
1. מבוא
סקירה כללית
השיעור הזה הוא המשך לשיעור יצירת מערכות מרובות סוכנים באמצעות ADK.
בשיעור ה-Lab הזה, יצרתם מערכת ליצירת קורסים שכוללת:
- סוכן המחקר: שימוש ב-google_search כדי למצוא מידע עדכני.
- סוכן שופט: מבקר את המחקר כדי לבדוק את האיכות והשלמות שלו.
- סוכן ליצירת תוכן: הופך את המחקר לקורס מובנה.
- Orchestrator Agent: ניהול תהליך העבודה והתקשורת בין המומחים האלה.
הוא כלל גם אפליקציית אינטרנט שאיפשרה למשתמשים לשלוח בקשה ליצירת קורס ולקבל קורס כתשובה.
Researcher, Judge ו-Content Builder נפרסים כסוכני A2A בשירותי Cloud Run נפרדים. Orchestrator הוא עוד שירות Cloud Run עם ADK Service API.
במעבדה הזו, שינינו את סוכן המחקר כך שישתמש בכלי Wikipedia Search במקום ביכולת חיפוש Google של Gemini. כך אנחנו יכולים לבדוק איך מתבצע מעקב אחרי קריאות מותאמות אישית לכלים ואיך הן מוערכות.
לכן, בנינו מערכת מבוזרת מרובת סוכנים. אבל איך יודעים אם זה באמת עובד טוב? האם הכלי 'חוקר' תמיד מוצא מידע רלוונטי? האם השופט מזהה נכון מחקרים לא טובים?
בשיעור ה-Lab הזה תלמדו להשתמש בשירות ההערכה של Vertex AI ל-AI גנרטיבי כדי להחליף את הבדיקות הסובייקטיביות בבדיקות מבוססות-נתונים. תטמיעו מדדים אדפטיביים להערכת איכות השימוש בכלים, כדי להעריך באופן קפדני את מערכת ה-AI המבוזרת עם כמה סוכנים שנבנתה במעבדה 1. לבסוף, תהפכו את התהליך הזה לאוטומטי בצינור CI/CD, כדי להבטיח שכל פריסה תשמור על האמינות והדיוק של סוכני הייצור שלכם.
תבנו פייפליין להערכה מתמשכת של הסוכנים. בשיעור הזה תלמדו איך:
- פריסת הסוכנים לגרסה מתויגת פרטית ב-Google Cloud Run (פריסת צל).
- מריצים חבילת הערכה אוטומטית מול הגרסה הספציפית הזו באמצעות שירות ההערכה של Vertex AI ל-AI גנרטיבי.
- הצגה חזותית של התוצאות וניתוח שלהן.
- להשתמש בהערכה כחלק מצינור ה-CI/CD.
2. מושגי ליבה: תיאוריה של הערכת סוכנים
בפיתוח והפעלה של סוכני AI, אנחנו מבצעים שני סוגים של הערכה: ניסויים אופליין והערכה רציפה עם בדיקות רגרסיה אוטומטיות. הראשון הוא מנוע הקריאייטיב של תהליך הפיתוח, שבו אנחנו מריצים ניסויים אד-הוק, משפרים את ההנחיות ומבצעים איטרציות במהירות כדי לפתח יכולות חדשות. השכבה השנייה היא שכבת ההגנה בצינור ה-CI/CD שלנו, שבה אנחנו מבצעים הערכות רציפות על מערך נתונים 'מוזהב' כדי לוודא ששינוי בקוד לא יפגע באיכות המוכחת של הסוכן.
ההבדל העיקרי הוא בין גילוי לבין הגנה:
- ניסויים אופליין הם תהליך של אופטימיזציה. היא פתוחה ומשתנה. אתם משנים באופן פעיל את הקלט (הנחיות, מודלים, פרמטרים) כדי למקסם את הציון או לפתור בעיה ספציפית. המטרה היא להעלות את "תקרת" היכולות של הסוכן.
- הערכה מתמשכת (בדיקות רגרסיה אוטומטיות) היא תהליך אימות. היא נוקשה וחוזרת על עצמה. אתם שומרים על קבוצת הקלט קבועה (מערך הנתונים 'המוזהב') כדי להבטיח שהפלט יישאר יציב. המטרה היא למנוע את קריסת רמת הביצועים המינימלית.
בשיעור ה-Lab הזה נתמקד בהערכה מתמשכת. נפתח צינור לבדיקת רגרסיה אוטומטית, שאמור לפעול בכל פעם שמישהו מבצע שינוי בסוכן ה-AI, בדיוק כמו בדיקות היחידה האלה.
לפני שכותבים קוד, חשוב להבין מה אנחנו מודדים.
