
1. Introducción
Descripción general
Eres desarrollador en una empresa de marketing de viajes. Tu departamento de ventas decidió que necesita una nueva aplicación de chat para mantenerse al día con las empresas de búsqueda y reservas más grandes. También escuchó hablar sobre la IA generativa, pero no sabe mucho al respecto. Otros departamentos se enteraron de esta iniciativa y tienen curiosidad por saber cómo podría ayudar también a su experiencia del cliente.
Actividades
En este lab, crearás un chatbot asistente de viajes con el modelo Gemini 2.5 Flash en Vertex AI.
La aplicación debe cumplir con los siguientes requisitos:
- Ayuda a los usuarios a hacer preguntas sobre viajes, reservar viajes y obtener información sobre los lugares a los que planean ir
- Proporciona a los usuarios formas de obtener ayuda sobre sus planes de viaje específicos
- Poder recuperar datos en tiempo real, como el clima, con herramientas
Trabajarás en un entorno de Google Cloud preconfigurado, específicamente en el editor de Cloud Shell. Ya se configuró un frontend básico de la aplicación web, junto con los permisos necesarios para acceder a Vertex AI. Esta app se compiló con Streamlit.
Qué aprenderás
En este lab, aprenderás a realizar las siguientes tareas:
- Explora la plataforma de Vertex AI para identificar los modelos de IA generativa disponibles.
- Desarrolla en el editor de Cloud Shell y la terminal
- Utiliza Gemini Code Assist para comprender el código.
- Usa el SDK de Vertex AI en Python para enviar instrucciones a un LLM de Gemini y recibir respuestas de él.
- Aplicar ingeniería de instrucciones básica (instrucciones del sistema, parámetros del modelo) para personalizar el resultado de un LLM de Gemini
- Probar y perfeccionar de forma iterativa una aplicación de chat potenciada por un LLM modificando instrucciones y parámetros para mejorar las respuestas
- Define y usa herramientas con el modelo de Gemini para habilitar la llamada a función.
- Refactoriza el código para usar una sesión de chat con estado, una práctica recomendada para las apps conversacionales.
2. Configura el proyecto
Cuenta de Google
Si aún no tienes una Cuenta de Google personal, debes crear una.
Usa una cuenta personal en lugar de una cuenta de trabajo o institución educativa.
Accede a la consola de Google Cloud
Accede a la consola de Google Cloud con una Cuenta de Google personal.
Habilitar facturación
Canjea créditos de Google Cloud (opcional)
Para realizar este taller, necesitas una cuenta de facturación con algo de crédito. Usa los créditos del banner que se encuentra en la parte superior de este codelab para comenzar. Si ya te conectaste a una cuenta de facturación, puedes omitir este paso.
Configura una cuenta de facturación personal
Si configuraste la facturación con créditos de Google Cloud, puedes omitir este paso.
Para configurar una cuenta de facturación personal, ve aquí para habilitar la facturación en la consola de Cloud.
Notas:
- Completar este lab debería costar menos de USD 1 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos pueden acceder a la prueba gratuita de USD 300.
Crear un proyecto (opcional)
Si no tienes un proyecto actual que quieras usar para este lab, crea uno nuevo aquí.
3. Abre el editor de Cloud Shell
- Haz clic en este vínculo para navegar directamente al editor de Cloud Shell.
- Si se te solicita autorización en algún momento, haz clic en Autorizar para continuar.
- Si la terminal no aparece en la parte inferior de la pantalla, ábrela:
- Haz clic en Ver.
- Haz clic en Terminal.
- En la terminal, configura tu proyecto con este comando:
gcloud config set project [PROJECT_ID]- Ejemplo:
gcloud config set project lab-project-id-example - Si no recuerdas el ID de tu proyecto, puedes enumerar todos tus IDs de proyecto con el siguiente comando:
gcloud projects list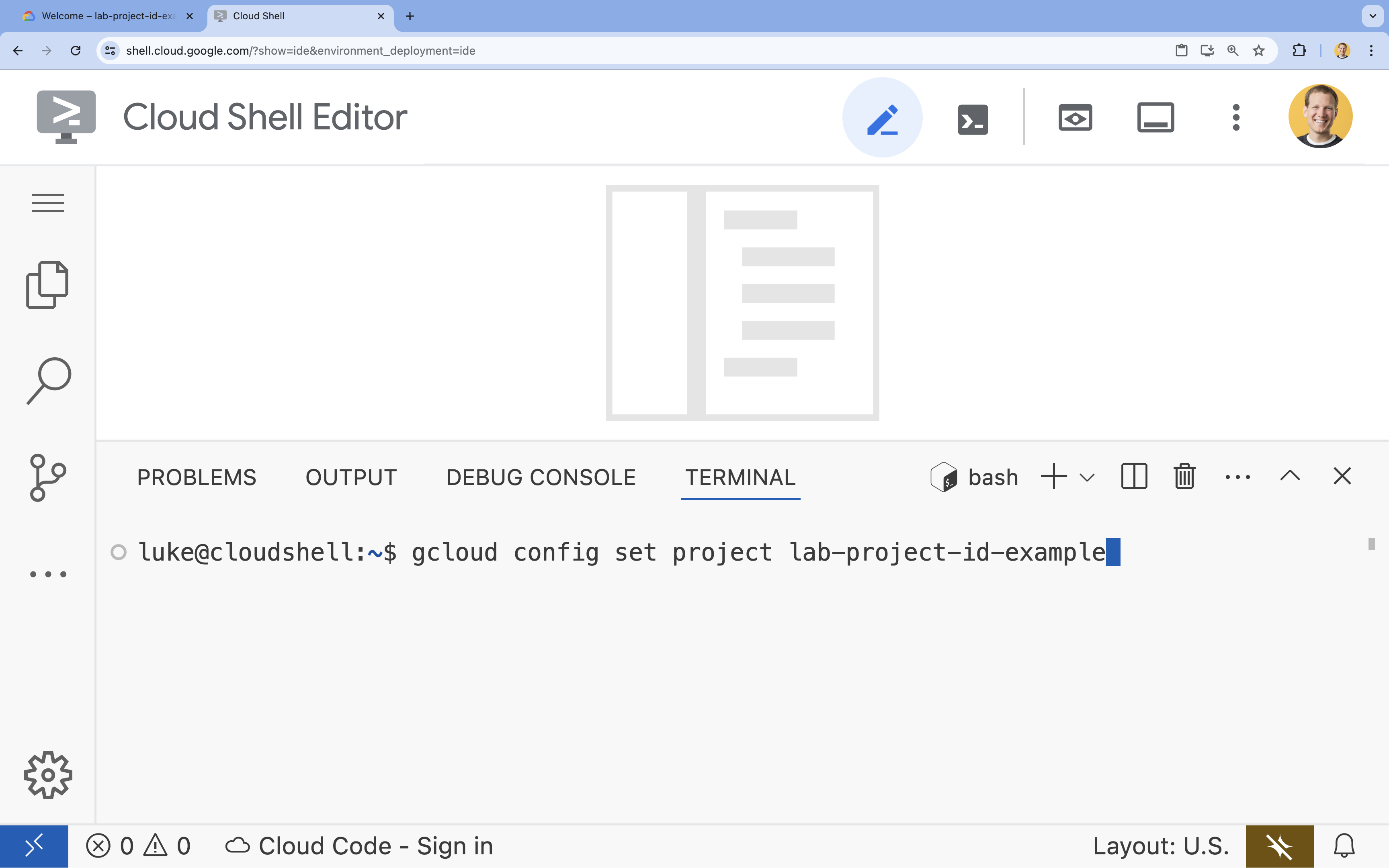
- Ejemplo:
- Deberías ver el siguiente mensaje:
Updated property [core/project].
4. Habilita las APIs
Para usar el SDK de Vertex AI y, luego, interactuar con el modelo de Gemini, debes habilitar la API de Vertex AI en tu proyecto de Google Cloud.
- En la terminal, habilita las APIs:
gcloud services enable \ aiplatform.googleapis.com
Introducción al SDK de Vertex AI para Python
Para interactuar con los modelos alojados en Vertex AI desde tu aplicación en Python, usarás el SDK de Vertex AI para Python. Este SDK simplifica el proceso de envío de instrucciones, especificación de parámetros del modelo y recepción de respuestas sin necesidad de controlar directamente las complejidades de las llamadas a la API subyacentes.
