
1. Einführung
Übersicht
Dieses Lab ist eine Fortsetzung von Multi-Agent-Systeme mit dem ADK erstellen.
In diesem Lab haben Sie ein System zur Kurserstellung entwickelt, das aus Folgendem besteht:
- Researcher Agent: Verwendet google_search, um aktuelle Informationen zu finden.
- Judge-Agent: Kritisiert die Recherche hinsichtlich Qualität und Vollständigkeit.
- Content Builder-Agent: Die Rechercheergebnisse werden in einen strukturierten Kurs umgewandelt.
- Orchestrator-Agent: Er verwaltet den Workflow und die Kommunikation zwischen diesen Spezialisten.
Außerdem war eine Web-App enthalten, mit der Nutzer eine Anfrage zum Erstellen eines Kurses senden und einen Kurs als Antwort erhalten konnten.
Researcher, Judge und Content Builder werden als A2A-Agents in separaten Cloud Run-Diensten bereitgestellt. Orchestrator ist ein weiterer Cloud Run-Dienst mit der ADK Service API.
Für dieses Lab haben wir den Researcher-Agenten so angepasst, dass er das Tool Wikipedia Search anstelle der Google Search-Funktion von Gemini verwendet. So können wir nachvollziehen, wie benutzerdefinierte Tool-Aufrufe nachverfolgt und ausgewertet werden.
Deshalb haben wir ein verteiltes Multi-Agenten-System entwickelt. Aber woher wissen wir, ob es wirklich gut funktioniert? Findet der Researcher immer relevante Informationen? Erkennt das Modell schlechte Recherche korrekt?
In diesem Lab ersetzen Sie subjektive „Vibe-Checks“ durch eine datengestützte Bewertung mit dem Vertex AI Gen AI Evaluation Service. Sie implementieren adaptive Bewertungsschemas und Messwerte für die Qualität der Toolnutzung, um das verteilte Multi-Agenten-System, das in Lab 1 erstellt wurde, gründlich zu bewerten. Schließlich automatisieren Sie diesen Prozess in einer CI/CD-Pipeline, um sicherzustellen, dass bei jeder Bereitstellung die Zuverlässigkeit und Genauigkeit Ihrer Produktions-Agents erhalten bleibt.
Sie erstellen eine Pipeline für die kontinuierliche Evaluierung für Ihre Agenten. Nach Abschluss können Sie:
- Stellen Sie Ihre Agenten in einer privaten Revision mit Tag in Google Cloud Run bereit (Shadow-Bereitstellung).
- Führen Sie eine automatisierte Bewertungsreihe für diese spezielle Überarbeitung mit dem Vertex AI Gen AI Evaluation Service aus.
- Ergebnisse visualisieren und analysieren
- Verwenden Sie die Auswertung als Teil Ihrer CI/CD-Pipeline.
2. Grundlegende Konzepte: Theorie zur KI-Agentenbewertung
Bei der Entwicklung und Ausführung von KI-Agents führen wir zwei Arten von Bewertungen durch: Offline-Experimente und kontinuierliche Bewertung mit automatisierten Regressionstests. Der erste ist die kreative Engine des Entwicklungsprozesses. Hier führen wir Ad-hoc-Tests durch, optimieren Prompts und iterieren schnell, um neue Funktionen zu entwickeln. Die zweite ist die defensive Ebene in unserer CI/CD-Pipeline. Hier führen wir kontinuierliche Tests anhand eines „Gold“-Datasets durch, um sicherzustellen, dass keine Codeänderung die bewährte Qualität des Agents versehentlich beeinträchtigt.
Der grundlegende Unterschied liegt in Discovery (Erkennung) im Gegensatz zu Defense (Abwehr):
- Offline-Tests sind ein Optimierungsprozess. Sie ist offen und variabel. Sie ändern aktiv Eingaben (Prompts, Modelle, Parameter), um eine Punktzahl zu maximieren oder ein bestimmtes Problem zu lösen. Ziel ist es, die Möglichkeiten des Agents zu erweitern.
- Die kontinuierliche Evaluierung (automatisierte Regressionstests) ist ein Überprüfungsprozess. Sie ist starr und repetitiv. Sie halten die Eingaben konstant (das „goldene“ Dataset), um sicherzustellen, dass die Ausgaben stabil bleiben. Ziel ist es, einen Leistungsabfall zu verhindern.
In diesem Lab konzentrieren wir uns auf die kontinuierliche Evaluierung. Wir entwickeln eine automatisierte Regressionstest-Pipeline, die jedes Mal ausgeführt werden soll, wenn jemand eine Änderung am KI-Agenten vornimmt, genau wie die Unittests.
