
1. Giới thiệu
Tổng quan
Lớp học này là phần tiếp theo của lớp học Xây dựng hệ thống nhiều tác nhân bằng ADK.
Trong lớp học đó, bạn đã tạo một Hệ thống tạo khoá học bao gồm:
- Tác nhân nghiên cứu: Sử dụng google_search để tìm thông tin mới nhất.
- Tác nhân đánh giá: Đánh giá nghiên cứu về chất lượng và tính đầy đủ.
- Tác nhân tạo nội dung: Biến thông tin nghiên cứu thành một khoá học có cấu trúc.
- Nhân viên điều phối: Quản lý quy trình làm việc và hoạt động giao tiếp giữa các chuyên gia này.
Ứng dụng này cũng bao gồm một Ứng dụng web cho phép người dùng gửi yêu cầu tạo khoá học và nhận được một khoá học làm phản hồi.
Nhà nghiên cứu, Người đánh giá và Nhà tạo nội dung được triển khai dưới dạng tác nhân A2A trong các dịch vụ Cloud Run riêng biệt. Orchestrator là một dịch vụ Cloud Run khác có ADK Service API.
Đối với phòng thí nghiệm này, chúng tôi đã sửa đổi tác nhân Nhà nghiên cứu để sử dụng công cụ Tìm kiếm trên Wikipedia thay vì khả năng Google Tìm kiếm của Gemini. Nhờ đó, chúng ta có thể kiểm tra cách các lệnh gọi công cụ tuỳ chỉnh được theo dõi và đánh giá.
Vì vậy, chúng tôi đã xây dựng một hệ thống nhiều tác nhân phân tán. Nhưng làm sao chúng ta biết được liệu chiến dịch có thực sự hoạt động hiệu quả hay không? Có phải Nhà nghiên cứu luôn tìm được thông tin phù hợp không? Thẩm phán có xác định chính xác nghiên cứu không phù hợp không?
Trong phòng thí nghiệm này, bạn sẽ thay thế các "vibe checks" cảm tính bằng hoạt động đánh giá dựa trên dữ liệu bằng cách sử dụng Dịch vụ đánh giá AI tạo sinh của Vertex AI. Bạn sẽ triển khai các chỉ số Thang điểm thích ứng và Chất lượng sử dụng công cụ để đánh giá một cách nghiêm ngặt Hệ thống đa tác nhân phân tán được xây dựng trong Phòng thí nghiệm 1. Cuối cùng, bạn sẽ tự động hoá quy trình này trong quy trình CI/CD, đảm bảo rằng mọi hoạt động triển khai đều duy trì độ tin cậy và độ chính xác của các tác nhân sản xuất.
Bạn sẽ xây dựng một Pipeline đánh giá liên tục cho các tác nhân của mình. Bạn sẽ tìm hiểu cách:
- Triển khai các tác nhân của bạn vào một bản sửa đổi được gắn thẻ riêng tư trong Google Cloud Run (triển khai bóng).
- Chạy một bộ đánh giá tự động dựa trên bản sửa đổi cụ thể đó bằng Dịch vụ đánh giá AI tạo sinh của Vertex AI.
- Trực quan hoá và phân tích kết quả.
- Sử dụng quy trình đánh giá trong quy trình CI/CD.
2. Khái niệm cốt lõi: Lý thuyết đánh giá tác nhân
Khi phát triển và chạy các Đặc vụ AI, chúng tôi thực hiện hai loại đánh giá: Thử nghiệm ngoại tuyến và Đánh giá liên tục bằng kiểm thử hồi quy tự động. Đầu tiên là công cụ sáng tạo trong quy trình phát triển, nơi chúng tôi chạy các thử nghiệm đặc biệt, tinh chỉnh câu lệnh và lặp lại nhanh chóng để khai thác các chức năng mới. Lớp thứ hai là lớp phòng thủ trong quy trình CI/CD của chúng tôi, nơi chúng tôi thực hiện các đánh giá liên tục dựa trên một tập dữ liệu "vàng" để đảm bảo rằng không có thay đổi nào về mã vô tình làm giảm chất lượng đã được chứng minh của tác nhân.
Sự khác biệt cơ bản nằm ở Khám phá so với Phòng thủ:
- Thử nghiệm ngoại tuyến là một quy trình tối ưu hoá. Đây là một câu hỏi mở và có thể thay đổi. Bạn đang tích cực thay đổi các dữ liệu đầu vào (câu lệnh, mô hình, thông số) để tối đa hoá điểm số hoặc giải quyết một vấn đề cụ thể. Mục tiêu là nâng "giới hạn" của những việc mà tác nhân có thể làm.
- Đánh giá liên tục (Kiểm thử hồi quy tự động) là một quy trình xác minh. Nó cứng nhắc và lặp đi lặp lại. Bạn giữ nguyên các dữ liệu đầu vào (tập dữ liệu "vàng") để đảm bảo dữ liệu đầu ra vẫn ổn định. Mục tiêu là ngăn chặn "sàn" hiệu suất sụt giảm.
