
1. Wprowadzenie
Przegląd
Ten moduł jest kontynuacją modułu Tworzenie systemów wieloagentowych z użyciem pakietu ADK.
W tym module utworzysz system tworzenia kursów składający się z:
- Agent badawczy: korzysta z google_search, aby znajdować aktualne informacje.
- Judge Agent: ocenia jakość i kompletność badań.
- Agent do tworzenia treści: przekształca wyniki badań w uporządkowany kurs.
- Agent koordynujący: zarządza przepływem pracy i komunikacją między tymi specjalistami.
Zawierała też aplikację internetową, która umożliwiała użytkownikom przesyłanie próśb o utworzenie kursu i otrzymywanie go w odpowiedzi.
Researcher, Judge i Content Builder są wdrażane jako agenci A2A w oddzielnych usługach Cloud Run. Orchestrator to kolejna usługa Cloud Run z interfejsem ADK Service API.
Na potrzeby tego laboratorium zmodyfikowaliśmy agenta badawczego, aby korzystał z narzędzia Wikipedia Search zamiast z funkcji Wyszukiwarki Google w Gemini. Umożliwia to sprawdzenie, jak śledzone i oceniane są wywołania niestandardowych narzędzi.
Dlatego stworzyliśmy rozproszony system wieloagentowy. Ale skąd wiemy, czy to faktycznie działa? Czy badacz zawsze znajduje odpowiednie informacje? Czy sędzia prawidłowo rozpoznaje nieprawidłowe badania?
W tym laboratorium zamienisz subiektywne „sprawdzanie nastroju” na ocenę opartą na danych za pomocą usługi oceny generatywnej AI w Vertex AI. Wdrożysz adaptacyjne oceny cząstkowe i wskaźniki jakości korzystania z narzędzi, aby dokładnie ocenić rozproszony system wieloagentowy utworzony w module 1. Na koniec zautomatyzujesz ten proces w potoku CI/CD, aby mieć pewność, że każde wdrożenie zachowuje niezawodność i dokładność agentów produkcyjnych.
Utworzysz potok oceny ciągłej dla swoich agentów. Zapoznasz się z tymi zagadnieniami:
- Wdróż agentów w prywatnej wersji z tagiem w Google Cloud Run (wdrożenie cieniowe).
- Uruchom automatyczny pakiet oceny dla tej konkretnej wersji za pomocą usługi oceny generatywnej AI w Vertex AI.
- Zwizualizuj i przeanalizuj wyniki.
- Użyj oceny w ramach potoku CI/CD.
2. Podstawowe pojęcia: teoria oceny agenta
Podczas opracowywania i uruchamiania agentów AI przeprowadzamy 2 rodzaje oceny: eksperymenty offline i ciągłą ocenę z automatycznym testowaniem regresji. Pierwszy to silnik kreatywny procesu rozwoju, w którym przeprowadzamy eksperymenty ad hoc, dopracowujemy prompty i szybko iterujemy, aby odblokować nowe możliwości. Drugą warstwą jest warstwa ochronna w naszym potoku CI/CD, w której przeprowadzamy ciągłe oceny na podstawie „złotego” zbioru danych, aby mieć pewność, że żadna zmiana kodu nie pogorszy przypadkowo sprawdzonej jakości agenta.
Zasadnicza różnica polega na wykrywaniu a obronie:
- Eksperymentowanie offline to proces optymalizacji. Jest ona otwarta i zmienna. Aktywnie zmieniasz dane wejściowe (prompty, modele, parametry), aby zmaksymalizować wynik lub rozwiązać konkretny problem. Celem jest podniesienie „sufitu” możliwości agenta.
- Ocena ciągła (automatyczne testy regresyjne) to proces weryfikacji. Jest sztywny i powtarzalny. Dane wejściowe są stałe (tzw. „złoty” zbiór danych), aby zapewnić stabilność danych wyjściowych. Celem jest zapobieganie spadkowi „dolnej granicy” skuteczności.
W tym module skupimy się na ocenie ciągłej. Opracujemy zautomatyzowany potok testów regresji, który będzie uruchamiany za każdym razem, gdy ktoś wprowadzi zmianę w agencie AI, podobnie jak testy jednostkowe.
Zanim zaczniesz pisać kod, musisz zrozumieć, co będziesz mierzyć.
