
1. Pengantar
Ringkasan
Lab ini merupakan lanjutan dari Membangun Sistem Multiagen dengan ADK.
Di lab tersebut, Anda telah membuat Sistem Pembuatan Kursus yang terdiri dari:
- Researcher Agent: Menggunakan google_search untuk menemukan informasi terbaru.
- Agen Penilai (Judge Agent): Mengkritik kualitas dan kelengkapan riset.
- Agen Pembuat Konten: Mengubah riset menjadi kursus terstruktur.
- Agen Pengelola: Mengelola alur kerja dan komunikasi antara spesialis ini.
Aplikasi ini juga menyertakan Aplikasi Web yang memungkinkan pengguna mengirimkan permintaan pembuatan kursus, dan mendapatkan kursus sebagai respons.
Researcher, Judge, dan Content Builder di-deploy sebagai agen A2A dalam layanan Cloud Run terpisah. Orchestrator adalah layanan Cloud Run lain dengan ADK Service API.
Untuk lab ini, kami mengubah agen Peneliti agar menggunakan alat Penelusuran Wikipedia, bukan kemampuan Penelusuran Google Gemini. Hal ini memungkinkan kita memeriksa cara panggilan alat kustom dilacak dan dievaluasi.
Jadi, kami membangun sistem multi-agen terdistribusi. Namun, bagaimana kita tahu apakah strategi tersebut benar-benar berfungsi dengan baik? Apakah Peneliti selalu menemukan info yang relevan? Apakah Hakim mengidentifikasi riset buruk dengan benar?
Di lab ini, Anda akan mengganti "penilaian suasana" subjektif dengan penilaian berbasis data menggunakan Layanan Evaluasi AI Generatif Vertex AI. Anda akan menerapkan metrik Rubrik Adaptif dan Kualitas Penggunaan Alat untuk mengevaluasi Sistem Multi-Agen terdistribusi yang dibangun di Lab 1 secara cermat. Terakhir, Anda akan mengotomatiskan proses ini dalam pipeline CI/CD, sehingga memastikan bahwa setiap deployment mempertahankan keandalan dan akurasi agen produksi Anda.
Anda akan membangun Pipeline Evaluasi Berkelanjutan untuk agen Anda. Anda akan mempelajari cara:
- Deploy agen Anda ke revisi yang diberi tag pribadi di Google Cloud Run (deployment bayangan).
- Jalankan rangkaian evaluasi otomatis terhadap revisi tertentu menggunakan Layanan Evaluasi AI Generatif Vertex AI.
- Memvisualisasikan dan menganalisis hasilnya.
- Gunakan evaluasi sebagai bagian dari pipeline CI/CD Anda.
2. Konsep Inti: Teori Evaluasi Agen
Saat mengembangkan dan menjalankan Agen AI, kami melakukan dua jenis penilaian: Eksperimen Offline dan Evaluasi Berkelanjutan dengan Pengujian Regresi Otomatis. Yang pertama adalah mesin kreatif dari proses pengembangan, tempat kami menjalankan eksperimen ad-hoc, menyempurnakan perintah, dan melakukan iterasi dengan cepat untuk membuka kemampuan baru. Yang kedua adalah lapisan defensif dalam pipeline CI/CD kami, tempat kami menjalankan evaluasi berkelanjutan terhadap set data "emas" untuk memastikan tidak ada perubahan kode yang secara tidak sengaja menurunkan kualitas agen yang telah terbukti.
Perbedaan mendasar terletak pada Penemuan versus Pertahanan:
- Eksperimen Offline adalah proses pengoptimalan. Ini bersifat terbuka dan bervariasi. Anda secara aktif mengubah input (perintah, model, parameter) untuk memaksimalkan skor atau menyelesaikan masalah tertentu. Tujuannya adalah untuk meningkatkan "batas atas" kemampuan agen.
- Evaluasi Berkelanjutan (Pengujian Regresi Otomatis) adalah proses verifikasi. Pola ini kaku dan berulang. Anda mempertahankan input tetap konstan (set data "emas") untuk memastikan output tetap stabil. Tujuannya adalah untuk mencegah "dasar" performa runtuh.
Di lab ini, kita akan berfokus pada Evaluasi Berkelanjutan. Kita akan mengembangkan Pipeline Pengujian Regresi Otomatis yang seharusnya berjalan setiap kali seseorang membuat perubahan pada Agen AI, seperti pengujian unit tersebut.
