
1. Giriş
Genel Bakış
Bu laboratuvar, ADK ile birden fazla temsilci sistemi oluşturma laboratuvarının devamıdır.
Bu laboratuvarda, aşağıdakilerden oluşan bir Kurs Oluşturma Sistemi oluşturmuştunuz:
- Araştırmacı Temsilci: Güncel bilgileri bulmak için google_search'ü kullanır.
- Değerlendirme Ajanı: Araştırmayı kalite ve eksiksizlik açısından eleştirir.
- İçerik Oluşturma Aracısı: Araştırmayı yapılandırılmış bir kursa dönüştürme.
- Orchestrator Agent: İş akışını ve bu uzmanlar arasındaki iletişimi yönetir.
Ayrıca, kullanıcıların kurs oluşturma isteği göndermesine ve yanıt olarak kurs almasına olanak tanıyan bir web uygulaması da içeriyordu.
Araştırmacı, Yargıç ve İçerik Oluşturucu, ayrı Cloud Run hizmetlerinde A2A temsilcileri olarak dağıtılır. Orchestrator, ADK Service API'ye sahip başka bir Cloud Run hizmetidir.
Bu laboratuvarda, Araştırmacı aracısını Gemini'ın Google Arama özelliği yerine Wikipedia Arama aracını kullanacak şekilde değiştirdik. Özel araç çağrılarının nasıl izlendiğini ve değerlendirildiğini incelememize olanak tanır.
Bu nedenle, dağıtılmış bir çoklu temsilci sistemi oluşturduk. Peki bu özelliğin gerçekten iyi çalıştığını nasıl anlarız? Araştırmacı her zaman alakalı bilgiler bulur mu? Does the Judge correctly identify bad research?
Bu laboratuvarda, Vertex AI Gen AI Evaluation Service'i kullanarak öznel "vibe check" yerine veriye dayalı değerlendirme yapmayı öğreneceksiniz. 1. laboratuvarda oluşturulan dağıtılmış çoklu aracı sistemini titizlikle değerlendirmek için uyarlanabilir değerlendirme ölçeklerini ve araç kullanım kalitesi metriklerini uygulayacaksınız. Son olarak, bu süreci bir CI/CD ardışık düzeni içinde otomatikleştirerek her dağıtımın üretim aracılarınızın güvenilirliğini ve doğruluğunu korumasını sağlayacaksınız.
Temsilcileriniz için Sürekli Değerlendirme Ardışık Düzeni oluşturacaksınız. Bu eğitimde şunları öğreneceksiniz:
- Ajanlarınızı Google Cloud Run'da özel bir etiketli sürüme dağıtın (gölge dağıtım).
- Vertex AI Gen AI Evaluation Service'i kullanarak söz konusu düzeltmeye karşı otomatik bir değerlendirme paketi çalıştırın.
- Sonuçları görselleştirin ve analiz edin.
- Değerlendirmeyi CI/CD ardışık düzeninizin bir parçası olarak kullanın.
2. Temel Kavramlar: Ajan Değerlendirme Teorisi
Yapay zeka aracı geliştirirken ve çalıştırırken iki tür değerlendirme yaparız: Çevrimdışı Deneme ve Otomatik Regresyon Testi ile Sürekli Değerlendirme. Birincisi, geliştirme sürecinin yaratıcı motorudur. Burada, yeni özellikleri kullanıma sunmak için özel denemeler yapar, istemleri iyileştirir ve hızlı bir şekilde yineleme yaparız. İkincisi ise CI/CD ardışık düzenimizdeki savunma katmanıdır. Burada, hiçbir kod değişikliğinin, aracının kanıtlanmış kalitesini istemeden düşürmemesini sağlamak için "altın" bir veri kümesine karşı sürekli değerlendirmeler yaparız.
Temel fark, Keşif ile Savunma arasındaki ayrımdır:
- Çevrimdışı deneme bir optimizasyon sürecidir. Açık uçlu ve değişkendir. Puanı en üst düzeye çıkarmak veya belirli bir sorunu çözmek için girişleri (istemler, modeller, parametreler) etkin bir şekilde değiştiriyorsunuz. Amaç, temsilcinin yapabileceklerinin sınırını yükseltmektir.
- Sürekli değerlendirme (otomatik regresyon testi), doğrulama sürecidir. Katı ve tekrarlayıcıdır. Çıkışların sabit kalmasını sağlamak için girişleri sabit tutarsınız ("altın" veri kümesi). Buradaki amaç, performansın "tabanının" çökmesini önlemektir.
