
১. ভূমিকা
সংক্ষিপ্ত বিবরণ
এই ল্যাবটি "Build Multi-Agent Systems with ADK"- এর একটি ফলো-আপ।
সেই ল্যাবে, আপনি একটি কোর্স তৈরির সিস্টেম তৈরি করেছেন যা নিম্নলিখিত উপাদানগুলো নিয়ে গঠিত:
- গবেষক প্রতিনিধি : হালনাগাদ তথ্য খোঁজার জন্য গুগল সার্চ ব্যবহার করছেন।
- বিচারক প্রতিনিধি : গবেষণার গুণমান ও সম্পূর্ণতা যাচাই করা।
- কন্টেন্ট বিল্ডার এজেন্ট : গবেষণাকে একটি কাঠামোগত কোর্সে রূপান্তর করা।
- অর্কেস্ট্রেটর এজেন্ট : এই বিশেষজ্ঞদের মধ্যে কর্মপ্রবাহ এবং যোগাযোগ পরিচালনা করা।
এতে একটি ওয়েব অ্যাপও অন্তর্ভুক্ত ছিল, যার মাধ্যমে ব্যবহারকারীরা কোর্স তৈরির অনুরোধ জমা দিতে পারতেন এবং তার জবাবে একটি কোর্স পেয়ে যেতেন।
Researcher , Judge , এবং Content Builder-কে আলাদা Cloud Run সার্ভিসে A2A এজেন্ট হিসেবে ডেপ্লয় করা হয়েছে। Orchestrator হলো ADK Service API সহ আরেকটি Cloud Run সার্ভিস।
এই ল্যাবের জন্য, আমরা জেমিনির গুগল সার্চ ক্ষমতার পরিবর্তে উইকিপিডিয়া সার্চ টুল ব্যবহার করার জন্য রিসার্চার এজেন্টকে পরিবর্তন করেছি। এটি আমাদের কাস্টম টুল কলগুলো কীভাবে ট্রেস এবং মূল্যায়ন করা হয় তা পরীক্ষা করার সুযোগ দেয়।
সুতরাং, আমরা একটি ডিস্ট্রিবিউটেড মাল্টি-এজেন্ট সিস্টেম তৈরি করেছি। কিন্তু আমরা কীভাবে জানব যে এটি আসলেই ভালোভাবে কাজ করছে? গবেষক কি সবসময় প্রাসঙ্গিক তথ্য খুঁজে পান? বিচারক কি ত্রুটিপূর্ণ গবেষণা সঠিকভাবে শনাক্ত করতে পারেন?
এই ল্যাবে, আপনি Vertex AI Gen AI Evaluation Service ব্যবহার করে ব্যক্তিগত "ভাইব চেক"-এর পরিবর্তে ডেটা-ভিত্তিক মূল্যায়ন করবেন। ল্যাব ১-এ তৈরি করা ডিস্ট্রিবিউটেড মাল্টি-এজেন্ট সিস্টেমটিকে পুঙ্খানুপুঙ্খভাবে মূল্যায়ন করার জন্য আপনি অ্যাডাপ্টিভ রুব্রিকস এবং টুল ইউজ কোয়ালিটি মেট্রিকস প্রয়োগ করবেন। সবশেষে, আপনি একটি CI/CD পাইপলাইনের মধ্যে এই প্রক্রিয়াটিকে স্বয়ংক্রিয় করবেন, যা নিশ্চিত করবে যে প্রতিটি ডেপ্লয়মেন্ট আপনার প্রোডাকশন এজেন্টগুলোর নির্ভরযোগ্যতা এবং নির্ভুলতা বজায় রাখে।
আপনি আপনার এজেন্টদের জন্য একটি নিরবচ্ছিন্ন মূল্যায়ন পাইপলাইন তৈরি করবেন। আপনি শিখবেন কীভাবে:
- গুগল ক্লাউড রান-এ আপনার এজেন্টগুলোকে একটি প্রাইভেট ট্যাগড রিভিশনে ডেপ্লয় করুন (শ্যাডো ডেপ্লয়মেন্ট)।
- Vertex AI Gen AI Evaluation Service ব্যবহার করে সেই নির্দিষ্ট রিভিশনটির উপর একটি স্বয়ংক্রিয় মূল্যায়ন স্যুট চালান।
- ফলাফলগুলো কল্পনা করুন এবং বিশ্লেষণ করুন।
- আপনার CI/CD পাইপলাইনের অংশ হিসেবে মূল্যায়নটি ব্যবহার করুন।
২. মূল ধারণা: এজেন্ট মূল্যায়ন তত্ত্ব
এআই এজেন্ট তৈরি ও পরিচালনার সময় আমরা দুই ধরনের মূল্যায়ন করে থাকি: অফলাইন পরীক্ষণ এবং স্বয়ংক্রিয় রিগ্রেশন টেস্টিং-এর মাধ্যমে ধারাবাহিক মূল্যায়ন । প্রথমটি হলো উন্নয়ন প্রক্রিয়ার সৃজনশীল চালিকাশক্তি, যেখানে আমরা প্রয়োজন অনুযায়ী পরীক্ষা চালাই, নির্দেশাবলী পরিমার্জন করি এবং নতুন সক্ষমতা উন্মোচনের জন্য দ্রুত পুনরাবৃত্তি করি। দ্বিতীয়টি হলো আমাদের CI/CD পাইপলাইনের প্রতিরক্ষামূলক স্তর, যেখানে আমরা একটি ‘গোল্ডেন’ ডেটাসেটের উপর ধারাবাহিক মূল্যায়ন চালাই, যাতে কোডের কোনো পরিবর্তন অনিচ্ছাকৃতভাবে এজেন্টের প্রমাণিত গুণমানকে ক্ষুণ্ণ না করে।
মৌলিক পার্থক্যটি হলো আবিষ্কার বনাম প্রতিরক্ষা ।