Sebelum menulis kode, penting untuk memahami apa yang kita ukur.
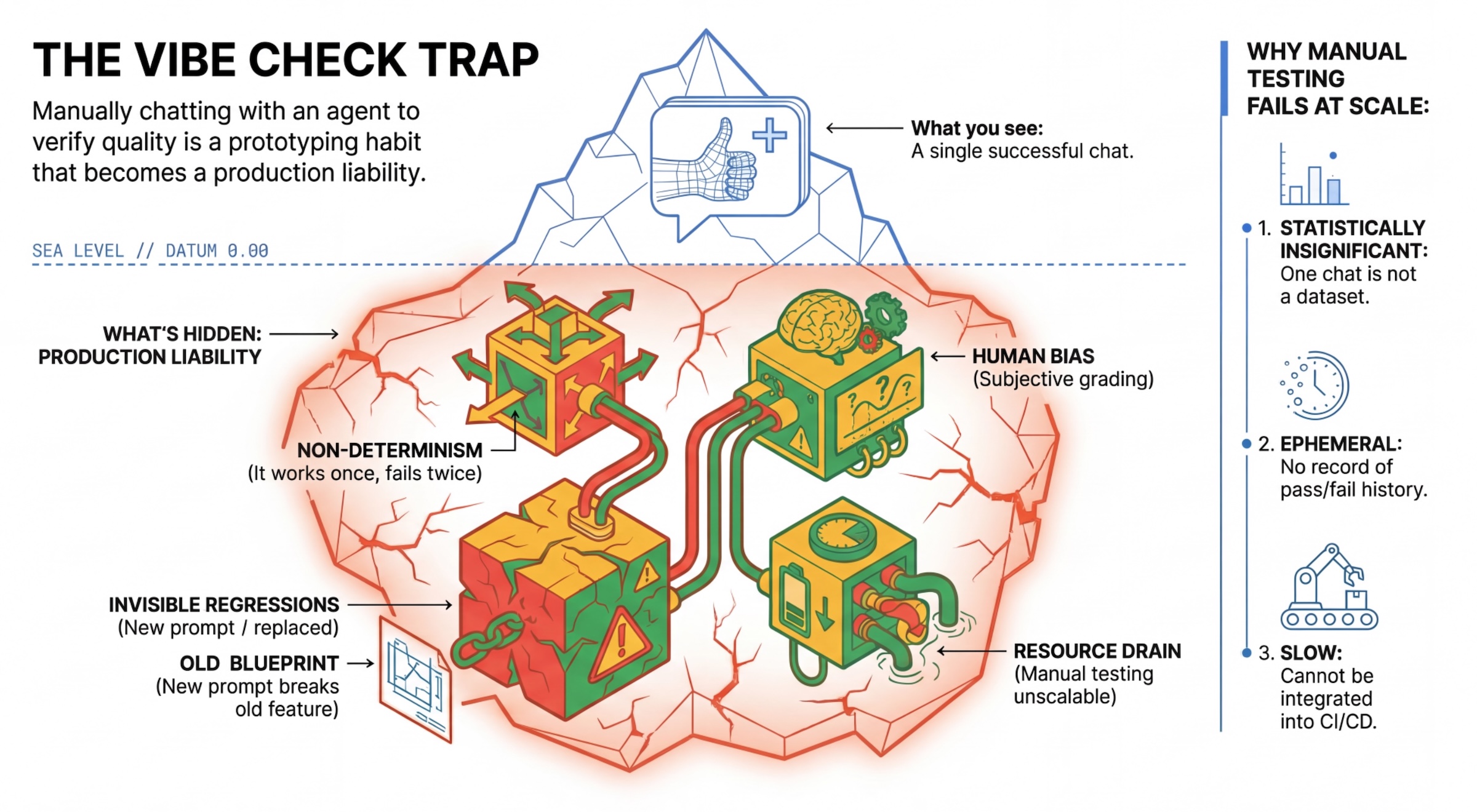
Perangkap "Cek Suasana"
Banyak developer menguji agen dengan melakukan percakapan secara manual dengan agen tersebut. Hal ini dikenal sebagai "pengecekan suasana". Meskipun berguna untuk pembuatan prototipe, hal ini gagal dalam produksi karena:
- Non-Determinisme: Agen dapat memberikan jawaban yang berbeda setiap kali. Anda memerlukan ukuran sampel yang signifikan secara statistik.
