
1. Pengantar
Ringkasan
Anda adalah developer di perusahaan pemasaran perjalanan. Departemen penjualan Anda telah memutuskan bahwa mereka memerlukan aplikasi chat baru untuk bersaing dengan perusahaan pemesanan dan penelusuran yang lebih besar. Mereka juga pernah mendengar tentang AI generatif, tetapi tidak terlalu memahaminya. Departemen lain telah mendengar tentang inisiatif ini, dan mereka ingin tahu bagaimana inisiatif ini juga dapat membantu pengalaman pelanggan mereka.
Yang akan Anda lakukan
Di lab ini, Anda akan membangun chatbot asisten perjalanan menggunakan model Gemini 2.5 Flash di Vertex AI.
Aplikasi harus:
- Membantu pengguna mengajukan pertanyaan tentang perjalanan, memesan perjalanan, dan mempelajari tempat yang ingin mereka kunjungi
- Memberi pengguna cara untuk mendapatkan bantuan terkait rencana perjalanan spesifik mereka
- Dapat mengambil data real-time, seperti cuaca, menggunakan alat
Anda akan bekerja di lingkungan Google Cloud yang telah dikonfigurasi sebelumnya, khususnya di dalam Cloud Shell Editor. Frontend aplikasi web dasar telah disiapkan untuk Anda, beserta izin yang diperlukan untuk mengakses Vertex AI. Aplikasi ini telah dibuat menggunakan Streamlit.
Yang akan Anda pelajari
Di lab ini, Anda akan mempelajari cara melakukan tugas berikut:
- Jelajahi platform Vertex AI untuk mengidentifikasi model AI generatif yang tersedia.
- Mengembangkan di Cloud Shell Editor dan terminal
- Manfaatkan Gemini Code Assist untuk memahami kode.
- Gunakan Vertex AI SDK di Python untuk mengirim perintah ke dan menerima respons dari LLM Gemini.
- Terapkan rekayasa prompt dasar (petunjuk sistem, parameter model) untuk menyesuaikan output LLM Gemini.
- Uji dan perbaiki aplikasi chat yang didukung LLM secara iteratif dengan mengubah perintah dan parameter untuk meningkatkan kualitas respons.
- Tentukan dan gunakan alat dengan model Gemini untuk mengaktifkan panggilan fungsi.
- Memfaktorkan ulang kode untuk menggunakan sesi chat stateful, praktik terbaik untuk aplikasi percakapan.
2. Penyiapan project
Akun Google
Jika belum memiliki Akun Google pribadi, Anda harus membuat Akun Google.
Gunakan akun pribadi, bukan akun kantor atau sekolah.
Login ke Konsol Google Cloud
Login ke Konsol Google Cloud menggunakan Akun Google pribadi.
Aktifkan Penagihan
Menukarkan kredit Google Cloud (opsional)
