
1. مقدمة
نظرة عامة
هذا التمرين العملي هو متابعة لـ إنشاء أنظمة متعددة الوكلاء باستخدام ADK.
في هذا الدرس التطبيقي، أنشأت "نظام إنشاء دورات تدريبية" يتألف من:
- Researcher Agent: استخدام google_search للعثور على معلومات محدّثة
- Judge Agent: ينتقد هذا الوكيل البحث من حيث الجودة والاكتمال.
- Content Builder Agent: تحويل البحث إلى دورة تدريبية منظَّمة
- وكيل التنسيق: إدارة سير العمل والتواصل بين هؤلاء المتخصصين
وتضمّن أيضًا تطبيق ويب يسمح للمستخدمين بإرسال طلب لإنشاء دورة تدريبية والحصول على دورة تدريبية كاستجابة.
يتم نشر الباحث والمقيّم ومنشئ المحتوى كوكلاء A2A في خدمات Cloud Run منفصلة. Orchestrator هي خدمة أخرى من Cloud Run تتضمّن واجهة برمجة تطبيقات ADK Service API.
في هذا المختبر، عدّلنا وكيل Researcher لاستخدام أداة البحث في ويكيبيديا بدلاً من إمكانية بحث Google في Gemini. يتيح لنا ذلك فحص كيفية تتبُّع طلبات الأدوات المخصّصة وتقييمها.
لذلك، أنشأنا نظامًا موزّعًا يستند إلى عدّة وكلاء. ولكن كيف نعرف ما إذا كان يعمل بشكل جيد؟ هل يعثر "الباحث" دائمًا على معلومات ذات صلة؟ هل يحدّد Judge الأبحاث السيئة بشكل صحيح؟
في هذا التمرين العملي، ستستبدل "عمليات التحقّق من الأداء" الذاتية بتقييم مستند إلى البيانات باستخدام خدمة Gen AI Evaluation من Vertex AI. ستطبّق مقاييس "النماذج التكيّفية" و"جودة استخدام الأدوات" لتقييم "نظام الوكلاء المتعدّدين" الموزّع الذي تم إنشاؤه في الدرس العملي 1 بدقة. أخيرًا، ستنفّذ هذه العملية آليًا ضمن مسار CI/CD، ما يضمن الحفاظ على موثوقية ودقة وكلاء الإنتاج في كل عملية نشر.
ستنشئ مسار تقييم مستمر للوكلاء. ستتعرّف على كيفية:
- يمكنك نشر عملائك إلى مراجعة موسومة خاصة في Google Cloud Run (النشر التجريبي).
- تشغيل مجموعة تقييم آلي مقابل هذه المراجعة المحدّدة باستخدام خدمة GenAI Evaluation من Vertex AI
- تصوُّر النتائج وتحليلها
- استخدِم التقييم كجزء من مسار CI/CD.
2. المفاهيم الأساسية: نظرية تقييم الموظفين
عند تطوير "وكلاء الذكاء الاصطناعي" وتشغيلهم، نجري نوعَين من التقييم: التجربة بلا إنترنت والتقييم المستمر من خلال اختبار الانحدار الآلي. أولاً، محرك التصميم الإبداعي في عملية التطوير، حيث نجري تجارب مخصّصة ونحسّن الطلبات ونكرّرها بسرعة للاستفادة من إمكانات جديدة. أما الإجراء الثاني، فهو طبقة الحماية داخل مسار CI/CD، حيث ننفّذ تقييمات مستمرة استنادًا إلى مجموعة بيانات "ذهبية" لضمان عدم تدهور جودة الوكيل المثبتة عن غير قصد بسبب أي تغيير في الرمز.
يكمن الاختلاف الأساسي في الاكتشاف مقابل الدفاع:
- التجربة بلا إنترنت هي عملية تحسين. وهي مفتوحة النهاية ومتغيرة. أن تغيّر بشكل نشط المدخلات (الطلبات والنماذج والمَعلمات) لزيادة النتيجة إلى أقصى حد أو حلّ مشكلة معيّنة والهدف هو رفع "سقف" الإجراءات التي يمكن للوكيل تنفيذها.
- التقييم المستمر (اختبار الانحدار الآلي) هو عملية تحقّق. وهي جامدة ومتكررة. عليك إبقاء المدخلات ثابتة (مجموعة البيانات "الذهبية") لضمان بقاء المخرجات ثابتة. والهدف هو منع "الحد الأدنى" للأداء من الانهيار.
في هذا التمرين العملي، سنركّز على التقييم المستمر. سنطوّر مسار اختبار آليًا للتحقّق من صحة الانحدار، ومن المفترض أن يتم تشغيله في كل مرة يُجري فيها أحد المستخدمين تغييرًا في "وكيل الذكاء الاصطناعي"، تمامًا مثل اختبارات الوحدات.
قبل كتابة الرمز، من المهم فهم ما الذي نقيسه.