- Regresi Tidak Terlihat (Invisible Regressions): Meningkatkan kualitas satu perintah dapat merusak kasus penggunaan yang berbeda.
- Bias Manusia: "Terlihat bagus" bersifat subjektif.
- Pekerjaan yang Memakan Waktu: Pengujian puluhan skenario secara manual dengan setiap commit akan lambat.
Dua cara untuk menilai Performa Agen
Untuk membangun pipeline yang andal, kami menggabungkan berbagai jenis pemberi skor:
- Pengoreksi Berbasis Kode (Deterministik):
- Yang diukur: Batasan ketat (misalnya, "Apakah JSON yang ditampilkan valid?", Apakah alat
searchdipanggil?"). - Kelebihan: Cepat, murah, akurat 100%.
- Kekurangan: Tidak dapat menilai nuansa atau kualitas.
- Yang diukur: Batasan ketat (misalnya, "Apakah JSON yang ditampilkan valid?", Apakah alat
- Pengoreksi Berbasis Model (Probabilistik):
- Juga dikenal sebagai "LLM-as-a-Judge". Kami menggunakan model yang kuat (seperti Gemini 3 Pro) untuk mengevaluasi output agen.
- Yang mereka ukur: Nuansa, penalaran, kegunaan, keamanan.
- Kelebihan: Dapat mengevaluasi tugas kompleks dan terbuka.
- Kontra: Lebih lambat, lebih mahal, memerlukan rekayasa perintah yang cermat untuk penilai.
Metrik Evaluasi Vertex AI
Di lab ini, kita menggunakan Layanan Evaluasi AI Generatif Vertex AI, yang menyediakan metrik terkelola sehingga Anda tidak perlu menulis setiap penilaian dari awal.
Ada beberapa cara untuk mengelompokkan metrik untuk evaluasi agen:
- Metrik berbasis rubrik: Menggabungkan LLM ke dalam alur kerja evaluasi.
- Rubrik adaptif: Rubrik dibuat secara dinamis untuk setiap perintah. Respons dievaluasi dengan umpan balik lulus atau gagal yang terperinci dan dapat dijelaskan, yang khusus untuk perintah.
- Rubrik statis: Rubrik ditentukan secara eksplisit dan rubrik yang sama berlaku untuk semua perintah. Respons dievaluasi dengan kumpulan evaluator berbasis skor numerik yang sama. Satu skor numerik (seperti 1-5) per perintah. Jika evaluasi diperlukan pada dimensi yang sangat spesifik atau jika rubrik yang sama persis diperlukan di semua perintah.
- Metrik berbasis komputasi: Mengevaluasi respons dengan algoritma deterministik, biasanya menggunakan data sebenarnya. Skor numerik (seperti 0,0-1,0) per perintah. Jika kebenaran dasar tersedia dan dapat dicocokkan dengan metode deterministik.
- Metrik fungsi kustom: Tentukan metrik Anda sendiri melalui fungsi Python.
Metrik Khusus yang akan kita gunakan:
Final Response Match: (Berbasis referensi) Apakah jawaban cocok dengan "Jawaban Terbaik" kami?Tool Use Quality: (Tanpa referensi) Apakah agen menggunakan alat yang relevan dengan cara yang tepat?Hallucination: (Tanpa rujukan) Apakah klaim dalam respons didukung oleh konteks yang diambil?Tool Trajectory PrecisiondanTool Trajectory Recall(Berbasis referensi) Apakah agen memilih alat yang tepat dan memberikan argumen yang valid? Tidak sepertiTool Use Quality, metrik kustom ini menggunakan lintasan referensi - urutan panggilan dan argumen alat yang diharapkan.
3. Penyiapan
Konfigurasi
- Buka Cloud Shell: Klik ikon Activate Cloud Shell di kanan atas Konsol Google Cloud.
- Jalankan perintah berikut untuk memuat ulang login dan memperbarui Kredensial Default Aplikasi (ADC):
gcloud auth login --update-adc - Tetapkan project aktif untuk gcloud CLI.Jalankan perintah berikut untuk mendapatkan project gcloud saat ini:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDdengan ID project Anda. - Tetapkan region default tempat layanan Cloud Run Anda akan di-deploy.
gcloud config set run/region us-west1us-west1, Anda dapat menggunakan region Cloud Run yang lebih dekat dengan Anda.
