
1. Introduzione
Panoramica
Sei uno sviluppatore di un'azienda di marketing per il settore dei viaggi. Il tuo reparto vendite ha deciso di aver bisogno di una nuova applicazione di chat per tenere il passo con le aziende di prenotazione e ricerca più grandi. Hanno anche sentito parlare di AI generativa, ma non ne sanno molto. Altri reparti hanno sentito parlare di questa iniziativa e sono curiosi di sapere come potrebbe migliorare anche la loro customer experience.
In questo lab proverai a:
In questo lab creerai un chatbot assistente di viaggio utilizzando il modello Gemini 2.5 Flash su Vertex AI.
L'applicazione deve:
- Aiuta gli utenti a fare domande sui viaggi, a prenotare viaggi e a scoprire i luoghi che intendono visitare
- Fornisce agli utenti modi per ricevere assistenza in merito ai loro piani di viaggio specifici
- Essere in grado di recuperare dati in tempo reale, come il meteo, utilizzando gli strumenti
Lavorerai in un ambiente Google Cloud preconfigurato, in particolare all'interno dell'editor di Cloud Shell. È già configurato un frontend di base dell'applicazione web, insieme alle autorizzazioni necessarie per accedere a Vertex AI. Questa app è stata creata utilizzando Streamlit.
Obiettivi didattici
In questo lab imparerai a:
- Esplora la piattaforma Vertex AI per identificare i modelli di AI generativa disponibili.
- Sviluppare nell'editor di Cloud Shell e nel terminale
- Utilizza Gemini Code Assist per comprendere il codice.
- Utilizza l'SDK Vertex AI in Python per inviare prompt e ricevere risposte da un LLM Gemini.
- Applica il prompt engineering di base (istruzioni di sistema, parametri del modello) per personalizzare l'output di un LLM Gemini.
- Testa e perfeziona in modo iterativo un'applicazione di chat basata su un LLM modificando prompt e parametri per migliorare le risposte.
- Definisci e utilizza gli strumenti con il modello Gemini per attivare la chiamata di funzione.
- Rimodella il codice per utilizzare una sessione di chat stateful, una best practice per le app conversazionali.
2. Configurazione del progetto
Account Google
Se non hai ancora un Account Google personale, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
Accedi alla console Google Cloud
Accedi a Google Cloud Console utilizzando un Account Google personale.
Abilita fatturazione
Riscatta i crediti Google Cloud (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 1 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Creare un progetto (facoltativo)
Se non hai un progetto attuale che vuoi utilizzare per questo lab, creane uno nuovo qui.
3. Apri editor di Cloud Shell
- Fai clic su questo link per andare direttamente all'editor di Cloud Shell.
- Se ti viene richiesto di concedere l'autorizzazione in qualsiasi momento della giornata, fai clic su Autorizza per continuare.
- Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale
 .
.
- Nel terminale, imposta il progetto con questo comando:
gcloud config set project [PROJECT_ID]- Esempio:
gcloud config set project lab-project-id-example - Se non ricordi l'ID progetto, puoi elencare tutti i tuoi ID progetto con:
gcloud projects list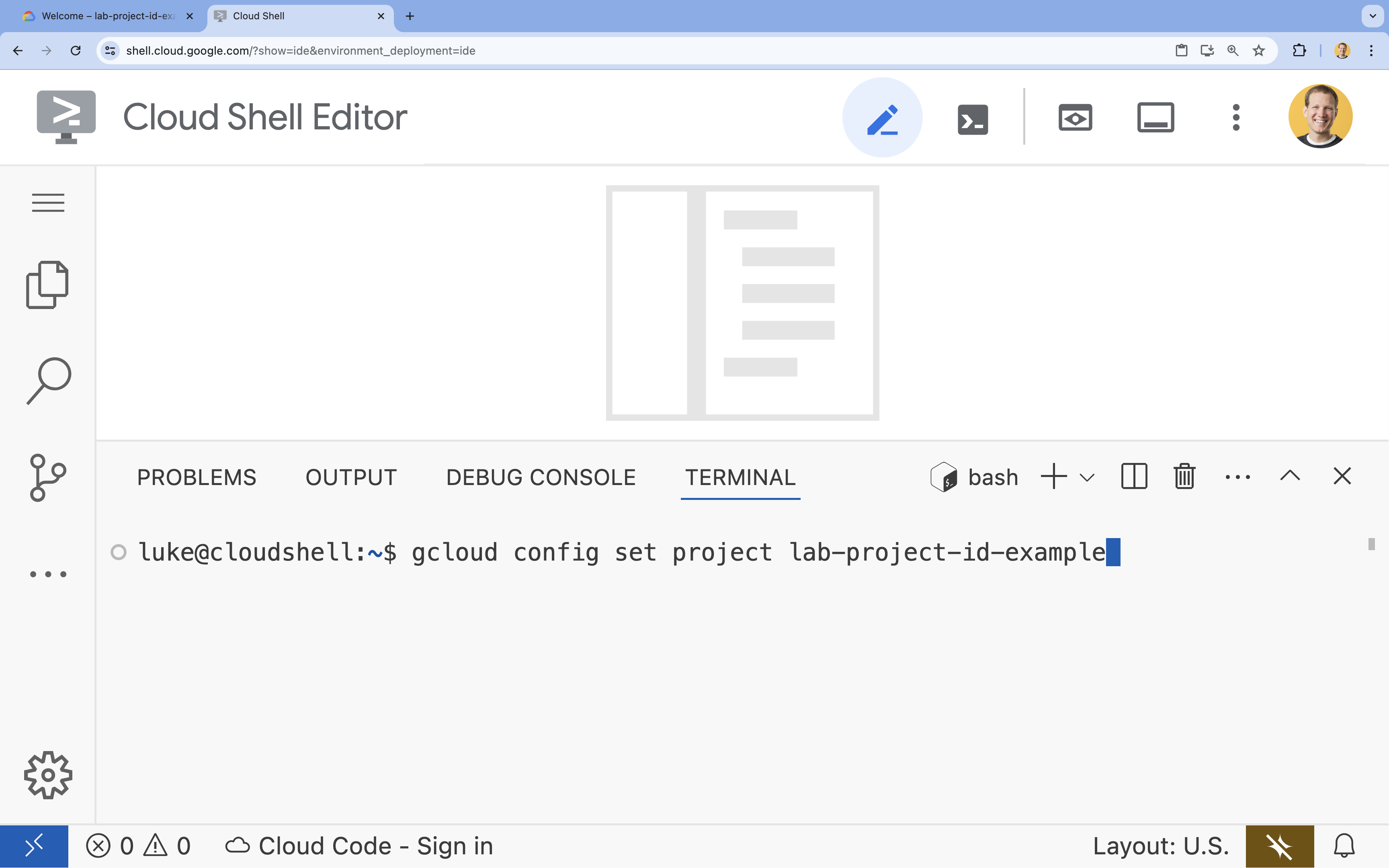
- Esempio:
- Dovresti visualizzare questo messaggio:
Updated property [core/project].
