
1. Введение
Обзор
Данная лабораторная работа является продолжением работы «Создание многоагентных систем с помощью ADK» .
В этой лабораторной работе вы создали систему создания курсов, состоящую из:
- Агент-исследователь : Использует поиск Google для поиска актуальной информации.
- Эксперт-оценщик : Критическая оценка исследования на предмет качества и полноты.
- Content Builder Agent : Превращение результатов исследования в структурированный курс.
- Агент-оркестратор : Управление рабочим процессом и коммуникацией между этими специалистами.
В состав пакета также входило веб-приложение, позволяющее пользователям отправлять запросы на создание курсов и получать готовый курс в ответ.
Исследователь , Судья и Конструктор контента развернуты в качестве агентов A2A в отдельных сервисах Cloud Run . Оркестратор — это еще один сервис Cloud Run с API сервиса ADK.
Для этой лабораторной работы мы модифицировали агента Researcher, чтобы он использовал инструмент поиска по Википедии вместо функции поиска Google в Gemini. Это позволяет нам отслеживать и оценивать вызовы пользовательских инструментов.
Итак, мы создали распределенную многоагентную систему. Но как узнать, действительно ли она хорошо работает? Всегда ли исследователь находит релевантную информацию? Правильно ли судья определяет некачественные исследования?
В этой лабораторной работе вы замените субъективные «проверки на эмоциональное состояние» на оценку, основанную на данных, используя сервис оценки искусственного интеллекта Vertex AI Gen. Вы внедрите адаптивные рубрики и метрики качества использования инструментов для тщательной оценки распределенной многоагентной системы, созданной в лабораторной работе 1. Наконец, вы автоматизируете этот процесс в рамках конвейера CI/CD, обеспечивая, чтобы каждое развертывание сохраняло надежность и точность ваших производственных агентов.
Вы создадите конвейер непрерывной оценки для своих агентов. Вы научитесь:
- Разверните своих агентов в частной помеченной ревизии в Google Cloud Run (теневое развертывание).
- Запустите автоматизированный набор оценочных тестов для этой конкретной версии, используя сервис оценки искусственного интеллекта Vertex AI Gen.
- Визуализируйте и проанализируйте результаты.
- Используйте результаты оценки в рамках вашего конвейера CI/CD.
2. Основные понятия: Теория оценки агентов
При разработке и запуске ИИ-агентов мы проводим два вида оценки: офлайн-эксперименты и непрерывную оценку с автоматизированным регрессионным тестированием . Первый — это творческий двигатель процесса разработки, где мы проводим ситуативные эксперименты, уточняем подсказки и быстро итеративно внедряем новые возможности. Второй — это защитный слой в нашем конвейере CI/CD, где мы проводим непрерывные оценки на «эталонном» наборе данных, чтобы гарантировать, что никакие изменения кода непреднамеренно не ухудшат проверенное качество агента.
Принципиальное различие заключается в обнаружении и защите :
- Офлайн-экспериментирование — это процесс оптимизации. Он является открытым и вариативным. Вы активно изменяете входные данные (подсказки, модели, параметры), чтобы максимизировать результат или решить конкретную задачу. Цель состоит в том, чтобы повысить «предел» возможностей агента.
- Непрерывная оценка (автоматизированное регрессионное тестирование) — это процесс верификации. Он жесткий и повторяющийся. Входные данные остаются постоянными (исходный набор данных), чтобы гарантировать стабильность выходных данных. Цель — предотвратить обвал «нижнего предела» производительности.
В этой лабораторной работе мы сосредоточимся на непрерывной оценке . Мы разработаем автоматизированный конвейер регрессионного тестирования, который должен запускаться каждый раз, когда кто-то вносит изменения в ИИ-агента, подобно модульным тестам.
Прежде чем писать код, крайне важно понять, что именно мы измеряем.