Puedes encontrar documentación completa para el SDK de Vertex AI para Python aquí: Introducción al SDK de Vertex AI para Python | Google Cloud.
5. Crea un entorno virtual y, luego, instala las dependencias
Antes de comenzar cualquier proyecto de Python, es una buena práctica crear un entorno virtual. Esto aísla las dependencias del proyecto y evita conflictos con otros proyectos o con los paquetes globales de Python del sistema.
- Crea una carpeta llamada
wanderbotpara almacenar el código de tu app de asistente de viajes. Ejecuta el siguiente código en la terminal:mkdir wanderbot && cd wanderbot - Crea y activa un entorno virtual:
uv venv --python 3.12 source .venv/bin/activatewanderbot) como prefijo en el prompt de la terminal, lo que indica que el entorno virtual está activo. Se vería similar a lo siguiente:
6. Crea archivos iniciales para Wanderbot
- Crea y abre un nuevo archivo
app.pypara la aplicación. Ejecuta el siguiente código en la terminal:cloudshell edit app.pycloudshell editabrirá el archivoapp.pyen el editor que se encuentra sobre la terminal. - Pega el siguiente código de inicio de la app en
app.py:import streamlit as st from google import genai from google.genai import types import requests import logging # --- Defining variables and parameters --- REGION = "global" PROJECT_ID = None # TODO: Insert Project ID GEMINI_MODEL_NAME = "gemini-2.5-flash" temperature = .2 top_p = 0.95 system_instructions = None # --- Tooling --- # TODO: Define the weather tool function declaration # TODO: Define the get_current_temperature function # --- Initialize the Vertex AI Client --- try: # TODO: Initialize the Vertex AI client print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}") except Exception as e: st.error(f"Error initializing VertexAI client: {e}") st.stop() # TODO: Add the get_chat function here in Task 15. # --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions. It will be replaced in a later step with a more advanced version that handles tooling. """ try: # TODO: Prepare the content for the model # TODO: Define generate_content configuration (needed for system instructions and parameters) # TODO: Define response logging.info(f"[call_model_response] LLM Response: \"{response.text}\"") # TODO: Uncomment the below "return response.text" line # return response.text except Exception as e: return f"Error: {e}" # --- Presentation Tier (Streamlit) --- # Set the title of the Streamlit application st.title("Travel Chat Bot") # Initialize session state variables if they don't exist if "messages" not in st.session_state: # Initialize the chat history with a welcome message st.session_state["messages"] = [ {"role": "assistant", "content": "How can I help you today?"} ] # Display the chat history for msg in st.session_state.messages: st.chat_message(msg["role"]).write(msg["content"]) # Get user input if prompt := st.chat_input(): # Add the user's message to the chat history st.session_state.messages.append({"role": "user", "content": prompt}) # Display the user's message st.chat_message("user").write(prompt) # Show a spinner while waiting for the model's response with st.spinner("Thinking..."): # Get the model's response using the call_model function model_response = call_model(prompt, GEMINI_MODEL_NAME) # Add the model's response to the chat history st.session_state.messages.append( {"role": "assistant", "content": model_response} ) # Display the model's response st.chat_message("assistant").write(model_response) - Crea y abre un nuevo archivo
requirements.txtpara el código de la aplicación. Ejecuta el siguiente código en la terminal:cloudshell edit requirements.txtcloudshell editabrirá el archivorequirements.txten el editor que se encuentra sobre la terminal. - Pega el siguiente código de inicio de la app en
requirements.txt.google-genai streamlit requests - Instala las dependencias de Python necesarias para este proyecto. Ejecuta el siguiente código en la terminal:
uv pip install -r requirements.txt
7. Cómo explorar el código
Los archivos que creaste incluyen un frontend básico de la aplicación de chat. Estas incluyen las siguientes:
app.py: Este es el archivo en el que trabajaremos. Actualmente, contiene lo siguiente:- Importaciones necesarias
- variables y parámetros de entorno (algunos de los cuales son marcadores de posición)
- una función
call_modelvacía que completaremos - Código de Streamlit para la app de chat de frontend
requirements.txt:- Incluye los requisitos de instalación para ejecutar
app.py.