4. Abilita API
Per utilizzare l'SDK Vertex AI e interagire con il modello Gemini, devi abilitare l'API Vertex AI nel tuo progetto Google Cloud.
- Nel terminale, abilita le API:
gcloud services enable \ aiplatform.googleapis.com
Introduzione all'SDK Vertex AI per Python
Per interagire con i modelli ospitati su Vertex AI dalla tua applicazione Python, utilizzerai l'SDK Vertex AI Python. Questo SDK semplifica il processo di invio di prompt, specifica i parametri del modello e riceve le risposte senza dover gestire direttamente le complessità delle chiamate API sottostanti.
Puoi trovare la documentazione completa per l'SDK Vertex AI Python qui: Introduzione all'SDK Vertex AI Python | Google Cloud.
5. Crea un ambiente virtuale e installa le dipendenze
Prima di iniziare qualsiasi progetto Python, è buona prassi creare un ambiente virtuale. In questo modo, le dipendenze del progetto vengono isolate, evitando conflitti con altri progetti o con i pacchetti Python globali del sistema.
- Crea una cartella denominata
wanderbotper archiviare il codice dell'app di assistenza per i viaggi. Esegui il seguente codice nel terminale:mkdir wanderbot && cd wanderbot - Crea e attiva un ambiente virtuale:
uv venv --python 3.12 source .venv/bin/activatewanderbot) davanti al prompt del terminale, a indicare che l'ambiente virtuale è attivo. Avrebbe un aspetto simile a questo:
6. Crea file iniziali per wanderbot
- Crea e apri un nuovo file
app.pyper l'applicazione. Esegui questo codice nel terminale:cloudshell edit app.pycloudshell editaprirà il fileapp.pynell'editor sopra il terminale. - Incolla il seguente codice di avvio dell'app in
app.py:import streamlit as st from google import genai from google.genai import types import requests import logging # --- Defining variables and parameters --- REGION = "global" PROJECT_ID = None # TODO: Insert Project ID GEMINI_MODEL_NAME = "gemini-2.5-flash" temperature = .2 top_p = 0.95 system_instructions = None # --- Tooling --- # TODO: Define the weather tool function declaration # TODO: Define the get_current_temperature function # --- Initialize the Vertex AI Client --- try: # TODO: Initialize the Vertex AI client print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}") except Exception as e: st.error(f"Error initializing VertexAI client: {e}") st.stop() # TODO: Add the get_chat function here in Task 15. # --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions. It will be replaced in a later step with a more advanced version that handles tooling. """ try: # TODO: Prepare the content for the model # TODO: Define generate_content configuration (needed for system instructions and parameters) # TODO: Define response logging.info(f"[call_model_response] LLM Response: \"{response.text}\"") # TODO: Uncomment the below "return response.text" line # return response.text except Exception as e: return f"Error: {e}" # --- Presentation Tier (Streamlit) --- # Set the title of the Streamlit application st.title("Travel Chat Bot") # Initialize session state variables if they don't exist if "messages" not in st.session_state: # Initialize the chat history with a welcome message st.session_state["messages"] = [ {"role": "assistant", "content": "How can I help you today?"} ] # Display the chat history for msg in st.session_state.messages: st.chat_message(msg["role"]).write(msg["content"]) # Get user input if prompt := st.chat_input(): # Add the user's message to the chat history st.session_state.messages.append({"role": "user", "content": prompt}) # Display the user's message st.chat_message("user").write(prompt) # Show a spinner while waiting for the model's response with st.spinner("Thinking..."): # Get the model's response using the call_model function model_response = call_model(prompt, GEMINI_MODEL_NAME) # Add the model's response to the chat history st.session_state.messages.append( {"role": "assistant", "content": model_response} ) # Display the model's response st.chat_message("assistant").write(model_response) - Crea e apri un nuovo file
requirements.txtper il codice dell'applicazione. Esegui questo codice nel terminale:cloudshell edit requirements.txtcloudshell editaprirà il filerequirements.txtnell'editor sopra il terminale. - Incolla il seguente codice di avvio dell'app in
requirements.txt.google-genai streamlit requests - Installa le dipendenze Python richieste per questo progetto. Esegui questo codice nel terminale:
uv pip install -r requirements.txt
7. Esplora il codice
I file che hai creato includono un frontend di base dell'applicazione di chat. ovvero:
app.py: questo è il file su cui lavoreremo. Attualmente contiene quanto segue:- importazioni necessarie
- variabili di ambiente e parametri (alcuni dei quali sono segnaposto)
- una funzione
call_modelvuota, che riempiremo - Codice Streamlit per l'app di chat frontend
requirements.txt:- include i requisiti di installazione per l'esecuzione di
app.py
- include i requisiti di installazione per l'esecuzione di
Ora è il momento di esplorare il codice.
