
1. Introducción
Descripción general
Este lab es una continuación de Crea sistemas multiagente con el ADK.
En ese lab, creaste un sistema de creación de cursos que consta de los siguientes elementos:
- Agente de investigación: Usa google_search para encontrar información actualizada.
- Agente de evaluación: Critica la investigación en cuanto a calidad y completitud.
- Agente de Content Builder: Convierte la investigación en un curso estructurado.
- Agente organizador: Administra el flujo de trabajo y la comunicación entre estos especialistas.
También incluía una app web que permitía a los usuarios enviar una solicitud de creación de cursos y obtener un curso como respuesta.
Researcher, Judge y Content Builder se implementan como agentes A2A en servicios de Cloud Run separados. Orchestrator es otro servicio de Cloud Run con la API de ADK Service.
Para este lab, modificamos el agente de Researcher para que use la herramienta Wikipedia Search en lugar de la capacidad de Búsqueda de Google de Gemini. Nos permite inspeccionar cómo se rastrean y evalúan las llamadas a herramientas personalizadas.
Por lo tanto, creamos un sistema multiagente distribuido. Pero ¿cómo sabemos si realmente funciona bien? ¿El Investigador siempre encuentra información pertinente? ¿El juez identifica correctamente la investigación deficiente?
En este lab, cambiarás las "verificaciones de ambiente" subjetivas por evaluaciones basadas en datos con Gen AI Evaluation Service de Vertex AI. Implementarás métricas de rúbricas adaptables y de calidad del uso de herramientas para evaluar de forma rigurosa el sistema multiagente distribuido que se creó en el lab 1. Por último, automatizarás este proceso dentro de una canalización de CI/CD, lo que garantizará que cada implementación mantenga la confiabilidad y la precisión de tus agentes de producción.
Crearás una canalización de evaluación continua para tus agentes. Aprenderás a hacer lo siguiente:
- Implementa tus agentes en una revisión etiquetada privada en Google Cloud Run (implementación oculta).
- Ejecuta un conjunto de evaluaciones automatizadas en esa revisión específica con Gen AI Evaluation Service de Vertex AI.
- Visualiza y analiza los resultados.
- Usa la evaluación como parte de tu canalización de CI/CD.
2. Conceptos básicos: teoría de la evaluación de agentes
Cuando desarrollamos y ejecutamos agentes de IA, realizamos dos tipos de evaluaciones: experimentación sin conexión y evaluación continua con pruebas de regresión automatizadas. La primera es el motor creativo del proceso de desarrollo, en el que realizamos experimentos ad hoc, perfeccionamos instrucciones y realizamos iteraciones rápidamente para desbloquear nuevas capacidades. La segunda es la capa defensiva dentro de nuestra canalización de CI/CD, en la que ejecutamos evaluaciones continuas en un conjunto de datos "dorado" para garantizar que ningún cambio de código degrade inadvertidamente la calidad comprobada del agente.
La diferencia fundamental radica en el descubrimiento frente a la defensa:
- La experimentación sin conexión es un proceso de optimización. Es abierta y variable. Cambias de forma activa las entradas (instrucciones, modelos, parámetros) para maximizar una puntuación o resolver un problema específico. El objetivo es aumentar el "límite" de lo que el agente puede hacer.
- La evaluación continua (pruebas de regresión automatizadas) es un proceso de verificación. Es rígido y repetitivo. Mantienes las entradas constantes (el conjunto de datos "dorado") para garantizar que los resultados sigan siendo estables. El objetivo es evitar que el "piso" del rendimiento se derrumbe.
En este lab, nos enfocaremos en la evaluación continua. Desarrollaremos una canalización de pruebas de regresión automatizadas que se ejecutará cada vez que alguien realice un cambio en el agente de IA, al igual que esas pruebas de unidades.
Antes de escribir código, es fundamental comprender qué medimos.
