
۱. مقدمه
نمای کلی
این آزمایشگاه، ادامهی «ساخت سیستمهای چندعاملی با ADK» است.
در آن آزمایشگاه، شما یک سیستم ایجاد دوره آموزشی ساختید که شامل موارد زیر بود:
- نماینده محقق : استفاده از google_search برای یافتن اطلاعات بهروز.
- قاضی نماینده : نقد تحقیق از نظر کیفیت و کامل بودن.
- عامل سازنده محتوا : تبدیل تحقیق به یک دوره آموزشی ساختارمند
- عامل هماهنگکننده : مدیریت گردش کار و ارتباط بین این متخصصان.
همچنین شامل یک برنامه وب بود که به کاربران اجازه میداد درخواست ایجاد دوره را ارسال کنند و یک دوره را به عنوان پاسخ دریافت کنند.
محقق ، قاضی و سازنده محتوا به عنوان عوامل A2A در سرویسهای Cloud Run جداگانه مستقر هستند. ارکستراتور یکی دیگر از سرویسهای Cloud Run با ADK Service API است.
برای این آزمایش، ما عامل محقق را اصلاح کردیم تا از ابزار جستجوی ویکیپدیا به جای قابلیت جستجوی گوگل در Gemini استفاده کند. این به ما امکان میدهد تا بررسی کنیم که چگونه فراخوانیهای ابزار سفارشی ردیابی و ارزیابی میشوند.
خب، ما یک سیستم چندعاملی توزیعشده ساختیم. اما چطور بفهمیم که واقعاً خوب کار میکند؟ آیا محقق همیشه اطلاعات مرتبط را پیدا میکند؟ آیا قاضی تحقیقات بد را به درستی تشخیص میدهد؟
در این آزمایشگاه، شما با استفاده از سرویس ارزیابی هوش مصنوعی Vertex AI Gen، «بررسیهای ارتعاشی» ذهنی را با ارزیابی دادهمحور جایگزین خواهید کرد. شما معیارهای Adaptive Rubrics و Tool Use Quality را برای ارزیابی دقیق سیستم چندعاملی توزیعشده ساختهشده در آزمایشگاه 1 پیادهسازی خواهید کرد. در نهایت، این فرآیند را در یک خط لوله CI/CD خودکار خواهید کرد و اطمینان حاصل خواهید کرد که هر استقرار، قابلیت اطمینان و دقت عوامل تولید شما را حفظ میکند.
شما یک خط لوله ارزیابی مداوم برای نمایندگان خود ایجاد خواهید کرد. یاد خواهید گرفت که چگونه:
- عوامل خود را در یک نسخه با برچسب خصوصی در Google Cloud Run مستقر کنید (استقرار سایه).
- با استفاده از سرویس ارزیابی هوش مصنوعی Vertex AI Gen، یک مجموعه ارزیابی خودکار را برای آن نسخه خاص اجرا کنید.
- نتایج را تجسم و تحلیل کنید.
- از ارزیابی به عنوان بخشی از خط لوله CI/CD خود استفاده کنید.
۲. مفاهیم اصلی: نظریه ارزیابی عامل
هنگام توسعه و اجرای عاملهای هوش مصنوعی، ما دو نوع ارزیابی انجام میدهیم: آزمایش آفلاین و ارزیابی مداوم با تست رگرسیون خودکار . مورد اول موتور خلاق فرآیند توسعه است، که در آن آزمایشهای موردی را اجرا میکنیم، دستورالعملها را اصلاح میکنیم و به سرعت تکرار میکنیم تا قابلیتهای جدید را آزاد کنیم. مورد دوم لایه دفاعی در خط لوله CI/CD ما است، که در آن ارزیابیهای مداوم را در برابر یک مجموعه داده "طلایی" انجام میدهیم تا اطمینان حاصل کنیم که هیچ تغییر کدی سهواً کیفیت اثبات شده عامل را کاهش نمیدهد.
تفاوت اساسی در کشف در مقابل دفاع نهفته است:
- آزمایش آفلاین یک فرآیند بهینهسازی است. این فرآیند باز و متغیر است. شما به طور فعال ورودیها (دستورالعملها، مدلها، پارامترها) را تغییر میدهید تا امتیاز را به حداکثر برسانید یا یک مشکل خاص را حل کنید. هدف، بالا بردن «سقف» کاری است که عامل میتواند انجام دهد.
- ارزیابی مداوم (آزمون رگرسیون خودکار) یک فرآیند تأیید است. این فرآیند، صلب و تکراری است. شما ورودیها (مجموعه دادههای «طلایی») را ثابت نگه میدارید تا از پایداری خروجیها اطمینان حاصل شود. هدف، جلوگیری از فروپاشی «کف» عملکرد است.
در این آزمایش، ما بر ارزیابی مداوم تمرکز خواهیم کرد. ما یک خط لوله تست رگرسیون خودکار توسعه خواهیم داد که قرار است هر بار که کسی تغییری در عامل هوش مصنوعی ایجاد میکند، اجرا شود، درست مانند آن تستهای واحد.