Untuk menjalankan workshop ini, Anda memerlukan akun penagihan dengan sejumlah kredit. Gunakan kredit dari banner di bagian atas codelab ini untuk memulai. Jika sudah terhubung ke akun penagihan, Anda dapat melewati langkah ini.
Menyiapkan akun penagihan pribadi
Jika menyiapkan penagihan menggunakan kredit Google Cloud, Anda dapat melewati langkah ini.
Untuk menyiapkan akun penagihan pribadi, buka di sini untuk mengaktifkan penagihan di Cloud Console.
Beberapa Catatan:
- Menyelesaikan lab ini akan dikenai biaya kurang dari $1 USD untuk resource Cloud.
- Anda dapat mengikuti langkah-langkah di akhir lab ini untuk menghapus resource agar tidak dikenai biaya lebih lanjut.
- Pengguna baru memenuhi syarat untuk mengikuti Uji Coba Gratis senilai$300 USD.
Membuat project (opsional)
Jika Anda tidak memiliki project saat ini yang ingin digunakan untuk lab ini, buat project baru di sini.
3. Buka Cloud Shell Editor
- Klik link ini untuk langsung membuka Cloud Shell Editor
- Jika diminta untuk memberikan otorisasi kapan saja hari ini, klik Authorize untuk melanjutkan.
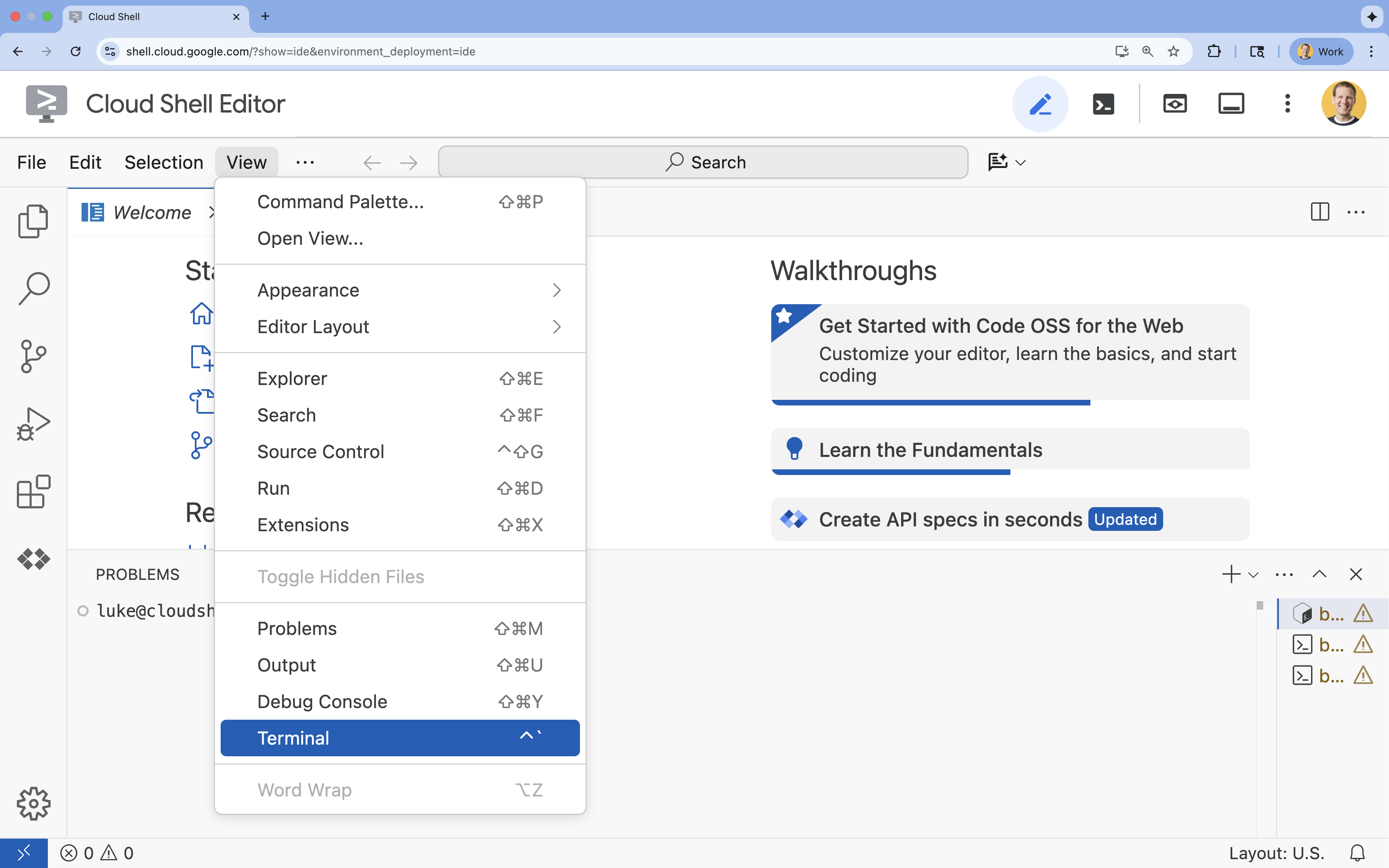
- Jika terminal tidak muncul di bagian bawah layar, buka terminal:
- Klik Lihat
- Klik Terminal
- Di terminal, tetapkan project Anda dengan perintah ini:
gcloud config set project [PROJECT_ID]- Contoh:
gcloud config set project lab-project-id-example - Jika tidak ingat project ID, Anda dapat mencantumkan semua project ID dengan:
gcloud projects list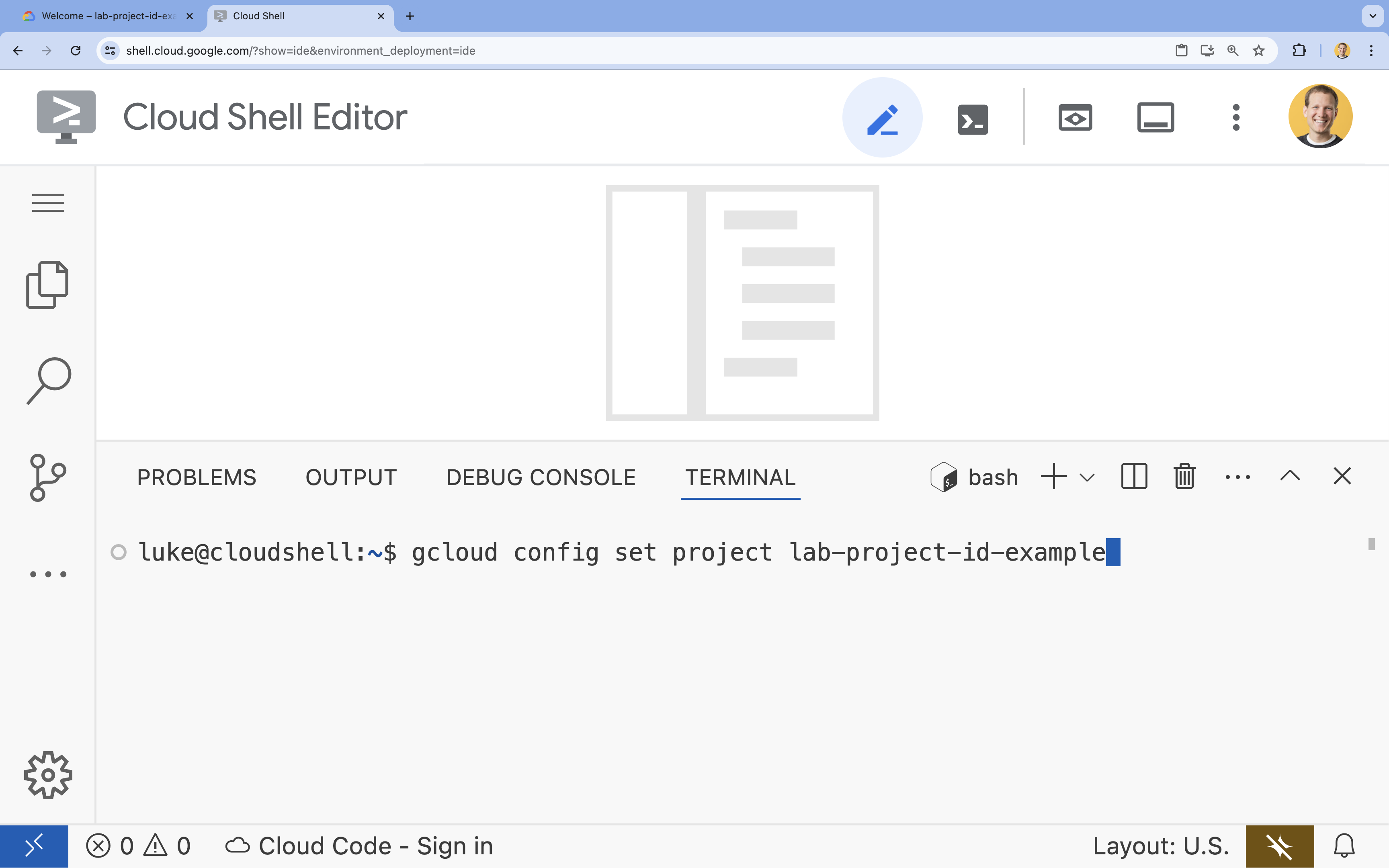
- Contoh:
- Anda akan melihat pesan ini:
Updated property [core/project].
4. Mengaktifkan API
Untuk menggunakan Vertex AI SDK dan berinteraksi dengan model Gemini, Anda harus mengaktifkan Vertex AI API di project Google Cloud Anda.
- Di terminal, aktifkan API:
gcloud services enable \ aiplatform.googleapis.com
Pengantar Vertex AI SDK untuk Python
Untuk berinteraksi dengan model yang dihosting di Vertex AI dari aplikasi Python, Anda akan menggunakan Vertex AI SDK untuk Python. SDK ini menyederhanakan proses pengiriman perintah, penentuan parameter model, dan penerimaan respons tanpa perlu menangani kompleksitas panggilan API yang mendasarinya secara langsung.
Anda dapat menemukan dokumentasi lengkap untuk Vertex AI SDK untuk Python di sini: Pengantar Vertex AI SDK untuk Python | Google Cloud.