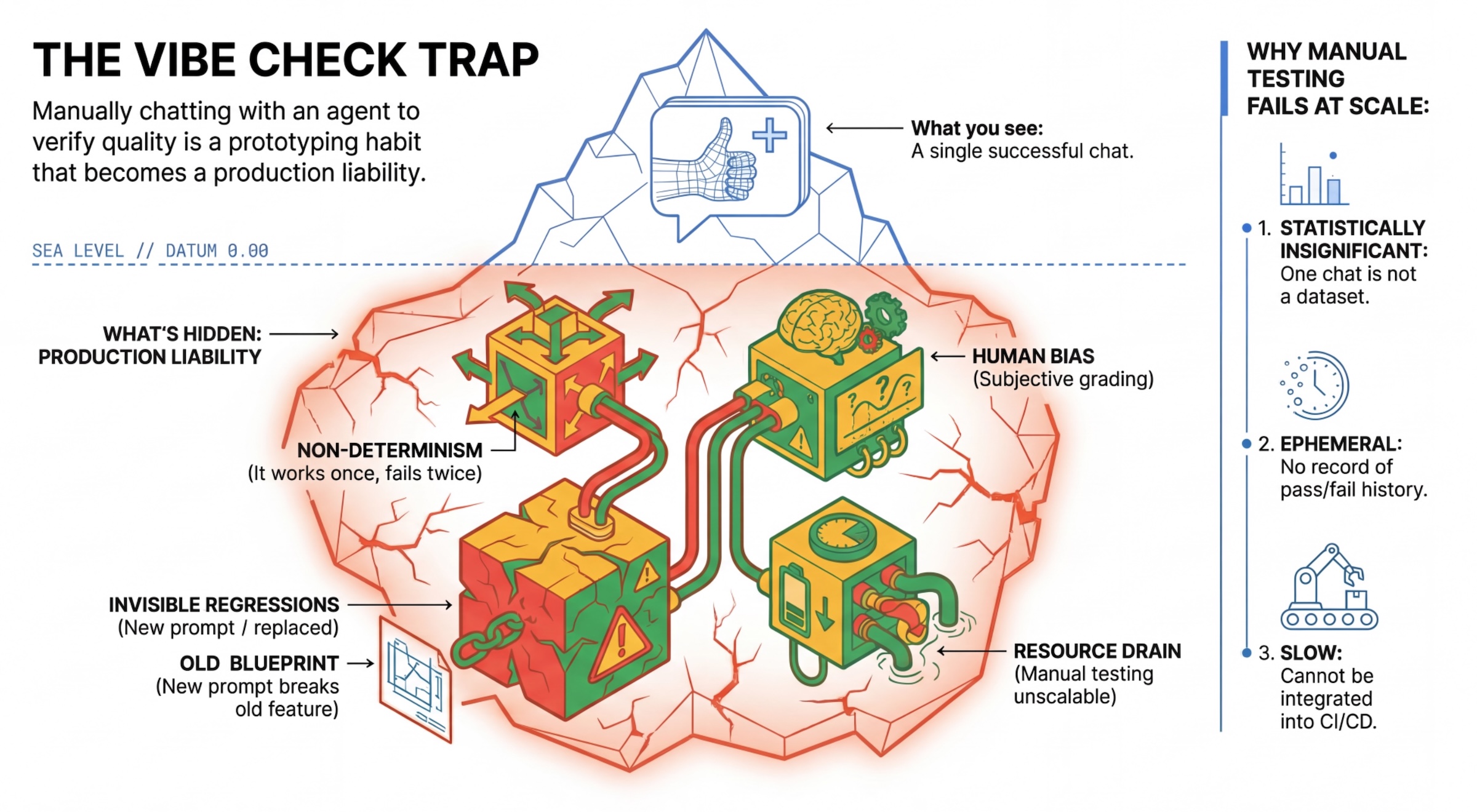
הטראפ 'חיפוש אוצרות הוא הקטע שלך'
מפתחים רבים בודקים סוכנים באמצעות שיחה ידנית איתם. הפעולה הזו נקראת 'בדיקת אווירה'. הוא שימושי ליצירת אב טיפוס, אבל הוא לא פועל בסביבת ייצור כי:
- אי-דטרמיניזם: סוכנים יכולים לתת תשובות שונות בכל פעם. צריך להשתמש בגדלים של מדגמים בעלי מובהקות סטטיסטית.
- רגרסיות בלתי נראות: שיפור הנחיה אחת עלול לשבש תרחיש שימוש אחר.
- הטיה אנושית: "נראה טוב" הוא מושג סובייקטיבי.