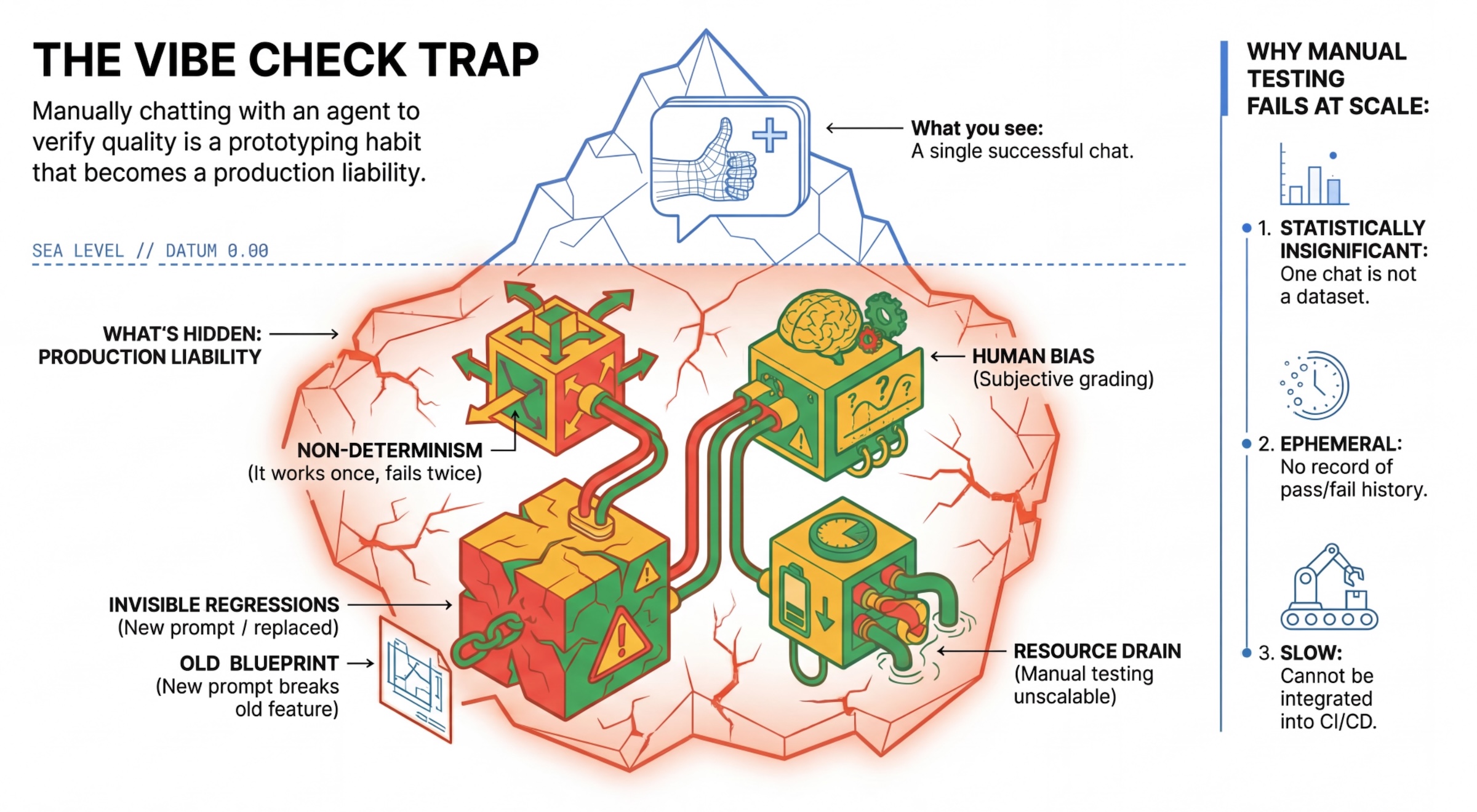
La trampa de la “Vibe Check”
Muchos desarrolladores prueban los agentes chateando con ellos de forma manual. Esto se conoce como "vibe checking". Si bien es útil para la creación de prototipos, falla en producción por los siguientes motivos:
- No determinismo: Los agentes pueden responder de manera diferente cada vez. Necesitas tamaños de muestra estadísticamente significativos.
