
1. 소개
개요
이 실습은 ADK를 사용한 멀티 에이전트 시스템 빌드의 후속 실습입니다.
이 실습에서는 다음으로 구성된 과정 생성 시스템을 빌드했습니다.
- 연구원 에이전트: google_search를 사용하여 최신 정보를 찾습니다.
- 심사 에이전트: 품질과 완전성을 위해 연구를 비판합니다.
- 콘텐츠 빌더 에이전트: 조사 결과를 구조화된 과정으로 변환합니다.
- 오케스트레이터 에이전트: 이러한 전문가 간의 워크플로와 커뮤니케이션을 관리합니다.
또한 사용자가 강의 생성 요청을 제출하고 강의를 응답으로 받을 수 있는 웹 앱도 포함되었습니다.
리서처, 심사자, 콘텐츠 빌더는 별도의 Cloud Run 서비스에 A2A 에이전트로 배포됩니다. 오케스트레이터는 ADK 서비스 API가 있는 또 다른 Cloud Run 서비스입니다.
이 실습에서는 연구원 에이전트가 Gemini의 Google 검색 기능 대신 Wikipedia 검색 도구를 사용하도록 수정했습니다. 이를 통해 맞춤 도구 호출이 추적되고 평가되는 방식을 검사할 수 있습니다.
그래서 분산 멀티 에이전트 시스템을 구축했습니다. 하지만 실제로 잘 작동하는지 어떻게 알 수 있을까요? 연구원이 항상 관련 정보를 찾나요? 심사자가 잘못된 조사를 올바르게 식별했나요?
이 실습에서는 주관적인 '분위기 확인' 대신 Vertex AI Gen AI Evaluation Service를 사용하여 데이터 기반 평가를 수행합니다. 적응형 기준표와 도구 사용 품질 측정항목을 구현하여 실습 1에서 빌드한 분산 멀티 에이전트 시스템을 엄격하게 평가합니다. 마지막으로 CI/CD 파이프라인 내에서 이 프로세스를 자동화하여 모든 배포가 프로덕션 에이전트의 안정성과 정확성을 유지하도록 합니다.
에이전트를 위한 지속적 평가 파이프라인을 빌드합니다. 다음을 수행하는 방법을 배우게 됩니다.
- Google Cloud Run의 비공개 태그가 지정된 버전에 에이전트를 배포합니다 (섀도우 배포).
- Vertex AI Gen AI Evaluation Service를 사용하여 특정 버전에 대해 자동 평가 모음을 실행합니다.
- 결과를 시각화하고 분석합니다.
- 평가를 CI/CD 파이프라인의 일부로 사용합니다.
2. 핵심 개념: 에이전트 평가 이론
AI 에이전트를 개발하고 실행할 때 Google에서는 오프라인 실험과 자동 회귀 테스트를 통한 지속적 평가라는 두 가지 종류의 평가를 수행합니다. 첫 번째는 개발 과정의 크리에이티브 엔진으로, 여기서 임시 실험을 실행하고, 프롬프트를 개선하고, 빠르게 반복하여 새로운 기능을 구현합니다. 두 번째는 CI/CD 파이프라인 내의 방어 계층으로, '골든' 데이터 세트에 대해 지속적 평가를 실행하여 코드 변경으로 인해 에이전트의 입증된 품질이 의도치 않게 저하되지 않도록 합니다.
근본적인 차이는 검색과 방어에 있습니다.
- 오프라인 실험은 최적화 프로세스입니다. 개방형이며 가변적입니다. 점수를 최대화하거나 특정 문제를 해결하기 위해 입력 (프롬프트, 모델, 매개변수)을 적극적으로 변경하고 있습니다. 목표는 에이전트가 할 수 있는 일의 '상한선'을 높이는 것입니다.
- 지속적 평가 (자동 회귀 테스트)는 검증 프로세스입니다. 엄격하고 반복적입니다. 출력이 안정적으로 유지되도록 입력을 일정하게 유지합니다('골든' 데이터 세트). 목표는 실적의 '바닥'이 무너지는 것을 방지하는 것입니다.
이 실습에서는 지속적 평가에 중점을 둡니다. 단위 테스트와 마찬가지로 누군가 AI 에이전트를 변경할 때마다 실행되는 자동 회귀 테스트 파이프라인을 개발할 것입니다.