- অফলাইন পরীক্ষণ হলো অপ্টিমাইজেশনের একটি প্রক্রিয়া। এটি উন্মুক্ত এবং পরিবর্তনশীল। একটি স্কোর সর্বোচ্চ করতে বা একটি নির্দিষ্ট সমস্যার সমাধান করতে আপনি সক্রিয়ভাবে ইনপুট (প্রম্পট, মডেল, প্যারামিটার) পরিবর্তন করতে থাকেন। এর লক্ষ্য হলো এজেন্টের সক্ষমতার সর্বোচ্চ সীমা বৃদ্ধি করা।
- ধারাবাহিক মূল্যায়ন (স্বয়ংক্রিয় রিগ্রেশন টেস্টিং) হলো একটি যাচাইকরণ প্রক্রিয়া। এটি কঠোর এবং পুনরাবৃত্তিমূলক। আউটপুট স্থিতিশীল থাকে তা নিশ্চিত করার জন্য আপনি ইনপুটগুলোকে (যাকে ‘গোল্ডেন’ ডেটাসেট বলা হয়) স্থির রাখেন। এর লক্ষ্য হলো পারফরম্যান্সের সর্বনিম্ন স্তরকে ধসে পড়া থেকে রক্ষা করা।
এই ল্যাবে, আমরা ধারাবাহিক মূল্যায়নের উপর মনোযোগ দেব। আমরা একটি স্বয়ংক্রিয় রিগ্রেশন টেস্টিং পাইপলাইন তৈরি করব যা ইউনিট টেস্টগুলোর মতোই, এআই এজেন্টে কেউ কোনো পরিবর্তন করলেই রান করবে।
কোড লেখার আগে, আমরা কী পরিমাপ করছি তা বোঝা অত্যন্ত গুরুত্বপূর্ণ।
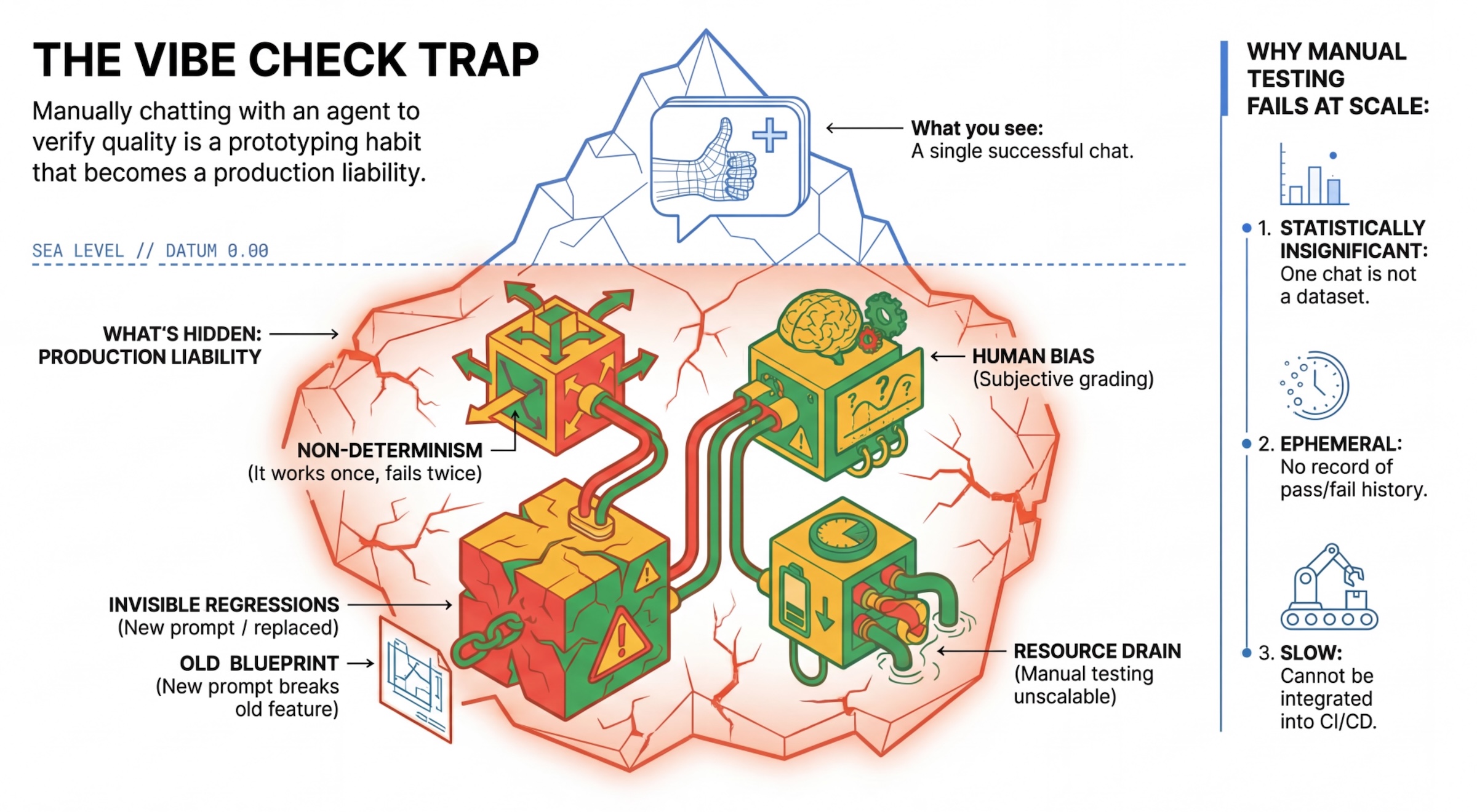
"ভাইব চেক" ফাঁদ
অনেক ডেভেলপার এজেন্টদের সাথে ম্যানুয়ালি চ্যাট করে তাদের পরীক্ষা করেন। এটি 'ভাইব চেকিং' নামে পরিচিত। প্রোটোটাইপিংয়ের জন্য কার্যকর হলেও, প্রোডাকশনে এটি ব্যর্থ হয় কারণ:
- অনির্দিষ্টতা : অংশগ্রহণকারীরা প্রতিবার ভিন্নভাবে উত্তর দিতে পারে। এর জন্য পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ নমুনার আকার প্রয়োজন।
- অদৃশ্য পশ্চাদপসরণ : একটি প্রম্পট উন্নত করলে অন্য একটি ব্যবহারের ক্ষেত্র ভেঙে যেতে পারে।
- মানবীয় পক্ষপাত : "দেখতে ভালো লাগছে" একটি ব্যক্তিগত অনুভূতি।
- সময়সাপেক্ষ কাজ : প্রতিটি কমিটের সাথে ম্যানুয়ালি কয়েক ডজন সিনারিও পরীক্ষা করা ধীরগতির।
এজেন্টের পারফরম্যান্স মূল্যায়নের দুটি উপায়
একটি শক্তিশালী কার্যপ্রক্রিয়া গড়ে তোলার জন্য, আমরা বিভিন্ন ধরনের মূল্যায়নকারীকে একত্রিত করি:
- কোড-ভিত্তিক গ্রেডার (নির্ধারণমূলক) :
- তারা যা পরিমাপ করে : কঠোর সীমাবদ্ধতা (যেমন, "এটি কি বৈধ JSON ফেরত দিয়েছে?", "এটি কি
searchটুলটিকে কল করেছে?")। - সুবিধা : দ্রুত, সাশ্রয়ী, শতভাগ নির্ভুল।
- অসুবিধা : সূক্ষ্মতা বা গুণমান বিচার করা যায় না।
- তারা যা পরিমাপ করে : কঠোর সীমাবদ্ধতা (যেমন, "এটি কি বৈধ JSON ফেরত দিয়েছে?", "এটি কি
- মডেল-ভিত্তিক গ্রেডার (সম্ভাব্যতামূলক) :
- এটি 'এলএলএম-অ্যাজ-এ-জাজ' নামেও পরিচিত। আমরা এজেন্টের আউটপুট মূল্যায়ন করার জন্য একটি শক্তিশালী মডেল (যেমন জেমিনি ৩ প্রো) ব্যবহার করি।
- তারা যা পরিমাপ করে : সূক্ষ্মতা, যুক্তিবোধ, উপযোগিতা, নিরাপত্তা।
- সুবিধা : জটিল ও উন্মুক্ত কাজ মূল্যায়ন করতে পারে।
- অসুবিধা : ধীরগতির, অধিক ব্যয়বহুল, এবং বিচারকের জন্য সতর্ক ও দ্রুত প্রকৌশলগত পরিকল্পনা প্রয়োজন।
ভার্টেক্স এআই মূল্যায়ন মেট্রিক্স
এই ল্যাবে, আমরা Vertex AI Gen AI Evaluation Service ব্যবহার করি, যা পরিচালিত মেট্রিক্স সরবরাহ করে, ফলে আপনাকে প্রতিটি জাজ একেবারে শুরু থেকে লিখতে হয় না।
এজেন্ট মূল্যায়নের জন্য মেট্রিকগুলিকে শ্রেণিবদ্ধ করার একাধিক উপায় রয়েছে:
- রুব্রিক-ভিত্তিক মেট্রিক্স : মূল্যায়ন কার্যপ্রবাহে এলএলএম অন্তর্ভুক্ত করুন।
- অভিযোজিত মূল্যায়ন নির্দেশিকা : প্রতিটি প্রশ্নের জন্য মূল্যায়ন নির্দেশিকা স্বয়ংক্রিয়ভাবে তৈরি করা হয়। প্রতিটি প্রশ্নের জন্য নির্দিষ্ট, বিশদ ও ব্যাখ্যাযোগ্য পাস বা ফেলের মতামতের মাধ্যমে উত্তরগুলো মূল্যায়ন করা হয়।