- Regresiones invisibles: Mejorar una instrucción puede afectar otro caso de uso.
- Sesgo humano: "Se ve bien" es subjetivo.
- Trabajo que requiere mucho tiempo: Probar manualmente docenas de situaciones con cada confirmación es un proceso lento.
Dos formas de calificar el rendimiento del agente
Para crear una canalización sólida, combinamos diferentes tipos de calificadores:
- Calificadores basados en código (determinísticos):
- Qué miden: Restricciones estrictas (p.ej., "¿Devolvió un JSON válido?", ¿Llamó a la herramienta
search?"). - Ventajas: Es rápido, económico y 100% preciso.
- Desventajas: No puede juzgar matices ni calidad.
- Qué miden: Restricciones estrictas (p.ej., "¿Devolvió un JSON válido?", ¿Llamó a la herramienta
- Calificadores basados en modelos (probabilísticos):
- También se conoce como "LLM-as-a-Judge". Usamos un modelo sólido (como Gemini 3 Pro) para evaluar el resultado del agente.
- Qué miden: Sutileza, razonamiento, utilidad y seguridad.
- Ventajas: Puede evaluar tareas complejas y abiertas.
- Desventajas: Es más lento y costoso, y requiere una ingeniería de instrucciones cuidadosa para el juez.
Métricas de evaluación de Vertex AI
En este lab, usaremos Vertex AI Gen AI Evaluation Service, que proporciona métricas administradas para que no tengas que escribir cada evaluador desde cero.
Existen varias formas de agrupar las métricas para la evaluación de agentes:
- Métricas basadas en rúbricas: Incorporan LLMs en los flujos de trabajo de evaluación.
- Rúbricas adaptables: Las rúbricas se generan de forma dinámica para cada instrucción. Las respuestas se evalúan con comentarios detallados y explicables de aprobación o rechazo específicos para la instrucción.
- Rúbricas estáticas: Las rúbricas se definen de forma explícita y se aplica la misma rúbrica a todas las instrucciones. Las respuestas se evalúan con el mismo conjunto de evaluadores basados en puntuaciones numéricas. Una sola puntuación numérica (por ejemplo, de 1 a 5) por instrucción. Cuando se requiere una evaluación en una dimensión muy específica o cuando se requiere la misma rúbrica exacta en todas las instrucciones.
- Métricas basadas en cálculos: Evalúan las respuestas con algoritmos determinísticos, por lo general, con datos de verdad fundamental. Es una puntuación numérica (por ejemplo, de 0.0 a 1.0) por instrucción. Cuando la verdad fundamental está disponible y se puede correlacionar con un método determinístico.
- Métricas de funciones personalizadas: Define tu propia métrica a través de una función de Python.
Métricas específicas que usaremos:
Final Response Match: (Basada en referencias) ¿La respuesta coincide con nuestra "Respuesta de oro"?Tool Use Quality: (Sin referencia) ¿El agente usó las herramientas pertinentes de manera adecuada?Hallucination: (Sin referencia) ¿Las afirmaciones de la respuesta se respaldan en el contexto recuperado?Tool Trajectory PrecisionyTool Trajectory Recall(basado en referencias): ¿El agente seleccionó la herramienta correcta y proporcionó argumentos válidos? A diferencia deTool Use Quality, estas métricas personalizadas usan una trayectoria de referencia, que es una secuencia de llamadas y argumentos esperados de las herramientas.
3. Configuración
Configuración
- Abre Cloud Shell: Haz clic en el ícono de Activar Cloud Shell en la parte superior derecha de la consola de Google Cloud.
- Ejecuta el siguiente comando para actualizar el acceso y las credenciales predeterminadas de la aplicación (ADC):
gcloud auth login --update-adc - Establece un proyecto activo para la CLI de gcloud.Ejecuta el siguiente comando para obtener el proyecto actual de gcloud:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDpor el ID de tu proyecto. - Establece la región predeterminada en la que se implementarán tus servicios de Cloud Run.
gcloud config set run/region us-west1us-west1, puedes usar cualquier región de Cloud Run más cercana a ti.