قبل از نوشتن کد، درک آنچه که اندازهگیری میکنیم بسیار مهم است.
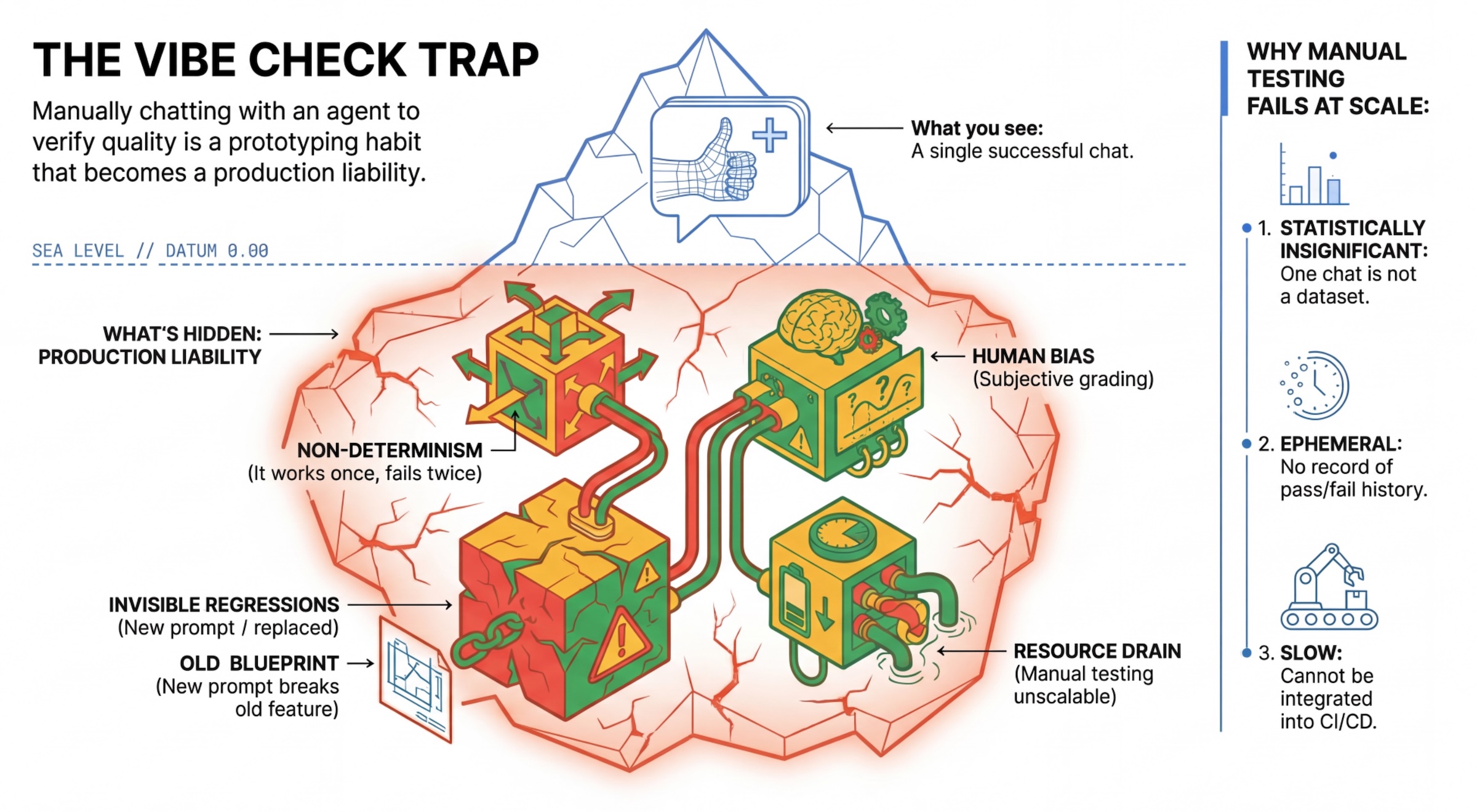
تلهی «بررسی حس و حال»
بسیاری از توسعهدهندگان، عاملها را با چت دستی با آنها آزمایش میکنند. این روش به عنوان "بررسی ارتعاش" شناخته میشود. اگرچه برای نمونهسازی مفید است، اما در تولید به دلایل زیر با شکست مواجه میشود:
- عدم قطعیت : عاملها میتوانند هر بار پاسخ متفاوتی بدهند. شما به حجم نمونه آماری معنیدار نیاز دارید.
- رگرسیونهای نامرئی : بهبود یک اعلان ممکن است یک مورد استفاده متفاوت را مختل کند.
- سوگیری انسانی : «خوب به نظر میرسد» یک امر ذهنی است.
- کار زمانبر : تست دستی دهها سناریو با هر کامیت، کند است.