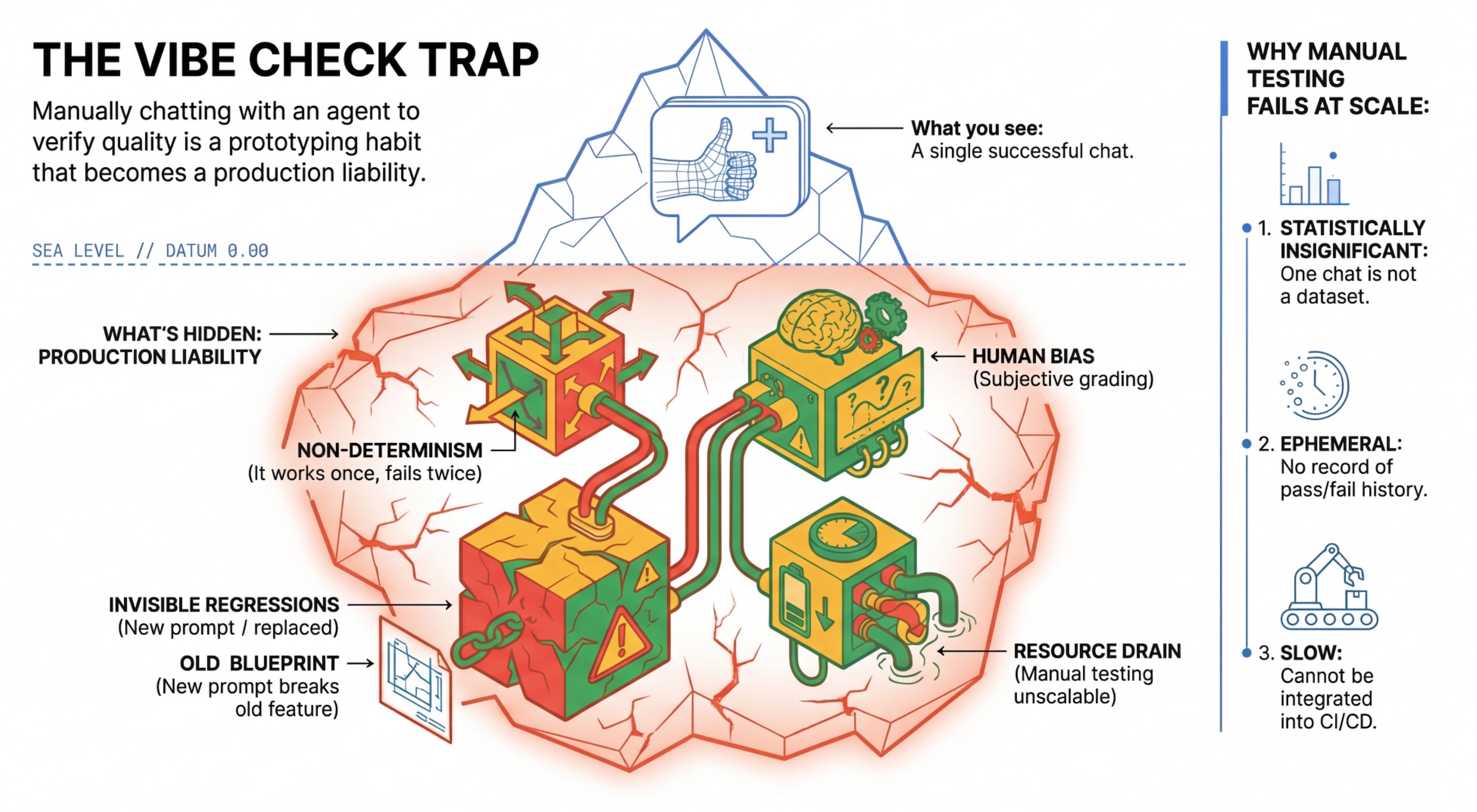
Pułapka „Vibe Check”
Wielu deweloperów testuje agentów, ręcznie z nimi rozmawiając. Jest to tzw. „vibe checking”. Chociaż jest przydatny do prototypowania, nie sprawdza się w środowisku produkcyjnym, ponieważ:
- Niedeterminizm: agenci mogą za każdym razem odpowiadać inaczej. Musisz mieć próbki o istotnej statystycznie wielkości.
- Niewidoczne regresje: ulepszenie jednego promptu może spowodować nieprawidłowe działanie w innym przypadku użycia.
- Ludzkie uprzedzenia: „Wygląda dobrze” to subiektywna ocena.