Código y dependencias
- Clona el código de partida y cambia el directorio a la raíz del proyecto.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - Crea el archivo
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - Ejecuta el siguiente comando en la ventana de la terminal para instalar las dependencias:
uv sync
4. Información sobre la implementación segura
Antes de evaluar, debemos implementar. Sin embargo, no queremos que la aplicación en producción deje de funcionar si nuestro código nuevo es malo.
Etiquetas de revisión y lanzamiento oculto
Google Cloud Run admite revisiones. Cada vez que implementas, se crea una nueva revisión inmutable. Puedes asignar etiquetas a estas revisiones para acceder a ellas a través de una URL específica, incluso si reciben el 0% del tráfico público.
¿Por qué no se ejecutan las evaluaciones de forma local?
Si bien el ADK admite la evaluación local, la implementación en una revisión oculta ofrece ventajas fundamentales para los sistemas de producción. Esto distingue la Evaluación a nivel del sistema (lo que estamos haciendo) de las Pruebas de unidades:
- Paridad del entorno: Los entornos locales son diferentes (diferente red, diferente CPU/memoria, diferentes secretos). Las pruebas en la nube garantizan que tu agente funcione en el entorno de ejecución real (prueba del sistema).
- Interacción multiagente: En un sistema distribuido, los agentes se comunican a través de HTTP. Las pruebas "locales" suelen simular estas conexiones. La implementación de sombra prueba la latencia de red real, la configuración de tiempo de espera y la autenticación entre tus microservicios.
- Secrets & Permissions: Verifica que tu cuenta de servicio realmente tenga los permisos que necesita (p.ej., para llamar a Vertex AI o leer desde Firestore).
Nota: Esta es la Evaluación proactiva (verificación antes de que los usuarios la vean). Una vez que se implemente, usarás Reactive Monitoring (Observabilidad) para detectar problemas en el entorno de producción.
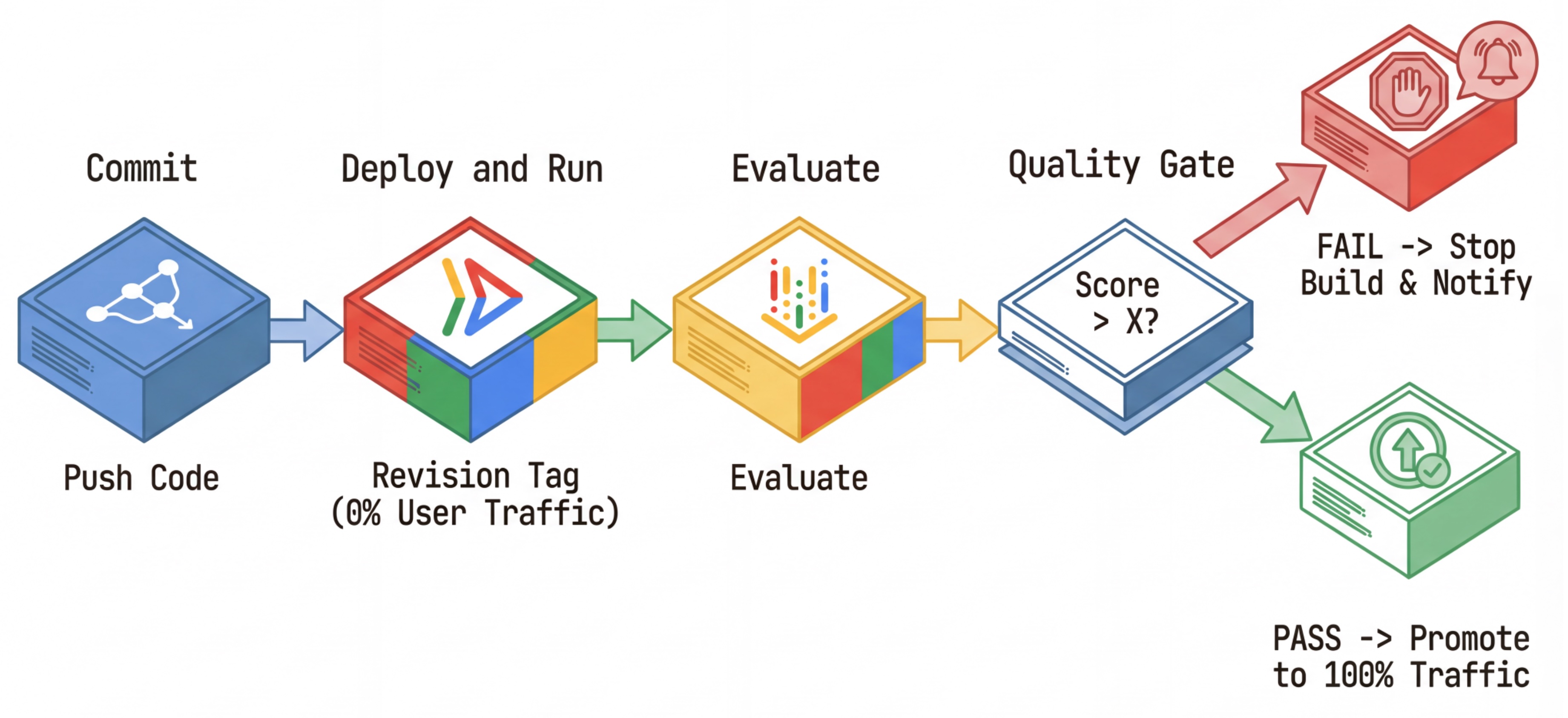
El flujo de trabajo de CI/CD: Implementar, evaluar y promover
