
۱. مقدمه
نمای کلی
شما یک توسعهدهنده در یک شرکت بازاریابی مسافرتی هستید. بخش فروش شما تصمیم گرفته است که برای رقابت با شرکتهای بزرگتر رزرو و جستجو، به یک برنامه چت جدید نیاز دارد. آنها همچنین در مورد هوش مصنوعی مولد شنیدهاند، اما اطلاعات زیادی در مورد آن ندارند. سایر بخشها در مورد این ابتکار شنیدهاند و کنجکاوند که چگونه این امر میتواند به تجربه مشتری آنها نیز کمک کند.
کاری که انجام خواهید داد
در این آزمایش، شما با استفاده از مدل Gemini 2.5 Flash روی Vertex AI یک چتبات دستیار مسافرتی خواهید ساخت.
برنامه باید:
- به کاربران کمک میکند تا در مورد سفر سوال بپرسند، سفر رزرو کنند و در مورد مکانهایی که قصد سفر به آنها را دارند، اطلاعات کسب کنند.
- به کاربران روشهایی برای دریافت کمک در مورد برنامههای سفر خاصشان ارائه میدهد
- بتوانید با استفاده از ابزارها، دادههای بلادرنگ، مانند آب و هوا، را دریافت کنید.
شما در یک محیط از پیش پیکربندی شده Google Cloud، به طور خاص در ویرایشگر Cloud Shell، کار خواهید کرد. یک رابط کاربری اولیه برنامه وب از قبل برای شما تنظیم شده است، به همراه مجوزهای لازم برای دسترسی به Vertex AI. این برنامه با استفاده از Streamlit ساخته شده است.
آنچه یاد خواهید گرفت
در این آزمایشگاه، شما یاد میگیرید که چگونه وظایف زیر را انجام دهید:
- برای شناسایی مدلهای هوش مصنوعی مولد موجود، پلتفرم هوش مصنوعی ورتکس (Vertex AI) را بررسی کنید.
- توسعه در ویرایشگر Cloud Shell و ترمینال
- برای درک کد از Gemini Code Assist استفاده کنید.
- از Vertex AI SDK در پایتون برای ارسال درخواستها و دریافت پاسخ از Gemini LLM استفاده کنید.
- مهندسی سریع اولیه ( دستورالعملهای سیستم ، پارامترهای مدل ) را برای سفارشیسازی خروجی Gemini LLM اعمال کنید.
- با تغییر اعلانها و پارامترها برای بهبود پاسخها، یک برنامه چت مبتنی بر LLM را آزمایش و به طور مکرر اصلاح کنید.
- تعریف و استفاده از ابزارها با مدل Gemini برای فعال کردن فراخوانی تابع .
- کد را برای استفاده از یک جلسه چت با وضعیت (stateful chat session)، که بهترین روش برای برنامههای مکالمهای است، اصلاح کنید.
۲. راهاندازی پروژه
حساب گوگل
اگر از قبل حساب گوگل شخصی ندارید، باید یک حساب گوگل ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید .
ورود به کنسول ابری گوگل
با استفاده از یک حساب کاربری شخصی گوگل، وارد کنسول ابری گوگل شوید.
فعال کردن صورتحساب
استفاده از اعتبار گوگل کلود (اختیاری)