Ловушка «проверки настроения»
Многие разработчики тестируют агентов, общаясь с ними вручную в чате. Это называется «проверка настроения». Хотя это полезно для прототипирования, в производственной среде это не работает, потому что:
- Недетерминизм : Агенты могут отвечать по-разному каждый раз. Необходимы статистически значимые размеры выборки.
- Незаметные регрессии : улучшение одного запроса может привести к сбою в другом сценарии использования.
- Человеческая предвзятость : "Это хорошо выглядит" — субъективное понятие.
- Трудоемкая работа : Ручное тестирование десятков сценариев при каждом коммите занимает много времени.
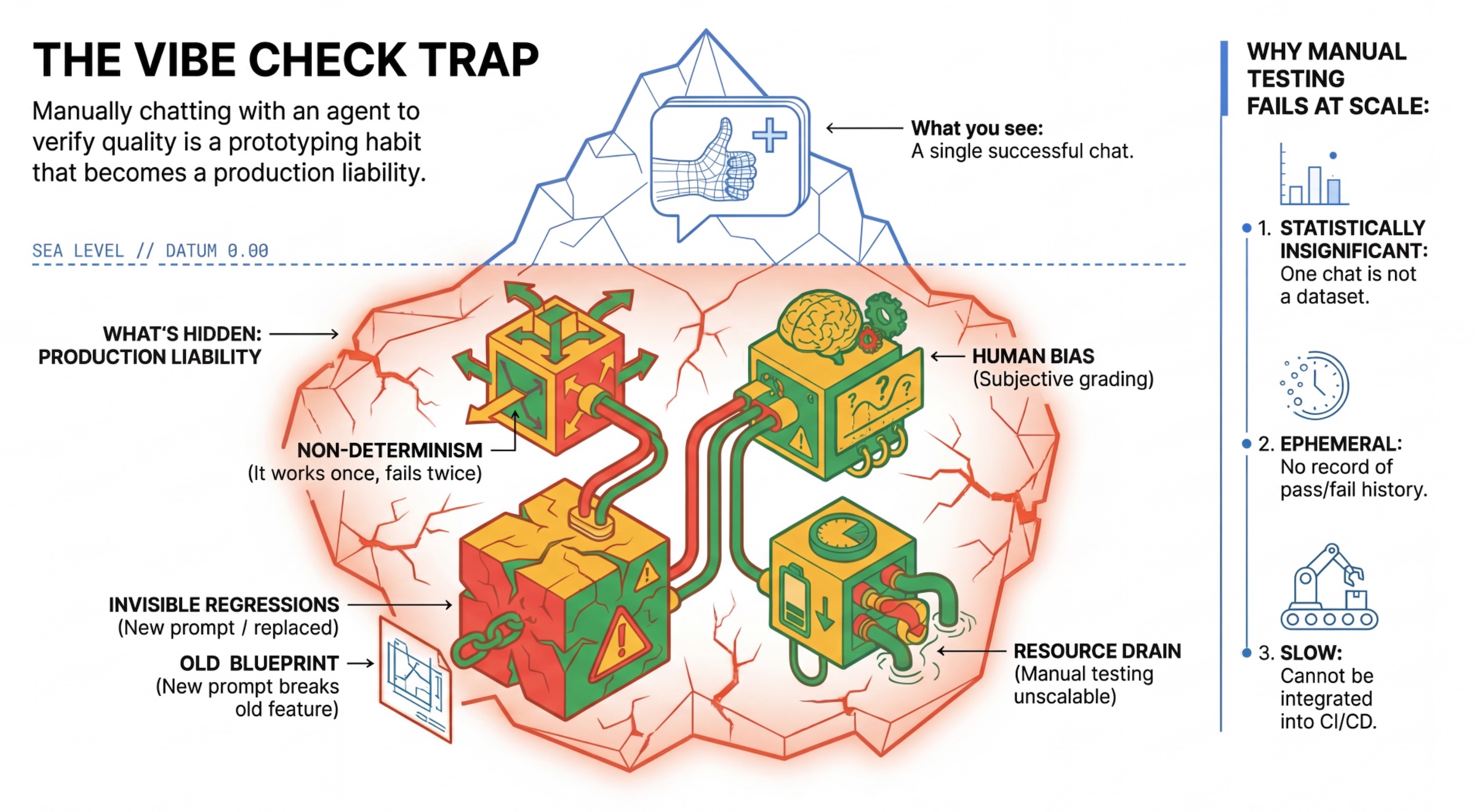
Два способа оценки эффективности работы агента.