- עבודה שגוזלת זמן: בדיקה ידנית של עשרות תרחישים בכל התחייבות היא תהליך איטי.
שתי דרכים לדרג את רמת הביצועים של הסוכנים
כדי לבנות צינור חזק, אנחנו משלבים בין סוגים שונים של בודקים:
- בודקי תשובות מבוססי-קוד (דטרמיניסטיים):
- מה הם מודדים: אילוצים מחמירים (למשל, 'האם הוחזר JSON תקין?', האם הוא הפעיל את הכלי
search? - יתרונות: מהיר, זול, מדויק ב-100%.
- חסרונות: אי אפשר לשפוט ניואנסים או איכות.
- מה הם מודדים: אילוצים מחמירים (למשל, 'האם הוחזר JSON תקין?', האם הוא הפעיל את הכלי
- בודקים מבוססי-מודל (הסתברותיים):
- נקרא גם "מודל שפה גדול כשופט". אנחנו משתמשים במודל חזק (כמו Gemini 3 Pro) כדי להעריך את הפלט של הסוכן.
- מה הם בודקים: ניואנסים, חשיבה רציונלית, מידת העזרה, בטיחות.
- יתרונות: יכול להעריך משימות מורכבות ופתוחות.
- חסרונות: איטי יותר, יקר יותר, דורש הנדסת הנחיות מדויקת כדי שהשופט יפעל בצורה נכונה.
מדדי הערכה של Vertex AI
בשיעור ה-Lab הזה נשתמש בVertex AI Gen AI Evaluation Service, שמספק מדדים מנוהלים כך שלא תצטרכו לכתוב כל שופט מאפס.
יש כמה דרכים לקבץ מדדים להערכת נציגים:
- מדדים שמבוססים על קריטריונים: שילוב של מודלים גדולים של שפה (LLM) בתהליכי עבודה של הערכה.
- קריטריונים דינמיים: קריטריונים נוצרים באופן דינמי לכל הנחיה. התשובות נבדקות באמצעות משוב מפורט וברור, שכולל ציון הצלחה או כישלון שספציפי להנחיה.
- קריטריונים סטטיים: קריטריונים מוגדרים באופן מפורש ואותו קריטריון חל על כל ההנחיות. התשובות נבדקות באמצעות אותה קבוצה של בודקים שמבוססים על ניקוד מספרי. ציון מספרי יחיד (למשל 1-5) לכל הנחיה. כשנדרשת הערכה בממד ספציפי מאוד או כשנדרשת אותה רובריקה בדיוק בכל ההנחיות.
- מדדים מבוססי-חישוב: הערכת התשובות באמצעות אלגוריתמים דטרמיניסטיים, בדרך כלל באמצעות נתוני אמת. ציון מספרי (למשל 0.0 עד 1.0) לכל הנחיה. כשיש נתוני אמת שאפשר להתאים להם שיטה דטרמיניסטית.
- מדדים של פונקציות מותאמות אישית: אפשר להגדיר מדד משלכם באמצעות פונקציית Python.
מדדים ספציפיים שבהם נשתמש:
Final Response Match: (מבוסס על הפניה) האם התשובה תואמת ל'תשובה המושלמת' שלנו?-
Tool Use Quality: (ללא הפניה) האם נציג התמיכה השתמש בכלים רלוונטיים בצורה נכונה? -
Hallucination: (ללא הפניה) האם הטענות בתשובה נתמכות על ידי ההקשר שאוחזר? -
Tool Trajectory Precisionו-Tool Trajectory Recall(מבוסס על הפניה) האם הסוכן בחר את הכלי הנכון וסיפק ארגומנטים תקפים? בניגוד ל-Tool Use Quality, המדדים המותאמים אישית האלה משתמשים בנתיב התייחסות – רצף של קריאות צפויות לכלים וארגומנטים.
3. הגדרה
הגדרות אישיות
- פותחים את Cloud Shell: לוחצים על הסמל Activate Cloud Shell (הפעלת Cloud Shell) בפינה הימנית העליונה של מסוף Google Cloud.
- מריצים את הפקודה הבאה כדי לרענן את הכניסה ולעדכן את Application Default Credentials (ADC):
gcloud auth login --update-adc - מגדירים פרויקט פעיל ל-CLI של gcloud.מריצים את הפקודה הבאה כדי לקבל את הפרויקט הנוכחי של gcloud:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDבמזהה הפרויקט. - מגדירים את אזור ברירת המחדל שבו ייפרסו שירותי Cloud Run.
gcloud config set run/region us-west1us-west1, אפשר להשתמש בכל אזור של Cloud Run שקרוב יותר למיקום שלכם.