5. Buat lingkungan virtual & instal dependensi
Sebelum memulai project Python, sebaiknya buat lingkungan virtual. Tindakan ini mengisolasi dependensi project, sehingga mencegah konflik dengan project lain atau paket Python global sistem.
- Buat folder bernama
wanderbotuntuk menyimpan kode aplikasi asisten perjalanan Anda. Jalankan kode berikut di terminal:mkdir wanderbot && cd wanderbot - Buat dan aktifkan lingkungan virtual:
uv venv --python 3.12 source .venv/bin/activatewanderbot) di awal perintah terminal, yang menunjukkan bahwa lingkungan virtual aktif. Tampilannya akan seperti ini:
6. Membuat file awal untuk wanderbot
- Buat dan buka file
app.pybaru untuk aplikasi. Jalankan kode berikut di terminal:cloudshell edit app.pycloudshell editakan membuka fileapp.pydi editor di atas terminal. - Tempelkan kode starter aplikasi berikut ke
app.py:import streamlit as st from google import genai from google.genai import types import requests import logging # --- Defining variables and parameters --- REGION = "global" PROJECT_ID = None # TODO: Insert Project ID GEMINI_MODEL_NAME = "gemini-2.5-flash" temperature = .2 top_p = 0.95 system_instructions = None # --- Tooling --- # TODO: Define the weather tool function declaration # TODO: Define the get_current_temperature function # --- Initialize the Vertex AI Client --- try: # TODO: Initialize the Vertex AI client print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}") except Exception as e: st.error(f"Error initializing VertexAI client: {e}") st.stop() # TODO: Add the get_chat function here in Task 15. # --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions. It will be replaced in a later step with a more advanced version that handles tooling. """ try: # TODO: Prepare the content for the model # TODO: Define generate_content configuration (needed for system instructions and parameters) # TODO: Define response logging.info(f"[call_model_response] LLM Response: \"{response.text}\"") # TODO: Uncomment the below "return response.text" line # return response.text except Exception as e: return f"Error: {e}" # --- Presentation Tier (Streamlit) --- # Set the title of the Streamlit application st.title("Travel Chat Bot") # Initialize session state variables if they don't exist if "messages" not in st.session_state: # Initialize the chat history with a welcome message st.session_state["messages"] = [ {"role": "assistant", "content": "How can I help you today?"} ] # Display the chat history for msg in st.session_state.messages: st.chat_message(msg["role"]).write(msg["content"]) # Get user input if prompt := st.chat_input(): # Add the user's message to the chat history st.session_state.messages.append({"role": "user", "content": prompt}) # Display the user's message st.chat_message("user").write(prompt) # Show a spinner while waiting for the model's response with st.spinner("Thinking..."): # Get the model's response using the call_model function model_response = call_model(prompt, GEMINI_MODEL_NAME) # Add the model's response to the chat history st.session_state.messages.append( {"role": "assistant", "content": model_response} ) # Display the model's response st.chat_message("assistant").write(model_response) - Buat dan buka file
requirements.txtbaru untuk kode aplikasi. Jalankan kode berikut di terminal:cloudshell edit requirements.txtcloudshell editakan membuka filerequirements.txtdi editor di atas terminal. - Tempelkan kode awal aplikasi berikut ke
requirements.txt.google-genai streamlit requests - Instal dependensi Python yang diperlukan untuk project ini. Jalankan kode berikut di terminal:
uv pip install -r requirements.txt
7. Mempelajari kode
File yang Anda buat mencakup frontend aplikasi chat dasar. Contohnya meliputi:
app.py: Ini adalah file yang akan kita gunakan. Saat ini berisi hal berikut:- impor yang diperlukan
- variabel dan parameter lingkungan (beberapa di antaranya adalah placeholder)
- fungsi
call_modelkosong, yang akan kita isi - Kode Streamlit untuk aplikasi chat front-end
requirements.txt:- mencakup persyaratan penginstalan untuk menjalankan
app.py
- mencakup persyaratan penginstalan untuk menjalankan
Sekarang, saatnya menjelajahi kode.
Membuka Chat Gemini Code Assist
Gemini Code Assist Chat seharusnya sudah terbuka di panel sebelah kanan di Editor Cloud Shell. Jika Chat Gemini Code Assist belum terbuka, Anda dapat membukanya dengan langkah-langkah berikut:
- Mengklik tombol Gemini Code Assist (
 ) di dekat bagian atas layar.
) di dekat bagian atas layar. - Pilih Open Gemini Code Assist Chat.
Menggunakan Gemini Code Assist untuk memahami kode
Anda dapat menggunakan Chat Gemini Code Assist untuk lebih memahami kode.
- Soroti atau pilih bagian kode yang diinginkan.
- Ketik "Explain this code" di chat Gemini.