Bu laboratuvarda Sürekli Değerlendirme'ye odaklanacağız. Birim testlerinde olduğu gibi, bir kullanıcı yapay zeka aracısında her değişiklik yaptığında çalışması gereken otomatik regresyon testi ardışık düzeni geliştireceğiz.
Kod yazmadan önce ne ölçtüğümüzü anlamak çok önemlidir.
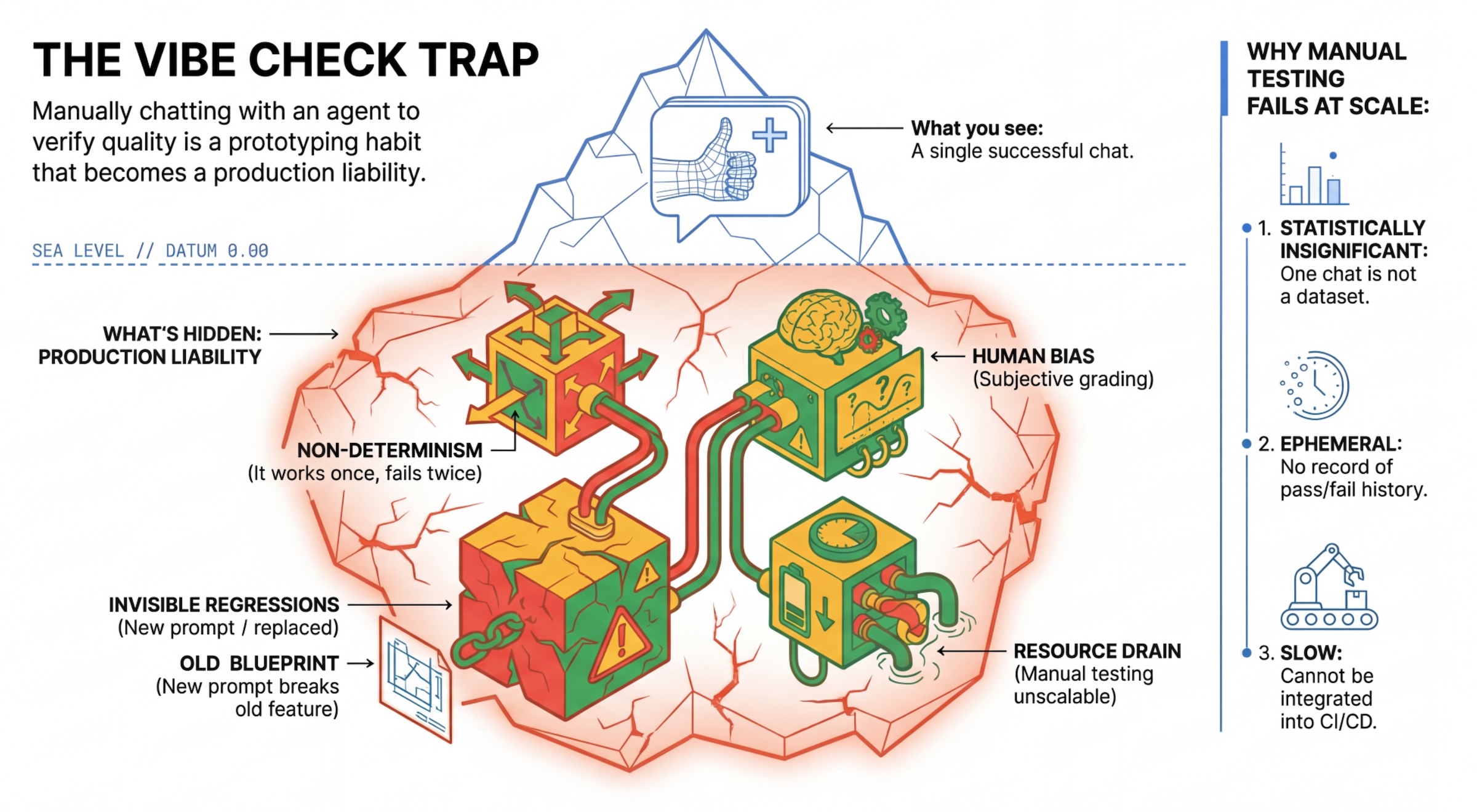
"Vibe Check" Tuzağı
Birçok geliştirici, manuel olarak sohbet ederek aracıları test eder. Buna "vibe checking" (enerji kontrolü) denir. Prototip oluşturma için faydalı olsa da üretimde başarısız olmasının nedenleri:
- Non-Determinism (Belirlenimsizlik): Ajanlar her seferinde farklı yanıtlar verebilir. İstatistiksel olarak anlamlı örnek boyutlarına ihtiyacınız vardır.
- Görünmeyen Gerilemeler: Bir istemi iyileştirmek farklı bir kullanım alanını bozabilir.