Usamos esto para una canalización de implementación continua sólida:
- Confirmar: Cambias la instrucción del agente y la envías al repositorio.
- Deploy (Hidden): Activa la implementación de una nueva revisión etiquetada con el hash de confirmación (p.ej.,
c-abc1234). Esta revisión recibe el 0% del tráfico público. - Evaluate: La secuencia de comandos de evaluación segmenta la URL de revisión específica
https://c-abc1234---researcher-xyz.run.app. - Promocionar: Si (y solo si) la evaluación pasa y otras pruebas se completan correctamente, migra el tráfico a esta nueva revisión.
- Reversión: Si falla, los usuarios nunca vieron la versión incorrecta, y puedes ignorar o borrar la revisión incorrecta.
Esta estrategia te permite realizar pruebas en producción sin afectar a los clientes.
Analizar evaluate.sh
Abre evaluate.sh. Esta secuencia de comandos automatiza el proceso.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh se encarga de la implementación de la revisión con las opciones --no-traffic y --tag. Si ya hay un servicio en ejecución, no se verá afectado. La nueva revisión "oculta" no recibirá tráfico, a menos que la llames de forma explícita con una URL especial que contenga la etiqueta de revisión (p. ej., https://c-abc1234---researcher-xyz.run.app).
5. Implementa la secuencia de comandos de evaluación
Ahora, escribamos el código que ejecuta las pruebas.
- Abre
evaluator/evaluate_agent.py. - Verás las importaciones y la configuración, pero faltarán las métricas y la lógica de ejecución.
Define las métricas
En el caso del Agente de investigación, tenemos "respuestas de oro" o "verdad fundamental" con las respuestas esperadas. Esta es una evaluación de capacidad: Medimos si el agente puede hacer el trabajo correctamente.
Queremos medir lo siguiente:
- Final Response Match: (Capacidad) ¿La respuesta coincide con la respuesta esperada? Esta es una métrica basada en referencias. Utiliza un LLM de juez para comparar el resultado del agente con la respuesta esperada. No espera que la respuesta sea exactamente la misma, sino similar desde el punto de vista semántico y fáctico.