코드를 작성하기 전에 측정하는 대상을 이해하는 것이 중요합니다.
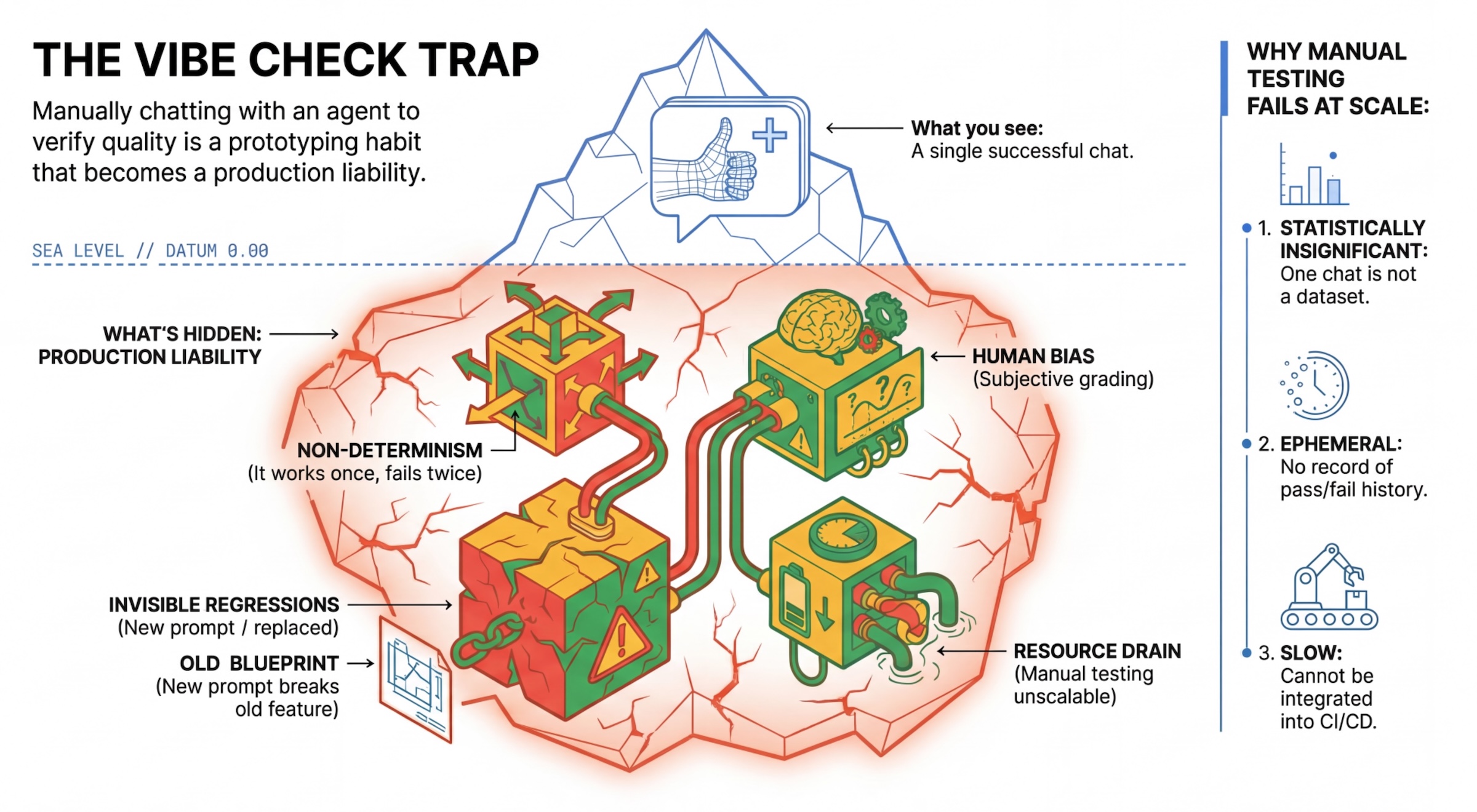
'바이브 확인' 트랩
많은 개발자가 에이전트와 수동으로 채팅하여 에이전트를 테스트합니다. 이를 '분위기 확인'이라고 합니다. 프로토타입 제작에는 유용하지만 다음과 같은 이유로 프로덕션에서는 실패합니다.
- 비결정론: 에이전트가 매번 다르게 대답할 수 있습니다. 통계적으로 유의미한 샘플 크기가 필요합니다.