دو روش برای ارزیابی عملکرد نماینده
برای ساخت یک خط لوله مستحکم، انواع مختلف گریدر را با هم ترکیب میکنیم:
- گریدرهای مبتنی بر کد (قطعی) :
- آنچه اندازهگیری میکنند : محدودیتهای سختگیرانه (مثلاً «آیا JSON معتبری برگرداند؟»، «آیا ابزار
searchرا فراخوانی کرد؟»). - مزایا : سریع، ارزان، ۱۰۰٪ دقیق.
- معایب : نمیتوان در مورد جزئیات یا کیفیت قضاوت کرد.
- آنچه اندازهگیری میکنند : محدودیتهای سختگیرانه (مثلاً «آیا JSON معتبری برگرداند؟»، «آیا ابزار
- گریدرهای مبتنی بر مدل (احتمالاتی) :
- همچنین به عنوان "LLM-as-a-Judge" شناخته میشود. ما از یک مدل قوی (مانند Gemini 3 Pro) برای ارزیابی خروجی عامل استفاده میکنیم.
- آنچه میسنجند : ظرافت، استدلال، مفید بودن، ایمنی.
- مزایا : میتواند وظایف پیچیده و بدون پاسخ را ارزیابی کند.
- معایب : کندتر، گرانتر، نیازمند مهندسی دقیق و سریع برای قاضی است.
معیارهای ارزیابی هوش مصنوعی Vertex
در این آزمایشگاه، ما از سرویس ارزیابی هوش مصنوعی Vertex AI Gen استفاده میکنیم که معیارهای مدیریتشدهای را ارائه میدهد، بنابراین لازم نیست هر قضاوت را از ابتدا بنویسید.
روشهای مختلفی برای گروهبندی معیارها برای ارزیابی عامل وجود دارد:
- معیارهای مبتنی بر روبریک : LLM ها را در گردشهای کاری ارزیابی بگنجانید.
- روبریکهای تطبیقی : روبریکها به صورت پویا برای هر سوال ایجاد میشوند. پاسخها با بازخورد دقیق و قابل توضیحِ قبول یا رد شدنِ مختص به سوال ارزیابی میشوند.
- روبریکهای ایستا : روبریکها به صراحت تعریف شدهاند و روبریک یکسانی برای همه سوالات اعمال میشود. پاسخها با مجموعهای یکسان از ارزیابهای مبتنی بر امتیازدهی عددی ارزیابی میشوند. یک امتیاز عددی واحد (مانند ۱-۵) برای هر سوال. هنگامی که ارزیابی در یک بعد بسیار خاص مورد نیاز است یا زمانی که روبریک دقیقاً یکسانی برای همه سوالات مورد نیاز است.
- معیارهای مبتنی بر محاسبات : ارزیابی پاسخها با الگوریتمهای قطعی، معمولاً با استفاده از دادههای پایه. یک امتیاز عددی (مانند 0.0-1.0) برای هر سوال. زمانی که دادههای پایه در دسترس باشند و بتوان آنها را با یک روش قطعی تطبیق داد.
- معیارهای عملکرد سفارشی : معیار خود را از طریق یک تابع پایتون تعریف کنید.
معیارهای خاصی که استفاده خواهیم کرد :
-
Final Response Match: (مبتنی بر مرجع) آیا پاسخ با «پاسخ طلایی» ما مطابقت دارد؟ -
Tool Use Quality: (بدون نیاز به مرجع) آیا عامل از ابزارهای مرتبط به شیوهای مناسب استفاده کرده است؟ -
Hallucination: (بدون مرجع) آیا ادعاهای موجود در پاسخ توسط متن بازیابی شده پشتیبانی میشوند؟ -
Tool Trajectory PrecisionوTool Trajectory Recall(مبتنی بر مرجع) آیا عامل ابزار مناسب را انتخاب کرده و آرگومانهای معتبری ارائه داده است؟ برخلافTool Use Quality، این معیارهای سفارشی از مسیر مرجع استفاده میکنند - دنباله ای از فراخوانیها و آرگومانهای مورد انتظار ابزارها.
۳. راهاندازی
پیکربندی
- باز کردن Cloud Shell : روی آیکون Activate Cloud Shell در بالا سمت راست کنسول Google Cloud کلیک کنید.
- دستور زیر را برای بهروزرسانی ورود به سیستم و بهروزرسانی اعتبارنامههای پیشفرض برنامه (ADC) اجرا کنید:
gcloud auth login --update-adc - یک پروژه فعال برای gcloud CLI تنظیم کنید. دستور زیر را برای دریافت پروژه فعلی gcloud اجرا کنید:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_ID، شناسه پروژه خود را قرار دهید. - منطقه پیشفرضی را که سرویسهای Cloud Run شما در آن مستقر خواهند شد، تنظیم کنید.
gcloud config set run/region us-west1us-west1، میتوانید از هر منطقه Cloud Run نزدیکتر به خودتان استفاده کنید.