קוד ויחסי תלות
- משכפלים את קוד ההתחלה ועוברים לספריית השורש של הפרויקט.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - יצירת קובץ
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - כדי להתקין את יחסי התלות, מריצים את הפקודה הבאה בחלון הטרמינל:
uv sync
4. הסבר על פריסה בטוחה
לפני שמעריכים, צריך לפרוס. אבל אנחנו לא רוצים לגרום להפסקת הפעולה של האפליקציה הפעילה אם הקוד החדש שלנו לא טוב.
תגי גרסה ופריסה שקופה
Google Cloud Run תומך בגרסאות. בכל פעם שמבצעים פריסה, נוצרת גרסה חדשה שלא ניתן לשנות. אתם יכולים להקצות תגים לגרסאות האלה כדי לגשת אליהן דרך כתובת URL ספציפית, גם אם הן מקבלות 0% מהתנועה הציבורית.
למה לא להריץ הערכות באופן מקומי?
למרות ש-ADK תומך בהערכה מקומית, פריסה לגרסה מוסתרת מציעה יתרונות חשובים למערכות ייצור. כך אפשר להבחין בין הערכה ברמת המערכת (מה שאנחנו עושים) לבין בדיקת יחידות:
- שוויון בין סביבות: סביבות מקומיות שונות (רשת שונה, מעבד/זיכרון שונים, סודות שונים). בדיקה בענן מבטיחה שהסוכן פועל בסביבת זמן הריצה בפועל (בדיקת מערכת).
- אינטראקציה בין סוכנים: במערכת מבוזרת, סוכנים מתקשרים באמצעות HTTP. בבדיקות 'מקומיות' בדרך כלל מדמים את החיבורים האלה. בפריסת צללים נבדקים זמן האחזור האמיתי של הרשת, הגדרות הזמן הקצוב לתפוגה והאימות בין המיקרו-שירותים.
- סודות והרשאות: המערכת מוודאת שלחשבון השירות יש את ההרשאות שהוא צריך (למשל, כדי להפעיל את Vertex AI או לקרוא מ-Firestore).
הערה: מדובר בהערכה יזומה (בדיקה לפני שהמשתמשים רואים את התוכן). אחרי הפריסה, תוכלו להשתמש במעקב תגובתי (יכולת מעקב) כדי לזהות בעיות בשטח.
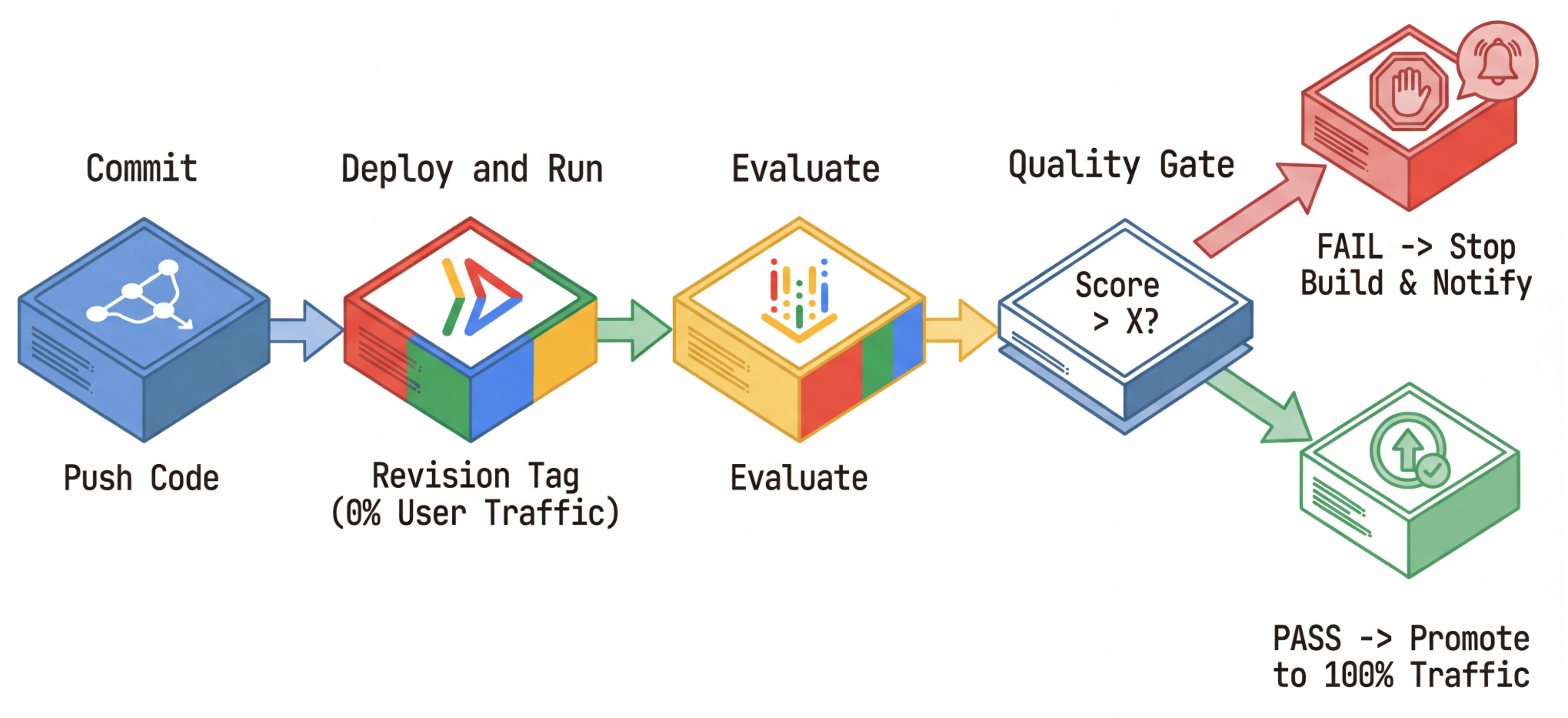
תהליך העבודה של CI/CD: פריסה, הערכה, קידום
אנחנו משתמשים בזה לצינור עיבוד נתונים חזק של פריסה רציפה:
- שמירה: אתם משנים את ההנחיה של הסוכן ושולחים אותה למאגר.
- Deploy (Hidden) (פריסה (מוסתרת)): מפעיל פריסה של גרסה חדשה שתויגה בגיבוב של הקומיט (למשל
c-abc1234). הגרסה הזו מקבלת 0% מהתנועה הציבורית. - הערכה: סקריפט ההערכה מטַרגט את כתובת ה-URL הספציפית של הגרסה