- 보이지 않는 회귀: 하나의 프롬프트를 개선하면 다른 사용 사례가 중단될 수 있습니다.
- 인간의 편향: '좋아 보인다'는 주관적입니다.
- 시간이 오래 걸리는 작업: 커밋할 때마다 수십 개의 시나리오를 수동으로 테스트하는 것은 느립니다.
에이전트의 실적을 평가하는 두 가지 방법
강력한 파이프라인을 구축하기 위해 다양한 유형의 그레이더를 결합합니다.
- 코드 기반 평가자 (결정적):
- 측정 대상: 엄격한 제약 조건 (예: '유효한 JSON을 반환했나요?', '
search도구를 호출했나요?') - 장점: 빠르고 저렴하며 정확도가 100% 입니다.
- 단점: 미묘한 차이나 품질을 판단할 수 없습니다.
- 측정 대상: 엄격한 제약 조건 (예: '유효한 JSON을 반환했나요?', '
- 모델 기반 평가자 (확률적):
- 'LLM-as-a-Judge'라고도 합니다. Google에서는 강력한 모델 (예: Gemini 3 Pro)을 사용하여 에이전트의 출력을 평가합니다.
- 측정 대상: 미묘한 차이, 추론, 유용성, 안전성
- 장점: 복잡하고 개방형인 작업을 평가할 수 있습니다.
- 단점: 속도가 느리고 비용이 많이 들며 심사위원을 위해 신중한 프롬프트 엔지니어링이 필요합니다.
Vertex AI 평가 측정항목
이 실습에서는 관리형 측정항목을 제공하여 처음부터 모든 심판을 작성하지 않아도 되는 Vertex AI Gen AI Evaluation Service를 사용합니다.
에이전트 평가를 위한 측정항목을 그룹화하는 방법에는 여러 가지가 있습니다.
- 기준표 기반 측정항목: 평가 워크플로에 LLM을 통합합니다.
- 적응형 기준표: 각 프롬프트에 대해 기준표가 동적으로 생성됩니다. 프롬프트에 관한 세부적이고 설명 가능한 통과 또는 실패 피드백으로 응답이 평가됩니다.
- 정적 기준표: 기준표가 명시적으로 정의되며 모든 프롬프트에 동일한 기준표가 적용됩니다. 대답은 동일한 숫자 점수 기반 평가자로 평가됩니다. 프롬프트당 단일 숫자 점수(예: 1~5)입니다. 매우 구체적인 측정기준에 대한 평가가 필요하거나 모든 프롬프트에 걸쳐 정확히 동일한 기준표가 필요한 경우에 사용합니다.
- 계산 기반 측정항목: 일반적으로 정답을 사용하여 결정론적 알고리즘으로 응답을 평가합니다. 프롬프트당 숫자 점수(예: 0.0~1.0)입니다. 정답을 사용할 수 있고 결정론적 방법과 일치시킬 수 있는 경우에 적합합니다.
- 커스텀 함수 측정항목: Python 함수를 통해 자체 측정항목을 정의합니다.
사용할 구체적인 측정항목:
Final Response Match: (참조 기반) 대답이 '모범 답안'과 일치하나요?Tool Use Quality: (참조 없음) 상담사가 관련 도구를 적절한 방식으로 사용했나요?Hallucination: (참조 없음) 대답의 주장이 검색된 컨텍스트에 의해 뒷받침되나요?Tool Trajectory Precision및Tool Trajectory Recall(참조 기반) 상담사가 올바른 도구를 선택하고 유효한 인수를 제공했나요?Tool Use Quality와 달리 이러한 맞춤 측정항목은 예상 도구 호출 및 인수의 시퀀스인 참조 트랙터리를 사용합니다.
3. 설정
구성
- Cloud Shell 열기: Google Cloud 콘솔의 오른쪽 상단에 있는 Cloud Shell 활성화 아이콘을 클릭합니다.
- 다음 명령어를 실행하여 로그인을 새로고침하고 애플리케이션 기본 사용자 인증 정보 (ADC)를 업데이트합니다.
gcloud auth login --update-adc - gcloud CLI의 활성 프로젝트를 설정합니다. 다음 명령어를 실행하여 현재 gcloud 프로젝트를 가져옵니다.