- স্থির রুব্রিক : রুব্রিকগুলো সুস্পষ্টভাবে সংজ্ঞায়িত করা হয় এবং একই রুব্রিক সমস্ত প্রশ্নের ক্ষেত্রে প্রযোজ্য হয়। উত্তরগুলো একই সংখ্যাসূচক স্কোর-ভিত্তিক মূল্যায়নকারীদের দ্বারা মূল্যায়ন করা হয়। প্রতিটি প্রশ্নের জন্য একটি একক সংখ্যাসূচক স্কোর (যেমন ১-৫)। যখন একটি খুব নির্দিষ্ট দিকের উপর মূল্যায়নের প্রয়োজন হয় অথবা যখন সমস্ত প্রশ্নের জন্য হুবহু একই রুব্রিকের প্রয়োজন হয়।
- গণনা-ভিত্তিক মেট্রিক্স : সাধারণত গ্রাউন্ড ট্রুথ ব্যবহার করে, ডিটারমিনিস্টিক অ্যালগরিদমের সাহায্যে প্রতিক্রিয়া মূল্যায়ন করা হয়। প্রতিটি প্রম্পটের জন্য একটি সাংখ্যিক স্কোর (যেমন ০.০-১.০)। যখন গ্রাউন্ড ট্রুথ উপলব্ধ থাকে এবং একটি ডিটারমিনিস্টিক পদ্ধতির সাথে মেলানো যায়।
- কাস্টম ফাংশন মেট্রিক্স : একটি পাইথন ফাংশনের মাধ্যমে আপনার নিজস্ব মেট্রিক নির্ধারণ করুন।
আমরা যে নির্দিষ্ট মেট্রিকগুলো ব্যবহার করব :
-
Final Response Match: (তথ্যসূত্র-ভিত্তিক) উত্তরটি কি আমাদের 'সর্বোত্তম উত্তর'-এর সাথে মেলে? -
Tool Use Quality: (তথ্যসূত্র ছাড়া) এজেন্ট কি প্রাসঙ্গিক সরঞ্জামগুলো যথাযথভাবে ব্যবহার করেছেন? -
Hallucination: (তথ্যসূত্র-বিহীন) উত্তরে করা দাবিগুলো কি সংগৃহীত প্রেক্ষাপট দ্বারা সমর্থিত? -
Tool Trajectory PrecisionএবংTool Trajectory Recall(রেফারেন্স-ভিত্তিক) এজেন্ট কি সঠিক টুল নির্বাচন করেছে এবং বৈধ আর্গুমেন্ট প্রদান করেছে?Tool Use Qualityবিপরীতে, এই কাস্টম মেট্রিকগুলো রেফারেন্স ট্র্যাজেক্টরি ব্যবহার করে – যা হলো প্রত্যাশিত টুল কল এবং আর্গুমেন্টের একটি ক্রম।
৩. সেটআপ
কনফিগারেশন
- ক্লাউড শেল খুলুন : গুগল ক্লাউড কনসোলের উপরের ডানদিকে থাকা ‘অ্যাক্টিভেট ক্লাউড শেল’ আইকনটিতে ক্লিক করুন।
- সাইন ইন রিফ্রেশ করতে এবং অ্যাপ্লিকেশন ডিফল্ট ক্রেডেনশিয়াল (ADC) আপডেট করতে নিম্নলিখিত কমান্ডটি চালান:
gcloud auth login --update-adc - gcloud CLI-এর জন্য একটি সক্রিয় প্রজেক্ট সেট করুন। বর্তমান gcloud প্রজেক্টটি পেতে নিম্নলিখিত কমান্ডটি চালান:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDএর জায়গায় আপনার প্রোজেক্টের আইডি বসান। - আপনার ক্লাউড রান পরিষেবাগুলি যে ডিফল্ট অঞ্চলে স্থাপন করা হবে, তা সেট করুন।
gcloud config set run/region us-west1us-west1এর পরিবর্তে, আপনি আপনার নিকটবর্তী যেকোনো ক্লাউড রান রিজিয়ন ব্যবহার করতে পারেন।
কোড এবং নির্ভরতা
- স্টার্টার কোডটি ক্লোন করুন এবং প্রজেক্টের রুট ডিরেক্টরিতে যান।
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab -
.envফাইল তৈরি করুন:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - টার্মিনাল উইন্ডোতে নিম্নলিখিত কমান্ডটি চালিয়ে নির্ভরতাগুলি ইনস্টল করুন:
uv sync
৪. নিরাপদ মোতায়েন বোঝা
মূল্যায়ন করার আগে আমাদের ডেপ্লয় করতে হবে। কিন্তু আমাদের নতুন কোডে কোনো সমস্যা হলে আমরা লাইভ অ্যাপ্লিকেশনটি নষ্ট করতে চাই না।
রিভিশন ট্যাগ এবং শ্যাডো ডিপ্লয়মেন্ট
গুগল ক্লাউড রান রিভিশন সমর্থন করে। প্রতিবার ডিপ্লয় করার সময় একটি নতুন অপরিবর্তনীয় রিভিশন তৈরি হয়। আপনি এই রিভিশনগুলোতে ট্যাগ যুক্ত করতে পারেন, যাতে একটি নির্দিষ্ট URL-এর মাধ্যমে সেগুলোতে অ্যাক্সেস করা যায়, এমনকি যদি সেগুলোতে পাবলিক ট্র্যাফিকের পরিমাণ ০%-ও থাকে।
স্থানীয়ভাবে মূল্যায়নগুলো চালালেই তো হয়?