- Incluye los requisitos de instalación para ejecutar
Ahora es momento de explorar el código.
Abre el chat de Gemini Code Assist
El chat de Gemini Code Assist ya debería estar abierto en un panel a la derecha en el editor de Cloud Shell. Si el chat de Gemini Code Assist aún no está abierto, puedes abrirlo con los siguientes pasos:
- Haz clic en el botón de Gemini Code Assist (
 ) cerca de la parte superior de la pantalla.
) cerca de la parte superior de la pantalla. - Selecciona Open Gemini Code Assist Chat.
Usa Gemini Code Assist para comprender el código
Puedes usar el chat de Gemini Code Assist para comprender mejor el código.
- Destaca o selecciona la sección de código deseada.
- Escribe "Explica este código" en el chat de Gemini.
- Haz clic en Intro para enviar.
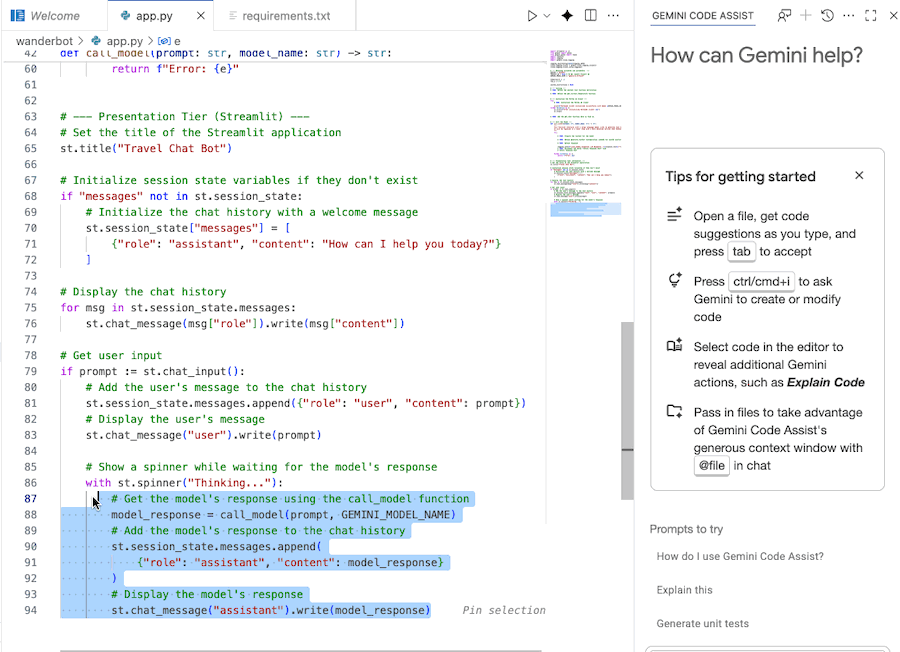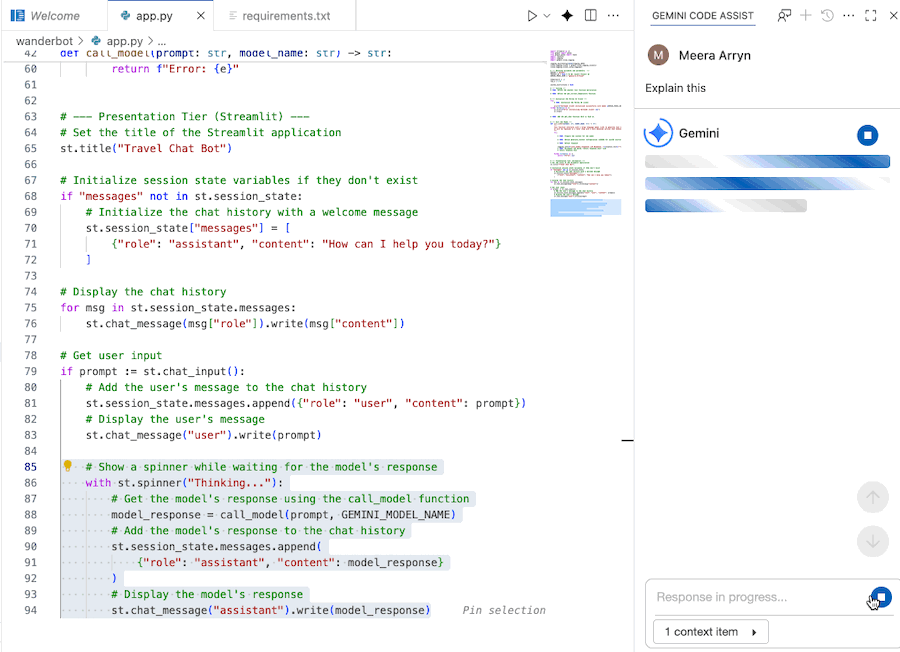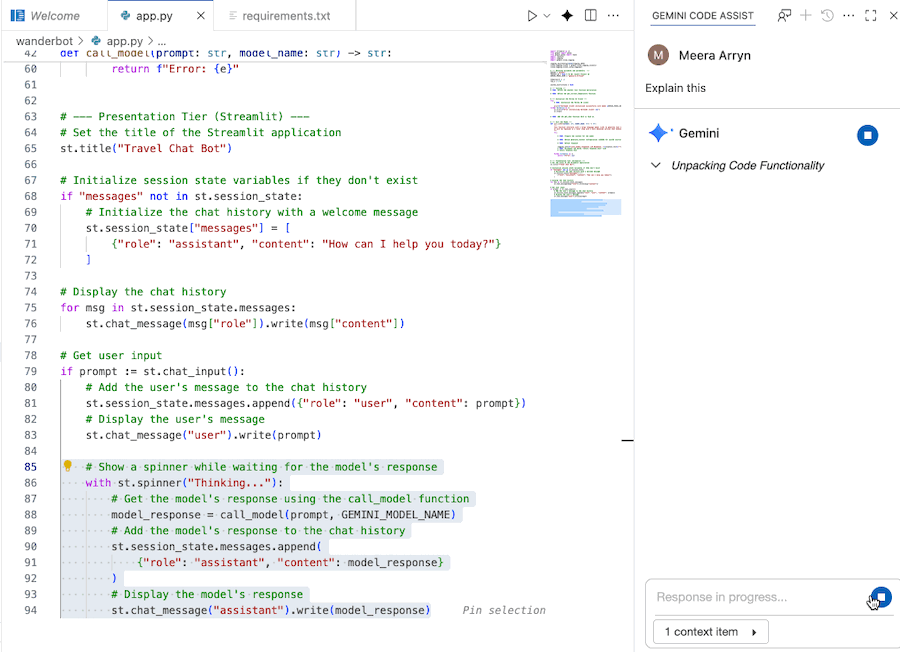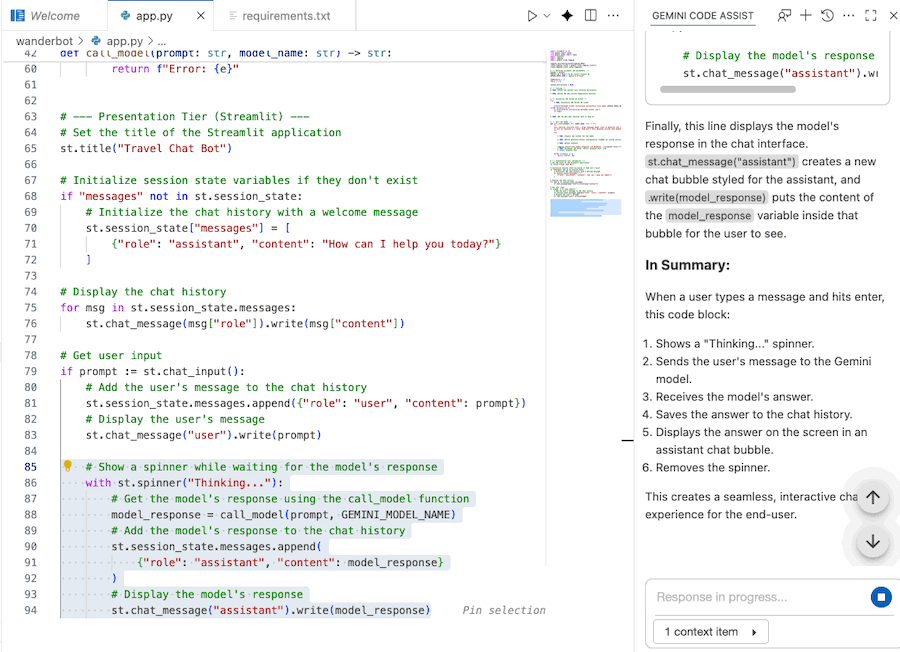
8. Inicia la app web
Antes de conectar esta app a un LLM, ejecútala para ver cómo se comporta inicialmente.
- En el directorio
wanderbot, ejecuta el siguiente comando en la terminal para iniciar la aplicación de Streamlit y hacer que sea accesible de forma local en tu entorno de Cloud Shell:streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Después de ejecutar el comando, haz clic en el botón Vista previa en la Web en la parte superior del editor de Cloud Shell y selecciona Vista previa en el puerto 8080.
Verás una interfaz de chat simple para tu app de viajes. - Escribe cualquier mensaje (p.ej.,
Hi!) y presiona INTRO.
Notarás que el mensaje aparecerá en el historial de chat, pero recibirás un mensaje de error en lugar de una respuesta del asistente. Esto se debe a que la aplicación aún no está conectada a un modelo de lenguaje grande. Observa este comportamiento para comprender el punto de partida del lab.
9. Inicializa el cliente de Vertex AI
Explora los modelos disponibles en Vertex AI
La plataforma Vertex AI de Google Cloud proporciona acceso a una variedad de modelos de IA generativa. Antes de integrar uno, puedes explorar las opciones disponibles en la consola de Google Cloud.
- En la consola de Google Cloud, navega a Model Garden. Para ello, busca “Model Garden” en la barra de búsqueda que se encuentra en la parte superior de la pantalla y selecciona Vertex AI.(
 )
) - Explora los modelos disponibles. Puedes filtrar por aspectos como modalidades, tipos de tareas y funciones.
Para los fines de este lab, usarás el modelo Gemini 2.5 Flash, que es una buena opción para crear aplicaciones de chat responsivas debido a su velocidad.
