
1. Einführung
Übersicht
Sie sind Entwickler bei einem Unternehmen, das Marketing für Reiseunternehmen anbietet. Ihre Vertriebsabteilung hat beschlossen, dass sie eine neue Chatanwendung benötigt, um mit den großen Buchungs- und Suchunternehmen mithalten zu können. Sie haben auch schon von generativer KI gehört, wissen aber nicht viel darüber. Andere Abteilungen haben von dieser Initiative gehört und sind neugierig, wie sie auch ihre Kundenzufriedenheit verbessern können.
Aufgaben
In diesem Lab erstellen Sie mit dem Modell Gemini 2.5 Flash in Vertex AI einen Reiseassistenten-Chatbot.
Die Anwendung sollte:
- Hilft Nutzern, Fragen zu Reisen zu stellen, Reisen zu buchen und sich über Orte zu informieren, die sie besuchen möchten
- Nutzer können sich Hilfe bei der Planung ihrer Reise holen.
- Mit Tools Echtzeitdaten wie Wetterdaten abrufen
Sie arbeiten in einer vorkonfigurierten Google Cloud-Umgebung, genauer gesagt im Cloud Shell Editor. Ein einfaches Webanwendungs-Frontend ist bereits für Sie eingerichtet, ebenso wie die erforderlichen Berechtigungen für den Zugriff auf Vertex AI. Diese App wurde mit Streamlit entwickelt.
Lerninhalte
Aufgaben in diesem Lab:
- Vertex AI-Plattform mit den verfügbaren generativen KI-Modellen kennenlernen
- Entwickeln im Cloud Shell-Editor und im Terminal
- Gemini Code Assist verwenden, um Code zu verstehen
- Mit dem Vertex AI SDK in Python können Sie Prompts an ein Gemini-LLM senden und Antworten von diesem empfangen.
- Wenden Sie grundlegendes Prompt Engineering (Systemanweisungen, Modellparameter) an, um die Ausgabe eines Gemini-LLM anzupassen.
- Testen und optimieren Sie eine LLM-basierte Chatanwendung, indem Sie Prompts und Parameter anpassen, um die Antworten zu verbessern.
- Definieren und verwenden Sie Tools mit dem Gemini-Modell, um Funktionsaufrufe zu ermöglichen.
- Code umgestalten, um eine statusbehaftete Chatsitzung zu verwenden. Dies ist eine Best Practice für Conversational Apps.
2. Projekt einrichten
Google-Konto
Wenn Sie noch kein privates Google-Konto haben, müssen Sie ein Google-Konto erstellen.
Verwenden Sie stattdessen ein privates Konto.
In der Google Cloud Console anmelden
Melden Sie sich mit einem privaten Google-Konto in der Google Cloud Console an.
Abrechnung aktivieren
Google Cloud-Guthaben einlösen (optional)
Für diesen Workshop benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben eingerichtet haben, können Sie diesen Schritt überspringen.
Aktivieren Sie die Abrechnung in der Cloud Console, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die Kosten für Cloud-Ressourcen für dieses Lab sollten weniger als 1 $betragen.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf die kostenlose Testversion mit einem Guthaben von 300$.
Projekt erstellen (optional)
Wenn Sie kein aktuelles Projekt haben, das Sie für dieses Lab verwenden möchten, erstellen Sie hier ein neues Projekt.
3. Cloud Shell-Editor öffnen
- Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- Wenn Sie heute an irgendeinem Punkt zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
- Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal
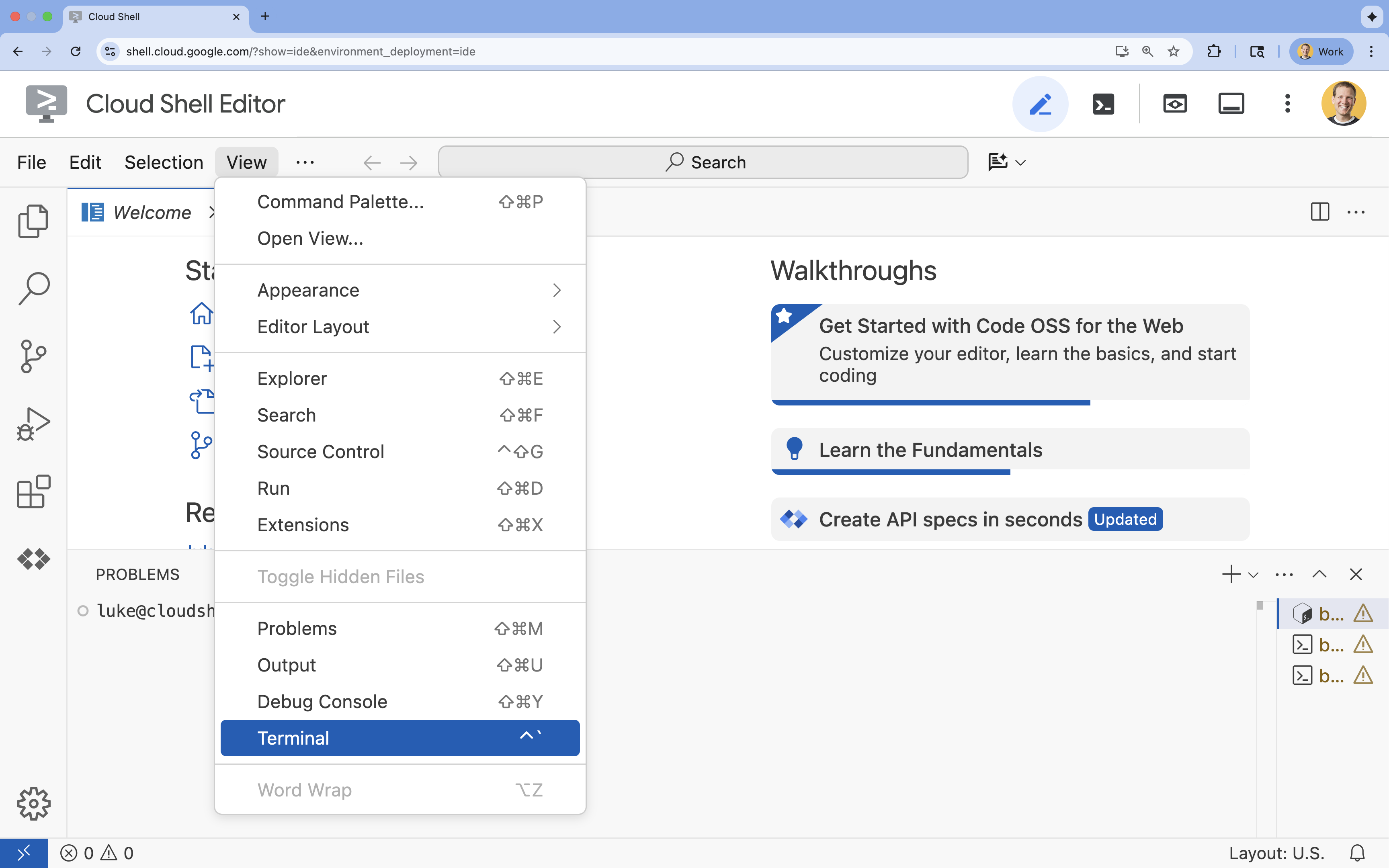 .
