
1. はじめに
概要
あなたは旅行マーケティング会社に勤務するデベロッパーです。営業部門は、予約や検索の大手企業に対抗するために、新しいチャット アプリケーションが必要だと判断しました。生成 AI についても聞いたことはあるが、あまりよく知らない。他の部門もこの取り組みについて耳にしており、カスタマー エクスペリエンスの向上にどのように役立つかに関心を持っています。
演習内容
このラボでは、Vertex AI の Gemini 2.5 Flash モデルを使用して旅行アシスタント チャットボットを構築します。
アプリケーションは次のことを行う必要があります。
- 旅行に関する質問をしたり、旅行を予約したり、旅行先の情報を調べたりするのに役立ちます
- ユーザーが特定の旅行プランについてサポートを受ける方法を提供する
- ツールを使用して天気などのリアルタイム データを取得できる
事前構成済みの Google Cloud 環境(具体的には Cloud Shell エディタ)で作業します。基本的なウェブ アプリケーションのフロントエンドは、Vertex AI にアクセスするために必要な権限とともに、すでに設定されています。このアプリは Streamlit を使用して構築されています。
学習内容
このラボでは、次のタスクの実行方法について学びます。
- Vertex AI プラットフォームで、利用可能な生成 AI モデルを確認します。
- Cloud Shell エディタとターミナルで開発する
- Gemini Code Assist を使用してコードを理解する。
- Python で Vertex AI SDK を使用して、Gemini LLM にプロンプトを送信し、レスポンスを受信します。
- 基本的なプロンプト エンジニアリング(システム指示、モデル パラメータ)を適用して、Gemini LLM の出力をカスタマイズします。
- プロンプトとパラメータを変更してレスポンスを改善し、LLM を活用したチャット アプリケーションをテストして反復的に改善します。
- Gemini モデルでツールを定義して使用し、関数呼び出しを有効にします。
- 会話型アプリのベスト プラクティスであるステートフル チャット セッションを使用するようにコードをリファクタリングします。
2. プロジェクトの設定
Google アカウント
個人の Google アカウントをお持ちでない場合は、Google アカウントを作成する必要があります。
仕事用または学校用アカウントではなく、個人アカウントを使用します。
Google Cloud コンソールにログインする
個人の Google アカウントを使用して Google Cloud コンソールにログインします。
課金を有効にする
Google Cloud クレジットを利用する(省略可)
このワークショップを実施するには、クレジットが設定された請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して、開始します。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 1 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
プロジェクトの作成(省略可)
このラボで使用する現在のプロジェクトがない場合は、こちらで新しいプロジェクトを作成します。
3. Cloud Shell エディタを開く
- このリンクをクリックすると、Cloud Shell エディタに直接移動します。
- 本日、承認を求めるメッセージがどこかの時点で表示された場合は、[承認] をクリックして続行します。
- ターミナルが画面の下部に表示されない場合は、ターミナルを開きます。
- [表示] をクリックします。
- [ターミナル] をクリックします。
- ターミナルで、次のコマンドを使用してプロジェクトを設定します。
gcloud config set project [PROJECT_ID]- 例:
gcloud config set project lab-project-id-example - プロジェクト ID が思い出せない場合は、次のコマンドでプロジェクト ID をすべて一覧表示できます。
gcloud projects list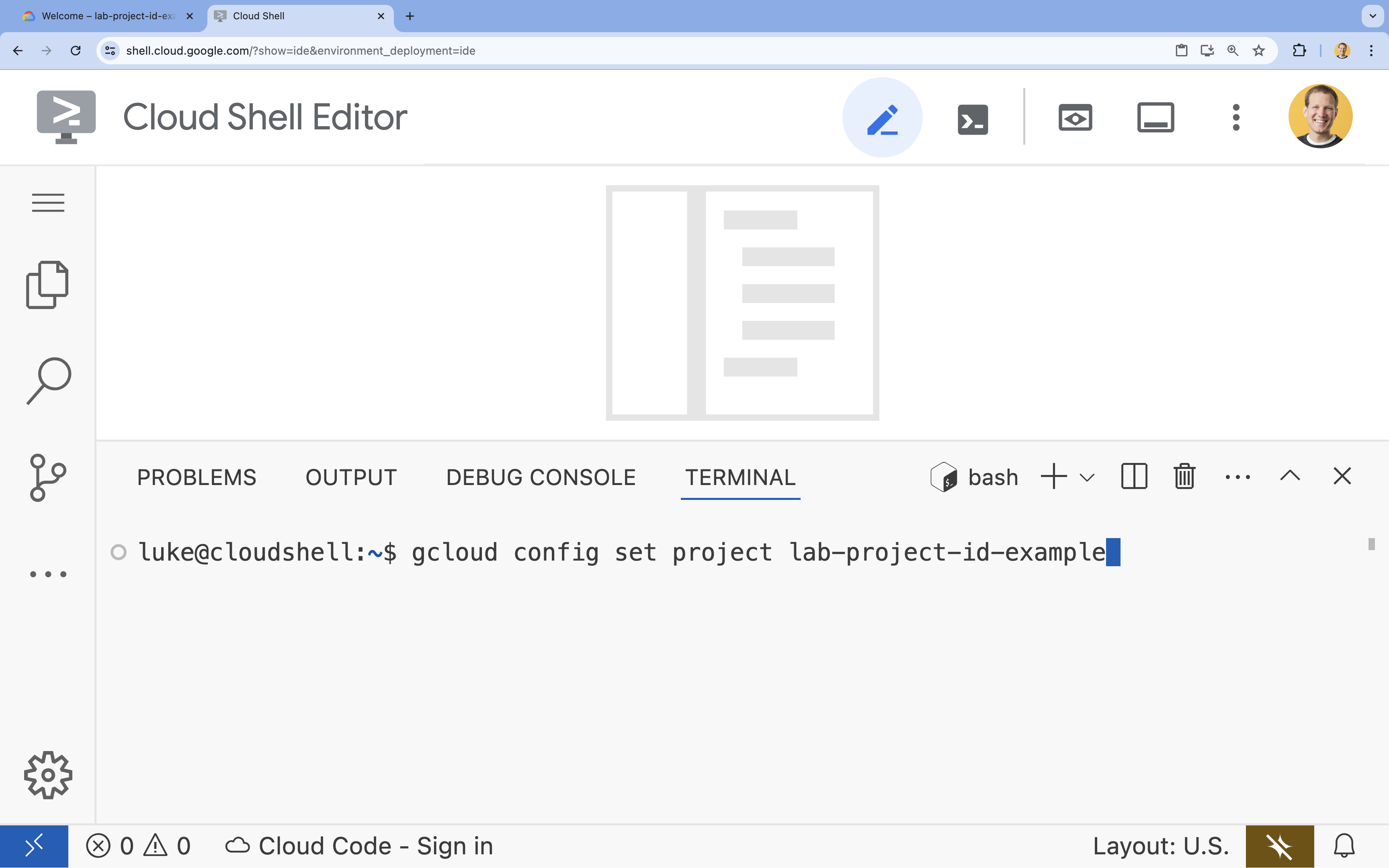
- 例:
- 次のようなメッセージが表示されます。
Updated property [core/project].
4. API を有効にする
Vertex AI SDK を使用して Gemini モデルを操作するには、Google Cloud プロジェクトで Vertex AI API を有効にする必要があります。
- ターミナルで API を有効にします。
gcloud services enable \ aiplatform.googleapis.com
Vertex AI SDK for Python の概要
Python アプリケーションから Vertex AI でホストされているモデルを操作するには、Vertex AI SDK for Python を使用します。この SDK を使用すると、基盤となる API 呼び出しの複雑さを直接処理することなく、プロンプトの送信、モデル パラメータの指定、レスポンスの受信のプロセスをシンプルにできます。
Vertex AI SDK for Python の包括的なドキュメントについては、Vertex AI SDK for Python の概要 | Google Cloud をご覧ください。
5. 仮想環境を作成して依存関係をインストールする
Python プロジェクトを開始する前に、仮想環境を作成することをおすすめします。これにより、プロジェクトの依存関係が分離され、他のプロジェクトやシステムのグローバル Python パッケージとの競合が回避されます。
- 旅行アシスタント アプリのコードを保存する
wanderbotという名前のフォルダを作成します。ターミナルで次のコードを実行します。mkdir wanderbot && cd wanderbot - 仮想環境を作成して有効にします。
uv venv --python 3.12 source .venv/bin/activatewanderbot)が表示され、仮想環境がアクティブになっていることが示されます。次のようになります。
6. wanderbot のスターター ファイルを作成する
- アプリケーションの新しい
app.pyファイルを作成して開きます。ターミナルで次のコードを実行します。cloudshell edit app.pycloudshell editコマンドを実行すると、ターミナルの上にエディタでapp.pyファイルが開きます。 - 次のアプリ スターター コードを