Bevor wir Code schreiben, müssen wir unbedingt verstehen, was wir messen.
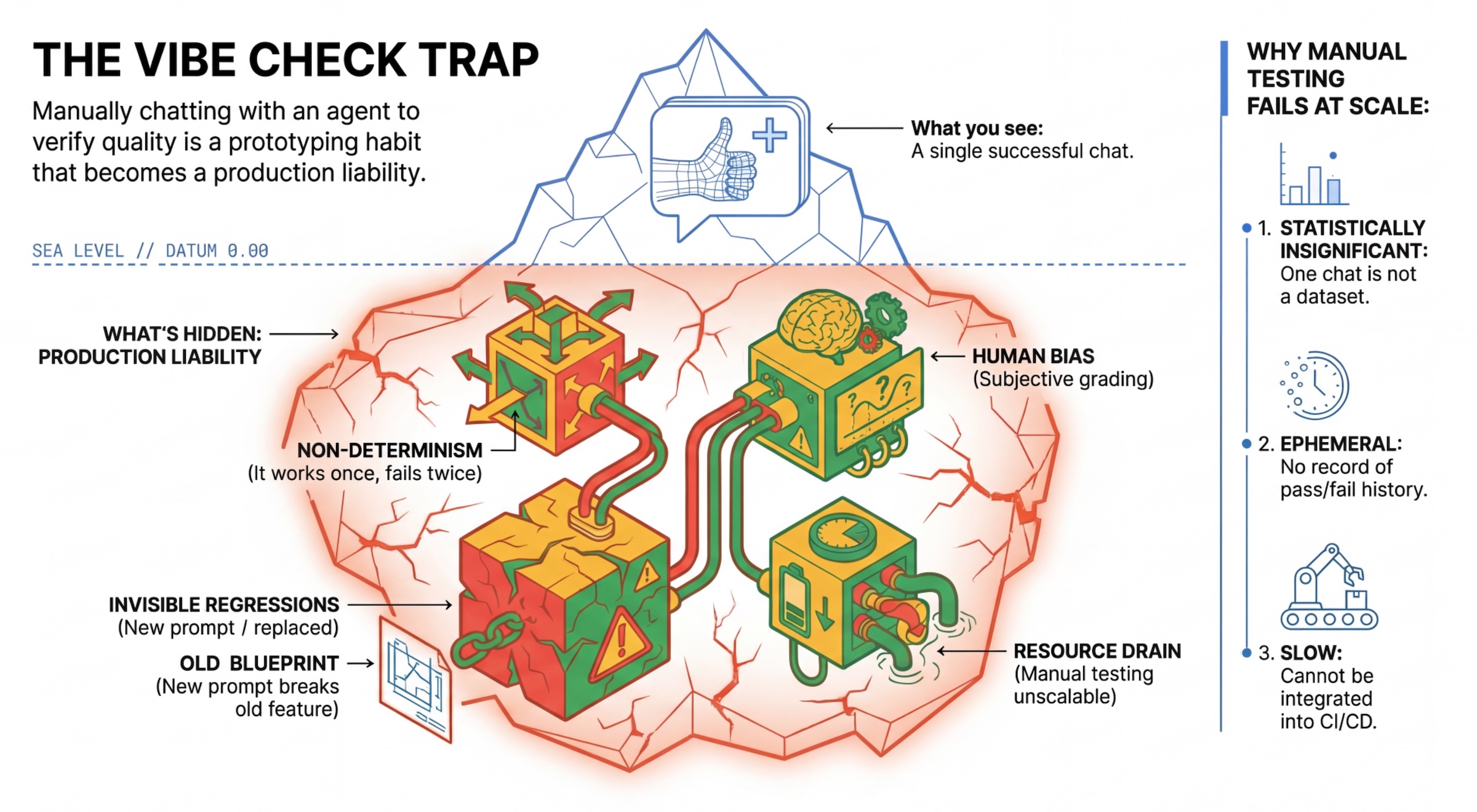
Die „Vibe Check“-Falle
Viele Entwickler testen Agents, indem sie manuell mit ihnen chatten. Dies wird als „Vibe-Check“ bezeichnet. Sie ist zwar für die Prototypenerstellung nützlich, schlägt aber in der Produktion fehl, weil:
- Nicht-Determinismus: Agents können jedes Mal anders antworten. Sie benötigen statistisch signifikante Stichprobengrößen.
- Unsichtbare Regressionen: Wenn Sie einen Prompt verbessern, kann das einen anderen Anwendungsfall beeinträchtigen.
- Menschliche Voreingenommenheit: „Sieht gut aus“ ist subjektiv.
- Zeitaufwendige Arbeit: Es ist langsam, bei jedem Commit Dutzende von Szenarien manuell zu testen.