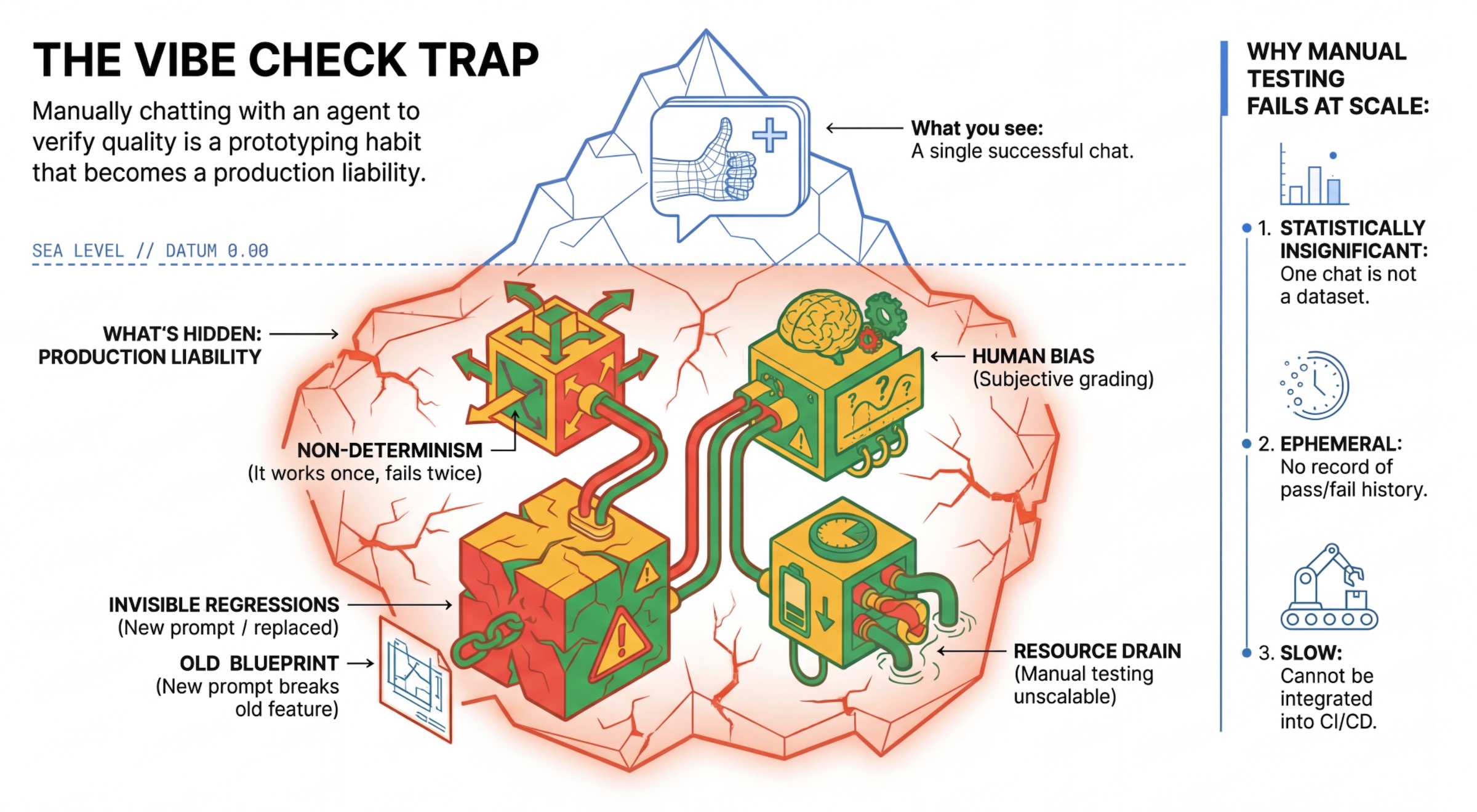
فخ "التحقّق من الأجواء"
يختبر العديد من المطوّرين الوكلاء من خلال الدردشة معهم يدويًا. ويُعرف ذلك باسم "التحقّق من الأجواء". على الرغم من أنّها مفيدة في إنشاء النماذج الأولية، إلا أنّها لا تعمل في مرحلة الإنتاج للأسباب التالية:
- عدم الحتمية: يمكن أن تقدّم الوكلاء إجابات مختلفة في كل مرة. يجب أن تكون أحجام العيّنات ذات دلالة إحصائية.
- تراجع غير مرئي: قد يؤدي تحسين طلب واحد إلى تعطيل حالة استخدام مختلفة.
- التحيّز البشري: "يبدو جيدًا" هو أمر نسبي.
- العمل الذي يستغرق وقتًا طويلاً: يستغرق اختبار عشرات السيناريوهات يدويًا وقتًا طويلاً مع كل عملية إرسال.