- Czasochłonna praca: ręczne testowanie dziesiątek scenariuszy przy każdej zmianie jest czasochłonne.
2 sposoby oceny skuteczności agenta
Aby stworzyć solidny potok, łączymy różne typy oceniających:
- Sprawdzanie na podstawie kodu (deterministyczne):
- Co mierzą: ścisłe ograniczenia (np. „Czy zwrócono prawidłowy plik JSON?”, „Czy wywołało narzędzie
search?” - Zalety: szybkie, tanie, w 100% dokładne.
- Wady: nie można ocenić niuansów ani jakości.
- Co mierzą: ścisłe ograniczenia (np. „Czy zwrócono prawidłowy plik JSON?”, „Czy wywołało narzędzie
- Ocenianie na podstawie modelu (probabilistyczne):
- Znany też jako „LLM-as-a-Judge”. Do oceny danych wyjściowych agenta używamy zaawansowanego modelu (np. Gemini 3 Pro).
- Co mierzą: niuanse, rozumowanie, przydatność i bezpieczeństwo.
- Zalety: potrafi oceniać złożone zadania otwarte.
- Wady: wolniejszy i droższy, wymaga starannego przygotowania promptów dla oceniającego.
Wskaźniki oceny Vertex AI
W tym laboratorium używamy usługi oceny generatywnej AI w Vertex AI, która udostępnia zarządzane wskaźniki, dzięki czemu nie musisz pisać każdego sędziego od zera.
Istnieje kilka sposobów grupowania wskaźników na potrzeby oceny agenta:
- Wskaźniki oparte na ocenach cząstkowych: włączają duże modele językowe do przepływów pracy oceny.
- Adaptacyjne kryteria oceniania: kryteria oceniania są generowane dynamicznie dla każdego prompta. Odpowiedzi są oceniane za pomocą szczegółowych, wyjaśniających informacji zwrotnych o tym, czy odpowiedź jest prawidłowa, czy nie.
- Statyczne kryteria oceny: kryteria oceny są zdefiniowane w sposób jawny i te same kryteria oceny są stosowane do wszystkich promptów. Odpowiedzi są oceniane za pomocą tego samego zestawu oceniających opartych na punktacji liczbowej. Pojedynczy wynik liczbowy (np. od 1 do 5) dla każdego prompta. Gdy ocena jest wymagana w przypadku bardzo konkretnego wymiaru lub gdy w przypadku wszystkich promptów wymagana jest dokładnie ta sama rubryka.
- Wskaźniki obliczeniowe: oceniaj odpowiedzi za pomocą algorytmów deterministycznych, zwykle na podstawie danych podstawowych. Wynik liczbowy (np. od 0,0 do 1,0) dla każdego promptu. Gdy dostępne są dane podstawowe, które można dopasować za pomocą metody deterministycznej.
- Dane funkcji niestandardowej: zdefiniuj własne dane za pomocą funkcji Pythona.
Konkretne dane, których będziemy używać:
Final Response Match: (na podstawie odniesienia) Czy odpowiedź pasuje do naszej „złotej odpowiedzi”?Tool Use Quality: (bez odniesienia) Czy agent używał odpowiednich narzędzi we właściwy sposób?Hallucination: (bez odniesienia) Czy twierdzenia w odpowiedzi są poparte pobranym kontekstem?Tool Trajectory PrecisioniTool Trajectory Recall(na podstawie odniesienia): czy pracownik wybrał odpowiednie narzędzie i podał prawidłowe argumenty? W przeciwieństwie doTool Use Qualityte dane niestandardowe korzystają z trajektorii referencyjnej, czyli sekwencji oczekiwanych wywołań narzędzi i argumentów.
3. Konfiguracja
Konfiguracja
- Otwórz Cloud Shell: w prawym górnym rogu konsoli Google Cloud kliknij ikonę Aktywuj Cloud Shell.
- Aby odświeżyć logowanie i zaktualizować domyślne uwierzytelnianie aplikacji (ADC), uruchom to polecenie:
gcloud auth login --update-adc - Ustaw aktywny projekt dla interfejsu wiersza poleceń gcloud.Aby uzyskać bieżący projekt gcloud, uruchom to polecenie:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDidentyfikatorem projektu. - Ustaw domyślny region, w którym będą wdrażane usługi Cloud Run.
gcloud config set run/region us-west1us-west1możesz użyć dowolnego regionu Cloud Run, który jest bliżej Ciebie.