Inicializa el cliente de Vertex AI
Ahora modificarás la sección --- Initialize the Vertex AI Client --- en app.py para inicializar el cliente de Vertex AI. Este objeto cliente se usará para enviar instrucciones al modelo.
- Abre
app.pyen el editor de Cloud Shell. - En
app.py, busca la líneaPROJECT_ID = None. - Reemplaza
Nonepor el ID de tu proyecto de Google Cloud entre comillas. (p.ej.,PROJECT_ID = "google-cloud-labs")
Si no recuerdas el ID de tu proyecto, puedes enumerar todos tus IDs de proyecto con el siguiente comando:gcloud projects list | awk '/PROJECT_ID/{print $2}' - Define el cliente: Dentro del bloque
try, inicializa el cliente de Vertex AI.client = genai.Client( vertexai=True, project=PROJECT_ID, location=REGION, )
Se actualizó la inicialización del cliente de Vertex AI
En este punto, la sección Initialize the Vertex AI Client se vería de la siguiente manera:
# --- Initialize the Vertex AI Client ---
try:
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=REGION,
)
print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}")
except Exception as e:
st.error(f"Error initializing VertexAI client: {e}")
st.stop()
10. Prepara los datos y llama al modelo
Ahora prepararás el contenido para enviarlo al modelo y realizarás una llamada al modelo de Gemini.
- Busca la sección
--- Call the Model ---en la que se define la funcióncall_model. - Define contents: En
# TODO: Prepare the content for the model, define el contenido de entrada que se enviará al modelo. En el caso de un mensaje básico, será el mensaje de entrada del usuario.contents = [prompt] - Define la respuesta: Pega este código debajo de
# TODO: Define response.response = client.models.generate_content( model=model_name, contents=contents, ) - Devuelve la respuesta: Borra los comentarios de la siguiente línea:
return response.text - Examina la línea en la que se llama a la función
call_model, cerca de la parte inferior del archivo en el bloquewith. Si no entiendes lo que sucede aquí, destaca la línea y pídele a Gemini Code Assist que te lo explique.
Una forma más explícita de definir contents
La forma anterior de definir contents funciona porque el SDK es lo suficientemente inteligente como para comprender que una lista que contiene cadenas representa la entrada de texto del usuario. Le da formato automáticamente de manera correcta para la API del modelo.
Sin embargo, la forma más explícita y fundamental de estructurar la entrada implica usar objetos types.Part y types.Content, como se muestra a continuación:
user_message_parts = [types.Part.from_text(text=prompt)]
contents = [
types.Content(
role="user", # Indicates the content is from the user
parts=user_message_parts, # A list, allowing multiple types of content
),
]
Se actualizó la función call_model
En este punto, la función call_model debería verse de la siguiente manera:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
# TODO: Define generate_content configuration (needed later for system instructions and parameters)
response = client.models.generate_content(
model=model_name,
contents=contents,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
11. Prueba la app conectada
- En la terminal, finaliza el proceso en ejecución (CTRL + C).
- Vuelve a ejecutar el comando para iniciar la aplicación de Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Actualiza la aplicación de Streamlit. Si la aplicación de Streamlit sigue en ejecución, puedes actualizar la página de vista previa web en tu navegador.
- Ahora, escribe una pregunta en la entrada del chat, como la siguiente:
What is the best time of year to go to Iceland? - Presiona INTRO.
Deberías ver que la aplicación muestra tu mensaje, un indicador de carga "Pensando…" y, luego, una respuesta generada por el modelo de Gemini. Si es así, conectaste correctamente tu aplicación web a un LLM en Vertex AI. 🙌 🥳
12. Cómo definir instrucciones del sistema
Si bien la conexión básica funciona, la calidad y el estilo de las respuestas del LLM se ven muy influenciados por la entrada que recibe. La ingeniería de instrucciones es el proceso de diseñar y perfeccionar estas entradas (instrucciones) para guiar al modelo hacia la generación del resultado deseado.
Para ello, comenzarás por crear algunas instrucciones del sistema y pasárselas al modelo.
Usarás Preguntarle a Gemini para crear instrucciones del sistema útiles.