যদিও ADK লোকাল ইভ্যালুয়েশন সমর্থন করে, প্রোডাকশন সিস্টেমের জন্য একটি হিডেন রিভিশনে ডেপ্লয় করা গুরুত্বপূর্ণ সুবিধা প্রদান করে। এটিই সিস্টেম-লেভেল ইভ্যালুয়েশনকে (যা আমরা করছি) ইউনিট টেস্টিং থেকে আলাদা করে।
- পরিবেশগত সমতা : স্থানীয় পরিবেশগুলো ভিন্ন (ভিন্ন নেটওয়ার্ক, ভিন্ন সিপিইউ/মেমরি, ভিন্ন গোপনীয় তথ্য)। ক্লাউডে পরীক্ষা করা নিশ্চিত করে যে আপনার এজেন্ট প্রকৃত রানটাইম পরিবেশে কাজ করে (সিস্টেম টেস্ট)।
- একাধিক এজেন্টের মধ্যে মিথস্ক্রিয়া : একটি ডিস্ট্রিবিউটেড সিস্টেমে, এজেন্টরা HTTP-এর মাধ্যমে যোগাযোগ করে। "লোকাল" টেস্টগুলো প্রায়শই এই সংযোগগুলোকে মক করে। শ্যাডো ডিপ্লয়মেন্ট আপনার মাইক্রোসার্ভিসগুলোর মধ্যেকার প্রকৃত নেটওয়ার্ক ল্যাটেন্সি, টাইমআউট কনফিগারেশন এবং অথেনটিকেশন পরীক্ষা করে।
- গোপনীয়তা ও অনুমতি : এটি যাচাই করে যে আপনার পরিষেবা অ্যাকাউন্টের প্রয়োজনীয় অনুমতিগুলো আছে কি না (যেমন, Vertex AI-কে কল করা বা Firestore থেকে ডেটা পড়া)।
দ্রষ্টব্য: এটি হলো সক্রিয় মূল্যায়ন (ব্যবহারকারীরা দেখার আগেই যাচাই করা)। একবার স্থাপন করা হয়ে গেলে, বাস্তব পরিস্থিতিতে সমস্যা ধরার জন্য আপনি প্রতিক্রিয়াশীল পর্যবেক্ষণ (অবজার্ভেবিলিটি) ব্যবহার করবেন।
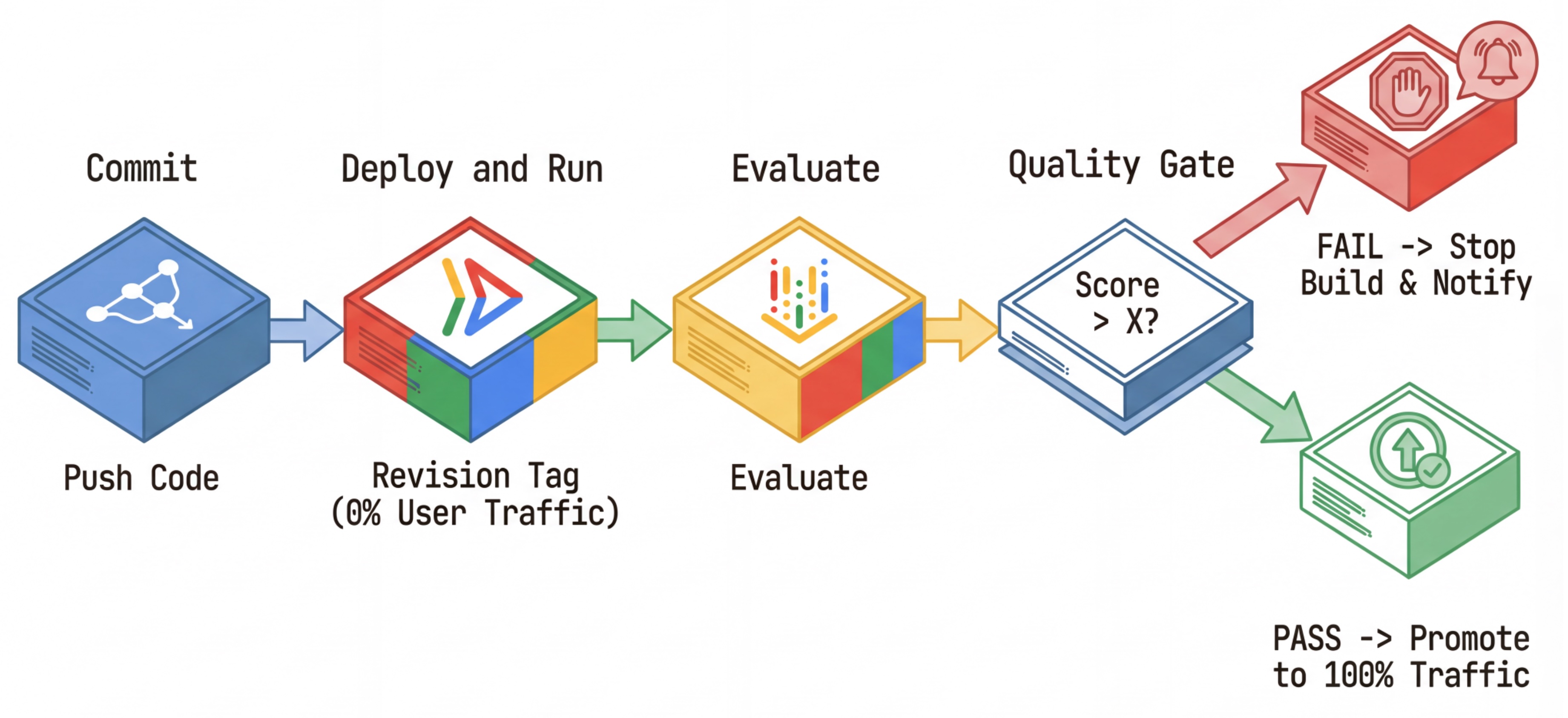
CI/CD কার্যপ্রবাহ: স্থাপন, মূল্যায়ন, প্রচার
একটি শক্তিশালী কন্টিনিউয়াস ডিপ্লয়মেন্ট পাইপলাইনের জন্য আমরা এটি ব্যবহার করি:
- কমিট : আপনি এজেন্টের প্রম্পট পরিবর্তন করেন এবং রিপোজিটরিতে পুশ করেন।
- ডিপ্লয় (লুকানো) : এটি কমিট হ্যাশ (যেমন,
c-abc1234) দিয়ে ট্যাগ করা একটি নতুন রিভিশনের ডিপ্লয়মেন্ট শুরু করে। এই রিভিশনটি ০% পাবলিক ট্র্যাফিক পায়। - মূল্যায়ন : মূল্যায়ন স্ক্রিপ্টটি নির্দিষ্ট রিভিশন ইউআরএল
https://c-abc1234---researcher-xyz.run.appলক্ষ্য করে। - উন্নীত করুন : যদি (এবং শুধুমাত্র যদি) মূল্যায়নটি উত্তীর্ণ হয় এবং অন্যান্য পরীক্ষাও সফল হয়, তাহলে আপনি ট্র্যাফিককে এই নতুন সংস্করণে স্থানান্তর করবেন ।
- রোলব্যাক : এটি ব্যর্থ হলে, ব্যবহারকারীরা ত্রুটিপূর্ণ সংস্করণটি কখনোই দেখতে পান না এবং আপনি সহজেই সেই ত্রুটিপূর্ণ সংস্করণটি উপেক্ষা বা মুছে ফেলতে পারেন।
এই কৌশলটি আপনাকে গ্রাহকদের প্রভাবিত না করেই প্রোডাকশনে পরীক্ষা করার সুযোগ দেয়।
Analyze evaluate.sh
evaluate.sh খুলুন। এই স্ক্রিপ্টটি প্রক্রিয়াটিকে স্বয়ংক্রিয় করে।