Apri la chat di Gemini Code Assist
La chat di Gemini Code Assist dovrebbe essere già aperta in un riquadro a destra nell'editor di Cloud Shell. Se la chat di Gemini Code Assist non è ancora aperta, puoi aprirla seguendo questi passaggi:
- Fare clic sul pulsante Gemini Code Assist (
 ) nella parte superiore dello schermo.
) nella parte superiore dello schermo. - Seleziona Apri chat di Gemini Code Assist.
Usare Gemini Code Assist per comprendere il codice
Puoi utilizzare la chat di Gemini Code Assist per comprendere meglio il codice.
- Evidenzia o seleziona la sezione di codice che ti interessa.
- Digita "Spiega questo codice" nella chat con Gemini.
- Fai clic su Invio per inviare
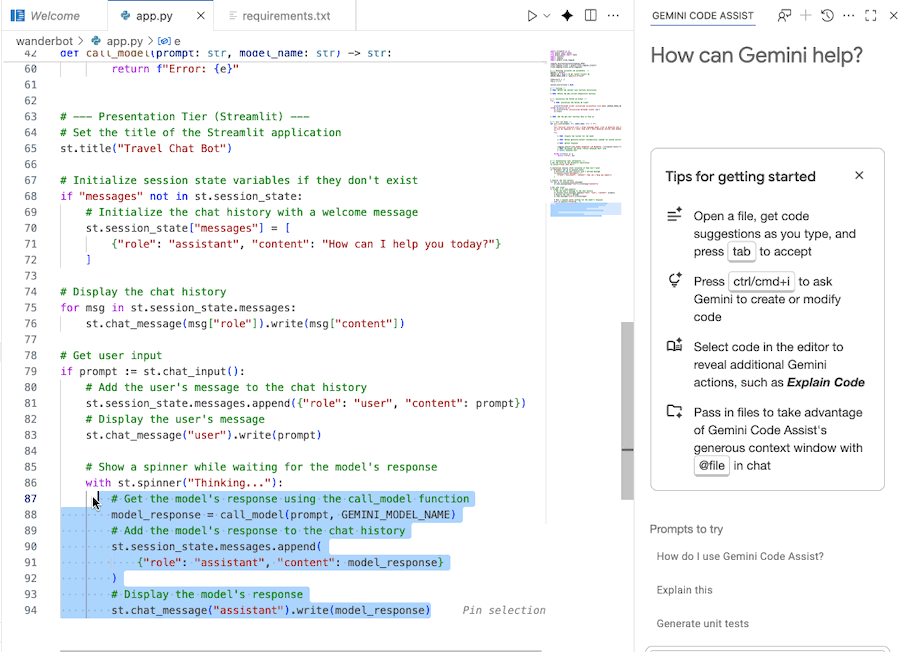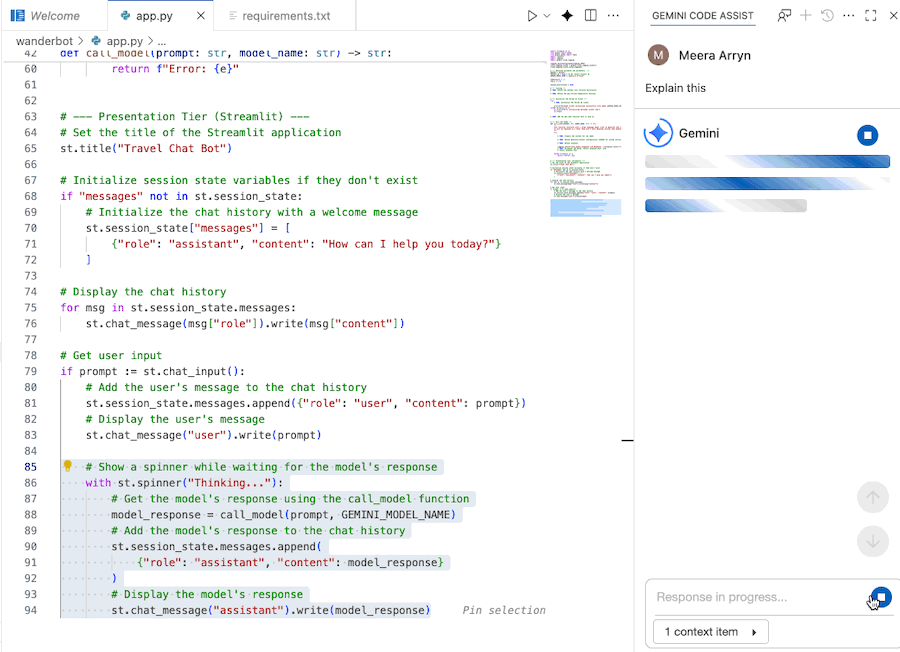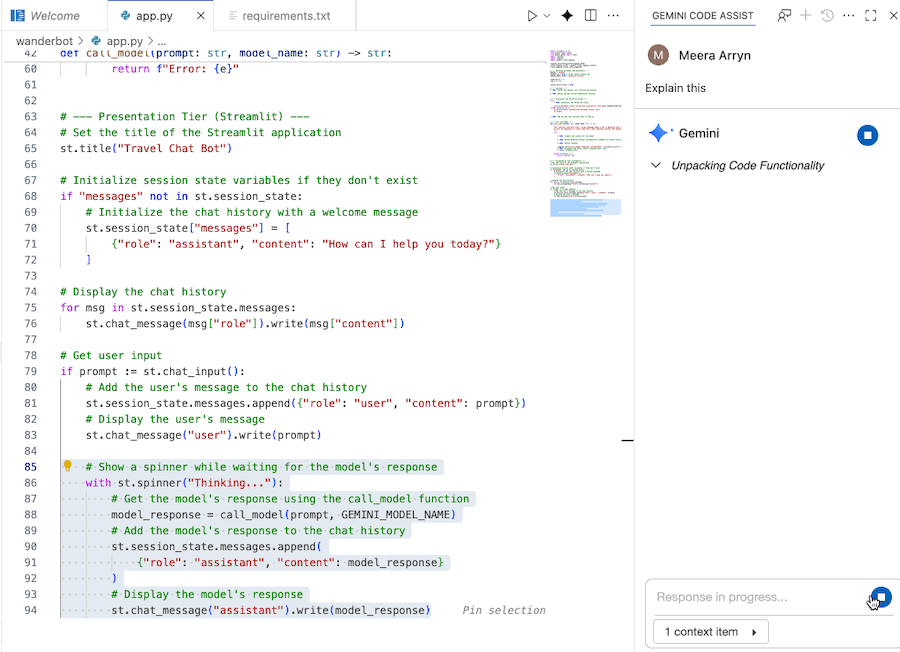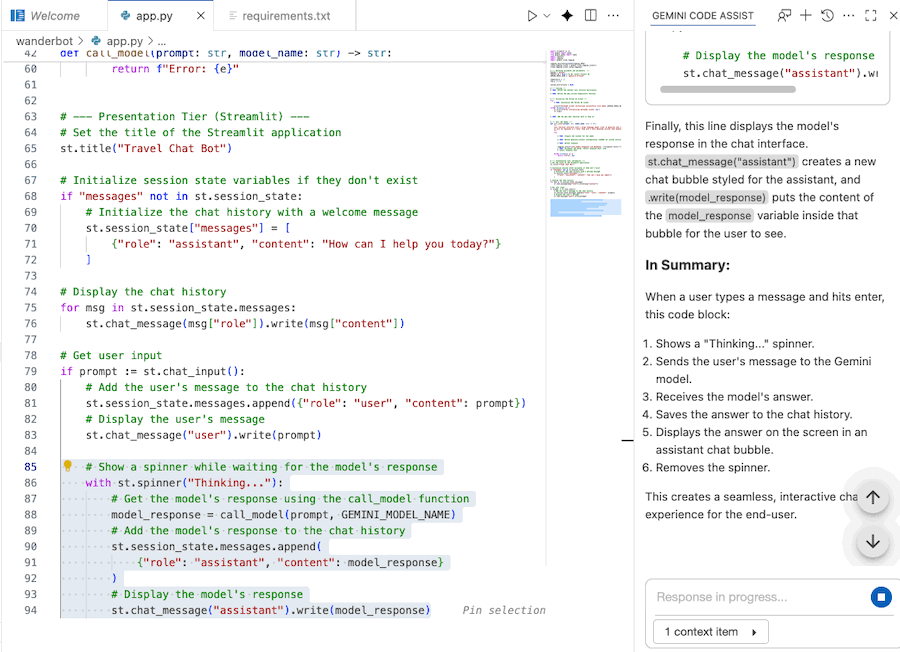
8. Avvia l'app web
Prima di connettere questa app a un LLM, avviala per vedere come si comporta inizialmente.
- Dalla directory
wanderbot, esegui il comando seguente nel terminale per avviare l'applicazione Streamlit e renderla accessibile localmente nel tuo ambiente Cloud Shell:streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Dopo aver eseguito il comando, fai clic sul pulsante Anteprima web nella parte superiore dell'editor Cloud Shell e seleziona Anteprima sulla porta 8080.