- En
app.py, busca la variablesystem_instructions, que actualmente está establecida enNone.system_instructions = NoneNonepor una cadena de varias líneas que proporciona instrucciones para nuestro bot asistente de viajes. - Pregúntale a Gemini Code Assist: Pasa la siguiente instrucción a Gemini Code Assist (o crea la tuya propia):
I am a developer at a travel marketing company, and my sales department has decided that they need a new chat application to keep up with the bigger booking and search companies. I'm building a simple travel assistant chatbot using the Gemini 2.5 Flash model on Vertex AI. The application should: - Helps users ask questions about travel, book travel, and learn about places they are going to go - Provides users ways to get help about their specific travel plans - Provides all this in a production quality way (multiple environments, logging and monitoring, etc.) Please create system instructions appropriate for that chat app. Be thorough. Do not alter the code in any way beyond providing me with system instructions. - Define
system_instructions: Establecesystem_instructionsigual a las instrucciones del sistema que generaste con Gemini Code Assist. También puedes usar estas instrucciones del sistema, que Gemini creó con una instrucción similar.system_instructions = """ You are a sophisticated travel assistant chatbot designed to provide comprehensive support to users throughout their travel journey. Your capabilities include answering travel-related questions, assisting with booking travel arrangements, offering detailed information about destinations, and providing support for existing travel plans. **Core Functionalities:** 1. **Travel Information and Recommendations:** * Answer user inquiries about travel destinations, including popular attractions, local customs, visa requirements, weather conditions, and safety advice. * Provide personalized recommendations for destinations, activities, and accommodations based on user preferences, interests, and budget. * Offer insights into the best times to visit specific locations, considering factors like weather, crowds, and pricing. * Suggest alternative destinations or activities if the user's initial choices are unavailable or unsuitable. 2. **Booking Assistance:** * Facilitate the booking of flights, hotels, rental cars, tours, and activities. * Search for available options based on user-specified criteria such as dates, destinations, budget, and preferences. * Present clear and concise information about available options, including pricing, amenities, and booking terms. * Guide users through the booking process, ensuring accurate information and secure transactions. * Provide booking confirmations and relevant details, such as booking references and contact information. 3. **Travel Planning and Itinerary Management:** * Assist users in creating detailed travel itineraries, including flights, accommodations, activities, and transportation. * Offer suggestions for optimizing travel plans, such as minimizing travel time or maximizing sightseeing opportunities. * Provide tools for managing and modifying existing itineraries, including adding or removing activities, changing booking dates, or upgrading accommodations. * Offer reminders and notifications for upcoming travel events, such as flight check-in or tour departure times. 4. **Customer Support and Troubleshooting:** * Provide prompt and helpful support to users with questions or issues related to their travel plans. * Assist with resolving booking discrepancies, cancellations, or modifications. * Offer guidance on travel-related emergencies, such as lost luggage or travel delays. * Provide access to relevant contact information for airlines, hotels, and other travel providers. **Interaction Guidelines:** * **Professionalism:** Maintain a polite, respectful, and professional tone in all interactions. * **Clarity and Conciseness:** Provide clear, concise, and easy-to-understand information. Avoid jargon or technical terms unless necessary and always explain them. * **Accuracy:** Ensure all information provided is accurate and up-to-date. Double-check details before sharing them with users. If unsure about something, admit that you don't know and offer to find the information. * **Personalization:** Tailor your responses and recommendations to the specific needs and preferences of each user. * **Proactive Assistance:** Anticipate user needs and offer relevant information or suggestions proactively. * **Error Handling:** Gracefully handle user errors or misunderstandings. Provide helpful guidance and alternative options when necessary. * **Confidentiality:** Respect user privacy and handle personal information with the utmost confidentiality and in compliance with data protection regulations. **Example Interactions:** **User:** "I want to go on a beach vacation in the Caribbean. I have a budget of $2000 per person for a week." **Chatbot:** "Certainly! The Caribbean offers many beautiful beach destinations within your budget. Some popular options include Punta Cana in the Dominican Republic, Cancun in Mexico, and Montego Bay in Jamaica. These destinations offer stunning beaches, all-inclusive resorts, and various activities. Would you like me to search for flights and accommodations for these locations based on your travel dates?" **User:** "My flight is delayed. What should I do?" **Chatbot:** "I'm sorry to hear about the delay. Please check with the airline for the updated departure time and any assistance they can offer. You may be entitled to compensation or rebooking options depending on the length of the delay and the airline's policy. Do you have your flight number handy so I can look up the current status for you?" **User:** "Tell me about the best time to visit Japan." **Chatbot:** "Japan is a fantastic destination with distinct seasons offering unique experiences. Spring (March-May) is famous for the beautiful cherry blossoms, while autumn (September-November) boasts stunning fall foliage. Both seasons have pleasant temperatures, making them ideal for sightseeing. Summer (June-August) can be hot and humid, but it's a great time for festivals and outdoor activities in the mountains. Winter (December-February) offers opportunities for skiing and snowboarding in the Japanese Alps, though some areas may experience heavy snowfall. To recommend the best time for you, could you tell me what you'd like to experience in Japan?" By following these instructions, you will be able to provide exceptional travel assistance and create a positive experience for every user. """ - Define la configuración de generate_content: Inicializa un objeto de configuración al que pasarás estas instrucciones del sistema. Como
system_instructionsse define de forma global en nuestro script, la función puede acceder a él directamente.generate_content_config = types.GenerateContentConfig( system_instruction=[ types.Part.from_text(text=system_instructions) ], ) logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}") - Para agregar las instrucciones del sistema a la respuesta, agrega un parámetro
configal métodogenerate_contenty configúralo igual que el objetogenerate_content_configcreado anteriormente.response = client.models.generate_content( model=model_name, contents=contents, config=generate_content_config, # This is the new line )
Se actualizó la función call_model
La función call_model completa ahora se ve de la siguiente manera:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
generate_content_config = types.GenerateContentConfig(
system_instruction=[
types.Part.from_text(text=system_instructions)
],
)
logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}")
response = client.models.generate_content(
model=model_name,
contents=contents,
config=generate_content_config,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
13. Prueba la app con instrucciones del sistema
- En la terminal, finaliza el proceso en ejecución (CTRL + C).
- Vuelve a ejecutar el comando para iniciar la aplicación de Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Actualiza la aplicación de Streamlit. Si la aplicación de Streamlit sigue en ejecución, puedes actualizar la página de vista previa web en tu navegador.
- Intenta hacer la misma pregunta que antes:
What is the best time of year to go to Iceland? - Presiona INTRO.
Compara cómo responde esta vez en comparación con la vez anterior.
14. Cómo definir una herramienta de clima
Hasta ahora, nuestro chatbot es inteligente, pero su conocimiento se limita a los datos con los que se entrenó. No puede acceder a información en tiempo real. En el caso de un bot de viajes, poder recuperar datos en vivo, como los pronósticos del clima, es una gran ventaja.
Aquí es donde entra en juego la herramienta, también conocida como llamada a función. Podemos definir un conjunto de herramientas (funciones de Python) que el LLM puede elegir llamar para obtener información externa.
Cómo funcionan las herramientas
- Describimos nuestras herramientas al modelo, incluido lo que hacen y los parámetros que toman.
- El usuario envía una instrucción (p.ej., "¿Cómo está el clima en Londres?").
- El modelo recibe la instrucción y ve que el usuario está preguntando sobre algo que puede averiguar con una de sus herramientas.