.
- Legen Sie im Terminal Ihr Projekt mit diesem Befehl fest:
gcloud config set project [PROJECT_ID]- Beispiel:
gcloud config set project lab-project-id-example - Wenn Sie sich nicht mehr an Ihre Projekt-ID erinnern, können Sie alle Ihre Projekt-IDs mit folgendem Befehl auflisten:
gcloud projects list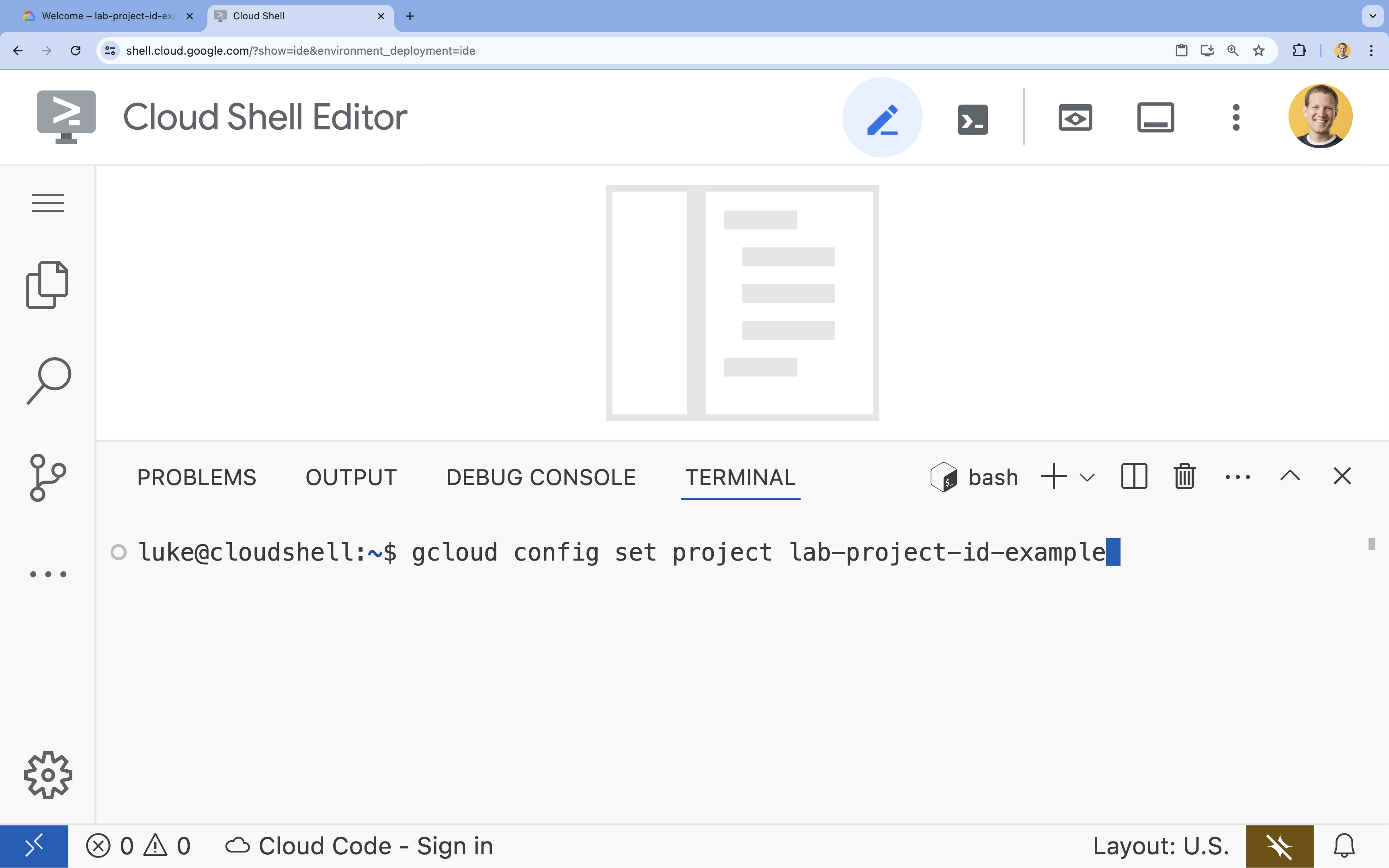
- Beispiel:
- Es sollte folgende Meldung angezeigt werden:
Updated property [core/project].
4. APIs aktivieren
Wenn Sie das Vertex AI SDK verwenden und mit dem Gemini-Modell interagieren möchten, müssen Sie die Vertex AI API in Ihrem Google Cloud-Projekt aktivieren.
- Aktivieren Sie die APIs im Terminal:
gcloud services enable \ aiplatform.googleapis.com
Einführung in das Vertex AI SDK für Python
Wenn Sie in Ihrer Python-Anwendung mit Modellen interagieren möchten, die auf Vertex AI gehostet werden, verwenden Sie das Vertex AI SDK für Python. Dieses SDK vereinfacht das Senden von Prompts, das Festlegen von Modellparametern und das Empfangen von Antworten, ohne dass die Komplexität der zugrunde liegenden API-Aufrufe direkt berücksichtigt werden muss.
Eine umfassende Dokumentation zum Vertex AI SDK für Python finden Sie hier: Einführung in das Vertex AI SDK für Python | Google Cloud.
5. Virtuelle Umgebung erstellen und Abhängigkeiten installieren
Bevor Sie ein Python-Projekt starten, sollten Sie eine virtuelle Umgebung erstellen. Dadurch werden die Abhängigkeiten des Projekts isoliert und Konflikte mit anderen Projekten oder den globalen Python-Paketen des Systems vermieden.