https://c-abc1234---researcher-xyz.run.app. - קידום: אם (ורק אם) ההערכה עוברת בהצלחה והבדיקות האחרות מצליחות, מעבירים את התנועה לגרסה החדשה הזו.
- חזרה לגרסה קודמת: אם הפריסה נכשלת, המשתמשים אף פעם לא ראו את הגרסה הבעייתית, ואפשר פשוט להתעלם מהגרסה הבעייתית או למחוק אותה.
האסטרטגיה הזו מאפשרת לכם לבצע בדיקות בסביבת הייצור בלי להשפיע על הלקוחות.
ניתוח הטווח evaluate.sh
פתיחת evaluate.sh. הסקריפט הזה מבצע את התהליך באופן אוטומטי.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
ה-deploy.sh מטפל בפריסת עדכונים עם אפשרויות --no-traffic ו---tag. אם כבר פועל שירות, הוא לא יושפע. הגרסה החדשה שמוגדרת כ'מוסתרת' לא תקבל תנועה, אלא אם תפעילו אותה באופן מפורש באמצעות כתובת URL מיוחדת שמכילה את תג הגרסה (למשל, https://c-abc1234---researcher-xyz.run.app)
5. הטמעה של סקריפט ההערכה
עכשיו נכתוב את הקוד שמריץ את הבדיקות.
- פתיחת
evaluator/evaluate_agent.py. - תוכלו לראות את הייבוא וההגדרה, אבל המדדים והלוגיקה של ההרצה לא יופיעו.
הגדרת המדדים
במקרה של סוכן המחקר, יש לנו 'תשובות מושלמות' או 'נתוני אמת' עם תשובות צפויות. זוהי הערכת יכולות: אנחנו בודקים אם הסוכן יכול לבצע את העבודה בצורה נכונה.
אנחנו רוצים למדוד:
- התאמה לתשובה הסופית: (יכולת) האם התשובה תואמת לתשובה הצפויה? זהו מדד שמבוסס על הפניה. הוא משתמש ב-LLM שמשמש כשופט כדי להשוות בין הפלט של הסוכן לבין התשובה הצפויה. היא לא מצפה שהתשובה תהיה זהה, אלא דומה מבחינה סמנטית ועובדתית.
- Tool Use Quality: (איכות) מדד מותאם אישית שמיועד להערכת הבחירה של כלים מתאימים, השימוש הנכון בפרמטרים וההקפדה על רצף הפעולות שצוין.
- המסלול של השימוש בכלי: (Trace) שני מדדים מותאמים אישית שמודדים את המסלול של השימוש בכלי על ידי הסוכן (דיוק והחזרה) בהשוואה למסלולים הצפויים. המדדים האלה מיושמים ב-
shared/evaluation/tool_metrics.pyכפונקציות בהתאמה אישית. בניגוד לאיכות השימוש בכלי, המדד הזה הוא מדד דטרמיניסטי מבוסס-הפניה – הקוד בודק באופן מילולי אם הקריאות בפועל לכלי תואמות לנתוני ההפניה (reference_trajectoryבנתוני ההערכה).