- İnsan önyargısı: "İyi görünüyor" öznel bir ifadedir.
- Zaman Alan Çalışma: Her işlemde düzinelerce senaryoyu manuel olarak test etmek yavaştır.
Temsilcinin performansını değerlendirmenin iki yolu
Güçlü bir ardışık düzen oluşturmak için farklı türlerde değerlendiricileri bir araya getiririz:
- Koda Dayalı Değerlendirme Araçları (Belirleyici):
- Ölçtükleri: Katı kısıtlamalar (ör. "Geçerli JSON döndürdü mü?",
searcharacını çağırdı mı?"). - Avantajları: Hızlı, ucuz ve% 100 doğru.
- Dezavantajları: Nüans veya kalite hakkında karar veremez.
- Ölçtükleri: Katı kısıtlamalar (ör. "Geçerli JSON döndürdü mü?",
- Modele Dayalı Not Vericiler (Olasılıklı):
- "LLM-as-a-Judge" olarak da bilinir. Aracının çıktısını değerlendirmek için güçlü bir model (ör. Gemini 3 Pro) kullanırız.
- Ölçülenler: Ayrıntı, mantık, fayda, güvenlik.
- Avantajları: Karmaşık ve açık uçlu görevleri değerlendirebilir.
- Dezavantajları: Daha yavaş, daha pahalı, değerlendirici için dikkatli istem mühendisliği gerektirir.
Vertex AI Değerlendirme Metrikleri
Bu laboratuvarda, her değerlendiriciyi sıfırdan yazmanıza gerek kalmaması için yönetilen metrikler sağlayan Vertex AI Gen AI Evaluation Service'i kullanıyoruz.
Aracı değerlendirmesi için metrikleri gruplandırmanın birden fazla yolu vardır:
- Değerlendirme ölçütlerine dayalı metrikler: Değerlendirme iş akışlarına büyük dil modellerini dahil edin.
- Uyarlanabilir değerlendirme ölçekleri: Her istem için dinamik olarak değerlendirme ölçekleri oluşturulur. Yanıtlar, isteme özel olarak ayrıntılı ve açıklanabilir bir şekilde başarılı veya başarısız geri bildirimiyle değerlendirilir.
- Statik puan anahtarları: Puan anahtarları açıkça tanımlanır ve tüm istemlere aynı puan anahtarı uygulanır. Yanıtlar, aynı sayısal puanlamaya dayalı değerlendiricilerle değerlendirilir. İstem başına tek bir sayısal puan (ör. 1-5). Çok spesifik bir boyutta değerlendirme yapılması gerektiğinde veya tüm istemlerde tam olarak aynı değerlendirme ölçeğinin kullanılması gerektiğinde.
- Hesaplamaya dayalı metrikler: Yanıtları genellikle temel gerçekleri kullanarak deterministik algoritmalarla değerlendirin. İstem başına sayısal puan (ör. 0,0-1,0). Kesin referans mevcut olduğunda ve deterministik bir yöntemle eşleştirilebildiğinde.
- Özel işlev metrikleri: Python işlevi aracılığıyla kendi metriğinizi tanımlayın.
Kullanacağımız belirli metrikler:
Final Response Match: (Referansa dayalı) Yanıt, "Altın Yanıt"ımızla eşleşiyor mu?Tool Use Quality: (Referanssız) Temsilci, ilgili araçları uygun şekilde kullandı mı?Hallucination: (Referanssız) Yanıttaki iddialar, alınan bağlam tarafından destekleniyor mu?Tool Trajectory PrecisionveTool Trajectory Recall(Referansa dayalı) Temsilci doğru aracı seçip geçerli argümanlar sundu mu?Tool Use Quality'dan farklı olarak bu özel metrikler, beklenen araç çağrıları ve bağımsız değişkenler dizisi olan referans yörüngesini kullanır.
3. Kurulum
Yapılandırma
- Cloud Shell'i açın: Google Cloud Console'un sağ üst kısmındaki Cloud Shell'i etkinleştir simgesini tıklayın.
- Oturum açmayı yenilemek ve Uygulama Varsayılan Kimlik Bilgileri'ni (ADC) güncellemek için aşağıdaki komutu çalıştırın:
gcloud auth login --update-adc - gcloud CLI için etkin bir proje ayarlayın.Mevcut gcloud projesini almak için aşağıdaki komutu çalıştırın:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDyerine projenizin kimliğini yazın. - Cloud Run hizmetlerinizin dağıtılacağı varsayılan bölgeyi ayarlayın.
gcloud config set run/region us-west1us-west1yerine size daha yakın olan herhangi bir Cloud Run bölgesini kullanabilirsiniz.