کد و وابستگیها
- کد آغازین را کپی کنید و دایرکتوری را به ریشه پروژه تغییر دهید.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - فایل
.envرا ایجاد کنید:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - با اجرای دستور زیر در پنجره ترمینال، وابستگیها را نصب کنید:
uv sync
۴. درک استقرار ایمن
قبل از ارزیابی، باید آن را مستقر کنیم. اما اگر کد جدیدمان بد باشد، نمیخواهیم برنامهی زنده را از کار بیندازیم.
برچسبهای بازبینی و استقرار سایه
Google Cloud Run از Revisionها پشتیبانی میکند. هر بار که شما مستقر میشوید، یک نسخه جدید و غیرقابل تغییر ایجاد میشود. میتوانید به این نسخهها Tag اختصاص دهید تا از طریق یک URL خاص به آنها دسترسی داشته باشید، حتی اگر 0٪ از ترافیک عمومی را دریافت کنند.
چرا ارزیابیها را فقط به صورت محلی انجام نمیدهیم؟
در حالی که ADK از ارزیابی محلی پشتیبانی میکند، استقرار در یک نسخه پنهان مزایای مهمی را برای سیستمهای تولیدی ارائه میدهد. این امر ارزیابی سطح سیستم (کاری که ما انجام میدهیم) را از تست واحد متمایز میکند:
- برابری محیطی : محیطهای محلی متفاوت هستند (شبکه متفاوت، CPU/حافظه متفاوت، رمزهای متفاوت). آزمایش در ابر تضمین میکند که عامل شما در محیط زمان اجرای واقعی (تست سیستم) کار میکند.
- تعامل چندعاملی : در یک سیستم توزیعشده، عاملها از طریق HTTP با هم صحبت میکنند. آزمایشهای «محلی» اغلب این اتصالات را شبیهسازی میکنند. استقرار سایه، تأخیر واقعی شبکه، پیکربندیهای زمانبندی و احراز هویت بین میکروسرویسهای شما را آزمایش میکند.
- اسرار و مجوزها : تأیید میکند که حساب سرویس شما واقعاً مجوزهای مورد نیاز خود را دارد (مثلاً برای تماس با Vertex AI یا خواندن از Firestore).
توجه: این ارزیابی پیشگیرانه (بررسی قبل از مشاهده توسط کاربران) است. پس از استقرار، از مانیتورینگ واکنشی (قابلیت مشاهده) برای شناسایی مشکلات در شرایط واقعی استفاده خواهید کرد.
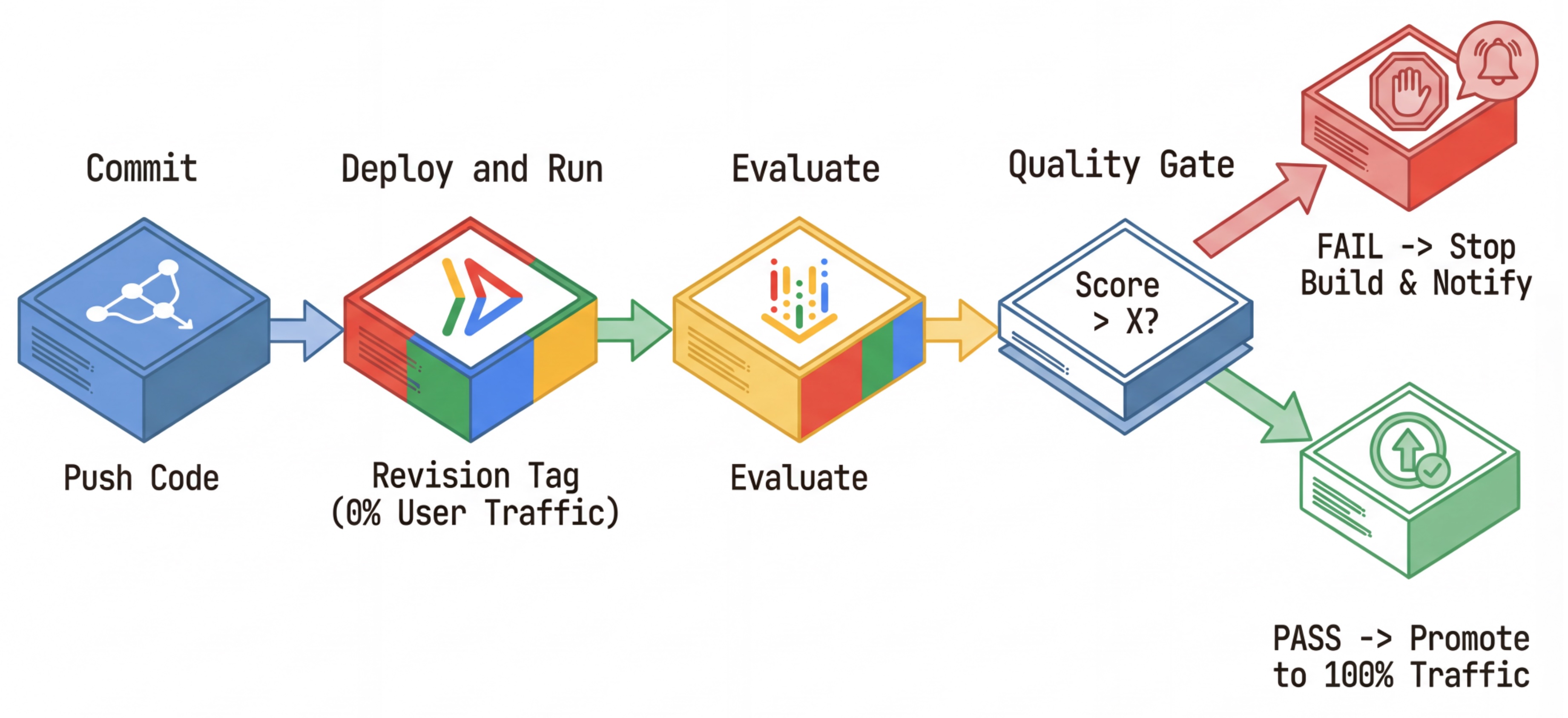
گردش کار CI/CD: استقرار، ارزیابی، ترویج
ما از این برای یک خط لوله استقرار مداوم قوی استفاده میکنیم:
- کامیت (Commit) : شما اعلان عامل را تغییر میدهید و آن را به مخزن ارسال میکنید.