Для создания надежного конвейера мы объединяем различные типы систем оценки:
- Система оценивания на основе кодов (детерминированная) :
- Что они измеряют : Строгие ограничения (например, "Возвращает ли он корректный JSON?", "Вызывает ли он инструмент
search?"). - Плюсы : Быстро, недорого, 100% точность.
- Минусы : Невозможно оценить нюансы или качество.
- Что они измеряют : Строгие ограничения (например, "Возвращает ли он корректный JSON?", "Вызывает ли он инструмент
- Системы оценивания на основе моделей (вероятностные) :
- Также известно как "LLM-в-роли-судье". Мы используем мощную модель (например, Gemini 3 Pro) для оценки результатов работы агента.
- Что они оценивают : нюансы, рассуждения, полезность, безопасность.
- Плюсы : Способен оценивать сложные задачи с открытым концом.
- Минусы : Более медленный, более дорогой, требует тщательной и оперативной разработки со стороны судьи.
Метрики оценки Vertex AI
В этой лабораторной работе мы используем сервис оценки искусственного интеллекта Vertex AI Gen , который предоставляет управляемые метрики, поэтому вам не нужно писать каждый судейский модуль с нуля.
Существует несколько способов группировки метрик для оценки работы агентов:
- Метрики на основе рубрик : Включите LLM в рабочие процессы оценки.
- Адаптивные критерии оценки : Критерии оценки генерируются динамически для каждого задания. Ответы оцениваются с помощью подробной, объяснимой обратной связи «прошел/не прошел», специфичной для данного задания.
- Статические критерии оценки : Критерии оценки определены явно, и один и тот же критерий применяется ко всем заданиям. Ответы оцениваются с помощью одного и того же набора числовых оценочных шкал. Единая числовая оценка (например, от 1 до 5) для каждого задания. Это применяется, когда требуется оценка по очень специфическому параметру или когда один и тот же критерий оценки необходим для всех заданий.
- Метрики, основанные на вычислениях : Оценка ответов с помощью детерминированных алгоритмов, обычно с использованием эталонных данных. Числовой балл (например, 0,0-1,0) для каждого запроса. Когда эталонные данные доступны и могут быть сопоставлены с помощью детерминированного метода.
- Пользовательские метрики функций : Определите собственную метрику с помощью функции Python.
Конкретные метрики, которые мы будем использовать :
-
Final Response Match: (На основе эталонного ответа) Соответствует ли ответ нашему «эталонному ответу»? -
Tool Use Quality: (Без ссылок) Использовал ли агент соответствующие инструменты надлежащим образом? -
Hallucination: (Без ссылок) Подтверждаются ли утверждения в ответе полученным контекстом? -
Tool Trajectory PrecisionиTool Trajectory Recall). Выбрал ли агент правильный инструмент и предоставил ли корректные аргументы? В отличие отTool Use Quality, эти пользовательские метрики используют эталонную траекторию — последовательность ожидаемых вызовов инструментов и аргументов.
3. Настройка
Конфигурация
- Откройте Cloud Shell : нажмите значок «Активировать Cloud Shell» в правом верхнем углу консоли Google Cloud.