מדדים מותאמים אישית של מסלול השימוש בכלי
כדי ליצור מדדים מותאמים אישית של מסלול השימוש בכלי, יצרנו קבוצה של פונקציות Python ב-shared/evaluation/tool_metrics.py. כדי לאפשר לשירות ההערכה של Vertex AI Gen AI להפעיל את הפונקציות האלה, צריך להעביר אליו את קוד ה-Python.
כדי לעשות את זה, מגדירים אובייקט EvaluationRunMetric עם הגדרות UnifiedMetric ו-CustomCodeExecutionSpec. הפרמטר remote_custom_function הוא מחרוזת שמכילה את קוד Python של הפונקציה. הפונקציה צריכה להיקרא evaluate:
def evaluate(
instance: dict
) -> float:
...
יצרנו את get_custom_function_metric helper (ב-shared/evaluation/evaluate.py) שממיר פונקציית Python למדד מותאם אישית להערכת קוד.
היא מקבלת את הקוד של מודול הפונקציה (כדי לתעד יחסי תלות מקומיים), יוצרת פונקציה נוספת evaluate שקוראת לפונקציה המקורית, ומחזירה אובייקט EvaluationRunMetric עם CustomCodeExecutionSpec.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
שירות ההערכה של AI גנרטיבי יריץ את הקוד הזה בסביבת הרצה של ארגז חול, ויעביר אליה את נתוני ההערכה.
הוספת המדדים וקוד ההערכה
מוסיפים את הקוד הבא אל evaluator/evaluate_agent.py אחרי השורה if __name__ == "__main__":.
היא מגדירה את רשימת המדדים של סוכן המחקר ומריצה את ההערכה.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
בצינור ייצור אמיתי, צריך קריטריונים להערכת הצלחה. אחרי שההערכה מסתיימת והמדדים מוכנים. במקום הזה יהיה שלב שבו נדרשת הסכמה. לדוגמה: "אם הציון Final Response Match נמוך מ-0.75, הבנייה תיכשל". כך נמנע מצב שבו גרסאות לא טובות יקבלו תנועה.
מוסיפים את הקוד הבא ל-evaluator/evaluate_agent.py:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
אם הערך mean של אחד ממדדי ההערכה נמוך מסף (0.75), הפריסה תיכשל.
[אופציונלי] הוספת הערכה באמצעות מדדים ללא הפניה עבור כלי התזמור
במקרה של סוכן Orchestrator, האינטראקציות מורכבות יותר, ולא תמיד יש תשובה 'נכונה' אחת. במקום זאת, אנחנו מעריכים את ההתנהגות הכללית באמצעות אחד מהמדדים ללא התייחסות.
- הזיה: מדד מבוסס-ציון שבודק את העובדות ואת העקביות של תגובות טקסטואליות על ידי חלוקת התגובה לטענות אטומיות. הוא בודק אם כל טענה מבוססת או לא על סמך השימוש בכלי באירועים הביניים. זה קריטי לסוכנים עם יכולות פתוחות, שבהם 'נכונות' היא סובייקטיבית אבל 'אמינות' היא חובה. הציון מחושב כאחוז הטענות שמבוססות על תוכן המקור. במקרה שלנו, אנחנו מצפים שהתשובה הסופית מהכלי לניהול תהליכים (שנוצרה על ידי הכלי ליצירת תוכן) תתבסס על עובדות שמופיעות בתוכן שאותר על ידי הכלי לחיפוש בוויקיפדיה.
מוסיפים את הלוגיקה של ההערכה ל-Orchestrator:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
בדיקת נתוני ההערכה
פותחים את הספרייה evaluator/. יוצגו שני קובצי נתונים:
-
eval_data_researcher.json: הנחיות והפניות לנתוני אמת (Golden/Ground-Truth) עבור החוקר. -
eval_data_orchestrator.json: הנחיות ל-Orchestrator (אנחנו מבצעים הערכה ללא הפניה רק ל-Orchestrator).
כל רשומה בדרך כלל מכילה:
prompt: ההנחיה לסוכן.-
reference: התשובה האידיאלית (האמת הבסיסית), אם רלוונטי. -
reference_trajectory: הרצף הצפוי של קריאות לכלים.
6. הסבר על קוד ההערכה
פתיחת shared/evaluation/evaluate.py. המודול הזה מכיל את לוגיקת הליבה להרצת הערכות. פונקציית המקש היא evaluate_agent.