app.pyに貼り付けます。import streamlit as st from google import genai from google.genai import types import requests import logging # --- Defining variables and parameters --- REGION = "global" PROJECT_ID = None # TODO: Insert Project ID GEMINI_MODEL_NAME = "gemini-2.5-flash" temperature = .2 top_p = 0.95 system_instructions = None # --- Tooling --- # TODO: Define the weather tool function declaration # TODO: Define the get_current_temperature function # --- Initialize the Vertex AI Client --- try: # TODO: Initialize the Vertex AI client print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}") except Exception as e: st.error(f"Error initializing VertexAI client: {e}") st.stop() # TODO: Add the get_chat function here in Task 15. # --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions. It will be replaced in a later step with a more advanced version that handles tooling. """ try: # TODO: Prepare the content for the model # TODO: Define generate_content configuration (needed for system instructions and parameters) # TODO: Define response logging.info(f"[call_model_response] LLM Response: \"{response.text}\"") # TODO: Uncomment the below "return response.text" line # return response.text except Exception as e: return f"Error: {e}" # --- Presentation Tier (Streamlit) --- # Set the title of the Streamlit application st.title("Travel Chat Bot") # Initialize session state variables if they don't exist if "messages" not in st.session_state: # Initialize the chat history with a welcome message st.session_state["messages"] = [ {"role": "assistant", "content": "How can I help you today?"} ] # Display the chat history for msg in st.session_state.messages: st.chat_message(msg["role"]).write(msg["content"]) # Get user input if prompt := st.chat_input(): # Add the user's message to the chat history st.session_state.messages.append({"role": "user", "content": prompt}) # Display the user's message st.chat_message("user").write(prompt) # Show a spinner while waiting for the model's response with st.spinner("Thinking..."): # Get the model's response using the call_model function model_response = call_model(prompt, GEMINI_MODEL_NAME) # Add the model's response to the chat history st.session_state.messages.append( {"role": "assistant", "content": model_response} ) # Display the model's response st.chat_message("assistant").write(model_response) - アプリケーション コード用の新しい
requirements.txtファイルを作成して開きます。ターミナルで次のコードを実行します。cloudshell edit requirements.txtcloudshell editコマンドを実行すると、ターミナルの上にエディタでrequirements.txtファイルが開きます。 - 次のアプリ スターター コードを
requirements.txtに貼り付けます。google-genai streamlit requests - このプロジェクトに必要な Python 依存関係をインストールします。ターミナルで次のコードを実行します。
uv pip install -r requirements.txt
7. コードを探索する
作成したファイルには、基本的なチャット アプリケーションのフロントエンドが含まれています。次のようなものがあります。
app.py: これは作業するファイルです。現在、次の内容が含まれています。- 必要なインポート
- 環境変数とパラメータ(プレースホルダを含む)
- 空の
call_model関数。この関数は後で入力します。 - フロントエンド チャットアプリの Streamlit コード
requirements.txt:app.pyの実行に必要なインストール要件が含まれています
それでは、コードを見ていきましょう。
Gemini Code Assist チャットを開く
Gemini Code Assist Chat は、Cloud Shell エディタの右側のパネルにすでに開いているはずです。Gemini Code Assist チャットがまだ開いていない場合は、次の手順で開くことができます。
- 画面上部にある Gemini Code Assist ボタン(
 )をクリックします。
)をクリックします。 - [Gemini Code Assist Chat を開く] を選択します。
Gemini Code Assist を使用してコードを理解する
Gemini Code Assist Chat を使用して、コードをより深く理解できます。
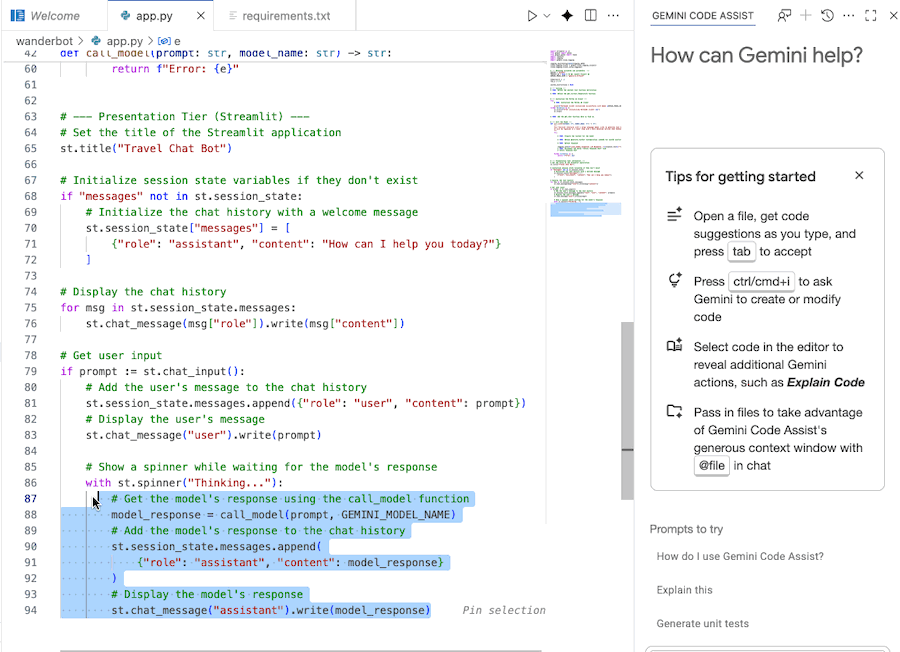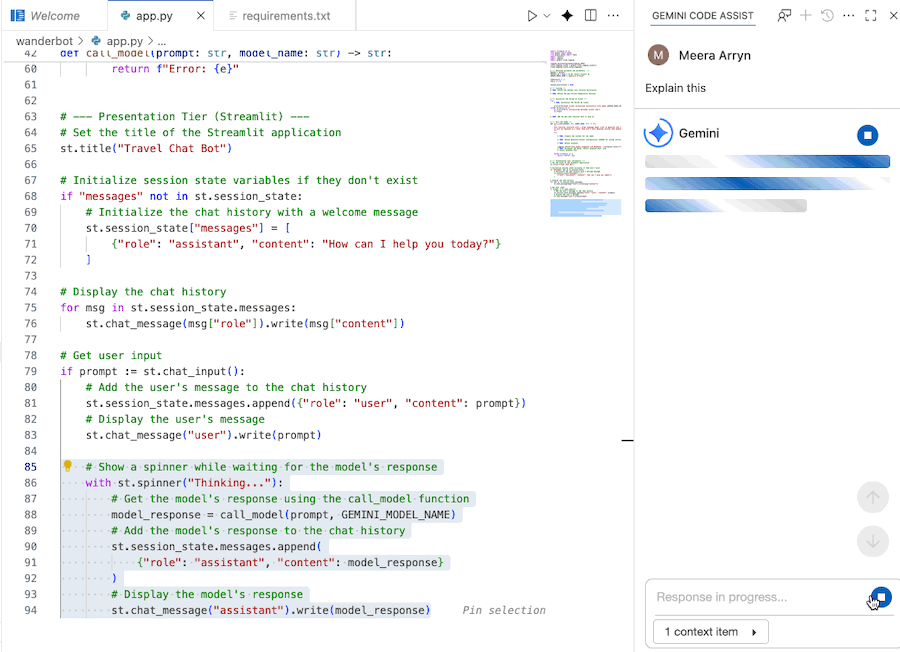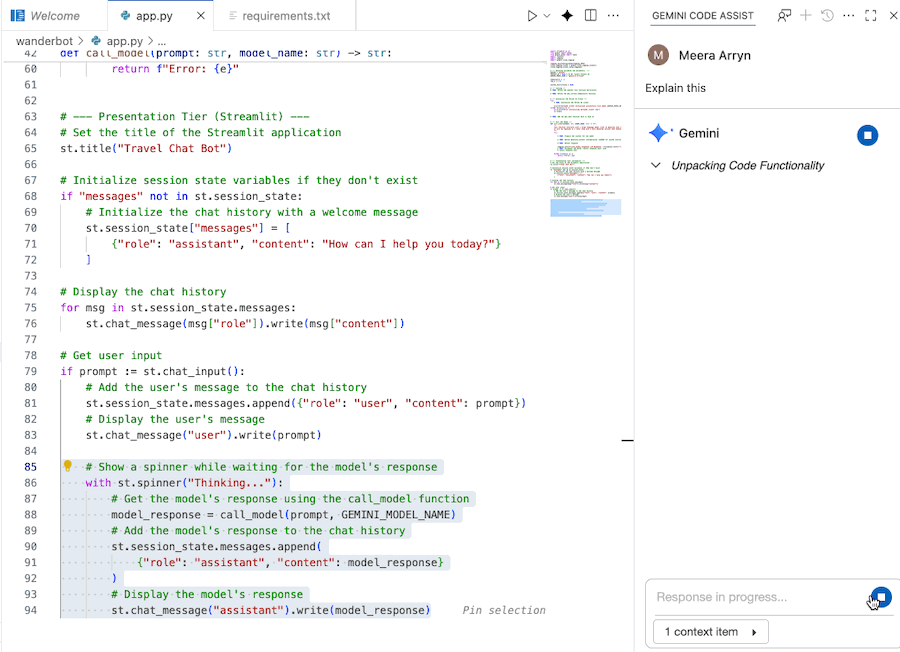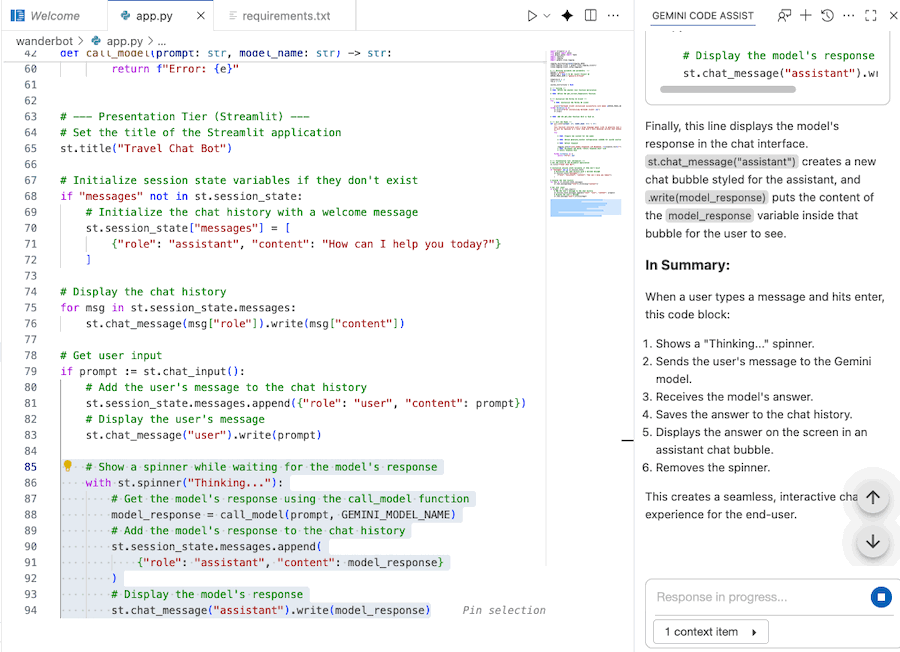
- 目的のコード セクションをハイライト表示または選択します。
- Gemini とのチャットに「このコードについて説明して」と入力します。
- Enter キーを押して送信します
8. ウェブアプリを起動する
このアプリを LLM に接続する前に、アプリを起動して初期動作を確認します。
wanderbotディレクトリ内で、ターミナルで次のコマンドを実行して、Streamlit アプリケーションを起動し、Cloud Shell シェル環境内でローカルにアクセスできるようにします。streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080- コマンドを実行したら、Cloud Shell エディタの上部にある [ウェブでプレビュー] ボタンをクリックし、[ポート 8080 でプレビュー] を選択します。