- Deploy (پنهان) : این دستور باعث میشود که یک نسخه جدید با برچسب هش کامیت (مثلاً
c-abc1234) منتشر شود. این نسخه ۰٪ از ترافیک عمومی را دریافت میکند. - ارزیابی : اسکریپت ارزیابی، آدرس اینترنتی (URL) خاص مربوط به نسخه
https://c-abc1234---researcher-xyz.run.appرا هدف قرار میدهد. - ترویج (Promote) : اگر (و فقط اگر) ارزیابی با موفقیت انجام شود و سایر تستها نیز موفقیتآمیز باشند، ترافیک را به این نسخه جدید منتقل میکنید .
- بازگرداندن نسخه به نسخه قبلی : اگر این کار با شکست مواجه شود، کاربران هرگز نسخه بد را ندیدهاند و شما میتوانید به سادگی نسخه بد را نادیده بگیرید یا حذف کنید.
این استراتژی به شما امکان میدهد بدون تأثیرگذاری بر مشتریان، در محیط تولید آزمایش کنید.
تجزیه و تحلیل، evaluate.sh
فایل evaluate.sh را باز کنید. این اسکریپت فرآیند را خودکار میکند.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
فایل deploy.sh با گزینههای --no-traffic و --tag عملیات استقرار نسخه را انجام میدهد. اگر از قبل سرویسی در حال اجرا باشد، تحت تأثیر قرار نمیگیرد. نسخه جدید "پنهان" هیچ ترافیکی دریافت نخواهد کرد، مگر اینکه صریحاً آن را با یک URL خاص حاوی برچسب نسخه فراخوانی کنید (مثلاً https://c-abc1234---researcher-xyz.run.app ).
۵. پیادهسازی اسکریپت ارزیابی
حالا، بیایید کدی بنویسیم که واقعاً تستها را اجرا کند.
-
evaluator/evaluate_agent.pyرا باز کنید. - شما واردات و تنظیمات را خواهید دید، اما معیارها و منطق اجرا وجود ندارند.
معیارها را تعریف کنید
برای عامل محقق ، ما یک «پاسخهای طلایی»/«حقیقت زمینهای» با پاسخهای مورد انتظار داریم. این یک ارزیابی قابلیت است: ما اندازهگیری میکنیم که آیا عامل میتواند کار را به درستی انجام دهد یا خیر.
ما میخواهیم اندازهگیری کنیم:
- تطابق پاسخ نهایی : (قابلیت) آیا پاسخ با پاسخ مورد انتظار مطابقت دارد؟ این یک معیار مبتنی بر مرجع است. از یک LLM قاضی برای مقایسه خروجی عامل با پاسخ مورد انتظار استفاده میکند. انتظار ندارد که پاسخ دقیقاً یکسان باشد، اما از نظر معنایی و واقعی مشابه باشد.
- کیفیت استفاده از ابزار : (کیفیت) یک معیار سنجش تطبیقی هدفمند که انتخاب ابزارهای مناسب، استفاده صحیح از پارامترها و پایبندی به توالی مشخص شده عملیات را ارزیابی میکند.
- مسیر استفاده از ابزار : (ردیابی) ۲ معیار سفارشی که مسیر استفاده از ابزار عامل (دقت و فراخوانی) را در مقایسه با مسیرهای مورد انتظار اندازهگیری میکنند. این معیارها در
shared/evaluation/tool_metrics.pyبه عنوان توابع سفارشی پیادهسازی شدهاند. برخلاف Tool Use Quality ، این معیار یک معیار قطعی مبتنی بر مرجع است - کد به معنای واقعی کلمه بررسی میکند که آیا فراخوانیهای واقعی ابزارها با دادههای مرجع (reference_trajectoryدر دادههای ارزیابی) مطابقت دارند یا خیر.