برای اجرای این کارگاه، به یک حساب صورتحساب با مقداری اعتبار نیاز دارید. برای شروع از اعتبارهای موجود در بنر بالای این codelab استفاده کنید. اگر از قبل به یک حساب صورتحساب متصل هستید، میتوانید از این مرحله صرف نظر کنید.
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۱ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
ایجاد پروژه (اختیاری)
اگر پروژه فعلی ندارید که بخواهید برای این آزمایشگاه استفاده کنید، اینجا یک پروژه جدید ایجاد کنید .
۳. ویرایشگر Cloud Shell را باز کنید
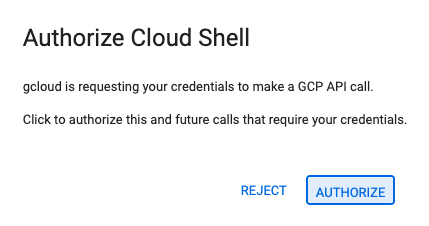
- برای دسترسی مستقیم به ویرایشگر Cloud Shell ، روی این لینک کلیک کنید.
- اگر امروز در هر مرحلهای از شما خواسته شد که مجوز دهید، برای ادامه روی تأیید کلیک کنید.
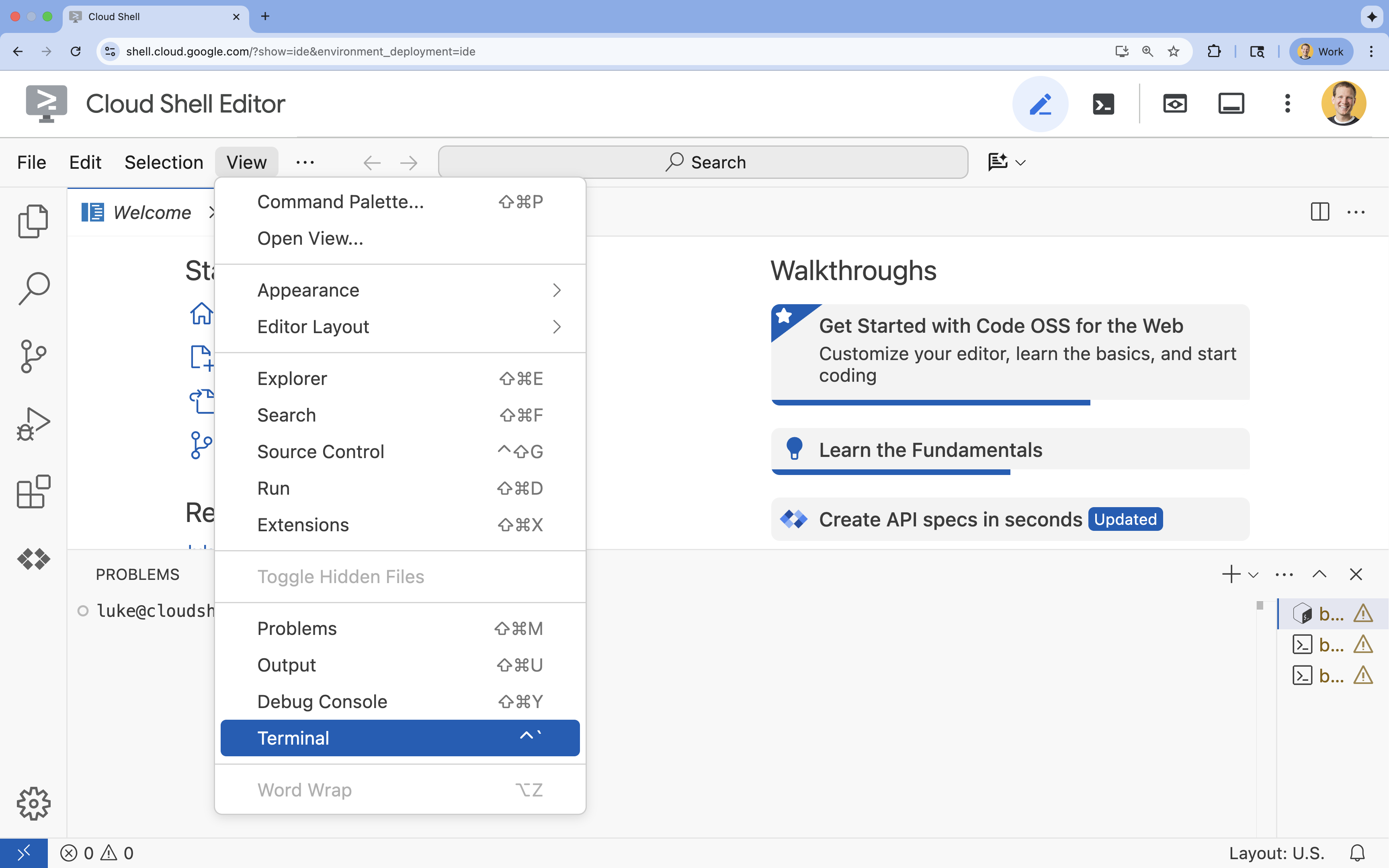
- اگر ترمینال در پایین صفحه نمایش داده نشد، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
- در ترمینال، پروژه خود را با این دستور تنظیم کنید:
gcloud config set project [PROJECT_ID]- مثال:
gcloud config set project lab-project-id-example - اگر نمیتوانید شناسه پروژه خود را به خاطر بیاورید، میتوانید تمام شناسههای پروژه خود را با استفاده از دستور زیر فهرست کنید:
gcloud projects list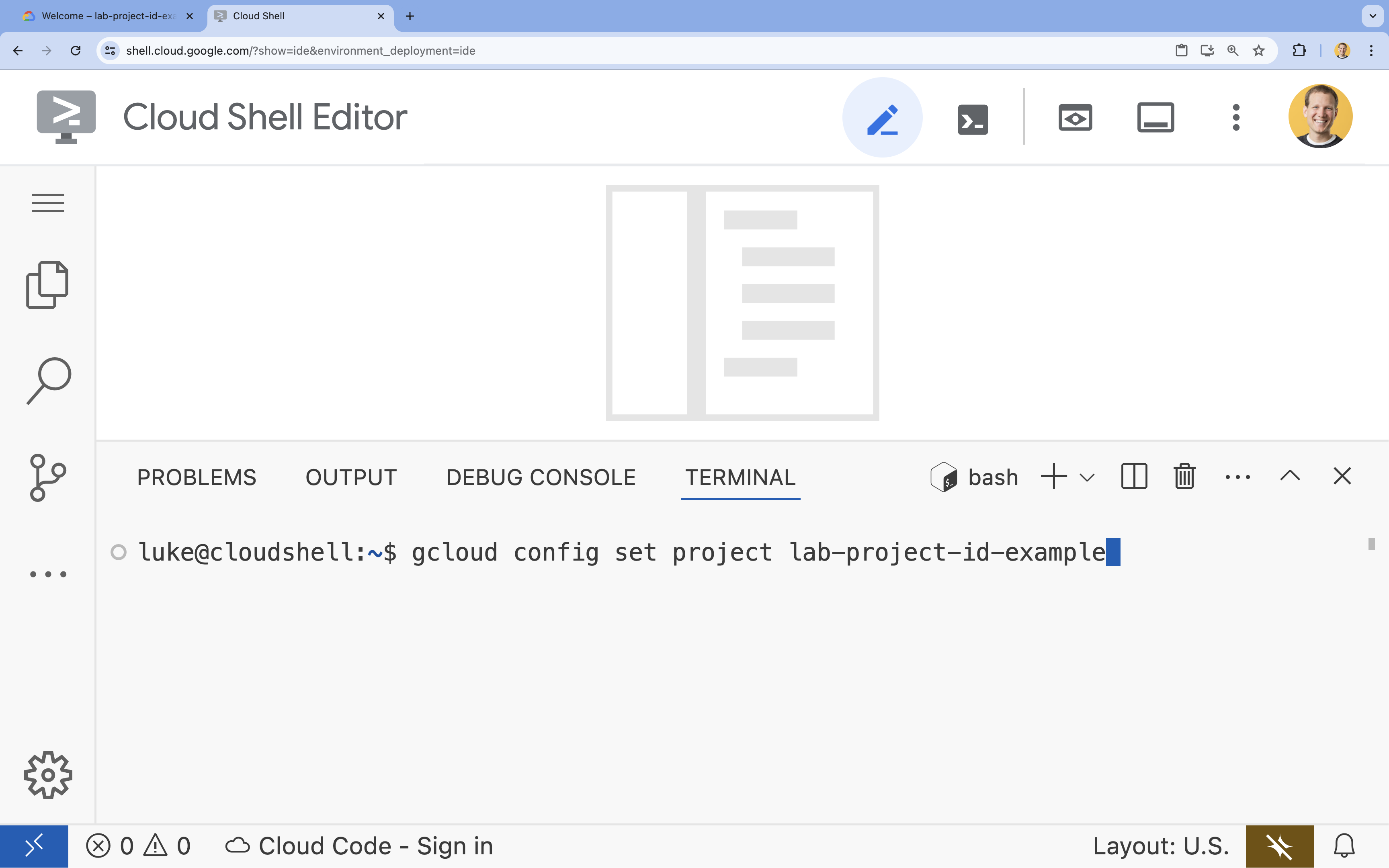
- مثال:
- شما باید این پیام را ببینید:
Updated property [core/project].
۴. فعال کردن APIها
برای استفاده از Vertex AI SDK و تعامل با مدل Gemini، باید Vertex AI API را در پروژه Google Cloud خود فعال کنید.
- در ترمینال، APIها را فعال کنید:
gcloud services enable \ aiplatform.googleapis.com
مقدمهای بر Vertex AI SDK برای پایتون
برای تعامل با مدلهای میزبانیشده در Vertex AI از طریق برنامه پایتون خود، از Vertex AI SDK برای پایتون استفاده خواهید کرد. این SDK فرآیند ارسال اعلانها، تعیین پارامترهای مدل و دریافت پاسخها را بدون نیاز به مدیریت مستقیم پیچیدگیهای فراخوانیهای API زیربنایی، ساده میکند.
میتوانید مستندات جامع مربوط به Vertex AI SDK برای پایتون را اینجا پیدا کنید: مقدمهای بر Vertex AI SDK برای پایتون | Google Cloud .
۵. یک محیط مجازی ایجاد کنید و وابستگیها را نصب کنید
قبل از شروع هر پروژه پایتون، ایجاد یک محیط مجازی تمرین خوبی است. این کار وابستگیهای پروژه را ایزوله میکند و از تداخل با سایر پروژهها یا بستههای پایتون سراسری سیستم جلوگیری میکند.