- Calidad del uso de herramientas: (Calidad) Es una métrica de rúbricas adaptables orientada que evalúa la selección de herramientas adecuadas, el uso correcto de los parámetros y el cumplimiento de la secuencia de operaciones especificada.
- Trayectoria de uso de herramientas: (Registro) 2 métricas personalizadas que miden la trayectoria de uso de herramientas del agente (precisión y recuperación) en comparación con las trayectorias esperadas. Estas métricas se implementan en
shared/evaluation/tool_metrics.pycomo funciones personalizadas. A diferencia de Tool Use Quality, esta métrica es determinística y se basa en referencias: el código literalmente verifica si las llamadas a herramientas reales coinciden con los datos de referencia (reference_trajectoryen los datos de evaluación).
Métricas de trayectoria de uso de herramientas personalizadas
Para las métricas personalizadas de Tool Use Trajectory, creamos un conjunto de funciones de Python en shared/evaluation/tool_metrics.py. Para permitir que Vertex AI Gen AI Evaluation Service ejecute estas funciones, debemos pasarle ese código de Python.
Para ello, se define un objeto EvaluationRunMetric con una configuración de UnifiedMetric y CustomCodeExecutionSpec. El parámetro remote_custom_function es una cadena que contiene el código Python de la función. La función debe llamarse evaluate:
def evaluate(
instance: dict
) -> float:
...
Creamos el asistente get_custom_function_metric (en shared/evaluation/evaluate.py) que convierte una función de Python en una métrica de evaluación de código personalizada.
Obtiene el código del módulo de la función (para capturar dependencias locales), crea una función evaluate adicional que llama a la función original y devuelve un objeto EvaluationRunMetric con un CustomCodeExecutionSpec.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
El servicio de evaluación de IA generativa ejecutará ese código en un entorno de ejecución de zona de pruebas y le pasará los datos de evaluación.
Agrega las métricas y el código de evaluación
Agrega el siguiente código a evaluator/evaluate_agent.py después de la línea if __name__ == "__main__":.
Define la lista de métricas para el agente de Researcher y ejecuta la evaluación.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
En una canalización de producción real, necesitas un criterio de éxito de la evaluación. Una vez que se completa la evaluación y las métricas están listas. Aquí tendrías un paso de puerta. Por ejemplo: "Si la puntuación de Final Response Match es inferior a 0.75, falla la compilación". Esto evita que las revisiones incorrectas reciban tráfico.
Agrega el siguiente código a evaluator/evaluate_agent.py:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Siempre que el valor de la media de cualquiera de las métricas de evaluación sea inferior a un límite (0.75), la implementación debe fallar.
[Opcional] Agrega la evaluación con métricas sin referencia para Orchestrator
En el caso del agente organizador, las interacciones son más complejas y es posible que no siempre tengamos una sola respuesta "correcta". En cambio, evaluamos el comportamiento general con una de las métricas sin referencia.
- Alucinación: Es una métrica basada en la puntuación que verifica la veracidad y la coherencia de las respuestas de texto segmentando la respuesta en afirmaciones atómicas. Verifica si cada afirmación está fundamentada o no en función del uso de la herramienta en los eventos intermedios. Esto es fundamental para los agentes de respuesta abierta, en los que la "corrección" es subjetiva, pero la "veracidad" no es negociable. La puntuación se calcula como el porcentaje de afirmaciones que se fundamentan en el contenido fuente. En nuestro caso, esperamos que la respuesta final del orquestador (que produjo Content Builder) se base en hechos del contenido que Researcher recuperó con la herramienta de búsqueda de Wikipedia.
Agrega la lógica de evaluación para el orquestador:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Inspecciona los datos de evaluación
Abre el directorio evaluator/. Verás dos archivos de datos:
eval_data_researcher.json: Son las instrucciones y las referencias de verdad fundamental o doradas para el investigador.eval_data_orchestrator.json: Son las instrucciones para el organizador (solo realizamos la evaluación sin referencia para el organizador).