- Выполните следующую команду, чтобы обновить данные для входа в систему и изменить учетные данные приложения по умолчанию (ADC):
gcloud auth login --update-adc - Установите активный проект для gcloud CLI. Выполните следующую команду, чтобы получить текущий проект gcloud:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDна идентификатор вашего проекта. - Укажите регион по умолчанию, в котором будут развернуты ваши сервисы Cloud Run.
gcloud config set run/region us-west1us-west1вы можете использовать любой регион Cloud Run, расположенный ближе к вам.
Код и зависимости
- Клонируйте стартовый код и перейдите в корневую директорию проекта.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - Создайте файл
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - Установите зависимости, выполнив следующую команду в окне терминала:
uv sync
4. Понимание безопасного развертывания
Прежде чем проводить оценку, нам нужно развернуть приложение. Но мы не хотим, чтобы наш новый код, если он окажется некорректным, сломал работающее приложение.
Метки ревизий и теневое развертывание
Google Cloud Run поддерживает ревизии . При каждом развертывании создается новая неизменяемая ревизия. Вы можете присваивать этим ревизиям теги для доступа к ним по определенному URL-адресу, даже если они не получают никакого публичного трафика.
Почему бы просто не проводить оценку локально?
Хотя ADK поддерживает локальную оценку, развертывание в скрытой ревизии предоставляет критически важные преимущества для производственных систем . Это отличает оценку на системном уровне (то, что мы делаем) от модульного тестирования :
- Идентичность среды : локальные среды различаются (разные сети, разные процессоры/память, разные секреты). Тестирование в облаке гарантирует, что ваш агент будет работать в реальной среде выполнения (системное тестирование).
- Взаимодействие нескольких агентов : В распределенной системе агенты обмениваются данными по протоколу HTTP. «Локальные» тесты часто имитируют эти соединения. Теневое развертывание проверяет фактическую задержку сети, настройки тайм-аута и аутентификацию между вашими микросервисами.
- Секреты и разрешения : Эта проверка подтверждает, что ваша учетная запись службы действительно имеет необходимые разрешения (например, для вызова Vertex AI или чтения из Firestore).
Примечание: Это проактивная оценка (проверка до того, как пользователи увидят проблему). После развертывания вы будете использовать реактивный мониторинг (наблюдаемость) для выявления проблем в реальных условиях.
Рабочий процесс CI/CD: развертывание, оценка, продвижение.
Мы используем это для создания надежного конвейера непрерывного развертывания :
- Commit : Вы изменяете приглашение агента и отправляете изменения в репозиторий.
- Развертывание (скрыто) : запускает развертывание новой ревизии, помеченной хешем коммита (например,
c-abc1234). Эта ревизия получает 0% публичного трафика. - Оценка : Скрипт оценки нацелен на конкретный URL-адрес ревизии
https://c-abc1234---researcher-xyz.run.app. - Продвижение : Если (и только если) оценка пройдена успешно и другие тесты пройдены успешно, вы перенаправляете трафик на эту новую версию.
- Откат : Если откат не удастся, пользователи никогда не увидят некорректную версию, и вы сможете просто проигнорировать или удалить некорректную ревизию.
Эта стратегия позволяет проводить тестирование в реальных условиях, не затрагивая клиентов.
Анализ evaluate.sh
Откройте файл evaluate.sh . Этот скрипт автоматизирует процесс.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
Скрипт deploy.sh выполняет развертывание ревизии с использованием опций --no-traffic и --tag . Если уже запущен сервис, это не повлияет на его работу. Новая «скрытая» ревизия не будет получать трафик, если вы явно не вызовете её со специальным URL-адресом, содержащим тег ревизии (например, https://c-abc1234---researcher-xyz.run.app ).
5. Реализация сценария оценки
Теперь давайте напишем код, который фактически запускает тесты.
- Откройте
evaluator/evaluate_agent.py. - Вы увидите импорт и настройку, но метрики и логика выполнения отсутствуют.
Определите метрики
Для агента-исследователя у нас есть «эталонные ответы»/«истинные значения» с ожидаемыми результатами. Это оценка возможностей : мы измеряем, может ли агент правильно выполнить свою работу.