旅行アプリのシンプルなチャット インターフェースが表示されます。 - メッセージ(例:
Hi!)を入力して、Enter キーを押します。
メッセージはチャット履歴に表示されますが、アシスタントからの返信ではなく、エラー メッセージが表示されます。これは、アプリケーションがまだ大規模言語モデルに接続されていないためです。この動作を観察して、ラボの出発点を理解します。
9. Vertex AI クライアントを初期化する
Vertex AI で利用可能なモデルを確認する
Google Cloud の Vertex AI プラットフォームは、さまざまな生成 AI モデルへのアクセスを提供します。統合する前に、Google Cloud コンソールで利用可能なオプションを確認できます。
- Google Cloud コンソールで、Model Garden に移動します。これを行うには、画面上部の検索バーで「Model Garden」を検索し、Vertex AI を選択します(
 )。
)。 - 利用可能なモデルを参照します。モダリティ、タスクタイプ、機能などでフィルタできます。
このラボでは、Gemini 2.5 Flash モデルを使用します。このモデルは、速度が速いため、レスポンスの速いチャット アプリケーションの構築に適しています。
Vertex AI クライアントを初期化する
次に、app.py の --- Initialize the Vertex AI Client --- セクションを変更して、Vertex AI クライアントを初期化します。このクライアント オブジェクトは、モデルにプロンプトを送信するために使用されます。
- Cloud Shell エディタで
app.pyを開きます。 app.pyで、PROJECT_ID = Noneという行を探します。Noneは、引用符で囲まれた Google Cloud プロジェクト ID に置き換えます。(例:PROJECT_ID = "google-cloud-labs")
プロジェクト ID を忘れた場合は、次のコマンドでプロジェクト ID をすべて一覧表示できます。gcloud projects list | awk '/PROJECT_ID/{print $2}'- クライアントを定義する:
tryブロック内で、Vertex AI クライアントを初期化します。client = genai.Client( vertexai=True, project=PROJECT_ID, location=REGION, )
Vertex AI クライアントの初期化を更新
この時点で、Vertex AI クライアントの初期化セクションは次のようになります。
# --- Initialize the Vertex AI Client ---
try:
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=REGION,
)
print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}")
except Exception as e:
st.error(f"Error initializing VertexAI client: {e}")
st.stop()
10. データを準備してモデルを呼び出す
モデルに送信するコンテンツを準備し、Gemini モデルを呼び出します。
call_model関数が定義されている--- Call the Model ---セクションを見つけます。- コンテンツを定義する:
# TODO: Prepare the content for the modelで、モデルに送信される入力コンテンツを定義します。基本的なプロンプトの場合、これはユーザーの入力メッセージになります。contents = [prompt] - レスポンスを定義する: 次のコードを
# TODO: Define responseの下に貼り付けます。response = client.models.generate_content( model=model_name, contents=contents, ) - レスポンスを返す: 次の行のコメントを解除します。
return response.text withブロックのファイルの末尾付近で、call_model関数が呼び出されている行を確認します。ここで何が起こっているかわからない場合は、行をハイライト表示して、Gemini Code Assist に相談してください。
contents をより明示的に定義する方法
上記のように contents を定義できるのは、文字列を含むリストがユーザーのテキスト入力を表すことを SDK が理解できるからです。モデル API 用に自動的に正しい形式に設定されます。
ただし、入力の構造をより明示的かつ基本的な方法で指定するには、次のように types.Part オブジェクトと types.Content オブジェクトを使用します。
user_message_parts = [types.Part.from_text(text=prompt)]
contents = [
types.Content(
role="user", # Indicates the content is from the user
parts=user_message_parts, # A list, allowing multiple types of content
),
]
call_model 関数を更新しました
この時点で、call_model 関数は次のようになります。
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
# TODO: Define generate_content configuration (needed later for system instructions and parameters)
response = client.models.generate_content(
model=model_name,
contents=contents,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
11. 接続済みアプリをテストする
- ターミナルで、現在実行中のプロセスを終了します(Ctrl+C)。
- コマンドを再実行して、Streamlit アプリケーションを再度起動します。
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Streamlit アプリケーションを更新します。Streamlit アプリケーションがまだ実行されている場合は、ブラウザでウェブ プレビュー ページを更新するだけです。
- チャット入力に次のような質問を入力します。
What is the best time of year to go to Iceland? - Enter キーを押します。
アプリケーションにメッセージと「Thinking...」スピナーが表示され、その後 Gemini モデルによって生成されたレスポンスが表示されます。接続されている場合は、ウェブ アプリケーションが Vertex AI の LLM に正常に接続されています。🙌 🥳
12. システム指示を定義する
基本的な接続は機能しますが、LLM の回答の品質とスタイルは、受け取る入力に大きく影響されます。プロンプト エンジニアリングは、モデルが目的の出力を生成するように、これらの入力(プロンプト)を設計して改良するプロセスです。
そのため、まずいくつかのシステム指示を作成し、モデルに渡します。
Gemini に相談を使用して、役立つシステム指示を作成します。