Trong lớp học lập trình này, chúng ta sẽ tập trung vào Đánh giá liên tục. Chúng tôi sẽ phát triển một quy trình kiểm thử hồi quy tự động, dự kiến sẽ chạy mỗi khi có người thay đổi trong tác nhân AI, giống như những kiểm thử đơn vị đó.
Trước khi viết mã, bạn cần hiểu rõ những gì chúng ta đang đo lường.
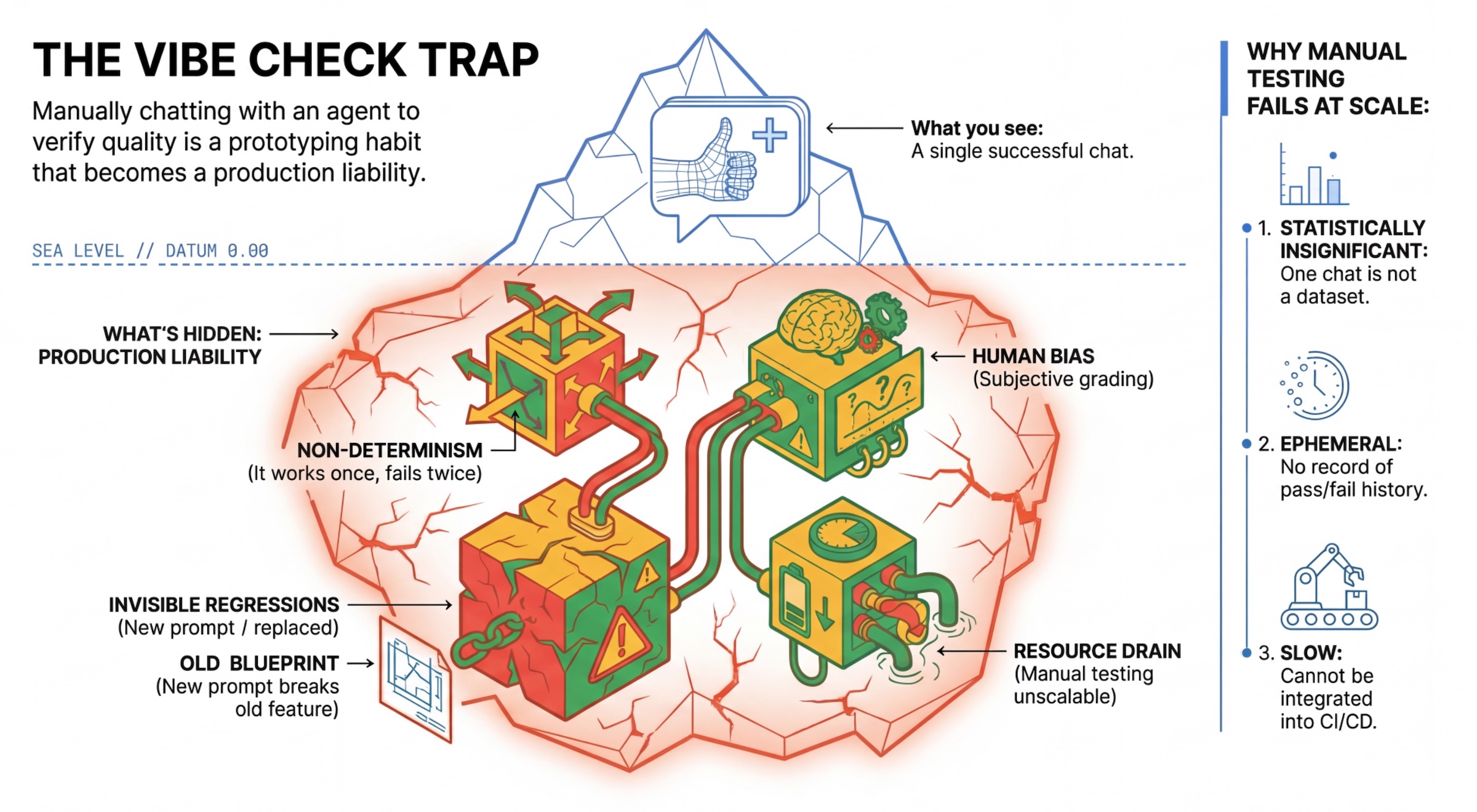
Bẫy "Vibe Check"
Nhiều nhà phát triển kiểm thử các tác nhân bằng cách trò chuyện thủ công với chúng. Đây được gọi là "vibe checking" (kiểm tra cảm xúc). Mặc dù hữu ích cho việc tạo mẫu, nhưng nó không hoạt động trong quá trình sản xuất vì:
- Tính không xác định: Các tác nhân có thể trả lời khác nhau mỗi lần. Bạn cần kích thước mẫu có ý nghĩa thống kê.
- Hồi quy vô hình: Việc cải thiện một câu lệnh có thể làm hỏng một trường hợp sử dụng khác.