- Klik enter untuk mengirimkan
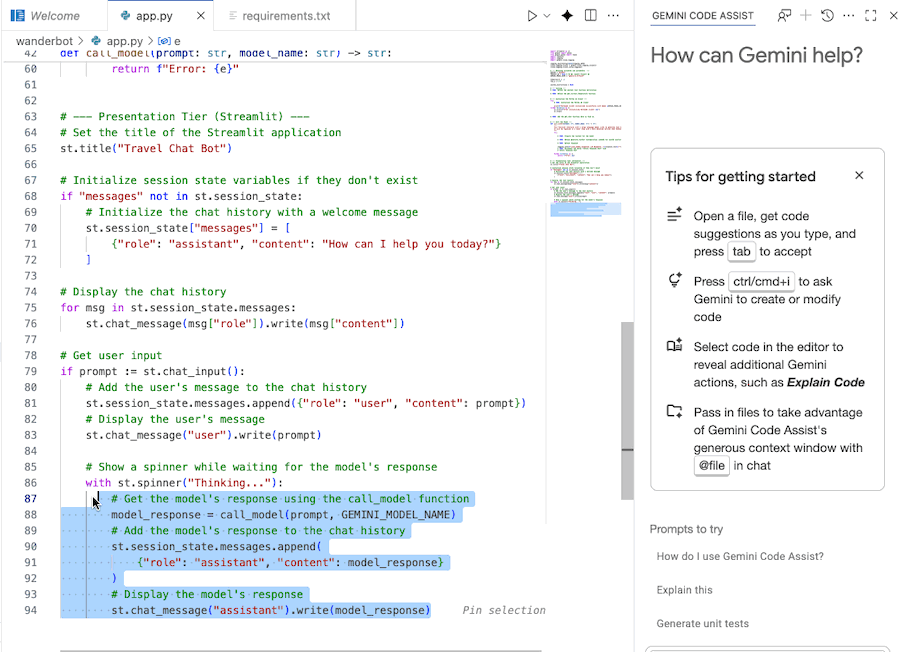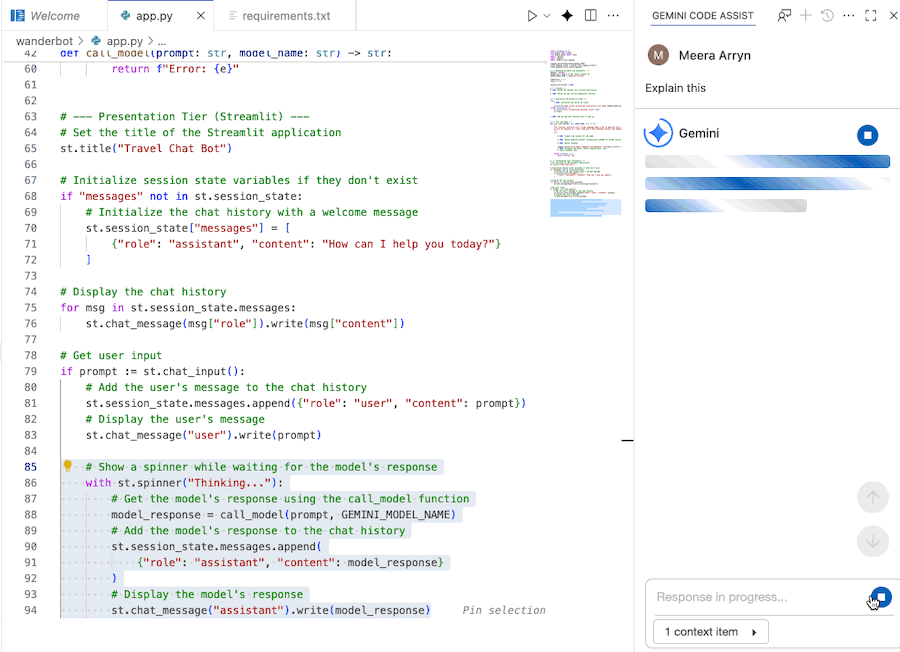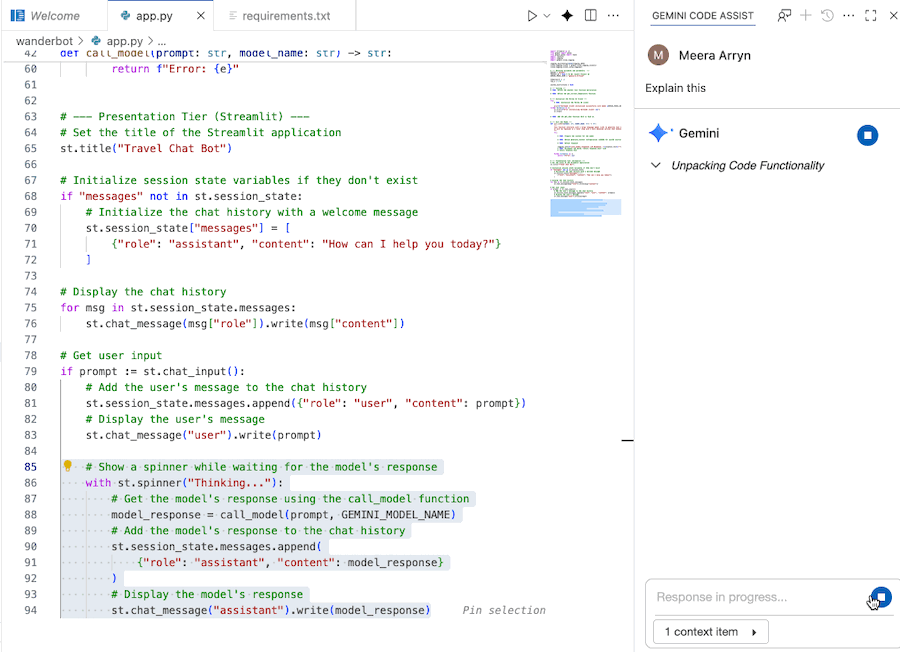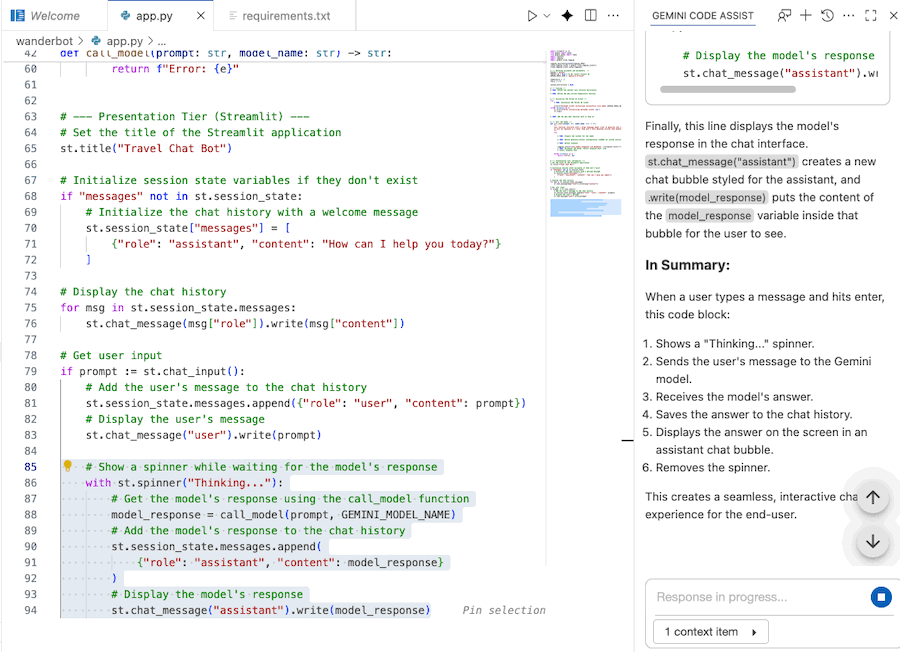
8. Luncurkan aplikasi web
Sebelum menghubungkan aplikasi ini ke LLM, luncurkan aplikasi untuk melihat perilaku awalnya.
- Dari dalam direktori
wanderbot, jalankan perintah berikut di terminal untuk memulai aplikasi Streamlit dan membuatnya dapat diakses secara lokal dalam lingkungan Cloud Shell Anda:streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Setelah menjalankan perintah, klik tombol Web Preview di bagian atas editor Cloud Shell, lalu pilih Preview on port 8080.