معیارهای مسیر استفاده از ابزار سفارشی
برای معیارهای سفارشی مسیر استفاده از ابزار، مجموعهای از توابع پایتون را در shared/evaluation/tool_metrics.py ایجاد کردیم. برای اینکه به Vertex AI Gen AI Evaluation Service اجازه دهیم این توابع را اجرا کند، باید آن کد پایتون را به آن منتقل کنیم.
این کار با تعریف یک شیء EvaluationRunMetric با پیکربندی UnifiedMetric و CustomCodeExecutionSpec انجام میشود. پارامتر remote_custom_function رشتهای است که شامل کد پایتون تابع است. نام تابع باید evaluate باشد:
def evaluate(
instance: dict
) -> float:
...
ما تابع کمکی get_custom_function_metric (در shared/evaluation/evaluate.py ) را ایجاد کردیم که یک تابع پایتون را به یک معیار ارزیابی کد سفارشی تبدیل میکند.
این تابع کد ماژول تابع را دریافت میکند (برای ثبت وابستگیهای محلی)، یک تابع evaluate اضافی ایجاد میکند که تابع اصلی را فراخوانی میکند و یک شیء EvaluationRunMetric با یک CustomCodeExecutionSpec برمیگرداند.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
سرویس ارزیابی Gen AI آن کد را در یک محیط اجرای sandbox اجرا میکند و دادههای ارزیابی را به آن منتقل میکند.
کد معیارها و ارزیابی را اضافه کنید
کد زیر را به evaluator/evaluate_agent.py بعد از خط if __name__ == "__main__": اضافه کنید.
این لیست معیارها را برای عامل محقق تعریف میکند و ارزیابی را اجرا میکند.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
در یک خط تولید واقعی، شما به یک معیار موفقیت ارزیابی نیاز دارید. پس از انجام ارزیابی و آماده شدن معیارها، در اینجا یک مرحله دروازهای خواهید داشت. به عنوان مثال: "اگر امتیاز Final Response Match کمتر از 0.75 باشد، ساخت با شکست مواجه میشود." این کار از دریافت ترافیک توسط نسخههای بد جلوگیری میکند.
کد زیر را به evaluator/evaluate_agent.py اضافه کنید:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
هر زمان که میانگین مقدار هر یک از معیارهای ارزیابی کمتر از یک آستانه ( 0.75 ) باشد، استقرار باید با شکست مواجه شود.
[اختیاری] ارزیابی با معیارهای بدون مرجع را برای هماهنگکننده اضافه کنید
برای عامل هماهنگکننده (Orchestrator Agent )، تعاملات پیچیدهتر هستند و ممکن است همیشه یک پاسخ «صحیح» نداشته باشیم. در عوض، ما رفتار کلی را با استفاده از یکی از معیارهای بدون مرجع (Reference-Free Metrics) ارزیابی میکنیم.
- توهم : یک معیار مبتنی بر امتیاز که با تقسیم پاسخ به ادعاهای اتمی، واقعی بودن و سازگاری پاسخهای متنی را بررسی میکند. این معیار تأیید میکند که آیا هر ادعا بر اساس استفاده از ابزار در رویدادهای میانی، پایهگذاری شده است یا خیر. این امر برای عاملهای باز-پایان که در آنها "صحت" ذهنی است اما "صداقت" غیرقابل مذاکره است، بسیار مهم است. امتیاز به عنوان درصد ادعاهایی که در محتوای منبع ریشه دارند محاسبه میشود. در مورد ما، انتظار داریم پاسخ نهایی از Orchestrator (که Content Builder تولید کرده است) به طور واقعی در محتوایی که محقق با استفاده از ابزار جستجوی ویکیپدیا بازیابی کرده است، ریشه داشته باشد.
منطق ارزیابی را برای Orchestrator اضافه کنید:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
بررسی دادههای ارزیابی
پوشه evaluator/ را باز کنید. دو فایل داده مشاهده خواهید کرد:
-
eval_data_researcher.json: دستورالعملها و ارجاعات طلایی/واقعیتهای پایه برای محقق. -
eval_data_orchestrator.json: درخواستهایی برای Orchestrator (ما فقط ارزیابی بدون مرجع را برای Orchestrator انجام میدهیم).
هر ورودی معمولاً شامل موارد زیر است:
-
prompt: دستور برای عامل. -
reference: پاسخ ایدهآل (حقیقت زمینهای)، در صورت وجود. -
reference_trajectory: توالی مورد انتظار فراخوانیهای ابزار.
۶. کد ارزیابی را درک کنید
shared/evaluation/evaluate.py باز کنید. این ماژول شامل منطق اصلی برای اجرای ارزیابیها است. تابع کلیدی evaluate_agent است.
مراحل زیر را انجام میدهد:
- بارگذاری دادهها : مجموعه دادههای ارزیابی (دستورالعملها و ارجاعات) را از یک فایل میخواند.