- Thiên kiến của con người: "Trông có vẻ ổn" là một nhận xét chủ quan.
- Tốn thời gian: Việc kiểm thử thủ công hàng chục trường hợp với mỗi lần xác nhận là rất chậm.
Hai cách để chấm điểm hiệu suất của nhân viên hỗ trợ
Để xây dựng một pipeline mạnh mẽ, chúng tôi kết hợp nhiều loại công cụ chấm điểm:
- Trình chấm điểm dựa trên mã (Xác định):
- Những gì họ đo lường: Các ràng buộc nghiêm ngặt (ví dụ: "Có trả về JSON hợp lệ không?", "Did it call the
searchtool?" (Có phải công cụ này đã gọi công cụsearchkhông?). - Ưu điểm: Nhanh chóng, rẻ tiền, chính xác 100%.
- Nhược điểm: Không thể đánh giá sắc thái hoặc chất lượng.
- Những gì họ đo lường: Các ràng buộc nghiêm ngặt (ví dụ: "Có trả về JSON hợp lệ không?", "Did it call the
- Trình chấm điểm dựa trên mô hình (xác suất):
- Còn được gọi là "LLM-as-a-Judge" (Mô hình ngôn ngữ lớn đóng vai trò là người đánh giá). Chúng tôi sử dụng một mô hình mạnh mẽ (như Gemini 3 Pro) để đánh giá đầu ra của tác nhân.
- Những yếu tố được đánh giá: Sắc thái, suy luận, mức độ hữu ích, độ an toàn.
- Ưu điểm: Có thể đánh giá các nhiệm vụ phức tạp, mang tính gợi mở.
- Nhược điểm: Chậm hơn, tốn kém hơn, cần phải thiết kế câu lệnh cẩn thận cho người đánh giá.
Chỉ số đánh giá Vertex AI
Trong phòng thí nghiệm này, chúng ta sẽ sử dụng Dịch vụ đánh giá AI tạo sinh của Vertex AI. Dịch vụ này cung cấp các chỉ số được quản lý để bạn không phải viết mọi tiêu chí đánh giá từ đầu.
Có nhiều cách để nhóm các chỉ số đánh giá nhân viên hỗ trợ:
- Chỉ số dựa trên bộ tiêu chí: Tích hợp LLM vào quy trình đánh giá.
- Thang điểm thích ứng: Thang điểm được tạo linh hoạt cho từng câu lệnh. Các câu trả lời được đánh giá bằng thông tin phản hồi chi tiết, dễ hiểu về việc đạt hoặc không đạt, dành riêng cho câu lệnh.
- Thang điểm tĩnh: Thang điểm được xác định rõ ràng và cùng một thang điểm áp dụng cho tất cả các câu lệnh. Các phản hồi được đánh giá bằng cùng một bộ công cụ đánh giá dựa trên điểm số bằng số. Một điểm số bằng số duy nhất (chẳng hạn như 1-5) cho mỗi câu lệnh. Khi cần đánh giá theo một phương diện rất cụ thể hoặc khi cần sử dụng chính xác cùng một thang điểm cho tất cả câu lệnh.
- Chỉ số dựa trên tính toán: Đánh giá các câu trả lời bằng thuật toán xác định, thường sử dụng đầu ra thực sự. Điểm số (chẳng hạn như 0,0 – 1,0) cho mỗi câu lệnh. Khi có dữ liệu thực tế và có thể so khớp bằng một phương thức xác định.
- Chỉ số hàm tuỳ chỉnh: Xác định chỉ số của riêng bạn thông qua một hàm Python.
Các chỉ số cụ thể mà chúng ta sẽ sử dụng:
Final Response Match: (Dựa trên thông tin tham khảo) Câu trả lời có khớp với "Câu trả lời mẫu" của chúng tôi không?Tool Use Quality: (Không cần tham khảo) Nhân viên hỗ trợ có sử dụng các công cụ liên quan một cách phù hợp không?Hallucination: (Không cần tham chiếu) Các tuyên bố trong câu trả lời có được ngữ cảnh đã truy xuất hỗ trợ không?Tool Trajectory PrecisionvàTool Trajectory Recall(Dựa trên thông tin tham khảo) Nhân viên có chọn đúng công cụ và đưa ra các đối số hợp lệ không? Không giống nhưTool Use Quality, các chỉ số tuỳ chỉnh này sử dụng quỹ đạo tham chiếu – một chuỗi các lệnh gọi và đối số công cụ dự kiến.
3. Thiết lập
Cấu hình
- Mở Cloud Shell: Nhấp vào biểu tượng Kích hoạt Cloud Shell ở trên cùng bên phải của Google Cloud Console.
- Chạy lệnh sau để làm mới thông tin đăng nhập và cập nhật Thông tin xác thực mặc định của ứng dụng (ADC):
gcloud auth login --update-adc - Đặt một dự án đang hoạt động cho gcloud CLI.Chạy lệnh sau để lấy dự án gcloud hiện tại:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDbằng mã dự án của bạn. - Đặt khu vực mặc định nơi các dịch vụ Cloud Run của bạn sẽ được triển khai.
gcloud config set run/region us-west1us-west1, bạn có thể sử dụng bất kỳ khu vực Cloud Run nào gần bạn hơn.