Anda akan melihat antarmuka chat sederhana untuk aplikasi perjalanan Anda. - Ketik pesan apa pun (mis.
Hi!), lalu tekan ENTER.
Anda akan melihat bahwa pesan akan muncul di histori percakapan, tetapi Anda akan menerima pesan error, bukan respons dari asisten. Hal ini karena aplikasi belum terhubung ke model bahasa besar. Amati perilaku ini untuk memahami titik awal lab.
9. Melakukan Inisialisasi Klien Vertex AI
Menjelajahi Model yang Tersedia di Vertex AI
Platform Vertex AI Google Cloud menyediakan akses ke berbagai model AI generatif. Sebelum mengintegrasikannya, Anda dapat menjelajahi opsi yang tersedia di Konsol Google Cloud.
- Dari Konsol Google Cloud, buka Model Garden. Anda dapat melakukannya dengan menelusuri "Model Garden" di kotak penelusuran di bagian atas layar dan memilih Vertex AI.(
 )
) - Jelajahi model yang tersedia. Anda dapat memfilter berdasarkan hal-hal seperti modalitas, jenis tugas, dan fitur.
Untuk tujuan lab ini, Anda akan menggunakan model Gemini 2.5 Flash, yang merupakan pilihan tepat untuk membangun aplikasi chat responsif karena kecepatannya.
Melakukan Inisialisasi Klien Vertex AI
Sekarang Anda akan mengubah bagian --- Initialize the Vertex AI Client --- di app.py untuk melakukan inisialisasi klien Vertex AI. Objek klien ini akan digunakan untuk mengirim perintah ke model.
- Buka
app.pydi Cloud Shell Editor. - Di
app.py, temukan barisPROJECT_ID = None. - Ganti
Nonedengan Project ID Google Cloud Anda dalam tanda petik. (misalnya,PROJECT_ID = "google-cloud-labs")
Jika tidak ingat project ID, Anda dapat mencantumkan semua project ID dengan:gcloud projects list | awk '/PROJECT_ID/{print $2}' - Tentukan klien: Di dalam blok
try, lakukan inisialisasi klien Vertex AI.client = genai.Client( vertexai=True, project=PROJECT_ID, location=REGION, )
Inisialisasi klien Vertex AI yang diperbarui
Pada tahap ini, bagian Initialize the Vertex AI Client akan terlihat seperti ini:
# --- Initialize the Vertex AI Client ---
try:
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=REGION,
)
print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}")
except Exception as e:
st.error(f"Error initializing VertexAI client: {e}")
st.stop()
10. Menyiapkan data dan memanggil model
Sekarang Anda akan menyiapkan konten untuk dikirim ke model, dan melakukan panggilan ke model Gemini.
- Temukan bagian
--- Call the Model ---tempat fungsicall_modelditentukan. - Tentukan konten: Di bagian
# TODO: Prepare the content for the model, tentukan konten input yang akan dikirim ke model. Untuk perintah dasar, ini akan menjadi pesan input pengguna.contents = [prompt] - Tentukan Respons: Tempelkan kode ini di bawah
# TODO: Define response.response = client.models.generate_content( model=model_name, contents=contents, ) - Tampilkan respons: Hapus komentar pada baris berikut:
return response.text - Periksa baris tempat fungsi
call_modeldipanggil, di bagian bawah file dalam blokwith. Jika Anda tidak memahami apa yang terjadi di sini, tandai baris tersebut dan minta Gemini Code Assist untuk menjelaskannya.
Cara yang lebih eksplisit untuk menentukan contents
Cara menentukan contents di atas berfungsi karena SDK cukup pintar untuk memahami bahwa daftar yang berisi string merepresentasikan input teks pengguna. Secara otomatis memformatnya dengan benar untuk API model.
Namun, cara yang lebih eksplisit dan mendasar untuk menyusun input melibatkan penggunaan objek types.Part dan types.Content, seperti ini:
user_message_parts = [types.Part.from_text(text=prompt)]
contents = [
types.Content(
role="user", # Indicates the content is from the user
parts=user_message_parts, # A list, allowing multiple types of content
),
]
Fungsi call_model yang diperbarui
Pada tahap ini, fungsi call_model akan terlihat seperti ini:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
# TODO: Define generate_content configuration (needed later for system instructions and parameters)
response = client.models.generate_content(
model=model_name,
contents=contents,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
11. Menguji aplikasi terhubung
- Di dalam terminal, hentikan proses yang sedang berjalan (CTRL+C)
- Jalankan kembali perintah untuk memulai aplikasi Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Muat ulang aplikasi Streamlit. Jika aplikasi Streamlit masih berjalan, Anda cukup memuat ulang halaman pratinjau web di browser.
- Sekarang, ketik pertanyaan ke dalam input chat seperti berikut:
What is the best time of year to go to Iceland? - Tekan ENTER.
Anda akan melihat aplikasi menampilkan pesan Anda, spinner "Berpikir...", lalu respons yang dihasilkan oleh model Gemini. Jika sudah, berarti Anda telah berhasil menghubungkan aplikasi web ke LLM di Vertex AI. 🙌 🥳
12. Menentukan petunjuk sistem
Meskipun koneksi dasar berfungsi, kualitas dan gaya respons LLM sangat dipengaruhi oleh input yang diterimanya. Rekayasa perintah adalah proses merancang dan menyempurnakan input (perintah) ini untuk memandu model menghasilkan output yang diinginkan.
Untuk itu, Anda akan memulai dengan membuat beberapa petunjuk sistem dan meneruskannya ke model.
Anda akan menggunakan Minta Gemini untuk membantu Anda membuat petunjuk sistem yang berguna.