- استنتاج موازی : عامل را به صورت موازی بر روی مجموعه دادهها اجرا میکند. این عامل ایجاد جلسه را مدیریت میکند، اعلانها را ارسال میکند و هم پاسخ نهایی و هم ردیابی اجرای ابزار میانی را ثبت میکند.
- ارزیابی هوش مصنوعی ورتکس : دادههای ارزیابی اصلی را با پاسخهای نهایی و ردیابی اجرای ابزار میانی ادغام میکند و نتایج را به سرویس ارزیابی هوش مصنوعی ورتکس با GenAI Client در Vertex AI SDK ارسال میکند. این سرویس معیارهای پیکربندی شده را برای درجهبندی عملکرد عامل اجرا میکند.
نکته کلیدی در مرحله آخر، فراخوانی تابع create_evaluation_run از ماژول eval از Gen AI SDK است:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
ما این کار را در تابع evaluate_agent در shared/evaluation/evaluate.py انجام میدهیم.
این تابع، مجموعه دادههای ارزیابی ادغامشده، اطلاعات مربوط به عامل، معیارهای مورد استفاده و آدرس اینترنتی (URI) ذخیرهسازی مقصد را دریافت میکند. این تابع یک اجرای ارزیابی در سرویس ارزیابی هوش مصنوعی ورتکس (Vertex AI Evaluation Service) ایجاد میکند و شیء اجرای ارزیابی را برمیگرداند.
API اطلاعات عامل
برای انجام ارزیابی دقیق، سرویس ارزیابی باید پیکربندی عامل (دستورالعملهای سیستم، توضیحات و ابزارهای موجود) را بداند. ما آن را به عنوان پارامتر agent_info به create_evaluation_run ارسال میکنیم.
اما چگونه این اطلاعات را دریافت کنیم؟ ما آن را بخشی از API سرویس ADK میکنیم.
فایل shared/adk_app.py باز کنید و عبارت def agent_info را جستجو کنید. خواهید دید که برنامه ADK یک نقطه پایانی کمکی (helper endpoint) را نمایش میدهد:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
این نقطه پایانی (که از طریق پرچم --publish_agent_info فعال میشود) به اسکریپت ارزیابی اجازه میدهد تا پیکربندی زمان اجرای عامل را به صورت پویا دریافت کند. این برای معیارهایی که میزان استفاده از ابزار را ارزیابی میکنند بسیار مهم است، زیرا مدل قاضی اگر به طور خاص بداند کدام ابزارها در طول مکالمه در دسترس عامل بودهاند، میتواند میزان استفاده از ابزار توسط عامل را بهتر ارزیابی کند.
۷. ارزیابی را اجرا کنید
حالا که ارزیاب را پیادهسازی کردهاید، بیایید آن را اجرا کنیم!
- اسکریپت ارزیابی را از ریشه مخزن اجرا کنید:
./evaluate.sh- این دستور هش کامیت گیت فعلی شما را دریافت میکند.
- این دستور
deploy.shبرای استقرار یک نسخه با برچسبی مبتنی بر هش کامیت فراخوانی میکند. - پس از استقرار،
evaluator.evaluate_agentآغاز میکند. - همزمان با اجرای موارد آزمایشی روی سرویس ابری شما، نوارهای پیشرفت را مشاهده خواهید کرد.
- در نهایت، خلاصهای از نتایج را در قالب JSON چاپ میکند.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
توجه: اولین اجرا ممکن است چند دقیقه طول بکشد تا سرویسها مستقر شوند.
۸. نتایج را در دفترچه یادداشت تجسم کنید
خواندن خروجی خام JSON دشوار است. Gen AI Client در Vertex AI SDK راهی برای پیگیری این اجراها در طول زمان ارائه میدهد. ما از یک دفترچه یادداشت Colab برای تجسم نتایج استفاده خواهیم کرد.
- با استفاده از این لینک،
evaluator/show_evaluation_run.ipynbرا در Google Colab باز کنید. - متغیرهای
GOOGLE_CLOUD_PROJECT،GOOGLE_CLOUD_REGIONوEVAL_RUN_IDرا روی شناسه پروژه، منطقه و شناسه اجرای خود تنظیم کنید.
- وابستگیها را نصب کنید و احراز هویت کنید.
بازیابی اجرای ارزیابی و نمایش نتایج
ما باید دادههای اجرای ارزیابی را از Vertex AI دریافت کنیم. سلول زیر Retrieve Evaluation Run and Display Results را پیدا کنید و خط # TODO را با بلوک کد زیر جایگزین کنید:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
تفسیر نتایج
هنگام مشاهده نتایج، نکات زیر را در نظر داشته باشید:
- رگرسیون در مقابل قابلیت :
- پسرفت : آیا نمره در آزمونهای قدیمی کاهش یافته است؟ (خوب نیست، نیاز به بررسی دارد).
- توانایی : آیا نمره در آزمونهای جدید بهبود یافته است؟ (خوب است، این پیشرفت است).
- تحلیل شکست : فقط به امتیاز نگاه نکنید.