Mã và phần phụ thuộc
- Nhân bản mã khởi đầu và thay đổi thư mục thành thư mục gốc của dự án.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - Tạo tệp
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - Cài đặt các phần phụ thuộc bằng cách chạy lệnh sau trong cửa sổ dòng lệnh:
uv sync
4. Tìm hiểu về tính năng Triển khai an toàn
Trước khi đánh giá, chúng ta cần triển khai. Nhưng chúng tôi không muốn làm hỏng ứng dụng đang hoạt động nếu mã mới của chúng tôi không tốt.
Thẻ sửa đổi và triển khai ngầm
Google Cloud Run hỗ trợ Bản sửa đổi. Mỗi lần bạn triển khai, một bản sửa đổi bất biến mới sẽ được tạo. Bạn có thể chỉ định Thẻ cho các bản sửa đổi này để truy cập vào chúng thông qua một URL cụ thể, ngay cả khi chúng nhận được 0% lưu lượng truy cập công khai.
Tại sao không chỉ chạy các quy trình đánh giá cục bộ?
Mặc dù ADK hỗ trợ việc đánh giá cục bộ, nhưng việc triển khai cho một bản sửa đổi ẩn mang lại những lợi thế quan trọng cho Hệ thống sản xuất. Điều này phân biệt Đánh giá ở cấp hệ thống (những gì chúng tôi đang làm) với Kiểm thử đơn vị:
- Tính tương đồng của môi trường: Môi trường cục bộ khác nhau (mạng khác nhau, CPU/Bộ nhớ khác nhau, các khoá bí mật khác nhau). Việc kiểm thử trên đám mây đảm bảo rằng tác nhân của bạn hoạt động trong môi trường thời gian chạy thực tế (Kiểm thử hệ thống).
- Tương tác giữa nhiều tác nhân: Trong một hệ thống phân tán, các tác nhân giao tiếp qua HTTP. Các bài kiểm thử "cục bộ" thường mô phỏng những kết nối này. Thử nghiệm triển khai song song sẽ kiểm thử độ trễ mạng thực tế, cấu hình thời gian chờ và quá trình xác thực giữa các vi dịch vụ của bạn.
- Bí mật và quyền: Xác minh rằng tài khoản dịch vụ của bạn thực sự có các quyền cần thiết (ví dụ: gọi Vertex AI hoặc đọc từ Firestore).
Lưu ý: Đây là Đánh giá chủ động (kiểm tra trước khi người dùng nhìn thấy). Sau khi triển khai, bạn sẽ sử dụng Tính năng giám sát phản ứng (Khả năng quan sát) để phát hiện các vấn đề.
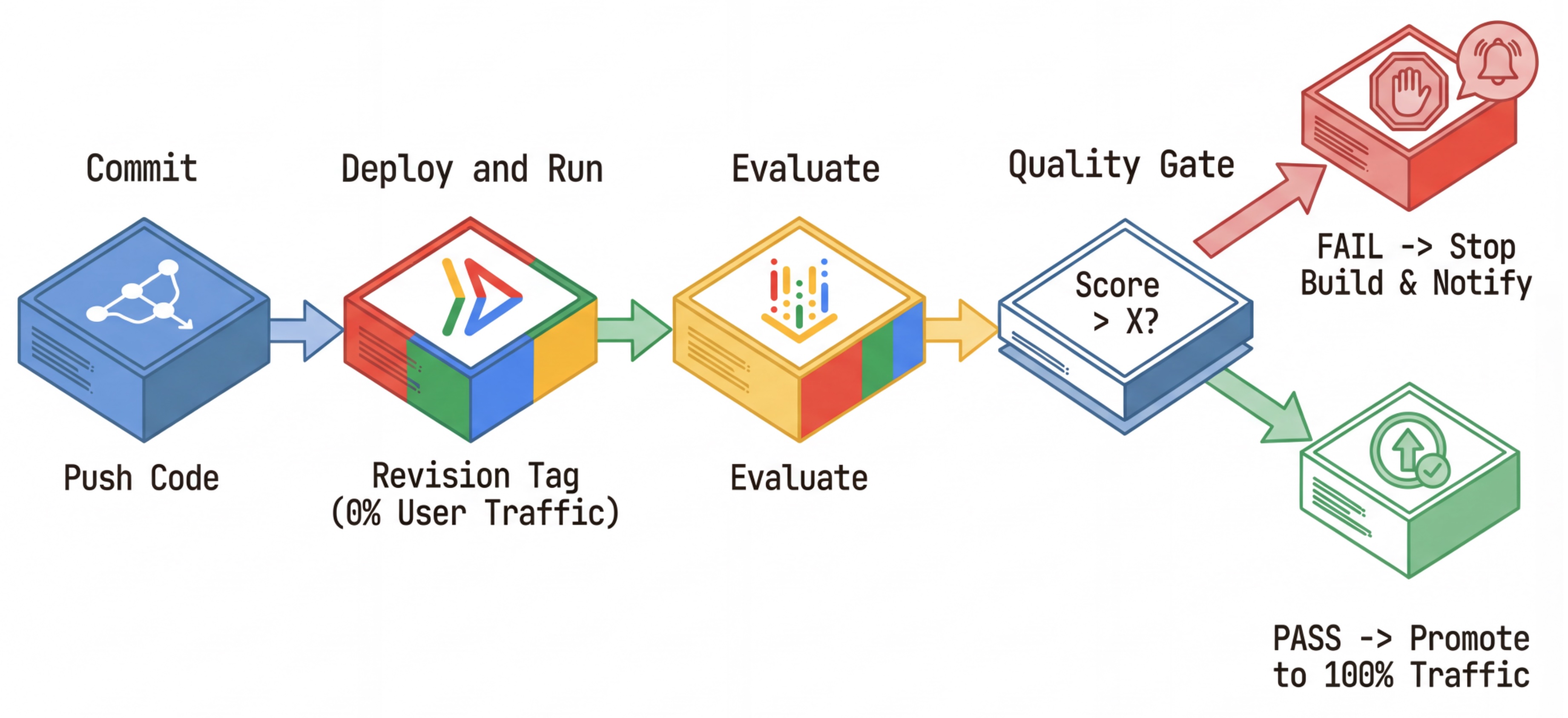
Quy trình CI/CD: Triển khai, Đánh giá, Thúc đẩy
Chúng tôi sử dụng quy trình này cho quy trình Triển khai liên tục mạnh mẽ:
- Cam kết: Bạn thay đổi câu lệnh của tác nhân và đẩy câu lệnh đó vào kho lưu trữ.