Kod i zależności
- Sklonuj kod startowy i przejdź do katalogu głównego projektu.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - Utwórz plik
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - Zainstaluj zależności, uruchamiając w oknie terminala to polecenie:
uv sync
4. Informacje o bezpiecznym wdrażaniu
Przed oceną musimy wdrożyć wersję. Nie chcemy jednak, aby w przypadku nieprawidłowego nowego kodu aplikacja działająca na żywo przestała działać.
Tagi wersji i wdrożenie w cieniu
Google Cloud Run obsługuje wersje. Za każdym razem, gdy wdrażasz usługę, tworzona jest nowa, stała wersja. Możesz przypisać do tych wersji tagi, aby uzyskać do nich dostęp za pomocą określonego adresu URL, nawet jeśli nie otrzymują one żadnego ruchu publicznego.
Dlaczego nie przeprowadzać ocen lokalnie?
Chociaż ADK obsługuje ocenę lokalną, wdrażanie w ukrytej wersji zapewnia kluczowe zalety w przypadku systemów produkcyjnych. Od testów jednostkowych odróżnia to ocenę na poziomie systemu (którą przeprowadzamy):
- Równoważność środowisk: środowiska lokalne są różne (inna sieć, inne zasoby procesora/pamięci, inne klucze tajne). Testowanie w chmurze zapewnia, że agent działa w rzeczywistym środowisku wykonawczym (test systemu).
- Interakcja między agentami: w systemie rozproszonym agenci komunikują się za pomocą protokołu HTTP. Testy „lokalne” często symulują te połączenia. Wdrożenie cieniowe testuje rzeczywiste opóźnienie sieci, konfiguracje limitów czasu i uwierzytelnianie między mikroserwisami.
- Obiekty tajne i uprawnienia: sprawdza, czy konto usługi ma uprawnienia, których potrzebuje (np. do wywoływania Vertex AI lub odczytywania danych z Firestore).
Uwaga: jest to proaktywna ocena (sprawdzanie przed wyświetleniem użytkownikom). Po wdrożeniu możesz używać reaktywnego monitorowania (dostrzegalności), aby wykrywać problemy w środowisku produkcyjnym.
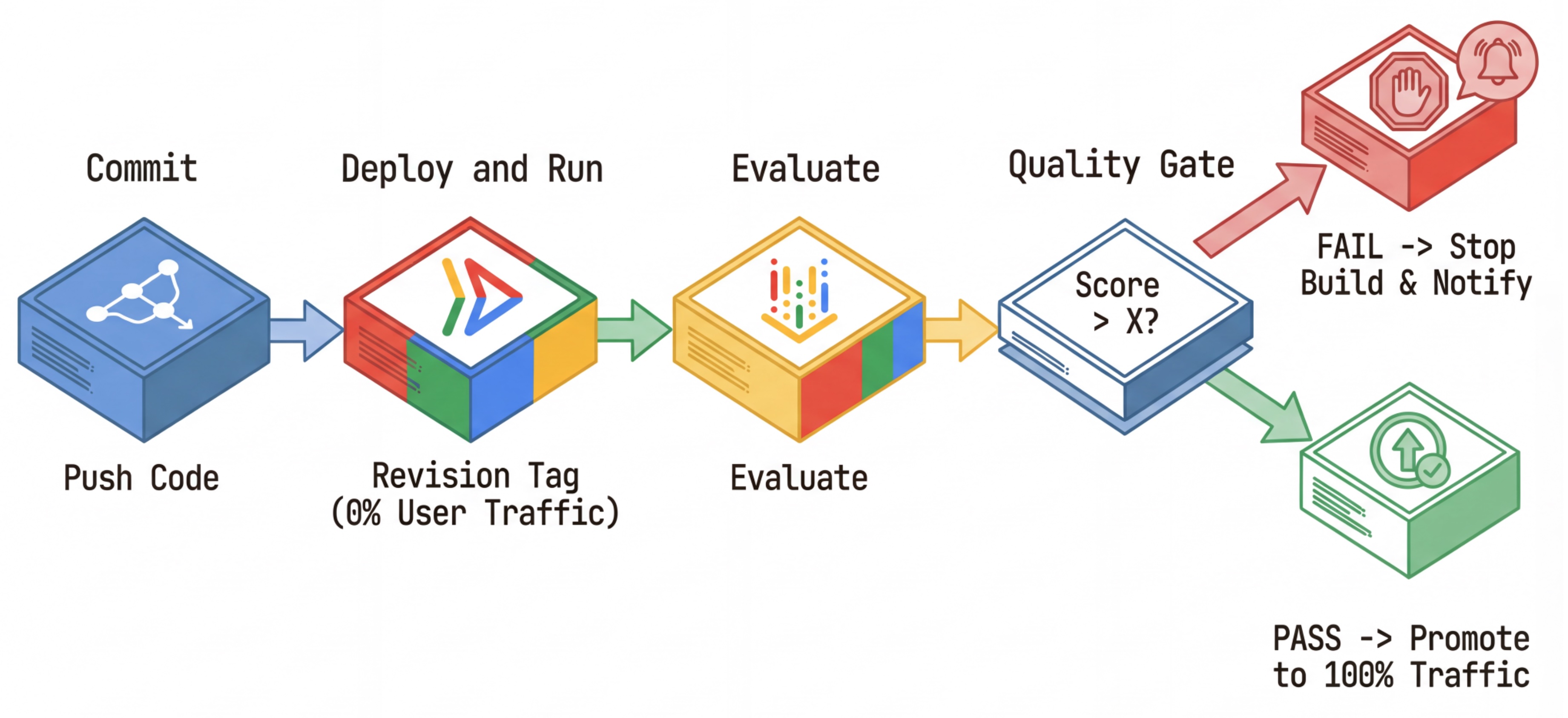
Przepływ pracy CI/CD: wdrażanie, ocena, promowanie
Używamy tego do tworzenia niezawodnego potoku ciągłego wdrażania:
- Zatwierdź: zmieniasz prompt agenta i przenosisz go do repozytorium.