הקוד מבצע את הפעולות הבאות:
- טעינת נתונים: קורא את מערך הנתונים של ההערכה (הנחיות והפניות) מקובץ.
- הסקת מסקנות מקבילית: הרצת הסוכן מול מערך הנתונים במקביל. הוא יוצר סשנים, שולח הנחיות ומתעד את התשובה הסופית ואת המעקב אחר הביצוע של הכלי.
- Vertex AI Evaluation: המערכת ממזגת את נתוני ההערכה המקוריים עם התשובות הסופיות ואת עקבות הביצוע של הכלי הביניים, ושולחת את התוצאות אל Vertex AI Evaluation Service באמצעות GenAI Client ב-Vertex AI SDK. השירות הזה מריץ את המדדים שהוגדרו כדי לדרג את ביצועי הנציג.
הרגע המרכזי בשלב האחרון הוא קריאה לפונקציה create_evaluation_run של מודול ההערכה של Gen AI SDK:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
אנחנו עושים זאת בפונקציה evaluate_agent ב-shared/evaluation/evaluate.py.
היא מקבלת את מערך הנתונים המשולב של ההערכה, את המידע על הסוכן, את המדדים לשימוש ואת ה-URI של יעד האחסון. הפונקציה יוצרת הפעלה של הערכה בשירות ההערכה של Vertex AI ומחזירה את אובייקט ההפעלה של ההערכה.
Agent Info API
כדי לבצע הערכה מדויקת, שירות ההערכה צריך לדעת את ההגדרות של הסוכן (הוראות מערכת, תיאור וכלי עזר זמינים). אנחנו מעבירים אותו אל create_evaluation_run כפרמטר agent_info.
אבל איך אנחנו משיגים את המידע הזה? אנחנו משלבים אותו ב-ADK Service API.
פותחים את shared/adk_app.py ומחפשים את def agent_info. אפשר לראות שאפליקציית ה-ADK חושפת נקודת קצה (endpoint) של כלי עזר:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
נקודת הקצה הזו (מופעלת באמצעות הדגל --publish_agent_info) מאפשרת לסקריפט ההערכה לאחזר באופן דינמי את הגדרות זמן הריצה של הסוכן. המידע הזה חשוב מאוד למדדים שמעריכים את השימוש בכלי, כי מודל השופט יכול להעריך טוב יותר את השימוש של הסוכן בכלי אם הוא יודע בדיוק אילו כלים היו זמינים לסוכן במהלך השיחה.
7. הרצת ההערכה
אחרי שמטמיעים את כלי ההערכה, מפעילים פתרונות חכמים.
- מריצים את סקריפט ההערכה מהרמה הבסיסית (root) של המאגר:
./evaluate.sh- הוא מקבל את הגיבוב (hash) הנוכחי של ה-commit ב-Git.
- היא מפעילה את
deploy.shכדי לפרוס עדכון עם תג שמבוסס על הגיבוב של הקומיט. - אחרי הפריסה, הוא מתחיל ב-
evaluator.evaluate_agent. - במהלך הפעלת תרחישי הבדיקה מול שירות הענן, יוצגו סרגלי התקדמות.
- בסוף, הוא מדפיס סיכום JSON של התוצאות.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
הערה: יכול להיות שההרצה הראשונה תימשך כמה דקות עד לפריסת השירותים.
8. הצגה חזותית של התוצאות ב-Notebook
קשה לקרוא את פלט ה-JSON הגולמי. הלקוח Gen AI ב-Vertex AI SDK מאפשר לעקוב אחרי ההרצות האלה לאורך זמן. נשתמש ב-notebook של Colab כדי להציג את התוצאות בצורה ויזואלית.
- אפשר לפתוח את
evaluator/show_evaluation_run.ipynbב-Google Colab באמצעות הקישור הזה. - מגדירים את המשתנים
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONו-EVAL_RUN_IDלמזהה הפרויקט, לאזור ולמזהה ההפעלה.
- מתקינים יחסי תלות ומבצעים אימות.
אחזור של ההרצה של ההערכה והצגת התוצאות
צריך לאחזר את נתוני ההרצה של ההערכה מ-Vertex AI. מחפשים את התא בקטע Retrieve Evaluation Run and Display Results ומחליפים את השורה # TODO בבלוק הקוד הבא:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
פירוש התוצאות
כשבודקים את התוצאות, חשוב לזכור:
- רגרסיה לעומת יכולת:
- רגרסיה: האם הניקוד ירד בבדיקות ישנות? (לא טוב, נדרשת חקירה).
- יכולת: האם הציון השתפר בבדיקות חדשות? (טוב, יש התקדמות).