Vedrai una semplice interfaccia di chat per la tua app di viaggi. - Digita un messaggio qualsiasi (ad es.
Hi!) e premi INVIO.
Noterai che il messaggio viene visualizzato nella cronologia della chat, ma riceverai un messaggio di errore anziché una risposta dall'assistente. Questo perché l'applicazione non è ancora connessa a un modello linguistico di grandi dimensioni. Osserva questo comportamento per comprendere il punto di partenza del lab.
9. Inizializza il client Vertex AI
Esplorare i modelli disponibili in Vertex AI
La piattaforma Vertex AI di Google Cloud fornisce l'accesso a una serie di modelli di AI generativa. Prima di integrarne uno, puoi esplorare le opzioni disponibili nella console Google Cloud.
- Nella console Google Cloud, vai a Model Garden. Per farlo, cerca "Model Garden" nella barra di ricerca nella parte superiore dello schermo e seleziona Vertex AI.(
 )
) - Sfoglia i modelli disponibili. Puoi filtrare in base a elementi come modalità, tipi di attività e funzionalità.
Ai fini di questo lab, utilizzerai il modello Gemini 2.5 Flash, che è una buona scelta per creare applicazioni di chat reattive grazie alla sua velocità.
Inizializza il client Vertex AI
Ora modificherai la sezione --- Initialize the Vertex AI Client --- in app.py per inizializzare il client Vertex AI. Questo oggetto client verrà utilizzato per inviare prompt al modello.