Kod ve Bağımlılıklar
- Başlangıç kodunu klonlayın ve dizini projenin köküne değiştirin.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab .envdosyası oluşturma:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env- Terminal penceresinde aşağıdaki komutu çalıştırarak bağımlılıkları yükleyin:
uv sync
4. Güvenli dağıtımı anlama
Değerlendirme yapmadan önce dağıtım yapmamız gerekir. Ancak yeni kodumuz kötü olursa canlı uygulamayı bozmak istemiyoruz.
Düzeltme Etiketleri ve Gölge Dağıtım
Google Cloud Run, düzeltmeleri destekler. Her dağıtım yaptığınızda yeni bir sabit düzeltme oluşturulur. Herkese açık trafiğin% 0'ını alsalar bile belirli bir URL üzerinden erişmek için bu düzeltmelere etiketler atayabilirsiniz.
Neden yalnızca yerel olarak değerlendirme yapmıyorsunuz?
ADK yerel değerlendirmeyi desteklese de gizli bir düzeltmeye dağıtım yapmak üretim sistemleri için önemli avantajlar sunar. Bu, Sistem Düzeyinde Değerlendirme (yaptığımız işlem) ile Birim Testi arasındaki farkı gösterir:
- Ortam Eşliği: Yerel ortamlar farklıdır (farklı ağ, farklı CPU/bellek, farklı sırlar). Bulutta test etme, aracınızın gerçek çalışma zamanı ortamında (sistem testi) çalışmasını sağlar.
- Çoklu aracı etkileşimi: Dağıtılmış bir sistemde aracılar HTTP üzerinden iletişim kurar. "Yerel" testlerde genellikle bu bağlantılar taklit edilir. Shadow dağıtımı, mikro hizmetleriniz arasındaki gerçek ağ gecikmesini, zaman aşımı yapılandırmalarını ve kimlik doğrulamasını test eder.
- Sırlar ve İzinler: Hizmet hesabınızın gerçekten ihtiyaç duyduğu izinlere (ör. Vertex AI'ı çağırmak veya Firestore'dan okumak için) sahip olduğunu doğrular.
Not: Bu, Proaktif Değerlendirme'dir (kullanıcılar görmeden önce kontrol etme). Dağıtım tamamlandıktan sonra, gerçek hayattaki sorunları yakalamak için Reactive Monitoring'i (Gözlemlenebilirlik) kullanırsınız.
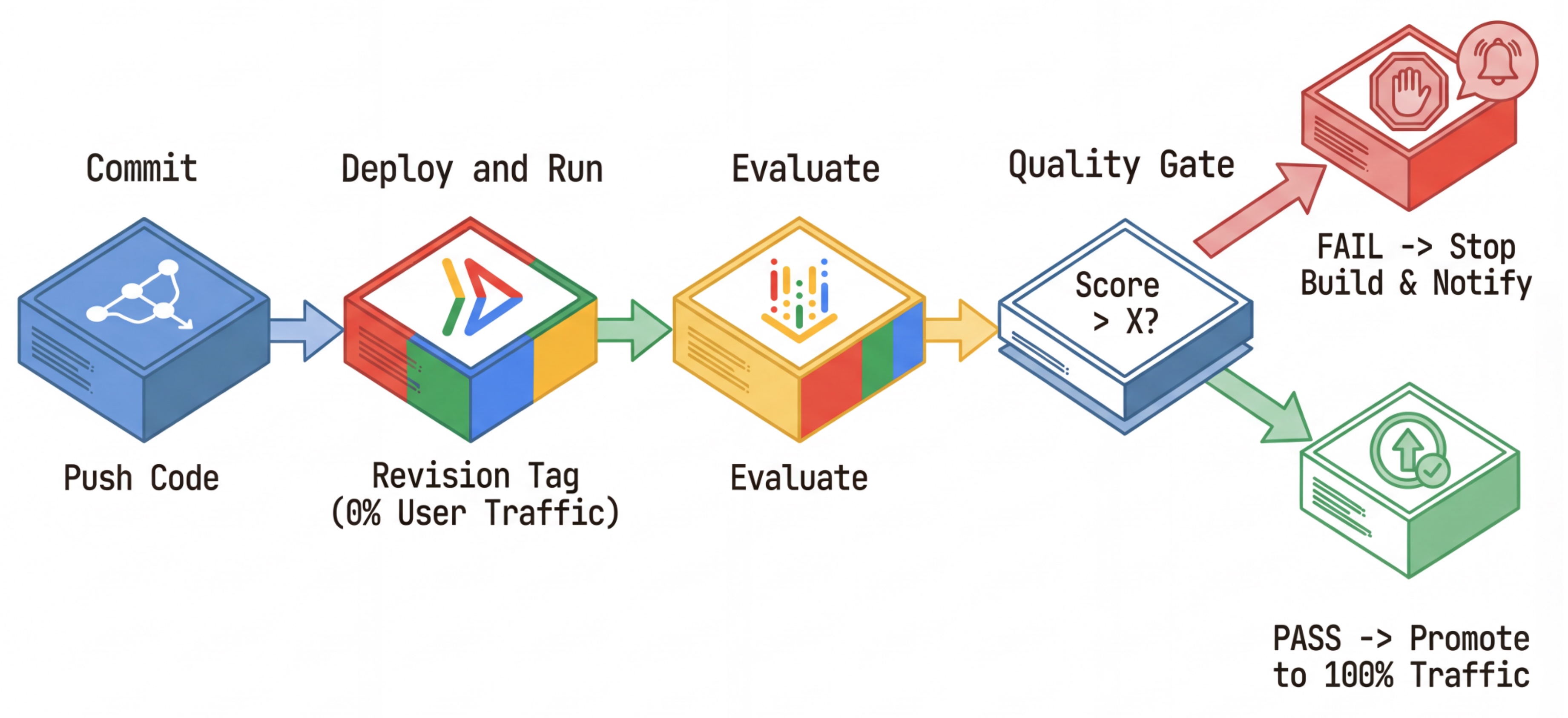
CI/CD iş akışı: Dağıtma, değerlendirme, yükseltme
Bunu, sağlam bir Sürekli Dağıtım ardışık düzeni için kullanırız:
- Commit: Temsilcinin istemini değiştirir ve depoya gönderirsiniz.