- ניתוח כשלים: אל תסתכלו רק על הניקוד.
- מעיינים בtrace. האם הוא הפעיל כלי לא מתאים? האם ניתוח הפלט נכשל? כאן מוצאים באגים.
- בודקים את ההסבר ואת פסיקות הדין שסופקו על ידי מודל ה-LLM של השופט. הם בדרך כלל מספקים מושג טוב לגבי הסיבה לכישלון הבדיקה.
Pass@1 לעומת Pass@k: כשמריצים בדיקה מסוימת פעם אחת, מקבלים את הציון Pass@1. אם סוכן נכשל, יכול להיות שהסיבה לכך היא חוסר דטרמיניזם. בהגדרות מורכבות, יכול להיות שתריצו כל בדיקה k פעמים (למשל, 5 פעמים) ותחשבו את pass@k (האם היא הצליחה לפחות פעם אחת?) או את pass^k (האם היא הצליחה בכל פעם?). זה מה שקורה כבר בהרבה מדדים מאחורי הקלעים. לדוגמה, types.RubricMetric.FINAL_RESPONSE_MATCH (התאמה לתשובה הסופית) מבצע 5 קריאות למודל שפה גדול (LLM) של השופט כדי לקבוע את ציון ההתאמה לתשובה הסופית.
9. אינטגרציה רציפה ופריסה רציפה (CI/CD)
במערכת ייצור, צריך להריץ את הערכת הסוכן כחלק מצינור ה-CI/CD. Cloud Build היא אפשרות טובה לכך.
לכל קומיט שנדחף למאגר קוד הסוכן, תתבצע הערכה יחד עם שאר הבדיקות. אם הם עוברים את הבדיקה, אפשר 'לקדם' את הפריסה כך שתשרת בקשות של משתמשים. אם הבדיקות נכשלות, הכול נשאר כמו שהיה, אבל המפתח יכול לבדוק מה השתבש.
הגדרות Cloud Build
עכשיו ניצור סקריפט להגדרת פריסה ב-Cloud Run שמבצע את הפעולות הבאות:
- פריסת שירותים לגרסה פרטית.
- מריץ הערכה של סוכן.
- אם ההערכה עוברת בהצלחה, המערכת מקדמת את פריסות הגרסאות כך שהן יציגו 100% מהתנועה.
יצירת cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
הפעלת הפייפליין
בסוף, אפשר להריץ את צינור ההערכה.
לפני שמריצים את צינור עיבוד הנתונים של ההערכה ששולח בקשות לשירותי Cloud Run, צריך חשבון שירות נפרד עם מספר הרשאות. נכתוב סקריפט שיעשה את זה ויפעיל את צינור עיבוד הנתונים.
- יצירת סקריפט
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- יוצר חשבון שירות ייעודי
agent-eval-build-sa. - מקצה לו את התפקידים הנדרשים (
roles/run.admin,roles/aiplatform.userוכו'). *. שולח את ה-build ל-Cloud Build.
- יוצר חשבון שירות ייעודי
- מריצים את הפייפליין:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
אפשר לעקוב אחרי התקדמות הבנייה במסוף או ללחוץ על הקישור ל-Cloud Console.
הערה: בסביבת ייצור אמיתית, צריך להגדיר טריגר של Cloud Build כדי להריץ את הפקודה הזו באופן אוטומטי בכל git push. תהליך העבודה זהה: הטריגר יפעיל את cloudbuild.yaml, וכך יבטיח שכל פעולת commit תיבדק.
10. סיכום
יצרתם בהצלחה צינור עיבוד נתונים להערכה.
- פריסה: השתמשתם בתגי עדכון עם גיבוב של git commit כדי לפרוס סוכנים בבטחה בסביבה אמיתית לצורך בדיקה, בלי להשפיע על פריסות בייצור.
- הערכה: הגדרתם מדדי הערכה, ויצרתם אוטומציה של תהליך ההערכה באמצעות שירות ההערכה של Vertex AI ל-AI גנרטיבי.
- ניתוח: השתמשתם ב-Colab Notebook כדי להציג את תוצאות ההערכה ולשפר את הסוכן.
- השקה: השתמשתם ב-Cloud Build כדי להפעיל את פייפליין ההערכה באופן אוטומטי, וקידמתם את הגרסה הטובה ביותר כדי להכניס אותה לשימוש בסביבת הייצור עבור 100% מתעבורת הנתונים.
המחזור הזה עריכת קוד -> פריסת תג -> הפעלת הערכה ובדיקות -> ניתוח -> השקה -> חזרה על הפעולות הוא הליבה של הנדסת סוכנים ברמת ייצור.