- یک پوشه به نام
wanderbotایجاد کنید تا کد مربوط به برنامه دستیار سفر خود را در آن ذخیره کنید. کد زیر را در ترمینال اجرا کنید:mkdir wanderbot && cd wanderbot - ایجاد و فعالسازی یک محیط مجازی:
uv venv --python 3.12 source .venv/bin/activatewanderbot) در ابتدای اعلان ترمینال شما قرار میگیرد که نشان میدهد محیط مجازی فعال است. چیزی شبیه به این خواهد بود:
۶. ایجاد فایلهای آغازین برای wanderbot
- یک فایل
app.pyجدید برای برنامه ایجاد و باز کنید. کد زیر را در ترمینال اجرا کنید:cloudshell edit app.pycloudshell editفایلapp.pyرا در ویرایشگر بالای ترمینال باز میکند. - کد آغازگر برنامه زیر را در
app.pyقرار دهید:import streamlit as st from google import genai from google.genai import types import requests import logging # --- Defining variables and parameters --- REGION = "global" PROJECT_ID = None # TODO: Insert Project ID GEMINI_MODEL_NAME = "gemini-2.5-flash" temperature = .2 top_p = 0.95 system_instructions = None # --- Tooling --- # TODO: Define the weather tool function declaration # TODO: Define the get_current_temperature function # --- Initialize the Vertex AI Client --- try: # TODO: Initialize the Vertex AI client print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}") except Exception as e: st.error(f"Error initializing VertexAI client: {e}") st.stop() # TODO: Add the get_chat function here in Task 15. # --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions. It will be replaced in a later step with a more advanced version that handles tooling. """ try: # TODO: Prepare the content for the model # TODO: Define generate_content configuration (needed for system instructions and parameters) # TODO: Define response logging.info(f"[call_model_response] LLM Response: \"{response.text}\"") # TODO: Uncomment the below "return response.text" line # return response.text except Exception as e: return f"Error: {e}" # --- Presentation Tier (Streamlit) --- # Set the title of the Streamlit application st.title("Travel Chat Bot") # Initialize session state variables if they don't exist if "messages" not in st.session_state: # Initialize the chat history with a welcome message st.session_state["messages"] = [ {"role": "assistant", "content": "How can I help you today?"} ] # Display the chat history for msg in st.session_state.messages: st.chat_message(msg["role"]).write(msg["content"]) # Get user input if prompt := st.chat_input(): # Add the user's message to the chat history st.session_state.messages.append({"role": "user", "content": prompt}) # Display the user's message st.chat_message("user").write(prompt) # Show a spinner while waiting for the model's response with st.spinner("Thinking..."): # Get the model's response using the call_model function model_response = call_model(prompt, GEMINI_MODEL_NAME) # Add the model's response to the chat history st.session_state.messages.append( {"role": "assistant", "content": model_response} ) # Display the model's response st.chat_message("assistant").write(model_response) - یک فایل