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_ID를 프로젝트 ID로 바꿉니다. - Cloud Run 서비스가 배포될 기본 리전을 설정합니다.
gcloud config set run/region us-west1us-west1대신 가까운 Cloud Run 리전을 사용할 수 있습니다.
코드 및 종속 항목
- 시작 코드를 클론하고 디렉터리를 프로젝트의 루트로 변경합니다.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab .env파일 만들기echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env- 터미널 창에서 다음 명령어를 실행하여 종속 항목을 설치합니다.
uv sync
4. 안전한 배포 이해하기
평가하기 전에 배포해야 합니다. 하지만 새 코드가 잘못된 경우 라이브 애플리케이션이 중단되지 않도록 해야 합니다.
버전 태그 및 섀도우 배포
Google Cloud Run은 버전을 지원합니다. 배포할 때마다 변경할 수 없는 새 버전이 생성됩니다. 이러한 버전에 태그를 할당하면 공개 트래픽을 0% 수신하더라도 특정 URL을 통해 액세스할 수 있습니다.
평가를 로컬에서 실행하면 안 되는 이유는 무엇인가요?
ADK는 로컬 평가를 지원하지만 숨겨진 버전으로 배포하면 프로덕션 시스템에 중요한 이점이 있습니다. 이를 통해 시스템 수준 평가 (Google에서 수행하는 작업)와 단위 테스트를 구분할 수 있습니다.
- 환경 패리티: 로컬 환경이 다릅니다 (네트워크, CPU/메모리, 비밀이 다름). 클라우드에서 테스트하면 에이전트가 실제 런타임 환경에서 작동하는지 확인할 수 있습니다 (시스템 테스트).
- 멀티 에이전트 상호작용: 분산 시스템에서 에이전트는 HTTP를 통해 대화합니다. '로컬' 테스트는 이러한 연결을 모의로 처리하는 경우가 많습니다. 섀도우 배포는 마이크로서비스 간의 실제 네트워크 지연 시간, 제한 시간 구성, 인증을 테스트합니다.
- 보안 비밀 및 권한: 서비스 계정에 실제로 필요한 권한 (예: Vertex AI 호출 또는 Firestore에서 읽기)이 있는지 확인합니다.
참고: 이는 사전 평가 (사용자에게 표시되기 전에 확인)입니다. 배포 후에는 사후 대응 모니터링 (관측 가능성)을 사용하여 실제 문제를 포착합니다.