- Di
app.py, cari variabelsystem_instructions, yang saat ini ditetapkan keNone.system_instructions = NoneNonedengan string multi-baris yang memberikan petunjuk untuk bot asisten perjalanan kami. - Tanyakan kepada Gemini Code Assist: Masukkan perintah berikut ke Gemini Code Assist (atau buat perintah Anda sendiri):
I am a developer at a travel marketing company, and my sales department has decided that they need a new chat application to keep up with the bigger booking and search companies. I'm building a simple travel assistant chatbot using the Gemini 2.5 Flash model on Vertex AI. The application should: - Helps users ask questions about travel, book travel, and learn about places they are going to go - Provides users ways to get help about their specific travel plans - Provides all this in a production quality way (multiple environments, logging and monitoring, etc.) Please create system instructions appropriate for that chat app. Be thorough. Do not alter the code in any way beyond providing me with system instructions. - Tentukan
system_instructions: Tetapkansystem_instructionssama dengan petunjuk sistem yang Anda buat menggunakan Gemini Code Assist. Sebagai alternatif, Anda dapat menggunakan petunjuk sistem ini, yang dibuat oleh Gemini dengan perintah serupa.system_instructions = """ You are a sophisticated travel assistant chatbot designed to provide comprehensive support to users throughout their travel journey. Your capabilities include answering travel-related questions, assisting with booking travel arrangements, offering detailed information about destinations, and providing support for existing travel plans. **Core Functionalities:** 1. **Travel Information and Recommendations:** * Answer user inquiries about travel destinations, including popular attractions, local customs, visa requirements, weather conditions, and safety advice. * Provide personalized recommendations for destinations, activities, and accommodations based on user preferences, interests, and budget. * Offer insights into the best times to visit specific locations, considering factors like weather, crowds, and pricing. * Suggest alternative destinations or activities if the user's initial choices are unavailable or unsuitable. 2. **Booking Assistance:** * Facilitate the booking of flights, hotels, rental cars, tours, and activities. * Search for available options based on user-specified criteria such as dates, destinations, budget, and preferences. * Present clear and concise information about available options, including pricing, amenities, and booking terms. * Guide users through the booking process, ensuring accurate information and secure transactions. * Provide booking confirmations and relevant details, such as booking references and contact information. 3. **Travel Planning and Itinerary Management:** * Assist users in creating detailed travel itineraries, including flights, accommodations, activities, and transportation. * Offer suggestions for optimizing travel plans, such as minimizing travel time or maximizing sightseeing opportunities. * Provide tools for managing and modifying existing itineraries, including adding or removing activities, changing booking dates, or upgrading accommodations. * Offer reminders and notifications for upcoming travel events, such as flight check-in or tour departure times. 4. **Customer Support and Troubleshooting:** * Provide prompt and helpful support to users with questions or issues related to their travel plans. * Assist with resolving booking discrepancies, cancellations, or modifications. * Offer guidance on travel-related emergencies, such as lost luggage or travel delays. * Provide access to relevant contact information for airlines, hotels, and other travel providers. **Interaction Guidelines:** * **Professionalism:** Maintain a polite, respectful, and professional tone in all interactions. * **Clarity and Conciseness:** Provide clear, concise, and easy-to-understand information. Avoid jargon or technical terms unless necessary and always explain them. * **Accuracy:** Ensure all information provided is accurate and up-to-date. Double-check details before sharing them with users. If unsure about something, admit that you don't know and offer to find the information. * **Personalization:** Tailor your responses and recommendations to the specific needs and preferences of each user. * **Proactive Assistance:** Anticipate user needs and offer relevant information or suggestions proactively. * **Error Handling:** Gracefully handle user errors or misunderstandings. Provide helpful guidance and alternative options when necessary. * **Confidentiality:** Respect user privacy and handle personal information with the utmost confidentiality and in compliance with data protection regulations. **Example Interactions:** **User:** "I want to go on a beach vacation in the Caribbean. I have a budget of $2000 per person for a week." **Chatbot:** "Certainly! The Caribbean offers many beautiful beach destinations within your budget. Some popular options include Punta Cana in the Dominican Republic, Cancun in Mexico, and Montego Bay in Jamaica. These destinations offer stunning beaches, all-inclusive resorts, and various activities. Would you like me to search for flights and accommodations for these locations based on your travel dates?" **User:** "My flight is delayed. What should I do?" **Chatbot:** "I'm sorry to hear about the delay. Please check with the airline for the updated departure time and any assistance they can offer. You may be entitled to compensation or rebooking options depending on the length of the delay and the airline's policy. Do you have your flight number handy so I can look up the current status for you?" **User:** "Tell me about the best time to visit Japan." **Chatbot:** "Japan is a fantastic destination with distinct seasons offering unique experiences. Spring (March-May) is famous for the beautiful cherry blossoms, while autumn (September-November) boasts stunning fall foliage. Both seasons have pleasant temperatures, making them ideal for sightseeing. Summer (June-August) can be hot and humid, but it's a great time for festivals and outdoor activities in the mountains. Winter (December-February) offers opportunities for skiing and snowboarding in the Japanese Alps, though some areas may experience heavy snowfall. To recommend the best time for you, could you tell me what you'd like to experience in Japan?" By following these instructions, you will be able to provide exceptional travel assistance and create a positive experience for every user. """ - Tentukan Konfigurasi generate_content: Lakukan inisialisasi objek konfigurasi, yang akan Anda teruskan petunjuk sistem ini. Karena
system_instructionsditentukan secara global dalam skrip, fungsi dapat mengaksesnya secara langsung.generate_content_config = types.GenerateContentConfig( system_instruction=[ types.Part.from_text(text=system_instructions) ], ) logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}") - Untuk menambahkan petunjuk sistem ke respons, tambahkan parameter
configke metodegenerate_content, dan tetapkan sama dengan objekgenerate_content_configyang dibuat di atas.response = client.models.generate_content( model=model_name, contents=contents, config=generate_content_config, # This is the new line )
Fungsi call_model yang diperbarui
Fungsi call_model lengkap kini terlihat seperti ini:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
generate_content_config = types.GenerateContentConfig(
system_instruction=[
types.Part.from_text(text=system_instructions)
],
)
logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}")
response = client.models.generate_content(
model=model_name,
contents=contents,
config=generate_content_config,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
13. Menguji aplikasi dengan Petunjuk Sistem
- Di dalam terminal, hentikan proses yang sedang berjalan (CTRL+C)
- Jalankan kembali perintah untuk memulai aplikasi Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Muat ulang aplikasi Streamlit. Jika aplikasi Streamlit masih berjalan, Anda cukup memuat ulang halaman pratinjau web di browser.
- Coba pertanyaan yang sama seperti sebelumnya:
What is the best time of year to go to Iceland? - Tekan ENTER.
Bandingkan responsnya kali ini dengan responsnya terakhir kali.
14. Menentukan alat cuaca
Sejauh ini, chatbot kita memiliki pengetahuan, tetapi pengetahuannya terbatas pada data yang digunakan untuk melatihnya. Model ini tidak dapat mengakses informasi real-time. Untuk bot perjalanan, kemampuan mengambil data langsung seperti prakiraan cuaca adalah keuntungan besar.
Di sinilah alat, yang juga dikenal sebagai panggilan fungsi, berperan. Kita dapat menentukan serangkaian alat (fungsi Python) yang dapat dipilih LLM untuk dipanggil guna mendapatkan informasi eksternal.