Zwei Möglichkeiten zur Bewertung der Leistung von KI-Agenten
Um eine robuste Pipeline zu erstellen, kombinieren wir verschiedene Arten von Prüfern:
- Codebasierte Grader (deterministisch):
- Was wird gemessen?: Strenge Einschränkungen (z.B. „Wurde gültiges JSON zurückgegeben?“, Wurde das Tool
searchaufgerufen? - Vorteile: Schnell, kostengünstig, 100% genau.
- Nachteile: Nuancen und Qualität können nicht beurteilt werden.
- Was wird gemessen?: Strenge Einschränkungen (z.B. „Wurde gültiges JSON zurückgegeben?“, Wurde das Tool
- Modellbasierte Korrektoren (probabilistisch):
- Auch als „LLM-as-a-Judge“ bezeichnet. Wir verwenden ein leistungsstarkes Modell wie Gemini 3 Pro, um die Ausgabe des Agenten zu bewerten.
- Was wird gemessen?: Nuance, Begründung, Nützlichkeit, Sicherheit.
- Vorteile: Kann komplexe, offene Aufgaben bewerten.
- Nachteile: Langsamer, teurer, erfordert sorgfältiges Prompt-Engineering für das Modell.
Vertex AI-Bewertungsmesswerte
In diesem Lab verwenden wir den Vertex AI Gen AI Evaluation Service, der verwaltete Messwerte bietet, sodass Sie nicht jeden Judge von Grund auf neu schreiben müssen.
Es gibt mehrere Möglichkeiten, Messwerte für die Agentenbewertung zu gruppieren:
- Auf Bewertungsschemas basierende Messwerte: LLMs werden in Bewertungs-Workflows eingebunden.
- Adaptive Rubrics: Rubrics werden dynamisch für jeden Prompt generiert. Antworten werden anhand von detailliertem, nachvollziehbarem Feedback zu bestanden oder nicht bestanden bewertet, das sich auf den jeweiligen Prompt bezieht.
- Statische Rubriken: Rubriken werden explizit definiert und dieselbe Rubrik wird auf alle Prompts angewendet. Antworten werden mit denselben numerischen Bewertungsmodellen bewertet. Eine einzelne numerische Bewertung (z. B. 1–5) pro Prompt. Wenn eine Bewertung für eine sehr spezifische Dimension erforderlich ist oder wenn für alle Prompts genau dieselbe Rubrik verwendet werden muss.
- Berechnungsbasierte Messwerte: Antworten werden mit deterministischen Algorithmen bewertet, in der Regel anhand von Ground Truth. Eine numerische Punktzahl (z.B.0,0–1,0) pro Prompt. Wenn Ground Truth verfügbar ist und mit einer deterministischen Methode abgeglichen werden kann.
- Messwerte für benutzerdefinierte Funktionen: Sie können einen eigenen Messwert über eine Python-Funktion definieren.
Spezifische Messwerte, die wir verwenden:
Final Response Match: (Referenzbasiert) Entspricht die Antwort unserer „Goldenen Antwort“?Tool Use Quality: (Referenzfrei) Hat der KI-Agent relevante Tools auf angemessene Weise verwendet?Hallucination: (Referenzfrei) Werden die Behauptungen in der Antwort durch den abgerufenen Kontext gestützt?Tool Trajectory PrecisionundTool Trajectory Recall(referenzbasiert): Hat der Kundenservicemitarbeiter das richtige Tool ausgewählt und gültige Argumente angeführt? Im Gegensatz zuTool Use Qualityverwenden diese benutzerdefinierten Messwerte einen Referenzpfad – eine Sequenz erwarteter Tool-Aufrufe und Argumente.
3. Einrichtung
Konfiguration
- Cloud Shell öffnen: Klicken Sie rechts oben in der Google Cloud Console auf das Symbol Cloud Shell aktivieren.
- Führen Sie den folgenden Befehl aus, um die Anmeldung zu aktualisieren und die Standardanmeldedaten für Anwendungen zu aktualisieren:
gcloud auth login --update-adc - Legen Sie ein aktives Projekt für die gcloud CLI fest.Führen Sie den folgenden Befehl aus, um das aktuelle gcloud-Projekt abzurufen:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDdurch die ID Ihres Projekts. - Legen Sie die Standardregion fest, in der Ihre Cloud Run-Dienste bereitgestellt werden.
gcloud config set run/region us-west1us-west1können Sie eine beliebige Cloud Run-Region verwenden, die sich näher an Ihrem Standort befindet.