- Dağıt (Gizli): Bu işlem, commit karmasıyla (ör.
c-abc1234) etiketlenmiş yeni bir düzeltmenin dağıtımını tetikler. Bu düzeltme, herkese açık trafiğin %0'ını alır. - Değerlendirme: Değerlendirme komut dosyası, belirli düzeltme URL'sini
https://c-abc1234---researcher-xyz.run.apphedefler. - Yükseltme: Değerlendirme başarılı olursa ve diğer testler de geçerse trafiği bu yeni düzeltmeye taşırsınız.
- Geri alma: Geri alma işlemi başarısız olursa kullanıcılar kötü sürümü hiç görmez ve kötü düzeltmeyi yok sayabilir veya silebilirsiniz.
Bu strateji, müşterileri etkilemeden üretimde test yapmanıza olanak tanır.
evaluate.sh aralığını analiz et
evaluate.sh adlı kişiyi aç. Bu komut dosyası, işlemi otomatikleştirir.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh, --no-traffic ve --tag seçenekleriyle revizyon dağıtımını gerçekleştirir. Zaten çalışan bir hizmet varsa bu hizmet etkilenmez. Yeni "gizli" düzeltme, düzeltme etiketini (ör.https://c-abc1234---researcher-xyz.run.app) içeren özel bir URL ile açıkça çağırmadığınız sürece trafik almaz.
5. Değerlendirme komut dosyasını uygulama
Şimdi de testleri gerçekten çalıştıran kodu yazalım.
evaluator/evaluate_agent.pyadlı kişiyi aç.- İçe aktarma işlemleri ve kurulumu görürsünüz ancak metrikler ve yürütme mantığı eksiktir.
Metrikleri tanımlama
Araştırmacı Ajan için beklenen yanıtları içeren bir "Altın Yanıtlar"/"Kesin Referans"ımız var. Bu bir Capability Eval (Yeterlilik Değerlendirmesi): Aracının işi doğru şekilde yapıp yapamayacağını ölçüyoruz.
Ölçmek istediğimiz:
- Nihai Yanıt Eşleşmesi: (Yeterlilik) Yanıt, beklenen yanıtla eşleşiyor mu? Bu, referansa dayalı bir metriktir. Aracının çıkışını beklenen yanıtla karşılaştırmak için bir hakem LLM kullanır. Yanıtın tam olarak aynı olmasını değil, anlamsal ve olgusal olarak benzer olmasını bekler.
- Araç Kullanım Kalitesi: (Kalite) Uygun araçların seçimi, parametrelerin doğru kullanımı ve belirtilen işlem sırasına uyulmasını değerlendiren, hedeflenmiş bir uyarlanabilir değerlendirme ölçütü metriği.
