธิ์: หากพบข้อผิดพลาดในการตรวจสอบสิทธิ์ (เช่น เกี่ยวข้องกับ
google-auth) ให้ตรวจสอบว่าคุณได้เรียกใช้gcloud auth application-default loginแล้วหากเรียกใช้ในเครื่อง ใน Cloud Shell ให้ตรวจสอบว่าได้ตั้งค่าGOOGLE_CLOUD_PROJECTตัวแปรสภาพแวดล้อมอย่างถูกต้อง - ข้อผิดพลาดของเทอร์มินัล: หากคำสั่งล้มเหลวในหน้าต่างเทอร์มินัลใหม่ อย่าลืมส่งออกตัวแปรสภาพแวดล้อมอีกครั้ง (
GOOGLE_CLOUD_PROJECTฯลฯ)
- หากใช้ Cloud Shell: คลิกปุ่มตัวอย่างเว็บ (ด้านขวาบนของเทอร์มินัล) -> แสดงตัวอย่างบนพอร์ต 8080 -> เปลี่ยนพอร์ตเป็น
- การทดสอบเอเจนต์แบบแยกกัน: แม้ว่าระบบทั้งหมดจะทำงานอยู่ คุณก็สามารถทดสอบเอเจนต์ที่เฉพาะเจาะจงได้โดยกำหนดเป้าหมายไปยังพอร์ตของเอเจนต์โดยตรง ซึ่งมีประโยชน์สำหรับการแก้ไขข้อบกพร่องของคอมโพเนนต์ที่เฉพาะเจาะจงโดยไม่ต้องเรียกใช้ทั้งเชนหมายเหตุ: นี่คือปลายทาง API ไม่ใช่หน้าเว็บ คุณเข้าถึงไฟล์เหล่านี้ผ่านเบราว์เซอร์ไม่ได้ แต่ให้ใช้
curlเพื่อยืนยันว่าเอเจนต์กำลังทำงานอยู่ (เช่น โดยการดึงการ์ดเอเจนต์)- นักวิจัยเท่านั้น (พอร์ต 8001):
- ตรวจสอบสถานะ (และค้นหา
urlปลายทาง)curl http://localhost:8001/a2a/agent/.well-known/agent-card.json - ส่งการค้นหา (โดยใช้โปรโตคอล A2A JSON-RPC)
curl -X POST http://localhost:8001/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-1", "role": "user", "parts": [ { "text": "What is the capital of France?", "kind": "text" } ] } } }'
- ตรวจสอบสถานะ (และค้นหา
- ผู้พิพากษาเท่านั้น (พอร์ต 8002):
- ตรวจสอบสถานะ
curl http://localhost:8002/a2a/agent/.well-known/agent-card.json - ส่งคำถาม
curl -X POST http://localhost:8002/a2a/agent \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "method": "message/send", "id": 1, "params": { "message": { "message_id": "test-2", "role": "user", "parts": [ { "text": "Topic: Tokyo. Findings: Tokyo is the capital of Japan.", "kind": "text" } ] } } }'
- ตรวจสอบสถานะ
- Content Builder เท่านั้น (พอร์ต 8003):
curl http://localhost:8003/a2a/agent/.well-known/agent-card.json - Orchestrator (พอร์ต 8004):
curl http://localhost:8004/a2a/agent/.well-known/agent-card.json
- นักวิจัยเท่านั้น (พอร์ต 8001):
12. 🚀 ทำให้ใช้งานได้กับ Cloud Run
การตรวจสอบขั้นสุดท้ายคือการเรียกใช้ในระบบคลาวด์ เราจะติดตั้งใช้งานเอเจนต์แต่ละตัวเป็นบริการแยกกัน
ทำความเข้าใจการกำหนดค่าการทำให้ใช้งานได้
เมื่อติดตั้งใช้งาน Agent ใน Cloud Run เราจะส่งตัวแปรสภาพแวดล้อมหลายรายการเพื่อกำหนดค่าลักษณะการทำงานและการเชื่อมต่อของ Agent ดังนี้
GOOGLE_CLOUD_PROJECT: ตรวจสอบว่า Agent ใช้โปรเจ็กต์ Google Cloud ที่ถูกต้องสำหรับการบันทึกและการเรียก Vertex AIGOOGLE_GENAI_USE_VERTEXAI: บอกให้เฟรมเวิร์กของ Agent (ADK) ใช้ Vertex AI สำหรับการอนุมานโมเดลแทนการเรียกใช้ Gemini API โดยตรงGOOGLE_CLOUD_LOCATION: บอกเฟรมเวิร์กของเอเจนต์ (ADK) ว่าจะใช้ปลายทางใด[AGENT]_AGENT_CARD_URL: ข้อมูลนี้มีความสำคัญอย่างยิ่งสำหรับ Orchestrator ซึ่งจะบอก Orchestrator ว่าจะค้นหา Agent ระยะไกลได้ที่ไหน การตั้งค่านี้เป็น URL ของ Cloud Run ที่ทำให้ใช้งานได้ (โดยเฉพาะเส้นทางการ์ดเอเจนต์) จะช่วยให้ Orchestrator ค้นพบและสื่อสารกับ Researcher, Judge และ Content Builder ผ่านอินเทอร์เน็ตได้
- ติดตั้งใช้งาน Sub-Agent (แบบขนาน): เพื่อประหยัดเวลา เราจะติดตั้งใช้งาน Researcher, Judge และ Content Builder พร้อมกัน เปิดแท็บเทอร์มินัลใหม่ 3 แท็บ ในแท็บใหม่แต่ละแท็บ ให้เรียกใช้คำสั่งต่อไปนี้เพื่อตั้งค่าสภาพแวดล้อม