- Apri
app.pynell'editor di Cloud Shell. - In
app.py, trova la rigaPROJECT_ID = None. - Sostituisci
Nonecon l'ID progetto Google Cloud tra virgolette. (ad es.PROJECT_ID = "google-cloud-labs")
Se non ricordi l'ID progetto, puoi elencare tutti i tuoi ID progetto con:gcloud projects list | awk '/PROJECT_ID/{print $2}' - Definisci il client: all'interno del blocco
try, inizializza il client Vertex AI.client = genai.Client( vertexai=True, project=PROJECT_ID, location=REGION, )
Inizializzazione aggiornata del client Vertex AI
A questo punto, la sezione Inizializza il client Vertex AI dovrebbe essere simile a questa:
# --- Initialize the Vertex AI Client ---
try:
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=REGION,
)
print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}")
except Exception as e:
st.error(f"Error initializing VertexAI client: {e}")
st.stop()
10. Preparare i dati e chiamare il modello
Ora preparerai i contenuti da inviare al modello ed effettuerai una chiamata al modello Gemini.
- Individua la sezione
--- Call the Model ---in cui è definita la funzionecall_model. - Definisci contenuti: in
# TODO: Prepare the content for the model, definisci i contenuti di input che verranno inviati al modello. Per un prompt di base, si tratta del messaggio di input dell'utente.contents = [prompt] - Definisci la risposta: incolla questo codice sotto
# TODO: Define response.response = client.models.generate_content( model=model_name, contents=contents, ) - Restituisci la risposta: rimuovi il commento dalla seguente riga:
return response.text - Esamina la riga in cui viene chiamata la funzione
call_model, verso la parte inferiore del file nel bloccowith. Se non capisci cosa sta succedendo, evidenzia la riga e chiedi a Gemini Code Assist di spiegartelo.
Un modo più esplicito per definire contents
Il modo sopra descritto per definire contents funziona perché l'SDK è abbastanza intelligente da capire che un elenco contenente stringhe rappresenta l'input di testo dell'utente. Lo formatta automaticamente in modo corretto per l'API del modello.
Tuttavia, il modo più esplicito e fondamentale per strutturare l'input prevede l'utilizzo di oggetti types.Part e types.Content, come segue:
user_message_parts = [types.Part.from_text(text=prompt)]
contents = [
types.Content(
role="user", # Indicates the content is from the user
parts=user_message_parts, # A list, allowing multiple types of content
),
]
Funzione call_model aggiornata
A questo punto, la funzione call_model dovrebbe avere il seguente aspetto:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
# TODO: Define generate_content configuration (needed later for system instructions and parameters)
response = client.models.generate_content(
model=model_name,
contents=contents,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
11. Testare l'app connessa
- Nel terminale, termina il processo attualmente in esecuzione (Ctrl+C).
- Esegui di nuovo il comando per avviare l'applicazione Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Aggiorna l'applicazione Streamlit. Se l'applicazione Streamlit è ancora in esecuzione, puoi semplicemente aggiornare la pagina di anteprima web nel browser.
- Ora digita una domanda nell'input della chat, ad esempio:
What is the best time of year to go to Iceland? - Premi Invio.
Dovresti vedere l'applicazione visualizzare il tuo messaggio, un indicatore di caricamento "Elaborazione in corso…" e poi una risposta generata dal modello Gemini. In questo caso, hai connesso correttamente la tua applicazione web a un LLM su Vertex AI. 🙌 🥳
12. Definisci le istruzioni di sistema
Sebbene la connessione di base funzioni, la qualità e lo stile delle risposte dell'LLM sono fortemente influenzati dall'input che riceve. Il prompt engineering è il processo di progettazione e perfezionamento di questi input (prompt) per guidare il modello verso la generazione dell'output desiderato.
A questo scopo, inizierai creando alcune istruzioni di sistema e trasmettendole al modello.
Utilizzerai Chiedi a Gemini per creare istruzioni di sistema utili.
- In
app.py, individua la variabilesystem_instructions, attualmente impostata suNone.system_instructions = NoneNonecon una stringa multilinea che fornisce istruzioni per il nostro bot assistente di viaggio. - Chiedi a Gemini Code Assist: inserisci il seguente prompt in Gemini Code Assist (o inventane uno tuo):
I am a developer at a travel marketing company, and my sales department has decided that they need a new chat application to keep up with the bigger booking and search companies. I'm building a simple travel assistant chatbot using the Gemini 2.5 Flash model on Vertex AI. The application should: - Helps users ask questions about travel, book travel, and learn about places they are going to go - Provides users ways to get help about their specific travel plans - Provides all this in a production quality way (multiple environments, logging and monitoring, etc.) Please create system instructions appropriate for that chat app. Be thorough. Do not alter the code in any way beyond providing me with system instructions. - Definisci
system_instructions: impostasystem_instructionsin modo che sia uguale alle istruzioni di sistema che hai generato utilizzando Gemini Code Assist. In alternativa, puoi utilizzare queste istruzioni di sistema, create da Gemini con un prompt simile.system_instructions = """ You are a sophisticated travel assistant chatbot designed to provide comprehensive support to users throughout their travel journey. Your capabilities include answering travel-related questions, assisting with booking travel arrangements, offering detailed information about destinations, and providing support for existing travel plans. **Core Functionalities:** 1. **Travel Information and Recommendations:** * Answer user inquiries about travel destinations, including popular attractions, local customs, visa requirements, weather conditions, and safety advice. * Provide personalized recommendations for destinations, activities, and accommodations based on user preferences, interests, and budget. * Offer insights into the best times to visit specific locations, considering factors like weather, crowds, and pricing. * Suggest alternative destinations or activities if the user's initial choices are unavailable or unsuitable. 2. **Booking Assistance:** * Facilitate the booking of flights, hotels, rental cars, tours, and activities. * Search for available options based on user-specified criteria such as dates, destinations, budget, and preferences. * Present clear and concise information about available options, including pricing, amenities, and booking terms. * Guide users through the booking process, ensuring accurate information and secure transactions. * Provide booking confirmations and relevant details, such as booking references and contact information. 