Kode dan Dependensi
- Buat clone kode awal dan ubah direktori ke root project.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - Buat file
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - Instal dependensi dengan menjalankan perintah berikut di jendela terminal:
uv sync
4. Memahami Deployment yang Aman
Sebelum mengevaluasi, kita perlu men-deploy. Namun, kita tidak ingin merusak aplikasi aktif jika kode baru kita buruk.
Tag Revisi dan Deployment Shadow
Google Cloud Run mendukung Revisi. Setiap kali Anda melakukan deployment, revisi baru yang tidak dapat diubah akan dibuat. Anda dapat menetapkan Tag ke revisi ini untuk mengaksesnya melalui URL tertentu, meskipun revisi tersebut menerima 0% traffic publik.
Mengapa tidak menjalankan penilaian secara lokal saja?
Meskipun ADK mendukung evaluasi lokal, men-deploy ke revisi tersembunyi memberikan keuntungan penting untuk Sistem Produksi. Hal ini membedakan Evaluasi Tingkat Sistem (yang kita lakukan) dari Pengujian Unit:
- Paritas Lingkungan: Lingkungan lokal berbeda (jaringan berbeda, CPU/Memori berbeda, secret berbeda). Pengujian di cloud memastikan agen Anda berfungsi di lingkungan runtime sebenarnya (Pengujian Sistem).
- Interaksi Multi-Agen: Dalam sistem terdistribusi, agen berkomunikasi melalui HTTP. Pengujian "Lokal" sering kali meniru koneksi ini. Deployment bayangan menguji latensi jaringan, konfigurasi waktu tunggu, dan autentikasi aktual antara microservice Anda.
- Secret & Izin: Memverifikasi bahwa akun layanan Anda benar-benar memiliki izin yang diperlukan (misalnya, untuk memanggil Vertex AI atau membaca dari Firestore).
Catatan: Ini adalah Evaluasi Proaktif (memeriksa sebelum pengguna melihatnya). Setelah di-deploy, Anda akan menggunakan Reactive Monitoring (Observability) untuk menangkap masalah di luar.
Alur Kerja CI/CD: Deploy, Nilai, Promosikan
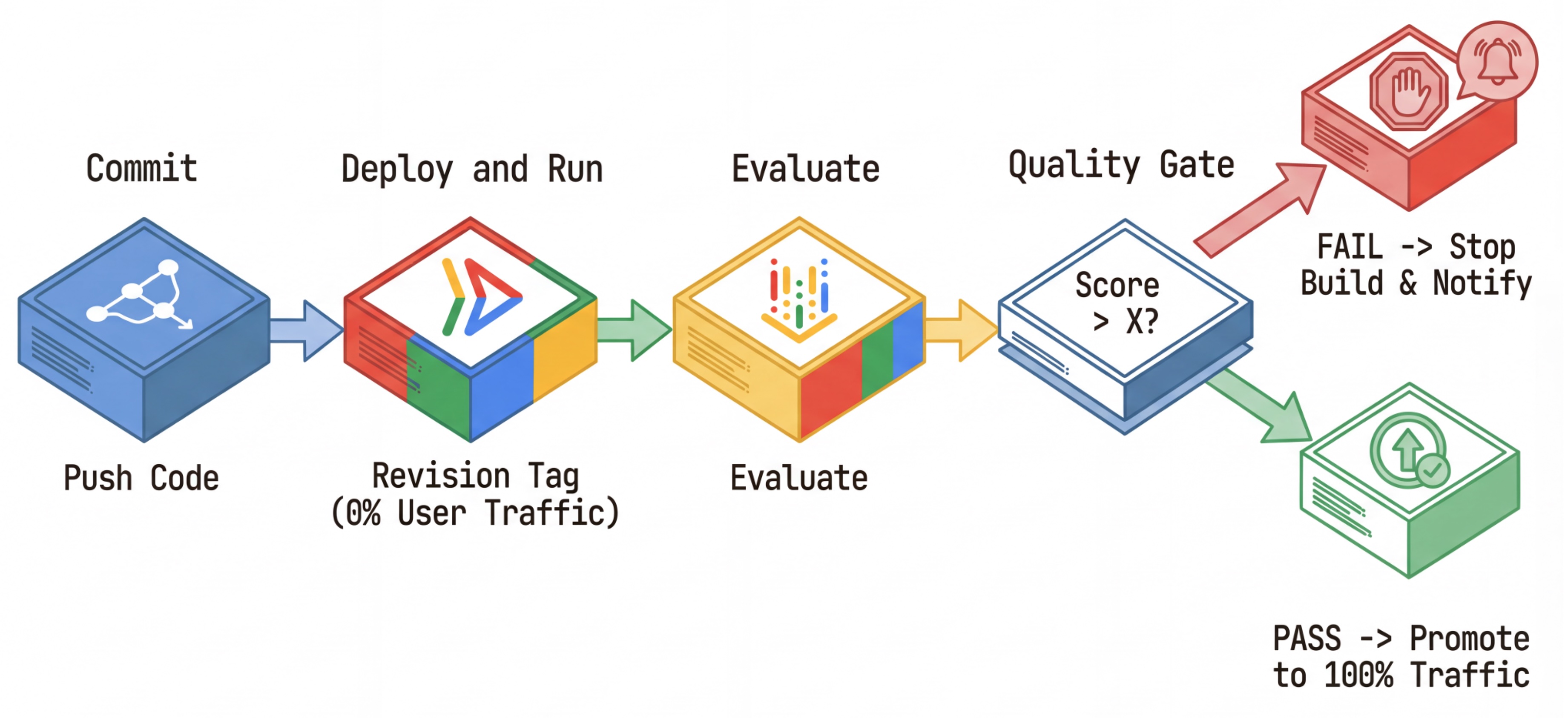
Kita menggunakannya untuk pipeline Deployment Berkelanjutan yang andal:
- Commit: Anda mengubah perintah agen, dan mengirimkannya ke repositori.