طريقتان لتقييم أداء الوكيل
لإنشاء مسار قوي، نجمع بين أنواع مختلفة من أدوات التقييم:
- أدوات التقييم المستندة إلى الرموز البرمجية (الحتمية):
- المقاييس: قيود صارمة (مثلاً، "هل تم عرض ملف JSON صالح؟" هل استدعى أداة
search؟"). - الإيجابيات: سريع، ورخيص، ودقيق بنسبة% 100.
- العيوب: لا يمكن الحكم على الفروق الدقيقة أو الجودة.
- المقاييس: قيود صارمة (مثلاً، "هل تم عرض ملف JSON صالح؟" هل استدعى أداة
- أدوات التقييم المستندة إلى النماذج (الاحتمالية):
- يُعرف أيضًا باسم "LLM-as-a-Judge". نستخدم نموذجًا قويًا (مثل Gemini 3 Pro) لتقييم نتائج الوكيل.
- ما تقيسه: الدقة، والاستدلال، والفائدة، والأمان
- المزايا: يمكنه تقييم المهام المعقّدة والمفتوحة.
- العيوب: أبطأ وأكثر تكلفة ويتطلّب هندسة دقيقة للمطالبات من أجل الحكم.
مقاييس التقييم في Vertex AI
في هذا المختبر، نستخدم خدمة تقييم الذكاء الاصطناعي التوليدي في Vertex AI التي توفّر مقاييس مُدارة حتى لا تضطر إلى كتابة كل مقياس من البداية.
هناك عدة طرق لتجميع المقاييس من أجل تقييم الموظفين:
- المقاييس المستندة إلى نماذج التقييم: دمج النماذج اللغوية الكبيرة في مسارات عمل التقييم
- نماذج التقييم التكيُّفية: يتم إنشاء نماذج التقييم بشكل ديناميكي لكل طلب. يتم تقييم الردود باستخدام ملاحظات تفصيلية وقابلة للتفسير حول النجاح أو الفشل، وتكون هذه الملاحظات خاصة بالطلب.
- قواعد التقييم الثابتة: يتم تحديد قواعد التقييم بشكلٍ صريح، ويتم تطبيق قواعد التقييم نفسها على جميع الطلبات. يتم تقييم الردود باستخدام المجموعة نفسها من أدوات التقييم المستندة إلى تسجيل الدرجات الرقمية. نتيجة رقمية واحدة (مثل 1-5) لكل طلب عندما يكون التقييم مطلوبًا في بُعد محدّد جدًا أو عندما تكون قواعد التقييم نفسها مطلوبة في جميع الطلبات.
- المقاييس المستندة إلى العمليات الحسابية: تقييم الردود باستخدام خوارزميات قطعية، وعادةً ما يتم ذلك باستخدام الحقيقة الأساسية. تمثّل هذه السمة درجة رقمية (مثل 0.0-1.0) لكل طلب. عندما تتوفّر بيانات صحيحة ويمكن مطابقتها باستخدام طريقة قطعية
- مقاييس الدوال المخصّصة: يمكنك تحديد مقياسك الخاص من خلال دالة Python.
المقاييس المحدّدة التي سنستخدمها:
Final Response Match: (استنادًا إلى المرجع) هل تتطابق الإجابة مع "الإجابة الذهبية"؟Tool Use Quality: (بدون مرجع) هل استخدم موظف الدعم الأدوات المناسبة بطريقة صحيحة؟Hallucination: (بدون مرجع) هل السياق الذي تم استرجاعه يؤيّد الادعاءات الواردة في الرد؟Tool Trajectory PrecisionوTool Trajectory Recall(استنادًا إلى المرجع): هل اختار الوكيل الأداة المناسبة وقدّم وسيطات صالحة؟ على عكسTool Use Quality، تستخدم هذه المقاييس المخصّصة مسارًا مرجعيًا، وهو عبارة عن سلسلة من طلبات الأدوات والحجج المتوقّعة.
3- الإعداد
التهيئة
- فتح Cloud Shell: انقر على رمز تفعيل Cloud Shell في أعلى يسار Google Cloud Console.
- نفِّذ الأمر التالي لإعادة تحميل بيانات تسجيل الدخول وتعديل بيانات الاعتماد التلقائية للتطبيق (ADC):
gcloud auth login --update-adc - اضبط مشروعًا نشطًا لواجهة سطر الأوامر gcloud.شغِّل الأمر التالي للحصول على مشروع gcloud الحالي:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDبرقم تعريف مشروعك. - اضبط المنطقة التلقائية التي سيتم نشر خدمات Cloud Run فيها.
gcloud config set run/region us-west1us-west1، يمكنك استخدام أي منطقة Cloud Run أقرب إليك.