Code und Abhängigkeiten
- Klonen Sie den Startercode und wechseln Sie in das Stammverzeichnis des Projekts.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab .env-Datei erstellen:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env- Installieren Sie die Abhängigkeiten, indem Sie den folgenden Befehl im Terminalfenster ausführen:
uv sync
4. Sichere Bereitstellung
Bevor wir das Modell bewerten können, müssen wir es bereitstellen. Wir möchten aber nicht, dass die Live-Anwendung durch unseren neuen Code beschädigt wird.
Versions-Tags und Shadow Deployment
Google Cloud Run unterstützt Überarbeitungen. Bei jeder Bereitstellung wird eine neue unveränderliche Version erstellt. Sie können diesen Überarbeitungen Tags zuweisen, um über eine bestimmte URL darauf zuzugreifen, auch wenn sie 0% des öffentlichen Traffics erhalten.
Warum führen Sie die Prüfungen nicht einfach lokal durch?
Das ADK unterstützt zwar die lokale Auswertung, die Bereitstellung in einer verborgenen Überarbeitung bietet jedoch entscheidende Vorteile für Produktionssysteme. Das unterscheidet die Bewertung auf Systemebene (die wir durchführen) vom Unittest:
- Umgebungsparität: Lokale Umgebungen sind unterschiedlich (anderes Netzwerk, andere CPU/Arbeitsspeicher, andere Secrets). Durch Tests in der Cloud wird sichergestellt, dass Ihr Agent in der tatsächlichen Laufzeitumgebung funktioniert (Systemtest).
- Multi-Agent Interaction: In einem verteilten System kommunizieren Agents über HTTP. Bei „lokalen“ Tests werden diese Verbindungen oft simuliert. Bei Shadow-Bereitstellungen werden die tatsächliche Netzwerklatenz, die Timeout-Konfigurationen und die Authentifizierung zwischen Ihren Mikrodiensten getestet.
- Secrets & Permissions (Secrets und Berechtigungen): Hier wird geprüft, ob Ihr Dienstkonto tatsächlich die erforderlichen Berechtigungen hat (z.B. zum Aufrufen von Vertex AI oder zum Lesen aus Firestore).
Community-Anmerkung:Dies ist die proaktive Überprüfung (Prüfung, bevor Nutzer die Inhalte sehen). Nach der Bereitstellung verwenden Sie Reactive Monitoring (Observability), um Probleme in der Produktion zu erkennen.
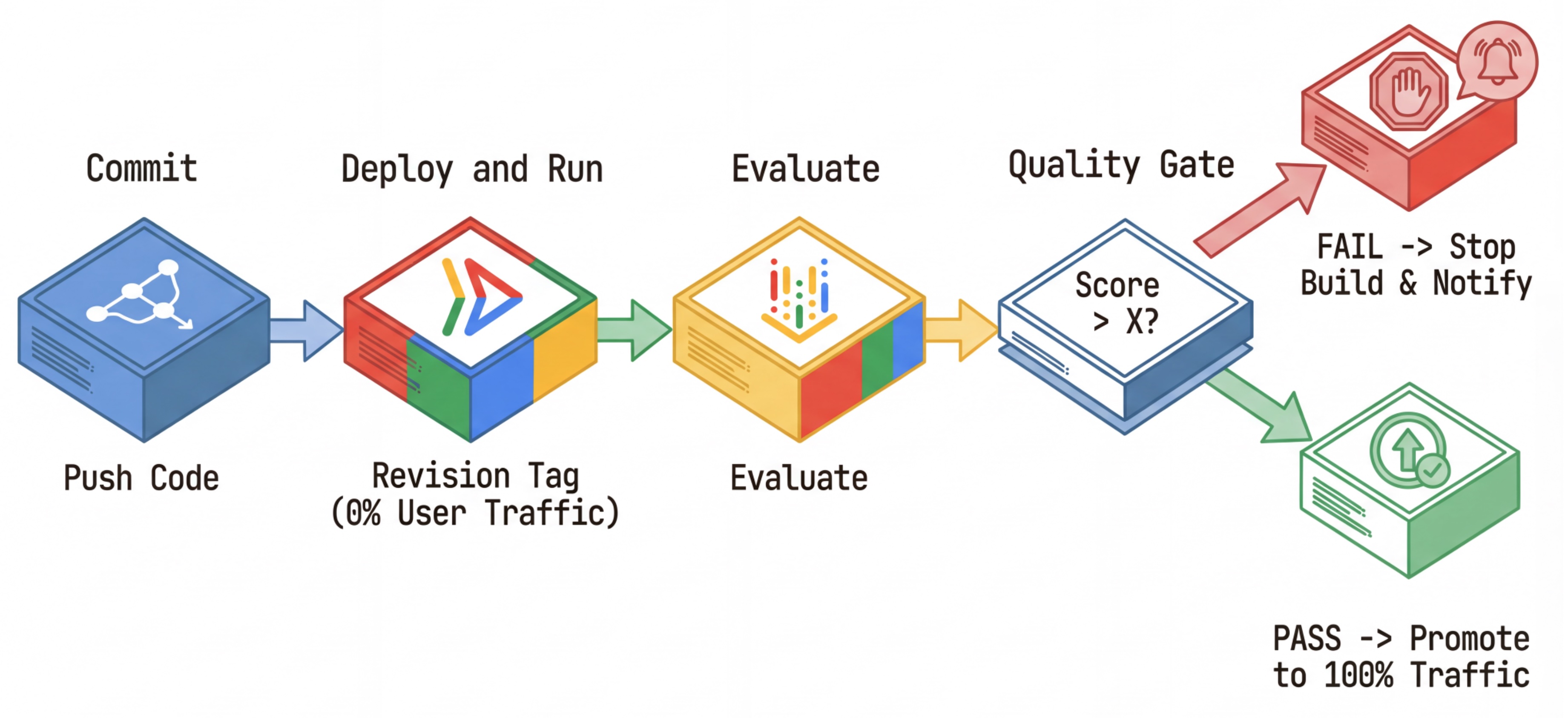
Der CI/CD-Workflow: Bereitstellen, Bewerten, Hochstufen
Wir verwenden dies für eine robuste Continuous Deployment-Pipeline:
- Commit: Sie ändern den Prompt des Agents und übertragen die Änderungen per Push in das Repository.
- Bereitstellen (verborgen): Dadurch wird die Bereitstellung einer neuen Revision ausgelöst, die mit dem Commit-Hash getaggt ist (z.B.
c-abc1234). Diese Revision erhält 0% des öffentlichen Traffics. - Bewerten: Das Bewertungsskript ist auf die spezifische Revisions-URL