- Deploy (Tersembunyi): Memicu deployment revisi baru yang diberi tag dengan hash commit (misalnya,
c-abc1234). Revisi ini menerima 0% traffic publik. - Evaluasi: Skrip evaluasi menargetkan URL revisi tertentu
https://c-abc1234---researcher-xyz.run.app. - Promosikan: Jika (dan hanya jika) evaluasi lulus dan pengujian lainnya berhasil, Anda akan memigrasikan traffic ke revisi baru ini.
- Rollback: Jika gagal, pengguna tidak pernah melihat versi yang buruk, dan Anda dapat mengabaikan atau menghapus revisi yang buruk.
Strategi ini memungkinkan Anda melakukan pengujian dalam produksi tanpa memengaruhi pelanggan.
Menganalisis evaluate.sh
Buka evaluate.sh. Skrip ini mengotomatiskan prosesnya.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh menangani deployment revisi dengan opsi --no-traffic dan --tag. Jika sudah ada layanan yang berjalan, layanan tersebut tidak akan terpengaruh. Revisi "tersembunyi" yang baru tidak akan menerima traffic kecuali jika Anda secara eksplisit memanggilnya dengan URL khusus yang berisi tag revisi (misalnya, https://c-abc1234---researcher-xyz.run.app)
5. Menerapkan Skrip Evaluasi
Sekarang, mari kita tulis kode yang benar-benar menjalankan pengujian.
- Buka
evaluator/evaluate_agent.py. - Anda akan melihat impor dan penyiapan, tetapi metrik dan logika eksekusi tidak ada.
Menentukan Metrik
Untuk Agen Peneliti, kami memiliki "Jawaban Terbaik"/"Kebenaran Dasar" dengan jawaban yang diharapkan. Ini adalah Evaluasi Kemampuan (Capability Eval): kami mengukur apakah agen dapat melakukan pekerjaan dengan benar.
Kami ingin mengukur:
- Kecocokan Respons Akhir: (Kemampuan) Apakah jawaban cocok dengan jawaban yang diharapkan? Ini adalah metrik berbasis referensi. Alat ini menggunakan LLM hakim untuk membandingkan output agen dengan jawaban yang diharapkan. Model tidak mengharapkan jawaban yang persis sama, tetapi serupa secara semantik dan faktual.
- Kualitas Penggunaan Alat: (Kualitas) Metrik rubrik adaptif bertarget yang mengevaluasi pemilihan alat yang sesuai, penggunaan parameter yang benar, dan kepatuhan terhadap urutan operasi yang ditentukan.