- Wdróż (ukryte): powoduje wdrożenie nowej wersji otagowanej haszem zatwierdzenia (np.
c-abc1234). Ta wersja otrzymuje 0% ruchu publicznego. - Ocena: skrypt oceniający jest kierowany na konkretny adres URL wersji
https://c-abc1234---researcher-xyz.run.app. - Promuj: jeśli (i tylko jeśli) ocena zakończy się powodzeniem, a inne testy również, przenieś ruch na tę nową wersję.
- Wycofanie: jeśli się nie powiedzie, użytkownicy nigdy nie zobaczą nieprawidłowej wersji, a Ty możesz po prostu zignorować lub usunąć nieprawidłową wersję.
Ta strategia umożliwia testowanie w środowisku produkcyjnym bez wpływu na klientów.
Przeanalizuj evaluate.sh
Otwórz pokój evaluate.sh. Ten skrypt automatyzuje ten proces.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh zajmuje się wdrażaniem wersji z opcjami --no-traffic i --tag. Jeśli usługa jest już uruchomiona, nie będzie to miało na nią wpływu. Nowa „ukryta” wersja nie będzie otrzymywać ruchu, chyba że wywołasz ją bezpośrednio za pomocą specjalnego adresu URL zawierającego tag wersji (np.https://c-abc1234---researcher-xyz.run.app).
5. Wdrażanie skryptu oceny
Teraz napiszemy kod, który faktycznie uruchamia testy.
- Otwórz pokój
evaluator/evaluate_agent.py. - Będziesz widzieć importy i konfigurację, ale nie zobaczysz danych ani logiki wykonywania.
Określanie danych
W przypadku agenta badawczego mamy „złote odpowiedzi” lub „odpowiedzi oparte na obserwacji rzeczywistości” z oczekiwanymi odpowiedziami. Jest to ocena możliwości: sprawdzamy, czy agent potrafi prawidłowo wykonać zadanie.
Chcemy mierzyć:
- Zgodność z ostateczną odpowiedzią: (możliwość) czy odpowiedź jest zgodna z oczekiwaną? Jest to wskaźnik oparty na wartościach referencyjnych. Wykorzystuje model LLM do porównania danych wyjściowych agenta z oczekiwaną odpowiedzią. Nie oczekuje, że odpowiedź będzie dokładnie taka sama, ale podobna pod względem semantycznym i merytorycznym.
- Jakość korzystania z narzędzi: (Jakość) ukierunkowany adaptacyjny wskaźnik ocen cząstkowych, który ocenia wybór odpowiednich narzędzi, prawidłowe użycie parametrów i zgodność z określoną sekwencją operacji.