app.pyで、現在Noneに設定されているsystem_instructions変数を見つけます。system_instructions = NoneNoneは、旅行アシスタント ボットの手順を提供する複数行の文字列に置き換えます。- Gemini Code Assist に相談する: 次のプロンプトを Gemini Code Assist に渡します(または独自のプロンプトを作成します)。
I am a developer at a travel marketing company, and my sales department has decided that they need a new chat application to keep up with the bigger booking and search companies. I'm building a simple travel assistant chatbot using the Gemini 2.5 Flash model on Vertex AI. The application should: - Helps users ask questions about travel, book travel, and learn about places they are going to go - Provides users ways to get help about their specific travel plans - Provides all this in a production quality way (multiple environments, logging and monitoring, etc.) Please create system instructions appropriate for that chat app. Be thorough. Do not alter the code in any way beyond providing me with system instructions. system_instructionsを定義する:system_instructionsを Gemini Code Assist を使用して生成したシステム指示と等しく設定します。代わりに、Gemini が同様のプロンプトで作成した次のシステム指示を使用することもできます。system_instructions = """ You are a sophisticated travel assistant chatbot designed to provide comprehensive support to users throughout their travel journey. Your capabilities include answering travel-related questions, assisting with booking travel arrangements, offering detailed information about destinations, and providing support for existing travel plans. **Core Functionalities:** 1. **Travel Information and Recommendations:** * Answer user inquiries about travel destinations, including popular attractions, local customs, visa requirements, weather conditions, and safety advice. * Provide personalized recommendations for destinations, activities, and accommodations based on user preferences, interests, and budget. * Offer insights into the best times to visit specific locations, considering factors like weather, crowds, and pricing. * Suggest alternative destinations or activities if the user's initial choices are unavailable or unsuitable. 2. **Booking Assistance:** * Facilitate the booking of flights, hotels, rental cars, tours, and activities. * Search for available options based on user-specified criteria such as dates, destinations, budget, and preferences. * Present clear and concise information about available options, including pricing, amenities, and booking terms. * Guide users through the booking process, ensuring accurate information and secure transactions. * Provide booking confirmations and relevant details, such as booking references and contact information. 3. **Travel Planning and Itinerary Management:** * Assist users in creating detailed travel itineraries, including flights, accommodations, activities, and transportation. * Offer suggestions for optimizing travel plans, such as minimizing travel time or maximizing sightseeing opportunities. * Provide tools for managing and modifying existing itineraries, including adding or removing activities, changing booking dates, or upgrading accommodations. * Offer reminders and notifications for upcoming travel events, such as flight check-in or tour departure times. 