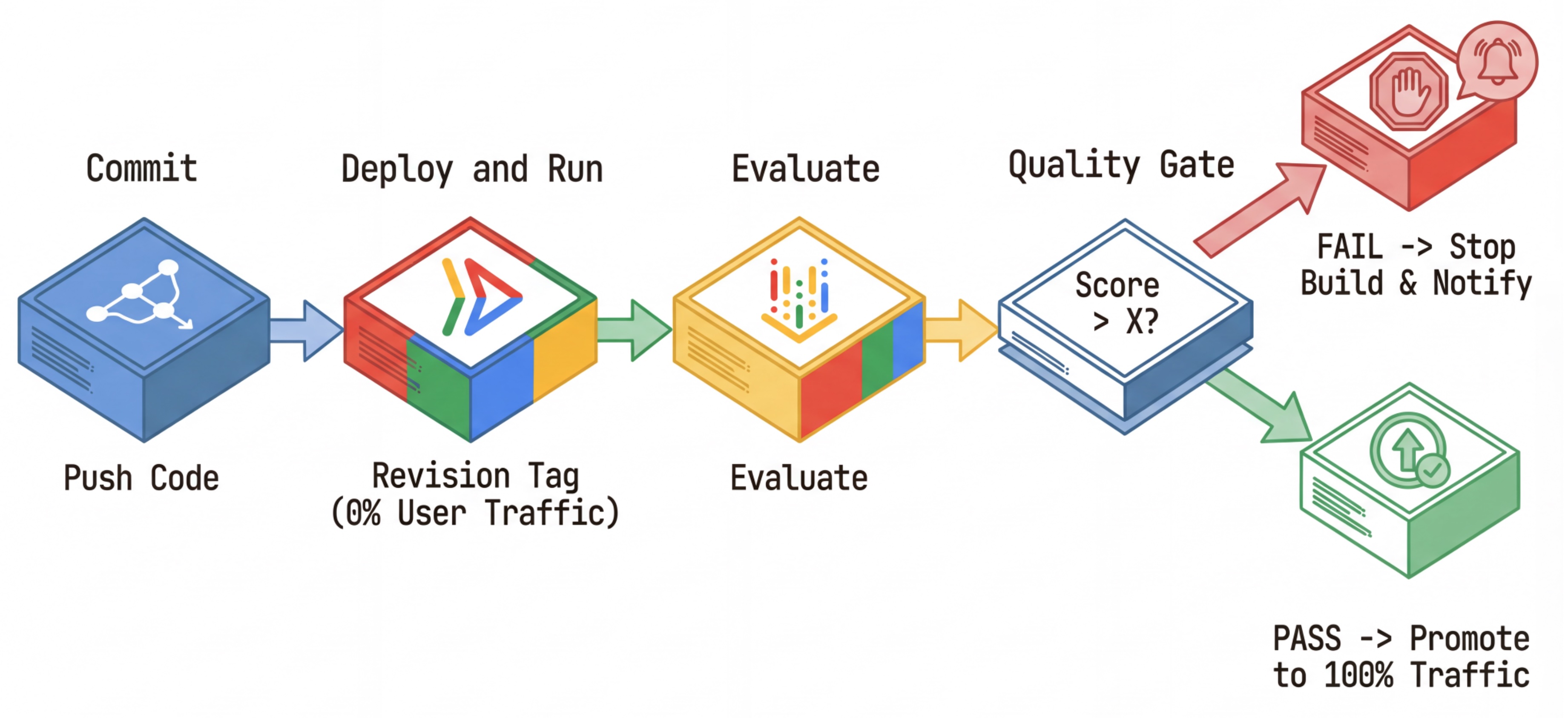
CI/CD 워크플로: 배포, 평가, 승격
이는 강력한 지속적 배포 파이프라인에 사용됩니다.
- 커밋: 에이전트의 프롬프트를 변경하고 저장소로 푸시합니다.
- 배포 (숨김): 커밋 해시 (예:
c-abc1234)로 태그가 지정된 새 버전의 배포를 트리거합니다. 이 버전은 공개 트래픽의 0%를 수신합니다. - 평가: 평가 스크립트가 특정 수정 버전 URL
https://c-abc1234---researcher-xyz.run.app을 타겟팅합니다. - 승격: 평가를 통과하고 다른 테스트가 성공한 경우에만 이 새 버전으로 트래픽을 이전합니다.
- 롤백: 실패하면 사용자에게 잘못된 버전이 표시되지 않으므로 잘못된 수정사항을 무시하거나 삭제하면 됩니다.
이 전략을 사용하면 고객에게 영향을 주지 않고 프로덕션에서 테스트할 수 있습니다.
evaluate.sh 분석
evaluate.sh를 엽니다. 이 스크립트는 프로세스를 자동화합니다.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh은 --no-traffic 및 --tag 옵션을 사용하여 버전 배포를 처리합니다. 이미 실행 중인 서비스가 있는 경우 영향을 받지 않습니다. 새 '숨겨진' 버전은 버전 태그 (예: https://c-abc1234---researcher-xyz.run.app)가 포함된 특수 URL로 명시적으로 호출하지 않는 한 트래픽을 수신하지 않습니다.
5. 평가 스크립트 구현
이제 실제로 테스트를 실행하는 코드를 작성해 보겠습니다.
evaluator/evaluate_agent.py를 엽니다.- 가져오기 및 설정은 표시되지만 측정항목과 실행 로직은 누락됩니다.
측정항목 정의
연구원 에이전트의 경우 예상 답변이 포함된 '골든 답변'/'정답'이 있습니다. 기능 평가: 에이전트가 작업을 올바르게 수행할 수 있는지 측정합니다.
측정하려는 대상은 다음과 같습니다.
- 최종 대답 일치: (기능) 대답이 예상 대답과 일치하나요? 참조 기반 측정항목입니다. 심사 LLM을 사용하여 에이전트의 출력을 예상 답변과 비교합니다. 답변이 정확히 동일하지는 않지만 의미론적으로 사실적으로 유사할 것으로 예상합니다.
- 도구 사용 품질: (품질) 적절한 도구 선택, 올바른 파라미터 사용, 지정된 작업 순서 준수를 평가하는 타겟팅된 적응형 기준표 측정항목입니다.