cd ~/prai-roadshow-lab-1-starter source .envgcloud run deploy researcher \ --source agents/researcher/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy judge \ --source agents/judge/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"gcloud run deploy content-builder \ --source agents/content_builder/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true" - บันทึก URL: เมื่อการติดตั้งใช้งานทั้ง 3 รายการเสร็จสิ้น ให้กลับไปที่เทอร์มินัลเดิม (ที่คุณจะติดตั้งใช้งาน Orchestrator) เรียกใช้คำสั่งต่อไปนี้เพื่อบันทึก URL ของบริการ
RESEARCHER_URL=$(gcloud run services describe researcher --region us-west1 --format='value(status.url)') JUDGE_URL=$(gcloud run services describe judge --region us-west1 --format='value(status.url)') CONTENT_BUILDER_URL=$(gcloud run services describe content-builder --region us-west1 --format='value(status.url)') echo "Researcher: $RESEARCHER_URL" echo "Judge: $JUDGE_URL" echo "Content Builder: $CONTENT_BUILDER_URL" - ติดตั้งใช้งาน Orchestrator: ใช้ตัวแปรสภาพแวดล้อมที่บันทึกไว้เพื่อกำหนดค่า Orchestrator
gcloud run deploy orchestrator \ --source agents/orchestrator/ \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars RESEARCHER_AGENT_CARD_URL=$RESEARCHER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars JUDGE_AGENT_CARD_URL=$JUDGE_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars CONTENT_BUILDER_AGENT_CARD_URL=$CONTENT_BUILDER_URL/a2a/agent/.well-known/agent-card.json \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT \ --set-env-vars GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION \ --set-env-vars GOOGLE_GENAI_USE_VERTEXAI="true"ORCHESTRATOR_URL=$(gcloud run services describe orchestrator --region us-west1 --format='value(status.url)') echo $ORCHESTRATOR_URL - ติดตั้งใช้งานฟรอนท์เอนด์
gcloud run deploy course-creator \ --source app \ --region us-west1 \ --allow-unauthenticated \ --labels dev-tutorial=prod-ready-1 \ --set-env-vars AGENT_SERVER_URL=$ORCHESTRATOR_URL \ --set-env-vars GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT - ทดสอบการทำให้ใช้งานได้จากระยะไกล: เปิด URL ของ Orchestrator ที่ทำให้ใช้งานได้ ตอนนี้ระบบทำงานในระบบคลาวด์ทั้งหมด โดยใช้โครงสร้างพื้นฐานแบบ Serverless ของ Google เพื่อปรับขนาด Agent ของคุณเคล็ดลับ: คุณจะเห็นไมโครเซอร์วิสและ URL ทั้งหมดในอินเทอร์เฟซ Cloud Run
13. สรุป
ยินดีด้วย คุณสร้างและติดตั้งใช้งานระบบ Multi-Agent แบบกระจายที่พร้อมใช้งานจริงเรียบร้อยแล้ว
สิ่งที่เราทำสำเร็จ
- แยกย่อยงานที่ซับซ้อน: เราแบ่งงานออกเป็นบทบาทเฉพาะทาง (นักวิจัย ผู้ตัดสิน ผู้สร้างเนื้อหา) แทนที่จะใช้พรอมต์ขนาดใหญ่เพียงรายการเดียว
- การควบคุมคุณภาพที่ใช้: เราใช้
LoopAgentและJudgeที่มีโครงสร้างเพื่อให้แน่ใจว่ามีเพียงข้อมูลคุณภาพสูงเท่านั้นที่จะไปถึงขั้นตอนสุดท้าย - สร้างขึ้นเพื่อการใช้งานจริง: เราได้สร้างระบบที่แต่ละ Agent เป็น Microservice แบบอิสระที่รองรับการปรับขนาดได้โดยใช้โปรโตคอล Agent-to-Agent (A2A) และ Cloud Run ซึ่งมีความแข็งแกร่งกว่าการเรียกใช้ทุกอย่างในสคริปต์ Python เดียวมาก
- การประสานงาน: เราใช้
SequentialAgentและLoopAgentเพื่อกำหนดรูปแบบโฟลว์การควบคุมที่ชัดเจน
ขั้นตอนถัดไป
เมื่อมีพื้นฐานแล้ว คุณจะขยายระบบนี้ได้โดยทำดังนี้
- เพิ่มเครื่องมืออื่นๆ: ให้สิทธิ์เข้าถึงเอกสารภายในหรือ API แก่นักวิจัย
- ปรับปรุงผู้ประเมิน: เพิ่มเกณฑ์ที่เฉพาะเจาะจงมากขึ้น หรือแม้แต่ขั้นตอน "มนุษย์ในวงจร"
- สลับโมเดล: ลองใช้โมเดลต่างๆ สำหรับเอเจนต์ต่างๆ (เช่น โมเดลที่เร็วกว่าสำหรับผู้ตรวจสอบ โมเดลที่แข็งแกร่งกว่าสำหรับผู้เขียนเนื้อหา)
ตอนนี้คุณพร้อมที่จะสร้างเวิร์กโฟลว์ที่เป็น Agent ที่ซับซ้อนและเชื่อถือได้ใน Google Cloud แล้ว