Por lo general, cada entrada contiene lo siguiente:
prompt: Es la instrucción para el agente.reference: La respuesta ideal (verdad fundamental), si corresponde.reference_trajectory: Es la secuencia esperada de llamadas a herramientas.
6. Comprende el código de evaluación
Abre shared/evaluation/evaluate.py. Este módulo contiene la lógica principal para ejecutar evaluaciones. La función clave es evaluate_agent.
Realiza los siguientes pasos:
- Carga de datos: Lee el conjunto de datos de evaluación (instrucciones y referencias) de un archivo.
- Parallel Inference: Ejecuta el agente en el conjunto de datos de forma paralela. Maneja la creación de sesiones, envía instrucciones y captura tanto la respuesta final como el registro de ejecución de herramientas intermedias.
- Vertex AI Evaluation: Combina los datos de evaluación originales con las respuestas finales y el registro de ejecución de la herramienta intermedia, y envía los resultados a Vertex AI Evaluation Service con el cliente de IA generativa en el SDK de Vertex AI. Este servicio ejecuta las métricas configuradas para calificar el rendimiento del agente.
El momento clave del último paso es llamar a la función create_evaluation_run del módulo de evaluación del SDK de IA generativa:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Lo hacemos en la función evaluate_agent en shared/evaluation/evaluate.py.
Obtiene el conjunto de datos de evaluación combinados, la información sobre el agente, las métricas que se usarán y el URI de almacenamiento de destino. La función crea una ejecución de evaluación en el servicio de evaluación de Vertex AI y devuelve el objeto de ejecución de evaluación.
La API de Agent Info
Para realizar una evaluación precisa, el Servicio de evaluación debe conocer la configuración del agente (instrucciones del sistema, descripción y herramientas disponibles). Lo pasamos a create_evaluation_run como parámetro agent_info.
Pero, ¿cómo obtenemos esta información? La incluimos en la API de ADK Service.
Abre shared/adk_app.py y busca def agent_info. Verás que la aplicación del ADK expone un extremo de ayuda:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Este extremo (habilitado a través de la marca --publish_agent_info) permite que la secuencia de comandos de evaluación recupere de forma dinámica la configuración del tiempo de ejecución del agente. Esto es fundamental para las métricas que evalúan el uso de herramientas, ya que el modelo de juez puede evaluar mejor el uso de herramientas del agente si sabe específicamente qué herramientas estaban disponibles para el agente durante la conversación.
7. Ejecuta la evaluación
Ahora que implementaste el evaluador, ejecutémoslo.
- Ejecuta la secuencia de comandos de evaluación desde la raíz del repositorio:
./evaluate.sh- Obtiene el hash de confirmación de Git actual.
- Invoca
deploy.shpara implementar una revisión con una etiqueta basada en el hash de confirmación. - Una vez implementado, se inicia
evaluator.evaluate_agent. - Verás barras de progreso a medida que se ejecuten los casos de prueba en tu servicio en la nube.
- Por último, imprime un resumen en formato JSON de los resultados.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Nota: La primera ejecución puede tardar unos minutos en implementar los servicios.
8. Visualiza los resultados en el notebook
El resultado de JSON sin procesar es difícil de leer. El cliente de IA generativa en el SDK de Vertex AI proporciona una forma de hacer un seguimiento de estas ejecuciones a lo largo del tiempo. Usaremos un notebook de Colab para visualizar los resultados.
- Abre
evaluator/show_evaluation_run.ipynben Google Colab con este vínculo. - Establece las variables
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONyEVAL_RUN_IDen el ID del proyecto, la región y el ID de ejecución.
- Instala dependencias y autentícate.
Recupera la ejecución de la evaluación y muestra los resultados
Necesitamos recuperar los datos de la ejecución de la evaluación de Vertex AI. Busca la celda en Retrieve Evaluation Run and Display Results y reemplaza la línea # TODO por el siguiente bloque de código:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Cómo interpretar los resultados
Cuando veas los resultados, ten en cuenta lo siguiente:
- Regresión vs. capacidad:
- Regresión: ¿La puntuación disminuyó en las pruebas anteriores? (No es bueno, requiere investigación).