- Araç Kullanım Yörüngesi: (İzleme) Aracın kullanım yörüngesini (kesinlik ve hatırlama) beklenen yörüngelere göre ölçen 2 özel metrik. Bu metrikler,
shared/evaluation/tool_metrics.pyiçinde özel işlevler olarak uygulanır. Araç Kullanım Kalitesi'nin aksine bu metrik, deterministik bir referansa dayalı metriktir. Kod, gerçek araç çağrılarının referans verilerle (değerlendirme verilerindekireference_trajectory) eşleşip eşleşmediğini kelimenin tam anlamıyla kontrol eder.
Özel Araç Kullanımı Yörünge Metrikleri
Özel Araç Kullanım Yörüngesi metrikleri için shared/evaluation/tool_metrics.py içinde bir dizi Python işlevi oluşturduk. Vertex AI Üretken Yapay Zeka Değerlendirme Hizmeti'nin bu işlevleri yürütmesine izin vermek için Python kodunu bu hizmete iletmemiz gerekir.
Bu işlem, UnifiedMetric ve CustomCodeExecutionSpec yapılandırması olan bir EvaluationRunMetric nesnesi tanımlanarak yapılır. Parametre remote_custom_function, işlevin Python kodunu içeren bir dizedir. İşlev evaluate olarak adlandırılmalıdır:
def evaluate(
instance: dict
) -> float:
...
Python işlevini özel kod değerlendirme metriğine dönüştüren bir get_custom_function_metric yardımcısı (shared/evaluation/evaluate.py içinde) oluşturduk.
İşlevin modülünün kodunu alır (yerel bağımlılıkları yakalamak için), orijinal işlevi çağıran ek bir evaluate işlevi oluşturur ve CustomCodeExecutionSpec ile bir EvaluationRunMetric nesnesi döndürür.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Üretken Yapay Zeka Değerlendirme Hizmeti, bu kodu korumalı alan yürütme ortamında yürütür ve değerlendirme verilerini bu ortama iletir.
Metrikleri ve değerlendirme kodunu ekleme
Aşağıdaki kodu if __name__ == "__main__": satırından sonra evaluator/evaluate_agent.py dosyasına ekleyin.
Araştırmacı aracısının metrik listesini tanımlar ve değerlendirmeyi çalıştırır.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
Gerçek bir üretim ardışık düzeninde Değerlendirme Başarı Kriterleri'ne ihtiyacınız vardır. Değerlendirme tamamlandıktan ve metrikler hazır olduktan sonra. Burada bir Gating Step (Kilitleme Adımı) olur. Örneğin: "Final Response Match puanı 0, 75'ten düşükse derleme başarısız olsun." Bu, kötü düzeltmelerin hiçbir zaman trafik almasını önler.
Aşağıdaki kodu evaluator/evaluate_agent.py dosyasına ekleyin:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Değerlendirme metriklerinden herhangi birinin ortalama değeri bir eşik değerin (0.75) altında olduğunda dağıtım başarısız olmalıdır.
[İsteğe bağlı] Düzenleyici için Referanssız Metriklerle Değerlendirme Ekleme
Orchestrator Agent'da etkileşimler daha karmaşıktır ve her zaman tek bir "doğru" yanıtımız olmayabilir. Bunun yerine, Referanssız Metrikler'den birini kullanarak genel davranışı değerlendiririz.
- Halüsinasyon: Yanıtı atomik iddialara ayırarak metin yanıtlarının doğruluğunu ve tutarlılığını kontrol eden, puana dayalı bir metriktir. Her iddianın, ara etkinliklerdeki araç kullanımına göre temellendirilip temellendirilmediğini doğrular. Bu, "doğruluk" kavramının öznel olduğu ancak "gerçeklik" kavramının tartışmaya açık olmadığı açık uçlu aracılar için kritik öneme sahiptir. Puan, kaynak içerikte temellendirilmiş iddiaların yüzdesi olarak hesaplanır. Bizim durumumuzda, Orchestrator'dan (Content Builder'ın oluşturduğu) gelen nihai yanıtın, Researcher'ın Wikipedia Arama aracını kullanarak aldığı içerikle olgusal olarak tutarlı olmasını bekliyoruz.
Düzenleyici için değerlendirme mantığını ekleyin:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Değerlendirme verilerini inceleme
evaluator/ dizinini açın. İki veri dosyası görürsünüz:
eval_data_researcher.json: Araştırmacı için istemler ve altın/gerçek referanslar.eval_data_orchestrator.json: Düzenleyici için istemler (Düzenleyici için yalnızca referanssız değerlendirme yaparız).
Her giriş genellikle şunları içerir:
prompt: Ajanın istemi.reference: Varsa ideal yanıt (gerçek doğru).reference_trajectory: Beklenen araç çağrısı sırası.