4. **Customer Support and Troubleshooting:** * Provide prompt and helpful support to users with questions or issues related to their travel plans. * Assist with resolving booking discrepancies, cancellations, or modifications. * Offer guidance on travel-related emergencies, such as lost luggage or travel delays. * Provide access to relevant contact information for airlines, hotels, and other travel providers. **Interaction Guidelines:** * **Professionalism:** Maintain a polite, respectful, and professional tone in all interactions. * **Clarity and Conciseness:** Provide clear, concise, and easy-to-understand information. Avoid jargon or technical terms unless necessary and always explain them. * **Accuracy:** Ensure all information provided is accurate and up-to-date. Double-check details before sharing them with users. If unsure about something, admit that you don't know and offer to find the information. * **Personalization:** Tailor your responses and recommendations to the specific needs and preferences of each user. * **Proactive Assistance:** Anticipate user needs and offer relevant information or suggestions proactively. * **Error Handling:** Gracefully handle user errors or misunderstandings. Provide helpful guidance and alternative options when necessary. * **Confidentiality:** Respect user privacy and handle personal information with the utmost confidentiality and in compliance with data protection regulations. **Example Interactions:** **User:** "I want to go on a beach vacation in the Caribbean. I have a budget of $2000 per person for a week." **Chatbot:** "Certainly! The Caribbean offers many beautiful beach destinations within your budget. Some popular options include Punta Cana in the Dominican Republic, Cancun in Mexico, and Montego Bay in Jamaica. These destinations offer stunning beaches, all-inclusive resorts, and various activities. Would you like me to search for flights and accommodations for these locations based on your travel dates?" **User:** "My flight is delayed. What should I do?" **Chatbot:** "I'm sorry to hear about the delay. Please check with the airline for the updated departure time and any assistance they can offer. You may be entitled to compensation or rebooking options depending on the length of the delay and the airline's policy. Do you have your flight number handy so I can look up the current status for you?" **User:** "Tell me about the best time to visit Japan." **Chatbot:** "Japan is a fantastic destination with distinct seasons offering unique experiences. Spring (March-May) is famous for the beautiful cherry blossoms, while autumn (September-November) boasts stunning fall foliage. Both seasons have pleasant temperatures, making them ideal for sightseeing. Summer (June-August) can be hot and humid, but it's a great time for festivals and outdoor activities in the mountains. Winter (December-February) offers opportunities for skiing and snowboarding in the Japanese Alps, though some areas may experience heavy snowfall. To recommend the best time for you, could you tell me what you'd like to experience in Japan?" By following these instructions, you will be able to provide exceptional travel assistance and create a positive experience for every user. """- generate_content 構成を定義する: これらのシステム指示を渡す構成オブジェクトを初期化します。
system_instructionsはスクリプト内でグローバルに定義されているため、関数は直接アクセスできます。generate_content_config = types.GenerateContentConfig( system_instruction=[ types.Part.from_text(text=system_instructions) ], ) logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}") - システム指示をレスポンスに追加するには、
generate_contentメソッドにconfigパラメータを追加し、上記で作成したgenerate_content_configオブジェクトに設定します。response = client.models.generate_content( model=model_name, contents=contents, config=generate_content_config, # This is the new line )