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh প্রোগ্রামটি --no-traffic এবং --tag অপশনগুলোর মাধ্যমে রিভিশন ডেপ্লয়মেন্টের কাজটি করে। যদি আগে থেকেই কোনো সার্ভিস চালু থাকে, তবে সেটি প্রভাবিত হবে না। নতুন 'হিডেন' রিভিশনটিতে কোনো ট্র্যাফিক আসবে না, যদি না আপনি রিভিশন ট্যাগযুক্ত কোনো বিশেষ URL (যেমন https://c-abc1234---researcher-xyz.run.app ) দিয়ে এটিকে স্পষ্টভাবে কল করেন।
৫. মূল্যায়ন স্ক্রিপ্টটি বাস্তবায়ন করুন
এবার, টেস্টগুলো চালানোর জন্য কোড লেখা যাক।
-
evaluator/evaluate_agent.pyখুলুন। - আপনি ইম্পোর্ট এবং সেটআপ দেখতে পাবেন, কিন্তু মেট্রিক্স এবং এক্সিকিউশন লজিক অনুপস্থিত।
মেট্রিকগুলো সংজ্ঞায়িত করুন
গবেষক এজেন্টের জন্য, আমাদের কাছে প্রত্যাশিত উত্তরসহ একটি "গোল্ডেন অ্যানসারস"/"গ্রাউন্ড ট্রুথ" রয়েছে। এটি একটি সক্ষমতা মূল্যায়ন : এর মাধ্যমে আমরা পরিমাপ করি যে এজেন্টটি কাজটি সঠিকভাবে করতে পারে কি না।
আমরা পরিমাপ করতে চাই:
- চূড়ান্ত প্রতিক্রিয়ার মিল : (সক্ষমতা) উত্তরটি কি প্রত্যাশিত উত্তরের সাথে মেলে? এটি একটি রেফারেন্স-ভিত্তিক মেট্রিক। এটি এজেন্টের আউটপুটকে প্রত্যাশিত উত্তরের সাথে তুলনা করার জন্য একটি জাজ এলএলএম (Judge LLM) ব্যবহার করে। এটি আশা করে না যে উত্তরটি হুবহু একই হবে, বরং শব্দার্থগতভাবে এবং তথ্যগতভাবে সাদৃশ্যপূর্ণ হবে।
- সরঞ্জাম ব্যবহারের গুণমান : (গুণমান) একটি লক্ষ্যভিত্তিক অভিযোজিত রুব্রিক্স মেট্রিক যা উপযুক্ত সরঞ্জাম নির্বাচন, সঠিক প্যারামিটার ব্যবহার এবং নির্দিষ্ট কার্যক্রম অনুসরণের মূল্যায়ন করে।
- টুল ব্যবহারের গতিপথ : (ট্রেস) ২টি কাস্টম মেট্রিক যা প্রত্যাশিত গতিপথের সাপেক্ষে এজেন্টের টুল ব্যবহারের গতিপথ (প্রিসিশন এবং রিকল) পরিমাপ করে। এই মেট্রিকগুলো
shared/evaluation/tool_metrics.pyফাইলে কাস্টম ফাংশন হিসেবে প্রয়োগ করা হয়েছে। টুল ব্যবহারের মানের (Tool Use Quality) থেকে ভিন্ন, এই মেট্রিকটি একটি ডিটারমিনিস্টিক রেফারেন্স-ভিত্তিক মেট্রিক — কোডটি আক্ষরিকভাবে দেখে যে প্রকৃত টুল কলগুলো রেফারেন্স ডেটার (ইভ্যালুয়েশন ডেটারreference_trajectory) সাথে মেলে কিনা।
কাস্টম টুল ব্যবহারের গতিপথ মেট্রিক্স
কাস্টম টুল ইউজ ট্র্যাজেক্টরি মেট্রিক্সের জন্য, আমরা shared/evaluation/tool_metrics.py ফাইলে এক সেট পাইথন ফাংশন তৈরি করেছি। Vertex AI Gen AI Evaluation Service-কে এই ফাংশনগুলো এক্সিকিউট করার সুযোগ দিতে, আমাদের সেই পাইথন কোডটি এর কাছে পাস করতে হবে।
এটি একটি UnifiedMetric এবং CustomCodeExecutionSpec কনফিগারেশন সহ একটি EvaluationRunMetric অবজেক্ট সংজ্ঞায়িত করার মাধ্যমে করা হয়। remote_custom_function প্যারামিটারটি একটি স্ট্রিং যা ফাংশনটির পাইথন কোড ধারণ করে। ফাংশনটির নাম অবশ্যই evaluate হতে হবে।
def evaluate(
instance: dict
) -> float:
...