requirements.txtجدید برای کد برنامه ایجاد و باز کنید. کد زیر را در ترمینال اجرا کنید:cloudshell edit requirements.txtcloudshell editفایلrequirements.txtرا در ویرایشگر بالای ترمینال باز میکند. - کد آغازگر برنامه زیر را در
requirements.txtقرار دهید.google-genai streamlit requests - وابستگیهای پایتون مورد نیاز برای این پروژه را نصب کنید. کد زیر را در ترمینال اجرا کنید:
uv pip install -r requirements.txt
۷. کد را بررسی کنید
فایلهایی که ایجاد کردید شامل یک رابط کاربری اولیه برای برنامه چت هستند. این فایلها عبارتند از:
-
app.py: این فایلی است که ما در آن کار خواهیم کرد. در حال حاضر شامل موارد زیر است:- واردات ضروری
- متغیرها و پارامترهای محیطی (که برخی از آنها متغیرهایی هستند)
- یک تابع
call_modelخالی که آن را پر خواهیم کرد - کد ساده برای برنامه چت front-end
-
requirements.txt:- شامل الزامات نصب برای اجرای
app.pyاست
- شامل الزامات نصب برای اجرای
حالا وقتشه که کد رو بررسی کنیم!
چت کمکی کد جمینی را باز کنید
چت کمکی کد Gemini باید از قبل در پنلی در سمت راست ویرایشگر Cloud Shell باز باشد. اگر چت کمکی کد Gemini از قبل باز نیست، میتوانید آن را با مراحل زیر باز کنید:
- کلیک بر روی دکمهی کمک به کد جمینی (
 ) نزدیک بالای صفحه نمایش.
) نزدیک بالای صفحه نمایش. - گزینه «گپ کمکی کد باز جمینی» را انتخاب کنید.
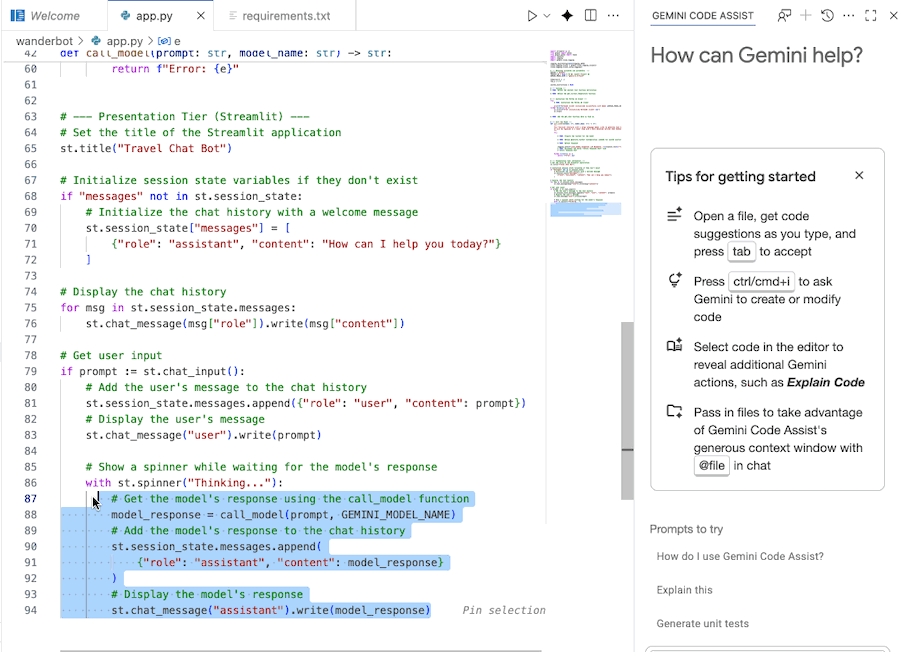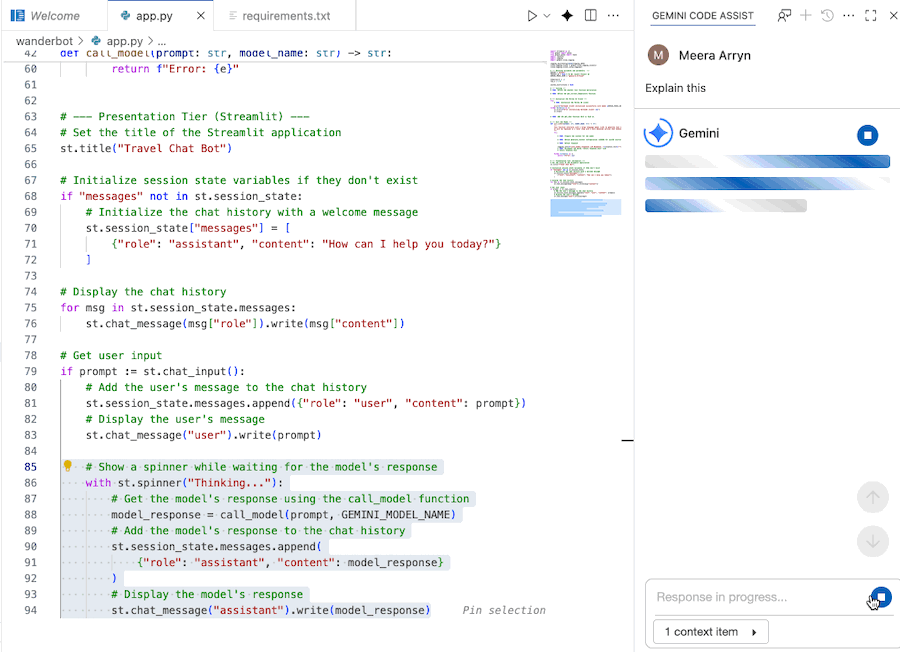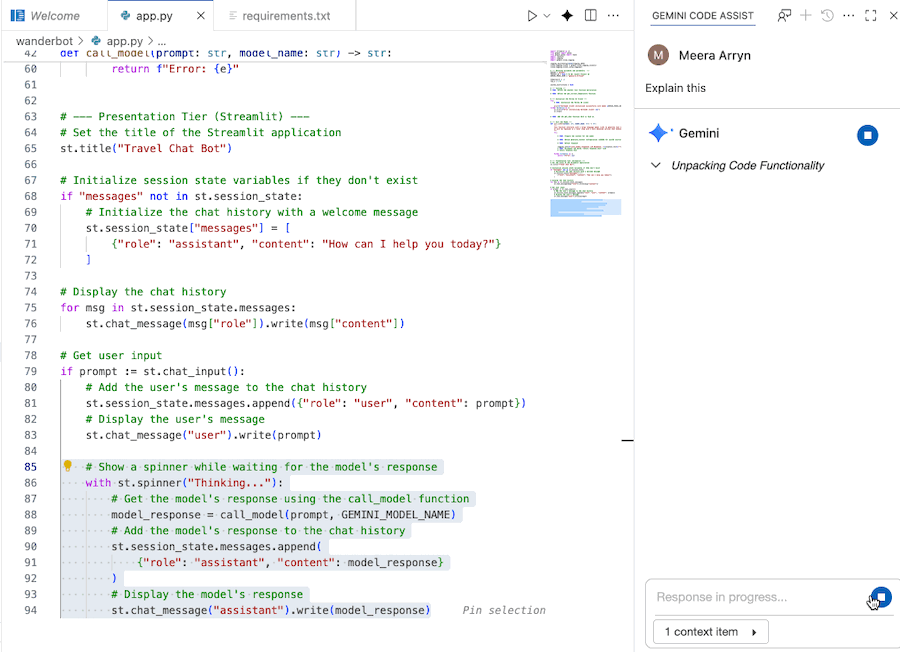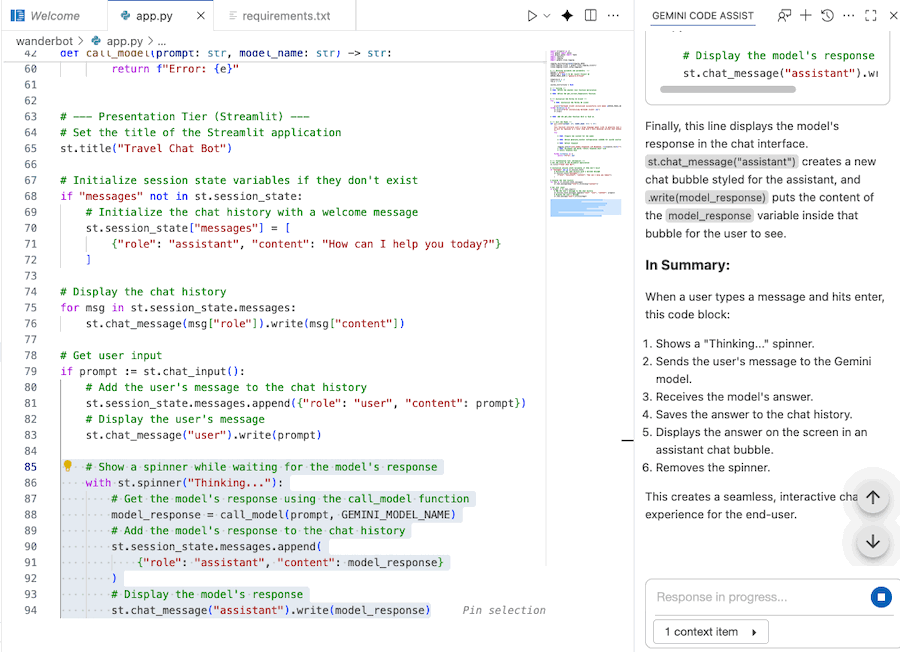
برای فهمیدن کد از Gemini Code Assist استفاده کنید
برای درک بهتر کد میتوانید از چت کمکی کد Gemini استفاده کنید.
- بخش کد مورد نظر را هایلایت یا انتخاب کنید.
- در چت Gemini عبارت «توضیح این کد» را تایپ کنید.
- برای ارسال، روی ورود کلیک کنید
۸. برنامه وب را اجرا کنید
قبل از اتصال این برنامه به یک LLM، آن را اجرا کنید تا ببینید در ابتدا چگونه رفتار میکند.
- از داخل دایرکتوری
wanderbot، دستور زیر را در ترمینال اجرا کنید تا برنامه Streamlit اجرا شود و به صورت محلی در محیط Cloud Shell شما قابل دسترسی باشد:streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - پس از اجرای دستور، روی دکمهی پیشنمایش وب در بالای ویرایشگر Cloud Shell کلیک کنید و پیشنمایش را روی پورت ۸۰۸۰ انتخاب کنید.
شما یک رابط چت ساده برای برنامه سفر خود خواهید دید. - هر پیامی را تایپ کنید (مثلاً
Hi!) و ENTER را فشار دهید.
متوجه خواهید شد که پیام در تاریخچه چت ظاهر میشود، اما به جای پاسخی از دستیار ، یک پیام خطا دریافت خواهید کرد . دلیل این امر این است که برنامه هنوز به یک مدل زبان بزرگ متصل نشده است. برای درک نقطه شروع آزمایش، این رفتار را مشاهده کنید.
۹. مقداردهی اولیه کلاینت هوش مصنوعی ورتکس
مدلهای موجود در Vertex AI را بررسی کنید
پلتفرم هوش مصنوعی ورتکس گوگل کلود (Google Cloud) دسترسی به انواع مدلهای هوش مصنوعی مولد (Generative AI) را فراهم میکند. قبل از ادغام هر یک، میتوانید گزینههای موجود را در کنسول گوگل کلود (Google Cloud Console) بررسی کنید.