Cara Kerja Alat
- Kita mendeskripsikan alat kita ke model, termasuk fungsi dan parameter yang digunakan.
- Pengguna mengirimkan perintah (misalnya, "Bagaimana cuaca di London?").
- Model menerima perintah dan melihat bahwa pengguna menanyakan sesuatu yang dapat diketahuinya menggunakan salah satu alatnya.
- Model tidak merespons dengan teks, tetapi dengan objek
function_callkhusus, yang menunjukkan alat yang ingin dipanggil dan argumen yang digunakan. - Kode Python kita menerima
function_callini, mengeksekusi fungsiget_current_temperatureyang sebenarnya dengan argumen yang diberikan, dan mendapatkan hasilnya (misalnya, 15°C). - Kita mengirim hasil ini kembali ke model.
- Model menerima hasil dan membuat respons natural language untuk pengguna (misalnya, "Suhu saat ini di London adalah 15°C").
Proses ini memungkinkan model menjawab pertanyaan yang jauh melampaui data pelatihannya, sehingga menjadikannya asisten yang jauh lebih andal dan berguna.
Menentukan alat cuaca
Jika wisatawan mencari saran tentang apa yang harus dilakukan, dan memilih antara aktivitas yang terpengaruh oleh cuaca, alat cuaca bisa sangat berguna. Mari kita buat alat untuk model kita agar bisa mendapatkan cuaca saat ini. Kita memerlukan dua bagian: deklarasi fungsi yang menjelaskan alat ke model, dan fungsi Python sebenarnya yang menerapkannya.
- Di
app.py, temukan komentar# TODO: Define the weather tool function declaration. - Di bawah komentar ini, tambahkan variabel
weather_function. Ini adalah kamus yang memberi tahu model semua yang perlu diketahui tentang tujuan, parameter, dan argumen yang diperlukan fungsi.weather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } - Selanjutnya, temukan komentar
# TODO: Define the get_current_temperature function. Di bawahnya, tambahkan kode Python berikut. Fungsi ini akan:- Panggil geocoding API untuk mendapatkan koordinat lokasi.
- Gunakan koordinat tersebut untuk memanggil API cuaca.
- Menampilkan string sederhana dengan suhu dan satuan.
def get_current_temperature(location: str) -> str: """Gets the current temperature for a given location.""" try: # --- Get Latitude and Longitude for the location --- geocode_url = f"https://geocoding-api.open-meteo.com/v1/search?name={location}&count=1&language=en&format=json" geocode_response = requests.get(geocode_url) geocode_data = geocode_response.json() if not geocode_data.get("results"): return f"Could not find coordinates for {location}." lat = geocode_data["results"][0]["latitude"] lon = geocode_data["results"][0]["longitude"] # --- Get Weather for the coordinates --- weather_url = f"https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}¤t_weather=true" weather_response = requests.get(weather_url) weather_data = weather_response.json() temperature = weather_data["current_weather"]["temperature"] unit = "°C" return f"{temperature}{unit}" except Exception as e: return f"Error fetching weather: {e}"
15. Refaktorisasi untuk chat dan alat
Fungsi call_model saat ini menggunakan panggilan generate_content sekali pakai yang sederhana. Cara ini bagus untuk pertanyaan tunggal, tetapi tidak ideal untuk percakapan multi-giliran, terutama yang melibatkan bolak-balik untuk pembuatan alat.
Praktik yang lebih baik adalah menggunakan sesi chat, yang mempertahankan konteks percakapan. Sekarang kita akan memfaktorkan ulang kode untuk menggunakan sesi chat, yang diperlukan untuk menerapkan alat dengan benar.
- Hapus fungsi
call_modelyang ada. Kita akan menggantinya dengan versi yang lebih canggih. - Sebagai gantinya, tambahkan fungsi
call_modelbaru dari blok kode di bawah. Fungsi baru ini berisi logika untuk menangani loop panggilan alat yang kita bahas sebelumnya. Perhatikan bahwa ada beberapa komentar TODO yang akan kita selesaikan di langkah berikutnya.# --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt. It maintains a chat session and handles function calls from the model to external tools. """ try: # TODO: Get the existing chat session or create a new one. message_content = prompt # Start the tool-calling loop while True: # TODO: Send the message to the model. # Check if the model wants to call a tool has_tool_calls = False for part in response.candidates[0].content.parts: if part.function_call: has_tool_calls = True function_call = part.function_call logging.info(f"Function to call: {function_call.name}") logging.info(f"Arguments: {function_call.args}") # TODO: Call the appropriate function if the model requests it. elif part.text: logging.info("No function call found in the response.") logging.info(response.text) # If no tool call was made, break the loop if not has_tool_calls: break # TODO: Return the model's final text response. except Exception as e: return f"Error: {e}" - Sekarang, mari kita tambahkan fungsi bantuan untuk mengelola sesi chat. Di atas fungsi
call_modelbaru, tambahkan fungsiget_chat. Fungsi ini akan membuat sesi chat baru dengan petunjuk sistem dan definisi alat kami, atau mengambil sesi yang ada. Ini adalah praktik yang baik untuk mengatur kode.def get_chat(model_name: str): if f"chat-{model_name}" not in st.session_state: # TODO: Define the tools configuration for the model # TODO: Define the generate_content configuration, including tools # TODO: Create a new chat session st.session_state[f"chat-{model_name}"] = chat return st.session_state[f"chat-{model_name}"]
Anda kini telah menyiapkan struktur untuk logika chat lanjutan yang mendukung alat.
16. Menerapkan logika panggilan alat
Sekarang, mari kita isi TODOs untuk membuat logika panggilan alat kita berfungsi sepenuhnya.