الرموز البرمجية والتبعيات
- استنسِخ الرمز الأولي وغيِّر الدليل إلى جذر المشروع.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - إنشاء ملف
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - ثبِّت التبعيات من خلال تنفيذ الأمر التالي في نافذة الوحدة الطرفية:
uv sync
4. التعرّف على ميزة "النشر الآمن"
قبل التقييم، علينا نشر التطبيق. ولكنّنا لا نريد أن يتعطّل التطبيق المباشر إذا كان الرمز الجديد غير صالح.
علامات المراجعة والنشر المخفي
تتيح خدمة Google Cloud Run استخدام المراجعات. في كل مرة تنشر فيها إصدارًا، يتم إنشاء إصدار جديد غير قابل للتغيير. يمكنك تعيين علامات لهذه المراجعات للوصول إليها من خلال عنوان URL معيّن، حتى إذا كانت لا تتلقّى أي زيارات من الجمهور.
لماذا لا يتم إجراء التقييمات محليًا فقط؟
على الرغم من أنّ حزمة تطوير التطبيقات (ADK) تتيح التقييم على الجهاز، فإنّ نشر مراجعة مخفية يوفّر مزايا مهمة لأنظمة الإنتاج. يفرّق هذا بين التقييم على مستوى النظام (ما نفعله) واختبار الوحدات:
- تطابق البيئة: تختلف البيئات المحلية (شبكة مختلفة، ووحدة معالجة مركزية/ذاكرة مختلفة، وأسرار مختلفة). يضمن الاختبار في السحابة الإلكترونية عمل وكيلك في بيئة وقت التشغيل الفعلية (اختبار النظام).
- التفاعل بين الوكلاء: في نظام موزّع، تتواصل الوكلاء عبر HTTP. غالبًا ما تحاكي الاختبارات "المحلية" عمليات الربط هذه. تختبر عملية النشر التجريبي الفعلية لوقت استجابة الشبكة وإعدادات المهلة والمصادقة بين الخدمات المصغّرة.
- الأسرار والأذونات: يتحقّق من أنّ حساب الخدمة لديه الأذونات التي يحتاجها (مثل طلب Vertex AI أو القراءة من Firestore).
ملاحظة: هذا هو التقييم الاستباقي (التحقّق قبل أن يظهر المحتوى للمستخدمين). بعد نشر التطبيق، يمكنك استخدام المراقبة التفاعلية (إمكانية تتبّع البيانات) لرصد المشاكل في بيئة التشغيل.
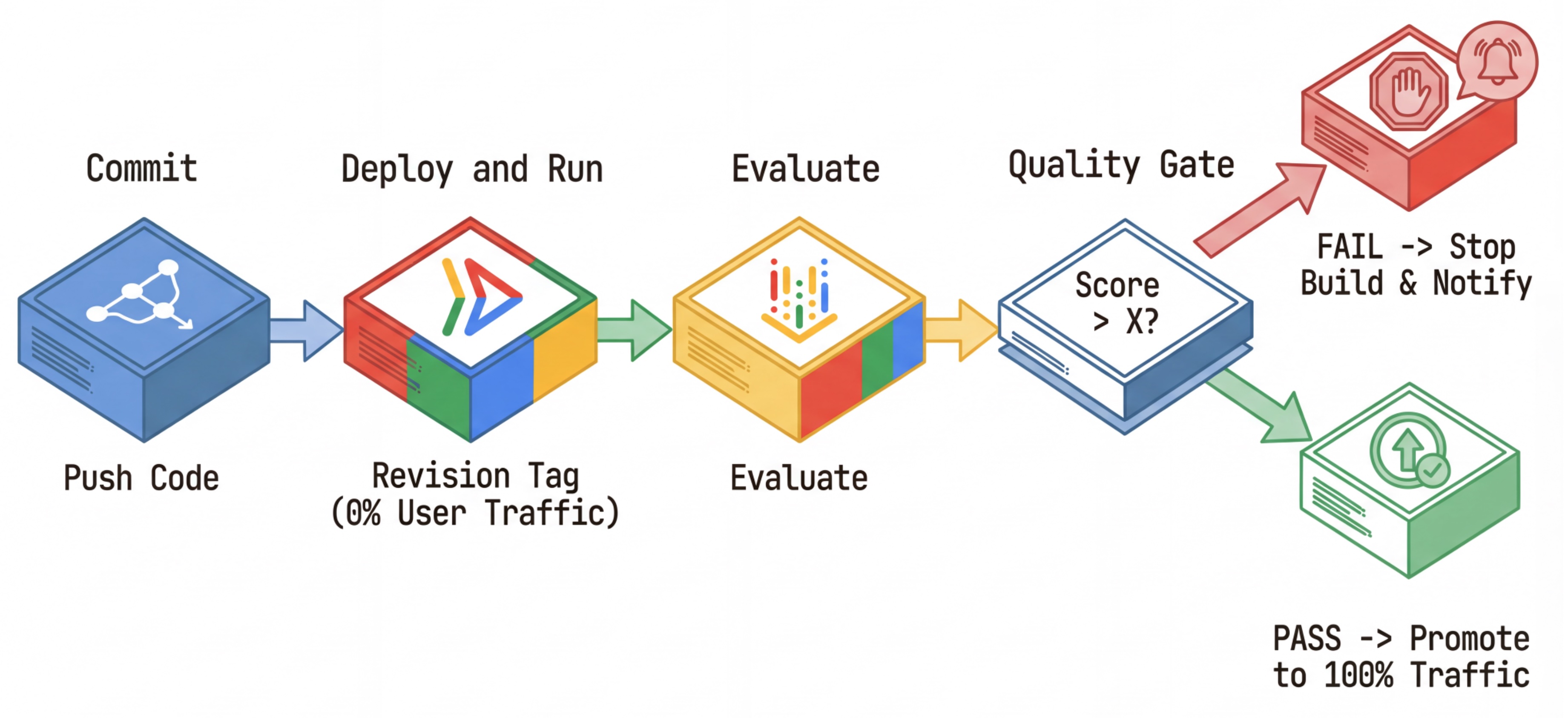
سير عمل التكامل المستمر/التسليم المستمر: النشر والتقييم والترقية
نستخدم ذلك لإنشاء مسار نشر مستمر قوي:
- الالتزام: يمكنك تغيير طلب الوكيل وإرساله إلى المستودع.