https://c-abc1234---researcher-xyz.run.appausgerichtet. - Hochstufen: Wenn (und nur wenn) die Auswertung erfolgreich ist und andere Tests bestanden werden, migrieren Sie den Traffic zu dieser neuen Version.
- Rollback: Wenn der Rollback fehlschlägt, haben Nutzer die fehlerhafte Version nie gesehen. Sie können die fehlerhafte Überarbeitung einfach ignorieren oder löschen.
Mit dieser Strategie können Sie in der Produktion testen, ohne Kunden zu beeinträchtigen.
evaluate.sh analysieren
Öffnen Sie evaluate.sh. Dieses Skript automatisiert den Prozess.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
Das deploy.sh übernimmt das Deployment von Überarbeitungen mit den Optionen --no-traffic und --tag. Wenn bereits ein Dienst ausgeführt wird, ist er davon nicht betroffen. Die neue „verborgene“ Überarbeitung erhält keinen Traffic, sofern Sie sie nicht explizit mit einer speziellen URL aufrufen, die das Überarbeitungs-Tag enthält (z. B. https://c-abc1234---researcher-xyz.run.app).
5. Bewertungsskript implementieren
Schreiben wir nun den Code, mit dem die Tests ausgeführt werden.
- Öffnen Sie
evaluator/evaluate_agent.py. - Sie sehen Importe und die Einrichtung, aber die Messwerte und die Ausführungslogik fehlen.
Messwerte definieren
Für den Researcher Agent haben wir „Golden Answers“/„Ground Truth“ mit erwarteten Antworten. Dies ist eine Capability Eval (Bewertung der Fähigkeit): Wir messen, ob der Agent die Aufgabe richtig ausführen kann.
Wir möchten Folgendes messen:
- Übereinstimmung der endgültigen Antwort: (Funktion) Entspricht die Antwort der erwarteten Antwort? Dies ist ein referenzbasierter Messwert. Dabei wird ein Judge-LLM verwendet, um die Ausgabe des Agenten mit der erwarteten Antwort zu vergleichen. Es wird nicht erwartet, dass die Antwort genau dieselbe ist, sondern semantisch und faktisch ähnlich.
- Qualität der Tool-Nutzung: (Qualität) Ein gezielter adaptiver Messwert des Bewertungsschemas, der die Auswahl geeigneter Tools, die korrekte Verwendung von Parametern und die Einhaltung der angegebenen Reihenfolge von Vorgängen bewertet.
- Tool-Einsatz: (Trace) Zwei benutzerdefinierte Messwerte, mit denen der Tool-Einsatz des Agenten (Precision und Recall) im Vergleich zu den erwarteten Abläufen gemessen wird. Diese Messwerte werden in
shared/evaluation/tool_metrics.pyals benutzerdefinierte Funktionen implementiert. Im Gegensatz zu Tool Use Quality ist dieser Messwert ein deterministischer referenzbasierter Messwert. Der Code prüft, ob die tatsächlichen Tool-Aufrufe mit den Referenzdaten (reference_trajectoryin den Auswertungsdaten) übereinstimmen.