আমরা get_custom_function_metric হেল্পারটি ( shared/evaluation/evaluate.py ফাইলে) তৈরি করেছি, যা একটি পাইথন ফাংশনকে নিজস্ব কোড মূল্যায়ন মেট্রিক-এ রূপান্তর করে।
এটি ফাংশনের মডিউলের কোড সংগ্রহ করে (স্থানীয় নির্ভরতাগুলো ধারণ করার জন্য), একটি অতিরিক্ত evaluate ফাংশন তৈরি করে যা মূল ফাংশনটিকে কল করে, এবং একটি CustomCodeExecutionSpec সহ একটি EvaluationRunMetric অবজেক্ট রিটার্ন করে।
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
জেন এআই ইভ্যালুয়েশন সার্ভিস সেই কোডটি একটি স্যান্ডবক্স এক্সিকিউশন এনভায়রনমেন্টে চালাবে এবং ইভ্যালুয়েশন ডেটা সেটির কাছে পাঠিয়ে দেবে।
মেট্রিক্স এবং মূল্যায়ন কোড যোগ করুন
evaluator/evaluate_agent.py ফাইলে if __name__ == "__main__": লাইনের পরে নিম্নলিখিত কোডটি যোগ করুন।
এটি রিসার্চার এজেন্টের জন্য মেট্রিক্স তালিকা নির্ধারণ করে এবং মূল্যায়নটি চালায়।
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
একটি বাস্তব প্রোডাকশন পাইপলাইনে, আপনার একটি 'ইভ্যালুয়েশন সাকসেস ক্রাইটেরিয়া' (মূল্যায়ন সফলতার মানদণ্ড ) প্রয়োজন। মূল্যায়ন সম্পন্ন হয়ে গেলে এবং মেট্রিক্স প্রস্তুত হয়ে গেলে, এখানে একটি 'গেটিং স্টেপ ' (প্রতীকী পদক্ষেপ) থাকবে। উদাহরণস্বরূপ: "যদি Final Response Match স্কোর < ০.৭৫ হয়, তাহলে বিল্ডটি ব্যর্থ করে দাও।" এটি ত্রুটিপূর্ণ রিভিশনগুলোকে কখনোই ট্র্যাফিক পাওয়া থেকে বিরত রাখে।
evaluator/evaluate_agent.py ফাইলে নিম্নলিখিত কোডটি যুক্ত করুন:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
যখনই মূল্যায়ন মেট্রিকগুলোর যেকোনো একটির গড় মান একটি নির্দিষ্ট থ্রেশহোল্ডের ( 0.75 ) নিচে নেমে যাবে, তখন ডেপ্লয়মেন্টটি ব্যর্থ হওয়া উচিত।
[ঐচ্ছিক] অর্কেস্ট্রেটরের জন্য রেফারেন্স-মুক্ত মেট্রিক্স সহ মূল্যায়ন যোগ করুন
অর্কেস্ট্রেটর এজেন্টের ক্ষেত্রে মিথস্ক্রিয়াগুলো আরও জটিল, এবং এক্ষেত্রে সবসময় একটিমাত্র 'সঠিক' উত্তর নাও থাকতে পারে। এর পরিবর্তে, আমরা রেফারেন্স-ফ্রি মেট্রিকগুলোর কোনো একটি ব্যবহার করে সাধারণ আচরণ মূল্যায়ন করি।
- হ্যালুসিনেশন : এটি একটি স্কোর-ভিত্তিক মেট্রিক যা কোনো টেক্সটকে তার মূল দাবিতে বিভক্ত করে তার সত্যতা ও সামঞ্জস্য যাচাই করে। এটি মধ্যবর্তী পর্যায়গুলোতে টুলের ব্যবহারের উপর ভিত্তি করে যাচাই করে যে প্রতিটি দাবির কোনো ভিত্তি আছে কি না। এটি সেইসব ওপেন-এন্ডেড এজেন্টের জন্য অত্যন্ত গুরুত্বপূর্ণ, যেখানে 'সঠিকতা' বিষয়ভিত্তিক হলেও 'সত্যতা' নিয়ে কোনো আপোষ চলে না। উৎস কন্টেন্টের উপর ভিত্তি করে থাকা দাবির শতাংশ হিসাবে স্কোরটি গণনা করা হয়। আমাদের ক্ষেত্রে, আমরা আশা করি যে অর্কেস্ট্রেটরের কাছ থেকে পাওয়া চূড়ান্ত প্রতিক্রিয়াটি (যা কন্টেন্ট বিল্ডার তৈরি করেছে) গবেষকের উইকিপিডিয়া সার্চ টুল ব্যবহার করে সংগ্রহ করা কন্টেন্টের উপর তথ্যগতভাবে ভিত্তিযুক্ত হবে।
অর্কেস্ট্রেটরের জন্য মূল্যায়ন লজিক যোগ করুন:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
মূল্যায়ন ডেটা পরিদর্শন করুন
evaluator/ ডিরেক্টরিটি খুলুন। আপনি দুটি ডেটা ফাইল দেখতে পাবেন:
-
eval_data_researcher.json: গবেষকের জন্য নির্দেশিকা এবং চূড়ান্ত/অপরিহার্য তথ্যের রেফারেন্স। -
eval_data_orchestrator.json: অর্কেস্ট্রেটরের জন্য প্রম্পট (আমরা শুধুমাত্র অর্কেস্ট্রেটরের জন্য রেফারেন্স-মুক্ত মূল্যায়ন করি)।
প্রতিটি এন্ট্রিতে সাধারণত থাকে:
-
prompt: এজেন্টের জন্য প্রম্পট। -
reference: আদর্শ উত্তর (বাস্তব সত্য), যদি প্রযোজ্য হয়। -
reference_trajectory: টুল কলগুলোর প্রত্যাশিত ক্রম।
৬. মূল্যায়ন কোডটি বুঝুন
shared/evaluation/evaluate.py খুলুন। এই মডিউলটিতে ইভ্যালুয়েশন চালানোর মূল লজিক রয়েছে। এর প্রধান ফাংশনটি হলো evaluate_agent ।
এটি নিম্নলিখিত ধাপগুলো সম্পাদন করে:
- ডেটা লোডিং : একটি ফাইল থেকে মূল্যায়ন ডেটাসেট (প্রম্পট এবং রেফারেন্স) পড়ে।
- প্যারালাল ইনফারেন্স : ডেটাসেটের উপর এজেন্টকে সমান্তরালভাবে চালায়। এটি সেশন তৈরি, প্রম্পট প্রেরণ এবং চূড়ান্ত প্রতিক্রিয়া ও মধ্যবর্তী টুল এক্সিকিউশন ট্রেস উভয়ই ক্যাপচার করে।