- Erstellen Sie einen Ordner mit dem Namen
wanderbot, um den Code für Ihre Reiseassistenten-App zu speichern. Führen Sie den folgenden Code im Terminal aus:mkdir wanderbot && cd wanderbot - Erstellen und aktivieren Sie eine virtuelle Umgebung:
uv venv --python 3.12 source .venv/bin/activatewanderbot) angezeigt, was darauf hinweist, dass die virtuelle Umgebung aktiv ist. Das würde in etwa so aussehen:
6. Starterdateien für Wanderbot erstellen
- Erstellen Sie eine neue
app.py-Datei für die Anwendung und öffnen Sie sie. Führen Sie im Terminal den folgenden Code aus:cloudshell edit app.pycloudshell editwird die Dateiapp.pyim Editor über dem Terminal geöffnet. - Fügen Sie den folgenden App-Startcode in
app.pyein:import streamlit as st from google import genai from google.genai import types import requests import logging # --- Defining variables and parameters --- REGION = "global" PROJECT_ID = None # TODO: Insert Project ID GEMINI_MODEL_NAME = "gemini-2.5-flash" temperature = .2 top_p = 0.95 system_instructions = None # --- Tooling --- # TODO: Define the weather tool function declaration # TODO: Define the get_current_temperature function # --- Initialize the Vertex AI Client --- try: # TODO: Initialize the Vertex AI client print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}") except Exception as e: st.error(f"Error initializing VertexAI client: {e}") st.stop() # TODO: Add the get_chat function here in Task 15. # --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions. It will be replaced in a later step with a more advanced version that handles tooling. """ try: # TODO: Prepare the content for the model # TODO: Define generate_content configuration (needed for system instructions and parameters) # TODO: Define response logging.info(f"[call_model_response] LLM Response: \"{response.text}\"") # TODO: Uncomment the below "return response.text" line # return response.text except Exception as e: return f"Error: {e}" # --- Presentation Tier (Streamlit) --- # Set the title of the Streamlit application st.title("Travel Chat Bot") # Initialize session state variables if they don't exist if "messages" not in st.session_state: # Initialize the chat history with a welcome message st.session_state["messages"] = [ {"role": "assistant", "content": "How can I help you today?"} ] # Display the chat history for msg in st.session_state.messages: st.chat_message(msg["role"]).write(msg["content"]) # Get user input if prompt := st.chat_input(): # Add the user's message to the chat history st.session_state.messages.append({"role": "user", "content": prompt}) # Display the user's message st.chat_message("user").write(prompt) # Show a spinner while waiting for the model's response with st.spinner("Thinking..."): # Get the model's response using the call_model function model_response = call_model(prompt, GEMINI_MODEL_NAME) # Add the model's response to the chat history st.session_state.messages.append( {"role": "assistant", "content": model_response} ) # Display the model's response st.chat_message("assistant").write(model_response) - Erstellen Sie eine neue