- از کنسول گوگل کلود، به Model Garden بروید. میتوانید این کار را با جستجوی «Model Garden» در نوار جستجوی بالای صفحه و انتخاب Vertex AI انجام دهید.
 )
) - مدلهای موجود را مرور کنید. میتوانید بر اساس مواردی مانند روشها، انواع وظایف و ویژگیها فیلتر کنید.
برای اهداف این آزمایش، شما از مدل Gemini 2.5 Flash استفاده خواهید کرد که به دلیل سرعت بالا، انتخاب خوبی برای ساخت برنامههای چت واکنشگرا است.
مقداردهی اولیه کلاینت هوش مصنوعی Vertex
حالا بخش --- Initialize the Vertex AI Client --- را در app.py تغییر خواهید داد تا کلاینت هوش مصنوعی ورتکس را مقداردهی اولیه کنید. این شیء کلاینت برای ارسال اعلانها به مدل استفاده خواهد شد.
-
app.pyدر ویرایشگر Cloud Shell باز کنید. - در
app.py، خطPROJECT_ID = Noneپیدا کنید. - به جای
None، شناسه پروژه گوگل کلود خود را که داخل گیومه قرار دارد، قرار دهید. (مثلاًPROJECT_ID = "google-cloud-labs")
اگر نمیتوانید شناسه پروژه خود را به خاطر بیاورید، میتوانید تمام شناسههای پروژه خود را با استفاده از دستور زیر فهرست کنید:gcloud projects list | awk '/PROJECT_ID/{print $2}' - تعریف کلاینت : درون بلوک
try، کلاینت Vertex AI را مقداردهی اولیه کنید.client = genai.Client( vertexai=True, project=PROJECT_ID, location=REGION, )
مقداردهی اولیه کلاینت Vertex AI بهروزرسانی شد.
در این مرحله، بخش Initialize the Vertex AI Client به شکل زیر خواهد بود:
# --- Initialize the Vertex AI Client ---
try:
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=REGION,
)
print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}")
except Exception as e:
st.error(f"Error initializing VertexAI client: {e}")
st.stop()
۱۰. آمادهسازی دادهها و فراخوانی مدل
اکنون محتوا را برای ارسال به مدل آماده میکنید و با مدل Gemini تماس برقرار میکنید.
- بخش
--- Call the Model ---که تابعcall_modelدر آن تعریف شده است را پیدا کنید. - تعریف محتوا : در قسمت
# TODO: Prepare the content for the model، محتوای ورودی که به مدل ارسال خواهد شد را تعریف کنید. برای یک اعلان اولیه، این پیام ورودی کاربر خواهد بود.contents = [prompt] - تعریف پاسخ : این کد را در زیر
# TODO: Define responseقرار دهید.response = client.models.generate_content( model=model_name, contents=contents, ) - پاسخ را برگردانید : خط زیر را از حالت کامنت خارج کنید:
return response.text - خطی را که تابع
call_modelدر آن فراخوانی میشود، در پایین فایل در بلوکwith، بررسی کنید. اگر متوجه نمیشوید چه اتفاقی در اینجا میافتد، خط را هایلایت کنید و از Gemini Code Assist بخواهید که توضیح دهد.
روشی صریحتر برای تعریف contents
روش بالا برای تعریف contents به این دلیل کار میکند که SDK به اندازه کافی هوشمند است که بفهمد لیستی حاوی رشتهها، ورودی متن کاربر را نشان میدهد. این SDK به طور خودکار آن را به درستی برای API مدل قالببندی میکند.
با این حال، روش صریحتر و اساسیتر برای ساختاردهی ورودی شامل استفاده از اشیاء types.Part و types.Content است، مانند این:
user_message_parts = [types.Part.from_text(text=prompt)]
contents = [
types.Content(
role="user", # Indicates the content is from the user
parts=user_message_parts, # A list, allowing multiple types of content
),
]
تابع call_model بهروزرسانی شد.
در این مرحله، تابع call_model باید به شکل زیر باشد:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
# TODO: Define generate_content configuration (needed later for system instructions and parameters)
response = client.models.generate_content(
model=model_name,
contents=contents,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
۱۱. برنامه متصل را آزمایش کنید
- در داخل ترمینال، فرآیند در حال اجرا را خاتمه دهید ( CTRL+C )
- برای شروع مجدد برنامه Streamlit، دستور را دوباره اجرا کنید.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - برنامه Streamlit را رفرش کنید. اگر برنامه Streamlit هنوز در حال اجرا است، میتوانید به سادگی صفحه پیشنمایش وب را در مرورگر خود رفرش کنید.
- حالا، یک سوال مانند زیر در ورودی چت تایپ کنید:
What is the best time of year to go to Iceland? - ENTER را فشار دهید.
باید ببینید که برنامه پیام شما، یک spinner با عبارت "Thinking..." و سپس پاسخی که توسط مدل Gemini تولید شده است را نمایش میدهد! اگر این اتفاق افتاده باشد، پس برنامه وب خود را با موفقیت به یک LLM در Vertex AI متصل کردهاید. 🙌 🥳
۱۲. دستورالعملهای سیستم را تعریف کنید
در حالی که اتصال اولیه کار میکند، کیفیت و سبک پاسخهای LLM به شدت تحت تأثیر ورودی دریافتی آن قرار دارد. مهندسی سریع فرآیند طراحی و اصلاح این ورودیها (دستورالعملها) برای هدایت مدل به سمت تولید خروجی مطلوب است.
برای این منظور، شما با ایجاد برخی دستورالعملهای سیستمی و ارسال آنها به مدل شروع خواهید کرد.
شما از «از جمینی بپرس» برای ارائه دستورالعملهای مفید سیستم استفاده خواهید کرد.