- ভার্টেক্স এআই ইভ্যালুয়েশন : এটি মূল মূল্যায়ন ডেটার সাথে চূড়ান্ত প্রতিক্রিয়া এবং মধ্যবর্তী টুল এক্সিকিউশন ট্রেস একত্রিত করে এবং ভার্টেক্স এআই এসডিকে-তে থাকা জেনএআই ক্লায়েন্টের মাধ্যমে ভার্টেক্স এআই ইভ্যালুয়েশন সার্ভিসে ফলাফল জমা দেয়। এই সার্ভিসটি এজেন্টের পারফরম্যান্স গ্রেড করার জন্য কনফিগার করা মেট্রিকগুলো চালায়।
শেষ ধাপের মূল মুহূর্তটি হলো Gen AI SDK-এর eval মডিউলের create_evaluation_run ফাংশনটিকে কল করা:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
আমরা shared/evaluation/evaluate.py ফাইলের evaluate_agent ফাংশনে এটি করে থাকি।
এটি মার্জ করা ইভ্যালুয়েশন ডেটাসেট, এজেন্ট সম্পর্কিত তথ্য, ব্যবহারযোগ্য মেট্রিকস এবং গন্তব্য স্টোরেজ ইউআরআই সংগ্রহ করে। ফাংশনটি ভার্টেক্স এআই ইভ্যালুয়েশন সার্ভিসে একটি ইভ্যালুয়েশন রান তৈরি করে এবং ইভ্যালুয়েশন রান অবজেক্টটি রিটার্ন করে।
এজেন্ট তথ্য এপিআই
সঠিক মূল্যায়ন করার জন্য, ইভ্যালুয়েশন সার্ভিসের এজেন্টের কনফিগারেশন (সিস্টেম নির্দেশাবলী, বিবরণ এবং উপলব্ধ টুলসমূহ) জানা প্রয়োজন। আমরা এটিকে agent_info প্যারামিটার হিসেবে create_evaluation_run ফাংশনে প্রেরণ করি।
কিন্তু আমরা এই তথ্য কীভাবে পাই? আমরা এটিকে ADK সার্ভিস API-এর অংশ করে দিই।
shared/adk_app.py খুলুন এবং def agent_info লাইনটি খুঁজুন। আপনি দেখতে পাবেন যে ADK অ্যাপ্লিকেশনটি একটি হেল্পার এন্ডপয়েন্ট উন্মুক্ত করে:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
এই এন্ডপয়েন্টটি (যা --publish_agent_info ফ্ল্যাগের মাধ্যমে সক্রিয় করা হয়) ইভ্যালুয়েশন স্ক্রিপ্টকে এজেন্টের রানটাইম কনফিগারেশন ডায়নামিকভাবে ফেচ করার সুযোগ দেয়। টুল ব্যবহারের মূল্যায়নকারী মেট্রিকগুলোর জন্য এটি অত্যন্ত গুরুত্বপূর্ণ, কারণ জাজ মডেলটি যদি সুনির্দিষ্টভাবে জানতে পারে যে কথোপকথনের সময় এজেন্টের কাছে কোন টুলগুলো উপলব্ধ ছিল, তবে এটি এজেন্টের টুল ব্যবহার আরও ভালোভাবে মূল্যায়ন করতে পারে।
৭. মূল্যায়নটি চালান
এখন যেহেতু আপনি ইভ্যালুয়েটরটি ইমপ্লিমেন্ট করেছেন, চলুন এটি রান করা যাক!
- রিপোজিটরির রুট থেকে মূল্যায়ন স্ক্রিপ্টটি চালান:
./evaluate.sh- এটি আপনার বর্তমান গিট কমিট হ্যাশটি সংগ্রহ করে।
- এটি কমিট হ্যাশের উপর ভিত্তি করে একটি ট্যাগসহ রিভিশন ডিপ্লয় করার জন্য
deploy.shআহ্বান করে। - একবার স্থাপন করা হলে, এটি
evaluator.evaluate_agentচালু করে। - আপনার ক্লাউড সার্ভিসে টেস্ট কেসগুলো চলার সময় আপনি অগ্রগতি বার দেখতে পাবেন।
- অবশেষে, এটি ফলাফলগুলোর একটি সারসংক্ষেপ JSON প্রিন্ট করে।
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
দ্রষ্টব্য: প্রথমবার সার্ভিসগুলো স্থাপন করতে কয়েক মিনিট সময় লাগতে পারে।
৮. নোটবুকে ফলাফল কল্পনা করুন
কাঁচা JSON আউটপুট পড়া কঠিন। Vertex AI SDK-এর Gen AI Client সময়ের সাথে সাথে এই রানগুলো ট্র্যাক করার একটি উপায় প্রদান করে। আমরা ফলাফলগুলো ভিজ্যুয়ালাইজ করার জন্য একটি Colab নোটবুক ব্যবহার করব।
- এই লিঙ্কটি ব্যবহার করে গুগল কোলাবে
evaluator/show_evaluation_run.ipynbখুলুন। -
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGION, এবংEVAL_RUN_IDভেরিয়েবলগুলোকে আপনার প্রজেক্ট আইডি, অঞ্চল এবং রান আইডিতে সেট করুন।
- নির্ভরশীলতাগুলো ইনস্টল করুন এবং প্রমাণীকরণ সম্পন্ন করুন।
মূল্যায়ন রানটি পুনরুদ্ধার করুন এবং ফলাফল প্রদর্শন করুন।
আমাদেরকে Vertex AI থেকে ইভ্যালুয়েশন রানের ডেটা আনতে হবে। Retrieve Evaluation Run এবং Display Results-এর অধীনে থাকা সেলটি খুঁজুন এবং # TODO লাইনটিকে নিম্নলিখিত কোড ব্লক দিয়ে প্রতিস্থাপন করুন:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
ফলাফলের ব্যাখ্যা
ফলাফলগুলো দেখার সময় নিম্নলিখিত বিষয়গুলো মনে রাখবেন:
- পশ্চাদপসরণ বনাম সক্ষমতা :
- রিগ্রেশন : পুরনো পরীক্ষাগুলোতে কি স্কোর কমে গেছে? (এটি ভালো লক্ষণ নয়, তদন্ত প্রয়োজন)।
- সক্ষমতা : নতুন পরীক্ষাগুলোতে স্কোরের কি উন্নতি হয়েছে? (ভালো, এটি একটি অগ্রগতি)।
- ব্যর্থতা বিশ্লেষণ : শুধু স্কোরের দিকে তাকাবেন না।