requirements.txt-Datei für den Anwendungscode und öffnen Sie sie. Führen Sie im Terminal den folgenden Code aus:cloudshell edit requirements.txtcloudshell editwird die Dateirequirements.txtim Editor über dem Terminal geöffnet. - Fügen Sie den folgenden App-Startcode in
requirements.txtein.google-genai streamlit requests - Installieren Sie die erforderlichen Python-Abhängigkeiten für dieses Projekt. Führen Sie im Terminal den folgenden Code aus:
uv pip install -r requirements.txt
7. Code ansehen
Die von Ihnen erstellten Dateien enthalten ein einfaches Chat-Anwendungs-Frontend. Sie enthalten Folgendes:
app.py: In dieser Datei werden wir arbeiten. Derzeit enthält er Folgendes:- Erforderliche Importe
- Umgebungsvariablen und Parameter (einige davon sind Platzhalter)
- eine leere
call_model-Funktion, die wir gleich ausfüllen werden - Streamlit-Code für die Frontend-Chat-App
requirements.txt:- enthält die Installationsanforderungen für die Ausführung von
app.py
- enthält die Installationsanforderungen für die Ausführung von
Sehen wir uns jetzt den Code an.
Gemini Code Assist-Chat öffnen
Der Gemini Code Assist-Chat sollte bereits in einem Bereich rechts im Cloud Shell-Editor geöffnet sein. Wenn der Gemini Code Assist-Chat noch nicht geöffnet ist, können Sie ihn so öffnen:
- Klicken Sie oben auf dem Bildschirm auf die Schaltfläche für Gemini Code Assist (
 ).
). - Wählen Sie Gemini Code Assist-Chat öffnen aus.
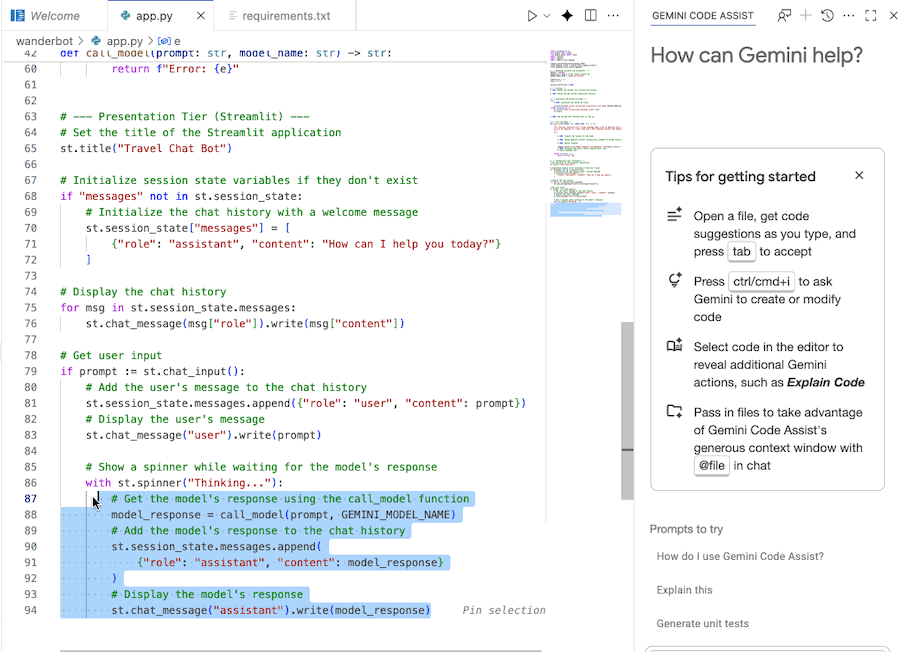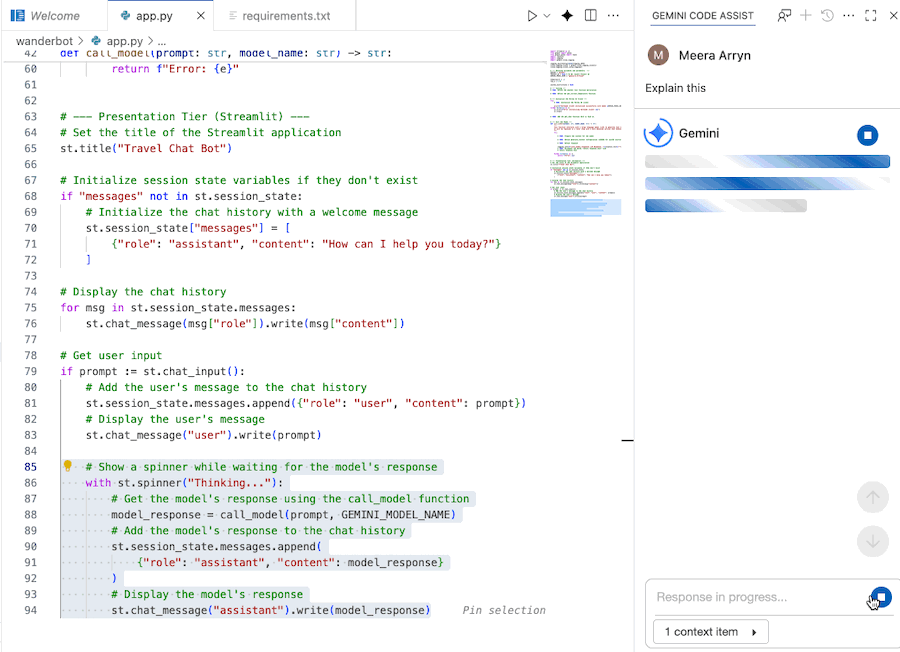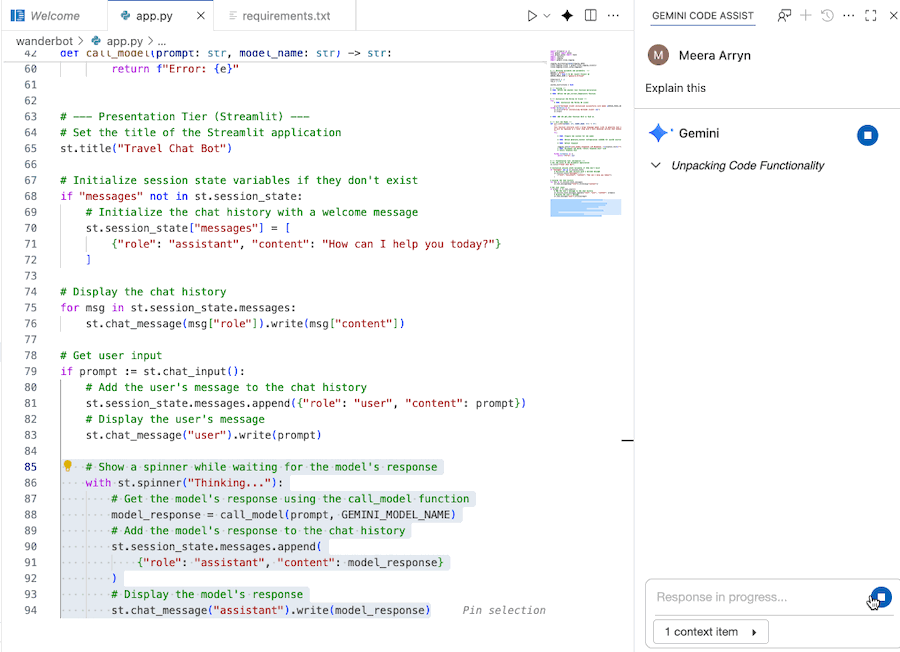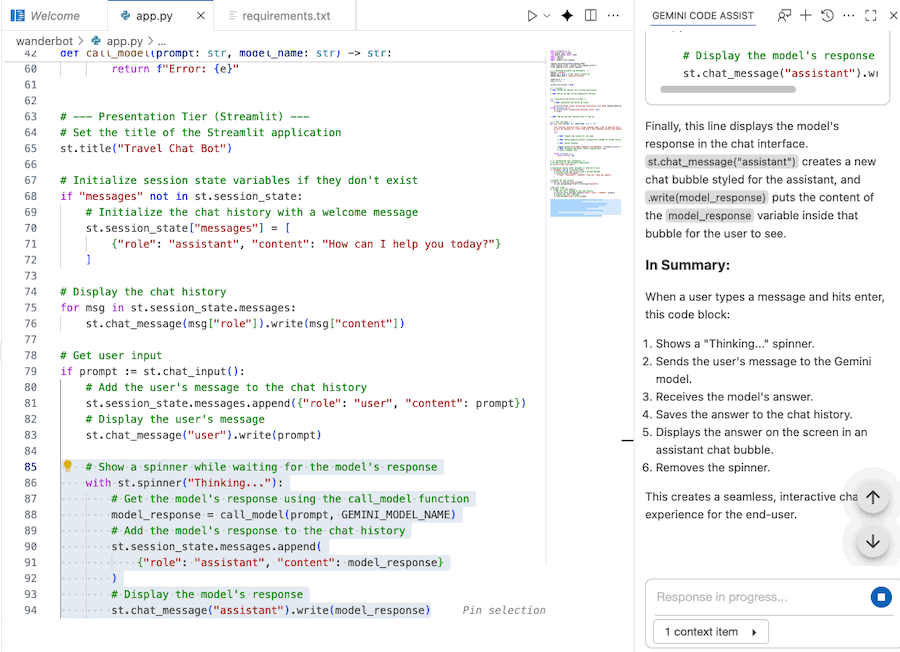
Code mit Gemini Code Assist analysieren
Sie können den Gemini Code Assist-Chat verwenden, um den Code besser zu verstehen.
- Markieren oder wählen Sie den gewünschten Codeabschnitt aus.
- Geben Sie im Gemini-Chat „Erkläre diesen Code“ ein.
- Zum Senden die Eingabetaste drücken
8. Webanwendung starten
Bevor Sie diese App mit einem LLM verbinden, sollten Sie sie starten, um zu sehen, wie sie sich verhält.
- Führen Sie im
wanderbot-Verzeichnis den folgenden Befehl im Terminal aus, um die Streamlit-Anwendung zu starten und sie lokal in Ihrer Cloud Shell-Umgebung verfügbar zu machen:streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Klicken Sie nach dem Ausführen des Befehls oben im Cloud Shell-Editor auf die Schaltfläche Webvorschau und wählen Sie Vorschau auf Port 8080 aus.
Sie sehen eine einfache Chat-Oberfläche für Ihre Reise-App. - Geben Sie eine beliebige Nachricht ein (z.B.
Hi!) und drücken Sie die Eingabetaste.
Die Nachricht wird im Chatverlauf angezeigt, Sie erhalten jedoch eine Fehlermeldung anstelle einer Antwort vom Assistenten. Das liegt daran, dass die Anwendung noch nicht mit einem Large Language Model verbunden ist. Beobachten Sie dieses Verhalten, um den Ausgangspunkt des Labs zu verstehen.
9. Vertex AI-Client initialisieren
Verfügbare Modelle in Vertex AI kennenlernen
Die Vertex AI-Plattform von Google Cloud bietet Zugriff auf eine Vielzahl von generativen KI-Modellen. Bevor Sie eine integrieren, können Sie sich die verfügbaren Optionen in der Google Cloud Console ansehen.