Messwerte für die Entwicklung der Nutzung benutzerdefinierter Tools
Für benutzerdefinierte Messwerte für den Tool-Nutzungsverlauf haben wir eine Reihe von Python-Funktionen in shared/evaluation/tool_metrics.py erstellt. Damit der Vertex AI Gen AI Evaluation Service diese Funktionen ausführen kann, müssen wir ihm diesen Python-Code übergeben.
Dazu wird ein EvaluationRunMetric-Objekt mit einer UnifiedMetric- und einer CustomCodeExecutionSpec-Konfiguration definiert. Der Parameter remote_custom_function ist ein String, der den Python-Code der Funktion enthält. Die Funktion muss den Namen evaluate haben:
def evaluate(
instance: dict
) -> float:
...
Wir haben den get_custom_function_metric-Helfer (in shared/evaluation/evaluate.py) erstellt, der eine Python-Funktion in einen benutzerdefinierten Messwert für die Codebewertung konvertiert.
Sie ruft den Code des Funktionsmoduls ab (um lokale Abhängigkeiten zu erfassen), erstellt eine zusätzliche evaluate-Funktion, die die ursprüngliche Funktion aufruft, und gibt ein EvaluationRunMetric-Objekt mit einem CustomCodeExecutionSpec zurück.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Der Gen AI Evaluation Service führt diesen Code in einer Sandbox-Ausführungsumgebung aus und übergibt die Bewertungsdaten.
Messwerte und Auswertungscode hinzufügen
Fügen Sie den folgenden Code in evaluator/evaluate_agent.py nach der Zeile if __name__ == "__main__": ein.
Hier wird die Messwertliste für den Researcher-Agent definiert und die Auswertung wird ausgeführt.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
In einer echten Produktionspipeline benötigen Sie Erfolgskriterien für die Evaluierung. Sobald die Auswertung abgeschlossen ist und die Messwerte verfügbar sind. Hier sehen Sie einen Gating Step. Beispiel: „Wenn der Final Response Match-Wert unter 0,75 liegt, schlägt der Build fehl.“ So wird verhindert, dass ungültige Überarbeitungen Traffic erhalten.
Hängen Sie den folgenden Code an evaluator/evaluate_agent.py an:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Wenn der Mittelwert eines der Bewertungsmesswerte unter einem Grenzwert (0.75) liegt, sollte die Bereitstellung fehlschlagen.
[Optional] Bewertung mit referenzfreien Messwerten für den Orchestrator hinzufügen
Beim Orchestrator-Agent sind die Interaktionen komplexer und es gibt möglicherweise nicht immer eine einzige „richtige“ Antwort. Stattdessen bewerten wir das allgemeine Verhalten anhand eines der referenzfreien Messwerte.
- Halluzination: Ein auf Bewertungen basierender Messwert, der die Faktizität und Konsistenz von Textantworten überprüft, indem er die Antwort in einzelne Behauptungen unterteilt. Der Messwert überprüft auf Basis der Toolnutzung in den Zwischenereignissen, ob die einzelnen Behauptungen fundiert sind oder nicht. Das ist entscheidend für Agents mit offenem Ende, bei denen „Richtigkeit“ subjektiv ist, „Wahrhaftigkeit“ aber nicht. Der Wert wird als Prozentsatz der Behauptungen berechnet, die auf den Quellinhalten basieren. In unserem Fall erwarten wir, dass die endgültige Antwort des Orchestrators (die von Content Builder erstellt wurde) auf den Fakten basiert, die Researcher mit dem Wikipedia Search-Tool abgerufen hat.
Fügen Sie die Bewertungslogik für den Orchestrator hinzu:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Bewertungsdaten prüfen
Öffnen Sie das Verzeichnis evaluator/. Es werden zwei Datendateien angezeigt:
eval_data_researcher.json: Prompts und Golden/Ground-Truth-Referenzen für den Researcher.eval_data_orchestrator.json: Prompts für den Orchestrator (wir führen nur eine referenzfreie Bewertung für den Orchestrator durch).
Jeder Eintrag enthält in der Regel Folgendes:
prompt: Die Eingabeaufforderung für den Agenten.reference: Die ideale Antwort (Ground Truth), falls zutreffend.reference_trajectory: Die erwartete Abfolge von Toolaufrufen.