- در
app.py، متغیرsystem_instructionsرا پیدا کنید که در حال حاضر رویNoneتنظیم شده است.system_instructions = NoneNoneبا یک رشته چندخطی جایگزین خواهید کرد که دستورالعملهایی را برای ربات دستیار سفر ما ارائه میدهد. - از دستیار کد Gemini بپرسید : دستور زیر را به دستیار کد Gemini بدهید (یا دستور خودتان را بسازید!):
I am a developer at a travel marketing company, and my sales department has decided that they need a new chat application to keep up with the bigger booking and search companies. I'm building a simple travel assistant chatbot using the Gemini 2.5 Flash model on Vertex AI. The application should: - Helps users ask questions about travel, book travel, and learn about places they are going to go - Provides users ways to get help about their specific travel plans - Provides all this in a production quality way (multiple environments, logging and monitoring, etc.) Please create system instructions appropriate for that chat app. Be thorough. Do not alter the code in any way beyond providing me with system instructions. - تعریف
system_instructions: مقدارsystem_instructionsرا برابر با دستورالعملهای سیستمی که با استفاده از Gemini Code Assist ایجاد کردهاید، تنظیم کنید. میتوانید به طور جایگزین از این دستورالعملهای سیستمی که توسط Gemini با یک اعلان مشابه ایجاد شدهاند، استفاده کنید.system_instructions = """ You are a sophisticated travel assistant chatbot designed to provide comprehensive support to users throughout their travel journey. Your capabilities include answering travel-related questions, assisting with booking travel arrangements, offering detailed information about destinations, and providing support for existing travel plans. **Core Functionalities:** 1. **Travel Information and Recommendations:** * Answer user inquiries about travel destinations, including popular attractions, local customs, visa requirements, weather conditions, and safety advice. * Provide personalized recommendations for destinations, activities, and accommodations based on user preferences, interests, and budget. * Offer insights into the best times to visit specific locations, considering factors like weather, crowds, and pricing. * Suggest alternative destinations or activities if the user's initial choices are unavailable or unsuitable. 2. **Booking Assistance:** * Facilitate the booking of flights, hotels, rental cars, tours, and activities. * Search for available options based on user-specified criteria such as dates, destinations, budget, and preferences. * Present clear and concise information about available options, including pricing, amenities, and booking terms. * Guide users through the booking process, ensuring accurate information and secure transactions. * Provide booking confirmations and relevant details, such as booking references and contact information. 3. **Travel Planning and Itinerary Management:** * Assist users in creating detailed travel itineraries, including flights, accommodations, activities, and transportation. * Offer suggestions for optimizing travel plans, such as minimizing travel time or maximizing sightseeing opportunities. * Provide tools for managing and modifying existing itineraries, including adding or removing activities, changing booking dates, or upgrading accommodations. * Offer reminders and notifications for upcoming travel events, such as flight check-in or tour departure times. 4. **Customer Support and Troubleshooting:** * Provide prompt and helpful support to users with questions or issues related to their travel plans. * Assist with resolving booking discrepancies, cancellations, or modifications. * Offer guidance on travel-related emergencies, such as lost luggage or travel delays. * Provide access to relevant contact information for airlines, hotels, and other travel providers. **Interaction Guidelines:** * **Professionalism:** Maintain a polite, respectful, and professional tone in all interactions. * **Clarity and Conciseness:** Provide clear, concise, and easy-to-understand information. Avoid jargon or technical terms unless necessary and always explain them. * **Accuracy:** Ensure all information provided is accurate and up-to-date. Double-check details before sharing them with users. If unsure about something, admit that you don't know and offer to find the information. * **Personalization:** Tailor your responses and recommendations to the specific needs and preferences of each user. * **Proactive Assistance:** Anticipate user needs and offer relevant information or suggestions proactively. * **Error Handling:** Gracefully handle user errors or misunderstandings. Provide helpful guidance and alternative options when necessary. * **Confidentiality:** Respect user privacy and handle personal information with the utmost confidentiality and in compliance with data protection regulations. **Example Interactions:** **User:** "I want to go on a beach vacation in the Caribbean. I have a budget of $2000 per person for a week." **Chatbot:** "Certainly! The Caribbean offers many beautiful beach destinations within your budget. Some popular options include Punta Cana in the Dominican Republic, Cancun in Mexico, and Montego Bay in Jamaica. These destinations offer stunning beaches, all-inclusive resorts, and various activities. Would you like me to search for flights and accommodations for these locations based on your travel dates?" **User:** "My flight is delayed. What should I do?" **Chatbot:** "I'm sorry to hear about the delay. Please check with the airline for the updated departure time and any assistance they can offer. You may be entitled to compensation or rebooking options depending on the length of the delay and the airline's policy. Do you have your flight number handy so I can look up the current status for you?" **User:** "Tell me about the best time to visit Japan." **Chatbot:** "Japan is a fantastic destination with distinct seasons offering unique experiences. Spring (March-May) is famous for the beautiful cherry blossoms, while autumn (September-November) boasts stunning fall foliage. Both seasons have pleasant temperatures, making them ideal for sightseeing. Summer (June-August) can be hot and humid, but it's a great time for festivals and outdoor activities in the mountains. Winter (December-February) offers opportunities for skiing and snowboarding in the Japanese Alps, though some areas may experience heavy snowfall. To recommend the best time for you, could you tell me what you'd like to experience in Japan?" By following these instructions, you will be able to provide exceptional travel assistance and create a positive experience for every user. """ - تعریف پیکربندی generate_content: یک شیء پیکربندی را که این دستورالعملهای سیستمی را به آن ارسال خواهید کرد، مقداردهی اولیه کنید. از آنجا که
system_instructionsدر اسکریپت ما به صورت سراسری تعریف شده است، تابع میتواند مستقیماً به آن دسترسی داشته باشد.generate_content_config = types.GenerateContentConfig( system_instruction=[ types.Part.from_text(text=system_instructions) ], ) logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}") - برای افزودن دستورالعملهای سیستم به پاسخ ، یک پارامتر
configبه متدgenerate_contentاضافه کنید و آن را برابر با شیءgenerate_content_configایجاد شده در بالا قرار دهید.response = client.models.generate_content( model=model_name, contents=contents, config=generate_content_config, # This is the new line )
تابع call_model بهروزرسانی شد.
تابع کامل call_model اکنون به این شکل است:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
generate_content_config = types.GenerateContentConfig(
system_instruction=[
types.Part.from_text(text=system_instructions)
],
)
logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}")
response = client.models.generate_content(
model=model_name,
contents=contents,
config=generate_content_config,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
۱۳. برنامه را با دستورالعملهای سیستمی تست کنید
- در داخل ترمینال، فرآیند در حال اجرا را خاتمه دهید ( CTRL+C )
- برای شروع مجدد برنامه Streamlit، دستور را دوباره اجرا کنید.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - برنامه Streamlit را رفرش کنید. اگر برنامه Streamlit هنوز در حال اجرا است، میتوانید به سادگی صفحه پیشنمایش وب را در مرورگر خود رفرش کنید.
- همان سوال قبلی را امتحان کنید:
What is the best time of year to go to Iceland? - ENTER را فشار دهید.
نحوه پاسخدهی این بار را با دفعه قبل مقایسه کنید.
۱۴. یک ابزار هواشناسی تعریف کنید
تا اینجا، چتبات ما آگاه است، اما دانش آن محدود به دادههایی است که بر اساس آنها آموزش دیده است. نمیتواند به اطلاعات بلادرنگ دسترسی داشته باشد. برای یک ربات مسافرتی، توانایی دریافت دادههای زنده مانند پیشبینی آب و هوا یک مزیت بزرگ است.
اینجاست که ابزارسازی ، که با نام فراخوانی تابع نیز شناخته میشود، وارد عمل میشود. ما میتوانیم مجموعهای از ابزارها (توابع پایتون) را تعریف کنیم که LLM میتواند برای دریافت اطلاعات خارجی، آنها را فراخوانی کند.
نحوه کار ابزارآلات
- ما ابزارهای خود را برای مدل توصیف میکنیم، از جمله اینکه چه کاری انجام میدهند و چه پارامترهایی را دریافت میکنند.
- کاربر یک پیام فوری ارسال میکند (مثلاً « هوای لندن چطور است؟ »).
- مدل اعلان را دریافت میکند و میبیند که کاربر در مورد چیزی سوال میکند که میتواند با استفاده از یکی از ابزارهایش آن را پیدا کند.