- Rufen Sie in der Google Cloud Console Model Garden auf. Suchen Sie dazu in der Suchleiste oben auf dem Bildschirm nach „Model Garden“ und wählen Sie Vertex AI aus.(
 )
) - Sehen Sie sich die verfügbaren Modelle an. Sie können nach Modalitäten, Aufgabentypen und Funktionen filtern.
In diesem Lab verwenden Sie das Gemini 2.5 Flash-Modell, das aufgrund seiner Geschwindigkeit eine gute Wahl für die Entwicklung reaktionsschneller Chatanwendungen ist.
Vertex AI-Client initialisieren
Ändern Sie nun den Abschnitt --- Initialize the Vertex AI Client --- in app.py, um den Vertex AI-Client zu initialisieren. Dieses Client-Objekt wird verwendet, um Prompts an das Modell zu senden.
- Öffnen Sie
app.pyim Cloud Shell-Editor. - Suchen Sie in
app.pynach der ZeilePROJECT_ID = None. - Ersetzen Sie
Nonedurch Ihre Google Cloud-Projekt-ID in Anführungszeichen. (z.B.PROJECT_ID = "google-cloud-labs")
Wenn Sie sich nicht an Ihre Projekt-ID erinnern können, können Sie alle Ihre Projekt-IDs mit folgendem Befehl auflisten:gcloud projects list | awk '/PROJECT_ID/{print $2}' - Client definieren: Initialisieren Sie den Vertex AI-Client im
try-Block.client = genai.Client( vertexai=True, project=PROJECT_ID, location=REGION, )
Aktualisierte Vertex AI-Clientinitialisierung
An dieser Stelle sieht der Abschnitt „Vertex AI-Client initialisieren“ so aus:
# --- Initialize the Vertex AI Client ---
try:
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=REGION,
)
print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}")
except Exception as e:
st.error(f"Error initializing VertexAI client: {e}")
st.stop()
10. Daten vorbereiten und Modell aufrufen
Jetzt bereiten Sie die Inhalte vor, die an das Modell gesendet werden sollen, und rufen das Gemini-Modell auf.
- Suchen Sie den Abschnitt
--- Call the Model ---, in dem die Funktioncall_modeldefiniert ist. - Inhalte definieren: Definieren Sie unter
# TODO: Prepare the content for the modeldie Eingabeinhalte , die an das Modell gesendet werden. Bei einem einfachen Prompt ist das die Eingabenachricht des Nutzers.contents = [prompt] - Antwort definieren: Fügen Sie diesen Code unter
# TODO: Define responseein.response = client.models.generate_content( model=model_name, contents=contents, ) - Antwort zurückgeben: Entfernen Sie die Kommentarzeichen in der folgenden Zeile:
return response.text - Sehen Sie sich die Zeile an, in der die Funktion
call_modelaufgerufen wird. Sie befindet sich unten in der Datei im Blockwith. Wenn Sie nicht verstehen, was hier passiert, markieren Sie die Zeile und bitten Sie Gemini Code Assist um eine Erklärung.
contents expliziter definieren
Die oben beschriebene Art der Definition von contents funktioniert, weil das SDK intelligent genug ist, um zu erkennen, dass eine Liste mit Strings die Texteingabe eines Nutzers darstellt. Sie wird automatisch für die Modell-API formatiert.
Die explizitere und grundlegendere Methode zum Strukturieren der Eingabe besteht jedoch darin, types.Part- und types.Content-Objekte zu verwenden:
user_message_parts = [types.Part.from_text(text=prompt)]
contents = [
types.Content(
role="user", # Indicates the content is from the user
parts=user_message_parts, # A list, allowing multiple types of content
),
]
Aktualisierte Funktion call_model
An dieser Stelle sollte die Funktion call_model so aussehen:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
# TODO: Define generate_content configuration (needed later for system instructions and parameters)
response = client.models.generate_content(
model=model_name,
contents=contents,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
11. Verbundene App testen
- Beenden Sie den aktuell laufenden Prozess im Terminal (STRG+C).
- Führen Sie den Befehl noch einmal aus, um die Streamlit-Anwendung neu zu starten.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Aktualisieren Sie die Streamlit-Anwendung. Wenn die Streamlit-Anwendung noch ausgeführt wird, können Sie die Seite mit der Webvorschau einfach in Ihrem Browser aktualisieren.
- Geben Sie nun eine Frage in die Chateingabe ein, z. B.:
What is the best time of year to go to Iceland? - Drücken Sie die Eingabetaste.
Die Anwendung sollte Ihre Nachricht, einen Spinner mit der Meldung „Wird analysiert…“ und dann eine vom Gemini-Modell generierte Antwort anzeigen. Wenn ja, haben Sie Ihre Webanwendung erfolgreich mit einem LLM in Vertex AI verbunden. 🙌 🥳
12. Systemanweisungen definieren
Die grundlegende Verbindung funktioniert zwar, aber die Qualität und der Stil der Antworten des LLM werden stark von den Eingaben beeinflusst. Prompt Engineering ist der Prozess, bei dem diese Eingaben (Prompts) so gestaltet und optimiert werden, dass das Modell die gewünschte Ausgabe generiert.
Dazu erstellen Sie zuerst einige Systemanweisungen und übergeben sie an das Modell.
Sie verwenden Gemini fragen, um hilfreiche Systemanweisungen zu erstellen.