- النشر (مخفي): يؤدي إلى نشر نسخة جديدة تمّت الإشارة إليها برمز التجزئة الخاص بالتعديل (مثل
c-abc1234). تتلقّى هذه النسخة %0 من الزيارات الواردة من الجمهور. - التقييم: يستهدف نص التقييم البرمجي عنوان URL المحدّد للمراجعة
https://c-abc1234---researcher-xyz.run.app. - الترقية: إذا اجتاز التقييم ونجحت الاختبارات الأخرى، يمكنك نقل عدد الزيارات إلى هذه المراجعة الجديدة.
- العودة إلى الحالة السابقة: إذا تعذّر ذلك، لن يرى المستخدمون الإصدار السيئ، ويمكنك ببساطة تجاهل المراجعة السيئة أو حذفها.
تتيح لك هذه الاستراتيجية إجراء الاختبار في مرحلة الإنتاج بدون التأثير في العملاء.
تحليل evaluate.sh
فتح "evaluate.sh" يعمل هذا النص البرمجي على أتمتة العملية.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
تتولّى deploy.sh عملية نشر المراجعات باستخدام الخيارَين --no-traffic و--tag. إذا كانت هناك خدمة قيد التشغيل، لن تتأثر. لن تتلقّى المراجعة "المخفية" الجديدة أي زيارات ما لم تطلبها بشكلٍ صريح باستخدام عنوان URL خاص يحتوي على علامة المراجعة (مثل https://c-abc1234---researcher-xyz.run.app).
5- تنفيذ نص التقييم البرمجي
الآن، لنكتب التعليمات البرمجية التي تُجري الاختبارات فعليًا.
- فتح "
evaluator/evaluate_agent.py" - ستظهر عمليات الاستيراد والإعداد، ولكن ستكون المقاييس ومنطق التنفيذ غير متوفّرَين.
تحديد المقاييس
بالنسبة إلى الباحث الآلي، لدينا "إجابات ذهبية"/"حقائق أساسية" تتضمّن الإجابات المتوقّعة. هذا تقييم للقدرات: نحن نقيس ما إذا كان الوكيل يمكنه إنجاز المهمة بشكل صحيح.
نريد قياس ما يلي:
- تطابق الردّ النهائي: (الإمكانية) هل تتطابق الإجابة مع الإجابة المتوقّعة؟ هذا مقياس مستند إلى المراجع. ويستخدم نموذجًا لغويًا كبيرًا للتقييم من أجل مقارنة ناتج الوكيل بالإجابة المتوقّعة. لا تتوقّع أن تكون الإجابة مطابقة تمامًا، ولكنها تتوقّع أن تكون مشابهة من الناحية الدلالية والواقعية.
- جودة استخدام الأداة: (الجودة) مقياس مستهدف لنموذج التقييم التكيّفي يقيّم اختيار الأدوات المناسبة، والاستخدام الصحيح للمَعلمات، والالتزام بالتسلسل المحدّد للعمليات.
- مسار استخدام الأداة: (تتبُّع) مقياسان مخصّصان يقيسان مسار استخدام الأداة من قِبل الوكيل (مقياس صحة النموذج ومقياس المراجعة) مقارنةً بالمسارات المتوقّعة. يتم تنفيذ هذه المقاييس في
shared/evaluation/tool_metrics.pyكدوالّ مخصّصة. على عكس مقياس جودة استخدام الأدوات، هذا المقياس هو مقياس حتمي مستند إلى المرجع، فالرمز يتحقّق حرفيًا مما إذا كانت طلبات الأدوات الفعلية تتطابق مع البيانات المرجعية (reference_trajectoryفي بيانات التقييم).