- Triển khai (Ẩn): Thao tác này sẽ kích hoạt việc triển khai một bản sửa đổi mới được gắn thẻ bằng hàm băm cam kết (ví dụ:
c-abc1234). Bản sửa đổi này nhận được 0% lưu lượng truy cập công khai. - Đánh giá: Tập lệnh đánh giá nhắm đến URL bản sửa đổi cụ thể
https://c-abc1234---researcher-xyz.run.app. - Quảng bá: Nếu (và chỉ khi) quá trình đánh giá vượt qua và các kiểm thử khác thành công, bạn sẽ di chuyển lưu lượng truy cập sang bản sửa đổi mới này.
- Khôi phục: Nếu không thành công, người dùng sẽ không bao giờ thấy phiên bản không tốt và bạn chỉ cần bỏ qua hoặc xoá bản sửa đổi không tốt.
Chiến lược này cho phép bạn kiểm thử trong quá trình phát hành mà không ảnh hưởng đến khách hàng.
Phân tích evaluate.sh
Mở evaluate.sh. Tập lệnh này sẽ tự động hoá quy trình.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh sẽ xử lý việc triển khai bản sửa đổi bằng các lựa chọn --no-traffic và --tag. Nếu đã có một dịch vụ đang chạy, thì dịch vụ đó sẽ không bị ảnh hưởng. Bản sửa đổi "ẩn" mới sẽ không nhận được lưu lượng truy cập, trừ phi bạn gọi rõ ràng bản sửa đổi đó bằng một URL đặc biệt có chứa thẻ bản sửa đổi (ví dụ: https://c-abc1234---researcher-xyz.run.app)
5. Triển khai Tập lệnh đánh giá
Bây giờ, hãy viết mã thực sự chạy các kiểm thử.
- Mở
evaluator/evaluate_agent.py. - Bạn sẽ thấy các mục nhập và chế độ thiết lập, nhưng thiếu các chỉ số và logic thực thi.
Xác định các chỉ số
Đối với Researcher Agent, chúng tôi có "Câu trả lời vàng"/"Thông tin thực tế" với các câu trả lời dự kiến. Đây là một Đánh giá năng lực: chúng tôi đang đo lường xem liệu tác nhân có thể hoàn thành công việc một cách chính xác hay không.
Chúng tôi muốn đo lường:
- Final Response Match (Khả năng): Câu trả lời có khớp với câu trả lời dự kiến không? Đây là một chỉ số dựa trên thông tin tham khảo. Công cụ này sử dụng một LLM đánh giá để so sánh kết quả đầu ra của tác nhân với câu trả lời dự kiến. Mô hình này không mong đợi câu trả lời hoàn toàn giống nhau, mà là tương tự về mặt ngữ nghĩa và thực tế.
- Chất lượng sử dụng công cụ: (Chất lượng) Một chỉ số về thang điểm thích ứng có mục tiêu, đánh giá việc lựa chọn công cụ phù hợp, việc sử dụng đúng tham số và việc tuân thủ trình tự hoạt động được chỉ định.