- Lintasan Penggunaan Alat: (Trace) 2 metrik kustom yang mengukur lintasan penggunaan alat agen (presisi dan recall) terhadap lintasan yang diharapkan. Metrik ini diterapkan di
shared/evaluation/tool_metrics.pysebagai fungsi kustom. Tidak seperti Kualitas Penggunaan Alat, metrik ini adalah metrik berbasis referensi deterministik - kode secara harfiah melihat apakah panggilan alat sebenarnya cocok dengan data referensi (reference_trajectorydalam data evaluasi).
Metrik Lintasan Penggunaan Alat Kustom
Untuk metrik Trajektori Penggunaan Alat kustom, kami membuat serangkaian fungsi Python di shared/evaluation/tool_metrics.py. Agar Layanan Evaluasi AI Generatif Vertex AI dapat menjalankan fungsi ini, kita perlu meneruskan kode Python tersebut ke layanan.
Hal ini dilakukan dengan menentukan objek EvaluationRunMetric dengan konfigurasi UnifiedMetric dan CustomCodeExecutionSpec. Parameter remote_custom_function adalah string yang berisi kode Python fungsi. Fungsi harus diberi nama evaluate:
def evaluate(
instance: dict
) -> float:
...
Kami membuat helper get_custom_function_metric (di shared/evaluation/evaluate.py) yang mengonversi fungsi Python menjadi metrik evaluasi kode kustom.
Fungsi ini akan mendapatkan kode modul fungsi (untuk mengambil dependensi lokal), membuat fungsi evaluate tambahan yang memanggil fungsi asli, dan menampilkan objek EvaluationRunMetric dengan CustomCodeExecutionSpec.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Layanan Evaluasi AI Generatif akan mengeksekusi kode tersebut di lingkungan eksekusi sandbox, dan akan meneruskan data evaluasi ke lingkungan tersebut.
Tambahkan kode Metrik dan Evaluasi
Tambahkan kode berikut ke evaluator/evaluate_agent.py setelah baris if __name__ == "__main__":.
Contoh ini menentukan daftar metrik untuk agen Peneliti, dan menjalankan evaluasi.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
Dalam pipeline produksi yang sebenarnya, Anda memerlukan Kriteria Keberhasilan Evaluasi. Setelah evaluasi selesai dan metrik siap. Anda akan memiliki Langkah Pembatasan di sini. Misalnya: "Jika skor Final Response Match < 0,75, gagal build." Tindakan ini mencegah revisi buruk menerima traffic.
Tambahkan kode berikut ke evaluator/evaluate_agent.py:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Setiap kali nilai mean dari salah satu metrik evaluasi berada di bawah nilai minimum (0.75), deployment akan gagal.
[Opsional] Menambahkan Evaluasi dengan Metrik Tanpa Referensi untuk Orchestrator
Untuk Agen Pengelola, interaksinya lebih kompleks, dan kami mungkin tidak selalu memiliki satu jawaban "benar". Sebagai gantinya, kami mengevaluasi perilaku umum menggunakan salah satu Metrik Tanpa Rujukan (Reference-Free Metrics).
- Halusinasi: Metrik berbasis skor yang memeriksa faktualitas dan konsistensi respons teks dengan mensegmentasi respons menjadi klaim atomik. Hal ini memverifikasi apakah setiap klaim memiliki dasar atau tidak berdasarkan penggunaan alat dalam peristiwa perantara. Hal ini sangat penting untuk agen yang bersifat terbuka, di mana "kebenaran" bersifat subjektif, tetapi "kejujuran" tidak dapat dinegosiasikan. Skor dihitung sebagai persentase klaim yang didasarkan pada konten sumber. Dalam kasus kita, kita mengharapkan respons akhir dari Orchestrator (yang dihasilkan Content Builder) didasarkan pada konten yang diambil Researcher menggunakan alat Wikipedia Search.
Tambahkan logika evaluasi untuk Orchestrator:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Memeriksa Data Evaluasi
Buka direktori evaluator/. Anda akan melihat dua file data:
eval_data_researcher.json: Perintah dan referensi Golden/Ground-Truth untuk Peneliti.eval_data_orchestrator.json: Perintah untuk Orchestrator (kami hanya melakukan evaluasi bebas rujukan untuk Orchestrator).