3. **Travel Planning and Itinerary Management:** * Assist users in creating detailed travel itineraries, including flights, accommodations, activities, and transportation. * Offer suggestions for optimizing travel plans, such as minimizing travel time or maximizing sightseeing opportunities. * Provide tools for managing and modifying existing itineraries, including adding or removing activities, changing booking dates, or upgrading accommodations. * Offer reminders and notifications for upcoming travel events, such as flight check-in or tour departure times. 4. **Customer Support and Troubleshooting:** * Provide prompt and helpful support to users with questions or issues related to their travel plans. * Assist with resolving booking discrepancies, cancellations, or modifications. * Offer guidance on travel-related emergencies, such as lost luggage or travel delays. * Provide access to relevant contact information for airlines, hotels, and other travel providers. **Interaction Guidelines:** * **Professionalism:** Maintain a polite, respectful, and professional tone in all interactions. * **Clarity and Conciseness:** Provide clear, concise, and easy-to-understand information. Avoid jargon or technical terms unless necessary and always explain them. * **Accuracy:** Ensure all information provided is accurate and up-to-date. Double-check details before sharing them with users. If unsure about something, admit that you don't know and offer to find the information. * **Personalization:** Tailor your responses and recommendations to the specific needs and preferences of each user. * **Proactive Assistance:** Anticipate user needs and offer relevant information or suggestions proactively. * **Error Handling:** Gracefully handle user errors or misunderstandings. Provide helpful guidance and alternative options when necessary. * **Confidentiality:** Respect user privacy and handle personal information with the utmost confidentiality and in compliance with data protection regulations. **Example Interactions:** **User:** "I want to go on a beach vacation in the Caribbean. I have a budget of $2000 per person for a week." **Chatbot:** "Certainly! The Caribbean offers many beautiful beach destinations within your budget. Some popular options include Punta Cana in the Dominican Republic, Cancun in Mexico, and Montego Bay in Jamaica. These destinations offer stunning beaches, all-inclusive resorts, and various activities. Would you like me to search for flights and accommodations for these locations based on your travel dates?" **User:** "My flight is delayed. What should I do?" **Chatbot:** "I'm sorry to hear about the delay. Please check with the airline for the updated departure time and any assistance they can offer. You may be entitled to compensation or rebooking options depending on the length of the delay and the airline's policy. Do you have your flight number handy so I can look up the current status for you?" **User:** "Tell me about the best time to visit Japan." **Chatbot:** "Japan is a fantastic destination with distinct seasons offering unique experiences. Spring (March-May) is famous for the beautiful cherry blossoms, while autumn (September-November) boasts stunning fall foliage. Both seasons have pleasant temperatures, making them ideal for sightseeing. Summer (June-August) can be hot and humid, but it's a great time for festivals and outdoor activities in the mountains. Winter (December-February) offers opportunities for skiing and snowboarding in the Japanese Alps, though some areas may experience heavy snowfall. To recommend the best time for you, could you tell me what you'd like to experience in Japan?" By following these instructions, you will be able to provide exceptional travel assistance and create a positive experience for every user. """ - Definisci la configurazione di generate_content:inizializza un oggetto di configurazione a cui trasmetterai queste istruzioni di sistema. Poiché
system_instructionsè definito a livello globale nel nostro script, la funzione può accedervi direttamente.generate_content_config = types.GenerateContentConfig( system_instruction=[ types.Part.from_text(text=system_instructions) ], ) logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}") - Per aggiungere le istruzioni di sistema alla risposta, aggiungi un parametro
configal metodogenerate_contente impostalo in modo che sia uguale all'oggettogenerate_content_configcreato sopra.response = client.models.generate_content( model=model_name, contents=contents, config=generate_content_config, # This is the new line )
Funzione call_model aggiornata
La funzione call_model completa ora ha il seguente aspetto:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
generate_content_config = types.GenerateContentConfig(
system_instruction=[
types.Part.from_text(text=system_instructions)
],
)
logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}")
response = client.models.generate_content(
model=model_name,
contents=contents,
config=generate_content_config,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
13. Testare l'app con le istruzioni di sistema
- Nel terminale, termina il processo attualmente in esecuzione (Ctrl+C).
- Esegui di nuovo il comando per avviare l'applicazione Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Aggiorna l'applicazione Streamlit. Se l'applicazione Streamlit è ancora in esecuzione, puoi semplicemente aggiornare la pagina di anteprima web nel browser.
- Prova a porre la stessa domanda di prima:
What is the best time of year to go to Iceland? - Premi Invio.
Confronta la risposta questa volta rispetto alla volta precedente.
14. Definire uno strumento meteo
Finora, il nostro chatbot è competente, ma le sue conoscenze sono limitate ai dati su cui è stato addestrato. Non può accedere alle informazioni in tempo reale. Per un bot di viaggio, la possibilità di recuperare dati in tempo reale come le previsioni meteo è un enorme vantaggio.
È qui che entra in gioco tooling, noto anche come chiamata di funzioni. Possiamo definire un insieme di strumenti (funzioni Python) che l'LLM può scegliere di chiamare per ottenere informazioni esterne.
Come funziona la strumentazione
- Descriviamo i nostri strumenti al modello, incluse le loro funzioni e i parametri che accettano.
- L'utente invia un prompt (ad es. "Che tempo fa a Londra?").
- Il modello riceve il prompt e vede che l'utente sta chiedendo informazioni su qualcosa che può scoprire utilizzando uno dei suoi strumenti.
- Invece di rispondere con del testo, il modello risponde con un oggetto speciale
function_call, che indica quale strumento vuole chiamare e con quali argomenti. - Il nostro codice Python riceve questo
function_call, esegue la nostra funzioneget_current_temperatureeffettiva con gli argomenti forniti e ottiene il risultato (ad es. 15 °C). - Inviamo questo risultato al modello.