- 도구 사용 궤적: (추적) 예상 궤적에 대한 에이전트의 도구 사용 궤적 (정밀도 및 재현율)을 측정하는 맞춤 측정항목 2개 이러한 측정항목은
shared/evaluation/tool_metrics.py에서 맞춤 함수로 구현됩니다. 도구 사용 품질과 달리 이 측정항목은 결정론적 참조 기반 측정항목입니다. 코드는 실제 도구 호출이 참조 데이터 (평가 데이터의reference_trajectory)와 일치하는지 확인합니다.
맞춤 도구 사용 궤적 측정항목
맞춤 도구 사용 궤적 측정항목의 경우 shared/evaluation/tool_metrics.py에 Python 함수 집합을 만들었습니다. Vertex AI Gen AI Evaluation Service가 이러한 함수를 실행하도록 하려면 해당 Python 코드를 전달해야 합니다.
UnifiedMetric 및 CustomCodeExecutionSpec 구성으로 EvaluationRunMetric 객체를 정의하면 됩니다. remote_custom_function 매개변수는 함수의 Python 코드가 포함된 문자열입니다. 함수의 이름은 evaluate여야 합니다.
def evaluate(
instance: dict
) -> float:
...
Python 함수를 맞춤 코드 평가 측정항목으로 변환하는 get_custom_function_metric 도우미 (shared/evaluation/evaluate.py에 있음)를 만들었습니다.
함수 모듈의 코드를 가져와 (로컬 종속 항목 캡처) 원래 함수를 호출하는 추가 evaluate 함수를 만들고 CustomCodeExecutionSpec가 있는 EvaluationRunMetric 객체를 반환합니다.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Gen AI Evaluation Service는 샌드박스 실행 환경에서 해당 코드를 실행하고 평가 데이터를 전달합니다.
측정항목 및 평가 코드 추가
if __name__ == "__main__": 줄 뒤에 evaluator/evaluate_agent.py에 다음 코드를 추가합니다.
연구원 에이전트의 측정항목 목록을 정의하고 평가를 실행합니다.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
실제 프로덕션 파이프라인에는 평가 성공 기준이 필요합니다. 평가가 완료되고 측정항목이 준비되면 여기에는 게이팅 단계가 있습니다. 예: 'Final Response Match 점수가 0.75 미만이면 빌드를 실패합니다.' 이렇게 하면 잘못된 버전이 트래픽을 수신하지 않습니다.
evaluator/evaluate_agent.py에 다음 코드를 추가합니다.
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
평가 측정항목의 평균 값이 기준 (0.75) 미만이면 배포가 실패해야 합니다.
[선택사항] Orchestrator의 참조 없는 측정항목으로 평가 추가
오케스트레이터 에이전트의 경우 상호작용이 더 복잡하며 항상 단일한 '정답'이 있는 것은 아닙니다. 대신 참조가 필요 없는 측정항목 중 하나를 사용하여 일반적인 동작을 평가합니다.
- 할루시네이션: 대답을 원자적 클레임으로 분할하여 텍스트 대답의 사실성과 일관성을 검사하는 점수 기반 측정항목입니다. 중간 이벤트의 도구 사용을 기준으로 각 클레임이 그라운딩되는지 여부를 확인합니다. 이는 '정확성'은 주관적이지만 '진실성'은 타협할 수 없는 개방형 에이전트에게 매우 중요합니다. 점수는 소스 콘텐츠에 그라운딩된 주장의 비율로 계산됩니다. 이 경우 오케스트레이터 (콘텐츠 빌더에서 생성)의 최종 대답은 리서처가 Wikipedia 검색 도구를 사용하여 검색한 콘텐츠에 사실적으로 기반해야 합니다.
오케스트레이터의 평가 로직을 추가합니다.
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
평가 데이터 검사
evaluator/ 디렉터리를 엽니다. 다음과 같은 두 개의 데이터 파일이 표시됩니다.
eval_data_researcher.json: 연구자를 위한 프롬프트 및 골든/그라운드 트루스 참조eval_data_orchestrator.json: 오케스트레이터 프롬프트 (오케스트레이터에 대해서만 참조가 없는 평가를 수행함)
각 항목에는 일반적으로 다음이 포함됩니다.
prompt: 에이전트의 프롬프트입니다.reference: 이상적인 답변(그라운드 트루스)(해당하는 경우)reference_trajectory: 예상되는 도구 호출 시퀀스입니다.