- به جای پاسخ دادن با متن، مدل با یک شیء
function_callخاص پاسخ میدهد که نشان میدهد کدام ابزار را میخواهد فراخوانی کند و با کدام آرگومانها. - کد پایتون ما این
function_callدریافت میکند، تابعget_current_temperatureواقعی ما را با آرگومانهای ارائه شده اجرا میکند و نتیجه (مثلاً ۱۵ درجه سانتیگراد) را دریافت میکند. - ما این نتیجه را به مدل ارسال میکنیم.
- مدل نتیجه را دریافت میکند و یک پاسخ به زبان طبیعی برای کاربر تولید میکند (مثلاً «دمای فعلی لندن ۱۵ درجه سانتیگراد است.»).
این فرآیند به مدل اجازه میدهد تا به سوالاتی بسیار فراتر از دادههای آموزشی خود پاسخ دهد و آن را به دستیاری بسیار قدرتمندتر و مفیدتر تبدیل کند.
تعریف ابزار هواشناسی
اگر مسافری به دنبال راهنمایی در مورد کارهایی که باید انجام دهد است و بین فعالیتهایی که تحت تأثیر آب و هوا قرار دارند، یکی را انتخاب میکند، یک ابزار آب و هوا میتواند مفید باشد! بیایید ابزاری برای مدل خود ایجاد کنیم تا آب و هوای فعلی را دریافت کند. ما به دو بخش نیاز داریم: یک تعریف تابع که ابزار را برای مدل توصیف میکند و تابع پایتون واقعی که آن را پیادهسازی میکند.
- در
app.py، عبارت# TODO: Define the weather tool function declarationپیدا کنید. - زیر این کامنت، متغیر
weather_functionرا اضافه کنید. این یک دیکشنری است که هر آنچه مدل باید در مورد هدف تابع، پارامترها و آرگومانهای مورد نیاز بداند را به آن میگوید.weather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } - سپس، کامنت
# TODO: Define the get_current_temperature functionپیدا کنید. در زیر آن، کد پایتون زیر را اضافه کنید. این تابع:- برای دریافت مختصات مکان، یک API مربوط به ژئوکدینگ را فراخوانی کنید.
- از آن مختصات برای فراخوانی یک API آب و هوا استفاده کنید.
- یک رشته ساده شامل دما و واحد را برگردانید.
def get_current_temperature(location: str) -> str: """Gets the current temperature for a given location.""" try: # --- Get Latitude and Longitude for the location --- geocode_url = f"https://geocoding-api.open-meteo.com/v1/search?name={location}&count=1&language=en&format=json" geocode_response = requests.get(geocode_url) geocode_data = geocode_response.json() if not geocode_data.get("results"): return f"Could not find coordinates for {location}." lat = geocode_data["results"][0]["latitude"] lon = geocode_data["results"][0]["longitude"] # --- Get Weather for the coordinates --- weather_url = f"https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}¤t_weather=true" weather_response = requests.get(weather_url) weather_data = weather_response.json() temperature = weather_data["current_weather"]["temperature"] unit = "°C" return f"{temperature}{unit}" except Exception as e: return f"Error fetching weather: {e}"
۱۵. ریفکتور کردن برای چت و ابزارها
تابع call_model فعلی ما از یک فراخوانی ساده و یکباره generate_content استفاده میکند. این برای سوالات تکی عالی است اما برای مکالمه چند نوبتی، به خصوص مکالمهای که شامل رفت و برگشت برای ابزارسازی است، ایدهآل نیست.
یک روش بهتر استفاده از یک جلسه چت است که زمینه مکالمه را حفظ میکند. اکنون کد خود را برای استفاده از یک جلسه چت که برای پیادهسازی صحیح ابزارها ضروری است، اصلاح خواهیم کرد.
- تابع
call_modelموجود را حذف کنید. ما آن را با یک نسخه پیشرفتهتر جایگزین خواهیم کرد. - به جای آن، تابع جدید
call_modelاز بلوک کد زیر اضافه کنید. این تابع جدید شامل منطق لازم برای مدیریت حلقه فراخوانی ابزار است که قبلاً در مورد آن صحبت کردیم. توجه داشته باشید که چندین کامنت TODO دارد که در مراحل بعدی آنها را تکمیل خواهیم کرد.# --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt. It maintains a chat session and handles function calls from the model to external tools. """ try: # TODO: Get the existing chat session or create a new one. message_content = prompt # Start the tool-calling loop while True: # TODO: Send the message to the model. # Check if the model wants to call a tool has_tool_calls = False for part in response.candidates[0].content.parts: if part.function_call: has_tool_calls = True function_call = part.function_call logging.info(f"Function to call: {function_call.name}") logging.info(f"Arguments: {function_call.args}") # TODO: Call the appropriate function if the model requests it. elif part.text: logging.info("No function call found in the response.") logging.info(response.text) # If no tool call was made, break the loop if not has_tool_calls: break # TODO: Return the model's final text response. except Exception as e: return f"Error: {e}" - حالا، بیایید یک تابع کمکی برای مدیریت جلسه چت اضافه کنیم. بالای تابع جدید
call_model، تابعget_chatرا اضافه کنید. این تابع یک جلسه چت جدید با دستورالعملهای سیستم و تعاریف ابزار ما ایجاد میکند، یا جلسه چت موجود را بازیابی میکند. این یک روش خوب برای سازماندهی کد است.def get_chat(model_name: str): if f"chat-{model_name}" not in st.session_state: # TODO: Define the tools configuration for the model # TODO: Define the generate_content configuration, including tools # TODO: Create a new chat session st.session_state[f"chat-{model_name}"] = chat return st.session_state[f"chat-{model_name}"]
اکنون داربست منطق چت پیشرفته و مجهز به ابزار ما را تنظیم کردهاید!
۱۶. منطق فراخوانی ابزار را پیادهسازی کنید
حالا، بیایید TODOs را پر کنیم تا منطق فراخوانی ابزارمان کاملاً کاربردی شود.
پیادهسازی get_chat
- در تابع
get_chatزیر# TODO: Define the tools configuration...comment، شیءtoolsرا با ایجاد یک نمونهtypes.Toolاز اعلانweather_functionخود تعریف کنید.tools = types.Tool(function_declarations=[weather_function]) - در زیر
# TODO: Define the generate_content configuration...، definegenerate_content_config، مطمئن شوید که شیءtoolsرا به مدل ارسال میکنید. اینگونه است که مدل در مورد ابزارهایی که میتواند استفاده کند، یاد میگیرد.generate_content_config = types.GenerateContentConfig( system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here ) - در زیر
# TODO: Create a new chat session، شیء چت را با استفاده ازclient.chats.create()ایجاد کنید و نام مدل و پیکربندی خود را به آن ارسال کنید.chat = client.chats.create( model=model_name, config=generate_content_config, )
پیادهسازی call_model
- در زیر
# TODO: Get the existing chat session...در تابعcall_model، تابع کمکی جدیدget_chatما را فراخوانی کنید.chat = get_chat(model_name) - سپس،
# TODO: Send the message to the modelپیدا کنید. پیام کاربر را با استفاده از متدchat.send_message()ارسال کنید.response = chat.send_message(message_content) - یافتن
# TODO: Call the appropriate function.... در اینجا بررسی میکنیم که مدل کدام تابع را میخواهد و آن را اجرا میکنیم.
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
- در آخر،
# TODO: Return the model's final text responseو عبارت return را اضافه کنید.return response.text
تابع get_chat بهروزرسانی شد
تابع get_chat بهروزرسانیشده، اکنون باید به شکل زیر باشد:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
تابع call_model بهروزرسانی شد.