- به ردیابی نگاه کنید. آیا ابزار اشتباهی را فراخوانی کرده است؟ آیا در تجزیه خروجی ناموفق بوده است؟ اینجاست که میتوانید اشکالات را پیدا کنید.
- به توضیحات و احکام ارائه شده توسط قاضی LLM نگاه کنید. آنها اغلب به شما ایده خوبی میدهند که چرا آزمون مردود شده است.
Pass@1 در مقابل Pass@k : وقتی یک تست خاص را یک بار اجرا میکنیم، امتیاز Pass@1 را میگیریم. اگر یک عامل شکست بخورد، ممکن است به دلیل عدم قطعیت باشد. در تنظیمات پیچیده، ممکن است هر تست را k بار (مثلاً ۵ بار) اجرا کنید و pass@k (آیا حداقل یک بار موفق شد؟) یا pass^k (آیا هر بار موفق شد؟) را محاسبه کنید. این کاری است که بسیاری از معیارها از قبل در پشت صحنه انجام میدهند. به عنوان مثال، types.RubricMetric.FINAL_RESPONSE_MATCH (تطبیق پاسخ نهایی) 5 بار به قاضی LLM فراخوانی میکند تا امتیاز تطابق پاسخ نهایی را تعیین کند.
۹. ادغام و استقرار مداوم (CI/CD)
در یک سیستم عملیاتی، ارزیابی عامل باید به عنوان بخشی از خط لوله CI/CD اجرا شود. Cloud Build انتخاب خوبی برای این کار است.
برای هر کامیت که به مخزن کد عامل ارسال میشود، ارزیابی به همراه بقیه تستها اجرا میشود. اگر تستها با موفقیت انجام شوند، میتوان استقرار را به سمت ارائه درخواستهای کاربر "ارتقاء" داد. اگر شکست بخورند، همه چیز به همان شکل باقی میماند، اما توسعهدهنده میتواند بررسی کند که چه مشکلی پیش آمده است.
پیکربندی ساخت ابری
حالا، بیایید یک اسکریپت پیکربندی استقرار Cloud Run ایجاد کنیم که مراحل زیر را انجام دهد:
- سرویسها را به یک نسخه خصوصی منتقل میکند.
- ارزیابی عامل را اجرا میکند.
- اگر ارزیابی با موفقیت انجام شود، استقرارهای اصلاحی را به سمت ارائه ۱۰۰٪ ترافیک «ارتقاء» میدهد.
cloudbuild.yaml را ایجاد کنید:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
اجرای خط لوله
در نهایت، میتوانیم خط لوله ارزیابی را اجرا کنیم.
قبل از اینکه خط لوله ارزیابی را که درخواستها را به سرویسهای Cloud Run ارسال میکند، اجرا کنیم، به یک حساب سرویس جداگانه با تعدادی مجوز نیاز داریم. بیایید اسکریپتی بنویسیم که این کار را انجام دهد و خط لوله را راهاندازی کند.
- اسکریپت
run_cloud_build.shرا ایجاد کنید:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- یک حساب کاربری سرویس اختصاصی
agent-eval-build-saایجاد میکند. - نقشهای لازم (
roles/run.admin،roles/aiplatform.userو غیره) را به آن اعطا میکند. *. ساخت را به Cloud Build ارسال میکند.
- یک حساب کاربری سرویس اختصاصی
- اجرای خط لوله:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
میتوانید پیشرفت ساخت را در ترمینال مشاهده کنید یا روی لینک کنسول ابری کلیک کنید.
نکته : در یک محیط تولید واقعی، شما باید یک Cloud Build Trigger تنظیم کنید تا این کار را به طور خودکار در هر git push اجرا کند. گردش کار یکسان است: trigger، cloudbuild.yaml را اجرا میکند و تضمین میکند که هر commit ارزیابی میشود.
۱۰. خلاصه
شما با موفقیت یک خط لوله ارزیابی ایجاد کردهاید!
- استقرار : شما از تگهای بازبینی با هش git commit استفاده کردید تا بدون تأثیر بر استقرارهای عملیاتی، عاملها را با خیال راحت در محیط واقعی برای آزمایش مستقر کنید.
- ارزیابی : شما معیارهای ارزیابی را تعریف کردید و فرآیند ارزیابی را با استفاده از سرویس ارزیابی هوش مصنوعی Vertex AI Gen خودکارسازی کردید.
- تحلیل : شما از یک دفترچه یادداشت Colab برای تجسم نتایج ارزیابی و بهبود نماینده خود استفاده کردید.
- پیادهسازی : شما از Cloud Build برای اجرای خودکار فرآیند ارزیابی و ارائه بهترین نسخه برای پوشش ۱۰۰٪ ترافیک استفاده کردید.
این چرخه ویرایش کد -> استقرار برچسب -> اجرای ارزیابی و آزمایشها -> تحلیل -> انتشار -> تکرار، هسته اصلی مهندسی عاملی در سطح تولید است.