call_model 関数を更新しました
完全な call_model 関数は次のようになります。
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
generate_content_config = types.GenerateContentConfig(
system_instruction=[
types.Part.from_text(text=system_instructions)
],
)
logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}")
response = client.models.generate_content(
model=model_name,
contents=contents,
config=generate_content_config,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
13. システム指示でアプリをテストする
- ターミナルで、現在実行中のプロセスを終了します(Ctrl+C)。
- コマンドを再実行して、Streamlit アプリケーションを再度起動します。
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Streamlit アプリケーションを更新します。Streamlit アプリケーションがまだ実行されている場合は、ブラウザでウェブ プレビュー ページを更新するだけです。
- 前と同じ質問を試します。
What is the best time of year to go to Iceland? - Enter キーを押します。
今回の応答と前回の応答を比較します。
14. 天気ツールを定義する
これまでのところ、chatbot は知識が豊富ですが、その知識はトレーニングに使用されたデータに限定されています。リアルタイムの情報にはアクセスできません。旅行ボットの場合、天気予報などのライブデータを取得できることは大きなメリットです。
ここで、ツール(関数呼び出しとも呼ばれます)が役立ちます。LLM が外部情報を取得するために呼び出すことができる一連のツール(Python 関数)を定義できます。
ツールの仕組み
- モデルにツールを説明します。ツールの機能や、受け取るパラメータなどについて説明します。
- ユーザーがプロンプト(「東京の天気は?」など)を送信します。
- モデルはプロンプトを受け取り、ユーザーがツールを使用して調べられることを質問していることを認識します。
- モデルは、テキストで応答する代わりに、呼び出すツールとその引数を示す特別な
function_callオブジェクトで応答します。 - Python コードは、この
function_callを受け取り、提供された引数を使用して実際のget_current_temperature関数を実行し、結果(15°C など)を取得します。 - この結果をモデルに送り返します。
- モデルは結果を受け取り、ユーザー向けの自然言語レスポンスを生成します(例: 「ロンドンの現在の気温は 15°C です。」)。
このプロセスにより、モデルはトレーニング データの範囲を超えて質問に答えることができるようになり、強力で便利なアシスタントを作成できます。
天気ツールを定義する
旅行者が何をするかについてアドバイスを求めており、天候に左右されるアクティビティのどちらかを選ぼうとしている場合は、天気予報ツールが役に立ちます。モデルが現在の天気を取得するためのツールを作成しましょう。ツールをモデルに説明する関数宣言と、それを実装する実際の Python 関数の 2 つの部分が必要です。
app.pyで、コメント# TODO: Define the weather tool function declarationを見つけます。- このコメントの下に
weather_function変数を追加します。これは、関数の目的、パラメータ、必須引数についてモデルが知っておくべきことをすべて伝える辞書です。weather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } - 次に、コメント
# TODO: Define the get_current_temperature functionを見つけます。その下に次の Python コードを追加します。この関数は次の処理を行います。- ジオコーディング API を呼び出して、位置の座標を取得します。
- これらの座標を使用して、天気予報 API を呼び出します。
- 温度と単位を含むシンプルな文字列を返します。
def get_current_temperature(location: str) -> str: """Gets the current temperature for a given location.""" try: # --- Get Latitude and Longitude for the location --- geocode_url = f"https://geocoding-api.open-meteo.com/v1/search?name={location}&count=1&language=en&format=json" geocode_response = requests.get(geocode_url) geocode_data = geocode_response.json() if not geocode_data.get("results"): return f"Could not find coordinates for {location}." lat = geocode_data["results"][0]["latitude"] lon = geocode_data["results"][0]["longitude"] # --- Get Weather for the coordinates --- weather_url = f"https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}¤t_weather=true" weather_response = requests.get(weather_url) weather_data = weather_response.json() temperature = weather_data["current_weather"]["temperature"] unit = "°C" return f"{temperature}{unit}" except Exception as e: return f"Error fetching weather: {e}"
15. チャットとツール用のリファクタリング
現在の call_model 関数は、シンプルな 1 回限りの generate_content 呼び出しを使用しています。これは単一の質問には適していますが、マルチターンの会話、特にツールに関するやり取りを伴う会話には適していません。
会話のコンテキストを維持するチャット セッションを使用することをおすすめします。ツールを正しく実装するために必要なチャット セッションを使用するように、コードをリファクタリングします。
- 既存の
call_model関数を削除します。より高度なバージョンに置き換えます。 - 代わりに、下のコードブロックから新しい