تابع call_model بهروزرسانیشده، اکنون باید به شکل زیر باشد:
def call_model(prompt: str, model_name: str) -> str:
try:
chat = get_chat(model_name)
message_content = prompt
while True:
response = chat.send_message(message_content)
has_tool_calls = False
for part in response.candidates[0].content.parts:
if part.function_call:
has_tool_calls = True
function_call = part.function_call
logging.info(f"Function to call: {function_call.name}")
logging.info(f"Arguments: {function_call.args}")
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
elif part.text:
logging.info("No function call found in the response.")
logging.info(response.text)
if not has_tool_calls:
break
return response.text
except Exception as e:
return f"Error: {e}"
۱۷. برنامهی مجهز به ابزار را آزمایش کنید
بیایید ویژگی جدید شما را در عمل ببینیم!
- در داخل ترمینال، فرآیند در حال اجرا را خاتمه دهید ( CTRL+C )
- برای شروع مجدد برنامه Streamlit، دستور را دوباره اجرا کنید.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - برنامه Streamlit را رفرش کنید. اگر برنامه Streamlit هنوز در حال اجرا است، میتوانید به سادگی صفحه پیشنمایش وب را در مرورگر خود رفرش کنید.
- حالا، سوالی بپرسید که باید ابزار جدید شما را فعال کند، مانند سوال زیر:
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - ENTER را فشار دهید
این پاسخ را با پاسخهای قبلی مقایسه کنید. چه تفاوتی وجود دارد؟
شما باید پاسخی ببینید که دمای تابع شما را در بر میگیرد! ترمینال Cloud Shell خود را نیز بررسی کنید؛ باید عبارات چاپی را ببینید که تأیید میکنند تابع پایتون شما اجرا شده است.
۱۸. خروجی مدل را با پارامترها اصلاح کنید
عالی بود! دستیار مسافرتی شما اکنون میتواند از ابزارهایی برای دریافت دادههای زنده و خارجی استفاده کند و این امر آن را به طور قابل توجهی قدرتمندتر میکند.
حالا که قابلیتهای مدلمان را بهبود بخشیدهایم، بیایید نحوهی پاسخدهی آن را تنظیم کنیم. پارامترهای مدل به شما امکان میدهند سبک و تصادفی بودن متن تولید شده توسط LLM را کنترل کنید. با تنظیم این تنظیمات، میتوانید خروجی ربات را متمرکزتر و قطعیتر یا خلاقانهتر و متنوعتر کنید.
در این آزمایش، ما روی temperature و top_p تمرکز خواهیم کرد. (برای مشاهده لیست کاملی از پارامترهای قابل تنظیم و توضیحات آنها، به GenerateContentConfig در مرجع API ما مراجعه کنید.)
-
temperature: میزان تصادفی بودن خروجی را کنترل میکند. مقدار کمتر (نزدیکتر به ۰) خروجی را قطعیتر و متمرکزتر میکند، در حالی که مقدار بالاتر (نزدیکتر به ۲) تصادفی بودن و خلاقیت را افزایش میدهد. برای یک ربات پرسش و پاسخ یا دستیار، معمولاً دمای پایینتر برای پاسخهای سازگارتر و واقعیتر ترجیح داده میشود. -
top_p: حداکثر احتمال تجمعی توکنها که هنگام نمونهبرداری باید در نظر گرفته شوند. توکنها بر اساس احتمالات اختصاص داده شده به آنها مرتب میشوند، به طوری که فقط محتملترین توکنها در نظر گرفته میشوند. مدل، محتملترین توکنهایی را در نظر میگیرد که مجموع احتمالات آنها برابر با مقدارtop_pباشد. مقدار پایینتر، انتخاب توکنها را محدود میکند و در نتیجه خروجی با تنوع کمتری حاصل میشود.
پارامترهای فراخوانی
- متغیرهای
temperatureوtop_pرا که در بالایapp.pyتعریف شدهاند، پیدا کنید. توجه داشته باشید که آنها هنوز در هیچ جایی فراخوانی نشدهاند. -
temperatureوtop_pرا به پارامترهای تعریف شده درGenerateContentConfigدر تابعget_chatاضافه کنید.generate_content_config = types.GenerateContentConfig( temperature=temperature, top_p=top_p, system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )
تابع get_chat بهروزرسانی شد
برنامه get_chat اکنون به این شکل است:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
temperature=temperature,
top_p=top_p,
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
۱۹. تست با پارامترهای مدل
- در داخل ترمینال، فرآیند در حال اجرا را خاتمه دهید ( CTRL+C )
- برای شروع مجدد برنامه Streamlit، دستور را دوباره اجرا کنید.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - برنامه Streamlit را رفرش کنید. اگر برنامه Streamlit هنوز در حال اجرا است، میتوانید به سادگی صفحه پیشنمایش وب را در مرورگر خود رفرش کنید.
- همان سوال قبلی را امتحان کنید،
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - ENTER را فشار دهید
این پاسخ را با پاسخهای قبلی مقایسه کنید.
۲۰. تبریک میگویم!
شما با موفقیت برنامه پرسش و پاسخ خود را با ابزار ارتقا دادهاید، یک ویژگی قدرتمند که به برنامه مبتنی بر Gemini شما اجازه میدهد تا با سیستمهای خارجی تعامل داشته باشد و به اطلاعات بلادرنگ دسترسی پیدا کند.
آزمایشهای مداوم
گزینههای زیادی برای ادامه بهینهسازی اعلان شما وجود دارد. در اینجا چند مورد برای بررسی آورده شده است:
-
temperatureوtop_pرا تنظیم کنید و ببینید که چگونه پاسخ داده شده توسط LLM را تغییر میدهد. - برای مشاهده لیست کاملی از پارامترهای قابل تنظیم و توضیحات آنها، به
GenerateContentConfigدر مرجع API ما مراجعه کنید. پارامترهای بیشتری را تعریف کنید و آنها را تنظیم کنید تا ببینید چه اتفاقی میافتد!
خلاصه
در این آزمایشگاه، شما موارد زیر را انجام دادید:
- از ویرایشگر و ترمینال Cloud Shell برای توسعه استفاده شد.
- از Vertex AI Python SDK برای اتصال برنامه خود به مدل Gemini استفاده کنید.
- دستورالعملهای سیستم و پارامترهای مدل را برای هدایت پاسخهای LLM به کار برد.
- مفهوم ابزارسازی ( فراخوانی تابع ) و مزایای آن را آموختم.
- کد شما را طوری تغییر دادم که از یک جلسه چت با وضعیت مشخص استفاده کند، که بهترین روش برای هوش مصنوعی محاورهای است.
- با استفاده از اعلان تابع، ابزاری برای مدل تعریف شد.
- تابع پایتون را برای ارائه منطق ابزار پیادهسازی کرد.
- کدی نوشتیم که درخواستهای فراخوانی تابع مدل را مدیریت کند و نتایج را برگرداند.