- En lugar de responder con texto, el modelo responde con un objeto
function_callespecial, que indica qué herramienta quiere llamar y con qué argumentos. - Nuestro código de Python recibe este
function_call, ejecuta nuestra funciónget_current_temperaturereal con los argumentos proporcionados y obtiene el resultado (p.ej., 15 °C). - Enviamos este resultado de vuelta al modelo.
- El modelo recibe el resultado y genera una respuesta de lenguaje natural para el usuario (p. ej., "La temperatura actual en Londres es de 15 °C").
Este proceso permite que el modelo responda preguntas que van mucho más allá de sus datos de entrenamiento, lo que lo convierte en un asistente mucho más potente y útil.
Cómo definir una herramienta de clima
Si un viajero busca consejos sobre qué hacer y debe elegir entre actividades afectadas por el clima, una herramienta del clima podría ser útil. Creemos una herramienta para que nuestro modelo obtenga el clima actual. Necesitamos dos partes: una declaración de función que describa la herramienta al modelo y la función de Python real que la implemente.
- En
app.py, busca el comentario# TODO: Define the weather tool function declaration. - Debajo de este comentario, agrega la variable
weather_function. Este es un diccionario que le indica al modelo todo lo que necesita saber sobre el propósito, los parámetros y los argumentos obligatorios de la función.weather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } - A continuación, busca el comentario
# TODO: Define the get_current_temperature function. Debajo, agrega el siguiente código de Python. Esta función hará lo siguiente:- Llama a una API de Geocoding para obtener las coordenadas de la ubicación.
- Usa esas coordenadas para llamar a una API de clima.
- Devuelve una cadena simple con la temperatura y la unidad.
def get_current_temperature(location: str) -> str: """Gets the current temperature for a given location.""" try: # --- Get Latitude and Longitude for the location --- geocode_url = f"https://geocoding-api.open-meteo.com/v1/search?name={location}&count=1&language=en&format=json" geocode_response = requests.get(geocode_url) geocode_data = geocode_response.json() if not geocode_data.get("results"): return f"Could not find coordinates for {location}." lat = geocode_data["results"][0]["latitude"] lon = geocode_data["results"][0]["longitude"] # --- Get Weather for the coordinates --- weather_url = f"https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}¤t_weather=true" weather_response = requests.get(weather_url) weather_data = weather_response.json() temperature = weather_data["current_weather"]["temperature"] unit = "°C" return f"{temperature}{unit}" except Exception as e: return f"Error fetching weather: {e}"
15. Refactorización para chat y herramientas
Nuestra función call_model actual usa una llamada generate_content simple de una sola vez. Esto es ideal para preguntas únicas, pero no para una conversación de varios turnos, en especial una que implica un intercambio de herramientas.
Una mejor práctica es usar una sesión de chat, que mantiene el contexto de la conversación. Ahora refactorizaremos nuestro código para usar una sesión de chat, lo que es necesario para implementar correctamente las herramientas.
- Borra la función
call_modelexistente. La reemplazaremos por una versión más avanzada. - En su lugar, agrega la nueva función
call_modeldel siguiente bloque de código. Esta nueva función contiene la lógica para controlar el bucle de llamada a herramientas que analizamos anteriormente. Observa que tiene varios comentarios TODO que completaremos en los próximos pasos.# --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt. It maintains a chat session and handles function calls from the model to external tools. """ try: # TODO: Get the existing chat session or create a new one. message_content = prompt # Start the tool-calling loop while True: # TODO: Send the message to the model. # Check if the model wants to call a tool has_tool_calls = False for part in response.candidates[0].content.parts: if part.function_call: has_tool_calls = True function_call = part.function_call logging.info(f"Function to call: {function_call.name}") logging.info(f"Arguments: {function_call.args}") # TODO: Call the appropriate function if the model requests it. elif part.text: logging.info("No function call found in the response.") logging.info(response.text) # If no tool call was made, break the loop if not has_tool_calls: break # TODO: Return the model's final text response. except Exception as e: return f"Error: {e}" - Ahora, agreguemos una función auxiliar para administrar la sesión de chat. Arriba de la nueva función
call_model, agrega la funciónget_chat. Esta función creará una nueva sesión de chat con nuestras instrucciones del sistema y definiciones de herramientas, o recuperará la existente. Esta es una buena práctica para organizar el código.def get_chat(model_name: str): if f"chat-{model_name}" not in st.session_state: # TODO: Define the tools configuration for the model # TODO: Define the generate_content configuration, including tools # TODO: Create a new chat session st.session_state[f"chat-{model_name}"] = chat return st.session_state[f"chat-{model_name}"]
Ya configuraste la estructura de nuestra lógica de chat avanzada habilitada para herramientas.
16. Implementa la lógica de llamada a herramientas
Ahora, completemos el TODOs para que nuestra lógica de llamada a herramientas funcione por completo.
Implementa get_chat.
- En la función
get_chat, debajo del comentario# TODO: Define the tools configuration..., define el objetotoolscreando una instanciatypes.Toola partir de nuestra declaraciónweather_function.tools = types.Tool(function_declarations=[weather_function]) - En
# TODO: Define the generate_content configuration..., definegenerate_content_configy asegúrate de pasar el objetotoolsal modelo. Así es como el modelo aprende sobre las herramientas que puede usar.generate_content_config = types.GenerateContentConfig( system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here ) - En
# TODO: Create a new chat session, crea el objeto de chat conclient.chats.create()y pasa el nombre y la configuración de nuestro modelo.chat = client.chats.create( model=model_name, config=generate_content_config, )
Implementa call_model.