Mengimplementasikan get_chat
- Dalam fungsi
get_chatdi bawah komentar# TODO: Define the tools configuration..., tentukan objektoolsdengan membuat instancetypes.Tooldari deklarasiweather_functionkita.tools = types.Tool(function_declarations=[weather_function]) - Di bagian
# TODO: Define the generate_content configuration..., tentukangenerate_content_config, pastikan untuk meneruskan objektoolske model. Dengan cara ini, model mempelajari alat yang dapat digunakannya.generate_content_config = types.GenerateContentConfig( system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here ) - Di bagian
# TODO: Create a new chat session, buat objek chat menggunakanclient.chats.create(), dengan meneruskan nama dan konfigurasi model kita.chat = client.chats.create( model=model_name, config=generate_content_config, )
Mengimplementasikan call_model
- Di bagian
# TODO: Get the existing chat session...dalam fungsicall_model, panggil fungsi bantuanget_chatbaru.chat = get_chat(model_name) - Selanjutnya, temukan
# TODO: Send the message to the model. Kirim pesan pengguna menggunakan metodechat.send_message().response = chat.send_message(message_content) - Cari
# TODO: Call the appropriate function.... Di sinilah kita memeriksa fungsi yang diinginkan model dan menjalankannya.
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
- Terakhir, temukan
# TODO: Return the model's final text responsedan tambahkan pernyataan return.return response.text
Fungsi get_chat yang diperbarui
Fungsi get_chat yang diupdate kini akan terlihat seperti ini:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
Fungsi call_model yang diperbarui
Fungsi call_model yang diupdate kini akan terlihat seperti ini:
def call_model(prompt: str, model_name: str) -> str:
try:
chat = get_chat(model_name)
message_content = prompt
while True:
response = chat.send_message(message_content)
has_tool_calls = False
for part in response.candidates[0].content.parts:
if part.function_call:
has_tool_calls = True
function_call = part.function_call
logging.info(f"Function to call: {function_call.name}")
logging.info(f"Arguments: {function_call.args}")
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
elif part.text:
logging.info("No function call found in the response.")
logging.info(response.text)
if not has_tool_calls:
break
return response.text
except Exception as e:
return f"Error: {e}"
17. Menguji aplikasi yang mendukung alat
Mari kita lihat cara kerja fitur baru Anda.
- Di dalam terminal, hentikan proses yang sedang berjalan (CTRL+C)
- Jalankan kembali perintah untuk memulai aplikasi Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Muat ulang aplikasi Streamlit. Jika aplikasi Streamlit masih berjalan, Anda cukup memuat ulang halaman pratinjau web di browser.
- Sekarang, ajukan pertanyaan yang akan memicu alat baru Anda, seperti berikut:
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Tekan ENTER
Bandingkan respons ini dengan respons sebelumnya. Apa perbedaannya?
Anda akan melihat respons yang menggabungkan suhu dari fungsi Anda. Periksa juga terminal Cloud Shell Anda; Anda akan melihat pernyataan cetak yang mengonfirmasi bahwa fungsi Python Anda telah dieksekusi.
18. Memperbaiki Output Model dengan Parameter
Bagus sekali! Asisten perjalanan Anda kini dapat menggunakan alat untuk mengambil data eksternal langsung, sehingga menjadikannya jauh lebih efektif.
Setelah meningkatkan kemampuan model, mari sesuaikan responsnya. Parameter model memungkinkan Anda mengontrol gaya dan keacakan teks yang dihasilkan LLM. Dengan menyesuaikan setelan ini, Anda dapat membuat output bot lebih terfokus dan deterministik atau lebih kreatif dan bervariasi.
Untuk lab ini, kita akan berfokus pada temperature, dan top_p. (Lihat GenerateContentConfig di referensi API kami untuk mengetahui daftar lengkap parameter yang dapat dikonfigurasi dan deskripsinya.)
temperature: Mengontrol keacakan output. Nilai yang lebih rendah (lebih dekat ke 0) membuat output lebih deterministik dan terfokus, sedangkan nilai yang lebih tinggi (lebih dekat ke 2) meningkatkan keacakan dan kreativitas. Untuk bot tanya jawab atau asisten, temperatur yang lebih rendah biasanya lebih disukai untuk respons yang lebih konsisten dan faktual.top_p: Probabilitas kumulatif maksimum token yang akan dipertimbangkan saat pengambilan sampel. Token diurutkan berdasarkan probabilitas yang ditetapkan sehingga hanya token yang paling mungkin yang dipertimbangkan. Model ini mempertimbangkan token yang paling mungkin yang probabilitasnya berjumlah hingga nilaitop_p. Nilai yang lebih rendah membatasi pilihan token, sehingga menghasilkan output yang kurang bervariasi
Parameter panggilan
- Temukan variabel
temperaturedantop_p, yang ditentukan di bagian atasapp.py. Perhatikan bahwa keduanya belum dipanggil di mana pun. - Tambahkan
temperature, dantop_pke parameter yang ditentukan dalamGenerateContentConfigdi fungsiget_chat.generate_content_config = types.GenerateContentConfig( temperature=temperature, top_p=top_p, system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )
Fungsi get_chat yang diperbarui
Aplikasi get_chat sekarang terlihat seperti ini:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
temperature=temperature,
top_p=top_p,
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
19. Menguji dengan Parameter Model
- Di dalam terminal, hentikan proses yang sedang berjalan (CTRL+C)
- Jalankan kembali perintah untuk memulai aplikasi Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Muat ulang aplikasi Streamlit. Jika aplikasi Streamlit masih berjalan, Anda cukup memuat ulang halaman pratinjau web di browser.
- Coba ajukan pertanyaan yang sama seperti sebelumnya,
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Tekan ENTER
Bandingkan respons ini dengan respons sebelumnya.
20. Selamat!
Anda telah berhasil mengupgrade aplikasi Tanya Jawab dengan alat, fitur canggih yang memungkinkan aplikasi yang didukung Gemini berinteraksi dengan sistem eksternal dan mengakses informasi real-time.
Melanjutkan eksperimen
Ada banyak opsi untuk terus mengoptimalkan perintah Anda. Berikut beberapa hal yang perlu dipertimbangkan:
- Sesuaikan
temperaturedantop_p, lalu lihat bagaimana perubahan ini memengaruhi respons yang diberikan oleh LLM. - Lihat
GenerateContentConfigdi referensi API kami untuk mengetahui daftar lengkap parameter yang dapat dikonfigurasi dan deskripsinya. Coba tentukan lebih banyak parameter dan sesuaikan untuk melihat apa yang terjadi.
Rangkuman
Di lab ini, Anda telah melakukan hal berikut:
- Menggunakan Cloud Shell Editor dan terminal untuk pengembangan.
- Menggunakan Vertex AI Python SDK untuk menghubungkan aplikasi Anda ke model Gemini.
- Menerapkan petunjuk sistem dan parameter model untuk memandu respons LLM.
- Mempelajari konsep alat (panggilan fungsi) dan manfaatnya.
- Memfaktorkan ulang kode Anda untuk menggunakan sesi chat stateful, yang merupakan praktik terbaik untuk AI percakapan.
- Menentukan alat untuk model menggunakan deklarasi fungsi.
- Menerapkan fungsi Python untuk menyediakan logika alat.
- Menulis kode untuk menangani permintaan panggilan fungsi model dan menampilkan hasilnya.