- Quỹ đạo sử dụng công cụ: (Dấu vết) 2 chỉ số tuỳ chỉnh đo lường quỹ đạo sử dụng công cụ của tác nhân (độ chính xác và khả năng thu hồi) so với quỹ đạo dự kiến. Các chỉ số này được triển khai trong
shared/evaluation/tool_metrics.pydưới dạng các hàm tuỳ chỉnh. Không giống như Chất lượng sử dụng công cụ, chỉ số này là một chỉ số dựa trên thông tin tham chiếu mang tính xác định – mã này thực sự xem xét liệu các lệnh gọi công cụ thực tế có khớp với dữ liệu tham chiếu hay không (reference_trajectorytrong dữ liệu đánh giá).
Chỉ số về quỹ đạo sử dụng công cụ tuỳ chỉnh
Đối với các chỉ số Tuỳ chỉnh về quỹ đạo sử dụng công cụ, chúng tôi đã tạo một bộ hàm Python trong shared/evaluation/tool_metrics.py. Để cho phép Vertex AI Gen AI Evaluation Service thực thi các hàm này, chúng ta cần truyền mã Python đó cho dịch vụ.
Bạn có thể thực hiện việc này bằng cách xác định một đối tượng EvaluationRunMetric có cấu hình UnifiedMetric và CustomCodeExecutionSpec. Tham số remote_custom_function là một chuỗi chứa mã Python của hàm. Hàm phải được đặt tên là evaluate:
def evaluate(
instance: dict
) -> float:
...
Chúng tôi đã tạo trình trợ giúp get_custom_function_metric (trong shared/evaluation/evaluate.py) để chuyển đổi một hàm Python thành chỉ số đánh giá mã tuỳ chỉnh.
Thao tác này sẽ lấy mã của mô-đun hàm (để nắm bắt các phần phụ thuộc cục bộ), tạo một hàm evaluate bổ sung gọi hàm ban đầu và trả về một đối tượng EvaluationRunMetric có CustomCodeExecutionSpec.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Gen AI Evaluation Service sẽ thực thi mã đó trong môi trường thực thi hộp cát và sẽ truyền dữ liệu đánh giá đến mã đó.
Thêm Chỉ số và Mã đánh giá
Thêm mã sau vào evaluator/evaluate_agent.py sau dòng if __name__ == "__main__":.
Thao tác này xác định danh sách chỉ số cho tác nhân Nhà nghiên cứu và chạy quy trình đánh giá.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
Trong quy trình sản xuất thực tế, bạn cần có Tiêu chí đánh giá mức độ thành công. Sau khi quá trình đánh giá hoàn tất và các chỉ số đã sẵn sàng. Bạn sẽ có một Bước sàng lọc tại đây. Ví dụ: "Nếu điểm Final Response Match < 0,75, thì không tạo được bản dựng." Điều này giúp ngăn các bản sửa đổi không phù hợp nhận được lưu lượng truy cập.
Thêm mã sau vào evaluator/evaluate_agent.py:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Bất cứ khi nào giá trị trung bình của bất kỳ chỉ số đánh giá nào thấp hơn một ngưỡng (0.75), quá trình triển khai sẽ thất bại.
[Không bắt buộc] Thêm quy trình Đánh giá bằng các chỉ số không cần tham chiếu cho Orchestrator
Đối với Orchestrator Agent, các hoạt động tương tác sẽ phức tạp hơn và không phải lúc nào chúng ta cũng có một câu trả lời "chính xác". Thay vào đó, chúng tôi đánh giá hành vi chung bằng một trong những Chỉ số không cần tham chiếu.
- Ảo giác: Một chỉ số dựa trên điểm số, kiểm tra tính xác thực và tính nhất quán của các câu trả lời bằng văn bản bằng cách phân đoạn câu trả lời thành các tuyên bố riêng lẻ. Công cụ này xác minh xem mỗi tuyên bố có căn cứ hay không dựa trên việc sử dụng công cụ trong các sự kiện trung gian. Điều này rất quan trọng đối với các tác nhân có phạm vi mở, trong đó "tính chính xác" mang tính chủ quan nhưng "tính chân thực" là điều không thể thương lượng. Điểm số này được tính bằng tỷ lệ phần trăm số tuyên bố dựa trên nội dung nguồn. Trong trường hợp này, chúng tôi kỳ vọng phản hồi cuối cùng của Orchestrator (do Content Builder tạo ra) sẽ dựa trên nội dung mà Researcher truy xuất bằng công cụ Tìm kiếm trên Wikipedia.
Thêm logic đánh giá cho Orchestrator:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Kiểm tra dữ liệu đánh giá
Mở thư mục evaluator/. Bạn sẽ thấy 2 tệp dữ liệu:
eval_data_researcher.json: Câu lệnh và thông tin tham khảo chính xác/cơ bản cho Nhà nghiên cứu.eval_data_orchestrator.json: Câu lệnh cho Orchestrator (chúng tôi chỉ thực hiện đánh giá không tham chiếu cho Orchestrator).