call_model関数を追加します。この新しい関数には、先ほど説明したツール呼び出しループを処理するロジックが含まれています。次のステップで完了する TODO コメントがいくつかあります。# --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt. It maintains a chat session and handles function calls from the model to external tools. """ try: # TODO: Get the existing chat session or create a new one. message_content = prompt # Start the tool-calling loop while True: # TODO: Send the message to the model. # Check if the model wants to call a tool has_tool_calls = False for part in response.candidates[0].content.parts: if part.function_call: has_tool_calls = True function_call = part.function_call logging.info(f"Function to call: {function_call.name}") logging.info(f"Arguments: {function_call.args}") # TODO: Call the appropriate function if the model requests it. elif part.text: logging.info("No function call found in the response.") logging.info(response.text) # If no tool call was made, break the loop if not has_tool_calls: break # TODO: Return the model's final text response. except Exception as e: return f"Error: {e}" - 次に、チャット セッションを管理するヘルパー関数を追加します。新しい
call_model関数の上にget_chat関数を追加します。この関数は、システム指示とツール定義を含む新しいチャット セッションを作成するか、既存のチャット セッションを取得します。これはコードを整理するための良い方法です。def get_chat(model_name: str): if f"chat-{model_name}" not in st.session_state: # TODO: Define the tools configuration for the model # TODO: Define the generate_content configuration, including tools # TODO: Create a new chat session st.session_state[f"chat-{model_name}"] = chat return st.session_state[f"chat-{model_name}"]
これで、高度なツール対応のチャット ロジックの足場が設定されました。
16. ツール呼び出しロジックを実装する
次に、TODOs に入力して、ツール呼び出しロジックを完全に機能させます。
get_chat を実装する
# TODO: Define the tools configuration...コメントの下のget_chat関数で、weather_function宣言からtypes.Toolインスタンスを作成してtoolsオブジェクトを定義します。tools = types.Tool(function_declarations=[weather_function])# TODO: Define the generate_content configuration...の下でgenerate_content_configを定義し、toolsオブジェクトをモデルに渡します。モデルは、このようにして使用できるツールについて学習します。generate_content_config = types.GenerateContentConfig( system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )# TODO: Create a new chat sessionで、client.chats.create()を使用してチャット オブジェクトを作成し、モデル名と構成を渡します。chat = client.chats.create( model=model_name, config=generate_content_config, )
call_model を実装する
call_model関数の# TODO: Get the existing chat session...で、新しいget_chatヘルパー関数を呼び出します。chat = get_chat(model_name)- 次に、
# TODO: Send the message to the modelを探します。chat.send_message()メソッドを使用して、ユーザーのメッセージを送信します。response = chat.send_message(message_content) # TODO: Call the appropriate function...を見つけます。ここで、モデルがどの関数を必要としているかを確認し、実行します。
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
- 最後に、
# TODO: Return the model's final text responseを見つけて、return 文を追加します。return response.text
get_chat 関数を更新しました
更新された get_chat 関数は次のようになります。
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
call_model 関数を更新しました
更新された call_model 関数は次のようになります。
def call_model(prompt: str, model_name: str) -> str:
try:
chat = get_chat(model_name)
message_content = prompt
while True:
response = chat.send_message(message_content)
has_tool_calls = False
for part in response.candidates[0].content.parts:
if part.function_call:
has_tool_calls = True
function_call = part.function_call
logging.info(f"Function to call: {function_call.name}")
logging.info(f"Arguments: {function_call.args}")
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
elif part.text:
logging.info("No function call found in the response.")