6. 평가 코드 이해하기
shared/evaluation/evaluate.py를 엽니다. 이 모듈에는 평가를 실행하는 핵심 로직이 포함되어 있습니다. 주요 기능은 evaluate_agent입니다.
다음 단계를 실행합니다.
- 데이터 로드: 파일에서 평가 데이터 세트 (프롬프트 및 참조)를 읽습니다.
- 병렬 추론: 데이터 세트에 대해 에이전트를 병렬로 실행합니다. 세션 생성을 처리하고, 프롬프트를 전송하고, 최종 응답과 중간 도구 실행 추적을 모두 캡처합니다.
- Vertex AI 평가: 원래 평가 데이터를 최종 응답 및 중간 도구 실행 추적과 병합하고 Vertex AI SDK의 생성형 AI 클라이언트를 사용하여 결과를 Vertex AI 평가 서비스에 제출합니다. 이 서비스는 구성된 측정항목을 실행하여 에이전트의 성능을 평가합니다.
마지막 단계의 핵심은 생성형 AI SDK의 평가 모듈의 create_evaluation_run 함수를 호출하는 것입니다.
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
shared/evaluation/evaluate.py의 evaluate_agent 함수에서 이를 실행합니다.
병합된 평가 데이터 세트, 에이전트에 관한 정보, 사용할 측정항목, 대상 스토리지 URI를 가져옵니다. 이 함수는 Vertex AI Evaluation Service에서 평가 실행을 만들고 평가 실행 객체를 반환합니다.
Agent Info API
정확한 평가를 수행하려면 평가 서비스가 에이전트의 구성 (시스템 요청 사항, 설명, 사용 가능한 도구)을 알아야 합니다. agent_info 매개변수로 create_evaluation_run에 전달합니다.
하지만 이 정보는 어떻게 얻을 수 있을까요? ADK 서비스 API의 일부로 만듭니다.
shared/adk_app.py를 열고 def agent_info을 검색합니다. ADK 애플리케이션이 도우미 엔드포인트를 노출하는 것을 확인할 수 있습니다.
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
이 엔드포인트 (--publish_agent_info 플래그를 통해 사용 설정됨)를 사용하면 평가 스크립트가 에이전트의 런타임 구성을 동적으로 가져올 수 있습니다. 이는 도구 사용을 평가하는 측정항목에 매우 중요합니다. 평가 모델이 대화 중에 에이전트가 사용할 수 있었던 도구를 구체적으로 알면 에이전트의 도구 사용을 더 잘 평가할 수 있기 때문입니다.
7. 평가 실행
이제 평가자를 구현했으므로 실행해 보겠습니다.
- 저장소의 루트에서 평가 스크립트를 실행합니다.
./evaluate.sh- 현재 git 커밋 해시를 가져옵니다.
- 커밋 해시를 기반으로 태그가 있는 버전을 배포하기 위해
deploy.sh를 호출합니다. - 배포되면
evaluator.evaluate_agent이 시작됩니다. - 클라우드 서비스에 대해 테스트 사례가 실행되면 진행률 표시줄이 표시됩니다.
- 마지막으로 결과의 요약 JSON을 출력합니다.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
참고: 서비스를 배포하는 데 처음 실행 시 몇 분 정도 걸릴 수 있습니다.
8. 노트북에서 결과 시각화
원시 JSON 출력은 읽기 어렵습니다. Vertex AI SDK의 생성형 AI 클라이언트는 이러한 실행을 시간 경과에 따라 추적하는 방법을 제공합니다. Colab 노트북을 사용하여 결과를 시각화합니다.
evaluator/show_evaluation_run.ipynbGoogle Colab에서 이 링크를 사용하여 엽니다.GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGION,EVAL_RUN_ID변수를 프로젝트 ID, 리전, 실행 ID로 설정합니다.
- 종속 항목을 설치하고 인증합니다.
평가 실행 가져오기 및 결과 표시
Vertex AI에서 평가 실행 데이터를 가져와야 합니다. 평가 실행 가져오기 및 결과 표시 아래의 셀을 찾아 # TODO 행을 다음 코드 블록으로 바꿉니다.
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
결과 해석
결과를 볼 때 다음 사항에 유의하세요.
- 회귀와 기능의 차이:
- 회귀: 이전 테스트에서 점수가 떨어졌나요? (좋지 않음, 조사가 필요함)
- 기능: 새로운 테스트에서 점수가 개선되었나요? (좋습니다. 진행 중입니다.)