- Ścieżka korzystania z narzędzi: (ślad) 2 dane niestandardowe, które mierzą ścieżkę korzystania z narzędzi przez agenta (precyzja i pełność) w porównaniu z oczekiwanymi ścieżkami. Te dane są implementowane w
shared/evaluation/tool_metrics.pyjako funkcje niestandardowe. W przeciwieństwie do jakości korzystania z narzędzi ten wskaźnik jest deterministycznym wskaźnikiem opartym na danych referencyjnych – kod dosłownie sprawdza, czy rzeczywiste wywołania narzędzi są zgodne z danymi referencyjnymi (reference_trajectoryw danych oceny).
Dane dotyczące trajektorii korzystania z narzędzi niestandardowych
W przypadku niestandardowych wskaźników ścieżki korzystania z narzędzi utworzyliśmy zestaw funkcji Pythona w shared/evaluation/tool_metrics.py. Aby umożliwić usłudze Vertex AI Gen AI Evaluation Service wykonywanie tych funkcji, musimy przekazać jej kod Pythona.
W tym celu zdefiniuj obiekt EvaluationRunMetric z konfiguracją UnifiedMetric i CustomCodeExecutionSpec. Parametr remote_custom_function to ciąg tekstowy zawierający kod Pythona funkcji. Funkcja musi mieć nazwę evaluate:
def evaluate(
instance: dict
) -> float:
...
Utworzyliśmy funkcję pomocniczą get_custom_function_metric (w shared/evaluation/evaluate.py), która przekształca funkcję Pythona w niestandardowe dane oceny kodu.
Pobiera kod modułu funkcji (aby przechwycić lokalne zależności), tworzy dodatkową funkcję evaluate, która wywołuje oryginalną funkcję, i zwraca obiekt EvaluationRunMetric z wartością CustomCodeExecutionSpec.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Usługa Gen AI Evaluation wykona ten kod w środowisku wykonawczym piaskownicy i przekaże do niego dane oceny.
Dodaj dane i kod oceny
Dodaj ten kod do pliku evaluator/evaluate_agent.py po wierszu if __name__ == "__main__":.
Określa listę wskaźników dla agenta Researcher i przeprowadza ocenę.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
W rzeczywistym potoku produkcyjnym potrzebujesz kryteriów sukcesu oceny. Po zakończeniu oceny i przygotowaniu danych. W tym miejscu znajdzie się krok blokujący. Na przykład: „Jeśli wynik Final Response Match jest mniejszy niż 0,75, przerwij kompilację”. Dzięki temu nieprawidłowe wersje nigdy nie będą otrzymywać ruchu.
Dołącz do pliku evaluator/evaluate_agent.py ten kod:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Jeśli wartość średnia któregokolwiek z rodzajów danych oceny jest niższa niż wartość progowa (0.75), wdrożenie powinno się nie powieść.
[Opcjonalnie] Dodaj ocenę za pomocą wskaźników bez odniesienia dla narzędzia Orchestrator
W przypadku agenta aranżera interakcje są bardziej złożone i nie zawsze mamy jedną „poprawną” odpowiedź. Zamiast tego oceniamy ogólne zachowanie za pomocą jednego z wskaźników bez odniesienia.
- Halucynacje: wskaźnik oparty na wynikach, który sprawdza zgodność z prawdą i spójność odpowiedzi tekstowych przez dzielenie odpowiedzi na pojedyncze stwierdzenia. Sprawdza, czy każde stwierdzenie jest oparte na wykorzystaniu narzędzi w zdarzeniach pośrednich. Jest to kluczowe w przypadku agentów o otwartej architekturze, w których „poprawność” jest subiektywna, ale „prawdziwość” jest bezwzględnie wymagana. Wynik jest obliczany jako odsetek twierdzeń, które są oparte na treści źródłowej. W naszym przypadku oczekujemy, że ostateczna odpowiedź Orchestratora (wygenerowana przez narzędzie do tworzenia treści) będzie oparta na faktach zawartych w treściach pobranych przez narzędzie do wyszukiwania w Wikipedii.
Dodaj logikę oceny dla Orchestratora:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Sprawdzanie danych oceny
Otwórz katalog evaluator/. Zobaczysz 2 pliki danych:
eval_data_researcher.json: prompty i odniesienia do złotych/rzeczywistych odpowiedzi dla badacza.eval_data_orchestrator.json: prompty dla aranżera (w przypadku aranżera przeprowadzamy tylko ocenę bez odniesienia).