مقاييس مسار استخدام الأدوات المخصّصة
بالنسبة إلى مقاييس "مسار استخدام الأدوات" المخصّصة، أنشأنا مجموعة من دوال Python في shared/evaluation/tool_metrics.py. للسماح لخدمة تقييم الذكاء الاصطناعي التوليدي في Vertex AI بتنفيذ هذه الوظائف، علينا تمرير رمز Python إليها.
يتم ذلك من خلال تحديد عنصر EvaluationRunMetric باستخدام إعداد UnifiedMetric وCustomCodeExecutionSpec. المعلَمة remote_custom_function هي سلسلة تحتوي على رمز Python الخاص بالدالة. يجب تسمية الدالة على النحو التالي: evaluate:
def evaluate(
instance: dict
) -> float:
...
أنشأنا get_custom_function_metric مساعدًا (في shared/evaluation/evaluate.py) يحوّل دالة Python إلى مقياس تقييم مخصّص للرموز البرمجية.
يحصل على رمز وحدة الدالة (لتسجيل التبعيات المحلية)، وينشئ دالة evaluate إضافية تستدعي الدالة الأصلية، ويعرض عنصر EvaluationRunMetric يتضمّن CustomCodeExecutionSpec.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
ستنفّذ "خدمة تقييم الذكاء الاصطناعي التوليدي" هذا الرمز في بيئة تنفيذ وضع الحماية، وستنقل إليها بيانات التقييم.
إضافة المقاييس ورمز التقييم
أضِف الرمز التالي إلى evaluator/evaluate_agent.py بعد السطر if __name__ == "__main__":.
تحدّد هذه الدالة قائمة المقاييس الخاصة بوكيل Researcher، وتنفّذ عملية التقييم.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
في مسار إنتاج حقيقي، تحتاج إلى معايير نجاح التقييم. بعد اكتمال التقييم وتوفّر المقاييس سيكون لديك خطوة حظر هنا. على سبيل المثال: "إذا كانت نتيجة Final Response Match أقل من 0.75، يجب إيقاف الإصدار." ويمنع ذلك تلقّي المراجعات السيئة لأي زيارات.
أضِف الرمز التالي إلى evaluator/evaluate_agent.py:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
في حال كانت قيمة المتوسط لأي من مقاييس التقييم أقل من الحدّ الأدنى (0.75)، يجب أن يتعذّر النشر.
[اختياري] إضافة التقييم باستخدام مقاييس لا تتطلّب مرجعًا لأداة التنسيق
بالنسبة إلى وكيل التنسيق، تكون التفاعلات أكثر تعقيدًا، وقد لا تكون لدينا دائمًا إجابة "صحيحة" واحدة. بدلاً من ذلك، نقوم بتقييم السلوك العام باستخدام أحد المقاييس غير المستندة إلى مرجع.
- الهلوسة: مقياس يستند إلى النتائج ويتحقّق من واقعية الردود النصية واتّساقها من خلال تقسيم الردّ إلى ادّعاءات أساسية. تتحقّق هذه الأداة ممّا إذا كانت كل مطالبة صحيحة أم لا استنادًا إلى استخدام الأداة في الأحداث الوسيطة. هذا أمر بالغ الأهمية بالنسبة إلى الوكلاء المفتوحين الذين تكون "الدقة" فيها أمرًا شخصيًا، ولكن "المصداقية" لا يمكن التنازل عنها. يتم احتساب النتيجة كنسبة مئوية من الادعاءات المستندة إلى المحتوى المصدر. في حالتنا، نتوقّع أن تكون الاستجابة النهائية من Orchestrator (التي أنشأتها "أداة إنشاء المحتوى") مستندة إلى الحقائق الواردة في المحتوى الذي استرجعه Researcher باستخدام أداة "بحث Wikipedia".
أضِف منطق التقييم الخاص بـ Orchestrator:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
فحص بيانات التقييم
افتح مجلد evaluator/. سيظهر لك ملفا بيانات:
-
eval_data_researcher.json: الطلبات والمراجع الذهبية/الأساسية الخاصة بالباحث -
eval_data_orchestrator.json: طلبات من "المنسّق" (نُجري تقييمًا بدون مرجع لـ "المنسّق" فقط).
يحتوي كل إدخال عادةً على ما يلي:
-
prompt: الطلب المقدَّم إلى الوكيل reference: الإجابة المثالية (الحقيقة الأساسية)، إذا كان ذلك منطبقًا-
reference_trajectory: التسلسل المتوقّع لاستدعاء الأدوات.
6. التعرّف على رمز التقييم
فتح "shared/evaluation/evaluate.py" تحتوي هذه الوحدة على المنطق الأساسي لتنفيذ عمليات التقييم. وظيفة المفتاح هي evaluate_agent.