6. Bewertungscode
Öffnen Sie shared/evaluation/evaluate.py. Dieses Modul enthält die Kernlogik für die Ausführung von Bewertungen. Die Hauptfunktion ist evaluate_agent.
Dabei werden die folgenden Schritte ausgeführt:
- Daten laden: Das Bewertungs-Dataset (Prompts und Referenzen) wird aus einer Datei gelesen.
- Parallele Inferenz: Der Agent wird parallel für das Dataset ausgeführt. Es übernimmt die Erstellung von Sitzungen, sendet Prompts und erfasst sowohl die endgültige Antwort als auch den Zwischenablauf der Tool-Ausführung.
- Vertex AI Evaluation: Die ursprünglichen Bewertungsdaten werden mit den endgültigen Antworten und dem Zwischenablauf der Toolausführung zusammengeführt und die Ergebnisse werden mit dem GenAI-Client im Vertex AI SDK an den Vertex AI Evaluation Service gesendet. Dieser Dienst führt die konfigurierten Messwerte aus, um die Leistung des Agents zu bewerten.
Der wichtigste Moment des letzten Schritts ist der Aufruf der create_evaluation_run-Funktion des Eval-Moduls des Gen AI SDK:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Dies geschieht in der Funktion evaluate_agent in shared/evaluation/evaluate.py.
Es ruft das zusammengeführte Auswertungs-Dataset, die Informationen zum Agent, die zu verwendenden Messwerte und den URI des Zielspeichers ab. Die Funktion erstellt einen Bewertungsdurchlauf im Vertex AI Evaluation Service und gibt das Bewertungsdurchlaufobjekt zurück.
Agent Info API
Für eine genaue Bewertung muss der Evaluation Service die Konfiguration des Agenten kennen (Systemanweisungen, Beschreibung und verfügbare Tools). Wir übergeben sie an create_evaluation_run als agent_info-Parameter.
Aber wie erhalten wir diese Informationen? Wir machen es zum Teil der ADK Service API.
Öffnen Sie shared/adk_app.py und suchen Sie nach def agent_info. Die ADK-Anwendung stellt einen Hilfs-Endpunkt bereit:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Über diesen Endpunkt (aktiviert über das Flag --publish_agent_info) kann das Auswertungsskript die Laufzeitkonfiguration des Agents dynamisch abrufen. Das ist entscheidend für Messwerte, mit denen die Tool-Nutzung bewertet wird, da das Judge-Modell die Tool-Nutzung des Agenten besser bewerten kann, wenn es genau weiß, welche Tools dem Agenten während der Unterhaltung zur Verfügung standen.
7. Bewertung ausführen
Nachdem Sie den Evaluator implementiert haben, führen wir ihn aus.
- Führen Sie das Bewertungsskript über das Stammverzeichnis des Repositorys aus:
./evaluate.sh- Ruft den aktuellen Git-Commit-Hash ab.
- Es ruft
deploy.shauf, um eine Version mit einem Tag basierend auf dem Commit-Hash bereitzustellen. - Nach der Bereitstellung wird
evaluator.evaluate_agentgestartet. - Während die Testläufe für Ihren Cloud-Dienst ausgeführt werden, sehen Sie Fortschrittsbalken.
- Schließlich wird eine JSON-Zusammenfassung der Ergebnisse ausgegeben.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Hinweis: Bei der ersten Ausführung kann es einige Minuten dauern, bis die Dienste bereitgestellt sind.
8. Ergebnisse in einem Notebook visualisieren
Die rohe JSON-Ausgabe ist schwer zu lesen. Der Gen AI-Client im Vertex AI SDK bietet eine Möglichkeit, diese Ausführungen im Zeitverlauf zu verfolgen. Wir verwenden ein Colab-Notebook, um die Ergebnisse zu visualisieren.
- Öffnen Sie
evaluator/show_evaluation_run.ipynbin Google Colab über diesen Link. - Legen Sie die Variablen
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONundEVAL_RUN_IDauf Ihre Projekt-ID, Region und Ausführungs-ID fest.
- Abhängigkeiten installieren und authentifizieren
Bewertungslauf abrufen und Ergebnisse anzeigen
Wir müssen die Daten des Bewertungslaufs aus Vertex AI abrufen. Suchen Sie die Zelle unter Retrieve Evaluation Run and Display Results (Evaluierungslauf abrufen und Ergebnisse anzeigen) und ersetzen Sie die Zeile # TODO durch den folgenden Codeblock:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Ergebnisse interpretieren
Beachten Sie bei der Auswertung der Ergebnisse Folgendes:
- Regression im Vergleich zu Funktion:
- Regression: Ist die Punktzahl bei alten Tests gesunken? (Nicht gut, muss untersucht werden)
- Leistungsfähigkeit: Hat sich der Wert bei neuen Tests verbessert? (Gut, das ist ein Fortschritt.)