- Il modello riceve il risultato e genera una risposta in linguaggio naturale per l'utente (ad es. "La temperatura attuale a Londra è di 15 °C").
Questo processo consente al modello di rispondere a domande che vanno ben oltre i dati di addestramento, rendendolo un assistente molto più potente e utile.
Definire uno strumento meteo
Se un viaggiatore sta cercando consigli su cosa fare e sta scegliendo tra attività influenzate dal meteo, uno strumento meteo potrebbe essere utile. Creiamo uno strumento per il nostro modello per ottenere il meteo attuale. Abbiamo bisogno di due parti: una dichiarazione di funzione che descriva lo strumento al modello e la funzione Python effettiva che lo implementa.
- In
app.py, trova il commento# TODO: Define the weather tool function declaration. - Sotto questo commento, aggiungi la variabile
weather_function. Si tratta di un dizionario che indica al modello tutto ciò che deve sapere sullo scopo, sui parametri e sugli argomenti richiesti della funzione.weather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } - Successivamente, trova il commento
# TODO: Define the get_current_temperature function. Sotto, aggiungi il seguente codice Python. Questa funzione:- Chiama un'API di geocodifica per ottenere le coordinate della posizione.
- Utilizza queste coordinate per chiamare un'API meteo.
- Restituisce una stringa semplice con la temperatura e l'unità.
def get_current_temperature(location: str) -> str: """Gets the current temperature for a given location.""" try: # --- Get Latitude and Longitude for the location --- geocode_url = f"https://geocoding-api.open-meteo.com/v1/search?name={location}&count=1&language=en&format=json" geocode_response = requests.get(geocode_url) geocode_data = geocode_response.json() if not geocode_data.get("results"): return f"Could not find coordinates for {location}." lat = geocode_data["results"][0]["latitude"] lon = geocode_data["results"][0]["longitude"] # --- Get Weather for the coordinates --- weather_url = f"https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}¤t_weather=true" weather_response = requests.get(weather_url) weather_data = weather_response.json() temperature = weather_data["current_weather"]["temperature"] unit = "°C" return f"{temperature}{unit}" except Exception as e: return f"Error fetching weather: {e}"
15. Refactoring per chat e strumenti
La nostra attuale funzione call_model utilizza una semplice chiamata generate_content una tantum. Questa soluzione è ideale per le singole domande, ma non per una conversazione multi-turno, soprattutto se prevede uno scambio di messaggi per l'utilizzo di strumenti.
Una pratica migliore è utilizzare una sessione di chat, che mantiene il contesto della conversazione. Ora eseguiremo il refactoring del codice per utilizzare una sessione di chat, necessaria per implementare correttamente gli strumenti.
- Elimina la funzione
call_modelesistente. Lo sostituiremo con una versione più avanzata. - Al suo posto, aggiungi la nuova funzione
call_modeldal blocco di codice riportato di seguito. Questa nuova funzione contiene la logica per gestire il ciclo di chiamata degli strumenti di cui abbiamo parlato in precedenza. Nota che contiene diversi commenti TODO che completeremo nei passaggi successivi.# --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt. It maintains a chat session and handles function calls from the model to external tools. """ try: # TODO: Get the existing chat session or create a new one. message_content = prompt # Start the tool-calling loop while True: # TODO: Send the message to the model. # Check if the model wants to call a tool has_tool_calls = False for part in response.candidates[0].content.parts: if part.function_call: has_tool_calls = True function_call = part.function_call logging.info(f"Function to call: {function_call.name}") logging.info(f"Arguments: {function_call.args}") # TODO: Call the appropriate function if the model requests it. elif part.text: logging.info("No function call found in the response.") logging.info(response.text) # If no tool call was made, break the loop if not has_tool_calls: break # TODO: Return the model's final text response. except Exception as e: return f"Error: {e}" - Ora aggiungiamo una funzione helper per gestire la sessione di chat. Sopra la nuova funzione
call_model, aggiungi la funzioneget_chat. Questa funzione creerà una nuova sessione di chat con le istruzioni di sistema e le definizioni degli strumenti oppure recupererà quella esistente. Si tratta di una buona pratica per organizzare il codice.def get_chat(model_name: str): if f"chat-{model_name}" not in st.session_state: # TODO: Define the tools configuration for the model # TODO: Define the generate_content configuration, including tools # TODO: Create a new chat session st.session_state[f"chat-{model_name}"] = chat return st.session_state[f"chat-{model_name}"]
Ora hai configurato l'impalcatura per la nostra logica di chat avanzata abilitata per gli strumenti.
16. Implementa la logica di chiamata degli strumenti
Ora compiliamo TODOs per rendere la logica di chiamata degli strumenti completamente funzionale.
Implementa get_chat
- Nella funzione
get_chatsotto il commento# TODO: Define the tools configuration..., definisci l'oggettotoolscreando un'istanzatypes.Tooldalla nostra dichiarazioneweather_function.tools = types.Tool(function_declarations=[weather_function]) - In
# TODO: Define the generate_content configuration..., definiscigenerate_content_config, assicurandoti di passare l'oggettotoolsal modello. In questo modo il modello apprende gli strumenti che può utilizzare.generate_content_config = types.GenerateContentConfig( system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here ) - In
# TODO: Create a new chat session, crea l'oggetto chat utilizzandoclient.chats.create(), passando il nome e la configurazione del modello.chat = client.chats.create( model=model_name, config=generate_content_config, )
Implementa call_model
- In
# TODO: Get the existing chat session...nella funzionecall_model, chiama la nostra nuova funzione helperget_chat.chat = get_chat(model_name) - Poi, trova
# TODO: Send the message to the model. Invia il messaggio dell'utente utilizzando il metodochat.send_message().response = chat.send_message(message_content) - Trova