Мы хотим измерить:
- Окончательное соответствие ответа : (Возможности) Соответствует ли ответ ожидаемому ответу? Это метрика, основанная на эталонных данных. Она использует оценочный инструмент LLM для сравнения результата работы агента с ожидаемым ответом. Не ожидается, что ответ будет абсолютно идентичным, но семантически и фактически схожим.
- Качество использования инструментов : (Качество) Целевой адаптивный показатель, оценивающий выбор подходящих инструментов, правильное использование параметров и соблюдение заданной последовательности операций.
- Траектория использования инструментов : (Трассировка) 2 пользовательские метрики, измеряющие траекторию использования инструментов агентом (точность и полнота) по сравнению с ожидаемыми траекториями. Эти метрики реализованы в
shared/evaluation/tool_metrics.pyв виде пользовательских функций. В отличие от качества использования инструментов , эта метрика является детерминированной эталонной метрикой — код буквально проверяет, соответствуют ли фактические вызовы инструментов эталонным данным (reference_trajectoryв данных оценки).
Метрики траектории использования пользовательских инструментов
Для создания пользовательских метрик траектории использования инструментов мы разработали набор функций на Python в shared/evaluation/tool_metrics.py . Чтобы служба оценки ИИ Vertex AI Gen могла выполнять эти функции, нам необходимо передать ей этот код на Python.
Это делается путем определения объекта EvaluationRunMetric с конфигурацией UnifiedMetric и CustomCodeExecutionSpec . Параметр remote_custom_function представляет собой строку, содержащую код функции на Python. Функция должна называться evaluate :
def evaluate(
instance: dict
) -> float:
...
Мы создали вспомогательную функцию get_custom_function_metric (в shared/evaluation/evaluate.py ), которая преобразует функцию Python в пользовательскую метрику оценки кода.
Он получает код модуля функции (для учета локальных зависимостей), создает дополнительную функцию evaluate , которая вызывает исходную функцию, и возвращает объект EvaluationRunMetric с параметром CustomCodeExecutionSpec .
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Сервис оценки Gen AI выполнит этот код в изолированной среде выполнения и передаст ему данные для оценки.
Добавьте метрики и код оценки.
Добавьте следующий код в файл evaluator/evaluate_agent.py после строки if __name__ == "__main__": :.
Он определяет список метрик для агента-исследователя и запускает оценку.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
В реальном производственном процессе необходимы критерии успешной оценки . После завершения оценки и получения метрик следует добавить этап контроля . Например: «Если оценка Final Response Match < 0,75, сборка завершается с ошибкой». Это предотвратит попадание некорректных версий в рабочую среду.
Добавьте следующий код в файл evaluator/evaluate_agent.py :
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Если среднее значение любого из показателей оценки окажется ниже порогового значения ( 0.75 ), развертывание должно завершиться неудачей.
[Необязательно] Добавить оценку с использованием метрик без привязки к конкретному объекту для оркестратора.
Для агента-оркестратора взаимодействия более сложны, и у нас не всегда может быть единственный «правильный» ответ. Вместо этого мы оцениваем общее поведение, используя одну из метрик, не зависящих от эталонных данных .
- Галлюцинация : метрика, основанная на оценке, которая проверяет достоверность и согласованность текстовых ответов путем сегментации ответа на атомарные утверждения. Она проверяет, обосновано ли каждое утверждение или нет, исходя из использования инструмента в промежуточных событиях. Это критически важно для агентов с открытым ответом, где «правильность» субъективна, а «правдивость» не подлежит обсуждению. Оценка рассчитывается как процент утверждений, основанных на исходном контенте. В нашем случае мы ожидаем, что окончательный ответ от Оркестратора (сгенерированный Конструктором контента) будет фактически обоснован контентом, полученным Исследователь с помощью инструмента поиска в Википедии.