Każdy wpis zwykle zawiera:
prompt: prompt dla agenta.reference: idealna odpowiedź (ground truth), jeśli ma zastosowanie.reference_trajectory: oczekiwana sekwencja wywołań narzędzi.
6. Informacje o kodzie oceny
Otwórz pokój shared/evaluation/evaluate.py. Ten moduł zawiera podstawową logikę uruchamiania ocen. Główna funkcja to evaluate_agent.
Wykonuje te czynności:
- Wczytywanie danych: odczytuje z pliku zbiór danych do oceny (prompty i odpowiedzi).
- Równoległe wnioskowanie: uruchamia agenta w zbiorze danych równolegle. Obsługuje tworzenie sesji, wysyła prompty i rejestruje zarówno ostateczną odpowiedź, jak i ślad wykonania narzędzia pośredniego.
- Vertex AI Evaluation: łączy oryginalne dane oceny z odpowiedziami końcowymi i śladem wykonania narzędzia pośredniego oraz przesyła wyniki do usługi oceny Vertex AI za pomocą klienta GenAI w pakiecie Vertex AI SDK. Ta usługa uruchamia skonfigurowane wskaźniki, aby ocenić skuteczność agenta.
Kluczowym momentem ostatniego kroku jest wywołanie funkcji create_evaluation_run modułu eval pakietu Gen AI SDK:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Robimy to w funkcji evaluate_agent w shared/evaluation/evaluate.py.
Pobiera scalony zbiór danych oceny, informacje o agencie, wskaźniki do użycia i docelowy identyfikator URI pamięci. Funkcja tworzy przebieg oceny w usłudze oceny Vertex AI i zwraca obiekt przebiegu oceny.
Agent Info API
Aby przeprowadzić dokładną ocenę, usługa oceny musi znać konfigurację agenta (instrukcje systemowe, opis i dostępne narzędzia). Przekazujemy go do create_evaluation_run jako parametr agent_info.
Ale skąd mamy te informacje? Udostępniamy go w ramach interfejsu ADK Service API.
Otwórz shared/adk_app.py i wyszukaj def agent_info. Zauważysz, że aplikacja ADK udostępnia punkt końcowy pomocnika:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Ten punkt końcowy (włączony za pomocą flagi --publish_agent_info) umożliwia skryptowi oceny dynamiczne pobieranie konfiguracji środowiska wykonawczego agenta. Jest to kluczowe w przypadku danych oceniających korzystanie z narzędzi, ponieważ model oceniający może lepiej ocenić korzystanie z narzędzi przez agenta, jeśli wie, które narzędzia były dokładnie dostępne dla agenta podczas rozmowy.
7. Przeprowadź ocenę
Po zaimplementowaniu oceniającego uruchom go.
- Uruchom skrypt oceny z katalogu głównego repozytorium:
./evaluate.sh- Pobiera bieżący skrót zatwierdzenia Git.
- Wywołuje polecenie
deploy.sh, aby wdrożyć wersję z tagiem opartym na haszu zatwierdzenia. - Po wdrożeniu zacznie się
evaluator.evaluate_agent. - Podczas wykonywania testów w usłudze w chmurze zobaczysz paski postępu.
- Na koniec wyświetla podsumowanie wyników w formacie JSON.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Uwaga: pierwsze uruchomienie może potrwać kilka minut, aby wdrożyć usługi.
8. Wizualizacja wyników w notatniku
Nieprzetworzone dane wyjściowe JSON są trudne do odczytania. Klient Gen AI w pakiecie Vertex AI SDK umożliwia śledzenie tych uruchomień w czasie. Do wizualizacji wyników użyjemy notatnika Colab.
- Otwórz
evaluator/show_evaluation_run.ipynbw Google Colab za pomocą tego linku. - Ustaw zmienne
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONiEVAL_RUN_IDna identyfikator projektu, region i identyfikator uruchomienia.
- Zainstaluj zależności i przeprowadź uwierzytelnianie.
Pobieranie przebiegu oceny i wyświetlanie wyników
Musimy pobrać dane przebiegu oceny z Vertex AI. Znajdź komórkę w sekcji Retrieve Evaluation Run and Display Results (Pobierz przebieg oceny i wyświetl wyniki) i zastąp wiersz # TODO tym blokiem kodu:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Interpretowanie wyników
Podczas analizowania wyników pamiętaj o tych kwestiach:
- Regresja a możliwości:
- Regresja: czy wynik spadł w przypadku starszych testów? (Nie jest dobrze, wymaga sprawdzenia).