- Fehleranalyse: Sehen Sie sich nicht nur die Punktzahl an.
- Sehen Sie sich den Trace an. Wurde das falsche Tool aufgerufen? Konnte die Ausgabe nicht geparst werden? Hier finden Sie Insekten.
- Sehen Sie sich die Erklärungen und Urteile des Richter-LLM an. Sie geben oft Aufschluss darüber, warum der Test fehlgeschlagen ist.
Pass@1 im Vergleich zu Pass@k: Wenn wir einen bestimmten Test einmal ausführen, erhalten wir den Pass@1-Wert. Wenn ein Agent fehlschlägt, kann das an Nichtdeterminismus liegen. Bei komplexen Setups führen Sie jeden Test möglicherweise k-mal aus (z.B. 5-mal) und berechnen pass@k (war er mindestens einmal erfolgreich?) oder pass^k (war er jedes Mal erfolgreich?). Das ist bei vielen Messwerten bereits der Fall. Bei types.RubricMetric.FINAL_RESPONSE_MATCH (Final Response Match) werden beispielsweise fünf Aufrufe an das Judge-LLM ausgeführt, um den Score für die Übereinstimmung der endgültigen Antwort zu ermitteln.
9. Continuous Integration und Continuous Deployment (CI/CD)
In einem Produktionssystem sollte die Agent-Bewertung als Teil der CI/CD-Pipeline ausgeführt werden. Dafür eignet sich Cloud Build.
Für jeden Commit, der in das Code-Repository des Agents übertragen wird, wird die Auswertung zusammen mit den anderen Tests ausgeführt. Wenn sie bestanden werden, kann die Bereitstellung für die Bearbeitung von Nutzeranfragen „hochgestuft“ werden. Wenn sie fehlschlagen, bleibt alles wie es ist, aber der Entwickler kann nachsehen, was schiefgelaufen ist.
Cloud Build-Konfiguration
Erstellen wir nun ein Cloud Run-Bereitstellungskonfigurationsskript, das die folgenden Schritte ausführt:
- Stellt Dienste in einer privaten Revision bereit.
- Führt die Bewertung des KI-Agenten aus.
- Wenn die Bewertung bestanden wird, werden Überarbeitungsbereitstellungen „hochgestuft“, sodass sie 100% des Traffics bereitstellen.
cloudbuild.yaml erstellen:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Pipeline ausführen
Schließlich können wir die Bewertungspipeline ausführen.
Bevor wir die Auswertungspipeline ausführen, mit der Anfragen an Cloud Run-Dienste gesendet werden, benötigen wir ein separates Dienstkonto mit einer Reihe von Berechtigungen. Wir schreiben ein Skript, das genau das tut und die Pipeline startet.
- Erstellen Sie das Skript
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Erstellt ein dediziertes Dienstkonto
agent-eval-build-sa. - Weist dem Dienstkonto die erforderlichen Rollen zu (
roles/run.admin,roles/aiplatform.userusw.). *. Senden Sie den Build an Cloud Build.
- Erstellt ein dediziertes Dienstkonto
- Führen Sie die Pipeline aus:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Sie können den Build-Fortschritt im Terminal verfolgen oder auf den Link zur Cloud Console klicken.
Hinweis: In einer echten Produktionsumgebung würden Sie einen Cloud Build-Trigger einrichten, damit dies bei jedem git push automatisch ausgeführt wird. Der Workflow ist derselbe: Der Trigger würde cloudbuild.yaml ausführen, sodass jeder Commit ausgewertet wird.
10. Zusammenfassung
Sie haben erfolgreich eine Bewertungs-Pipeline erstellt.
- Bereitstellung: Sie haben Überarbeitungs-Tags mit dem Git-Commit-Hash verwendet, um Agents sicher in einer realen Umgebung zum Testen bereitzustellen, ohne Produktionsbereitstellungen zu beeinträchtigen.
- Bewertung: Sie haben Bewertungsmetriken definiert und den Bewertungsprozess mit dem Vertex AI Gen AI Evaluation Service automatisiert.
- Analyse: Sie haben ein Colab-Notebook verwendet, um die Bewertungsergebnisse zu visualisieren und Ihren Agent zu verbessern.
- Rollout: Sie haben Cloud Build verwendet, um die Evaluierungspipeline automatisch auszuführen und die beste Revision für die Verarbeitung von 100% des Traffics hochzustufen.
Dieser Zyklus Code bearbeiten > Tag bereitstellen > Bewertung und Tests ausführen > Analysieren > Einführen > Wiederholen ist das Herzstück von Production-Grade Agentic Engineering.