logging.info(response.text)
if not has_tool_calls:
break
return response.text
except Exception as e:
return f"Error: {e}"
17. ツール対応アプリをテストする
新機能の動作を見てみましょう。
- ターミナルで、現在実行中のプロセスを終了します(Ctrl+C)。
- コマンドを再実行して、Streamlit アプリケーションを再度起動します。
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Streamlit アプリケーションを更新します。Streamlit アプリケーションがまだ実行されている場合は、ブラウザでウェブ プレビュー ページを更新するだけです。
- 次に、新しいツールをトリガーする質問をします。たとえば、次のようにします。
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Enter キーを押します。
このレスポンスを以前のレスポンスと比較します。相違点
関数から取得した温度が組み込まれたレスポンスが表示されます。Cloud Shell ターミナルも確認します。Python 関数が実行されたことを確認する print ステートメントが表示されます。
18. パラメータを使用してモデルの出力を絞り込む
これで完了です。旅行アシスタントがツールを使用して外部のライブデータを取得できるようになり、機能が大幅に強化されました。
モデルの機能を強化したので、応答方法をファインチューニングしましょう。モデル パラメータを使用すると、LLM が生成するテキストのスタイルとランダム性を制御できます。これらの設定を調整することで、ボットの出力をより焦点が絞られた決定的なものにしたり、よりクリエイティブで多様なものにしたりできます。
このラボでは、temperature と top_p に焦点を当てます。(構成可能なパラメータとその説明の一覧については、API リファレンスの GenerateContentConfig をご覧ください)。
temperature: 出力のランダム性を制御します。値が小さいほど(0 に近いほど)、出力がより決定的で焦点が絞られます。値が大きいほど(2 に近いほど)、ランダム性と創造性が高まります。Q&A ボットやアシスタント ボットでは、より一貫性があり、事実に基づいた回答を得るために、通常は Temperature を低くすることが推奨されます。top_p: サンプリング時に考慮するトークンの累積確率の最大値。トークンは割り当てられた確率に基づいて並べ替えられ、最も可能性の高いトークンのみが考慮されます。モデルは、確率の合計がtop_p値になる最も可能性の高いトークンを考慮します。値が小さいほど、トークンの選択肢が制限され、出力の多様性が低下します。
呼び出しパラメータ
app.pyの先頭で定義されている変数temperatureとtop_pを見つけます。これらの関数はまだどこからも呼び出されていません。get_chat関数のGenerateContentConfig内で定義されたパラメータにtemperatureとtop_pを追加します。generate_content_config = types.GenerateContentConfig( temperature=temperature, top_p=top_p, system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )
get_chat 関数を更新しました
get_chat アプリは次のようになります。
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
temperature=temperature,
top_p=top_p,
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
19. モデル パラメータでテストする
- ターミナルで、現在実行中のプロセスを終了します(Ctrl+C)。
- コマンドを再実行して、Streamlit アプリケーションを再度起動します。
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Streamlit アプリケーションを更新します。Streamlit アプリケーションがまだ実行されている場合は、ブラウザでウェブ プレビュー ページを更新するだけです。
- 前と同じ質問を試してください。
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Enter キーを押します。
このレスポンスを以前のレスポンスと比較します。
20. 完了
ツールを使用して Q&A アプリケーションをアップグレードしました。ツールは、Gemini を搭載したアプリが外部システムとやり取りし、リアルタイムの情報にアクセスできるようにする強力な機能です。
継続的なテスト
プロンプトの最適化を継続する方法は数多くあります。以下に考慮すべき点をいくつか示します。
temperatureとtop_pを調整して、LLM から返されるレスポンスがどのように変化するかを確認します。- 構成可能なパラメータとその説明の完全なリストについては、API リファレンスの
GenerateContentConfigをご覧ください。パラメータをさらに定義して調整し、何が起こるかを確認してみてください。
内容のまとめ
このラボでは次の作業を行いました。
- 開発に Cloud Shell エディタとターミナルを使用しました。
- Vertex AI Python SDK を使用して、アプリケーションを Gemini モデルに接続しました。
- LLM のレスポンスを誘導するために、システム指示とモデル パラメータを適用しました。
- ツール(関数呼び出し)のコンセプトとそのメリットについて学習しました。
- 会話型 AI のベスト プラクティスであるステートフル チャット セッションを使用するようにコードをリファクタリングしました。
- 関数宣言を使用してモデルのツールを定義しました。
- ツールのロジックを提供する Python 関数を実装しました。
- モデルの関数呼び出しリクエストを処理して結果を返すコードを作成しました。