- En
# TODO: Get the existing chat session..., dentro de la funcióncall_model, llama a nuestra nueva función auxiliarget_chat.chat = get_chat(model_name) - A continuación, busca
# TODO: Send the message to the model. Envía el mensaje del usuario con el métodochat.send_message().response = chat.send_message(message_content) - Busca
# TODO: Call the appropriate function.... Aquí es donde verificamos qué función quiere el modelo y la ejecutamos.
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
- Por último, busca
# TODO: Return the model's final text responsey agrega la instrucción de devolución.return response.text
Se actualizó la función get_chat
La función get_chat actualizada ahora debería verse de la siguiente manera:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
Se actualizó la función call_model
La función call_model actualizada ahora debería verse de la siguiente manera:
def call_model(prompt: str, model_name: str) -> str:
try:
chat = get_chat(model_name)
message_content = prompt
while True:
response = chat.send_message(message_content)
has_tool_calls = False
for part in response.candidates[0].content.parts:
if part.function_call:
has_tool_calls = True
function_call = part.function_call
logging.info(f"Function to call: {function_call.name}")
logging.info(f"Arguments: {function_call.args}")
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
elif part.text:
logging.info("No function call found in the response.")
logging.info(response.text)
if not has_tool_calls:
break
return response.text
except Exception as e:
return f"Error: {e}"
17. Prueba la app habilitada para herramientas
Veamos tu nueva función en acción.
- En la terminal, finaliza el proceso en ejecución (CTRL + C).
- Vuelve a ejecutar el comando para iniciar la aplicación de Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Actualiza la aplicación de Streamlit. Si la aplicación de Streamlit sigue en ejecución, puedes actualizar la página de vista previa web en tu navegador.
- Ahora, haz una pregunta que debería activar tu nueva herramienta, como la siguiente:
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Presiona INTRO
Compara esta respuesta con las anteriores. ¿Qué tiene de diferente?
Deberías ver una respuesta que incorpore la temperatura de tu función. También debes revisar tu terminal de Cloud Shell. Deberías ver instrucciones de impresión que confirmen que se ejecutó tu función de Python.
18. Cómo refinar el resultado del modelo con parámetros
¡Muy bien! Tu asistente de viaje ahora puede usar herramientas para obtener datos externos en vivo, lo que lo hace mucho más potente.
Ahora que mejoramos las capacidades de nuestro modelo, ajustemos su forma de responder. Los parámetros del modelo te permiten controlar el estilo y la aleatoriedad del texto generado por el LLM. Si ajustas estos parámetros, puedes hacer que el resultado del bot sea más enfocado y determinístico, o más creativo y variado.
En este lab, nos enfocaremos en temperature y top_p. (Consulta GenerateContentConfig en nuestra referencia de la API para obtener una lista completa de los parámetros configurables y sus descripciones).
temperature: Controla la aleatoriedad del resultado. Un valor más bajo (más cercano a 0) hace que el resultado sea más determinístico y enfocado, mientras que un valor más alto (más cercano a 2) aumenta la aleatoriedad y la creatividad. En el caso de un bot de preguntas y respuestas o asistente, suele preferirse una temperatura más baja para obtener respuestas más coherentes y fácticas.top_p: Es la probabilidad acumulativa máxima de los tokens que se deben tener en cuenta durante el muestreo. Los tokens se ordenan según las probabilidades asignadas para que solo se tengan en cuenta los tokens más probables. El modelo considera los tokens más probables cuyas probabilidades suman el valor detop_p. Un valor más bajo restringe las opciones de tokens, lo que genera un resultado menos variado.
Parámetros de la llamada
- Busca las variables
temperatureytop_p, definidas en la parte superior deapp.py. Ten en cuenta que aún no se llamaron en ningún lugar. - Agrega
temperatureytop_pa los parámetros definidos dentro deGenerateContentConfigen la funciónget_chat.generate_content_config = types.GenerateContentConfig( temperature=temperature, top_p=top_p, system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )
Se actualizó la función get_chat
Ahora, la app de get_chat se ve de la siguiente manera:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
temperature=temperature,
top_p=top_p,
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
19. Prueba con parámetros del modelo
- En la terminal, finaliza el proceso en ejecución (CTRL + C).
- Vuelve a ejecutar el comando para iniciar la aplicación de Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Actualiza la aplicación de Streamlit. Si la aplicación de Streamlit sigue en ejecución, puedes actualizar la página de vista previa web en tu navegador.
- Intenta hacer la misma pregunta que antes.
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Presiona INTRO
Compara esta respuesta con las anteriores.
20. ¡Felicitaciones!
Actualizaste correctamente tu aplicación de preguntas y respuestas con herramientas, una función potente que permite que tu app potenciada por Gemini interactúe con sistemas externos y acceda a información en tiempo real.
Experimentación continua
Existen muchas opciones para seguir optimizando tu instrucción. Estos son algunos que puedes considerar:
- Ajusta
temperatureytop_p, y observa cómo cambia la respuesta que proporciona el LLM. - Consulta
GenerateContentConfigen nuestra referencia de la API para obtener una lista completa de los parámetros configurables y sus descripciones. Intenta definir más parámetros y ajustarlos para ver qué sucede.
Resumen
En este lab, realizaste las siguientes tareas:
- Se utilizaron el editor de Cloud Shell y la terminal para el desarrollo.
- Usaste el SDK de Vertex AI para Python para conectar tu aplicación a un modelo de Gemini.
- Se aplicaron instrucciones del sistema y parámetros del modelo para guiar las respuestas del LLM.
- Aprendiste el concepto de herramientas (llamada a función) y sus beneficios.
- Se refactorizó tu código para usar una sesión de chat con estado, una práctica recomendada para la IA conversacional.
- Se definió una herramienta para el modelo con una declaración de función.
- Implementaste la función de Python para proporcionar la lógica de la herramienta.
- Escribió el código para controlar las solicitudes de llamadas a funciones del modelo y devolver los resultados.