6. Değerlendirme kodunu anlama
shared/evaluation/evaluate.py adlı kişiyi aç. Bu modül, değerlendirmeleri çalıştırmaya yönelik temel mantığı içerir. Temel işlev evaluate_agent'dır.
Aşağıdaki adımları gerçekleştirir:
- Veri Yükleme: Değerlendirme veri kümesini (istemler ve referanslar) bir dosyadan okur.
- Paralel çıkarım: Aracıyı veri kümesine karşı paralel olarak çalıştırır. Oturum oluşturma, istem gönderme, nihai yanıtı ve araç yürütme izini yakalama işlemlerini gerçekleştirir.
- Vertex AI Evaluation: Orijinal değerlendirme verilerini nihai yanıtlarla ve ara araç yürütme iziyle birleştirir ve sonuçları Vertex AI SDK'daki GenAI Client ile Vertex AI Evaluation Service'e gönderir. Bu hizmet, temsilcinin performansını derecelendirmek için yapılandırılmış metrikleri çalıştırır.
Son adımın önemli anı, Gen AI SDK'nın eval modülünün create_evaluation_run işlevini çağırmaktır:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Bu işlemi shared/evaluation/evaluate.py işlevinde evaluate_agent içinde yapıyoruz.
Birleştirilmiş değerlendirme veri kümesini, aracı hakkındaki bilgileri, kullanılacak metrikleri ve hedef depolama URI'sini alır. İşlev, Vertex AI Evaluation Service'te bir değerlendirme çalıştırması oluşturur ve değerlendirme çalıştırması nesnesini döndürür.
Agent Info API
Değerlendirme Hizmeti'nin doğru bir değerlendirme yapabilmesi için aracının yapılandırmasını (sistem talimatları, açıklama ve mevcut araçlar) bilmesi gerekir. Bu değer, create_evaluation_run öğesine agent_info parametresi olarak aktarılır.
Peki bu bilgileri nasıl elde ederiz? ADK Service API'ye dahil ederiz.
shared/adk_app.py uygulamasını açıp def agent_info ifadesini arayın. ADK uygulamasının bir yardımcı uç nokta sunduğunu görürsünüz:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Bu uç nokta (--publish_agent_info işaretiyle etkinleştirilir), değerlendirme komut dosyasının aracının çalışma zamanı yapılandırmasını dinamik olarak getirmesine olanak tanır. Bu, araç kullanımını değerlendiren metrikler için çok önemlidir. Çünkü yargıç modeli, görüşme sırasında ajanın hangi araçları kullandığını net bir şekilde bilirse ajanın araç kullanımını daha iyi değerlendirebilir.
7. Değerlendirmeyi çalıştırma
Değerlendiriciyi uyguladığınıza göre şimdi çalıştıralım.
- Değerlendirme komut dosyasını deponun kökünden çalıştırın:
./evaluate.sh- Geçerli Git kaydetme karmasını alır.
- Bir düzeltmeyi, taahhüt karmasına dayalı bir etiketle dağıtmak için
deploy.shçağrılır. - Dağıtıldıktan sonra
evaluator.evaluate_agentbaşlar. - Test senaryolarını bulut hizmetinizde çalıştırırken ilerleme çubukları görürsünüz.
- Son olarak, sonuçların özet JSON'unu yazdırır.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Not: Hizmetlerin dağıtılması ilk çalıştırmada birkaç dakika sürebilir.
8. Sonuçları not defterinde görselleştirme
Ham JSON çıkışının okunması zordur. Vertex AI SDK'daki Gen AI Client, bu çalıştırmaları zaman içinde izlemenin bir yolunu sunar. Sonuçları görselleştirmek için Colab not defteri kullanacağız.
evaluator/show_evaluation_run.ipynbGoogle Colab'de bu bağlantıyı kullanarak açın.GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONveEVAL_RUN_IDdeğişkenlerini proje kimliğinize, bölgenize ve çalıştırma kimliğinize ayarlayın.
- Bağımlılıkları yükleyin ve kimliğinizi doğrulayın.
Değerlendirme çalıştırmasını alma ve sonuçları görüntüleme
Değerlendirme çalıştırma verilerini Vertex AI'dan getirmemiz gerekir. Retrieve Evaluation Run and Display Results (Değerlendirme Çalıştırmasını Al ve Sonuçları Göster) bölümündeki hücreyi bulun ve # TODO satırını aşağıdaki kod bloğuyla değiştirin:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Sonuçları yorumlama
Sonuçlara bakarken aşağıdakileri göz önünde bulundurun:
- Regresyon ve Yetenek:
- Regresyon: Eski testlerde puan düştü mü? (İyi değil, araştırma gerektiriyor.)
- Yeterlilik: Puan, yeni testlerde yükseldi mi? (İyi, bu bir gelişme.)