Mỗi mục nhập thường chứa:
prompt: Câu lệnh cho trợ lý.reference: Câu trả lời lý tưởng (sự thật cơ bản), nếu có.reference_trajectory: Trình tự dự kiến của các lệnh gọi công cụ.
6. Tìm hiểu về Mã đánh giá
Mở shared/evaluation/evaluate.py. Mô-đun này chứa logic cốt lõi để chạy các quy trình đánh giá. Chức năng chính là evaluate_agent.
Thao tác này thực hiện các bước sau:
- Tải dữ liệu: Đọc tập dữ liệu đánh giá (câu lệnh và thông tin tham khảo) từ một tệp.
- Suy luận song song: Chạy tác nhân song song với tập dữ liệu. Thao tác này xử lý việc tạo phiên, gửi câu lệnh và ghi lại cả phản hồi cuối cùng cũng như dấu vết thực thi công cụ trung gian.
- Vertex AI Evaluation: Hợp nhất dữ liệu đánh giá ban đầu với các câu trả lời cuối cùng và dấu vết thực thi công cụ trung gian, đồng thời gửi kết quả đến Vertex AI Evaluation Service bằng GenAI Client trong Vertex AI SDK. Dịch vụ này chạy các Chỉ số đã định cấu hình để chấm điểm hiệu suất của nhân viên hỗ trợ.
Khoảnh khắc quan trọng của bước cuối cùng là gọi hàm create_evaluation_run của mô-đun eval trong Gen AI SDK:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Chúng ta thực hiện việc này trong hàm evaluate_agent trong shared/evaluation/evaluate.py.
Thao tác này sẽ lấy tập dữ liệu đánh giá đã hợp nhất, thông tin về tác nhân, các chỉ số cần sử dụng và URI lưu trữ đích. Hàm này tạo một lần chạy đánh giá trong Dịch vụ đánh giá Vertex AI và trả về đối tượng lần chạy đánh giá.
Agent Info API
Để thực hiện đánh giá chính xác, Dịch vụ đánh giá cần biết cấu hình của tác nhân (hướng dẫn hệ thống, nội dung mô tả và các công cụ có sẵn). Chúng ta truyền nó đến create_evaluation_run dưới dạng tham số agent_info.
Nhưng làm cách nào để chúng tôi có được thông tin này? Chúng tôi đưa nó vào API Dịch vụ ADK.
Mở shared/adk_app.py rồi tìm def agent_info. Bạn sẽ thấy rằng ứng dụng ADK hiển thị một điểm cuối trợ giúp:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Điểm cuối này (được bật thông qua cờ --publish_agent_info) cho phép tập lệnh đánh giá linh hoạt tìm nạp cấu hình thời gian chạy của tác nhân. Điều này rất quan trọng đối với những chỉ số đánh giá mức độ sử dụng công cụ, vì mô hình đánh giá có thể đánh giá mức độ sử dụng công cụ của tác nhân hiệu quả hơn nếu biết cụ thể những công cụ mà tác nhân có thể sử dụng trong cuộc trò chuyện.
7. Chạy quy trình Đánh giá
Giờ đây, bạn đã triển khai trình đánh giá, hãy kích hoạt trình đánh giá này!
- Chạy tập lệnh đánh giá từ gốc của kho lưu trữ:
./evaluate.sh- Lệnh này sẽ lấy hàm băm của cam kết git hiện tại.
- Thao tác này sẽ gọi
deploy.shđể triển khai một bản sửa đổi có thẻ dựa trên hàm băm của cam kết. - Sau khi triển khai, quá trình này sẽ bắt đầu
evaluator.evaluate_agent. - Bạn sẽ thấy các thanh tiến trình khi công cụ này chạy các trường hợp kiểm thử đối với dịch vụ đám mây của bạn.
- Cuối cùng, nó in một tệp JSON tóm tắt về kết quả.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Lưu ý: Lần chạy đầu tiên có thể mất vài phút để triển khai các dịch vụ.
8. Trực quan hoá kết quả trong sổ tay
Khó đọc thông tin xuất JSON thô. Ứng dụng Gen AI Client trong Vertex AI SDK cung cấp một cách để theo dõi các lần chạy này theo thời gian. Chúng ta sẽ sử dụng một sổ tay Colab để trực quan hoá kết quả.
- Mở
evaluator/show_evaluation_run.ipynbtrong Google Colab bằng đường liên kết này. - Đặt các biến
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONvàEVAL_RUN_IDthành mã dự án, vùng và mã chạy của bạn.
- Cài đặt các phần phụ thuộc và xác thực.
Truy xuất Lần đánh giá và hiển thị kết quả
Chúng ta cần tìm nạp dữ liệu chạy đánh giá từ Vertex AI. Tìm ô trong phần Truy xuất kết quả chạy đánh giá và hiển thị kết quả rồi thay thế dòng # TODO bằng khối mã sau:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Diễn giải kết quả
Khi xem kết quả, hãy lưu ý những điều sau:
- Hồi quy so với Khả năng:
- Hồi quy: Điểm số có giảm trong các bài kiểm thử cũ không? (Không tốt, cần điều tra).