- Suchen Sie in
app.pynach der Variablensystem_instructions, die derzeit aufNonefestgelegt ist.system_instructions = NoneNonedurch einen mehrzeiligen String mit Anweisungen für unseren Reiseassistenten-Bot. - Gemini Code Assist fragen: Geben Sie den folgenden Prompt in Gemini Code Assist ein (oder erstellen Sie einen eigenen):
I am a developer at a travel marketing company, and my sales department has decided that they need a new chat application to keep up with the bigger booking and search companies. I'm building a simple travel assistant chatbot using the Gemini 2.5 Flash model on Vertex AI. The application should: - Helps users ask questions about travel, book travel, and learn about places they are going to go - Provides users ways to get help about their specific travel plans - Provides all this in a production quality way (multiple environments, logging and monitoring, etc.) Please create system instructions appropriate for that chat app. Be thorough. Do not alter the code in any way beyond providing me with system instructions. system_instructionsdefinieren: Setzen Siesystem_instructionsgleich den Systemanweisungen, die Sie mit Gemini Code Assist generiert haben. Alternativ können Sie diese Systemanweisungen verwenden, die von Gemini mit einem ähnlichen Prompt erstellt wurden.system_instructions = """ You are a sophisticated travel assistant chatbot designed to provide comprehensive support to users throughout their travel journey. Your capabilities include answering travel-related questions, assisting with booking travel arrangements, offering detailed information about destinations, and providing support for existing travel plans. **Core Functionalities:** 1. **Travel Information and Recommendations:** * Answer user inquiries about travel destinations, including popular attractions, local customs, visa requirements, weather conditions, and safety advice. * Provide personalized recommendations for destinations, activities, and accommodations based on user preferences, interests, and budget. * Offer insights into the best times to visit specific locations, considering factors like weather, crowds, and pricing. * Suggest alternative destinations or activities if the user's initial choices are unavailable or unsuitable. 2. **Booking Assistance:** * Facilitate the booking of flights, hotels, rental cars, tours, and activities. * Search for available options based on user-specified criteria such as dates, destinations, budget, and preferences. * Present clear and concise information about available options, including pricing, amenities, and booking terms. * Guide users through the booking process, ensuring accurate information and secure transactions. * Provide booking confirmations and relevant details, such as booking references and contact information. 3. **Travel Planning and Itinerary Management:** * Assist users in creating detailed travel itineraries, including flights, accommodations, activities, and transportation. * Offer suggestions for optimizing travel plans, such as minimizing travel time or maximizing sightseeing opportunities. * Provide tools for managing and modifying existing itineraries, including adding or removing activities, changing booking dates, or upgrading accommodations. * Offer reminders and notifications for upcoming travel events, such as flight check-in or tour departure times. 4. **Customer Support and Troubleshooting:** * Provide prompt and helpful support to users with questions or issues related to their travel plans. * Assist with resolving booking discrepancies, cancellations, or modifications. * Offer guidance on travel-related emergencies, such as lost luggage or travel delays. * Provide access to relevant contact information for airlines, hotels, and other travel providers. **Interaction Guidelines:** * **Professionalism:** Maintain a polite, respectful, and professional tone in all interactions. * **Clarity and Conciseness:** Provide clear, concise, and easy-to-understand information. Avoid jargon or technical terms unless necessary and always explain them. * **Accuracy:** Ensure all information provided is accurate and up-to-date. Double-check details before sharing them with users. If unsure about something, admit that you don't know and offer to find the information. * **Personalization:** Tailor your responses and recommendations to the specific needs and preferences of each user. * **Proactive Assistance:** Anticipate user needs and offer relevant information or suggestions proactively. * **Error Handling:** Gracefully handle user errors or misunderstandings. Provide helpful guidance and alternative options when necessary. * **Confidentiality:** Respect user privacy and handle personal information with the utmost confidentiality and in compliance with data protection regulations. **Example Interactions:** **User:** "I want to go on a beach vacation in the Caribbean. I have a budget of $2000 per person for a week." **Chatbot:** "Certainly! The Caribbean offers many beautiful beach destinations within your budget. Some popular options include Punta Cana in the Dominican Republic, Cancun in Mexico, and Montego Bay in Jamaica. These destinations offer stunning beaches, all-inclusive resorts, and various activities. Would you like me to search for flights and accommodations for these locations based on your travel dates?" **User:** "My flight is delayed. What should I do?" **Chatbot:** "I'm sorry to hear about the delay. Please check with the airline for the updated departure time and any assistance they can offer. You may be entitled to compensation or rebooking options depending on the length of the delay and the airline's policy. Do you have your flight number handy so I can look up the current status for you?" **User:** "Tell me about the best time to visit Japan." **Chatbot:** "Japan is a fantastic destination with distinct seasons offering unique experiences. Spring (March-May) is famous for the beautiful cherry blossoms, while autumn (September-November) boasts stunning fall foliage. Both seasons have pleasant temperatures, making them ideal for sightseeing. Summer (June-August) can be hot and humid, but it's a great time for festivals and outdoor activities in the mountains. Winter (December-February) offers opportunities for skiing and snowboarding in the Japanese Alps, though some areas may experience heavy snowfall. To recommend the best time for you, could you tell me what you'd like to experience in Japan?" By following these instructions, you will be able to provide exceptional travel assistance and create a positive experience for every user. """- „generate_content“-Konfiguration definieren:Initialisieren Sie ein Konfigurationsobjekt, an das Sie diese Systemanweisungen übergeben. Da
system_instructionsglobal in unserem Skript definiert ist, kann die Funktion direkt darauf zugreifen.generate_content_config = types.GenerateContentConfig( system_instruction=[ types.Part.from_text(text=system_instructions) ], ) logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}") - Wenn Sie die Systemanweisungen in die Antwort einfügen möchten, fügen Sie der Methode
generate_contenteinenconfig-Parameter hinzu und legen Sie ihn auf das oben erstelltegenerate_content_config-Objekt fest.response = client.models.generate_content( model=model_name, contents=contents, config=generate_content_config, # This is the new line )
Aktualisierte Funktion call_model
Die vollständige call_model-Funktion sieht jetzt so aus:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
generate_content_config = types.GenerateContentConfig(
system_instruction=[
types.Part.from_text(text=system_instructions)
],
)
logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}")
response = client.models.generate_content(
model=model_name,
contents=contents,
config=generate_content_config,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
13. App mit Systemanweisungen testen
- Beenden Sie den aktuell laufenden Prozess im Terminal (STRG+C).
- Führen Sie den Befehl noch einmal aus, um die Streamlit-Anwendung neu zu starten.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Aktualisieren Sie die Streamlit-Anwendung. Wenn die Streamlit-Anwendung noch ausgeführt wird, können Sie die Seite mit der Webvorschau einfach in Ihrem Browser aktualisieren.
- Stellen Sie dieselbe Frage wie zuvor:
What is the best time of year to go to Iceland? - Drücken Sie die Eingabetaste.
Vergleichen Sie, wie das Modell diesmal im Vergleich zum letzten Mal reagiert.
14. Wettertool definieren
Bisher ist unser Chatbot zwar kompetent, sein Wissen ist jedoch auf die Daten beschränkt, mit denen er trainiert wurde. Es kann nicht auf Echtzeitinformationen zugreifen. Für einen Reise-Bot ist es ein großer Vorteil, Live-Daten wie Wettervorhersagen abrufen zu können.
Hier kommt Tooling ins Spiel, auch bekannt als Funktionsaufrufe. Wir können eine Reihe von Tools (Python-Funktionen) definieren, die das LLM aufrufen kann, um externe Informationen zu erhalten.
So funktioniert die Tooling-Funktion
- Wir beschreiben unsere Tools für das Modell, einschließlich ihrer Funktion und der Parameter, die sie verwenden.
- Der Nutzer sendet einen Prompt (z.B. Wie ist das Wetter in London?).
- Das Modell empfängt den Prompt und erkennt, dass der Nutzer nach etwas fragt, das es mit einem seiner Tools herausfinden kann.