وينفِّذ الخطوات التالية:
- تحميل البيانات: يقرأ مجموعة بيانات التقييم (الطلبات والمراجع) من ملف.
- الاستدلال المتوازي: ينفّذ الوكيل على مجموعة البيانات بالتوازي. يتولّى إنشاء الجلسات وإرسال الطلبات وتسجيل كلّ من الردّ النهائي وتتبُّع تنفيذ الأداة الوسيطة.
- Vertex AI Evaluation: تدمج هذه الخدمة بيانات التقييم الأصلية مع الردود النهائية وتتبُّع تنفيذ الأداة الوسيطة، ثم ترسل النتائج إلى خدمة Vertex AI Evaluation باستخدام GenAI Client في حزمة تطوير البرامج (SDK) الخاصة بمنصة Vertex AI. تشغّل هذه الخدمة المقاييس التي تم ضبطها لتقييم أداء الوكيل.
اللحظة الأساسية في الخطوة الأخيرة هي استدعاء الدالة create_evaluation_run من وحدة eval في حزمة تطوير البرامج (SDK) الخاصة بالذكاء الاصطناعي التوليدي:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
ونفعل ذلك في الدالة evaluate_agent في shared/evaluation/evaluate.py.
يحصل على مجموعة بيانات التقييم المدمجة ومعلومات حول الوكيل والمقاييس التي سيتم استخدامها ومعرّف الموارد المنتظم (URI) لمساحة التخزين الوجهة. تنشئ الدالة عملية تقييم في خدمة Vertex AI Evaluation Service وتعرض عنصر عملية التقييم.
The Agent Info API
لإجراء تقييم دقيق، تحتاج "خدمة التقييم" إلى معرفة إعدادات الوكيل (تعليمات النظام والوصف والأدوات المتاحة). نمرّرها إلى create_evaluation_run كمعلّمة agent_info.
ولكن كيف نحصل على هذه المعلومات؟ ونجعلها جزءًا من واجهة برمجة التطبيقات لخدمة ADK.
افتح shared/adk_app.py وابحث عن def agent_info. ستلاحظ أنّ تطبيق ADK يعرض نقطة نهاية مساعدة:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
تتيح نقطة النهاية هذه (التي يتم تفعيلها من خلال العلامة --publish_agent_info) لبرنامج التقييم النصي جلب إعدادات وقت التشغيل الخاصة بالوكيل بشكل ديناميكي. وهذا أمر بالغ الأهمية للمقاييس التي تقيّم استخدام الأدوات، لأنّ نموذج التقييم يمكنه تقييم استخدام الوكيل للأدوات بشكل أفضل إذا كان يعرف بالتحديد الأدوات التي كانت متاحة للوكيل أثناء المحادثة.
7. إجراء التقييم
بعد تنفيذ أداة التقييم، لنشغّلها الآن.
- نفِّذ نص التقييم البرمجي من جذر المستودع:
./evaluate.sh- يحصل هذا الأمر على رمز التجزئة الحالي لعملية الإيداع في git.
- يتم استدعاء
deploy.shلنشر مراجعة باستخدام علامة استنادًا إلى تجزئة عملية الدمج. - بعد نشرها، تبدأ
evaluator.evaluate_agent. - ستظهر لك أشرطة تقدّم أثناء تنفيذ حالات الاختبار على خدمتك السحابية.
- وأخيرًا، يطبع ملخّصًا بتنسيق JSON للنتائج.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
ملاحظة: قد يستغرق التشغيل الأول بضع دقائق لنشر الخدمات.
8. عرض النتائج بشكل مرئي في "المفكرة"
يصعب قراءة الناتج بتنسيق JSON غير المعالَج. توفّر أداة Gen AI Client في حزمة تطوير البرامج (SDK) الخاصة بمنصة Vertex AI طريقة لتتبُّع عمليات التشغيل هذه بمرور الوقت. سنستخدم ورقة ملاحظات Colab لتصوير النتائج.
- افتح
evaluator/show_evaluation_run.ipynbفي Google Colab باستخدام هذا الرابط. - اضبط المتغيّرات
GOOGLE_CLOUD_PROJECTوGOOGLE_CLOUD_REGIONوEVAL_RUN_IDعلى رقم تعريف مشروعك ومنطقتك ورقم تعريف عملية التشغيل.
- تثبيت التبعيات والمصادقة
استرداد عملية التقييم وعرض النتائج
علينا استرداد بيانات عملية التقييم من Vertex AI. ابحث عن الخلية ضمن استرداد عملية التقييم وعرض النتائج واستبدِل السطر # TODO بمجموعة الرموز التالية:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
تفسير النتائج
عند الاطّلاع على النتائج، يُرجى مراعاة ما يلي:
- التراجع مقابل الإمكانية:
- التراجع: هل انخفضت النتيجة في الاختبارات القديمة؟ (هذا ليس جيدًا ويتطلّب إجراء تحقيق).