Setiap entri biasanya berisi:
prompt: Perintah untuk agen.reference: Jawaban ideal (kebenaran nyata), jika ada.reference_trajectory: Urutan panggilan alat yang diharapkan.
6. Memahami Kode Evaluasi
Buka shared/evaluation/evaluate.py. Modul ini berisi logika inti untuk menjalankan evaluasi. Fungsi utamanya adalah evaluate_agent.
Skrip ini melakukan langkah-langkah berikut:
- Pemuatan Data: Membaca set data evaluasi (perintah dan referensi) dari file.
- Inferensi Paralel: Menjalankan agen terhadap set data secara paralel. Ia menangani pembuatan sesi, mengirim perintah, dan merekam respons akhir serta rekaman aktivitas eksekusi alat perantara.
- Evaluasi Vertex AI: Menggabungkan data evaluasi asli dengan respons akhir dan rekaman aktivitas eksekusi alat perantara, lalu mengirimkan hasilnya ke Layanan Evaluasi Vertex AI dengan Klien GenAI di Vertex AI SDK. Layanan ini menjalankan Metrik yang dikonfigurasi untuk menilai performa agen.
Momen penting pada langkah terakhir adalah memanggil fungsi create_evaluation_run dari modul evaluasi Gen AI SDK:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Kita melakukannya dalam fungsi evaluate_agent di shared/evaluation/evaluate.py.
Langkah ini akan mendapatkan set data evaluasi gabungan, informasi tentang agen, metrik yang akan digunakan, dan URI penyimpanan tujuan. Fungsi ini membuat proses evaluasi di Layanan Evaluasi Vertex AI dan menampilkan objek proses evaluasi.
Agent Info API
Untuk melakukan evaluasi yang akurat, Layanan Evaluasi perlu mengetahui konfigurasi agen (petunjuk sistem, deskripsi, dan alat yang tersedia). Kita meneruskannya ke create_evaluation_run sebagai parameter agent_info.
Namun, bagaimana cara mendapatkan informasi ini? Kami menjadikannya bagian dari ADK Service API.
Buka shared/adk_app.py dan cari def agent_info. Anda akan melihat bahwa aplikasi ADK mengekspos endpoint helper:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Endpoint ini (diaktifkan melalui tanda --publish_agent_info) memungkinkan skrip evaluasi mengambil konfigurasi runtime agen secara dinamis. Hal ini sangat penting untuk metrik yang menilai penggunaan alat, karena model penilai dapat mengevaluasi penggunaan alat agen dengan lebih baik jika mengetahui secara khusus alat mana yang tersedia untuk agen selama percakapan.
7. Menjalankan Evaluasi
Setelah Anda menerapkan evaluator, mari kita jalankan.
- Jalankan skrip evaluasi dari root repositori:
./evaluate.sh- Tindakan ini akan mendapatkan hash commit git Anda saat ini.
- Tindakan ini memanggil
deploy.shuntuk men-deploy revisi dengan tag berdasarkan hash commit. - Setelah di-deploy,
evaluator.evaluate_agentakan dimulai. - Anda akan melihat status progres saat menjalankan kasus pengujian terhadap layanan cloud Anda.
- Terakhir, kode ini mencetak JSON ringkasan hasil.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Catatan: Proses pertama mungkin memerlukan waktu beberapa menit untuk men-deploy layanan.
8. Memvisualisasikan Hasil di Notebook
Output JSON mentah sulit dibaca. Klien AI Generatif di Vertex AI SDK menyediakan cara untuk melacak eksekusi ini dari waktu ke waktu. Kita akan menggunakan notebook Colab untuk memvisualisasikan hasilnya.
- Buka
evaluator/show_evaluation_run.ipynbdi Google Colab menggunakan link ini. - Tetapkan variabel
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGION, danEVAL_RUN_IDke project ID, region, dan ID run Anda.
- Instal dependensi dan lakukan autentikasi.
Mengambil Jalankan Evaluasi dan Menampilkan Hasil
Kita perlu mengambil data proses evaluasi dari Vertex AI. Temukan sel di bagian Retrieve Evaluation Run and Display Results dan ganti baris # TODO dengan blok kode berikut:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Menafsirkan Hasil
Saat Anda melihat hasilnya, perhatikan hal-hal berikut:
- Regresi vs. Kemampuan:
- Regresi: Apakah skor menurun pada pengujian lama? (Tidak bagus, memerlukan penyelidikan).