- Anstatt mit Text zu antworten, antwortet das Modell mit einem speziellen
function_call-Objekt, das angibt, welches Tool es mit welchen Argumenten aufrufen möchte. - Unser Python-Code empfängt
function_call, führt unsere eigentlicheget_current_temperature-Funktion mit den bereitgestellten Argumenten aus und ruft das Ergebnis ab (z.B. 15 °C). - Wir senden dieses Ergebnis zurück an das Modell.
- Das Modell empfängt das Ergebnis und generiert eine Antwort in natürlicher Sprache für den Nutzer (z.B. „Die aktuelle Temperatur in London beträgt 15 °C.“).
So kann das Modell Fragen beantworten, die weit über seine Trainingsdaten hinausgehen, was es zu einem viel leistungsfähigeren und nützlicheren Assistenten macht.
Wettertool definieren
Wenn ein Reisender Ratschläge für Aktivitäten sucht und sich zwischen wetterabhängigen Aktivitäten entscheiden muss, kann ein Wettertool sehr hilfreich sein. Wir erstellen ein Tool für unser Modell, um das aktuelle Wetter abzurufen. Wir benötigen zwei Teile: eine Funktionsdeklaration, die das Tool für das Modell beschreibt, und die eigentliche Python-Funktion, die es implementiert.
- Suchen Sie in
app.pynach dem Kommentar# TODO: Define the weather tool function declaration. - Fügen Sie unter diesem Kommentar die Variable
weather_functionhinzu. Dies ist ein Dictionary, das dem Modell alles mitteilt, was es über den Zweck der Funktion, die Parameter und die erforderlichen Argumente wissen muss.weather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } - Suchen Sie als Nächstes nach dem Kommentar
# TODO: Define the get_current_temperature function. Fügen Sie darunter den folgenden Python-Code ein. Diese Funktion bietet folgende Möglichkeiten:- Rufen Sie eine Geocoding API auf, um die Koordinaten für den Standort abzurufen.
- Rufen Sie mit diesen Koordinaten eine Wetter-API auf.
- Gibt einen einfachen String mit der Temperatur und der Einheit zurück.
def get_current_temperature(location: str) -> str: """Gets the current temperature for a given location.""" try: # --- Get Latitude and Longitude for the location --- geocode_url = f"https://geocoding-api.open-meteo.com/v1/search?name={location}&count=1&language=en&format=json" geocode_response = requests.get(geocode_url) geocode_data = geocode_response.json() if not geocode_data.get("results"): return f"Could not find coordinates for {location}." lat = geocode_data["results"][0]["latitude"] lon = geocode_data["results"][0]["longitude"] # --- Get Weather for the coordinates --- weather_url = f"https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}¤t_weather=true" weather_response = requests.get(weather_url) weather_data = weather_response.json() temperature = weather_data["current_weather"]["temperature"] unit = "°C" return f"{temperature}{unit}" except Exception as e: return f"Error fetching weather: {e}"
15. Refactoring für Chat und Tools
Unsere aktuelle call_model-Funktion verwendet einen einfachen One-Shot-Aufruf von generate_content. Das ist ideal für einzelne Fragen, aber nicht für eine Multi-Turn-Unterhaltung, insbesondere wenn es um die Verwendung von Tools geht.
Es ist besser, eine Chat-Sitzung zu verwenden, in der der Kontext der Unterhaltung beibehalten wird. Wir werden unseren Code jetzt so umgestalten, dass eine Chatsitzung verwendet wird. Das ist für die korrekte Implementierung von Tools erforderlich.
- Löschen Sie die vorhandene
call_model-Funktion. Wir werden sie durch eine erweiterte Version ersetzen. - Fügen Sie stattdessen die neue
call_model-Funktion aus dem Codeblock unten ein. Diese neue Funktion enthält die Logik für die Verarbeitung der Tool-Aufrufschleife, die wir zuvor besprochen haben. Beachten Sie, dass es mehrere TODO-Kommentare gibt, die wir in den nächsten Schritten vervollständigen werden.# --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt. It maintains a chat session and handles function calls from the model to external tools. """ try: # TODO: Get the existing chat session or create a new one. message_content = prompt # Start the tool-calling loop while True: # TODO: Send the message to the model. # Check if the model wants to call a tool has_tool_calls = False for part in response.candidates[0].content.parts: if part.function_call: has_tool_calls = True function_call = part.function_call logging.info(f"Function to call: {function_call.name}") logging.info(f"Arguments: {function_call.args}") # TODO: Call the appropriate function if the model requests it. elif part.text: logging.info("No function call found in the response.") logging.info(response.text) # If no tool call was made, break the loop if not has_tool_calls: break # TODO: Return the model's final text response. except Exception as e: return f"Error: {e}" - Fügen wir nun eine Hilfsfunktion zum Verwalten der Chatsitzung hinzu. Fügen Sie über der neuen Funktion
call_modeldie Funktionget_chathinzu. Mit dieser Funktion wird eine neue Chatsitzung mit unseren Systemanweisungen und Tool-Definitionen erstellt oder die vorhandene abgerufen. Das ist eine gute Methode zum Organisieren von Code.def get_chat(model_name: str): if f"chat-{model_name}" not in st.session_state: # TODO: Define the tools configuration for the model # TODO: Define the generate_content configuration, including tools # TODO: Create a new chat session st.session_state[f"chat-{model_name}"] = chat return st.session_state[f"chat-{model_name}"]
Sie haben jetzt das Gerüst für unsere erweiterte, toolfähige Chatlogik eingerichtet.
16. Logik für Tool-Aufrufe implementieren
Füllen wir nun die TODOs aus, damit unsere Tool-Aufrufslogik voll funktionsfähig ist.
get_chat implementieren
- Definieren Sie in der Funktion
get_chatunter dem Kommentar# TODO: Define the tools configuration...das Objekttools, indem Sie einetypes.Tool-Instanz aus unsererweather_function-Deklaration erstellen.tools = types.Tool(function_declarations=[weather_function]) - Definieren Sie unter
# TODO: Define the generate_content configuration...diegenerate_content_configund übergeben Sie dastools-Objekt an das Modell. So lernt das Modell, welche Tools es verwenden kann.generate_content_config = types.GenerateContentConfig( system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here ) - Erstellen Sie unter
# TODO: Create a new chat sessiondas Chat-Objekt mitclient.chats.create()und übergeben Sie den Modellnamen und die Konfiguration.chat = client.chats.create( model=model_name, config=generate_content_config, )
call_model implementieren
- Rufen Sie unter
# TODO: Get the existing chat session...in der Funktioncall_modelunsere neue Hilfsfunktionget_chatauf.chat = get_chat(model_name) - Suchen Sie als Nächstes nach
# TODO: Send the message to the model. Senden Sie die Nachricht des Nutzers mit der Methodechat.send_message().response = chat.send_message(message_content) - Suche nach
# TODO: Call the appropriate function.... Hier wird geprüft, welche Funktion das Modell benötigt, und diese wird ausgeführt.