- Hata Analizi: Yalnızca puana bakmayın.
- İzlemeye bakın. Yanlış aracı mı çağırdı? Çıkış ayrıştırılamadı mı? Hataları burada bulabilirsiniz.
- Hakim LLM'nin sağladığı açıklamaya ve kararlara bakın. Bu mesajlar genellikle testin neden başarısız olduğu hakkında iyi bir fikir verir.
Pass@1 ve Pass@k: Belirli bir testi bir kez çalıştırdığımızda Pass@1 puanı elde ederiz. Bir temsilcinin başarısız olmasının nedeni, deterministik olmaması olabilir. Gelişmiş ayarlarda, her testi k kez (ör. 5 kez) çalıştırabilir ve pass@k (en az bir kez başarılı oldu mu?) veya pass^k (her seferinde başarılı oldu mu?) değerini hesaplayabilirsiniz. Birçok metrik zaten arka planda bu şekilde çalışır. Örneğin, types.RubricMetric.FINAL_RESPONSE_MATCH (Nihai Yanıt Eşleşmesi), nihai yanıt eşleşmesi puanını belirlemek için yargıç LLM'ye 5 çağrı yapar.
9. Sürekli Entegrasyon ve Dağıtım (CI/CD)
Üretim sisteminde, aracı değerlendirmesi CI/CD ardışık düzeninin bir parçası olarak çalıştırılmalıdır. Bu amaçla Cloud Build'i kullanabilirsiniz.
Ajanın kod deposuna gönderilen her bir commit için değerlendirme, diğer testlerle birlikte çalıştırılır. Testi geçen dağıtımlar, kullanıcı isteklerine hizmet verecek şekilde "yükseltilebilir". Testler başarısız olursa her şey olduğu gibi kalır ancak geliştirici, sorunun nedenini inceleyebilir.
Cloud Build Yapılandırması
Şimdi aşağıdaki adımları gerçekleştiren bir Cloud Run dağıtım yapılandırma komut dosyası oluşturalım:
- Hizmetleri özel bir revizyona dağıtır.
- Temsilci değerlendirmesini çalıştırır.
- Değerlendirme başarılı olursa düzeltme dağıtımları, trafiğin% 100'üne hizmet verecek şekilde "yükseltilir".
Oluşturma cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Ardışık düzeni çalıştırma
Son olarak, değerlendirme işlem hattını çalıştırabiliriz.
Cloud Run hizmetlerine istek gönderen değerlendirme ardışık düzenini çalıştırmadan önce, belirli sayıda izne sahip ayrı bir hizmet hesabına ihtiyacımız var. Bunu yapacak ve ardışık düzeni başlatacak bir komut dosyası yazalım.
- Komut dosyası oluşturma
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Özel bir hizmet hesabı
agent-eval-build-saoluşturur. - Gerekli rolleri (
roles/run.admin,roles/aiplatform.uservb.) atar. *. Derlemeyi Cloud Build'e gönderir.
- Özel bir hizmet hesabı
- Ardışık düzeni çalıştırın:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Derleme ilerleme durumunu terminalde izleyebilir veya Cloud Console bağlantısını tıklayabilirsiniz.
Not: Gerçek bir üretim ortamında, bu işlemi her git push'da otomatik olarak çalıştırmak için bir Cloud Build tetikleyicisi ayarlarsınız. İş akışı aynıdır: Tetikleyici cloudbuild.yaml komutunu çalıştırarak her commit'in değerlendirilmesini sağlar.
10. Özet
Değerlendirme ardışık düzenini başarıyla oluşturdunuz.
- Dağıtım: Üretim dağıtımlarını etkilemeden test için aracıları gerçek ortama güvenli bir şekilde dağıtmak üzere git commit karmasıyla revizyon etiketleri kullandınız.
- Değerlendirme: Değerlendirme metrikleri tanımladınız ve Vertex AI Gen AI Evaluation Service'i kullanarak değerlendirme sürecini otomatik hale getirdiniz.
- Analiz: Değerlendirme sonuçlarını görselleştirmek ve aracınızı iyileştirmek için Colab not defteri kullandınız.
- Kullanıma sunma: Değerlendirme ardışık düzenini otomatik olarak yürütmek ve trafiğin% 100'üne hizmet vermek için en iyi düzeltmeyi tanıtmak üzere Cloud Build'i kullandınız.
Bu döngü Kodu Düzenle -> Etiketi Dağıt -> Değerlendirme ve Testleri Çalıştır -> Analiz Et -> Kullanıma Sun -> Tekrarla, Üretim Düzeyinde Ajan Tabanlı Mühendisliğin temelini oluşturur.