Добавьте логику оценки для оркестратора:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Проверьте данные оценки.
Откройте каталог evaluator/ . Вы увидите два файла данных:
-
eval_data_researcher.json: Подсказки и эталонные/достоверные источники информации для исследователя. -
eval_data_orchestrator.json: Запросы для оркестратора (мы выполняем оценку без использования ссылок только для оркестратора).
Каждая запись обычно содержит:
-
prompt: Подсказка для агента. -
reference: Идеальный ответ (эталонный ответ), если применимо. -
reference_trajectory: Ожидаемая последовательность вызовов инструмента.
6. Ознакомьтесь с Кодексом оценки.
Откройте файл shared/evaluation/evaluate.py . Этот модуль содержит основную логику для выполнения оценок. Ключевая функция — evaluate_agent .
Она выполняет следующие шаги:
- Загрузка данных : Считывает набор данных для оценки (подсказки и ссылки) из файла.
- Параллельный вывод : Агент запускается на наборе данных параллельно. Он обрабатывает создание сессии, отправляет запросы и фиксирует как окончательный ответ, так и трассировку выполнения промежуточного инструмента .
- Оценка Vertex AI : она объединяет исходные данные оценки с окончательными ответами и трассировкой выполнения промежуточного инструмента, а затем отправляет результаты в службу оценки Vertex AI с помощью GenAI Client в Vertex AI SDK. Эта служба запускает настроенные метрики для оценки производительности агента.
Ключевым моментом последнего шага является вызов функции create_evaluation_run из модуля eval SDK Gen AI:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Мы делаем это в функции evaluate_agent в shared/evaluation/evaluate.py .
Функция получает объединенный набор данных для оценки, информацию об агенте, используемые метрики и URI целевого хранилища. Функция создает запуск оценки в службе оценки Vertex AI и возвращает объект запуска оценки.
API информации об агенте
Для проведения точной оценки службе оценки необходимо знать конфигурацию агента (системные инструкции, описание и доступные инструменты). Мы передаем эту информацию в create_evaluation_run в качестве параметра agent_info .
Но как мы получаем эту информацию? Мы делаем её частью API сервиса ADK.
Откройте файл shared/adk_app.py и найдите строку def agent_info . Вы увидите, что приложение ADK предоставляет вспомогательную конечную точку:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Эта конечная точка (включаемая с помощью флага --publish_agent_info ) позволяет скрипту оценки динамически получать конфигурацию агента во время выполнения. Это крайне важно для метрик, оценивающих использование инструментов, поскольку модель оценки может лучше оценить использование инструментов агентом, если она точно знает, какие инструменты были доступны агенту во время разговора.
7. Проведите оценку.
Теперь, когда вы внедрили инструмент оценки, давайте запустим его!
- Запустите скрипт оценки из корневой папки репозитория:
./evaluate.sh- Эта функция получает хэш вашего текущего коммита Git.
- Он запускает
deploy.shдля развертывания ревизии с тегом, основанным на хеше коммита. - После развертывания запускается
evaluator.evaluate_agent. - По мере выполнения тестовых сценариев для вашего облачного сервиса вы будете видеть индикаторы выполнения.
- В заключение программа выводит сводную JSON-информацию о результатах.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Примечание: Первый запуск может занять несколько минут для развертывания сервисов.
8. Визуализируйте результаты в блокноте.
Исходные данные в формате JSON сложно читать. Gen AI Client в Vertex AI SDK предоставляет возможность отслеживать эти запуски во времени. Для визуализации результатов мы будем использовать блокнот Colab.
- Откройте
evaluator/show_evaluation_run.ipynbв Google Colab , используя эту ссылку . - Установите переменные
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONиEVAL_RUN_IDравными идентификатору вашего проекта, региону и идентификатору запуска.
- Установите зависимости и пройдите аутентификацию.
Получите результаты выполнения оценки и отобразите их.