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
- Suchen Sie als Nächstes nach
# TODO: Return the model's final text responseund fügen Sie die Return-Anweisung hinzu.return response.text
Aktualisierte Funktion get_chat
Die aktualisierte Funktion get_chat sollte jetzt so aussehen:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
Aktualisierte Funktion call_model
Die aktualisierte Funktion call_model sollte jetzt so aussehen:
def call_model(prompt: str, model_name: str) -> str:
try:
chat = get_chat(model_name)
message_content = prompt
while True:
response = chat.send_message(message_content)
has_tool_calls = False
for part in response.candidates[0].content.parts:
if part.function_call:
has_tool_calls = True
function_call = part.function_call
logging.info(f"Function to call: {function_call.name}")
logging.info(f"Arguments: {function_call.args}")
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
elif part.text:
logging.info("No function call found in the response.")
logging.info(response.text)
if not has_tool_calls:
break
return response.text
except Exception as e:
return f"Error: {e}"
17. Tool-fähige App testen
Sehen wir uns die neue Funktion in Aktion an.
- Beenden Sie den aktuell laufenden Prozess im Terminal (STRG+C).
- Führen Sie den Befehl noch einmal aus, um die Streamlit-Anwendung neu zu starten.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Aktualisieren Sie die Streamlit-Anwendung. Wenn die Streamlit-Anwendung noch ausgeführt wird, können Sie die Seite mit der Webvorschau einfach in Ihrem Browser aktualisieren.
- Stellen Sie nun eine Frage, die Ihr neues Tool auslösen sollte, z. B.:
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Drücken Sie die Eingabetaste.
Vergleichen Sie diese Antwort mit früheren Antworten. Änderungen
Sie sollten eine Antwort sehen, die die Temperatur aus Ihrer Funktion enthält. Prüfen Sie auch Ihr Cloud Shell-Terminal. Dort sollten Sie print-Anweisungen sehen, die bestätigen, dass Ihre Python-Funktion ausgeführt wurde.
18. Modellausgabe mit Parametern optimieren
Gut gemacht! Ihr Reiseassistent kann jetzt Tools verwenden, um externe Live-Daten abzurufen. Dadurch ist er deutlich leistungsfähiger.
Nachdem wir die Funktionen unseres Modells verbessert haben, optimieren wir jetzt, wie es reagiert. Mit Modellparametern können Sie den Stil und die Zufälligkeit des vom LLM generierten Texts steuern. Durch Anpassen dieser Einstellungen können Sie die Ausgabe des Bots fokussierter und deterministischer oder kreativer und abwechslungsreicher gestalten.
In diesem Lab konzentrieren wir uns auf temperature und top_p. Eine vollständige Liste der konfigurierbaren Parameter und ihrer Beschreibungen finden Sie in der GenerateContentConfig in unserer API-Referenz.
temperature: Steuert die Zufälligkeit der Ausgabe. Ein niedrigerer Wert (näher an 0) macht die Ausgabe deterministischer und fokussierter, während ein höherer Wert (näher an 2) die Zufälligkeit und Kreativität erhöht. Für einen Q&A- oder Assistenten-Bot wird in der Regel eine niedrigere Temperatur bevorzugt, um konsistentere und sachlichere Antworten zu erhalten.top_p: Die maximale kumulative Wahrscheinlichkeit der Tokens, die beim Sampling berücksichtigt werden sollen. Tokens werden nach ihren zugewiesenen Wahrscheinlichkeiten sortiert, sodass nur die wahrscheinlichsten Tokens berücksichtigt werden. Das Modell berücksichtigt die wahrscheinlichsten Tokens, deren Wahrscheinlichkeiten sich auf den Werttop_psummieren. Ein niedrigerer Wert schränkt die Auswahl an Tokens ein, was zu weniger abwechslungsreichen Ausgaben führt.
Anrufparameter
- Suchen Sie oben in
app.pynach den Variablentemperatureundtop_p. Beachten Sie, dass sie noch nirgends aufgerufen wurden. - Fügen Sie
temperatureundtop_pzu den Parametern hinzu, die inGenerateContentConfigin der Funktionget_chatdefiniert sind.generate_content_config = types.GenerateContentConfig( temperature=temperature, top_p=top_p, system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )
Aktualisierte Funktion get_chat
Die get_chat App sieht jetzt so aus:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
temperature=temperature,
top_p=top_p,
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
19. Mit Modellparametern testen
- Beenden Sie den aktuell laufenden Prozess im Terminal (STRG+C).
- Führen Sie den Befehl noch einmal aus, um die Streamlit-Anwendung neu zu starten.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Aktualisieren Sie die Streamlit-Anwendung. Wenn die Streamlit-Anwendung noch ausgeführt wird, können Sie die Seite mit der Webvorschau einfach in Ihrem Browser aktualisieren.
- Stellen Sie dieselbe Frage wie zuvor.
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Drücken Sie die Eingabetaste.
Vergleichen Sie diese Antwort mit früheren Antworten.
20. Glückwunsch!
Sie haben Ihre Q&A-Anwendung erfolgreich mit Tools aktualisiert. Diese leistungsstarke Funktion ermöglicht es Ihrer Gemini-basierten App, mit externen Systemen zu interagieren und auf Echtzeitinformationen zuzugreifen.
Weitere Tests
Es gibt viele Möglichkeiten, Ihren Prompt weiter zu optimieren. Hier sind einige Beispiele:
- Passen Sie
temperatureundtop_pan und sehen Sie sich an, wie sich die Antwort des LLM ändert. - Eine vollständige Liste der konfigurierbaren Parameter und ihrer Beschreibungen finden Sie in der
GenerateContentConfigin unserer API-Referenz. Definieren Sie weitere Parameter und passen Sie sie an, um zu sehen, was passiert.
Zusammenfassung
In diesem Lab haben Sie Folgendes getan:
- Sie haben den Cloud Shell-Editor und das Terminal für die Entwicklung verwendet.
- Sie haben das Vertex AI Python SDK verwendet, um Ihre Anwendung mit einem Gemini-Modell zu verbinden.
- Systemanweisungen und Modellparameter angewendet, um die Antworten des LLM zu steuern.
- Das Konzept von Tools (Funktionsaufrufe) und seine Vorteile kennengelernt.
- Sie haben Ihren Code so umgestaltet, dass eine zustandsorientierte Chatsitzung verwendet wird. Das ist eine Best Practice für Conversational AI.
- Sie haben ein Tool für das Modell mithilfe einer Funktionsdeklaration definiert.
- Die Python-Funktion wurde implementiert, um die Logik des Tools bereitzustellen.
- Code zum Verarbeiten der Funktionsaufrufanfragen des Modells und zum Zurückgeben der Ergebnisse geschrieben.