- ট্রেসটি দেখুন। এটি কি ভুল টুল কল করেছে? এটি কি আউটপুট পার্স করতে ব্যর্থ হয়েছে? এখানেই বাগ খুঁজে পাওয়া যায়।
- বিচারক এলএলএম কর্তৃক প্রদত্ত ব্যাখ্যা ও রায়গুলো দেখুন। সেগুলো থেকে প্রায়শই পরীক্ষাটি কেন ব্যর্থ হয়েছিল সে সম্পর্কে একটি ভালো ধারণা পাওয়া যায়।
Pass@1 বনাম Pass@k : কোনো একটি নির্দিষ্ট পরীক্ষা একবার চালালে আমরা Pass@1 স্কোর পাই। যদি কোনো এজেন্ট ব্যর্থ হয়, তবে তা নন-ডিটারমিনিজমের কারণে হতে পারে। উন্নত সেটআপে, আপনি প্রতিটি পরীক্ষা k বার (যেমন, ৫ বার) চালাতে পারেন এবং pass@k (এটি কি অন্তত একবার সফল হয়েছে?) অথবা pass^k (এটি কি প্রতিবার সফল হয়েছে?) গণনা করতে পারেন। অনেক মেট্রিকই নেপথ্যে এই কাজটি করে থাকে। উদাহরণস্বরূপ, types.RubricMetric.FINAL_RESPONSE_MATCH (ফাইনাল রেসপন্স ম্যাচ) চূড়ান্ত রেসপন্স ম্যাচ স্কোর নির্ধারণ করতে judge LLM-কে ৫ বার কল করে।
৯. নিরবচ্ছিন্ন ইন্টিগ্রেশন এবং ডেপ্লয়মেন্ট (CI/CD)
প্রোডাকশন সিস্টেমে, এজেন্ট ইভ্যালুয়েশন CI/CD পাইপলাইনের অংশ হিসেবে চালানো উচিত। এর জন্য ক্লাউড বিল্ড একটি ভালো বিকল্প।
এজেন্টের কোড রিপোজিটরিতে পুশ করা প্রতিটি কমিটের জন্য, বাকি টেস্টগুলোর সাথে ইভ্যালুয়েশনও চলবে। যদি সেগুলো পাস করে, তবে ডেপ্লয়মেন্টটিকে ব্যবহারকারীর অনুরোধ পরিষেবা দেওয়ার জন্য "প্রমোট" করা যেতে পারে। যদি সেগুলো ফেল করে, সবকিছু আগের মতোই থাকবে, কিন্তু ডেভেলপার দেখতে পারবেন কী ভুল হয়েছে।
ক্লাউড বিল্ড কনফিগারেশন
এখন, চলুন একটি ক্লাউড রান ডেপ্লয়মেন্ট কনফিগারেশন স্ক্রিপ্ট তৈরি করি যা নিম্নলিখিত ধাপগুলো সম্পাদন করবে:
- একটি ব্যক্তিগত সংস্করণে পরিষেবাগুলি স্থাপন করে।
- এজেন্ট মূল্যায়ন চালায়।
- মূল্যায়ন সফল হলে, এটি রিভিশন ডেপ্লয়মেন্টগুলোকে ১০০% ট্র্যাফিক পরিষেবা দেওয়ার জন্য "উন্নীত" করে।
cloudbuild.yaml তৈরি করুন:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
পাইপলাইন চালানো
অবশেষে, আমরা মূল্যায়ন পাইপলাইনটি চালাতে পারি।
ক্লাউড রান পরিষেবাগুলিতে অনুরোধ পাঠানোর জন্য ইভ্যালুয়েশন পাইপলাইনটি চালানোর আগে, আমাদের নির্দিষ্ট কিছু অনুমতিসহ একটি পৃথক সার্ভিস অ্যাকাউন্ট প্রয়োজন। চলুন এমন একটি স্ক্রিপ্ট লিখি যা এই কাজটি করবে এবং পাইপলাইনটি চালু করবে।
-
run_cloud_build.shস্ক্রিপ্ট তৈরি করুন:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION-
agent-eval-build-saএকটি ডেডিকেটেড সার্ভিস অ্যাকাউন্ট তৈরি করে। - এটিকে প্রয়োজনীয় রোলগুলো (
roles/run.admin,roles/aiplatform.user, ইত্যাদি) প্রদান করে। ক্লাউড বিল্ড-এ বিল্ডটি জমা দেয়।
-
- পাইপলাইনটি চালান:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
আপনি টার্মিনালে বিল্ডের অগ্রগতি দেখতে পারেন অথবা ক্লাউড কনসোলের লিঙ্কে ক্লিক করতে পারেন।
দ্রষ্টব্য : একটি বাস্তব প্রোডাকশন পরিবেশে, আপনি প্রতিটি git push এ এটি স্বয়ংক্রিয়ভাবে চালানোর জন্য একটি ক্লাউড বিল্ড ট্রিগার সেট আপ করবেন। কার্যপ্রবাহটি একই: ট্রিগারটি cloudbuild.yaml এক্সিকিউট করবে, যা প্রতিটি কমিট মূল্যায়ন করা নিশ্চিত করবে।
১০. সারসংক্ষেপ
আপনি সফলভাবে একটি মূল্যায়ন পাইপলাইন তৈরি করেছেন!
- ডেপ্লয়মেন্ট : আপনি প্রোডাকশন ডেপ্লয়মেন্টকে প্রভাবিত না করে পরীক্ষার জন্য এজেন্টগুলোকে নিরাপদে বাস্তব পরিবেশে ডেপ্লয় করতে গিট কমিট হ্যাশের সাথে রিভিশন ট্যাগ ব্যবহার করেছেন।
- মূল্যায়ন : আপনি মূল্যায়নের মানদণ্ড নির্ধারণ করেছেন এবং Vertex AI Gen AI Evaluation Service ব্যবহার করে মূল্যায়ন প্রক্রিয়াটিকে স্বয়ংক্রিয় করেছেন।
- বিশ্লেষণ : আপনি মূল্যায়নের ফলাফলগুলো দৃশ্যমান করতে এবং আপনার এজেন্টের উন্নতি সাধন করতে একটি কোলাব নোটবুক ব্যবহার করেছেন।
- রোলআউট : আপনি ক্লাউড বিল্ড ব্যবহার করে মূল্যায়ন পাইপলাইনটি স্বয়ংক্রিয়ভাবে কার্যকর করেছেন এবং ১০০% ট্র্যাফিক পরিষেবা দেওয়ার জন্য সেরা রিভিশনটিকে উন্নীত করেছেন।
এই চক্রটি —কোড সম্পাদনা -> ট্যাগ স্থাপন -> মূল্যায়ন ও পরীক্ষা চালানো -> বিশ্লেষণ -> চালু করা -> পুনরাবৃত্তি — প্রোডাকশন-গ্রেড এজেন্টিক ইঞ্জিনিয়ারিংয়ের মূল ভিত্তি।