- Kemampuan: Apakah skor meningkat pada pengujian baru? (Bagus, ini adalah kemajuan).
- Analisis Kegagalan: Jangan hanya melihat skor.
- Lihat trace. Apakah alat yang dipanggil salah? Apakah gagal mengurai output? Di sinilah Anda dapat menemukan bug.
- Lihat penjelasan dan putusan yang diberikan oleh LLM hakim. Log ini sering kali memberi Anda gambaran yang baik tentang alasan kegagalan pengujian.
Pass@1 vs Pass@k: Saat menjalankan pengujian tertentu satu kali, kita akan mendapatkan skor Pass@1. Jika agen gagal, hal ini mungkin disebabkan oleh non-determinisme. Dalam penyiapan yang canggih, Anda dapat menjalankan setiap pengujian k kali (misalnya, 5 kali) dan menghitung pass@k (apakah berhasil setidaknya sekali?) atau pass^k (apakah berhasil setiap kali?). Hal ini sudah dilakukan oleh banyak metrik di balik layar. Misalnya, types.RubricMetric.FINAL_RESPONSE_MATCH (Kecocokan Respons Akhir) melakukan 5 panggilan ke LLM hakim untuk menentukan skor kecocokan respons akhir.
9. Continuous Integration and Deployment (CI/CD)
Dalam sistem produksi, evaluasi agen harus dijalankan sebagai bagian dari pipeline CI/CD. Cloud Build adalah pilihan yang tepat untuk itu.
Untuk setiap commit yang di-push ke repositori kode agen, evaluasi akan berjalan bersama dengan pengujian lainnya. Jika lulus, deployment dapat "dipromosikan" untuk melayani permintaan pengguna. Jika gagal, semuanya akan tetap seperti semula, tetapi developer dapat melihat apa yang salah.
Konfigurasi Cloud Build
Sekarang, buat skrip konfigurasi deployment Cloud Run yang melakukan langkah-langkah berikut:
- Men-deploy Layanan ke revisi pribadi.
- Menjalankan Evaluasi Agen.
- Jika evaluasi berhasil, revisi deployment akan "dipromosikan" untuk menayangkan 100% traffic.
Buat cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Menjalankan Pipeline
Terakhir, kita dapat menjalankan pipeline evaluasi.
Sebelum menjalankan pipeline evaluasi yang membuat permintaan ke layanan Cloud Run, kita memerlukan Akun Layanan terpisah dengan sejumlah izin. Mari kita tulis skrip yang melakukan hal tersebut dan meluncurkan pipeline.
- Buat skrip
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Membuat Akun Layanan khusus
agent-eval-build-sa. - Memberikan peran yang diperlukan (
roles/run.admin,roles/aiplatform.user, dll.). *. Mengirimkan build ke Cloud Build.
- Membuat Akun Layanan khusus
- Menjalankan pipeline:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Anda dapat mengamati progres build di terminal atau mengklik link ke Konsol Cloud.
Catatan: Di lingkungan produksi yang sebenarnya, Anda akan menyiapkan Pemicu Cloud Build untuk menjalankan ini secara otomatis di setiap git push. Alur kerjanya sama: pemicu akan menjalankan cloudbuild.yaml, sehingga setiap commit dievaluasi.
10. Ringkasan
Anda telah berhasil membuat Pipeline Evaluasi.
- Deployment: Anda menggunakan tag revisi dengan hash commit git untuk men-deploy agen dengan aman ke lingkungan nyata untuk pengujian tanpa memengaruhi deployment produksi.
- Evaluasi: Anda menentukan metrik evaluasi, dan mengotomatiskan proses evaluasi menggunakan Layanan Evaluasi AI Generatif Vertex AI.
- Analisis: Anda menggunakan Notebook Colab untuk memvisualisasikan hasil evaluasi dan meningkatkan kualitas agen Anda.
- Peluncuran: Anda menggunakan Cloud Build untuk menjalankan pipeline evaluasi secara otomatis dan mempromosikan revisi terbaik untuk menayangkan 100% traffic.
Siklus Edit Kode -> Deploy Tag -> Jalankan Evaluasi dan Pengujian -> Analisis -> Peluncuran -> Ulangi ini adalah inti dari Rekayasa Agentik Tingkat Produksi.