- الأداء: هل تحسّنت النتيجة في اختبارات جديدة؟ (هذا تقدّم جيد).
- تحليل الأخطاء: لا تنظر إلى النتيجة فقط.
- اطّلِع على التتبُّع. هل تم استدعاء الأداة الخاطئة؟ هل تعذّر تحليل النتيجة؟ هذا هو المكان الذي يمكنك فيه العثور على الأخطاء.
- اطّلِع على التفسير والأحكام التي قدّمها نموذج اللغة الكبير "القاضي". وغالبًا ما تقدّم لك فكرة جيدة عن سبب تعذّر إكمال الاختبار.
Pass@1 مقابل Pass@k: عند إجراء اختبار معيّن مرة واحدة، نحصل على نتيجة Pass@1. إذا تعذّر تنفيذ أحد الوكلاء، قد يكون ذلك بسبب عدم التحديد. في عمليات الإعداد المعقّدة، يمكنك إجراء كل اختبار k مرّة (مثل 5 مرات) وحساب pass@k (هل نجح الاختبار مرة واحدة على الأقل؟) أو pass^k (هل نجح الاختبار في كل مرة؟). وهذا ما تفعله العديد من المقاييس حاليًا في الخلفية. على سبيل المثال، ينفّذ types.RubricMetric.FINAL_RESPONSE_MATCH (مطابقة الردّ النهائي) 5 طلبات إلى النموذج اللغوي الكبير الخاص بالتقييم لتحديد نتيجة مطابقة الردّ النهائي.
9- التكامل المستمر والنشر المستمر (CI/CD)
في نظام الإنتاج، يجب إجراء تقييم الوكيل كجزء من مسار CI/CD. Cloud Build هي الخيار المناسب لذلك.
في كل عملية إرسال يتم إجراؤها إلى مستودع رموز الوكيل، سيتم تشغيل عملية التقييم مع بقية الاختبارات. وفي حال اجتيازها، يمكن "ترقية" عملية النشر لتلبية طلبات المستخدمين. وفي حال عدم اجتيازها، ستبقى جميع الإعدادات كما هي، ولكن يمكن للمطوّر الاطّلاع على المشكلة.
إعدادات Cloud Build
لننشئ الآن نصًا برمجيًا لإعداد عملية نشر Cloud Run ينفّذ الخطوات التالية:
- تنشر هذه السمة الخدمات في إصدار خاص.
- إجراء تقييم الوكيل
- في حال اجتياز التقييم، يتم "ترقية" عمليات نشر المراجعات لعرضها على% 100 من الزيارات.
إنشاء cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
تنفيذ مسار المعالجة
أخيرًا، يمكننا تشغيل مسار التقييم.
قبل تشغيل مسار التقييم الذي يرسل طلبات إلى خدمات Cloud Run، نحتاج إلى حساب خدمة منفصل يتضمّن عددًا من الأذونات. لنكتب نصًا برمجيًا ينفّذ ذلك ويشغّل مسار التعلّم.
- إنشاء نص برمجي
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- يتم إنشاء حساب خدمة مخصّص
agent-eval-build-sa. - يمنحها الأدوار اللازمة (
roles/run.adminوroles/aiplatform.userوما إلى ذلك). *. إرسال الإصدار إلى Cloud Build
- يتم إنشاء حساب خدمة مخصّص
- نفِّذ المسار:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
يمكنك مشاهدة مستوى تقدّم الإنشاء في نافذة الأوامر أو النقر على الرابط إلى Cloud Console.
ملاحظة: في بيئة التشغيل الفعلي، عليك إعداد مشغّل Cloud Build لتنفيذ ذلك تلقائيًا في كل git push. سير العمل هو نفسه: سيتم تنفيذ المشغّل cloudbuild.yaml، ما يضمن تقييم كل عملية إيداع.
10. ملخّص
لقد أنشأت مسار تقييم بنجاح.
- النشر: استخدمت علامات المراجعة مع تجزئة git commit لنشر البرامج بأمان في بيئة حقيقية لإجراء الاختبارات بدون التأثير في عمليات النشر النهائية.
- التقييم: حدّدت مقاييس التقييم وأتمتت عملية التقييم باستخدام خدمة Vertex AI Gen AI Evaluation Service.
- التحليل: استخدمت "دفتر ملاحظات Colab" لتصوّر نتائج التقييم وتحسين الوكيل.
- الطرح: استخدمت Cloud Build لتنفيذ مسار التقييم تلقائيًا وترقية أفضل مراجعة لعرضها على% 100 من الزيارات.
هذه الدورة تعديل الرمز -> نشر العلامة -> تشغيل التقييم والاختبارات -> التحليل -> الطرح -> التكرار هي جوهر هندسة الوكلاء بجودة الإنتاج.