- 실패 분석: 점수만 보지 마세요.
- trace를 확인합니다. 잘못된 도구를 호출했나요? 출력을 파싱하지 못했나요? 여기에서 버그를 찾을 수 있습니다.
- 판사 LLM이 제공하는 설명과 평결을 확인합니다. 테스트가 실패한 이유를 파악하는 데 도움이 되는 경우가 많습니다.
Pass@1 대 Pass@k: 특정 테스트를 한 번 실행하면 Pass@1 점수가 표시됩니다. 에이전트가 실패하는 경우 비결정론 때문일 수 있습니다. 복잡한 설정에서는 각 테스트를 k회 (예: 5회) 실행하고 pass@k (한 번 이상 성공했는지) 또는 pass^k (매번 성공했는지)를 계산할 수 있습니다. 이는 많은 측정항목이 이미 내부적으로 수행하는 작업입니다. 예를 들어 types.RubricMetric.FINAL_RESPONSE_MATCH (최종 대답 일치)는 심판 LLM을 5번 호출하여 최종 대답 일치 점수를 결정합니다.
9. 지속적 통합 및 배포 (CI/CD)
프로덕션 시스템에서는 에이전트 평가가 CI/CD 파이프라인의 일부로 실행되어야 합니다. 이 경우 Cloud Build가 적합합니다.
에이전트의 코드 저장소에 푸시된 모든 커밋에 대해 평가가 나머지 테스트와 함께 실행됩니다. 테스트를 통과하면 배포가 사용자 요청을 처리하도록 '승격'될 수 있습니다. 실패하면 모든 것이 그대로 유지되지만 개발자가 무엇이 잘못되었는지 확인할 수 있습니다.
Cloud Build 구성
이제 다음 단계를 실행하는 Cloud Run 배포 구성 스크립트를 만들어 보겠습니다.
- 서비스를 비공개 버전으로 배포합니다.
- 에이전트 평가를 실행합니다.
- 평가를 통과하면 버전 배포가 트래픽의 100% 를 제공하도록 '승격'됩니다.
cloudbuild.yaml 만들기:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
파이프라인 실행
마지막으로 평가 파이프라인을 실행할 수 있습니다.
Cloud Run 서비스에 요청을 보내는 평가 파이프라인을 실행하기 전에 여러 권한이 있는 별도의 서비스 계정이 필요합니다. 이를 실행하고 파이프라인을 실행하는 스크립트를 작성해 보겠습니다.
- 스크립트
run_cloud_build.sh만들기:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- 전용 서비스 계정
agent-eval-build-sa을 만듭니다. - 필요한 역할 (
roles/run.admin,roles/aiplatform.user등)을 부여합니다. *. Cloud Build에 빌드를 제출합니다.
- 전용 서비스 계정
- 파이프라인을 실행합니다.
chmod +x run_cloud_build.sh ./run_cloud_build.sh
터미널에서 빌드 진행 상황을 확인하거나 Cloud 콘솔 링크를 클릭할 수 있습니다.
참고: 실제 프로덕션 환경에서는 Cloud Build 트리거를 설정하여 모든 git push에서 자동으로 실행합니다. 워크플로는 동일합니다. 트리거가 cloudbuild.yaml를 실행하여 모든 커밋이 평가되도록 합니다.
10. 요약
평가 파이프라인을 빌드했습니다.
- 배포: 수정 버전 태그와 git 커밋 해시를 사용하여 프로덕션 배포에 영향을 주지 않고 테스트를 위해 실제 환경에 에이전트를 안전하게 배포했습니다.
- 평가: 평가 측정항목을 정의하고 Vertex AI Gen AI Evaluation Service를 사용하여 평가 프로세스를 자동화했습니다.
- 분석: Colab 노트북을 사용하여 평가 결과를 시각화하고 에이전트를 개선했습니다.
- 롤아웃: Cloud Build를 사용하여 평가 파이프라인을 자동으로 실행하고 최적의 수정 버전을 승격하여 트래픽의 100% 를 처리했습니다.
코드 수정 -> 태그 배포 -> 평가 및 테스트 실행 -> 분석 -> 출시 -> 반복으로 이어지는 이 사이클이 프로덕션 등급 에이전트 엔지니어링의 핵심입니다.