- Możliwości: czy wynik poprawił się w nowych testach? (Dobrze, to postęp).
- Analiza niepowodzeń: nie patrz tylko na wynik.
- Sprawdź log czasu. Czy wywołał nieprawidłowe narzędzie? Czy nie udało się przeanalizować danych wyjściowych? To tutaj znajdziesz robaki.
- Zapoznaj się z wyjaśnieniem i wyrokami podanymi przez model LLM sędziego. Często dają one dobrą wskazówkę, dlaczego test się nie powiódł.
Pass@1 a Pass@k: gdy przeprowadzimy dany test raz, otrzymamy wynik Pass@1. Jeśli agent nie działa prawidłowo, przyczyną może być niedeterminizm. W bardziej zaawansowanych konfiguracjach możesz przeprowadzić każdy test k razy (np. 5 razy) i obliczyć pass@k (czy test zakończył się sukcesem co najmniej raz?) lub pass^k (czy test zakończył się sukcesem za każdym razem?). Wiele rodzajów danych już tak działa. Na przykład types.RubricMetric.FINAL_RESPONSE_MATCH (Final Response Match) wykonuje 5 wywołań do modelu LLM oceniającego, aby określić ostateczny wynik dopasowania odpowiedzi.
9. Ciągła integracja i wdrażanie (CI/CD)
W systemie produkcyjnym ocena agenta powinna być przeprowadzana w ramach potoku CI/CD. Cloud Build to dobry wybór.
W przypadku każdego zatwierdzenia przesłanego do repozytorium kodu agenta ocena będzie przeprowadzana wraz z pozostałymi testami. Jeśli testy zakończą się pomyślnie, wdrożenie można „promować”, aby obsługiwało żądania użytkowników. Jeśli się nie powiodą, wszystko pozostanie bez zmian, ale deweloper może sprawdzić, co poszło nie tak.
Konfiguracja Cloud Build
Teraz utwórzmy skrypt konfiguracji wdrożenia Cloud Run, który wykonuje te czynności:
- Wdraża usługi w prywatnej wersji.
- Uruchamia ocenę agenta.
- Jeśli ocena zakończy się powodzeniem, wdrożenia wersji zostaną „promowane” do obsługi 100% ruchu.
Utwórz cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Uruchamianie potoku
Na koniec możemy uruchomić potok oceny.
Zanim uruchomimy potok oceny, który wysyła żądania do usług Cloud Run, potrzebujemy osobnego konta usługi z określonymi uprawnieniami. Napiszmy skrypt, który to zrobi i uruchomi potok.
- Utwórz skrypt
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Tworzy dedykowane konto usługi
agent-eval-build-sa. - przyznaje mu niezbędne role (
roles/run.admin,roles/aiplatform.useritp.); *. Przesyła kompilację do Cloud Build.
- Tworzy dedykowane konto usługi
- Uruchom potok:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Postępy kompilacji możesz śledzić w terminalu lub kliknąć link do konsoli Google Cloud.
Uwaga: w prawdziwym środowisku produkcyjnym skonfigurujesz aktywator Cloud Build, aby automatycznie uruchamiać to działanie przy każdej zmianie w git push. Przepływ pracy jest taki sam: wyzwalacz wykona cloudbuild.yaml, co zapewni ocenę każdego zatwierdzenia.
10. Podsumowanie
Udało Ci się utworzyć potok oceny.
- Wdrażanie: używasz tagów wersji z haszem zatwierdzenia git, aby bezpiecznie wdrażać agentów w rzeczywistym środowisku na potrzeby testowania bez wpływu na wdrożenia produkcyjne.
- Ocena: zdefiniowano wskaźniki oceny i zautomatyzowano proces oceny za pomocą usługi Gen AI Evaluation Service w Vertex AI.
- Analiza: za pomocą notatnika Colab wizualizujesz wyniki oceny i ulepszasz agenta.
- Wdrożenie: za pomocą Cloud Build automatycznie wykonano potok oceny i promowano najlepszą wersję, aby obsługiwała 100% ruchu.
Ten cykl Edytuj kod –> Wdróż tag –> Przeprowadź ocenę i testy –> Przeanalizuj –> Wdróż –> Powtórz to podstawa inżynierii agentów na poziomie produkcyjnym.