# TODO: Call the appropriate function.... Qui controlliamo quale funzione vuole il modello ed eseguiamo.
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
- Infine, trova
# TODO: Return the model's final text responsee aggiungi la dichiarazione return.return response.text
Funzione get_chat aggiornata
La funzione get_chat aggiornata ora dovrebbe avere il seguente aspetto:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
Funzione call_model aggiornata
La funzione call_model aggiornata ora dovrebbe avere il seguente aspetto:
def call_model(prompt: str, model_name: str) -> str:
try:
chat = get_chat(model_name)
message_content = prompt
while True:
response = chat.send_message(message_content)
has_tool_calls = False
for part in response.candidates[0].content.parts:
if part.function_call:
has_tool_calls = True
function_call = part.function_call
logging.info(f"Function to call: {function_call.name}")
logging.info(f"Arguments: {function_call.args}")
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
elif part.text:
logging.info("No function call found in the response.")
logging.info(response.text)
if not has_tool_calls:
break
return response.text
except Exception as e:
return f"Error: {e}"
17. Testare l'app abilitata allo strumento
Vediamo la tua nuova funzionalità in azione.
- Nel terminale, termina il processo attualmente in esecuzione (Ctrl+C).
- Esegui di nuovo il comando per avviare l'applicazione Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Aggiorna l'applicazione Streamlit. Se l'applicazione Streamlit è ancora in esecuzione, puoi semplicemente aggiornare la pagina di anteprima web nel browser.
- Ora, fai una domanda che dovrebbe attivare il nuovo strumento, ad esempio:
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Premi INVIO
Confronta questa risposta con le precedenti. Novità
Dovresti visualizzare una risposta che incorpora la temperatura della tua funzione. Controlla anche il terminale Cloud Shell: dovresti visualizzare le istruzioni di stampa che confermano l'esecuzione della funzione Python.
18. Perfeziona l'output del modello con i parametri
Ottimo! L'assistente di viaggio ora può utilizzare strumenti per recuperare dati esterni in tempo reale, il che lo rende molto più potente.
Ora che abbiamo migliorato le funzionalità del nostro modello, perfezioniamo il modo in cui risponde. I parametri del modello ti consentono di controllare lo stile e la casualità del testo generato dall'LLM. Modificando queste impostazioni, puoi rendere l'output del bot più mirato e deterministico o più creativo e vario.
Per questo lab, ci concentreremo su temperature e top_p. Per un elenco completo dei parametri configurabili e delle relative descrizioni, consulta la sezione GenerateContentConfig del nostro riferimento API.
temperature: controlla la casualità dell'output. Un valore più basso (più vicino a 0) rende l'output più deterministico e mirato, mentre un valore più alto (più vicino a 2) aumenta la casualità e la creatività. Per un bot di domande e risposte o un assistente, di solito è preferibile una temperatura più bassa per risposte più coerenti e basate sui fatti.top_p: la probabilità cumulativa massima dei token da considerare durante il campionamento. I token vengono ordinati in base alle probabilità assegnate, in modo che vengano presi in considerazione solo i token più probabili. Il modello considera i token più probabili le cui probabilità sommano fino al valore ditop_p. Un valore più basso limita le scelte dei token, con un output meno vario.
Parametri di chiamata
- Trova le variabili
temperatureetop_pdefinite nella parte superiore diapp.py. Tieni presente che non sono ancora stati chiamati da nessuna parte. - Aggiungi
temperatureetop_pai parametri definiti all'interno diGenerateContentConfignella funzioneget_chat.generate_content_config = types.GenerateContentConfig( temperature=temperature, top_p=top_p, system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )
Funzione get_chat aggiornata
Ora l'app get_chat ha questo aspetto:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
temperature=temperature,
top_p=top_p,
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
19. Testare con i parametri del modello
- Nel terminale, termina il processo attualmente in esecuzione (Ctrl+C).
- Esegui di nuovo il comando per avviare l'applicazione Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Aggiorna l'applicazione Streamlit. Se l'applicazione Streamlit è ancora in esecuzione, puoi semplicemente aggiornare la pagina di anteprima web nel browser.
- Prova a fare la stessa domanda di prima.
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Premi INVIO
Confronta questa risposta con le precedenti.
20. Complimenti!
Hai eseguito l'upgrade dell'applicazione Q&A con strumenti, una funzionalità potente che consente alla tua app basata su Gemini di interagire con sistemi esterni e accedere a informazioni in tempo reale.
Sperimentazione continua
Esistono molte opzioni per continuare a ottimizzare il prompt. Ecco alcuni aspetti da considerare:
- Modifica
temperatureetop_pe vedi come cambia la risposta fornita dal LLM. - Per un elenco completo dei parametri configurabili e delle relative descrizioni, consulta la sezione
GenerateContentConfignel nostro riferimento API. Prova a definire più parametri e a modificarli per vedere cosa succede.
Riepilogo
In questo lab hai:
- Utilizzato l'editor di Cloud Shell e il terminale per lo sviluppo.
- Utilizza l'SDK Vertex AI Python per connettere l'applicazione a un modello Gemini.
- Sono state applicate istruzioni di sistema e parametri del modello per guidare le risposte del LLM.
- Appreso il concetto di strumentazione (chiamata di funzioni) e i relativi vantaggi.
- È stato eseguito il refactoring del codice per utilizzare una sessione di chat con stato, una best practice per l'AI conversazionale.
- Definisci uno strumento per il modello utilizzando una dichiarazione di funzione.
- Implementata la funzione Python per fornire la logica dello strumento.
- Ha scritto il codice per gestire le richieste di chiamata di funzione del modello e restituire i risultati.