- Capacidad: ¿Mejoró la puntuación en las pruebas nuevas? (Bien, esto es un avance).
- Análisis de fallas: No solo mires la puntuación.
- Observa el registro. ¿Llamó a la herramienta incorrecta? ¿No se pudo analizar el resultado? Aquí es donde encuentras errores.
- Observa la explicación y los veredictos que proporciona el LLM del juez. A menudo, te dan una buena idea de por qué falló la prueba.
Pass@1 vs. Pass@k: Cuando ejecutamos una prueba determinada una vez, obtenemos la puntuación de Pass@1. Si un agente falla, podría deberse a un no determinismo. En configuraciones sofisticadas, puedes ejecutar cada prueba k veces (p.ej., 5 veces) y calcular pass@k (¿se completó correctamente al menos una vez?) o pass^k (¿se completó correctamente todas las veces?). Esto es lo que muchas métricas ya hacen de forma interna. Por ejemplo, types.RubricMetric.FINAL_RESPONSE_MATCH (Final Response Match) realiza 5 llamadas al LLM de juez para determinar la puntuación de coincidencia de la respuesta final.
9. Integración y desarrollo continuos (CI/CD)
En un sistema de producción, la evaluación del agente debe ejecutarse como parte de la canalización de CI/CD. Cloud Build es una buena opción para eso.
Para cada confirmación enviada al repositorio de código del agente, la evaluación se ejecutará junto con el resto de las pruebas. Si las pruebas son satisfactorias, la implementación se puede "promocionar" para atender las solicitudes de los usuarios. Si fallan, todo permanece como está, pero el desarrollador puede ver qué salió mal.
Configuración de Cloud Build
Ahora, crearemos una secuencia de comandos de configuración de implementación de Cloud Run que realizará los siguientes pasos:
- Implementa servicios en una revisión privada.
- Ejecuta la evaluación del agente.
- Si la evaluación se aprueba, se "promueven" las implementaciones de revisiones para que entreguen el 100% del tráfico.
Crea cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Ejecuta la canalización
Por último, podemos ejecutar la canalización de evaluación.
Antes de ejecutar la canalización de evaluación que realiza solicitudes a los servicios de Cloud Run, necesitamos una cuenta de servicio independiente con varios permisos. Escribamos una secuencia de comandos que haga eso y lance la canalización.
- Crea el script
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Crea una cuenta de servicio dedicada
agent-eval-build-sa. - Otorga los roles necesarios (
roles/run.admin,roles/aiplatform.user, etc.). *. Envía la compilación a Cloud Build.
- Crea una cuenta de servicio dedicada
- Ejecuta la canalización:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Puedes ver el progreso de la compilación en la terminal o hacer clic en el vínculo a la consola de Cloud.
Nota: En un entorno de producción real, configurarías un activador de Cloud Build para que se ejecute automáticamente en cada git push. El flujo de trabajo es el mismo: el activador ejecutaría cloudbuild.yaml, lo que garantizaría que se evalúe cada confirmación.
10. Resumen
Creaste correctamente una canalización de evaluación.
- Implementación: Usaste etiquetas de revisión con el hash de confirmación de Git para implementar de forma segura agentes en el entorno real para realizar pruebas sin afectar las implementaciones de producción.
- Evaluación: Definiste métricas de evaluación y automatizaste el proceso de evaluación con Gen AI Evaluation Service de Vertex AI.
- Análisis: Usaste un notebook de Colab para visualizar los resultados de la evaluación y mejorar tu agente.
- Lanzamiento: Usaste Cloud Build para ejecutar automáticamente la canalización de evaluación y promover la mejor revisión para entregar el 100% del tráfico.
Este ciclo de Editar código -> Implementar etiqueta -> Ejecutar evaluación y pruebas -> Analizar -> Lanzar -> Repetir es el núcleo de la Ingeniería de agentes de nivel de producción.