- Khả năng: Điểm số có cải thiện trong các bài kiểm tra mới không? (Tốt, đây là một bước tiến).
- Phân tích lỗi: Đừng chỉ xem điểm số.
- Xem dấu vết. Có phải trợ lý đã gọi sai công cụ không? Có phải nó không phân tích cú pháp được đầu ra không? Đây là nơi bạn tìm thấy lỗi.
- Xem phần giải thích và kết quả do LLM thẩm phán đưa ra. Chúng thường cho bạn biết lý do khiến kiểm thử không thành công.
Pass@1 so với Pass@k: Khi chạy một kiểm thử nhất định một lần, chúng ta sẽ nhận được điểm Pass@1. Nếu một tác nhân không hoạt động, thì có thể là do tính không xác định. Trong các chế độ thiết lập phức tạp, bạn có thể chạy mỗi thử nghiệm k lần (ví dụ: 5 lần) và tính pass@k (có thành công ít nhất một lần không?) hoặc pass^k (có thành công mỗi lần không?). Đây là điều mà nhiều chỉ số đã thực hiện nâng cao. Ví dụ: types.RubricMetric.FINAL_RESPONSE_MATCH (So khớp câu trả lời cuối cùng) thực hiện 5 lệnh gọi đến LLM của người đánh giá để xác định điểm số so khớp câu trả lời cuối cùng.
9. Tích hợp và triển khai liên tục (CI/CD)
Trong hệ thống sản xuất, quá trình đánh giá tác nhân phải được chạy trong quy trình CI/CD. Cloud Build là một lựa chọn phù hợp cho việc này.
Đối với mỗi cam kết được chuyển đến kho lưu trữ mã của tác nhân, quá trình đánh giá sẽ chạy cùng với các kiểm thử còn lại. Nếu vượt qua, quá trình triển khai có thể được "quảng bá" để phục vụ các yêu cầu của người dùng. Nếu không thành công, mọi thứ vẫn giữ nguyên, nhưng nhà phát triển có thể xem xét vấn đề đã xảy ra.
Cấu hình Cloud Build
Bây giờ, hãy tạo một tập lệnh cấu hình triển khai Cloud Run thực hiện các bước sau:
- Triển khai Dịch vụ cho một bản sửa đổi riêng tư.
- Chạy quy trình Đánh giá tác nhân.
- Nếu vượt qua quy trình đánh giá, thì quy trình này sẽ "xúc tiến" việc triển khai bản sửa đổi để phân phát 100% lưu lượng truy cập.
Tạo cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Chạy quy trình
Cuối cùng, chúng ta có thể chạy quy trình đánh giá.
Trước khi chạy quy trình đánh giá đưa ra các yêu cầu đối với dịch vụ Cloud Run, chúng ta cần một Tài khoản dịch vụ riêng biệt có một số quyền. Hãy viết một tập lệnh thực hiện việc đó và khởi chạy quy trình.
- Tạo tập lệnh
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Tạo một Tài khoản dịch vụ chuyên dụng
agent-eval-build-sa. - Cấp cho ứng dụng các vai trò cần thiết (
roles/run.admin,roles/aiplatform.user, v.v.). *. Gửi bản dựng đến Cloud Build.
- Tạo một Tài khoản dịch vụ chuyên dụng
- Chạy quy trình:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Bạn có thể xem tiến trình tạo trong thiết bị đầu cuối hoặc nhấp vào đường liên kết đến Bảng điều khiển Cloud.
Lưu ý: Trong môi trường sản xuất thực tế, bạn sẽ thiết lập một Trình kích hoạt Cloud Build để tự động chạy quy trình này trên mọi git push. Quy trình này vẫn giữ nguyên: điều kiện kích hoạt sẽ thực thi cloudbuild.yaml, đảm bảo mọi cam kết đều được đánh giá.
10. Tóm tắt
Bạn đã tạo thành công một Quy trình đánh giá!
- Triển khai: Bạn đã sử dụng thẻ sửa đổi có hàm băm cam kết git để triển khai các tác nhân một cách an toàn vào môi trường thực để kiểm thử mà không ảnh hưởng đến việc triển khai sản xuất.
- Đánh giá: Bạn đã xác định các chỉ số đánh giá và tự động hoá quy trình đánh giá bằng Dịch vụ đánh giá AI tạo sinh của Vertex AI.
- Phân tích: Bạn đã sử dụng Sổ tay Colab để trực quan hoá kết quả đánh giá và cải thiện tác nhân của mình.
- Triển khai: Bạn đã sử dụng Cloud Build để tự động thực thi quy trình đánh giá và đề xuất bản sửa đổi tốt nhất để phân phát 100% lưu lượng truy cập.
Chu trình Chỉnh sửa mã -> Triển khai thẻ -> Chạy quy trình đánh giá và kiểm thử -> Phân tích -> Triển khai -> Lặp lại là cốt lõi của Kỹ thuật dựa trên tác nhân cấp sản xuất.