Нам необходимо получить данные о результатах оценочного запуска из Vertex AI. Найдите ячейку в разделе «Получить результаты оценочного запуска и отобразить результаты» и замените строку # TODO следующим блоком кода:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Интерпретация результатов
При анализе результатов учитывайте следующее:
- Регрессия против возможностей :
- Регрессия : Снизился ли результат по старым тестам? (Нехорошо, требует расследования).
- Способности : Улучшились ли результаты в новых тестах? (Хорошо, это прогресс).
- Анализ причин неудачи : не смотрите только на результат.
- Посмотрите на трассировку . Возможно, был вызван не тот инструмент? Возможно, не удалось обработать выходные данные? Именно здесь и обнаруживаются ошибки.
- Ознакомьтесь с объяснениями и вердиктами, предоставленными судьей, имеющим степень магистра права. Зачастую они дают хорошее представление о причинах провала теста.
Pass@1 против Pass@k : При однократном выполнении определенного теста мы получаем оценку Pass@1. Если агент не проходит тест, это может быть связано с недетерминированностью. В сложных системах каждый тест может выполняться k раз (например, 5 раз), и вычисляется pass@k (был ли он успешным хотя бы один раз?) или pass^k (был ли он успешным каждый раз?). Многие метрики уже делают это автоматически. Например, types.RubricMetric.FINAL_RESPONSE_MATCH (Final Response Match) выполняет 5 вызовов к LLM-контроллеру для определения оценки соответствия окончательного ответа.
9. Непрерывная интеграция и развертывание (CI/CD)
В производственной системе оценка агентов должна выполняться в рамках конвейера CI/CD. Cloud Build — хороший выбор для этой цели.
Для каждого коммита, отправленного в репозиторий кода агента, будет выполняться оценка вместе с остальными тестами. Если они пройдут успешно, развертывание может быть «переведено» на обработку запросов пользователей. Если они не пройдут успешно, все останется как есть, но разработчик сможет посмотреть, что пошло не так.
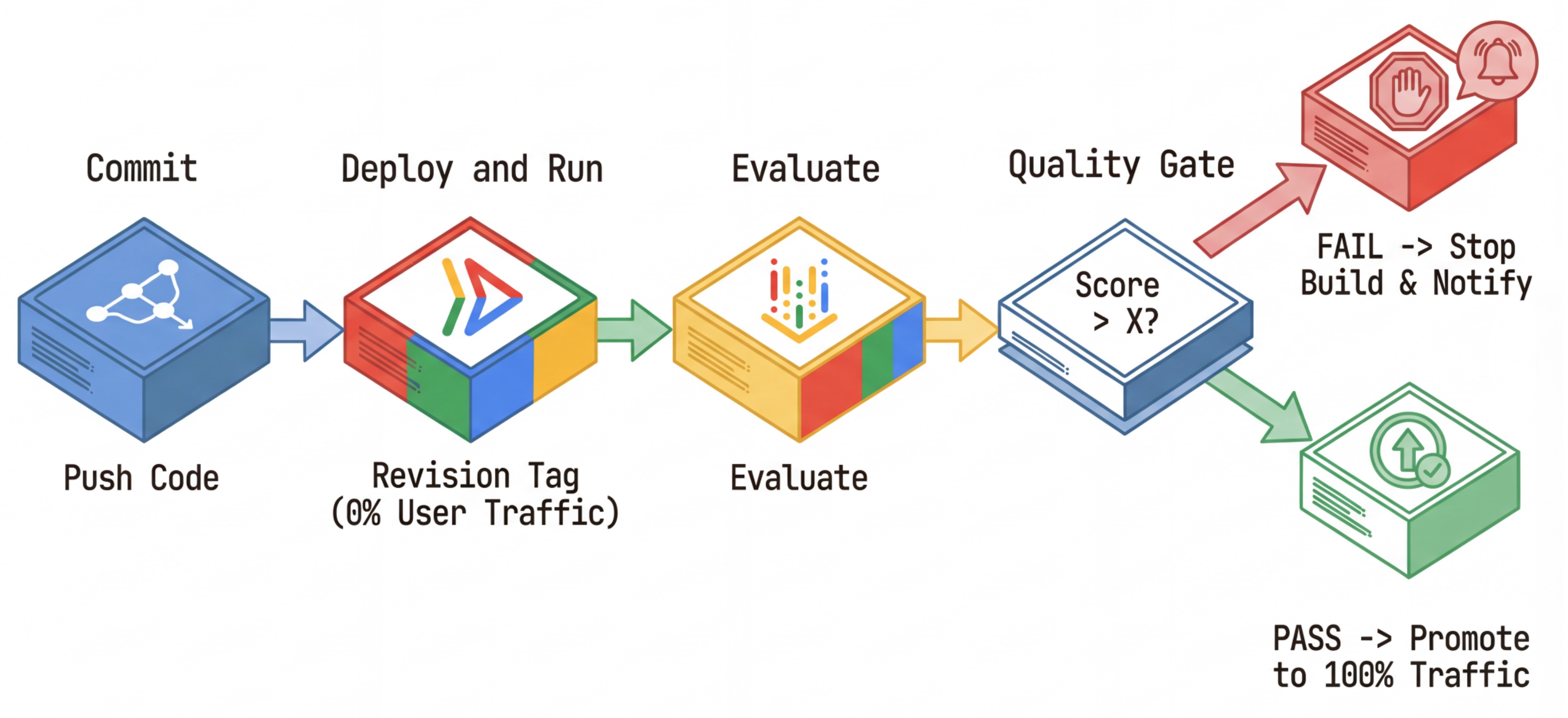
Конфигурация облачной сборки
Теперь давайте создадим скрипт конфигурации развертывания Cloud Run, который выполнит следующие шаги:
- Развертывает сервисы в частной версии.
- Выполняет оценку агента.
- Если проверка пройдена успешно, система "переводит" развертывание обновленных версий на обслуживание 100% трафика.
Создайте cloudbuild.yaml :
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Управление конвейером
Наконец, мы можем запустить конвейер оценки.
Прежде чем запускать конвейер оценки, который отправляет запросы к сервисам Cloud Run, нам потребуется отдельная учетная запись службы с рядом разрешений. Давайте напишем скрипт, который это сделает и запустит конвейер.
- Создайте скрипт
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Создает выделенную учетную запись службы
agent-eval-build-sa. - Предоставляет необходимые роли (
roles/run.admin,roles/aiplatform.userи т. д.). *. Отправляет сборку в Cloud Build.
- Создает выделенную учетную запись службы
- Запустите конвейер:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Вы можете отслеживать ход сборки в терминале или перейти по ссылке в облачную консоль.
Примечание : В реальной производственной среде вам потребуется настроить триггер Cloud Build для автоматического запуска этого процесса при каждом git push . Рабочий процесс тот же: триггер будет выполнять cloudbuild.yaml , гарантируя, что каждый коммит будет оценен.
10. Резюме
Вы успешно создали конвейер оценки !
- Развертывание : Вы использовали теги ревизий с хэшами коммитов Git для безопасного развертывания агентов в реальной среде для тестирования без влияния на развертывание в производственной среде.
- Оценка : Вы определили метрики оценки и автоматизировали процесс оценки с помощью сервиса оценки искусственного интеллекта Vertex AI Gen.
- Анализ : Вы использовали блокнот Colab для визуализации результатов оценки и улучшения работы вашего агента.
- Внедрение : Вы использовали Cloud Build для автоматического выполнения конвейера оценки и продвижения лучшей версии для обслуживания 100% трафика.
Этот цикл «Редактирование кода -> Развертывание тега -> Запуск оценки и тестов -> Анализ -> Внедрение -> Повторение» является основой агентной инженерии производственного уровня .